Interestingly, when you start reading books about Linux or going through different tutorials, they often don’t tell you about some of the cool commands that make your work sometimes so much easier. Maybe they are hiding them from you to make sure you still have to learn something in the future? ¯\_(ツ)_/¯
Anyway, today I decided to make a quick overview of some of the commands which I find useful, but which are sometimes hard to find out about.
tee
tee command allows you to write to the stdout and a file (or files) at the same time.
This is useful when you want to store and view the output of any command.
And you can also use it to save the output to multiple files.
This command is incredibly useful when you want to store the output of a command to a file but also redirect it as an input to another command.
As you can see, we are able to take snapshots of the data as it flows through the pipes.
pbcopy (Mac) or xclip (Linux)
This allows you to copy a file’s content to the clipboard.
Now if you try to paste, you’ll get cucaracha, which by the way means a cockroach in Spanish :)
This command makes copying from the terminal a breeze. I find it especially useful when I need to copy SSH or GPG keys.
watch
watch runs a specified command repeatedly at regular intervals and displays its output on a console.
This is used when you need to continuously monitor some command’s output.
Simple examples include monitoring who is logged in to the system with watch who command or watching for changes inside a directory with watch ls
We should note the -d option that allows you to highlight the changes that happen in the command’s output.
Just to show you how it works, we’ll use it with a date command.
script & scriptreplay
These are 2 awesome commands which allow you to record and replay a shell session for you.
To use a script command, we can just type script in which case the session will be stored in a default file named typescript. We can also specify the name of the file in which we want to store our session as the first argument to the script command.
An alternative to the script command is history, but it only keeps track of the commands you use and
not their outputs.
Another cool thing about the script command is that the shell session that you have recorded can then be replayed in your terminal with a scriptreplay command. This is particularly helpful if during the session you start interacting with some programs like htop.
To be able to replay a recorded shell session, we need to specify a filename for storing the timing information.
$ script --timing=time.txt myshell.log
Then after we’re done recording, we can use the scriptreplaycommand to replay the session.
$ scriptreplay --timing=time.txt myshell.info
It’s also important to note the -c option to this command which allows to record the output of a single command. For example, this might come in handy when we need to record a command’s output in our bash script. The syntax goes like this:
$ script -c 'ping -c 3 google.com' myshell3.log
jq
jq is a handy JSON processor that allows you to extract necessary fields from a JSON object.
Let’s take a simple JSON file and extract some specific fields.
If being run without any arguments, this command will show you a list of current environment variables.
It also allows you to run commands with specific environment variables without actually changing your environment.
This can be helpful when you need to run a one time command that requires some specific env variable, but you don’t really want to change your environment. For example, to build a GO binary for Ubuntu on my Macbook I would run a command like this.
$ env GOOS=linux GOARCH=amd64 go build src/hello-world.go
This runs the go build command with two additional environment variables. If I run env command right after that, I won’t find those variables in my environment.
Hopefully, you’ve found this post useful. And if you have some interesting commands to share with me, please leave a comment below!
Business continuity is important for building mission-critical workloads on AWS. As an AWS customer, you might define recovery point objectives (RPO) and recovery time objectives (RTO) for different tier applications in your business. After the RPO and RTO requirements are defined, it is up to your architects to determine how to meet those requirements.
You probably store persistent data in Amazon EBS volumes, which live within a single Availability Zone. And, following best practices, you take snapshots of your EBS volumes to back up the data on Amazon S3, which provides 11 9's of durability. If you are following these best practices, then you've probably recognized the need to manage the number of snapshots you keep for a particular EBS volume and delete older, unneeded snapshots. Doing this cleanup helps save on storage costs.
Some customers also have policies stating that backups need to be stored a certain number of miles away as part of a disaster recovery (DR) plan. To meet these requirements, customers copy their EBS snapshots to the DR region. Then, the same snapshot management and cleanup has to also be done in the DR region.
All of this snapshot management logic consists of different components. You would first tag your snapshots so you could manage them. Then, determine how many snapshots you currently have for a particular EBS volume and assess that value against a retention rule. If the number of snapshots was greater than your retention value, then you would clean up old snapshots. And finally, you might copy the latest snapshot to your DR region. All these steps are just an example of a simple snapshot management workflow. But how do you automate something like this in AWS? How do you do it without servers?
One of the most powerful AWS services released in 2016 was Amazon CloudWatch Events. It enables you to build event-driven IT automation, based on events happening within your AWS infrastructure. CloudWatch Events integrates with AWS Lambda to let you execute your custom code when one of those events occurs. However, the actions to take based on those events aren't always composed of a single Lambda function. Instead, your business logic may consist of multiple steps (like in the case of the example snapshot management flow described earlier). And you may want to run those steps in sequence or in parallel. You may also want to have retry logic or exception handling for each step.
AWS Step Functions serves just this purpose―to help you coordinate your functions and microservices. Step Functions enables you to simplify your effort and pull the error handling, retry logic, and workflow logic out of your Lambda code. Step Functions integrates with Lambda to provide a mechanism for building complex serverless applications. Now, you can kick off a Step Functions state machine based on a CloudWatch event.
In this post, I discuss how you can target Step Functions in a CloudWatch Events rule. This allows you to have event-driven snapshot management based on snapshot completion events firing in CloudWatch Event rules.
As an example of what you could do with Step Functions and CloudWatch Events, we've developed a reference architecture that performs management of your EBS snapshots.
Automating EBS Snapshot Management with Step Functions
The state machine then tags the snapshot, cleans up the oldest snapshots if the number of snapshots is greater than the defined number to retain, and copies the snapshot to a DR region.
When the DR region snapshot copy is completed, another state machine kicks off in the DR region. The new state machine has a similar flow and uses some of the same Lambda code to clean up the oldest snapshots that are greater than the defined number to retain.
Also, both state machines demonstrate how you can use Step Functions to handle errors within your workflow. Any errors that are caught during execution result in the execution of a Lambda function that writes a message to an SNS topic. Therefore, if any errors occur, you can subscribe to the SNS topic and get notified.
The following is an architecture diagram of the reference architecture:
Creating the Lambda functions and Step Functions state machines
First, pull the code from GitHub and use the AWS CLI to create S3 buckets for the Lambda code in the primary and DR regions. For this example, assume that the primary region is us-west-2 and the DR region is us-east-2. Run the following commands, replacing the italicized text in <> with your own unique bucket names.
git clone https://github.com/awslabs/aws-step-functions-ebs-snapshot-mgmt.git
cd aws-step-functions-ebs-snapshot-mgmt/
aws s3 mb s3://<primary region bucket name> --region us-west-2
aws s3 mb s3://<DR region bucket name> --region us-east-2
Next, use the Serverless Application Model (SAM), which uses AWS CloudFormation to deploy the Lambda functions and Step Functions state machines in the primary and DR regions. Replace the italicized text in <> with the S3 bucket names that you created earlier.
The CloudFormation templates deploy the following resources:
The Lambda functions that are coordinated by Step Functions
The Step Functions state machine
The SNS topic
The CloudWatch Events rules that trigger the state machine execution
So, all of the CloudWatch event rules have been created for you by performing the preceding commands. The next section demonstrates how you could create the CloudWatch event rule manually. To jump straight to testing the workflow, see the “Testing in your Account” section. Otherwise, you begin by setting up the CloudWatch event rule in the primary region for the createSnapshot event and also the CloudWatch event rule in the DR region for the copySnapshot command.
First, open the CloudWatch console in the primary region.
Choose Create Rule and create a rule for the createSnapshot command, with your newly created Step Function state machine as the target.
For Event Source, choose Event Pattern and specify the following values:
Service Name: EC2
Event Type: EBS Snapshot Notification
Specific Event: createSnapshot
For Target, choose Step Functions state machine, then choose the state machine created by the CloudFormation commands. Choose Create a new role for this specific resource. Your completed rule should look like the following:
Choose Configure Details and give the rule a name and description.
Choose Create Rule. You now have a CloudWatch Events rule that triggers a Step Functions state machine execution when the EBS snapshot creation is complete.
Now, set up the CloudWatch Events rule in the DR region as well. This looks almost same, but is based off the copySnapshot event instead of createSnapshot.
In the upper right corner in the console, switch to your DR region. Choose CloudWatch, Create Rule.
For Event Source, choose Event Pattern and specify the following values:
Service Name: EC2
Event Type: EBS Snapshot Notification
Specific Event: copySnapshot
For Target, choose Step Functions state machine, then select the state machine created by the CloudFormation commands. Choose Create a new role for this specific resource. Your completed rule should look like in the following:
As in the primary region, choose Configure Details and then give this rule a name and description. Complete the creation of the rule.
Testing in your account
To test this setup, open the EC2 console and choose Volumes. Select a volume to snapshot. Choose Actions, Create Snapshot, and then create a snapshot.
This results in a new execution of your state machine in the primary and DR regions. You can view these executions by going to the Step Functions console and selecting your state machine.
From there, you can see the execution of the state machine.
Primary region state machine:
DR region state machine:
I've also provided CloudFormation templates that perform all the earlier setup without using git clone and running the CloudFormation commands. Choose the Launch Stack buttons below to launch the primary and DR region stacks in Dublin and Ohio, respectively. From there, you can pick up at the Testing in Your Account section above to finish the example. All of the code for this example architecture is located in the aws-step-functions-ebs-snapshot-mgmt AWSLabs repo.
Primary Region eu-west-1 (Ireland)
DR Region us-east-2 (Ohio)
Summary
This reference architecture is just an example of how you can use Step Functions and CloudWatch Events to build event-driven IT automation. The possibilities are endless:
Use this pattern to perform other common cleanup type jobs such as managing Amazon RDS snapshots, old versions of Lambda functions, or old Amazon ECR images—all triggered by scheduled events.
Use Trusted Advisor events to identify unused EC2 instances or EBS volumes, then coordinate actions on them, such as alerting owners, stopping, or snapshotting.
Happy coding and please let me know what useful state machines you build!
Esse tal de GraphQL tem causado bastante burburinho. Dizem que é uma alternativa mais flexível e eficiente a APIs REST. Já foi detectado pelo seu radar?
No episódio 55 do Hipsters Ponto Tech, o pessoal da Pipefy disse que uma API GraphQL no back-end, junto ao React e shadow DOM no front-end, levaram a uma melhoria drástica na performance. Outras empresas brasileiras como a GetNinjas e a Taller também tem usado o GraphQL.
Empresas gringas como a Shopify, Artsy e Yelp provêem APIs com suporte ao GraphQL. O GitHub migrou sua API de REST para GraphQL.
E claro, o Facebook, que desenvolveu o GraphQL em 2012 para uso interno e o abriu ao público em 2015.
Quais as limitações de uma API REST?
Para ilustrar o que pode ser melhorado em uma API REST, vamos utilizar a versão 3 da API do GitHub, considerada muito consistente e aderente aos princípios REST.
Queremos uma maneira de avaliar bibliotecas open-source. Para isso, dado um repositório do GitHub, desejamos descobrir:
o número de stars
o número de pull requests abertos
Como exemplo, vamos usar o repositório de uma biblioteca NodeJS muito usada: o framework Web minimalista Express.
Obtendo detalhes de um repositório
Lendo a documentação da API do GitHub, descobrimos que para obter detalhes sobre um repositório, devemos enviar uma requisição GET para /repos/:owner/:repo. Então, para o repositório do Express, devemos fazer:
GET https://api.github.com/repos/expressjs/express
Como resposta, obtemos:
2.2 KB gzipados transferidos, incluindo cabeçalhos
6.1 KB de JSON em 110 linhas, quando descompactado
200 OK
Content-type: application/json; charset=utf-8
O JSON retornado tem diversas informações sobre o repositório do Express. Por meio da propriedade stargazers_count, descobrimos que há mais de 33 mil stars.
Porém, não temos o número de pull requests abertos.
Obtendo os pull requests de um repositório
Na propriedade pulls_url, temos apenas uma URL: https://api.github.com/repos/expressjs/express/pulls{/number}.
Um bom palpite é que sem esse {/number} teremos a lista de todos os pull requests, o que pode ser confirmado na seção de pull requests da documentação da API REST do GitHub.
Mas como filtrar apenas pelos pull requests abertos?
Na mesma documentação, verificamos que podemos usar a URL /repos/:owner/:repo/pulls?state=open ou simplesmente /repos/:owner/:repo/pulls, já que o filtro por pull requests abertos é aplicado por padrão. Em outras palavras, precisamos de outra requisição:
GET https://api.github.com/repos/expressjs/express/pulls
A resposta é:
54.1 KB gzipados transferidos, incluindo cabeçalhos
514 KB de JSON em 9150 linhas, quando descompactado
200 OK
Content-type: application/json; charset=utf-8
Link: <https://api.github.com/repositories/237159/pulls?page=2>; rel="next",
<https://api.github.com/repositories/237159/pulls?page=2>; rel="last"
É retornado um array de 30 objetos que representam os pull requests. Cada objeto ocupa uma média de 300 linhas, com informações sobre status, descrição, autores, commits e diversas URLs relacionadas.
Disso tudo, só queremos saber a contagem: 30 pull requests. Não precisamos de nenhuma outra informação.
Mas há outra questão: o resultado é paginado com 30 resultados por página, por padrão, conforme descrito na seção de paginação da documentação da API REST do GitHub.
As URLs das próximas páginas devem ser obtidas a partir do cabeçalho de resposta Link, extraindo o rel (link relation) next.
Os links para as próximas páginas seguem o conceito de hipermídia do REST e foram implementados usando o cabeçalho Link e o formato descrito na RFC 5988 (Web Linking). Essa RFC sugere um punhado de link relations padronizados.
Então, a partir do next, seguimos para a próxima página:
GET https://api.github.com/repositories/237159/pulls?page=2
Temos como resposta:
26.9 KB gzipados transferidos, incluindo cabeçalhos
248 KB de JSON em 4394 linhas, quando descompactado
200 OK
Content-type: application/json; charset=utf-8
Link: <https://api.github.com/repositories/237159/pulls?page=1>; rel="first",
<https://api.github.com/repositories/237159/pulls?page=1>; rel="prev"
O array retornado contabiliza mais 14 objetos representando os pull requests. Dessa vez, não há o link relation next, indicando que é a última página.
Então, sabemos que há 44 (30 + 14) pull requests abertos no repositório do Express.
Resumindo
No momento da escrita desse artigo, o número de stars do Express no GitHub é 33508 e o de pull requests abertos é 44. Para descobrir isso, tivemos que:
disparar 3 requisições ao servidor
baixar 83.2 KB de informações gzipadas e cabeçalhos
fazer parse de 768.1 KB de JSON ou 13654 linhas
O que daria pra melhorar? Ir menos vezes ao servidor, baixando menos dados!
Não é um problema com o REST em si, mas uma discrepância entre a modelagem atual da API e as nossas necessidades.
Poderíamos pedir para o GitHub implementar um recurso específico que retornasse somente as informações, tudo em apenas um request.
Mas será que o pessoal do GitHub vai nos atender?
Mais flexibilidade e eficiência com GraphQL
Numa API GraphQL, o cliente diz exatamente os dados que quer da API, tornando a requisição muito flexível.
A API, por sua vez, retorna apenas os dados que o cliente pediu, fazendo com que a transferência da resposta seja bastante eficiente.
Mas afinal de contas, o que é GraphQL?
GraphQL não é um banco de dados, não é um substituto do SQL, não é uma ferramenta do lado do servidor e não é específico para React (apesar de muito usado por essa comunidade).
Um servidor que aceita requisições GraphQL poderia ser implementado em qualquer linguagem usando qualquer banco de dados. Há várias bibliotecas de diferentes plataformas que ajudam a implementar esse servidor.
Clientes que enviam requisições GraphQL também poderiam ser implementados em qualquer tecnologia: web, mobile, desktop, etc. Diversas bibliotecas auxiliam nessa tarefa.
GraphQL é uma query language para APIs que foi especificada pelo Facebook.
A query language do GraphQL é fortemente tipada e descreve, através de um schema, o modelo de dados oferecido pelo serviço. Esse schema pode ser usado para verificar se uma dada requisição é válida e, caso seja, executar as tarefas no back-end e estruturar os dados da resposta.
Um cliente pode enviar 3 tipos de requisições GraphQL, os root types:
subscription, para comunicação baseada em eventos.
Montando uma consulta GraphQL
A versão 4 da API do GitHub, a mais recente, dá suporte a requisições GraphQL.
Para fazer nossa consulta às stars e aos pull requests abertos do repositório do Express usando a API GraphQL do GitHub, devemos começar com a query:
query {
}
Vamos usar o campo repository da query, que recebe os argumentos owner e name, ambos obrigatórios e do tipo String. Para buscar pelo Express, devemos fazer:
A partir do objeto repository, podemos descobrir o número de stars por meio do campo stargazers. Como queremos apenas a quantidade de itens, só precisamos obter propriedade totalCount dessa connection.
Para encontrarmos o número de pull requests abertos, basta usarmos o campo pullRequests do repository. O filtro por pull requests abertos não é aplicado por padrão. Por isso, usaremos o argumento states. Da connection, obteremos apenas o totalCount.
Basicamente, é essa a nossa consulta! Bacana, não?
Uma maneira de “rascunhar” consultas GraphQL é usar a ferramenta GraphiQL, que permite explorar APIs pelo navegador. Há até code completion! Boa parte das APIs GraphQL dá suporte, incluindo a do GitHub.
Tá, mas como enviar a consulta para a API?
A maneira mais comum de publicar APIs GraphQL é usar a boa e velha Web, com seu protocolo HTTP.
Apesar do HTTP ser o mais usado para publicar APIs GraphQL, teoricamente não há limitações em usar outros protocolos.
Uma API GraphQL possui apenas um endpoint e, consequentemente, só uma URL.
É possível enviar requisições GraphQL usando o método GET do HTTP, com a consulta como um parâmetro na URL. Porém, como as consultas são relativamente grandes e requisições GET tem um limite de tamanho, o método mais utilizado pelas APIs GraphQL é o POST, com a consulta no corpo da requisição.
No caso do GitHub a URL do endpoint GraphQL é: https://api.github.com/graphql
O GitHub só dá suporte ao método POST e o corpo da requisição deve ser um JSON cuja propriedade query conterá uma String com a nossa consulta.
Mesmo para consultas a repositórios públicos, a API GraphQL do GitHub precisa de um token de autorização.
POST https://api.github.com/graphql
Content-type: application/json
Authorization: bearer f023615deb415e...
Na verdade, os JSONs de requisição e resposta ficam em apenas 1 linha. Formatamos o código anterior em várias linhas para melhor legibilidade.
Repare que os campos da consulta, dentro da query, tem exatamente a mesma estrutura do retorno da API. É como se a resposta fosse a própria consulta, mas com os valores preenchidos. Por isso, montar consultas com GraphQL é razoavelmente intuitivo.
Resumindo
Obtivemos os mesmos resultados: 33508 stars e 44 pull requests. Para isso, tivemos que:
disparar apenas 1 requisição ao servidor
baixar somente 996 bytes de informações gzipadas, incluindo cabeçalhos
fazer parse só de 93 bytes de JSON
São 66,67% requisições a menos, 98,82% menos dados e cabeçalhos trafegados e 99,99% menos JSON a ser “parseado”. Ou seja, MUITO mais rápido.
Considerações finais
Poderíamos buscar outros dados da API do GitHub: o número de issues abertas, a data da última release, informações sobre o último commit, etc.
Uma coisa é certa: com uma consulta GraphQL, eu faria menos requisições e receberia menos dados desnecessários. Mais flexibilidade e mais eficiência.
Porém, existem várias outras questões que surgem ao estudar o GraphQL:
como fazer um servidor que atenda a toda essa flexibilidade?
é possível gerar uma documentação a partir do código para a minha API?
vale a pena migrar minha API pra GraphQL?
posso fazer uma “casca” GraphQL para uma API REST já existente?
como implementar um cliente sem muito trabalho?
quais os pontos ruins dessa tecnologia e desafios na implementação?
Quando fazemos o design de um sistema distribuído, eventualmente baseado em microservices, e ao considerar utilizar uma arquitetura orientada a eventos, podemos escolher vários modelos e tecnologias. Descrevendo diferentes estilos de arquiteturas orientadas a eventos, David Dawson alega que requisitos não funcionais são o fator principal na escolha de como implementar uma arquitetura deste tipo.
A replicação nativa em bancos de dados PostgreSQL já é realidade a alguns anos. Porém aplicar um remaster em grandes bases de dados, a partir de um slave sincronizado, pode demorar muito tempo e estourar seu SLA. Para resolver este problema, foi implementado o pg_rewind. Em que situações ele se aplica, quais são os requisitos para seu uso e um exemplo prático são os temas desta sessão.
Back in the old days, you needed to buy or lease a server if you needed access to compute power. When we launched EC2 back in 2006, the ability to use an instance for an hour, and to pay only for that hour, was big news. The pay-as-you-go model inspired our customers to think about new ways to develop, test, and run applications of all types.
Today, services like AWS Lambda prove that we can do a lot of useful work in a short time. Many of our customers are dreaming up applications for EC2 that can make good use of a large number of instances for shorter amounts of time, sometimes just a few minutes.
Per-Second Billing for EC2 and EBS
Effective October 2nd, usage of Linux instances that are launched in On-Demand, Reserved, and Spot form will be billed in one-second increments. Similarly, provisioned storage for EBS volumes will be billed in one-second increments.
Per-second billing also applies to several other AWS services:
Amazon EMR – Our customers add capacity to their EMR clusters in order to get their results more quickly. With per-second billing for the EC2 instances in the clusters, adding nodes is more cost-effective than ever. To learn more, read Amazon EMR Now Supports Per-Second Billing.
AWS Batch – Many of the batch jobs that our customers run complete in less than an hour. AWS Batch already launches and terminates Spot Instances; with per-second billing for the EC2 instances, batch processing will become even more economical.
Elastic GPUs – Usage of Elastic GPUs is billed by the second, with a 1 minute minimum.
Provisioned IOPS – Provisioned IOPS for io1 EBS volumes is billed by the second.
Some of our more sophisticated customers have built systems to get the most value from EC2 by strategically choosing the most advantageous target instances when managing their gaming, ad tech, or 3D rendering fleets. Per-second billing obviates the need for this extra layer of instance management, and brings the costs savings to all customers and all workloads.
While this will result in a price reduction for many workloads (and you know we love price reductions), I don’t think that’s the most important aspect of this change. I believe that this change will inspire you to innovate and to think about your compute-bound problems in new ways. How can you use it to improve your support for continuous integration? Can it change the way that you provision transient environments for your dev and test workloads? What about your analytics, batch processing, and 3D rendering?
One of the many advantages of cloud computing is the elastic nature of provisioning or deprovisioning resources as you need them. By billing usage down to the second we will enable customers to level up their elasticity, save money, and customers will be positioned to take advantage of continuing advances in computing.
Things to Know
This change is effective in all AWS Regions and will be effective October 2, for all Linux instances that are newly launched or already running. There is a 1 minute minimum charge per-instance.
Per-second billing is not currently applicable to instances running Microsoft Windows or Linux distributions that have a separate hourly charge. Marketplace AMIs that do not have a separate hourly charge are eligible for per-second billing.
List prices and Spot Market prices are still listed on a per-hour basis, but bills are calculated down to the second, as is Reserved Instance usage (you can launch, use, and terminate multiple instances within an hour and get the Reserved Instance Benefit for all of the instances). Also, bills will show times in decimal form, like this:
The Dedicated Per Region Fee, EBS Snapshots, and products in AWS Marketplace are still billed on an hourly basis.
Earlier this year I told you about our plan to launch EC2 instances with up to 16 TB of memory. Today I am happy to announce that the new x1e.32xlarge instances with 4 TB of DDR4 memory are available in four AWS Regions. As I wrote in my earlier post, these instances are designed to run SAP HANA and other memory intensive, in-memory applications. Many of our customers are already running production SAP applications on the existing x1.32xlarge instances. With today’s launch, these customers can now store and process far larger data sets, making them a great fit for larger production deployments.
Like the x1.32xlarge, the x1e.32xlarge is powered by quad socket Intel Xeon E7 8880 v3 Haswell processors running at 2.3GHz (128 vCPUs), with large L3 caches, plenty of memory bandwidth, and support for C-state and P-state management.
On the network side, the instances offer up to 25 Gbps of network bandwidth when launched within an EC2 placement group, powered by the Elastic Network Adapter (ENA), with support for up to 8 Elastic Network Interfaces (ENIs) per instance. The instances are EBS-optimized by default, with an additional 14 Gbps of dedicated bandwidth to your EBS volumes, and support for up to 80,000 IOPS per instance. Each instance also includes a pair of 1,920 GB SSD volumes.
A Few Notes
Here are a couple of things to keep in mind regarding the x1e.32xlarge:
SAP Certification – The x1e.32xlarge instances are our largest cloud-native instances certified and supported by SAP for production HANA deployments of SAP Business Suite on HANA (SoH), SAP Business Warehouse on HANA (BWoH), and the next-generation SAP S/4HANA ERP and SAP BW/4HANA data warehouse solution. If you are already running SAP HANA workloads on smaller X1 instances, scaling up will be quick and easy. The SAP HANA on the AWS Cloud Quick Start Reference Deployment has been updated and will help you to set up a deployment that follows SAP and AWS standards for high performance and reliability. The SAP HANA Hardware Directory and the SAP HANA Sizing Guidelines are also relevant.
Reserved Instances – The regional size flexibility for Reserved Instances does not apply across x1 and x1e.
Elastic Load Balancing (ELB) has been an important part of AWS since 2009, when it was launched as part of a three-pack that also included Auto Scaling and Amazon CloudWatch. Since that time we have added many features, and also introduced the Application Load Balancer. Designed to support application-level, content-based routing to applications that run in containers, Application Load Balancers pair well with microservices, streaming, and real-time workloads.
Over the years, our customers have used ELB to support web sites and applications that run at almost any scale — from simple sites running on a T2 instance or two, all the way up to complex applications that run on large fleets of higher-end instances and handle massive amounts of traffic. Behind the scenes, ELB monitors traffic and automatically scales to meet demand. This process, which includes a generous buffer of headroom, has become quicker and more responsive over the years and works well even for our customers who use ELB to support live broadcasts, “flash” sales, and holidays. However, in some situations such as instantaneous fail-over between regions, or extremely spiky workloads, we have worked with our customers to pre-provision ELBs in anticipation of a traffic surge.
New Network Load Balancer
Today we are introducing the new Network Load Balancer (NLB). It is designed to handle tens of millions of requests per second while maintaining high throughput at ultra low latency, with no effort on your part. The Network Load Balancer is API-compatible with the Application Load Balancer, including full programmatic control of Target Groups and Targets. Here are some of the most important features:
Static IP Addresses – Each Network Load Balancer provides a single IP address for each Availability Zone in its purview. If you have targets in us-west-2a and other targets in us-west-2c, NLB will create and manage two IP addresses (one per AZ); connections to that IP address will spread traffic across the instances in all the VPC subnets in the AZ. You can also specify an existing Elastic IP for each AZ for even greater control. With full control over your IP addresses, Network Load Balancer can be used in situations where IP addresses need to be hard-coded into DNS records, customer firewall rules, and so forth.
Zonality – The IP-per-AZ feature reduces latency with improved performance, improves availability through isolation and fault tolerance and makes the use of Network Load Balancers transparent to your client applications. Network Load Balancers also attempt to route a series of requests from a particular source to targets in a single AZ while still providing automatic failover should those targets become unavailable.
Source Address Preservation – With Network Load Balancer, the original source IP address and source ports for the incoming connections remain unmodified, so application software need not support X-Forwarded-For, proxy protocol, or other workarounds. This also means that normal firewall rules, including VPC Security Groups, can be used on targets.
Long-running Connections – NLB handles connections with built-in fault tolerance, and can handle connections that are open for months or years, making them a great fit for IoT, gaming, and messaging applications.
Failover – Powered by Route 53 health checks, NLB supports failover between IP addresses within and across regions.
Creating a Network Load Balancer
I can create a Network Load Balancer opening up the EC2 Console, selecting Load Balancers, and clicking on Create Load Balancer:
I choose Network Load Balancer and click on Create, then enter the details. I can choose an Elastic IP address for each subnet in the target VPC and I can tag the Network Load Balancer:
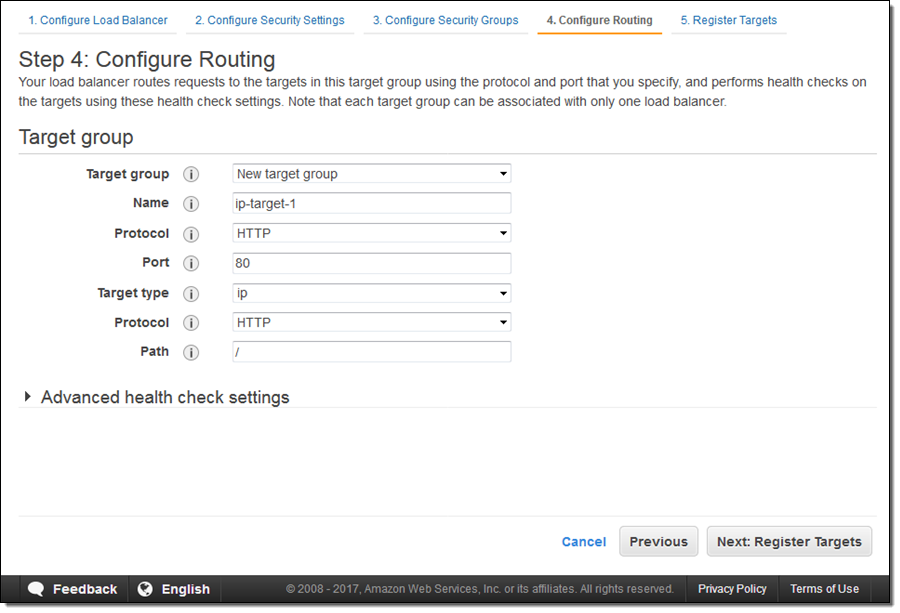
Then I click on Configure Routing and create a new target group. I enter a name, and then choose the protocol and port. I can also set up health checks that go to the traffic port or to the alternate of my choice:
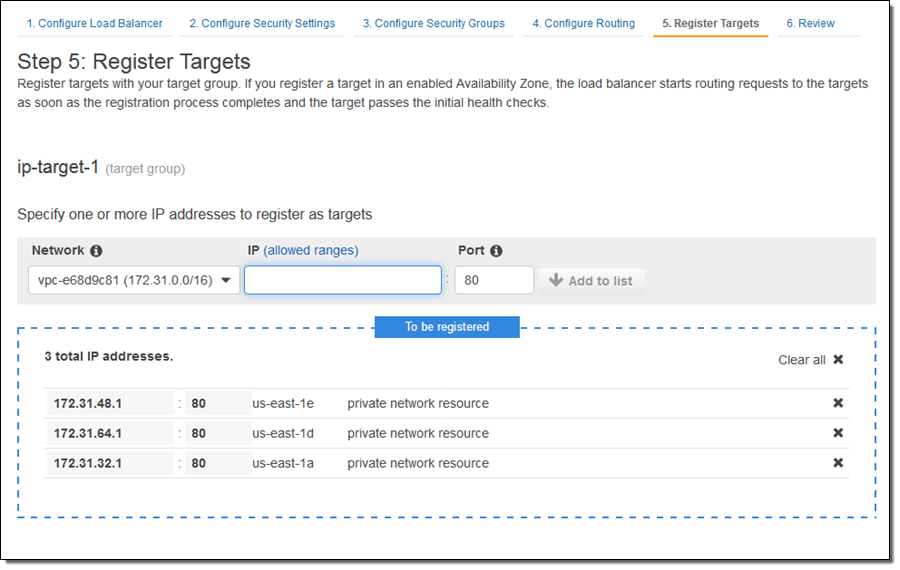
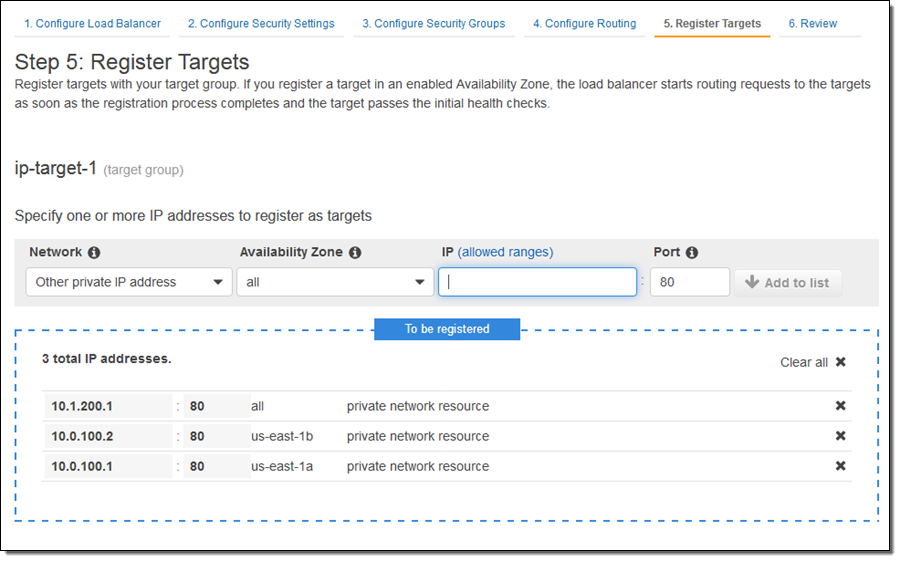
Then I click on Register Targets and the EC2 instances that will receive traffic, and click on Add to registered:
I make sure that everything looks good and then click on Create:
The state of my new Load Balancer is provisioning, switching to active within a minute or so:
For testing purposes, I simply grab the DNS name of the Load Balancer from the console (in practice I would use Amazon Route 53 and a more friendly name):
Then I sent it a ton of traffic (I intended to let it run for just a second or two but got distracted and it created a huge number of processes, so this was a happy accident):
$ while true;
> do
> wget http://nlb-1-6386cc6bf24701af.elb.us-west-2.amazonaws.com/phpinfo2.php &
> done
I took a quick break to let some traffic flow and then checked the CloudWatch metrics for my Load Balancer, finding that it was able to handle the sudden onslaught of traffic with ease:
I also looked at my EC2 instances to see how they were faring under the load (really well, it turns out):
It turns out that my colleagues did run a more disciplined test than I did. They set up a Network Load Balancer and backed it with an Auto Scaled fleet of EC2 instances. They set up a second fleet composed of hundreds of EC2 instances, each running Bees with Machine Guns and configured to generate traffic with highly variable request and response sizes. Beginning at 1.5 million requests per second, they quickly turned the dial all the way up, reaching over 3 million requests per second and 30 Gbps of aggregate bandwidth before maxing out their test resources.
Choosing a Load Balancer
As always, you should consider the needs of your application when you choose a load balancer. Here are some guidelines:
Network Load Balancer (NLB) – Ideal for load balancing of TCP traffic, NLB is capable of handling millions of requests per second while maintaining ultra-low latencies. NLB is optimized to handle sudden and volatile traffic patterns while using a single static IP address per Availability Zone.
Application Load Balancer (ALB) – Ideal for advanced load balancing of HTTP and HTTPS traffic, ALB provides advanced request routing that supports modern application architectures, including microservices and container-based applications.
Classic Load Balancer (CLB) – Ideal for applications that were built within the EC2-Classic network.
If you are currently using a Classic Load Balancer and would like to migrate to a Network Load Balancer, take a look at our new Load Balancer Copy Utility. This Python tool will help you to create a Network Load Balancer with the same configuration as an existing Classic Load Balancer. It can also register your existing EC2 instances with the new load balancer.
Pricing & Availability
Like the Application Load Balancer, pricing is based on Load Balancer Capacity Units, or LCUs. Billing is $0.006 per LCU, based on the highest value seen across the following dimensions:
Bandwidth – 1 GB per LCU.
New Connections – 800 per LCU.
Active Connections – 100,000 per LCU.
Most applications are bandwidth-bound and should see a cost reduction (for load balancing) of about 25% when compared to Application or Classic Load Balancers.
Com o passar do tempo e as demandas de mercado, as aplicações têm ficado cada vez mais complexas, múltiplos serviços, e para gerenciar todo esse ambiente é necessário lidar com o volume de informações que esse conjunto pode gerar.
De acordo com wikipedia, logs de dados “é uma expressão utilizada para descrever o processo de registro de eventos relevantes num sistema computacional.”
Quando falamos de obter informações sobre nosso sistemas, analisar os logs é uma maneira bastante eficaz para um tratamento proativo de incidentes em seu ambiente, pois ao coletar registros em pontos distintos da sua arquitetura é possível correlacionar informações a fim de perceber anomalias antes que que o cliente perceba qualquer mal funcionamento.
Falaremos nesse artigo sobre tratamento de logs em um ecossistema de containers docker.
Tipos de logs
Vale salientar quais os tipos de logs podemos encontrar e como podemos organizá-los:
Logs de Infra do container
Eles são gerados pelos softwares que normalmente suportam a aplicação, um container de mysql em execução mostrará informações de seu funcionamento interno e quais possíveis erros está passando. É possível visualizar os logs do container mysql ao digitar esse comando em seu console com docker instalado:
docker container run -it mysql
Logs de app do container
Eles são gerados pela aplicação que foi executada a partir do código movido para o container. Vale atentar que essa aplicação precisará enviar o log para STDOUT/STDERR, pois o docker será responsável por coletar esses logs e dar devido tratamento a ele. De acordo com o 12factor, sua aplicação não deve ser preocupar com armazenamento de log, apenas jogue na console do container.
Para testar execute esse container e veja os logs produzidos pela aplicação dele:
docker container run -it hello-world
Logs do docker host
Esses são os logs que mais importam para o time de sustentação da infraestrutura docker, pois nele tem informações do tipo “level=warning msg=”Your kernel does not support swap memory limit”.
Essas informações são relevantes para uma manutenção e os maiores problemas arquiteturais serão obtidos nessa categoria.
Para ter acesso a esse log localmente em máquinas com systemd, basta digitar esse comando:
sudo journalctl -u docker.service
Log local ou remoto
Cada container que é iniciado no docker tem uma forma de gerenciar seus logs e por padrão os logs (tanto de infraestrutura ou aplicação) dele é armazenado em arquivos do tipo json.
Armazenar em json é um dos piores modelos, pois existe uma alta possibilidade desses arquivos consumirem todo espaço livre em disco e impactar negativamente na disponibilidade do mesmo. Isso pode ser evitado utilizando opções de max-size e max-file. Onde max-size especifica a quantidade máxima de cada arquivo json e o max-file a quantidade de arquivos que serão gerados até que o mais antigo seja reciclado. Perceba que utilizar apenas uma das opções não surtirá efeito no controle de uso indevido do espaço em disco, você precisa utilizar ambas (max-size e max-file).
Para iniciar um container com driver de log json com essas opções:
É possível modificar o padrão de drivers de log, e assim não precisa dizer em cada container qual driver e opções serão utilizadas. Acesse o arquivo /etc/docker/daemon.json (Ao menos esse é o caminho do Debian) e modifique a seguinte configuração:
Depois de modificar, você deve reiniciar o daemon do docker para que as novas definições sejam aplicadas. Depois dessa modificação e restart, os novos containers executados desde então terão limites de 10 megabytes e apenas 2 arquivos.
Perceba que até então o log será armazenado localmente, ou seja, caso esse host apresente problemas, perderemos todos os registros tanto da infra do container, como da aplicação que está nela hospedada e isso não é algo aceitável nos tempos modernos.
O docker tem outros drivers para armazenamento remoto, porém cada tipo tem suas vantagens e desvantagens:
Nome
Vantagem
Desvantagem
none
Ultra-secreto, pois não gera nenhum registro de log para ser obtido informação
Difícil de realizar tratamento de problemas, uma vez que não há registro das falhas
json-file
O padrão. Suporto o uso do comando ‘docker logs’ e tags
Logs armazenados locais e não agregados. Esses logs podem encher seu disco
syslog
Maioria dos hosts já contém syslog instalado. Suporta tag e com suporte a TLS no envio de logs
Precisa de configuração de alta disponibilidade(HA) no serviço de syslog, pois em caso de falha de enviar logs para o servidor syslog, o container não inicia
journald
Suporta o uso do comando ‘docker logs’ e agregação de logs sem impacto
Log binário, precisa de um trato extra para armazenamento externo e não suporta tag
gelf
Provê campos indexáveis por padrão (container id, host, container name, etc.) e suporte a tags
Suporta apenas protocolo UDP, sem suporte ao comando ‘docker logs’
fluentd
Provê os campos container_name e container_id por padrão, fluentd suporta multiples output
Sem suporte ao comando ‘docker logs’
awslogs
Fácil integração quando usado com AWS e suporte a tags
Não ideal para ambientes multi-clouds e sem suporte ao comando ‘docker logs’
splunk
Fácil integração com Splunk, suporte a envio de log com TLS, suporte a tags e métricas adicionais
Sem suporte ao comando ‘docker logs’. Precisa de configuração de alta disponibilidade(HA), pois em caso de falha de enviar logs para o splunk, o container não inicia
etwlogs
Framework comum para log Windows. Valores indexáveis por padrão
Apenas funciona para Windows
gcplogs
Fácil integração quando usado com Google Cloud e suporte a tags
Não ideal para ambientes multi-clouds e sem suporte ao comando ‘docker logs’
Para exemplificar o uso de log remoto vamos usar o driver syslog, e para testar iniciaremos um syslog em um container docker para simular um serviço centralizado de log da sua rede.
Primeiro acesse novamente o arquivo /etc/docker/daemon.json e modifique a seguinte opção:
No console que iniciou o container do syslog você já verá o log de novos containers já enviado para esse serviço.
Docker service
Antes de falarmos sobre logs em contexto de cluster docker, vale a pena contextualizar como funciona o service do docker.
A forma convencional de se iniciar um container em um docker host é o comando “docker container run” e essa instrução é executada em um determinado servidor docker, mas quando estamos falando de cluster, a ideia de iniciar um container em um nó específico perde relevância, pois a ideia de ter um grupo de nós, é escalabilidade e alta disponibilidade.
No contexto de cluster, o container está incluído em uma estrutura mais complexa que permite abstração de onde o container será executado.
A estrutura de organização funciona da seguinte forma:
service: Na estrutura de organização, essa é a camada mais alto nível. Cada service contém N tasks.
task: Camada de organização intermediária. Foi criada para abstrair uso de containers e outra coisa que há por vir (Unikernels?) o número de tasks é exatamente igual ao número de réplicas solicitadas no inicio do service ou igual ao número de nós, caso https://docs.docker.com/engine/admin/logging/log_tags/o service seja do tipo global.
container: É o container que já conhecemos, ele é iniciado dentro da task
Como podem ver, ao criar um service você não tem controle direto do container, já que ele está contido em uma task, que por sua vez está dentro de um service.
Parece complicado, mas se lembrar que uma aplicação ao iniciar pode ter N cópias, em N nós diferentes, essa estruturação começa a fazer mais sentido. E quando se leva em consideração que os containers são de fato descartáveis, a ideia de gerir containers diretamente perde ainda mais relevância.
Para criar um service você pode utilizar o comando de exemplo abaixo:
docker service create --replicas 2 nginx
docker container logs VS docker service logshttps://docs.docker.com/engine/admin/logging/log_tags/
Basicamente o comando docker container logs só analisa dados armazenados locais em um determinado docker host, ou seja, como já vimos na tabela de drivers acima, alguns logs são enviados pela rede e por isso esse comando não é suportado para esses drivers.
O comando docker container logs obtém todos os dados enviados para STDOUT e STDERR do container. Isso quer dizer que se você envia seus logs para um arquivo específico, dentro de uma pasta qualquer, de seu container, esse comando não mostrará esse dados.
Se você utilizar o comando abaixo ele mostrará os logs enviados para console em tempo real:
docker container logs -f id_ou_nome_do_container
No caso do docker service logs funciona da maneira parecida, pegando os logs enviados para console apenas e sendo limitado pelos mesmos drivers de log do docker container logs, mas a diferença está no fato dele pegar os logs a nível service e task. Dessa forma você pode a nível de service perceber um problema e então “descer” para uma determinada task para isolar o comportamento.
Os logs obtidos com docker service logs são correspondentes a todos registros enviados para STDOUT e STDERR do service ou task em questão, não importando em qual nó eles estão.
Tags
Os logs obtidos, tanto por docker container logs ou docker service logs, são exibidos da seguinte maneira por padrão:
Aug 7 18:33:19 HOSTNAME 5790672ab6a0[9103]: Hello from Docker.
O ID 5790672ab6a0 corresponde a identificação de 12 dígitos do container, que no contexto de uma máquina pessoal, ou apenas um docker host dedicado a hospedar esse serviço, é mais do que suficiente para um tratamento de problema pontual.
Agora imagine esse mesmo log em uma arquitetura de múltiplos nós, com vários serviços, cada um com diversas réplicas dispostas em vários docker hosts distintos. Um caos, certo? Você não terá ideia onde está o problema, já que o ID de um container em um nível de gerência que sua visualização é de service. Para resolver esse problema e identificar o problema de uma forma mais eficaz deve ser fazer o uso de tags.
Para usar tags basta utilizar a opção do seu driver de log escolhido, no caso de um exemplo utilizando o fluentd ficaria da seguinte forma:
docker container run --log-driver=fluentd --log-opt fluentd-address=myhost.local:24224 --log-opt tag="mailer" hello-world
Com essa opção o log teria a seguinte saída:
Aug 7 18:33:19 HOSTNAME mailer[9103]: Hello from Docker.
Pode ser utilizado algumas marcações especiais para construção dessas tags:
Marcação
Descrição
{{.ID}}
Os 12 primeiros caracteres do ID do container
{.FullID}}
O ID completo do container
{{.Name}}
O nome do container
{{.ImageID}}
Os 12 primeiros caracteres do ID da imagem do container
{{.ImageFullID}}
O ID completo da imagem do container
{{.DaemonName}}
O nome do programa docker (docker)
Segue abaixo um exemplo utilizando essa marcação:
docker container run --log-driver=fluentd --log-opt fluentd-address=myhost.local:24224 --log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}" hello-world
A saída de log seria assim:
Aug 7 18:33:19 HOSTNAME hello-world/foobar/5790672ab6a0[9103]: Hello from Docker.
É possível configurar tags padrão no arquivo /etc/docker/daemon.json, junto a configuração do driver já apresentado anteriormente nesse capítulo:
Nesta semana a TP-Link disponibilizou no Brasil um novo roteador, o Deco M5. Este roteador é um dos primeiros a chegar no país com conceito mesh, com um kit com três pontos de acesso, além da cobertura de uma área de até 400m².
A novidade da PC-Link proporciona aos usuários maior facilidade de instalação, uma vez que não é necessária a configuração manual. O roteador consegue interligar os pontos de acesso de forma automática.
Gerenciamento pode ser feito através de aplicativo
O gerenciamento da rede também pode ser feito através de um aplicativo para celular, podendo configurar o QoS, limite de velocidade disponível, para dispositivos conectados à rede ou em aplicativos. Além disso, ainda é possível bloquear sites e conteúdos inapropriados para crianças, assim como aplicativos de mensagens e as redes sociais, com isso, consegue-se um melhor controle da rede Wi-Fi. O roteador ainda traz consigo a tecnologia de roteamento dinâmico (ART) que permite que os dispositivos estejam sempre conectados no ponto de acesso mais próximo.
A grande mudança na recém lançada versão 1.9 do Go é o avanço no suporte para a melhoria de código através da utilização da declaração de alias de tipos. A nova versão também traz melhorias no garbage collector e no compilador.
By Sergio De Simone Translated by Leandro Guimarães
Os comandos arp, ifconfig, iptunnel, netstat, route, iwconfig e nameif foram (ainda são) essenciais para administrar configurações de rede no Linux, mas estão obsoletos há anos e, provavelmente, você ainda os usa; deixaram de ser mantidos e passaram ao status, de desenvolvimento, “deprecated” por várias distribuições Linux. Embora ainda funcionais, elas são, realmente, consideradas obsoletas e, portanto, devem ser renunciadas em favor de ferramentas mais “modernas”.
Pacote net-tools
Os comandos de rede Linux, em questão, arp, ifconfig, iptunnel, netstat, route, iwconfig e nameif fazem parte do pacote “net-tools”. Contudo, esse pacote não é mantido há anos (décadas), tornando as ferramentas presentes nele obsoletas.
Qualquer pessoa que tenha administrado sistemas Linux por qualquer período de tempo certamente aprendeu a usar os utilitários de ferramentas de rede para realizar suas tarefas. Se você está acostumado a usar comandos como ifconfig, arp e netstat para executar tarefas de rede, você deve repensar seus hábitos.
Por enquanto, os usuários que estão acostumados a digitar comandos como estes, provavelmente, ainda estão seguros. Na pior das hipóteses, eles precisam instalar o pacote “net-tools”, explicitamente, caso já esteja instalado na sua distribuição Linux (o Debian 9 parece não mais tê-lo instalado por default).
Em resumo, o status “deprecated” representa que um pacote não está mais sendo mantido, mas ainda funciona, podendo deixar de funcionar caso os desenvolvedores das distribuições o decidam fazer. Portanto, é bom ter em mente os “novos” comandos de rede que devem ser usados em substituição aos “antigos”.
O sucessor
O iproute2 é uma coleção de utilitários para controle de redes TCP/IP e controle de rede no Linux. Atualmente, é mantida por Stephen Hemminger. O autor original é o Alexey Kuznetsov, conhecido pela implementação da QoS no kernel do Linux.
Quem nunca solicitou a senha de um Wifi público em um restaurante, por exemplo? É bem legal poder navegar numa rede sem fio de graça, não é mesmo? Mas você sabe dos riscos que poderia estar correndo? Sabia que é muit fácil capturar seus dados, inclusive login/senha de rede social?
No vídeo que compartilhamos hj iremos demonstrar como é feito um ataque de phishing em redes wireless com a criação de um falso AP (Access Point) e uma página de autenticação na rede (OAuth) para roubo de dados de login em rede social (como o Facebook, por exemplo).
IMPORTANTE: este é um conteúdo educacional e tem carácter informativo sobre cuiados com a segurança digital. Nós não nos responsabilizamos pelo uso indevido destas técnicas e nem incentivamos o roubo de informações de terceiros.
Lista dos 35 melhores cursos de Python gratuitos disponíveis na internet, 9 deles em português, o que vai facilitar bastante os estudos para quem ainda não fala inglês.
Se você conhece mais algum curso online gratuito de programação em Python que não consta na lista, deixe o link no campo de comentários na parte de baixo do blog.
O iFood enfrenta desafios de suportar uma "Black Friday" por dia e ao mesmo tempo manter estratégias para evolução rápida, dadas as perspectivas de crescimento intenso no curto prazo. Nessa palestra vamos mostrar como conciliamos um ambiente de colaboração DevOps com segurança, desempenho e disponibilidade, de forma que o time de TI continue suportando as demandas do negócio.
A publicação de agosto de 2017 da lista de linguagens mais populares, promovida pela TIOBE, mostra o Java como a linguagem de programação mais popular do mundo. Porém, a publicação relata uma queda da popularidade do Java, uma tendência dentro das mais populares linguagens de programação identificadas pela pesquisa. Para onde estão migrando essas pessoas?
A maioria esmagadora dos desenvolvedores Android que conheço estão interessados ou ativamente estudando novos tópicos relacionados à plataforma. Arquitetura Clean, padrões de projeto aplicados ao Android, Rx e programação reativa, Kotlin, são de fato muitos assuntos e pouco tempo disponível para explorar todos eles.
Apesar do investimento no aprendizado contínuo feito pelos desenvolvedores ser um esforço válido e muito importante, a aplicação e o entendimento corretos destas ferramentas são apenas os primeiros passos para garantir que o aplicativo realmente entregue valor aos usuários. Ainda é necessário que todo código criado seja integrado à base de código principal, compilado em um apk, testado e devidamente publicado em um local onde os usuários possam baixar o aplicativo.
Sendo um desenvolvedor Android, ou de qualquer tecnologia, pare agora e pense: quantas vezes por dia você faz esse fluxo? Quantas vezes você já teve problemas com essas etapas que atrasaram a entrega ou impactaram seus usuários? Quanto tempo leva todo esse processo? Como isso afeta a sua produtividade como desenvolvedor? Quanto tempo levaria para você corrigir um bug em produção?
Se as respostas para estas perguntas lhe trouxeram lembranças dolorosas, ou se o processo de integração de suas mudanças e entrega de uma nova versão são motivos recorrentes de ansiedade em seu dia a dia como desenvolvedor, aqui tratarei de uma prática que pode lhe ajudar nesta batalha.
Integração Contínua para quê?
CI (Continuous Integration), é definida no livro Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation como uma prática que requer que toda vez que um membro do time faça o commit de uma alteração, toda a aplicação deve ser construída e testada por um conjunto de testes automatizados; se a build ou testes falharem o time deve parar e resolver o problema imediatamente.
Essa é uma mudança de comportamento e mentalidade interessante, ao invés de nos fecharmos por dias (em alguns casos semanas) para desenvolver uma feature ou corrigir um bug, acabamos por ter de quebrar essas alterações em pequenas mudanças incrementais integradas e validadas no mínimo diariamente.
Ao aumentar a frequência na qual alterações são integradas e verificadas contra a base de código principal é possível obtermos alguns benefícios como: redução no risco de quebra da aplicação no momento da release para produção, bugs são detectados e corrigidos prematuramente, aumento na velocidade e qualidade das entregas, feedback rápido aos desenvolvedores quanto ao impacto de suas alterações no código.
Entre os benefícios citados, como desenvolvedor, acredito que Feedback Rápido seja o mais interessante, pois ajuda a eliminar aquele medo perturbador do impacto de sua alteração no código e dá segurança para trabalhar em refactorings, em módulos e partes desconhecidas. Certa vez em um projeto, o time do qual eu fazia parte recebeu o relato de um bug que, após análise, descobrimos que havia sido causado por uma alteração realizada 6 meses antes e só foi descoberto pois era uma funcionalidade usada apenas por clientes específicos em datas específicas, que tipo de ansiedade essa situação gera no time em mudanças posteriores?
Adotando CI
Apesar de parecer uma prática simples, sua implementação requer disciplina e atenção, pois boa parte do trabalho consiste na colaboração dos membros do time em adotar as atividades propostas pela integração contínua.
Antes de Começar
Pressupõe-se que o time já tenha se munido de algumas coisas importantes.
Um Sistema de Controle de Versionamento
Para poder integrar suas alterações à base de código principal é necessário ter o código principal disponibilizado em uma ferramenta que não somente possibilite a integração e o controle mas que seja flexível e facilite o processo.
Uma combinação de Git com Github, Gitlab, Bitbucket ou similares é um ótimo começo a um custo relativamente baixo.
Processo de Build Automatizado
Esta etapa é a que a maioria dos desenvolvedores acaba dando maior foco, já que entrega algum ganho de produtividade logo após sua implementação. No entanto, boa parte esquece que além da construção propriamente dita é fundamental que se configure etapas onde os testes automatizados são executados, ferramentas de análise estática de código gerem seus relatórios, e até mesmo o aplicativo final seja disponibilizado para quem for de interesse.
A automatização do processo é o que ajuda a garantir o Feedback Rápido já mencionado anteriormente, sem ela é muito provável que se perca confiabilidade e que os membros do time aos poucos abandonem a prática de CI.
Para Android, geralmente a build é automatizada com uso do Gradle em conjunto com alguma ferramenta específica para CI (listo algumas delas logo adiante).
Práticas de CI
Com os pré-requisitos já configurados e prontos para serem utilizados, a integração contínua foca em práticas a serem adotadas pelo time de desenvolvimento. Mais uma vez, o livro Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation traz um conjunto dessas práticas que podem ser avaliadas e adotadas pelos times de desenvolvimento, são elas:
Faça check in regularmente
Crie um conjunto de testes automatizados
Mantenha o processo de testes e build curtos e rápidos
Faça uma gestão adequada do seu ambiente de desenvolvimento
Não faça check in de uma build quebrada
Sempre rode os testes localmente ou no CI antes de integrar as alterações
Espere o resultado dos testes antes de iniciar uma nova atividade
Nunca vá para casa com uma build quebrada
Sempre esteja pronto para reverter suas alterações
Tente corrigir por um tempo determinado antes de reverter
Não comente/desative testes que estão falhando
Assuma a responsabilidade por quebras causadas por suas mudanças
Pratique Test Driven Development (se possível)
Além das práticas acima, consideradas essenciais, o mesmo livro sugere um conjunto de práticas complementares que em geral se referem a verificação da qualidade do código, aderência a padrões de desenvolvimento do time e outras métricas de interesse do próprio time.
Um ponto importante a se verificar é que essas práticas não dependem diretamente de ferramentas, mas da disciplina dos membros do time em executar essas atividades em seu dia a dia. Por isso é muito importante que todos estejam focados em adotar essas práticas e colaborar com a melhoria do processo de desenvolvimento.
Dicas e Cuidados de CI para o Robozinho Verde
Todas as práticas voltadas à integração contínua são aplicáveis ao universo Android, no entanto existem alguns pontos que podem ser avaliados especificamente para esta plataforma e que podem ajudar na adoção do CI.
Ambiente, API Level e Build Tools
Todo sabemos o quão chato pode ser a configuração de ambiente para Android: baixar gigabytes de ferramentas, acertar a versão correta das ferramentas de build e diversos pequenos detalhes que se tornam tão automáticos que acabamos esquecendo de sua importância.
Como geralmente a build automatizada irá rodar em uma máquina limpa, é muito importante automatizar este processo de configuração. Se você adotar uma ferramenta SaaS procure uma que possibilite a configuração automática do ambiente. Caso prepare um ambiente por conta própria, tente usar Docker ou scripts que automatizem esta configuração.
Lint
Quem nunca teve uma build de release interrompida por um warning do Lint que atire a primeira pedra. O Lint pode ser a primeira linha de defesa contra bugs que podem chegar a seus usuários.
Configure o Lint para que rode em suas builds, monitore a evolução da quantidade de warnings ou crie regras para que a build seja interrompida sempre que esse número cresça e o time foque em analisar e corrigir potenciais problemas encontrados pela ferramenta.
Dependências e Velocidade das Builds
Com a facilidade proporcionada pelo Gradle para incluir bibliotecas e utilitários em nossos projetos muitas vezes não prestamos atenção em como isso pode impactar no tempo de build de nossas aplicações.
Se sua build na ferramenta de CI estiver levando muito tempo, lembre-se de verificar quanto tempo o processo está levando para baixar dependências. Como a build na ferramenta de CI pode estar rodando em uma máquina limpa, procure ferramentas que possibilitem o cache de dependências para acelerar o processo.
Também fique de olho em dependências que incluem ferramentas de pré-processamento como o Dagger2 ou mesmo o Kotlin que também podem adicionar tempo ao seu processo de build.
Uma outra causa para o aumento do tempo de build é o crescimento natural da aplicação. Nestes casos considere a modularização por funcionalidades e crie processos de CI separados para cada módulo e para a aplicação principal.
Rode seus Testes
Sempre busque ferramentas de CI que possibilitem que seus testes rodem de forma automática. Para todos os commits que dispararem uma build na ferramenta de CI rode pelo menos os testes unitários (./gradlew testReleaseUnitTest), para commits que são integrados ao branch principal rode testes unitários, de integração e todas as verificações configuradas (./gradlew check).
Lembrem-se de garantir que todos os desenvolvedores saibam como rodar os testes automatizados em suas máquinas, crie guias e páginas wiki, organize seus testes em Test Suites de forma que os desenvolvedores possam rapidamente rodar testes relacionados a um módulo no qual estejam trabalhando.
Testes instrumentados levam muito tempo para serem executados e exigem um emulador ou device externo. Sempre que possível foque-os em testes de aceitação e monitore quantidade e tempo de execução para evitar um crescimento descontrolado do tempo de build. Esse tipo de teste pode ser rodado localmente com o comando ./gradlew connectedAndroidTest. Para ter diversidade de dispositivos para testes por um custo relativamente acessível procure ferramentas de CI que possibilitem a integração com clouds de dispositivos para testes como Firebase Test Lab, Xamarin Test Cloud, AWS Device Farm, Bitbar Testing, Kobiton, Perfecto Mobile, Sauce Labs Mobile Testing, Experitest Mobile Cloud Testing ou crie seu próprio farm com o Open STF.
Automatize o Release e Utilize Ferramentas de Beta
Ter a aplicação sempre disponível e pronta para deploy é realmente algo excelente. No entanto, no universo mobile não é interessante fazer seu usuário baixar atualizações múltiplas vezes por dia. A frequência de releases de um app Android pode afetar a percepção dos usuários sobre o app, se for muito frequente a aplicação pode parecer cheia de problemas e se pouco frequente, abandonada. Faça testes e encontre o equilíbrio para o seu público. De qualquer maneira, é importante escolher ferramentas que possibilitem o deploy diretamente para Play Store quando desejado.
Releases frequentes podem ser especialmente importantes para distribuir o aplicativo para públicos internos ou selecionados e coletar feedbacks o mais rápido possível. Algumas opções incluem o Crashlytics Beta, Hockey App, Buddy Build, Fastlane, TestFairy.
Ferramentas de CI com Suporte ao Android
Existem diversas ferramentas que podem ser utilizadas para criação de uma estrutura CI para um projeto Android. Abaixo segue uma lista não definitiva e não priorizada de algumas delas:
Recentemente participei de um projeto no qual, ao conversar com o time e áreas relacionadas, percebi uma oportunidade de melhoria do processo de integração contínua. A aplicação Android já era desenvolvida a aproximadamente 4 anos, o time de desenvolvimento era bem novo (os desenvolvedores Android tinham menos de 1 ano de projeto), o sistema de controle de versionamento utilizado era o Git em combinação com o Github e a ferramenta de CI que estava sendo utilizada era o TeamCity.
Apesar de possuir uma ferramenta de CI que automatizava o processo de build, poucas das outras práticas de CI foram implementadas e algumas reclamações eram muito comuns: medo de refatorar o código e integrar novas alterações, falta de visibilidade de quais solicitações faziam parte de cada release, ocorrência de bugs alta, bugs corrigidos que ressurgiam, demora na liberação de novas versões finais e intermediárias, difícil saber qual o estado atual da aplicação e dificuldade em manter a ferramenta de CI.
Inicialmente resolvemos atuar na melhoria da utilização do Git. O projeto não possuía um fluxo bem definido de utilização, o que impactava diretamente no entendimento do time do que estava sendo integrado e na eficiência dessas integrações. Adotamos como referência o Git Flow que nos permitiu organizar e ter uma visão clara do que estava em produção, desenvolvimento, releases candidatas etc. Uma parte importante desta etapa foi o trabalho conjunto com os desenvolvedores para deixá-los mais confortáveis no uso do Git, facilitando a continuidade do uso do modelo escolhido.
O passo seguinte foi atuar na ferramenta de integração contínua. A ferramenta em uso era o TeamCity que, apesar de madura, no setup que havia sido feito trazia algumas dificuldades: configuração manual do ambiente Android em máquina Windows, mistura de scripts de build em powershell e gradle, disparo da build manual, complexidade de configuração e manutenção da ferramenta para um time com poucos recursos. Optou-se pela migração para uma ferramenta SaaS sem necessidade de gestão e que fosse produtiva na configuração da build para Android, a ferramenta escolhida foi o Bitrise.io que possibilitou: a configuração completa em poucas horas, configuração de cache de dependências, integrações com Slack, Github (para tagging), Crashlytics Beta, publicação de apks em repositório próprio, o disparo de builds automático de acordo com as branches que recebem alterações no github, além da execução de testes unitários.
A terceira etapa, que está em andamento no momento, é a adoção das práticas de CI pelo time que, mesmo com comprometimento, leva um pouco mais de tempo e disciplina para que todo o processo se torne um hábito. Além disso, melhorar a cobertura da suite de testes para que o time tenha mais confiança ao submeter alterações tem sido um grande desafio, já que a cobertura atual é baixa e a arquitetura em uso no momento não colabora com este processo.
Para o futuro a ideia é aumentar a cobertura dos testes unitários e criar suites específicas para testes de aceitação, estudar formas de viabilizar os testes instrumentados em conjunto com o Bitrise.io e incluir ferramentas de análise estática de código como o FindBugs e o CheckStyle.
Conclusão
CI não é algo novo ou revolucionário, Kent Beck já falava dessa prática em seu livro Extreme Programming Explained de 1999. Seu conjunto de técnicas e sugestões simples continuam sendo atuais e podem ser aplicados para beneficiar seu dia a dia como desenvolvedor trazendo ganhos de produtividade e de qualidade nas entregas.
Portanto, se você tem perdido o sono, e talvez os cabelos, toda vez que precisa integrar mudanças ou liberar uma nova versão de sua aplicação, considere aplicar práticas de CI no seu dia a dia. A maioria delas depende apenas do comprometimento do time, com uma boa conversa e dedicação em pouco tempo é possível perceber a evolução na produtividade e qualidade das entregas, além do retorno de uma boa dose de tranquilidade à suas atividades.
Você tem adotado integração contínua em seus projetos Android? Como tem sido a experiência?
I told you about the new AWS Application Load Balancer last year and showed you how to use it to do implement Layer 7 (application) routing to EC2 instances and to microservices running in containers.
Some of our customers are building hybrid applications as part of a longer-term move to AWS. These customers have told us that they would like to use a single Application Load Balancer to spread traffic across a combination of existing on-premises resources and new resources running in the AWS Cloud. Other customers would like to spread traffic to web or database servers that are scattered across two or more Virtual Private Clouds (VPCs), host multiple services on the same instance with distinct IP addresses but a common port number, and to offer support for IP-based virtual hosting for clients that do not support Server Name Indication (SNI). Another group of customers would like to host multiple instances of a service on the same instance (perhaps within containers), while using multiple interfaces and security groups to implement fine-grained access control.
These situations arise within a broad set of hybrid, migration, disaster recovery, and on-premises use cases and scenarios.
Route to IP Addresses
In order to address these use cases, Application Load Balancers can now route traffic directly to IP addresses. These addresses can be in the same VPC as the ALB, a peer VPC in the same region, on an EC2 instance connected to a VPC by way of ClassicLink, or on on-premises resources at the other end of a VPN connection or AWS Direct Connect connection.
Application Load Balancers already group targets in to target groups. As part of today’s launch, each target group now has a target type attribute:
instance – Targets are registered by way of EC2 instance IDs, as before.
ip – Targets are registered as IP addresses. You can use any IPv4 address from the load balancer’s VPC CIDR for targets within load balancer’s VPC and any IPv4 address from the RFC 1918 ranges (10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16) or the RFC 6598 range (100.64.0.0/10) for targets located outside the load balancer’s VPC (this includes Peered VPC, EC2-Classic, and on-premises targets reachable over Direct Connect or VPN).
Each target group has a load balancer and health check configuration, and publishes metrics to CloudWatch, as has always been the case.
Let’s say that you are in the transition phase of an application migration to AWS or want to use AWS to augment on-premises resources with EC2 instances and you need to distribute application traffic across both your AWS and on-premises resources. You can achieve this by registering all the resources (AWS and on-premises) to the same target group and associate the target group with a load balancer. Alternatively, you can use DNS based weighted load balancing across AWS and on-premises resources using two load balancers i.e. one load balancer for AWS and other for on-premises resources. In the scenario where application-A back-ends are in VPC and application-B back-ends are in on-premises locations then you can put back-ends for each application in different target groups and use content based routing to route traffic to each target group.
Creating a Target Group
Here’s how I create a target group that sends traffic to some IP addresses as part of the process of creating an Application Load Balancer. I enter a name (ip-target-1) and select ip as the Target type:
Then I enter IP address targets. These can be from the VPC that hosts the load balancer:
Or they can be other private IP addresses within one of the private ranges listed above, for targets outside of the VPC that hosts the load balancer:
After I review the settings and create the load balancer, traffic will be sent to the designated IP addresses as soon as they pass the health checks. Each load balancer can accommodate up to 1000 targets.
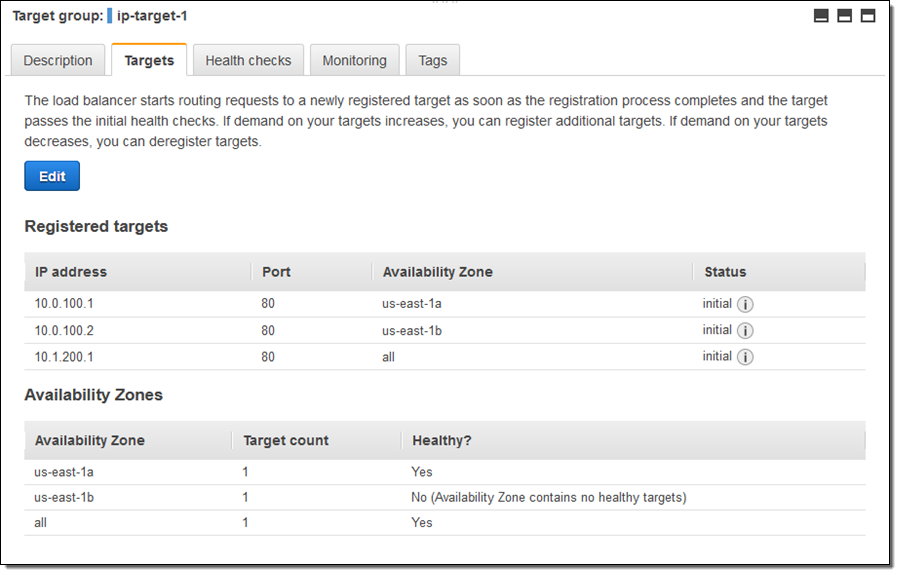
I can examine my target group and edit the set of targets at any time:
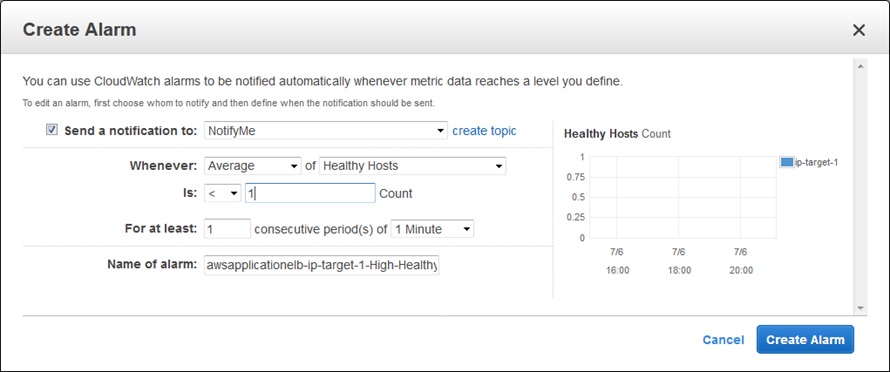
As you can see, one of my targets was not healthy when I took this screen shot (this was by design). Metrics are published to CloudWatch for each target group; I can see them in the Console and I can create CloudWatch Alarms:
Available Now
This feature is available now and you can start using it today in all AWS Regions.
Ferramentas como o tmate e shellshare tem como função compartilhar seu terminal, instantaneamente, de qualquer lugar e com qualquer pessoa autorizada. Muito útil para compartilhar com colegas de trabalho, clientes ou em sala de aula. Esses programas são usados para que outros possam ver o que está sendo executado e, em alguns casos, interagir com o sistema.
Compartilhamento do terminal
Caso necessite compartilhar algo que está sendo feito no terminal Linux, ferramentas com este fim são uteis para você! Gravar toda a tela do computador é uma opção, mas talvez não das melhores, principalmente, se deseja que a outra pessoa interaja com sua sessão.
Pode ser bem interessante para treinamentos, apresentações práticas ou, simplesmente, compartilhamento de recursos. A ideia é semelhante a grandes serviços de compartilhamento de área de trabalho, como o TeamViewer e o Guacamole. Contudo, essas têm o foco no terminal Linux
tmate – “Instant terminal sharing”
tmate é um fork, multiplataforma (GNU/Linux, MacOS e BSD), do famoso tmux – multiplexador terminal que permite usar vários programas com um único terminal como se tivéssemos vários. O tmate estabelecerá uma conexão segura através do SSH para o servidor tmate.io e gerará uma URL aleatória, de conexão SSH, para cada sessão.
Assim, você poderá compartilhar essa URL com quem você quiser, desde que seja de sua confiança para que eles possam se conectar através deste link no seu terminal. Com a conexão ativa/estabelecida, a outra pessoa poderá administrar remotamente seu sistema, igualmente numa conexão SSH. A diferença é que você poderá visualizar tudo o que estiver sendo feito e encerrar a conexão quando achar conveniente; executando o comando ‘exit’. Um espécie de TeamViewer para terminal Linux
tar -zxvf tmate-*.tar.gz
cd tmate-2.2.1-static-linux-amd64/
./tmate
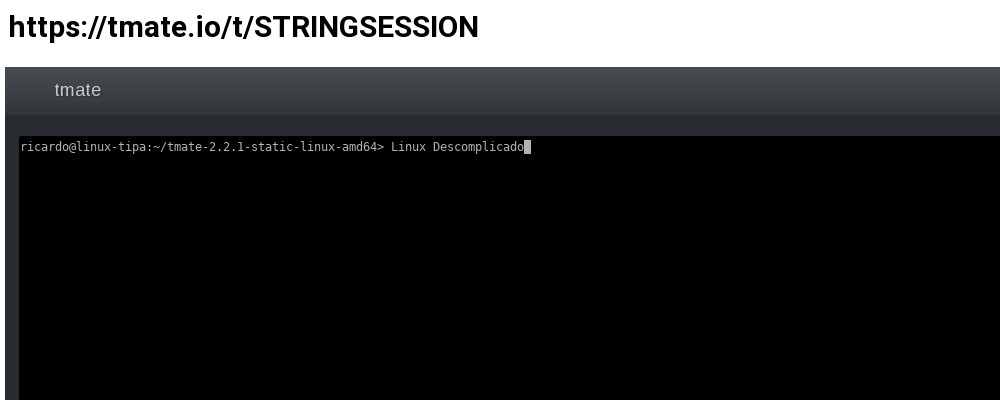
Uma vez instalado (ou arquivo tar.gz descompactado), você poderá executar um simples ‘tmate’ para iniciar uma conexão e compartilhá-la com qualquer pessoa. Caso queira compartilhar e interagir via web, através de uma URL, você poderá capturar a URL gerada para sua sessão e repassar para quem desejar. Depois de iniciado a sessão tmate, execute:
./tmate show-messages
Tue Aug 22 15:56:04 2017 [tmate] Connecting to ssh.tmate.io…
Tue Aug 22 15:56:05 2017 [tmate] Note: clear your terminal before sharing readonly access
Tue Aug 22 15:56:05 2017 [tmate] web session read only: https://tmate.io/t/ro-mfyWNJPDd4DMcf9t2aEVS7WV9
Tue Aug 22 15:56:05 2017 [tmate] ssh session read only: ssh ro-mfyWNJPDd4DMcf9t2aEVS7WV9@ny2.tmate.io Tue Aug 22 15:56:05 2017 [tmate] web session: https://tmate.io/t/Dvidjm8Ty6a6YgbC4pHD97hXW
Tue Aug 22 15:56:05 2017 [tmate] ssh session: ssh Dvidjm8Ty6a6YgbC4pHD97hXW@ny2.tmate.io
Compartilhe a URL gerada e veja no navegador web o resultado:
Para mais informações sobre seu funcionamento você pode visitar o site oficial do projeto. Por exemplo, você pode montar seu próprio servidor local tmate.io
O objetivo do shellshare é fornecer uma maneira fácil de transmitir ao vivo o que está sendo feito no terminal. Sem inscrição, configurações ou qualquer coisa: simplesmente baixar e executar um script python Assim, basicamente, o requisito é ter o python instalado e com versão superior a 2.7:
Current terminal size is 40×151.
It’s too big to be viewed on smaller screens.
You can resize it anytime. Sharing terminal in https://shellshare.net/r/YcwilfVWn5zmiHOM7s
Através da URL gerada você poderá visualizar, em tempo real, o que está sendo feito na sessão de terminal liberada para apresentação! Contudo, diferentemente, do tmate, ele não permite interação; apenas visualização. Também, não permite gravação.
Os serviços da Uber dependem da precisão das ferramentas de previsão de eventos. Desde estimar a demanda do motorista em uma determinada data até prever quando uma ordem UberEATS chegará, a Uber usa algoritmos de previsão para melhorar as experiências do usuário (UX) em nosso portfólio de produtos.
Para arquitetar uma experiência de previsão precisa e facilmente interpretável para engenharia e operações, nós construímos um sistema de previsão personalizado, alavancando um mecanismo open source de pesquisa RESTful distribuído, composto pelo mecanismo de consulta Elasticsearch, o pipeline de indexação de dados Logstash e a ferramenta de visualização Kibana (ELK). Simples, mas poderosa, nossa arquitetura resultante é facilmente escalável e funciona em tempo real.
Neste artigo, nós discutimos por que e como construímos esse sistema e compartilhamos as melhores práticas e lições aprendidas com o trabalho com o Elasticsearch.
Projetando um sistema de previsão personalizado
A qualidade das nossas previsões é medida pela forma como elas correspondem aos resultados finais dos recursos de viagem, como a taxa de conrrespondencia do uberPOOL, a qualidade da correpondência etc.
Precisávamos criar uma arquitetura altamente personalizável para que nosso sistema de previsão pudesse se sincronizar com nossos produtos existentes porque:
Alguns recursos de viagem só se aplicam a uberPOOL, por exemplo, taxa de correspondência e qualidade da correspondência.
Características específicas de nossos produtos – uberPOOL, uberX, UberBLACK etc. – muitas vezes apresentam características de viagem de impacto. Por exemplo, pickup dinâmico e dropoff é um recurso que existe no uberPOOL, mas não no uberX ou no UberBLACK, e pode afetar a equação geral.
O comportamento do motorista e do passageiro, como ir a uma rota diferente da sugerida pela Uber, pode afetar as previsões.
Para cumprir as especificações acima, definimos os requisitos de produto do nosso novo sistema de previsão como:
Ser consciente do produto. Distinguir com precisão o produto que o motorista estava usando e alterar nossas previsões, se necessário, é fundamental para um UX contínuo.
Garantir um erro médio baixo por produto. O erro médio de previsão de cada produto precisa ser o mais próximo possível de zero para manter a precisão geral de nossas previsões.
Manter um erro absoluto médio baixo por produto. Além disso, o erro de previsão absoluta média de cada produto precisa ser o mais próximo possível do zero para garantir a precisão de tempo ou local.
Além de atender aos requisitos do produto, precisávamos cumprir padrões específicos de engenharia. Alta disponibilidade, baixa latência, escalabilidade e facilidade de operação são cruciais para o sucesso do nosso sistema de previsão, já que o modelo serviria para milhões de usuários em centenas de cidades e dezenas de países. Depois de definir essas diretrizes, apresentamos os planos para algoritmos que poderiam atender a esses benchmarks, avaliando os designs online e offline.
Arquitetando um algoritmo online
Na Uber, muitas vezes usamos uma combinação de dados de viagem no histórico e em tempo real para treinar nossos algoritmos de previsão de viagem. Embora possamos prever alguns padrões como a densidade da viagem e a taxa de conrrespondência, dependendo da localização, data, hora e outras variáveis estabelecidas, esses padrões se ajustam à medida que nossos sistemas avançam e as operações se expandem para novos mercados. Como resultado, capturar a dinâmica do sistema em tempo real ou em tempo quase real é fundamental para a precisão da previsão.
Em nosso esforço para maximizar a precisão, decidimos usar um algoritmo online que não requer muito treinamento e trabalho de manutenção de modelos. Escolhemos o algoritmo de vizinhos mais próximos (KNN), que encontra k vizinhos mais próximos (ou seja, viagens no histórico semelhantes durante um período de tempo) e, em seguida, executa uma regressão sobre elas para criar uma previsão. Esse algoritmo de dois passos funciona:
Escolhendo k candidatos com base em nossa função de similaridade autodefinida derivada de recursos como: geolocalização, tempo etc.
Calculando os pesos para cada candidato selecionado com base na função de similaridade e na média ponderada para cada variável de resposta como saída.
Enquanto a segunda parte desse algoritmo é principalmente computação local e apresenta pouco desafio de engenharia, a primeira parte é mais desafiadora. Essencialmente um problema de busca em larga escala, esta etapa requer uma função de similaridade relativamente complexa para classificar os candidatos e selecionar o K classificado como o melhor para a segunda parte do algoritmo. Nosso objetivo aqui é agrupar o histórico das viagens mais parecidas de uma grande quantidade de viagens. É muito difícil classificar todas as viagens usando a função de similaridade em um mecanismo de busca devido à diversidade e à quantidade de dados. Em vez disso, conseguimos isso em duas etapas:
Reduzir o espaço de pesquisa aplicando uma lógica de filtragem de alto nível, por exemplo, filtragem de dados por cidade ou ID do produto.
Executar um ranking baseado em similaridade no conjunto de dados reduzido e selecionar o K com o melhor ranking.
Embora seja poderoso, o KNN é um algoritmo desafiador para usar ao se lidar com dados em grande escala. Para utilizá-lo efetivamente, precisávamos de um armazenamento robusto e um mecanismo de busca capaz de lidar com milhares de consultas por segundo (QPS) e centenas de milhões de registros por vez. Também precisávamos de suporte para consulta geoespacial para auxiliar na filtragem de candidatos k.
Usando ELK como armazenamento de dados e mecanismo de pesquisa
Embora tenhamos observado brevemente outros bancos de dados que suportam consultas geoespaciais como o MySQL, nossas exigências de flexibilidade de esquema e requisitos de pesquisa facilitaram a decisão de usar uma solução ELK open source para alimentar nossa loja de dados e mecanismo de busca.
O ELK, construído com Elasticsearch, Logstash e Kibana, é uma solução integrada para pesquisar e analisar dados em tempo real. O Elasticsearch, peça central da solução, é um mecanismo de busca construído em cima do Apache Lucene. Ele fornece pesquisa distribuída e de texto completo com uma interface RESTful e documentos JSON schema-free. O Logstash é um mecanismo de coleta de dados e log-parsing, e o Kibana é um plugin de visualização de dados e analytics para o Elasticsearch.
O ELK foi uma escolha fácil para nós, porque ele oferece pesquisa de texto completo, consulta geoespacial, flexibilidade de esquema e um pipeline de dados fácil de montar (ele pode carregar dados em tempo quase real ingerindo tópicos da Kafka.) O ELK forneceu a flexibilidade necessária para atender às nossas diretrizes de engenharia e fornecer um sistema de previsão preciso e rápido para nossos passageiros.
Arquitetura do sistema
Em um nível básico, nossa arquitetura de previsão foi construída usando Kafka para streaming de dados, Hive como data warehouse para gerenciar consultas e analytics, e quatro serviços internos separados que usam a pilha ELK para criar um sistema de previsão robusto. Abaixo, descrevemos esses quatro serviços e a arquitetura geral:
Serviço de previsão: entrega previsões em tempo real para usuários.
Serviço de treinamento: treina parâmetros e pipelines de dados offline.
Serviço de viagem: administra o estado das viagens através do seu ciclo de vida, desde o pedido até a conclusão.
Serviço de configuração: armazena e serve parâmetros treinados para outros serviços.
Legenda da imagem: A arquitetura completa do nosso sistema de previsão em tempo real é composta por pipelines de dados, treinamento e lógica de serviço.
Pipelines de dados
Nosso armazenamento de dados é composto de dados de viagem completos e métricas, como tempo de viagem, distância e custo. Para trabalhar de forma rápida e eficiente, nosso pipeline deve ser capaz de ingerir e entregar esses dados de viagem em tempo quase real. Nossa solução é publicar dados em um tópico Kafka no final de uma viagem. A partir daí, o Logstash ingeriu o tópico Kafka, transformando e indexando os dados no Elasticsearch. O pipeline de dados é configurado para consultas imediatas de dados, garantindo o melhor desempenho usando as viagens mais recentes. Também precisamos de uma loja primária para armazenamento e analytics; nós alavancamos o Hive como uma ferramenta de extrato, transformação e carga (ETL) para gerenciar dados processados pelo Kafka. Com esses dois pipelines de dados, usamos o ELK para consultas em tempo real e o Hive para treinamento e analytics.
Parâmetros de treinamento
A regressão KNN é um algoritmo online, o que significa que não precisamos treinar modelos para isso. Mas os valores para k e os parâmetros de regressão ainda precisam ser treinados e selecionados de forma apropriada. Construímos um serviço de treinamento para selecionar valores para K e parâmetros de regressão. Esse serviço pode treinar esses parâmetros em diferentes granularidades, bem como produzir valores padrão globais, valores por país, valores por cidade e valores por produto. Uma vez que esses parâmetros são treinados, o serviço de treinamento empurra os valores para o nosso serviço de configuração dinâmico.
A partir daí, o serviço de configuração entrega parâmetros acionáveis para o nosso serviço de previsão. O serviço de viagem então chama as métricas previstas do nosso serviço de previsão para a próxima viagem. Nessa etapa, nosso serviço de previsão consulta o Elasticsearch para candidatos e o serviço de configuração para parâmetros, alimentando-os no algoritmo para gerar previsões. Os resultados da previsão são devolvidos ao nosso serviço de viagem e armazenados como dados de viagem, mais tarde serão publicados no Elasticsearch e no Hive para que possamos acompanhar o desempenho de nossas previsões para treinar os futuros parâmetros e melhorar a precisão.
Crescendo em uma escala Uber
Nosso sistema de previsão foi otimizado para escalabilidade horizontal em mercados e produtos, por isso foi relativamente fácil implementá-lo e mantê-lo no início. No entanto, à medida que expandimos nossa escala para incorporar mais produtos em mais cidades, tivemos que considerar a alta latência causada por uma pausa de garbage collection e falhas em cascata induzidas por excesso de CPU. Essas duas questões são causadas pela sobrecarga dos nós Elasticsearch, por isso focamos nossos esforços em melhorar o desempenho da pesquisa e projetar uma arquitetura mais escalável.
Reduzindo o tamanho da consulta para melhorar o desempenho da pesquisa
O tamanho dos dados importa no Elasticsearch; um índice grande significa dados demais, caching churn e tempo de resposta ruim. Quando os volumes de consulta são grandes, os nós ELK ficam sobrecarregados, causando longas pausas de coleta de lixo ou até interrupções do sistema.
Para resolver isso, mudamos para consultas hexagonais, dividindo nossos mapas em células hexagonais. Cada célula hexagonal tem uma ID de string determinada pelo nível de resolução hexagonal. Uma consulta de geodistância pode ser aproximadamente traduzida em um anel de IDs de hexágono; embora um anel hexagonal não seja uma superfície circular, está próximo o suficiente para o nosso caso de uso. Devido a esse ajuste, a capacidade de consulta do nosso sistema mais do que triplicou.
Escalando horizontalmente com clusters virtuais
À medida que o sistema se expande para novos mercados, precisamos adicionar mais nós aos nossos clusters. Um método comum de escalar o Elasticsearch é adicionar mais nós horizontalmente. Para isso, organizamos dados de viagem em índices diários, com cada índice possuindo um único fragmento replicado para todos os nós de dados no cluster. Um HAProxy é implementado para equilibrar o tráfego de pesquisa em todos os nós de dados no cluster. Nesse modelo, o sistema é linearmente escalável em relação ao número de nós do cluster.
Entretanto, conforme os nós são adicionados, o cluster desestabiliza. Enquanto uma única arquitetura de cluster pode lidar com aproximadamente três mil consultas por segundo, nosso sistema totaliza 40 nós (e contando) em um tamanho de 500 GB por nó. Nesse escopo, o custo da comunicação inter-nó de cluster começa a superar o benefício de usar um grande cluster.
Para superar essa limitação, desenvolvemos um cluster virtual. Uma escolha arquitetônica incomum, os clusters virtuais consistem em múltiplos clusters físicos que compartilham o mesmo alias de cluster. Os aplicativos acessam o cluster virtual através do HAPROxy, especificando o alias de cluster, e as solicitações podem ser encaminhadas para qualquer um dos clusters com o alias de cluster. Com essa arquitetura, conseguimos escalabilidade praticamente ilimitada, apenas adicionando mais clusters.
Lições aprendidas: Elasticsearch como um banco de dados NoSQL
Usamos o Elasticsearch como um armazenamento secundário que empurra dados para ele de forma assíncrona, porque não foi projetado para ter consistência. Para efetivamente utilizar seus valiosos recursos de pesquisa, precisamos operar o Elasticsearch com cuidado. Abaixo, descrevemos algumas lições aprendidas trabalhando com essa base de dados poderosa mas complexa:
Proporcionar recursos suficientes. O Elasticsearch funciona bem quando é alimentado por recursos amplos. Ele é projetado para velocidade e recursos poderosos, com a suposição de que hardware e pessoal são abundantes. No entanto, ele hesita quando os recursos são restritos. Para tirar o máximo de proveito do Elasticsearch, você precisa entender a escala com a qual está lidando e fornecer recursos suficientes.
Organize dados de acordo com sua lógica de negócios. Quando o tamanho de seus dados é muito grande para caber em um nó, você precisa organizar seus dados de forma inteligente.
Solicite consultas Elasticsearch para obter ganhos de eficiência. O Elasticsearch suporta muitos filtros em sua consulta, e essa solicitação afeta muito o desempenho. Os filtros mais específicos devem ser priorizados e colocados antes de filtros menos específicos para que possam filtrar o máximo de dados possível, o mais cedo possível, no processo de consulta. Filtros menos intensivos em recursos devem ser implementados antes de filtros mais intensivos em recursos para que eles tenham menos dados para filtrar. Da mesma forma, os filtros armazenáveis em cache devem ser exibidos antes dos filtros não-cacheáveis, para que os caches possam ser alavancados.
Nossa jornada com previsão e ELK apenas começou – você está pronto?
Atualização: desde que a Uber começou a usar o ELK, a pilha ELK se expandiu para incluir tecnologias adicionais e agora é chamada de Elastic Stack.
***
Este artigo é do Uber Engineering. Ele foi escrito por Guocheng Xie e Yanjun Huang. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em:https://eng.uber.com/elk/
Você ouve falar frequentemente sobre o React, mas sabe pouco sobre assunto? Ou já até estudou a respeito da biblioteca desenvolvida pelo Facebook, mas quer consolidar seus conhecimentos?
Então este artigo é para você.
Introdução
Para começar, precisamos saber o que é o React. Para isso, não há nada melhor do que utilizar a definição de quem o criou, o próprio Facebook:
Uma biblioteca JavaScript declarativa, eficiente e flexível para criar interfaces visuais.
Com isso, sabemos que:
O React não é um framework, mas uma biblioteca (library);
O React serve para criar interfaces visuais (UI).
Essas duas informações juntas criam a primeira grande confusão para quem está começando: se o React é apenas uma biblioteca e só serve para criar UI, como posso criar aplicações completas com ele?
Para resolver esta questão precisamos entender que quando a comunidade se refere ao React ela está querendo dizer ‘o React e o seu ecossistema‘. E esse ecossistema é formado por:
React
JSX
ES2015
Webpack
Flux/Redux
Axios/Fetch
Jest/Mocha
Assim, com todos esses itens que fazem parte do ecossistema do React, conseguimos afirmar que é possível sim criar aplicações completas usando ele.
JSX
Explicando de forma rápida, o JSX é uma extensão de sintaxe do JavaScript (daí o nome JavaScript Syntax eXtension) que nos permite escrever HTML dentro do JavaScript.
Nos primórdios, o JSX era um dos grandes motivos das críticas e piadas em relação ao React, porque, em teoria, estávamos voltando no tempo ao misturar HTML com JavaScript.
Os críticos mais ferrenhos afirmavam que o JSX quebrava um dos princípios básicos do desenvolvimento de software, que é o Separation of Concerns. Na minha opinião, essa visão é errada por dois motivos:
O React em si, a biblioteca e não o ecossistema, como já falei anteriormente, representa apenas a parte da view da sua aplicação. Portanto, por definição, ele tem apenas um concern: renderizar a UI. Então quais concerns estão sendo violados?
E mesmo que o JSX violasse esse princípio a área de tecnologia evolui (e muito) com o tempo. Se um dos princípios que nós sempre demos como verdade não fizer mais sentido para um determinado cenário, deveremos nos forçar a seguir esse princípio mesmo assim?
Independente das minhas opiniões pessoais, com o tempo a comunidade percebeu que o JSX foi uma decisão acertada e que acabou se tornando um dos grandes alicerces do sucesso do React.
Componentes
Como foi dito anteriormente, o React tem como função principal auxiliar na criação da UI. Só deixei um detalhe importante de fora: o React usa componentes e apenas componentes para que seja possível aumentar o máximo do reuso em sua aplicação.
Para exemplificar, vamos ver um pouco de código para entender como é um componente React:
A função acima (sim, componentes React podem ser simplesmente funções em JavaScript) gera um botão que mostra um alert para o usuário ao ser clicado.
Se precisarmos de outro botão como esse, basta reaproveita-lo sem a necessidade de adicionar mais código na aplicação. Lembrando que ‘mais código’ é sinônimo de mais trabalho, mais testes unitários e mais potenciais bugs inseridos.
E se a necessidade for um botão parecido com esse, basta editarmos passando por alguns parâmetros (vamos falar mais sobre eles na próxima seção) para transformá-lo no que precisamos.
Se houver algum bug no comportamento, ou mesmo no layout do botão, sabemos exatamente onde devemos mexer no código para fazer o conserto rápido.
Em todos os tipos de paradigmas no desenvolvimento de software, passar parâmetros é extremamente comum. Com os componentes do React isso não poderia ser diferente. A diferença é que no React usamos os props (abreviação para properties).
A ideia é simples.
O componente abaixo mostra para o usuário um Hello World:
Imaginando que precisamos mudar a mensagem ‘World’ para alguma outra que for enviada dinamicamente, podemos reescrever esse componente usando as props dessa forma:
Com isso feito, podemos chamar esse componente dentro de outros, dessa maneira:
Além disso, podemos fazer uma validação das props que são passadas pelo componente para evitar bugs desnecessários e assim facilitar o desenvolvimento da aplicação usando os PropTypes:
Agora, informamos explicitamente ao React para que apenas aceite a prop quando ela for uma string. Se qualquer outra coisa for passada para esse componente, a aplicação irá falhar e receberemos uma mensagem de erro nos avisando o porquê.
O Flow e o TypeScript são outras possibilidades para lidar com os PropTypes.
State
O estado (ou state) da sua aplicação pode ser definido como o lugar onde os dados vêm e se transformam ao longo do tempo. Dito isso, os componentes React podem ser divididos em duas categorias: Presentational e Container. Outra nomenclatura usada na comunidade para esses dois é Stateless (sem estado) e Stateful (com estado).
Os componentes do tipo Presentational se importam somente com a apresentação dos dados, portanto não tem estado (stateless). Eles podem ser escritos como uma simples função:
O ideal é escrever o máximo possível de componentes dessa categoria; eles são mais fáceis de desenvolver, manter e testar.
Já os componentes do tipo Container, além da apresentação dos dados, têm que lidar também com algum tipo de lógica ou transformação de dados, por isso necessitam de estado (stateful). Esses componentes não podem ser escritos como uma função, eles obrigatoriamente devem ser uma classe:
Os dois exemplos mostrados acima têm exatamente o mesmo resultado final. A única diferença é que o primeiro deles não usa o state do React, enquanto o segundo usa.
Podemos ainda complicar um pouco mais o segundo exemplo para demonstrar como é possível alterar o estado do seu componente React:
Em cada mudança que ocorrer no input (linha 16) um evento é disparado na função change, que por sua vez altera o estado do componente usando a função setState, nativa do React.
Toda vez que o estado for alterado o React automaticamente invoca de novo a função render, que irá renderizar a UI com os novos dados inputados pelo usuário.
One-way data binding
É bem mais fácil falar dos benefícios do one-way data binding (ou one-way data flow) demonstrando o fracasso do seu “concorrente”, o two-way data binding.
O Angular.js ganhou muitos usuários, principalmente entre 2012 e 2015, e um dos principais motivos disso foi justamente o two-way data binding.
https://docs.angularjs.org/guide/databinding
O two-way data binding funciona assim: se uma mudança acontece na view, ela é refletida automaticamente no model, e vice-versa.
No começo, o two-way data binding parecia uma excelente ideia. Com o tempo, após inúmeros projetos construídos usando essa tecnologia, ela se mostrou extremamente nociva principalmente por dois motivos:
A própria equipe do Angular resolveu limitar essa funcionalidade nas novas versões do framework.
O React porém, percebeu essa falha desde o início e estimulou apenas o uso do one-way data binding.
Não existe um mecanismo no React que permita com que o HTML altere os dados do componente ou vice-versa. Essa mudança é sempre feita de forma explícita pelo desenvolvedor. Lembrando que explícito é muito melhor em termos de desenvolvimento, manutenção e testes, do que implícito.
Um exemplo simples de one-way data binding em ação no React pode ser visto no componente abaixo:
Se estivéssemos no mundo two-way data binding do Angular.js, o model e a view estariam conectados implicitamente e ambos mudariam juntos.
Porém, com o one-way data binding do React, precisamos explicitamente invocar a função setState para que o estado seja alterado. Dessa forma temos muito mais previsibilidade e segurança da nossa aplicação, o que fica evidente conforme a aplicação cresce.
Lifecycle
Para que seja possível o desenvolvimento de componentes mais complexos, alguns métodos foram adicionados na API dos componentes React. Eles fazem parte do Component Lifecycle (ciclo de vida dos componentes).
Com esses métodos, os desenvolvedores podem saber, por exemplo, quando um componente vai ser criado, destruído, atualizado etc.
São esses os métodos de Lifecycle dos componentes:
componentWillMount: executado logo antes do primeiro render. Não é muito usado, geralmente faz mais sentido simplesmente usar o próprio construtor da classe;
componentDidMount: executado logo após o primeiro render, provavelmente o método mais usado. Alguns exemplos de casos de uso são: chamadas AJAX, manipulação do DOM, início de setTimeouts e setIntervals etc;
componentWillReceiveProps: executado quando as props que o componente recebe são atualizadas. Geralmente é usado quando os componentes precisam reagir aos eventos externos;
componentWillUpdate: é igual ao componentWillMount, só que ele executa logo antes da atualização de um componente;
componentDidUpdate, é igual ao componentDidMount, só que ele executa logo depois da atualização de um componente.
componentWillUnmount, executado quando o ciclo de vida de um componente termina e ele vai ser removido do DOM. É muito usado para remover setTimeouts e setIntervals que foram adicionados.
shouldComponentUpdate, deve retornar true/false. Esse valor vai dizer que se o componente deve ser atualizado ou não, com base em certos parâmetros. Geralmente é usado para resolver questões de performance.
Um exemplo simples de uso dos métodos de lifecycle é o contador de segundos abaixo:
Assim que o componente é montado (componentDidMount), iniciamos o setInterval que a cada 1000ms invoca a função tick. E quando o componente for destruído (componentWillUnmount) removemos o setInterval para que a função tick não continue sendo chamada desnecessariamente.
Virtual DOM
A manipulação do DOM está no centro do desenvolvimento front-end moderno. Fazemos isso basicamente todos os dias, o que acarreta dois problemas:
Essa manipulação direta do DOM é mais lenta do que a maioria das operações feitas pelo JavaScript;
A maioria dos frameworks JavaScript alteram muito mais o DOM do que deveriam.
Sabendo disso, o Facebook criou o Virtual DOM, que funciona da seguinte forma: no React, uma cópia de todos os nodes do DOM são replicados em código JavaScript. Em vez de fazer alterações diretamente no DOM (que são lentas) elas são feitas no Virtual DOM (rápidas) e somente quando realmente necessário, essas alterações são repassadas para o DOM original.
Esse é um dos principais motivos para os excelentes benchmarks de performance que o React tem.
Agora que já entendemos as partes fundamentais do React, precisamos entender também o seu ecossistema.
create-react-app
Nos primeiros anos do React, uma das principais críticas era de que iniciar uma aplicação era muito mais complicada do que deveria ser, o que acabava excluindo diversos iniciantes.
Antes de sequer começar a primeira linha de código em React, os desenvolvedores precisavam aprender no mínimo o Webpack e ES2015.
Hoje isso não é mais um problema. A equipe do Facebook vem trabalhando diariamente no projeto create-react-app, logo, agora com apenas quatro simples comandos, sem ter que criar ou editar qualquer configuração, temos um arcabouço completo para começar a desenvolver aplicações em React.
CSS-in-JS
Todas as boas práticas ao se escrever CSS apontavam para um mesmo caminho por anos: escrever CSS o mais desacoplado possível do JavaScript e do HTML, usando nomes bem descritivos para as classes.
O problema dessa abordagem é que ela não resolve o maior defeito do CSS: tudo o que você cria é global.
Cada vez que você cria uma nova classe CSS ela é, por definição, global, o que gera diversos problemas na manutenção, principalmente em aplicações maiores.
Com o grande sucesso da componentização no React, a forma de se escrever CSS vem mudando drasticamente.
A ideia é simples: escrever o mesmo CSS de sempre com apenas uma diferença: esse CSS só vai valer para aquele componente, ou seja, será um módulo (daí o nome, CSS Modules).
Segue um exemplo simples de uso do CSS Modules e o arquivo de estilos que só valerá para o componente acima:
Nele, o próprio componente já teria seus estilos escritos em JavaScript, sem que nenhum arquivo CSS fosse sequer criado. Uma das vantagens do styled-components é que o code-splitting fica muito mais fácil de ser feito e assim como o CSS Modules, não existe CSS global. A desvantagem é que você não escreve o CSS padrão, o qual muitos já estão acostumados, o que pode não ser muito intuitivo.
Um exemplo simples:
Bundlers
Resolver dependências no front-end, apesar de ser uma questão comum, sempre foi extremamente problemático.
Na maioria dos projetos temos que lidar, no mínimo, com essas questões:
A concatenação e minificação do JavaScript (ou TypeScript, ES2015, CoffeScript, etc) e do CSS (ou Sass, Less, Stylus etc)
Inclusão de Imagens
Adição de Fontes
Dessa necessidade frequente das aplicações front-end surgiram os module bundlers, e no mundo React o bundler mais usado pela comunidade é o Webpack.
O Webpack também consegue prover, além de resolver todos os problemas acima (imagens, fontes e a minificação/concatenação de JavaScript e CSS):
Hot Module Replacement (após salvar o código novo, ele já aparece no browser em ambiente de desenvolvimento sem a necessidade de refresh)
Além de outras features também muito interessantes.
State containers
Para aplicações mais complexas, usar apenas o setState nativo do React pode não ser o suficiente para controlar toda a lógica da aplicação.
Existem diversos gerenciadores de estado feitos exclusivamente para lidar com esse problema, entre eles Flux, MobX, Reflux e o mais famoso deles, o Redux.
Dito isso, toda vez que tivermos que tomar uma decisão de adicionar uma nova biblioteca no projeto temos que pesar o custo/benefício dessa decisão. E para a grande maioria das aplicações que não são complexas o bastante nenhuma das opções acima (inclusive o Redux) são necessárias.
Me preocupa ver na comunidade diversos iniciantes começando a aprender o Redux antes mesmo de entender bem o próprio React ou até mesmo criando projetos já com o Redux, sem antes ter visto se há de fato uma necessidade.
O próprio criador do Redux já falou sobre isso:
Testes
Outro ponto crucial para o desenvolvimento de aplicações web é o uso de testes unitários. As garantias de que os testes nos dão são consideráveis. Podemos refatorar, encontrar e evitar novos bugs e até mesmo para escrever código a partir dos testes (TDD).
No mundo React, a principal ferramenta para escrever testes unitários é o Jest, mais um open source do Facebook.
O Jest tem três vantagens principais em relação aos concorrentes:
Vem com tudo o que você precisa para testar: o runner, as assertions, o report de coverage etc. Não é mais necessário instalar diversas bibliotecas diferentes para poder escrever testes unitários;
Este último é tão interessante que vale a pena nos aprofundar um pouco mais. A ideia das Snapshots é simples: o Jest tira uma “foto” do seu componente e se algo mudar o teste vai quebrar e te avisar dessa mudança, mostrando exatamente como o componente era e como ele ficou.
E isso tudo com pouquíssimas linhas de código:
Conclusão
Para recapitular, neste post aprendemos as partes mais centrais do React como JSX, Virtual DOM, Lifecycle, Componentização, One-way data binding etc. Além disso, conhecemos também os principais atores que fazem parte do ecossistema do React, entre eles Webpack, create-react-app, Jest, CSS Modules etc.
Mas se mesmo assim ficou alguma dúvida, basta colocar nos comentários abaixo.
O AngularJS surgiu dentro do Google em meados de 2008 meio que sem querer.
Um desenvolvedor chamado Misko Hevery precisava resolver um problema específico dentro de algumas aplicações e, depois de codar muito, olhou pro que ele tinha feito e pensou:
“Olha só, acho que dá pra eu deixar isso um pouco mais genérico e liberar pra galera usar”.
E assim nascia o Angular.
Por várias razões, este framework se tornou extremamente popular entre os desenvolvedores e ganhou muita força na comunidade e uma quantidade enorme de adeptos. Teve até muita gente que não precisava, mas mesmo assim construiu sua aplicação com Angular.
O tempo foi passando e o pessoal do Google viu que o monstrinho que eles tinham criado era muito legal, mas havia várias questões que poderiam ser melhoradas. Eles resolveram, então, criar um framework novo, o Angular 2.
Foram lá e reescreveram tudo do zero! Tomando muito cuidado de não repetir os erros da primeira versão e fazendo tudo o melhor possível.
Quando essa segunda versão saiu, alguns devs ficaram um pouco chateados pensando:
“poxa, mas eu estudei tanto a versão 1, agora vou ter que reaprender do zero?”
E eles ficaram ainda mais chocados quando, pouco tempo depois desta segunda versão sair, o Google vir de supetão anunciar o Angular 4!
“Mas pera… Eles acabaram de lançar uma versão nova e logo em seguida lançaram outra? Tá meio estranho isso aí, não tá não?”
De início, pode parecer um pouco confuso sim. Mas no fim das contas é mais simples do que parece!
Pra desmistificar tudo isso aí, eu chamei a Vanessa Tonini pra um episódio do Alura Live!
A Vanessa é instrutora da Caelum e entre os cursos que ela dá, está o de Angular
Nesta palestra será apresentado como elaboramos um sistema IoT de gerenciamento e inferência de dados de sensores em instalações elétricas, e como temos lidado com os desafios da implantação do sistema em um projeto de iluminação pública e em um condomínio corporativo. Vamos discutir as dificuldades encontradas no registro de novos dispositivos, e mais.
“Na primeira vez, eu me emocionei ao ver a tela funcionar com o programa que eu criei”, declarou Masako Wakamiya, 82 anos, revelando uma alegria quase infantil quando fala de sua paixão pela informática.
Desde que se aposentou, esta ex-bancária se diverte com um PC e, mais recentemente, um Mac e um smartphone. A mulher que viveu nos anos 60, 70 e 80 o auge do Japão como potência tecnológica, foi este ano a participante mais veterana na conferência dos desenvolvedores da Apple.
Masako Wakamiya é a criadora do programa lúdico para iPhone “Hinadan”, inspirado no tradicional Festival de Bonecas Hina Matsuri.
Todo 3 de março, os japoneses expõem em uma plataforma de vários níveis bonecas que representam os membros da corte imperial do período Heian (séculos IX a XII) em suas casas, escolas e qualquer outro lugar onde haja meninas.
O palco em forma de escada se instala dias antes de 3 de março e se desmonta nessa mesma noite porque senão, segundo a crença popular, as meninas do lugar podem ficam solteiras quando crescerem.
Em “Hinadan”, o jogador tem que colocar as bonecas (“o imperador”, “a imperatriz”, etc.) no lugar correto. Não há limite de tempo, porque isso seria muito estressante para os idosos, explica Masako Wakamiya, ajoelhada em um tatame em frente à uma tela no seu apartamento de Fujisawa, na periferia de Tóquio.
Seu primeiro encontro com a informática foi no início dos anos 1990. “Nessa época trocava mensagens através do sistema BBS”, precursor dos fóruns modernos, lembra a octogenária.
Do ábaco ao Skype
Quando se começou a desenvolver os smartphones, Masako Wakamiya pensou que não havia aplicativos suficientes para os idosos. Falou com desenvolvedores, sem sucesso. Até que um conhecido lhe perguntou: “Por que você mesma não faz isso?”, conta.
A idosa, que durante décadas contou com um “soroban” (ábaco japonês), se apoiou em livros e pediu conselhos a um amigo que já tinha desenvolvido aplicativos, com quem se comunicava por Skype.
Foi tudo muito rápido. Desenvolvido entre 2016 e o início de 2017, “Hinadan” foi aceito pela Apple e lançado em fevereiro, pouco antes do Hina Matsuri.
“Escrever as linhas de código foi difícil”, reconhece antes de destacar a simplicidade das ferramentas recentes, que considera “muito boas para descobrir as falhas” nos programas.
“Quando se envelhece, se perde muitas coisas: o marido, o salário, o cabelo, a visão… Há muitos ‘menos’. Mas quando se aprende algo, a programar ou a tocar piano, são ‘mais’. O que não sabíamos fazer até ontem, hoje dominamos. É uma motivação”, se entusiasma.
Ocupada demais para envelhecer
Wakamiya acaba de voltar dos Estados Unidos e da Rússia, e se prepara para ir a uma conferência em Sapporo, no norte do Japão.
A empreendedora, cujo aplicativo foi baixado 42.000 vezes, foi a convidada especial do diretor-executivo da Apple na Conferência Mundial de Desenvolvedores que foi realizada na Califórnia no início de junho.
“Falei com Tim Cook sobre aspectos muito concretos. Ele me perguntou o que eu tinha feito para garantir que as pessoas mais velhas pudessem usar o aplicativo. Expliquei que levei em conta o fato de que os idosos perdem a audiência e a visão, e seus dedos podem não funcionar tão bem”, conta.
“Ele me elogiou. Me disse que eu era uma fonte de inspiração para ele”, diz com orgulho.
Em “Hinadan”, as respostas geram sons muito diferentes e acompanhados na tela pelas palavras “erro” ou “certo”, e não é necessário arrastar a boneca com o dedo, mas clicar no lugar escolhido.
O sucesso deu ainda mais energia a Masako-san, que prevê versões do seu aplicativo em inglês, chinês e francês. “Quero aprender as bases da programação, porque até agora só estudei os elementos necessários para criar o Hinadan”.
O objetivo: “Desenvolver outros aplicativos que possam entreter os mais velhos e transmitir aos jovens a cultura e a tradição dos idosos”, afirma, lamentando que sua agenda não lhe deixe muito tempo para mergulhar nos manuais de desenvolvimento que colocou ao lado do seu computador.
“Quando você termina sua vida profissional, seria bom voltar à escola. A maioria dos idosos abandonam a ideia de aprender, mas isso não é bom só para eles mas também para a economia do país”, diz Wakamiya, que começou a tocar piano aos 75 anos e é membro de várias associações para promover a informática entre os idosos.
“Estou tão ocupada todos os dias que não tenho tempo para descobrir se tenho alguma doença”, diz risonha.
"Spam de Améns" faz sistema do Facebook excluir fan pages religiosas "sem querer".
Flavinho, missionário e deputado federal pelo estado de São Paulo, esclareceu o que houve no episódio do banimento de páginas católicas que reuniam milhões de seguidores pelo Facebook no início desta semana sem qualquer aviso prévio ou explicação plausível. O parlamentar relatou que nesta quarta-feira, dia 19, questionou ao diretor de relacionamentos do Facebook Brasil o porquê desta exclusão.
A explicação técnica dada pela rede social é que foi um erro de uma ferramenta de spam do Facebook. “Essa ferramenta detectou nestas páginas bloqueadas uma palavra que gerou a confusão. A palavra foi o amém”, disse o parlamentar citando a explicação do diretor da rede social.
Então teria sido o “uso excessivo” desse termo em pouco espaço de tempo que gerou a exclusão. “A ferramenta que é robotizada detectou esse termo como excessivo e derrubou as páginas”. O deputado assegurou que o diretor do Facebook entendeu o episódio,de fato, como um erro. Ainda segundo ele não foi perseguição religiosa mas erro técnico. Segundo o diretor eles estão trabalhando para que isto não aconteça. Flavinho afirmou que acompanhará os desdobramentos do caso.
Assista ao vídeo em que o deputado esclarece o ocorrido clicando aqui.
Tivemos diversas novidades com o lançamento das versões 17.05 e 17.06 do Docker, que ocorreram nos últimos meses, nosso objetivo é trazer para vocês algumas dessas novidades, iniciaremos com o multi-stage builds, ou em português claro: construção em múltiplos estágios, vamos entender um pouco mais sobre esse conceito, como utiliza-lo e onde ele pode te ajudar no dia-a-dia.
Antes de mais nada, gostaríamos de nos desculpar pelo hiato na publicação de posts, mas garantimos que foi por alguns bons motivos
O que é?
O multi-stage build foi lançado na versão 17.05 e permite que um build possa ser reutilizado em diversas etapas da geração da imagem, deixando os Dockerfiles mais fáceis de ler e manter.
O estado da arte
Uma das coisas mais desafiadoras sobre a construção de imagens é manter o tamanho da imagem reduzido. Cada instrução no Dockerfile adiciona uma camada à imagem, e você precisa se lembrar de limpar todos os artefatos que não precisa antes de passar para a próxima camada. Para escrever um Dockerfile realmente eficiente, você tradicionalmente precisa empregar truques de shell e outra lógica para manter as camadas o mais pequenas possíveis e garantir que cada camada tenha os artefatos que ela precisa da camada anterior e nada mais.
Na verdade, era muito comum ter um Dockerfile para uso para o desenvolvimento (que continha tudo o que era necessário para construir sua aplicação), e outro para usar em produção, que só continha sua aplicação e exatamente o que era necessário para executá-la. Obviamente a manutenção de dois Dockerfiles não é o ideal.
Aqui está um exemplo de Dockerfile.build e Dockerfile exemplifica o caso acima:
Dockerfile.build:
FROM golang:1.7.3
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN go get -d -v golang.org/x/net/html \
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
Observe que este exemplo também comprime artificialmente dois comandos RUN juntando-os com o parâmetro “&&” do bash, para evitar criar uma camada adicional na imagem. Isso é propenso a falhas e difícil de manter. É fácil inserir outro comando e esquecer de continuar a linha usando este parâmetro , por exemplo.
Dockerfile:
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY app .
CMD ["./app"]
Quando você executa o script build.sh, ele cria a primeira imagem com o artefato, a partir da qual cria-se um container que é utilizado para copiar o artefato, em seguida, ele cria a segunda imagem copiando o artefato para essa segunda imagem. Ambas as imagens ocupam espaço em seu sistema e você ainda tem o artefato em seu disco local também.
O que melhorou
Com o multi-stage, você usa várias instruções FROM no seu Dockerfile, cada instrução FROM pode usar uma base diferente, e cada uma delas começa um novo estágio da compilação. Você pode copiar artefatos de um estágio para outro, deixando para trás tudo que você não quer na imagem final. Para mostrar como isso funciona, vamos adaptar o Dockerfile anterior para usar multi-stage:
Dockerfile:
FROM golang:1.7.3
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=0 /go/src/github.com/alexellis/href-counter/app .
CMD ["./app"]
Você só precisa do único Dockerfile, além de não precisar de um script de compilação separado, basta buildar sua imagem docker:
O resultado final é a mesma pequena imagem de produção que antes, com uma redução significativa na complexidade. Você não precisa criar nenhuma imagem intermediária e você não precisa extrair nenhum artefato para o seu sistema local.
Como funciona? A segunda instrução FROM inicia um novo estágio de compilação com a imagem base sendo alpine. A instrução “COPY –from=0” copia apenas o artefato construído do estágio anterior para esta nova imagem, o Go SDK e quaisquer artefatos intermediários são deixados para trás e não são salvos na imagem final.
Deixando mais claro
Por padrão, as etapas não são nomeadas, e você referencia elas por seu número inteiro, começando por 0 na primeira instrução FROM. No entanto, você pode nomear seus estágios, adicionando a instrução “as <nome>” na mesma linha do FROM. O exemplo abaixo deixa mais claro isso e melhora a forma como manipulamos nossos builds nomeando as etapas e usando o nome na instrução COPY. Isso significa que, mesmo que as instruções no seu Dockerfile sejam reordenadas, a cópia do artefado não será interrompida.
FROM golang:1.7.3 as builder
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
CMD ["./app"]
Ficou fácil né? Essa feature auxilia ainda mais as equipes no momento de administrar seus builds, pois centraliza e deixa mais transparente cada passo na geração dos pacotes/artefatos de uma aplicação.
Gostaríamos de agradecer ao @alexellisuk pela contribuição a comunidade com os exemplos utilizados acima. Esperamos ter ajudado, e como sempre, se tiver dúvidas avisa ai que vamos te ajudar.
15 plataformas de e-commerce sofrem ataque hacker e usuários tem senhas roubadas.
Mais de 200 logins e senhas de usuários das principais plataformas de e-commerce no Brasil foram hackeadas neste mês. Ao todo, 15 empresas foram alvo da ação, entre elas, Extra, Casas Bahia, Centauro, PagSeguro e Ponto Frio. As informações foram descritas em um arquivo, descoberto nesta segunda-feira pelo Laboratório de Segurança da Antecipe, uma plataforma de gerenciamento de vulnerabilidade e educação de usuários referente à segurança na internet.
— Nós temos uma equipe que monitora as possíveis ameaças de cibercriminosos, para conhecer novos tipos de ataques, e encontramos essa lista. O mais provável é que ela tenha sido divulgada pelos próprios hackers, que vivem fazendo competições internas para mostrar quem tem mais capacidade técnica. Por isso mesmo, não podemos afirmar que a lista esteja completa — explicou Renoir do Reis, cofundador e líder de desenvolvimento da empresa.
O número de usuários afetados — considerado baixo para um ataque hacker — é um dos indicativos que levam a empresa a defender a hipótese de que elas não foram invadidas, mas sim que as informações foram conseguidas por meio de um método conhecido como “phishing”. A manobra consiste em enganar usuários a revelar suas próprias informações pessoais, como senhas, cartão de crédito, CPF e número de contas bancárias, por meio de e-mails ou sites falsos.
— Pela pouca quantidade, o mais provável é que usuários tenham sido enganados por phishings que se faziam passar pelos sites e serviços e, devido à falta de atenção, eles digitaram os logins e senhas nesses sites — disse Reis, alertando ainda para a importância de prevenção em casos como esse: — é preciso trocar a senha imediatamente e tomar mais atenção na hora de navegar, verificando URL e, até mesmo, checando se o site é oficial com telefone de contato da empresa. Todo cuidado é pouco em relação a segurança da informação — concluiu. Nota do PagSeguro
O PagSeguro esclarece que não houve quebra de sigilo de nenhum dado de seus clientes. É falsa a informação veiculada em redes sociais. O PagSeguro reforça ainda que disponibiliza ambiente seguro para as transações, e que também ajuda seus clientes na prevenção de fraudes na internet, por meio de um material educativo disponível aqui.






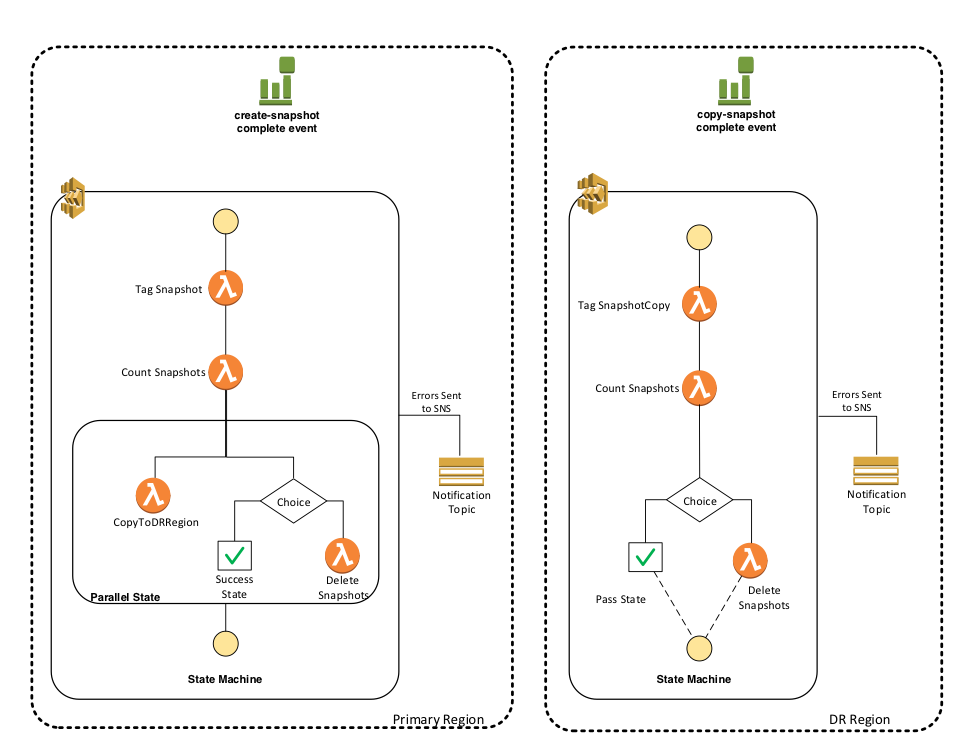



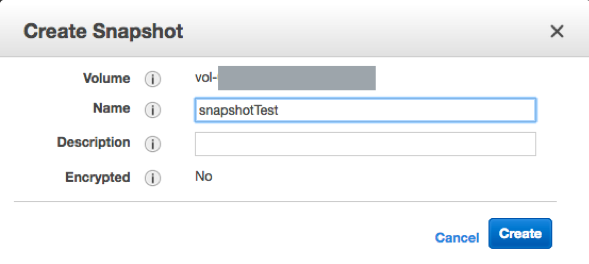








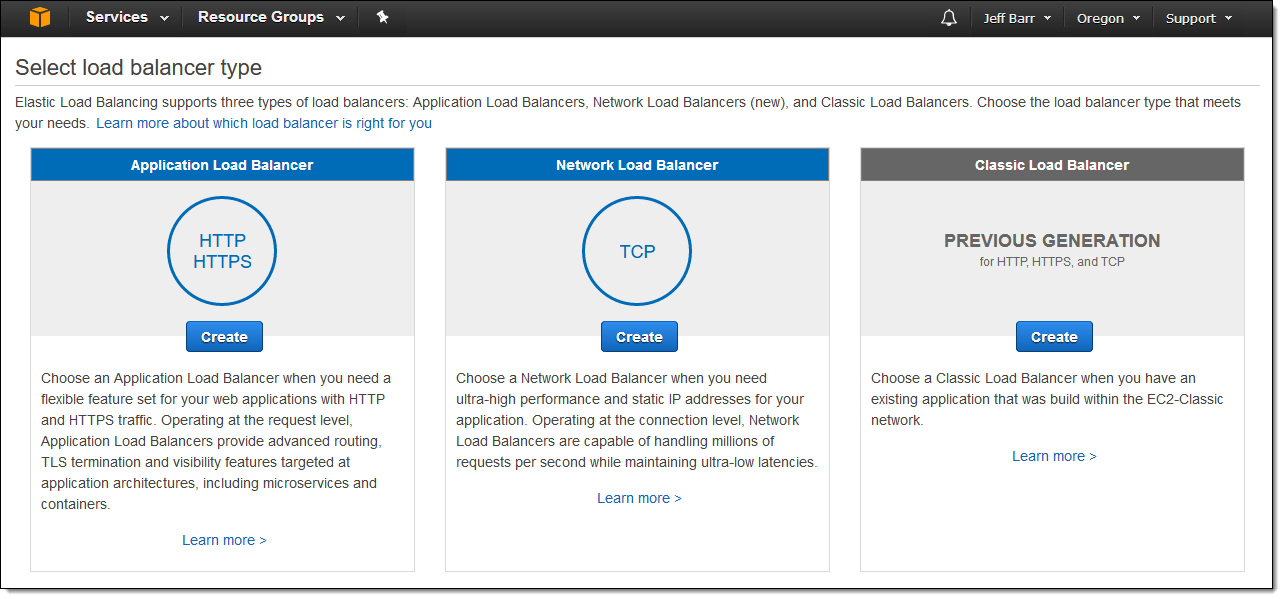
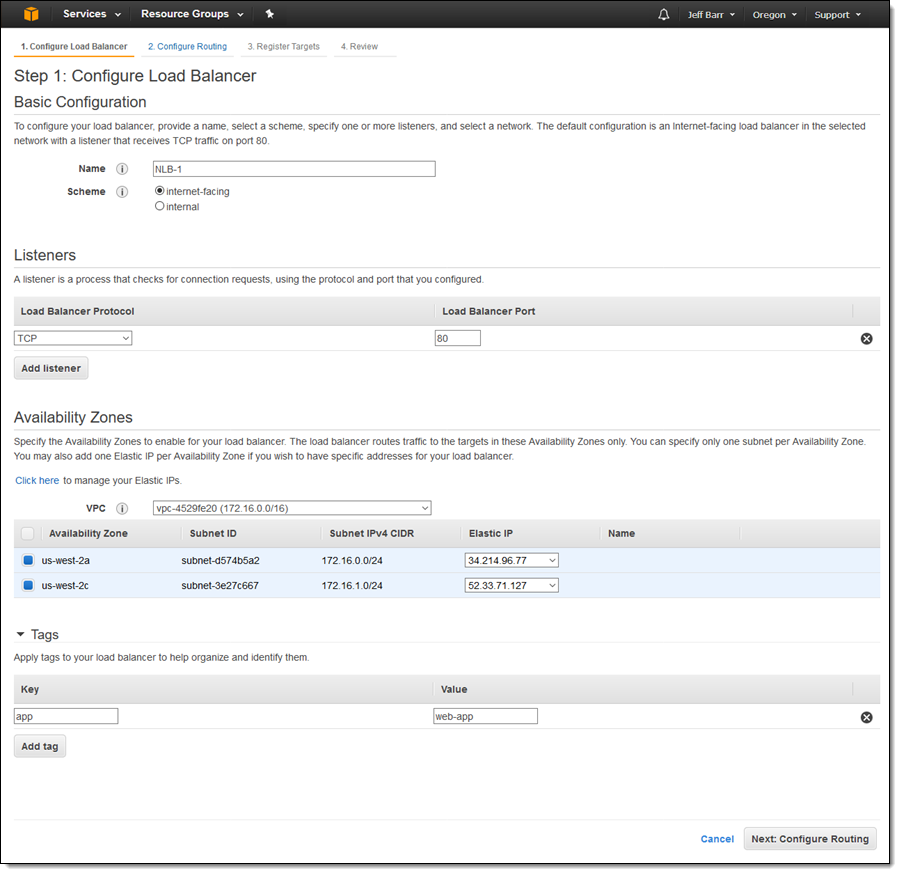
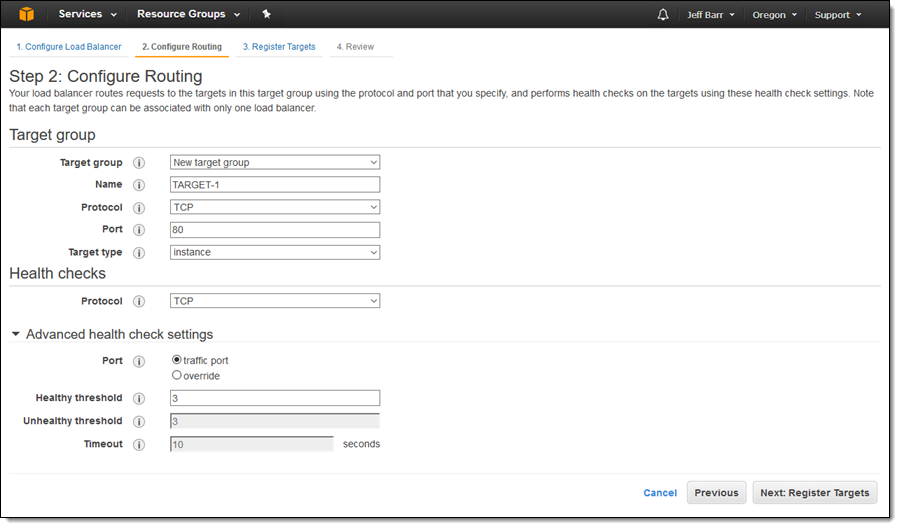
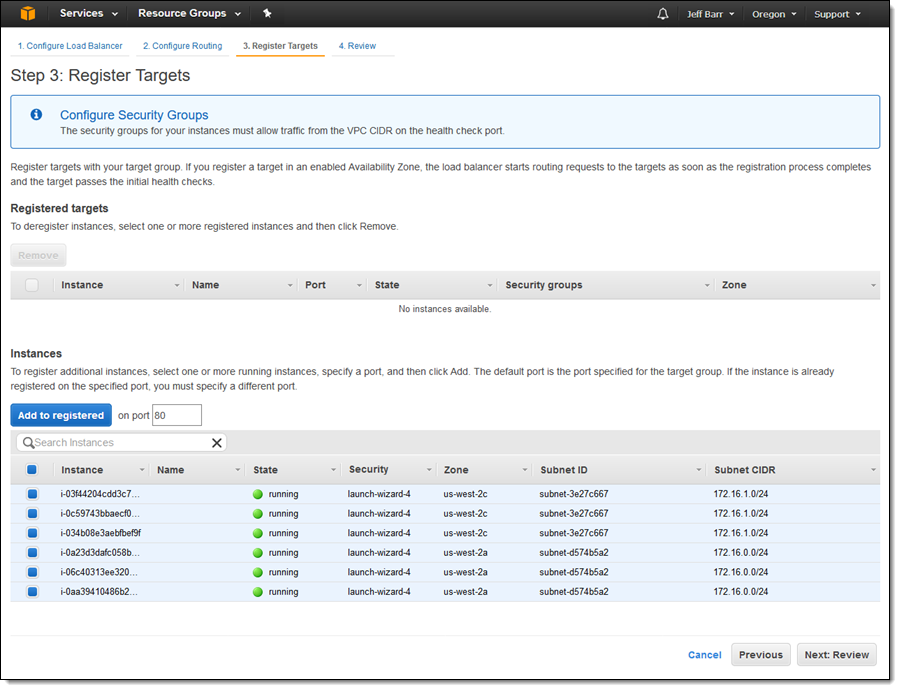
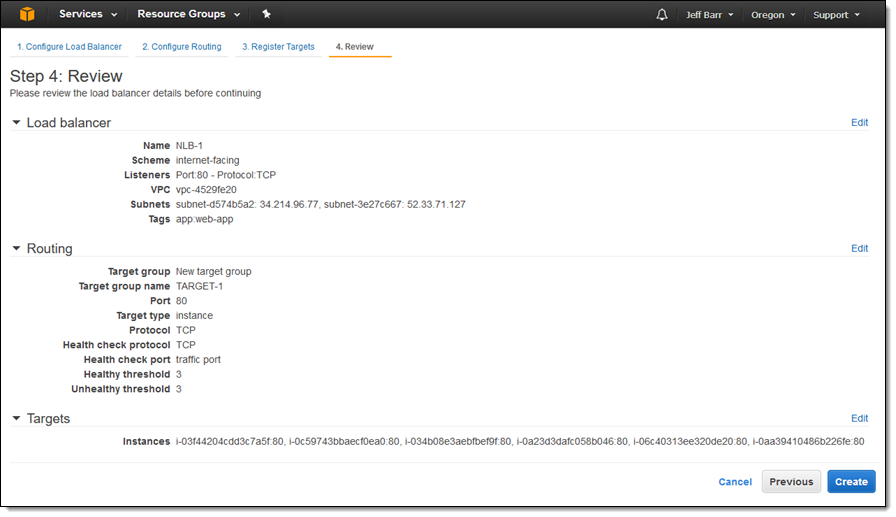
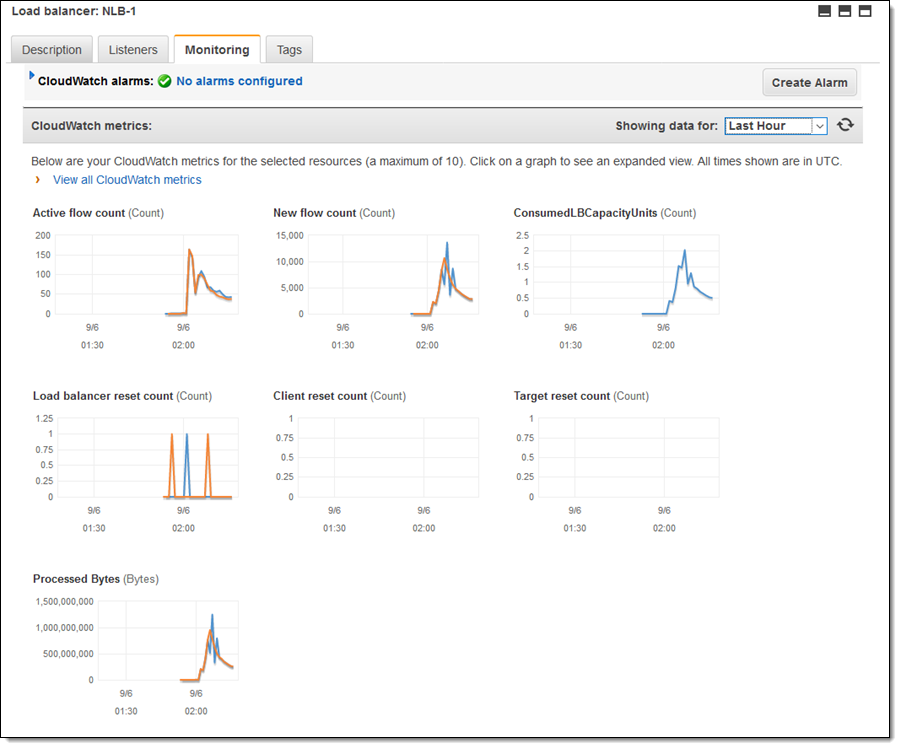
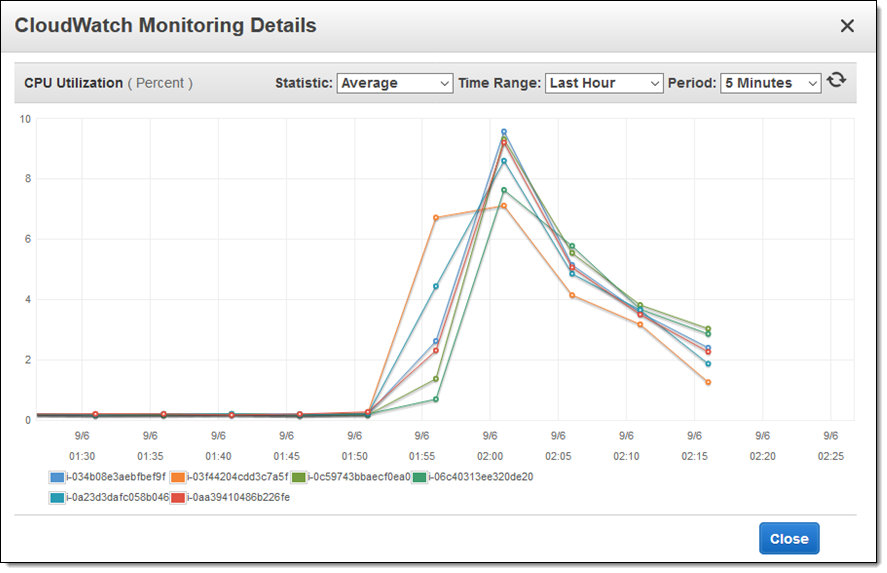

 Gerenciamento pode ser feito através de aplicativo
Gerenciamento pode ser feito através de aplicativo








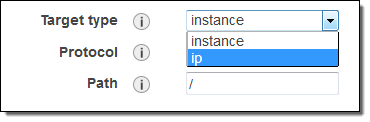 instance – Targets are registered by way of EC2 instance IDs, as before.
instance – Targets are registered by way of EC2 instance IDs, as before.