Last week, I posted about statisticians’ constant battle against the belief that the p-value associated (for example) with a regression coefficient  is equal to the probability that the null hypothesis is true,
is equal to the probability that the null hypothesis is true,  for a null hypothesis that beta is zero or negative. I argued that (despite our long pedagogical practice) there are, in fact, many situations where this interpretation of the p-value is actually the correct one (or at least close: it’s our rational belief about this probability, given the observed evidence).
for a null hypothesis that beta is zero or negative. I argued that (despite our long pedagogical practice) there are, in fact, many situations where this interpretation of the p-value is actually the correct one (or at least close: it’s our rational belief about this probability, given the observed evidence).
In brief, according to Bayes’ rule, equals 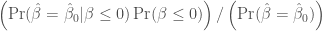 , or
, or  . Under the prior belief that all values of
. Under the prior belief that all values of  are equally likely a priori, this expression reduces to
are equally likely a priori, this expression reduces to  ; this is just the p-value (where we consider starting with the likelihood density conditional on
; this is just the p-value (where we consider starting with the likelihood density conditional on 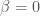 with a horizontal line at , and then sliding the entire distribution to the left adding up the area swept under the likelihood by that line).
with a horizontal line at , and then sliding the entire distribution to the left adding up the area swept under the likelihood by that line).
As I also explained in the earlier post, everything about my training and teaching experience tells me that this way lies madness. But despite the apparent unorthodoxy of the statement–that the p-value really is the probability that the null hypothesis is true, at least under some circumstances–this is a well-known and non-controversial result (see Greenland and Poole’s 2013 article in Epidemiology). Even better, it is easily verified with a simple R simulation.
rm(list=ls())
set.seed(12391)
require(hdrcde)
require(Bolstad)
b<-runif(15000, min=-2, max=2)
hist(b)
t<-c()
for(i in 1:length(b)){
x<-runif(500)
y<-x*b[i]+rnorm(500, sd=2)
t[i]<-summary(lm(y~x))$coefficients[2,3]
}
b.eval<-seq(from=-1, to=2, by=0.005)
t.cde <- cde(t, b, x.name="t statistic", y.name="beta coefficient", y.margin=b.eval, x.margin=qt(0.95, df=498))
plot(t.cde)
abline(v=0, lty=2)
den.val<-cde(t, b, y.margin=b.eval, x.margin=qt(0.95, df=498))$z
sintegral(x=b.eval[which(b.eval<=0)], fx=den.val[which(b.eval<=0)])$value
This draws 15,000 “true” beta values from the uniform density from -2 to 2, generates a 500 observation data set for each one out of  , estimates a correctly specified regression on the data set, and records the estimated t-statistic on the estimate of beta. The plotted figure below shows the estimated conditional density of true beta values given
, estimates a correctly specified regression on the data set, and records the estimated t-statistic on the estimate of beta. The plotted figure below shows the estimated conditional density of true beta values given 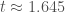 ; using Simpson’s rule integration, I calculated that the probability that
; using Simpson’s rule integration, I calculated that the probability that 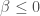 given
given 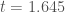 is 5.68%. This is very close to the theoretical 5% expectation for a one-tailed test of the null that .
is 5.68%. This is very close to the theoretical 5% expectation for a one-tailed test of the null that .

The trouble, at least from where I stand, is that I wouldn’t want to substitute one falsehood (that the p-value is never equal to the probability that the null hypothesis is true) for another (that the p-value is always a great estimate of the probability that the null hypothesis is true). What am I supposed to tell my students?
Well, I have an idea. We’re very used to teaching the idea that, for example, OLS Regression is the best linear unbiased estimator for regression coefficients–but only when certain assumptions are true. We could teach students that p-values are a good estimate of the probability that the null hypothesis is true, but only when certain assumptions are true. Those assumptions include:
- The null hypothesis is an interval, not a point null. One-tailed alternative hypotheses (implying one-tailed nulls) are the most obvious candidates for this interpretation.
- The population of coefficients out of which this particular relationship’s is drawn (a.k.a. the prior belief distribution) must be uniformly distributed over the real number line (a.k.a. an uninformative improper prior). This means that we must presume total ignorance of the phenomenon before this study, and the justifiable belief in ignorance that
 is just as probable as
is just as probable as 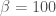 a priori.
a priori.
- Whatever other assumptions are needed to sustain the validity of parameters estimated by the model. This just says that if we’re going to talk about the probability that the null hypothesis about a parameter is true, we have to have a belief that this parameter is a valid estimator of some aspect of the DGP. We might classify the Classical Linear Normal Regression Model assumptions underlying OLS linear models under this rubric.
When one or more of these assumptions is not true, p-value estimates could well be a biased estimate of the probability that the null hypothesis is true. What will this bias look like, and how bad will it be? We can demonstrate with some R simulations. As before, we assume a correctly specified linear model between two variables, , with an interval null hypothesis that .
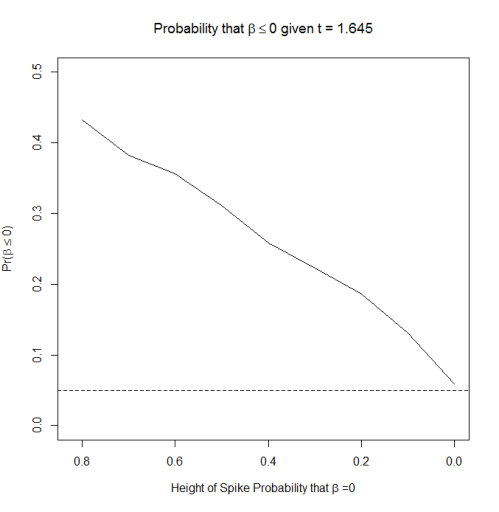
The first set of simulations keeps the uniform distribution of that I used from the first simulation, but adds in a spike at of varying height. This is equivalent to saying that there is some fixed probability that , and one minus that probability that lies anywhere between -2 and 2. I vary the height of the spike between 0 and 0.8.
rm(list=ls())
set.seed(12391)
require(hdrcde)
require(Bolstad)
spike.prob<-c(0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8)
calc.prob<-c()
for(j in 1:length(spike.prob)){
cat("Currently Calculating for spike probability = ", spike.prob[j], "\n")
b.temp<-runif(15000, min=-2, max=2)
b<-ifelse(runif(15000)<spike.prob[j], 0, b.temp)
t<-c()
for(i in 1:length(b)){
x<-runif(500)
y<-x*b[i]+rnorm(500, sd=2)
t[i]<-summary(lm(y~x))$coefficients[2,3]
}
b.eval<-seq(from=-2, to=2, by=0.005)
den.val<-cde(t, b, y.margin=b.eval, x.margin=qt(0.95, df=498))$z
calc.prob[j]<-sintegral(x=b.eval[which(b.eval<=0)], fx=den.val[which(b.eval<=0)])$value
}
plot(calc.prob~spike.prob, type="l", xlim=c(0.82,0), ylim=c(0, 0.5), main=expression(paste("Probability that ", beta <=0, " given ", t>=1.645)), xlab=expression(paste("Height of Spike Probability that ", beta, " =0")), ylab=expression(paste("Pr(", beta <= 0,")")))
abline(h=0.05, lty=2)
The results are depicted in the plot below; the x-axis is reversed to put higher spikes on the left hand side and lower spikes on the right hand side. As you can see, the greater the chance that (that there is no relationship between x and y in a regression), the higher the probability that given that is statistically significant (the dotted line is at 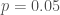 , the theoretical expectation). The distance between the solid and dotted line is the “bias” in the estimate of the probability that the null hypothesis is true; the p-value is almost always extremely overconfident. That is, seeing a p-value of 0.05 and concluding that there was a 5% chance that the null was true would substantially underestimate the true probability that there was no relationship between x and y.
, the theoretical expectation). The distance between the solid and dotted line is the “bias” in the estimate of the probability that the null hypothesis is true; the p-value is almost always extremely overconfident. That is, seeing a p-value of 0.05 and concluding that there was a 5% chance that the null was true would substantially underestimate the true probability that there was no relationship between x and y.
The second set of simulations replaces the uniform distribution of true values with a normal distribution, where we center each distribution on zero but vary its standard deviation from wide to narrow.
rm(list=ls())
set.seed(12391)
require(hdrcde)
require(Bolstad)
sd.vec<-c(2, 1, 0.5, 0.25, 0.1)
calc.prob<-c()
for(j in 1:length(sd.vec)){
cat("Currently Calculating for sigma = ", sd.vec[j], "\n")
b<-rnorm(15000, mean=0, sd=sd.vec[j])
t<-c()
for(i in 1:length(b)){
x<-runif(500)
y<-x*b[i]+rnorm(500, sd=2)
t[i]<-summary(lm(y~x))$coefficients[2,3]
}
b.eval<-seq(from=-3*sd.vec[j], to=3*sd.vec[j], by=0.005)
den.val<-cde(t, b, y.margin=b.eval, x.margin=qt(0.95, df=498))$z
calc.prob[j]<-sintegral(x=b.eval[which(b.eval<=0)], fx=den.val[which(b.eval<=0)])$value
}
plot(calc.prob~sd.vec, type="l", xlim=c(0, 2), ylim=c(0, 0.35), main=expression(paste("Probability that ", beta <=0, " given ", t>=1.645)), xlab=expression(paste(sigma, ", standard deviation of ", Phi, "(", beta, ")")), ylab=expression(paste("Pr(", beta <= 0,")")))
abline(h=0.05, lty=2)
The results are depicted below; once again, p = 0.05 is depicted with a dotted line. As you can see, when is narrowly concentrated on zero, the p-value is once again an underestimate of the true probability that the null hypothesis is true given 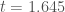 . But as the distribution becomes more and more diffuse, the p-value becomes a reasonably accurate approximation of the probability that the null is true.
. But as the distribution becomes more and more diffuse, the p-value becomes a reasonably accurate approximation of the probability that the null is true.

In conclusion, it may be more productive to focus on explaining the situations in which we expect a p-value to actually be the probability that the null hypothesis is true, and situations where we would not expect this to be the case. Furthermore, we could tell people that, when p-values are wrong, we expect them to underestimate the probability that the null hypothesis is true. That is, when the p-value is 0.05, the probability that the null hypothesis is true is probably larger than 5%.
Isn’t that at least as useful (and a lot easier) than trying to explain the difference between a sampling distribution and a posterior probability density?





