A month ago, I built a personal search engine called Monocle that let me search through a trove of personal information I’ve saved over time, from notes to journal entries to bookmarks and tweets. Shortly thereafter, I switched my default search engine in my web browser from Google to Monocle, marking the start of my slow descent into the fascinating rabbit hole that is transmogrifying my web browser into my best, most flexible, most versatile tool for thinking, learning, and remembering.
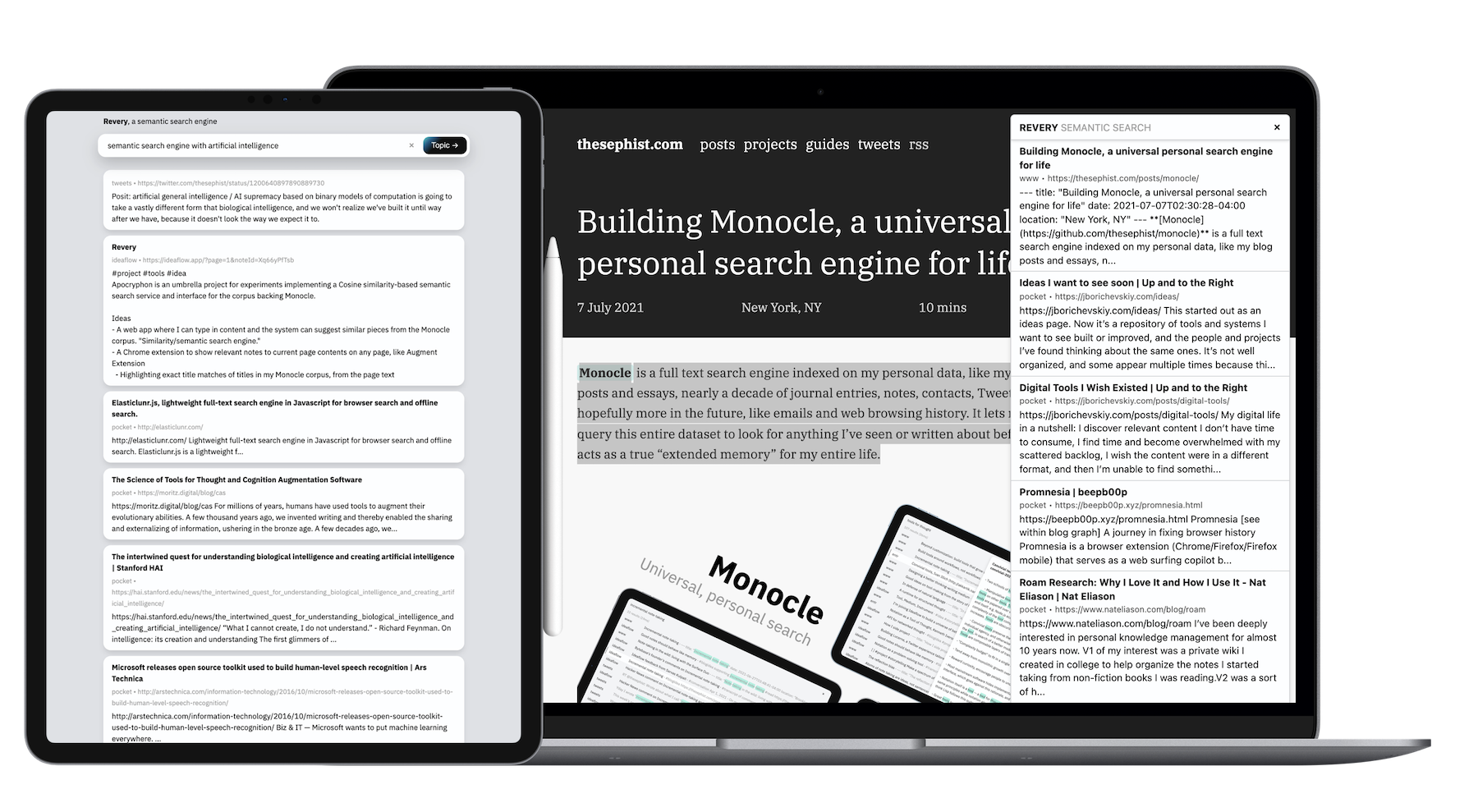
A couple of weeks later, I built and started using Revery, a browser extension that shows quick summaries and topically related notes and bookmarks from my collection whenever I’m reading anything on the Web.
Living with these small bits of customization and intelligence scattered throughout my browser, I’m increasingly convinced that the future of the web browser is the best tool – nay, medium – for thought.
This conviction comes from a myriad of ideas and realizations, but most significant among them are three insights I’ve discovered while building and living with these projects for the last month:
- Medium for thought, not just a tool
- Information lives outside of tools
- To surf the Web, you must first understand it
At the end, I’ll try to bring these ideas together to muse a little on what I want to see as the future of the browser.
Medium for thought, not just a tool
In Designing a better thinking-writing medium, I wrote on the difference between a tool and a medium:
A tool is something that takes an existing workflow, and makes it more efficient. A nail is an efficient way of holding pieces of wood together; a to-do app is an efficient way of remembering your responsibilities. A medium, on the other hand, gives us new agency or power by which we can do something we couldn’t do before.
As with any dichotomy, there are grey areas. Powerful, effective tools can become mediums and enablers too. The graphical computer user interface wasn’t just a better way to write scientific simulations or data processing systems – it also became a new medium for creative work. Programming languages began history as a more efficient way to store and maintain punchcard programs, but a half-century of innovation has made it a medium for expressing programs that couldn’t be written before.
Despite the renewed focus I see in the community of people and companies trying to build better tools for thought, I think much of our work is still confined to tool-making. That is, most of our efforts are about creating more automatic, more efficient ways to do what we already know how to do – spaced repetition, Zettelkasten, journaling, and so on. We are busy making more effective command-line apps for thought, rather than dreaming up graphical interfaces.
Building a tool is a relatively straightforward affair. We can look around at existing workflows and needs that people have, and design some set of features around the workflows and needs that we observe.
However, to build an enabling medium that’s more than a single-purpose tool, it isn’t simply enough to look at existing workflows and build tools around them. To design a good creative medium, we can’t solve for a particular use case. The best mediums are instead collections of generic, multi-purpose components that mesh together well to let the user construct their own solutions. For example, Microsoft Excel is ostensibly a tool for calculation, but it’s also a medium for manipulating data in a 2-D grid for lots of other use cases, from organizing a budget to collecting a poll to even creating simple graphics. This flexibility comes from the fact that Excel is really just composed of a few powerful primitive components: the 2-D grid of cells, formulas that can reference other cells, and a responsive programming model that lets the whole table change anytime a value somewhere changes.
Designing a medium for thought requires that we discover what these primitive components of a thinking medium should be. Should there be some sense of geometry and space? How important should text be, against drawings and images? How should people collaborate and share their thoughts? I propose that the solution to these questions are not an opinionated tool with a “Share” button and a rigid way to use an image in a project, but something with a collection of capabilities that happen to include inserting and positioning text and images, sharing and collaborating on those objects on the page, and connecting ideas. These capabilities should work well together, to leave room for any combination of use cases. The line here can be blurry, so I don’t think it’s worthwhile to argue whether any particular tool is a good tool or a good medium, but in the future, I want to see more mediums like Excel, Google Docs, and Figma that seem like multi-purpose canvases that leave room for creativity, and fewer tools like Zoom, Slack, and of course the venerable web browser of today that lock you into particular use cases and make you feel like you need to “learn how to use” the thing.
The current state web browsers is particularly damning from this perspective. Web browsers have access to such a treasure trove of valuable, often well-structured information about what we learn and how we think, what interests we have, and who we talk to. Rather than trying to take that information and let us build workflows out of them, browsers remain a strictly utilitarian tool – a rectangular window into documents and apps that play dumb, ignorant of the valuable information that transits through them every day. I think we can do better.
Information lives outside of tools
Once I started using my personal search engine, Monocle, day-to-day, I made an observation about how Monocle seemed different than most of my other software tools. I wrote on my newsletter:
Every productivity app company these days seems to embrace the phrase “second brain,” as in “make X app your second brain.” One of my big takeaways from using Monocle on a daily basis for the last week has been that no single app can be my second brain. There are going to be parts of my life that are inherently spread out across different apps. For example, there’s a huge amount of knowledge sitting in my email inbox and my blog, and there are some things I only remember because I tweeted about it once, or recorded in a quick journal entry. There are ideas saved in text messages and contacts. “Notes apps,” it turns out, are not the only places where knowledge lives. And a true “second brain”, or whatever you want to call it, needs to recognize that and let you wield its magic over all of your digital footprint.
Most of us don’t realize just how much the “app-centric” mindset is ingrained into us, until we get a chance to think in a “problem-centric” way free from the limitations of apps. One of my most frequent kinds of search on Monocle is a search for people – people whose names I vaguely remember, people whom I’ve never heard of but might have been mentioned in a news article, people whose birthdays might be coming up. Before Monocle, to find some information about a person, my first thought would have been “What app did I write that down in? Should I check my messages or my contacts?” I might even have given up, after searching a couple of apps without finding the result I was looking for. With Monocle, the question doesn’t need to be asked. I just search for the right person, and Monocle searches across all my data.
If we want to organize information that flows through our lives, we simply can’t restrict our design space to be a single product or app. No matter how great a note-taking app is, my emails are going to live outside of it. No matter how seamless the experience in my contacts app, my text conversations are going to live outside of it. We should acknowledge this fundamental limitation of the “note-taking app” approach to building tools for thought, and shift our focus away from building such siloed apps to designing something that lives on top of these smaller alcoves of personal knowledge to help us organize it regardless of its provenance.
If we want to build a software system that can organize information across apps, what better place to start than the one piece of software that has access to it all, where most of us live and work nearly all the time? I think the browser is a rich place to build experiments in this space, and my personal experience building Monocle and Revery support this idea so far.
To surf the Web, you must first understand it
One of my perennial complaints about the current crop of “tools for thought” has been that most of them aren’t really about thinking per se, just about improving memory. We can take down information into apps like Roam Research or Notion and recall them easily later, but it’s an overstatement to call them tools for thought. Recollection is such a small, basic part of thinking! There is so much more to thinking than simply remembering something accurately. I think we can acknowledge the benefits these apps bring while also admitting that better tools for thought should help us do more with ideas than just remember and recall.
Even when using the best of these apps, it’s up to the human users to manually annotate every single connection, every single hierarchy, and every single highlight and summary we want to remember about what we write. Humans are still doing most of the “thinking” work. It’s as if we had invented a “calculator” that was purely a record of the results of our arithmetic, rather than a machine that performed calculations. Sure, a record of our computation is helpful, but it’s hardly an effective calculator. It almost feels disingenuous to say that this current generation of tools help us think. I think it’s more accurate to say they encourage us to think with the promise of perfect recall, but we are not yet living amongst tools that truly help us think better thoughts, faster.
So, what are the building blocks of a powerful thinking medium that can actually help us think, more than just recall? For a tool that has such broad access to information like a web browser, I think a critical piece of the puzzle is better machine understanding of language.
Most existing tools and browsers treat web pages and pieces of notes like complete black boxes of information. These tools know how to scan for keywords, and they have access to the metadata we use to tag our information like hashtags and timestamps, but unlike a human, most current tools don’t try to peer into the contents of our notes or reading materials and operate with an understanding of our information.
With ratcheting progress in machine understanding of language, I think we have good high-quality building blocks to start building thinking mediums and information systems that operate with some understanding of our ideas themselves, rather than simply “this is some text”.
Take my custom browser extension Revery as an example. I’ve been using it as the testing ground for some of my own ideas about what these tools should be able to do. While it doesn’t take advantage of any of the more recent advancements in NLP, its current capabilities are still changing how I browse the web. For any webpage I visit, Revery currently:
- Scans the page and surfaces information from my personal search index that might be topically relevant to what I’m reading. For example, on an article about South Korea’s economic and cultural ascent, Revery surfaced my bookmarks on parallel stories from Taiwan and Singapore, letting me contextualize the current article.
- Provides a quick extractive summary of long articles for me to scan before I decide to spend time reading the rest of the page.
In addition, Revery could in the future pick out important keywords and topics from the page and automatically search my search engine for them, or help me spot key people and places I know that appear on the page.
Because all of these experiments are grounded in my web browser rather than any particular application, these tricks and workflows work on any website, including other notes applications. I could visit my Ideaflow notes or someone else’s Roam graph and take advantage of these capabilities of my browser just as easily. It’s not that far-fetched to imagine a scenario in which I visit a well-connected Roam graph, and realize that my browser has made just as many connections between their notes and my notes as the author of the Roam notes have across their information.
If we were to build a medium for better thinking on top of the web browser, it’s reckless to expect the average user to manually connect, organize, and annotate the information they come across. Just as the early World Wide Web started out manually-curated and eventually became curated by algorithms and communities, I think we’ll see a shift in how individual personal landscapes of information are curated, from manual organization to mostly machine-driven organization. Humans will leave connections and highlights as a trail of their thinking, rather than as their primary way of exploring their knowledge and memory.
In the browser of the future, the boundary between my personal information and the wider Web’s information landscape will blur, and a smarter, more literate browser will help me navigate both worlds with a deeper understanding of what I’m thinking about and what I want to discover. It’ll remind me of relevant bookmarks when I’m taking lecture notes; it’ll summarize and pick out interesting details from long news articles for me; it’ll let me search across the Web and my personal data to remember more and learn faster.
A web browser for thoughts, not documents or apps
The web browser has advanced remarkably far in the first couple of decades of its history. But despite the technical achievements, it staunchly remains a pure utility, a tool meant to be used almost exclusively for visiting what lies at the other end of URLs.
There’s a renewed attention in the web browser space today. Too many of them are simply focused on making existing browsers faster and more powerful, but there’s an exciting small clan of founders and engineers trying to make the browser something more.
The vision of the web browser that excites me the most is one where the browser is a medium for creativity, learning, and thinking deeply that spans personal and public spheres of knowledge. This browser will be fast and private, of course, but more than that, this browser will let me explore the Web from the comfort of my own garden of information. It’ll break the barriers between different apps that silo our information to help us search and remember across all of them. It’ll use a deeper machine understanding of language and images to summarize articles, highlight important ideas, and remind me what I should remember. It’ll let me do it all together with other people in a way that feels like real presence, rather than just avatars on screen.
Forget space tourism – the most thought-provoking ideas, the most romantic stories, the most beautiful reveries of the future are right here, on the Web. There is still much to explore, and such beautiful worlds deserve a better spacecraft. One built to help us think new thoughts, together.
This post is a culmination of ideas sparked by conversations with Jess Martin, Raj Thimmiah, Jacob Cole, Molly Mielke, Karina Nguyen, and Josh Miller. Thanks to them for such enlightening conversations, and in many cases, for their own work in pushing these ideas forward!








 ) (
) (










 ) I wonder if I should do more of that, if Pavlov’s chops should be flexed to gather more into the fold. But I know that it’s an over-served field. There are enough videos for people who like that stuff, whether they know it or not. It’s a space that distracts, that stops me from doing what I care about, and stops me from connecting with that audience who give meaning and context to the work, who tell me what it means to them, how they use it, who invite me to Do My Thing. One of the ways I try to keep my head clear is to have mini-manifestos for what I’m trying to do. They’re more for me than anyone else, but making them public helps with accountability – “trying to make music that’s important without pretending I’m special”, “making the music that I think should be in the world but isn’t” – that sort of thing. Even the strapline from my website started out here – “the soundtrack to the day you wish you’d had” – an invitation to myself to make music imbued with hope.
) I wonder if I should do more of that, if Pavlov’s chops should be flexed to gather more into the fold. But I know that it’s an over-served field. There are enough videos for people who like that stuff, whether they know it or not. It’s a space that distracts, that stops me from doing what I care about, and stops me from connecting with that audience who give meaning and context to the work, who tell me what it means to them, how they use it, who invite me to Do My Thing. One of the ways I try to keep my head clear is to have mini-manifestos for what I’m trying to do. They’re more for me than anyone else, but making them public helps with accountability – “trying to make music that’s important without pretending I’m special”, “making the music that I think should be in the world but isn’t” – that sort of thing. Even the strapline from my website started out here – “the soundtrack to the day you wish you’d had” – an invitation to myself to make music imbued with hope.