In this series I’m exploring how to work in a code base that lives in two places: Metabase questions that encapsulate chunks of SQL, and Postgres functions/procedures/views that also encapsulate chunks of SQL. To be effective working with this hybrid collection of SQL chunks, I needed to reason about their interrelationships. One way to do that entailed the creation of a documentation generator that writes a concordance of callers and callees.
Here’s the entry for the function sparklines_for_guid(_guid).

The called by column says that this function is called from two different contexts. One is a Metabase question, All courses: Weekly activity. If you’re viewing that question in Metabase, you’ll find that its SQL text is simply this:
select * from sparklines_for_guid( {{guid}} )
The same function call appears in a procedure, cache warmer, that preemptively memoizes the function for a set of the most active schools in the system. In either case, you can look up the function in the concordance, view its definition, and review how it’s called.
In the definition of sparkline_for_guid, names of other functions (like guid_hashed_view_exists) appear and are linked to their definitions. Similarly, names of views appearing in SELECT or JOIN contexts are linked to their definitions.
Here’s the entry for the function guid_hashed_view_exists. It is called by sparklines_for_guid as well as by functions that drive panels on the school dashboard. It links to the functions it uses: hash_for_guid and exists_view.

Here’s the entry for the view lms_course_groups which appears as a JOIN target in sparklines_for_guid. This central view is invoked — in SELECT or JOIN context — from many functions, from dependent views, and from Metabase questions.

Metabase questions can also “call” other Metabase questions. In A virtuous cycle for analytics I noted: “Queries can emit URLs in order to compose themselves with other queries.” Here’s an example of that.

This Metabase question (985) calls various linked functions, and is called by two other Metabase questions. Here is one of those.

Because this Metabase question (600) emits an URL that refers to 985, it links to the definition of 985. It also links to the view, top_annotated_domains_last_week, from which it SELECTs.
It was straightforward to include Postgres functions, views, and procedures in the concordance since these live in files that reside in the fileystem under source control. Metabase questions, however, live in a database — in our case, a Postgres database that’s separate from our primary Postgres analytics db. In order to extract them into a file I use this SQL snippet.
select r.id, m.name as dbname, r.name, r.description, r.dataset_query from report_card r join metabase_database m on m.id = cast(r.dataset_query::jsonb->>'database' as int) where not r.archived order by r.id;
The doc generator downloads that Metabase data as a CSV file, queries.csv, and processes it along with the files that contain the definitions of functions, procedures, and views in the Postgres data warehouse. It also emits queries.txt which is a more convenient way to diff changes from one commit to the next.
This technique solved a couple of problems. First, when we were only using Metabase — unaugmented by anything in Postgres — it enabled us to put our Metabase SQL under source control and helped us visualize relationships among queries.
Later, as we augmented Metabase with Postgres functions, procedures, and views, it became even more powerful. Developing a new panel for a school or course dashboard means writing a new memoized function. That process begins as a Metabase question with SQL code that calls existing Postgres functions, and/or JOINs/SELECTs FROM existing Postgres views. Typically it then leads to the creation of new supporting Postgres functions and/or views. All this can be tested by internal users, or even invited external users, in Metabase, with the concordance available to help understand the relationships among the evolving set of functions and views.
When supporting functions and views are finalized, the SQL content of the Metabase question gets wrapped up in a memoized Postgres function that’s invoked from a panel of a dashboard app. At that point the concordance links the new wrapper function to the same set of supporting functions and views. I’ve found this to be an effective way to reason about a hybrid code base as features move from Metabase for prototyping to Postgres in production, while maintaining all the code under source control.
That foundation of source control is necessary, but maybe not sufficient, for a team to consider this whole approach viable. The use of two complementary languages for in-database programming will certainly raise eyebrows, and if it’s not your cup of tea I completely understand. If you do find it appealing, though, one thing you’ll wonder about next will be tooling. I work in VSCode nowadays, for which I’ve not yet found a useful extension for pl/pgsql or pl/python. With metaprogramming life gets even harder for aspiring pl/pgsql or pl/python VSCode extensions. I can envision them, but I’m not holding my breath awaiting them. Meanwhile, two factors enable VSCode to be helpful even without deep language-specific intelligence.
The first factor, and by far the dominant one, is outlining. In Products and capabilities I reflect on how I’ve never adopted an outlining product, but often rely on outlining capability infused into a product. In VSCode that’s “only” basic indentation-driven folding and unfolding. But I find it works remarkably well across SQL queries, views and functions that embed them, CTEs that comprise them, and pl/pgsql or pl/python functions called by them.
The second factor, nascent thus far, is GitHub Copilot. It’s a complementary kind of language intelligence that’s aware of, but not bounded by, what a file extension of .sql or .py implies. It can sometimes discern patterns that mix language syntaxes and offer helpful suggestions. That hasn’t happened often so far, but it’s striking when it does. I don’t yet know the extent to which it may be training me while I train it, or how those interactions might influence others. At this point I’m not a major Copilot booster, but I am very much an interested observer of and participant in the experiment.
All in all, I’m guardedly optimistic that existing or feasible tooling can enable individuals and teams to sanely navigate the hybrid corpus of source code discussed in this series. If you’re along for the ride, you’ll next wonder about debugging and monitoring a system built this way. That’s a topic for a future episode.
—
1 https://blog.jonudell.net/2021/07/21/a-virtuous-cycle-for-analytics/
2 https://blog.jonudell.net/2021/07/24/pl-pgsql-versus-pl-python-heres-why-im-using-both-to-write-postgres-functions/
3 https://blog.jonudell.net/2021/07/27/working-with-postgres-types/
4 https://blog.jonudell.net/2021/08/05/the-tao-of-unicode-sparklines/
5 https://blog.jonudell.net/2021/08/13/pl-python-metaprogramming/
6 https://blog.jonudell.net/2021/08/15/postgres-and-json-finding-document-hotspots-part-1/
7 https://blog.jonudell.net/2021/08/19/postgres-set-returning-functions-that-self-memoize-as-materialized-views/
8 https://blog.jonudell.net/2021/08/21/postgres-functional-style/
9 https://blog.jonudell.net/2021/08/26/working-in-a-hybrid-metabase-postgres-code-base/
10 https://blog.jonudell.net/2021/08/28/working-with-interdependent-postgres-functions-and-materialized-views/
11 https://blog.jonudell.net/2021/09/05/metabase-as-a-lightweight-app-server/
12 https://blog.jonudell.net/2021/09/07/the-postgres-repl/









 ; the y-axis uses a log scale so that under/over estimates appear symmetrical (
; the y-axis uses a log scale so that under/over estimates appear symmetrical (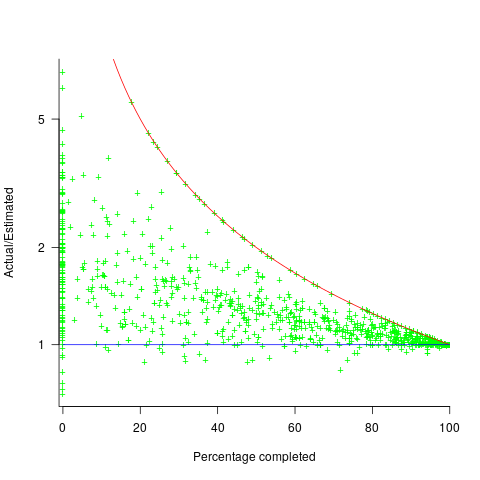
 , and
, and  .
. (plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
(plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.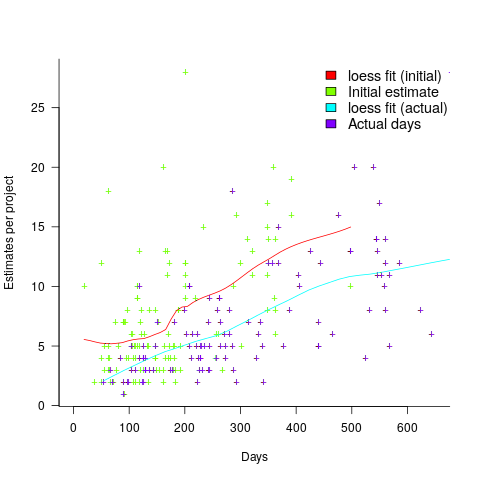



















{kind=link}