Observable notebooks recently added a SQL cell type, allowing SQL queries to be executed as part of an interactive notebook workflow. Alex Garcia built a Datasette Client for these which allows you to excute queries against any Datasette instance and explore and visualize the results using JavaScript code running in a notebook.
Just as D’Arcy Norman pauses his weekly reflections I’m contemplating starting mine. While browsing D’Arcy’s site a while ago I really dug his quick, snapshot summries of what he was up to the previous week. He’s been doing these weekly reflections for awhile, and it should come as no surprise he should lead the charge and burn out before I even become fully aware of the power of what he’s done—that’s often the case with D’Arcy. He quietly and consistently does great work in edtech, and it sounds like he’ll soon have a Ph.D. to augment his already formative super powers … avanti!
I have a few things happening across various contexts any given week, and I appreciate the way D’Arcy categorizes his reflections: work, Ph.D., reading, personal, etc. I’m thinking of categorizing things along the following lines:
Reclaim Hosting: much of my time is still spent working and thinking about Reclaim Hosting, and a weekly synopsis would definitely be useful for me to reflect on for posterity. Plus, catching all the ideas we chat about any given week would be a way to start collecting material for the Reclaim Hosting newsletter we are architecting for 2022.
I'm happy to share that @TaylorJadin has joined the @ReclaimHosting team as our first Community Instructional Technologist.?This marks a new chapter for Reclaim, and I'm so excited for what's to come! Welcome, Taylor!!
bavacade: Reclaim Arcade is increasingly Tim’s domain, and what an awesome one it is! Given my geographic isolation from that arcade nirvana, I’ve started acquiring games for the Italian outpost. Collecting and working on arcade cabinets has become a total blast for me, and the process of building out a home arcade here in Italy keeps me busy and happy.
It took some doing, but I got the 440 multi Exidy game mod running on Cheyenne. So now you can play all 10 Exidy shooter classics on the cabinet, including my fav Crossbow! pic.twitter.com/9GimRYl7Cm
Reading/Watching/Listening: I probably watch more movies/series than I read these days—a casualty of not teaching That said, I’ve returned to reading more literature the last few months, and this might be a good way to take stock of my media consumption with lists, short reflections, etc.* Also, I’m listening to a fair amount of music during any given work day, and incorporating that into more streaming (see below) is a goal for 2022.
Broadcasting (Radio/Video Streaming): As part of all the above interests I have streamed a fair bit over the last two years on ds106radio, karaoke video ds106.tv sessions, bava.tv, Reclaim Today, Reclaim Arcade stuff, etc. It was my favorite lockdown activity that has since become another fun past time to play around with. At the same time I rarely blog that stuff and it can quickly get buried in the black hole that is my hard drive, so this is a good way to take stock, even if it’s just lists and links: the primordial ooze of any great blog
Personal: Duke updates? I have heard on good authority that my dog needs more airtime across all my mediaz. Not only will it help me document some of the hikes, trips, highlights, etc., but also have a reason to upload and vet the photos I have taken any given week given l haven’t really found a place/workflow beyond Twitter to share them—having abandoned Instagram earlier this year. That said, I have started uploading several thousand photos I took this year to Flickr again, so we’ll see if I can get back into that habit. I love to document all the stuff I do here in Italy, but I find time is moving a bit faster than my fingers these days, so an attempt to try and capture a bit of this without a separate post for everything may help in that regard. But then again, mapping it out here in a blog post filled with hope and possibility is a bit easier than actually doing it on the regular for 52 weeks, but it would be great if I did because archives of thought and reflection like that have been the greatest joy of playing the long web on this blog for the last 16 years.
Ok, so now that I built it up, I’m gonna try it on for the remaining weeks of December. I intend to post them Monday mornings as a way to jump start the week, but if you never hear mention of the “bava weekly” again, you know what happened
______________________________
*I would like to link to blog posts, sites, projects, etc. I mean folks like Stephen Downes, Audrey Watters and Chris Lott have been doing awesome newsletters for a long while (OL Daily, Hack Education, and/or Katexic anyone?), but I’m afraid these weekly reflections will be far more self-indulgent and idiosyncratic than anything resembling a newsletter—it’s a “b” blog after all. It’s not lost on me how much work goes into a well curated newsletter, and between family, job, arcade games, hikes, and dogs I just don’t have that kinda time. Truth be told, it’s really just a weekly blog post, so even comparing it to anything resembling a newsletter is already wishful thinking and false advertising.
Over the past four decades, governments have slashed budgets and privatized basic services. This has two important consequences for public health. First, people are unlikely to trust institutions that do little for them. And second, public health is no longer viewed as a collective endeavor, based on the principle of social solidarity and mutual obligation. People are conditioned to believe they’re on their own and responsible only for themselves. That means an important source of vaccine hesitancy is the erosion of the idea of a common good.
One of the most striking examples of this transformation is in the United States, where anti-vaccination attitudes have been growing for decades. For Covid-19, commentators have chalked up vaccine distrust to everything from online misinformation campaigns, to our tribal political culture, to a fear of needles. Race has been highlighted in particular: In the early months of the vaccine rollout, white Americans were twice as likely as Black Americans to get vaccinated. Dr. Anthony Fauci pointed to the long shadow of racism on our country’s medical institutions, like the notorious Tuskegee syphilis trials, while others emphasized the negative experiences of Black and Latinos in the examination room. These views are not wrong; compared to white Americans, communities of color do experience the American health care system differently. But a closer look at the data reveals a more complicated picture.
Since the spring, when most American adults became eligible for Covid vaccines, the racial gap in vaccination rates between Black and white people has been halved. In September, a national survey found that vaccination rates among Black and white Americans were almost identical. Other surveys have determined that a much more significant factor was college attendance: Those without a college degree were the most likely to go unvaccinated.
Education is a reliable predictor of socioeconomic status, and other studies have similarly found a link between income and vaccination. An analysis in June of census tract data in Michigan showed, for example, that vaccination rates in the heavily Black neighborhoods of Saginaw County were below 35 percent, and the rates in nearby poor white areas were not much different. Voters who identify as Democrats are much more likely than Republicans to get vaccinated, but, according to the Michigan data, this gap also disappears when accounting for income and education. It turns out that the real vaccination divide is class.
So if we really have to find a villain to blame for vaccine hesitancy, we might want to look at the forces that create and sustain the class, or caste, divides. The obvious candidate would be capitalism, that enables and encourages obscene inequality of wealth and power, that blames its victims for the problems it creates, that perpetuates deliberate falsehoods to sell us stuff, that pits us mercilessly as consumers of products and political beliefs against each other, and that in general profits most from creating misinformation, disinformation, fear and distrust, and then selling us remedies for it.
There is, of course, no such thing as capitalism — it’s merely a label we put on aspects of our dysfunctional and devolving economic and political systems to try to make sense of what’s wrong (or right) with them. All the systems and -isms we imagine are just our attempt to make sense of the apparent patterns in the behaviour of 7.8B bewildered humans. We’re all doing our best, and no one is to blame. What we call disaster capitalism is just a description of what that collective behaviour has brought us to.
We believe what we want to believe, and the facts be damned. That is how we cope, how we make meaning, how we organize our thoughts to be able, we hope, to function in this dizzying, fragmented, collapsing civilization. And it also helps us get along with those in our circles, ie the others in our class, or to use Isabel Wilkerson’s more robust term, our caste, when we believe the same things they do.
What Anita and Anand are asserting is that that leads us to align our beliefs with theirs. The loss of collective trust in governments and institutions makes it easier to do that, since we and the rest of our caste can comfortably ignore what health professionals and scientists are saying, when it doesn’t align with what our caste believes. We need to believe something, and we all need the support of our peeps.
This is not about class war, although it has all the trappings of one. Civilization has damaged, traumatized, and left us all deeply skeptical of everything we hear, no matter what caste(s) we belong to. That is not to say that civilization isn’t inequitable, racist, sexist, and more brutal to some castes than others. The ship is sinking, we’ve burned all the lifeboats, and the fact that each caste is heading for the exits designated for that caste, will make no difference to the final outcomes. Those in the lower steerage areas will, of course, go sooner and more terribly than those on the upper decks rearranging the deck chairs in the belief a bit more consultation will come up with magical solutions to save them. Those on the upper decks have, of course, locked the stairwells and elevators to prevent those in the lower castes from moving higher. Those in the lower castes are ramming the barricades, outraged. Meanwhile, the bulkheads have been breached by the sea, and those in the bottom half of the ship are already gasping for breath.
We have created a global civilization (with the best of collective intentions) that is enormously fragile (efficiency is cheaper and faster than effectiveness), and it has no resiliency. It has grown to such enormous scale that no one controls, or can control, any of it, as hard as those with wealth and power might try. It cannot possibly hope to contend with global pandemics, especially with trust across castes at its nadir. For the same reasons it cannot hope to contend with the accelerating ecological collapse and economic collapse that will soon be the undoing of all of us and everything we have created.
A friend recently pointed out to me that, statistically, every person who has declined to get a vaccine since they have become available has, directly or indirectly, produced an average of 30-50 more infections, one of which will, on average, require hospitalization. One of every six thus hospitalized will die of the disease. The unvaccinated, he said, have blood on their hands. And about ten of the 30-50 needlessly infected will suffer with Long CoVid.
I understand his position, but he completely misunderstands the lessons that Anita and Anand are trying to convey. The facts (and statistics) don’t matter — not because ‘some people’ are willfully ignorant or in denial about them, but because our culture has destroyed our trust in knowing with any confidence which facts are true and which are false. So we retreat to accepting the beliefs of those in our caste(s), and ignoring those of other castes when they hold something different.
This is human conditioning. We have evolved this way. When the facts are in doubt, we follow the herd. I watch this all the time in the behaviour of birds and deer, and there is no reason to believe we are any different. Our actions, and beliefs, are the products of our conditioning.
This propensity makes us even more bewildered when it comes to questions of “what can/should I do personally?” For wild creatures this is not an issue, but for us self-afflicted humans it is something most of are conditioned to take seriously. What difference do personal actions make? Followers of the Jevons Paradox know that buying a more fuel-efficient car will likely lead to increased use of the vehicle, so that fuel use actually increases. We know that flying is ecologically disastrous, but what difference does it make if that flight takes off with one more empty seat?
If I decide not to have any children, to avoid exponentially increasing my, and my descendants’, carbon footprint, the resources they would otherwise have consumed will simply be taken by someone else and their descendants, surely? The logic is false, but it doesn’t matter. As long as my caste is flying in airplanes (and getting upset if I refuse to), and having children (and getting upset if I urge them not to), we will all keep following the herd. That’s our conditioning, and until the planes are all grounded and until having a child is obviously condemning it to a ghastly life and early death, we will continue to do so. Then we’ll be reconditioned, by our caste (not by our politicians or the media) to behave differently.
As for the next pandemic, or the potential of omicron to essentially restart this one, the die is now cast. Those who trust the science, and the scientists, will mostly live, though the constraints on their lives will be much more severe, and their situation much more precarious, because next time even fewer will get vaccinated. Those who don’t trust the science, or the scientists, or those who employ them, for perfectly understandable reasons, will make the last two years under CoVid-19 look like a picnic. Our civilization can simply no longer cope with global crises — the trust needed to respond quickly and unanimously has been lost, if it ever really existed at all. And no one is to blame. This is what collapse looks like.
This is such a great idea: jc is a CLI tool which knows how to convert the output of dozens of different classic Unix utilities to JSON, so you can more easily process it programmatically, pipe it through jq and suchlike. "pipx install jc" to install, then "dig example.com | jc --dig" to try it out.
From 2018, a write-up from Segment explaining how they solved the problem of delivering webhooks from thousands of different producers to hundreds of potentially unreliable endpoints. They started with Kafka and ended up on a custom system written in Go against RDS MySQL that was specifically tuned to their write-heavy requirements.
One of the notebooks I tested was an HP 17″ notebook with a recent 11th generation Intel i5-1135G7 processor. Despite being a rather cheap notebook (560 euros without operating system, including tax), it comes with the latest Intel CPU on the market today and dual channel RAM, i.e. two RAM slots, both equipped with 4 GB RAM modules. So by removing one module, it’s easy to check what kind of impact a Dual Channel RAM configuration has to such a workload. From a memory perspective, the workload should be rather light. The input file is around 200 MB, while the output file is around 150 MB. My baseline on this notebook is an execution time of 7 minutes 54 seconds and a speedup factor of 6,35 times (see my original article + my note at the bottom for details).
Single Channel vs. Dual Channel RAM
When running the test again with a single memory bank, ffmpeg took 9 minutes and nine seconds to transcode the video. That’s a speedup of 5,95x and hence 20% slower compared to both RAM modules in the notebook.Quite a difference!
Hyper-threading
Hyper-threading can be switch-off in the BIOS and after a reboot, only 4 instead of 8 CPUs are visible to the operating system. With the default dual channel RAM in the notebook, ffmpeg took 8 minutes and 2 seconds to complete and a speedup of 5,22x. That’s only 6% slower than with hyper-threading being turned on. In other words, for this kind of compute job, it doesn’t do very much.
Summary:
I’m not sure what I kind of result I expected in the single vs. dual channel RAM comparison, but it’s good to see there is a significant difference. When I buy notebooks in the future for myself, I will make sure that I won’t settle for a single channel option. As far as hyper-threading is concerned, I would have expected a more sizable gain. Perhaps there is for other kinds of workloads.
Note: For unknown reasons the speedup on my HP notebook was 6,05 when measured a few weeks ago. This time around I got a speedup of 6,35 doing exactly the same test. The only difference is that back then I was using an external SSD connected over USB, while this time around I used an internal M.2 attached NVMe SSD. Also, I tried different kernel versions on Ubuntu 20.04 (the stock 5.11 and the latest mainline 5.15) and got exactly the same speedup.
The internet—essential to modern life and also the world’s largest coal-powered machine.
Like the shipping industry, packets zigzag across the globe and connect billions of people through a colossal distributed infrastructure we rarely see until it chokes, like a container ship stuck in the Suez Canal or Facebook going down.
Ships run on bunker fuel, some of the dirtiest sludge on the planet. Much of the internet burns on coal, the historically the cheapest, most convenient fuel available. And while the IPCC is calling “a code red for humanity,” the tech sector and shipping each emit 1-3% of the world’s carbon a year with projections rising.
The internet is becoming a brittle and polluting monoculture. Seven Big Tech companies predominantly control the internet and its infrastructure, and they are among the wealthiest in the world.
As the climate crisis intensifies, with more frequent and severe weather events, and more wealth is consolidated in the tech sector even during a pandemic, we’re seeing how this destructive default doesn’t serve humanity or the planet.
What’s more, when we do see chances to change the rules for a fairer, more sustainable, more just set of defaults, to steer us away from the cliff, we see these same firms lobbying to kill this progress in the name of short-term profits.
A Dissonance
Like many tech workers who grew up loving the possibilities of the internet to connect and empower people, learning about its destructive power causes us to experience a dissonance. How can this tool, with so much potential, speed up fire and floods and human suffering? What are we going to do about it?
Tech is built and maintained by people. What tech workers do each day can either accelerate the climate crisis or slow it down. As tech ownership and profits become concentrated to the hands of a few, how can workers advocate for their rights and more equitable futures? More than transitioning energy, we must shift power.
Divest from Big Tech
Today, we’re seeing tech workers unite across geography and pay grade to link arms with climate activists to demand better.
Big Tech sells itself as a solution to the crisis. But it’s part of the problem, too. The tech sector is rife with lucrative contracts with fossil fuel companies. Brilliant software engineering—optimizing this, improving a model for that—ends up accelerating the extraction of oil and gas, which when burned, pollutes the air, heats the planet and cuts short the lives of millions of plants, animals and people.
Big Tech must end its business with fossil fuels companies. And we, the people who dream of a sustainable, just and diverse internet, need to divest from Big Tech.
A Fossil Free Internet by 2030
That why we want to focus our efforts on achieving a fossil-free internet. And we want to make that happen by 2030.
The urgency and scale of the climate crisis demands action. With a big push, the internet could be decarbonized in a few years. And in that transition, we could reform the internet and turn it into a positive force for climate justice.
To get there, we need new narratives that shift what is desirable and possible. We need to transform our practices and make strategic partnerships with allied causes. And we need open infrastructure—data, code, poetry and repeatable pilots—to model how we can build bridges across social movements and achieve a fossil-free internet by 2030.
This issue of Branch uplifts the people and projects who are making that vision a reality. We want to situate these issues in larger movements for sustainable and just societies. We want to think at a network-level and in open partnership to gain momentum. We want to challenge colonial solutions on how to get to a fossil-free internet through further extraction of the Global South.
The next few years will be critical for the future of the planet and the internet. We need to expand the coalition of people working towards this shift. We hope you find some inspiration for action here.
In high school and college, I was a big fan of the Creative Commons. I even had a shirt with the copyleft logo on it.
The idea of freely sharing creative works, to be recombined by a community, was exhilarating: I would contribute raw materials to the collective - photographs, code, writing - and recombine the works of others, in Photoshop competitions or remixes. Practically every photo I’d license as CC-BY-SA. If someone used one of my photos in their blog, I felt a little jolt of approval and recognition. It felt cool.
The same went for open source. The early communities around Drupal and Node.js were radically open source. Companies were releasing their entire products for free and writing detailed blog posts about how they figured out hard problems. Whatever trade secrets they had were narrow: the value of the company was in its people and ability to move fast, not in its exclusive rights to code. And people actually, really did believe in leaving the world better than they found it.
Things changed gradually, but this is one of the milestones that I remember: when IBM mined Creative Commons-licensed photos for machine learning. The initial news reports said Flickr “handed over” the photos, then the correction was that they didn’t have to, because the license permitted the usage. What IBM did wasn’t nefarious, it was perfectly within the letter of the law. Was it in the spirit of the law? In one sense, it was IBM creating a product with unpaid labor. But also, their intent was to make more equitable algorithms. It’s a mixed bag.
But anyway, things got worse. A culture emerged from re-uploading Creative Commons videos on YouTube and profiting from the ads. I stopped licensing anything as Creative Commons, because it would inevitably be used on some content farm or sold in some fashion. My art would end up on a print-to-order site like RedBubble on a mug somewhere. My writing would be copied for SEO spam. It was easier to picture nefarious uses than creative ones.
Placemark, the application, won’t be open source. I didn’t even consider the possibility: open sourcing the application layer of a product just doesn’t work. You get all the downsides of community support, white-labeling, process friction, confusion around why people have to pay, confusion around whether to use the open source version or the paid version, and none of the benefits.
But how much of Placemark should be open source? And how much should I share? While Placemark has plenty of bugs and problems, there are a few elements which are really good, and they’re good because I’ve invested time, energy, and now money into learning and progressing through failure. Is it good to just spill every secret, when someone might just quietly implement it in a purely-proprietary system?
What’s changed is that more of the internet is for-profit. There are more entities, like YouTube profiteers or machine-learning startups, eager to copy and ingest anything that’s legally unencumbered. That fewer startups are interested in contributing to open source in any significant way. Fewer still will open source major components of their product. And major companies with lots of existing contracts have started building their fortunes on open source in a way that feels - to me, on an emotional level - exploitative. Startups shouldn’t be their unpaid R&D department.
I can’t claim that what’s happening is good or bad, objectively. Whether the utopian vision was silly, or the mega-corps are evil, or the open source community is defaulting on its values. And it’s impossible to factor out my aging, the increasing jadedness that you feel having seen some history.
But the community feels different now, now that many of its participants have different values. When you share something for free, the first thing that happens is that someone else will sell it.
The most common use of Jinja2 is in web applications, where it is used to create HTML files from template files. But I have used it outside web applications too.
I have used it to create images using SVG. I have an SVG template. I add or remove segments or text in that using Jinja2 templating language. So for example you want to create labels or certificates, you can do this.
I also create student report cards using Jinja2. I use data from CSV, create a custom HTML report using Jinja2, and then convert that into a beautiful PDF report using WeasyPrint.
I also have some Jinja2 templates that take some variables and create a bunch of SQLs to achieve something. Mostly if I am doing customer support.
As you can see, I use Jinja2, where I have data and a template and am expected to produce text output. In most cases, it would be a simple python script like this.
from jinja2 import Template
template = Template(TEMPLATE)
print(template.render(data=data))
Suppose I could call a CLI tool that takes data JSON (or any other format) and a template file. And outputs the rendered text or file. Then I can avoid writing this python script. I can also use piping from the UNIX world to mix with other UNIX tools.
This is where jinja2-cli package comes into the picture. It's a python package, once installed, brings the power of Jinja2 library to a command-line tool called jinja2.
pip install jinja2-cli
The command takes a template file and a data file. And returns the rendered file or prints to STDOUT.
jinja2 takes template and data, and outputs rendered content.
jinja2 [options] <input template> <input data>
It can take data in the form of JSON, XML, YAML, querystring, ini, auto, key=value pairs etc. That's almost any kind of data.
For example, I can render the email.html template using the data from data.json and pipe it to swaks to email me.
Here is something that is more practical and I use on daily basis. I pull the data from an RSS feed. I format it and send the rendered HTML as an email.
In the second part jinja2 renders the template and outputs to the STDOUT
jinja2 email.html data.json
In the final and third part swaks reads piped data and sends the HTML email to me
swaks --header "Subject: Reading list for Colossal" \
--to i@thejeshgn.com --tls \
--add-header "Content-Type: text/html" \
--body -
The email template looks like this
<html>
<body>
<h2> Headlines </h2>
<ol>
{% for item in data[0] %}
<li><a href="{{data[1][loop.index-1]}}">{{item}}</a></li>
{% endfor %}
</body>
<ol>
</html>
JSON produced by xidel looks like this
{ "data":[[
"Celebrating Kenyan Culture, Bold Textile Patterns Disguise Subjects in Thandiwe Muriu’s Portraits",
"Illuminated Dinosaurs Stalk Paris’s Jardin des Plantes in a Spectacular Journey Through Time",
"A New Book Captures Roger A. Deakins’s Signature Cinematic Style Through Ironic Black-and-White Photos",
"Cut from Found Feathers, Minuscule Silhouettes Become Intricate Symbolic Works",
"Jane Goodall, Paul Nicklen, and 100 Photographers and Conservationists Join a Print Sale to Protect the Environment",
"Bars of Light Pierce a Dilapidated Sydney-Area Home in Ian Strange’s Illuminated Intervention",
"December 2021 Opportunities: Open Calls, Residencies, and Grants for Artists",
"Canning the Sunset: Hundreds of Jars of Dyed Sand Preserve the Swirling Colors of a Skyline Before Dusk",
"Vintage Fabrics Encase Ceramic Shards in Zoë Hillyard’s Mended Pottery",
"Two Curious Rats Endure the Disastrous Effects of an Experiment Gone Haywire in an Animated Short"
],
[
"https://www.thisiscolossal.com/2021/12/thandiwe-murius-portraits/",
"https://www.thisiscolossal.com/2021/12/dinosaur-exhibition-paris/",
"https://www.thisiscolossal.com/2021/12/roger-a-deakins-byways/",
"https://www.thisiscolossal.com/2021/12/chris-maynard-feathers/",
"https://www.thisiscolossal.com/2021/12/vital-impacts-print-sale/",
"https://www.thisiscolossal.com/2021/12/ian-strange-light-intersections/",
"https://www.thisiscolossal.com/2021/12/december-2021-opportunities/",
"https://www.thisiscolossal.com/2021/12/carly-glovinski-sand-sunsets/",
"https://www.thisiscolossal.com/2021/12/zoe-hillyard-ceramic-patchwork/",
"https://www.thisiscolossal.com/2021/12/experiment-animated-short/"
]]}
You can read this blog using RSS Feed. But if you are the person who loves getting emails, then you can join my readers by signing up.
Can you help me find additional blogs to follow? I am looking to broaden the scope of blogs in my reader. That broadening has two main dimensions: language and geography. Right now, because they’re often easier to find, and more regularly linked to, my feed reader is heavily anglosphere centric.
Some specifications for the type of blogs I am looking for:
Individual or group authored blogs, not company or organisational blogs. A blog maintained by a research group is an acceptable ‘in-between’ version. The reason is I see blogging as distributed conversations. Companies don’t have conversations. As a result I follow people, not blogs, in my feedreader
Some thematic overlap with my interests is needed, something to have those distributed conversations around. Such interests are: making, open data/source/access/everything, agency, civic tech, ethics, digital transformation for all, climate adaptation, knowledge work, complexity, philosophy of science/tech, change, learning
The areas I am looking to extend my blog reading towards are:
Indian bloggers, or India based blogs in English
Chinese bloggers, or China based blogs in English
EU based bloggers, in Spanish, French, Italian or German languages. Or Spain, France, Italy, or Germany based bloggers in English
Middle-, South-American bloggers in Spanish/Portuguese or English
Bloggers based in SE-Asia
Bloggers based in Nigeria, Kenya, Tanzania, Uganda, South-Africa
Any pointers, or pointers to list- or aggregator sites to explore are appreciated.
I've stopped considering my projects "shipped" until I've written a proper blog entry about them, so yesterday I finally shipped git-history, coinciding with the release of version 0.6 - a full 27 days after the first 0.1.
It took way more work than I was expecting to get to this point!
I wrote the first version of git-history in an afternoon, as a tool for a workshop I was presenting on Git scraping and Datasette.
Before promoting it more widely, I wanted to make some improvements to the schema. In particular, I wanted to record only the updated values in the item_version table - which otherwise could end up duplicating a full copy of each item in the database hundreds or even thousands of times.
Getting this right took a lot of work, and I kept on getting stumped by weird bugs and edge-cases. This bug in particular added a couple of days to the project.
The whole project turned out to be something of a bug magnet, partly because of a design decision I made concerning column names.
git-history creates tables with columns that correspond to the underlying data. Since it also needs its own columns for tracking things like commits and incremental versions, I decided to use underscore prefixes for reserved columns such as _item and _version
Datasette uses underscore prefixes for its own purposes - special table arguments such as ?_facet=column-name. It's supposed to work with existing columns that use underscores by converting query string arguments like ?_item=3 into ?_item__exact=3 - but git-history was the first of my projects to really exercise this, and I kept on finding bugs. Datasette 0.59.2 and 0.59.4 both have related bug fixes, and there's a re-opened bug that I have yet to resolve.
The git-history live demos are built and deployed by this GitHub Actions workflow. The workflow works by checking out three separate repos and running git-history against them. It takes advantage of that tool's ability to add just new commits to an existing database to run faster, so it needs to persist database files in between runs.
Since these files can be several hundred MBs, I decided to persist them in an S3 bucket.
My s3-credentials tool provides the ability to create a new S3 bucket along with restricted read-write credentials just for that bucket, ideal for use in a GitHub Actions workflow.
I decided to make the bucket public such that anyone can download files from it, since there was no reason to keep it private. I've been wanting to add this ability to s3-credentials for a while now, so this was the impetus I needed to finally ship that feature.
It's surprisingly hard to figure out how to make an S3 bucket public these days! It turned out the magic recipe was adding a JSON bucket policy document to the bucket granting s3:GetObject permission to principal * - here's that policy in full.
I released s3-credentials 0.8 with a new --public option for creating public buckets - here are the release notes in full:
s3-credentials create my-bucket --public option for creating public buckets, which allow anyone with knowledge of a filename to download that file. This works by attaching this public bucket policy to the bucket after it is created. #42
s3-credentials put-object now sets the Content-Type header on the uploaded object. The type is detected based on the filename, or can be specified using the new --content-type option. #43
s3-credentials policy my-bucket --public-bucket outputs the public bucket policy that would be attached to a bucket of that name. #44
This was a quick experiment which turned into a prototype Datasette plugin. I really like how GitHub show hover card previews of links to issues in their interface:
I decided to see if I could build something similar for links within Datasette, specifically the links that show up when a column is a foreign key to another record.
It still needs a bunch of work - in particular I need to think harder about when the card is shown, where it displays relative to the mouse pointer, what causes it to be hidden again and how it should handle different page widths. Ideally I'd like to figure out a useful mobile / touch-screen variant, but I'm not sure how that could work.
The prototype plugin is called datasette-hovercards - I'd like to eventually merge this back into Datasette core once I'm happy with how it works.
I am pleased to share that Kristen Trubey has joined Mozilla as our Chief People Officer. Kristen initially came to Mozilla in August in an interim capacity but she quickly settled in and made an immediate impact. Her expertise, experience and focus to create connections between company culture, employee experience, and business results proved to be exactly the kind of leadership we were looking for to lead our people teams.
As Chief People Officer, Kristen will be responsible for all areas of HR and Organizational Development at Mozilla Corporation with an overall focus on ensuring we’re building and growing a resilient, high impact global organization to support Mozilla’s next chapter.
“It was clear after my first days as interim CPO that Mozilla’s culture was one I would be lucky to be part of and months later that feeling has only grown,” said Trubey. “Mozilla’s core values and mission aren’t just slogans on a website, they are truly woven throughout every part of the company. I am excited to come on as a steward of that culture and to help scale an organization that promotes growth, inclusion, and excellence to help us reach our goals.”
Kristen comes to us most recently from Patreon, where she spent eight-months providing HR leadership and support. Prior to that, Kristen was Chief People Officer at Hearsay Systems, a mid-sized startup with offices around the world. She also spent more than five years at Netflix where she supported a variety of teams including a two year assignment in Amsterdam as the first HR leader in Europe as part of the company’s strategy to scale Netflix’s culture globally.
Kristen will continue to report to me and sit on the steering committee.
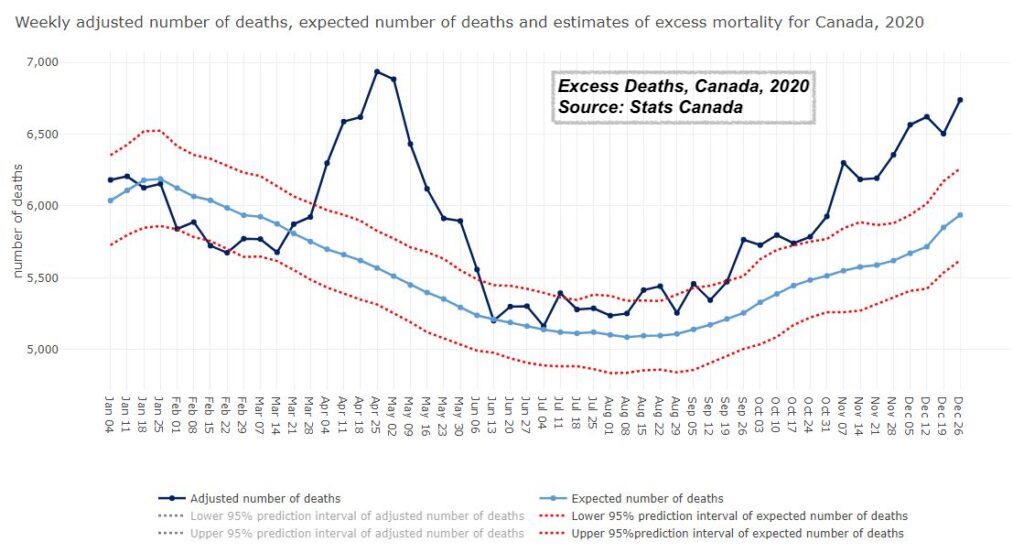
Actual vs “normal” weekly deaths from all causes, 2020 and 2021-to-date, from Statistics Canada data via Alberta Business Council
Since I first reported on the World Mortality Database (WMD), and its argument that IHME’s excess deaths data, and hence their estimates of actual deaths from CoVid-19, are completely untenable, I’ve been digging more into the WMD data, specifically the Canadian data.
The WMD data suggest that, far from the 40% CoVid-19 deaths undercount that many earlier studies had suggested for Canada (and the US), and the 50% undercount that IHME is now, preposterously, using (for Canada, but no longer for the US), the reported Canadian CoVid-19 death count appears to have been, and continues to be, extremely accurate. Some CoVid-19 deaths have been missed, of course, but it appears that for a comparable number of deaths attributed to CoVid-19 because the deceased showed evidence of having been infected, the actual cause of death was something else — most likely a pre-existing condition.
This phenomenon doesn’t only apply to Canada, but to quite a few other countries with advanced health care reporting systems, such as Belgium, France, Sweden, Switzerland and Austria. What distinguishes these countries is that the ratio of excess deaths during the pandemic to reported CoVid-19 deaths to date, is less than 1.0.
This doesn’t mean that global CoVid-19 deaths are anywhere near as low as the 5.3M reported to date — the correct number is probably triple that. That’s because countries with poor reporting systems or a political agenda to suppress reported death counts have drastically undercounted their death totals — by from 10% in the US to over 100% in countries like Russia, Brasil and India.
But it does mean that countries like Canada, Belgium, France, Sweden etc have actually done a pretty amazing job at identifying all the dead, and, consequently, adjusting for factors like demographics and average immune system health, have done a pretty amazing job at limiting the number of citizens infected in those countries, and hence their future toll of Long Covid sufferers.
If you look at the most recent statistics for Canada, for example, what is remarkable is that for Jan-May 2021 (the data after that date is not yet finalized) there have been zero net excess deaths. Despite increases in some months in the number of reported cases (partly due, most likely, to better reporting and more access to testing), the total number of Canadian deaths in 2021 to date would seem to be slightly lower than in an average year.
What does this mean? It means that for every CoVid-19 death in Canada in 2021, more than one death has been prevented, or at least forestalled, that would have occurred over a typical similar recent period. Many things could account for this:
The huge number of people wearing masks (in my neighbourhoods it’s been 80+% of the people I see in public, all year) has reduced the incidence of flu and other respiratory diseases transmitted by air.
People are just being more conscious of their health — washing their hands more often, for example, and getting tested when symptoms arose that they might “normally” have shrugged off, and hence identifying and treating other conditions.
While “mobility” has returned to near “normal” levels, de facto social distancing protocols remain in place for most people, especially the most vulnerable, and will until the pandemic is declared “over”.
What’s remarkable is that this “net zero” excess deaths has been achieved despite some of the mortality factors that CoVid-19 would tend to exacerbate:
People deferring or avoiding surgery and other medical interventions out of fear of getting CoVid-19 in hospitals, or because medical facilities became less available due to CoVid-19 hospitalizations.
Increased deaths from suicide, street drug poisonings, domestic homicide and other consequences of people’s inability to deal with the challenges and isolation of living in a pandemic.
Reported increases in some causes of death that are related to stress, and related to increased levels of obesity during the pandemic.
And that’s not even including the surges in deaths from some non-CoVid-19 related causes in 2021 such as “heat domes” (the leading cause of death among all causes in BC one week this past summer), wildfires, flooding etc.
What this means is that, for Canada at least, while we haven’t got the pandemic “under control”, total Canadian death tolls from all causes (including the pandemic) are back to pre-CoVid-19 levels. This despite the fact that the WMD data suggests that the percentage of Canadians infected with CoVid-19 so far is a lot lower than we feared earlier — perhaps as few as 10% of Canadians, a third the proportion of our neighbours to the south.
Close to 90% of Canadians are now fully vaccinated (the US percentage is closer to 60%). Canada is now fast-tracking booster shots, which show promising results against omicron. Canada’s death toll to date has been about 30,000 (0.08% of the population, compared to 0.27% of Americans), and probably another 2,000 Canadians will die over the four coming winter months. But if recent trends hold true, at least 2,000 fewer Canadians will die of other causes this winter than in a normal winter.
This doesn’t mean we should let up on what we’re doing. In fact it would be great if we could get free CoVid-19 tests into every Canadian’s hands to get better tabs on the pandemic’s progress here (we don’t have to deal with a Jen Psaki or a for-profit health care system in this country, so this should be possible).
What this data shows is that — at last — we in Canada are doing very well dealing with the pandemic, and we should be grateful to our public health system for this remarkable accomplishment.
The game may be far from over, but, at least in this country, it looks like we’ve tied up the score.
Noting for posterity that (a) we are expecting our first significant snowfall tonight and (b) my appointment to have my winter tires installed is tomorrow morning.
It’s fairly common to automatically close discussions after they have gone a few weeks (or months) without a response.
The benefit of this is it keeps the community fresh.
It’s tiring to see newcomers responding to discussions that haven’t received an update in several years. The common case is the member arrives via search to an outdated post, tries the advice provided, and points out it no longer works.
If the discussion was closed for new posts, that’s a good indicator that it’s out of date (or the matter is ‘settled’). It would also encourage the newcomer to create a new post that might solicit more recent, up-to-date, information.
The downside of this approach is you’re likely to get a lot more repeat discussions on the same topic. It can be exhausting for members to repeatedly answer the same questions.
So, what’s the best option? In most cases, it’s usually best to close discussions that haven’t received a new update in several weeks. For extremely large communities where repeat questions would be a problem, it’s probably best to try and have ongoing, definitive, threads (and up-to-date knowledge-base articles), which members can reply to.
When Apple ditched the headphone jack on its iPhones in 2016, I was annoyed. Don’t get me wrong—my wireless Bluetooth earbuds, with their breezy untethered liberation, will always have a place in my heart for jogging, working, and puttering about the house. But I deeply resent the need to fish out that 3.5 mm–to–Lightning adapter because I still love my wired headphones, too.
I’m on hold right now waiting for a customer service rep — to investigate a serious problem that I neither caused nor asked for. I’d give up, except that resolving this is crucial to my future. And it’s hell. If the experience of calling your call center is a hellscape, your customer experience is terrible. … Continued
This 1929 Vancouver Public Library image, photographed by Philip Timms, shows the nearly new Loyal Order of Moose Lodge No. 888 on the east side of the street at 636 Burrard. The builder for the $70,000 development was the Dominion Construction Co. It’s possible the company designed the project in-house; Charles Bentall was not averse to sketching how projects could be built, even though he wasn’t a qualified architect.
Down the street is Southard Motors Ltd. at 600 Burrard. Designed by R A McKenzie, it cost $15,000, was built by Bedford Davidson, and developed by G G McGeer – former Liberal politician Gerry McGeer. He had represented Richmond in the Provincial government in the 1920s, and would be re-elected in the early 1930s both as MLA and mayor of Vancouver, and then as an MP.
Southard had been on West Georgia in 1925, selling Essex cars – a part of Hudson Motors of Detroit. In 1930 they had this branch, and one in a different West Georgia location. As well as the Essex Super-Six they were selling the Hudson Super-Eight.
Archelaus Southard was president of the company, with a house in Shaughnessy. He was from a Methodist family, was born in Ontario, and was more often called Archie. In 1895 he was in Alberta, working as a tailor. That year he married Flora McDonald, and in 1911 they were living in Medicine Hat, where he was a merchant. He must have been successful; they had an 11-year-old daughter at home, Kathleen, an American governess and a Swedish maid. They appear to have had a son, also christened Archelaus, in 1918. The Southard name traces back to a family living in New York in the 1700s, and had a tradition of sons being christened Archelaus stretching back several generations; (-some in the the 1800s were Quakers). The owner of Southard’s Motors was 77 when he died in 1950, and his wife Flora was 85 on her death in 1959.
In 1930 the company relocated to Granville Street – in 1938 they were selling Chrysler cars. Knight Motors moved in here, selling Chevrolet motors in the early 1930, although by 1936 De Wolfe Motors had replaced them. Like Southard’s operation here, they apparently sold pre-owned vehicles, but De Wolfe seem to have specialized in trucks, and were Reo Distributors for B C. Named after Ransom Eli Olds, and based in Lancing, Michigan, as well as cars, Reo (or REO, the company favoured either option) were best known for their Speedwagon trucks.
At the start of the war the premises were vacant, and by 1941 Empire Motors had moved in. They sold Ford and Mercury cars, and Ford trucks. They stayed here until the early 1950s, when the site was redeveloped as a Home Gas Station, with the Midtown Motors garage, run by Philip and David Kobayashi, specializing in body repairs and like Empire, offering u-drive cars.
On the north side of Dunsmuir, the half-timbered English styled building was the YWCA, developed in 1905 to W T Dalton’s design, with a 1909 addition.
Today Park Place, addressed as 666 Burrard and completed in 1984, occupies the sites of the lodge and the garage. The YWCA was replaced with a much larger building in 1969, that was closed in 1995 and demolished in 1997. It was replaced several years later by the Cactus Club Cafe a low-rise building associated with Bentall 5, an office tower built in two stages to eventually reach 33 floors in 2007, (but initially only 22 in 2002).
Wallpaper has published an in-depth profile of Apple’s Design Team that takes readers behind-the-scenes at Apple Park for a peek at the wide array of disciplines for which it is responsible. The story covers everything from hardware design to typography and sound design and includes interviews with Apple’s Evans Hankey, vice president of industrial design, and Alan Dye, vice president of human interface design.
For Apple Watch, the team had to design, build, and implement a physical notification system. How strong? How long? What felt natural? ‘We knew that the Watch was going to be the most intimate, the most personal product that we’ve ever made,’ says Hankey. ‘We also knew it needed to get your attention at some point.’ It was Duncan Kerr, a long-standing member of the Design Team, who suggested the idea of the ‘tap’. ‘It’s such a lovely simple thing, but we had no idea how to bring that to life,’ Hankey says. Through a series of clunky prototypes and the work of haptics expert Camille Moussette, the ‘tap’ was refined and perfected.
Apple’s design process is rarely on display, which makes Wallpaper’s story, which includes loads of photos of the Design Team in action, one that you won’t want to miss.
I have this fantastic Behringer Flow 8 digital mixer, that I cannot use for one missing feature: per channel post-fader monitor.
Let me explain.
The Flow 8 has 8 channels of which 4 are mono, and 2 are dual channel stereo. The stereo channels can be fed from four line-in, USB 1/2 or USB 3/4. You can also connect a Bluetooth source.
Behringer Flow 8 with Beyerdynamic DT 297
There are three mixes: main, monitor 1 and monitor 2. I connect the two monitor busses as a stereo bus, so I have two busses: main and monitor. The main mix is what I send out, the monitor mix is what I hear on my headphones. I need a mix-minus configuration, which means the monitor mix has one channel more than the main mix. This is where I listen to an audio source that I do not send out. This would be Clubhouse or any other communication software like Zoom or Teams. You do not want to loop the incoming channel back into the main mix. So far this works well.
Here is what I am missing: I cannot listen to the main mix. I do not know what I am sending out. If I fade in some background music, I do not know how loud it is on the main mix since I am listening to the monitor mix. If that monitor mix would be post fader, I could hear the music at the correct level. I could do this for every channel, except the extra one that I do not want to have in the main mix. This channel would be set to pre-fader. Even if the main fader would be down to zero, I could still hear it in the monitor mix.
This is so frustrating. This machine would be perfect if it only had this one feature. Uli Behringer, can you make this happen in a software update?
Christian Finnegan@ChristFinnegan
Ooh, I know this one! Your mythical Conservatism is a niche brand of elite narcissism incapable of winning national… twitter.com/i/web/status/1…
Meta-owned Instagram plans to bring back "a version" of its chronological feed next year, according to company head Adam Mosseri.
During a Senate hearing on Instagram and teen safety (via Engadget), Mosseri said he supports "giving people the option to have a chronological feed."
"We're currently working on a version of a chronological feed that we hope to launch next year," said Mosseri, noting that the company had been working on it "for months" and that it aimed to launch the feature in the first quarter of 2022.
Instagram later confirmed to Engadget that it was working on a chronological feed option as well as a 'favourites' feed that will surface posts from designated friends. Both will be optional, and Instagram shared on Twitter that it's adding choices so users "can decide what works best for them."
The confirmation comes after developer and reverse engineer Alessandro Paluzzi recently found an Instagram feature that would let users sort their feed by 'home,' 'favourites' or 'following.'
It's not clear if any of those include the chronological feed. Another recent Instagram test saw the company add 'suggested posts' to users' feeds.
Adding a chronological feed would be a significant shift for Instagram, which previously removed its chronological feed more than five years ago. Since then, Instagram has vigorously defended its algorithmic feed even as it faced increased scrutiny over how its algorithms ranked and suggested content, particularly for younger users.
Regardless, fans of the chronological feed will be happy to hear Instagram is bringing it back. However, it remains to be seen if Instagram's "version" of a chronological feed will satiate users, if it will be beneficial or if it will perpetuate existing problems with the platform.
Snap is a company that most people are overlooking, argues Casey Newton, but it has slowly been developing a solid foundation for augmented reality (AR) glasses that will eclipse its rivals. He makes a good argument. This, for example, is tantalizing: restaurants have been telling customers to scan QR codes to access the menu, but Snap has a 'lens' that displays what the menu item would look like on the table in front of you. "When I opened it up using Spectacles, I waved my hands to advance through the virtual goods: a burger, a sushi roll, a piece of pie. The donut looked realistic enough that I developed slight hunger pangs." Forget the bits that don't work yet. Focus on the things that are amazing.
I see in my email that Reclaim is requiring that we move all "advanced CloudLinux applications" from cpanel to Reclaim Cloud, which means for me the long-anticipated migration of my whole website to cloud containers, something I've been hesitant to commit to because clouds can go poof! "This risk is important to understand," write the authors, "otherwise, all the vital SaaS data you rely on each and every day could disappear in the blink of an eye." Of course, there are ways to minimize that risk, and it's a risk that exists for any digital data, not just cloud data. But the main point here is that "a data continuity strategy is essential," and that's as true for individuals like myself as it is for large enterprises (indeed, maybe even more true).
Wombo Dream is a fun app that lets you enter some words to output a related AI-powered artwork in various styles. You can get the app, or you can play with it in your browser. I entered my dissertation title.
While the shop sells all manner of Japanese sundries, from candy to iced coffee, the standout for me is that from Monday to Friday, over the lunch hour, they serve onigiri–Japanese rice balls–something that heretofore there’s not been a source for in Charlottetown. They have two types, tuna and grilled salmon. And they are lovely: just the thing for a quick lunch or snack.
The new Manifesto For Ubiquitous Linking calls on software designers to ensure that resources inside the software are linkable. Original signers include (among others) Eric Böhnisch-Volkmann (DEVONthink), Brett Terpstra (Marked), Frode Hegland (Liquid/The Future Of Text), David Sparks (MacSparky), Luc Beaudoin (Hook), Michael Tsai (EagleFiler), Rich Siegel (BBEdit), Ken Case (Omni), and me.
Cloudflare's 1.1.1.1 DNS service has a tool that anyone can use to flush a specific DNS entry from their cache - could be useful for assisting rollouts of new DNS configurations.
I’m a big fan of biking with wool socks all year round, but most people only consider them when it turns cold. Here is a picture of some Defeet wooleators, which are my default three season sock (i.e. not winter).
However, it would appear that I am pretty hard on socks and I tend to wear them out; the thinner socks most only last a year or so. This doesn’t really have much to do with biking. I take my shoes off at the front door, and I don’t use slippers so apparently hardwood floors are hard on my socks.
I’ve tried many brands of wool socks over the years, and I’ve noticed two different failure modes. For most socks, I usually wear them out at the heel.
However some brands like Teko appear to have a synthetic sock upon which the wool is woven around somehow, and so they have a tendency to thin out before tearing.
One brand that caught my eye was Follow Hollow. It was featured on kickstarter so I couldn’t resist.
The claim was that since they used alpaca wool, they were warmer than a regular sock of the same thickness. I’ve been pretty happy with them. One note is that I wash my wool socks with regular clothes at low temperature and then hang to dry. Over time I have noticed that the follow hollow socks do shrink.
I also noted that my oldest pair of these socks that I got around January 2020 finally wore out at the heel. Almost two years is decent wear.
I’ve stitched close the hole, and we’ll see how much longer I can extend the life of these socks.
I also have tried a brand called Darn Tough, which has a lifetime warranty on their socks.
I wore out the heels on a pair of their dress socks after about six months.
I sent them back as per the warranty instructions, and then I got a replacement pair, just as promised.
and then the replacement pair wore out
which were again replaced by this pair.
It is a bit of a hassle to keep sending back socks, but as long as they are willing to replace them, I guess that is OK. To be fair to the company, I hear that their thicker hiking socks are very durable.
Overall, I’d say that I’ve been happiest with DeFeet socks, and so I just stocked up on their woollie boolies for the rest of the winter.
I will note that my icebreaker socks have also been holding up pretty well, both the thin dress sock type as well as the thicker padded versions for hiking.
Update: I’ve been informed by several people that icebreaker also has a good warranty. I have two pairs of these bike themed socks, along with several pairs of their hiking socks.
 That said, I’ve returned to reading more literature the last few months, and this might be a good way to take stock of my media consumption with lists, short reflections, etc.* Also, I’m listening to a fair amount of music during any given work day, and incorporating that into more streaming (see below) is a goal for 2022.
That said, I’ve returned to reading more literature the last few months, and this might be a good way to take stock of my media consumption with lists, short reflections, etc.* Also, I’m listening to a fair amount of music during any given work day, and incorporating that into more streaming (see below) is a goal for 2022.














 Christian Finnegan @ChristFinnegan
Christian Finnegan @ChristFinnegan


 Wombo Dream is a fun app that lets you enter some words to output a related AI-powered artwork in various styles. You can get the app, or you can play with it in your browser. I entered my dissertation title.
Wombo Dream is a fun app that lets you enter some words to output a related AI-powered artwork in various styles. You can get the app, or you can play with it in your browser. I entered my dissertation title.























