cartoon by Will McPhail from his website; click on image to view larger size
One of my favourite New Yorker cartoonists, Edinburgh’s Will McPhail, has published his first graphic novel. It’s just out, and it’s called In. And it’s astonishing. It’s unlike anything I’ve ever read before.
Like many graphic novels since the genre began, this book is not just a graphic novel. It might be described as an art exhibition with an accompanying story. Imagine if Vincent van Gogh had written a blog entry, or a poem, to accompany Starry Night.
The book contains a host of ‘chapters’ in the life of Nick, a scarily-familiar, slightly shy white guy who’s completely out of touch with his emotions and neither capable of, nor, at first, interested in, talking about them. What we get, instead of just the balloons of what the characters are saying, is extra text in each panel of what Nick is thinking and feeling (but not saying). It’s an internal monologue that I’m sure many, many male readers, and the women who know them, will relate to.
In interviews, Will says that the Nick character is semi-autobiographical, but that the events and other characters are just invented. This is a story-telling approach that seems to work well — all the characters ring true, and the dialogue is natural but still snappy and often very funny.
The ‘story’ chapters are all in black and white. But interspersed are panels in vibrant colour, wordless and mysterious, dreamlike, portraying what would seem to be the full-bodied inner life of Nick and occasionally the other characters in the book. They work on a completely different level to the ‘story’ pages, and strike the brain and the heart (and perhaps the amygdala, if you believe in that sort of thing) of the reader in very different ways.
The coloured pages stand alone, sometimes gloriously, as works of art in their own right, and I could imagine hanging some of them on my wall. Perhaps where people who know me, but don’t really know me, could see them when they visit. Perhaps on my bathroom wall near the mirror, where they could remind me who I really am when I get up in the morning, and have forgotten.
The characters include Nick’s family members (all more self-aware than he is, including his very young nephew); Nick’s new girlfriend; and a host of baristas. They go through some familiar crises.
But then Will hits you with the coloured art panels, and suddenly you’re relating to Nick, and the other characters, and perhaps yourself, in a very different way, the way you relate to a beloved work of art, music or literature.
This got me thinking about what art really is. I’d always thought of culture as the shared beliefs, sensibilities and behaviours of a group of people, and art as the ways in which that culture is expressed.
But of course art is far more than that, and to the extent it is usually an individual, sometimes even lonely, undertaking, it naturally conveys more than any group’s shared beliefs and sensibilities (how they, familiarly, see and make sense of the world). Rather, it conveys how the artist sees the world both through the eyes of the artist’s conditioning culture, and through the artist’s own, very personal lens — perspectives that can be jarringly incongruent.
And that’s how the ‘story’ chapters of the book (the world seen through the cultural lens), banging up against the coloured panels (the world seen from the character’s own, hyper-personal, unfiltered lens), struck me. Intimate, somewhat irreconcilable and jarring (in a necessary, shake-you-up, Starry Night kind of way), and absolutely raw.
The story has some hilarious and moving moments that made me laugh out loud, and it has its moments of ‘ordinary’, commonplace tragedy. But it was the coloured panels, not the story chapters, that had me weeping like a child, like I have not cried in as long as I can remember. And this happened, spontaneously, all three times I read the book.
Like all good art, In made me envious of the artist’s ability to convey so much so powerfully, with words but also, more importantly and viscerally, without words. I ache to be able to ‘say’ these things without the flatness and enormous effort and imprecision of language. I want to give a copy of this book to everyone who has ever cared about me, or might one day in the future, to let them know who I was, and am, instead of having to rely on my blog, which cannot hope to convey a fraction of as much truth, and which does so far less articulately.
On another level, like many of his cartoons, Will’s book is a paean to women, their grace, their groundedness, their capacity to understand, and to give, and to carry on in spite of everything. I try to do that with the female characters in my short stories, but Will does it consistently, pointedly, and accurately.
When I’d finished the book (all three times, so far) I wanted there to be a sequel about Wren, Nick’s remarkable, patient girlfriend. I suspect it would be a huge challenge for Will to produce one, but I suppose he could find a woman collaborator, and pull it off. Wren is so real, I want to know more about her!
I hope I can get a discount on In with a bulk order. It’s going to end up in the homes of a lot of people I know.
A couple more of my favourite Will cartoons below.
If you want to follow the debate about crypto’s impact on society, which I believe is one of the most important topics in tech today, you better sharpen your Twitter skills – most of the interesting thinking is happening across Twitter’s decidedly chaotic platform. I’ve been using the service for nearly 15 years, and I still find it difficult to bring to heel. When following a complex topic, I find myself back where I started – in a draft blog post, trying to pull it all together.
That’s where I’ve been this past weekend as I watched the response to a thoughtful post from Signal founder Moxie Marlinspike. (And yes, the fact that the Twitter conversation was driven by a blog post is not lost on me…)
For those of you who might not use Marlinspike’s service, Signal is an encrypted messaging platform favored by pretty much everyone in the tech and media world. Marlinspike’s post laid out several shortcomings of the current web3 world, all of it based on his own extensive “tinkering” with things like minting NFTs and building distributed apps, or dapps. It’s worth reading the whole thing, but to summarize, his critique has three key points:
First, while web3 is supposed to be about a world free of centralized services, it turns out most of the well-known web3 platforms (OpenSea, Coinbase) are, in fact, centralized just like web2 (this echoes a criticism brought up earlier in the week by Ben Thompson (sub required, worth it).
Secondly, technical protocols evolve slowly – and protocols are the basis for a lot of web3’s magic. Marlinspike points out that most web1 protocols – like SMTP for mail – are stuck in time and fail to evolve. This is often because the protocols are decentralized – no one is in charge of improving them.
Thirdly, there’s a lot of room for error, mischief, or worse in how many of these services and protocols currently interact – particularly around fundamental issues of trust and privacy, two pillars of web3 philosophy. Marlinspike uses the example of an NFT he created which was banned by OpenSea and subsequently disappeared from his MetaMask wallet to make his point.
If you’re still reading, congrats – that’s a lot and we’ve not yet gotten to the good stuff, which for me is the discussion that’s evolved since Marlinspike’s post. Watching the responses come in felt a lot like reading the early blogosphere – one by one, people I admire built on Marlinspike’s thinking, challenging some of it here, deconstructing other parts there. The tone was respectful, considered – no one reacted as if their religion had been impugned.
The first response I noticed was from Vitalik Buterin, co-creator of Ethereum.
Responded!
I think the status quo comes from a present-day "missing middle" where we have centralized-but-easy things and decentralized-but-hard things, but new tech (w lots of cryptography!) actually is on the cusp of giving us the best of both worlds.https://t.co/XIx8f2oiVipic.twitter.com/phTSrGW0OR
Buterin challenges Marlinspike’s focus on technical grounds, particularly the term “servers,” and reminds us that there’s still a ton of infrastructure and foundational software work to be done. He points out that 2022 will be a big year for ETH, given its shift from the slower and most costly proof of work to the more nimble and efficient proof of stake.
I then realized I had missed Brian Armstrong’s response, which came a few hours after Marlinspoke’s initial post:
3. I agree there is an overall move toward using platforms. But there is a big difference between using a platform that also owns all the data also (web2) and a platform that is merely a proxy to decentralized data (web3).
Armstrong runs Coinbase, arguably one of the most centralized “web3” companies built so far. His last point is key: There’s a big difference between a company built to control data (Facebook) and one that acts as a useful wrapper for data owned and controlled by the end user. VC Chris Dixon elaborates in a thread the next morning:
How web3 data portability reduces the power of centralized services
Dixon is pointing out a key distinction between web2 and web3 services, regardless of their potentially centralized nature: Ease of data portability. I’ve long argued that any apps or platforms based on leveraging our data should compete on the quality of service they provide, rather than the data they lock in. In 2008, I wrote “It’s time that services on the web compete on more than just the data they aggregate.” This is Dixon’s point in a nutshell: “web3 works like web1 did. There will be centralized services built in web3 — and many will be quite useful — but their economic power and overall control will be limited by the lower switching costs due to data portability.”
The discussion continued later that day with Matt Mullenweg, the CEO of Automattic, the company behind WordPress. WordPress drives more than 40% of the current internet, and Mullenweg has long been a standard bearer for web2’s original philosophy – that of interoperability.
Anyway the most interesting conversation to me is how to make all the new stuff as user-friendly as possible without recreating the same centralized bottlenecks and gatekeepers.
Mullenweg name checks my former partner Tim O’Reilly, whose seminal “What Is Web 2.0” paper kicked off our Web2Summit conference series and has helped frame my thinking about the Internet for the past 15+ years. Mullenweg’s point is that many original web2 services are entirely consistent with web3 philosophies. That is still true today – whether or not web3 technologies are at the core of it (Mullenweg himself might best be described as “extremely crypto curious.”)
Debate on Marlinspike’s post continued throughout the weekend, and by Sunday, former Dropbox CTO Aditya Agarwal responded elegantly to Marlinspike’s second point, that of protocols.
1/ @moxie wrote a fantastic blog post about his observations on Web3 that really got me thinking about some underlying questions of centralization, protocols, platforms and lastly our ability to predict stuff in this space.
Remember that Marlinspike’s criticism of protocols is that they are slow to evolve. Agarwal explains that while this was true of protocols in the early web, it’s not necessarily true in web3 architectures. “…everyone’s mental model of ‘protocols’ is that of current ones like HTTP, SMTP etc. All of those protocols are *stateless*. That has been the accepted (and generally right) model of protocol design. The biggest difference for web3 is that they are stateful protocols. In that sense, I think that pace of protocol evolution isn’t really the right mental model. If the state is generally accessible, then it is much easier to remix and compose. There haven’t been too many instances of such ‘protocols’ which is why it isn’t surprising that all of us are unsure about how to compare this to traditional models.”
This was a light bulb insight for me – perhaps we’ve been thinking about this all wrong. There’s an entire chapter to be written in the Great Book of Internet History about statefulness* – but to boil it down, being stateless means the computer/network does not know who or what you are as you interact with it. Agarwal’s thread reminded me of Albert Wenger’s post from last week, describing how, in the early days of digital computing, many disparaged “inferior” PCs to “superior” mainframes based on performance (they were slow) and price (they were cheap). Wenger points out that critics of PCs dismissed them as toys incapable of doing what mainframes could do. But those same critics missed one key point: Prior to the introduction of PCs, almost nobody had access to compute power of any kind.
Today, the same might be said of access to data power. To me the point isn’t whether or not the model that manages my data across the internet is centralized or not. What matters is whether, at the very base level of a platform’s governance architecture, it is seamless, afforded, and simple for me – and others – to build on top of the data I own and co-create. That, to me, is the essence of web3.
—–
*And that chapter would focus, necessarily, on the web’s original sin – how its advertising model evolved as a response to the HTTP protocol’s stateless nature.
Looking back at one of the first real projects I attempted which combined 3D printing and microprocessors. I received an Creality Ender 3 V2 a year ago and after playing around with some test prints, I wanted to try building some more interesting and complex projects. I came across this fiber optic LED lamp project via Instructables. It was just the right amount of 3D printing, microprocessors, and coding I was looking for at the time.
I tend to use components from Adafruit. They have a strong focus on learning. The guides and CircuitPython are great for getting started. So given the great set of instructions, my challenge was basically recreating the 3D models and porting to an Adafruit microprocessor running CircuitPython. The author already provided the 3D models as STLs and in Tinkercad (I also really like the simplicity of Tinkercad), but I wanted to reduce the number of fiber strands and make the lamp slightly smaller.
I figured out the general structure and process of the original model pieces by investigating the Tinkercad project. It didn’t take long to recreate some shapes that I could use to build the lamp structure.
CircuitPython has great support for individually addressable WS2818 / NeoPixel strands, so it was relatively simple to get some code working that would create some simple LED animations. I was using a Trinket M0, which is so tiny. I ran into some space issues where I couldn’t add all the animation support code I wanted onto the board. If I ever revisit this project, I’ll probably switch to a QT Py RP2040 or QT Py ESP32-S2, both of which have plenty of space, way more power, and the ESP32-S2 board would even allow for some network/web configuration UX.
Here are a few photos of the assembly process of the LEDs and optic fiber in the frame.
The fiber optic cable is a “side glow” type used for decorations. It’s designed to create a glow.
Here is the base with the wires and a breadboard for the Trinket M0 (not inserted yet), along with a small button which can be used to change the animation modes.
The CircuitPython code is very simple and is available in a Github repo. I’m pretty happy with the finished project. Some things I’d want to address if I decide to work on a revision:
Using CircuitPython doesn’t leave much room for user code on the Trinket M0, so I’d probably just bump up to one of the newer QT Py models. I’ll be able to add more animation modes too.
Hot gluing the breadboard into the base isn’t sturdy enough. I’ll need to attach the next board with screws/nuts.
Selecting animation modes using the button is not very friendly. If I bump up to a QT Py ESP32-S2, I’ll add a web setup UI.
Browser maker Mozilla today announced a partnership with The Markup, the non-profit newsroom that investigates how technology is reshaping society, on a research project to provide insights into and data about a space that’s opaque to policymakers, researchers and users themselves. By joining Mozilla and The Markup’s “Facebook Pixel Hunt” in Firefox, people can help Rally and The Markup unravel how Facebook’s tracking infrastructure massively collects data about people online – data that is used to target ads, tailor content recommendations and spread misinformation – all by simply browsing the web.
The Markup is the newest partner for Rally, the privacy-first data-sharing platformthat was created by Mozilla in 2021 to take back control from platforms that are not transparent about how they use people’s data and make it very difficult for independent outside research to take place. Rally is a novel way for people to help answer systemic questions by contributing their own browsing behavior data, putting it to work as part of a collective effort to solve societal problems that start online and that we have not been able to investigate this way before.
Using tools provided by Rally, the two organizations will research how Facebook tracks people across the web through its Facebook pixel-powered ad network and shine a light on what Facebook knows about their online life. By opting into “The Facebook Pixel Hunt” study, Rally gives Firefox users the power to help answer questions like: What kind of data does the Facebook pixel collect? Which sites share this data? What can this data reveal about people? What other ways does Facebook track people? How widespread is Facebook’s tracking network?
Mozilla is excited to partner with The Markup. Cited by legislators to combat discriminatory tenant screening and mortgage lending, The Markup’s journalism has distinguished itself with its direct impact on people’s lives. The partnership of the two organizations brings together Rally’s technical skill and The Markup’s data-driven investigative journalism, exposing the problems of informational asymmetry on the internet and shedding light on systems of online surveillance used by companies like Facebook.
“A tool like Rally can bring the full force of communities of people joining together to provide insights into one of the most opaque parts of the internet that have such a dramatic impact on our individual lives and on society. This is a rare opportunity to lift the veil over Facebook’s tracking and data collection practices outside of the Facebook platforms.”
“The Internet and the world cannot wait on platforms to do the right thing, especially when so much depends on it. This partnership seeks to lead the way in providing new and critical ways of illuminating the reality of the internet, led by the people who make it. This partnership comes at a time when the consequences of fragmented awareness have never been more stark.”
Ted Han, Rally Product Lead at Mozilla
“We’re thrilled to partner with Mozilla, which shares our commitment to a more transparent and trusted internet. Rally is an open invitation for the public to contribute to important research into some of today’s most pressing issues, and we’re excited to investigate wherever it leads.”
Julia Angwin, editor-in-chief and founder of The Markup
For most, the New Year marks a time to reflect, reset and re-prioritize. While learning a new language, creating a budget or starting up a new hobby have become staples of our New Years’ Resolutions, as our lives increasingly shift online, it’s important we also use this opportunity to reassess our digital habits. Whether you received a new device this holiday season or just want to make sure you’re protecting yourself online, there’s no better time to partake in some New Year's cyber cleaning.
To get 2022 off to a strong start, here's a helpful and easy checklist to help you tidy up your browsing, tighten your security and ensure your online health isn’t left at the wayside.
Tidy your browser
With most of us browsing the web daily, it’s inevitable that our searches begin to add up and clutter our browsing experience. To start the New Year off right, give your browser a deep clean to ensure it’s running smoothly for the months ahead so you have an organized space to access, consume and save all of the web’s great content.
Start off by clearing your browser history, which will not only help your devices run faster but will prevent websites from tracking your information (more on that later). Consider also enabling Private Browsing, which temporarily halts data from being stored, or changing your browser to automatically delete your history when you quit the application.
It’s also a good idea to take a look at your bookmarks and extensions. Use this opportunity to go through your bookmarks and delete pages you no longer need and consider using Firefox’s tagging feature, which allows you to categorize bookmarks with keywords to make them easily searchable. And while extensions like adblockers and translators can be enormously useful, a quick review of these tools to ensure everything is up-to-date and still helpful will go a long way in keeping your browser moving fast and uncluttered.
Unsubscribe from junk mail
It’s easy for junk mail to pile up throughout the year — especially as more and more sites require us to share our contact details to gain access. Just as you’ve resolved to clean out your closet every January, use this opportunity to actually scrub your inbox so it is organized and manageable in the year to come.
Many of us fall prey to handing over our personal information to e-commerce sites in return for discounts, but in the process, open our inbox to a flood of unsolicited emails. To keep scoring these deals while maintaining a clean inbox, use Firefox Relay, which provides email aliases to use in these situations while protecting your real address.
While it may seem like a herculean task to unsubscribe from each individual sender, there are tools that can automate the process for you, like Clean Email, which provides a list of all your subscription emails and allows you to unsubscribe easily. Spam comes in many different forms, so if it’s telemarketers’ calls that are ringing your phone off the hook, try removing your information from major data brokers’ databases — such as this one — to reduce the likelihood of your number ending up in spammers’ hands.
For emails you do actually want to read, but just can’t keep up with — like content-dense newsletters or Substacks — consider using Pocket to save your must-read articles for later while giving your inbox a break.
Get serious about privacy
The longer you’ve lived online, the bigger your digital footprint, and with that comes greater privacy concerns. Ever been served an ad that was eerily similar to something you just searched? It was likely from a company that tracks your every move online. While the world of cookies can be confusing, and sometimes it feels easier to opt-in than figure out how to opt-out, consider incorporating a few new habits into your browsing routine to protect your data in 2022.
To increase your privacy, you can:
Use alternatives to big tech platforms like Google, Facebook and Amazon, which are known to store large amounts of user data. Instead of using Google Chrome as your browser, try a more privacy-focused option like Firefox.
Clear your cookies, which erases all information saved in your browser and makes it harder for sites from tracking you long after you’ve visited them.
Consider exploring a Virtual Private Network (VPN). VPNs, such as Mozilla VPN, hide your IP address, protecting your identity and location. They also encrypt the traffic between you and your VPN provider for an additional layer of privacy.
Limit how much social platforms can track your activity by unlinking your social profiles from accounts on other sites, and adding extensions like Facebook Container to your browser, which prevent platforms from tracking you across the web.
This one is so important, it deserved its own heading. Much of what we can do to protect ourselves online boils down to our passwords, which hold the key to our personal information online. While good password practices do require some discipline, it’s worth the inconvenience to keep your online life infinitely safer. Take these straightforward steps to protect yours in 2022.
For starters, make sure you use a different password for every account, so if one site is breached, the attacker cannot access other accounts. While doing so, update your passwords to be as strong as possible — the longer and harder the phrase is to guess, the more difficult it is to steal. Try combining two or more unrelated words, adding numbers and symbols and making it longer than 8 characters.
Beyond passwords, try to avoid using security questions whenever possible. Since they’re often based on personal information like where you grew up or what your first car was, they’re essentially additional, less secure passwords. If you don’t have that option, avoid answering them accurately and instead opt for answers that are long and random, just like your passwords.
PRO TIP: Not sure what a good password is? Many browsers, including Firefox, have integrated Password Managers that can generate strong password options, as well as store usernames and passwords and automatically fill them in when you visit sites.
Protect your health and new devices
As we spend more time on our devices, especially during the pandemic and work-from-home, it can be easy to forget the toll that too much screen time takes on our physical health.
In 2022, fight eye strain by switching your phones and computers to dark or yellow mode, which both cut screen glare to reduce visual fatigue. The blue light emitted from screens can wreak havoc on your sleep cycle, as it’s been found to suppress the body’s release of melatonin. Combat this by investing in a pair of blue light glasses, or installing a blue light extension on your browser.
More and moreresearch has also found that too much time on social media can negatively impact your mental health. As you reset for the New Year, consider using tools to limit your time on these sites, such as Impulse Blocker, an extension that allows you to limit access to distracting sites.
2022, here we come!
As the internet expands and becomes more ingrained in our lives, it’s crucial we take this moment to assess our digital habits and ensure we are protected online in the year to come. However, it’s important we remember why we do this — not just to defend ourselves from potential online threats to our privacy and security, but so that we can keep enjoying all the infinite goodies the web has to offer. The internet is an amazing place with so much to explore in 2022, so let’s make sure we are prepared to make the most of it!
I came across this relic during a brief stop along the A3 Autobahn driving home frome Switzerland earlier this week. I almost overlooked it completely, as you ignore so much street furniture and loud advertising you come across. Only on second glance it registered as a public telephone.
Public phone, at the Siegburg-Ost Raststätte along the A3 near Köln. A relic in an open air museum almost.
Of all the writerly discoveries I made last year, James A. Reeves has emerged as a favourite:
Nobody’s sure what they should be doing, plague-wise. Uncertainty hangs in the air alongside the virus. We’re still vaporizing each other with our voices. Our breath. But they say it’s mild now, mostly upper respiratory. But it’s also sweeping the nation and disrupting public life. They’re still making alarming charts. No matter how this shakes out, uncertainty is here to stay—and how do you learn to live with that? Meanwhile, I’m keeping an eye on the statistics again, wondering if we’ll go to London next month.
Someone on the Mozilla Foundation's social team inexplicably thought that tweeting "Dabble in @dogecoin? HODLing some #Bitcoin & #Ethereum? We're using @BitPay to accept donations in #cryptocurrency" would go over well with their supporters. Unsurprisingly it did not, and it also earned them scathing replies from the founder of Mozilla and the designer of the Gecko browser engine (upon which Firefox is built). Mozilla tweeted on January 6 that they were "listening, and taking action", and that they would review "if and how our current policy on crypto donations fits with our climate goals", pausing cryptocurrency donations in the meantime.
Finding and sharing resources is like finding and sharing good shopping deals. Don’t agree? Let me change your mind.
Hot UK Deals (HUKD) is a website where people from the UK share ‘deals’ with one another. There are other, similar websites around the world, some of which are part of the Pepper network. I’m not affiliated with any of them, apart from being an avid user of HUKD.
I’ve used the site for many years now, and it’s grown exponentially. There are literally millions of people using this site, and it’s grown and developed with them. It was one of my touchstones as we developed MoodleNet between 2018 and 2020 (see this screencast).
As we identified in the early days of MoodleNet, there are two ways of finding relevant learning and teaching resources. The first is to know what you’re looking for, and to search directly for that thing. The second is more serendipitous, and involves discovering things that you didn’t even know you were looking for.
The same is true of HUKD. While I do occasionally go on there looking for something in particular, more often I discover things that I didn’t even know I needed in my life. I don’t necessarily mean in a materialistic way — it could be a kitchen gadget that makes peeling potatoes 10x easier, for example. (Realistically, though, it’s things like the giant mousepad with edge lighting I’ve got on my desk currently!)
The other thing that’s great about HUKD is the (produtive) ambiguity about what constitutes a ‘deal’. Some assume it’s just that the thing on offer is available more cheaply than it was previously. Some, and I’d include myself in this group, factor in other things such as whether it’s worth spending this amount of money on Product X when Product Y is so superior and available for just a bit more.
As a result, the HUKD comments section is a hotbed (no pun intended) of informed commentary. At the time of publishing, there’s 151 comments on a deal for home broadband. These range from people’s subjective experience, to supplier’s customer service, to very technical details about the difference between various technologies. I find it so useful.
I’ve chosen the above HUKD user somewhat at random. They’ve been a member for over 14 years! As you can see, they primarily share deals relating to technology, and comment on other people’s deals. There are contributing moderators (‘Deal Editors’) for different categories, but by-and-large the community is positive and self-policing. For example, it’s very poor form to try and ‘steal’ someone’s heat by re-posting a deal.
And, of course, there’s gamification and badges. These reward pro-social behaviours such as commenting or submitting deals that reach a certain level of ‘heat’. The badges then show up on the small profile when hovering over a username. It adds kudos. Overall, there’s so much to learn from the way HUKD has approached the UX and UI of their site. We don’t have to just do what’s been done before when it comes to learning design and everything which surrounds it!
This post was prompted by noticing that, 18 months after I left Moodle, there’s finally some progress being made again on MoodleNet (see here). I do hope that they maintain the goal of federation and decentralisation, and that they take it in a direction that provides community value. Right now, it seems most of the social elements have been removed, but hopefully they will reappear at some point…
Jim Groom and his colleagues at Reclaim are returning to their roots in educational technology, a development that makes me happy. Not that I don't love old arcade games and online radio and karaoke and all the rest, but ed tech is where I make my home, and all this fancy cloud stuff is where I see the future. Not all of it will be for me (including especially the WordPress stuff and the on-campus ed tech stuff) but a lot of it will be. Just to celebrate, I followed Groom's instructions on how to set up Ghost on Reclaim Cloud in one of my patented Stephen Follows Instructions videos.
Good post that was directly responsible for me ordering a new (gigantic) mousepad. "There two ways of finding relevant learning and teaching resources. The first is to know what you’re looking for, and to search directly for that thing. The second is more serendipitous, and involves discovering things that you didn’t even know you were looking for." Pretty much all of what appears in OLDaily falls into the second category, while resources used for something like my ethics course are a mixture of the two.
What is the real reason, according to Matt Crosslin? "It’s all about the power and control. Leaders can’t control their students, faculty, and staff remotely like they can on campus." Now it's true people say online learning is inherently worse. But the research says otherwise: "one of the best sources to look at for research is the National Research Center for Distance Education and Technological Advancements (DETA) at the University of Wisconsin – Milwaukee’s No Significant Different database." I personally remember this debate playing out for years in the early 2000s before it was finally put to rest. The results of that work are unlikely to be overturned by recent experience.
While many people think of enterprise computers in terms of systems running Windows or MacOS, there have long been millions of enterprise users running a GNU/Linux-based enterprise Linux distribution and entire industries where all employees run Linux. While sometimes this is for philosophical reasons, often it’s also for practical reasons: a Linux desktop is the […]
Sharon was a great supporter to Catherine, and to me.
Sharon sent me an email on this day two years ago, writing, in part:
I am so glad to know that Catherine feels ‘finished’. That is my one hope, that when I die I will feel I have finished my life. Well more or less finished, as I suppose one might always want to tie up a few loose ends. But Catherine’s contentment tells me she feels she has finished. This is peace.
You and Catherine and Oliver will not leave my heart. Every morning I will hold you in my reflections and every evening I will light a candle for her,
For you long suffering readers of this blog (this is year 17) you know that my blog is often just where I keep my notes. This one is going to be my ‘working with dave’ notes for new student employees.
I have been fortunate to work with a fair number of excellent students on a number of different projects over the years. At UPEI I worked with the student union for a number of years to introduce some basic project planning and management. I led New Student Orientation for a couple of years, and had some students working for me full in a number of previous roles. In the last two years (’cause Covid) that number has shot through the roof as I’ve had about 80 CoOp students working with me in the Office of Open Learning.
It’s an interesting group to work with. I’ve only got them for four months and, for many of them, this is the first job where they are expected to do things beyond simply repeating a pattern they’ve been given. This term I have three students, two of them are returning from previous CoOp terms. It means that instead of allowing the ‘this is how we do stuff’ to come naturally through conversations, I’m going to do some one on one training with the new students to avoid forcing the returning students to hear all my introductory advice again. In preparation for that, I thought I’d jot down some notes.
Would love some feedback on this so I can turn it into a long term document.
Choosing to be interested
One of the challenges for CoOp students who are working with us in the department, is that they would not have (with a few exceptions) ever have imagined working in education. They are predominantly engineering students who have been unable to find in-field CoOp placements because of the pandemic. Many students (and not just engineers) have been sold the fantasy that they can go to school to get a job that is going to be easy to love.
I mean, that can happen, I guess. But it probably wont. Liking the work you do is mostly about mindset. It’s something I was fortunate to learn in my house when I grew up. My mother can have fun peeling apples. Or raking the lawn. She turns things into a game for herself (and others), tries to get better at it. Tries to do it more efficiently. That mindset is a critical one to develop for people to live happy lives. Most of us have to work. Most of us will never have jobs that are ‘fun all the time’. Learning to find things to like in your job is critical. Even if that thing you like is playing cards at lunch with coworkers (I learned to play 5-way cribbage working at a lead-silver refinery)
I approach this in a number of ways. I try to bring a positivity and enthusiasm to our staff meetings. Try to model it. More importantly, I talk to students about finding a project during the term that they can invest in. Something that they can find interesting that they are responsible for. That they can take pride in doing well.
You need to choose to be interested.
(but not all tasks are going to be interesting)
Being prepared
Such an easy thing to do. Such an obvious oversight if you don’t do it. If someone says “read this over” then read it. Yes. But read it to the point that you have an opinion about it. Come to our meetings with thoughts about the work that you’ve been given.
You could even read around it. A 2 minute google search where you’ve looked at what other people have done or checked the meaning of an industry term can make all the difference to you enjoying the next meeting.
Be prepared
(it doesn’t have to be a big thing. Just think about the work BEFORE the meeting)
Handling multiple tasks
I have consistently seen students struggle managing multiple tasks. If I forget (early on in the term) to say “hey, when i give you a new thing to do it doesn’t mean you stop doing the other one” I will have at least one project totally fall off the radar. Students have had their lives jammed into 60 minute sections (classes) for basically all of their lives. They are accustomed to being TOLD when to work on things, and when to change tasks.
This is super easy to fix. You just have to say “look, segment out your day so you can keep working on different projects.”
Be conscious in managing your work day.
(this might take a while to get used to)
Learning to prioritize
“Wasn’t it obvious that this was more important? The VP asked for this!”
This is something I once found coming out of my mouth before I stopped and realized that, obviously, if my employee didn’t understand the priorities, it’s because I never explained them. A big part of working with student employees is to pass along these cultural norms, but you need to say them out loud. These are very different based on cultural backgrounds.
I like to think of it in terms of ‘right now’, ‘next 24 hours’ or ‘next two weeks’. YMMV. But a big part of the job is to get students thinking about how they are prioritizing their multiple projects. Talking it through… “hey, i know you’re working on three things right now, how have you got them mapped out?” really helps.
Some things are going to be more important than others
(You don’t have to do everything at once, you just have to keep track)
Managing up
This might be the most important piece. We often hire students to do projects that we don’t want to do. We also hire them to do things we don’t necessarily know HOW to do. So many students end up working for people with very little management experience or, worse, for people who think management is some kind of guessing game where they say ‘go do stuff’ with some expectation that students know what’s hidden in your brain.
I talk to my students about how to manage me. I can get a little scattered, so I tell them it’s perfectly ok to remind me that I said I would send them something or to answer their questions. You can ask me questions about what I’m asking you to do, but I’d like it if you read everything first and get a sense of what’s happening before you ask.
That’s the way I like to work. But one of the biggest jobs of any employee is to figure out how your boss ticks. I mean, some of them are just jerks, BUT we all have to work. Learning to manage your boss in a way that allows you to find out what success looks like is going to make you happier and make your boss happier.
You need to manage your boss, as much as they need to manage you
(figure out what success looks like, it’s almost never obvious)
The project charter
I love me a project charter. It’s just a document that lays out what a project is and keeps track of high level issues. The beauty of your average project charter is it gives you a place to put decisions, to clarify outcomes and timelines and to keep track of risks and scope creep.
It becomes the official record of the project and gives you something to go back to. To make sure everyone’s on the same page. I use various versions of this one, which you are free to steal.
Filling out a project charter is also a great way to frame your questions for your boss (see managing up). “hey i was just going through my notes and realized I don’t think you ever told me when you needed this finished”
Keep track of what you’ve been told to do
(and everything else that’s been said about your project)
Dealing with uncertainty
This is the hardest. When I ask a student to do something or I ask them for their opinion, they almost always assume that I already know the answer. 15 years of school has told them that it’s what adults do. They ask questions to test you.
It takes a lot of convincing from me to get students to realize that when I ask them a questions it’s because I DON’T KNOW THE ANSWER. It’s one of the things that slows down the work the most. Students think they are trying to figure out what I’m withholding and I’m waiting for the work to get done. It’s bad for everybody.
There is not a ‘right way’ to do most things. There are local customs at different places of employment that you need to follow, but a lot of the time you just have to make choices AND learn to be ok with being wrong sometimes. It can take a while before a student gets their mind around that. It requires patience.
Face uncertainty, make decisions
(just not decisions that can get you into too much trouble )
Learning to be wrong and to fix it
Today I showed the edit that my own supervisor did on a grant application I wrote. It was GLOWING it had so many edits. Students have been trained to believe that they get one chance to submit something and that if there’s anything ‘wrong’ with it, that they have failed somehow.
Real life is mostly not like that. You need to get used to the fact that your supervisor is going to ask you to change things… sometimes in ways that you wont like. You can certainly talk about why you made those decisions, but being open to critique is a necessity.
Be open to critique
(just bring it back better next time)
Talk about what you don’t know
This is a touchy one. I want students to tell me when they don’t know how to do something, but I also want them to try and figure it out. It’s a delicate balance. If you ask me a simple question you could have easily found the answer to, I’m just going to send you a lmgtfy. So, as a student, you need to try something first. Asking questions without trying just leads to bad questions.
But. If you don’t know how to do something, or you don’t understand the scope of something… your work is going to suck. And people are mostly bad at telling students what to do. That means that students need to advocate for themselves. They also need to make an effort to learn the stuff they don’t know on their own.
Working is all about learning.
(sometimes that learning is your job, sometime’s it’s your boss’ job to help you)
Overall…
Working is hard. You’re going to find, a lot of the time, that you aren’t sure what you’re supposed to be doing or how to do it well. Figuring out the job is a big part of getting good at it.
Drawing by Derek Evernden at New Year’s, a year ago. Oops!
The outcome of this match was hard to predict at the outset. Humans have fared pretty well over the last century at dealing with viruses. But the problem is, if you don’t keep practicing, you lose your edge. And compared to humans, the viruses have been getting in a lot of practice in the 21st century. Here’s how the moves have gone so far:
Viruses: The game began, it seems, in a bat cave in China, in 2019. Bats, which have a natural immunity to most viruses, can have up to 15,000 different pathogenic viruses , each with lots of strains, and the viruses are constantly mutating. Some of the bats in one cave in Yunnan in particular*, seemed to have hosted a range of randomly mutated coronaviruses that had not previously been seen. The cave was near a station on the new Chinese high-speed train that had Wuhan as a major stop. So the virus’ first move was a novel one — a move never before tried in the game. But then many, many viruses are novel. Your body contains about 400 trillion of them at any one time.
Humans: The humans, flummoxed by this bold and unorthodox first move, hesitated before deciding on their response. In this game, time is of the essence, and hesitation can be disastrous. The humans nodded and smiled to their fans, telling them this was nothing to worry about, it was all in hand. But meanwhile they were huddling furiously to decide how to respond. Under cover of their public display of confidence, the humans decided on two equally bold and unusual responses. First, the Chinese mapped the genome of the new virus and immediately sent it to scientists all over the world, so that a first vaccine candidate would be identified a mere week later (January 2020). And secondly, they decided to lock down much of a country of 1.4 billion people.
Viruses: The virus had anticipated this, and was way ahead of the humans. This was an extremely transmissible virus, and it had the element of surprise on its side. The humans knew, from SARS-CoV-1 early in the century, that global mobility of humans had reached such a high level that attempting to limit the spread of highly transmissible viruses by closing airports and restricting travel was utterly futile. Back in 2008, the US DHS had even recommended that such measures not be even tried, as it would be a waste of time and energy. Instead, the public health scientists knew, it was important to test everywhere and everyone quickly and repeatedly to isolate all cases, and to use universal masking if the virus was transmitted by aerosol particles. This virus put everything into transmissibility, trading off for lower morbidity (it had lost previous matches with SARS and MERS, using a higher-morbidity, lower-transmissibility strategy).
Humans: A combination of cockiness and ignorance meant that the humans’ next move was totally bungled. The public health scientists knew that there had been none of the preparation for a high-transmissibility virus that had been recommended a decade earlier, so there were pitifully few medical masks available for the public, and no infrastructure in place to test even a tiny proportion of the population for infection and isolation, so their early advantage in sequencing the new virus was useless. So instead, the humans responded with a feeble attempt to encourage, rather tepidly, use of hand-and surface-washing and inadequate cloth masks, an idea they ‘sold’ poorly to the population, and supplement that with ‘social distancing’ — which might work if the virus only spread via droplets and was not transmitted through aerosol means. They tried to convince themselves, and the public, that this was likely a droplet-transmitted virus — A fatal mistake. Worse than that, the political humans, embarrassed at how quickly this virus had seized its advantage and how unprepared they were, and wanting to believe the whole thing wasn’t happening, suggested that (a) it was probably ‘no worse than the seasonal flu’, and (b) it was the result of human error in China, so it was up to the Chinese to ‘fix’ it. Meanwhile, absolutely nothing was done to resolve the problem of grossly inadequate masks and tests. It was as if the humans were in denial that anything was happening at all. To “protect patient privacy”, most citizens saw nothing of the horror occurring in thousands of hospitals and institutions. Most human energy was now diverted to the blame game, and finding dubious scientists who would explain the virus’ astonishing early success away.
Viruses: Thanks to the almost total lack of preparedness by the humans, there were not even enough high-quality aerosol-preventing masks for front-line professionals, so the virus’ strategy of high aerosol transmissibility had clearly been the right one to try. Further stealth was achieved in two ways: (a) a 21-day lag between onset of symptoms, which at first seemed usually rather innocent and flu-like, and death, and almost as long a lag between first symptoms and hospitalization; and (b) the majority of transmission was asymptomatic, so millions of people were unknowingly spreading the disease, and the virus was busy damaging 19 different human internal organs, including the heart and brain, in unique and subtle ways that would mostly only be discovered months later, or when autopsies were performed.
Humans: Belatedly and inadequately, the humans acknowledged that this virus had more than ten times the morbidity of seasonal flu, and was far more prevalent worldwide than anyone had thought, and they introduced mask mandates, encouraged use of at least medical-quality masks (but not N95-quality), and introduced lockdowns where and while cases were high. It was the summer of 2020, and the tide seemed to be turning — cases dropped, and then so did death rates, dramatically in many cases. But then, as if they were determined to undercut their own success, the humans made the stupidest move yet — they relaxed the mandates and lockdowns. Almost immediately, the virus recovered.
Viruses: Stealth had proved to be the best strategy for the virus, so it stuck with that strategy. Laying low for the summer, it continued its largely invisible damage to the bodies of the billion or so humans infected so far, setting the stage for up to 20% of the survivors to develop Long CoVid chronic ailments in, and destruction to, their bodies’ organs. And with its vast experience and spread, it now began to develop mutations. In September of 2020, when the humans were beginning to publicly declare victory, the alpha variant debuted and quickly became the prevalent strain. Two other, very different strains followed soon after.
Humans: Psychologically rocked by being seemingly so close to defeating the virus and then undone by overconfident relaxations and lack of diligence, the humans again turned to the blame game, blaming poor health care advice (true in part, since most public health care research and most pandemic preparedness programs in many countries had been gutted over the previous four decades), blaming other humans (especially the young, the uneducated, the already-sick, and the old), blaming governments and pharmaceutical companies, and blaming others’ ideologies and the media that fanned them. Still there were inadequate and insufficient masks. Still there were absurdly insufficient test resources. So now, demoralized, the humans went ‘all in’ on a giant gamble — a vaccine would be found, soon, and everyone would take it.
Viruses: The winter of 2020-21 belonged, like the winter before it, to the viruses, as cases again soared. After the daily death toll had dropped 90% in the previous summer, to the point a “Go For Zero” strategy was actually viable in some places, the humans instead again relaxed mandates and restrictions in the late summer and fall, and deaths subsequently reached record levels in most countries. Only the vaccine now stood between the viruses, which had now claimed close to 30% of the human population, and victory.
Humans: The vaccine arrived in January 2021, a monument to human ingenuity, global scientific collaboration, and collective capacity in times of crisis. Although it had taken a year to test, this was a fraction of the time that previous vaccines had taken to develop, and these vaccines were novel too, relying on a different mechanism, rather than infecting the patient with a small amount of the actual virus to prompt an immune response. So these vaccines were also safer. And there were several on offer, so that if one underperformed humans could switch to another. This seemed like it would be the deciding blow in this match — the virus would soon be on the ropes. But again, the humans undermined their own success. Because of decades of neglect and privatization, the infrastructure needed to order, distribute and administer the vaccines was almost entirely absent, and it would have to be built from scratch. And worse, the political humans interfered and tried to discredit other ‘unfriendly’ countries’ vaccines and hoard their own for their own citizens. Still, the race was now on.
Viruses: It was coming down to whether the virus could mutate fast enough to beat the new vaccine into the bodies of the remaining 70% of humans. Thanks to the slow production and distribution of vaccines, the virus quickly unleashed the delta variant, and cases again soared. This was especially advantageous for the viruses, because when cases were rising even as a massive vaccination program was underway, it played into the doubts of the vaccine hesitant and the fevered imaginations of the conspiracy theorists. Now, not only did the humans have to deal with inadequate systems for delivering the vaccine, they had to deal with a large proportion of the population who refused to take it. It looked as if the match might end in a tie, with half the humans getting the disease (and a significant proportion of them getting Long CoVid), and the other half getting inoculated.
Humans: Trying to tip the game to their advantage, humans began to offer third “booster” vaccines, especially to the most vulnerable. There was disturbing evidence that, while it was rare and their symptoms usually mild, some fully vaccinated people were getting infected with the delta variant. The “booster” seemed to restore the vaccine immunity, but the real challenge was still the enormous reservoir of disease that those who refused to get vaccinated offered to the virus as it continued to mutate. A “tie” match was looking to be the best that humans could now hope for, especially if the game went into overtime, and with another winter on the horizon, overtime looked like a distinct possibility.
Viruses: Human hesitation, lack of preparedness, and foolishly giving up on mandates and restrictions, provided the viruses with all the time they needed to mutate into yet another variant, called omicron. This was exactly what the virus needed to win — it was even more transmissible, including to those who had been vaccinated (though it was much less transmissible and had a much lower viral load in vaccinated bodies). Again, it sacrificed morbidity for more transmissibility, since this was now a sprint, not a marathon. Even with much lower morbidity it could still infect more people (and that is its existential purpose) because essentially everyone who had not been vaccinated, and some who had, would get the disease. By any judge’s criteria, that would be a ‘win’.
Humans: So here we are now, in January of 2022, and it’s our move again. One of the moves we tried in earlier rounds is now, suddenly, not available to us: With positivity rates in the 15-50% range in most areas, sending people home to isolate after infection would so deplete essential services that they would largely cease to function. We still have a woefully inadequate testing capacity and infrastructure and a woefully inadequate vaccine supply and infrastructure in much of the world. Most people do not own an N95 mask (which are still out of stock in most places) and many do not even use a hospital-grade mask; many others use their masks improperly or only intermittently.
So, given continuing high rates of vaccine hesitancy, there would now seem to be only two moves left: (a) the massive deployment of N95 masks and their ubiquitous use everywhere indoors until the virus is starved of new victims and test-and-isolate once again becomes a viable strategy, or (b) resign the game, and cede victory to the virus, allowing it to spread freely to all except the most vulnerable (essentially isolating the most vulnerable instead of the infected) until it runs out of potential victims.
As ghastly and depressing as the latter strategy seems to me, I can’t see the former strategy working at all. It depends on a patient, enforced, consistent, effective and ubiquitous mask mandate that all of our experience to date indicates simply will not be forthcoming, either from us as citizens, or by those who are charged with enforcing it. A half-way move of asking people nicely to mask up all the time is a worse-than-nothing compromise. As the Chinese and other countries who have been successful at stemming the virus (so far anyway) have learned, you don’t compromise with a deadly pandemic that has already killed about 14 million people in two years (including about 1 out of every 80 people over age 65), and could well double that toll before the game is finally over.
To put this in perspective, globally, about 20 million people die each year from cardiovascular disease, and about another 10 million die of cancer. Most of those deaths are probably preventable, if we had the will to require and enable people to eat a healthy diet, and to exercise properly, and if we had the capacity to rid our world of the toxic substances that our civilization has produced, and the massive chronic stress of precarity it induces. We have, of course, no such will or capacity. Adding another 7-14 million lost lives for a year or so before the pandemic runs out of steam, will, I suspect, soon become a devil’s bargain we are prepared to accept to get over the tumult, disruption, shame, and psychological, social and economic turmoil we have lived with for the last two years. Though the burden on hospitals will be pretty horrific, even as we continue to look the other way.
When that happens, and I think it will come this spring (and seriously hope the additional deaths will be much lower than another 14 million), we will not want to hear the daily numbers any more, much as we tired of hearing the death toll from HIV after 1995, when it finally ceased to be the #1 cause of death for young Americans, though it still killed two million globally in 2004.
My sense is that we’re quickly running out of options, since we failed to take the actions necessary to bring this pandemic to a close at least five different times over the past two years. No one is to blame for that. This played out the only way it could have.
We have played our best game, and lost. Hope we do better next time.
* For those new to this virologists’ discussion thread on the origins of CoVid-19, I’d recommend you read the last (bottom, September 2021) entry first, and then go back to the top and read through the entire thread. It’s technical, but not hard to follow.
I think of this as the second pillar of jazzycoffeeshopvibe. So relentlessly 80s. Everything old is new again. I remember hating this on TOTP. Horribly uncool. But loving it at the Coop Disco. That bass sound. Fantastic. (The lately bass?)
Confusingly named because it's not really a hash - this library (available in 40+ languages) offers a way to convert integer IDs to and from short strings of text based on a salt which, if kept secret, should help prevent people from deriving the IDs and using them to measure growth of your service. It works using a base62 alphabet that is shuffled using the salt.
The association representing Ontario pharmacists says roughly half of all people who are offered\xc2\xa0the Moderna vaccine are refusing it.
"They may cancel their appointment. They may walk out," said Justin Bates, CEO of the Ontario Pharmacists Association.\xc2\xa0
"That\'s creating a significant challenge," said Bates, as pharmacists also have to deal with combative patients who want to shop around for vaccines.\xc2\xa0
Many people did the same thing last spring when they questioned the safety of Moderna or mixing vaccines during the rollout of second doses.\xc2\xa0
Now, they have less choice in the matter because many public health units are reserving Pfizer for younger people because there\'s now a greater\xc2\xa0supply of Moderna. In Toronto, those 18 and up will only be offered Moderna at city-run clinics as of Jan. 6. The same goes for people aged 30 and up in Durham region.\xc2\xa0
Last fall, the Ontario government recommended\xc2\xa0people between 18 and 24 receive the Pfizer vaccine due to a "mild\xc2\xa0risk" of the rare heart condition\xc2\xa0myocarditis "out of an abundance of caution." Pfizer is also only being offered to those aged\xc2\xa012 to 17.\xc2\xa0
Jason Chomik opted to get Moderna for his third shot\xc2\xa0on New Year\'s Day, even though\xc2\xa0he put off two appointments before getting Pfizer for his second dose. He says the surging Omicron variant finally prompted him to make the move.
"If the numbers hadn\'t been climbing as rapidly as they are now, I probably would have waited," he said.\xc2\xa0
"I\'m glad I got the booster but I\'m still concerned around the long-term effects of mixing the vaccines."
\'They only want Pfizer\'
Despite public messaging that mixing vaccines is safe, as is Moderna, many are still reluctant to get it. Aside from pharmacies, health workers at other vaccine clinics are seeing this, too.\xc2\xa0
"When they sit down in the chair, they immediately confirm [they\'re getting Pfizer] with me," said Allan Grill, who has been administering vaccines in\xc2\xa0York Region, north of Toronto,\xc2\xa0and is chief of family medicine at Markham Stouffville Hospital.\xc2\xa0
"Omicron is spreading like crazy and people are getting sick," he said.\xc2\xa0
Even Ontario\'s Chief Medical Officer of Health Dr. Kieran Moore made a plea during his briefing on Thursday.\xc2\xa0
"I, too, got Moderna as my booster," he said.\xc2\xa0
"The latest evidence demonstrates the protection provided by the Moderna vaccine, particularly for older individuals, is very robust."
More brand awareness
Bates said there\'s more brand awareness around Pfizer\'s vaccine, especially since many got it for their first or second dose.\xc2\xa0He also said the pandemic continues to change policy with time and new research.
"People aren\'t used to seeing science evolve in real time," he said. "And changing public perception is the hardest thing to do."
Toronto\'s Medical Officer of Health Dr. Eileen de Villa said the city is "doing everything we can" to make sure people are aware vaccines are safe and effective.\xc2\xa0
"In fact, there are some studies showing a particular benefit to those who receive the Moderna vaccine and its effectiveness against the Omicron variant."\xc2\xa0
The allure of crypto is ducking with people. Some see things that are wrong in the world, or think there are too many regulations without ever understanding that the financial markets started out like crypto.
Then people lost their shirts, and some their life’s, and then we decided a “free for all” was a really bad idea.
But I am sure this time it’s different.
b'In the last week, I have been referred to as "Daddy" more times than ever before in my life. And apparently I\'m a "boomer" now.
I\'ve also been told that my blog is a psyop to protect the dollar.
Since the twit-shitshow (twitshow) began, it looks like I got 1.7M "impressions", around 30K likes, 7K RTs, 700 replies, and my number of followers went from 15K to 24K. (But then I immediately blocked about 1000 of those new followers, so I\'m not sure if those are reflected.)
The top response (number one with a bullet) was "do your research". I used to think that "do your research" was a signifier of people who like a little bleach in their horse paste, but it turns out that it is also the rallying cry of cryptobros. There\'s probably significant overlap between those two groups.
The coinsplainers just cannot fathom that someone wouldn\'t want to sell Amway with them. You must Just Not Get It, that\'s the only explanation.
But once they move on to the insults, those usually include "virtue signalling". Is it safe to assume that anyone who uses that phrase is also mad that they aren\'t allowed to use the N word? I think it is.
There was also a fair amount of whataboutism. None of them have seen Mr. Gotcha and it shows.
I keep seeing people adding me to twitter lists like "tech" and "founders" and it makes me remember that I need to post more poop jokes.
ON BLOCKING
\nI am forever advising people, "Why hit Reply when the Block button is right there?"
But the struggle is real. I feel it too, especially these last few days. There are so many people who are wrong on the internet. So many! You don\'t owe them your time. Block with righteous glee.
It helps if you think of the "Block" button as the "Go Fuck Yourself" button. Maybe try to imagine Jeff Goldblum singing the "It\'s maaaahhh birthhhhhday" song every time you press it.
Basically, I block someone if they have said something stupid enough to make me want to hit reply and frustratedly explain it to them. We all know that there is no future in sending that reply, but as I said, the struggle is real. So instead I block them, because the chance that this person will ever say something I want to hear is... not large.
But, maybe some day Mr. Firstname Bunchanumbers dot Eth and I woulda been pals. My loss!
And those blocks happen not just for people who have replied to me. If I see your comment, and you\'re a dumbass, you get a block. This sometimes leads to perplexed people saying "but he blocked me and we\'ve never spoken!" So if that\'s you, and it made you sad, my sympathies. But this is a matter of self-defense and one does what one must.
Now some people may think that if you blocked them, they have "won", but I don\'t care about that even a little bit. What they think is irrelevant to me. The goal is to remove them permanently from my experience. I will, by definition, never see their "he actually blocked me lmao" posts.
"You mean I can push one button and make this weird guy I\'ve never heard of go away forever? Neat."
But, if you do reply to a dumbass before you block them -- let\'s bring back *plonk*.
During the Recent Unpleasantness, I blocked over a thousand new followers based on keywords in their profiles (dot-eth, etc.) Fortunately, crypto-bros always self-identify, because it\'s a cult. The grift requires total commitment. (Don\'t ask for the script, it was messy.)\n
I have also made good use of megablock.xyz -- it blocks a bad tweet\'s author and every person who liked it.\n
I reported a couple dozen of the more abusive ones, but to the shock of absolute no one, Twitter finds nothing to be against their terms of service. I would like to be in the habit of reporting twits more, but it is so many clicks, and it\'s about as useless as telling 311 about a blocked bike lane.\n
\nBecause Twitter is terrible, after you\'ve blocked someone, all of the replies from people who are making the mistake of continuing to engage with them still show up in your mentions. You can mute the entire thread, but then you lose everything, not just the sub-thread with the dipshit you blocked.\n
Blocking is time management. You block someone who\'s spending their time trying to waste yours. When you block someone on twitter it\'s because both you AND THEY agree that your time is more valuable than their time.
A reminder that may not be obvious: amplification on social networks has monetary value. Twitter\'s algorithm counts it as engagement even if you shared a tweet to criticize it or mock it, and uses that signal to amplify the tweet further. Only RT what you would pay to promote.
Do not reply to, retweet, or quote a tweet from a fascist unless you would give them your money. Apparently some people would rather make that gift than change their behavior online, and I don\'t know what to do about that.
If you think that quote-tweeting does not juice the engagement numbers of the bad take, you are wrong. If you think that screenshotting it does not do the same thing, you are probably wrong. Twitter has very good OCR, and if they aren\'t scanning screenshots for twitter links and handles in order to decide what to show to more people, I would be shocked.
SHAMELESS PROMO
And since we\'re talking about "engagement" and all of that horseshit, how about giving a follow to @dnalounge and @dnapizza? It would be nice to get those numbers up. My staff thanks you in advance. Tip your bartenders.
Also, please follow @dnalounge on Instagram -- we are getting very close to 10K followers, and I understand that once we reach that, we unlock a secret prize: the ability to add a "swipe up" link to our posts, so that it\'s possible to go from a post about an event, to the actual ticket page, rather than having just the one Lincoln Bio. Imagine that.
Thunderbird moved it's settings from a dedicated window to a tab in Thunderbird 68. Along with this change came a search box that was to replace the well defined layout that made describing the location of setting fairly simple.
I am increasingly getting the feeling that people are not using this search option and continue to plow through the options looking for what they want. This can be helpful if you have no idea what you think will be used as a term to describe what you are looking for, or to familiarise yourself with what options appear to be available. But when you are looking for things you know the names of it is a very slow way to do things. I must emphasise that this is a setting search, not a help search.
One instance is the Thunderbird config editor. There is a button for this right at the bottom of the general tab, I know this and can tell you. But that is a long list under "general" to scroll through
Using the search option, which refines the search on every key stroke is a faster method. The following image is what is displayed when type CO in the search box
Then we have the same list following the typing of config
and finally typing the complete term config editor
All three of these searches, as well as the option of scrolling, would all eventually get you to the config editor button. Personally, I think typing the whole thing makes it easiest, but it is whatever souit you.
This search really comes into it's own on searches like PDF which does not return a "result" as such but displays only the list box for "content type" actions. The list has an action for PDF content.
Another good demonstration of it's ability to find setting is to type "file". This returns a number of "secondary" results where the search term is in a list that is not visible, like the list of actions for content types.
This does not help when you type things that you expect to have results and don't like attachments, so sometime the old plow through is the only way to find something. But I do recommend the use of searching to get where you are going, until it lets you down.
Before May 2021, the master key in MetaMask was called the “Seed Phrase”. Through user research and insights from our customer support team, we have concluded that this name does not properly convey the critical importance that this master key has for user security. This is why we will be changing our naming of this master key to “Secret Recovery Phrase”. Through May and June of 2021, we will be phasing out the use of “seed phrase” in our application and support articles, and eventually exclusively calling it a “Secret Recovery Phrase.” No action is required, this is only a name change. We will be rolling this out on both the extension and the mobile app for all users.
It’s amazing how in the past year or so, efforts in the telecom industry to move next generation systems into containers and manage them with Kubernetes have moved from theory to practice. The 5G core, for example, was specified by 3GPP in a cloud native way from the start, and even things like Open Radio Access Network (Open-RAN), whose specification effort started a bit earlier and hence is still based on Virtual Machine technology is moving quickly to container based solutions in the real world. This was one of the reasons while about a year ago I had another look at Docker and Kubernetes which resulted in my Docker and Kubernetes introduction posts on this blog. Also, I have dockerized a number of services I host for myself (e.g. this blog!) and use containers in my own software development and deployment process. This has made it much easier to spawn independent instances of my document research database for various friends in minutes instead of hours. But as far as Kubernetes is concerned, I don’t really have a practical use case myself, so I did not go beyond a Minikube installation. So one thing that always remained a bit opaque to me is how Amazon and other hyperscalers make Kubernetes clusters available from their data centers.
What I imaged was that perhaps one would have to get a username and password for a hyperscaler Kubernetes service, and would then interact with single and gigantic Kubernetes cluster used by thousands of companies and deploy services into that. But how would one access those services from outside, would I get a dedicated IP address for them, how would I get TLS certificates for https and how would the whole thing be built? How would the hyperscaler know how much processing power and storage I would want and bill that? Many questions that I finally had a bit of time to follow up. The answers to all of these questions are surprisingly simple if you have some basic Kubernetes knowledge and have perhaps already installed Minikube locally.
A friend recently pointed me to this great 3+ hours video on YouTube by Nana Janashia which follows pretty much the same path as my 4 part Kubernetes intro. In addition she also has a section on Helm Charts and Kubernetes Ingress, which I did not look at so far. There are a bunch of other interesting videos on here Youtube channel, including an introduction of how to deploy a Kubernetes project on Linode or Amazon.
Kubernetes at a hyperscaler works very differently from what I thought so far. Instead of getting an account on a huge Kubernetes cluster, you virtually build your own Kubernetes cluster for your project. On Linode, that’s straight forward. Once registered, you go to the Kubernetes session, create a new cluster and then tell Linode how many worker nodes you require for that cluster. The worker nodes are virtual machines and you can choose how much RAM and storage you require for that cluster. Once done, the cluster is created and can be accessed from your notebook or local machine with the kubectl command just like that local Minikube cluster I experimented with. No difference!
So how do I access my services in that cluster over https? This is done by using the Kubernetes Ingress module. Basically, the module needs to be told in a yaml file which domain name and path should be routed to which internal service (i.e. to which container to abstract it a bit). And if you want https instead of http, a TLS certificate has to be provided (e.g. generated with Letsencrypt). And that’s it, no need to install a reverse proxy or anything, just a domain name, path and a TLS certificate need to be configured. And if you have several projects and want to use different worker nodes for them, you just create several Kubernetes clusters. Why only have one when you can have several?
Nana also has a video where she shows how Amazon (AWS) makes Kubernetes available. In principle this works the same way as described above, but there are many more configuration options that make the setup process of a cluster look way more complicated than it actually is.
Matt Mullenweg@photomatt
People seem to be redefining Web 2.0 as Facebook, etc, that own data, but Web 2.0 at the time was platforms like Wo… twitter.com/i/web/status/1…
A few years back I used to mentor data scientists in a bootcamp. One of the requirements was that the students complete a capstone project to demonstrate what they've learned. Many students struggled coming up with ideas for this, often trying to pick ambitious projects that they didn't now how to start. My advice was always the same:
Start simple. Take anything you are interested in, the list out the basic facts you believe about this, then start using data to provide evidence for these facts.
Despite living in the "information age", my experience is that we very rarely actually have any data to support some common assumptions we make. Almost always, when looking at the data, you'll find something that surprises you, and in the end you'll either have changed your beliefs slightly or have a much stronger foundation for them (sometimes both!).
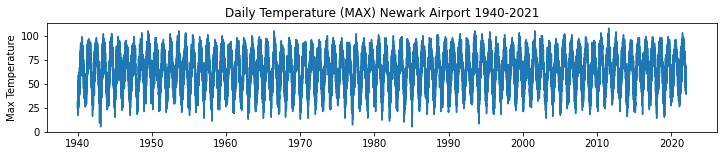
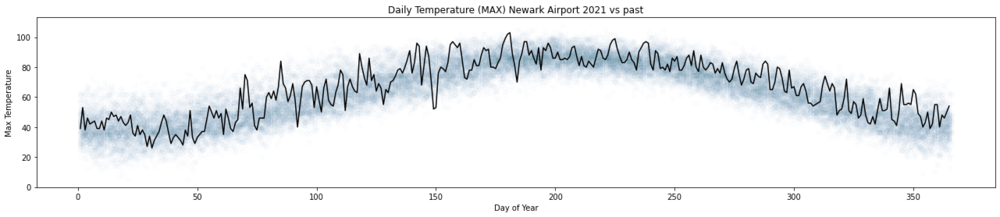
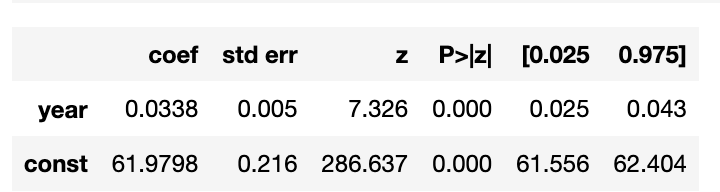
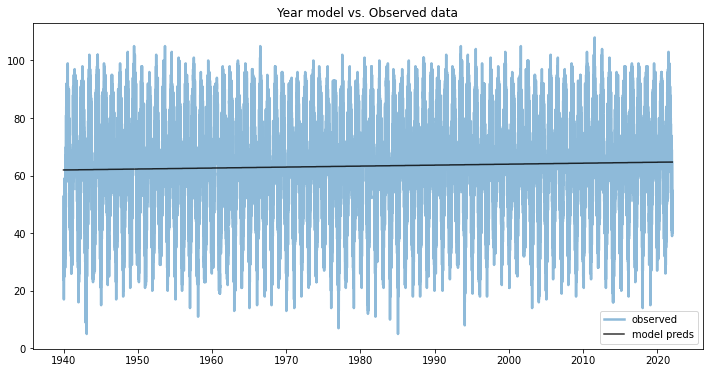
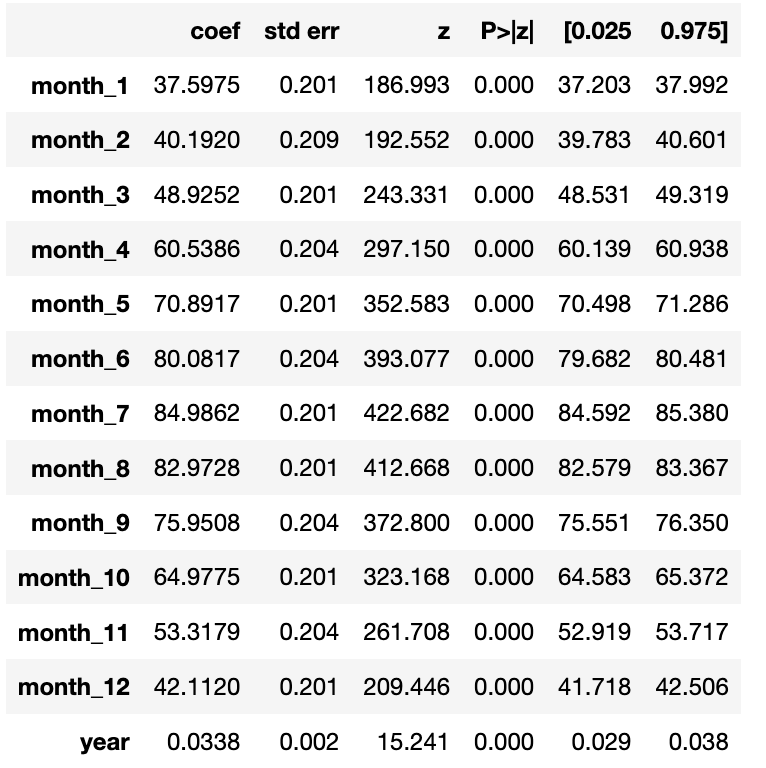
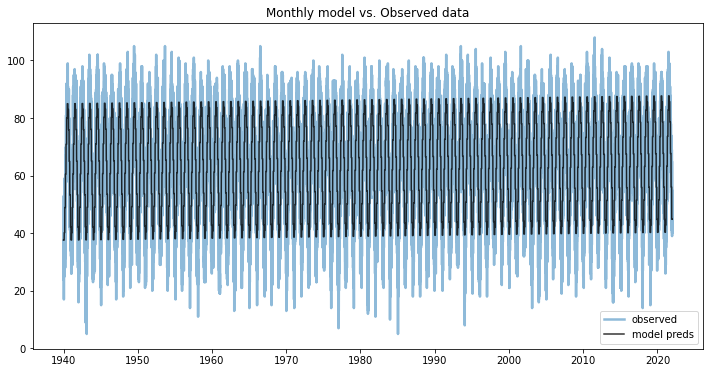
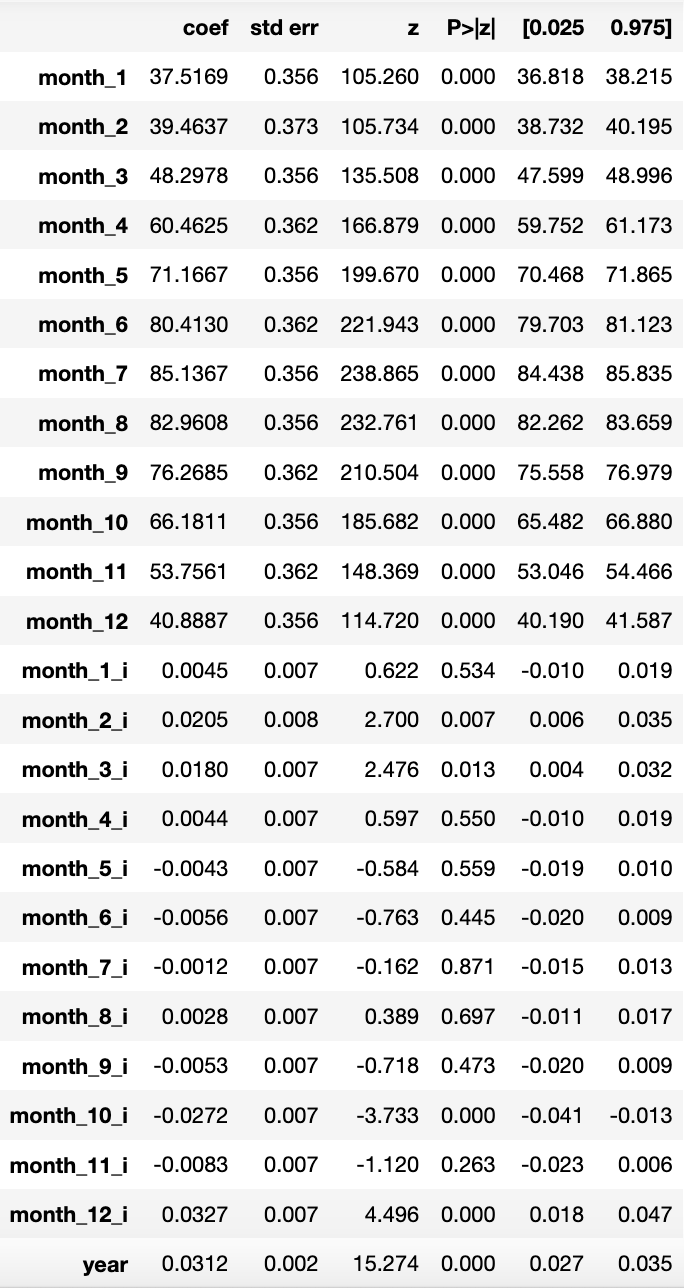
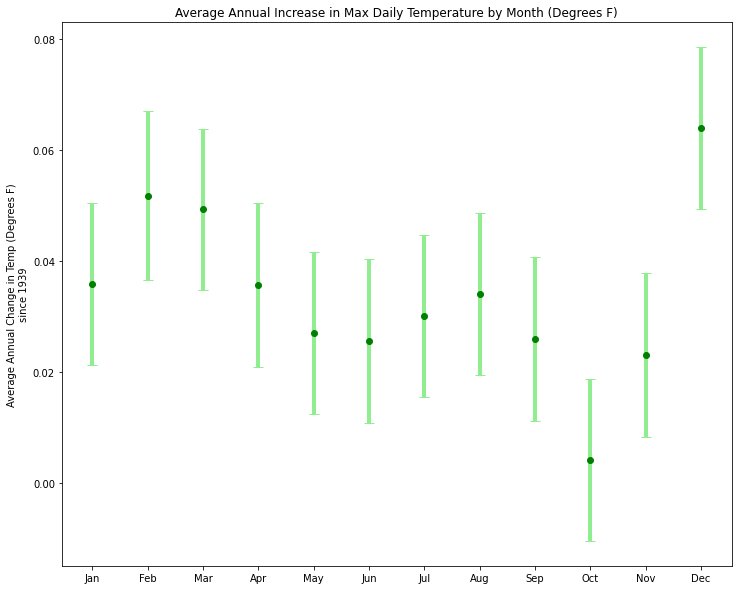
In this post we'll take a look at the weather in December in NJ. To me it's certainly feels warmer than when I grew up, and I clearly see the evidence for climate change, but is it really getting warmer in NJ?
Winters in New Jersey
After many years living in other states I've recently returned to living in the state a grew up in: New Jersey. During this late Fall (2021) I noticed, what seemed to me, extremely warm weather, especially in December.
As someone who spends a lot of time exploring information related to climate change my immediate reaction is "of course it is getting warmer!" However, I find these type of quick causal assumptions to be the most dangerous. It is, of course, possible for climate change to be happening and also for the winters in New Jersey to currently be roughly the same as they were when I was a kid 30 years ago. Especially being in the middle of pandemic, and worrying a lot about the state of the world, it's easy for biases to creep into our daily observations and let our imaginations take over. Especially because it makes sense to me that winters are getting warmers, and it's something I expect to see, I should be extra cautious about confirming this is the case.
Getting the data
Thankfully it is very easy to get data to understand this problem better (though we'll soon see we still need models to understand what’s really going on). The National Oceanic and Atomspheric Administration (NOAA) provides extensive daily temperature readings for the nearby Newark Liberty International Airport.
Here we can see what the data looks like. The columns we are interested in are the date (which I have starting at 1940) and the daily temperature max, TMAX.
Example of the data we’ll be using to model NJ weather patterns.
Visualizing the data
The first thing to do is just look at what these values look like over time. Since I feel that this December is warmer, I expect to see some notable drift over the years. Let's see what this data tells us visually:
It’s not obvious to me that, visually, anything is happening here.
When I'm exploring data and I already know what I'm looking for I tend to be extra skeptical of what I see. For some people it may look like we see sloping upwards over time, but personally I don't see an obvious trend.
Next we can take another look at this data, this time overlapping each year to see how this year compares to past years:
Looking at the end of the year it does look like December is a bit warmer.
Looking specifically at the end of the year, which is the period in question, it does look a bit warmer this year than past years. But again, I want to be extra skeptical about what I'm seeing because I expect to see it warmer, and I really want the data to convince me. Honestly, looking at this plot doesn't do it.
In order to really see if something is happening over time we need to use a model. Modeling this data will tell us a lot more about things that might not be visible, and we can get statistical information about our claims so we aren't just going with a "feeling".
Modeling our New Jersey weather
We're going to start with a simple linear model. The basic hypothesis I have is that the temperature in New Jersey is increasing each year (specifically in December, but we'll get to that in a bit).
Modeling temperature change each year
Let's start by building a model that assumes that for each year from 1940 the average temperature has gone up by a fixed amount each year. Here’s the code for my basic model:
# get rid of the occasional nan values
w_df = weather_df[np.isnan(weather_df['TMAX']) == False]
X_df = pd.DataFrame(w_df['year'] - np.min(w_df['year']))
X_df['const'] = 1.0
y = w_df['TMAX']
year_model = sm.GLM(y, X_df).fit()
year_model.summary()
Results from our simple linear model assuming a constant increase in temperature each year.
Looking at this model we see that there is a year and a const. The const represents the average temperature at the start of our time line, and year represent the increase (modeling in years since 1940), in degrees Fahrenheit that temperature has risen each year.
This model makes the claim that each year the average temperature has risen by 0.0338 degrees Fahrenheit. This means on average we would have expected annual temperature averages in New Jersey to go up by 2.7F degrees since 1940.
The p-values and standard error here tell us that our model is pretty confident in these claims, but I always like to compare real data with the model. Here we can see what our simple model predicts for each year with the actual data:
With our simple regression we can see that it is getting warmer each year.
As we can see the model does seem to follow the data reasonably well.
Still a straight line doesn't quite seem answer the question I have which is "are Decembers warmer?" This model does say that throughout the year, on average, we see an increase in temperature, but maybe that all happens in July?
To answer the question I have we need to make two changes to our model.
Modeling individual months
The issue with our current model is that it has only one intercept, which is the year. But each month clearly has different average temperatures, so we should really have an intercept for each month.
By one-hot encoding (or creating "dummy" variables) we can create a distinct intercept for each month. When we add monthly values we can get a better look at what's happening:
Now we have an average temperature for each month and the average yearly change across all months.
Notice we're still getting the same value for the increase each year, but now we can see what the average temperature each month is. This is pretty useful information. We can now see that January is typically the coldest month in this part of New Jersey, while December is the 3rd coldest month. Maybe I feel that December is getting warmer because I remember how cold February is and when December rolls around again it feels warmer?
We can really see the improvements in our modeling process we get when we look at this model against the observed data:
We can see that this model is a much better fit of the data.
While this is a much better model, capturing more the monthly variation than the previous one, we still can't answer the question "Is it getting warmer in December?". To do that we need to model the interaction between month and year.
Modeling Month/Year Interactions
The hypothesis I want to model now is that each month of the year is changing each year in a different way. So far we still have only modeled annual changes but can't be sure if Decembers are getting warmer or if maybe just the Summer months are doing most of the heavy lifting here.
For our next model we will model the interactions of each month with each year. An interaction is just literally the month_var * year. This will allow us to model how each month changes each year. We'll also still be learning a year coefficient since this will let us know if there is a general trend across all months.
The output of this model is pretty big but we get some interesting results!
Month, year and month*year interactions are able to capture how much each month is changing over time.
We can read these new interaction coefficients as:
"the average rate each of these months changes each year since 1940"
First we have to notice something important about our p-values column: we are no longer confident in the way each month changes! With this in mind let's take a look at these observations.
To start with we have the year which says that, across all months, we are seeing an overall increase in 0.0312 F each month each year. The p-value here is 0 and the standard error is small, so this is fairly certain.
July Trends
If you look at July we can see a very high p-value. This means that in general we aren't really sure if July is changing much faster than the general trend of 0.0312. We can gain more insight into looking at the standard error which is quite low of 0.007. With a mean of -0.0012 this means that our beliefs in what the real difference for July could be all hover very close to zero. Even though we don’t have “significance” we still can see that it’s very likely July isn’t much different than our average annual increase. So each year each day in July should be roughly 0.03F warmer than the previous year.
October stays the same
Next let's look at October. October's coefficient is -0.0272 and the p-value is nearly 0 and standard error is low. To understand what this means we can get the add the year effect to the October effect to get 0.004. This means that in the 81 years of data we have, Octobers on average have only changed about 0.3F. This means that Octobers feel, more-or-less, exactly the same as they did in 1940.
Here is a great example of where data can change our view. The comedian Bo Burnham wrote a doomer anthem That Funny Feeling (the Phoebe Bridges version is, imho, even better). A line from that song is:
That unapparent summer air in early fall
Which is talking about the impacts of climate change on early fall. But here we see that if you do "feel" that October is warmer, at least in New Jersey, you are just feeling the impact of media bias or general climate anxiety. The summer, at least right now, is not creeping into early Fall (…well a bit in September).
December is a lot warmer.
Finally we get to our conclusion: that feeling that December is getting warmer is absolutely correct. The December interaction coefficient is 0.0327, and our p-value is nearly 0 and standard error very low. This means that December is warming at twice the rate as the average annual increase.
I moved to NJ as a kid in 1990. Which means that December winters are on average 2F warmer than they were when I first moved to this state.
Visualizing average change in temperature per month
By combining the average yearly change plus the estimate for interaction we can visualize (with uncertainty from standard error) how much each month is changing:
As we can see, December is warming much faster than the other months in Newark, NJ.
After this journey we can clearly see that the "funny feeling" that December is getting strangely warm is backed up by the data. We can even put error bars on it and know with strong stastical confidence that winter in New Jersey in 2021 is much warmer than I remember it being in 1990.
Conclusion
One of the reasons that I like to teach statistics is because I deeply believe that statistics are essential in understanding our every day world. This becomes especially true as that world begins to change rapidly.
It's easy to imagine someone panicking about warm Octobers because of climate change and someone arguing that Decembers are always the warmest part of the winter so there's nothing happening. Depending our your worldview you might have very different naive opinions of both of these hypotheses. It turns out they're both wrong when we look at the data.
It is also very important to recognize why we need models rather than just data visualization. Visualizations can be incredibly helpful and are an essential part of the modeling process, but without a model we are forced to go on feelings and our own way of reading a plot.
After doing this exercise I was surprised to see that October is more or less the same, and despite having a prior belief in warmer Decembers, surprised by the degree of this warming. Based on our model the average December day today in 2021 should be about 46F while the average day in March in 1940 was 48F. In 30 more years, assuming the same constant rate of change (which is a big assumption in a changing world) Decembers will feel like March did to my grandparents.
I've found that many people find detailed analysis into data like this can make them uncomfortable, since they'd often rather not know that things are, in fact, changing in a way that might be scary. For me, it's exploring the data that gives me some grounding in a quickly changing and increasingly uncertain world. It maybe disconcerting to realize how quickly December is warming, but it is also comforting to have a break from the cognitive dissonance that is part of mainstream discussions on climate change.
Support on Patreon
Support my writing on Patreon and gain access to the source code and video commentary for this article as well as access to much more of my writing!
Stay up to date and notified whenever a new post is up!
Sign up with your email address and you’ll get a link to Field Notes #1 a story about the time I almost replace a RNN with the average of 3 numbers!
A recent software update has reportedly wreaked havoc on several Tesla owners' vehicles in the Canadian prairies as temperatures drop and some of the EVs' heat pumps have failed.
The update rolled out in the middle of December for both the Model Y and the Model 3, Tesla's more popular vehicles. However, since then, CTV News has received multiple reports of drivers with broken in-cabin heating.
Diving deeper, it appears this may be a wider Tesla issue as many users have shared stories of a wide variety of components related to heating failing far further back than mid-December.
Tesla Northstates that last year, Tesla replaced sensors related to heating on all vehicles after encountering bugs. It's difficult to tell if the users in the prairies are driving outdated cars or if a new software update has added additional heating system issues.
One driver was even caught out on a drive in -40 degree weather with young children in the car when the heat cut out.
According to CTV News, a representative of a Tesla Owners Club in Alberta says that they've been told Tesla is aware of the issue and it's been "sent up the chain."
Hopefully, a software update will solve this problem, or perhaps Tesla will need to update its hardware to perform better in low temperatures.
Overall, this isn't reassuring Canadians considering buying an electric vehicle (EV). The only EV I've been able to test under winter conditions has been a few Porsche Taycans models. In both instances, I didn't encounter issues related to in-car heating, but I did find that took onger to top up the vehicle and that the battery doesn't last as long when the temperatures are colder.
If you wanna feel old in the mobile industry, this is a great yardstick since there is at least as much history behind the iPhone announcement as there is after it, and in some ways it’s quite surprising to realize that the pace of innovation has actually slowed comparatively to the bubbling cauldron of the early 2000s.
I remember getting e-mails and watching a video of the event while I was at Vodafone and realizing that everything we had on the portfolio was essentially dead in comparison – and the ensuing weeks (and months) of shock and denial inside the industry were an amazing thing to witness (and, again, something I should probably write about some time).
Also, it bears reminding that there was a lot of pre-announcement history and rumors. Sadly, I lost most of the links from my iPhone timeline pages over the years, and some day I’ll dig through older backups and try to restore them, but the from announcement to launch page has a lot of interesting things…
Software engineering data, that can be made publicly available, is very rare; most people don’t attempt to collect data, and when data is collected, people rarely make any attempt to hang onto the data they do collect.
Having just one person actively searching for software engineering data (i.e., me) restricts potential sources of data to be English speaking and to a subset of development ecosystems.
This post is my attempt to start a crowdsourced campaign to search for software engineering data.
Finding data is about finding the people who have the data and have the authority to make it available (no hacking into websites).
Who might have software engineering data?
In the past, I have emailed chief technology officers at companies with less than 100 employees (larger companies have lawyers who introduce serious amounts of friction into releasing company data), and this last week I have been targeting Agile coaches. For my evidence-based software engineering book I mostly emailed the authors of data driven papers.
A lot of software is developed in India, China, South America, Russia, and Europe; unless these developers are active in the English-speaking world, I don’t see them.
If you work in one of these regions, you can help locate data by finding people who might have software engineering data.
If you want to be actively involved, you can email possible sources directly, alternatively I can email them.
If you want to be actively involved in the data analysis, you can work on the analysis yourself, or we can do it together, or I am happy to do it.
In the English-speaking development ecosystems, my connection to the various embedded ecosystems is limited. The embedded ecosystems are huge, there must be software data waiting to be found. If you are active within an embedded ecosystem, you can help locate data by finding people who might have software engineering data.
The email template I use for emailing people is below. The introduction is intended to create a connection with their interests, followed by a brief summary of my interest, examples of previous analysis, and the link to my book to show the depth of my interest.
By all means cut and paste this template, or create one that you feel is likely to work better in your environment. If you have a blog or Twitter feed, then tell them about it and why you think that evidence-based software engineering is important.
Be responsible and only email people who appear to have an interest in applying data analysis to software engineering. Don’t spam entire development groups, but pick the person most likely to be in a position to give a positive response.
This is a search for gold nuggets, and the response rate will be very low; a 10% rate of reply, saying sorry not data, would be better than what I get. I don’t have enough data to be able to calculate a percentage, but a ballpark figure is that 1% of emails might result in data.
My experience is that people are very unsure that anything useful will be found in their data. My response has been that I am always willing to have a look.
I always promise to anonymize their data, and not release it until they have agreed; but working on the assumption that the intent is to make a public release.
I treat the search as a background task, taking months to locate and email, say, 100-people considered worth sending a targeted email. My experience is that I come up with a search idea or encounter a blog post that suggests a line of enquiry, that may result in sending half-a-dozen emails. The following week, if I’m lucky, the same thing might happen again (perhaps with fewer emails). It’s a slow process.
Hello,
A personalized introduction, such as: I have been reading
your blog posts on XXX, your tweets about YYY,
your youtube video on ZZZ.
My interest is in trying to figure out the human issues
driving the software process.
Here are two detailed analysis of Agile estimation data:
https://arxiv.org/abs/1901.01621
and
https://arxiv.org/abs/2106.03679
My book Evidence-based Software Engineering discusses what is
currently known about software engineering, based on an
analysis of all the publicly available data.
pdf+code+all data freely available here:
http://knosof.co.uk/ESEUR/
and I'm always on the lookout for more software data.
This email is a fishing request for software engineering data.
I offer a free analysis of software data, provided an
anonymised version of the data can be made public.






 If you want to follow the debate about crypto’s impact on society, which I believe is one of the most important topics in tech today, you better sharpen your Twitter skills – most of the interesting thinking is happening across Twitter’s decidedly chaotic platform. I’ve been using the service for nearly 15 years, and I still find it difficult to bring to heel. When following a complex topic, I find myself back where I started – in a draft blog post, trying to pull it all together.
If you want to follow the debate about crypto’s impact on society, which I believe is one of the most important topics in tech today, you better sharpen your Twitter skills – most of the interesting thinking is happening across Twitter’s decidedly chaotic platform. I’ve been using the service for nearly 15 years, and I still find it difficult to bring to heel. When following a complex topic, I find myself back where I started – in a draft blog post, trying to pull it all together.










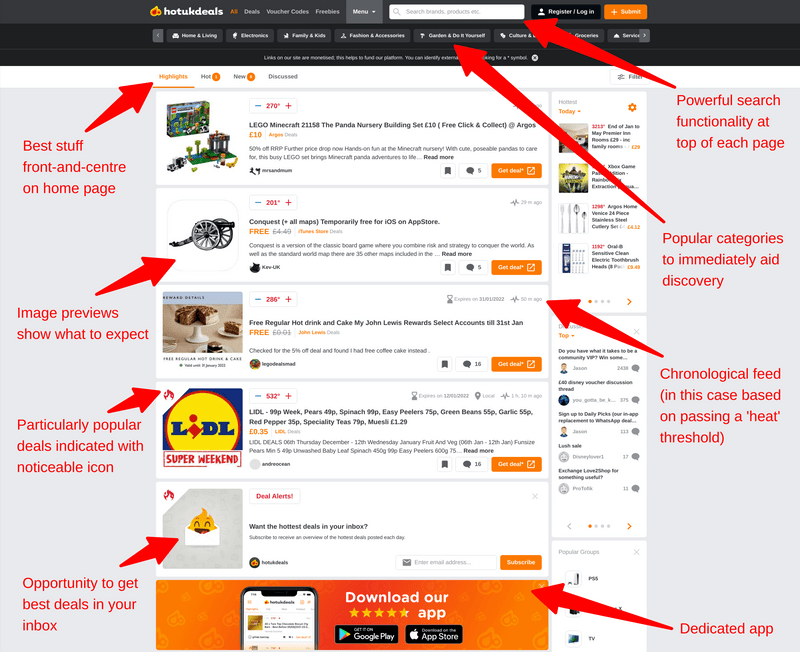
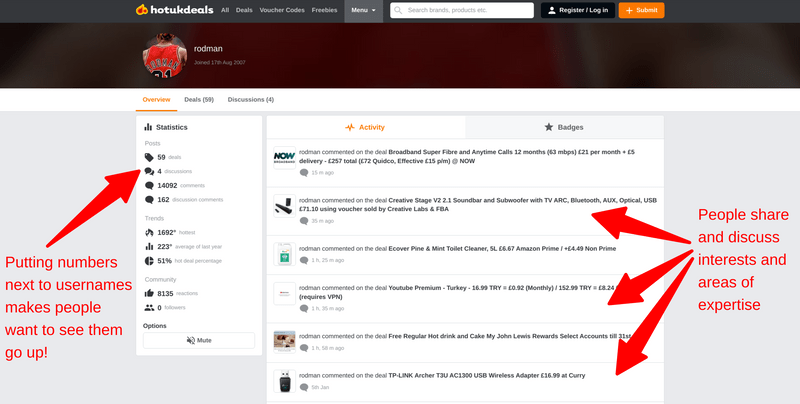
 )
)