
A map of the approximate situation on the ground in Ukraine as of 00:00 UTC 14/05/22.
by @War_Mapper
A map of the approximate situation on the ground in Ukraine as of 00:00 UTC 14/05/22.
by @War_Mapper
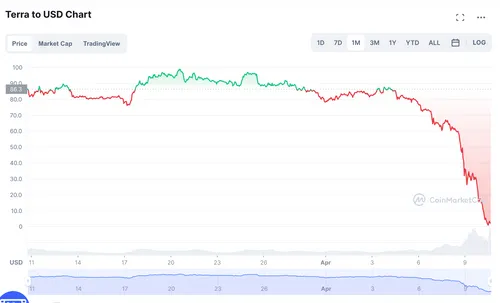
Terraform Labs develops two cryptocurrencies: TerraUSD ($UST), an algorithmic stablecoin meant to be pegged to the U.S. dollar, and $LUNA, a crypto asset used both for speculation and to help maintain the UST peg. As UST dramatically lost its peg throughout early May, Luna plummeted in value alongside it. Luna was trading between $80 and $90 in the first days of May, but as of May 11 had lost 98% of its value and was hovering between $2 and $3. By midday on May 12, the token was trading at or below $0.01.
Such a dramatic crash in a cryptocurrency that was in the top ten by market cap has been devastating to some. Some members of the Terra/Luna community on Reddit have spoken of being massively over-invested in Luna, with some describing losing their life savings and appearing to be in crisis.

In a scoop published shortly after the catastrophes began with TerraUSD and Luna, CoinDesk reported that Terraform Labs CEO Do Kwan had also previously led a different failed stablecoin project. Using the pseudonym "Rick Sanchez", Kwon created "Basis Cash" (BAC), another algorithmic stablecoin. Basis Cash also aimed to peg to the US dollar, but never actually achieved this value. The coin has traded far below $1 for most of its existence, dropping and remaining below $0.01 in early 2021.
Do Kwon has never disclosed his involvement with this failed project. CoinDesk wrote that although their "default position is to respect the privacy of pseudonymous actors with established reputations under their well-known handles unless there is an overwhelming public interest in revealing their real-world identities", there was now "such public interest as Kwon’s UST stablecoin death spirals, wreaking havoc across the broader cryptocurrency market. Amid this precarious situation, investors deserve to know that UST was not Kwon’s sole attempt at making an algorithmic stablecoin work." It was not made clear in the article when CoinDesk first learned of Kwon's connection to Basis Cash, though the authors later stated they'd learned of it the night before they published.
We’re still working on the videos from our April 27 lightning talks, so I’ve taken some time to add 29 recent papers to our review queue:
These are in addition to 23 papers that have been awaiting for months (in some cases more than a year):
If you’re interested in summarizing one or more of these for practitioners’ benefit, please reach out: I’m sure readers would appreciate other perspectives than mine.
I had a conversation yesterday with a data scientist who is now working for a large IT consulting company. We got to talking about the tension between the scripts that data scientists cobble together to get a particular answer and the multi-level cloud architectures with complete integration test suites that software engineers believe are the “right” way to build software that routinely makes hundred million dollar decisions. In my mind the argument about “hacked-up scripts” versus “over-engineered collections of microservices” arises from a conflation of two distinct ideas; since quadrant diagrams are almost always a sign that someone’s trying to sell you bullshit, here’s mine:

The Beatles’ version of “Twist and Shout” is harmonically, melodically, and rhythmically much simpler than Coltrane’s 1967 recording of “My Favorite Things”, but both tracks were recorded in a single take. In contrast, Ravel spent months rewriting his “Pavane for a Deceased Princess” and Beethoven spent almost two years tearing his Ninth Symphony apart and putting it back together. While every single note of each was carefully considered, the former is once again much simpler than the latter.
But here’s the thing: Coltrane and the Beatles were able to create something great in a single take because they didn’t actually do it in a single take: they had both played those particular songs many (many) times before doing it in the studio. Similarly, if you watch Bruce Springsteen and the E-Street Band play You Never Can Tell for the first time, they pull it off because they’ve played songs like it literally thousands of times.
I think the same can be true of software. I can’t count the number of tools I’ve written over the last forty years to transform text from one format to another; asking me to write another is like asking a seasoned session musician to play a twelve-bar blues, or asking the data scientist I was speaking to yesterday to fit a linear model to some time-series data. We don’t need to write design docs or unit tests this time because we’ve worked through the problem and its variations so many times before that our fingers are just going to find the right chords.
Expertise doesn’t emerge without reflective practice: if you want to be Wes Montgomery, at some point you have to lock yourself in your room and play standards for a year. I wish more people who program and do data science knew that; more, I wish the people who hire them knew it too and gave them the time to practice so that they could do something great in just one take.
Shake it up baby…
The tulips in the front garden at 100 Prince Street are earlier this year. And they are stunning.
 ,
,  ,
,  ,
, 
Here is a follow-up to my
comments at the pre-rulemaking stakeholder sessions for CPRA
last week: Example CCPA workflow. 
This is one where I had to print out and sign a form, and have it notarized.
As I pointed out before, making Right to Know work is really a critical first step for all the other
CCPA tasks. If you don't know which companies have which info, it's almost impossible to prioritize
who gets a CCPA delete, which requires more effort, and who gets a Do Not Sell
.
If every data broker and surveillence marketing firm could make the Right to Know process a little different, then it would be nearly impossible for anybody to get anywhere with CCPA, and we might as well not have it.
What would be good to see in the CPRA rulemaking is one standard baseline process for Right to Know, that any company would have to do. They could, of course, add additional, more convenient processes, but there should at least be one that is of known difficulty.
Here is my suggestion.
As a California resident, I go to the California DMV, show my California ID, and get a stack of printed Right to Know slips. These are pieces of paper and have my identifying information on them. The DMV is allowed to charge me for the printing costs.
When I want to exercise my Right to Know, I fill out a company's Right to Know form on their web site, and provide my contact info and postal address.
If the company doesn't have any info on me, they can email me to say so.
If the company does have info on me, they send me a Business Reply Mail envelope.
I put one of my Right to Know slips from step 1 in the Business Reply Mail envelope and send it back.
The company checks my Right to Know slip and sends me a copy of my info.
This puts all the sensitive data handling either under the DMV's roof, or in postal mail space where mail fraud is a Federal crime.
Naturally, a lot of people will come up with ways to do this more cheaply and conveniently on the Internet. That would be great. Putting a simple, standard, postal process in the regulations will set the baseline: you can't make it too much harder than DMV+postal, or people will do DMV+postal.
FACEBOOK Doesn't Know What It Does With Your Data, Or Where It Goes?
Why target ads at pregnant women
Apple Mail Now Blocks Email Tracking. Here’s What It Means For You, by Justin Pot, Wired
Land value tax in online games and virtual worlds: A how-to guide
The Unreasonable Fight for Municipal Broadband
I Commanded U.S. Army Europe. Here’s What I Saw in the Russian and Ukrainian Armies.
The Unsung Women of the Betty Crocker Test Kitchens
Lawsuit Highlights How Little Control Brokers Have Over Location Data – The Markup
Problems Persist With Google’s Privacy Sandbox Proposals as Trials Open

Last month, when I came back from three weeks off, my good friend and fellow WAO co-op member Laura mentioned that she hadn’t worked as much while I’d been away. I thought that was odd; we’ve got plenty of client work to be getting on with, after all. But now, I think I understand.
For the past couple of weeks it’s been her turn to be away, sailing around the Mediterranean and sporadically sending photos that have turned me green with envy. Although I’ve enjoyed collaborating with Anne, our intern-turned collaborator, Laura and I gain energy from working with one another in a way that I haven’t experienced with too many other people.
So I’ve done some work this week in and around some other things. They have included:
I did get plenty of work done this week, however. As I’ve said many times before, because I don’t get pulled into pointless meetings and have any of the other aspects of bullshit jobs, I can focus on getting the work done, and then do whatever I want to do. Given the weather’s been getting nicer and I’m trying to get back to my peak fitness levels, that’s meant closing the office door and going for a run or to the gym!
This week’s work included:
I haven’t done as much non-fiction reading as usual recently, which is shown by the lack of posts on Thought Shrapnel. I’ve also listened to fewer podcasts, partly because of the BBC’s stupid decision to make their podcasts available only in the BBC Sounds app for the first month after release. Not only is this antithetical to their mission, but the BBC Sounds app UX kinda sucks.
I’ve been playing a lot more Red Dead Redemption 2 which is objectively one of the best games ever made. There’s something so satisfying about being an outlaw and doing such despicable acts such that your bounty goes high enough to get both the law and bounty hunters after you! I’m not great at the game, but that’s not the point. I’ve streamed out a couple of my sessions on Twitch.
Next week, Laura’s back which is great as we’ll really be able to get our teeth into new and existing work. I’m also attending the Thinking Digital conference, which is my favourite professional event and one that hasn’t been held for the past couple of years due to the pandemic. Other than that, it’s all about keeping up the positive regime around exercise and nutrition — and trying not to let hayfever interfere with my sleep!
Photo of bluebells in the local churchyard which I walk through on the way to the gym. (I usually try and compress photos for this blog as much as possible, but I hope you’ll forgive me the extra few kilobytes for this one!)
The post Weeknote 19/2022 first appeared on Open Thinkering.Comment on Reddit to an individual considering a move to Ottawa.
I’ve been all over the world, including most major European cities, and have a good basis for comparison. You will find Ottawa very clean, very modern and very safe with excellent schools and health care.
That said, the experience will feel more like living in a rural setting compared to a European city, even in heavily populated areas. Ottawa has numerous parks and forests, and public buildings are also in park-like settings. There is a large experimental farm in the middle of the city, a ‘green belt’ around the older part and the newer part (Kanata is outside the Greenbelt). As a result, public transportation is not up to European standards.
People have commented on the health care. First of all, it’s free (for Canadian citizens and permanent residents; I’m not sure what you’re status will be but check on this) except for prescriptions, dental and optical. There are no deductibles, user fees, or limits to this coverage. It’s good to have a family doctor – when we arrived five years ago (after a long absence) we got one almost right away. But post-covid, your experience may vary. There are clinics, or in emergencies, go directly to the hospital. There will be little to no wait for emergency services. Overall the standard of care is very high and Canadians have some of the longest life expectancies in the world.
Ontario’s education is world class, no matter where you go. That’s not just me saying it; the province scores at the very top of international student rankings. Primary and secondary education are available in English and French, and if you are Catholic, you can attend a separate Catholic school in English or French. Education is again a public service and there are no fees (though some schools will ask parents to contribute for extras). There are private schools in the city, and International Baccalaureate is available, but really, they’re not at all needed here.
It’s safe everywhere in the city. And by ‘safe’ I mean really safe, world-class safe, even in the supposed ‘bad areas’ (those areas, by the way, are in east downtown, though this is changing because of the cost of housing).
Housing is expensive by Canadian standards but not by European standards. Shop around. Although the cost of housing has increased a lot in recent years reasonable housing is not out of reach for most people with decent jobs (especially considering you’re not paying for health care or education).
Some people commented on culture in Ottawa. Culture in Canada is different from culture in Europe. You won’t find (many) corner cafes (but look for them eg. in Manotick and Stittsville, or in higher traffic areas like Westboro). You will find abundant outdoor activities at your doorstep – cycling, sports of all kinds, skiing and more. The city has professional hockey (in Kanata!), football, basketball and baseball teams (the latter two at a lower level) and there are numerous opportunities for children to play any of these. There are numerous museums and galleries. Outside the city (which you can visit because you’ll have a car) are farms, forests, fantastic parks, historical areas, and more. You will never lack a new place to visit with the kids.
Again, by Canadian standards, Ottawa is expensive, but not like Vancouver or Toronto. Public transit is substandard. Winter is cold, but comperable to northern Europe, with a bit more snow. It’s not Prague or Vienna or Berlin, but it doesn’t try to be any of those things. And if it’s accepted on those terms, then with a standard of living that is one of the highest in the world, it is an enviable destination.

How America Reached One Million Covid Deaths | Jeremy White, Amy Harmon, Danielle Ivory, Lauren Leatherby, Albert Sun and Sarah Almukhtar
The virus did not claim lives evenly, or randomly. The New York Times analyzed 25 months of data on deaths during the pandemic and found that some demographic groups, occupations and communities were far more vulnerable than others. A significant proportion of the nation’s oldest residents died, making up about three-quarters of the total deaths. And among younger adults across the nation, Black and Hispanic people died at much higher rates than white people.
Understanding the toll — who makes up the one million and how the country failed them — is essential as the pandemic continues. More than 300 people are still dying of Covid every day.
“We are a country with the best doctors in the world, we got a vaccine in an astoundingly short period of time, and yet we’ve had so many deaths,” said Mary T. Bassett, the health commissioner for New York State.
“It really should be a moment for us all to reflect on what sort of society we want to have,” she added.
Bookmarked Data altruism: how the EU is screwing up a good idea (by Winfried Veil)
I find this an unconvincing critique of the data altruism concept in the new EU Data Governance Act (caveat: the final consolidated text of the new law has not been published yet).
“If the EU had truly wanted to facilitate processing of personal data for altruistic purposes, it could have lifted the requirements of the GDPR”
GDPR slackened for common good purposes? Let’s loosen citizen rights requirements? It asumes common good purposes can be well enough defined to not endanger citizen rights, turtles all the way down. The GDPR is a foundational block, one in which the author, some googling shows, is disappointed with having had some first hand experience in its writing process. The GDPR is a quality assurance instrument, meaning, like with ISO style QA systems, it doesn’t make anything impossible or unallowed per se but does require you organise it responsibly upfront. That most organisations have implemented it as a compliance checklist to be applied post hoc is the primary reason for it being perceived as “straight jacket” and for the occurring GDPR related breaches to me.
It is also worth noting that data altruism also covers data that is not covered by the GDPR. It’s not just about person identifiable data, but also about otherwise non-public or confidential organisational data.
The article suggests it makes it harder for data altruistic entities to do something that already now can be done under the GDPR by anyone, by adding even more rules.
The GDPR pertains to the grounds for data collection in the context of usage specified at the time of collection. Whereas data altruism is also aimed at non-specified and at not yet known future use of data collected here and now. As such it covers an unaddressed element in the GDPR and offers a path out of the purpose binding the GDPR stipulates. It’s not a surprise that a data altruism entity needs to comply with both the GDPR and a new set of rules, because those additional rules do not add to the GDPR responsibilities but cover other activities. The type of entities envisioned for it already exist in the Netherlands, common good oriented entities called public benefit organisations: ANBI‘s. These too do not absolve you from other legal obligations, or loosen the rules for you. On the contrary these too have additional (public) accountability requirements, similar to those described in the DGA (centrally registered, must publish year reports). The DGA creates ANBI’s for data, Data-ANBI’s. I’ve been involved in data projects that could have benefited from that possibility but never happened in the end because it couldn’t be made to work without this legal instrument.
To me the biggest blind spot in the criticism is that each of the examples cited as probably more hindered than helped by the new rules are single projects that set up their own data collection processes. That’s what I think data altruism is least useful for. You won’t be setting up a data altruism entity for your project, because by then you already know what you want the data for and start collecting that data after designing the project. It’s useful as a general purpose data holding entity, without pre-existing project designs, where later, with the data already collected, such projects as cited as example will be applicants to use the data held. A data altruistic entity will not cater to or be created for a single project but will serve data as a utility service to many projects. I envision that universities, or better yet networks of universities, will set up their own data altruistic entities, to cater to e.g. medical or social research in general. This is useful because there currently are many examples where handling the data requirements being left to the research team is the source of not just GDPR breaches but also other ethical problems with data use. It will save individual projects such as the examples mentioned a lot of time and hassle if there’s one or more fitting data altruistic entities for them to go to as a data source. This as there will then be no need for data collection, no need to obtain your own consent or other grounds for data collection for each single respondent, or create enough trust in your project. All that will be reduced to guaranteeing your responsible data use and convince an ethical board of having set up your project in a responsible way so that you get access to pre-existing data sources with pre-existing trust structures.
It seems to me sentences cited below require a lot more thorough argumentation than the article and accompanying PDF try to provide. Ever since I’ve been involved in open data I’ve seen plenty of data innovations, especially if you switch your ‘only unicorns count’ filter off. Barriers that unintentionally do exist typically stem more from a lack of a unified market for data in Europe, something the DGA (and the GDPR) is actually aimed at.
“So long as the anti-processing straitjacket of the GDPR is not loosened even a little for altruistic purposes, there will be little hope for data innovations from Europe.” “In any case, the EU’s bureaucratic ideas threaten to stifle any altruism.”
Winfried Veil
Disclaimer: GV is an investor in Warp.
Whenever I start a new Python project, I have to go look up the syntax for creating a virtual environment. Somehow it can never stick in my brain, but it seems too trivial to add a script for. I’ve been using Warp as my main shell for a few months now and noticed they they have a feature called “workflows,” which seems to make it easy to add a searchable, documented command you frequently use right to the shell.
To add a workflow to the Warp shell, create a ~/.warp/workflows directory and add a YAML file describing the workflow:
$ mkdir -p ~/.warp/workflows
$ emacs ~/.warp/workflows/venv.yamlThen I used one of the built-in workflows as a template and modified it to create a virtual environment:
---
name: Create a virtual environment
command: "python3 -m venv {{directory}}"
tags: ["python"]
description: Creates a virtual environment for the current directory.
arguments:
- name: directory
description: The directory to contain the virtual environment.
default_value: .venv
source_url: "https://docs.python.org/3/library/venv.html"
author: kchodorow
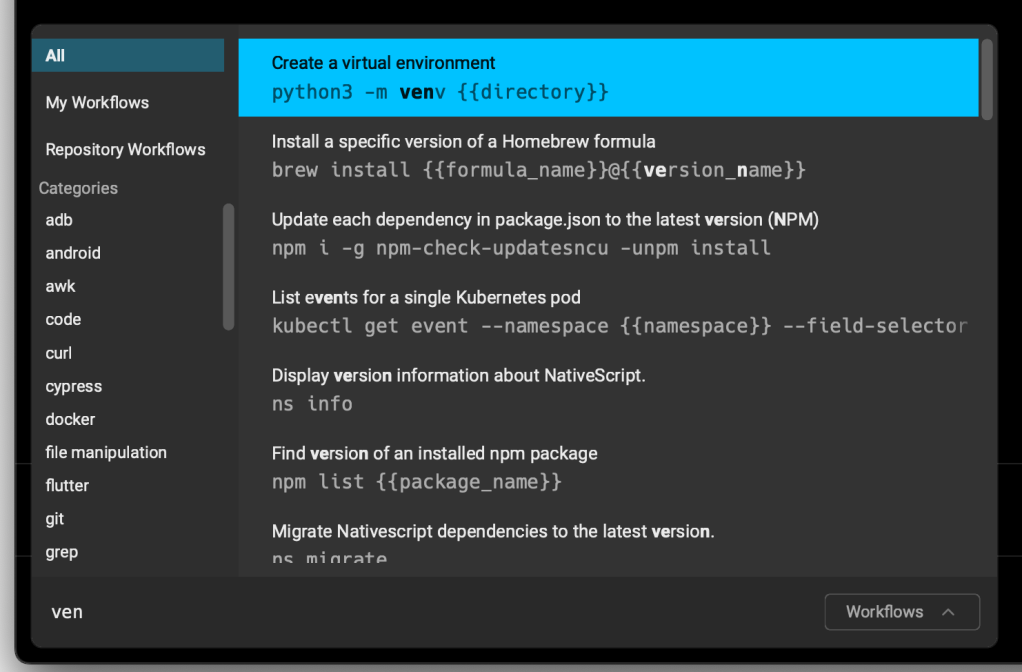
author_url: "https://www.kchodorow.com"
shells: []I saved the file, typed Ctrl-Shift-R, and typed venv and my nice, documented workflow popped up:
However, I’d really like this to handle creating or activating it, so I changed the command to:
command: "[ -d '{{directory}}' ] && source '{{directory}}/bin/activate' || python3 -m venv {{directory}}"Which now yields:
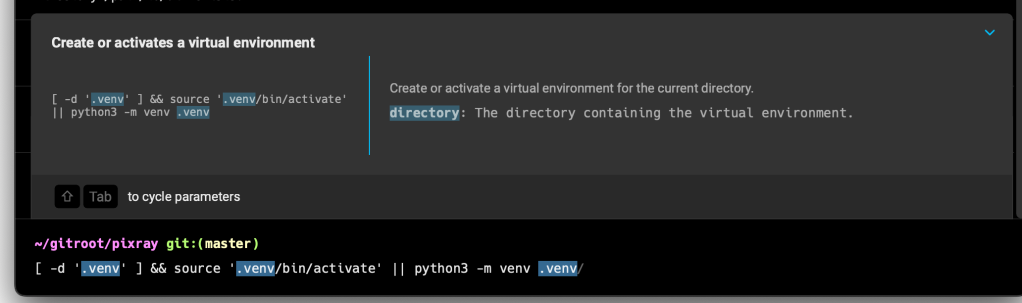
So nice.
Update: I realized I actually always want to activate the virtual environment, but I also want to create it first if it doesn’t exist. So I updated the command to: ! [ -d '{{directory}}' ] && python3 -m venv {{directory}}; source '{{directory}}/bin/activate'". This creates the virtual environment if it doesn’t exist, and then activates it regardless.

The death of the Lightning port really seems to be coming.
Backing up a report earlier this week from analyst Ming-Chi Kuo, Bloomberg's Mark Gurman, a nearly always reliable source of Apple leaks, says that the Cupertino, California-based tech giant is testing an iPhone that features a USB-C port instead of Lightning.
Don't get too excited, though -- at least not yet. According to Gurman, this switch won't happen until 2023 "at the earliest," once again backing up Kuo's report indicating the port changeover will first appear in the iPhone 15.
While not a complete surprise, given Apple has already adopted USB-C with the iPad Pro, iPad Air and iPad Mini, this would still be a monumental shift for the company that would transform its MFI-certified accessories business and the overall smartphone landscape.
Gurman says that the EU's proposal to require all devices, including smartphones, to feature a USB-C port is a "key reason" for Apple's decision to ditch Lightning. The Bloomberg reporter and Apple leaker says that the tech giant is still working on an iPhone that doesn't feature a charging port, but that it won't be ready to release anytime soon.
Apple first launched the current version of its lightning port alongside the iPhone 5 back in 2012.
Source: Bloomberg
Ich habe bisher bei Videoaufnahmen für TikTok ein Headset mit gescheitem Mikrofon aufgesetzt. Das sieht allerdings doof aus, wenn man damit im Bild ist und es ist auch ein ziemlicher Kabelsalat.
Das wird jetzt mit diesen Lavalier-Mikrofon besser. Es hat einen Lightning-Stecker, ein 1,5 m, 2 m oder 3 m langes, stabiles Kabel mit geflochtenem Mantel und wird vom iPhone als Mfi-zertifiziertes Headset erkannt. Der Klang ist so viel besser als von den iPhone Mikros! Ihr könnt Euch den Unterschied in diesem Video anhören. Am besten tragt Ihr dabei Kopfhörer.

Super für Aufnahmen, aber untauglich zum Telefonieren. Wenn das iPhone ein Headset erkennt, dann schickt es die Ausgabe dort hin. Und da es am Pixel Finch weder Hörer noch Buchse für Hörer gibt, ist das eine Einbahnstraße. Wenn man auch hören will, dann nimmt man ein V Moda BoomPro und einen Kopfhörer.
@vowe.netAudio ist wichtig. Ein kleines Mikrofon macht einen Riesenunterschied. Kopfhörer aufsetzen!
♬ original sound – Volker Weber
sqlite-utils: a nice way to import data into SQLite for analysis
Julia Evans on my sqlite-utils Python library and CLI tool.
Via Chris Adams

Last month at DrupalCon Portland, I was honoured to receive the Aaron Winborn Award, named after one of Drupal’s most kindhearted and prolific contributors, who we lost far too soon to ALS back in 2015. (If you were not lucky enough to know Aaron, you can read more about him through many others’ words in his Community Spotlight)
I am tremendously grateful to so, SO many people who have mentored and encouraged me along this journey, from all the way back when I was a wee Google Summer of Code student in 2005 trying to figure out what on earth a “hook” was. :D Each and every time I became excited and passionate about a new way to help the project—joining ALL of the teams (Documentation, Webmasters, Security, etc.), becoming a Drupal core maintainer, joining the Drupal Association Board, improving contribution tools and processes, driving user experience improvements and quality assurance efforts, scaling the governance of the project, etc.—folks would rally to help set me up for success, and assist in ripping blockers out of the way.
The Drupal community really is something incredibly special. There’s an innate desire to enthusiastically share knowledge, to celebrate the wins of others, and to jump in and help where help is needed. We’ve forged long-standing friendships (and at least a couple of marriages! :D), we’ve had many, many laughs (and also a few cries), and we’ve all come together from all over the world to build something truly amazing. Come for the Code, stay for the Community, indeed. :) So an immense THANK YOU to each and every one of you who contributes every day to making this community so truly awesome. (That word gets overused a lot, especially by me ;), but in this case it is extremely apt. <3)
Incidentally, a few people have also asked how I did not have this award before. First, I was a founding member of the Drupal Community Working Group, so receiving it back then would’ve been a supreme conflict of interest. :P Additionally, much of my community work over the years has also been sponsored by Lullabot and Acquia, so that it could have a bigger impact, and this was a *very* unique privilege that most other community contributors do not have. The list of previous winners includes such community luminaries as Gábor Hojtsy, Dr. Nikki Stevens, Baddý Sonja Breidert, and more. I’m *very* happy they all got the spotlight before me. :)
While these days I'm making community happen over at MongoDB, I'm still very much involved in the Drupal community, and it was GREAT to see so many friendly faces at DrupalCon! :D Thank you SO much again for this incredible honour. <3
This turned into an even longer essay than expected, and whilst it’s a personal narrative about cycling, the important part is: I’m riding RideLondon 100 for charity, you can find a link to the details – and the fundraising – at the end. But first, an essay about riding bikes.
Since moving to London, I had kept cycling down to the odd hirebike ride. The roads all seemed a bit hectic; the idea of commuting on a bike, half-awake, never appealed; when I didn’t drive, getting a mountain bike somewhere mountain-bike-worthy was challenging. And I liked walking anyway.
That first 2020 lockdown, barely leaving the radius of our house on foot, suggested that perhaps I could revisit that decision. So I grabbed my old bike from home – bought from eBay back in the very early 2000s. The tyres were flat, the grips had perished, and I didn’t really trust any of the cables.
I set about refurbishing it, learning how to cable a bike, re-index gears, and so forth. That was pretty satisfying. Then I took it for some rides. What I learned was:
I bought a different bike that winter. Something more suitable for the road, drop handlebars, appropriate tyres, sensible price. And I started riding it.
I started riding circles: 11 or 12km down the back roads to Greenwich, out to see the river, and back through Lewisham; out to nearby parks. I had not ridden in years, never in this area of London, never mind on drop bars. Lots to get used to. And I did, so the circle got larger: I found a 20-something kilometre circuit out through Greenwich, through the tunnel, and over to the cablecar, before heading back along the Thames path. And then I started heading south.
South takes you out to Kent – to The Lanes, as a south London cyclist might say. First, out to Keston and back through Bromley, beginning to see glimpses of green, other cyclists waving as they pass. I started doing 30-35km loops, coming home quite tired. I described the bike as “the bike that £20 built” – every now and then, a canny £20 in the classifieds would adjust or add to it – a new saddle, a longer stem, some pedals from a friend, some cleated shoes from a chap down the road selling up, a old winter jacket from an audaxer. I keep turning the pedals.
(I am doing this in the cold: I have managed to scrabble together enough kit (thank you, leg-warmers, thank you, thick winter jacket) that it’s not too noticeable, but later on, people would express surprise that I really started getting into cycling over a cold winter. What can I say: rain is rubbish, but cold I can put up with. It was just good to be out.)
Not entirely expectedly, I discover I am really enjoying riding – even more than I thought I would, when I decided it was time for a bike that fitted. It is time away from screens, away from work, and requires enough of my brain that I can’t daydream. I pedal, I breathe, I look around me. I keep wanting to go further. At this point, I wonder about cycling with other people. Everybody I know who cycles is much fitter, rides much further, but maybe I could chip away at this. I know of a local club that seems friendly; their low-end ride is around 60k. Maybe I could build up to that? If I can get myself to 50k, it’s time to sign up, I tell myself.
I keep pedalling.
There’s a moment I really remember, from spring 2021, when I’m on something like a 40k route I’ve plotted out. It’s my first time really heading for the Kentish lanes, out up Layham’s and up to Skid Hill. The further up Layham’s you ride, the greener it gets. I love that within an hour from home, under my own steam, I’m hitting something I’d recognisably call “countryside”. Cross the Croydon Road, pedal up Skid Hill Lane, dodging the flytipping, and you get to a right-angled corner. Everyone who’s ridden it knows the 90º right-hander. It looks out over a valley, a dip between two hills. Later, I will learn to love the combination of Hesier’s and Beddlestead lanes that joins the hills more directly, a fast, sharp descent into a just-right climb. But for now, I’m looking through a gap in the hedge, and I’m not in London. Rolling fields, lines of trees at the top, open skies. Nothing but Outdoors. And it’s invigorating: I came here on my own steam, this is the reward. My heart leapt a little.
I’ve now ridden that corner umpteen times, and not much leaps any more, but I always enjoy the view; I always enjoy the sensation that I am Somewhere Else, and I will return home later. Similar views still lead to similar heartleaps, though: east Kent lanes surrounded by rapeseed; flying down through rows of heather; sweeping down Star Hill, the mist sitting on fields full of haybales; a first glimpse of the sea; and always, the end of a long ride coming into sight.
I keep pedalling. I hit a 51k route, and sign up for a social ride with London Velo. (I found them via Tobias, and much of what follows comes, perhaps, down to someone I know once deciding to ride with such a nice bunch of folks.)
Riding in a group is, as expected, fun: less for the aerodynamic benefits, more for the company, people whose main thing in common is that they want to be out on a bike on a Sunday morning. There’s chatter, about what we’re doing, what we’re seeing; notes of support as we rifle down gears to grind up hills; the chatter dims as the climbs rack up; but always, there’s friendly faces waiting at the top.
(“Where do you go?” people often ask when we’re out, and I tend to say: “in a circle!” “What do you mean?” “Well, we’re coming back here. It’s just the circle is 60km long.” I am still riding circles.)
My first ride, I find myself beginning to bonk on a hill I will later come to dislike – steep, ugly, in the way of getting home – near St Mary Cray. Another rider is near the back, and they drop down to my pace, grinding up with me. I feel useless, and yet I feel supported. Nobody cares; the point is we all get home together, that we did the thing together. That afternoon, I am a wreck: I spend it on the sofa, overwhelmed with tiredness.
I learn that I need to manage nutrition better through rides. Keep eating, that’s the main trick.
Another week, another hill, and I’m grinding up at the back. There is something I begin to refer to as a Pushing Incident. I get to the top, and apologise profusely, and am reminded that nobody minds.
Our rides are “no-drop”: that means, if we get spread out, because some people are faster than others, we wait for everybody. Usually, this is the top of a hill. Staying together on the flat is fine, descents aren’t an effort to catch up on, or to take a little slower if you’re outpacing others, but it’s hard to climb slower than you’d like; you have to do a hill at your own pace. And so we wait, because we’ve agreed we will.
This aspect of group sport – doing a thing together, collaboratively – is new for me. I reach the top, and apologise, and nobody minds, but something in me doesn’t believe them. It takes me a little while to realise this is an idea rooted in my head: I am not an athlete; I am the out-of-breath kid at the back of cross-country.
(Cross-country is a muddy, outdoors kind of running. In more adventurous terrains, it is something like fell-running. But when you’re 11, it’s a thing to be done in PE class, that takes a winding path around the school grounds and often outside, requires no equipment, no track, no indoors. We do it in the winter and spring months, and I only ever remember it in the damp. It is awful. I dislike running, I dislike the stitch I get. I am certainly not fit, and at that point in my life, I am highly disinterested in the physical. I am at the back, I don’t see how to get nearer the front, and I’d rather talk to my friends, because I’m definitely, definitely bored.)
No. I am not at the back of cross-country, nor am I bored. I am a man, almost in his forties, out doing something for fun with like-minded adults. When we say “no-drop”, we mean it. Everyone was at the back at some point. When you go up a ride tier, you will be at the back of a faster ride.
It will take me many rides to fully internalise this, that there is no Back, that some of us are slower up hills because we’re heavier, some because we’re recovering from injury, some because we’re taking it easy. The point, for me at least, is getting there – and getting there together.
(I will also begin to change my perspective on what it means to Be Athletic. Or rather, what I’m slowly changing my perspective on is Having A Body. My mental image of myself is so often a “brain in a jar” – I think, I type, I’m good at being smart, I have some dangly arms and legs attached. What will happen in the next eighteen months is that I begin to like having a body, as well. I begin to extend beyond the jar.)
“After two rides, we ask that you join the club“, but it’s a no-brainer, of course I’ll join the club. Every other week, new company, new routes, new people to meet, a way out of the house and lockdown.
The club have a day ride one weekend to Whitstable. A hundred kilometres. Far too far. I decline. Stick to the 60s.
Slowly, I get faster. The data says so. The secondhand cycle computer is saving my data, and I’m throwing it all into Strava (because That’s What You Do). Not for the likes, for the socials; just to see how I’m doing. It’s for me. Besides, everyone else I know on it is so much faster, going so much further. Months later, a friend will share a long ride in Scotland, and I will cheer them on; they point out – and I paraphrase – that whilst nobody wants to hear your Strava Boasts, Strava Pride is different. Sharing pride is important. Look at this, you say, I did this, me.
Months later, another ride. I chat to someone who’s coming out for the first time, grinding up a hill. As I pull away a bit later, I point out that there is no Back, we’ll be waiting, and there’s nothing to apologise about. I should know. I remember the friendly faces who pushed me on when I had no idea what has happening, and I am pleased that I can offer support to someone I recognise.
(Next year, she will pull away from me at the end of a long ride, having been more dutiful on the turbo than I. And: we are both going far faster than on the ride I am describing in the previous sentences.)
I keep pedalling, and pedalling further. The summer ‘22 season hits and I’m on regular 80km+ rides with the club… and it feels fine. I’m at the back of a slightly faster group. Each week, I can’t wait to get out: to feel the wind, to feel the snicker-snack of the drivetrain, to see new sights, to see how far my body can take me. I’m enjoying getting a little faster, but I enjoy going new places, going further, much more. Distance, places, are the things beginning to appeal.
One day, I decide to ride 100km to the sea; it is no longer too far. It is slower than planned owing to a brutal headwind, but I roll through Rochester, out to the marshes, past Sheppey and up to Thanet, and there’s a tickle of adventure.
After 12 months on the starter bike, I buy a new one, ending up with something both more capable and flexible. It’s taken me on off-road trails in the New Forest – a real delight – and, with a quick change of wheels, back on to the lanes and roads of the south east. It is magical: a spot-on drivetrain, brakes with remarkable modulation, a frame that supports and cushions. I regularly wonder if it is “too good” for me, as if there is an upper bound on the quality of sporting goods I am allowed – as if I am not ‘good enough’ for it. I wonder where this peculiar kind of guilt comes from. I have already ridden it nearly as far in five months as I did in a year on the starter bike.
The first bike, that I fixed up that lockdown summer, is given a new home. I take it to the Bike Project, a charity based up the road in Deptford. They give bikes to refugees new to the UK: getting around a new country, when you have very little money, and a lot of places to be, is hard. A bike (and lock and helmet) makes that easier. So Bike Project give people bikes; they also refurbish and sell used bikes, in order to raise money for charity.
A week later, they email to tell me they have sold my bike for exactly what I paid for it on eBay, in 2002. Good. Someone else can use it, enjoy it, and maybe more people can benefit from the funds it raises.
In about three weeks from now, I’m going to take part in the longest ride I’ll have ever done: RideLondon 100, covering 100 miles – 162km – from central London, out to Essex, and back. (Really, that’s why I rode to the coast: part of the training plan). I am largely, but not entirely, looking forward to it. This is the deeply, deeply buried lede of the essay.
A lot of friends and clubmembers are riding; I’ll be in good company, and am looking forward to seeing everyone out there. I chose to do it as both a challenge – further than I’ve ever ridden by a good deal – but also as a bit of a luxury: a day out on entirely closed roads, in the summer! When I signed up, 160km still felt a long way off. It still feels a long way; I am hoping that company and adrenalin will carry me over the line.
I’m going to be 40 this year, and whilst I’m glad I’ve made peace with my corporality at this point in life… I’m also aware that the time in my life to embrace that physicality is probably shrinking rather than growing. My knees certainly remind me of this.
So in the meantime, I will ride. There has been something like a training plan – some longer rides, some interval work – and I’m hoping it pays off. I certainly am fitter than I’ve been in my life. It feels a long way from 11k loops to Greenwich.
London Velo – my club – is a Deptford club, and so we’re raising money for a Deptford charity: The Bike Project. The club as a whole has a fundraising page, and, if you feel like supporting us on our ride, you can do so there. Bike Project would appreciate it, especially in a time when it’s harder than ever to be a refugee in this country. I will appreciate your support for them, when I’m somewhere in Essex, and the thing I need to do is keep turning the pedals.
I’m excited for it, though. It turns out, that November, that buying a bike was a very good idea. Not just for my body – though I’m enjoying that new relationship – but also for my brain. Well done, past me.
TL;DR: I bought a 5GEE router from EE in the UK on a business contract. I returned it within the 14-day “cool-off” period as, despite dramatically-improved download and upload speeds, there were issues with it that affected online gaming. The user guide doesn’t seem to be online anywhere, so I’ve hosted it here.

A friend of mine who lives in the south of England is currently moving house. His new place has access to a full fibre connection, which is not only ridiculously fast but also ridiculously cheap. I live in a market town in the north-east of England, which seems to be the land that time forgot in terms of fibre broadband rollout. While he’s experiencing symmetrical 900Mbps speeds and a ping of 3ms, I’m getting 42Mbps downloads, 16Mbps upload, and a ping of 16ms. This is important, as we’re part of a group of friends who play PlayStation together online regularly. It’s competitive advantage territory 😂
As a result, and because I’m always looking at these kinds of things anyway, I re-evaluated my options. The ISP I’m with, Andrews & Arnold, are absolutely excellent but can only offer me the infrastructure rolled out by Openreach. They could offer me a second line, bonded to my existing one, but this would double my cost while not-quite doubling my speed. I’m already paying £56/month (including VoIP charges) so that seemed like… a lot for not much improvement?
So I investigated Starlink which looked OK, but potentially not that reliable with expensive setup costs. I also looked at 5G networks and was more than a little excited to find that EE’s “5G indoor and outdoor” coverage checker put our row of houses right on the edge of their availability. So went into my local EE shop to double-check. In the end, the friendly and obliging store manager literally walked the few hundred metres up the road from the shop to my house to confirm that I could indeed get EE 5G at my property. I immediately ordered a 5GEE router on a 24-month business contract, working out at £35 + VAT per month.
I live in a three-storey house, as we’ve converted the loft. My wife’s office is up there, while my office is in the converted garage out the back which is separate to the house. Getting a fast wifi connection both up and out is challenging, but our Netgear Orbi system with the router and three satellites seems to cope.
I thought my wife’s office in the loft would be a good place to connect and test the 5GEE router. I have to say that I was absolutely blown away by the speeds after I plugged it in and the blue 5G connection lights lit up. It was providing over 200Mbps down, and over 60Mbps up, with a ping of around 33ms. Happy Doug was happy.
Having done some research into directional antennas, I got a bit greedy and wondered what would happen if I connected one of those to the router? Could I double those numbers? I ordered a Bluespot 4G/5G directional antenna from Amazon, because they’re so good at no-questions-asked returns.
I thought I knew where the 5G mast was, but when it arrived, connecting the antenna it didn’t seem to make much difference. In fact, it actually seemed to make things worse. There was a note in the box to get in touch with Bluespot for a free virtual site survey, so I fired off an email with the relevant details. The information that came back was excellent, and revealed that there’s a mast around 200 metres from my house that I didn’t know about, and then another one across the other side of the ‘valley’. I don’t know this for a fact, but it seems like the closer one is 4G-only. Either way, I couldn’t really get a better connection with the external antenna compared to the internal antennas, even when I bought some splitter cables.
I must have read pretty much every forum thread that mentions the 5GEE router. I’m reasonably technical in general sense, but I’m by no means an expert at networking. So I’ve spent a lot of time piecing together information between forum posts, calling EE, and experimenting with the device itself. My daughter called it a “part-time job”.
During my investigations, I found that:
In closing, I came a lot of very helpful people and some great websites. The EE community forums contain such as wealth of knowledge that EE staff themselves refer to them! The ISPreview UK forums are more generally useful for context, too. I didn’t use Router Mods but I can imagine that if a mobile connection is your only viable option, investing in their kit might be an idea. And of course, Andrews & Arnold my current ISP whose live chat function gets you directly to people who aren’t scared to get technical.
At the time of writing, despite advertising it on their website, EE flat out refused to come and try and fit an external aerial to my property. They told me the ones they have are 4G-only. Based on what I’ve read from other customers, I don’t think this is true, but I called them four times and they gave me the same answer.
I’ve learned a lot from this experience, so although it could be classed as a ‘failed experiment’ I’ve gained knowledge which will stand me in good stead:
If you’re not a gamer, I wonder whether buying a (unlocked) 4G router with an unlimited data SIM might be a better investment?
This isn’t a forum, and I’ve written down everything I can remember that’s relevant about what I learned during this experience. So I’m closing comments here, but feel free to ask me stuff on the Fediverse (@dajbelshaw@nullfosstodon.org) and I’ll see if I can help.
The post Documenting my attempts to replace VDSL home broadband with a 5GEE router first appeared on Open Thinkering.Yesterday was spent working with my friend and colleague Carolyn Camman yesterday on a design for a workshop on evaluation in complexity. We had the utter joy of being able to be together, having a high bandwidth human experience, which enabled us to really dive into some interesting existential questions after which we were famished and so we retreated to Kulinarya Filipino Eatery for dinner, feasting on Crispy Binagoongan and Batil Patong.
The food was great and as usual our conversation wandered all over the place and at some point – possibly when we were standing outside a small rehearsal space listening through an open window to a jazz combo swinging nicely inside, the thought came to me: “forget about your theory of change…what is your theory of stability?”
It occurred to us that in the non-profit and philanthropic world, we are constantly asked for a theory of change which is intended to explain how our intervention will change things for the better. There is a trap in this of course, that these theories are often linear and predictive, which is the antithesis of complexity as a theory of change, and in fact, in most cases the only answer to the question “Please describe your theory of change?” should rightly be “complexity.” I even wrote a post about that once which should serve as a companion to this one.
Interestingly however, I have never heard anyone ask “What is your theory of stability?” and that strikes me as a fundamental question to address fs one is to be making change, especially in a complex system. For instance, if you are looking at a set of unhealthy patterns in a system, like racial discrimination or persistent and chronic poverty or disparate health outcomes among different populations, it strikes me as really important that you talk about WHY you think those situations are stable over time. What is your theory about what keeps them in place? This is important because what you believe about how to create stability will affect HOW to design and act to create new stability. And that can be fraught with category errors.
To me this is where the work around constraints really hits home. And so to recap, typically I introduce this work with folks as:
When we spot stable patterns in a system, we can look at the constraints that are keeping them in place and try changing one or more to see what kinds of results we get. That is the essence of complexity as a theory of change. But what is the mechanism used to create stability?
Cynefin is helpful here as it describes different types of systems and different kinds of ways to both make change AND to stabilize things. So here is a Cynefin framework with the constraints and action language rephrased to help us think through a theory of stability for a project:
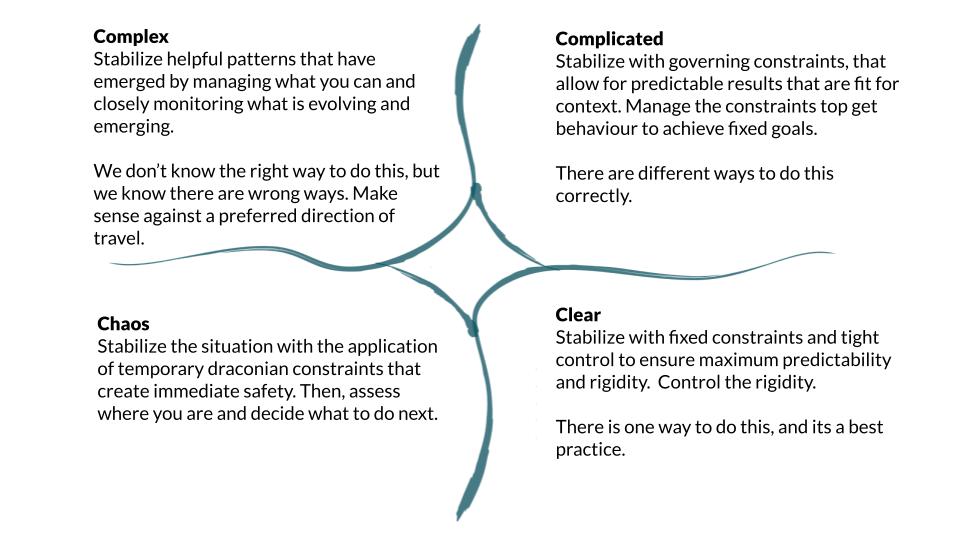
As always, knowing which domain you are working in will help you think about how the problem you are working on is constrained. From there, I think it’s worth asking “How do you think the stability in this situation is functioning?” It is very important to note that if you are indeed working in complexity, you need to avoid taking action to disrupt and stabilize the system as if you are working in the complicated domain. Is that situation really be held together by someone who is controlling things and pulling the strings?
The question is not “What is the root cause of the fentanyl crisis?” but rather “What is maintaining the stability of the fentanyl crisis? And how?” One could be tempted to answer something like “someone is controlling the drug supply, or is actively preventing us from making that supply safer.” In complexity, your theory of stability is as much a hypothesis as your theory of change, and it seems crucially important that we begin change initiatives by alos questioning whether we have the stability mechanisms right. In a complex and emergent context it is highly unlikely that the emergent phenomena that we are trying to change are produced by a single actor doing a single thing. And yet, I recognognize the seduction of that thinking, which critically influences the action I will take.
So that’s important for starting, but a theory of stability is alos critical for understanding how any positive work done in the initiative will be sustained. Funding cycles, for example, are powerful periodic attractors for change making meaning that they often dictate the time frame in which a problem needs to be solved and they alos dictate the pace and cadence of the work to solve it. They also dictate the stability strategy.
Many foundations are happy to fund a community group that is aiming to double literacy rates in vulnerable communities and will support a set of interventions to do so. But when the goal is hit, the work doesn’t end, and who is willing to invest in a stability strategy that is also complex? High literacy rates are maintained in some places not because there is a well funded literacy program. Literacy is an emergent outcome of privilege and wealth, among other constraints, that help maintain a stable pattern of high degrees of literacy. There are certainly deeper and less visible constraints that enable concentrations of wealth and privilege including historical policy choices that limit access to housing finances, like redlining certain neighbourhood and people to restrict their access to credit.
So when you find practices that support increased literacy rates, what are the constraints that you can work with to enable the continued emergence of these outcomes? And what happens if, after the intervention funding ends, the needle starts turning downward again?
So I’m just thinking out loud here but the takeaway from this post is this:
Thoughts?
I have been using maps inside WordPress using Maps Maker Pro. You can see all my major road trips were mapped using that. I like it so much that I paid for it. But recently, I have been thinking about moving map content outside WordPress and maybe using WordPress only to display. Then came the question of how and where to store GIS content.
So I went back to my trusted CouchDB to store the GeoJSON. And use Leaflet Map to display the GeoJSON. It doesn't have the features of Maps Maker Pro, but it does an excellent job of showing GeoJSON and its FOSS.
So any map is just a GeoJSON file that I can use any of my favorite GIS tools to edit. It's stored and served by CouchDB. I don't have any case for performing GIS functions on the data, so it works. It's just a URL that can be used anywhere. Also, since it's served through a CDN, it's fast. Now I am slowly migrating my map content.
For example I have a small Craft Beer Walk Path project. It has its own page but i have embedded the same here too.
I miss mapping the posts to geolocation ( I don't do that much), filtering them. I also miss creating a new layer by remixing features. Maybe one day, I will store the individual GeoJSON features as a separate CouchDB document and combine them dynamically to form a FeatureCollection. Currently, I store the whole FeatureCollection as a single document.
The post GeoJSON and WordPress first appeared on Thejesh GN.What if the dominant model of company ownership inverts? What if we’re at the end of an era of companies being owned by external stockholders, and at the beginning of bottom-up ownership by the people who do the work – the employees? Feels unlikely I know, HOWEVER:
This morning’s news is that ustwo is now employee-owned.
You’ll likely know ustwo. Here’s their Wikipedia page. They’re behind the hit puzzle game Monument Valley; long-time digital design agency (founded in London in 2004) with a couple hundred staff; part of many joint ventures to provide design/software/marketing/etc for startups, e.g. DICE. I know Mills (@millsustwo), one of the two founders, from the general scene - huge congrats mate, brilliant move.
I have a soft spot for an ancient bit of ustwo work, being home screens designed for the Sony Ericsson XPERIA X2 (bloody hell that’s a mouthful) smartphone from 2009. Watch the Pixel City video on Vimeo: "Pixel city moves through a cityscape, its different elements linking to the functionality of your phone. Text messages appear playfully on billboards, calendar events arrive by train, a passing aeroplane shows your call history and much more."
ustwo have always been as inventive and pioneering with their business model as their design work. They’ve been blogging today about going employee-owned:
It’s great that they’re sharing the nuts and bolts of how this works. It’ll demystify the process for others who want to follow the same path.
And I’m sure there will be a bunch of future lessons in how to make this work – like, how can there be meaningful employee involvement in how to chose work or influence big bets or what happens when there are lean cycles in the agency cycle? I hope ustwo’s sharing will continue.
A shout-out at this point to my friends at Clearleft! A smaller but also well-established agency and extremely well-regarded for their design work and community presence, the Brighton-based design studio went employee-owned in 2020.
Two makes a trend right?
Exciting times for design. And for the agency model, which has been in a state of perpetual reinvention for as long as I remember.
RELATED: There’s something fascinating in thinking about succession planning as the founders handing control not to another individual to the machine. It makes me think of Sikhism which, after a line of 10 gurus, handed over leadership to an “eternal living guru,” the Sikh community itself. As previously discussed.
There’s always been the question about how founders exit from an agency. Two traditional routes:
The agency world has its own nature and own norms – it’s like a more established, parallel world to the startup ecosystem.
One feature is the presence of behemoth networks like WPP plc (that’s their Wikipedia page). There are a handful of agency networks around the world. WPP is UK-based and owns a few hundred agencies, with collectively 100,000 employees and somewhere north of 10 billion annual revenue. They coordinate, share work, get scale (a small agency can be part of a global project), and save on back-office.
So while I love that ustwo and Clearleft are figuring out the path to employee-ownership – the eternal living guru of the organisation…
…thinking about the larger scale makes me ASK:
What is the equivalent of the agency network for employee-owned orgs?
Can we imagine some kind of multinational network organisation that coordinates, shares work, achieves scale, etc, without taking full control of the member agencies?
Going further:
The agency world has a fractal structure. Agencies are often 50% freelancers and they subcontract like crazy. Then they roll up into bigger firms – the Coasean logic of travel towards lower internal transaction costs means agencies combine and combine again until you get the network giants.
(The startup world parallel is the data-driven gravitational force which results in Big Tech, a.k.a. Srnicek’s platform capitalism.)
Can employee-ownership exist at all scales?
Hey and here’s an example in the UK! CoTech is a network of 45 creative technology companies, all individually organised as co-ops, providing digital services together. More like that pls.
(Thank you to the folks at the co-op Common Knowledge for letting me know about this. Common Knowledge itself creates digital tools to force-multiply social movements.)
Perhaps we’re at the beginning of an ownership inversion where organisations from big to small will follow the principle of bottom-up agency.
Dominant models change every so often! I remember reading that the dominant model in the US relatively recently (1900s?) was family-owned businesses. I’ll have to hunt down that reference.
The analogy here is to geomagnetic reversal, the process by which the Earth’s magnetic poles flip – the North Pole becomes the South Pole; the south becomes the north. It happens periodically: "There have been 183 reversals over the last 83 million years (on average once every ~450,000 years). The latest, the Brunhes-Matuyama reversal, occurred 780,000 years ago."
(i.e. we’re overdue, just in case you were wondering what else the 2020s may deliver.)
So I guess something happens such that the pole-flip kicks off, and sheer magnetism drags everything else with it to complete the process? There is no halfway house.
Once I started looking for signs of an ownership inversion, labour becomes capital and capital becomes labour, then I started seeing it everywhere:
THE COMMON THREAD:
How an organisation’s self-determination, ownership, and value-creating work become indivisible, held by the same people: the employees?
It turns out this same question is being asked at all scales.
So let’s assume the magnetic pole flip is in progress!
Or at least, let’s assume this: there is tectonic tension towards this corporate ownership inversion, even if as yet unrealised. So enabling tools will quickly find traction and unlock behaviour.
Answering questions like…
And so on.
If you were a VC you might invest in this, as a long term bet.
When TikTok first began to amass media attention, a narrative about its “eerily accurate algorithm” became so popular it was almost a self-fulfilling prophecy. Users talked about its algorithm as if it were sentient. (“The TikTok Algorithm Knew My Sexuality Better Than I Did” one headline memorably claimed.) In winter 2020, the idea of its omniscience had become so pervasive, it became folded into a particular TikTok genre in which spirit workers — mediums, astrologers, tarot readers, Reiki healers and other “SpiritualTok” creators — make predictions about everything from money and love to politics, government, and the economy. This content, which had risen to prominence amid anxieties about the pandemic, posed the physical realm as one of metaphor and synchronicity, where signs from the universe were waiting to be divined — even on your For You page. “This message was meant to find you,” a TikTok spiritualist would say, or, “Your ancestors guided you to this message.” “If you’re seeing this, it was meant for you.”
Such videos appeared between dances, pranks, and other viral content as if by fate, often purporting to diagnose a personal issue or failing, or offering predictions about love, careers, fortune, and spiritual growth. The easy rhythm of scrolling through the app, combined with content about feeling lonely, scared, anxious, and depressed, made this appeal to the heavens especially tempting. It reflected an anxiety about a precarity many were feeling, whether about the pandemic, politics, or just a general sense of being overwhelmed by an information-saturated world. At the time, it wasn’t rare to to see a tarot reader deliver a message about your romantic partner (“They have been hiding their emotions or juggling two things”) or drag you for exhibiting avoidant tendencies in relationships. A few scrolls over, a Reiki healer might try to relieve you of your anxiety with distance healing, and shortly after, another crafty healer might try to discern your soulmate from a set of runes. (“It’s actually your best friend! I think you already knew that.”)
Spiritualists draw on a collective awareness that the algorithm acts as social engineer
Prediction videos have cemented themselves as popular practice on the app, in which TikTok spiritualists draw on a collective awareness that the algorithm acts as social engineer, while exploring the mystical potential of the opacity of this fundamentally rationalized process. Anything that crosses your path can be taken as a “sign from the universe” rather than a consequence of data collection and processing. “If you’re watching more tarot readings you’re of the vibration of accepting those messages,” one tarot reader told a Wired reporter. TikTok is positioned as a conduit for the cosmic. Whether it’s the data hoarding of a popular AI company or the good grace of the universe makes little difference when everything is a puzzle meant to be decoded. Viewers are invited to ascribe a video’s serendipitous arrival to a higher power, aligning the algorithm with spirit guides, the ancestors, the universe.
This is not to cast doubt on spiritual practices that may have deep cultural significance, but to consider their proliferation through seemingly antithetical means. TikTok’s algorithm, in this sense, is a contemporary example of how the scientific rationalism often associated with technology tends to generate a counterreaction by means of its very success. Classics scholar E.R. Dodds once characterized the Roman Empire as an Age of Anxiety where “the regimented and mechanical efficiency of the empire could no longer bottle up the chaos growing inside the souls of its subjects and outside its civic walls.” This led to a massive explosion of cults, mystics, and alternative belief systems. Similarly the supremely rational method of using empirical data analysis to power predictive technologies has generated a popular sense that such predictions are oracular or magical. References to moods and “vibes” and other similar concepts help create an illusion of algorithmic kismet — tech so advanced that it works like divine intervention.
Tech companies have long tried to promote the convenience of their products as a form of magic to hide the kinds of labor exploitation and material consumption they necessitate from their consumers. Their devices and interfaces were “magic” in part because they gave a sense of unprecedented power or control, not just because users didn’t understand how they worked. Content algorithms are magic in a different sense, evoking an impression of fate beyond our control, that we must surrender to a fundamental inability to understand our world or even ourselves and our own desires.
Given algorithms’ power and obscurity, it seems almost inevitable that they would be regarded as capricious gods. They are something we can’t touch or see directly but affect our everyday lives, bringing rewarding attention to some and swarming punishments to others. The fantasy of “revealing the algorithm” — as Elon Musk spuriously promised in the wake of his proposed Twitter purchase — reinforces the idea of hidden, higher knowledge, as if code might reveal the secrets of humanity. The Algorithm can thereby seem almost benevolent rather than opportunistic and exploitative.
This blurring between the machinic and the mystic suggests how new streams of tech profit can become reliant on drawing from or even establishing systems of spiritual belief. From the popularity of QAnon to the spiritual-adjacent content my TikTok feed shows me — not just astrology readings and Reiki cleansings, but videos about the Law of Attraction, astral projection, and timeline shifting — there is a near limitless number of belief systems to funnel energy into. The algorithm itself captures users with a general interest in spiritualist or astrology memes and feeds them more esoteric content. At the same time, practitioners have become acclimated to the idea that TikTok’s algorithm is itself a spiritual tool, and entire practices of engagement have emerged from it.
Viewers are invited to ascribe a video’s serendipitous arrival to a higher power
TikTok promotes the idea that its algorithm shows you content out of some greater benevolence to fuel your own pleasure and growth. In the U.S., it spent hundreds of millions of dollars on ads and paid a number of social media influencers to adopt the app. This strategy was successful enough that in the first year of the pandemic, the company was valued at 50 times its expected revenue. This hype is partly the reason that its machine learning algorithms — which have similar counterparts already in use at streaming platforms like Netflix and Spotify — can appear omniscient.
There is nothing particularly mystical about these feats of engineering, matching users with content based on data collection and correlation detection, and using various signals of “engagement” as the basis for optimization. But when TikTok creators insist that a piece of content “was meant for you” — that is when a video centers its own availability to the algorithm and reinforces a sense of algorithmic kismet — it deflects curiosity about the forces defining and designating what is “meant for you.” Deification of the algorithm shields tech companies from questions about the privacy invasion and coercive design required to make their systems work, and the advertisers whose interests are ultimately being served.
The willingness to believe in the “algorithm” as though it were a kind of god is not entirely surprising. New technologies have long been incorporated into spiritual practices, especially during times of mass crisis. In the mid-to-late 19th century, emergent technologies from the lightbulb to the telephone called the limitations of the physical world into question. New spiritual leaders, beliefs, and full-blown religions cropped up, inspired by the invisible electric currents powering scientific developments. If we could summon light and sound by unseen forces, what other invisible specters lurked beneath the surface of everyday life?
The casualties of the U.S. Civil War gave birth to new spiritual practices, including contacting the dead through spirit photography and the telegraph dial. Practices like table rapping used fairly low-tech objects — walls, tables — as conduits to the spirit realm, where ghosts would tap out responses. The rapping noise was reminiscent of Morse code, leading to comparisons with the telegraph. In fact, in 1854, a U.S. senator campaigned for a scientific commission that would establish a “spiritual telegraph” between our world and the spiritual world. (He was unsuccessful.)
William Mumler’s practice of spirit photography is perhaps better known. Mumler claimed that he could photograph a dead relative or loved one when photographing a living subject. His most famous photograph depicts the widowed Mary Todd Lincoln with the shadowy image of her decreased husband holding her shoulder. Though widely debunked as a fraud, the practice itself continued on, even earning a book written in its defense by Sir Arthur Conan Doyle.
Similar investigations into otherworldly communication and esoteric knowledge would be mainstreamed after World War I, bolstered by the creation of the radio and wireless telegraphy. Amid a boom in table rapping, spirit photography, and the host of usual suspects, Thomas Edison spoke openly about his hopes to create a machine, based on early gramophones, to communicate with the dead, specifically referencing the work of mediums and spiritualists. Radio, in particular, provided a new way to think about the physical and spiritual worlds, with its language of tuning in, channels, frequencies, and wavelengths still employed today.
The algorithms offer to concentrate our expression of belief based on engagement
As new technologies are adopted into society, their logics permeate fundamental aspects of our lives, including the spiritual — offering new deities and values that redefine what it means to worship. Online, many young people are now keenly aware that their lives are fodder for attention algorithms — that all digital expressions of thoughts, hobbies, and experiences operate within a larger ecosystem of data analysis. Friends spend hours curating their Spotify feeds, or post “algoselfies” on Instagram to maximize reach. On TikTok, spiritualists encourage you to “like, comment, and interact” to claim your message from the universe and help others find it, a tacit acknowledgement and befitting offering to the workings of the algorithm.
We have been trained to measure personal success, impact, and meaning by how many views and comments we get, which, in times of precarity, can be understood as both an economic necessity and a mode of self-actualization. The algorithms offer to center our lives and concentrate our expression of self, and thus our expression of belief, into new practices based on performance and engagement. In place of being subject to forms of algorithmic control, one can see oneself instead as engaging in algorithmically inflected rituals, tapping into the power of faith.
As a symptom of this, many creators focus their practice on abundance, proselytizing about how TikTok spirituality can connect users with wealth, health, new audiences, and more. In this prosperity gospel, the algorithm is our idol. Dedicated posting, liking, following, and commenting becomes a form of worship to be rewarded with more followers, visibility, and money. This approach, which conflates and confuses technology and magical thinking, is currently salient in the promotion of crypto, which defies coherent explanation for even its most outspoken salespeople. “To the average person, it does sound like voodoo,” Web3 promoter Bobby Allyn declared in an All Things Considered segment on NPR. “But when you press a button to switch on lights, do you understand how the electricity is made? You don’t have to know how electricity works to understand the benefits. Same is true of the blockchain.”
This, of course, is not an explanation but a demand of faith that mirrors the attitude of 19th-century spiritualists toward the telephone. The promoters hope to spiritualize “blockchain” in the same way as “the algorithm” has already been spiritualized, as an all-powerful force capable of performing miracles and benevolently reorganizing our everyday experience. At the recent Bitcoin 2022 conference, one acolyte told a Daily Beast reporter that Bitcoin “gets into your life from every point of view — not only the economic point of view.”
Today, marketing hype creates worshippers out of their target audiences, almost by necessity. The inspiration-sales-pitch language of tech bros — talk of freedom and decentralization — offers a complement to TikTok’s spiritually inclined users, who speak of liberation and abundance. In each instance, a new technology is defined not by its material impact, but lofty ideals that resonate with an increasingly desperate population. As tech companies navigate a competitive field for funding, their outsize promises of innovation are adopted as scripture. In this world, TikTok’s algorithm isn’t just another attention trap but a powerful new tool for self discovery and spiritual awakening. Similarly, crypto promises freedom and success — particularly for people of color — and Web3 a new social order altogether. It’s no longer enough for a technology to solve a singular problem. In the cult of techno-optimist hype, we’re all one innovation away from being saved. We just have to believe.
This morning the wind and rain continue here in the islands of the south coast of British Columbia. It has been a wet fall and winter – perhaps the wettest since the time of the Flood stories – and this is the coldest May we’ve had for a long time, which brings its own hazards. It’s all down to an extended La Nina event that pipes cool water into the north Pacific and keeps the air masses cold and turbulent, resulting in reliable patterns of convection, instability and therefore precipitation and windy weather weather.
I live in a very rainy part of the world, and so to really love living here, one has to love the rain. This morning as I took my coffee to sit by the sea, I was struck by just how immersed I was in water. The sea of course, which bathes the shoreline and brings all kind of nutrients into our inlet. The creek beside me, channelling the rain from the mountain into the bay, delivering different nutrients back to the shore line. The rain that was falling into my coffee cup, spattering against my hood. And my breath, precipitating in small clouds that echoed their larger cousins across the channel, covering the mountains on the mainland. An entire symphony of sound all played on the same instrument.
For me, actually, water is my favourite image of God. If you are a spiritual or religious person, your engagement with the Divine is of course fraught with reductionist peril. As Lao Tzu wrote in the very first line of a book about the Tao, “The Tao that can be spoken is not the eternal Tao.” It’s a disclaimer. He says, “look, everything I am about to write here isn’t the things I am actually writing about, so take that under advisement.” One must be very cautious talking about images of God, the Creator, the Divine. Every name severly limits your experience of that which you are trying to talk about. Whatever name or image you have is like trying to watch Barcelona FC play through a tiny keyhole, in the outside door of the Camp Nou.
And yet, the image that works best for me is “water.” It brings life, and it can sweep it away. It can induce terror and soothe the soul. One can go for a hair raising boat trip from which you barely escape alive and then heal yourself with a soothing cup of tea and a bath. Water also has a characteristic of non-duality which gives it an important characteristic as it relates to my spiritual practice. As our atmosphere is made of water vapour, and so are we, it is true to say that “I am in the water and the water is in me.”
To end, here is a poem by William Stafford that I used in our fifth Complexity from the Inside Out course this morning, borrowed from a blog post by my buddy Tenneson. It points towards this non-dual whole I am talking about.
Being a Person
William Stafford
Be a person here. Stand by the river, invoke
the owls. Invoke winter, then spring.
Let any season that wants to come here make its own
call. After that sound goes away, wait.
A slow bubble rises through the earth
and begins to include sky, stars, all space,
even the outracing, expanding thought.
Come back and hear the little sound again.
Suddenly this dream you are having matches
everyone’s dream, and the result is the world.
If a different call came there wouldn’t be any
world, or you, or the river, or the owls calling.
How you stand here is important. How you
listen for the next things to happen. How you breathe.

A massive improvement (the multiple tapes feature is something I’d love to have, and hope some of it might be back-ported to older hardware), at the usual Teenage Engineering price point (€1999 right now).
I still love my classic version, but this is going to cause a stir for sure.
No parent will name a favorite among their children. But I do have one among my brainchildren, my software contributions over the decades: The event-streaming code I helped build at AWS. After rage-quitting I missed it so much that over the last few months, I wrote a library (in Go) called Quamina (GitHub) that does some of the same things. This is about that.
Quamina offers an API to a construct called a “Matcher”. You add one or a hundred or a million “Patterns” to a Matcher then feed “Events” (data objects with possibly-nested fields and values) to it, and it will return you an array (possibly empty) of the Patterns each Event matches. Both Patterns and Events are represented by JSON objects (but it should be easy to support other Event encodings).
Quamina (and here I beg pardon for a bit of
chest-pounding) is really freaking fast. But what’s more interesting is that its speed doesn’t depend much
on the number of Patterns that have been added. (Not strictly speaking O(1), but pretty close.) Concretely:
On my 2019 Intel MacBook Pro, it can pattern-match several hundred thousand Events per second without much regard for how many
Patterns are loaded into the Matcher. The benchmark I use most for optimization has maliciously-constructed rules that force the
Matcher to
look at basically all the fields in 1KB-ish Events, where the values are arrays of long floating-point numbers. I try to keep this
worst-case running at 150K/second or better.
Back in 2014-15 I wrote v1.0 of a conceptually similar library operating inside AWS, which now implements pattern-matching capabilities for EventBridge and quite a few other teams around Amazon, filtering millions and millions of events per second so they can be accepted, rejected, or routed. Lots of super-talented collaborators emerged over the years and I bet that these days, my code isn’t even a majority of the thing.
I’ve been lobbying AWS to open-source it and that conversation continues, it might happen. But I missed working on it so much that I built Quamina. Also, the AWS version isn’t in Go and I thought a Go library might be nice.
I plan to write a few pieces about Quamina. Whether or not its features interest you, it illustrates lessons in dealing with data in motion at a scale that not very many people are lucky enough to be given a chance to code for.
Quamina is based on finite state machines a.k.a. finite automata. There is a rich body of academic investigation into the discrete-math theory of automata, almost none of which I’ve studied. But once I got the basic idea, state machines have been the first tool I’ve reached for across the decades when faced with hard programming problems. I’m not going to introduce the concept here because anyone who’s either got a CS degree or written much software knows the basics.
I like using automata because they have very, very predictable performance. If you’re processing a row of data items you only have to look at each item once, which is a pretty strong constraint on the time you’re going to spend. Also, the typical unit of work in stepping through an automaton is small. Thus, fast and predictable. Assuming I write more on Quamina, there’ll be lots of digging into details of how to make automata useful.
This is going to be easier if we have an example to work with. Here’s a sample Event:
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": 100
},
"Animated" : false,
"IDs": [116, 943, 234, 38793]
}
}(This is actually the canonical example of a JSON object from RFC8259.)
Here are two Patterns that would match the Event:
{"Image": {"Width": [800]}}{
"Image": {
"Animated": [ false ],
"Thumbnail": {
"Height": [ 125 ]
},
"IDs": [ 943, 811 ]
}
}For more examples and explanation, see the README.
This doesn’t look much like a typical query or pattern-matching language; the Pattern echoes the “shape” of the Event you’re trying to match. This turns out to have pleased a few developers, one or two of whom have said nice things to me.
Unfortunately I have no recollection of the thought processes that got us there in the white heat of the early design sprints for what became EventBridge. I remember a meeting in Seattle where I got up and sketched a few of these on the whiteboard and people said “It’s not SQL should it be?” and then eventually “Yeah, looks OK”, then we moved on. There must have been some discussion before that?
The idea of compiling together a bunch of automata and using them to match data is not exactly new; I think the “|” operator was introduced to grep while I was still in high school. The idea of using it on data that takes the form of JSON objects is a little less obvious. Here’s how it’s done:
First, you flatten the Event fields into name/value pairs. Here are a few of the fields in flattened form:
Image.Width: 800 Image.Thumbnail.Width: 100 Image.IDs: [116, 943]
Then you sort them by pathname. This is perfectly OK, because the order of fields in a JSON object doesn’t matter.
Image.IDs: [116, 943] Image.Thumbnail.Width: 100 Image.Width: 800
Then you do the same trick with the Pattern. For example, let’s use the second one above:
Image.Animated: false Image.IDs: 943 Image.Thumbnail.Height: 125
Then you make a state machine based on the flattened sorted Pattern and run it against the flattened sorted Event, and away you go.
Quamina has enough features to be useful and the unit test coverage isn’t terrible. I’d like people to look at it and see if solves any problems they have, or alternately if they see a reason why it’s All Wrong. Bear in mind that there’ll probably be another (more feature-rich) version in another popular programming language coming from AWS later this summer.
It isn’t at 1.0 yet and has no CI/CD, which means I reserve the right to change the APIs. In particular, should the MatchesForJsonEvent() be made a Go generic? (Quamina already has generics internally). I couldn’t stop anyone putting it into production, but I probably wouldn’t if I were you. But if that idea even crosses your mind, please get in touch.







