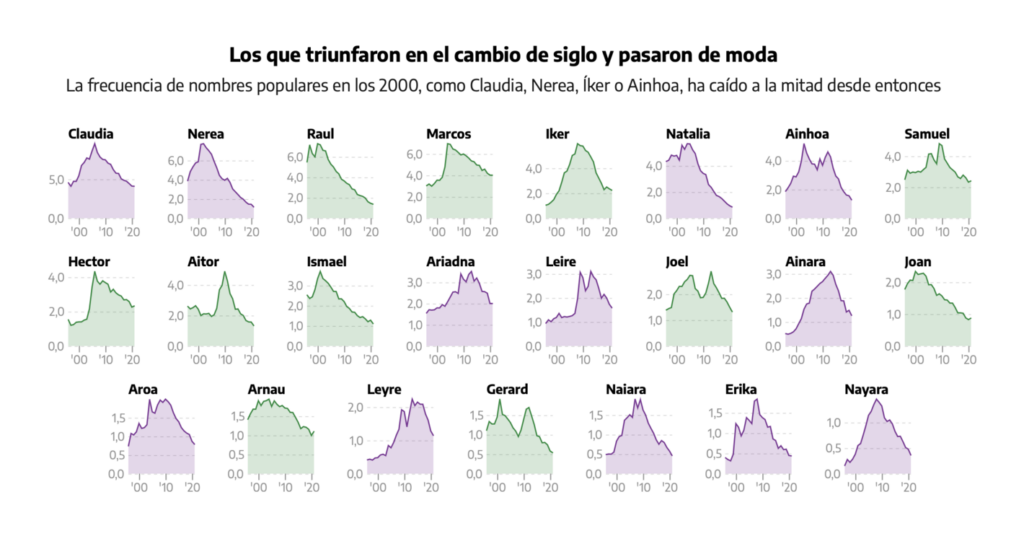
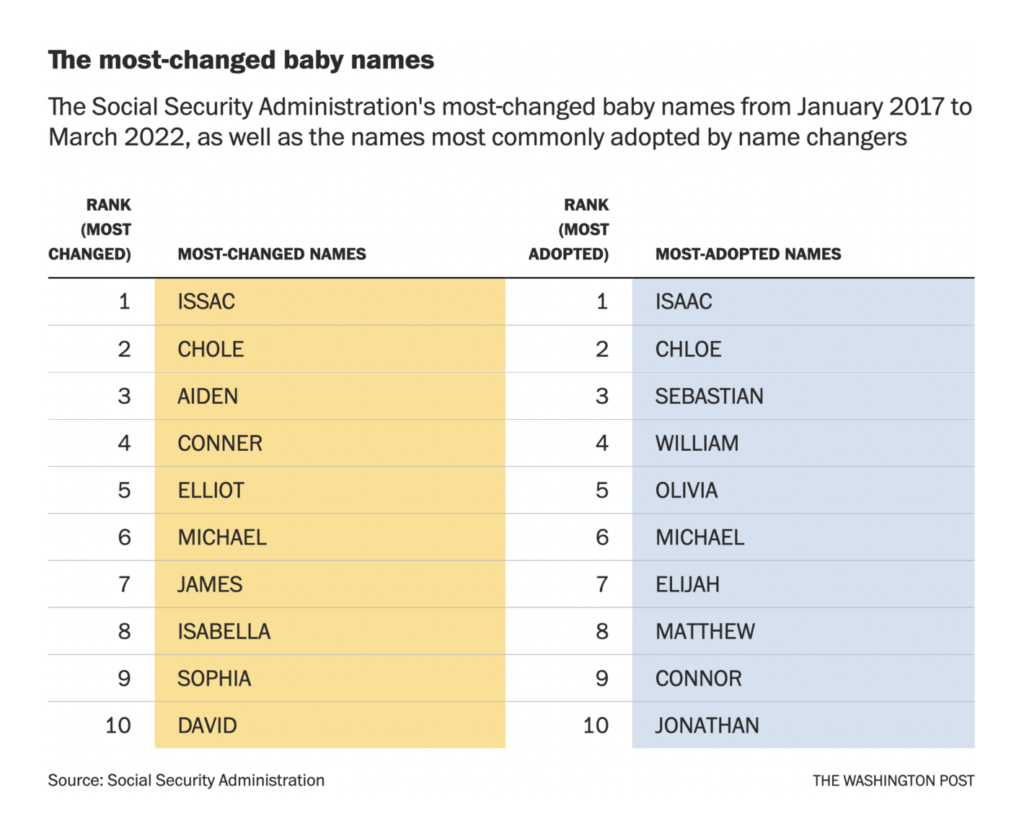
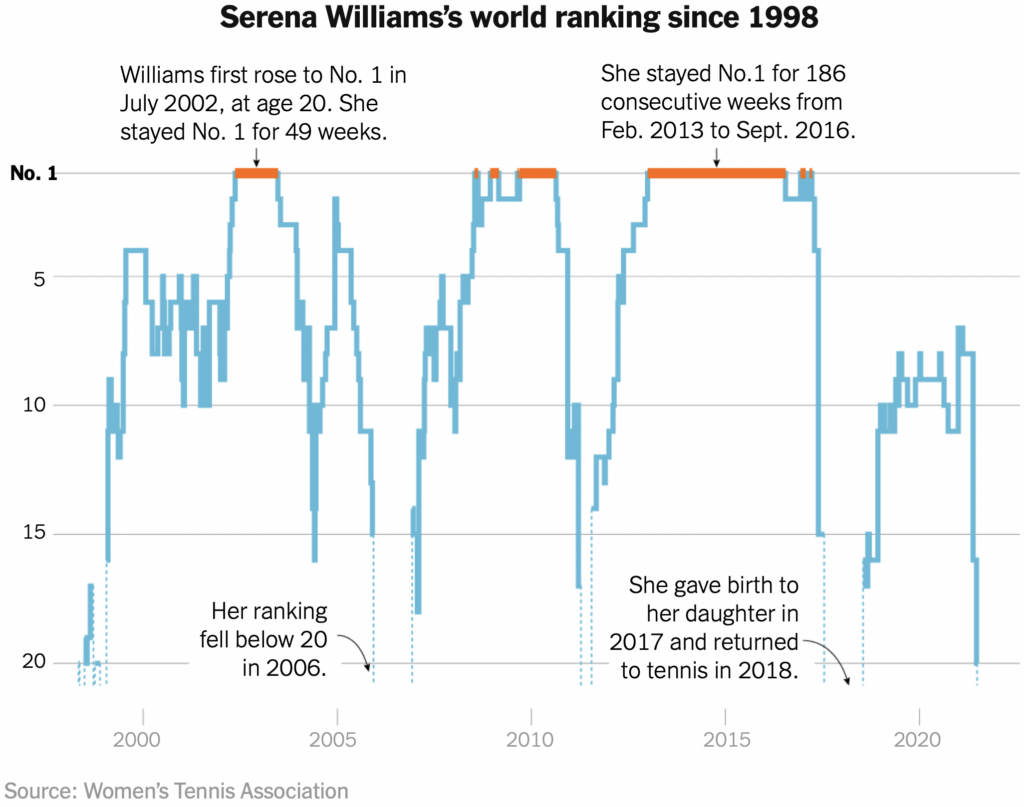
This summer, I learned (the hard way) 4 lessons about health, overwork, and life as an academic.
(1) “If you don’t make time for your wellness, you’ll be forced to make time for your sickness” — Joyce Sunada
I was, in fact, forced to take time off because of COVID and its sequelae. This week I sat down with my physician and we did a “post mortem” of my illness. He said: “you have overworked for a very long time. You push your physical limits all the time. You are very energetic, active and passionate about your work, but you keep pushing yourself. Not healthy”.
This was really embarrassing to hear from my treating doctor and a wake up call: I keep advocating for NOT overworking, and yet, in some twisted way, I kept doing it because it didn’t feel (yet) like I was exhausted.
Until it did.
In May, I went to Germany and the US. In normal times, and under normal circumstances, these two trips would have been a piece of cake because I am/was used to travel All The Time. However, this year has been particularly busy with teaching, administrative duties, and course preparation, reading theses, providing feedback. SUPER BUSY.
So (we all know where this is going…) I did not pay attention to my tiredness (in May 2022) because I attributed it to jet lag from going to Germany. But when I went to Washington DC, I was already tired, and kept pushing myself. The last day, two dear friends of mine said: “you look TIRED. You need to take care of yourself. We need you healthy.” (Thanks, Leila and Sameer).
When I returned from Washington DC, my Mom got COVID, so I had to take care of her. She had a very mild case, but I think being stressed about her health was the straw that broke the camel’s back. I then got COVID, and my body was already very weakened from travel, stress and overwork.
We all know how this went. I spent all of June sick (and taking care of a COVID patient and then getting it myself!), July so sick with COVID sequelae that I almost died 3-4 times (depends on how you count), and August in slow-but-steady recovery.
The second lesson is, therefore:
(2) Pay attention to signs of potential burnout.
I had felt burnt out before and could recognise the signs: de-motivated, didn’t want to read academic articles, exhausted with no apparent reason. But again, the travel hid all the signs. I had them all, I just didn’t see them. This is particularly important in academia: we attribute burnout to other factors: “maybe I’m just tired this week”, or “it will get better once I get all these 457 things out of the way and I can clear my deck”. Well, I got news for you: the deck is never cleared.
I’ve written on my blog several times about the importance of not overwork, but for some reason, when it came down to it, I did not recognise the signs that clearly showed anybody except me (because I was too blind to see them) that I was entirely, completely and absolutely burnt out.
(3) Seek support (and this includes emotional support).
In desperation about my lack of health improvement, I tweeted “I’ve lost all interest in academia and all I care about is being healthy again”. I received HUNDREDS of responses sending love and wishes for good health.
The unthinkable has happened: for 9 weeks, I’ve been sick. For 5 of those I’ve struggled to remain alive. And I’ve lost all interest in doing any academic work. My only interest right now is staying alive and improving my health.
The bird app can be hell sometimes, but it is definitely a truth that my Twitter community kept me afloat (my Facebook friends also deserve a very big Thank You because they kept checking in on me, daily). I did not realize I could have so much support from the Twitter hellsite, and it really helped me improve. I received so much emotional support that I began feeling extremely hopeful that I would be, eventuallly, able to recover fully (and I am currently in the process of doing just that).
My physician has prohibited me from returning to my usual hyper-energetic self. He said, deadpan: “I want you to return to normal people’s normal, not YOUR normal — this means dialing it down on the workload and intensity”. As a neoinstitutional theorist, I follow rules to a T. And I have no plans of dying any time soon, so I am paying close attention to my body and how I well am feeling on an hourly, daily and weekly basis. If I need to take a rest, I take it, work life be damned.
But I did not get well UNTIL I went to see a pulmonologist.
So the fourth lesson is:
(4) Be your own advocate for your health.
I went to a general MD, then the otorrhinolaryngologist, and it wasn’t until I went to the pulmonologist that we figured out what was wrong and how to fix it. COVID is an extraordinarily strange illness, and it’s so unpredictable nobody really knows the potential outcomes. I am lucky to be alive. Given that I had an immune system weakened from overwork and exhaustion, it was pure sheer luck that I made it alive and in one piece.
What really brought home the severity of my illness and the importance of taking care of myself was this utterance by my pulmonologist: “you survived this time – you probably won’t get another chance – your body won’t withstand another crisis like this. TAKE CARE!”.
YIKES.
In closing: Academic friends: look at yourselves in my mirror. Take care of yourselves *before* you are forced to take time off to take do exactly that: take care of yourselves.
The Internet isn't just a way to access the web, it is fundamental infrastructure -- the Public Packet Infrastructure. The infrastructure has seemingly unlimited capacity because we can innovate and take advantage of opportunities instead of negotiating for passage.
We need to bring public policy and public perception into alignment with this new realty.
This is also available on CircleID
It's similar to models like Open AI's DALL-E, but with one crucial difference: they released the whole thing.
You can try it out online at beta.dreamstudio.ai (currently for free). Type in a text prompt and the model will generate an image.
You can download and run the model on your own computer (if you have a powerful enough graphics card). Here's an FAQ on how to do that.
You can use it for commercial and non-commercial purposes, under the terms of the Creative ML OpenRAIL-M license - which lists some usage restrictions that include avoiding using it to break applicable laws, generate false information, discriminate against individuals or provide medical advice.
In just a few days, there has been an explosion of innovation around it. The things people are building are absolutely astonishing.
A distant futuristic city full of tall buildings inside a huge transparent glass dome, In the middle of a barren desert full of large dunes, Sun rays, Artstation, Dark sky full of stars with a shiny sun, Massive scale, Fog, Highly detailed, Cinematic, Colorful
The model produced the following two images:
These are amazing. In my previous experiments with DALL-E I've tried to recreate photographs I have taken, but getting the exact composition I wanted has always proved impossible using just text. With this new capability I feel like I could get the AI to do pretty much exactly what I have in my mind.
Imagine having an on-demand concept artist that can generate anything you can imagine, and can iterate with you towards your ideal result. For free (or at least for very-cheap).
You can run this today on your own computer, if you can figure out how to set it up. You can try it in your browser using Replicate, or Hugging Face. This capability is apparently coming to the DreamStudio interface next week.
Reddit user alpacaAI shared a video demo of a Photoshop plugin they are developing which has to be seen to be believed. They have a registration form up on getalpaca.io for people who want to try it out once it's ready.
Reddit user Hoppss ran a 2D animated clip from Disney's Aladdin through img2img frame-by frame, using the following parameters:
The result was a 3D animated video. Not a great quality one, but pretty stunning for a shell script and a two word prompt!
The best description I've seen so far of an iterative process to build up an image using Stable Diffusion comes from Andy Salerno: 4.2 Gigabytes, or: How to Draw Anything.
All of this happened in just six days since the model release. Emad Mostaque on Twitter:
We use as much compute as stable diffusion used every 36 hours for our upcoming open source models
This made me think of Google's Parti paper, which included a demonstration that showed that once the model was trained to 200bn parameters it could generate images with correctly spelled text!
Ethics: will you be an AI vegan?
I'm finding the ethics of all of this extremely difficult.
Stable Diffusion has been trained on millions of copyrighted images scraped from the web.
The Stable Diffusion v1 Model Card has the full details, but the short version is that it uses LAION-5B (5.85 billion image-text pairs) and its laion-aesthetics v2 5+ subset (which I think is ~600M pairs filtered for aesthetics). These images were scraped from the web.
I'm not qualified to speak to the legality of this. I'm personally more concerned with the morality.
The final model is I believe around 4.2GB of data - a binary blob of floating point numbers. The fact that it can compress such an enormous quantity of visual information into such a small space is itself a fascinating detail.
As such, each image in the training set contributes only a tiny amount of information - a few tweaks to some numeric weights spread across the entire network.
But... the people who created these images did not give their consent. And the model can be seen as a direct threat to their livelihoods. No-one expected creative AIs to come for the artist jobs first, but here we are!
I'm still thinking through this, and I'm eager to consume more commentary about it. But my current mental model is to think about this in terms of veganism, as an analogy for people making their own personal ethical decisions.
I know many vegans. They have access to the same information as I do about the treatment of animals, and they have made informed decisions about their lifestyle, which I fully respect.
I myself remain a meat-eater.
There will be many people who will decide that the AI models trained on copyrighted images are incompatible with their values. I understand and respect that decision.
But when I look at that img2img example of the futuristic city in the dome, I can't resist imagining what I could do with that capability.
If someone were to create a vegan model, trained entirely on out-of-copyright images, I would be delighted to promote it and try it out. If its results were good enough, I might even switch to it entirely.
Just a few months ago, if I'd seen someone on a fictional TV show using an interface like that Photoshop plugin I'd have grumbled about how that was a step too far even by the standards of American network TV dramas.
Science fiction is real now. Machine learning generative models are here, and the rate with which they are improving is unreal. It's worth paying real attention to what they can do and how they are developing.
Update: World Photography Day Contest dates extended! You’re right on time—Submissions close September 19.
World Photography Day 2022 is August 19, and for the second year in a row, we’re celebrating with a multi-category photo contest! This year, besides some fantastic prizes, we will have a new, special category dedicated to virtual photography. Are your photos ready for the spotlight?
The categories for this year’s World Photography Day contest are:
Nature: Give us your view of the natural world, whether that’s aerial shots, landscapes, underwater, astrophotography, weather, or anything else based in nature.
People: Get ready for your close-up with photos of fashion, portrait, wedding, family, travel, street, documentary, and more.
Animals: Put your four-legged friends (or six-legged, or winged!) in the spotlight, with a category focused on pets, wildlife, and insects.
Objects and structures: Show us your unique vision with this category made for architecture, abstract, still life, and other objects and gadgets of the photography world.
Virtual: Bring digital worlds to life with our virtual photography category, encompassing digital avatars, in-game photography, screen captures, and more.
How to enter?
To join the fun, add up to five (5) photos to the World Photography Day Contest 2022 group photo pool and tag them with one of the following category tags: WPD22Nature, WPD22People, WPD22Animals, WPD22Objects, or WPD22Virtual—depending on which category or categories you are entering. One category tag per entry, please! The contest will remain open until September 19, 2022, and winners will be announced on or about September 22, 2022.
More questions? Find answers in the contest FAQs here.
What can I win?
Five winners (one from each category) will receive:
A camera strap of your choice from our partners at Peak Design
A free 1-Year Flickr Pro subscription
An 11”x14” Flickr Metal Print of your prize-winning photo
We’re looking forward to seeing your photos in one or all of these contest categories, so get over to the World Photography Day group to join in and read the full contest details. Happy shooting!
It is well worth the time for any educator to become familiar with Wittgenstein's concept of the 'language game' - that is, the idea that language is not a set of rules, meanings and syntax but rather a "community-wide game of charades, where each new game builds on those that have gone before." This is important because "it is constantly re-contrived generation after generation." Indeed, "we talk without knowing the rules of our language just as we play tennis without knowing the laws of physics, or sing without knowing music theory. In this very real sense, we speak, and do so skillfully and effectively, without knowing our language at all."
It doesn't matter what the story is, I'm just glad someone besides me is using this phrase, because it's exactly right. Poynter is very limited in its advocacy: "Paywalls bolster news organizations' bottom lines, but leave Americans in the dark. As a public service, let everyone read election stories for free." It should be more than just election stories, and it should be for everyone. There's a very close link to being able to access knowledge and being able to govern ourselves, as the developers of the first libraries knew very well.
Now that our institutions are rebounding back to 'the way things were' after the pandemic, we're seeing the first glimpses of people saying "no, no, I don't want to go back" in the media (though tbh the piece feels like a paid placement). This article (with a wonderfully puzzling illustration of online learning in which almost everything is completely analog) is an indicator of that. "We have a generation of young people who have grown up on personal devices that allow them to customise anything important to them: playlists, blogs, chats. They successfully communicate with friends, family and partners, expressing their passions and interests via remote devices. For the most part, they understand how to use those devices effectively for their needs. Why can't it be the same with learning?"
Suppose you believe, as I do, that we have to slash our carbon emissions drastically and urgently to ameliorate the worst
effects of the climate catastrophe that is beginning to engulf us. And that you believe, as I do, that travel is a good thing
for individuals and societies, and that in principle every human should enjoy the opportunity to visit every neighborhood around
our fair planet. Can these beliefs be reconciled?
I used to joke, when people looked askance at my refusal to leave Vancouver, that it was the center
of the world: “Ten hours to Heathrow, ten hours to Narita!” I was right, but…
Earth can’t afford for everyone to routinely hop on a jet-fueled aluminium cylinder and fly ten hours at a time.
Narita and Heathrow both suck. Arriving at either of them after one of those long flights is usually
pretty awful. I speak from painful experience.
The unpleasantness of Narita and Heathrow is not entirely their own fault. After you’ve flown ten hours east or west,
when the plane comes down you’ve descended into a nasty fog of jet-lag. Words cannot express my loathing for this
condition — tossing and turning in an unfamiliar hotel bed during the wee hours, fighting off nap
attacks in the middle of business meetings, feeling paralyzed after a single glass of wine with dinner.
The lame old anecdote applies here: “Doctor, it hurts when I do this!” “So, stop doing that.” No kidding, and you might help
save the planet too.
I have read that recovery from jet-lag takes on the order of one day per timezone crossed. Thus, our current mode of travel,
which crosses roughly one time zone per hour while spewing CO2 to poison our children’s futures is simply a
bad thing and we should Stop Doing That.
Disclosure: I have been an egregious lifelong travel offender. I’ve enjoyed Damascus and Antibes and São Paolo and Tokyo and
Memphis and, well, the list goes on.
A world in which those destination options are no longer open to anyone would be a sad place.
What are you suggesting?
That we travel more slowly, which is to say more humanely, and which will enable us to cut down on the greenhouse gas per
unit of distance.
Concretely, that for every trip we want to take, we maximize the distance that is covered by train, and minimize those legs
that require becoming airborne.
For example
So let’s suppose I want to sample the delights of the
Côte d'Azur one more time. Starting, of course, from Vancouver.
The big problem, of course, is the Atlantic ocean. Water travel is unacceptably slow and not notably energy-efficient. So
let’s concede that it has to be done by air.
Today, I’d fly to Heathrow (sigh),
7,574km. Then I’d spend unpleasant airport time waiting for my connection to Nice or Cannes or somewhere, another 1000km or so.
And I’d arrive feeling like deep-fried shit, wouldn’t really be in the swing of things for another couple of days.
(By the way, I’ve done this, back in the Nineties. There were two immigration lines in Cannes and when we got to the front of ours I
noticed that each was being served by a young woman and both of them were flushing and giggling. I glanced left and there was
Andre Agassi arriving in France to play in the Monaco open.)
Let’s do this more humanely. By consulting Google Earth I observe that the minimum as-the-plane-flies distance between the
North American mainland and Europe is probably
Portland, Maine to
Brest, France. So our trip becomes three-legged:
Train: Vancouver to Portland, ME: 4,023km.
Fly: Portland to Brest: 4,944km.
Train: Brest to Cannes: 1,034k.
How long is this going to take? Let’s assume that all train travel averages 300km/h. Don’t tell me that’s crazy,
I traveled 2000km
from Hong Kong to Beijing that way in 2019, averaging 306km/h. It can and should be done.
Modern aircraft cruise at somewhere around 900km/h. Thus:
Vancouver to Portland: 13.4hrs.
Portland to Brest: 5.5hrs
Brest to Cannes: 3.4hrs
Realistically, I probably would have to go to Seattle to catch this imagined future train. But anyhow, the idea is
that you wouldn’t
do all three legs as a single 22.3hr marathon. You’d start the first leg early and get to Portland late, and stay overnight in
a hotel with real beds and real breakfasts. Presumably since Portland is now a major rail hub the locals
would have recognized a business opportunity and made it
attractive to spend a day there taking the sights in, eating lobster, catching up on minor jetlag, and spending another
night before you took off
for Brest.
I’ve been to Brest, but only the train station on a trip to the countryside of Brittany.
It’s well-worth a day or two’s visit, poking around taking in the standing stones and ciders and country cooking. Why not do that while
you recover from the trans-Atlantic jet-lag? Remember that a 5000km leg will hurt less than the currently-typical 7500km
jolt.
And then that last leg is a doddle, although France being France you probably have to go through Paris to get from Brest to the
Riviera. Why not stop? Yes, you’re a tourist so Parisians hate you, but it’s still a cool place. And I guarantee that with four
nights off, you’ll show up at the edge of the Mediterranean in a much better condition to enjoy it.
But wait, there’s more!
The thing that bothers me about this trip is still that trans-Atlantic leg. Yes, we’ve chopped a third off the carbon cost by
shortening the route, but it’s still damn expensive, measured in CO2. Is there an alternative?
Maybe so. The airships being manufactured by
Luftschiffbau Zeppelin cruise at 115km/h. So the leg from
Portland to Brest would take about 43 hours. And to be realistic, the Zeppelin products do not have the scale or range
to do this economically.
But let’s throw this challenge in the face of the world’s aircraft designers: Build us a way to travel 5000km or so that
spews less carbon and provides a reasonably pleasant experience. We don’t require the 900km/h velocity of the current
product, but we’d like it to be faster than 115km/h.
The profession built the current nasty-experience climate-destroying
product line because they could, and because we decided incorrectly that we needed to travel one time-zone per hour. Let’s just drop
that last constraint, and rejoice in doing so.
The real cost
It’s time, of course. Instead of waking up in Vancouver and going to bed in the South of France, it’s taken us the best part
of a week to get there. That’s awful!
No it isn’t, it’s civilized. We’ve seen interesting places, we’ve eaten good meals, we’ve arrived in a decent condition to
enjoy ourselves, and we’ve avoided pissing on our children’s future.
Of course, I’ve just ruined everyone’s vacation plans because they don’t get enough time off work for this kind of
extravaganza. Well, that’s a bug too. As is the notion that it’s ever a good idea to travel at one time-zone per hour.
What is “faith”, anyhow? The answers can become abstract, but concretely it’s what gets Salman Rushdie stabbed in the face.
Oh wait, is that statement anti-Islamic? Guilty as charged; but then I’m also anti-Christian, anti-Hindu, anti-Buddhist, and,
well, there are too many organized religions to list them all. Herewith too many words on Faith and Truth, albeit with pretty
pictures. I do find positive things to say, but at the end of the day, well, no.
I’m not a moderate on this issue. I don’t believe, in general, that any supernatural event has ever occurred or, in
particular, that any prayer has ever been answered. In my lifetime the outputs of organized religion have been mostly war,
sexual abuse, and political support for venal rightist hypocrites.
Does it even matter?
Maybe religion has become irrelevant to your life, a common experience these days. It’s worth studying anyhow, as an example
of the human propensity to believe things that are not just untrue, but wildly unlikely. Things that entirely lack supporting
evidence. Things that make you shake your head.
I may not partake in faith but I’m a keen amateur student of religions. Perhaps it comes of having grown up in Lebanon, where
a whole lot of ‘em run up against each other with a mostly disastrous impact on the civic fabric. I’ve visited Jerusalem and
Damascus and Chartres and Stonehenge and Avebury and Carnac and Kamakura and Izumo and Beijing’s Temple of Heaven, and some of the world’s
great forests.
Faith is real
I think that in my youth I maybe knew a saint. No, really; Father Leonard Guay, a Jesuit architect and astronomer. He built a
university in Baghdad which was taken over by the Ba’ath, so he built another in Aleppo; the same thing happened. He
offered no regrets. An American Midwesterner, he was in a combination monastery, winery, and observatory in rural Lebanon when we knew him. He
loved coming over to talk English, eat corn-on-the-cob, and swap crossword-puzzle books; he took regular puzzles and did them
diagramless, with just the clues. He loved kids, knew a million utterly lame jokes, and enjoyed telling us about the current research
in the observatory, apologizing for using pagan language, as in the names of constellations and Zodiac signs. His faith glowed
within him and around him.
This is the challenge to my personal aversion to the supernatural. I observe empirically that faith exists and that it’s real
and that it appears to be good for some people. But my mind recoils at all the crazily baroque apparatus that is inextricably
attached to every organized religion. I believe in belief and have no faith in faith.
But I went to Sunday School and my Dad even taught it in his youth. Once, when I boarded for a semester with family friends,
I attended a Southern Baptist congregation which even at the age of twelve struck me as pretty looney-tunes. In my own
mainstream-Protestant scientist family, the religious pressure was more or less zero.
Jodo Buddhist Mission in Lahaina, Maui
What I’m not buying
So I understand pretty well what it is. I’m not buying a deity who hardens Pharaoh’s heart, provoking plague
and child slaughter across a whole population. Nor, in general, gods that purport to exhibit gender. Nor any who thrive on
praise and consider it essential from their devotees. Hindutva smells to me like old-fashioned ethnofascism with Pujas. I
scoff at a putative Savior who lectures that lust is morally equivalent to adultery. I’m not down with Wahhabi support for
autocratic murdering princes nor with Crusading nor with throwing settler garbage down into lower Hebron. And the phrase
“blasphemy law” makes me shiver with anger.
Faith and humans
But religion comes naturally to Homo sapiens. Perhaps the first big reason is that for much of humanity’s passage across time
we were manifestly not in control of our destiny, just ephemeral sparks of life blown about by whims of climate and disease and
geography and the population dynamics of our prey and predators, those sparks often snuffed out with no warning. It would have
been comforting to think that Someone was in control. Maybe the improved ability to steer one’s own life, enjoyed today by those
in developed societies and with an education, is partly responsible for the fading of faith?
Second, worship is a human built-in. We are small after all, regularly confronted by things much greater than ourselves: Our
starfield, away from light pollution. The meeting of the Eastern Pacific with the Western Americas. Canyons and waterfalls and
great ancient trees.
Candles in Chartres cathedral.
Of course, we build some of the things we worship. I know of two people who say they acquired faith following on a visit to
Chartres, and I believe them. If you can enter that great stone poem without your sense of worship activating, I think you’re
weird. The first time I walked in, it felt like a giant hand round my chest, interfering with my breathing.
But I dunno, I’ve had the same feeling at concerts by Laurie Anderson and Slava Rostropovich and The Clash and a host of
other artists. Is my gratitude for being alive at the same time as these exceptional people “worship”?
Trees
My family has the great good fortune to own a cabin on a small island in Howe Sound near Vancouver, where I regularly
experience worship of that Pacific perimeter, and especially the island’s great evergreens and bigleaf maples that tower into
the filtered forest light, never still, wind never entirely absent in the greenery. I keep telling my kids they should shut up
and listen to the damn trees and they’ll learn things and I’m right but they don’t, usually.
Feeling reverent around trees has the advantage that they’re not avatars of anything that is said to be twitchily concerned
about how and with whom you deploy your genitals, or whose intercedents will require your cash to support their lifestyles.
Positives
I think it probable that religion will continue to decline, to the extent that its concerns are absent from public
discourse. In my own civic landscape it already has.
That’s not entirely a good thing; you can admire aspects of religion without actually believing it. One of them is ritual,
prescribed and choreographed public actions. It’s a thing that a high proportion of humans once experienced on a weekly basis;
but no longer. I think we miss it. Military services retain rituals, as do the centers of government – consider America’s State
of the Union address, or the opening of various nations’ parliaments. Weddings and funerals retain a ritual dimension but are
infrequent. While I have no patience for Catholic dogma I often tune in their midnight Christmas mass for its own sake – the
singing and chanting, the inner space of St Peter’s basilica, and priestly processions carrying the Host. I love the opening
and closing of each Olympic games.
Sacred texts
Every faith has them. While I decline to honor their claims, it’s good to believe
that written-down words are important, because they are. The use of language defines what’s special about our species as much as
anything else does and I believe the single greatest cultural shift in humanity’s story came when it could be written, and
lessons could outlast the storage provided by a human skull.
Shinto shrine at Izumo
The worlds of sci-fi, fantasy, and computer games are full of powerful and magical texts; obviously this notion speaks to
many people. Religious texts are also historically important because they were replicated a lot and are thus well-represented
among the fragments of language that have survived the ravages of centuries. Some of the books and the verses and words are very
beautiful.
In fact, the Christian Bible, particularly in its seventeenth-century “King James” embodiment, has been at the center of the
cultural experience of my own ethnic group to the extent that I think it probably deserves routine study at some point in the
standard curriculum. A whole lot of our ancestral history and much wonderful literature and art is going to elude understanding
without at least a basic grasp of its scriptural embedding.
If you want
to get inside the head of someone who really held close to those values, go listen to Hildegard von Bingen’s
O vis aeternitatis
(“The Power of Eternity), probably written around 1150. It’s wonderful music! The world Hildegard inhabited, of faith made real
in cloisters and their communities, is as remote from mine as that lived by the characters in the sci-fi I enjoy reading.
At the Abbey of Montserrat, near Barcelona
The flavor of truth
Of course, since sacred texts are said to express eternal absolutes, they must necessarily be immutable.
Which seems boring and just wrong. It is a core value of scientists and engineers and philosophers and
reference publishers that truth is contingent and dynamic; always capable of being better-expressed or deepened or falsified. On
top of which, the language we use to express truths grows and mutates across the centuries. I’m not holding my breath waiting
for Christendom to convene a Third Council of Nicaea and revise the doctrine of the Trinity. Still, we should respect and
preserve and study the sacred texts because they are full of lessons about the people who wrote them and believe them.
Exegesis
Around those scriptural mountains are the rolling hills of exegesis; works of commentary and analysis, for example the Hadith
and the Talmud. Christian exegesis is unimaginably vast in scale although it lacks a single named center.
I got lost in the exegetical maze during a failed youthful attempt to write a novel about the rise and wreck of the Tower of
Babel, when I tried to understand what that crazy story might really be about.
Exegesis is fun to read! Intellectually challenging on its own terms, and if you have any familiarity at all with the Bible,
the depth of meaning apparently waiting to be uncovered in the crevasses between adjacent words is astonishing. Next time
you’re in a good library, I recommend looking up “Anchor Bible” in the catalog and poking around the stacks where the
call-number takes you. If you’re like me your mind will be boggled at the vastness and complexity of the collection.
On this subject, if you ever find yourself in a colloquy of theologians or bibliophiles or antiquarians, even a brief mention
of “The Church Fathers” will get you nods and smiles. They constitute the first few waves of Christian theological writing,
there were really a lot of them (no Church Mothers, though), and they wrote an incredible number of books, many beautiful in
form and content.
At Jing’an Temple in Shanghai
What a certain number of these theologians are trying to do is very similar to the goals of Physics theorists: An explanation
of the universe from pure logical principles, showing how it really couldn’t possibly be any way other than the way it
is. Christian theologians assert that this must be the Best of All Possible Worlds because what else could God have made?
They want the necessary outcome, via pure logical reasoning, to include an omnipotent omniscient male-gendered Creator and
also a Savior, a single instance of God-made-flesh, plus a really hard to understand “Holy Spirit”. Which is to say, they have a
heavier lift than physicists do. But to this day, Proofs of the Existence of God remain an amusing sub-sub-domain of theology
and exegesis.
[I think you were supposed to be writing about the redeeming features? -Ed.] [Oh, right, thanks. -T.] Finally, it would be
unfair to consider religion without acknowledging its leading role in philanthropy across the generations and continents.
Faith why?
None of which means we need to believe what the religiosos claim is true. But why, in the 21st century, do they still believe
it? I really don’t have much to add to the two points I made above: The feeling that Someone must be in charge, and our
built-in capacity for worship.
Let me offer an incredibly cynical but kind of entertaining take on the subject from Edward Gibbon, in his monumental Decline
and Fall of the Roman Empire, six massive volumes dating from the late 1700s.
[You didn’t actually buy it and read it, did you?
-Ed.] [Sometime around 1984 I joined the “Book of the Month Club” and these great-looking books were the sign-up bonus. I read a
lot of it, but got bored around 1000AD in Vol. 5, all that endless Byzantine treachery. -T.]
In a garden across the street from a Catholic school
Gibbon is discussing the rise of Christianity in the Empire, which he argues contributed to its fall, but that’s neither here
nor there. He includes a sprawling survey of the religious landscape and, while discussing the Jews, notes that unlike many
other faiths of the time, they weren’t prepared to go along and get along, host an occasional sacrifice to one Caesar or another
in their temple; they resisted militantly and to the death. So, quoting from Chapter XV, Part I:
But the devout and even scrupulous attachment to the Mosaic religion, so conspicuous among the Jews who lived under the
second temple, becomes still more surprising, if it is compared with the stubborn incredulity of their forefathers. When the law
was given in thunder from Mount Sinai, when the tides of the ocean and the course of the planets were suspended for the
convenience of the Israelites, and when temporal rewards and punishments were the immediate consequences of their piety or
disobedience, they perpetually relapsed into rebellion against the visible majesty of their Divine King, placed the idols of the
nations in the sanctuary of Jehovah, and imitated every fantastic ceremony that was practised in the tents of the Arabs, or in
the cities of Phœnicia.10 As the protection of Heaven was deservedly withdrawn from the ungrateful race, their faith acquired a
proportionable degree of vigor and purity. The contemporaries of Moses and Joshua had beheld with careless indifference the most
amazing miracles. Under the pressure of every calamity, the belief of those miracles has preserved the Jews of a later period
from the universal contagion of idolatry; and in contradiction to every known principle of the human mind, that singular people
seems to have yielded a stronger and more ready assent to the traditions of their remote ancestors, than to the evidence of
their own senses.11
10 For the enumeration of the Syrian and Arabian deities, it may be observed that Milton has comprised, in one hundred and
thirty very beautiful lines, the two large and learned syntagmas which Selden had composed on that abstruse subject.
11 “How long will this people provoke me? And how long will it be ere they believe me, for all the signs which I have shewn
among them?” (Numbers xiv 11). It would be easy, but it would be unbecoming, to justify the complaint of the Deity, from the
whole tenor of the Mosaic history.
(Gibbons’ footnotes, included just for fun.)
Um, is that anti-Semitic? Maybe… and some other things Gibbon said definitely were. But he was also anti-Muslim and arguably
anti-Christian. And his scoffing seems more aimed at theologies than ethnicities. In fact, the only religion to get many kind
words was Rome’s indigenous paganism, because of its tolerance.
While his text is loaded with nods to Christianity being The Right Answer because of Its Divine Provenance, those passages
glisten with cynicism (see above) and he was frequently attacked as an enemy of the faith. Gibbon is fun to read.
A miracle
Finally, let’s consider what miracles are: Things that happen for which there is no conventional explanation in our physical
understanding of the universe. At least one miracle has happened. The universe, including its cosmic background radiation, its
galaxy clusters, its black holes, me and my thread of consciousness, you and yours, and the text I’m writing and you’re reading: They all exist.
There’s no explanation at hand as to why anything at all should. Miraculous!
However, check out Why Does the World Exist?: An Existential Detective Story, by Jim Holt (Norton, 2012), a serious but
entertaining tour through metaphysics and religion looking for an answer to the question in the title. Spoiler alert: While
Holt’s best attempts are stimulating, I was still left thinking of the existence of anything and everything as a miracle.
Former Lutheran church, property soon to be filled with condos.
Future?
You could think of religion as a pathology of society as a whole, consequent on ignorance, fear, and certain built-in
features of the human mind. I don’t think it’s going away, although a faith-free world would probably be a kinder, more humane
place.
With these words, I may have offended some who partake in faith. I can’t honestly apologize, because an apology is at
some level a promise to Stop Doing That.
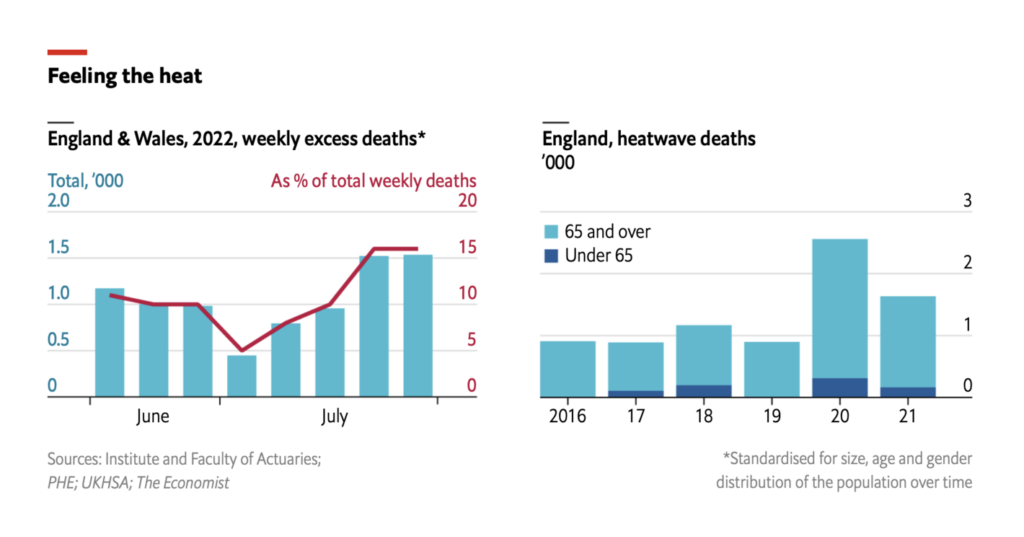
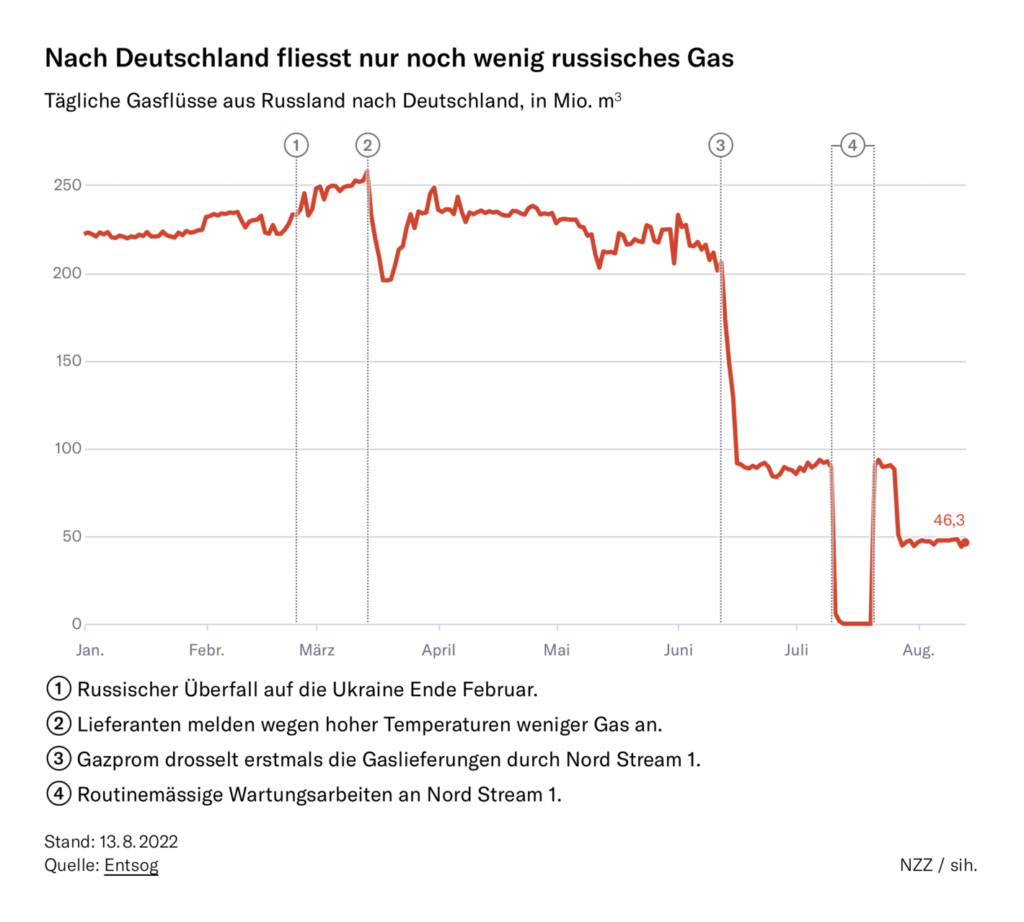
Cumulative CoVid-19 deaths for BC, three sources: BC CDC (blue), BC CoVid-19 Modelling Group (green), U of Washington IHME (grey)
Early in the pandemic, there was some statistical evidence that BC had been slow on the uptake in capturing and reporting CoVid-19 deaths in the province, and had missed 300-400 deaths in the first months of the pandemic. The health officers shrugged it off, and there is of course always some debate about whether the “cause” of a death was CoVid-19, just because the patient happened to have the disease when they died.
Since the provincial health officer, Dr Bonnie Henry, seemed to be providing candid and complete disclosures about the pandemic (she has won several awards, and commendations bordering on adulation from her peers and fans) I was inclined to give her the benefit of the doubt.
I was one of the earliest advocates of using “excess deaths” as a more reliable way of computing the pandemic’s true toll. It can be dicey of course: In the case of BC, the skyrocketing increase of deaths from toxic street drugs has outpaced the reported CoVid-19 death rate, and severely skewed the “excess deaths” number, as did the 2021 “heat dome” that took a minimum of 600 and perhaps double that number of lives, largely among the same demographic dying of CoVid-19.
And there are people who would have died if there’d been no pandemic (auto accident and industrial accident victims in 2020 and 2021 for example were down sharply). And there were people who died because they delayed surgery and other health interventions because they were afraid of getting the disease or because the hospitals were full.
There has been a fair bit of evidence that, on balance, the excess deaths number is probably a much better surrogate for actual CoVid-19 deaths than the reported deaths number, especially in jurisdictions with poor health reporting or which deliberately suppressed CoVid-19 numbers for political reasons. Over a large enough population, any significant deviation from past year’s average total death tolls almost certainly has a reason, and CoVid-19 is the obvious one.
Sure enough, when you look at global excess deaths data, the patterns and numbers, based on each country’s political, economic, and health care system, start to look not only consistent but predictable. These excess death numbers also align much better with seroprevalence and other data on the actual proportion of the country that’s been infected and inoculated.
It’s when you get down to the sub-national level that these data start to get a bit mind-boggling. In Canada, for instance, excess deaths in the three westernmost provinces have been on average twice the number of reported CoVid-19 deaths, while in Québec and some Atlantic provinces excess deaths have been less than reported CoVid-19 numbers. Québec has a very different reporting system, but the other provinces purport to follow consistent reporting standards.
So are the three westernmost provinces radically underreporting actual CoVid-19 deaths, or not, and if they are, how and why? Alberta has an extreme right-wing CoVid-19-denying and -minimizing government, while BC appeared to be letting Dr Henry lay it all out there and call the shots on what to mandate, at least in the early part of the pandemic. Yet the two provinces have very similar discrepancies between excess deaths (even adjusting for the toxic street drug epidemic and the ‘heat dome’) and reported CoVid-19 deaths. So what’s going on here?
Dr Henry continues to say that, while she doesn’t deny the Statistics Canada excess deaths data, she believes the reported numbers are quite accurate, and that there may be other, perfectly valid reasons for the discrepancy.
But a few months ago, BC changed both the frequency (to once a week, with a 10-day lag) and method of computing deaths, and pretty much stopped reporting case data entirely, using ‘surrogates’ in lieu of precise tabulations. They stressed that data before the change was not comparable to data after the changes, so they should not be combined. In other words, if you want to know how many people have actually died of CoVid-19 in BC, you’re pretty much out of luck.
Unless you use “excess deaths”, that is. At the same time the politicians have shrugged off the use of excess deaths as a most likely estimate of CoVid-19 deaths, and basically taken the podium away from health officers, they have failed to provide any useful data to use instead.
The chart for cumulative reported CoVid-19 deaths versus cumulative excess deaths since the pandemic began is shown above.
It suggests 10,000 British Columbians, not 4,000, have perished from CoVid-19 so far, rising at an annual rate of 3,000, unless you assume, as IHME does, that we’ve seen the last wave. That’s 1 in 7 British Columbians over age 80.
So sorry, Dr Henry, but until you actually present some data to show otherwise, I have to think that your estimate of the province’s CoVid-19 deaths is wildly wrong. Eight people per day, not four, are dying of CoVid-19 in BC this month, and this level of understatement has been going on since the pandemic began. How, and why? I think we need some answers from you.
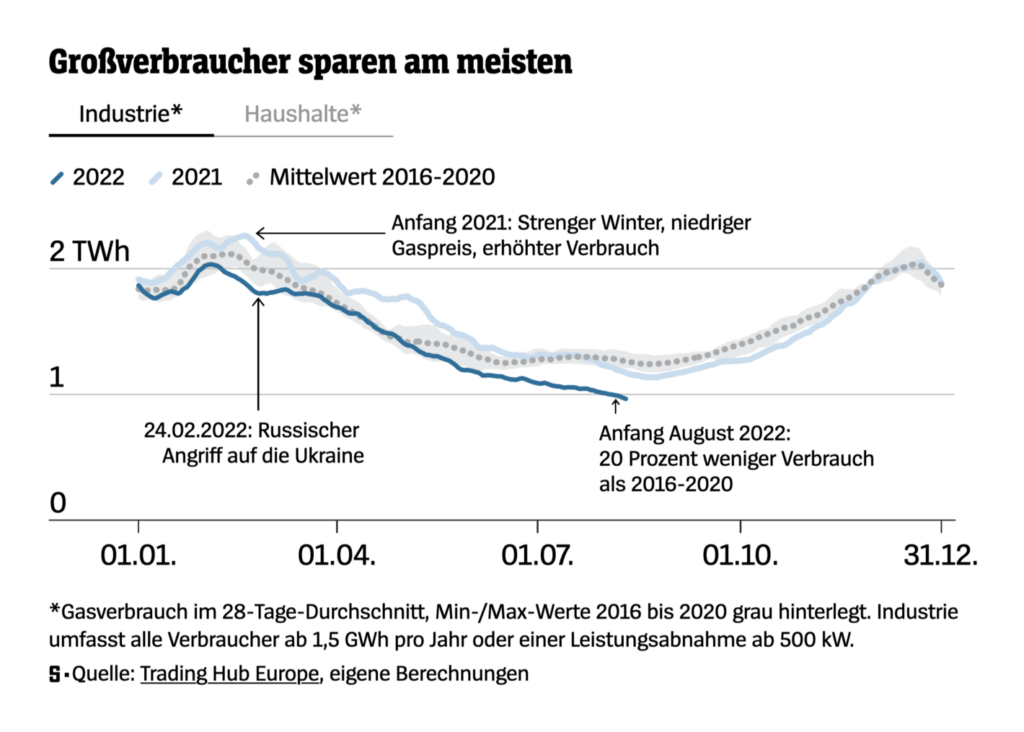
Turning from deaths to cases: Here’s the chart of seroprevalence data showing how the percentage of British Columbians catching the disease is skyrocketing since Omicron emerged:
data from BC COVID-19 Modelling Group and CoVid-29 Immunity Task Force
As of August 13, total reported cases in BC equate to 7% of the population, while seroprevalence studies suggest 56% of the population, 8 times this number, has actually contracted the disease at some point during the pandemic. Current reported daily new cases in the province average about 125, while the seroprevalence data suggests actual new cases in BC are currently running about 13,500 per day.
As this data shows, the BC CDC only catches and reports a tiny percentage of new cases (about 1%, according to most recent estimates). They are now forcing us to use seroprevalence data (mostly from regular blood donors, demographically adjusted) or sewer water prevalence, to figure out how many people are now getting the disease. This data suggests that about 8% of the population, or 400,000 British Columbians are catching the disease or being reinfected each month, and about 2% of the population, or 100,000 British Columbians, are actively infectious today.
In other words, if you are a British Columbian, it is likely that one out of every 50 people you work with, or share a restaurant or bus or train ride with, each day, is actively infectious, and that number is not declining. And more than one out of every 12 of us will be infected, or reinfected, this month. That means your chances of getting it, or getting it again, this month, are, unless you take unusual precautions, one in 12 this month. And probably next month. And the month after that.
““`
The good news, if there is any, is that estimates of the proportion of the infected population (which will soon be just about everyone) getting significant ‘Long CoVid’ symptoms have come down from as high as 1-in-3 to about 1-in-8-or-10, and for those previously fully vaccinated and boostered, the risk is significantly lower again (as is the risk of hospitalization or death when you do get the disease).
That’s still a staggering number of Long Covid patients, one that threatens to wreak long-term havoc on our already-teetering health care system, and on participation in our labour force.
The data for most other provinces and states in North America are comparable to the above BC data — it’s just that, until we took a closer look, we thought we in BC had been doing so much better than everyone else.
So, of course, with that high risk of infection, we should be N95 masking in all indoor locations outside the home, and whenever we’re in a crowded location. And testing and isolating and letting people know when learn we’ve been exposed to someone with the disease until we again test negative or have no fever or symptoms remaining. We’re still only at half-time in this pandemic.
And with the still-unacceptably-high risk of death (at least for those over 60, or obese, or immunocompromised) and of Long Covid, we should be taking extra precautions, avoiding crowds and risky environments (like restaurants and parties) where there is no testing and low mask use. And, of course, getting all our vaccinations and boosters.
As a recent report in the Tyee put it, quoting the above new research: “If the public knew just how much BA5 we have at the moment, we’d see a lot more masking than we currently have.”
So why doesn’t the public know this? And why is our province apparently understating its CoVid-19 death toll by more than half? And what are we going to do when we get yet another surge this coming winter?
I don’t have any answers. And I can’t seem to find anyone that has.
I’ve long imagined a tool that would enable a teacher to help students learn how to write and edit. In Thoughts in motion I explored what might be possible in Federated Wiki, a writing tool that keeps version history for each paragraph. I thought it could be extended to enable the kind of didactic editing I have in mind, but never found a way forward.
In How to write a press release I tried bending Google Docs to this purpose. To narrate the process of editing a press release, I dropped a sample release into a GDoc and captured a series of edits as named versions. Then I captured the versions as screenshots and combined them with narration, so the reader of the blog post can see each edit as a color-coded diff with an explanation.
The key enabler is GDoc’s File -> Version history -> Name current version, along with File -> See version history‘s click-driven navigation of the set of diffs. It’s easy to capture a sequence of editing steps that way.
But it’s much harder to present those steps as I do in the post. That required me to make, name, and organize a set of images, then link them to chunks of narration. It’s tedious work. And if you want to build something like this for students, that’s work you shouldn’t be doing. You just want to do the edits, narrate them, and share the result.
This week I tried a different approach when editing a document written by a colleague. Again the goal was not only to produce an edited version, but also to narrate the edits in a didactic way. In this case I tried bending GitHub to my purpose. I put the original doc in a repository, made step-by-step edits in a branch, and created a pull request. We were then able to review the pull request, step through the changes, and review each as a color-coded diff with an explanation. No screenshots had to be made, named, organized, or linked to the narration. I could focus all my attention on doing and narrating the edits. Perfect!
Well, perfect for someone like me who uses GitHub every day. If that’s not you, could this technique possibly work?
In GitHub for the rest of us I argued that GitHub’s superpowers could serve everyone, not just programmers. In retrospect I felt that I’d overstated the case. GitHub was, and remains, a tool that’s deeply optimized for programmers who create and review versioned source code. Other uses are possible, but awkward.
As an experiment, though, let’s explore how awkward it would be to recreate my Google Docs example in GitHub. I will assume that you aren’t a programmer, have never used GitHub, and don’t know (or want to know) anything about branches or commits or pull requests. But you would like to be able to create a presentation that walks a learner though a sequence of edits, with step-by-step narration and color-coded diffs. At the end of this tutorial you’ll know how to do that. The method isn’t as straightforward as I wish it were. But I’ll describe it carefully, so you can try it for yourself and decide whether it’s practical.
Here’s the final result of the technique I’ll describe.
If you want to replicate that, and don’t already have a GitHub account, create one now and log in.
Ready to go? OK, let’s get started.
Step 1: Create a repository
Click the + button in the top right corner, then click New repository.
Here’s the next screen. All you must do here is name the repository, e.g. editing-step-by-step, then click Create repository. I’ve ticked the Add a README file box, and chosen the Apache 2.0 license, but you could leave the defaults — box unchecked, license None — as neither matters for our purpose here.
Step 2: Create a new file
On your GitHub home page, click the Repositories tab. Your new repo shows up first. Click its link to open it, then click the Add file dropdown and choose Create new file. Here’s where you land.
Step 3: Add the original text, create a new branch, commit the change, and create a pull request
What happens on the next screen is bewildering, but I will spare you the details because I’m assuming you don’t want to know about branches or commits or pull requests, you just want to build the kind of presentation I’ve promised you can. So, just follow this recipe.
Name the file (e.g. sample-press-release.txt
Copy/paste the text of the document into the edit box
Select Create a new branch for this commit and start a pull request
Name the branch (e.g. edits)
Click Propose new file
On the next screen, title the pull request (e.g. edit the press release) and click Create pull request.
Step 4: Visit the new branch and begin editing
On the home page of your repo, use the main dropdown to open the list of branches. There are now two: main and edits. Select edits
Here’s the next screen.
Click the name of the document you created (e.g. sample-press-release.txt to open it.
Click the pencil icon’s dropdown, and select Edit this file.
Make and preview your first edit. Here, that’s my initial rewrite of the headline. I’ve written a title for the commit (Step 1: revise headline), and I’ve added a detailed explanation in the box below the title. You can see the color-coded diff above, and the rationale for the change below.
Click Commit changes, and you’re back in the editor ready to make the next change.
Step 5: Visit the pull request to review the change
Click the name of the pull request (e.g. edit the press release) to open it. In the rightmost column you’ll see links with alphanumeric labels.
Click the first one of those to land here.
This is the first commit, the one that added the original text. Now click Next to review the first change.
This, finally, is the effect we want to create: a granular edit, with an explanation and a color-coded diff, encapsulated in a link that you can give to a learner who can then click Next to step through a series of narrated edits.
Lather, rinse, repeat
To continue building the presentation, repeat Step 4 (above) once per edit. I’m doing that now.
… time passes …
OK, done. Here’s the final edited copy. To step through the edits, start here and use the Next button to advance step-by-step.
If this were a software project you’d merge the edits branch into the main branch and close the pull request. But you don’t need to worry about any of that. The edits branch, with its open pull request, is the final product, and the link to the first commit in the pull request is how you make it available to a learner who wants to review the presentation.
GitHub enables what I’ve shown here by wrapping the byzantine complexity of the underlying tool, Git, in a much friendlier interface. But what’s friendly to a programmer is still pretty overwhelming for an English teacher. I still envision another layer of packaging that would make this technique simpler for teachers and learners focused on the craft of writing and editing. Meanwhile, though, it’s possible to use GitHub to achieve a compelling result. Is it practical? That’s not for me to say, I’m way past being able to see this stuff through the eyes of a beginner. But if that’s you, and you’re motivated to give this a try, I would love to know whether you’re able to follow this recipe, and if so whether you think it could help you to help learners become better writers and editors.
Once it has been agreed to implement new functionality, how long do the associated tasks have to wait in the to-do queue?
An analysis of the SiP task data finds that waiting time has a power law distribution, i.e., , where is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
Queueing theory analyses the properties of systems involving the arrival of tasks, one or more queues, and limited implementation resources.
A basic result of queueing theory is that task waiting time has an exponential distribution, i.e., not a power law. What software task implementation behavior is sufficiently different from basic queueing theory to cause its waiting time to have a power law?
As always, my first line of attack was to find data from other domains, hopefully with an accompanying analysis modelling the behavior. It’s possible that my two samples are just way outside the norm.
Eventually I found an analysis of the letter writing response time of Darwin, Einstein and Freud (my email asking for the data has not yet received a reply). Somebody writes to a famous scientist (the scientist has to be famous enough for people to want to create a collection of their papers and letters), the scientist decides to add this letter to the pile (i.e., queue) of letters to reply to, eventually a reply is written. What is the distribution of waiting times for replies? Yes, it’s a power law, but with an exponent of -1.5, rather than -1.
The change made to the basic queueing model is to assign priorities to tasks, and then choose the task with the highest priority (rather than a random task, or the one that has been waiting the longest). Provided the queue never becomes empty (i.e., there are always waiting tasks), the waiting time is a power law with exponent -1.5; this behavior is independent of queue length and distribution of priorities (simulations confirm this behavior).
However, the exponent for my software data, and other data, is not -1.5, it is -1. A 2008 paper by Albert-László Barabási ( detailed analysis)showed how a modification to the task selection process produces the desired exponent of -1. Each of the tasks currently in the queue is assigned a probability of selection, this probability is proportional to the priority of the corresponding task (i.e., the sum of the priorities/probabilities of all the tasks in the queue is assumed to be constant); task selection is weighted by this probability.
So we have a queueing model whose task waiting time is a power law with an exponent of -1. How well does this model map to software task selection behavior?
One apparent difference between the queueing model and waiting software tasks is that software tasks are assigned to a small number of priorities (e.g., Critical, Major, Minor), while each task in the model queue has a unique priority (otherwise a tie-break rule would have to be specified). In practice, I think that the developers involved do assign unique priorities to tasks.
Why wouldn’t a developer simply select what they consider to be the highest priority task to work on next?
Perhaps each developer does select what they consider to be the highest priority task, but different developers have different opinions about which task has the highest priority. The priority assigned to a task by different developers will have some probability distribution. If task priority assignment by developers is correlated, then the behavior is effectively the same as the queueing model, i.e., the probability component is supplied by different developers having different opinions and the correlation provides a clustering of priorities assigned to each task (i.e., not a uniform distribution).
If this mapping is correct, the task waiting time for a system implemented by one developer should have a power law exponent of -1.5, just like letter writing data.
The number of sprints that a story is assigned to, before being completely implemented, is a power law whose exponent varies around -3. An explanation of this behavior based on priority queues looks possible; we shall see…
The queueing models discussed above are a subset of the field known as bursty dynamics; see the review paper Bursty Human Dynamics for human behavior related aspects.
Earlier this month, I wrote about Razer's DeathAdder V3 Pro. It's a great wireless mouse, but those looking for the ultimate gaming mouse experience should consider Razer's latest mouse, the Basilisk V3 Pro.
Although it was released on August 23rd, I've been using one for a little longer and am quite impressed with it so far. It sports everything I liked about the DeathAdder V3 Pro, but with a more ergonomic shape. Plus, I really like the fancy wireless charger / wireless dongle combo, the Razer Mouse Dock Pro.
First, let's run through the specs: the Basilisk V3 Pro sports a HyperScroll Tilt Wheel, Optical Mouse Switches Gen-3, a ton of programmable buttons, Focus Pro 30K Optical Sensor, and all the RGB lighting you could want in a gaming mouse.
Even better, if you get Razer's Mouse Dock Pro (more on this below), the RGB lights on the dock and mouse can sync up, and when charging, they show the battery level too.
Although the Basilisk V3 Pro is a gaming mouse, I primarily used it while working during the testing period. I gamed with it too, of course, but these days the majority of my time at my computer is spent working. Regardless, the Basilisk V3 Pro worked great for both.
Wireless charging is sick until you need to use the mouse while charging
https://youtu.be/cUxzYlSFalA
Still, the Basilisk V3 Pro isn't perfect. It's heavier than the DeathAdder (112g to 64g, respectively), and in my experience, the battery life isn't as good. Razer claims up to 90 hours when using the HyperSpeed wireless dongle, but I found the mouse on the charger every few days. To be fair, that was in part due to using the higher 4,000Hz polling rate, but even after going back to 1,000Hz, I found the Basilisk V3 Pro didn't last that long. (As an aside, I personally didn't notice a significant difference between 1,000 and 4,000Hz polling, but at least the feature is there for those who want it.)
Depending on your set-up, however, the battery life may range from mildly annoying to downright inconvenient. I was testing Razer's Mouse Dock Pro alongside the Basilisk. The Mouse Dock effectively replaces the need to use the included wireless dongle, as it includes a built-in HyperSense transceiver with support for up to 4,000Hz polling (the HyperSense dongle included with the Basilisk V3 Pro only does up to 1,000Hz). The Mouse Dock Pro lets you wirelessly charge the Basilisk, which is honestly really cool, and I loved it. The downside, however, is if your mouse dies when you need to use it, you can't charge it on the Mouse Dock.
The Basilisk V3 Pro sports a USB-C port on the front so you can plug it in and use it while charging, which means you can keep using it when the battery's dead if you forgo the wireless charging. The only real complaint here is that the cable included with the Mouse Dock Pro isn't ideal for use when plugged into the mouse (the cable that comes with the Basilisk V3 Pro is lighter and more flexible). Either way, these are nitpicking in the grand scheme -- if you keep an eye on your battery level and put the mouse on the Mouse Dock Pro when you're not using it, keeping the battery topped off isn't a problem.
One other thing worth noting about the Basilisk V3 Pro is it relies on a 'wireless charging puck' to use the Mouse Dock Pro or other wireless chargers. You get one with the Mouse Dock Pro, or you can buy one separately for $24.99 -- either way, you'll need to swap out the plastic placeholder puck on the bottom of the mouse with the wireless charging puck before you can use wireless charging.
A few software goodies and other nice features
Before I wrap up, there were a few other small things I appreciated about the Basilisk V3 Pro during my time with it. First, and not really specific to the Basilisk, is the ease of remapping certain keys.
I don't often remap keys on mice, but the Basilisk V3 Pro sports a thumb button for activating the 'Sensitivity Clutch,' a feature to temporarily reduce mouse sensitivity. It's handy for certain games, like first-person shooters, when you're trying to line up that perfect snipe. However, it's something I've never really used, and the Sensitivity Clutch button's placement felt more accessible than the other thumb buttons, which I often use to activate abilities in games like Destiny 2 or Apex Legends. So, I remapped it, and it's been great.
Another feature that stood out to me was the 'Smart-Reel' option, which lets the scroll wheel flip between tactile and free-spin modes on the fly. I thought I'd be a fan of this since I generally prefer tactile scroll but occasionally appreciate free-spin scrolling when I'm working and need to zip around a long article on MobileSyrup. However, in practice, I found Smart-Reel easily flipped between the two, and it felt really weird when I was using it. I'd love to see an option to customize the activation threshold for Smart-Reel in the future. Still, it's great to have both options available on the Basilisk since the DeathAdder only had tactile scroll.
Finally, the Basilisk V3 Pro sports a button to cycle through different DPI settings. That's a fairly common inclusion on mice these days, but what I appreciated with the Basilisk V3 is it would show the DPI on my computer screen when I cycled through. This is much more accessible than showing a little LED light with a different colour for each DPI setting, especially since I could never remember which LED colour was for the setting I actually wanted.
The Basilisk V3 Pro is overall great, but it's pricey too
After my time with the Basilisk V3 Pro, I'm a fan and will likely keep using it as my daily driver. Ultimately, I'd like something just a tad lighter, but the ergonomics of the Basilisk will keep it on my desk over other, lighter options.
Unfortunately, the Basilisk V3 Pro doesn't come cheap. There are a few options to pick from, which I'll highlight below:
Basilisk V3 Pro - $219.99
Basilisk V3 Pro with Wireless Charging Puck - $231.99 (regular $244.98)
Basilisk V3 Pro with Mouse Dock Pro - $268.99 (regular $309.98)
Again, the wireless charging puck costs $24.99 on its own, and works with Qi charging pads, while the Mouse Dock Pro costs $89.99 and comes with a charging puck.
You can learn more about Basilisk V3 Pro, or buy one, on Razer's website.
MiniRust, by Ralf Jung.
“The purpose of MiniRust is to describe the semantics of an
interesting fragment of Rust in a way that is both precise and
understandable to as many people as possible.”
Combinatory Logic and Combinators in Array Languages (PDF), by Conor Hoekstra.
“This paper will look at the existence of combinators in the modern
array languages Dyalog APL, J and BQN and how the support for them
differs between these languages.”
Trealla Prolog, a compact, efficient Prolog interpreter with ISO
compliant aspirations.
I've previously covered getting your HackRF set up in Linux and getting the firmware updated. In that guide we installed the very easy to use CubicSDR application and were able to easily tune to various audio signals.
Today we're going to do something more interactive and actually use the transmitter. We're going to unlock and lock my vehicle using the HackRF! Let's get started.
Trends in medium, AI, and user interaction underpin Instagram's response to TikTok, and will determine Meta's long-term moat.
Back in 2010, during my first year of Business School, I helped give a presentation entitled “Twitter 101”:
My section was “The Twitter Value Proposition”, and after admitting that yes, you can find out what people are eating for lunch on Twitter, I stated “The truth is you can find anything you want on Twitter, and that’s a good thing.” The Twitter value proposition was that you could “See exactly what you need to see, in real-time, in one place, and nothing more”; I illustrated this by showing people how they could unfollow me:
The point was that Twitter required active management of your feed, but if you put in the effort, you could get something uniquely interesting to you that was incredibly valuable.
Most of the audience didn’t take me up on it.
Facebook Versus Instagram
If there is one axiom that governs the consumer Internet — consumer anything, really — it is that convenience matters more than anything. That was the problem with Twitter: it just wasn’t convenient for nearly enough people to figure out how to follow the right people. It was Facebook, which digitized offline relationships, that dominated the social media space.
Facebook’s social graph was the ultimate growth hack: from the moment you created an account Facebook worked assiduously to connect you with everyone you knew or wish you knew from high school, college, your hometown, workplace, you name an offline network and Facebook digitized it. Of course this meant that there were far too many updates and photos to keep track of, so Facebook ranked them, and presented them in a feed that you could scroll endlessly.
Users, famously, hated the News Feed when it was first launched: Facebook had protesters outside their doors in Palo Alto when it was introduced, and far more online; most were, ironically enough, organized on Facebook. CEO Mark Zuckerberg penned an apology:
We really messed this one up. When we launched News Feed and Mini-Feed we were trying to provide you with a stream of information about your social world. Instead, we did a bad job of explaining what the new features were and an even worse job of giving you control of them. I’d like to try to correct those errors now…
The errors to be corrected were better controls over what might be shared; Facebook did not give the users what they claimed to want, which was abolishing the News Feed completely. That’s because the company correctly intuited a significant gap between its users stated preference — no News Feed — and their revealed preference, which was that they liked News Feed quite a bit. The next fifteen years would prove the company right.
It was hard to not think of that non-apology apology while watching Adam Mosseri’s Instagram update three weeks ago; Mosseri was clear that videos were going to be an ever great part of the Instagram experience, along with recommended posts. Zuckerberg reiterated the point on Facebook’s earnings call, noting that recommended posts in both Facebook and Instagram would continue to increase. A day later Mosseri told Casey Newton on Platformer that Instagram would scale back recommended posts, but was clear that the pullback was temporary:
“When you discover something in your feed that you didn’t follow before, there should be a high bar — it should just be great,” Mosseri said. “You should be delighted to see it. And I don’t think that’s happening enough right now. So I think we need to take a step back, in terms of the percentage of feed that are recommendations, get better at ranking and recommendations, and then — if and when we do — we can start to grow again.” (“I’m confident we will,” he added.)
Michael Mignano calls this recommendation media in an article entitled The End of Social Media:
In recommendation media, content is not distributed to networks of connected people as the primary means of distribution. Instead, the main mechanism for the distribution of content is through opaque, platform-defined algorithms that favor maximum attention and engagement from consumers. The exact type of attention these recommendations seek is always defined by the platform and often tailored specifically to the user who is consuming content. For example, if the platform determines that someone loves movies, that person will likely see a lot of movie related content because that’s what captures that person’s attention best. This means platforms can also decide what consumers won’t see, such as problematic or polarizing content.
It’s ultimately up to the platform to decide what type of content gets recommended, not the social graph of the person producing the content. In contrast to social media, recommendation media is not a competition based on popularity; instead, it is a competition based on the absolute best content. Through this lens, it’s no wonder why Kylie Jenner opposes this change; her more than 360 million followers are simply worth less in a version of media dominated by algorithms and not followers.
Sam Lessin, a former Facebook executive, traced this evolution from the analog days to what is next in a Twitter screenshot entitled “The Digital Media ‘Attention’ Food Chain in Progress”:
The coming fall of the Kardashians in context of how entertainment is evolving… (aka why they are so pissed about tiktok) pic.twitter.com/wtYrvxbS35
Kardashians/Professional ‘friends’ kill real friends
Algorithmic everyone kills Kardashians
Next is pure-AI content which beats ‘algorithmic everyone’
This is a meta observation and, to make a cheap play on words, the first reason why it made sense for Facebook to change its name: Facebook the app is eternally stuck on Step 2 in terms of entertainment (the app has evolved to become much more of a utility, with a focus on groups, marketplace, etc.). It’s Instagram that is barreling forward. I wrote last summer about Instagram’s Evolution:
The reality, though, is that this is what Instagram is best at. When Mosseri said that Instagram was no longer a photo-sharing app — particularly a “square photo-sharing app” — he was not making a forward-looking pronouncement, but simply stating what has been true for many years now. More broadly, Instagram from the very beginning — including under former CEO Kevin Systrom — has been marked first and foremost by evolution.
To put this in Lessin’s framework, Instagram started out as a utility for adding filters to photos put on other social networks, then it developed into a social network in its own right. What always made Instagram different than Facebook, though, is the fact that its content was default-public; this gave the space for the rise of brands, meme and highlight accounts, and the Instagram influencer. Sure, some number of people continued to use Instagram primarily as a social network, but Meta, more than anyone, had an understanding of how Instagram usage had evolved over time.
In other words, when Kylie Jenner posts a petition demanding that Meta “Make Instagram Instagram again”, the honest answer is that changing Instagram is the most Instagram-like behavior possible.
Three Trends
Still, it’s understandable why Instagram did back off, at least for now: the company is attempting to navigate three distinct trends, all at the same time.
The first trend is the shift towards ever more immersive mediums. Facebook, for example, started with text but exploded with the addition of photos. Instagram started with photos and expanded into video. Gaming was the first to make this progression, and is well into the 3D era. The next step is full immersion — virtual reality — and while the format has yet to penetrate the mainstream this progression in mediums is perhaps the most obvious reason to be bullish about the possibility.
The second trend is the increase in artificial intelligence. I’m using the term colloquially to refer to the overall trend of computers getting smarter and more useful, even if those smarts are a function of simple algorithms, machine learning, or, perhaps someday, something approaching general intelligence. To go back to Facebook, the original site didn’t have any smarts at all: it was just a collection of profile pages. Twitter came along and had the timeline, but the only smarts there was the ability to read a time stamp: all of the content was presented in chronological order. What made Facebook’s News Feed work was the application of ranking: from the very beginning the company tried to present users the content from their network that it thought you might be most interested in, mostly using simple signals and weights. Over time this ranking algorithm has evolved into a machine-learning driven model that is constantly iterating based on every click and linger, but on the limited set of content constrained by who you follow. Recommendations is the step beyond ranking: now the pool is not who you follow but all of the content on the entire network; it is a computation challenge that is many orders of magnitude beyond mere ranking (and AI-created content another massive step-change beyond that).
The third trend is the change in interaction models from user-directed to computer-controlled. The first version of Facebook relied on users clicking on links to visit different profiles; the News Feed changed the interaction model to scrolling. Stories reduced that to tapping, and Reels/TikTok is about swiping. YouTube has gone further than anyone here: Autoplay simply plays the next video without any interaction required at all.
One of the reasons Instagram got itself in trouble over the last few months is by introducing changes along all of these vectors at the same time. The company introduced more video into the feed (Trend 1), increased the percentage of recommended posts (Trend 2), and rolled out a new version of the app that was effectively a re-skinned TikTok to a limited set of users (Trend 3). It stands to reason that the comany would have been better off doing one at a time.
That, though, would only be a temporary solution: it seems likely that all of these trends are inextricably intertwined.
Medium, Computing, and Interaction Models
Start with medium: text is easy, which is why it was the original medium of the Internet; effectively anyone can create it. The first implication is that there is far more text on the Internet than anything else; it also follows that the amount of high quality text is correspondingly high as well (a small fraction of a large number is still very large). The second implication has to do with AI: it is easier to process and glean insight from text. Text, meanwhile, takes focus and the application of an acquired skill for humans to interpret, not dissimilar to the deliberate movement of a mouse to interact with a link.
Photos used to be more difficult: digital cameras came along around the same time as the web, but even then you needed to have a dedicated device, move those photos to your computer, then upload them to a network. What is striking about the impact of smartphones is that not only did they make the device used to take pictures the same device used to upload and consume them, but they actually made it easier to take a picture than to write text. Still, it took time for AI to catch up: at first photos were ranked using the metadata surrounding them; only over the last few years has it become possible for services to understand what the photo actually is. The most reliable indicator of quality — beyond a like — remains the photo that you stop at while scrolling.
The ease of making a video followed a similar path to photos, but more extreme: making and uploading your own videos before the smartphone was even more difficult than photos; today the mechanics are just as easy, and it’s arguably even easier to make something interesting, given the amount of information conveyed by a video relative to photos, much less a text. Still, videos require more of a commitement than text or videos, because consuming them takes time; this is where the user interaction layer really matters. Lessin again, in another Twitter screenshot:
FB’s has an interface problem, not an algorithm problem… because people won’t affirmatively click on the things they actually deep down want to watch pic.twitter.com/QfEiaOf13j
I saw someone recently complaining that Facebook was recommending to them…a very crass but probably pretty hilarious video. Their indignant response [was that] “the ranking must be broken.” Here is the thing: the ranking probably isn’t broken. He probably would love that video, but the fact that in order to engage with it he would have to go proactively click makes him feel bad. He doesn’t want to see himself as the type of person that clicks on things like that, even if he would enjoy it.
This is the brilliance of Tiktok and Facebook/Instagram’s challenge: TikTok’s interface eliminates the key problem of what people want to view themselves as wanting to follow/see versus what they actually want to see…it isn’t really about some big algorithm upgrade, it is about relesing emotional inner tension for people who show up to be entertained.
This is the same tension between stated and revealed preference that Facebook encounted so many years ago, and its exactly why I fully expect the company to, after this pullback, continue to push forward with all three of the Instagram changes it is exploring.
Instagram’s Risk
Still, there is considerably more risk this time around: when Facebook pushed forward with the News Feed it was the young upstart moving aside incumbents like MySpace; it’s not as if its userbase was going to go backwards. This case is the opposite: Instagram is clearly aping TikTok, which is the young upstart in the space. It’s possible its users decide that if they must experience TikTok, they might as well go for the genuine thing.
This also highlights why TikTok is a much more serious challenge than Snapchat was: in that case Instagram’s network was the sword used to cut Snapchat off at the knees. I wrote in The Audacity of Copying Well:
For all of Snapchat’s explosive growth, Instagram is still more than double the size, with far more penetration across multiple demographics and international users. Rather than launch a “Stories” app without the network that is the most fundamental feature of any app built on sharing, Facebook is leveraging one of their most valuable assets: Instagram’s 500 million users…Instagram and Facebook are smart enough to know that Instagram Stories are not going to displace Snapchat’s place in its users lives. What Instagram Stories can do, though, is remove the motivation for the hundreds of millions of users on Instagram to even give Snapchat a shot.
Instagram has no such power over TikTok, beyond inertia; in fact, the competitive situation is the opposite: if the goal is not to rank content from your network, but to recommend videos from the best creators anywhere, then it follows that TikTok is in the stronger relative position. Indeed, this is why Mosseri spent so much time talking about “small creators” with Newton:
I think one of the most important things is that we help new talent find an audience. I care a lot about large creators; I would like to do better than we have historically by smaller creators. I think we’ve done pretty well by large creators overall — I’m sure some people will disagree, but in general, that’s what the data suggests. I don’t think we’ve done nearly as well helping new talent break. And I think that’s super important. If we want to be a place where people push culture forward, to help realize the promise of the internet, which was to push power into the hands of more people, I think that we need to get better at that.
There is the old Internet AMA question as to whether you would rather fight a horse-sized duck or 100 duck-sized horses. The analogy here is that in a world of ranking a horse-sized duck that everyone follows is valuable; in a world of recommendations 100 duck-sized horses are much more valuable, and Instagram is willing to sacrifice the former for the latter.
Meta’s Reward
The payoff, though, will not be “power” for these small creators: the implication of entertainment being dictated by recommendations and AI instead of reputation and ranking is that all of the power accrues to the platform doing the recommending. Indeed, this is where the potential reward comes in: this power isn’t only based on the sort of Aggregator dynamics underpinning dominant platforms today, but also absolutely massive amounts of investment in the computing necessary to power the AI that makes all of this possible.
In fact, you can make the case that if Meta survives the TikTok challenge, it will be on its way to the sort of moat enjoyed by the likes of Apple, Amazon, Google, and Microsoft, all of which have real world aspects to their differentiation. There is lots of talk about the $10 billion the company is spending on the Metaverse, but that is R&D; the more important number for this moat is the $30 billion this year in capital expditures, most of which is going to servers for AI. That AI is doing recommendations now, but Meta’s moat will only deepen if Lessin is right about a future where creators can be taken out of the equation entirely, in favor of artificially-generated content.
What is fascinating about DALL-E is that it points to a future where these three trends can be combined. DALL-E, at the end of the day, is ultimately a product of human-generated content, just like its GPT-3 cousin. The latter, of course, is about text, while DALL-E is about images. Notice, though, that progression from text to images; it follows that machine learning-generated video is next. This will likely take several years, of course; video is a much more difficult problem, and responsive 3D environments more difficult yet, but this is a path the industry has trod before:
Game developers pushed the limits on text, then images, then video, then 3D
Social media drives content creation costs to zero first on text, then images, then video
Machine learning models can now create text and images for zero marginal cost
In the very long run this points to a metaverse vision that is much less deterministic than your typical video game, yet much richer than what is generated on social media. Imagine environments that are not drawn by artists but rather created by AI: this not only increases the possibilities, but crucially, decreases the costs.
These AI challenges, I would add, apply to monetization as well: one of the outcomes of Apple’s App Tracking Transparency changes is that advertising needs to shift from a deterministic model to a probabilistic one; the companies with the most data and the greatest amount of computing resources are going to make that shift more quickly and effectively, and I expect Meta to be top of the list.
None of this matters, though, without engagement. Instagram is following the medium trend to video, and Meta’s resources give it the long-term advantage in AI; the big question is which service users choose to interact with. To put it another way, Facebook’s next two decades are coming into sharper focus than ever; it is how well it navigates the TikTok minefield over the next two years that will determine if that long-term vision becomes a reality.
Back in 2010, during my first year of Business School, I helped give a presentation entitled “Twitter 101”:
My section was “The Twitter Value Proposition”, and after admitting that yes, you can find out what people are eating for lunch on Twitter, I stated “The truth is you can find anything you want on Twitter, and that’s a good thing.” The Twitter value proposition was that you could “See exactly what you need to see, in real-time, in one place, and nothing more”; I illustrated this by showing people how they could unfollow me:
The point was that Twitter required active management of your feed, but if you put in the effort, you could get something uniquely interesting to you that was incredibly valuable.
Most of the audience didn’t take me up on it.
Facebook Versus Instagram
If there is one axiom that governs the consumer Internet — consumer anything, really — it is that convenience matters more than anything. That was the problem with Twitter: it just wasn’t convenient for nearly enough people to figure out how to follow the right people. It was Facebook, which digitized offline relationships, that dominated the social media space.
Facebook’s social graph was the ultimate growth hack: from the moment you created an account Facebook worked assiduously to connect you with everyone you knew or wish you knew from high school, college, your hometown, workplace, you name an offline network and Facebook digitized it. Of course this meant that there were far too many updates and photos to keep track of, so Facebook ranked them, and presented them in a feed that you could scroll endlessly.
Users, famously, hated the News Feed when it was first launched: Facebook had protesters outside their doors in Palo Alto when it was introduced, and far more online; most were, ironically enough, organized on Facebook. CEO Mark Zuckerberg penned an apology:
We really messed this one up. When we launched News Feed and Mini-Feed we were trying to provide you with a stream of information about your social world. Instead, we did a bad job of explaining what the new features were and an even worse job of giving you control of them. I’d like to try to correct those errors now…
The errors to be corrected were better controls over what might be shared; Facebook did not give the users what they claimed to want, which was abolishing the News Feed completely. That’s because the company correctly intuited a significant gap between its users stated preference — no News Feed — and their revealed preference, which was that they liked News Feed quite a bit. The next fifteen years would prove the company right.
It was hard to not think of that non-apology apology while watching Adam Mosseri’s Instagram update three weeks ago; Mosseri was clear that videos were going to be an ever great part of the Instagram experience, along with recommended posts. Zuckerberg reiterated the point on Facebook’s earnings call, noting that recommended posts in both Facebook and Instagram would continue to increase. A day later Mosseri told Casey Newton on Platformer that Instagram would scale back recommended posts, but was clear that the pullback was temporary:
“When you discover something in your feed that you didn’t follow before, there should be a high bar — it should just be great,” Mosseri said. “You should be delighted to see it. And I don’t think that’s happening enough right now. So I think we need to take a step back, in terms of the percentage of feed that are recommendations, get better at ranking and recommendations, and then — if and when we do — we can start to grow again.” (“I’m confident we will,” he added.)
Michael Mignano calls this recommendation media in an article entitled The End of Social Media:
In recommendation media, content is not distributed to networks of connected people as the primary means of distribution. Instead, the main mechanism for the distribution of content is through opaque, platform-defined algorithms that favor maximum attention and engagement from consumers. The exact type of attention these recommendations seek is always defined by the platform and often tailored specifically to the user who is consuming content. For example, if the platform determines that someone loves movies, that person will likely see a lot of movie related content because that’s what captures that person’s attention best. This means platforms can also decide what consumers won’t see, such as problematic or polarizing content.
It’s ultimately up to the platform to decide what type of content gets recommended, not the social graph of the person producing the content. In contrast to social media, recommendation media is not a competition based on popularity; instead, it is a competition based on the absolute best content. Through this lens, it’s no wonder why Kylie Jenner opposes this change; her more than 360 million followers are simply worth less in a version of media dominated by algorithms and not followers.
Sam Lessin, a former Facebook executive, traced this evolution from the analog days to what is next in a Twitter screenshot entitled “The Digital Media ‘Attention’ Food Chain in Progress”:
The coming fall of the Kardashians in context of how entertainment is evolving… (aka why they are so pissed about tiktok) pic.twitter.com/wtYrvxbS35
Kardashians/Professional ‘friends’ kill real friends
Algorithmic everyone kills Kardashians
Next is pure-AI content which beats ‘algorithmic everyone’
This is a meta observation and, to make a cheap play on words, the first reason why it made sense for Facebook to change its name: Facebook the app is eternally stuck on Step 2 in terms of entertainment (the app has evolved to become much more of a utility, with a focus on groups, marketplace, etc.). It’s Instagram that is barreling forward. I wrote last summer about Instagram’s Evolution:
The reality, though, is that this is what Instagram is best at. When Mosseri said that Instagram was no longer a photo-sharing app — particularly a “square photo-sharing app” — he was not making a forward-looking pronouncement, but simply stating what has been true for many years now. More broadly, Instagram from the very beginning — including under former CEO Kevin Systrom — has been marked first and foremost by evolution.
To put this in Lessin’s framework, Instagram started out as a utility for adding filters to photos put on other social networks, then it developed into a social network in its own right. What always made Instagram different than Facebook, though, is the fact that its content was default-public; this gave the space for the rise of brands, meme and highlight accounts, and the Instagram influencer. Sure, some number of people continued to use Instagram primarily as a social network, but Meta, more than anyone, had an understanding of how Instagram usage had evolved over time.
In other words, when Kylie Jenner posts a petition demanding that Meta “Make Instagram Instagram again”, the honest answer is that changing Instagram is the most Instagram-like behavior possible.
Three Trends
Still, it’s understandable why Instagram did back off, at least for now: the company is attempting to navigate three distinct trends, all at the same time.
The first trend is the shift towards ever more immersive mediums. Facebook, for example, started with text but exploded with the addition of photos. Instagram started with photos and expanded into video. Gaming was the first to make this progression, and is well into the 3D era. The next step is full immersion — virtual reality — and while the format has yet to penetrate the mainstream this progression in mediums is perhaps the most obvious reason to be bullish about the possibility.
The second trend is the increase in artificial intelligence. I’m using the term colloquially to refer to the overall trend of computers getting smarter and more useful, even if those smarts are a function of simple algorithms, machine learning, or, perhaps someday, something approaching general intelligence. To go back to Facebook, the original site didn’t have any smarts at all: it was just a collection of profile pages. Twitter came along and had the timeline, but the only smarts there was the ability to read a time stamp: all of the content was presented in chronological order. What made Facebook’s News Feed work was the application of ranking: from the very beginning the company tried to present users the content from their network that it thought you might be most interested in, mostly using simple signals and weights. Over time this ranking algorithm has evolved into a machine-learning driven model that is constantly iterating based on every click and linger, but on the limited set of content constrained by who you follow. Recommendations is the step beyond ranking: now the pool is not who you follow but all of the content on the entire network; it is a computation challenge that is many orders of magnitude beyond mere ranking (and AI-created content another massive step-change beyond that).
The third trend is the change in interaction models from user-directed to computer-controlled. The first version of Facebook relied on users clicking on links to visit different profiles; the News Feed changed the interaction model to scrolling. Stories reduced that to tapping, and Reels/TikTok is about swiping. YouTube has gone further than anyone here: Autoplay simply plays the next video without any interaction required at all.
One of the reasons Instagram got itself in trouble over the last few months is by introducing changes along all of these vectors at the same time. The company introduced more video into the feed (Trend 1), increased the percentage of recommended posts (Trend 2), and rolled out a new version of the app that was effectively a re-skinned TikTok to a limited set of users (Trend 3). It stands to reason that the company would have been better off doing one at a time.
That, though, would only be a temporary solution: it seems likely that all of these trends are inextricably intertwined.
Medium, Computing, and Interaction Models
Start with medium: text is easy, which is why it was the original medium of the Internet; effectively anyone can create it. The first implication is that there is far more text on the Internet than anything else; it also follows that the amount of high quality text is correspondingly high as well (a small fraction of a large number is still very large). The second implication has to do with AI: it is easier to process and glean insight from text. Text, meanwhile, takes focus and the application of an acquired skill for humans to interpret, not dissimilar to the deliberate movement of a mouse to interact with a link.
Photos used to be more difficult: digital cameras came along around the same time as the web, but even then you needed to have a dedicated device, move those photos to your computer, then upload them to a network. What is striking about the impact of smartphones is that not only did they make the device used to take pictures the same device used to upload and consume them, but they actually made it easier to take a picture than to write text. Still, it took time for AI to catch up: at first photos were ranked using the metadata surrounding them; only over the last few years has it become possible for services to understand what the photo actually is. The most reliable indicator of quality — beyond a like — remains the photo that you stop at while scrolling.
The ease of making a video followed a similar path to photos, but more extreme: making and uploading your own videos before the smartphone was even more difficult than photos; today the mechanics are just as easy, and it’s arguably even easier to make something interesting, given the amount of information conveyed by a video relative to photos, much less a text. Still, videos require more of a commitment than text or photos, because consuming them takes time; this is where the user interaction layer really matters. Lessin again, in another Twitter screenshot:
FB’s has an interface problem, not an algorithm problem… because people won’t affirmatively click on the things they actually deep down want to watch pic.twitter.com/QfEiaOf13j
I saw someone recently complaining that Facebook was recommending to them…a very crass but probably pretty hilarious video. Their indignant response [was that] “the ranking must be broken.” Here is the thing: the ranking probably isn’t broken. He probably would love that video, but the fact that in order to engage with it he would have to go proactively click makes him feel bad. He doesn’t want to see himself as the type of person that clicks on things like that, even if he would enjoy it.
This is the brilliance of Tiktok and Facebook/Instagram’s challenge: TikTok’s interface eliminates the key problem of what people want to view themselves as wanting to follow/see versus what they actually want to see…it isn’t really about some big algorithm upgrade, it is about relesing emotional inner tension for people who show up to be entertained.
This is the same tension between stated and revealed preference that Facebook encountered so many years ago, and its exactly why I fully expect the company to, after this pullback, continue to push forward with all three of the Instagram changes it is exploring.
Instagram’s Risk
Still, there is considerably more risk this time around: when Facebook pushed forward with the News Feed it was the young upstart moving aside incumbents like MySpace; it’s not as if its userbase was going to go backwards. This case is the opposite: Instagram is clearly aping TikTok, which is the young upstart in the space. It’s possible its users decide that if they must experience TikTok, they might as well go for the genuine thing.
This also highlights why TikTok is a much more serious challenge than Snapchat was: in that case Instagram’s network was the sword used to cut Snapchat off at the knees. I wrote in The Audacity of Copying Well:
For all of Snapchat’s explosive growth, Instagram is still more than double the size, with far more penetration across multiple demographics and international users. Rather than launch a “Stories” app without the network that is the most fundamental feature of any app built on sharing, Facebook is leveraging one of their most valuable assets: Instagram’s 500 million users…Instagram and Facebook are smart enough to know that Instagram Stories are not going to displace Snapchat’s place in its users lives. What Instagram Stories can do, though, is remove the motivation for the hundreds of millions of users on Instagram to even give Snapchat a shot.
Instagram has no such power over TikTok, beyond inertia; in fact, the competitive situation is the opposite: if the goal is not to rank content from your network, but to recommend videos from the best creators anywhere, then it follows that TikTok is in the stronger relative position. Indeed, this is why Mosseri spent so much time talking about “small creators” with Newton:
I think one of the most important things is that we help new talent find an audience. I care a lot about large creators; I would like to do better than we have historically by smaller creators. I think we’ve done pretty well by large creators overall — I’m sure some people will disagree, but in general, that’s what the data suggests. I don’t think we’ve done nearly as well helping new talent break. And I think that’s super important. If we want to be a place where people push culture forward, to help realize the promise of the internet, which was to push power into the hands of more people, I think that we need to get better at that.
There is the old Internet AMA question as to whether you would rather fight a horse-sized duck or 100 duck-sized horses. The analogy here is that in a world of ranking a horse-sized duck that everyone follows is valuable; in a world of recommendations 100 duck-sized horses are much more valuable, and Instagram is willing to sacrifice the former for the latter.
Meta’s Reward
The payoff, though, will not be “power” for these small creators: the implication of entertainment being dictated by recommendations and AI instead of reputation and ranking is that all of the power accrues to the platform doing the recommending. Indeed, this is where the potential reward comes in: this power isn’t only based on the sort of Aggregator dynamics underpinning dominant platforms today, but also absolutely massive amounts of investment in the computing necessary to power the AI that makes all of this possible.
In fact, you can make the case that if Meta survives the TikTok challenge, it will be on its way to the sort of moat enjoyed by the likes of Apple, Amazon, Google, and Microsoft, all of which have real world aspects to their differentiation. There is lots of talk about the $10 billion the company is spending on the Metaverse, but that is R&D; the more important number for this moat is the $30 billion this year in capital expditures, most of which is going to servers for AI. That AI is doing recommendations now, but Meta’s moat will only deepen if Lessin is right about a future where creators can be taken out of the equation entirely, in favor of artificially-generated content.
What is fascinating about DALL-E is that it points to a future where these three trends can be combined. DALL-E, at the end of the day, is ultimately a product of human-generated content, just like its GPT-3 cousin. The latter, of course, is about text, while DALL-E is about images. Notice, though, that progression from text to images; it follows that machine learning-generated video is next. This will likely take several years, of course; video is a much more difficult problem, and responsive 3D environments more difficult yet, but this is a path the industry has trod before:
Game developers pushed the limits on text, then images, then video, then 3D
Social media drives content creation costs to zero first on text, then images, then video
Machine learning models can now create text and images for zero marginal cost
In the very long run this points to a metaverse vision that is much less deterministic than your typical video game, yet much richer than what is generated on social media. Imagine environments that are not drawn by artists but rather created by AI: this not only increases the possibilities, but crucially, decreases the costs.
These AI challenges, I would add, apply to monetization as well: one of the outcomes of Apple’s App Tracking Transparency changes is that advertising needs to shift from a deterministic model to a probabilistic one; the companies with the most data and the greatest amount of computing resources are going to make that shift more quickly and effectively, and I expect Meta to be top of the list.
None of this matters, though, without engagement. Instagram is following the medium trend to video, and Meta’s resources give it the long-term advantage in AI; the big question is which service users choose to interact with. To put it another way, Facebook’s next two decades are coming into sharper focus than ever; it is how well it navigates the TikTok minefield over the next two years that will determine if that long-term vision becomes a reality.
Welcome back to the 58th edition of Data Vis Dispatch! Every week, we’ll be publishing a collection of the best small and large data visualizations we find, especially from news organizations — to celebrate data journalism, data visualization, simple charts, elaborate maps, and their creators.
Recurring topics this week include drought, babies, and historical anniversaries.
Meanwhile, in the near future climate change will create an “extreme heat belt” around the Mississippi and increase the likelihood of a devastating megastorm in California:
Several anniversaries got attention this week. It’s been one year since the Taliban took control of Kabul, 75 years since the independence and partition of India and Pakistan, and 500 years since the first trip around the world:
Help us make this dispatch better! We’d love to hear which newsletters, blogs, or social media accounts we need to follow to learn about interesting projects, especially from less-covered parts of the world (Asia, South America, Africa). Write us at hello@datawrapper.de or leave a comment below.
I think that, because we’re a capitalist society, we think of AIs as amplifiers for production and consumption. But they can force-multiply on any vector if suitably directed.
And, I don’t know, could you weaponise the fearsome AI that is the Gen Z fashion app Shein?
Developed by Amazon’s San Francisco-based Lab126 - the company’s research and development hub - the algorithm uses a tool called generative adversarial network (GAN). … In a nutshell, the algorithm may spot a trend on Instagram, Pinterest, Facebook, or in its own collection images generated by Amazon’s Echo Look camera, and come up with new styles.
AI fashion.
A GAN is actually two AIs, a generator and a discriminator.
The generator sits there pumping out new dresses (or whatever). The discriminator does its best to recognises the dresses (or whatever) and score them. The generator learns how to improve its score. Ta-da, amazing dresses.
It starts with algorithmically scouring the internet and Shein’s own data to pull out fashion trends. As one of Google’s largest China-based customers, Shein has access to Google’s Trend Finder product, which allows for real-time granular tracking of clothing related search terms across various countries. This allowed Shein, for example, to accurately predict the popularity of lace in America during the summer of 2018. Combine that with Shein’s huge volume of 1st party data through its app from around the globe and software-human teams that scour competitors’ sites, and Shein understands what clothes consumers want now better than anyone with the possible exception of Amazon.
Shein feeds that data to its massive in-house design and prototyping team who can get a product from drawing board to production and live-online in as little as three-days.
From there, "it can start with incredibly small batches, around as small as 10 items."
(Go read that entire breakdown of Shein’s business. The ERP innovation is remarkable.)
The discriminator:
Products in very small numbers are added to the app, and then clicks, views, purchases, and shares are monitored - automatically scaling orders to the network of factories. At great scale.
Shein churns out and tests thousands of different items simultaneously. Between July and December of 2021, it added anywhere between 2,000 and 10,000 individual styles to its app each day, according to data collected in the course of Rest of World’s investigations. The company confirmed that it starts by ordering a small batch of each garment, often a few dozen pieces, and then waits to see how buyers respond. If the cropped sweater vest is a hit, Shein orders more. It calls the system a “large-scale automated test and re-order (LATR) model”.
While the bit of Shein that surfaces trends makes use of AI, it isn’t an AI designer in itself (the team of human designers was already 800 strong by 2016).
But throw consumerism into the loop, with feedback into ordering, and the entire thing resembles a giant Generative Adversarial Network, an AI for producing fashion lashed together out of software, supply chains, designers, and desire, teaching itself how to improve all the time.
Likewise I wouldn’t call the Facebook newsfeed algorithm an AI, but coupled with user clicks and eyeballs as a discriminator, I most definitely would. The trick is to include the human response.
(If we could talk to the Shein AI, I wonder what it would say? It would be like trying to talk to an intelligence emergent from the fluid dynamical storms of Jupiter. I wonder how we could send it a message, and if we would recognise any response?)
It’s tempting to think of this giant fashion GAN as neutral somehow. Like: it generates, we discriminate, and what comes out is fashion.
But it’s trivially possible to reach inside the machine. The prince of Shein could decide that everyone is going to wear blue next month, and could choose to only generate blue garments, and of course the thresher of consumerism can only discriminate over what it’s given…
So at that point the AI would grasp the flywheel, and blindly optimise its way to figuring out exactly how to make blue garments appealing and profitable.
I mean, AI is a fearsomely powerful gradient climber. It’s a weapon.
And it occurs to me that:
Shein is China-owned, and GANs its fashion into the world
TikTok is China-owned, and can boost trends, and suggests filters for how we look
Zoom’s software is developed in China, serves 3.3 trillion meeting minutes annually, and could - if it wanted - subtly and silently change my appearance, like my shirt colour or my weight or the percentage of eye contact, and you would never know.
I’m not picking on China especially here or suggesting they are actually up to anything or would have a motivation to do so, but this combination of appearance mediators makes me ask:
What would a state-sponsored fashion hack look like?
A fashion hack isn’t like the other global infrastructure exploits I’ve previously wondered about because it isn’t entirely obvious what you’d use it for. But the thing about state-sponsored attacks is that they’re a bit like magic tricks: they operate at a scale which is absurd, which makes them unimaginable, and that’s why they work. Like artificial weather or guided influenza.
It’s absurd to contemplate that plausibly deniable rainstorms might be directed to disrupt a UN weapons inspection team, or people peaking on the infectivity curve with flu are quietly standing next to diplomats 48 hours ahead of an important negotiation - but I bet it has happened.
Could a malevolent state actor
tweak the timings and appearances in online meetings to make the exec team of a competitor company simply… not like each other as much, or never have an effective conversation? (Could you measure that in the stock price, against corporate meeting software contracts?)
deliberately diverge the clothes preferences of two friendly nations, to undermine the common feeling they previously experienced?
associate a particular look with transcendant beauty, and deny sales that would create that look to particular nations, immediately creating a status gradient? (I mean, this is no different from how pop music and abstract expressionism were deployed in the 1960s by the West, only with new technology.)
get people to wear stupid hats, simply for their own amusement?
Dunno.
Hey, follow-up question: if we were in the middle of a giant fashion hack, how would we know?
If I got to pull the levers, I’d use Shein and TikTok to target my own civilians, and I would artificially boost acceptance and desire for cybernetically enhanced clothing, catalysing an arms race for cyborg prostheses providing the wearer with both superhuman powers (such as strength, speed, and musical accomplishment) and astounding aesthetics.
This took a couple of minutes but gave me a 1GB SQLite file. I opened that in Datasette Desktop.
I decided to slim it down to make it easier to work with, and to turn some of the nested JSON into regular columns so I could facet by them more easily.
Here's the eventual recipe I figured out for creating that useful subset:
sqlite-utils /tmp/subset.db --attach billing /tmp/billing.db '
create table items as select
json_extract(invoice, "$.month") as month,
cost,
json_extract(service, "$.description") as service,
json_extract(sku, "$.description") as sku_description,
usage_start_time,
usage_end_time,
json_extract(project, "$.id") as project_id,
json_extract(labels, "$[0].value") as service_name,
json_extract(location, "$.location") as location,
json_extract(resource, "$.name") as resource_name,
currency,
currency_conversion_rate,
credits,
invoice,
cost_type,
adjustment_info
from
billing.lines
'
/tmp/subset.db is now a 295MB database.
Some interesting queries
This query showed me a cost breakdown by month:
select month, count(*), sum(cost) from items group by month
This query showed my my most expensive Cloud Run services:
select service_name, cast('' || sum(cost) as float) as total_cost
from items group by service_name order by total_cost desc;
The responsibilities of the front-end web are ever increasing.
The person responsible for knowing the 3,000 programmable property-value pairs to make the site look like the design comp… is the same person in charge of understanding the language and ecosystem required to query the data layer.
The person who must understand a thousand page compendium of making your website accessible for every person to avoid legal peril… is also the person who copy-pastes a script tag so invasive marketing can track users across the entire web.
The person who configures the metadata for social media cards and Google search results… is the same person who oversees the quality and security of thousands of third-party packages.
The person who animates elements on the page as you scroll… is also the person in charge of creating images with math-based vectors using data sources resulting in impactful charts and graphs of infinite combinations.
The person who writes asynchronous workers to control the way a browser paints a box with a code-based canvas drawing application… is the same person responsible for wiring up interactive form controls and client-side error messages.
The person who creates a high-level system of serialized design tokens and components defined to meet specific user stories consumed by all internal and external web properties… is the same person responsible for controlling client side cache mechanisms.
All these jobs are the same person! In some ways the front-end web is like a bad manager; the scope keeps growing over time. I don’t have anything other than anecdotal evidence, but I’d wager this is a problem that leads to burnout due to context switching among front-end people. Learning new skills is admirable, but the unending list of topics to learn and the vast swings of urgent demands puts you in a state of constant stress and reinvention. “Full-stack”, asmanyhavenotedbeforeme, exacerbates this situation.
Years ago, Chris Coyier summed this struggle up in his post The Great Divide. That post was informed by a series we did on ShopTalk called “How to think like a Front-End Developer”. In that series, Brad Frost divined two sides of the divide as “front of the front” and “back of the front” and it still resonates with me today. We could probably split the front-end a few ways and still have plenty of jobs to do. Some are proposing bridge roles…
Natalya Shelburne expresses this idea as a bridge role she calls Design Engineering. This is someone who acts as a bridge between design and engineering. Together with Adekunle Oduye, Kim Williams, and Eddie Lou she wrote the Design Engineering Handbook which outlines all the roles and responsibilities of a Design Engineer saying it “involves setting up individual workflows and organizational structures that facilitate collaboration and communication across the intersection of design and engineering, as well as across product, marketing, and stakeholders.” If you’re paying money for good design, this makes sense; protect your investment to make sure the designs get engineered well.
Alex Sexton proposed a Front-end Ops role as a “bridge between an application’s intent and an application’s reality”, managing builds and deployments, performance and error monitoring, and updating dependencies. Even at a modest scale this feels like enough work for a full time job. These are all critical operations that go sideways if not prioritized.
And there are other bridge roles we haven’t discovered yet. I personally see the need for new specializations as well. I’d argue for a “CSS Engineer” title, someone who knows the ins-and-outs of good CSS architecture that can save your app thousands of lines of code. But that title probably wouldn’t pay enough, so it’d need to be more official sounding like “Render Optimization Engineer Level 6” or something. Now that’ll get the Amazon bucks.
I don’t have answers, only questions as I find myself traversing the spectrum of different jobs a “front-end” person can do this week. It’s hard to be an expert at the front-end. And I’m not sure I like the conclusion of “You need 12 people just to make a website (or else you get yelled at on Twitter)” either. That’s a lot of money, frankly, and would lead to less websites. What’s one change we could make to eliminate 80% of the work?
One of the earliest maps I ever discovered in my facilitation career was Sam Kaner et. al.’s Diamond of Participation. It has been a stalwart companion for more than 20 years in my work and forms a key part of the way the Art of Hosting community talks about process architecture, usually referred to as “the breath of design” owing to its pulsation between divergence and convergence.
The Diamond of Participation is a map of group process created by Sam Kaner and colleague that identifies several phases a group goes through on the way to creating participatory decisions.
As groups engage with complex decisions there is a very common journey that goes through emotional and creative phases. Our ability to stay open to this journey enables us to discover new ideas, enter into the unknown, engage with difficult dynamics and make sustainable decisions. As a map, the diamond of participation helps us navigate the terrain of participatory decision making, and can help a group identify common traps, pitfalls and opportunities. Alongside personal leadership capacities to host and participate with presence and openness this map, with tools and practices to help move through each of the stages, can support engaging, creative, participatory decision making.
The diamond is divided into five zones or phases that groups go through. In each of these zones, leaders can help groups make good decisions by paying attention to the emotional terrain and use good tools at the right time.
Zone 1: “Business as usual”
Most decisions and conversations go quickly. You might need a few ideas, a couple of options, but the pathway is clear and there is little or no controversy about what to do. Because we are conditioned to make decisions this way, it is common for groups to close a conversation down early, and for complex conversations this can have the effect of both avoiding conflict and limiting choices and possibilities.
When important decisions are on the table and there is no easy or obvious solution, groups enter the diamond of participation. Good leaders, with an awareness of the underlying patterns the diamond illustrates, can help guide a group through these stages toward more effectively participatory decisions.
Business as usual involves:
Quick decisions
Debate over dialogue
No focus on relationships
Zone 2: The Divergence Zone
Once it is clear that there is no obvious or clear decision, groups enter the Divergence zone. Familiar opinions get bandied back and forth and diverse perspectives on the problem begin to surface. This can be an enlivening time as a group searches for options and brainstorms possible paths forward. In the early stages of the divergence zone leaders can invite teams to explore different points of view and perspectives and introduce three key types of thinking: Surveying the territory, searching for alternatives and raising difficult issues.
Surveying the territory is done with methods that collect stories, perspective and data and share them between the group members to build a shared picture of the diversity that the group is working with.
As a group searches for alternatives, holding intentional dialogue interviews, undertaking learning journeys or gathering stakeholders together can provide valuable information and insight.
But in truly complex processes, the answers are still not evident and emotions can turn negative, with frustration and impatience beginning to appear. At this time leaders need to be able to host the difficult conversations that come up so that diversity and difference doesn’t turn to unproductive conflict. In these moments, working with limiting beliefs and taking the time to sit in processes like circle and hear feelings and emotions becomes an important part of the work.
From this point, the group enters the Groan Zone, a sometimes painful part of the journey that can lead to fresh thinking and innovative decisions if it is well hosted.
Zone 3: The Groan Zone
As a group enters the groan zone, people begin to struggle in the service of integration and in releasing their attachment to their own perspectives. To create something new requires mixing, combining, and letting go. This can be a fraught experience rife with confusion, irritation, discouragement, anxiety, exasperation, pain, anger, and blame. It is no surprise that we want to avoid the groan zone, but for a group to discover new things, leaders can help people through the groan zone by engaging two types of thinking: creating shared context and strengthening relationships.
Creating shared context helps to re-ground a group in their work. This can take the form of paired interviews or group conversations where people explore different perspectives with a deliberate intention to listen for difference and where each other is coming from. Focusing on need and purpose can be valuable here as it gets a group “out of the weeds” and into remembering the deeper intention and the bigger picture.
Strengthening relationships is important in the groan zone, because frayed relationships will undermine the sustainability of a decision. Practices as simple as sharing stories, or going for a walk together can alleviate acute conflict and give people a chance to shift out of positions and reconnect to each other.
Work in the groan zone is heavily influenced by emotions and it is a lifelong practice for leaders to work on their own comfort and resourcefulness around conflict and strong emotions if they are to hold a group through this work.
Personal leadership practices are key to developing the ability to stay present and host process effectively in the groan zone. Developing deep self-awareness and presence, and using self-inquiry practices to shift reactive patterns can be helpful.
Zone 4: The Convergence Zone
When a group has worked through the groan zone, it comes time for convergence. This is where new ideas, fresh thinking and innovation can rise to the fore. The convergence zone precedes decision making as options are weighed, paths forward are discerned and, in larger processes, prototypes are designed for the purpose of testing new ideas.
When working towards a decision, three types of thinking are helpful: applying inclusive principles, creative reframing and strengthening good ideas.
Moving through the transition from groan zone to convergence requires a change in the container and the work. Inclusive solutions require a commitment to an inclusive decision making process, so it can be good practice to have the group design and adopt a set of inclusive principles to guide their work. These can be used later in the decision making phase as well.
Creative reframing invites the group to look at the work with new eyes. Having come through the groan zone together, all of the ideas that were gathered and discussed in the divergence zone take on new life. Looking at solutions with creative processes like scenario planning and TRIZ helps to introduce new ideas and perspectives to strengthen proposals.
And strengthening good ideas is the way towards making a sustainable agreement. Once ideas are contested, experimented with and considered it comes time to strengthen them through prototyping and piloting. The idea is to move the new ideas towards a decision by working with them through various scenarios first. Whatever can be done to strengthen an idea helps.
Zone 5: The Closure Zone
In participatory decision making processes closure usually involves making a decision together. This could be through a vote, or a consensus process, or it could even mean that the leader takes the decision alone with the consent of the group. Regardless of how closure comes about it is useful to agree together on the rules of decision making and then facilitate a decision.
Starting with agreeing on the rules and process gives you a chance to have a dry run through decision making with your group and this is especially useful if the decision you are making is contentious. Start by agreeing what would constitute a good decision and what a good, robust process is for making that decision. There are different versions of what consensus decision making can mean. You can research and try different approaches that best suit your context. For example, you may want to test consensus and have a rule that if someone is opposed to a proposal that they must bring an alternative to consider. You also might want to make some rules about timeliness of the decision or the maximum amount of resources available. When the group owns the process, it goes a long way to having them own the outcome.
Facilitating a decision can take various forms but typically goes through four stages: First, prepare a proposal that is simple and clear and that ensures that everyone knows what they are voting on. In some cases you might prepare two or three proposals in order to poll the group of options. Regardless, a proposal for a decision should be something taht is easily understood and easy to compare against other options.
Second, test the group for consensus. See who agrees with the proposal and who has questions or other things they would like to add. This process allows for a final set of conversations to strengthen the proposal. If you experience blocks and vetos at this stage of the process, this can give you good information about changes that need to be made or ongoing relationships that will need to be tended after the decision is made.
Third, iterate the proposal and review it again. Focusing on the major issues and questions means that the iteration process can be focused and aimed at creating a stronger proposal. Finally, make a final decision. That may be a vote or a consensus decision depending on what is required of the process.
Once the decision is made, the process is closed and the work continues. It can be important to give some thought to how the decision is communicated and implemented as part of your next steps.
The Downtown Eastside is again making news this summer.
Which is not really news.
In the 20 years of writing about poverty, drug addiction, mental illness and homelessness along the East Hastings Street corridor, the story remains the same: people are suffering, people are dying and politicians make promises to do better.
The pandemic coupled with a poisoned drug supply, and the lack of housing for more than 2,000 unhoused people across the city, has noticeably exacerbated and exposed the human tragedy.
The summer heat, as it has done for decades, forces people out of their single-room-occupancy hotels to the street for fresh air and safety; many of the hotels are in disrepair, without proper ventilation, infested with rodents and bugs and have been and continue to be scenes of violence.
So make of it what you will of the population currently living/surviving/loitering on the sidewalks up and down East Hastings Street, where — yes — drugs are being sold and consumed, where stolen goods are being hawked and people are being assaulted, even lit on fire.
That version of the Downtown Eastside is on a chronic news cycle.
Community courage award
The music, the art and the poetry of the community is not often celebrated in news pages. Anyone remember poet Bud Osborn?
Engaging programs for seniors (ping pong, line dancing, "survival" English courses) and clubs for kids at community centres haven't made for a lot of front page copy. Anyone remember the RayCam youth running club led by national team runner Matt Johnston?
The community work of Indigenous elders like Marjorie White and young people like Genoa Point — both winners of a “community courage award” in 2012 — should also be considered for a different perspective on the neighbourhood.
Musicians are well represented, too.
But I digress.
As long as I’ve been in this job, I’ve heard countless strategies, ideas, recommendations and plans from well-meaning folks to better conditions for people living in the Downtown Eastside.
Doctors, health care workers, housing advocates, community residents, business owners, non-profit leaders, cops and politicians have all weighed in.
Still, the poverty persists.
Larry Campbell's inauguration speech
Last Friday at city hall, I pointed out to Mayor Kennedy Stewart that there has been a succession of mayors and provincial and federal politicians over the past 20 years who have promised to do better, although Stephen Harper’s government led an unsuccessful battle to shut down the Insite drug injection site and was absent on the housing file.
Larry Campbell was mayor when Insite opened in 2003.
Here’s some of what he said at his inauguration speech in 2002:
“If we do our work well, we should be able to eliminate the open drug market on the Downtown Eastside by the next election. We should see more people in treatment and detox. A comprehensive education and prevention program should be in place to reduce the toll of drug addiction. New housing and business investment should be generating new activity in the community.”
Then along came Sam Sullivan, who launched his “project civil city” program and drug treatment proposal in an effort to reduce street disorder and homelessness by 50 per cent. Gregor Robertson then pledged to end “street homelessness” by 2015.
A look at the strip today will tell you the result of their efforts.
Stewart has pushed for a safe supply of drugs, decriminalization and often boasts about the amount of housing being built or in the pipeline because of $1 billion he has secured in funds from the provincial and federal governments.
He’s right that more modular housing, more hotels converted into housing, more stand-alone supportive and social buildings have opened up in the past few years for unhoused people and those at risk of homelessness.
But it’s 2022 and the Downtown Eastside and other parts of the city remain desperate scenes.
“It's a typical case where demand is outstripping supply,” the mayor said. “And as fast as we can build affordable housing, whether it's modular, which has been built at a record pace —over 1000 of those units — or it's securing more permanent social housing, the supply is not keeping pace with demand.”
'Pressure is greater than ever'
Stewart said Vancouver is often the first place in B.C. that people in need come to because of the concentration of social services — food, clothing, drug consumption sites, medical clinics and shelter space, if it’s available.
Encampments in parks have also attracted people from outside the city.
“Talking with police and social service agencies and nonprofits, the pressure is greater than ever, but I do think our response is the proper one — to invest in housing first,” he said. “We've literally housed hundreds of people over the last four years, like actually moved them off the street into a stable situation.”
But, of course, the province and the feds have to invest more, as Stewart and his predecessors have all repeatedly said — to which Vancouver-Granville Liberal MP Taleeb Noormohamed, who was with the mayor at city hall for an unrelated news conference, responded:
“The folks who live in the Downtown Eastside, the people on Hastings deserve dignified places to live, they deserve access to the services that they need, they deserve, as the mayor said, to be lifted up. We have to be able to do that in partnership with organizations that know those populations best and are able to serve them.”
Noormohamed went on to say the Liberal government has made record investments in housing and support services in Vancouver.
No one from the provincial government was with Noormohamed and Stewart, but previous statements sent my way in recent years from various ministries have pointed to investments in temporary modular housing, stand-alone housing, the purchase of hotels and efforts to reduce overdose deaths and treat people living with a mental illness.
VPD Chief: 'Nobody's in charge'
At a city council-sponsored forum in April, Police Chief Adam Palmer was blunt about whether the provincial government’s efforts were having the desired effect.
“Nobody’s in charge, like nobody's in charge of the grand picture,” he said, before pointing to Strathcona as a neighbourhood that has issues requiring responses from several provincial ministries.
“You’ve got poverty reduction, you've got employment issues, you've got housing issues, you've got criminal justice issues, you've got attorney general issues, education — there's so many different ministries…that all overlap in that neighbourhood.”
Added Palmer: “But there's nobody really pulling it all together. There's a lot of silos happening in government.”
At the same time, the chief said, there is “great work” occurring with various agencies working together, including the VPD-Vancouver Coastal Health mental health teams, but it is being conducted in a piecemeal way.
So what’s the solution?
It’s not magic, to borrow a phrase from former Carnegie Community Centre director Michael Clague, who sent me a “prescription” in 2019 for improving the lives of people in the Downtown Eastside.
At one time, Clague was also the co-chairperson of the Downtown Eastside Local Area Planning Committee. So his prescription has some educated thought and experiential weight to it.
Thought I’d repeat it here again for those who missed it.
Give it a read, tell me what you think.
Seven priorities:
• Build shelter-rate housing in the DTES and throughout the city.
• Raise the shelter rate allowance.
• Give those currently living in the DTES the option of remaining in the community or relocating to elsewhere in the city.
• Provide social and health supports within a continuum of care 24/7 in those residences where they are required for the welfare of residents.
• Provide safe custodial residential care for residents whose condition is such that they are a risk to themselves and to others. This means that people at risk for self-harm and for harm to others are voluntarily and involuntarily living in supervised residences for designated periods of time to ensure they have the best available health care. Advocacy and legal guarantees are designed so that their inherent rights and liberties are respected.
• Remove restrictions on access to addictive drugs (decriminalize).
• Design and provide culturally relevant programs and services, especially involving the large Aboriginal community.
Six conditions:
• Work respectfully with and learn from those most affected in the planning and provision of these seven priorities.
• Build on the strengths inherent in the community.
• Create volunteer and employment opportunities in the DTES and in the city at large, geared to people’s readiness, emphasizing opportunities to contribute to community life.
• Recognize and support the community arts as one of the most accessible, proven means for personal and community development.
• Recognize that the Downtown Eastside can be a healthy, predominately low-income community.
• Build informed support throughout Vancouver for these measures.
OK, also wir haben Nord Stream 1 und Nord Stream 2. Putin will gerne über Nord Stream 2 Gas liefern, unsere Sanktionen gegen Russland nehmen Gas-Importe explizit aus.
Wir haben aber auf Druck der Amerikaner Nord Stream 2 nicht in Betrieb genommen, und Putin liefert jetzt halt auf Nord Stream 1 weniger, um uns zum Betrieb von Nord Stream 2 zu zwingen.
Ich verstehe ehrlich gesagt gerade nicht, was dagegen spricht, Putin das Gas über Nord Stream 2 liefern zu lassen. Wir haben ja laufende Verträge, die Infrastruktur liegt da jetzt fertig rum, und wir sind uns alle einig, dass wir das Gas aus Russland importieren wollen, sonst gäbe es ja kein Geheule über die reduzierten Mengen in Nord Stream 1.
Was war jetzt noch gleich das Argument dagegen, Nord Stream 2 zu aktivieren für den Winter?
Gab es welche?
Das verstehe ich gerade echt nicht. Ist das Gas weniger verwerflich, wenn es über die rechte Pipeline kommt als über die linke? Was geht hier ab?
Update: Außerdem könnte man damit Putins Strategie kaputtmachen, denn wenn wir dann den Gashahn aufdrehen geht die Verfügbarkeit hoch und der Preis wieder runter und wir zahlen am Ende unterm Strich weniger als jetzt, was heißt: Putin verdient auch weniger als jetzt an unseren Gaskäufen.
Ich weiß nicht, ob ihr das gesehen habt, aber die EU kauft gerade systematisch den außerrussischen Gasmarkt leer, was dazu geführt hat, dass auf Pakistans Gaskauf-Ausschreibung niemand auch nur reagiert hat, weil die EU tiefere Taschen hat.
I've added a new feature to Datasette Lite, my distribution of Datasette that runs entirely in the browser using Python and SQLite compiled to WebAssembly. You can now install additional Datasette plugins by passing them in the URL.
Datasette Lite background
Datasette Lite runs Datasette in the browser. I initially built it as a fun technical proof of concept, but I'm increasingly finding it to be a genuinely useful tool for quick ad-hock data analysis and publication. Not having any server-side components at all makes it effectively free to use without fear of racking up cloud computing costs for a throwaway project.
You can read more about Datasette Lite in these posts:
Scraping data into Datasette Lite shows an example project where I scraped PSF board resolutions, stored the results in a CSV file in a GitHub Gist and then constructed this URL to open the result in Datasette Lite and execute a SQL query.
Adding plugins to Datasette Lite
One of Datasette's key features is support for plugins. There are over 90 listed in the plugin directory now, with more emerging all the time. They're a fantastic way to explore new feature ideas and extend the software to handle non-default use cases.
Plugins are Python packages, published to PyPI. You can add them to Datasette Lite using the new ?install=name-of-plugin query string parameter.
Here's an example URL that loads the datasette-jellyfish plugin, which adds new SQL functions for calculating distances between strings, then executes a SQL query that demonstrates that plugin:
It sets s1 to "barack obama" and s2 to "barrack h obama".
Plugin compatibility
Unfortunately, many existing Datasette plugins don't aren't yet compatible with Datasette Lite. Most importantly, visualization plugins such as datasette-cluster-map and datasette-vega don't work.
This is because I haven't yet solved the challenge of loading additional JavaScript and CSS into Datasette Lite - see issue #8.
Here's the full list of plugins that I've confirmed work with Datasette Lite so far:
datasette-copyable - Datasette plugin for outputting tables in formats suitable for copy and paste - demo
How it works
The implementation is pretty simple - it can be seen in this commit. The short version is that ?install= options are passed through to the Python web worker that powers Datasette Lite, which then runs the following:
for install_url in install_urls:
await micropip.install(install_url)
micropip is a component of Pyodide which knows how to install pure Python wheels directly from PyPI into the browser's emulated Python environment. If you open up the browser devtools networking panel you can see that in action!
Since the ?install= parameter is being passed directly to micropip.install() you don't even need to provide names of packages hosted on PyPI - you could instead provide the URL to a wheel file that you're hosting elsewhere.
This means you can use ?install= as a code injection attack - you can install any Python code you want into the environent. I think that's fine - the only person who will be affected by this is the user who is viewing the page, and the lite.datasette.io domain deliberately doesn't have any cookies set that could cause problems if someone were to steal them in some way.
Crunchy Data have a new PostgreSQL tutorial series, with a very cool twist: they have a build of PostgreSQL compiled to WebAssembly which runs in the browser, so each tutorial is accompanied by a working psql terminal that lets you try out the tutorial contents interactively. It even has support for PostGIS, though that particular tutorial has to load 80MB of assets in order to get it to work!
The ghost bike was replaced by Geoffrey this past Tuesday. It is now affixed to a hydro pole, rather than the original placement against the cable supports in the foreground.
I went by this afternoon to replace the sign, and to add a few flowers.
While I was installing the sign, yet another ML concrete mixer went by. This is a continuing issue for the neighbourhood since the nearby concrete plant was supposed to move years ago. With the construction of a high-rise condo on the western side of the intersection, there is going to be even more car, bike and pedestrian traffic moving through.
Log in to Facebook and check Ad Settings. Look at Audience-based advertising.
If the name of the company you bought from is in there, they sold (exchanged for something of value) your info, probably
by sending it to Facebook as part of a Custom Audience, or possibly by using Facebook Conversions API. Anyway, they broke the law
and got caught.
Simple, right? Looks like a way to make open-and-shut CCPA cases
at scale. The new California privacy agency will be able to just
copy over the same paperwork, because all the surveillance marketers
are following the same tutorials.
Unfortunately, surveillance marketers already have a workaround. I have seen this doing RtKs (which is
a good example of why RtKs matter).
The original company (the business) collects customer email address from an opted-out customer, and possibly hashes it.
Business passes the email address, or hash, to a third party.
The third party passes the email address or hash to Facebook, and then deletes it. They can't tell which of their client
businesses passed information on which people (or they claim not to be able to).
That way, the name of the third party, not the name of the business, shows up in Facebook Ad Settings. Under the draft CPRA
regulations, the third party is required to comply with a Right to Know or Right to Delete, but as far as I can tell,
there's no additional requirement for the third party to disclose who the original business was, or to be able to.
So a business that wants to violate the CCPA can run their Custom
Audiences through a third party, and switch to a new third party
if the old one builds up too many RtDs.
It looks like all we can really do is list the third parties involved
in this scheme and RtD them? I know this is a good argument for
why everybody needs an Authorized Agent service, but it would be
less total work if there were a better way to find the original
business that broke the law.







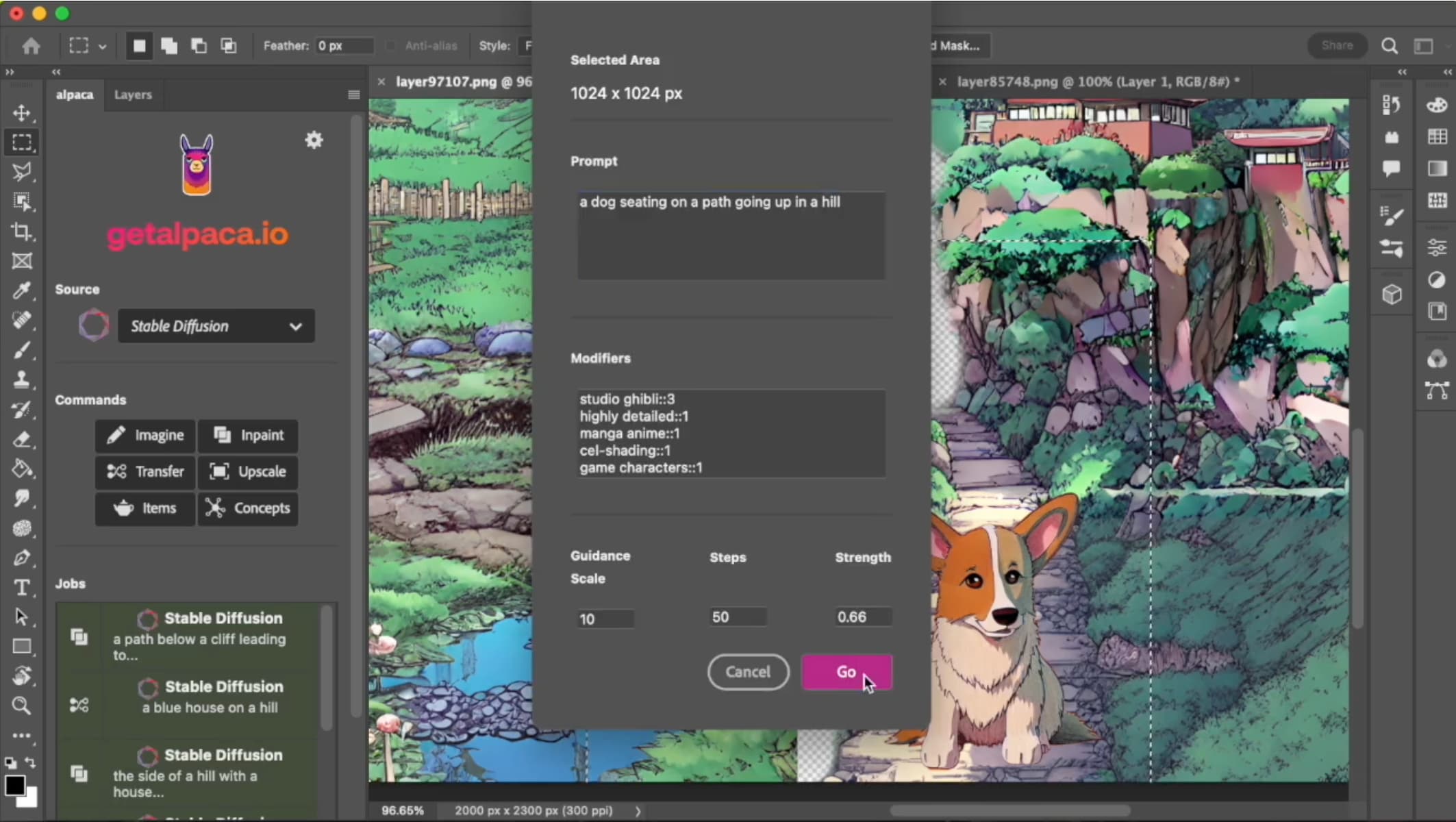














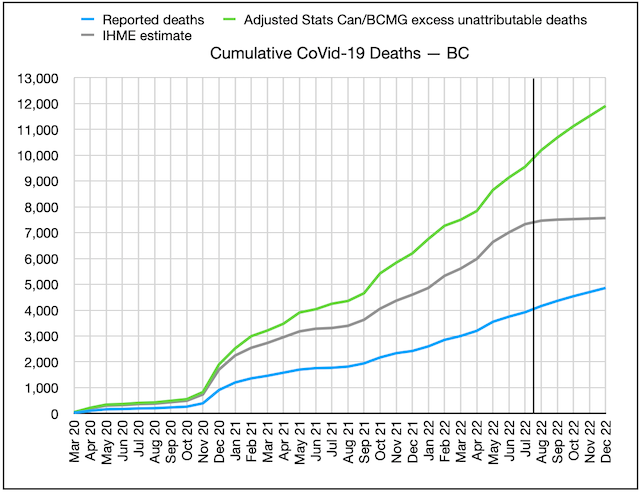
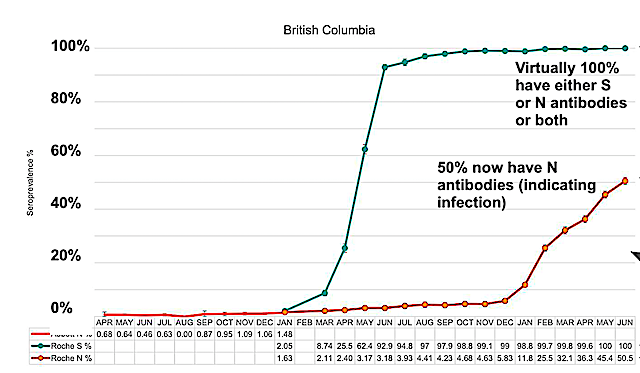















 , where
, where  is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?





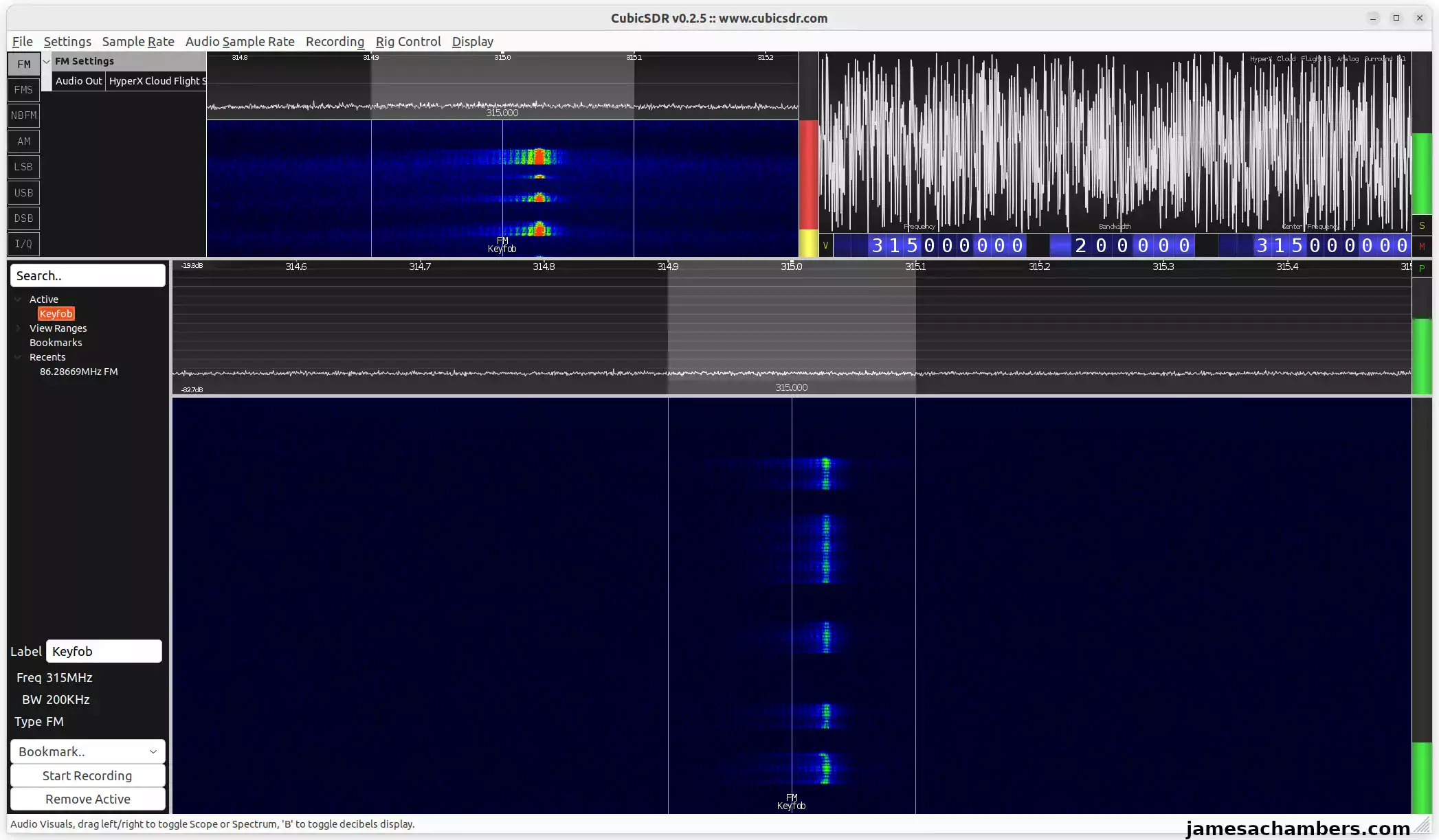 I've previously covered getting your HackRF set up in Linux and getting the firmware updated. In that guide we installed the very easy to use CubicSDR application and were able to easily tune to various audio signals.
Today we're going to do something more interactive and actually use the transmitter. We're going to unlock and lock my vehicle using the HackRF! Let's get started.
I've previously covered getting your HackRF set up in Linux and getting the firmware updated. In that guide we installed the very easy to use CubicSDR application and were able to easily tune to various audio signals.
Today we're going to do something more interactive and actually use the transmitter. We're going to unlock and lock my vehicle using the HackRF! Let's get started.






(@lessin) July 26, 2022