To be frank I wanted to learn something new. Something different but still part of my ecosystem. I looked at Go and Rust. I settled with Rust. Rust is very different from what I have learnt ( C, Java, JS, Python ) until now. It also looked like a language that would take time to pickup unlike Python. I think it’s mostly because it’s different from the languages that I have learnt until now. It’s been a week. I must say I am enjoying reading, experimenting and scribbling bits and pieces of code. I don’t have any projects to use the skill now. I am looking for already popular Rust projects where I can do some big fixes. I think debugging and fixing bugs is the best way to learn a language or frameworks. Let me know if you know any interesting FOSS projects that I can explore.
It’s been a week. I must say I am enjoying reading, experimenting and scribbling bits and pieces of code. I don’t have any projects to use the skill now. I am looking for already popular Rust projects where I can do some big fixes. I think debugging and fixing bugs is the best way to learn a language or frameworks. Let me know if you know any interesting FOSS projects that I can explore.
Rolandt
Shared posts
Now Rusting
How to Read a Book: The Classic Guide to Intelligent Reading (Adler/Van Doren) – my reading notes
I am very much on record with my view that books should be read in-depth, and that skimming is an important strategy out of a broad repertoire of reading heuristics. Although, I’ll admit that after reading “How to Read a Book: The Classic Guide to Intelligent Reading” by Adler and Van Doren, my priors have been updated. I don’t think I can say the same thing that I used to say before: teach people to read in-depth before skimming. I think one can use Adler and Van Doren’s Levels of Reading as sequencing heuristics to teach various strategies. You can read an excerpt from the book here, specifically the table of contents.

That said, I still insist that we ought to avoid teaching students to ONLY skim. OF COURSE, we also need to learn and teach how to triage our reading workload, too. It’s equally problematic to insist that they ONLY read in-depth. I think we ought to provide them with a broad range of reading strategies (which is why I write so often about the topic – also in hopes to help my students develop these skills).
Someone on Twitter, I can’t recall whom, asked me if I had ever read Adler and Van Doren’s book. Well, no, I hadn’t. So I made some time last night to go through it. As I’ve noted before, I am an extremely fast reader, so I could absorb the entire 350 pages in a very short period of time. I wrote a Twitter thread summarizing my reading notes from the book.
First off: it’s a HUGE book. On how to read books. YIKES.
Adler and Van Doren’s “How to Read a Book” has TWENTY ONE CHAPTERS.
21.
Fellow professors: I recognize that I don’t teach writing, but if I did, I would need a semester-long class (16 weeks) assigning more than one chapter per week as core reading.
Seriously?!
pic.twitter.com/0MRUKh7wxe
— Dr Raul Pacheco-Vega (@raulpacheco) August 30, 2019
The above said, it IS a great book.
There’s an inherent assumption in Adler and Van Doren’s approach to reading a book. You’ve at least achieved skills and competencies of US and Canadian ninth grade.
This is problematic for non-native speakers of English who now have to read A LOT of stuff quickly under pressure pic.twitter.com/y3FKuRkTN2
— Dr Raul Pacheco-Vega (@raulpacheco) August 30, 2019
So, you may wonder/ask me: “would I recommend this book?”
Sure. OF COURSE!
Jesus, people.
Do you think I would spend my time reading a book about reading books and then write a Twitter thread at 5:20 in the morning Mexico City time, my prime writing time, just for naught? pic.twitter.com/WDlnRH4czk
— Dr Raul Pacheco-Vega (@raulpacheco) August 30, 2019
So, you may ask me: “professor Pacheco-Vega, what’s the strategy then to use Adler and Van Doren?”. Well, grad you asked.
This is the strategy *I* plan to use with my graduate students (remember, they’re all Spanish-speakers, who have learned English as a second language)
For graduate students
1) Give a 1 lecture summary of the entire book, maybe in a workshop format.
2) Produce a Coles’ Notes summary and,
3) Give my students my Coles’ Notes, have them read them, then have them read AVD up until the “reading different types of material” chapter (16, I think?)
4) Have THEM write Synthetic Notes of each chapter (to note, I won’t let them do AIC skim reads. These synthetic notes should be mini-memorandums on ADV).
What would be my strategy for undergraduates?
Most institutions (at least mine does) have an “Argumentative Writing” course. What I plan to do is tell the professor about this book, and suggest that they replicate my strategy up (1 and 2) but then assign a chapter per week.
At the core, AVD is about developing a repertoire of reading strategies, which I emphasized last week we need to do https://t.co/dQvzmr9lZx (I also have a page on reading strategies for undergrads) https://t.co/0Dnb2ITySI
Adler and Van Doren’s book would be the guide for HOW TO
— Dr Raul Pacheco-Vega (@raulpacheco) August 30, 2019
Bottom line: like Adler and Van Doren, we need to teach different levels of reading and various types of strategies to achieve our own learning goals and those of our students. 10/10 do recommend.
Bottom line: My assessment of AVD H2RAB
YES, WORTH READING, WORTH ASSIGNING, WORTH USING IT AS A TEACHING TOOL.
AND… I found it on Amazon super cheap (I know, we hate Amazon, it’s evil, but … https://t.co/8Ctd22iH3n)
</end thread>
— Dr Raul Pacheco-Vega (@raulpacheco) August 30, 2019
Huawei Mate 30 Series Will Launch on September 19 in Munich
 Huawei today announced that it would be announcing the Mate 30 series at a media event in Munich on September 19th. The teaser accompanying the announcement hints at the Mate 30 series coming with a circular camera hump at the rear as pointed out by the leaks.
Continue reading →
Huawei today announced that it would be announcing the Mate 30 series at a media event in Munich on September 19th. The teaser accompanying the announcement hints at the Mate 30 series coming with a circular camera hump at the rear as pointed out by the leaks.
Continue reading →
mkalus shared this story ...
|
mkalus
shared this story
from |
Lester B. Pearson: "If a man has an apartment stacked to the ceiling with newspapers, we call him crazy. If a woman has a trailer house full of cats, we call her nuts. But when people pathologically hoard so much cash that they impoverish the entire nation, we put them on the cover of Fortune magazine and pretend that they are role models."
God save us from the smug fortysomethings | Will Self | Opinion
|
mkalus
shared this story
from |
It’s a truth pretty universally unacknowledged – but for all that, blindingly obvious once you’ve been told by One Who Knows – that the world is ruled by a sinister cabal of deeply egotistic – and, by extension, viciously bigoted – individuals. I’m not referring here to the usual suspects – I know there isn’t a Jewish conspiracy, because I’ve never been invited along to any of its meetings, any more than I have to those of the so-called establishment, and since my Wiki entry fingers me as both a Jew and an arch-establishmentarian, I know that at least these things must be true.
Nor, indeed, is this a conspiracy of the believers against the secular, the ugly contra the lovely, lizard-paedophiles averse to… everyone, or the rich versus the poor. As to our fates being determined by some weird historic determinism, whereby humanity “realises” itself through successive class antagonisms... Nope, sorry Jezzer. Far from being wreathed in false consciousness, the cabal I’m talking about hide in plain view – and perhaps the best way I have of getting you to eat the proverbial red pill, and so see for the first time the true horror that enfolds you, is for me to describe a group of these evil svengalis I saw only yesterday evening, outside a pub in Mortlake, south-west London.
True, they aren’t an especially metropolitan phenomenon – but can be found anywhere human society tries to flourish. Nevertheless, there is a certain kind of affluent-but-slightly-quirky suburb, exemplified by Mortlake, and often featuring mean-featured little Victorian villas, that seems to attract them. There they were: two women sporting boldly patterned pregnancy dresses, their men folk in khaki cargo shorts and collared T-shirts. All were talking animatedly – one of the men was actually stroking his jazz beard as I hurried past, my face averted. I refer, of course, to people in their 40s.
Yes: forget whatever ologies you may have studied along the way, demography is the only science that matters when it comes to the harsh terms of everyone’s existence (everyone who isn’t currently aged between 40 and 49, that is), for this is the cohort that has it all. St George of Orwell said “by the age of 50 every man has the face he deserves” – but the truth is, rather, “by the age of 50 every man and woman has the fate he or she deserves”, because, let’s face it, with one or two exceptions if you haven’t cut the mustard by then it’s cress sandwiches all the way into that perfect picnic spot: your grave.
Yes, yes, I know: for a long while now it’s looked as if our main problem was the bizarre demographic bouléversément that’s happened in the past 70 very odd years. I’m not the only Nytol-addled Nostradamus to have pointed out that if current trends persist our few remaining young folk will, soon enough, be crushed to death beneath the huge prolapsed denim-covered collective arse of superannuated baby boomerdom. Nor have I been alone when it comes to bemoaning the talentless hipster culture we’ve bequeathed our children – we’ve all seen it happen: the once proud artistic avant gardes of western Europe plummeting through clouds of frothy coffee, down into a brownish gloop comprising one part “crafted” gin to three of moustache wax.
While there were still some baby boomers left in our 40s, I thought we were the problem – but now I know the hideous truth: it doesn’t matter that David Cameron turned 50 a few months after leaving office, or, for that matter, that Nick “Bend over for Zuckerberg” Clegg reached that noble age early the next year – the point is: there are always more ready to follow them: dead-eyed thirtysomethings on the verge of becoming the true Illuminati! Yes, yes, I know: the current prime minister is 55 – but if he resembles an amoral and Struwwelpeter-haired puppet, it’s because he is one, manipulated by Dominic Cummings (47). And if Johnson, with his bellowing, pants-down antics, also appears decadent – in the true sense of aping the mores of 10 years past – it’s because he is indeed channelling his own inner 45-year-old.
Yes, those in their 40s have the swaggering self-confidence of people-who’ve-arrived, but far from this destination being the dark wood that inspired Dante to deep spiritual reflection, theirs is the smugness of those whose position in the hierarchy is well established, plus the antics of the boorish teenagers they so clearly remain. See them paint their faces and go to Glastonbury! See them disappear into a k-hole while actually eating Special K to ease their costive and ageing bowels! Moreover, with advances in the technology of human fertilisation, fortysomethings are now able to reproduce themselves – which accounts for the creepily philoprogenitive group on the riverside at Mortlake.
When I swallowed the red pill and saw them for the first time in all their old-young hideousness, it occurred to me: is it only this generation of 40-year-olds that’s quite so repulsive (and quite so powerful), or has this Masonic order of the middle-aged always been so smugly unreflective? True, the current incumbents are a grisly bunch – but what can you expect of people whose cultural hinterland has been formed by the likes of Coldplay and Radiohead, and who came of age listening to the peculiar banging whine of dial-up internet connections, as, feverishly, they waited to play some dumb and wholly unrealistic computer game?
Granted, I do have this obvious partisanship – and there’s also a further objection to my thesis: that I approach the issue with a perspective warped by my own 57 (and rising) years. But let me reassure you: when I recall how smugly self-satisfied I was in my own 40s – and how convinced I was of the importance of me and my fellow quadragenarians, well, I can tell you: I feel like giving that fellow a few sharp slaps in his metro-moisturised face, until it shines like a baby’s bottom. Or, alternatively, like the face of David Cameron, who, as I believe I may have made clear, is the leader of the fortysomethings’ revolution, and whose inappropriate Chelsea boot heel we’re all still being ground beneath.
"I am so hot!"
It’s Sunday afternoon. Oliver is out with his University of PEI peers participating in a downtown scavenger hunt.
My phone rings: it’s Oliver, making a Google Duo video call.
Oliver: I am so hot!
Me: Where are you?
Oliver: I’m downtown, in the park by your old office.
Me: What about your water bottle?
Oliver: It’s empty.
Me: Okay, look in the corner, over by Richmond Centre; you will see a blue water fountain with a water bottle refiller. Go and refill your water bottle.
Oliver: Okay.
I happened to know that there was a water fountain there because I added it to OpenStreetMap two months ago.
All kinds of interoperating technology FTW.
Congrats, Amazon, you are now Big Brother twitter.com/beep/status/11…
|
mkalus
shared this story
from |
Congrats, Amazon, you are now Big Brother twitter.com/beep/status/11…
Police departments in 405 cities have “partnered” with Amazon Ring, allowing them to automatically request footage recorded by homeowners’ cameras. cnet.com/news/amazons-r…
253 likes, 284 retweets


1550 likes, 701 retweets
There are better ways to save journalism
 In a Columbia Journalism Review op-ed, Bernie Sanders presents a plan to save journalism that begins,
In a Columbia Journalism Review op-ed, Bernie Sanders presents a plan to save journalism that begins,
WALTER CRONKITE ONCE SAID that “journalism is what we need to make democracy work.” He was absolutely right, which is why today’s assault on journalism by Wall Street, billionaire businessmen, Silicon Valley, and Donald Trump presents a crisis—and why we must take concrete action.
His prescriptive remedies run ten paragraphs long, and all involve heavy government intervention. Rob Williams (@RobWilliamsNY) of MediaPost provides a brief summary in Bernie Sanders Has Misguided Plan To Save Journalism:
Almost two weeks after walking back his criticism of The Washington Post, which he had suggested was a mouthpiece for owner Jeff Bezos, Sanders described a scheme that would re-order the news business with taxes, cross-subsidies and trust-busting…
Sanders also proposes new taxes on online targeted ads, and using the proceeds to fund nonprofit civic-minded media. It’s highly doubtful that a government-funded news provider will be a better watchdog of local officials than an independent publisher. Also, a tax-funded news source will compete with local publishers that already face enough threats.
Then Rob adds,
Sanders needs to recognize that the news business is subject to market forces too big to tame with more government regulation. Consumers have found other sources for news, including pay-TV and a superabundance of digital publishers.
Here’s a lightly edited copy of the comment I put up under Rob’s post:
Journalism as we knew it—scarce and authoritative media resources on print and air—has boundless competition now from, well, everybody.
Because digital.
Meaning we are digital now. (Proof: try living without your computer and smartphone.) As digital beings we float in a sea of “content,” very little of which is curated, and much of which is both fake and funded by the same systems (Google, Facebook and the four-dimensional shell game called adtech) that today rewards publishers for bringing tracked eyeballs to robots so those eyeballs can be speared with “relevant” and “interactive” ads.
The systems urging those eyeballs toward advertising spears are algorithmically biased to fan emotional fires, much of which reduces to enmity toward “the other,” dividing worlds of people into opposing camps (each an “other” for the “other”). Because, hey, it’s good for the ad business, which includes everyone it pays, including what’s left of mainstream and wannabe mainstream journalism.
Meanwhile, the surviving authoritative sources in that mainstream have themselves become fat with opinion while carving away reporters, editors, bureaus and beats. Brand advertising, for a century the most reliable and generous source of funding for good journalism (admittedly, along with some bad), is now mostly self-quarantined to major broadcast media, while the eyeball-spearing “behavioral” kind of advertising rules online, despite attempts by regulators (especially in Europe) to stamp it out. (Because it is in fact totally rude.)
Then there’s the problem of news surfeit, which trivializes everything with its abundance, no matter how essential and important a given story may be. It’s all just too freaking much. (More about that here.)
And finally there’s the problem of “the story”—journalism’s stock-in-trade. Not everything that matters fits the story format (character, problem, movement). Worse, we’re living in a time when the most effective political leaders are giant characters who traffic in generating problems that attract news coverage like a black hole attracts everything nearby that might give light. (More about that here.)
Against all those developments at once, there is hardly a damn thing lawmakers or regulators can do. Grandstanding such as Sanders does in this case only adds to the noise, which Google’s and Facebook’s giant robots are still happy to fund.
Good luck, folks.
So. How do we save journalism—if in fact we can? Three ideas:
- Start at the local level, because the physical world is where the Internet gets real. It’s hard to play the fake news game there, and that alone is a huge advantage (This is what my TED talk last year was about, by the way.)
- Whatever Dave Winer is working on. I don’t know anybody with as much high-power insight and invention, plus the ability to make stuff happen. (Heard of blogging and podcasting? You might not have if them weren’t for Dave. Some history here, here and here.)
- Align incentives between journalism, its funding sources and its readers, listeners and viewers. Surveillance-based adtech is massively misaligned with the moral core of journalism, the brand promises of advertisers and the privacy of every human being exposed to it. Bernie and too many others miss all that, largely because the big publishers have been chickenshit about admitting their role in adtech’s surveillance system—and reporting on it.
- Put the users of news in charge of their relationships with the producers of it. Which can be done. For example, we can get rid of those shitty adtech-protecting cookie notices on the front doors of websites with terms that readers can proffer and publishers can agree to, because those terms are a good deal for both. Here’s one.
I think we’ll start seeing the tide turn when when what’s left of responsible ad-funded online publishing cringes in shame at having participated in adtech’s inexcusable surveillance business—and reports on it thoroughly.
Credit where due: The New York Times has started, with its Privacy Project. An excellent report by Farhad Manjoo (@fmanjoo) in that series contains this long-overdue line:”Among all the sites I visited, news sites, including The New York Times and The Washington Post, had the most tracking resources.”
Hats off to Farhad for grabbing a third rail there. I’ve been urging this for a long time, and working especially on #4, through ProjectVRM, CustomerCommons and the IEEE’s working group (P7012) on Standard for Machine Readable Personal Privacy Terms. If you want to roll up your sleeves and help with this stuff, join one or more of those efforts.
Recommended on Medium: Work, Automation, Cyborgs: Why Japan’s Present is Our Future
Whatever your opinion of Andrew Yang’s presidential campaign, it’s elevated an important conversation we’ve barely just begun in the United States: How automation and robotics will shape the future of work. However, it’s one thing to advocate for a Universal Basic Income, and another to paint a picture of the future we can see ourselves in, where our lives still have meaning. It’s a topic that’s been a key focus of my work at the Institute for the Future, and in our 10 year forecast.
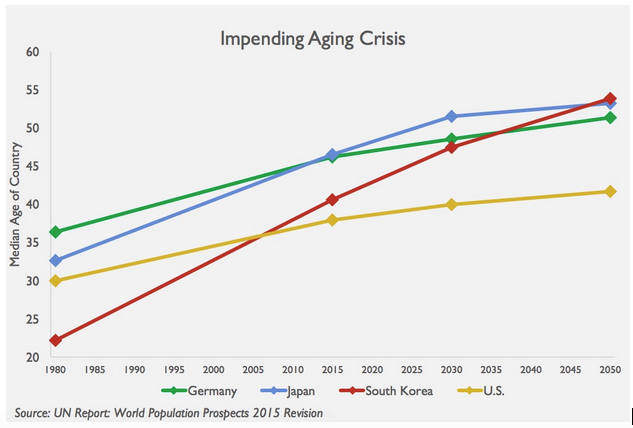
Japan has much inspiration to offer. Because contrary to the country’s technophile stereotype, the Japanese embraced automation not because they saw it as cool or exciting, but out of sheer necessity. This chart above illustrates why.
Japan’s workforce has been aging for decades, forcing the country to subsist on fewer and fewer employees in their physical prime. On my recent creative sabbatical in Japan, the imbalance between old and young on the streets was hard to miss during daily walks — as were the automated solutions. While the US is only recently seeing the slow introduction of semi-automated restaurants, they are everywhere in Japan, as are sophisticated vending machines offering a wide variety of products that might otherwise be sold in (human staffed) retail stores.
While the US population is aging at a slower clip, our fertility rates are starting to fall drastically. It’s expensive to reproduce, and collective uncertainty over economic stability will help create a future in which there are less young people to take over for our retirement-age population.
What we’re seeing in Japan brings some nuance to pessimistic forecasts of automation. Instead of a future in which our workforce will be obsoleted by robotics, it’s just as likely that we will see the introduction of cyborg technology, in which humans work alongside and in concert machines. It’s a theme I’ve been thinking and writing about for the last few years, but my time in Japan helped put the urgency of this solution into sharper focus.

As an example of our cyborg future, consider exoskeletons, like the one depicted above, already in regular use in the factories of Japan. It suggests one solution to both an aging population and the nature of work in an era of pervasive automation: human-driven, robotics-enhanced work which enables skilled laborers to continue bringing their experience to projects beyond traditional retirement age. As people age and want to continue their craft, they can work with machines which enhance safety and agility. (As such, it’s a middle futurist approach to automation.)
But while we are starting to see some highly promising examples of human/machine automation in the United States (more on that below), its widespread adoption isn’t completely assured.
The Cyborg Cultural Gap
Japan’s rapid embrace of automation has happened not just out of necessity, but by a cultural affinity that accelerated it. In the country’s traditional animist beliefs, everything — even tools — are imbued with a life force spirit. This has probably done much to encourage the Japanese to see the machines serving them as benevolent, and non-threatening, helpful.

In the United States, by contrast, we’re still weathering under a fear of automation tinged by its association with the military-industrial complex, and our cautionary 20th century tales of deadly robots resisting our control, and enslaving us. In the final conflict in the first Star Wars trilogy, Luke Skywalker looks down at his robotic hand, and doesn’t see a helpful tool, but instead, a clear sign that he’s losing his soul.
You can see how much this discomfort still exists by our social media reactions, whenever Boston Dynamics releases a new demo video — or for that matter, in frequent stories of security robots being assaulted, or self-driving cars pelted with rocks. In Japan, both in popular fiction and real life, the robots are trying to be kind and helpful; here, the robots are more likely to be seen in the Terminator/Robocop vein — trying to kill us, replace us, or both.
A Human-Scale Approach to Automation

If Japan’s age gap is a sign of our future, the Japanese approach to automation is a model for how we can overcome our trepidation with robotics. By and large, Japan’s robot force are modeled after cartoon animals. For instance, this robot bear designed to assist the elderly, or this small baby seal robot created to assist people with dementia.
While some might dismiss this fixation with cuteness, it’s an extremely savvy design approach. We don’t respect robots when they’re dehumanizing, and we can’t see clear intentions of friendliness. Cartoon animals have consistent, simplified behaviors that are far easier to automate and very rarely need to include the spoken word; not only are they more approachable, they embody shared narratives that connect across generations, ethnic communities, classes. For similar reasons, Japan’s robots usually come in bright, harmonious colors — rarely drab or gray, as is often the default in US industrial design.

You can see the difference in the aesthetic approach to automation in these exoskeletons from US-based company Ekso Bionics (left) and Panasonic (right). The Ekso design is black matte and deadly serious, evoking a Robocop/space marine quality. Panasonic’s solution is decidedly cute, with cheerful green and purple colors. It’s not only more approachable, it’s bright, so people can see you wearing it from far away. Cuter is safer.
Amazon has been rolling out a model for automation that follows the Japanese approach more closely. After hitting the limits of what both traditional robotics and exhausted humans could do, the Internet retail giant introduced a line of robots designed to work hand-in-hand with their employees:

Amazon’s delivery robots are notably bright orange, and reminiscent of the friendly cartoon cars from the Pixar movies. Working alongside humans, they act as multipliers for human-driven work.
Just as Japan automated out of necessity, we will need to automate more and more out of necessity. The question of what we automate, and what remains human, becomes ever more crucial.
I look forward to your own answers and feedback on Twitter. In future posts, we’ll discuss the stark differences between sci-fi automation and genuine automation, and consider design solutions to the non-spaces problem in the workplace.
Passports, pets and GB stickers: the Brexit advice issued to Britons | Politics
|
mkalus
shared this story
from |
Renew your passport earlier than planned, buy a GB sticker for your car, and prepare to wait four months before you can take your ferret on holiday: these are all among the snippets of advice offered by the government’s new Brexit website for British citizens planning to travel to the EU after 31 October.
The Get Ready site, which is accompanied by a major advertising campaign, launched on Sunday and unequivocally states that Brexit will happen by the end of next month. It asks users a series of multiple choice questions and spells out the precautions that individuals should take immediately to make sure they are prepared for the UK to crash out of the EU without a deal.
British citizens
British citizens resident in the UK who have become used to easily travelling across Europe are warned to ensure that their passport has at least six months to run and told they may once again have to pay roaming charges on their mobile phones.
They are also recommended to allow extra time for border checks at ports and airports and told to make sure they have travel insurance as the European health insurance card – which covers the cost of state-provided healthcare in EU countries – will not be valid in the event of a no-deal exit.
People taking their UK-registered vehicles abroad will have to carry additional paperwork proving their ownership of the vehicle and potentially obtain an international driving permit, while British drivers will face a fine if they do not stick a large GB sticker on their rear bumper, even if they already have the country listed on their numberplate.
Pets
Pet passports, which have made it easy for people who regularly travel abroad to take their cat, dog or ferret overseas, could become invalid in the event of no deal, with owners warned it could take up to four months to get the appropriate paperwork and blood tests from vets.
EU citizens in the UK
Although the Get Ready site largely collates existing government advice, the list of suggestions spells out in exacting detail the impact Brexit will have on people and businesses. EU citizens living in the UK are reminded to apply to the settlement scheme “as soon as possible” if they want to remain in the country, while European students are warned that their Erasmus+ placements at British universities may no longer be valid.
British citizens living in Europe
The advice is not detailed and does not spell out the seriousness of the consequences for Britons settled in Europe in the event of no deal. Under EU law they will become third-country nationals and will not be able to offer services to another EU country automatically or to travel for work in another EU country.
The campaign group British in Europe has frequently protested that the British government has forgotten about them. The new website merely advises that “you may not be able to continue living and using services in the EU if you are not a resident”, without spelling out the gravity of the end of free movement for Britons living in the EU.
The more complicated warnings are saved for businesses, although the website does not offer a hierarchy of risks. British companies are warned that they may need to pay for extra legal advice, should consider whether they need to appoint agents and representatives based in Europe, and warned of the extra regulation required if they want to continue trading in the EU after Brexit.
Businesses
The site warns manufacturers that they may need to change their labelling, companies that handle the data of EU citizens are told they may no longer be able to access it in the same way, and almost all companies are warned starkly: “You may not be able to trade goods with the EU if you do not get your business ready.”
Most of the recommended actions are listed with a warning to “do it as soon as possible”, but with fewer than 60 days to go until the planned Brexit day, small businesses checking the website for the first time may not have time to do all the required work.
Those unaffected
However, the site shows that not everyone is affected by Brexit. British nationals who live and work in the UK, do not run a business and have no plans to travel abroad are told to sit back and relax: “Based on your responses, you do not need to take any action to prepare for the Brexit deadline of 31 October 2019.”
I registered my bicycle in Bike Index
There was a reference to Bike Index in this video about securing your bicycle:
Cofounded by Seth Herr and Bryan Hance in 2013, Bike Index is a 501(c)(3) nonprofit.
It is the most widely used and successful bicycle registration service in the world with over 272,000 cataloged bikes, 810 community partners and tens of thousands of daily searches.
Seth built Bike Index when he was a bike mechanic because he wanted to be able to register bikes for his customers. Bryan developed and ran a community driven bicycle recovery service (StolenBikeRegistry.com) that recovered bikes from the first week it was created in 2004.
Merging the two services Seth and Bryan created the universal bike registration service they both dreamed of — a database used and searched by individuals, bike shops, police departments and other apps. A bike registry that gives everyone the ability to register and recover bicycles.
Simple. Efficient. Effective.
I followed through and registered my own bicycle (and in the process learned that my bicycle, like many, has a serial number stamped on the bottom bracket. Who knew!
Shipping Faster: The Hackday Mentality
We recently held our Summer Hackday at Tumblr and the results were impressive. I started to think about the mentality of a Hackday and how it differs from a more traditional product feature workflow.
It’s amazing what can be accomplished in a day.
Individuals or small groups start planning their projects in the days leading up to the event. On the day of the event, they’re off and running. They have 24 hours to get something working and demo it to the rest of the company.
Dead-end technical approaches are quickly discarded for alternatives, usually something more simple — the clock is ticking. There is no time for complexity or grand schemes. Get the basics working so you can impress your coworkers.

After the demo presentations, there is always discussion about “how close this project is to shipping?” or “what’s left to do before we could release this project?” or some other notion that we could productize certain projects after a little clean-up work.
Productize — The death knell of the Hackday project. But why? I think it’s scope creep. Scope of the purpose, but also scope of the code.
The constraint of limited time is a gift, forcing or removing decisions which create a better environment for completing the project. Hackday projects are often more aligned with the core purpose of the product as well.
- Focus on a singular purpose — try to be good at one thing.
- No time or space for complexity — you can’t build whole new architectures.
- Built on existing frameworks, patterns, and primitives — it fits into the existing product structure.
The Hackday mentality seems like a better process for building better products. It reminds me of the “fixed time, variable scope” principle from Basecamp’s Shape Up, a book describing their product process. They use six week time-boxes for any project.
Constraints limit our options without requiring us to do any of the cognitive work. With fewer decisions involved when we’re constrained, we’re less prone to decision fatigue. Constraints can actually speed up development.
Ship faster.
It’s a Long Game After All
Rolandtj
Reading this post feels a bit like reading one side of a conversation. David Wiley writes of responses to his recent post about the role of practice in learning, but with only four comments, and no links to other responses, we are left guessing a bit, especially about the responses that "called the discussion of practice unimaginative and accused me of underestimating the pedagogical change that OER is capable of catalyzing." Wiley's response to this criticism is to point out that "faculty can’t re-imagine their pedagogy in the context of the affordances of OER if they’re not using OER." I don't think that's strictly true; people can imagine the effects of things they're not currently doing. Indeed, they're not likely to start using OER unless they can predict at least some of the outcomes in advance.
Web: [Direct Link] [This Post]Weeknote 35/2019
You know that feeling after you come back from holiday and you let out a sigh and then get back to work? I did that again this week after a five-day long Bank Holiday weekend spent in Devon at my in-laws. We had a great time.
Don’t get me wrong, I enjoy the work I do, as far as work goes. But like most people, I think, given the current state of the world, there’s plenty of other things we could be doing with our time. MoodleNet will help with some of that, but obliquely. It’s going to help a certain group of people (educators) better teach another group of people (learners) so that they can, hopefully, improve our world.
I’ve written an update on the MoodleNet blog about where we are with the project. I have no major concerns right now, although the timeline for testing federation has slipped a bit.
The thing that’s taken a lot of my brain space this week is getting out the last two ever episodes of the TIDE podcast, which I recorded with my late co-host Dai Barnes. I added an intro and edited out part of the original recording we made back in June to publish Episode 119: AirDrop Crossfire on Thursday. Next week, I’ll release a memorial episode that I recorded with the help of Eylan Ezekiel and many audio contributions from friends and listeners to TIDE.
So it’s been a quiet week: driving back from Devon, working four days for Moodle, editing two podcast episodes, producing stuff for Thought Shrapnel, and then dealing with some drama when my son had to go to hospital after an accident involving him attempting some parkour. He’s OK, thankfully.
Next week, it’s back-to-school week for my kids, including a new school building for our youngest on the far side of town. So some logistics to deal with there, as she’s (just!) too young to walk there alone. Other than that, I’m taking Monday off and then working on MoodleNet stuff Tuesday to Friday.
Header image: photo of some street art at a skate park in Honiton, Devon
Welcome to the Econolypse | Part 1
We face an economic paradigm shift reshaping trade, markets, businesses, and how we live and work
Power
Some people choose to spend a lot of their time writing open source software and giving it to the world, freely. In this exchange, they aren’t quite employees, or volunteers, or entrepreneurs. It’s something new.
They build essential infrastructure, and people use it: companies, individuals, people just getting started in their programming careers. Companies especially benefit from these people’s free work, and in exchange the people who do that work get…
Well, nothing.
No, that’s not right: they get power.
They can delete projects, like how Azer Koçulu deleted left-pad, and cause some chaos. They can ban bad companies from their communities, like how entropic might ban Palantir. They can add whatever they want to their projects, like ads that fund their work, as Feross tried. They can ban those people with license text, like Jamie Kyle did.
Or maybe they can’t. NPM will intervene to make sure that the interests of companies are protected. The open source license that took a political stand is reverted to one that’s loose and company-friendly. The message is clear: keep working for free. Don’t quit: that would be irresponsible. Don’t protest: that’s disruptive. Your power, your control of your work, will disappear if you try to use it.
These Weeks in Firefox: Issue 63
Highlights
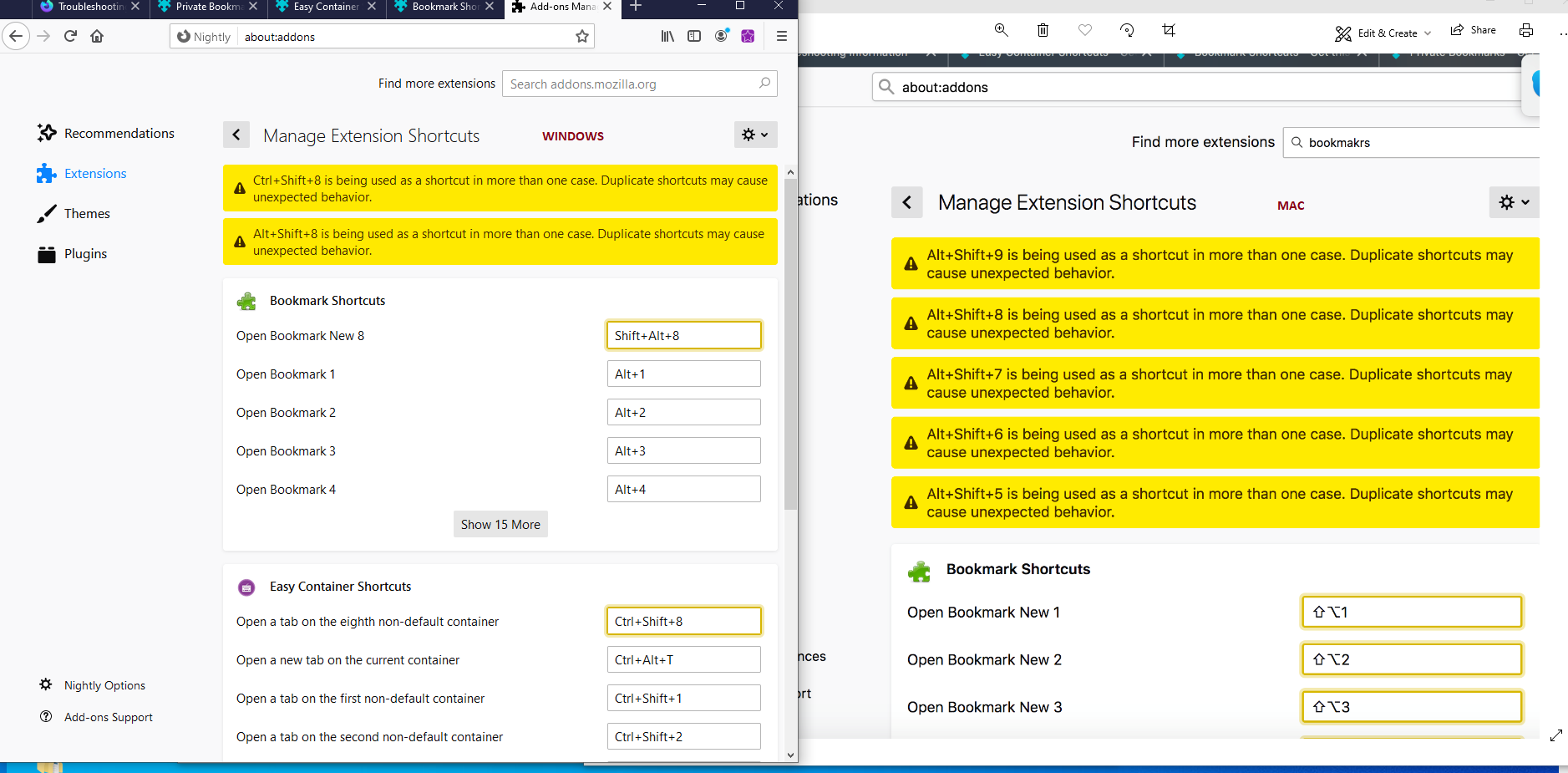
- The about:addons shortcut management view is now notifying users when there extensions are using the same shortcuts. Thanks to Trishul for contributing this enhancement.
- The new DOM Mutation Breakpoint feature allows the user to pause JS execution when the DOM structure changes. It’s now available behind a flag and ready for testing in Nightly! You need to flip the two following prefs to enable it:
- devtools.debugger.features.dom-mutation-breakpoints devtools.markup.mutationBreakpoints.enabled
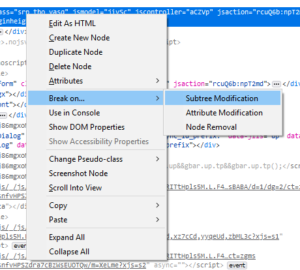
Use the Inspector panel context menu to create new DOM Mutation Breakpoints
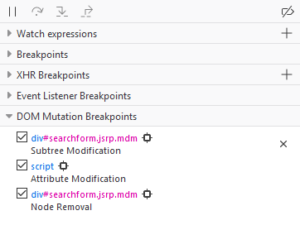
Use the debugger side panel to see existing DOM Mutation Breakpoints.
-
Inline Previews in the Debugger – showing actual variable values inline. This feature is also available behind a flag and ready for testing. You need to flip the following pref to enable it:
- Devtools.debugger.features.inline-preview
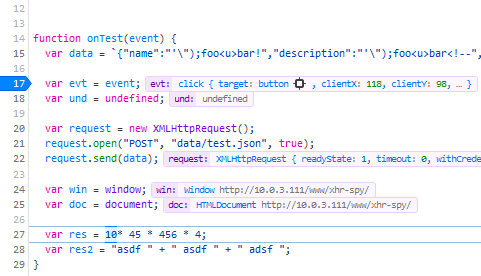
Note the inline boxes showing actual variable values
- We shipped an intervention for the Kazakh Government MitM, along with other major browsers.
- A big shout out to Carolina and Danielle, our Outreachy interns who built a new certificate viewer. Their internship ended a week ago, and their project is shipping in Firefox 71. It’s in Nightly right now, you should try it out.
- We’re still doing some polishing and fixing, you can follow development in the meta-bug.
Friends of the Firefox team
Resolved bugs (excluding employees)
Fixed more than one bug
- Arun Kumar Mohan
- Dennis van der Schagt [:dennisschagt]
- Dhyey Thakore [:dhyey35]
- Florens Verschelde :fvsch
- Heng Yeow (:tanhengyeow)
- Itiel
- Krishnal Ciccolella
- Megha [ :meghaaa ]
- Priyank Singh
New contributors (🌟 = first patch)
- Alex R. fixed a bug where the conditional / logpoint input field in the DevTools Debugger would collapse and not be able to come back
- Chris Muldoon fixed a visual glitch where sometimes the inspector icon would overlap the close icon in the Watch Expression list of the DevTools Debugger
- 🌟 Anurag Aggarwal brought the Responsive Design Mode input field borders in-line with the Photon design guidelines
- 🌟 Megha [ :meghaaa ] got rid of a chunk of dead code, removed an unnecessary variable from the Page Info dialog, and updated some of our tests to use the global waitForCondition utility!
- Priyank Singh made it so that long study names are properly displayed in about:studies, and also cleaned up some of our autocomplete-richlistitem custom element markup
- ruthra[:ruthra] eliminated some main-thread IO that the search service was doing during start-up!
- Krishnal Ciccolella made it so that variable tooltips in the DevTools Debugger have a height limit, and also updated the Scopes panel in the DevTools Debugger to use a monospace font
- singuliere improved our dynamically registered Telemetry Event support
Project Updates
Add-ons / Web Extensions
- Haik Aftandilian fixed a regression related to the macOS Notarization/Hardened Runtime that prevented Adobe Acrobat WebExtensions from working correctly on Catalina(macOs) Beta version because of a missing com.apple.security.automation.apple-events entitlement
- Luca fixed a bug that was preventing Firefox from being able to remove the temporary xpi files for the installed extensions on Windows, and a couple of followup fixes related to the Abuse Reporting feature (Bug 1574431 and Bug 1572173)
- Shane landed the initial version of the Extension’s ActivityLogging privileged API (which allows a privileged extension to monitor the activity of the other installed extensions)
- Privileged extensions can now access the HttpTrafficAnalyzer urlClassification as part of the details received by the webRequest event listeners
- Mark fixed a regression in the screen reader accessibility of the new HTML about:addons views, and also applied some other improvements to the new HTML about:addons views (Bug 1557175, Bug 1560155)
- Tom Schuster enabled the downloads API to set the Referer header
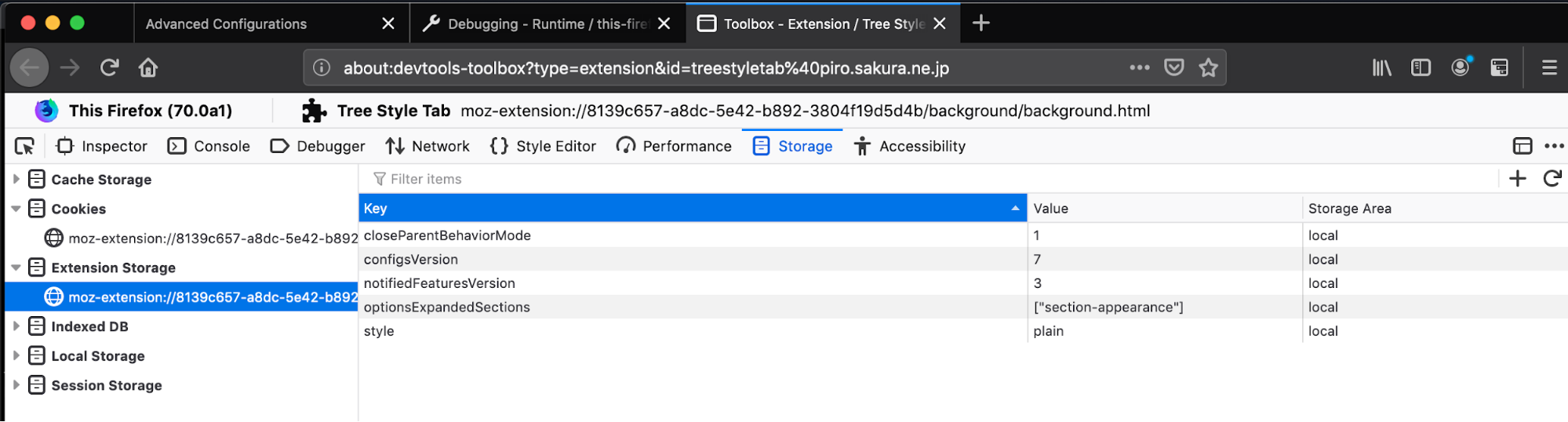
- Firefox can now inspect Extensions storage.local data from the Addon Debugging DevTools storage panel (a feature request tracked by a 3+ years old meta bug), thanks a lot to Bianca Danforth for working on this feature! (the feature is currently locked behind the devtools.storage.extensionStorage.enabled pref, we invite you to give the feature a try in a recent Nighty build by flipping the pref and provide us your feedback)
Developer Tools
Debugger
- Disable debugger; statement – It is now possible to disable a debugger statement via a false-conditional breakpoint created at the same location (bug).
Network
-
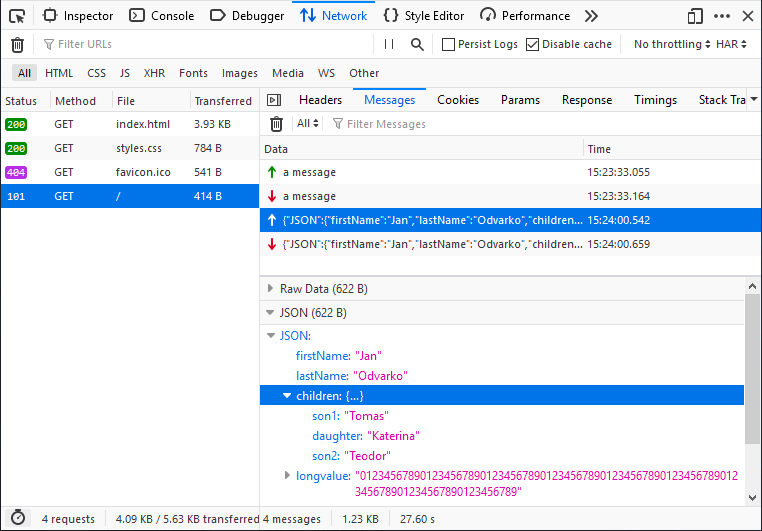
WebSocket Inspection (GSoC project) – This feature is enabled on Nightly by default (devtools.netmonitor.features.webSockets)
- Supported protocols Socket.IO, SockJS, plain JSON (and MQTT soon)
- WS frames Filtering supported (by type & by free text)
- A test page
- Heads Up: Search across all files/cookies/headers in the Network panel coming soon! (Outreachy)
Perf Tools
-
JavaScript Allocations – tracking for JS allocations added. It’s still experimental but you can enable it by checking “JS Allocations” in recording panel feature flags
- (Example profile: https://perfht.ml/301avXy)

Accessibility Panel
- A new option to auto-scroll to the selected node has been added to the panel tree
Fission
- You can now run mochitest locally with Fission-enabled using –enable-fission.
- Work to get tests working with Fission-enabled is proceeding well. Here’s a spreadsheet with a graph.
- Neil is very close to getting the LoginManager and Autocomplete code ported over to be Fission-compatible
- emalysz has a patch up to port the Page Info dialog to be Fission-compatible
- Abdoulaye got the following chunks of work done:
- Thank you to Abdoulaye for a great job during his internship!
Lint
- ESLint has been updated to 6.1.0 (from 5.16.0). This helped us with a few things:
- Running –fix over the entire tree should now work for pretty much everything that’s auto-fixable. Previously it would stop working at the `js/` directories, and then you’d have to run it manually on the remaining sub-directories (e.g. services, toolkit etc etc).
- If you have an /* global foo */ statement for ESLint and foo is unused, it will now throw an error.
- There’s also now a new rule enabled on most of the tree: no-async-promise-executor. This aims to avoid issues with having asynchronous functions within new Promise()
- ESLint will also be upgraded to 6.2.2 within the next couple of days. The main addition here is support for BigInt and dynamic imports.
New Tab Page
- In Firefox 69 we’re launching “Discovery Stream” which is a newtab experience with more Pocket content. We’re doing this with a rollout on Sept 10th.
Password Manager
-
Management UI
- Footer advertising links to Lockwise mobile apps
- Set a maxVersion of 69 for Lockwise extension and update the description to tell users the feature is built-in now
- Now displaying HTTP auth realms in about:logins and autocomplete
- Enable breach alerts in about:logins for all releases
- Loading about:logins during session restore now shows all logins as expected
- Various design tweaks
- (Bugzilla query for all bugs fixed in the last two weeks)
Performance
- A new Talos test is being added to measure warm start-up times with a number of popular real-world add-ons installed
- dthayer and mconley met with rhelmer about trying to do more work behind-the-scenes in the stub installer before launching the first browser window to improve perceived startup time
- Mandy has a patch up to avoid doing more main-thread IO during start-up, and also has her eyes set on one other bug before her internship closes out
- dthayer has a prototype where the content process is launched really early during Firefox start-up with a static about:newtab page
- Initial measurements are encouraging. We’re going to take more measurement to build our confidence and then see how we can go about making this happen.
- Florian has a prototype of a tool that distills BHR (Background Hang Reporter) data to give us a sense of where we’re dropping the ball for responsiveness
- Gijs is trying to avoid some main-thread IO during start-up caused by our plugins code. The fact that Flash is now click-to-play by default makes this a bit easier.
- mconley disabled the Privileged About Content Process for about:home, since it’s been held to Nightly for long enough without riding, and it’s better to test what we ship.
- mconley finished off aswan’s patch to make Firefox Monitor a built-in browser component
- emalysz has a WIP patch up for review to make some more Telemetry stuff lazier, and avoid mainthread IO during start-up.
- Thank you to Mandy for all her excellent work during her internship!
Picture-in-Picture
- A preference has been added to about:preferences to control the Picture-in-Picture video toggle
- A context menu has been added to the Picture-in-Picture video toggle to make it easier to hide
- The VIDEO_PLAY_TIME_MS Telemetry probe has been revived so we can measure whether or not there’s a correlation between users who use Picture-in-Picture, and the amount of video they watch.
- We’ve settled on a keyboard shortcut (Ctrl-Shift-]) for initializing Picture-in-Picture for the first available video in the focused window
- Fixed a bug where some videos are displayed with strange padding in the Picture-in-Picture player window
Privacy/Security
- We announced that we’re moving the EV indicators out of the URL bar.
- The lock icon is now grey.
- Steven enabled fingerprinting protection by default in all channels.
- Cryptomining is already shipping with 69.
- Cryptoming and Fingerprinting protections are now available as enterprise policies
- jkt sent out an intent to unship for AppCache
- We’ll be slowly and carefully phasing it out
- Plans for better MitM response mechanisms with customized error messages: https://bugzilla.mozilla.org/show_bug.cgi?id=1569357
- Based on recent experiment data we updated the notification permission doorhanger to “Never Allow” by default.
Search and Navigation
-
Search
- Work continues on modernising the search configuration.
- Work has also started on allowing users to define a separate search engine to use in private browsing mode.
-
Quantum Bar
- Work continues on the “megabar” redesign
- Simplified one-off buttons design landed
- The TopSites experiment (use new tab page sites list as the empty search result) is close to be ready for deployment. First experiment running on Quantum Bar.
User Journey
- Lots of work around messaging for Skyline to increase Firefox Accounts
- What’s New panel with tracking protection block counts
- Protections Panel and additional teams building on CFR, e.g., password save trigger, social tracking protection
Uplifted to 69 beta: Moments page, New Monitor snippet, Extended Triplets
Unknown Knowns and Explanation-Based Learning
Like me, you probably see references to this classic quote from Donald Rumsfeld all the time:
There are known knowns; there are things we know we know. We also know there are known unknowns; that is to say, we know there are some things we do not know. But there are also unknown unknowns -- the ones we don't know we don't know.
I recently ran across it again in an old Epsilon Theory post that uses it to frame the difference between decision making under risk (the known unknowns) and decision-making under uncertainty (the unknown unknowns). It's a good read.
Seeing the passage again for the umpteenth time, it occurred to me that no one ever seems to talk about the fourth quadrant in that grid: the unknown knowns. A quick web search turns up a few articles such as this one, which consider unknown knowns from the perspective of others in a community: maybe there are other people who know something that you do not. But my curiosity was focused on the first-person perspective that Rumsfeld was implying. As a knower, what does it mean for something to be an unknown known?
My first thought was that this combination might not be all that useful in the real world, such as the investing context that Ben Hunt writes about in Epsilon Theory. Perhaps it doesn't make any sense to think about things you don't know that you know.
As a student of AI, though, I suddenly made an odd connection ... to explanation-based learning. As I described in a blog post twelve years ago:
Back when I taught Artificial Intelligence every year, I used to relate a story from Russell and Norvig when talking about the role knowledge plays in how an agent can learn. Here is the quote that was my inspiration, from Pages 687-688 of their 2nd edition:Sometimes one leaps to general conclusions after only one observation. Gary Larson once drew a cartoon in which a bespectacled caveman, Zog, is roasting his lizard on the end of a pointed stick. He is watched by an amazed crowd of his less intellectual contemporaries, who have been using their bare hands to hold their victuals over the fire. This enlightening experience is enough to convince the watchers of a general principle of painless cooking.
I continued to use this story long after I had moved on from this textbook, because it is a wonderful example of explanation-based learning.
In a mathematical sense, explanation-based learning isn't learning at all. The new fact that the program learns follows directly from other facts and inference rules already in its database. In EBL, the program constructs a proof of a new fact and adds the fact to its database, so that it is ready-at-hand the next time it needs it. The program has compiled a new fact, but in principle it doesn't know anything more than it did before, because it could always have deduced that fact from things it already knows.
As I read the Epsilon Theory article, it struck me that EBL helps a learner to surface unknown knowns by using specific experiences as triggers to combine knowledge it already into a piece of knowledge that is usable immediately without having to repeat the (perhaps costly) chain of inference ever again. Deducing deep truths every time you need them can indeed be quite costly, as anyone who has ever looked at the complexity of search in logical inference systems can tell you.
When I begin to think about unknown knowns in this way, perhaps it does make sense in some real-world scenarios to think about things you don't know you know. If I can figure it all out, maybe I can finally make my fortune in the stock market.
Imagine if we didn’t know how to use books – notes on a digital practices framework
How do we solve for – “but we need to train everyone to teach with the internet?” It’s a problem.
No really. We’ve got a bunch of yahoos wandering around telling people that all we need to do is code and we’ll be fine. That actually has nothing to do with the actual real problem we have. We have this massive knowledge making engine that we aren’t in any way prepared to teach anyone how to use. Not morally. Not ethically. Not practically. Imagine if we didn’t know how to use books… THAT’S WHERE WE ARE. This is a vision on how you might think about training hundreds/thousands of people to learn how to use books… if books were the internet.

This image is a draft of a model i had designed for preparing an education system for the internet. As you see it here it has had some input from folks like Lawrie Phipps but it hasn’t gone through any kind of review process. The idea is that some people are never going to make it all the way to being ready to teach with or on the internet. At least not in the short term. I offer it as a draft for feedback.
I’ve talked a bit about the 20/60/20 model of change. The idea is that the top 20% of any group will be game for anything, they are your early adopters, always willing to try the next best thing. The bottom 20% of a group will hate everything and spend most of their time either subtly slowly things down or in open rebellion. The middle 60% are the people who have the potential to be won or lost depending on how good your plan is. They are the core of your group, the practical folks who will take on new things if they make sense, if they see that they have time. They are always the people we want to encourage. If they buy into your project… you’re a winner.
There are three streams to this model that eventually leads towards people being able to function as good online learning facilitators. The top stream is about all the sunshine and light about working with others on the internet. It’s advantages and pitfalls, ways in which to promote prosocial discourse. The middle stream is about pragmatics. The how’s of doing things, it starts out with simple guidelines and moves forward the technical realities of licensing, content production and tech using. The bottom stream is about the self. How to keep yourself safe, how to have a healthy relationship with the internet from a personal perspective.
Level 1 – Awareness
This model is an attempt to set some standards for things that everyone should be aware of. This is a non-negotiable, you can’t opt out of this conversation, you must participate to this level kind of thing. There are any number of reasons why some people wouldn’t want to participate passed the first literacy level. There are people, certainly, who are just ornery and hate anything that isn’t what they currently see as normal. Lets leave those people aside.
There are many marginalized people, who have been stalked, attacked or otherwise had very negative experiences on the web. There are people with legitimate fears of what their interactions on the internet could turn out to look like. There are others with religious reasons for not collaborating in one fashion or another. I don’t think that we should force those people to go beyond the level of awareness.
Every teacher (and anyone else responsible for a child) should be aware of the dangers of private, obfuscated or otherwise dark communities online. There are an abundance of folks out there who are directly targeting young people in an attempt to radicalize them for one reason or another. Whether its groups that target misinformation against common searches or discussion forums that misrepresent cultural groups, there are a lot of dangerous places on the internet. Everyone should understand this.
This level responds to best practice. The people who never make it past awareness will not be able to necessarily understand the complexity of digital practices and therefore should have a list of dos and don’ts that they can refer to that needed have interpretation. “Don’t let kids use reddit” Does that mean that no one should use it? No. Just that if you haven’t put the time in to understand your own digital practices and those of others, you should stay on the safe side.
If training people is something that you are going to do, I would suggest that the development of these best practices should be at the top of your list. Keeping learners safe is as much about explaining the simple dangers as anything else. Make a postcard of info, steal it from the internet, and paste it next to every computer.
Level 2 – Learning
As we move past awareness to learning online, you’ll notice we’ve left our bottom 20% behind. I don’t think it makes sense to try and bring every person to this point. There are people just before retirement who may be uninterested (though, I should add, many of the best digital practices people I’ve met have been near the end of their career) and for a myriad of other reasons… we shall leave the resistors behind.
This level is going to respond well to some complicated challenges that allow participants to see the power of digital practices to influence and improve their learning experience. I say complicated activities and not complex ones, here, because for the tentative, early success is important. When I’ve given overly open ended projects to people new to working on the internet, they can often flounder. Too much abundance of content too quickly. Try for projects where multiple but not indefinite outcomes are possible. Gradual release of responsibility is key to ensure that you can ensure the best possible first experiences.
This is also where the deprogramming should start. People are going to be coming to these activities expecting to hear about a new app or to get ‘training’ on how to use a particular piece of software. They’re going to be looking for ‘take-aways’ that they can use in their own lives that will make the time spent worthwhile. I’m not suggesting that you shouldn’t throw in a couple of those (some people will never make it passed level 2) but you should make it clear that this is an early spot on the journey. This is less about a few tricks that can make your life easier, and more about a shift to understanding how knowledge actually works now.
As people make their first claims to identity (twitter/blog/discussion space?) it’s important to build on the early identity and safety discussions from level 1. I make particular note here to straight, white, heterosexual males. The internet can be a dangerous place to other people in ways that it simply isn’t to you. Including people into the internet discussion requires full disclosure on the trainer/guide’s part. If you don’t have a good grasp on what those dangers are, do some reading and call in a friend.
Learning on the internet… that sense that you can find the things that you need if you know how to search for them properly, takes time and authentic activities. It also takes a growing understanding that ‘the thing’ you are looking for is not actually one thing. With access to so many perspectives, ‘the thing’ can be elusive. The learner’s key skills shift away from certainty and towards decision making between various options. It also takes reflexive activities. You need to give people a chance to find, the opportunity to ask others they don’t know, and then the time to have successes and failures.
There are certainly some technical pieces that should be introduced at this point I suppose… A good example is the usage of citation services. Zotero allows you to keep track of the things you find and has the advantage, if you’re going to do any academic writing, of formatting your pages into proper citations. More importantly, however, it’s a way of keeping track of the stuff you’ve found that you might need later and applying a little bit of structure to it. A good, simple technical piece that allows the work done at this stage to be useful later.
Level 3 Interacting and making
Things start to get messy here as learners should be introduced to both the complex end of working on the internet AND some of the complicated PITA that is associated with being a producer as well as a consumer of content. People are going to gravitate with their predilections (technical knowledge or complex application) but i think a good balance here is important.
So much of the ‘learning how’ technical pieces, however, are actually about realizing that things are possible. If you’re using a wordpress blog to claim your digital identity space, develop ideas or track your research, a quick look behind the curtain will show you what you can add to your wordpress setup. Basically, if you can think of it (and its possible) someone has probably made a plugin that will allow you to do it. The ‘technical’ part here is more about understanding the conceptual way the internet is made and how you can use that to your advantage. We aren’t, most of us, coding our way to solutions anymore, it’s not really necessary.
Some of the technical pieces here are also about what the technology can’t do. With all the yacking about Artificial intelligence and machine learning right now, it’s important that we demystify its usage in the learning process. Much of the research around AI’s advantages speak to improvement in student’s memory retention or adoption of repetitive skills. I mean, those are useful, but they may not be goals that you have for the learning process. Analytics and the rights of students is a critical topic that simply can’t be overlooked.
At this point we’re also hoping that people are able to connect with social groups and being able to discern whether or not the space they are looking to work is a healthy one or not. Some folks would suggest that reddit is best avoided, but some of those spaces can be the best places to meet like minded people. Its the analysis of the space and its safety/fit that’s the critical literacy at this point.
That kind of active participation where people are not only using the internet to ask questions but also giving back is not for everyone. The suggested participation here is about 60%… that may be high. You have to take your profession pretty seriously to be willing to contribute, and the contribution experience is not positive and supportive for all people alike.
Level 4 – Teaching
Once we’ve made our way through the literacies, we get to the point of preparing to actually organize a learning experience online. There are a number of shifts that occur when we get to this point, but perhaps the most important one is that people are not going to be working with self-selecting folks in your fun community looking to learn together. I mean… they might be, it’s just not likely to happen as much as you’d like. While it would be awesome if we were all able to teach in environments where our learners were ecstatic to learn what we have to teach them, the truth of the matter is a different thing entirely.
There are many folks who would argue that teaching online (well) requires more effort than teaching face 2 face. There are certainly different pitfalls, and starting is much harder online than it is face 2 face. Everyone’s teaching journey is going to be a different one and, as indicated in the percentages in the chart, I don’t really expect the majority of people to get there.
If we see the preparation for teaching online to include the key factors of personal identity management and wellness, a keen understanding of the collaborative power of abundance and community networks and a relatively good understanding of the complicated pieces involved in the tech… I think we’re doing a reasonable job preparing folks for the road ahead.
At the end of the day teaching online, like any teaching, is a personal journey. You can learn from others, adopt skills and literacies through study and observation, but we are all going to be different teachers in the end. Experience can be the only long term guide.

Recommended on Medium: Service Workers at Slack: Our Quest for Faster Boot Times and Offline Support

By Jim Whimpey
We recently rolled out a new version of Slack on the desktop, and one of its headlining features is a faster boot time. In this post, we’ll take a look back at our quest to get Slack running quickly, so you can get to work.
The rewrite began as a prototype called “speedy boots” that aimed to–you guessed it–boot Slack as quickly as possible. Using a CDN-cached HTML file, a persisted Redux store, and a Service Worker, we were able to boot a stripped-down version of the client in less than a second (at the time, normal boot times for users with 1–2 workspaces was around 5 seconds). The Service Worker was at the center of this speed increase, and it unlocked the oft-requested ability to run Slack offline as well. This prototype showed us a glimpse of what a radically reimagined desktop client architecture could do. Based on this potential, we set about rebuilding a Slack client with these core expectations of boot performance and offline support baked in. Let’s dive into how it works.
What is a Service Worker?
A Service Worker is a powerful proxy for network requests that allows developers to take control of the way the browser responds to individual HTTP requests using a small amount of JavaScript. They come with a rich and flexible cache API designed to use Request objects as keys and Response objects as values. Like Web Workers, they live and run in their own process outside of any individually running window.
Service Workers are a follow-up to the now-deprecated Application Cache, a set of APIs previously used to enable offline-capable websites. AppCache worked by providing a static manifest of files you’d like to cache for offline use… and that was it. It was simple but inflexible and offered no control to developers. The W3C took that feedback to heart when they wrote the Service Worker specification that provides nuanced control of every network interaction your app or website makes.
When we first dove into this technology, Chrome was the only browser with released support, but we knew universal support was on its way. Now support is ubiquitous across all major browsers.
How We’re Using Service Workers
When you first boot the new version of Slack we fetch a full set of assets (HTML, JavaScript, CSS, fonts, and sounds) and place them in the Service Worker’s cache. We also take a copy of your in-memory Redux store and push it to IndexedDB. When you next boot we detect the existence of these caches; if they’re present we’ll use them to boot the app. If you’re online we’ll fetch fresh data post-boot. If not, you’re still left with a usable client.
To distinguish between these two paths we’ve given them names: warm and cold boots. A cold boot is most typically a user’s first ever boot with no cached assets and no persisted data. A warm boot has all we need to boot Slack on a user’s local computer. Note that most binary assets (images, PDFs, videos, etc.) are handled by the browser’s cache (and controlled by normal cache headers). They don’t need explicit handling by the Service Worker to load offline.
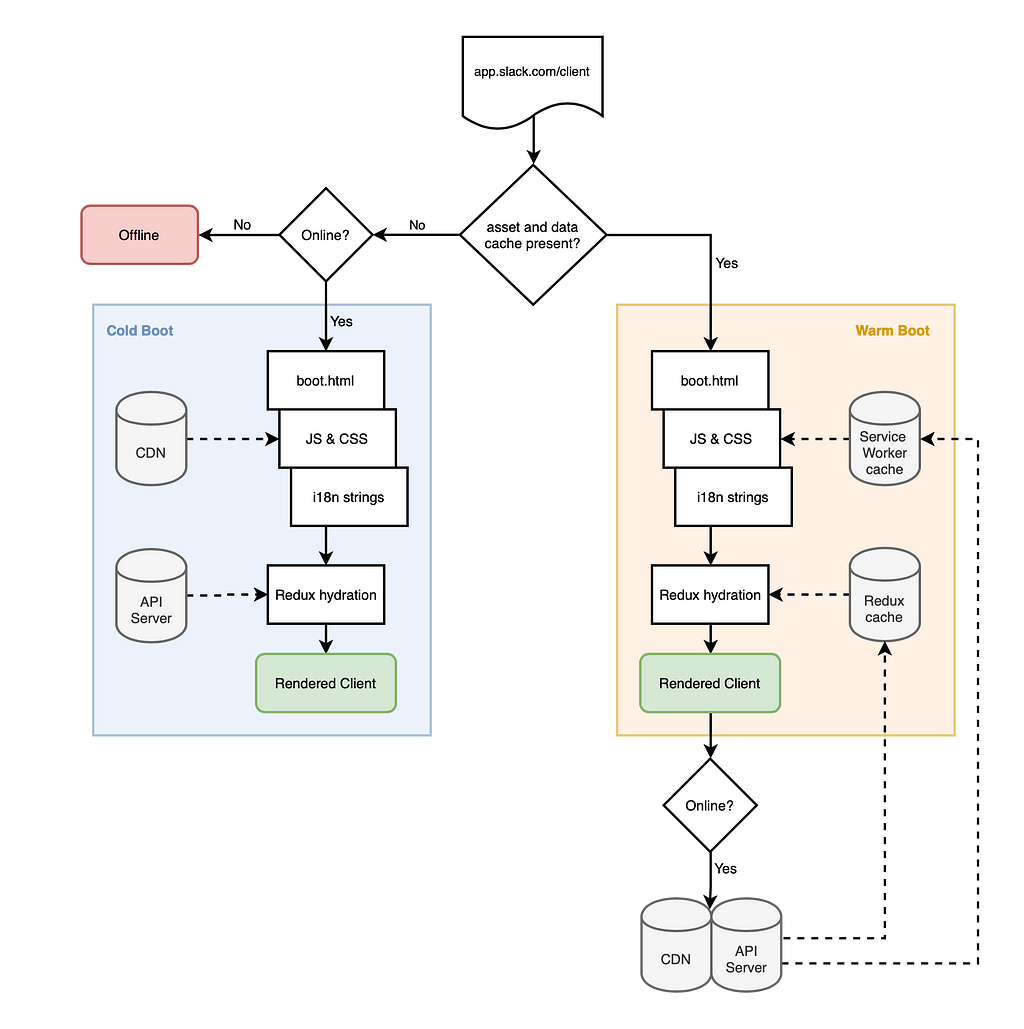
The Service Worker Lifecycle
There are three events a Service Worker can handle: install, fetch, and activate. We’ll dig into how we handle each but first we’ve got to download and register the Service Worker itself. The lifecycle depends on the way browsers handle updates to the Service Worker file. From MDN’s API docs:
Installation is attempted when the downloaded file is found to be new — either different to an existing Service Worker (byte-wisecompared), or the first Service Worker encountered for this page/site.
Every time we update a relevant JavaScript, CSS, or HTML file it runs through a custom webpack plugin that produces a manifest of those files with unique hashes (here’s a truncated example). This gets embedded into the Service Worker, triggering an update on the next boot even though the implementation itself hasn’t changed.
Install
Whenever the Service Worker is updated, we receive an install event. In response, we loop through the files in the embedded manifest, fetching each and putting them in a shared cache bucket. Files are stored using the new Cache API, another part of the Service Worker spec. It stores Response objects keyed by Request objects: delightfully straight-forward and in perfect harmony with the way Service Worker events receive requests and return responses.
We key our cache buckets by deploy time. The timestamp is embedded in our HTML so it can be passed to every asset request as part of the filename. Caching the assets from each deploy separately is important to prevent mismatches. With this setup we can ensure our initially fetched HTML file will only ever fetch compatible assets whether they be from the cache or network.
Fetch
Once registered, our Service Worker is setup to handle every network request from the same origin. You don’t have a choice about whether or not you want the Service Worker to handle the request but you do have total control over what to do with the request.
First we inspect the request. If it’s in the manifest and present in the cache we return the response we have cached. If not, we return a fetch call for the same request, passing the request through to the network as though the Service Worker was never involved at all. Here’s a simplified version of our fetch handler:
self.addEventListener('fetch', (e) => {
if (assetManifest.includes(e.request.url) {
e.respondWith(
caches
.open(cacheKey)
.then(cache => cache.match(e.request))
.then(response => {
if (response) return response;
return fetch(e.request);
});
);
} else {
e.respondWith(fetch(e.request));
}
});In the actual implementation there’s much more Slack-specific logic but at its core the fetch handler is that simple.

Activate
The activate event triggers after a new or updated Service Worker has been successfully installed. We use it to look back at our cached assets and invalidate any cache buckets more than 7 days old. This is generally good housekeeping but it also prevents clients booting with assets too far out of date.
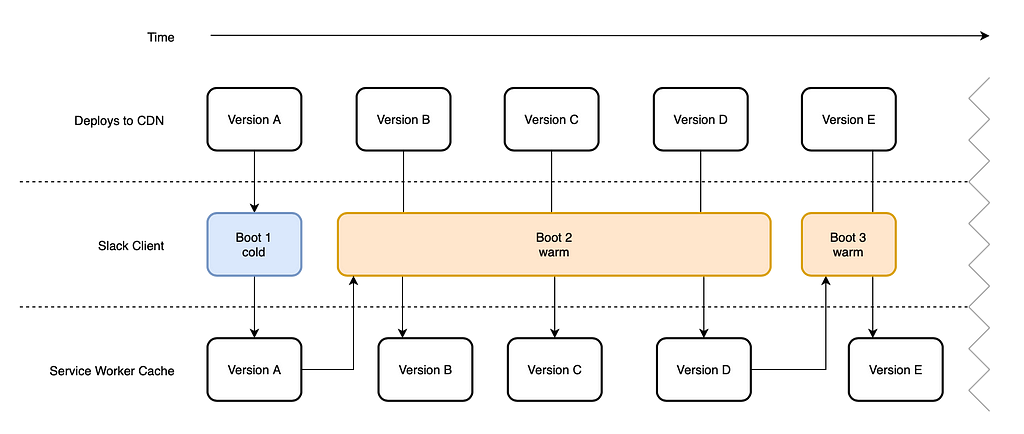
One Version Behind
You might have noticed that our implementation means anyone booting the Slack client after the very first time will be receiving assets that were fetched last time the Service Worker was registered, rather than the latest deployed assets at the time of boot. Our initial implementation attempted to update the Service Worker after every boot. However, a typical Slack customer may boot just once each morning and could find themselves perpetually a full day’s worth of releases behind (we release new code multiple times a day).
Unlike a typical website that you visit and quickly move on from, Slack remains open for many hours on a person’s computer as they go about their work. This gives our code a long shelf life, and requires some different approaches to keep it up to date.
We still want users on the latest possible version so they receive the most up-to-date bug fixes, performance improvements, and feature roll outs. Soon after we released the new client, we added registration on a jittered interval to bring the gap down. If there’s been a deploy since the last update, we’ll fetch fresh assets ready for the next boot. If not, the registration will do nothing. After making this change, the average age of assets that a client booted with was reduced by half.
Feature Flag Syncing
Feature flags are conditions in our codebase that let us merge incomplete work before it’s ready for public release. It reduces risk by allowing features to be tested freely alongside the rest of our application, long before they’re finished.
A common workflow at Slack is to release new features alongside corresponding changes in our APIs. Before Service Workers were introduced, we had a guarantee the two would be in sync, but with our one-version-behind cache assets our client was now more likely to be out of sync with the backend. To combat this, we cache not only assets but some API responses too.
The power of Service Workers handling every network request made the solution simple. With each Service Worker update we also make API requests and cache the responses in the same bucket as the assets. This ties our features and experiments to the right assets — potentially out-of-date but sure to be in sync.
This is the tip of the iceberg for what’s possible with Service Workers. A problem that would have been impossible to solve with AppCache or required a complex full stack solution is simple and natural using Service Workers and the Cache API.
Bringing It All Together
The Service Worker enables faster boots by storing Slack’s assets locally, ready to be used by the next boot. Our biggest source of latency and variability, the network, is taken out of the equation. And if you can take the network out of the equation, you’ve got yourself a head start on adding offline support too. Right now, our support for offline functionality is straightforward — you can boot, read messages from conversations you’ve previously read and set your unread marker to be synced once you’re back online — but the stage is set for us to build more advanced offline functionality in the future.
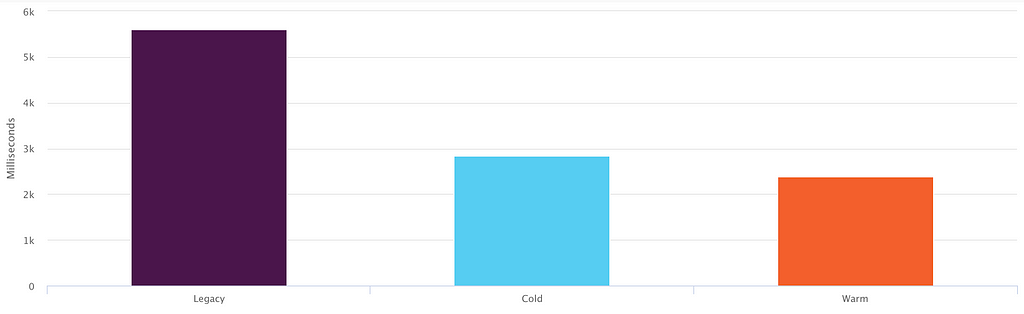
After many months of development, experimentation, and optimization, we’ve learned a lot about how Service Workers operate in practice. And the technology has proven itself at scale: less than a month into our public release, we’re successfully serving tens of millions requests per day through millions of installed Service Workers. This has translated into a ~50% reduction in boot time over the legacy client and a ~25% improvement in start time for warm over cold boots.
If you like optimizing the performance of a complex and highly-used web app, come work with us! We still have a lot of work left to do.
Huge thanks to Rowan Oulton and Anuj Nair who helped implement our Service Worker and put together this blog post.
Service Workers at Slack: Our Quest for Faster Boot Times and Offline Support was originally published in Several People Are Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This GoPro sucks
|
mkalus
shared this story
from |
As our steel bar surface is doused with a range of solvents on a daily basis, the pattern on it changes over time. I wanted to shoot a time lapse of it to watch it seethe. I was thinking like: a photo a day for six months.
First, I bought a Brinno camera, which is advertised as a time-lapse camera for job sites, with long battery life. They have 8 models, no grid comparing the features or specs, and no rhyme or reason to their pricing or model number ordering. I bought the one that claimed it had 20x optical zoom, but that was a lie, it's unadjustable super-wide-angle just like the others. The only way to get photos off of it is to pop the card. It's junk.
First, the maximum delay between photos is 60 seconds. So that's a whole lot of extra photos that I don't need. Which means I will have to offload those photos every few days to avoid filling up the card.
Getting photos off of it is incredibly tedious:
- Connect phone to GoPro over some Frankenfuckery that requires both Bluetooth and a private wifi network, WTF;
- Stop camera from recording;
- Download photos from GoPro to GoPro phone app (very slow);
- Delete photos from GoPro;
- Adjust camera zoom, because it resets every time;
- Start camera recording again;
- Transfer photos from GoPro phone app to Photos app (very slow);
- Delete photos from GoPro phone app;
- Finally you can get the photos from your phone to your computer.
Also it just... turns off at random. It's on unswitched wall power and it won't seem to stay awake for longer than 16 hours. Several times it has stopped after exactly 81 shots (minutes). There's a "go to sleep after" setting which defaults to 15 minutes but I have set to "none" and this is still happening. Also 81 is notably not 15.
And sometimes, my phone just won't connect to it. Rebooting the phone didn't work, but rebooting the GoPro did -- you know how you do that? You get up on a ladder, pull it down from the ceiling, unplug the wall power, take it out of the case, and pull the battery because there's no actual power button. Super convenient.
So, I've got this old cracked iPhone 6, and now I'm thinking maybe I should just tape that to the ceiling and run some time-lapse software on that instead. Probably should have started with that.
Dear Lazyweb, any recommendations on iOS time-lapse software? What I'm looking for is:
- Ability to set the delay between shots to a large number, preferably 1 to 24 hours;
- Ability to offload photos/videos without needing to un-mount the phone from the ceiling or attach a computer to it;
- Bonus points if it will upload the photos/videos to iClown or Dropbox or somesuch on a semi-regular basis.
'Cars don't cause crashes, drivers do': New ICBC premium rates take effect Sunday
| mkalus shared this story . |
The Insurance Corporation of British Columbia (ICBC) is introducing a new way of calculating basic insurance premiums, effective Sept. 1.
For drivers renewing their policies under the new system, the difference in insurance premiums can range from hundreds of dollars to a couple thousand — either in savings or in additional costs, depending on the individual case.
"This is about calculating rates in a way that is more fair," said Tyler McGilvery, business process advisor for ICBC. "Cars don't cause crashes, drivers do."
Starting Sunday, driving experience and crash history play a bigger role in determining the cost of insurance than before.
Ahead of the changes, ICBC released an online rate calculator tool where British Columbians can get an estimate of their basic insurance premiums.
Playing around with the calculator and changing the variables — like years of experience and crash history of a secondary listed driver — leads to a price shift of a couple hundred dollars in either direction.
The premium is primarily determined by who's behind the wheel, based 75 per cent on the main driver and 25 per cent on the incidental driver with the highest level of risk.
Previously, crash history followed the vehicle rather than the driver.
One in five crashes in B.C. are caused by someone who is not a registered owner or principal driver, according to McGilvery.
"By asking customers to provide their drivers, we're able to more accurately rate based on the true risk of who is driving the vehicle," he said.
Although the changes take effect Sept. 1, roughly 1,200 British Columbians insured their vehicles under the new algorithm by renewing in advance.
Of those, about 43 per cent saw an average insurance increase of $212 a year, while 56 per cent saw an average decrease of $329 annually.
For some outliers though, the change is much more drastic, with changes of up to $2,000 because of previous crash history.
"We're holding drivers more accountable for their driving decisions," McGilvery said.
"Drivers who demonstrate risky driving behaviour or cause crashes will pay more so that safe drivers pay less."
Proud UPEI Parent
Today is the start of New Student Orientation week at the University of PEI and Oliver is diving in with all feet.
As I write he is off on a campus tour while I chill in the parent lounge and drink coffee from my parent mug.
Thirty-five years ago this week I was in Oliver’s shoes; I told him, as we were cycling up to campus this morning, that I felt nervous, to which his response was “what have you got to be nervous about?!”
I am, indeed, a proud UPEI parent.

Nokia Tops the List When It Comes to Smartphone Software and Security Updates
 Android has always received flak for not offering timely updates to a majority of its devices. Most of us don’t realize that manufacturers have to put in extra efforts in order to release the update. And some of the devices won’t even receive a single major Android update in their lifetime. Counterpoint has released a report that shows the frequency of updates by different manufacturers.
Continue reading →
Android has always received flak for not offering timely updates to a majority of its devices. Most of us don’t realize that manufacturers have to put in extra efforts in order to release the update. And some of the devices won’t even receive a single major Android update in their lifetime. Counterpoint has released a report that shows the frequency of updates by different manufacturers.
Continue reading →
Google found five iPhone exploits used by malicious websites for years

Google Project Zero researchers have uncovered a slew of hacked websites that delivered attacks to iPhones.
The attacks were not targeted: any iPhone that visited one of the websites would receive malware designed to hack into it and gain access to files and steal location data. Google says the sites were operational for years and received thousands of visitors every week.
Project Zero worker Ian Beer shared a blog post outlining the five exploit chains which allowed for a total of 14 vulnerabilities: seven for the iPhone’s web browser, five for the kernel and two separate ‘sandbox escapes.’ In computer security, a ‘sandbox’ typically refers to a mechanism for separating running programs to execute untested or untrusted software. Sandboxes usually control resources tightly and restrict or prevent access to essential system functions.
Project Zero worked with Google’s Threat Analysis Group (TAG), which initially uncovered the websites and vulnerabilities. According to Beer, the exploits covered versions of Apple’s mobile operating system from iOS 10 to the current version of iOS 12.
At least one of the vulnerabilities made use of a zero day exploit. Zero day exploits refer to vulnerabilities that companies — in this case, Apple — aren’t aware of. In other words, the company has zero days to find a fix.
Google warned Apple of the vulnerabilities in February, and the company has since fixed the issues, according to Beer.
Exploits stole files, location data and gained keychain access
Once the attack successfully exploited an iPhone, it could deploy malware on the device. Beer wrote that the malware implant primarily focused on stealing files and uploading location data.
It also accesses the user’s keychain, which contains passwords and databases of end-to-end encrypted messaging apps like Telegram, WhatsApp and iMessage. While the encryption on these apps can protect messages in transit, it doesn’t protect messages if a hacker compromises one of the end devices.
Thankfully, the malware doesn’t have persistence. In other words, if you reboot your iPhone, it wipes the malware. However, the infection can still provide plenty of sensitive data to attackers and, thanks to the keychain access, allow attackers to maintain access to various accounts and services.
Beer writes that the attack indicates “a group making a sustained effort to hack the users of iPhones in certain communities over a period of at least two years.”
This doesn’t mark the first time Project Zero has uncovered iPhone vulnerabilities, but past exploits were, by nature, more targeted. Typically, attackers had to send a text message to the target, often with a malicious link.
iPhone exploits like this are worth a lot of money as well, as much as $2 to $4 million USD (about $2.7 million to $5.3 million CAD), according to CrowdFense.
Source: Project Zero Via: Motherboard
The post Google found five iPhone exploits used by malicious websites for years appeared first on MobileSyrup.
CRTC launches review into carriers’ 36-month device financing plans

Canadian carriers have tried to circumvent the two-year contract limit this year by separating device financing from the plans they offer. Now, the CRTC is launching a review of the new practice.
The commission said it planned to review the new structure in an August 2nd tweet, and asked carriers to stop offering 36-month financing options until it finishes its review.
The CRTC is now launching its full review and is looking for input on the new financing offers until October 15th. In the regulatory body’s press release, it says it’s looking for input regarding a variety of questions.
Below are a few examples:
- What are the benefits for customers of having access to wireless device financing plans that exceed 24 months?
- How to ensure that device financing plans comply with the Wireless Code’s objectives of making it easier for Canadians to understand their mobile contracts and switch service providers, and of preventing bill shock?
The CRTC is hoping for a few outcomes from the review. It wants to be able to help the Commission for Complaints for Telecom-television Services understand the new carrier option so it can address consumer complaints related to them. It’s also aiming to find out if the new financing option complies with the wireless code.
In a press release, Ian Scott the CRTC’s chairman said, “The CRTC is concerned by these financing plans as they appear to make it difficult for a customer to switch service providers even after 24 months.”
Bell, Rogers and Telus all started offering these plans in July. They allow anyone to get a phone for $0 upfront while paying it off over a period of either 24 or 36 months. This uncouples the cost of the device from the carrier’s data and calling plans to circumvent the CRTC’s Wireless code.
Source: CRTC
The post CRTC launches review into carriers’ 36-month device financing plans appeared first on MobileSyrup.
Rogers leaks September 3rd release date for Android 10

Rogers is usually pretty good at letting its customers know when phones are set to get the latest Android updates. Now, it turns out the carrier is maybe too good at this, since Rogers has revealed what is likely the release date for the next full version of Google’s mobile operating system, Android 10.
On the carrier’s OS upgrade schedule, Rogers lists every Pixel device as getting ‘Q OS’ on Tuesday, September 3rd. What’s a bit odd is that it’s still labelling Android 10 as Q OS.
Google revealed Android 10 is the full name of its next operating system on August 22nd. This means if you have a Pixel 1, Pixel 2, Pixel 3 or 3a, get ready for a new version of Android. Either way, this date seems to line up with previous leaks.
The operating system upgrade includes a new dark mode, more theme colours, gesture navigation and other new features.
Usually Essential phones get updated very shortly after Pixel devices, so the device is likely getting the new version of Android the same day as Pixel smartphones.
To get a feel for what Android 10 will be like, check out our coverage of the OS’ beta.
Source: Rogers
The post Rogers leaks September 3rd release date for Android 10 appeared first on MobileSyrup.
Google Play Store listings will auto-play videos starting in September
Google Play is set to follow apps like YouTube and Facebook and include auto-playing videos.
According to Google Play Console Help, auto-playing videos will come to Play Store listings starting September 2019. You can find the details under the ‘Promo Video’ section on the ‘Graphic assets, screenshots & video’ page.
Google says that auto-playing videos on store listings will “help more users discover your content at a glance.”
Unfortunately, most people don’t like auto-playing videos, and for good reason. They can be quite annoying, especially when browsing websites and suddenly a video begins to play.
That said, if handled tastefully, the addition won’t be too egregious. For one, if videos play silently, like on YouTube, that will be more tolerable than if they auto-play with sound. Further, there should be an option to disable auto-playing videos, at the very least when using mobile data.
One interesting tidbit from Google’s help page is that the company wants to keep the Play Store ad-free. The Play Store leverages YouTube to host promo videos. Google has asked developers to demonetize promo videos so that when they auto-play, users see the promo for the app, not a YouTube ad.
Developers have until November 1st, 2019, to do this. Google Play won’t show promo videos with ads.
Alternatively, developers can upload a second, demonetized version of the video specifically for use with Google Play. It’s a small hassle, but it should help improve the overall experience for users.
Source: Google Via: XDA Developers, Android Police
The post Google Play Store listings will auto-play videos starting in September appeared first on MobileSyrup.