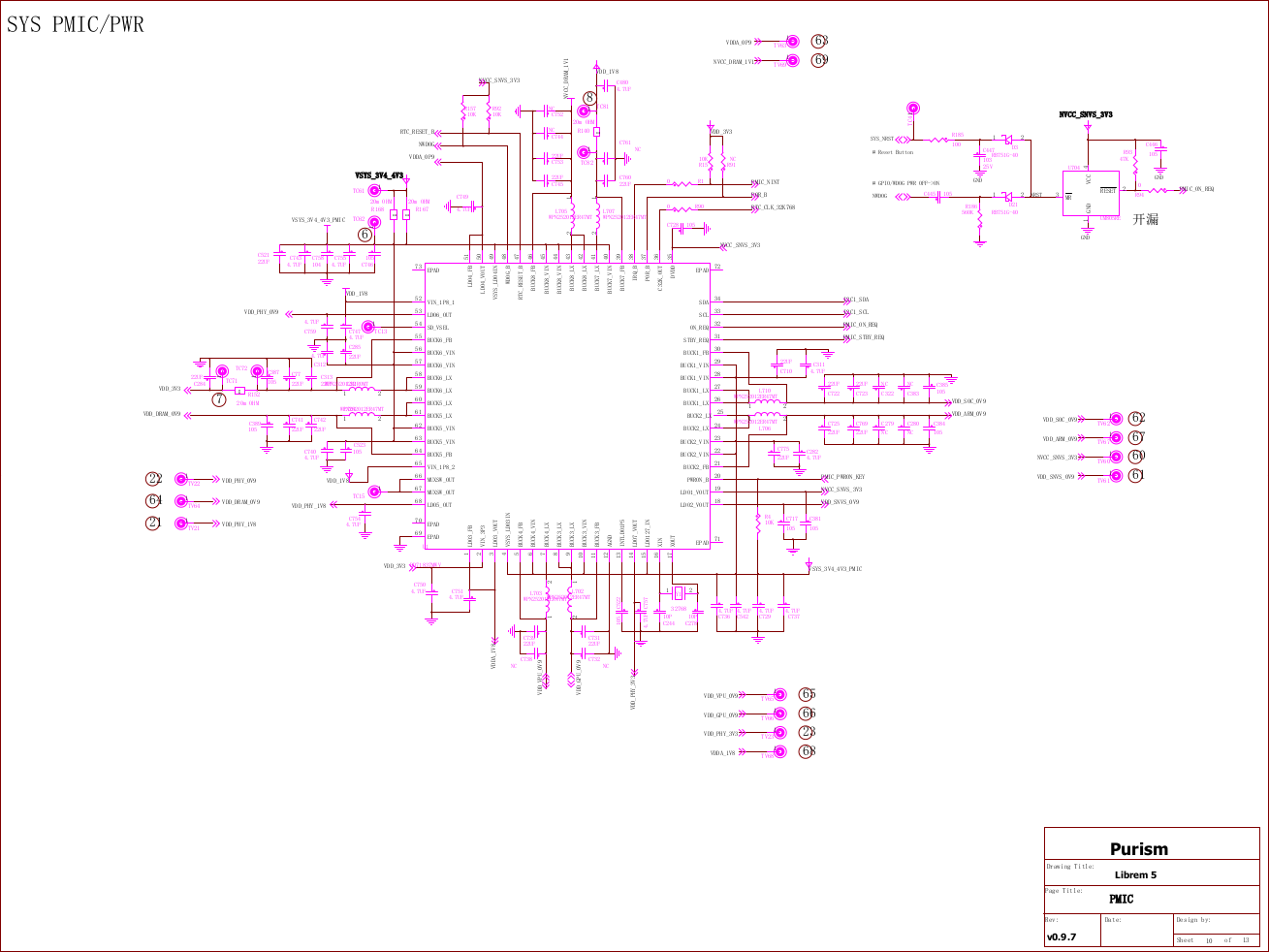
It can seem as if the tide has begun to turn against facial recognition technology. Controversies — from racist and transphobic implementations appearing in policing to the concerns of privacy advocates about the billions of images these systems gather — have drawn attention to the risks the technology poses and its potential to strengthen an already overwhelming carceral state while perpetuating so-called surveillance capitalism.
Citing concerns around civil liberties and racial discrimination, the cities of Oakland, San Francisco, and Somerville, Massachusetts, have all recently banned the technology’s use by law enforcement. The state of California is considering a bill to curtail facial recognition use in body cameras. And activists from Chicago to Massachusetts have mobilized to prevent the expansion of facial recognition systems in, for example, public housing. It’s almost as though the techno-dystopia of ubiquitous state and corporate surveillance could be stopped — or at least delayed until the next train.
All this organizing and protesting is good and vital work; the groups doing it need support, plaudits, and solidarity. Facial recognition is a dangerous technology, and prohibiting it — and in the interim, resisting its normalization — is vital. But focusing on “facial recognition” — a specific technology, and its specific institutional uses — carries risks. It treats the technology as if it were a discrete concept that could be fought in isolation, as if it could simply be subtracted to “fix” a particular concern. But facial recognition, like every other technology, is dependent on a wide range of infrastructures — the existing technologies, practices, and flows that make it possible. Pushing back against facial recognition technology without considering its supporting infrastructure may leave us in the position of having avoided future horrors, but only future horrors.
Some of the preconditions for facial recognition technology are cultural and historically rooted. As I’ve previously pointed to, the work of Simone Browne, C. Riley Snorton, Toby Beauchamp, and many others shows how unsurprising it is that much of this technology — originating as it does in a society built on xenophobia, settler colonialism, and antiblackness — has been developed for biased and oppressive surveillance. The expansion of surveillance over the past few decades — as well as the pushback sparked when it begins to affect the white and wealthy — cannot be understood without reference to the long history of surveilling the (racialized, gendered) other. U.S. passports originated in anti-Chinese sentiment; state-oriented classification (undergirded by scientists and technologists) often structured itself around anti-indigenous and/or anti-Black efforts to separate out the other. Most recently, the war on drugs, the border panics of the 1990s, and the anxious paranoia of the Cold War have all legitimized the expansion of surveillance by raising fears of a dangerous other who seeks to do “us” (that is, normative U.S. citizens) harm and is either so dangerous as to need new technologies, so subtle as to be undetectable without them, or both.
It is that history which works to justify the current development of technologies of exclusion and control — facial recognition, fingerprinting, and other forms of tracking and biometrics. These technologies — frequently tested at borders, prisons, and other sites “out of sight” — are then naturalized to monitor and control the “normal” as well as the “deviant.”
But beyond the sociocultural conditions that make it ideologically possible, a facial recognition system requires a whole series of other technological systems to make it work. Historically, facial-recognition technology worked like this: a single static image of a human face would have points and lines mapped on it by an algorithm. Those points and lines, and the relationship between them, would then be sent to a vast database of existing data from other images, with associated names, dates, and similar records. A second algorithm would compare this extracted structure to existing ones and alert the operator if one or more matching photographs were found. To make this possible, we needed cultural conventions and norms (presenting identity cards when asked; the acceptability of CCTV cameras) but also technical infrastructure — those algorithms, that database, the hardware they run on, and the cables connecting them to an operator and their equipment.
Unfortunately (or fortunately) this approach to facial recognition did not work very well. As late as this 2010 report on the impact of lighting on its accuracy, the best–performing algorithm in “uncontrolled” settings (i.e. any environment less consistent than a passport-photo booth) had a 15 percent false-positive rate. The reason you have to make the same face on the same background in every passport photo isn’t just because the State Department wants to make you suffer (although, for clarity, it absolutely does); it’s because facial-recognition algorithms for the longest time were utterly incapable of handling even minor differences in head angle or lighting between a “source” photo and “target” photos.
The technology has since improved, but not because of a series of incremental algorithmic tweaks. Rather, the massive increase in high-resolution cameras, including video cameras, over the past decade has led to an overhaul in how facial-recognition technology works. Rather than being limited to a single hazy frame of a person, facial-recognition systems can now draw on composite images from a series of video stills taken in sequence, smoothing out some of the worst issues with lighting and angle and so making the traditional approach to facial-recognition usable. As long as you had high-quality video rather than pixelated single-frame CCTV shots, you could correct for most of the problems that appear in uncontrolled capture.
But then researchers took this one step further: Realizing that they had these such high-quality image sequences available from these new (higher resolution, video-based) cameras, they decided to write algorithms that would not simply cut out the face from a particular image and assess it through points and lines, but reconstruct the face as a 3D model that could be adjusted as necessary, making it “fit” the angle and conditions of any image it might be compared with. This approach led to a massive increase in the accuracy of facial recognition. Rather than the accuracy rate of 85 percent in “uncontrolled capture” that once prevailed, researchers in 2018 testing against 10 data sets (including the standard one produced by the U.S. government) found accuracy rates of, at worst, 98 percent.
This level of accuracy in current facial recognition technology allows authorities to dream of an idealized, ubiquitous system of tracking and monitoring — one that meshes together pre-existing CCTV systems and new “smart” city technology (witness San Diego’s default integration of cameras into their new streetlights) to trace individuals from place to place and produce archives that can be monitored and analyzed after the fact. But to buy into this dream — to sign up for facial recognition technology — a city often also has to sign up for a network of HD video cameras, streaming data into central repositories where it can be stored ad infinitum and combed through to find those who are at any time identified as “suspicious.”
A contract for the algorithms comes with a contract for the hardware they run on (or, in the case of Amazon’s Ring, free hardware pour encourager les autres). There is no standalone facial-recognition algorithm; it depends on certain other hardware, other software, certain infrastructure. And that infrastructure, once put into place, always contains the potential for facial recognition, whether facial recognition is banned or not, and can frequently be repurposed for other surveillance purposes in its absence.
The layers of infrastructure involved make facial recognition technology hard to constrain. San Francisco’s ordinance, for example, bans facial recognition outright but is much more lenient when it comes to the camera networks and databases feeding the algorithms. If a city introduces facial-recognition technology and you spend a year campaigning against it and win, that’s great — but the city still has myriad video cameras logging public spaces and storing them for god knows how long, and it still has people monitoring that footage too. This process may be much less efficient than facial recognition, but it’s still the case that we’ve succeeded in just swapping out analytics technology for a bored police officer, and such creatures aren’t widely known for their deep commitment to anti-racism. And this isn’t hypothetical: 24/7 monitoring of live, integrated video feeds is exactly what Atlanta does.
Beyond that, leaving the skeleton of the surveillance infrastructure intact means quite simply that it can be resurrected. Anyone who watches horror films knows that monsters have a nasty tendency to be remarkably resilient. The same is true of surveillance infrastructure. Facial recognition is prohibited in Somerville now. In one election’s time, if a nativist wind blows the wrong way, that might no longer be the case. And if the city was using the technology prior to banning it and has left the infrastructure in place, switched on and recording, it will be able to surveil people not only in the future but in the past to boot. It becomes trivial, when the technology is re-authorized, to analyze past footage and extract data about those who appear in it. This enacts what Bonnie Sheehey has called “temporal governmentality,” where one must, even in the absence of algorithmic surveillance, operate as if it were occurring because it might in the future be able to retroactively undertake the same biased practices. And when facial recognition is as cheap and easy as a single software update, it’s not going to take long to turn it back on.
Luckily, the movie solutions to killing monsters line up with facial recognition too: removing the head or destroying the brain. That is, eliminating the infrastructures on which it depends — infrastructures that can, in the interim, be used for less efficient but still dangerous forms of social control. Banning facial recognition formally is absolutely a start, but it provides lasting protection only if you plan to print off the ordinance and glue it over every surveillance camera that’s already installed. We must rip out those cameras, unplug those servers. Even “just” a network of always on, eternally stored HD cameras is too much — and such a network leaves us far more vulnerable to facial recognition technology’s resurrection than we were before its installation.
There is nothing wrong with the tactics of activist movements set up around facial recognition specifically; protesting, organizing, forcing transparency on the state and using that to critically interrogate and educate on surveillance practices is both good work and effective. But what we need to do is ensure we are placing this technology in context: that we fight not only facial recognition, a single symptom of this wider disease, but the underlying condition itself. We should work to ban facial recognition, and we should celebrate when we succeed — but we should also understand that “success” doesn’t just look like putting the technology in the grave. It looks like grinding down the bones so it could never be resurrected.












 The Heritage Designation of the buildings says: “Built in 1900 by architect George W. Grant for R. W. Ormidale, the building housed the offices of several wholesale importers.” With a carved terracotta plaque saying “Ormidale RW 1900” above the oriel window, it seems an appropriate attribution, although quite who R W Ormidale might be was never made clear. There are no records of anybody in the city with that name, (or indeed, in Canada).
The Heritage Designation of the buildings says: “Built in 1900 by architect George W. Grant for R. W. Ormidale, the building housed the offices of several wholesale importers.” With a carved terracotta plaque saying “Ormidale RW 1900” above the oriel window, it seems an appropriate attribution, although quite who R W Ormidale might be was never made clear. There are no records of anybody in the city with that name, (or indeed, in Canada).