Martin Weller has released his book
25 Years of Ed Tech today. It's a nice read; you are encouraged to check it out. But I have to confess, on having looked at the table of contents, I thought that it captured my career pretty well. Of course, that was not Weller's objective. But this is my lived history. So I thought I'd quickly summarize those 25 years from my perspective. Headings in bold are Weller's; subheadings in italics are mine.
By way of a preface, I want to say that I get that Weller wasn't attempting a comprehensive history of ed tech. As he says, it's more akin to selecting a top 100 than it is a full documentation. And I also get that the assignment of years is a bit arbitrary (but I also think it's telling, as we'll see below). At the same time, he's going to use his history of ed tech to say a lot of things about the discipline and technologists in general. As the title of his introduction suggests, he wants to say that they suffer from historical amnesia. It's a popular criticism; I've heard it many times. But it's not true.
More accurately, what it
is true of is the people
he reads. But I don't think he's reading the right people. His history of ed tech isn't a history of ed tech, it's a history of academics writing about ed tech. And that's a very different thing. The people I know - and credit - who have been doing the hard work of developing an entire infrastructure from the ground up have known since day one that they're in it for the long game. And it's not that we don't know the history of universities and distance education and learning theories, it's that so much of it and so many of them are
wrong. That, though, is a different article.
My point with
this article is that, in writing about the last 25 years of technology, Weller is writing about
my history. This has been my work; I have been a learning technologist (and more, I hope) for that entire time, and for pretty much all of it I have a pretty good feeling that
I knew - that
we knew - what we were doing. And I'm proud of this work, that of myself and my colleagues around the world. And far from being a failure, we have made the world a better place, brought learning opportunities to hundreds of millions of people, and touched in the most
human way possible the lives of countless individuals.
Want to edit this post? There's a version on Google Docs that anyone can edit.
Click here.
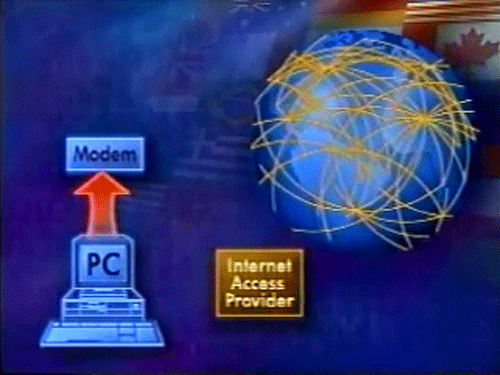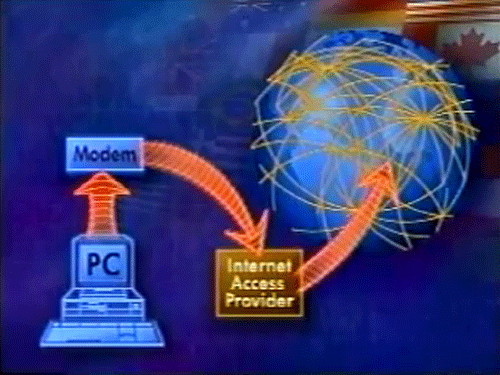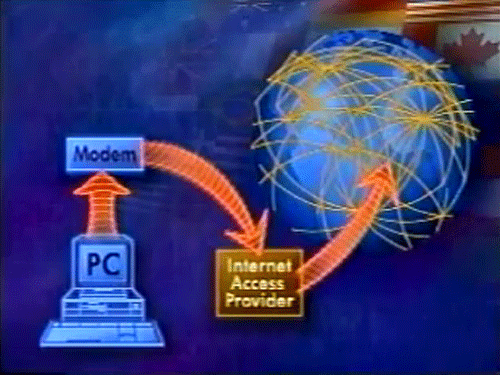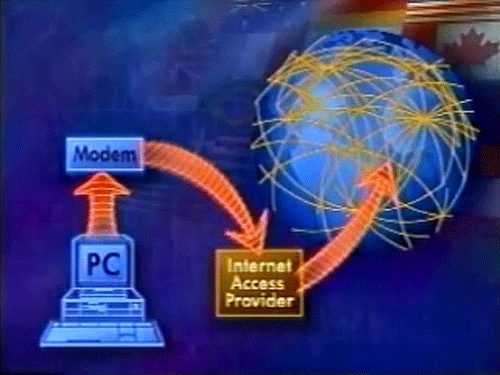
1994 – Bulletin Board SystemsAlso: Video, Mainframe conferencing, Telephone, Compugraphics, MUD Weller's list actually starts a little late for me. My very first experience with ed tech was with Texas Instruments when, in 1981, I was sent to Texas for training. In addition to the usual hands-on instructor-led learning, I discovered the training room, which was stocked with training videos. I taught myself something called MVS-JES3 and also took a communications course called 'On the Way Up'. On the mainframe, I also found this fun game called 'Adventure'.
My first experience of
online learning was in 1986 when the students in John A. Baker's philosophy of mind class used a mainframe discussion board to argue course topics back and forth - I still have the complete archives from those discussions. A year later I would write my Master's Thesis on the mainframe.
My other major ed tech experience in those years was the telephone. From 1987-1994 I was a tutor for Athabasca University and would spend hours on the phone helping students from across Canada. In the latter years I would also drive to remote communities and teach there, and we experimented with a system called 'compugraphics' to deliver a course using telephone and images sent directly from computer to computer (this was my first actual course development experience).
In the early 1990s I was also working on a Bulletin Board Service called 'Athabaska BBS', an unofficial (hence the K) adjunct to my work as a tutor with Athabasca University. I ran it off my 286 desktop using a Maximus BBS system. I was defeated, ultimately, by long distance. That, plus 99 percent of my students didn't have computers. I notice Weller
cites Alan Levine's early use of BBS technology (it's unfortunate that this is the only bit of Levine's massive contribution he cites, and that it's nothing more than a comment on Weller's own blog).
In 1994 I was teaching at Grande Prairie Regional college. For me, in 1994, I was working on the internet proper, using Multi User Dungeon (MUD) technology, which we rebranded as Multi User Domain (and then Multi User Academic Domain). My colleagues and I built one called the Painted Porch MAUD, and we used this at Athabasca, Assiniboine Community College, and Cariboo College in B.C.
Diversity University started out as an educational MUD;
Walden University was also an early adopter, and a
whole bunch more. One initiative worth noting is
MediaMOO , built to support Seymour Papert's constructionism (there's a whole thread of ed tech there; there's no mention of Seymour Papert in Weller's history of ed tech, astonishingly) and involving people like
Amy Bruckman and
Mitchel Resnick.
1995 – The WebAlso: Plato, the Home Page In 1995 I started at Assiniboine Community College. I built the college's first website (and also one for myself, for the city of Brandon, and for my cat). And I started teaching courses, both for staff and evening students, teaching them about the fundamentals of the internet.
I remember a long and interesting conversation with a representative from Plato, who was trying to sell us on their course system. I liked Plato a lot, and asked him when they expected to put it on the internet. Of course there were no such plans, and so I went one way and Plato went another.
I also needed to prove that the web could be used for online learning, so I took a guide I had created for my Grande Prairie students,
Stephen's Guide to the Logical Fallacies, and published it on my website, openly licensed, free for all to use (the license was based on similar open licensing I had seen in the MUD community). Over the years, it has been my most enduring and popular resource. With a year of so we had created our first web-based course, 'Introduction to Instruction', with professor Shirley Chapman.
If 1995 was anything, it was the year of the home page. I don't know whether
GeoCities was ever used for educational purposes, Launched in 1994, it was widely known (and maligned) by 1995. But it was brilliantly engineered; I learned tons by digging through the source, learning how all the Javascript worked, and adapting it for my own purposes. Like so many things, it was acquired by Yahoo and destroyed.
1996 – Computer-Mediated Communication Also: Usenet, IRC, Mailing Lists, Bulletin Boards, ICQ
Like Weller, we at Assiniboine experimented with
FirstClass around this tine - we had a partnership with a school in Winkler/Morden (Manitoba) and worked back and forth with them. It was 'graphical' only in the sense that Windows 3.1 was graphical - you used icons instead of commands on the command line. The problem with FirstClass was that it required a
lot of teacher preparation and intervention, and after a year, they were burned out. So I started focusing a lot more on content than on interaction.
While at Athabasca University (between 1991-1994) we had used the CoSy conferencing application, but I hated it. Hated it. We also had access to UseNet but I was never a UseNet person. I used to say at the time that there are two types of internet users: those who like dynamic content, such as games and email, and those who like static content, like Usenet and conferencing. If I were
really a dynamic content person I would have used IRC, but that was for real geeks.
By 1996 I was a regular user of email mailing lists, including DEOS-L and NAWeb. A lot of my early articles were in reality long posts to these lists (that was back in the days when long posts were still acceptable, and nobody had considered a 128 character limit). I also took a massive open email course (MOEC?) called something like 'Welcome to the Internet' (I don't have the reference, but it's somewhere in my online
corpus). People like
Mauri Collins and
Rik Hall were instrumental in establishing some of the first email exchanges connecting learning technologists worldwide, and in so doing, learning some core lessons (like, for example, how to moderate online forums).
A lot of people were using some of the earliest online bulletin boards by this time. The best were the boards that would automatically send you emails when a post was created. I participated a couple of years running in online conferences hosted by the University of Maryland University College (
UMUC), which was running experiments in the genre. My contributions included
this effort in learning design.
Finally, around this time I also started using instant messaging, and to be specific, an application called ICQ. ICQ was eventually run into the ground by America Online, and people migrated to things like MSN messenger and AOL.It's easy to forget the importance of the early instant messaging services, because they played such a significant role in developing a lot of the thinking that would eventually result on social networks and more.
1997 – ConstructivismAlso: Connectionism We had our 'behaviourism-for-or-against' moment back in 1986, and at the same time were studying Bas van Fraassen's 1982 book
The Scientific Image, in which he set out the agenda for 'constructive empiricism'. But by 1997 I had long since moved on past constructivism (and
never took it seriously as a learning theory; people like Piaget and Vygotsky were wrong, and more importantly,
known to be wrong); in 1987 I wrote my Master's Thesis on
Models and Modality in which I took an anti-constructivist stance.
While constructivism was big in education, the new philosophy of
connectionism was catching the eye of computer scientists and philosophers. On my own I developed something called a 'logic of modification' based on similarity theory, which resembled the nascent theory of 'connectionism'. I saw a talk by Francisco Varela at the U of A hospital and in 1990 a group of us travelled to Vancouver for the famous
Connectionism conference at SFU. By 1993 I had written
The Network Phenomenon, which is essentially a post-constructivist post-cognitivist theory of knowledge.
Weller makes an interesting point: "It also marked the first time many educators engaged with educational theory. This may sound surprising, but lecturers rarely undertook any formal education training at the time; it was usually a progression from researching a PhD into lecturing, with little consideration on models of teaching." (p.32) I recall that I
did participate in such training, in part with Athabasca, but more explicitly with Grande Prairie Regional College (GPRC), where we learned about learning styles and Bloom's taxonomy (Weller doesn't mention either of these anywhere). In the Manitoba system, which I joined in 1995, the
Certificate in Adult Education was required for all instructors. So maybe it was true in Weller's world, but it wasn't true in my world.
1998 – WikisAlso: CMSs, RSSI didn't bother with Wikis. Oh, sure, I looked at them, I liked Wikipedia, but for the most part, the idea of everybody writing a single article didn't appeal to me.
Instead, for me, 1998 was the year of
RSS and content syndication. I did a
lot of work with RSS, combining it with content management systems (CMS). I wrote my own CMS, however, a number of bulletin board services had evolved into CMSs and were being used for courses and such around the internet (places like UMUC were still in the lead).
Around this time I realized that bulletin boards were not going to last forever, and so I gathered the posts I had written to mailing lists and boards around the internet, but them in my own CMS, and started my own RSS feed. I soon started collecting 'links' as wells as 'posts' for my website. This was the beginning of OLDaily, though it wouldn't get that name for another three years.
1999 – E-LearningAlso: LMS, LOMThe term e-learning was coined by Jay Cross, whom I would meet a couple years later in Anaheim. I didn't like the term because I thought it was a way for (static) content providers to try to represent themselves as being 'online'. E-learning thus included things like static courses on CDs and DVDs, which did not interest me at all.
Instead, I spent 1998 and 1998 building a learning management system (LMS) called OLe (for 'Online Learning Environment'). I remember meeting
Murray Goldberg at a NAWeb conference, who had written WebCT (in Perl, the ultimate (C?) version would come a number of years later). We used OLe to offer some high school courses through the Brandon Adult Learning Centre and the General Business Certificate through the College.
The
big news for 1998, for me at least, was the arrival of the IMS learning Object Metadata specification, which made a lot of sense to me. I had designed OLe so that it used free-standing 'modules', and the IMS-LOM was perfect for this.
2000 – Learning ObjectsAlso: Portals, CoII wrote my paper 'Learning Objects' in 2000 - it was the product of a presentation I did on IMS-LOM a few months earlier, building on a lot of the idea people like Dan Rehak had already developed. What made my paper different, I think, was that I had already worked out a number of the practical applications (and problems) with OLe, and so I was in a good position to present the full case from principle to product.
By 2000 I had been hired by the University of Alberta. By now, online communities were big - Cliff Figello had written his book of that title, Wenger had written about Communities of Practice (CoP), and Hegel and Armstrong had written Net:Gain about the use of subject-specific portals. At the U of A I worked with Terry Anderson; Randy Garrison was Dean at that time, and Walter Archer was also there; they were fresh from developing the
Community of Inquiry (CoI) model. All this was perfect for the while combination of CMSs and RSS syndication and newsletters, and we spent the year building MuniMall.
2001 – E-learning StandardsAlso: Javascript, Email newslettersIn 2001 my term at the University of Alberta ended and I traveled to Melbourne, Australia, for work on ed tech projects with Tim van Gelder (the same Tim that spoke at the Connectionism conference in 1990, though this is purely a coincidence - he had seen my Logical Fallacies page and hired me because of that). I experimented with Javascript-based comment forms embedded in web pages. And I began experimenting with email newsletters, eventually figuring out how to use my content management system to automatically create the newsletter. Thus, OLDaily was born.
2002 – The Learning Management SystemAlso: Open Archives, Repositories, Resource NetworksIt's odd that Weller put e-learning standards chronologically before the LMS because in fact the provenance is the reverse: first came the LMS, and then, much later, came e-learning standards.
For me, 2002 was the year of learning object repository networks. This was work pioneered by the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and supported a variety of metadata formats, including Dublin Core. At the same time, MIT came out with DSpace, which was their version of OAI-PMH. We built on this type of work in the EduSource national repository network project, work that included
CanCore, spearheaded by Norm Friesen. I remember Griff Richards proposing a peer-to-peer metadata exchange system, and my criticism that at 27 megabytes it was far too large a download.
2003 – BlogsAlso: Podcasting, DRMAs mentioned above, blogs started much earlier than 2003. I had been posting my articles since 1998 and my email newsletter since 2001. But blogging was indeed catching on in educational circles around 2003 and I would write my article on educational blogging in 2004. I remember the black "I'm blogging this" t-shirts. Also, blogrolls and blogwheels. I built a blog 'referrer system' in 2003 that at its peak had 800,000 hits a day (it's the sort of thing that, had things worked slightly differently, would have made me a billionaire).
Podcasting was invented in 2003 by Dave Winer (the father of RSS) and Adam Curry (Daily Source Code). It entered a milieu where people were figuring out how to format content streams, so while in education we were seeing things like Simple Sequencing and Rob Koper's
Educational Modeling Language (EML), in the wider web we were seeing things like Synchronized Multimedia Integration Language (
SMIL). That's what I used for my own
Ed Radio of 2003, which extracted MP3 links from RSS files and inserted them into SMIL, which I then exported into RealMedia and an online service called
WebJay (later acquired and killed by Yahoo). There were some significant early educational podcast, for example, Dave Cormier and Jeff Lebow's
Ed Tech Talk, as well as
Ed Tech Posse by Alex Couros, Rick Schwier and Dean Shareski.
The other big thing that was happening in 2003 was digital rights management. These standards were getting off the ground, the commercially-inspired XrML, owned by ContentGuard, and the Open Digital Rights Language. We did work in ODRL and I created a 'distributed DRM' system using the language. There was a
lot of debate around that time about openness and licensing, and a lot of complaints about the intrusive DRM systems being employed by commercial content providers, all of which overlapped into the field of ed tech.
2004 – Open Educational ResourcesAlso: The Semantic Web, Social Networks David Wiley had been running his Open Content Project since 1998. MERLOT was started in 1997 and opened up in 2000. Creative Commons was founded in 2001. UNESCO formally defined 'Open Educational Resources' in 2002. There was a lot of debate about whether education should support federated repositories, like ADL's CORDRA, which would be closed, or would adopt more open repositories along the model of OAI.
Also in 2004, social networks burst onto the scene with the launch of sites MySpace and LinkedIn (2003) and thefacebook (exclusively for the Hah Vad community) and Flickr (2004). These were arguably an outgrowth of CMSs that became blogging platforms, and were presaged by sites like LiveJournal (1999) and Deviant Art (2000).
Meanwhile, the develop of the web, XML and standards all coalesced into the Semantic Web. The Resource Description Format (RDF) had been around for a while; I wrote about it in relation to RSS and learning objects. It was gradually joined by ontologies (OWL), query (SPARQL), and would form the foundation for web services properly so-called (SOAP and WSDL). If all this sounds like alphabet soup, well, that's how it felt in 2004. To me, a 'semantic social network' was a natural, and I wrote about that. I also combined the idea of distributed DRL with all this to propose something I called Resource Profiles (which we now think of as resource graphs).
2005 – VideoAlso: OpenID, E-Learning 2.0YouTube launched in 2005, which explains its inclusion here. But it was more about what YouTube represented than it was about videos. It was not just a place you could upload videos (though it was certainly that) but it was also very much a social network. This is why we see Weller quoting people like Henry Jenkins suggesting that we should begin to see learning online as creative and fundamentally participatory. And that's why we also see things like the Khan Academy and the flipped classroom (temporarily branded the 'Fisch flip' after Karl Fisch). Like so many other people, I had a Flip video camera (which was affordable) long before I had a smart phone (which was not).
But 2005 wasn't really about video for me. It was about authentication and identification. This made sense in the context of DRM, and also in the context of social networks. Meanwhile, LMSs, repositories and resource networks had never gone away, and so the question of how to identify people became urgent. FOAF was developed to help people identify themselves (and their nearest airports) on their websites, just like an alternative RSS feed. I developed my own system, mIDM, and five days later, OpenID was released to the world. Eventually this open approach to authentication would give way to 'Login with Google' and the like, though the dream never disappeared entirely. The academic community, meanwhile, adopted a federated approach, closed to outsiders, which resulted in protocols like Shibboleth (which saw a major release in 2005) and eduRoam (which was just beginning to expand outside Europe in 2005).
All of this was part and parcel of what was called Web 2.0., which was popularized by the O'Reilly Web 2.0 Conference in late 2004. All of this came together for me, and I wrote a paper called E-Learning 2.0. Before the MOOC, and after Learning Objects, this is what I was most well-known for.
2006 – Web 2.0Also: SkypeWeller writes quite a negative chapter on Web 2.0, though he does get some of the essential elements right. First of all is the idea that web 2.0 is a bottom-up concept. Second is the emergence of the idea of tagging (or, more formally, the folksonomy) rather than metadata. Yes, some web 2.0 sites like del.icio.us and Technorati are gone, but the core ideas of web 2.0 live on to this day, as do some of the key underlying technologies, like OAuth, for distributed identity management, and representational state transfer (REST), which eventually replaced the top-heavy model of web services. Weller says "everyone (including myself ) is now rather embarrassed by the enthusiasm they felt for Web 2.0." I don't understand that. Web 2.0 left a huge legacy and we would be much poorer off without it.
Skype is a good example of this. I began working with Skype in earnest in 2006, using it not only for its intended purpose of voice chat (then video chat) with faily and friends over long distances, but also with the world's first educational Skypecast, which would be a forerunner of the webcasts we have today. This first Skypecast was broadcast from Bloemfontein, South Africa, where I gave a talk to a theatre audience and a global audience measured in single digits. Skype eventually discontinued its Skypecast feature, but you could see the future through that crack in the door.
2007 – Second Life and Virtual WorldAlso: Twitter, OLPCVirtual worlds date back to the Adventure mainframe game, and then MUDs, both mentioned above. In those days, there were two Holy Grails: first, transportation between MUDs, which was partially achieved with the InterMUD protocol, which at least allowed people in different MUDs to communicate with each other; and second, graphical MUDs, which would await the development of video games like DOOM and 3D modelling software like VRML. By 20087 a lot of work had been done in educational simulations using VRML, especially in military learning, but I wasn't involved in any of it.
Into this environment came Second Life, which was distinct in two ways: it was commercialized and heavily marketed, leading institutions and organizations to buy and build 'islands', and second, there was nothing to do, which led to it being mostly empty. Weller documents this pretty well, including the use of Second Life to give lectures, and the Second Life-Moodle integration called Sloodle.
Another thing that got started (at least for me) in 2007 was Twitter. I wasn't exactly an enthusiastic user, but it clearly had potential. It's worth noting that Twitter inherited a number of web 2.0 ideas, including especially following and tagging, which gave it an instant graph-like structure characteristic of the genre. I was never a fan of the idea that my communications with individuals could be read by
everyone and I didn't like the idea of publicly posting a select list of people that I follow (it felt too much like high school cliques to me; I never had a blogroll either).
Weller also doesn't mention Nicholas Negroponte's One Laptop Per Child (OLPC), which is a surprising and serious omission in a book about Ed Tech. It was an ambitious plan that had some good ideas - first of all, the idea of an affordable personal computer for everyone, with a full suite of educational applications, with mesh networking for regions without internet, and alternative power sources. OLPC was widely viewed as a failure, partially because of cost, partially because the product wasn't very good, and partially because Negroponte's model required governments to invest in millions of the units. But it resulted in the widespread deployment of affordable tablets, influenced the development open operating systems like Android, and has a legacy today of products like Raspberry Pi and Arduino. I've done far too little work in this area, but I get it.
2008 – E-PortfoliosAlso: Edupunk, Networks, MOOC It's hard to imagine writing a history of e-Portfolios without mentioning
Helen Barrett, but Weller has done that. From her original pioneering work in 2001 and more more than a decade on, Barrett was at the core of the development and popularization of e-Portfolios. They are now standard parts of LMSs, widely used in educational institutions (as a quick Google search will show), and invaluable to students for job applications, especially in creative fields. My own work with e-Portfolios included work on using them to establish a digital identity. Yes there were issues, including the institutional ownership of e-Portfolio websites, as Weller notes. But the more significant issue was in the use of e-Portfolios for assessment as opposed to e-Portfolios for growth and development.
Edupunk was Jim Groom's idea. He drew on the punk
ethos of 'do it yourself' and of making things do what they weren't intended to do. It's what you get, I think, if you take Web 2.0 and remove the corporations.
The other big think for me in 2008 was networks. For me the start of all this is my 2004 'networks' edition of OLDaily. This was an outgrowth of the Future of Learning in a Networked World project run by Leigh Blackall in New Zealand, and I followed it up by elaborating on the idea of 'Groups vs Networks', which attracted some attention from Terry Anderson and Jon Dron. It was also an outgrowth of my longstanding interest in connectionism, which meshed perfectly with George Siemens's description of connectivism, and by the fall of 2008 we were embarked on our first MOOC.
2009 – Twitter and Social MediaAlso: PLE If there's a trend in Weller's book, it's that he's generally about four years behind the date something actually happened. And here again with social networks. I think this represents the time it takes for something to be developed in the field, and for it to be recognized in academia. But of course that's just a theory. Anyhow, in 2009 social media had been around for five years, Twitter for three. In passing, let me note that here Weller mentions Twitter's use of the hashtag (and reading this, it strikes me that maybe he does not know that the folksonomy and the hashtag are the same thing, as they are treated completely separately).
There's a good point to be made about the benefit of social media, and especially the way it democratizes access to distribution and influence, and the harm of social media, where it serves as a platform for harassment, bullying and fake news. Social networks are also the locus of context collapse, discussed by people like
danah boyd and Michael Wesch, where there's no distinction between talking to one person and talking to everyone.
In 2009 we were talking about things like the Orange and Rose revolutions (and the next year, the Arab Spring), thinking how good it all was, and didn't imagine it being used
against us. But we should have, had sufficient attention been paid to things like the harassment of
Kathy Sierra. And it was only later we saw how sites like Reddit and 4chan inspired things like GamerGate and, a few years later, profoundly influenced politics.
My focus in 2009 was the personal learning environment. This concept was already a couple of years old; I participated in a conference with people like Scott Wilson in Manchester and developed a project at NRC called PLEARN. It was an attempt to take what we already knew about things like Web 3.0, social networks and e-portfolios and move them from institutional ownership (or corporate ownership) and into the hands of individuals.
2010 – ConnectivismAlso: digital literacy, critical literacies George wrote his connectivism paper in 2004 (and I made sure it got published in
IJITDL), and my own Introduction to Connective Knowledge followed shortly in 2005. And of course our Connectivism and Connective Knowledge MOOC was in 2008. So I don't really know why it shows up under '2010' in Weller's book, save for the theory I mentioned above. That would explain why he credits Kop's (2011) version of my four principles of aggregation, remix, repurpose and feed forward. After discussing Dave Cormier's rhizomatic learning (which I think was developed independently of, and not following, Deleuze and Guattari) and his own theory, Weller writes, "it feels that the sense of experimentation and exploration that connectivism represented has dried up." I don't agree.
My focus in 2010 was on knowledge. I had taken the observations of people like Bell, Mackness and Kop seriously and was working through what it was that people needed to be successful in a MOOC, and what it was even for a person 'to know'. I eventually settled on the idea of 'knowledge as recognition', but my focus in 2010 was the critical literacies, a set of ideas that I had developed in a couple of talks in late 2009 and expanded into a full concept in 2010. My thinking was this: in traditional learning, students need to be literate, so we teach them literacies first thing. In an online world, there's a distinct literacy, often called digital literacy, sometimes called
twenty-first century skills. What underlies these? Kop and I would eventually teach a
Critical Literacies MOOC later in 2010.
There's a whole pile of work in digital literacies that was being done by others around this time, especially in relation to education. See for example
Doug Belshaw's work. But the term appears exactly once in Weller's book.
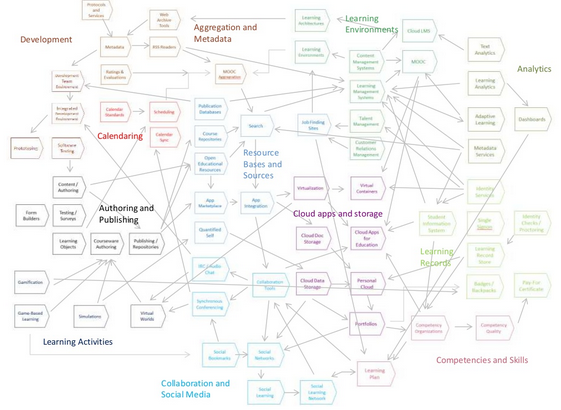
2011 – Personal Learning EnvironmentsAlso: performance support, LTI In 2011 I was still working on the PLEARN projects and beginning to ramp up for what would be the Learning and Performance Support Systems project. The idea of the PLE had now been around for some six years with no real progress being made. The PLE encompasses a bunch of
hard problems. These are only hinted at in Scott Wilson's famous diagram (and the many other diagrams that followed). Weller mentions Wilson's
Plex, which was a PLE (though to me it looked like a file manager) and Dave Tosh and Ben Werdmuller's ELGG, which was not (it was a social network service).
Weller also references the term PLN, or 'personal learning network', which refers to the network of connections a person makes using social network services. To me it was nothing but a branding exercise; people taking the
idea of the PLE, applying it to something that already existed, and giving it a new name.
He finishes the section saying "personalized learning remains one of the dreams of ed tech, with learners enjoying a personalized curriculum, based on analytics." This has
nothing to do with the PLE. It's a common confusion, though. A lot of people see personalization as the core of performance support, for example (and that's how LPSS became an ungainly attempt to merge those two concepts, and how so many people thought we were building a recommendation engine, but that's another story). I spent most of 2011 trying to explain this difference.
I'm also going to use 2011 as the year for learning tools interoperability (LTI), even though the specification came out in 2010, because LTI is a natural complement to what we were trying to do with PLEs. We did some preliminary work with LTI, and in the PLEARN application we build, we used LTI to help
learners (not designers or instructors) define what applications they would use (PLEARN was shut down prematurely by NRC management, much to my regret).
2012 – Massive Open Online CoursesAlso: learning experience design Laura Pappano in the New York Times
declared 2012 'the year of the MOOC' so I guess I can see why Weller chose 2012, though I remember it more as the end of the Mayan calendar. And looking back, I can see I did a
lot of talking about MOOCs in 2012, as the phenomenon swept me up along with all the publicity.
But I also started talking about the learning experience around that time. This was the big difference between the PLE as I saw it and the content-based learning-path based systems emerging both in the commercial MOOCs and in the nascent learning analytics movement (which I was watching but not a part of at all). In my view, what we're designing when we design learning is an
environment that is open-ended and characterized by its
affordances. Today of course learning experience design means something totally different, but that's what it meant to me then.
More recently, people have been talking about the death of MOOCs. But there are more MOOC providers than ever, all the MOOC companies managed to somehow find success, and (to my mond) most importantly of all, MOOCs cemented the idea of open access as mainstream. As Weller says, "there is no real driver for educators to focus on open access above other resources. But when universities started creating MOOC, this placed pressure on people to use open access resources, because the open learners probably wouldn’t have library access privileges." I think focusing on the few commercial approaches (as Weller does) is a mistake; far more interesting are the many more open MOOC initiatives around the world in less commercially-minded nations.
2013 – Open TextbooksAlso: ownership, cooperatives In 2013 I was still talking about MOOCs. The interest was intense, and that's what people wanted me to talk about. I talked about how they needed open educational resources, about how they were needed to create learning communities, and how they supported open-ended informal learning and performance support. We were just designing the LPSS program, trying the meet the government's objective of corporatizing NRC, and I was thinking of issues of community and ownership. My main project at the time was Moncton Free Press, an Occupy-inspired journalism cooperative.
Needless to say, I wasn't interested in open textbooks at all. That's not to sell them short; as Weller notes, initiatives like OpenStax and BCcampus (where people like Paul Stacey and David Porter should get a lot of credit) have saved students millions of dollars.But they strike me as old technology, and a problem that was solved years before by things like
Project Gutenberg and even (to a degree)
Internet Archive. Weller claims (p.181) that open textbooks are an outcome of learning objects and OER, but that is hardly the case.
2014 – Learning AnalyticsAlso: cooperation, recognition After MOOCs and connectivism, when I made the turn toward personal learning, George Siemens made the turn toward learning analytics. His turn was more successful than mine, at least in the short term. Weller quite properly credits George with a lot of this early work (though for some reason credits Sclater, Peasgood, and Mullan (2016) for the definition instead of Siemens and Long (2011)). Another case where the Weller version is several years too late and credits the wrong people. Anyhow, I document many uses of learning analytics
here.
Given my interest in neural networks I should have been more interested in learning analytics, I suppose, but I wasn't, and for several reasons. First, learning analytics was (and is) about creating personalized learning paths, based on analyses if students' performance. Second, most learning analytics of the time was (and is) based on clustering and regression, which aren't really network properties. Weller has a couple of cases that show this sort of failure: the indifferent success of CourseSignals, and the 'six myths' about students at the Open University.
Weller also notes, "The downsides to learning analytics are that they can reduce students to data and that ownership of this data becomes a commodity in itself." They don't "reduce" students to data, but they do
extract data from students. And this is something that had been noted long before; it is the dichotomy inherent in Michael Wesch's (2007) "The machine is us/ing us" and the
2010 statement that "If you are not paying for it, you're not the customer; you're the product being sold."
Weller also talks about ethics in learning analytics, quoting Slade and Prinsloo, who did indeed write an interesting paper (2013). But it should be noted that by 2013 a
ton of other work has been done in this area, which I've been digging into
elsewhere.
In 2014 I was still deeply immersed in LPSS, and still talking a lot about PLEs and MOOCs. Subtopics that were of interest were the idea of cooperation (as opposed to collaboration), and automated student assessment. I didn't actually build anything related to these (I was typing to get LPSS interested in them) but I wrote a number of articles on both topics.
2015 – Digital BadgesAlso: competenciesAs Weller notes, the beginning of digital badges is probably best placed in 2011 with the launch of Mozilla's backpack and badge infrastructure project. It was a neat idea (and if you look at the mechanics you can see that it parallels almost exactly the distributed DRM and authentication approaches of earlier years, with a three-part relationship established between an issuer, a recipient, and a badge hosting service. What made it tricky for people to adopt was that the badge data was 'cooked' into the digital badge image, which was taking the tech a step too far. And of course the idea of the badge itself is a direct descendant from the original idea of smaller chunks of learning found in concepts like learning objects.
I wrote nothing about competencies during that period, but it was the first bit of LPSS that was really developed (though it never did see a wide release). There was quite a bit of activity in the field with numerous efforts to develop various competency standards. They were a natural adjunct to badges, and mentioned by Weller briefly in that context. What competency definitions added, crucially, was to define what would count as
evidence for an assertion. So you could see the chain of connections from performance support to competencies to assessment to recognition, and from assessment to learning resources (via learning object metadata). I remember John Baker calling all this "magic rubrics" back in 2008 or so, and it made total sense to me.
The problem with badges and competencies wasn't "the credibility issue," as Weller notes (if Harvard started giving out badges the credibility issue would disappear overnight). It was in the idea of
defining what constituted performance, competence, and evidence. I remember arguing at the time that assessment was based on
recognition, not specific performance outcomes. But whether or not I am right about this, the actual practice of defining competencies is difficult, and for many, poses an intractable problem.
2016 – The Return of Artificial IntelligenceAlso: deep learning, fake news, personal learningWeller discusses 2016 as 'the return of artificial intelligence' but most of the chapter is an extended argument explaining 'why AI will not work'. Most of the discussion is focused on 'expert systems', a rule-based approach widely considered to have limited applications because of the difficulty in defining the rules and the inherent complexity of the problem space, as Weller (in so many words) notes. But the list of 'reasons why AI will fail' offered by Selwyn (2018) are just so much nonsense.
By 2016 the entire learning analytics community (and the entire AI community in general) was abuzz over the potential of 'deep learning'. This is an approach based in neural networks, and hence, the connectivism of old. What makes the networks 'deep' is the use of multiple 'hidden' layers. All this was described by people like Rumelhart and MacClelland in the 1990s, but it took this long to develop a solid set of applications. While much to the 'learning analytics' touted in previous years was based in rule-based approaches, by 2016 the bulk of the work was being done with neural networks, and these were beginning to work quite well. It's true that none of these amount to 'general AI', which emulated full human capabilities. But this isn't a serious issue at trhe moment.
The
big issue in 2016 was that AI was beginning to work and that it was immediately being put to less honourable purposes. The emergence of fake news wasn't so much the result of social networks - these had been around now for a decade - but the use of bots and analytics to craft messages, identify recipients, and spread propaganda. Complicit in these efforts were data-gathering technologies to feel the algorithms with the input they needed to learn and recommendation algorithms that would gradually lead people to more and more extreme content.
My response to this is personal learning. This is a response on several levels. First, a personal learning network is much more distributed than social networks, and thus much less amenable to take-over by bot networks. Second, personal learning networks allow people to select the people and messages
they want to receive, this preventing unwarranted influence by algorithms. And third, personal learning helps each individual develop a personal immunity to fake news, rather than relying on experts. The jury is still out on whether personal learning will come to the fore. It's not going to be supported by institutions of experts like schools and universities.
2017 – BlockchainAlso: xAPI, Caliper, cloud, virtualization Blockchain is an interesting technology that will have future applications, though it is far from prime time. Weller cites Tapscott and Tapscott (2016) to define it (yet another secondary source) though it originated in 2008 with Satoshi Nakimoto's white paper. There's a
really good overview in Ethereum. To really understand blockchain, though, is to recognize it as a combination of two underlying technologies: consensus (that is, the theory of distributed networks), and encryption. Weller, citing Grech and Camilleri (2017), identifies four areas impact; in fact, there are a
lot more, as I have documented here in my notes for a (forthcoming?) book
The Blockchain Papers.
As many commentators have noted, blockchain is a natural for badges. As Weller notes, Mozilla passed off the badge infrastructure to Badgr. Other companies, like Credly, were also in the mix. And most significantly, IMS took over the formal badge specification in 2017. This reflected a community-wide interest in assessment standards. In 2017 IMS also released its competencies standard, in 2018 it would release Caliper, and then the Competencies and Academic Standards Exchange (CASE) standard. Weller doesn't mention xAPI or Caliper anywhere, though these are crucial pieces of the developing ed tech infrastructure.
In 2017 I spent a lot of time trying to learn about the cloud and virtualization, something that cumulated with my (less than successful) gRSShopper in a Box workshop. By 2017 cloud technology was becoming huge, with a whole infrastructure developing under it. I covered a lot of this in
my presentation late that year in Tunisia. The use of cloud technologies for learning probably first emerged in a big way with the Stanford MOOCs, which used AWS for scaling. Ed tech infrastructure companies have been building on that ever since. In 2017 I found myself playing catch-up, but also, we were reaching the point where
individuals could begin doing a lot with tools like VirtualBox, Vagrant, Docker and more. Weller's book mentions none of this, though it's probably the most significant development in ed tech in the last decade.
2018 – Ed Tech’s Dystopian TurnAlso: open practices, fediverse, distributed learning technology, domain of one's ownI'm not really sure 2018 was more dystopian than any of the other years, but Weller picks this year to make the point. To be sure, it is the year many of the more dystopian aspects of learning analytics began to appear in the literature, and Weller highlights several. Much of this chapter consists of lists of examples. I've compiled a comprehensive and categorized summation of
these issues here. But in any case, there's a long history of ed tech dystopianism. We have things like David Noble's
Digital Diploma Mills.
Kearsley. The whole history of
education deform movement. And for every one of the 100 ed tech debacles described in
Audrey Watters's seminal article, there was a chorus of critics. I get that things go wrong. But I don't know of any industry in which they haven't. To me, ed tech is doing a lot better than a more traditional model of schooling that involved hazing and bullying, corporal punishment, suicide, child sex abuse, and worse. I mean, we can pick our criticisms, can't we?
The issue that really emerged in 2018, to my observation, was open practices (or practises) (sometimes also called open pedagogy). There are various aspects: learning by doing, working and learning openly, communities of knowledge. All of these have roots in the earlier technologies we've talked about, from blogs and social networks to e-Portfolios to MOOCs (where we mentioned it explicitly), to performance support, and the definition first emerged in 2010; see, eg.,
Ehlers and Conole (
also here). Also (especially to people like David Wiley, who
defined it back in 2013 in terms of what could be done with openly licensed resources), things like open source and OER. You also see it in things like OERu's '
Logic Model', originally developed in 2017 by Jeff Taylor. The issue came to a head with the two versions - summarized by Cromin (
2017) and Wiley and Hilton (
2018) establishing their respective ground.
For me, 2018 was the year of E-Learning 3.0, more properly called 'distributed learning technology'. It's essentially what you get if you combine the cloud with the core ideas of the blockchain (consensus and cryptography). There's a lot of serious thinking happening about things like federated social networks (including ActivityPub, decentralized IDs, Mastodon, WebMentions, microblogs, and much more) as well as cloud-based learning networks, data-driven learning resources, and more. I covered a lot of it in my 2018
E-Learning 3.0 course. I would also mention Jim Groom's Domain of One's Own as an important initiative in this space, reinforcing once again the idea that learning networks should be centred around people, not institutions or corporations.
2019 - VRAlso: Advanced Decentralized Learning Ecosystem, Duty of Care If Martin Weller had included a chapter for 2019, I expect it would have been VR, based on what I expect to see in the literature in 2022 and 2023. VR has recently coalesced around two popular engines, Unreal and Unity. My own colleagues have been doing development of learning simulations in Unity. We're also seeing the emergence of much more affordable VR headsets, such as the Oculus Rift and Hololens (of course, 'affordable' here is still relative; I can't afford one persoanlly yet). As always, there's a long history of work happening in the background, and I remember
Donald Clark being big on the technology a number of years ago. The other thing that's making it more mainstream is the emergence of GPUs and distributed processing. Because of them I can play games like No Man's Sky on my laptop. Ah, bliss.
For me, 2019 was all about the Advanced Decentralized Learning Ecosystem (ADLE?) (my answer, I guess, to EDUCAUSE's
NGDLE (which probably belongs in the 2015 section)). I ran a number of experiments, publishing results related to the electron infrastructure, connectivism, badges and blockchain, the future of OERs, and related topics.
I also started my monolithic
Ethics, Analytics and the Duty of Care. As a colleague recently commented, everybody is getting on the ethics bandwagon these days (and I should be working on
that, not this article). The other side of it is the analysis from the perspective of feminist 'Care' ethics. My first exposure to this was at a seminar hosted by the department of public affairs at Carleton (I can't find the reference, but I wrote about it). It's where I heard the name Carol Gilligan for the first time.
Conclusions: Reclaiming Ed TechAlso: historical amnesia, academic isolationismIt there's an overall theme to Weller's work, it's this: "in ed tech, the tech part of the phrase “walks taller.'" And this, he says, has been largely unsuccessful. "Some of the innocence and optimism invested in new technologies is no longer a valid stance." This is because education technologists fail to serve
educational objectives, he suggests. "The technologies that are most widely adopted and deeply embedded in higher education institutions tend to correlate closely with core university functions, which are broadly categorized as content, delivery, and recognition."
But it's hard to reconcile his criticism that the ed tech sector suffers from historical amnesia with the treatment of ed tech in this book. There's just
so much of the rich history of ed tech that doesn't sho up in these pages. Even in my own treatment, I can think of dozens of things I should have mentioned - things varying from Flash to XSL to Webheads in Action to the Flat World Network, informal learning, and so much more. With Weller, I didn't include mobile learning, game-based learning, and learning design, and they deserve a place. I don't know
how you can say that, in essence, nothing has changed over twenty-five years, when from a broader perspective it becomes apparent that
everything has changed. Forget Christensen's disruption theory, which never had anything to do with education technology. Look at real people: how they learn, where they learn, what they learn. Nothing is the same. And most of the change has been for the better.
One example of this is academic publication itself. If you're relying on journal articles to understand ed tech, then you're years behind, you're missing most of the story, and you're crediting the wrong people for innovation. Weller notes at one point,
In examining the different subcommunities that have evolved under the broad heading of “open education” Weller, Jordan, DeVries, and Rolfe (2018), using a citation analysis method, discovered eight distinct communities. The published papers in these areas rarely cross over and reference work from other communities, which is symptomatic of the year-zero mentality. Right. That's how the
academic community is approaching the subject. Closed citation networks, in-groups, self-centered societies, no regard for primary literature. Weller's book doesn't mention Jay Cross once. Can you believe it? But the practitioners on the ground have been engaged in the same enterprise from year one, working the same themes and the same ideas, developing the ideas and infrastrcuture that really
is rewriting how we learn. The really
big things are already evident: open access education, learning communities, informal learning. The rest of it - the really
hard work of building an entire infrastructure from scratch - is still in progress.
After reading this book, I want to say to Weller the same thing I say to so many baseball umpires and referees: "Hey, open your eyes, you're missing a really good game out there."




















 ,
,  ,
,  ,
, 

 Source:
Source: 






