Ethics, write Emanuel Moss and Jacob Metcalf, is too big a word to use to describe the state of affairs in the technology world. It actually encompasses four overlapping concepts: moral justice, corporate values, legal risk, and compliance. "The question of what ethics is has very different answers depending on where one sits." they write. "The ethics of technology looks very different outside the tech industry than it does on the inside, and not simply because of conflicting principles or values between techies and their critics... it is a different goal from that of moral justice, which seeks to hold tech companies accountable for their enormous leverage over how our lives are lived and our society is organized. " One could say cynically that such confusion has arisen because in a corporate environment ethics has been reduced to a minimum standard of legal compliance.
Web: [Direct Link] [This Post]Rolandt
Shared posts
Emanuel Moss and Jacob Metcalf
A state-of-the-art open source chatbot
A large number of people are talking today about this article. In it, Facebook announces that it has built and open-sourced Blender, its "largest-ever open-domain chatbot." The reviews are mixed. After trolling through the training logs, Tomer Ullman writes, "1. Clearly some 'humans' are bots. 2. Some of this probably wouldn't get through an IRB." Others questioned the wisdom of basing its training set on Reddit posts. Jesse Lehrich comments, "Facebook has a new chatbot prone to lying. Or as they call it... hallucinating knowledge."
Web: [Direct Link] [This Post]Understanding the Internet vs. Telephony
Twitter Favorites: [JodiesJumpsuit] Every homemade facemask is now a family artifact, whether we recognize it or not.

Every homemade facemask is now a family artifact, whether we recognize it or not.
Twitter Favorites: [jeffjedras] @sillygwailo Yeah, you would think maybe the racism thing would be the bigger priority.

@sillygwailo Yeah, you would think maybe the racism thing would be the bigger priority.


Twitter Favorites: [Planta] I'm going to say May the 1st be with you all day tomorrow, and do it for every day of the fucking month. See how yo… https://t.co/PbehLKYar3

I'm going to say May the 1st be with you all day tomorrow, and do it for every day of the fucking month. See how yo… twitter.com/i/web/status/1…
Perogie Run
Lori Jaworski has refashioned her perogie dealership for pick-up: order by Tuesday, pick up Thursday, at the Charlottetown Farmers’ Market, between 5:00 p.m. and 6:00 p.m.
It was the warmest sunniest day today, so we donned our bicycles for our perogie run. It should have been a harder cycle, what with the winter kinks still in place, but it wasn’t: we glided up the Confederation Trail on a cloud of spring moxie.
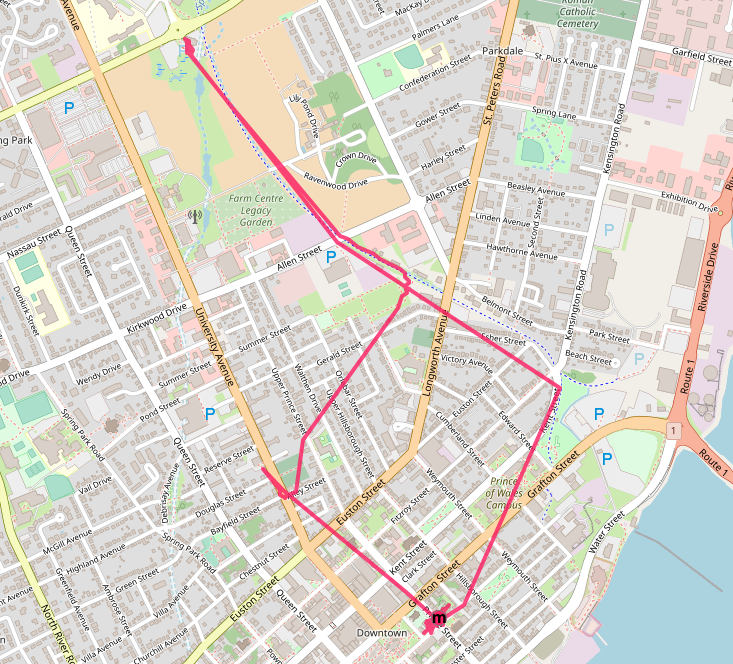
We arrived much too early, but that afforded us a chance to have a 2 metre conversation with Market Bernie—talking, with other people, face to face, imagine!–and a chance to rest up for the coast home.
Once we’d retrieved our bag of potato, onion, cheese and our bag of potato, onion, sauerkraut, handed over the 5 twonies, and bid our farewell, we did, indeed, coast home. At least as far as Orlebar Park, where we detoured east for a trip to the credit union, and ran into a quintet of Atkinson-Batemans out for a walk, thus giving us another unexpected chance at a face to face commiseration.
The mood on the roads was decidedly more frenetic than it has been of late: there were too many cars on the roads with too much pent up energy (want to drive a car crazy with rage? ride two-abreast down Upper Prince Street with a “the cars will understand that we’re doing God’s work” halo over your head).
The reward for our travails was half a dozen POS perogies and some leek kimchi for supper.

Turn your smartphone into a cassette recorder* - The ThumbsUp iRecorder
|
mkalus
shared this story
from |
*Not actually a recorder, and doesn't fit anything larger than an iPhone 5. But it's still available new today, if you want one.

NetNewsWire Code Layout
I don’t claim that this is a beautiful diagram, and it might scale weirdly, but it does show how NetNewsWire is layered.

When writing an iOS or Mac app — or an app that’s both, as in this case — I like to 1) break up the app into separate components, and 2) make those components depend on each other as little as possible, and 3) when there are dependencies, make them clear and sensible.
Submodules
Starting at the bottom level are the submodules: RSCore, RSDatabase, RSParser, RSTree, and RSWeb. These are built as frameworks: RSCore.framework and so on.
Each of these is in a standalone repo and is useful on its own. They don’t even depend on each other — they don’t depend on RSCore, for instance, though you might have expected that they do.
The lack of dependencies promotes reuse — not just by me, among my projects, but by other people too.
It also makes these easier to work on. I don’t have to worry that a change in one affects another one. I don’t have to pull the latest RSCore before working on RSDatabase, for instance.
In NetNewsWire we treat these as Git submodules. It would be great to switch to Swift Package Manager, but I’m not sure if that has all the features we need yet. (Maybe it does. If so, then great, but there’s no rush.)
In-app Frameworks
We continue our bias, inside the app itself, toward using actual frameworks.
The bottom layer is Articles.framework, which is the data model for articles, article status, authors, and so on. Articles depends on nothing else in the app.
ArticlesDatabase.framework and SyncDatabase.framework depend on Articles. ArticlesDatabase stores actual articles data; SyncDatabase stores data used to implement syncing.
The last in-app framework is Account.framework, and it depends on everything below it. An Account is what you think it is: it’s an On My Mac (or iPhone or iPad) account or it’s an account that connects to a syncing system (such as Feedbin or Feedly). It’s at the top of the data storage — to fetch articles for the timeline, for instance, the code asks an Account.
All of these in-app frameworks — like everything in the actual app — may depend on the submodules.
Shared Code
Here live a number of controllers that do various things like OPML import and export, downloading feed icons and favicons, rendering articles, handling user commands and undo (such as mark-all-read).
Some could be broken out into yet more in-app frameworks. (We would be more vigilant about that if we felt, at this point, that we’re losing the battle against app complexity. I’m glad to say we’re not in that position.)
UI Code
NetNewsWire is a Mac and iOS app. It’s built on AppKit on Macs and UIKit on iOS (as opposed to using Catalyst, which would have let us use UIKit for both).
As the diagram shows, there’s a lot of code shared between the platforms, but that stops at the UI code. The UI level is the top level, and it depends on everything below it.
Why use actual frameworks?
The benefits of components and being careful with dependencies are clear — but why use actual frameworks? After all, a conceptual module doesn’t have to translate to an actual separate library target.
I’ve found that it’s easier, when using a framework, to ensure for a fact that you don’t let an unwanted dependency to slip in. It’s kind of like treat-warnings-as-errors — it makes sure you’re not getting sloppy with dependencies.
Other reasons: when I’m working on a framework, I find it easier to just concentrate on exactly what I’m doing there and let the rest of the app slip from my mind temporarily. And, finally, we’re more likely to write tests for frameworks.
It may just be psychology, but it’s important anyway: smaller, self-contained (or mostly so) things are just easier to treat well.
Give Yourself Gout For Fame And Profit
Rolandtj
|
mkalus
shared this story
from |
I.
Actually, no. You should not do this. Most of you were probably already not doing this, and I support your decision. But if you want a 2000 word essay on some reasons to consider this, and then some other reasons why those reasons are wrong, keep reading.
Gout is a disease caused by high levels of uric acid in the blood. Everyone has some uric acid in their blood, but when you get too much, it can form little crystals that get deposited around your body and cause various problems, most commonly joint pain. Some uric acid comes from chemicals found in certain foods (especially meat), so the first step for a gout patient is to change their diet. If that doesn’t work, they can take various chemicals that affect uric acid metabolism or prevent inflammation.
Gout is traditionally associated with kings, probably because they used to be the only people who ate enough meat to be affected. Veal, venison, duck, and beer are among the highest-risk foods; that list sounds a lot like a medieval king’s dinner menu. But as kings faded from view, gout started affecting a new class of movers and shakers. King George III had gout, but so did many of his American enemies, including Franklin, Jefferson, and Hancock (beginning a long line of gout-stricken US politicians, most recently Bernie Sanders). Lists of other famous historical gout sufferers are contradictory and sometimes based on flimsy evidence, but frequently mentioned names include Alexander the Great, Charlemagne, Leonardo da Vinci, Martin Luther, John Milton, Isaac Newton, Ludwig von Beethoven, Karl Marx, Charles Dickens, and Mark Twain.
Question: isn’t this just a list of every famous person ever? It sure seems that way, and even today gout seems to disproportionately strike the rich and powerful. In 1963, Dunn, Brooks, and Mausner published Social Class Gradient Of Serum Uric Acid Levels In Males, showing that in many different domains, the highest-ranking and most successful men had the highest uric acid (and so, presumably, the most gout). Executives have higher uric acid than blue-collar workers. College graduates have higher levels than dropouts. Good students have higher levels than bad students. Top professors have higher levels than mediocre professors. DB&M admitted rich people probably still eat more meat than poor people, but didn’t think this explained the magnitude or universality of the effect. They proposed a different theory: maybe uric acid makes you more successful.
Before we mock them, let’s take more of a look at why they might think that, and at the people who have tried to flesh out their theory over the years.
Most animals don’t have uric acid in their blood. They use an enzyme called uricase to metabolize it into a harmless chemical called allantoin. About ten million years ago, the common ancestor of apes and humans got a mutation that broke uricase, causing uric acid levels to rise. The mutation spread very quickly, suggesting that evolution really wanted primates to have lots of uric acid for some reason. Since discovering this, scientists have been trying to figure out exactly what that reason was, with most people thinking it’s probably an antioxidant or neuroprotectant or something else helpful if you’re trying to evolve giant brains. Other researchers note that in lower animals, uric acid is a “come out of hibernation” sign which seems to induce energetic foraging and goal-directed behavior more generally.
Some of these people note the similarity between uric acid and caffeine:

If uric acid had caffeine-like effects, then high levels of uric acid in the blood would be like being on a constant caffeine drip. The exact numbers don’t really work out, but you can fix this by assuming uric acid is an order of magnitude or so weaker than straight caffeine. Add this fudge factor, and Benjamin Franklin was on exactly one espresso all the time.
But you can’t actually be hyperproductive by being on one espresso all the time, can you? Don’t you eventually gain tolerance to caffeine and lose any benefits?
Although uric acid is structurally similar to caffeine, it’s even more similar to a chemical called theacrine. In fact, theacrine is just 1,3,7,9-tetramethyl-uric acid:

Theacrine (not the same as theanine, be careful with this one!) is a caffeine-like substance found in an unusual Chinese variety of tea plant. It’s recently gained fame in the nootropic community for not producing tolerance the same way regular caffeine does – see eg Theacrine: Caffeine-Like Alkaloid Without Tolerance Build-Up. This makes the theory work even better: Franklin (and other gout sufferers) were constantly on one espresso worth of magic no-tolerance caffeine. Seems plausible!
II.
This theory is hilarious, but is it true?
I was able to find eleven studies comparing achievement and uric acid levels. I’ve put them into a table below.
| Study | sample size | finding | significant at | awfulness |
| Kasi | 155 tenth-graders | r = 0.28 w/ test scores | 0.001 | significant |
| Bloch | 84 med students | r = 0.23 w/ test scores | 0.05 | immense |
| Steaton & Herron | 817 army recruits | r = 0.07 w/ test scores | 0.02 | significant |
| Mueller & French | 114 professors | r = 0.5 with achievement-oriented behavior | 0.01 | astronomical |
| Montoye & Mikkelsen | 467 high-schoolers | negative result | N/A | unclear |
| Cervini & Zampa | 270 children | positive result | unknown | what even is this? |
| Inouye & Park | ??? | r = 0.33 with IQ | 0.025 | what even is this? |
| Anumonye | 100 businessmen, 40 controls | r = 0.21 with drive | 0.05 | immense |
| Ooki | 88 twins | r = 0.17 with 'rhathymia' | 0.05 | how is this even real? |
| Dunn I | 58 executives | positive | ??? | immense |
| Dunn II | 10 medical students | negative | N/A | astronomical |
Nine out of eleven are positive. But I find it hard to be confident in any of them. Modern studies can be pretty bad, but studies from the 1960s ask you to take even more things on trust, while inspiring a lot less of it. Many of these studies were unable to find the outcomes that the others found, but discovered new outcomes of their own. Many failed to report basic pieces of information. The largest experiments usually found the least impressive results. Overall this looks a lot like you would expect from something forty years before anyone realized there was a replication crisis.
I also notice that the most positive studies compare business executives to people in other walks of life, and the least positive studies compare good students with bad students. Business executives get a lot of chances to differ from the general population – maybe they still eat more meat and richer food? Maybe they’re stressed and stress affects uric acid levels?
What about the list of very famous people with gout? I agree it’s a lot of people, but what’s the base rate? Kings were born to their position, so we have no reason to think they were especially high achievers (someone in their family might have been, but that gene could have gotten pretty diluted). Since so many kings got gout, this suggests rich old people in the past had gout pretty often regardless of achievement. Also, this was before people invented good medical diagnosis, so probably arthritis, injuries, and any other form of joint pain got rounded off to gout too. What percent of rich old people in the past had some kind of joint pain? I’m prepared to guess “a lot”.
The biochemists report equally confusing results around the uric acid / caffeine connection. Caffeine mostly works by antagonizing adenosine, a chemical involved in sleepiness. According to Hunter et al, Effects of uric acid and caffeine on A1 adenosine receptor binding in developing rat brain, uric acid does not affect adenosine, and so probably does not have a caffeine-like mechanism of action. On the other hand, caffeine probably has a small additional effect on catecholamine (eg dopamine, norepinephrine) release, and a different paper finds that uric acid does share this mechanism. So it doesn’t have caffeine’s main effect, but it does seem to have some kind of mild stimulant properties.
Given this level of uncertainty around every step in the hypothesis, I would describe any link between uric acid and achievement as kind of a stretch at this point. I feel bad about this, because it’s an elegant theory with mostly positive studies in support, but I’m just not feeling like it’s met its burden of proof.
III.
But some recent research is trying to bring this field back from the dead. At least this is what I get from Ortiz et al, Purinergic System Dysfunction In Mood Disorders, which synthesizes some more modern evidence that “uric acid and purines (such as adenosine) regulate mood, sleep, activity, appetite, cognition, memory, convulsive threshold, social interaction, drive, and impulsivity”. It argues that we know there are neurorecptors for adenosine (another similar-looking molecule) and ATP (adenosine triphosphate, the body’s main form of chemical energy). These seem to be involved in depression and mania, in the predicted direction (manic people have too much ATP, depressed people have too little, and treatments for both conditions seem to normalize ATP levels). These results seem to be daring someone to make up a theory where mania is just too much chemical energy floating around, but if Ortiz et al are doing that, it’s sandwiched in between so many dense paragraphs on receptor binding that I can’t make it out.
More interesting for us, uric acid is related to all these chemicals and also seems to be involved in mania. See eg de Berardis et al, Evaluation of plasma antioxidant levels during different phases of illness in adult patients with bipolar disorder, which finds that uric acid is elevated in manic patients, and the more manic, the higher the uric acid levels. And Machado-Vieria claims to have gotten pretty good results treating bipolar mania with allopurinol, a gout medication that decreases uric acid – and the more the allopurinol decreased uric acid, the better the results. There’s also a little evidence that depressed people have lower uric acid than normal. None of this is a large effect – there are still a lot of depressed people with higher-than-normal uric acid and a lot of manic people with lower – but it’s around the same size as all the other infuriatingly suggestive effects we find in psychiatry that never lead to overarching theories or go anywhere useful.
Future studies should try to replicate the link between uric acid and mania, and come up with a better understanding of why it might be true – maybe since uric acid is a decay product of ATP, the body interprets it as a sign that energy is plentiful? They should try to explain away anomalies – if gout is maniogenic, how come so many people with gout are depressed? Is it just because having a painful illness is inherently depressing? And then it should investigate how mania bleeds into normal personality. Is someone with slightly higher uric acid a tiny bit hypomanic all the time?
If they can fill in all those steps, I’ll be willing to take a fresh look at the old papers linking gout and achievement. Until then, you should probably hold off on eating megadoses of venison to become the next Ben Franklin.
Justice League - Anatomy of a Disaster (Part 1)
|
mkalus
shared this story
from |
Join me as I explore the problems, failures and mistakes that led to Justice League, one of the biggest cinematic failures of all time.

A Simple Request to the Transport Modelers Out There
Expect to hear a lot more of this: ‘Transit is contagious. Cars are clean. Gas is cheap. Density is dangerous. Let’s drive!’
So let’s try to get drivers on side in supporting transit with this message: ‘The more people who switch from transit to the car, the worse it is for you and everyone.’
Therefore, it will be very useful to know how many ‘switchers’ – from transit to the car – it would take for the road system to start to ‘fail’.
![]()
![]()
Given that we have accommodated growth in the region though the expansion of transit, and we already have a heavily used road system for motor vehicles, it likely won’t take many to switch from transit to driving to create significant problems overall for transportation.
Just imagine a worsening problem for goods movement and deliveries as we do more online consumption and the roads become increasingly full – beyond the pre-covid use. We actually need more people to switch the other way – from cars to transit – just to accommodate the additional impact of home delivery.
Unfortunately, ‘switchers’ will assume that the per-trip cost of using the road will be the same as pre-covid – i.e. free – and will do what people did with the ‘free parking’ that became available at hospitals and in zones with meters or resident-only parking. They will fill it up almost immediately, they abuse it.


We know that the ‘freeway’ is not free, even if the marginal cost for use is zero. We’ve seen that ‘free’ is almost always abused, quickly making the real cost apparent. Congestion, pollution and injuries beyond what a balanced transportation system would provide are just others ways of paying.
Therefore, road pricing that helps pay for maintaining transit, given that it relieves the pressure on the overall road system and accommodates economic growth at lower cost, is a bargain. Curb pricing too.
So this is what we need now from the modelers: Give us a sense of what the cost (in terms of congestion and loss of options) will be if switching occurs from transit to car. How much, how many and how fast will it take for our transportation system to get viscerally and objectively worse? It may not be a single number, but we need some relatively simple way to covey it.
What is it?
Zoom Is YouTube, Instagram, and WhatsApp – All in Two Months.

If you’ve read Shoshana Zuboff’s Surveillance Capitalism, you likely agree that the most important asset for a data-driven advertising platform is consumer engagement. That engagement throws off data, that data drives prediction models, those models inform algorithms, those algorithms drive advertising engines, and those engines drive revenue, which drives profit. And profit, of course, drives stock price, the highest and holiest metric of our capitalistic economy.
So when an upstart company exhibits exponential growth in consumer engagement – say, oh, 3,000-percent growth in a matter of two months – well, that’s going to get the attention of the world’s leading purveyors of surveillance capitalism.
And in the past week, Facebook and Google have certainly been paying attention to a formerly obscure video conferencing company called Zoom.
As I’ve already pointed out, Zoom has become a verb faster than any company in history, including Google. The COVID-19 pandemic shifted nearly all of us into a new mode of video-based communication – and Zoom just happened to be at the right place, at the right time, with … a better product than anyone else. As of this writing, the company’s user base has grown from 10 million users a day to 300 million users a day – that’s two times bigger than Twitter, and nearly 20 percent of Facebook’s entire daily user base.
That, my friends, is an existential threat if you’re in the business of consumer engagement. Which is exactly why we saw news on the videoconferencing front from both Facebook and Google this week.
Item #1: This past Friday, Facebook announced Messenger Rooms, a video conferencing app that allows up to 50 people to have Zoom like experiences for free.
Item #2: Not to be outdone, Google today announced that its Meet videoconferencing tool, which formerly came with its paid G Suite service, is now free and will support 100 simultaneous users.
Item #3: Zoom’s high flying stock has lost 13% of its value since those two events.
Both companies are attacking Zoom’s core business model: paid software as a service. As I’ve explained in earlier posts, Zoom offers a limited free service, and is in the business of convincing folks to pay for more premium features. This SaaS model works well in the world of enterprise (business to business) but when it comes to us consumers, well, the only place we’re willing to pony up at scale is entertainment (think Spotify, Netflix, etc.). Anything else, we’re fine with ads, even if they’re annoying.
The research we’ve done at Columbia SIPA shows that Zoom’s privacy policies would allow it to get into the ads business. Will it?
Facebook and Google’s news certainly forces Zoom’s hand. It’s now squarely in the crosshairs of the two most valuable advertising companies ever created. Will it pivot to an advertising model, as I speculated earlier? Will it succumb to an acquisition offer, as engagement traps Instagram, YouTube, and WhatsApp did before it? Or will it find a third way, and build an entirely new consumer behavior based on a paid service, free of the surveillance capitalism model that has dominated consumer apps for the past ten years?
Pass the popcorn, folks. This is going to be a great show.
The British Museum and Digital Appropriaton
The Britsh Museum is chock full of fascinating artefacts, even if the sourcing of some of those artefacts means their ownership of them is disputed. While that sourcing happened in different times perhaps (which doesn’t mean our current perspective can’t be different), in these times echoes of that can be heard in the form of digital appropriation.
Earlier this week the British Museum announced they had revamped their website. Part of the revamp is providing more and better digital images of artefacts. Digitising artefacts well is a lot of work and effort, and making them available to the public is very laudable. Especially as the British Museum says, since we’re now only capable of visiting from home.
Director Hartwig Fischer in the museum’s communication is quoted saying
We hope that these important objects can provide inspiration, reflection or even just quiet moments of distraction during this difficult time
Inspiration, cool. Let’s do. Jason Kottke wrote about it and posted some beautiful images.
I went to the BM’s site as well and browsed. Then I came across this artefact:
 Screenshot of the British Museum showing a 1725 etching, with copyright claim
Screenshot of the British Museum showing a 1725 etching, with copyright claim
I didn’t know the British Museum had a print of the water gates in my hometown!
Then I noticed an oddity: a ‘(c) Trustees of the British Museum’ statement on it. I have the image (remixed with a Mondriaan painting, by E after my idea) on my wall. This as the etching by A. Rademaker is also in the collection of the Rijksmuseum, and they too have digitised their collection and made it available. At the Rijksmuseum that image however is public domain.
The British Museum also allows downloading images. For ‘my’ image at least that download is of distinctly lower resolution than the Rijksmuseum download (the BM’s download is 365Kb, the Rijks’ 2.8MB). Here you see them side by side, BM on the left, Rijks on the right.
 ‘high-ish’ res BM image on the left, higher res Rijks image on the right
‘high-ish’ res BM image on the left, higher res Rijks image on the right
Moving on from inspiration to reflection then, as per the director’s words: What’s up with that copyright claim? The etching itself, being from the 18th century, is clearly in the public domain. Are they saying making a photo of an artefact is creating a new copyright? As Cory Doctorow also noted, that is a wild claim to make. Making a photo of an artefact to show just that artefact is not considered a creative act, and thus not protected under copyright rules, in the UK (PDF) and the EU.
The actual licensing terms attached by the British Museum to a downloaded image are Creative Commons BY NC SA, meaning only non-commercial use is allowed, if the results are shared under the same conditions and the British Museum is mentioned as the source. This is not an open license. It means that Jason Kottke who, inspired as hoped by the BM’s director, put images on his site is in breach of this license, as he also sollicits membership payments through his blog. Appropriate would be a CC0 license, or public domain mark. Claiming copyright on an image that actually is in the public domain because its subject matter is in the public domain on the other hand is digital appropriation.
A second question is why would the British Museum do this? A clue is the information shown when you want to download an image:
 BM allows download for non-commercial use, but for commercial use requires a request
BM allows download for non-commercial use, but for commercial use requires a request
The distinction between commercial and non-commercial forms of use, I suspect, may have something to do with the effort of digitisation. Digitisation is generally very costly. Museums fall under the EU PSI Directive on the re-use of public information. In that Directive a possibility exists to temporarily make the exploitation of digitised material exclusive to a certain party as reward for help with the digitisation. Under this exemption tech companies can enter into agreements with museums and libraries to digitise their collections and have a handful of years before the results become generally available to the public. The fact that the BM publishes some images for the general public, at lower quality, is another potential clue. It’s my speculation, but it may mean that the BM tries to provide at least some publicly available material, while the exclusive exploitation rights for whoever is paying for the digitisation still exist. In other countries we’ve seen that material isn’t published until those rights expire, and it would indeed be a useful step to find a way of providing at least some access.
However, none of that has any relation to copyright, as the digitisation itself does not create new rights to license. It would I think better be solved by providing lower quality material as public domain material, while higher quality material is made available as part of the exclusive exploitation deal. If this is what is happening, again it’s just my assumption, using a restrictive CC license is the wrong instrument. If it has nothing to do with the digitisation process and surrounding contracts, but only to create revenue for the museum, then using Creative Commons licenses to do so is just plain wrong and digital appropriation that should be corrected.
Raspberry Pi HQ Camera

Very nice and timely. A full kit (camera + lens) is pricey at $75-$100, and you do need at least a 3A+ to capture things at a decent rate, but on the whole it’s not bad - I might get one and see if my Canon lenses fit, and if it could be made to stream NDI video it would likely be an awesome webcam to use with OBS (even if I do think not having autofocus makes it somewhat unsuitable for that).
I can get RTSP streaming to work somewhat painfully with a Zero W, so there’s a lot of potential there. Let’s wait for some reviews and more test shots.
How to Navigate Your First Recession

What you are, I once was.
Starting your career in the midst of economic wreckage is scary. Job prospects dry up, debt amasses, and your optimism deflates. You wonder: If things are this hard now, how will I make it for the next four decades?
Jabra Elite 85h :: Der Schlaumeier unter den Headsets

Ich kenne das ganze Bluetooth-Sortiment von Plantronics rauf und runter, aber bei dem direkten Konkurrenten Jabra fehlt mir der Überblick. Das will ich jetzt aufholen und fange mit einem Ausreißer im Programm an, dem Jabra Elite 85h. Der Grund ist, dass ich einige Leute kenne, die damit super zufrieden sind. Das Elite 85h ist ein Kopfhörer mit aktiver Geräuschunterdrückung, der vor allem geeignet ist, konzentriert Musik zu hören, sei es zu Hause oder unterwegs.

Das Headset kommt in einem sehr stabilen Case aus schwarzem Kunstleder, das mit einem Reisverschluss und einer Trageschlaufe versehen ist. Innen ist das Case von einem weichen Textilband unterteilt, das Platz hat für die mitgelieferten Kabel (USB-A auf USB-C, Audiokabel mit 3,5mm Stecker auf beiden Seiten) und einen Adapter mit zwei Mono-Steckern, wie man manchmal in alten Flugzeugen benötigt. Das erste Aufklappen bereitet eine kleine Überraschung: Wenn man die Ohrmuscheln 90 Grad in Richung der Ohren dreht, schaltet sich das Headset ein. Gegenprobe: Zusammenklappen und es geht wieder aus. Das ist clever. Man muss nie nachdenken, mit welchem Schalter man ausschaltet, und man sieht auf einen Blick, ob es aus oder an ist. Wie ich später entdecken werde, hat es außerdem eine einstellbare Sleep-Funktion, falls man doch mal vergisst, die Ohrmuscheln zu drehen.

Der Elite 85h kommt mit zwei Buttons und drei Bedienelemente auf der rechten Ohrmuschel aus. Links schaltet man die Soundprofile um, rechts das Mikrofon stumm. Drückt man in die Mitte der rechten Muschel, bedient man Play/Pause oder nimmt Anrufe an bzw. legt auf. Oberhalb und unterhalb fühlt man zwei winzige Nippel. Auf den oberene gedrückt wird es lauter, unten leiser. Ungewöhnlich ist, dass man durch langes Halten einen Track nach vorne (oben) oder hinten (unten) springt. Das muss man sich erst mal trauen. Bei anderen Headsets würde es sehr schnell laut werden.

Das Headset fühlt sich sehr solide an und sitzt sicher und bequem auf dem Kopf. Ein großer Teil der Flächen, die man berührt, sind mit einem groben Stoff bespannt, der leider Hautschuppen magisch anzieht. Die Ohrpolster sind sehr tief, so dass sie auch Platz für weiter abstehende Ohren haben. Geladen wird das Headset über einen USB-C-Anschluss. Der Akku soll bei eingeschaltetem ANC für 36 Stunden reichen, was ich gerne glaube. Das wird der neue Standard, an dem man sich messen muss. Surface Headphones etwa schaffen nur ein Drittel davon, die Bose NC 700 zwanzig, die Marshall Monitor ANC dreißig Stunden.
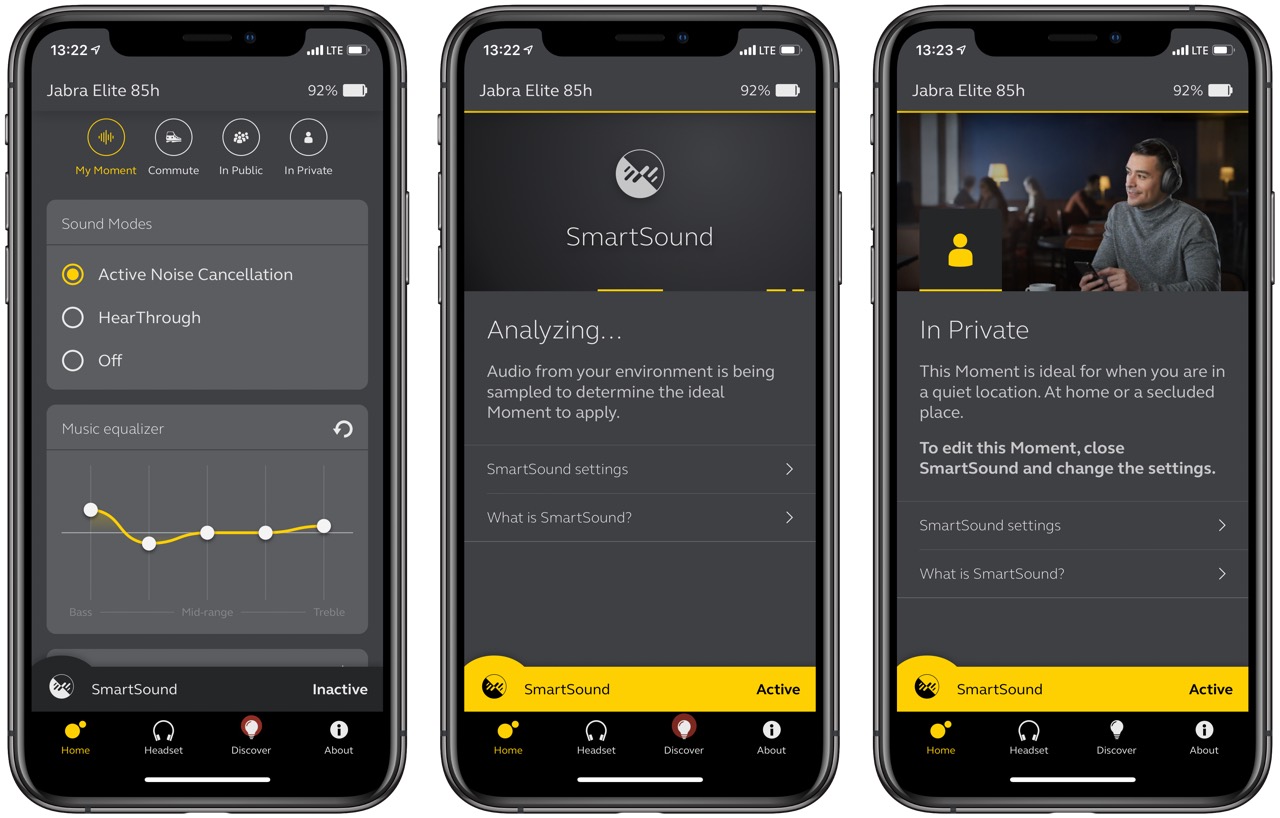
Einmal ausgepackt, aufgesetzt, mit dem iPhone gepaart und schon ging es los. Ich war von Anfang an vom dem Sound recht angetan. Das ANC funktioniert gut. Aber dann habe ich die Jabra Sound+ App installiert und mir ist schlicht das Blech weggeflogen. Die Intelligenz, die in diesem Headset steckt, ist schlicht unglaublich. Und das hängt mit hoher Wahrscheinlichkeit daran, dass Jabra seit 20 Jahren zum dänischen Unternehmen GN gehört, dessen Hearing-Sparte ein führender Anbieter von Hörgeräten ist.
Der zentrale Baustein nennt sich Smart Sound. Mehrmals pro Minute nimmt das Headset ein Sample der Umgebungsgeräusche und ordnet es einem von drei Momenten zu: Commute, In Public, In Private. Bei Commute schaltet es das ANC an, bei In Private dagegen aus. In Public schaltet das Headset auf Durchzug, das heißt, man hört seine Umgebung gut. So kommt man auf der Straße nicht unter die Räder und dennoch wird geschwind das Gedröhne eines vorbeifahrenden Busses vom ANC weggedrückt. So zumindest die Theorie. Ich persönlich mag das lieber selbst regeln und genau das macht die Taste hinter dem linken Ohr.
Die Taste hinter dem rechten Ohr schaltet das Mikrofon stumm. Auch das lässt sich automatisieren, denn wie die Plantronics-Konkurrenz hat das Elite einen Sensor, der erkennt, wenn man das Headset absetzt. Dann kann man Musik anhalten oder das Mikro stumm schalten. Setzt man das Headset wieder auf, geht es weiter.
Zur Anpassung des Klangs hat das Headset einen fünfbändigen Equalizer und sechs voreingestellte Profile. Dazu kann man weitere eigene anlegen und speichern. Für mich ist das Overkill. Ich erwarte, dass der Hersteller diesen Job für mich macht und das Headset gut ausbalanciert. Aber wer will, kann sich hier das Profil schaffen, das ihm am meisten liegt.
Kann das Jabra Elite 85h irgendetwas besser als andere Headsets? Da fallen mir zwei Eigenschaften ein: Der Akku hält sehr lang und das Headset ist gegen Staub und Feuchtigkeit geschützt. Der Klang ist nicht besser als etwa bei den Surface Headphones. Was ich gar nicht nachvollziehen kann, ist die Werbeaussage von Jabra, das Headset sei besonders gut zum Telefonieren geeignet, weil es sechs der acht Mikrofone nutzt, um die Stimme perfekt rüberzubringen. Das funktioniert bei mir eher unterdurchschnittlich.
Es bleibt ein sehr cleveres Headset mir ordentlicher, aber nicht herausragender Klangqualität und ebensolcher aktiver Geräuschunterdrückung zu einem fairen Preis. Der Listenpreis liegt bei 250 Euro, aktuell wird er für etwa 185 Euro gehandelt.
How much is music worth to you?
Hi! This is Ivan, developer here at Datawrapper. This week we’ll look at the ridiculous amount of money that some people pay for music.
In the age of digital streaming, it’s hard to imagine that anyone would value music at over $10 per month that a Spotify (or an alternative service) subscription costs. This relatively low fee gives access to pretty much all music ever recorded, so why would anyone pay more?
Turns out that sometimes it’s not that simple. For some people, there is a certain value attached to owning music and not just having the ability to listen to it. It’s not only owning the music but owning an object that music is recorded on that is important.
Discogs is a database that attempts to list all music ever released in physical formats[1]. Alongside it, there is a marketplace where private persons buy and sell releases[2].
So let’s find out exactly how much some records have been sold for:
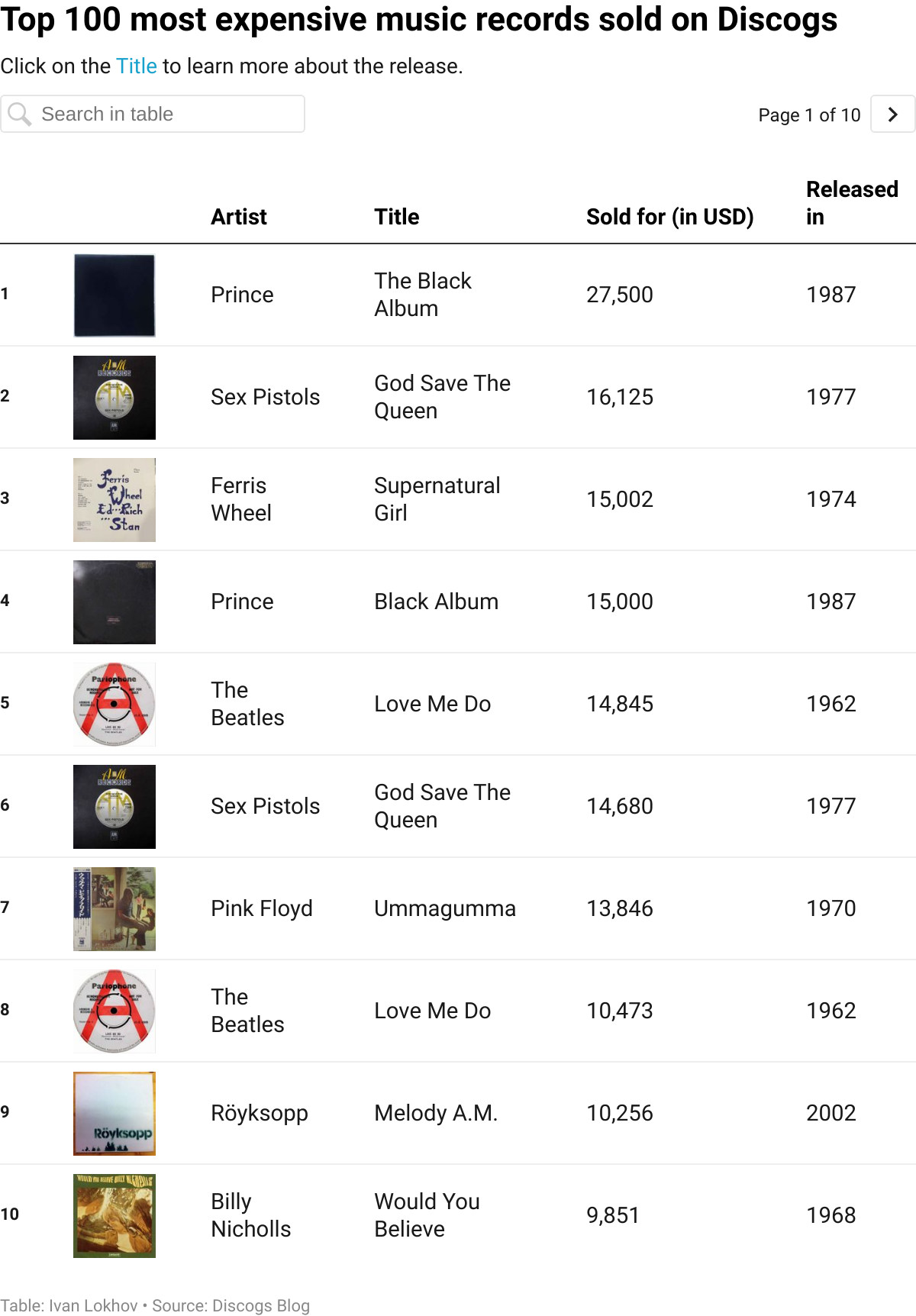
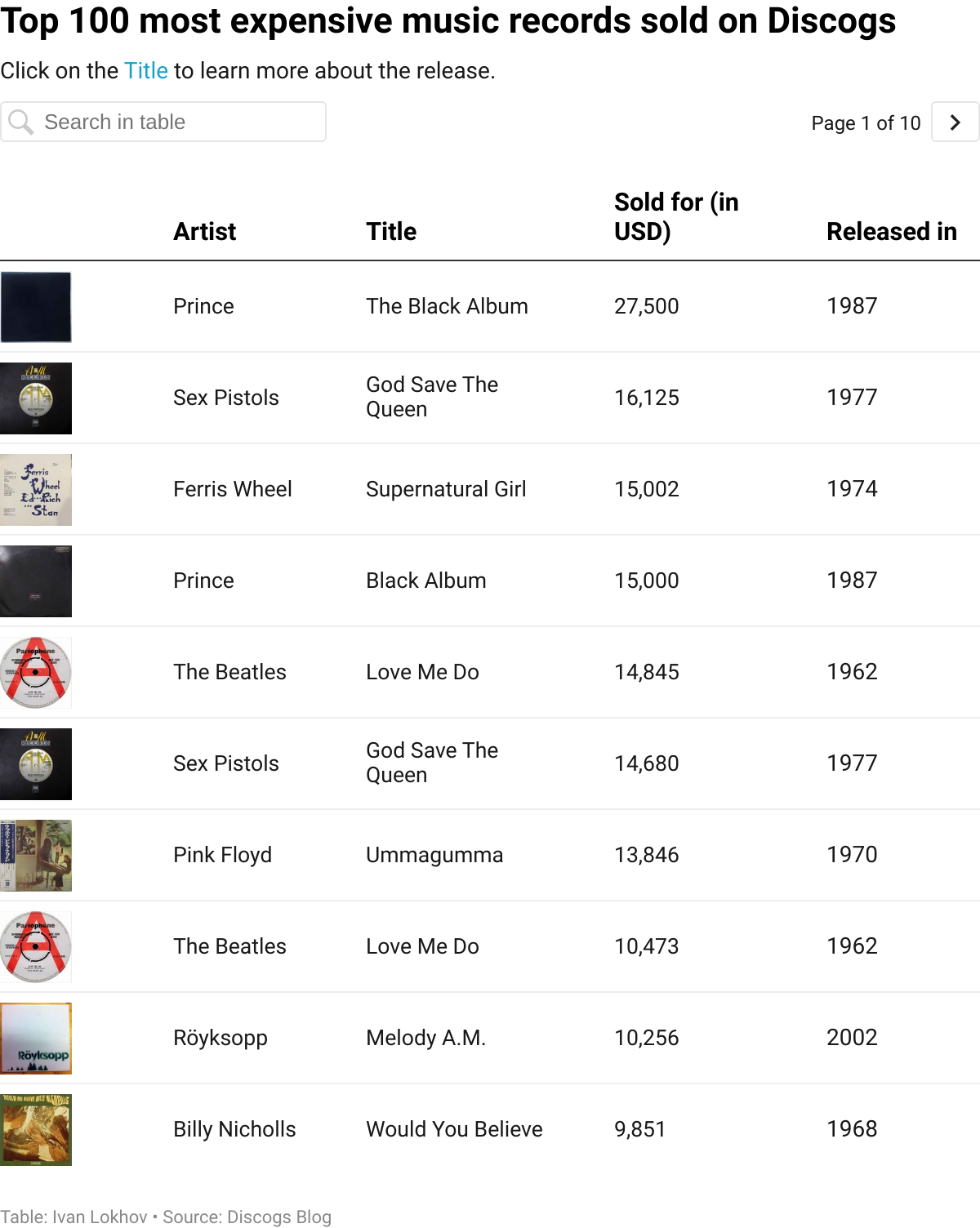
And the winner is: The Black Album by Prince which reportedly sold for $27,500. That’s quite a lot of money to pay for 8 songs. In fact, you could get a Spotify subscription in the US that would last 2,750 months (that’s a little over 229 years) for the same amount of money. I checked and you can’t stream The Black Album on Spotify (at least in Germany), but you can listen to it for free on YouTube.
We can only speculate about the exact reasons why someone would pay $27,500 for a single vinyl record, but I think it must be related to exclusivity. Most records that sell for a lot of money are rare (sometimes first) editions, or they are special in some other way. For example, the Prince record mentioned above is an album that was never properly released, so there must be only a few copies of it in existence. This scarcity is what drives prices up and some music collectors are prepared to pay up to own these records.
Chart choices
I chose to present the data in a table. Each music release transaction in the dataset is unique and a table is a great medium to showcase detailed and precise information for each entry. A table also lets you easily explore the data.
It’s possible to sort the table, so you can, for example, see if any recently released records sell for a lot of money (click on Released in twice to do that). You can also search the table! So you find out if your favorite artist makes an appearance. Or you can search for “Melody A.M.” and see how often this release by Röyksopp made it into the list (turns out that Banksy hand-made the artwork for it — hence the price).
Each entry in the table also includes a link to Discogs, so you can find out more information about it: for example, some users leave interesting comments or you can see if there is a copy that you want to buy on the marketplace. I used the awesome Markdown feature to put links and images into the table.
Getting and preparing the data
The table was really easy to make thanks to Datawrapper, but unfortunately, the data itself was not as easy to obtain.
The Discogs API does not allow searching the marketplace for current listings or purchase history, so I had to pull the data from the Discogs blog. There is a blog post on top 100 most expensive records sold on Discogs, but it came out more than a year ago, so I also had to include monthly posts that list top 30 expensive records sold in that month. I ended up scraping all those blog posts and combining the data to get the dataset that I required.
I won’t go into full details in this post, but will instead outline the steps that I took to get the dataset.
- Get a list of releases by scraping the blog post with top 100 most expensive records which was published in March 2019 (to make multiple requests I used the same technique as I described on my personal blog recently).
- Get a list of releases by scraping monthly top 30 posts from March 2019 to February 2020.
- Combine the two lists from above, sort them by price, and include top 100 in the final list.
- Download and resize images for the top 100 entries that made it into the final list.
- Assemble the dataset in the correct format for Markdown and export the columns as CSV.
If you’re interested, you can find all scripts that I used to get the dataset here.
After doing all the above steps I finally had the dataset which I used to create the table above!
I hope you enjoyed my journey into the music collectors’ world. Next time you’re looking through a stack of vinyl at a flea market or a charity shop, watch out, you might be flipping through a goldmine! If you have any questions or comments, you can reach me at ivan@datawrapper.de or on Twitter. See you next week!
A release on Discogs is a specific version of a music release which shares all the same features. For example, an LP album by a band might have been originally released in 1970 in the US, whereby 10,000 copies of it got pressed on vinyl. This counts as a single release. If the same album got pressed on vinyl in the same year in Germany, that’s a different release. If the same album got re-pressed in 1975 in the US, that’s yet another release. And so on. ↩︎
When a purchase is made on the Discogs marketplace, we don’t know exactly which copy of the release gets sold. So for all the duplicate entries in the table above, we don’t know if they were different copies of the release or the same copy that got sold. To use an example from the table: Melody A.M. by Röyksopp is included 5 times. However we don’t know if it’s literally the same copy of it that got sold 5 times from one person to the next, or if 5 different copies of it each got sold once (or a combination of the two). ↩︎
Peter asked me if it is possible to change my R...
Peter asked me if it is possible to change my RSS feed for my comments. Right now it contains any reaction, which come in the form of webmentions, likes, reposts, as well as actual replies and comments. Essentially it is currently not a comment feed, but a reaction feed. As part of my site tweaks I will see if I can turn it into a real comment feed (that includes webmentions that are replies), and how to change the way some things are displayed (I had that but it got overwritten by plugin updates).
For now I have renamed the comment feed, so new subscribers have the right expectations.
Steamed Lunch
Sushi rice topped with steamed carrots and kale (both from Heart Beet Organics).
Remind me again why we need restaurants?
 ,
, 
New Report Shows Protecting the Car Industry More Important than Saving Vulnerable Road User Lives
 Photo by Katie E on Pexels.com
Photo by Katie E on Pexels.comYou would think that people dying on the road would attract a furore of voices for change. But somehow we just accept those deaths as the accepted collateral for ease, timeliness and convenience, just a side effect of car use.
Earlier this year I wrote about the National Highway Traffic Safety Administration (NHTSA) that does NOT use female crash test dummies in their test vehicles despite the fact they’ve known for forty years that the bodies of males and females react differently in crashes.
In fact it was Consumer Reports that revealed that although most Americans killed in car crashes are male, data shows women are at a greater risk of death or serious injury in a car crash. A female driver or front row passenger with a seatbelt is 17 percent more likely to die, and 73 percent more likely to have a serious injury.
Automotive research still stubbornly clings to the “50th percentile male” which is understood to be a 171 pound 5 foot 9 inch dummy first developed in the 1970’s. And that crash test dummy has not substantially changed, despite the fact that the average American man weighs 26 pounds more.
Quite simply women are not factored in for crash survival tests, despite the fact they are 50 percent of the drivers.
In 2018 36,000 people in the USA died in car crashes, roughly the population of Penticton British Columbia. Twenty percent of those killed were vulnerable road users, pedestrians or cyclists, and those numbers are increasing annually. Statistically deaths of vulnerable road users have increased by 43 percent since 2008.
Statistics also show that SUVs are twice as likely to kill pedestrians because of the high front end profile, but this information has not been well publicized. Indeed an American federal initiative to include pedestrian crash survival into the vehicle ranking system was halted by opposing automakers.
It’s no surprise that Aaron Gordon in Vice.com writes on a Government Accountability Office (GAO) report which discovered that the increasing pedestrian and cyclist deaths were “due to the total inaction of government safety regulators, who have known about the dangers to pedestrians increasingly large vehicles on American roads present, but have done nothing about it.”
The findings in the report are troubling. There are international agreements to develop protocol to protect vulnerable road users from vehicular crashes, but it simply has not been followed up on, despite the fact that this could save hundreds of lives.
I have written before how trucks and SUVs now comprise 73 percent of the new vehicle purchases in the United States. That means that of every four vehicles on the road, three are more likely to kill pedestrians or cyclists.
From 2009 to 2016 pedestrian deaths have risen 46 percent and are directly linked to the increase of these large vehicles on the road.
It is the weight and size of the vehicle and bumper height that are crucial for pedestrian and cyclist survival of a crash. But surprise! The NHTSA’s bumper regulations are written to “limit vehicle body damage. It has nothing to do with protecting people hit by said bumper. Nor do any regulations exist for vehicle hoods to absorb energy efficiently (cushion the victim) during a crash”.
What this all means is that the NHTSA is doing absolutely no studies or assessments on the survivability of people outside the vehicle during a crash. The only assessment that is done is the survivability of the people inside the vehicle.
And that is a huge ethical inequity that should not be tolerated.
The same organization that does not use female crash test dummies to help the survivability rate in a crash also does not do any research or grading to protect vulnerable road users in crashes.
As author Aaron Gordon bluntly states “The upshot to all this is NHTSA knows more pedestrians are dying but, despite being the regulatory agency with “highway traffic safety” in its name, refuses to do anything about it.”
When people buy a SUV or a truck because it’s seen as a moving den providing safety and security for their immediate family, they have no idea that what they are buying is a killing machine that can mow other vulnerable road users down.
It’s a problem that the National Highway Traffic Safety Administration should be addressing but is not. It appears that despite the fact “traffic safety” is in the name, the organization simply does not have the political independence from car makers to do the right ethical thing.
This is why I believe that SUVs should be banned from cities.
 Photo by Aleksandr Neplokhov on Pexels.com
Photo by Aleksandr Neplokhov on Pexels.comTo Apply Machine Learning Responsibly, We Use It in Moderation

Concerns over implicit bias in machine-learning software raised important questions about how New York Times comment moderators can leverage this powerful tool, while also mitigating the risks.
By Matthew J. Salganik and Robin C. Lee
It’s a common refrain on the internet: never read the comments. All too often, the comment section is where trolls and toxic behavior thrive, and where measured debate and cordial conversation ends. The New York Times comment section, however, is different. It is generally civil, thoughtful and even witty. This did not happen by itself; it is the result of careful design and hard work by the Times Community Desk.
For years, people on the Community Desk manually moderated all comments that were submitted to Times articles. The work led to high-quality comments, but it was time consuming and meant that only a small number of stories could be open to comments each day.
In 2017, this changed. To enable comments on many more stories, The Times introduced a new system named Moderator, which was created in partnership with Jigsaw. Moderator is powered by a widely available machine-learning system called Perspective that is designed to help make the comment review process more efficient. After deploying Moderator, The Times dramatically increased the number of stories that are open to comments.
This might sound like another machine learning success story, but it is not that simple.
Since 2017, researchers have discovered that some well-intentioned machine-learning tools can unintentionally and invisibly discriminate or reinforce historical bias at a massive scale. These discoveries raised important questions about how to use machine-learning systems responsibly, and they led us to take a second look at how machine learning was being used in The Times’s comment moderation process.
How a comment makes it onto The Times
When a comment is submitted by a reader, Perspective assigns it a score along a number of dimensions, such as whether the comment is toxic, spam-like or obscene. A comment that includes the line, “free Viagra, free Viagra, free Viagra” might get a high spam score, and a comment that uses a lot of four-letter words might get a high obscenity score. Perspective assigns these scores entirely based on the content of the text; it does not know anything about the identity of the commenter or the article that attracted the comment. In addition to providing scores, Perspective also identifies specific phrases that it thinks might be problematic.
Next, the Community Desk, made up of about 15 trained moderators, reads the highlighted comments for each story and decides whether to approve or deny them for publication based on whether they meet The Times’s standards for civility and taste. This review is enabled by Moderator’s interactive dashboard, which was designed to empower the human moderators, making it easier for them to do their work efficiently and accurately. The dashboard presents the scores and the potentially problematic phrases, as well as other contextual information about the original story.

All of the human moderators have a background in journalism and have been Times employees for many years. In other words, the work of moderation is not outsourced; instead, it is treated as an important responsibility.
Together, this hybrid system combines sophisticated machine learning and skilled human moderators to sift through the thousands of comments submitted each day. It has allowed The Times to foster high-quality conversations around our journalism.
A reason for concern
With the concern about potential bias in machine-learning technology in mind, our colleague Robin Berjon, who is the Vice President of Data Governance at The Times, decided to run an experiment to see if he could trick Perspective, the machine-learning system that powers Moderator. Berjon created duplicate pairs of fake comments with names that are strongly associated with different racial groups to see whether Perspective gave different scores to the comments. It did.
This looked bad for Perspective, but it was actually more complicated. The fake comments that Berjon created didn’t look anything like the real comments that readers submit to The Times — those are typically long and almost never include anyone’s name. And Berjon only attempted to trick Perspective; his fake comments never made it to The Times’s human moderators, who would have detected them.
Despite these limitations, Berjon’s demonstration inspired us to further investigate. We discovered that we were not the first people to be interested in biases in Perspective’s scores.
A team of researchers at the University of Washington assessed Perspective using Tweets and found that the machine-learning software was more likely to rate African-American English as toxic. Researchers at Jigsaw — the very people who created Perspective — published several academic papers attempting to understand, describe and reduce the unintended biases in Perspective. Critically, none of this research was available in 2017 when The Times first started using Perspective as part of the comment moderation process.
Like Berjon’s experiment, this academic research was provocative but incomplete for our purposes. None of it used comments like those submitted to The Times, and none of it accounted for the human moderators who are part of the Times system.
One might suppose that the right response to this research is to build a better machine-learning system without bias. In an ideal world, this response would be correct. However, given the world and the state of current technology, we don’t think that’s possible right now. Roughly speaking, machine-learning systems learn from identifying patterns that exist in data. Because the world contains racism and sexism, the patterns that exist in data will likely contain racial and gender bias.
As an example, a machine-learning system might learn that comments are more likely to be toxic if they include the phrase “Jewish man.” This pattern might exist in the data because the phrase is more frequently used in online comments with the intent to harass. It is not because Jewish men are toxic or because the algorithm is biased against Jewish men.
If the machine-learning system was taught to unlearn this pattern, it could make the system less useful at identifying anti-semitic comments, which might actually make the system less practical for promoting healthy conversation.
Given that a quick technical fix was not possible, we decided to build on prior research and conduct our own investigation to see how these issues might play out in the context of The Times.
Our investigation at The Times
Our investigation of the role of machine learning in Times comment moderation had three parts: digging through the comment moderation database logs; creating comments that tried to trick Perspective; and learning more about the human moderators who ultimately decide whether a comment gets published.
Combing through the database logs of past comments, we wanted to know whether comments scored as more problematic by Perspective were getting rejected by the Times moderators more often. They were. Then, we looked for cases where Perspective and the moderators disagreed. We examined some comments that Perspective scored as risky but were published by The Times’s human moderators, and some comments that were scored as not risky but were rejected. We did not see any systematic patterns related to issues like race or gender bias.
To further test how Perspective works with Times comments, we created a set of 10 identity phrases such as, “Speaking as a Jewish man” and “Speaking as an Asian-American woman,” and we added them to the beginning of one thousand comments that had been published on the Times website. We then had Perspective score all of these modified comments and we compared the results to the scores for the original, unmodified comments.
Similar to what others have found, we saw that these identity phrases led Perspective to score the comments as riskier. But, critically, we saw that these effects were much smaller when the identity phrases were added to real comments, rather than submitted on their own. And we found that the longer the comment, the less impact the identity phrase had on the scores.
The distinctive, and perhaps most important, part of the Times system is the human moderators. We wanted to understand how the moderators used and interpreted the Moderator software to make decisions about what comments to publish on the Times website.
To learn more about the process, we went through comment moderator training and shadowed moderators as they worked. Through observation and discussion, we learned that the moderators felt free to overrule the scores generated by Perspective (and from the log data we could see that this did indeed happen).
The human moderators were keenly aware of Perspective’s limitations, yet they found Moderator’s user interface to be helpful, especially the way it highlights phrases in comments that might be problematic. They told us that having comments ordered by estimated risk makes it easier to make consistent decisions about what to publish.
To be clear, Perspective is not perfect and neither are the human moderators. However, creating a system that maximizes the number of Times stories that allow comments, while also fostering a healthy and safe forum for discussion, requires trade-offs. An all-human model would limit the number of stories that are open for comment, and an all-machine-learning model would not be able to moderate according to The Times’s standards.
Just as Perspective and the moderators are imperfect, so is our investigation. We ruled out large patterns of racial and gender bias, but we might have missed small biases along these dimensions or biases along other dimensions. Also, our investigation happened during a specific point in time, but both Perspective itself and the comments submitted to The Times are always changing.
Overall, our three-pronged investigation of the role of machine learning in comment moderation at The Times led us to conclude that the system — one that combines machine learning and skilled people — strikes a good balance.
General recommendations
Our investigation focused on the role of one specific machine-learning system in comment moderation at The Times. However, the concerns that sparked our investigation apply to all machine-learning systems. Therefore, based on our investigation, we offer three general recommendations:
Don’t blindly trust machine-learning systems
Just because someone tells you that a tool was built with machine learning does not mean that it will automatically work well. Instead, examine how it was built and test how it works in your setting. Don’t assume that machine-learning systems are neutral, objective and accurate.
Focus on the people using the machine-learning systems
An imperfect machine learning tool can still be useful if it is surrounded by dedicated, experienced and knowledgeable people. For example, it did not matter if Perspective occasionally produced inaccurate scores as long as the human moderators ultimately made the correct decisions. Sometimes the best way to improve a socio-technical system is to empower the people using the machine-learning system; this can be done by providing training on how the system works and by giving them the authority to push back against it whenever necessary.
Socio-technical systems need continual oversight.
The initial deployment of a machine-learning system can require difficult technical and organizational changes, but the work does not end there. Just as organizations routinely audit their operation and accounting, they should regularly assess the use of machine-learning systems.
The New York Times has created a thriving comments section through years of effort and innovation. We hope this investigation contributes to that long-term project and also serves as a blueprint for examining the responsible use of machine learning in other areas.
Matthew J. Salganik was a Professor in Residence at the New York Times, and he is a Professor of Sociology at Princeton University, where he serves as the Interim Director of the Center for Information Technology Policy. He is the author of “Bit by Bit: Social Research in the Digital Age”. Follow him on Twitter.
Robin Lee is a PhD student in Sociology at Princeton University. He was a Data Analyst for the Data & Insights team at The New York Times. Outside of work, he’s a data meetup organizer. Follow him on Twitter.
To Apply Machine Learning Responsibly, We Use It in Moderation was originally published in NYT Open on Medium, where people are continuing the conversation by highlighting and responding to this story.
We Want YOU to Test Ulysses 20
|
mkalus
shared this story
from |

There’s some major stuff in the pipeline, which we would like to have tested thoroughly with a larger crowd, starting in May. We're very excited about what's coming, but we need to keep the details under wraps for now. We can only say this much: The following features will definitely be part of Ulysses 20 and therefore subject to beta testing:
- new attachments,
- a new navigator,
- a new dashboard
- … and an advanced text check.
The last one is the true crown jewel of this release, especially if you’re already familiar with grammar and style checking tools. So, if you would like to help and are interested in getting a sneak peek of the new features, please consider signing up!
During the process, you’ll be prompted to answer a couple of questions. Among other things, we’re interested in the language you write in, what’s your preferred device, and if you’re a VoiceOver user. Your answers will help us ensure that we receive the feedback we need regarding any important subject and all supported languages.
Finally, to be on the safe side, a note on what you should be clear about: a beta is a beta is a beta. The existence of bugs and flaws is not only natural but the heart of the endeavor. If you’re not ready for this, please don’t sign up. If you are, please don’t forget to back up your data properly before it begins.
To sign up for the Ulysses 20 beta, this way please. See you soon!
Ripping CDs with foobar2000 in Windows 10
Edit yourself. It’s cheaper and it makes you smarter.
You wrote something. It’s not the best it can be. You could hire an editor. Or you could fix it yourself. Sure, if you can’t really figure out what you’re saying, you might need outside help. But before you do, try these tricks: Make sentences shorter. Find sentences of more than 20 words. Break them … Continued
The post Edit yourself. It’s cheaper and it makes you smarter. appeared first on without bullshit.
Zoom retracts claim that it has 300 million daily active users
Zoom has quietly admitted that it doesn’t actually have 300 million daily active users, which is the number it has been touting for the past few weeks.
The videoconferencing service, which has gained immense popularity amid the COVID-19 pandemic, has clarified that it actually has “300 million daily Zoom meeting participants.”
The big difference in wording is that daily meeting participants can be counted numerous times. For instance, if you attend four Zoom meetings in a day, you will be counted four times. A daily active user references one user a day, regardless of how many meetings they have attended.
By only keeping track of daily meeting participants, a company is able to make its service appear much more popular than it actually may be.
The Verge noticed the change in wording and received the following statement from Zoom: “We are humbled and proud to help over 300 million daily meeting participants stay connected during this pandemic.”
“In a blog post on April 22, we unintentionally referred to these participants as ‘users’ and ‘people.’ When we realized this error, we adjusted the wording to ‘participants.’ This was a genuine oversight on our part.”
Although Zoom’s growth has been expansive, since it did grow from 10 million daily participants to 300 million daily participants from December to March, its competitors are catching up.
Microsoft has noted that it has seen a 70 percent increase in daily active users on Teams, which totals to 75 million. Microsoft has also stated that it saw 200 million meeting participants in one day.
The COVID-19 pandemic has resulted in several companies pushing to garner more users as people work, study and socialize from home. Facebook rolled out a new videoconferencing feature that supports 50 participants, and Google plans to make its Meet service free for all users in the coming weeks.
Source: The Verge
The post Zoom retracts claim that it has 300 million daily active users appeared first on MobileSyrup.
Apple Q2 2020 Results - $58.3 Billion Revenue

Apple has just published its financial results for Q2 2020. The company posted revenue of $58.3 billion. Apple CEO Tim Cook said:
“Despite COVID-19’s unprecedented global impact, we’re proud to report that Apple grew for the quarter, driven by an all-time record in Services and a quarterly record for Wearables,” said Tim Cook, Apple’s CEO. “In this difficult environment, our users are depending on Apple products in renewed ways to stay connected, informed, creative, and productive. We feel motivated and inspired to not only keep meeting these needs in innovative ways, but to continue giving back to support the global response, from the tens of millions of face masks and custom-built face shields we’ve sent to medical professionals around the world, to the millions we’ve donated to organizations like Global Citizen and America’s Food Fund.”
Estimates and Expectations for Q2 2020 and the Year-Ago Quarter (Q2 2019)
Apple’s revenue guidance for Q2 2020 originally fell between $63.0 billion and $67.0 billion, with gross margin estimated to be between 38.0% and 39.0%, but in a press release issued on February 17, 2020, the company said it expected to miss that guidance due to iPhone supply constraints and lower demand in China resulting from the COVID-19 pandemic.
Going into today’s earnings call, Barron’s said:
The current Wall Street analyst consensus revenue forecast is $54.6 billion, but the estimates vary dramatically, with the low end of the Street range at $45.6 billion. The consensus profit forecast is $2.27 a share, but again, the range is wide, with estimates running from $1.73 to $2.73 a share.
In the year-ago quarter (Q2 2019), Apple earned $58 billion in revenue.
Graphical Visualization
After the break, we’ve compiled a graphical visualization of Apple’s Q1 2020 financial results.




















Apple Q1 2020 on Twitter
Early coverage of Apple’s results is varied, but one theme seems to be “stock falls after Apple refuses to issue Q3 guidance.”
— MacJournals.com (@macjournals) April 30, 2020
Cook, on Apple Q2 earnings call, says co felt temporary supply constraints in February but production was back in full swing by end of March. Aligns with what some analysts have been saying for past month as well; as China opens back up, demand could be a more of a Q than supply.
— Lauren Goode (@LaurenGoode) April 30, 2020
Apple share are down 1.9% in after hours trading, despite revenue beat.
— Patrick McGee (@PatrickMcGee_) April 30, 2020
Our recent #Workingfromhome study certainly confirms how much both #FaceTime and #iMessage are part of the go to apps people rely on for collaboration @BenBajarin https://t.co/gbC9vrhdsp
— Carolina Milanesi (@caro_milanesi) April 30, 2020
#AAPL retail up thanks to online sales really shows how much better that has become over the years and a lot of that is thanks to the time Angela Ahrendts spent at Apple.
— Carolina Milanesi (@caro_milanesi) April 30, 2020
FaceTime, Messages, new all time records for daily usage.
— Rene Ritchie (@reneritchie) April 30, 2020
https://twitter.com/macjournals/status/1255966633606119425
Covid-19 Boosted App Store & TV+, Hurt AppleCare & Ads, Cook Says w/ @emilychangtv https://t.co/r6SJbRCyhM
— Mark Gurman (@markgurman) April 30, 2020
Apple Saw Sales Pick Up in Second Half of April After “Depressed” Second Half of March and First Half of April, CEO Cook Says w/ @emilychangtv https://t.co/e1gcJ2eeVU
— Mark Gurman (@markgurman) April 30, 2020
*APPLE SAYS ACTIVE INSTALLED BASE OF DEVICES AT ALL-TIME HIGH
— Eric Jackson (@ericjackson) April 30, 2020
Ok #Apple attention to detail goes all the way to picking the right music for their #earnings call #AAPL a lot somber than usual today and clearly not because of their results! pic.twitter.com/miCZv03Mgt
— Carolina Milanesi (@caro_milanesi) April 30, 2020
Apple CEO Says Austria, Australia Stores to Reopen in 1-2 Weeks w/ @emilychangtv https://t.co/c6VKsFQZ0L
— Mark Gurman (@markgurman) April 30, 2020
Apple Squeezes Growth Out of Pandemic-Ravaged Quarter https://t.co/Td7jVLqgE2 https://t.co/O6sO5stZWk
— Mark Gurman (@markgurman) April 30, 2020
Depending on what one believes Apple’s quarterly iPhone ASP is, iPhone unit sales were somewhere between 38-42m units.
— Ben Bajarin (@BenBajarin) April 30, 2020
“We have great confidence in the long-term of our business. In the short-term, it’s hard to see out the windshield to know what the next 60 days look like, and so we’re not going guidance because of that lack of visibility and uncertainty…” (8/10)
— MacJournals.com (@macjournals) April 30, 2020
“There was a significant, very steep fall-off in February. That began to recover some in March, and we’ve seen further recovery in April. So it leaves us room for optimism…It’s hard to tell [if that’s a leading indicator]…” (2/10)
— MacJournals.com (@macjournals) April 30, 2020
Tim Cook, to CNBC, on iPhone demand in China: (1/10)
— MacJournals.com (@macjournals) April 30, 2020
Apple reports: $58.3 billion in revenue, up 1% despite Covid-19.
— Mark Gurman (@markgurman) April 30, 2020
Support MacStories Directly
Club MacStories offers exclusive access to extra MacStories content, delivered every week; it’s also a way to support us directly.
Club MacStories will help you discover the best apps for your devices and get the most out of your iPhone, iPad, and Mac. Plus, it’s made in Italy.
Join NowAmazon posts Q1 2020 revenue, commits $4 billion USD to workplace safety
Rolandtj

Amazon has played a critical role in the COVID-19 pandemic as more people turn to the online retailer to deliver their goods so they don’t need to leave home.
As a result, the company has experienced a mostly positive Q2 2020, with a revenue of $75.45 billion USD (roughly $103 billion CAD).
Last year in Q1 Amazon posted net sales of $59.7 billion USD (roughly $83.1 billion CAD), so this quarter is a 26 percent increase. In terms of income, the retail giant brought in $2.5 billion USD (roughly $3.4 billion CAD).
At the top of its letter to shareholders, Jeff Bezos, the company’s CEO, stated that the company aims to make $4 billion USD (roughly $5.5 billion CAD) in operating profit, and it’s planning to put all of that amount — if not more — to COVID-19 related expenses. This includes ensuring products are still getting to customers, employee safety, higher wages for hourly workers, more space in its warehouses to allow for better social distancing, and improved protective equipment.
Bezos also mentions that hundreds of millions of dollars will go towards Amazon’s own efforts to develop COVID-19 testing.
This is the first quarter that Amazon Web Service’s (AWS) revenue topped $10 billion USD (roughly $13.9 billion CAD). It’s likely that this was related to more people working from home and relying on cloud-based platforms to get work done. Notably, AWS powered the NFL’s remote draft this year.
Looking forward to Q2, Amazon is aiming to post an operating income loss of $1.5 billion depending on how spending goes next quarter and the amount of money it needs to spend on its coronavirus prevention efforts.
Source: Amazon
The post Amazon posts Q1 2020 revenue, commits $4 billion USD to workplace safety appeared first on MobileSyrup.
Editing sent messages could be coming to iPhone users

iPhone users may eventually get the ability to edit messages, according to a new US patent filed by Apple.
There’s no mention if this is SMS text messages or iMessage, but because iMessage is web-based it makes more sense we’ll likely see this feature arrive there.
The 200,000-word document describes several features many are likely familiar with, but one section of note relates to editing as well as building an application launcher within the iPhone’s Messages app.
The patent says that, “… current messaging applications have numerous drawbacks and limitations.” Things like not being able to edit messages, sending private chats, and making sure everyone in the chat is seeing the same messages in the correct order, are all issues that plague messaging apps.
This patent acknowledges, at least internally by Apple, that its current messaging app could be improved on in a few key ways.
“There is a need for electronic devices with improved methods and interfaces for selecting an impact effect for a message. Such methods and interfaces may complement or replace conventional methods for selecting an impact effect for a message,” the patent says.
The real meat of the patent is how it illustrates Apple’s message editing interface.
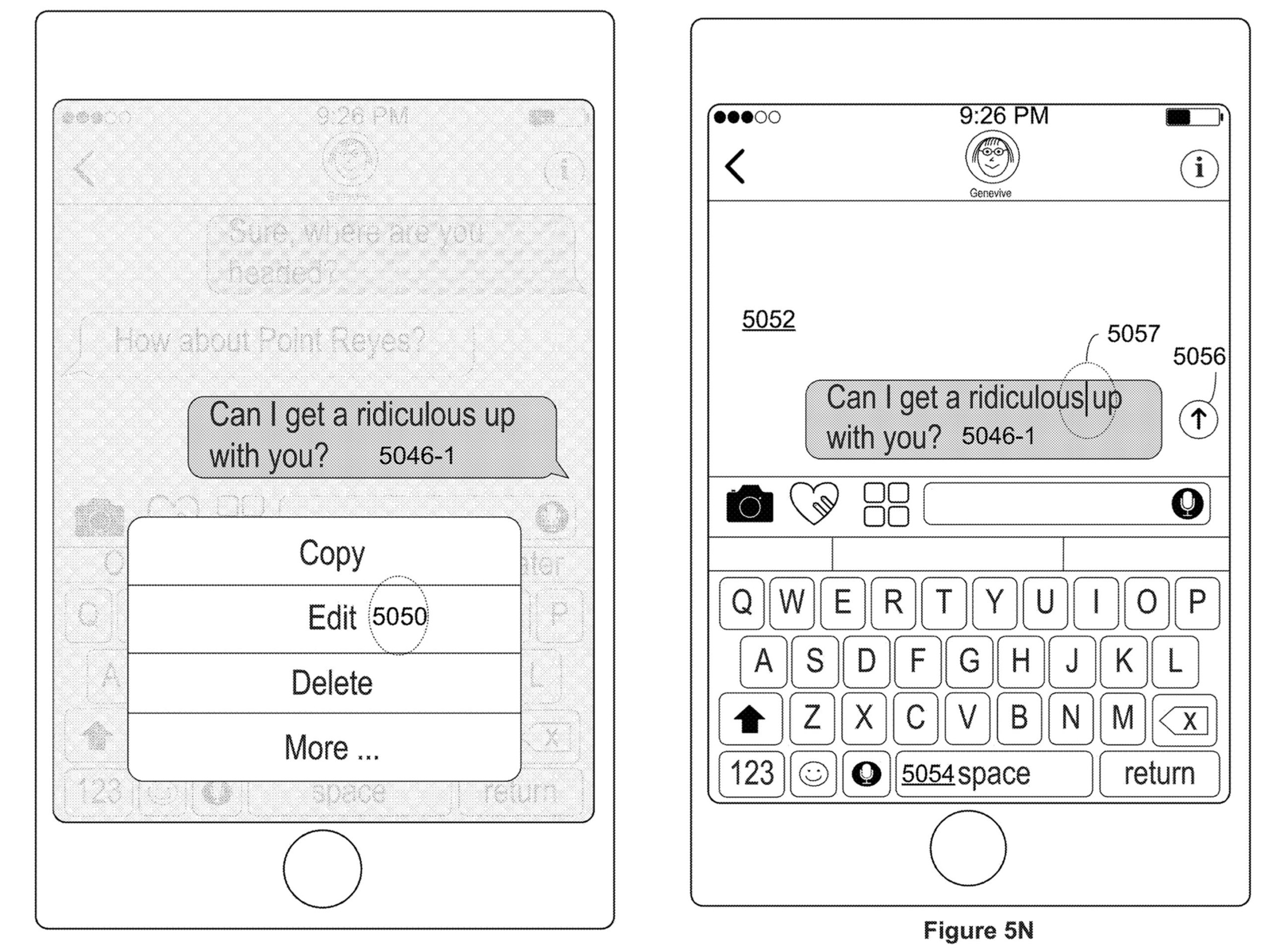
Messaging services like Slack allow users to edit messages after posting within the app itself, but this isn’t done through a cellular network. Adding the ability to edit text messages might be what Apple is after with this patent in the long term. However, it’s likely we’ll see this implemented in iMessage first.
As always, it’s important to note that this is just a patent filing and may not result in Apple ever releasing the ability to edit messages
Source: US Patent and Trademark Office Via: AppleInsider
The post Editing sent messages could be coming to iPhone users appeared first on MobileSyrup.