I have been a happy customer of Spotify for several years now, after flirting back and forth with Apple Music, Google Play Music and the late Rdio for several years before that. We have a family subscription, which we all three use extensively, no more so than Oliver who, for many months now has been making nightly playlists to go to sleep listening to.
Spotify has recently been promoting itself as much a podcast player as a streaming music service, and Oliver has followed the lead and has accumulated a subscription list of 1500+ podcasts in Spotify.
Last night, though, he was thinking about migrating to something else for his podcast listening: he didn’t like the fact that, although the Android Spotify app sports an “episodes” tab, the desktop player for the Mac does not, which makes tracking recently-released episodes on his Mac more challenging.
Having found a possible alternative, Oliver set out to move his list of podcasts from Spotify to a new app, and was immediately faced with a task that would have extended for several days: for each of the podcasts in Spotify he was taking the title, copying and pasting it into the new app, and subscribing there. Over and over and over. When this job threatened to take over his Friday, to the exclusion of other activities, I interceded and told him that we should simply export his list of podcasts from Spotify and import it into the new app.
How naive I was.
Spotify, it turns out, is a prison for podcasts.
Spotify takes podcasting, a system that is a marvel of decentralized openness, built on the strong and flexible (and open) foundation of RSS, and locks it inside a closed, proprietary system with no way of getting data in or out. You can’t import lists of podcasts. You can’t export lists of podcasts. You can’t add your own podcasts.
Surely, I thought, given the GDPR, there must be a way of getting Oliver’s personal information–including his podcasts–out of Spotify.
And there is, in theory: if you visit your Account page in Spotify, and then navigate to Privacy, and scroll down to the bottom, you will see a section called Download your data, full of promise.
Until you read the fine print and learn that “This can take up to 30 days to complete”:
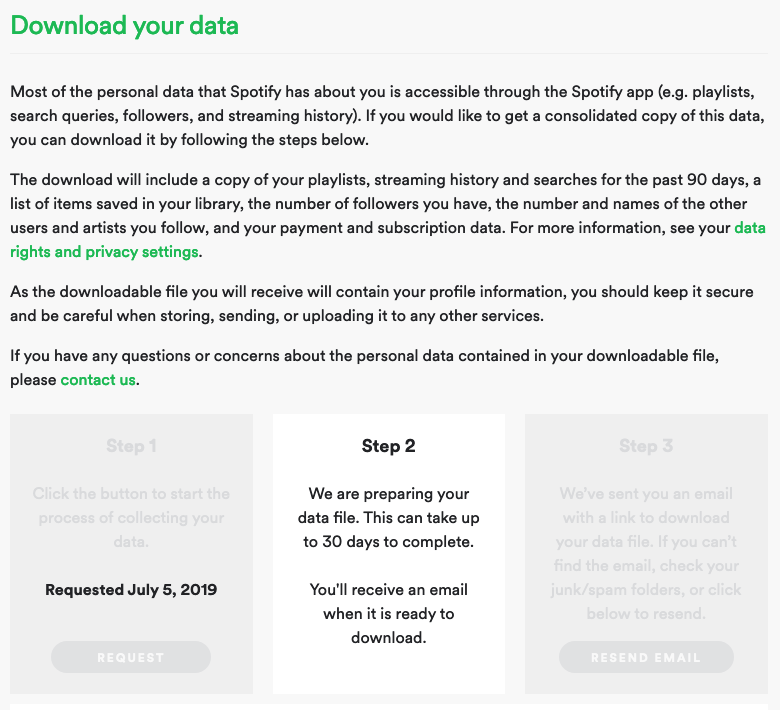
How it’s possible to create a system that takes 30 days to assemble digital data boggles the mind, and while it may live up to the letter of the GDPR, it surely defies the spirit.
What about using the Spotify API?
Although it’s not documented, there is and endpoint that exposes the list of podcasts for a user.
Here’s how you can get at it (with the caveat, detailed below, that you are wasting your time).
Go to the Web API Console for the “Get User’s Profile” endpoint and click Get Token and then copy the cURL command on the right side (I’ve redacted Oliver’s token):
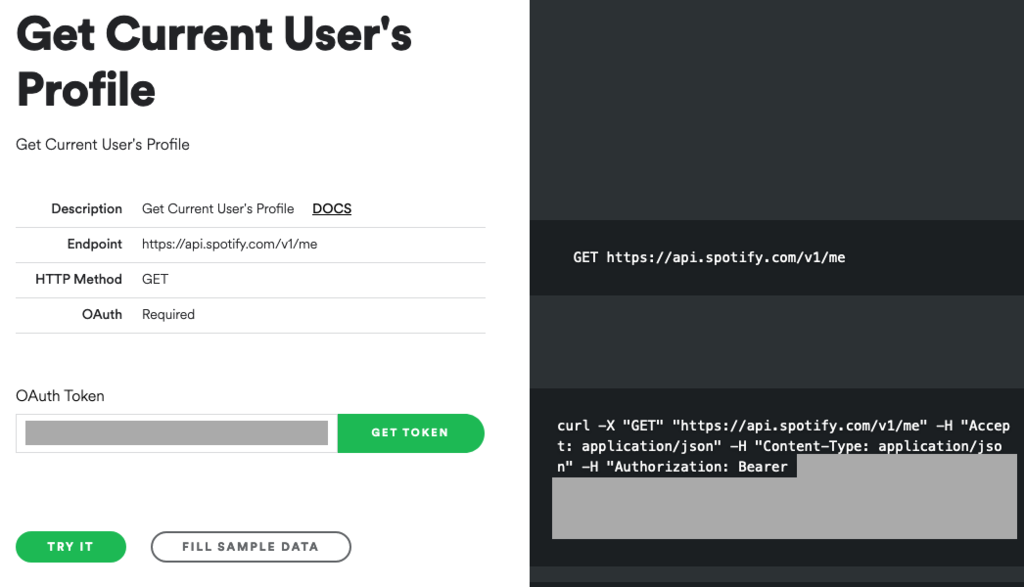
If you simply paste this cURL into the Mac command line, you’ll get back your basic account information:
{
"birthdate" : "XXXX-XX-XX",
"country" : "CA",
"display_name" : "Oliver Rukavina",
"email" : "o@ruk.ca",
"explicit_content" : {
"filter_enabled" : false,
"filter_locked" : false
},
"external_urls" : {
"spotify" : "https://open.spotify.com/user/12154891049"
},
"followers" : {
"href" : null,
"total" : 13
},
"href" : "https://api.spotify.com/v1/users/12154891049",
"id" : "12154891049",
"images" : [ {
"height" : null,
"url" : "https://profile-images.scdn.co/images/userprofile/default/6a5a73861526ed7cece0ea757ab1f043277d7ebb",
"width" : null
} ],
"product" : "premium",
"type" : "user",
"uri" : "spotify:user:12154891049"
}
If you edit this command, however, and tack shows onto the end of the URL, replacing https://api.spotify.com/v1/me with https://api.spotify.com/v1/me/shows, you’ll get back a JSON representation of your first 20 podcast subscriptions, with each one represented by an object like this:
{
"added_at" : "2019-03-27T02:16:27Z",
"show" : {
"available_markets" : [ "AD", "AE", "AR", "AT", "AU", "BE", "BG", "BH", "BO", "BR", "CA", "CH", "CL", "CO", "CR", "CY", "CZ", "DE", "DK", "DO", "DZ", "EC", "EE", "ES", "FI", "FR", "GB", "GR", "GT", "HK", "HN", "HU", "ID", "IE", "IL", "IN", "IS", "IT", "JO", "JP", "KW", "LB", "LI", "LT", "LU", "LV", "MA", "MC", "MT", "MX", "MY", "NI", "NL", "NO", "NZ", "OM", "PA", "PE", "PH", "PL", "PS", "PT", "PY", "QA", "RO", "SE", "SG", "SK", "SV", "TH", "TN", "TR", "TW", "US", "UY", "VN", "ZA" ],
"copyrights" : [ ],
"description" : "It's the Peter and Oliver podcast all grown up. ",
"explicit" : false,
"external_urls" : {
"spotify" : "https://open.spotify.com/show/6bDdMX7OmjDG1u5ebEhNRX"
},
"href" : "https://api.spotify.com/v1/shows/6bDdMX7OmjDG1u5ebEhNRX",
"id" : "6bDdMX7OmjDG1u5ebEhNRX",
"images" : [ {
"height" : 640,
"url" : "https://i.scdn.co/image/8beec05386bfef3e095bcdf46aafaee112d55fdb",
"width" : 640
}, {
"height" : 300,
"url" : "https://i.scdn.co/image/4f70272b77c24c619a79486d6c88445b976151f7",
"width" : 300
}, {
"height" : 64,
"url" : "https://i.scdn.co/image/807d9151f7fa4a0ccd96c80d0c9bc265152b6012",
"width" : 64
} ],
"languages" : [ "en-US" ],
"media_type" : "audio",
"name" : "Oliver And Peter Podcast",
"publisher" : "Oliver Rukavina",
"type" : "show",
"uri" : "spotify:show:6bDdMX7OmjDG1u5ebEhNRX"
}
}
You may be thinking “wow, this is amazing!” until you notice that nowhere in that JSON is any information that falls outside the Spotify universe: none of the standard trappings of open podcast data–the feed URL, the website, the non-Spotify-hosted artwork–are there.
And these details also aren’t there if you follow the URL in the “href” to get all the show details:
{
"available_markets" : [ "AD", "AE", "AR", "AT", "AU", "BE", "BG", "BH", "BO", "BR", "CA", "CH", "CL", "CO", "CR", "CY", "CZ", "DE", "DK", "DO", "DZ", "EC", "EE", "ES", "FI", "FR", "GB", "GR", "GT", "HK", "HN", "HU", "ID", "IE", "IL", "IN", "IS", "IT", "JO", "JP", "KW", "LB", "LI", "LT", "LU", "LV", "MA", "MC", "MT", "MX", "MY", "NI", "NL", "NO", "NZ", "OM", "PA", "PE", "PH", "PL", "PS", "PT", "PY", "QA", "RO", "SE", "SG", "SK", "SV", "TH", "TN", "TR", "TW", "US", "UY", "VN", "ZA" ],
"copyrights" : [ ],
"description" : "It's the Peter and Oliver podcast all grown up. ",
"episodes" : {
"href" : "https://api.spotify.com/v1/shows/6bDdMX7OmjDG1u5ebEhNRX/episodes?offset=0&limit=50",
"items" : [ {
"audio_preview_url" : "https://p.scdn.co/mp3-preview/1c405e3e511e5e7199a45b1de32f83e5f88c7e24",
"description" : "This first episode is about Vancouver BC Canada ",
"duration_ms" : 92624,
"explicit" : false,
"external_urls" : {
"spotify" : "https://open.spotify.com/episode/79W2zHGuUttBOInh642kNR"
},
"href" : "https://api.spotify.com/v1/episodes/79W2zHGuUttBOInh642kNR",
"id" : "79W2zHGuUttBOInh642kNR",
"images" : [ {
"height" : 640,
"url" : "https://i.scdn.co/image/53b71df32a85645777ba73afa2e9e738bd788534",
"width" : 640
}, {
"height" : 300,
"url" : "https://i.scdn.co/image/2cc3d2acae39674b3c3bfdc53ae2286a692b1376",
"width" : 300
}, {
"height" : 64,
"url" : "https://i.scdn.co/image/2f6bd66373d51f8f6f62b55997539e1554a3df4a",
"width" : 64
} ],
"is_externally_hosted" : false,
"is_playable" : true,
"language" : "en-US",
"name" : "Oliver and Peter Podcast episode 1",
"release_date" : "2019-03-20",
"release_date_precision" : "day",
"type" : "episode",
"uri" : "spotify:episode:79W2zHGuUttBOInh642kNR"
}, {
"audio_preview_url" : "https://p.scdn.co/mp3-preview/1b3548d7561908fd8b4c6625e5e4d1fdbc8198bd",
"description" : "Episode 1 is about Vancouver BC Canada ",
"duration_ms" : 26958,
"explicit" : false,
"external_urls" : {
"spotify" : "https://open.spotify.com/episode/5bH6wVgbHQ5aCJdthQLZrk"
},
"href" : "https://api.spotify.com/v1/episodes/5bH6wVgbHQ5aCJdthQLZrk",
"id" : "5bH6wVgbHQ5aCJdthQLZrk",
"images" : [ {
"height" : 640,
"url" : "https://i.scdn.co/image/53b71df32a85645777ba73afa2e9e738bd788534",
"width" : 640
}, {
"height" : 300,
"url" : "https://i.scdn.co/image/2cc3d2acae39674b3c3bfdc53ae2286a692b1376",
"width" : 300
}, {
"height" : 64,
"url" : "https://i.scdn.co/image/2f6bd66373d51f8f6f62b55997539e1554a3df4a",
"width" : 64
} ],
"is_externally_hosted" : false,
"is_playable" : true,
"language" : "en-US",
"name" : "Oliver and Peter Podcast episode 1",
"release_date" : "2019-03-20",
"release_date_precision" : "day",
"type" : "episode",
"uri" : "spotify:episode:5bH6wVgbHQ5aCJdthQLZrk"
} ],
"limit" : 50,
"next" : null,
"offset" : 0,
"previous" : null,
"total" : 2
},
"explicit" : false,
"external_urls" : {
"spotify" : "https://open.spotify.com/show/6bDdMX7OmjDG1u5ebEhNRX"
},
"href" : "https://api.spotify.com/v1/shows/6bDdMX7OmjDG1u5ebEhNRX",
"id" : "6bDdMX7OmjDG1u5ebEhNRX",
"images" : [ {
"height" : 640,
"url" : "https://i.scdn.co/image/8beec05386bfef3e095bcdf46aafaee112d55fdb",
"width" : 640
}, {
"height" : 300,
"url" : "https://i.scdn.co/image/4f70272b77c24c619a79486d6c88445b976151f7",
"width" : 300
}, {
"height" : 64,
"url" : "https://i.scdn.co/image/807d9151f7fa4a0ccd96c80d0c9bc265152b6012",
"width" : 64
} ],
"is_externally_hosted" : false,
"languages" : [ "en-US" ],
"media_type" : "audio",
"name" : "Oliver And Peter Podcast",
"publisher" : "Oliver Rukavina",
"type" : "show",
"uri" : "spotify:show:6bDdMX7OmjDG1u5ebEhNRX"
}
Like I said: a prison.
And there’s another problem: this is both an undocumented API call and a broken one.
In theory you should be able to specify a “limit” and an “offset” parameter to page through podcasts and retrieve them all, like:
curl -X "GET" "https://api.spotify.com/v1/me/shows?offset=0&limit=20"
curl -X "GET" "https://api.spotify.com/v1/me/shows?offset=20&limit=20"
curl -X "GET" "https://api.spotify.com/v1/me/shows?offset=40&limit=20"
curl -X "GET" "https://api.spotify.com/v1/me/shows?offset=60&limit=20"
and so on.
But that doesn’t work.
I’m able to retrieve at most 50 podcasts (out of Oliver’s 1,986 total subscriptions). And using the Spotify web player confirms this breakage, showing a scrolling list of 50 podcasts that repeats and repeats and repeats.
Because this is an undocumented, and thus unsupported API call, it’s not like I can dial 1-800-SPOTIFY to ask for help.
But I’m not willing to give up the fight, so I forge on with this crazy, destructive nuclear option, which involves working around this bug in the undocumented API by pulling the podcasts 50 at a time, saving their name and ID, and then deleting them using another undocumented API call, so that I can then get the next 50 podcasts. And so on. Until I have them all.
(Warning: if you use this code you will be unsubscribing from all your podcasts, one by one by one).
items as $oneshow) {
$id = $oneshow->show->id;
$name = $oneshow->show->name;
// Write the name and ID of the podcast into the text file opened earlier
fwrite($fpout, $name . "\t" . $id . "\n");
// Unsubscribe from the podcast via the Spotify API
$url = 'curl -s -X "DELETE" "https://api.spotify.com/v1/me/shows?ids=' . $id .
'" -H "Accept: application/json" -H "Content-Type: application/json" -H "Authorization: Bearer ' .
$bearer .
'"';
exec($url);
}
}
fclose($fpout);
And even this code won’t work completely, or at least it wouldn’t work in Oliver’s case: with 905 podcasts still to extract, it simply stopped returning anything from the API call to get shows, and the web player, at this point, showed Oliver with no subscriptions at all. So perhaps the API only works for the first 1,081 podcasts?
In any case, Oliver now has a text file with 1,081 podcasts in it. Or, more accurately, the names of 1,081 podcasts in it. But how to get the feed URLs? There’s no obvious way to do this right now, although the Listen Notes API might work. Barring that, Oliver has a lot of copying and pasting ahead of him.
In summary, let this be a warning to you: if you use Spotify as your podcast app, you are a prisoner to Spotify, and if you decide to switch to another podcast app there isn’t any way to get your data out of Spotify.





 Work from home is the new norm these days. The COVID-19 pandemic around the world has forced the majority to start working from home. The practice has led to a surge in demand for work from home tools and equipment including routers, webcams, microphones, laptop stand, and more. Most of them are out of stock and the ones in stock are costing double/triple from the original price. Thankfully, you can use your Android phone as a webcam and on PC and Mac. In this article, we will help you set up your Android phone as a webcam on PC and Mac.
Work from home is the new norm these days. The COVID-19 pandemic around the world has forced the majority to start working from home. The practice has led to a surge in demand for work from home tools and equipment including routers, webcams, microphones, laptop stand, and more. Most of them are out of stock and the ones in stock are costing double/triple from the original price. Thankfully, you can use your Android phone as a webcam and on PC and Mac. In this article, we will help you set up your Android phone as a webcam on PC and Mac.