According to the Apple Photos internal SQLite database, this is the most aesthetically pleasing photograph I have ever taken of a pelican:

Here's the SQL query that found me my best ten pelican photos:
select
sha256,
ext,
uuid,
date,
ZOVERALLAESTHETICSCORE
from
photos_with_apple_metadata
where
uuid in (
select
uuid
from
labels
where
normalized_string = 'pelican'
)
order by
ZOVERALLAESTHETICSCORE desc
limit
10You can try it out here (with some extra datasette-json-html magic to display the actual photos). Or try lemur or seal.
I actually think this is my best pelican photo, but Apple Photos rated it fifth:

How this works
Apple Photos keeps photo metadata in a SQLite database. It runs machine learning models to identify the contents of every photo, and separate machine learning models to calculate quality scores for those photographs. All of this data lives in SQLite files on my laptop. The trick is knowing where to look.
I'm not running queries directly against the Apple Photos SQLite file - it's a little hard to work with, and the label metadata is stored in a separate database file. Instead, this query runs against a combined database created by my new dogsheep-photos tool.
An aside: Why I love Apple Photos
The Apple Photos app - on both macOS and iOS - is in my opinion Apple's most underappreciated piece of software. In my experience most people who use it are missing some of the most valuable features. A few highlights:
- It can show you ALL of your photos on a map. On iOS go to the "Albums" tab, scroll half way down and then click on "Places" (no wonder people miss this feature!) - on macOS Photos it's the "Library -> Places" sidebar item. It still baffles me that Google Photos doesn't do this (I have conspiracy theories about it). This is my most common way for finding a photo I've taken - I remember where it was, then zoom in on that area of the map.
- It runs machine learning models on your phone (or laptop) to identify the subject of your photos, and makes them searchable. Try searching for "dog" and you'll see all of the photos you've taken of dogs! I love that this runs on-device: it's much less creepy than uploading your photos to the cloud in order to do this.
- It has a really great faceted search implementation - particularly in the phone app. Try searching for "dog", then add "selfie" and the name of a city to see all of the selfies you've taken with dogs in that place!
- It has facial recognition, again running on device, which you can use to teach it who your friends are (autocompleting against your contacts). A little bit of effort spent training this and you can see photos you've taken of specific friends in specific places and with specific animals!
As with most Apple software, Photos uses SQLite under the hood. The underlying database is undocumented and clearly not intended as a public API, but it exists. And I've wanted to gain access to what's in it for years.
Querying the Apple Photos SQLite database
If you run Apple Photos on a Mac (which will synchronize with your phone via iCloud) then most of your photo metadata can be found in a database file that lives here:
~/Pictures/Photos\ Library.photoslibrary/database/Photos.sqliteMine is 752MB, for aroud 40,000 photos. There's a lot of detailed metadata in there!
Querying the database isn't straight-forward. Firstly it's almost always locked by some other process - the workaround for that is to create a copy of the file. Secondly, it uses some custom undocumented Apple SQLite extensions. I've not figured out a way to load these, and without them a lot of my queries ended up throwing errors.
osxphotos to the rescue! I ran a GitHub code search for one of the tables in that database (searching for RKPerson in Python code) and was delighted to stumble across the osxphotos project by Rhet Turnbull. It's a well designed and extremely actively maintained Python tool for accessing the Apple Photos database, including code to handle several iterations of the underlying database structure.
Thanks to osxphotos the first iteration of my own code for accessing the Apple Photos metadata was less than 100 lines of code. This gave me locations, people, albums and places (human names of geographical areas) almost for free!
Quality scores
Apple Photos has a fascinating database table called ZCOMPUTEDASSETATTRIBUTES, with a bewildering collection of columns. Each one is a floating point number calculated presumably by some kind of machine learning model. Here's a full list, each one linking to my public photos sorted by that score:
- ZBEHAVIORALSCORE
- ZFAILURESCORE
- ZHARMONIOUSCOLORSCORE
- ZIMMERSIVENESSSCORE
- ZINTERACTIONSCORE
- ZINTERESTINGSUBJECTSCORE
- ZINTRUSIVEOBJECTPRESENCESCORE
- ZLIVELYCOLORSCORE
- ZLOWLIGHT
- ZNOISESCORE
- ZPLEASANTCAMERATILTSCORE
- ZPLEASANTCOMPOSITIONSCORE
- ZPLEASANTLIGHTINGSCORE
- ZPLEASANTPATTERNSCORE
- ZPLEASANTPERSPECTIVESCORE
- ZPLEASANTPOSTPROCESSINGSCORE
- ZPLEASANTREFLECTIONSSCORE
- ZPLEASANTSYMMETRYSCORE
- ZSHARPLYFOCUSEDSUBJECTSCORE
- ZTASTEFULLYBLURREDSCORE
- ZWELLCHOSENSUBJECTSCORE
- ZWELLFRAMEDSUBJECTSCORE
- ZWELLTIMEDSHOTSCORE
I'm not enormously impressed with the results I get from these. They're clearly not intended for end-user visibility, and sorting them might not even be something that makes sense.
The ZGENERICASSET table provides four more scores, which seem to provide much more useful results:
My guess is that these overall scores are derived from the ZCOMPUTEDASSETATTRIBUTES ones. I've seen the best results from ZOVERALLAESTHETICSCORE, so that's the one I used in my "show me my best photo of a pelican" query.
A note about the demo
The demo I'm running at dogsheep-photos.dogsheep.net currently only contains 496 photos. My private instance of this has over 40,000, but I decided to just publish a subset of that in the demo so I wouldn't have to carefully filter out private screenshots and photos with sensitive locations and suchlike. Details of how the demo work (using the dogsheep-photos create-subset command to create a subset database containing just photos in my Public album) can be found in this issue.
Automatic labeling of photo contents
Even more impressive than the quality scores are the machine learning labels.
Automatically labeling the content of a photo is surprisingly easy these days, thanks to convolutional neural networks. I wrote a bit about these in Automatically playing science communication games with transfer learning and fastai.
Apple download a machine learning model to your device and do the label classification there. After quite a bit of hunting (I ended up using Activity Monitor's Inspect -> Open Files and Ports option against the photoanalysisd process) I finally figured out where the results go: the ~/Pictures/Photos\ Library.photoslibrary/database/search/psi.sqlite database file.
(Inspecting photoanalysisd also lead me to the /System/Library/Frameworks/Vision.framework/Versions/A/Resources/ folder, which solved another mystery: where do Apple keep the models? There are some fascinating files in there.)
It took some work to figure out how to match those labels with their corresponding photos, mainly because the psi.sqlite database stores photo UUIDs as a pair of signed integers whereas the Photos.sqlite database stores a UUID string.
I'm now pulling the labels out into a separate labels table. You can browse that in the demo to see how it is structured. Labels belong to numeric categories - here are some of my guesses as to what those mean:
- Category 2024 appears to be actual content labels - Seal, Water Body, Pelican etc.
- Category 2027 is more contextual: Entertainment, Trip, Travel, Museum, Beach Activity etc.
- Category 1014 is simply the month the photo was taken. 1015 is the year, and 2030 is the season.
- Category 2056 is the original filename.
- Category 12 is the country the photo was taken in.
Geography
Photos taken on an iPhone have embedded latitudes and longitudes... which means I can display them on a map!
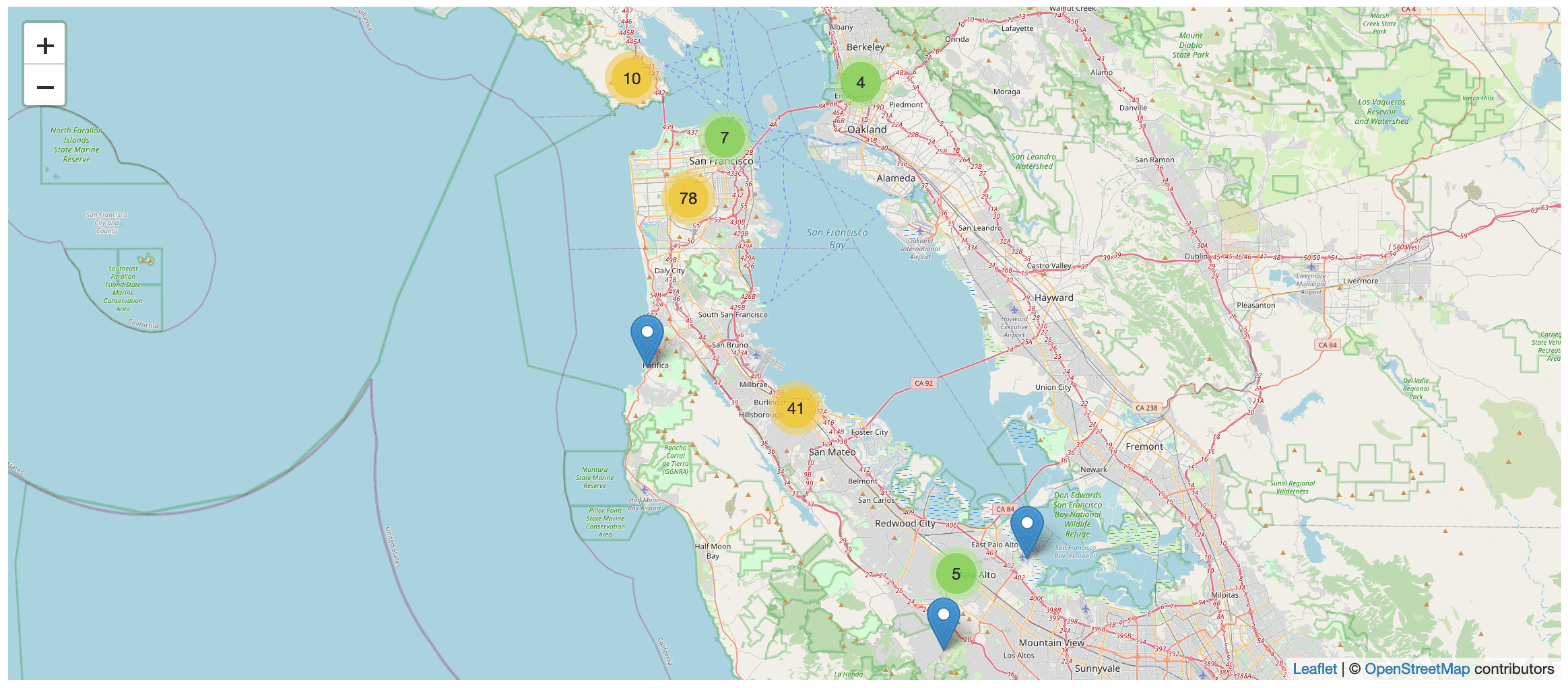
Apple also perform reverse-geocoding on those photos, resolving them to cities, regions and countries. This is great for faceted browse: here are my photos faceted by country, city and state/province.
Hosting and serving the images
My least favourite thing about Apple Photos is how hard it is to get images from it onto the internet. If you enable iCloud sharing your images are accessible through icloud.com - but they aren't given publicly accessible URLs, so you can't embed them in blog entries or do other webby things with them.
I also really want to "own" my images. I want them in a place that I control.
Amazon S3 is ideal for image storage. It's incredibly inexpensive and essentially infinite.
The dogsheep-photos upload command takes ANY directory as input, scans through that directory for image files and then uploads them to the configured S3 bucket.
I designed this to work independently of Apple Photos, mainly to preserve my ability to switch to alternative image solutions in the future.
I'm using the content addressable storage pattern to store the images. Their filename is the sha256 hash of the file contents. The idea is that since sensible photo management software leaves the original files unmodified I should be able to de-duplicate my photo files no matter where they are from and store everything in the one bucket.
Original image files come with privacy concerns: they embed accurate latitude and longitude data in the EXIF data, so they can be used to reconstruct your exact location history and even figure out your address. This is why systems like Google Photos make it difficult to export images with location data intact.
I've addressed this by making the content in my S3 bucket private. Access to the images takes place through s3-image-proxy - a proxy server I wrote and deployed on Vercel (previously Zeit Now). The proxy strips EXIF data and can optionally resize images based on querystring parameters. It also serves them with far-future cache expire headers, which means they sit in Vercel's CDN cache rather than being resized every time they are accessed.
iPhones default to saving photos in HEIC format, which fails to display using with the <img src=""> tag in the browsers I tested. The proxy uses pyheif to convert those into JPEGs.
Here's an example HEIC image, resized by the proxy and converted to JPEG: https://photos.simonwillison.net/i/59854a70f125154cdf8dad89a4c730e6afde06466d4a6de24689439539c2d863.heic?w=600
Next steps
This project is a little daunting in that there are so many possibilities for where to take it next!
In the short term:
- Import EXIF data from the images into a table. The Apple Photos tables give me some of this already (particularly GPS data) but I want things like ISO, aperture, what lens I used.
- Load the labels into SQLite full-text search.
- I'd like other people to be able to play with this easily. Getting it all up and running right now is a fair amount of work - I think I can improve this with usability improvements and better documentation.
- The system only handles static images at the moment. I'd like to get my movies and more importantly my live photos in there as well.
And in the longer term:
- Only iPhone photos have location data at the moment - I'd like to derive approximate latitude/longitude points for my DSLR images by matching against images from my phone based on date.
- Running my photos through other computer vision systems like Google's Cloud Vision APIs could be really interesting.
- For better spotting of duplicate images I'm interested in exploring image content hashing.
- The UI for all of this right now is just regular Datasette. Building a custom UI (running against the Datasette JSON API) could be a lot of fun.


























{kind=link}