TIL today. I have 3 data sim subscriptions and a phone/data subscription with the same telco. However two of those data subscriptions (which I added last year), never show up in my admin console with the telco. Meaning I don’t have easy access to older invoices, usage stats, and most importantly the subscription settings. This was odd, as all run under my personal company’s registration. The telco, now that I asked about it, told me that because I picked up those 2 additional data sims in one of their shops, staff booked both separately as a new customer, not under my existing customer account. The reason is shop staff receive a commission for new accounts, not for existing ones. Said the guy on the phone “and then we get to sort everything out manually on the back-end to match all those records up again”. It took him a few minutes to fix, and may take a few days to propagate through their systems. It also took extra time from me when I bought those data bundles, as it meant more steps (like proving the company is mine, id verification etc.). Commissions, in short, are a perverse impulse causing inefficiency and friction for both the customer and the telco.
Rolandt
Shared posts
Second Order Notes, Zettelkasten
I’ve been exploring my note taking, trying to shape it as a more deliberate practice. As part of that exploration I’ve been reading Sönke Ahrens ‘How to take smart notes’ on Luhmann‘s Zettelkasten (now digitised). More later on that book. What stands out in all things I find about note taking is the importance of taking time to process. Going through notes iteratively, at least once after you created them first.
My own main issue with a lot of the stuff I collect, is just that, it’s a collection. They’re not notes, so the collection mostly never gets used. Of course I also have a heap of written notes, from conversations, presentations I attended etc. There too a second step is missing, that of going through it to really digest it and lift the things out that are of interest to myself and taking note of that. Putting it into the context of the things I’m interested in. The thing I regularly do is marking elements in notes I took afterwards (e.g. marking them as an idea, an action, or something to blog), but that is not lifting them out of the original notes into a place and form where they might get re-used. Ahrens/Luhmann suggest to daily take time for a first step of processing rough notes (the thinking about the notes and capturing the results). Tiago Forte describes a process of progressive summarisation, every time you happen to go back to something you captured (often other’s content), for up to 4 iterations.
There are different steps to shape in such a process. There is how material gets collected / ends up in my inbox, and there’s the second stage of capturing things from it.
I started with looking at reading non-fiction books. With my new e-ink reader, it is easy to export any notes / markings I make in or alongside a book. Zotero is a good tool to capture bibliographic references, and allows me to add those exported notes easily. This covers the first step of getting material in a place I can process it.
The second step, creating notes based on me digesting my reading, I’m now experimenting which form that should take. There are several note apps that might be useful, but some assume too much about the usage process, which is a form of lock-in itself, or store it in a way that might create a hurdle further down the line. So, to get a feel for how I want to make those notes I am first doing it in tools I already use, to see how that feels in terms of low barrier to entry and low friction while doing it. Those two tools are a) Evernote (yes I know, I want to ditch Evernote, but using it now is a way of seeing what is process friction, what is tool friction), and b) my local WordPress instance, that basically works as a Wiki for me. I’m adding key board shortcuts using TextExpander to help easily adding structure to my notes. I’ll do that for a few days to be able to compare.
I made 7 note cards in the past 2 days, and as the number grows, it will get easier to build links between them, threading them, which is part of what I want to experience.
GDPR and adtech tracking cannot be reconciled, ...
GDPR and adtech tracking cannot be reconciled, a point the bookmark below shows once more: 91% will not provide consent when given a clear unambiguous choice. GDPR enforcement needs a boost. So that adtech may die.
Marko Saric points to various options available to adtech users: targeted ads for consenting visitors only, showing ads just based on the page visited (as he says, “Google made their first billions that way“), use GDPR compliant statistics tools, and switch to more ethical monetisation methods. A likely result of publishers trying to get consent without offering a clear way to not opt-in (it’s not about opting-out, GDPR requires informed and unforced consent through opt-in, no consent is the default and may not impact service), while most websurfers don’t want to share their data, will mean blanket solutions like ad and tracker blocking by browsers as default. As Saric says most advertisers are very aware that visitors don’t want to be tracked, they might just be waiting to be actively stopped by GDPR enforcement and the cash stops coming in (FB e.g. has some $6 billion reasons every single month to continue tracking you).
(ht Peter O’Shaughnessy)
Bookmarked Only 9% of visitors give GDPR consent to be trackedPrivacy regulations such as the GDPR say that you need to seek permission from your website visitors before tracking them. Most GDPR consent banner implementations are deliberately engineered to be difficult to use and are full of dark patterns that are illegal according to the law..... If you implement a proper GDPR consent banner, a vast majority of visitors will most probably decline to give you consent. 91% to be exact out of 19,000 visitors in my study.
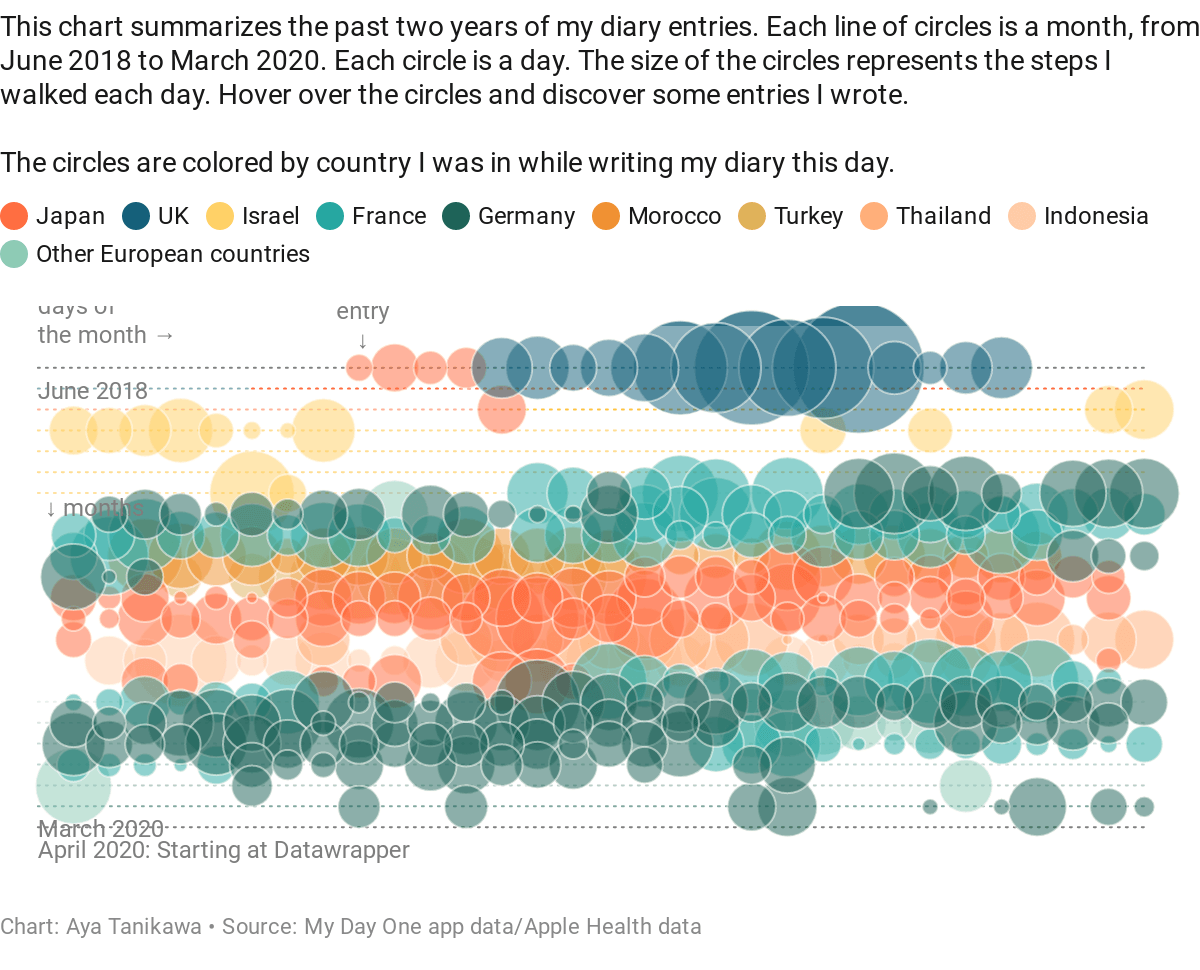
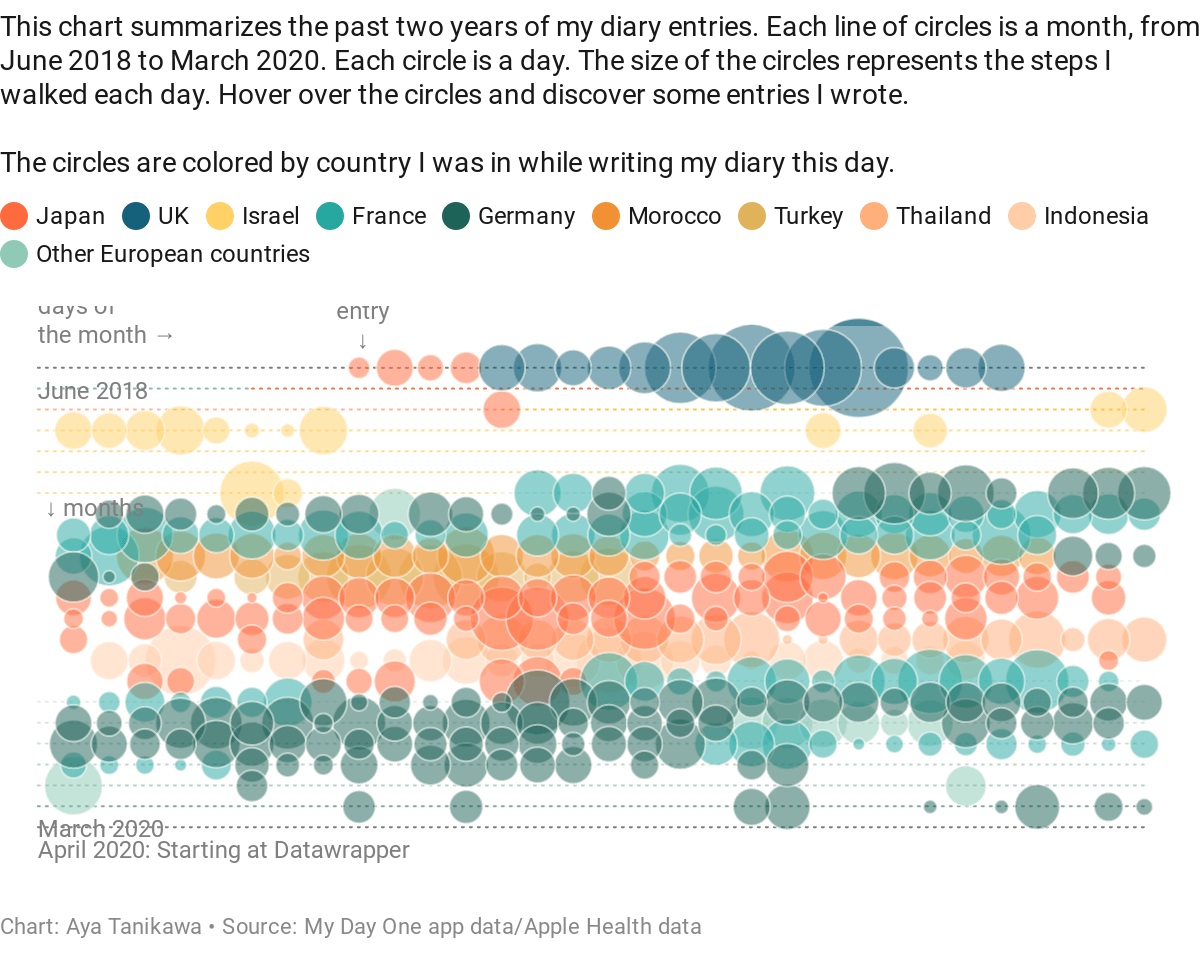
Say Hi to Aya!
 Photo by Keita Mitsuhashi
Photo by Keita Mitsuhashi
We’re excited to introduce you all to a new member of the Datawrapper team: Aya Tanikawa, our new support engineer. She’s working five days a week, answering your questions and making sure you get the most out of Datawrapper.
As the coronavirus crisis gave data visualization a new, more important standing within organizations, our support requests multiplied. Luckily, we quickly found Aya, who helped our Head of Customer Success, Elana, as a support intern since April (maybe you already know her because she replied to a question you sent to support@datawrapper.de). Since June, she’s our support engineer, and we’re very happy about that.
Let’s hear from herself:
Hi Aya! Can you please introduce yourself?
Yes! Hi, I’m Aya. I’m from Tokyo, Japan, but also grew up in Egypt and England.
Before moving to Berlin in the fall of 2019, I studied Bioscience and helped out in a lab doing research on piezoelectric materials. I went on to do my Master’s in the same lab, but I was interested in everything and took random courses from many different faculties. I almost didn’t know anymore what I majored in. I had always dreamed of being an expert in a scientific field, but soon realized that I was more drawn to science communication, positioned between the experts and the general public.
I decided to take a break from my studies and travel while working odd jobs here and there:
What are you doing at Datawrapper?
I mainly answer questions from our lovely users, troubleshooting any issues they encounter. I also write Academy articles. I hope to help and guide users to be able to use Datawrapper to create visualizations suited to their needs.
I’d also like to reach out to more Datawrapper users who may be encountering issues, not just the ones who get in touch with us. This could come in the form of creating easily digestible educational content for beginner users. I’d also love to reach people back home in Japan.
I’m also learning a lot! I’m learning and growing with our users.
Why did you want to join the Datawrapper team?
Because of the people! I had been interested in the world of data visualization for about a year before moving to Berlin. Once here, I went to a datavis meetup organized by Lisa and Jonas where I learned about an open internship position at Datawrapper.
After reading everyone’s profiles and doing some online stalking, I really just wanted to meet the whole team! I was excited to work together with d3.js & datavis experts and developers. And with cartographers!
 “I used this map when hinking in winter near Mount Norikura, Japan, which is why it says “pit” sometimes – that was my cue to check the snow conditions to avoid e.g. avalanches.”
“I used this map when hinking in winter near Mount Norikura, Japan, which is why it says “pit” sometimes – that was my cue to check the snow conditions to avoid e.g. avalanches.”
I used to spend weekends and holidays getting lost wandering in the mountains, so staring at topographic maps became a big part of my life. I also love that I get to interact with many journalists.
How did you get interested in data visualization?
6 years ago, I picked up a book called Design for Information by Isabel Meirelles in my university library. That was my first encounter with information design.
 “Design for Information” and its author, Isabel Meirelles.
“Design for Information” and its author, Isabel Meirelles.
I didn’t even know that data visualization was a thing back then, but I was always drawn to making sense of information and data through visual representation. I also loved the concept of maps, not just geographical, but conceptual too. I like searching for patterns and finding connections.
Last year, I read about the Dear Data project by Giorgia Lupi and Stefanie Posavec, and I really liked the concept of visualizing and seeing patterns in one’s daily life and sharing that with someone. Then I found Data Sketches, a project by Nadieh Bremer and Shirley Wu, which was my first time learning about d3.js. I slowly started reading more about data visualization, following newsletters and communities.
Thanks, Aya! Last question: What are you looking forward to learn in the future?
I’d really like to navigate the world of data and communicate it better. I’m learning web development, data analysis and design and I’d love to document the process and share the journeys for other newbies out there.
I get insecure about not having a specific skill or experience to offer, but I believe being a beginner can also be a skill. I can share my journey of going from zero to one.
Welcome, Aya! It’s great to have you here. If you, dear reader, want to learn more about Aya, make sure to follow her on Twitter (@ayatnkw).
The battle of the shifting base: why only zombies can have a tenfold decrease in mortality
Beware percentages of increase and decrease. They don’t behave in an intuitive way — because of the “battle of the shifting base.” According to a tweet by our president, we’ve had “A Tenfold Decrease In Mortality” from COVID-19. While there’s a lot wrong with this tweet — here’s a fact check on why the statement … Continued
The post The battle of the shifting base: why only zombies can have a tenfold decrease in mortality appeared first on without bullshit.
Could Ugly Broadway become a beautiful swan? City says yes
There are going to be many changes along Broadway in the coming years, as the subway goes in, 99 buses no long roar along both sides of the street, density of some description is added (once the new city plan or Broadway plan is decided on), and more residents and businesses are added to the area.
It’s been a utilitarian traffic corridor, except for one brief stretch through western Kitsilano, for a long time. But it doesn’t have to be like that forever, as city engineers told me for a recent story.
Text below for those who don’t want to link
There is a short section on the western end of Broadway that feels like the high street of a pleasant village – trees, a stretch of small local shops with canopies, a few sidewalk tables, interesting paving blocks at the intersections and drivers who suddenly slow to a meander.
But the rest of one of Vancouver’s most important east-west arteries is simply ugly.
Large, characterless buildings. Some office towers and some big boxes. Six wide lanes of traffic. Minimal greenery. Double-sized diesel-spewing buses carting full loads of passengers from one end to the other, roaring along the curb lanes.
No wonder, says local public space expert Sandy James. The street was designed that way – as a car, bus and truck corridor, with some temporary parking for limited hours.
And it’s been kept that way for decades because the city and region needed to have that road space available in case it was decided that light rail might be put down the middle of the street, Ms. James said.
But the decision was made two years ago to build a SkyTrain extension along Broadway and to go underground, instead of a street-level light rail system. The preliminary work has now started. In late June, as part of that process, trolley buses were removed from the street and replaced with the diesel models, which don’t need to be attached to the overhead wires.
That activity has many optimistic locals hoping the long blocks of featureless Broadway, from Fraser Street in the east to Macdonald Street in the west, can be transformed into an urban-street swan in the future.
City engineers and planners were certainly talking about it, just before the COVID-19 pandemic temporarily altered street life in every city.
“It’s definitely our goal that it will be a street that people will love,” said Lon LaClaire, the head of Vancouver’s engineering department. “Yes, Ugly Broadway becomes beautiful.” Even, he says, a Great Street – the term planners use for the movement to create streets that become people magnets.
Both Mr. LaClaire and the city’s manager of transportation planning, Dale Bracewell, are quick to talk about some startling ideas for Broadway.
STORY CONTINUES BELOW ADVERTISEMENT
Dedicated bus lanes: gone. No need for rapid-bus priority once the subway is there. “In the future scenario, all 99-B riders disappear,” says Mr. LaClaire.
A new design would also give Broadway, which has a lot of generic medical and office buildings, more character – different types of character in different parts of it.
New parking rules would allow cars, which can help form a protective barrier between traffic and a sidewalk, to stay longer. Ironically, in the meantime, there are plans to remove even more parking on the street in order to move buses faster, something that has local businesses alarmed.
There would be more trees, planters and wider sidewalks.
That widening is likely to get a big boost from the “living through the pandemic” dynamic — residents of many areas have complained about narrow sidewalks as they have tried to keep their distance from other walkers or lined up on the roadway for groceries, alcohol and drugstores.
Finally, the key and likely to be controversial element that inevitably arises from all those measures: less road space.
One of the characteristics that makes the small Kitsilano section of Broadway so attractive is the narrowing of the street in the neighbourhood. Broadway still has six lanes, but it is just 17 metres wide, whereas much of the rest of it is 23 metres wide.
Mr. Bracewell is enthusiastic about the idea of narrowing other segments, although he said in a Twitter message that it will take a conversation.
“Need lots of public engagement on values of reallocation of that space & need to respect its still part of the Major Road Network and a truck and local bus route,” he wrote.
The conversation was due to start in April. But there’s no sense yet when regular programming in city departments will resume.
When it does, some of the most enthusiastic supporters of reimagining Broadway are likely to be groups of small businesses on streets that cross Broadway where the subway is going: Main, Cambie and Granville.
Directors of the business associations in the area have already had some informal meetings with city planners, though not with the province, which is in charge of construction.
Their primary concern is that, whatever changes arrive, they make the neighbourhoods better and don’t tear the heart out of them in one way or another, the way the Canada Line of the SkyTrain system did along Cambie when it was built before the 2010 Winter Olympics.
“If our businesses around that area are surviving on pedestrian traffic and that goes underground, that changes everything,” said Rania Hatz, the director of the Cambie Village Business Association. There needs to be a plan for helping them survive the change.
Dumping a transit-station box with generic chain stores in it isn’t what they want either.
“There’s a Mount Pleasant look that you want to retain,” said Neil Wyles, from the business association representing that neighbourhood. “If it all ends up being glass and concrete and some unique businesses move away and don’t come back, that’s not what we want.”
He and his fellow business-association directors are hoping the whole exercise will mean their cross streets improve.
“The Broadway plan is going to have a really big impact on the viability of our neighbourhood,” says Ivy Haisell, who represents South Granville businesses. Changing Broadway, she said, will be the spur to create more of a village shopping street feel for Granville in the blocks near where it crosses.
That desire for less of a car thoroughfare, more of a street with wider sidewalks and a better atmosphere for the streets’ walkers, shoppers and restaurant patrons, is constant.
“We want something that’s more pedestrian-friendly, flowing easily into Broadway,” Ms. Hatz said.
If the city makes all these changes a reality, it could mean a big difference to those businesses. As Ms. James notes, all kinds of research demonstrates that shoppers hang around more in attractive areas.
In a study two years ago, London’s transit agency found there was an explosion in street use when sidewalks become attractive, instead of just narrow cowpaths alongside truck, bus and car traffic.
Retail vacancies went down by 17 per cent and time spent on commercial streets increased by 216 per cent, because people walked around, did more shopping, went to local cafés and just hung out on benches.
Broadway could be an ideal place to see a boom like that, says Ms. James, because it has no parks nearby.
If the street became a great place to hang out — with wide sidewalks, benches, trees, plants and café tables — it could be like a park that cuts through the city. Not a highway any more, as it is now.
Overthinking CSV With Cesil: Adopting Nullable Reference Types
In the previous post I went over how Cesil has adopted all the cool, new, C# 8 things – except for the coolest new thing, nullable reference types. C#’s answer to the billion dollar mistake, I treated this new feature differently from all the rest – I intentionally delayed adopting it until Cesil was fairly far along in development.
I delayed because I felt it was important to learn how an established codebase would adopt nullable reference types. Unlike other features, nullable references types aren’t a feature you want to use in only a few places (though they can be adopted piecemeal, more on that below) – you want them everywhere. Unfortunately (or fortunately, I suppose) as nullable reference types force you to prove to the compiler that a reference can never be null, or explicitly check that a value is non-null before using it, an awful lot of existing code will get new compiler warnings. I put my first pass at adopting nullable reference types into a single squashed commit, which nicely illustrates how it required updates to nearly everything in Cesil.

A Refresher On Nullable Reference Types
Before getting any further into the Cesil specific bits, a quick refresher on nullable reference types. In short, when enabled, all types in C# are assumed to be non-nullable unless a ? is appended to the type name. Take for example, this code:
public string GetFoo() { /* something */ }
In older versions of C# it would be legal for this method to return an instance of a string or null since null is a legal value for all reference types. In C# 8+, if nullable reference types are enabled, the compiler will raise a warning if it cannot prove that /* something */ won’t return a non-null value. If we wanted to be able to return a null, then we’d instead use string? as it’s return type. One additional bit of new syntax, the “null forgiving” ! in suffix position, lets you declare to the compiler that a value is non-null.
Importantly, this is purely a compile time check – there’s nothing preventing a null from sneaking into a variable at runtime. This is a necessary limitation given the need to interoperate with existing .NET code, but it does mean that you have to be diligent about references that come from code that has not opted into nullable reference types or is outside your control. Accordingly, it’s perfectly legal to lie using the null forgiveness operator.
Adopting Nullable Reference Types
If you’ve got a large existing codebase, adopting nullable references type all at once is basically impossible in my opinion. I tried a couple times with Cesil and abandoned each attempt, you just drown in warnings and it’s really difficult to make progress given all the noise. The C# team anticipated this, thankfully, and has made it possible to enable or disable nullable reference times on subsets of your project with the #nullable directive. I worked through Cesil file by file, enable nullable reference types and fixing warnings until everything was converted over at which point I enabled them project wide.
The changes I had to make fell into four buckets:
- Adding explicit null checks in places where I “knew” things were always non-null, but needed to prove it to the compiler
- An example are the reflection extension methods I added, that now assert that, say, looking up a method actually succeeds
- These also aided in debugging, since operations now fail faster and with more useful information
- Wrapping “should be initialized before use” nullable reference types in a helper struct or method that asserts a non-null value is available.
- I used a NonNull struct and Utils.NonNull method I wrote for the purpose
- A good example of these are optional parts of (de)serialization, like Resets. A DeserializeMember won’t always have a non-null Reset, but it should never read a non-null Reset during correct operation
- Explicit checks at the public interface for consumers violating (knowingly or otherwise) the nullability constraints on parameters.
- I used a Utils.CheckArgumentNull method for this
- You have to have these because, as noted earlier, nullable reference types are purely a compile time construct
- Interestingly, there is a proposal for a future version of C# that would make it simpler to do this kind of check
- Refactoring code so a reference can be proven to always be non-null
- A lot of times this has minor stuff, like always fully initializing in a constructor
- In some cases what was needed was some value to serve as a placeholder, so I introduced types like EmptyMemoryOwner
Initially most changes fell into the first two buckets, but over time more was converted into the fourth bucket. Once I started doing some light profiling, I found a lot of time was being spent in null checks which prompted even more refactoring.
At time of writing, there are a handful of places where I do use the null forgiving operator. Few enough that an explicit accounting can be given, which can illustrate some of the limitations I found with adopting nullable reference types:
- In DEBUG builds of AwaitHelper
- In AsyncEnumerable’s constructor
- Five times for local variables in AsyncReaderBase
- In DynamicRow.GetAtTyped
- Four times in DynamicRowEnumerator
- Four times in PassthroughRowEnumerator
- In Enumerable’s constructor
- Two in DEBUG builds of ReaderStateMachineToDebugString()
- Four default!s in NeedsHoldRowConstructor
- Four, not all defaults this time, in SimpleRowConstructor
- Three in SyncReaderBase
- In ReadResult’s constructor
- Two in ReadResultWithComment’s constructors
That’s a total of 32 uses over ~32K lines of code, which isn’t all that bad – but any violations of safety are by definition not great. Upon further inspection, you’ll see that 29 of them are some variation of default! being assigned to a generic type – and the one in DynamicRow.GetAtTyped is around casting to a generic type (the remaining two are in DEBUG-only test code). Basically, and unfortunately, nullable references can get awkward around unconstrained generics. The problem is an unconstrained generic T could be any combination of nullable and value or reference types at compile time, but default(T) is going to produce a null for all reference types – it’s a mismatch you can’t easily work around. I’d definitely be interested in solutions to this, admittedly rare, annoyance.
Accommodating Clients In Different Nullable Reference Modes
That covers Cesil’s adoption of nullable reference types, but there’s one big Open Question around client’s adoption of them. A client using Cesil could be in several different “modes”:
- Completely oblivious to nullable reference types, neither using nullable annotations themselves nor using types from libraries that do
- All pre-C# 8 will be in this mode
- Post-C# 8 code that has not enabled nullable reference types, and whose relevant types aren’t provided by libraries that have enabled them are also in this mode
- At time of writing this is probably the most common mode
- Oblivious themselves, but using types with Cesil that do have nullable annotations
- Pre-C# 8 code that uses types provided by dependencies that have been updated with nullable references types is in this mode
- Post-C# 8 code with a mix of files with nullable reference types enabled will also be in this mode
- Opted into nullable reference types, but using types with Cesil from dependencies that have not enabled nullable reference types
- Post-C# 8 code with dependencies that have not yet enabled nullable reference types will be in this mode
- Opted into nullable reference types, and all types used with Cesil likewise have them enabled
- At time of writing this is the least common mode
Cesil currently does not look for nullable annotations, instead if you want to require a reference type be non-null you must annotate with a DataMemberAttribute setting IsRequired (if you’re using the DefaultTypeDescriber), provide a Parser that never produces a null value, or a Setter that rejects null values. This is behavior is most inline with the “completely oblivious” case (mode #1 above). However, Cesil could check for nullable annotations and default to enforcing them (as always, you’d be able to change that behavior with a custom ITypeDescriber). This aligns most with mode #4, which represents the desired future of C# code. Either behavior can result in some weirdness, with Cesil either doing things the compiler would prevent a client from doing or failing to do things a client could easily do.
To illustrate, if Cesil ignores nullable annotations (as it does today) but client has enabled them (ie. they are in modes #3 or #4) this could happen:
class Example
{
public string Foo { get; set; } // note that Foo is non-nullable
}
// ...
var cesilFoo = CesilUtils.ReadFromString(@”Foo\r\n”).Single().Foo;
cesilFoo.ToString(); // this will throw NullReferenceException
// ...
var clientExample = new Example();
clientExample.Foo = null; // this will raise a warning
Basically, Cesil could set Example.Foo to null but the client’s own code couldn’t.
However, if Cesil instead enforces nullable annotations but the client is oblivious to them (the client is in mode #2 above) then this is possible:
// Example is defined in some place that _has_ opted into nullable references
public class Example
{
public string Foo { get; set; } // note that Foo is non-nullable
}
// ...
// Cesil will throw an exception, since Foo has no value
var cesilFoo = CesilUtils.ReadFromString(@”Foo\r\n”);
// ...
var clientExample = new Example();
clientExample.Foo = null; // this code from the client raises no warnings
In this case, Cesil cannot do something that the client can trivially do.
As I see it there are a few different options, and Cesil needs to commit to one of them. The Open Question is:
-
Which of these options for nullable reference treatment should Cesil adopt?
- Ignore nullable annotations, clients should perform their own null checks
- Enforce nullable annotations as part of the DefaultTypeDescriber, if a client needs to disable it they can provider their own ITypeDescriber
- Provide an Option to enable/disable nullable reference type enforcement
- This will move the logic out of ITypeDescribers, so client control via that method will no longer be available
- If this is the route to take, what should the value for Options.(Dynamic)Default be?
As before, I’ve opened an issue to gather long form responses. Remember that, as part of the sustainable open source experiment I detailed in the first post of this series, any commentary from a Tier 2 GitHub Sponsor will be addressed in a future comment or post. Feedback from non-sponsors will receive equal consideration, but may not be directly addressed.
The next post in this series will cover how I went about developing tests for Cesil.
Shipping Container becomes Temporary Parklet in City of North Vancouver


We have had the City of Vancouver and other municipalities develop streamlined approval processes for businesses that want to build “pandemic patios” either on adjacent rights of way or in parking spaces.
The City of North Vancouver is going one step further in paying $20,000 to convert an existing 40 foot container bought by the City for $20 into a covered respite, a mobile “parklet” intended for central Lonsdale.
As Jane Seyd in the North Shore News writes:
“The idea is to convert the container into an outside seating area with lighting and a roof that will fit into curbside parking zones. The “parklet” will provide a public place to sit for customers of businesses that can’t expand patios into the public realm, according to staff, who hope it will be in place this month.”
The concept is to provide a place for people to sit and to eat meals bought from Lonsdale businesses. The upscaled container can be transported to different parking spaces to serve different businesses, and the City may expand the project after evaluating the effectiveness of this first installation.
This newly released YouTube video below features a container that has been transformed into a bar for a private home. The story of its transformation starts at 2:40 on the video.
Image: Coolthings.com
Stanley Park, Horses & Vehicular Conflict~Here’s How They Do it In London

Gerry O’Neil is the well regarded horseman that has been offering horse drawn tours of Stanley Park for several decades. For $50.00 for an adult or $20.00 for a child you can take a one hour tour around the park in a horse powered tram that can accommodate 26 people.
Of course Mr. O’Neil is also dealing with the current Covid Stanley Park provisions that have meant that only one lane of Park Drive is open for vehicular traffic, with the other lane dedicated for cyclists, separated by the traditional orange traffic cones.
While vehicular traffic in Stanley Park is supposed to go along Park Drive at 30 km/h per hour, it rarely is that slow as any park visitor can attest. And Mr. O’Neil’s carriage rides were for some reason dedicated to the vehicular lane as opposed to the temporary cycling lane. The average horse moves about 6 kilometers an hour at a walk, meaning that vehicular traffic stacked up behind Mr. O’Neil’s horse drawn trolley.
As Ben Miljure with CTV news reported Mr. ONeil is frustrated. ” As you can imagine, when you’ve got 30 0r 40 cars behind you waiting, there’s a level of stress that you’re hoping to get out of their way,”
While the one lane closure for cycling on Park Drive is temporary to alleviate overcrowding on the seawall during the pandemic, it is a surprise that the horse drawn trolleys were classified as vehicles as they have no motors. That is often the litmus test for whether a use belongs in the bike lane or not in many municipalities.
Take a look at Hyde Park in London where there is a generous walking lane beside a surprisingly wide bicycle lane. There the bike lane is shared with the Queen’s horses on their way to and from Buckingham Palace. Perhaps moving the horse drawn tram to the cycling lane might be a temporary consideration during this unusual summer of short-term pandemic park modifications.

Username und Passwort sind letztes Jahrtausend
Steffen Siguda, Chief Security Officer von OSRAM, fokussierte in seinem Vortrag auf sichere Identitäten. Alle Angriffe, die gegen sein Unternehmen unternommen würden, haben im Grunde mit gefälschten Identitäten zu tun. Daher sei der stärkere Schutz von Identitäten, den der Zero-Trust-Ansatz bringe, für ihn ein ganz wichtiges Argument.
OSRAM nutzt folgende Building Blocks für seine Zero-Trust-Security:
Identity (kein Zugang nur mit Benutzername und Passwort)Access (kein wirklicher Unterschied zwischen innen und außen)
- Starke Authentisierung wo immer möglich über Biometrie oder PIN
- Single-Sign-On über alle Applikationen hinweg
- Bedingter Zugriff (conditional access) in der Regel über Unternehmens-Device oder Zertifikat, Multifaktor-Authentifizierung als Ausnahme
- Sämtliche IaaS/PaaS Workloads liegen hinter Application Level Firewalls, (Intranet-Verkehr wird ebenfalls gefiltert).
- Erlaubter Traffic wird auf bekannte Angriffsmuster untersucht.
- Als riskant eingestufte Zugriffe werden blockiert und überprüft.
- Alle Nutzer, die nicht über ein Company-Device zugreifen, werden authentifiziert.
The Best Bluetooth and Wireless Keyboards

A great wireless keyboard can reduce clutter on your desk and help you type faster and more comfortably — on your computer as well as on your tablet, your phone, or even your TV.
After testing more than 100 wireless and Bluetooth keyboards over the years, we’ve found the Logitech Pop Icon Keys to be the best wireless keyboard because it’s enjoyable to type on, it’s versatile, and it has years-long battery life.
everyone gets a wunderkammer!
everyone gets a wunderkammer!

There have been a handful of significant updates to the wunderkammer application I talked about in the bring your own pen device
blog post. The application now has the ability to work with multiple collections, specifically SFO Museum and the whole of the Smithsonian. Clicking on an image will open the web page for that object and there is support for the operating system's share
option to send an object's URL to another person or application.
The latest releast also introduces the notion of capabilities
for each collection. Some collections, like the Cooper Hewitt support NFC tag scanning and querying for random objects while some, like SFO Museum and the Smithsonian, only support the latter. Some collections (Cooper Hewitt) have fully fledged API endpoints for retrieving random objects. Some collections (SFO Museum) have a simpler and less-sophisticated oEmbed endpoint for retrieving random objects. Some collections (Smithsonian) have neither but because the wunderkammer application bundles all of the Smithsonian collection data locally it's able to query for random items itself.

In fact the wunderkammer application's own database is itself modeled as collection
. It doesn't have the capability
to scan NFC tags or query for random objects (yet) but it does have the ability to save collection objects.
Collections are described using a Swift language protocol definition that looks like this:
public protocol Collection {
func GetRandomURL(completion: @escaping (Result<URL, Error>) -> ())
func SaveObject(object: CollectionObject) -> Result<CollectionObjectSaveResponse, Error>
func GetOEmbed(url: URL) -> Result<CollectionOEmbed, Error>
func HasCapability(capability: CollectionCapabilities) -> Result<Bool, Error>
func NFCTagTemplate() -> Result<URITemplate, Error>
func ObjectURLTemplate() -> Result<URITemplate, Error>
func OEmbedURLTemplate() -> Result<URITemplate, Error>
}
Each collection implements that protocol according to its capabilities and specific requirements but they all present a uniform interface for communicating with the wunderkammer application. There is a corresponding CollectionOEmbed protocol that looks like this:
public protocol CollectionOEmbed {
func ObjectID() -> String
func ObjectURL() -> String
func ObjectTitle() -> String
func Collection() -> String
func ImageURL() -> String
func Raw() -> OEmbedResponse
}
There is still a need for an abstract collection-specific oEmbed protocol because some of the necessary attributes, for the purposes of a wunderkammer-style application, aren't defined in the oEmbed specification and to account for the different ways that different collections return that data. To date the work on the wunderkammer application has used oEmbed as the storage and retrieval protocol for both objects which may have multiple representations and each one of those atomic representations that depict the same object.

The database models, as they are currently defined, don't necessarily account for or allow all the different ways people may want to do things but I've been modeling things using oEmbed precisely because it is so simple to extend and reshape.
In the first blog post about the wunderkammer application I wrote:
Providing an oEmbed endpointis not a zero-cost proposition but, setting aside the technical details for another post, I can say with confidence it's not very hard or expensive either. If a museum has ever put together a spreadsheet for ingesting their collection in to the Google Art Project, for example, they are about 75% of the way towards making it possible. I may build a tool to deal with the other 25% soon but anyone on any of the digital teams in the cultural heritage sector could do the same. Someone should build that tool and it should be made broadly available to the sector as a common good.
I remain cautiously optimistic that the simplest and dumbest thing going forward is simply to define two bespoke oEmbed types
: collection_object and collection_image. Both would be modeled on the existing photo type with minimal additional properties to define an object URL alongside its object image URL and a suitable creditline. These are things which can be shoehorned in to the existing author and author_url properties but it might also be easiest just to agree on a handful of new key value pairs to meet the baseline requirements for showing collection objects across institutions.

This approach follows the work that SFO Museum has been doing to create the building blocks for a collection agnostic geotagging application:
oEmbed is not the only way to retrieve image and descriptive metadata information for a “resource” (for example, a collection object) on the web. There’s a similar concept in the IIIF Presentation API that talks about “manifest” files. The IIIF documentation states that:
The manifest response contains sufficient information for the client to initialize itself and begin to display something quickly to the user. The manifest resource represents a single object and any intellectual work or works embodied within that object. In particular it includes the descriptive, rights and linking information for the object. It then embeds the sequence(s) of canvases that should be rendered to the user.
Which sounds a lot like oEmbed, doesn’t it? The reason we chose to start with oEmbed rather than IIIF is that while neither is especially complicated the former was simply faster and easier to set up and deploy. This echoes the rationale we talked about in the last blog post about the lack of polish, in the short-term, for the geocoding functionality in the go-www-geotag application:
We have a basic interaction model and we understand how to account for its shortcomings while we continue to develop the rest of the application.
We plan to add support for IIIF manifests ... but it was important to start with something very simple that could be implemented by as many institutions as possible with as little overhead as possible. It’s not so much that IIIF is harder as it is that oEmbed is easier, if that makes sense.
Almost everything that the wunderkammer application does is precisely why the IIIF standards exist. There would be a real and tangible benefit in using those standards and in time we might. I also hope that there is benefit in demonstrating, by virtue of not starting with IIIF, some of the challenges in using those standards. I have a pretty good understanding of how IIIF is designed and meant to work but I also looked elsewhere, at the oEmbed specification, when it came time to try and build a working prototype. I offer that not as a lack of support for the IIIF project but as a well-intentioned critique of it.

Earlier I said that the wunderkammer application bundles all of the Smithsonian collection data locally
. This is done by producing SQLite databases containing pre-generated oEmbed data from the Smithsonian Open Access Metadata Repository which contains 11 million metadata records of which there are approximately 3 million openly licensed object images.
These SQLite databases are produced using two Go language packages, go-smithsonian-openaccess for reading the Open Access data and go-smithsonian-openaccess-database for creating the oEmbed databases, and copied manually in to the application's documents folder. This last step is an inconvenience that needs to be automated, probably by downloading those databases over the internet, but that is still work for a later date.
Here is how I created a database of objects from the National Air and Space Museum:
$> cd /usr/local/go-smithsonian-openaccess-data $> sqlite3 nasm.db < schema/sqlite/oembed.sqlite $> /usr/local/go-smithsonian-openaccess/bin/emit -bucket-uri file:///usr/local/OpenAccess \ -oembed \ metadata/objects/NASM \ | bin/oembed-populate \ -database-dsn sql://sqlite3/usr/local/go-smithsonian-openaccess-database/nasm.db $> sqlite3 nasm.db sqlite> SELECT COUNT(url) FROM oembed; 2407
The wunderkammer application also supports multiple databases associated with a given collection. This was done to accomodate the Smithsonian collection which yields a 1.5GB document if all 3 million image records are bundled in to a single database file.

One notable thing about the code that handles the Smithsonian data is that it's not really specific to the Smithsonian. It is code that simply assumes everything about a collection is local to the device stored in one or more SQLite databases, with the exception being object image files that are still assumed to be published on the web. It is code that can, and will, be adapted to support any collection with enough openly licensed metadata to produce oEmbed-style records. It is code that can support any collection regardless of whether or not they have a publicly available API.
It is also code that makes possible a few other things, but I will save that for a future blog post.

The wunderkammer application itself is still very much a work in progress and not ready for general use, if only because it is not available on the App Store and requires that you build and install it manually. I don't know whether or not I will make the application on the App Store at all. It is a tool I am building because it's a tool that I want and it helps me to prove, and disprove, some larger ideas about how the cultural heritage sector makes its collections available beyond the museum visit
.
It is code that is offered to the cultural heritage sector in a spirit of generousity and if you'd like to help out there is a growing list of details to attend to in order to make the application better and more useful.

Things I don’t understand
The Washington Post: Trump administration sends letter withdrawing U.S. from World Health Organization over coronavirus response.
“The Trump administration has sent a letter to the United Nations withdrawing the United States from the World Health Organization over its handling of the coronavirus pandemic, a dramatic move that could reshape public health diplomacy.
The notice of withdrawal was delivered to United Nations Secretary General Antonio Guterres, said a senior administration official who spoke on the condition of anonymity because the letter has not been made public. Under the terms of a joint resolution passed by Congress in 1948, the United States must give a year’s notice in writing and pay its debts to the agency in order to leave.
It is not clear whether the president can pull the United States out of the organization and withdraw funding without Congress. When Trump first threatened to withdraw, Democratic lawmakers argued that doing so would be illegal and vowed to push back.”
The Washington Post: A high-risk Florida teen who died from covid-19 attended a huge church party, then was given hydroxychloroquine by her parents, report says.
“A medical examiner’s report recently made public, however, has raised questions about Carsyn’s case. The Miami-Dade County Medical Examiner found that the immunocompromised teen went to a large church party with roughly 100 other children where she did not wear a mask and social distancing was not enforced. Then, after getting sick, nearly a week passed before she was taken to the hospital, and during that time her parents gave her hydroxychloroquine, an anti-malarial drug touted by President Trump that the Food and Drug Administration has issued warnings about, saying usage could cause potentially deadly heart rhythm problems.
Carsyn’s case, which gained renewed interest on Sunday after it was publicized by Florida data scientist Rebekah Jones, drew fierce backlash from critics, including a number of medical professionals, who condemned the actions taken by the teen’s family in the weeks before her death.”
When data is messy
I love this story: a neural network trained on images was asked what the most significant pixels in pictures of tench (a kind of fish) were: it returned pictures of fingers on a green background, because most of the tench photos it had seen were fisherfolk showing off their catch.
Example of where GDPR compliance doesn't get you CCPA compliance
You can't just cut and paste a set of existing GDPR compliance tools and processes (or a subset of what you do for GDPR) and get to CCPA compliance.
One area where CCPA and GDPR are substantially different is identity verification. (This is something that published articles on CCPA compliance often get wrong. Check with your lawyer.)
GDPR: where the controller has reasonable doubts concerning the identity of the natural person making the request referred to in Articles 15 to 21, the controller may request the provision of additional information necessary to confirm the identity of the data subject.
CCPA regulations: A request to opt-out need not be a verifiable consumer request. If a business, however, has a good-faith, reasonable, and documented belief that a request to opt-out is fraudulent, the business may deny the request. The business shall inform the requestor that it will not comply with the request and shall provide an explanation why it believes the request is fraudulent.
If someone sends a GDPR Article 21 objection,
the recipient is allowed to ask them for additional info to
verify themselves, and doesn't have to explain why.
But if someone sends a CCPA opt-out, the recipient has to act
on it unless they have a good-faith, reasonable, and
documented belief
that it's actually fraudulent.
And, on denying an opt-out, the recipient must provide an explanation of why they believe the request to be fraudulent. This writing assignment for the recipient is in CCPA but not GDPR.
(This only applies to out outs. The recipient can verify identity if someone asks for right to know and/or right to delete.)
Also, the CCPA opt-out doesn't have to come directly
from the natural person. It can be from an authorized
agent or a browser setting. The recipient still has
to have that good-faith, reasonable, and documented
belief
in order to deny it, and they still have
the writing assignment.
Bonus links
How publishers can reset to serve a cookie-less digital marketplace
Deep Dive: How publishers must adapt to the new normal
W3C Ad Tech Members Panicked About Slow Progress For Third-Party Cookie Alternative
The Wall Street Journal, Barron’s Group Emphasize First-Party Data to Advertisers
New data shows publisher revenue impact of cutting 3rd party trackers
Bruce Schneier says we need to embrace inefficiency to save our economy
After 7-year wait, South Africa's Data Protection Act enters into force
The new CCPA draft regulations: Identity verification
Andrew Yang's Data Dividend Isn't Radical, It's Useless
How to Remove YouTube Tracking
CCPA Compliance: Facebook Announces ‘Limited Data Use’ Feature
Spurious Precision
When I pestered Conway for more details regarding the seminal Moscow meeting that inspired his triumphant half-day of discovery, he begged off. He was loath to add any "spurious precision", as he came to refer to his embellishments, advertent or accidental. "My memory. My memory is a liar," he said. "It's a good liar. It deceives even me."
I love the phrase "spurious precision". It's a great name for something I see in the world -- and, all too often, in my own mind. I should be as careful with my own memory as Conway tried to be in this instance.
(From a 2015 profile in The Guardian.)
Masked Men Coming Home
Our night and day in Halifax was an invaluable respite; even though the visit was short, I’m so glad we went.
Halifax is as ghost town-like as Charlottetown, perhaps even more so: we walked from Quinpool Road downtown to the harbour and back, stopping for tacos on the way, and didn’t see more than isolated pockets of people.
Otherwise we enjoyed spending time with Yvonne, eating quinoa salad and brownies and drinking strong coffee, with the occasional phone-in special guest family members.
Mask-wearing is much more prevalent in and around Halifax; not near total by any means, but a lot more than on the Island, where it remains rare. Everyone in the service industry was wearing a mask, save our taco server, who volunteered to put one on if we wanted.
As I write we’re about to board the Holiday Island ferry for the voyage home.

My dad’s letter to kids of the future

Two weeks ago my dad died.
We had a year warning that day was coming, after he was diagnosed with pancreatic cancer last July. We had more days with him than we expected. Which I was very grateful for.
My dad took our family out of poverty. He grew up in the projects in Brooklyn (which, I believe, are still there). He was the first to go to college and chose engineering almost by accident, which he writes about below. His first job out of college, after earning a PhD in electrical engineering and material science, was as an engineer at Ampex. He moved us across the country to a place none of us had heard of: Cupertino, California. This was in 1971. That move gave me an unbelievable amount of privilege which I’ve been thinking about a lot. Because Silicon Valley grew up around us, literally, I had a front-row seat from a very early age (I got a tour of Apple when it was only a building or two back when I was 13 in 1977. I was in the first computer club at Hyde Jr. High in Cupertino that same year. Apple started a mile away from my house, so close that I stole apricots from where many of its buildings now sit.
Funny, one of the things we actually did like talking about was companies. He watched CNBC right up to his death and enjoyed the stock market. One of his last things he did was put some money into a trust fund for our kids and put it all onto Tesla. That was about a month ago. Since then it has gone up about 40%. He always did do pretty well in the stock market.
I talked about that and him a bit in a video today on Twitter, I was so proud that he got to see my newest book, which definitely is the best one of my career, and explains why autonomous cars, robots, and augmented reality glasses will transform industries. Doing that work let me to believe Tesla would go way up, but it was my brother who convinced him to buy the kids Tesla. My dad always had a golden touch with stocks.
My mid-summer report:1. F##k cancer (my dad died two weeks ago).2. Why I predict @Tesla will go to $10,000 *but… https://t.co/cNYsIG4zEQ
— Robert Scoble (offline until September) (@Scobleizer) July 6, 2020
But if there’s one defining thing I remember always taking heat from my dad about it was that he wanted us to get a technical education because he saw just how much that changed his life. He was disappointed I chose journalism and economics to study when I went to University and later in life he turned after he saw how I turned that into a successful career.
That said, he wrote down just how important he sees education being and he wanted me to share that with everyone here. The rest of the story is that he went into the Army, learned all sorts of things including how radiation worked (which led him to 25 years of work on military satellites where he designed microelectronic circuits that were radiation resistant for Lockheed Missiles and Space Company) and he used the GI Bill which got him the support to go to college and, eventually, Rutgers University where he earned his PhD. I believe strongly that we need a new GI Bill to help retrain Americans and get them to go to University to learn the skills they need to support their families and our nation. Here’s his words about how a few small changes can make a huge change in one’s life:
I think attending college is such a potential life changing event that everyone who wants to go (and is mentally able) should be able to go although I would suggest Junior or Community Colleges as most students who don’t finish college drop out the first or second year. Two of my sons dropped out and enlisted in the service from 2 year colleges.
I considered how people get to college who are both poor and not motivated by family. No one in my family discussed the need or possibility of going to college nor even what kind of job I might go for. I realize that where you live has a tremendous effect on ones decision to go to college.
My parents were both the children of coal miners from the Pittston, PA, area who married and moved to New York City in 1935-6 for work. My father dropped out of school in the 8th grade and my mom graduated from high school.
My dad didn’t have a trade and so had odd jobs including cooking. I was born in 37 and my parents applied for an apartment at the new low income Red Hook Housing Project in Brooklyn. At the time they were the largest housing project in the US with room for thousands of residents. We moved into our apartment in 1939 (our building was 6 stories high with 5 entrances holding 30 families per entrance). It was a safe place to live and I used to frequently wander away and get lost (I was 3-4) and one time was found lying on a nearby shore sleeping. The police recommended putting my name/address on my clothes which solved the getting lost phase.
During the war my dad was trained and got a job as a machinist. My parents knew nothing about education or the educational system in NYC so I was enrolled at the local elementary school, PS27, where I spent 8-1/2 years, kindergarten through 8th grade (around 2nd grade, the NYC education system switched from starting classes in January and September to starting all classes in September and, thus, I skipped ahead a half year). I was not a great or serious student and I estimate that I was usually rated in the 3rd quartile and cannot remember ever failing a subject.
In 7th and 8th grade students who were taking the entrance exam for advanced high schools were given algebra on a voluntary basis after school. Since my parents and I didn’t have a clue about these schools, I didn’t volunteer. At the end of 8th grade, we were given a booklet containing all of the public high schools in NYC with the curriculum, subjects and general information about each. We were told which academic high school we would be sent to unless we selected another school. There were 64 public high schools in NYC in 1950 which included the special high schools requiring an entrance exam, vocational high schools and academic high schools.
After the war, my dad obtained a regular job as a machinist in Jersey City where he had to work nights. None of his coworkers wanted to be the union steward so my dad accepted it. This meant that although he was the most junior member of his group, he was immune from layoffs which really helped us financially.
I went to my assigned high school (called Manual Training HS although it was an academic high school) and took the classes I was assigned. A Puerto Rican friend who lived in the same building entrance as me, who started high school a year before me, talked me into joining the swimming team. This was one of those life changing moments as virtually everyone on the swim team became a life guard at one of the city’s pools or beaches. This was significant because every single lifeguard I worked with was planning on attending college and some were talking of attending that fall. Some of the classes I took required that I take a statewide test called the NY State Regents Exam. Test/Answer booklets were available which contained the tests given over the past 10 years. These interested me for some reason and I studied them for the 4 classes I took (biology, geometry, earth science and intermediate algebra) and did very well on these exams averaging 95%.
As I said we lived in low income public housing which had the requirement that you had to move if your income exceeded a certain amount. My parents income exceeded this amount and they were put on a waiting list for intermediate income housing. This list was not moving quickly enough for the housing authority and so we were given a 30 day notice to move or be evicted in June 1953, just prior to going into my senior year. We couldn’t find a satisfactory place in Brooklyn and so my parents decided to move to Jersey City since my dad’s job was there.
I was enrolled at Lincoln HS for my senior year and joined the swim team. New Jersey required an extra year of history to graduate so I had a full schedule with no optional classes. I quickly made some friends and had no difficulty passing the classes. I was unable to take Physics or Chemistry in high school due to my lack of knowledge of what might be important for the future and did not know about the College Board exams. The extraordinary thing about my high school is that Jersey City Junior College occupied the building at night, starting at 4pm and accepted any high school graduate from Jersey City, tuition free. In March of my senior year I finally figured out that I had essentially no salable skills and so decided to go to JCJC. I selected Pre Engineering as my field of study and started in September 1954.
He, She, One, They, Ho, Hus, Hum, Ita
What we need to understand is that everything is like this, not just language: "While no single individual can, by fiat, change the meaning of a word, groups of individuals, by changing patterns of usage, can... What words mean and which words exist is not up to any single person. But it is up to us, collectively." This is understood by conservatives, writes Amia Srinivasan, "who love to make fun of linguistic innovators as if they were divorced from reality, privately recognise and fear," just as it is understood by progressives, "in which too much hope can be invested." Anyhow, this is a long and interesting read about gender in language and especially in pronouns. And it shows how we teach and learn through every sentence we speak or hear. Every action we take both at once displays and informs our understanding of the world.
Web: [Direct Link] [This Post]Who Decides Who Is A Grandmaster?
Chess has been around since the 6th century – but there wasn’t a grandmaster until a journalist used the phrase in 1838.
Even for the next decade, it was largely an informal term – used at the subject whim of journalists and players to describe great players in history. A grandmaster recognised by one player (or by one country) wasn’t necessarily recognised as a grandmaster by others.
This changed in the 1950s when FIDE (The World Chess Federation) put together a simple criteria which has gradually grown in complexity over the years.
The criteria doesn’t aim to identify the best players, chess has another system for that. It instead recognises players whose achievements can’t be fully captured within the rating system. It’s a title many will aspire to but few will ever gain.
You can probably see the parallels. I suspect many more communities would benefit from a dedicated leader like yourself putting together a simple criteria to recognise their grandmasters. Simple badges and superuser systems don’t quite cut it. You might put together a criteria that includes:
- Speaking on stage at a major event in your industry.
- Publishing a popular book in the field (or publishing an article/video with 50k+ views)
- Replying to over 1000 questions with 500 accepted solutions.
- 3 ideas incorporated into the community or the product.
If you research the people who have created a hall of fame, launched industry federations and associations, or set up their own grandmaster systems, you soon find they were rarely given permission. They simply saw the need and created it. Over time, it stuck.
Who are your Grandmasters going to be?
From my inbox

Ein großer Greenscreen. Und ich habe keine Ahnung, wer mir das geschickt hat. Vielen Dank!
Ein erster Test mit Teams ist leider ernüchternd. Dafür ist das Ergebnis mit Zoom sehr überzeugend. Man sieht sogar den Hintergrund zwischen Kopf und Headset. Ohne Greenscreen geht das nicht.
Vague hand-wringing on cancel culture from J.K. Rowling and friends
Is it time to back away from “cancel culture,” which calls for demonizing the voices of those whom others deem to be transgressors? This is an important question. Now 150 writers and other figures have published a letter addressing it in Harper’s — and done a terrible job of it. Analyzing the Harper’s letter The … Continued
The post Vague hand-wringing on cancel culture from J.K. Rowling and friends appeared first on without bullshit.
Looking at UK Arts & Culture funding
Introduction
This post is a branching off from my (George) personal blog, where I have been writing throughout lockdown about various things. I am interested to try to teach myself more about the Arts & Culture funding landscape in the UK, especially as the government has just announced their £1.57M grant, and because I’ve been trying harder to see where systemic racism and sexism live. I want to know how the funding will be distributed. I’m curious to see if I can draw the overall arts and culture funding picture a bit more clearly for myself, and thought others might be interested.
I would love for this to a be a conversation, especially if I’m really missing very important aspects as I explore. Comments are welcome.
Assets vs Need?
Today I haven’t been able to stop thinking of something that struck me when I first moved to the UK in 2014. One day, fairly soon after I’d moved here, I happened to have a coffee with Ed Vaizey, with my friend Wolfgang. He was very pleasant. I was not at all prepared as well as I should have been, and nothing came of it, which is one of my few regrets. But, the thing I noticed and remember most was that Mr. Vaizey’s shirt collar was frayed. How strange, I thought, that the Minster for Digital and Creative Industries couldn’t afford a shirt that wasn’t frayed. I mean, he has his own coat of arms.

I remember mentioning this to a new English friend who informed me that this was an ever so subtle class marker. That upper class people like to wear things out instead of buying new replacements. Very, very wealthy people apparently don’t have much actual cash, since all their wealth is tied up in things that are difficult to extract their wealth from, like a big house, or, say, most of the real estate in Bloomsbury, as is the case with the British Museum, whose total net assets were listed as £1,001,693,000 in its 2018/19 Annual Report on the Consolidated Balance Sheet, as at 31 March 2019. How hard it must be to see all that money listed as a line item in a balance sheet and not be able to use it.
I’ve been thinking about that £1,570,000,000 cash injection offered by the government to the arts sector, and trying to think about Who Needs This Funding The Least? It’s early days for my data gathering and poking, and sadly, the decisions have likely already been made about who is going to benefit, although I understand there will be some form of application for some. I’ve found it easy to let the various giant numbers flying around wash over me… 1 billion here, 120 million there so step one is to try to see some of these numbers, and particularly to see them against other comparators, to get a sense of the scale of the situation.
Today I learned that the Department of Culture, Media and Sport (DCMS) gives funds each year to what’s called “Arm’s Length Bodies” which receive what’s called “Grant in Aid”. I found a DCMS Estimate Memorandum containing a certain Table 3: Comparing the Grant in Aid funding of our Arm’s length bodies in 2016-17 through to 2018-19, which I share with you below:
| Organisation | 2017 projected | 2017 actual | 2018 projected |
|---|---|---|---|
| British Broadcasting Corporation | £3,156,700,000 | £3,185,400,000 | £3,255,500,000 |
| Arts Council England | £460,526,000 | £494,183,000 | £479,972,000 |
| Ofcom1 | £72,295,000 | £123,039,000 | £106,300,000 |
| Sport England | £105,649,000 | £101,787,000 | £104,795,000 |
| British Library | £93,911,000 | £93,893,000 | £93,443,000 |
| Historic England | £87,806,000 | £87,912,000 | £90,734,000 |
| UK Sport | £53,536,000 | £60,890,000 | £61,431,000 |
| VisitBritain | £56,972,000 | £60,458,000 | £56,818,000 |
| British Museum | £53,569,000 | £53,473,000 | £42,046,000 |
| Natural History Museum | £49,115,000 | £41,815,000 | £41,815,000 |
| Science Museum Group | £43,343,000 | £46,903,000 | £40,428,000 |
| Tate Gallery | £40,251,000 | £38,066,000 | £37,566,000 |
| Victoria & Albert Museum | £40,257,000 | £37,726,000 | £37,176,000 |
| National Gallery | £24,092,000 | £24,092,000 | £24,092,000 |
| Imperial War Museum | £32,136,000 | £25,347,000 | £23,634,000 |
| British Film Institute | £23,965,000 | £23,587,000 | £20,878,000 |
| National Museums Liverpool | £20,050,000 | £19,761,000 | £19,761,000 |
| Royal Museums Greenwich | £16,019,000 | £16,019,000 | £15,869,000 |
| S4C3 | £6,762,000 | £6,956,000 | £15,097,000 |
| Royal Armouries | £7,088,000 | £7,788,000 | £8,938,000 |
| UKAD | £6,096,000 | £6,046,000 | £7,998,000 |
| National Portrait Gallery | £6,637,000 | £9,734,000 | £6,634,000 |
| National Heritage Memorial Fund | £35,250,000 | £5,489,000 | £5,000,000 |
| Horniman Museum and Gardens | £4,549,000 | £4,320,000 | £3,820,000 |
| Information Commissioners Office | £3,790,000 | £5,740,000 | £3,750,000 |
| The Wallace Collection | £2,711,000 | £3,711,000 | £2,711,000 |
| Churches Conservation Trust | £2,749,000 | £2,738,000 | £2,604,000 |
| Geffrye Museum | £1,696,000 | £1,786,000 | £1,796,000 |
| Sports Grounds Safety Authority 2 | £0 | £1,542,000 | £1,601,000 |
| Sir John Soane’s | £1,983,000 | £1,012,000 | £1,012,000 |
Isn’t that interesting? That is a bunch of support. What robust affirmative action! A total of £4,613,219,000 projected to be granted to these 30 “arm’s length” organisations in 2018. There’s the British Museum up there in the list, which was projected to receive £42,046,000 in 2018. The BM’s annual report (linked above) confirms for us that indeed: “The British Museum received £39.4 million revenue and £13.1 million capital grant-in-aid from the DCMS in 2018/19” on page 16.
All 30 organisations who receive this Grant in Aid are required to sign a Management Agreement with DCMS, and report back in a standard way so DCMS can see how well the grants are being used and measure performance consistently. For example, here is the Total income of DCMS-funded cultural organisations 2018/19 report from DCMS.
Big numbers can be numbing
The government’s support package announced this week to be spread across lots more organisations is about 34.03% of that total annual “arms length” grant in aid dispensed in 2018. I hope my maths is correct, otherwise I’m going to look even more naive and foolish. I am very willing to be called out on this if I have made mistakes, so I can learn more. I have tried to not make mistakes. I found Will Gompertz’s analysis of the situation useful, and he notes the basic breakdown of the COVID arts and culture grant we know today:
The £1.15bn support pot for cultural organisations in England is made up of £880m in grants and £270m of repayable loans. The government said the loans would be “issued on generous terms”.
Funding will also go to the devolved administrations – £33m to Northern Ireland, £97m to Scotland and £59m to Wales.
A further £100m will be earmarked for national cultural institutions in England and the English Heritage Trust.
There will also be £120m to restart construction on cultural infrastructure and for heritage construction projects in England that were paused due to the pandemic.
The government said decisions on who will get the funding would be made “alongside expert independent figures from the sector”.
Coronavirus: Emergency money for culture ‘won’t save every job’ 7 July 2020
I am definitely glad to see that the cultural sector has been recognised as having value and need for support. This is unequivocally good. The very early point I am trying to make is that there might be a way to look past and around and through the giant nationals with the loudest voices and ongoing DCMS support in the millions and with vast assets (many of whom as speaking to us via that 5 July government press release to say how happy they are) to see if it’s possible, finally, to illuminate the smaller players, the dynamic and struggling groups, the covens of freelance talent, the support companies, and basically everyone else who isn’t one of the biggies.
Staring into the status quo
I chatted about this with a few arts-related friends, and Clare directed me to a report called The Art of Dying written in 2005 by John Knell. I hope everyone who’s dispensing funds has studied it and can recite it from start to finish. It’s a response to a conference held the year before, where these three main insights were born, and I quote:
1. That the portfolio of arts organisations in the UK has become too fixed
2. That there are too many undercapitalised arts organisations, operating at near breaking point organisationally and financially, whose main preoccupation is survival diverting their energies from the central mission of cultural creativity
3. That we need to provoke a more challenging public conversation about the infrastructure supporting the arts in the UK, and the strategy and modus operandi of arts organisation
The Art of Dying
I really like what Mr. Knell is writing in this paper – it’s definitely worth your time to read it. It’s important to be able to look at each other and agree that an organisation with £1,001,693,000 worth of assets is stable. Or bloody well should be.
So interesting.
Chatting further with more arts and culture colleagues, I was encouraged — thanks, Fiona — to reframe the question to: Who Needs It The Most? This is a much harder question. I’d consider myself to be a true friend to all museums everywhere, but I have to admit I particularly love the small ones that are super fucked, and definitely don’t have £1,001,693,000 hiding away in real estate or other investments that are difficult to access because there’s some form of governance in the way of deciding to release them.
As I look at the big, open, reported numbers, I will also be on the hunt for the numbers hiding in plain sight, or not documented at all. And please, if you can direct me to good reporting on arts and culture networks and their funding, I would absolutely love the steer.
Everlasting pie chart
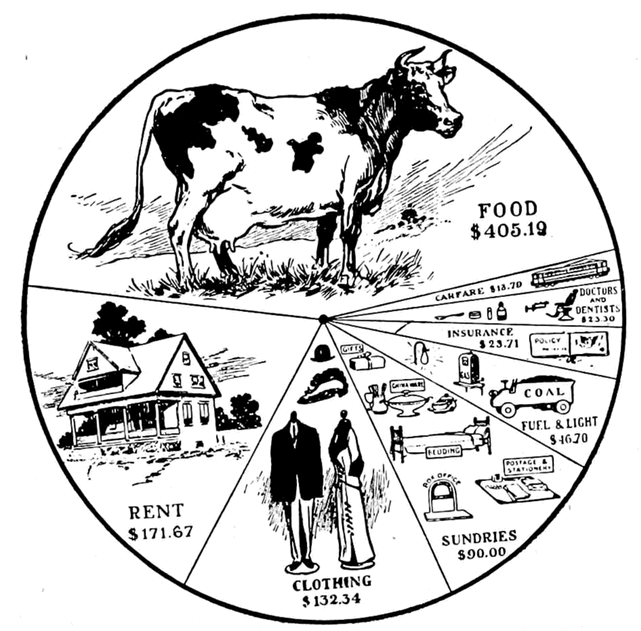
Manuel Lima goes into the history of the pie chart, or rather, circle representations in general. Despite many people poo-pooing the chart type over the decades, it keeps hanging around:
We might think of the pie chart as a fairly recent invention, with arguably more flaws than benefits, in regards to the statistical portrayal of data. However, if we look deep into history we realize this popular chart is only a recent manifestation of an ancient visual motif that carried meaning to numerous civilizations over space and time. A graphical construct of radiating lines enclosed by a circle, this motif is also a powerful perceptual recipe. If we look deep into ourselves we uncover a strong proclivity for such a visual pattern, despite the final message it might carry. As one of the oldest archetypes of the circular diagram, the sectioned circle will certainly outlast all of us, and indifferent to criticism, I suspect, so will the pie chart.
Yep.
Lima wrote a whole book on the use of circles in information design, in case you’re feeling yourself drawn to the shape for some unexplained reason.
Tags: circle, Manuel Lima, pie chart
An Unlived Life
I will not die an unlived life
I will not live in fear
of falling or catching fire.
I choose to inhabit my days,
to allow my living to open me,
to make me less afraid,
more accessible,
to loosen my heart
until it becomes a wing,
a torch, a promise.
I choose to risk my significance;
to live so that which came to me as seed
goes to the next as blossom
and that which came to me as blossom,
goes on as fruit.
— Dawna Markova
A Survival Guide for Black, Indigenous, and Other Women of Color in Academe
Very good advice: "Talk to your aunties and other women of color whom you trust. Every single one of us has been told these same lies. Vipers are old news. We will help keep your eyes on your big vision, not on this petty tyrant. We will remind you of the research that inspired you down this path. That perspective will help shrink the viper down to size."
Web: [Direct Link] [This Post]Read “Data Feminism” by Catherine D’Ignazio and Lauren F. Klein with us!

Do you keep getting recommendations for data vis books, maybe even buy them, but don’t make it a priority to read them? Let’s read these books together – and let’s discuss them, to get more out of them. That’s what the Data Vis Book Club is about. Join us! Here’s what we’ll read next.
After the great joy of dicussing Andy Kirk’s “Data Visualisation – A Handbook for Data Driven Design” in May, we’ll read what’s one of the most exciting books about data that came out this year: “Data Feminism” by Catherine D’Ignazio and Lauren F. Klein. We’ll read the whole book, but if you just find the time to read one chapter, make it chapter 3.
We will discuss Data Feminism
on Tuesday, 1st of September at 5pm UTC here: notes.datawrapper.de/p/bookclub-datafeminism
That’s 10am on the US west coast, 1pm on the US east coast, Colombia & Peru, 2pm in Argentina, 6pm for readers in the UK & Portugal, 7pm for most other Europeans and 10.30pm in India.
Catherine and Lauren will take part in the conversation as well, joining around 45min into the discussion and answering all our questions.
Like always, everyone is welcomed to join! Just open the notepad at the correct date and time and start typing. Many participants will be new to the conversation – we’ll figure it out as we go.
Should you read this book?
Catherine D’Ignazio (@kanarinka/kanarinka.com) is an Assistant Professor at the MIT who I met first at the Responsible Data Visualization forum at the beginning of January 2016. In anticipation of this event, she wrote a blog post called “What would feminist data visualization look like?” Around the same time, Lauren F. Klein (@laurenfklein/fklein.com), now Associate Professor at Emory University, talked and wrote about feminist data visualization.
They joined forces quickly. “We wrote a short paper, Feminist Data Visualization for the IEEE Vis conference, then realized we can’t think about just feminist data visualization — because the visualization part comes at the end. You can’t make feminist data visualization if all the stuff that came earlier in the process was accomplished in some oppressive or terrible way that was reinforcing existing power structures. That’s kind of where the impetus for Data Feminism came about,” Catherine told Jason Forrest in an interview for Nightingale.
 A book and its authors. Top: Lauren F. Klein, bottom: Catherine D’Ignazio.
A book and its authors. Top: Lauren F. Klein, bottom: Catherine D’Ignazio.
So even if you’re far more interested in the visualization aspect than the data aspect of data vis, don’t write Data Feminism off. I asked Lauren why data vis fans should read their book. Here’s what she told me:
Feminism opens up the data visualization toolbox and allows us to focus on what truly matters in a design process: honoring context, architecting attention, and taking action to defy stereotypes and reimagine the world. – Lauren Klein
If you’re looking for practical data vis advice, this book isn’t for you. If, however, you want to reflect on the work you do, see where it fits in the greater context and learn how to think & talk about data more deeply, do read Data Feminism and discuss it with us.
And while Catherine’s and Lauren’s book explains more serious issues than the books we normally read in this book club, it’s “a surprisingly light book, one told with generosity and humor,” Jason states in the mentioned interview.
Sounds good to you? Read the book with us!
How does the book club work?
1. You get the Data Feminism book. Ask your local library to order it for you, buy it, borrow it from a friend, ask around on your preferred social network. Lauren and Catherine were so kind to provide the intro, chapter 1, chapter 2 and chapter 3 (out of 7 chapters) as PDFs for a reading club they were organizing. There’s also a draft of the whole book online. You can find the whole book online here!
2. We all read the book. That’s where the fun begins! Please mention @datavisclub or use the hashtag #datavisclub if you want to share your process, insights, and surprises – I’ll make sure to tweet them out as @datavisclub, as motivation for us all. We’ll discuss the whole book, but focus on chapter 3, since it’s most relevant to data vis designers.
3. We get together to talk about the book. This will happen digitally on September 1st, 2020 at 5pm UTC over at notes.datawrapper.de/p/bookclub-datafeminism.
It won’t be a call or a video chat; we’ll just write down our thoughts. The discussion will be structured into three questions:
Three questions
During the conversation, I’ll ask these three questions in the following order:
1 What was your general impression of the book? Would you recommend it, and if so, to whom?
2 What was most inspiring, insightful, or surprising to you while reading through the book? What did you learn that you didn’t expect to? What will you remember?
3 What will you take away? Having read the book, what will you do differently the next time you visualize data?
For each question, you can prepare a short answer, but there’s no need to. We’ll quickly get into discussion mode.
After going through the three questions within approx. 45min, Lauren and Catherine will join us to answer questions we might have about their book.
More questions?
Here’s a short FAQ for you, in case you have more questions:
So what will happen, exactly, during the book club?
A digital book club is a new experience for many of us. See how our book club discussions have looked like in the past:

You can also read the review of the first book club, to learn how people found the experience.
This is what others have said about some of the last book club discussions:
- “Just wanted to say this was my first time joining the book club and I JUST LOVED IT! Thank you everyone! This experience was incredible.”
- “Such a great experience connecting with the authors and fans of this unique book that I love.”
- “Great experience! It was fun reading all of the questions and answers as they popped up and to scroll up and down the screen to check out any new comments.”
- “OMG! First time that I do it and I just loved it!!! I like that I can write everything I’m thinking about live and comment on other people’s ideas easily.”
Why don’t we do a call? Why the notepad?
Because it works well for introverts & people who prefer to stay anonymous in the discussion. Plus, the documentation of our meeting writes itself.
I can’t make it on this date / this time.
Do you have a lunch date? Vacation? Need to bring the kids to bed? No problem! The conversation will be archived in the notes and can still be extended over the next day(s).
I’m very, very much looking forward to working through Catherine’s and Lauren’s important book with all of you. If you have any more questions, write in the comments, at lisa@datawrapper.de or to Lisa / Datawrapper on Twitter. Also, make sure to follow @datavisclub, to stay up-to-date and get a dose of motivation from time to time.
Getting to Like Obsidian
In the past days I have been both exploring my process for second order note taking, and part of that is evaluating tools. I’ve been trying the note taking process in both WordPress and Evernote. In parallel I have also been looking at other tools for note taking. I’ve looked at a few tools that say to have implemented the Zettelkasten method, but I don’t want tools that assume to shape my process. I want to shape my tools, based on my routines.
In terms of tools that support me, I want tools that increase networked agency. Tools that treat data as fully mine, the tool itself as a view on the data, and its interface(s) as queries on that data.
Between WP and Evernote, the first does that, the second most definitely not. At the same time Evernote makes note taking much easier than WP can ever do. This is not surprising as WP is a blogging tool that I am using as a wiki on my local host while Evernote was designed for note taking. From the other tools I looked at, Joplin and Obsidian stood out, both tools that use markdown. Joplin because it is open source, allows easy import from Evernote, and can save webpages locally, can sync with Nextcloud allowing easy mobile access. It does store notes in a sqllite database which makes accessing my data more difficult.
Obsidian is still in beta but already looks pretty amazing to me (similar to Roam it seems). It operates on text files in a folder, thus allowing direct access through my file system to any data I add. It provides a view on that data that allows easy linking between notes, and you can split off any number of panes in the interface with whatever content or query. This means you can have a variety of notes open, pin them, see what links to what etc. There is also a graphical view, that allows you to explore notes based on the cloud of links they form. That makes it look a bit like the Brain of old. It’s all in markdown, so easy to use on mobile with a different client if I sync it through Nextcloud. I added the same notes I previously added to WP and EN in Obsidian, to experience differences and commonalities. In comparison with the other notes tools I tried a key difference is that I left this app open since I started it up this morning. A key difference with WP and EN is that I want to add notes to this tool. It does mean I need to relearn markdown, which has gone rusty since I last used markdown (in a locally hosted wiki), but of course it was easy to make a note and pin it to use as cheat sheet.
 Obsidian screenshot, list and search pane on the left, a graphical overview middle top, a note middle bottom, and my markdown cheat sheet on the right
Obsidian screenshot, list and search pane on the left, a graphical overview middle top, a note middle bottom, and my markdown cheat sheet on the right
Having used Obsidian for a day, I am now wondering if I still need my local WP instance. The combination of Obsidian and Zotero which I started using for reading references even looks like something to replace Evernote with. This is the first time I’ve thought that in the past 4 years for longer than an hour.
The Best Kitchen Scale

A good kitchen scale can streamline and elevate all kinds of culinary endeavors, from baking to fermenting to brewing pour-over coffee. It offers a level of precision that measuring cups and spoons can’t provide, and it cuts down on dishes, to boot.
After years of research and testing, we’re confident that the Escali Primo Digital Scale is the best one. It’s among the fastest and most accurate scales we tested, and it stays powered on for longer than most others before automatically shutting off.
A Near-Ultrasound (NUS) Data Link
We were requested to investigate “near ultrasound” (NUS) links as part of our research on developing the Simmel reference design for a privacy-preserving COVID-19 contact tracing device. After a month of poking at it, the TL;DR is that, as suspected, the physics of NUS is not conducive to reliable contact tracing. While BLE has the problem that you have too many false positive contacts, NUS has the problem of too many false negatives: pockets, purses, and your own body can effectively block the signal.
That being said, we did develop a pretty decent-performing NUS data link, so we’ve packed up what we did into an open source reference design that you can clone and use in your own projects.
Top trace: demodulated data at 1 meter, 50dB background noise. Bottom trace: raw signal, normalized so it is visible. Without normalization the trace just looks like a flat line.
I imagine one use for this would be a way to provision IoT devices: the “how do I get wifi credentials into an IoT device that lacks both screen and keyboard?” problem. With the addition of a ~$1 microphone to a Cortex-M4 class device, you get a short-range data link to a host device, such as a phone. You can use a web page (via Javascript) to generate the modulated audio directly (relevant example), thus bypassing a host of multi-platform issues, or you can generate a file off-line and send it to any standard music player.
The TL;DR on the link is it uses a 20,833Hz carrier modulated with BPSK. We use PSK31 coding, so our baud rate is ~651 symbols per second (this is the 1/0 symbol rate before Varicode encoding). This isn’t breaking any speed records, but it’s good enough to send a UUID and some keys over the air in a couple seconds. Tests show decent performance over a distance of 1 meter with about 60dB ambient noise (normal conversation or background music playing at the same time).
The demodulator uses a Costas loop. We’ve documented its details, including comments on porting to other chipsets than the NRF52.
We also have a reference modulator using a non-linear transducer (e.g. a piezo element), which uses some of the more advanced features of the NRF52 PWM block to eliminate audible sidebands. We also have a rough C program to generate a .wav file, which needs to be run through a high-pass filter using e.g. Audacity to eliminate the low-frequency modulation sidebands; but the resulting .wav file can be played directly on your smartphone and it will demodulate correctly.
Acknowledgements: Sean ‘xobs’ Cross is an equal contributor to this research. This research is funded through the NGI0 PET Fund, a fund established by NLnet with financial support from the European Commission’s Next Generation Internet programme, under the aegis of DG Communications Networks, Content and Technology under grant agreement No 825310.