
The #MEC sale episode on @eachforall is now available! It features founding member Rob Brusse, former board member… twitter.com/i/web/status/1…
[This is part of a series by our guest blogger Tre Scranton covering video creation on the Librem Mini.]

Video content is one of the most popular forms of media for communication on and off the internet. Many creatives spend hundreds, if not thousands – to obtain licensed use to hardware and software as a means to create quality video that can stand on it’s own next to Hollywood-level productions. Fortunately, Purism, a company that respects your digital rights and privacy – has created a free software ecosystem to help restore ownership and control to the hands of the user. With PureOS, you can download KDenLive – an free software video editor – from the PureOS Store and create high-quality video using tools that rival more expensive editors like Adobe Premiere or Final Cut Pro.

The Librem Mini, a small but powerful desktop PC, is perfect for processor intensive tasks like video editing and rendering. Packing an Intel Core i7-8565U (Whiskey Lake) CPU with 4 core and 8 threads with clock speeds at up to 4.9 GHZ and up to 64GB of RAM, it’s capable of being the centerpiece of any film studio. To demonstrate the capabilities of content creation on a Librem Mini, check out the video below:
Tre Scranton is an open source advocate, electronic musician, and writer for LBFQ. He likes researching about current practices in the Cybersecurity and Data Analytics fields.
The post Video Editing with KDenLive and the Librem Mini appeared first on Purism.
No-one expects you to be an expert in the topic, there are other people for that.
But you should be passionate about the topic. You should be interested in what’s new and what’s going on in your sector.
This means a few things.
When you know what’s going on, you can start discussions in those areas, ask people for their opinion, and reply to questions with honest opinions.
Better yet, when you subscribe to the topic you might find yourself gradually becoming more passionate about it.
Jason Snell at Six Colors, providing some historical context for the current wave of iOS 14 Home Screen customization:
The Mac has a long history of customization. When I became a Mac user in the early 90s, it was de rigueur to give your Mac hard drive a name and a custom icon. Ideally, you had a custom wallpaper pattern or image, too. Apps like SoundMaster let you set custom sounds for various actions. The list went on and on. Your Mac felt like home—and like no one else’s.
What’s more surprising is that Apple was so slow in bringing real customization to the iPhone home screen. If adding widgets to iOS 14 has caused enormous burst of creativity, it’s only because all that desire had built up over years and years with very little outlet.
This is not a surprise. This is not the effect of young whippersnappers raised on social media wanting to do goofy things with their phones. Users of computer platforms have wanted to customize and personalize for decades.
Lots of people are having lots of fun making all kinds of personalized Home Screens and even themed ones. This is made possible by a combination of iOS 14, app launchers configured through Shortcuts with custom icons, and a new crop of widget creation apps.
These Home Screen designs may not be for everyone, but that’s kind of the point: they’re not for everyone, they’re built by and for individual users. Let’s celebrate that creativity, and hope Apple provides better tools for this kind of customization in the future.
→ Source: sixcolors.com
It occurred to me yesterday after finally listening to Terry Greene‘s interview with Bryan Mathers for the Gettin Air podcast that I never blogged about our Reclaim Cloud artwork. That needs to be rectified, and I will share the awesome below, but before I do I just wanted to say how much I enjoyed the interview between these two. Possibly the coolest part was when Bryan started interviewing Terry in order to see if he could “draw” out of him some ideas that he could refactor as a visual for the podcast, and voilà Gettin Air has a new logo!

I dig it, especially given I have returned to snowboarding these last few years, but even better was Bryan getting Terry to talk about his idea behind the name, his articulation of what he’s doing and why—it was all so effortless and real. It was a beautiful demonstration of how the interview can become the thing it wants to share. So genius, well worth a listen if you have some time.
Anyway, that whole process reminded me I have not yet shared the work Reclaim Hosting did with Bryan this summer to get started on the Reclaim Cloud aesthetic. Given Reclaim Cloud is premised on a container-based architecture, we initially explored if we wanted to go down the road of shipping containers, and we have some initial sketches from Bryan that I absolutely love.

The containers are actually VHS tapes! A point made clearer in the heavy lifting image that follows:

It really is brilliant, it captures the idea of Reclaim Cloud as both container-based and industrial-strength, which it is! But ultimately after talking with Bryan we realized the hard limits of the nautical/container metaphor. So we moved on to Cloud City, an idea Martha Burtis and I came up with for Domain of One’s Own back in the day.

I still love that poster, in fact I have a stamped copy of it framed and hanging on the wall behind me as I write this. So we got to talking a bit about it, although Tim was a bit reluctant given he is not a Star Wars fan, but through conversation the idea of a retro-futurism aesthetic began to emerge a la The Jetsons.
And Bryan’s rough sketches had us very intrigued:



The idea of scaling your domain was fun, and the way Bryan mapped that onto retro-futuristic housing and was brilliant. In the final image the beginnings of a logo/cloudlet begin to take shape already. This was our aesthetic, and we kind of knew it during the discussion, but the seeds of the sketches sealed it.


The final option was to stick with the music/video metaphor we already have and push it further with mixed tapes. But it just felt forced, and I think Tim and I both wanted the freedom to jump out of that metaphor and explore something new, and I am really glad we did.

The next conversation after deciding on Cloud City was to scout the internet for some ideas for our next conversations, and that is when Tim landed on industrial designer Arthur Radebough’s Closer than We Think comic strip from the late 1950s through 1963. The way in which the art incorporate an explanatory panel and then the actual art incorporates various explicit arrows illustrating the future gels nicely with our idea of introducing Reclaim Cloud as a way of highlighting for higher ed what’s possible in this new space. So, we got to talking, and the first round of art was amazing:
![]()
I really love the industrial logo for Reclaim Cloud which is itself an encapsulated container, a cloudlet if you will, and this idea of self-contained cities became a bit part of our aesthetic. And the fact that Bryan Ollendyke said it reminded him of Bioshock on Twitter just sealed it for me 

We were sold after this image, a kind of brochure for Cloud City which enabled us to start exploring the idea of what it would mean to try and create a series of vignettes of the different options for anyone interested in moving to the Cloud. It was just too fun, so the follow-up discussion was to explore the Closer than You Think comic strips to highlight some of the one-click applications we have for courses, organizations, and digital scholarship:



Pure magic! The way in which the container has become an organic part of these images is just so awesome. I love the one outside the window of the home classroom. This idea that it is all connected yet separate is one way to understand the cloud, and Bryan really brought it home. And as amazing as all the art is, I think his breakdown of the various elements of a Reclaim Cloud container that could incur costs in a fullblown masterpiece:

This sphere is everything, literally. I just love the way the aesthetic has evolved and the final bit is thinking through how we’re going to highlight what is happening within each cloud. This led us to the idea of “What’s in your Cloud?” wherein we talk to folks to provide us a peak into their Cloud, what are they running, how, etc. The following image is a placeholder, but we are thinking through ways of trying to capture the individual nature of folks’ cloud for each episode, and Bryan mentioned some kind of comic-like avatar, like my Cotton Mather avatar in a spacesuit hold my Cloud sphere, which would be awesome!

Anyway, I think that brings us up to date, and to be clear this has only just begun. We are thinking of Reclaim Cloud as a long-game. We know it will not replace cPanel hosting; we have plenty of time to experiment with the possibilities; and we can slowly start moving our existing infrastructure over as we become increasingly comfortable with the environment. Not to mention it has forced us to dig in and learn a lot more as a company, and as much as I was kicking myself given I was just start to feel a bit liberated from the day-to-day, in the end I love it. We’ve been dreaming of this kind of infrastructure since we started Reclaim Hosting, and in 3 short months we went from nothing to a pretty full blown product that provides some concrete solutions for academics wanting to host something outside of the LAMP stack. And this retro-future aesthetic is our way to start experimenting in this space without pretending there aren’t also real problems baked into every solution—we’re here to explore right along side you.
For the past month or so, as an experiment, I’ve been opening my calendar each week for video calls with whoever books a time. It’s been amazing. Wednesday is now my favourite day.
I’m calling it Unoffice Hours. (Everything that works needs a name.)
You can book 30 minutes in my calendar here. No agenda required, no need to mail first.
I set aside a couple hours each Wednesday for Unoffice Hours. The 23 conversations I’ve had since the start of August run the gamut:
And those are all good, so feel free. I’ll keep this going for a while.
Now office hours is an old idea. Here’s some history from a 2009 piece in the Harvard Business Review:
The concept of “office hours” for business goes back to a universal ritual from our college days. We’d take classes with professors who were busy, distracted from teaching with research in the lab or the library, and otherwise remote and unapproachable. But we knew that for a couple of hours, at least one day a week, we could stop by their office, ask for advice, try out an idea, and get the guidance we needed.
– Harvard Business Review, Should You Hold “Office Hours”?
The article tracks the evolution of office hours into tech, with people opening their calendars for networking and mentoring. It’s pretty common now.
Office hours have become in a staple in startup support. Here’s how office hours worked for me when I was running the R/GA Ventures accelerators in London.
So why un-office hours?
Well, I’m not in an office, for one…
This all started because of lockdown and because I was missing the serendipity of grabbing coffee.
I loved those open conversations over coffee in the Before Times. There’s an ostensible reason to connect, so you talk about work, or compare notes about an idea, or whatever. But then the unexpected emerges. (Sometimes you have to hunt for it.) There are things in your head that you only know are there when you say them. And there are encounters with new ideas and new perspectives. 1:1 conversation is a vital part of my process in finding work, but also simply in thinking.
But with us all going remote in a giant forced experiment, I wasn’t getting that input. Could it work over Zoom? It turns out it can. And Calendly is a genius service to allow online booking and have the meeting appear automagically in your Google Calendar.
(One tip if you do this yourself: schedule the calls for 30 minutes, but add a 15 minute buffer after each. Otherwise you’ll have to end calls super abruptly.)
So I’m not in an office.
Secondly, the heritage of office hours is about professors and students. And it’s not about that hierarchy for me: grabbing coffee - my model for this - is an informal meeting of peers. The un- is there to signal that difference. The purpose, instead, is manufactured serendipity.
I know there are a few other folks doing this too. Call it Unoffice Hours, let’s make it a movement!
I’ve added a link to this post to the sidebar on my website. It’s there if you’d like to chat. See you on the zooms.
I have been using TextExpander for a long time to speed up typing by using keywords for often used and repeating snippets.
Things like .TZ to type my name Ton Zijlstra, .url to type my blog’s url https://www.zylstra.org/blog, and .@blog for my blog’s mail addressblog@zylstra.org. That way filling out a comment form on a blog is .TZ .@blog .url, and then the comment.
With their latest release TextExpander has gone the route of so many software packages, and started charging a yearly subscription. I don’t mind buying software but paying yearly for the same package adds up quickly over the many software tools I use. I don’t mind the occasional payment for an upgrade (I happily pay Tinderbox $100 every time I do a major upgrade), but forcing a subscription on me is a form of economic tethering I fundamentally dislike.
So whenever a software tool moves away from ‘pay me once now, and pay again once you choose to upgrade’ to ‘let us set the frequency of payments’ I try to move away from that software tool. Currently I am moving my TextExpander snippets into Alfred, a tool that does the same thing next to doing a whole host of other things and that I also already had installed.
It’s been about 4 months since I started this series on Cesil. In that I’ve published 12 blog posts and made numerous updates to Cesil. Having just released a new version (0.6.0), it feels like a good time to do a small retrospective on some of the less technical parts of my efforts.
First, the GitHub sponsors update – not a single one. I find this unsurprising, as I’m sure most readers do – honestly, it took some effort to not snark about the likely outcome in earlier posts. I do think this serves as a good experimental validation of my expectations though.
I’m not exactly new to OSS, I’ve got a couple libraries with 1M+ downloads, this non-trivial blog, and have some contributions back to the broader ecosystem. In other words, I’m probably a bit above average in terms of OSS footprint. But, I do this for fun (like many others) – I’ve never gone out and solicited sponsorships, or otherwise tried to cultivate a following. Some have seen success with Patreons, or consulting, or sponsored screencasts – all of which I find decidedly unfun.
My big takeaway from this little sponsorship experiment is: things like GitHub Sponsors are tools you can use but creating a sustainable open source project is ultimately a job, and if you’re coding for fun you probably aren’t going to do that job. Modulate your expectations accordingly.
Second, all the Open Questions. I’ve sprinkled nine throughout the blog series so far, and four (~44%) have seen some engagement – not a bad ratio in my opinion.
The “answered” Open Questions which all shipped in version 0.6.0:
Remaining Open Questions at time of writing are:
Third and finally, an aside on naming. When I first started on what became Cesil, I was expecting to do a lot of IL generation which meant I’d probably pull in Sigil, and thus “CSV with Sigil” became Cesil in the same way “JSON with Sigil” became Jil. However that never happened, as I got more into development I became convinced that the future is going to look more AOT-y, more source-generator-y, and just less ILGenerator-y.
Then the second I published Cesil folks pointed out how close it was to Cecil, a library for manipulating IL. Given the above, I’m not particularly attached to the name but didn’t have a good alternative and figured both libraries were in different enough areas it was unlikely to be an issue in practice. So naturally I was immediately proven wrong, as I went to contribute some small improvements to Coverlet… which makes extensive use of Cecil. Discussing these changes (which kept happening as Stack Overflow was also considering using Coverlet) was a real laugh riot.
So, I should really change the name of Cesil. I still don’t have any great ideas (naming is hard, after all) so I’ve opened another “Open Question” Issue to collect alternatives. Primary goal is to find something that won’t be confused for other projects, while still at least hinting at “CSV”.
And that wraps up the Open Source update. In the next post, I’ll be digging into performance and maybe giving an update on naming.
Hi, this is Gregor, co-founder and CTO of Datawrapper. With this week’s Weekly Chart, I’m returning to my favorite topic: the climate crisis.
Last week deadly wildfires were raging at the U.S. west coast in California, Oregon, and Washington (and they still are). At the same time, Hurricane Sally hit Florida and Alabama, causing major floods and damages. This bizarre episode reminded me of a paradox of the climate crisis we’re now living in. While temperatures are rising and droughts and wildfires become the new normal, there is more rain in a lot of places than there has been in the past.
I first read about it this phenomenon in the German national weather service (DWD) yearly report about climate change[1], and almost couldn’t believe it. How can there be more rain now than thirty years ago? After the extremely hot summers of 2018 and 2019, this year has again been very dry. As a hobby gardener, I follow the weather closely and remember the long stretches of days without rain.
That’s why for this week’s Weekly Chart, I set out to find a visualization that shows this paradox. And I found a chart with the weird Latin name thermo-pluvio diagram (thermo for heat, and pluvio for rainfall)[2]. It shows anomalies[3] in air surface temperature and precipitation for each month of a year in a scatterplot:
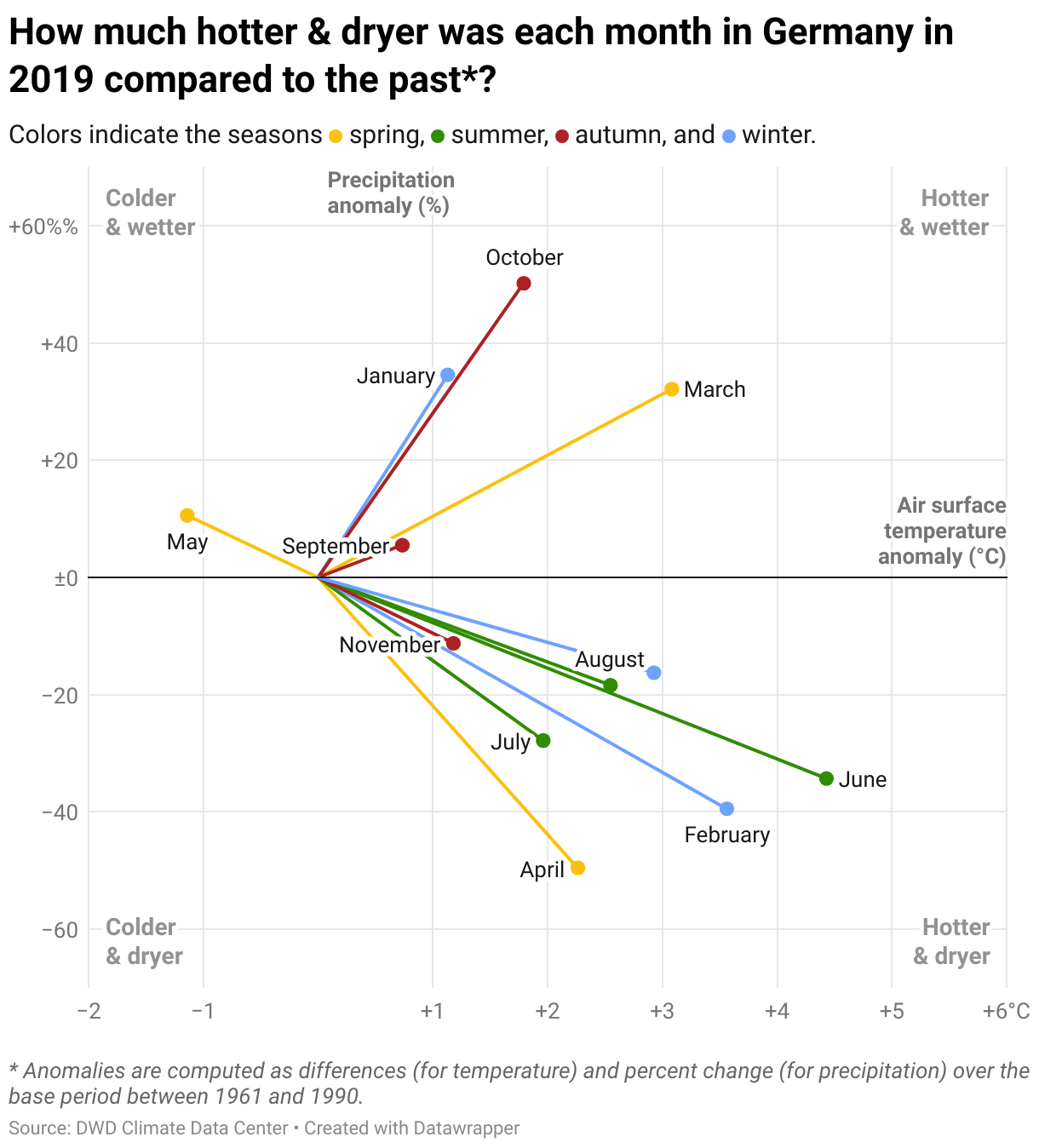
I like these kinds of four-quadrants scatterplots because they describe a clear contextual “map” in which we can quickly find each data point. The added lines make it clear that we’re talking about anomalies.[4]
The diagram shows that January, March, and October 2019 where hotter and wetter than the base period, while April, February, and June were hotter and dryer. We also see May jump out as the only month in 2019 that has been colder.
When looking at the current year, it seems as if most of the rain that was “missing” in other months fell in February 2020:
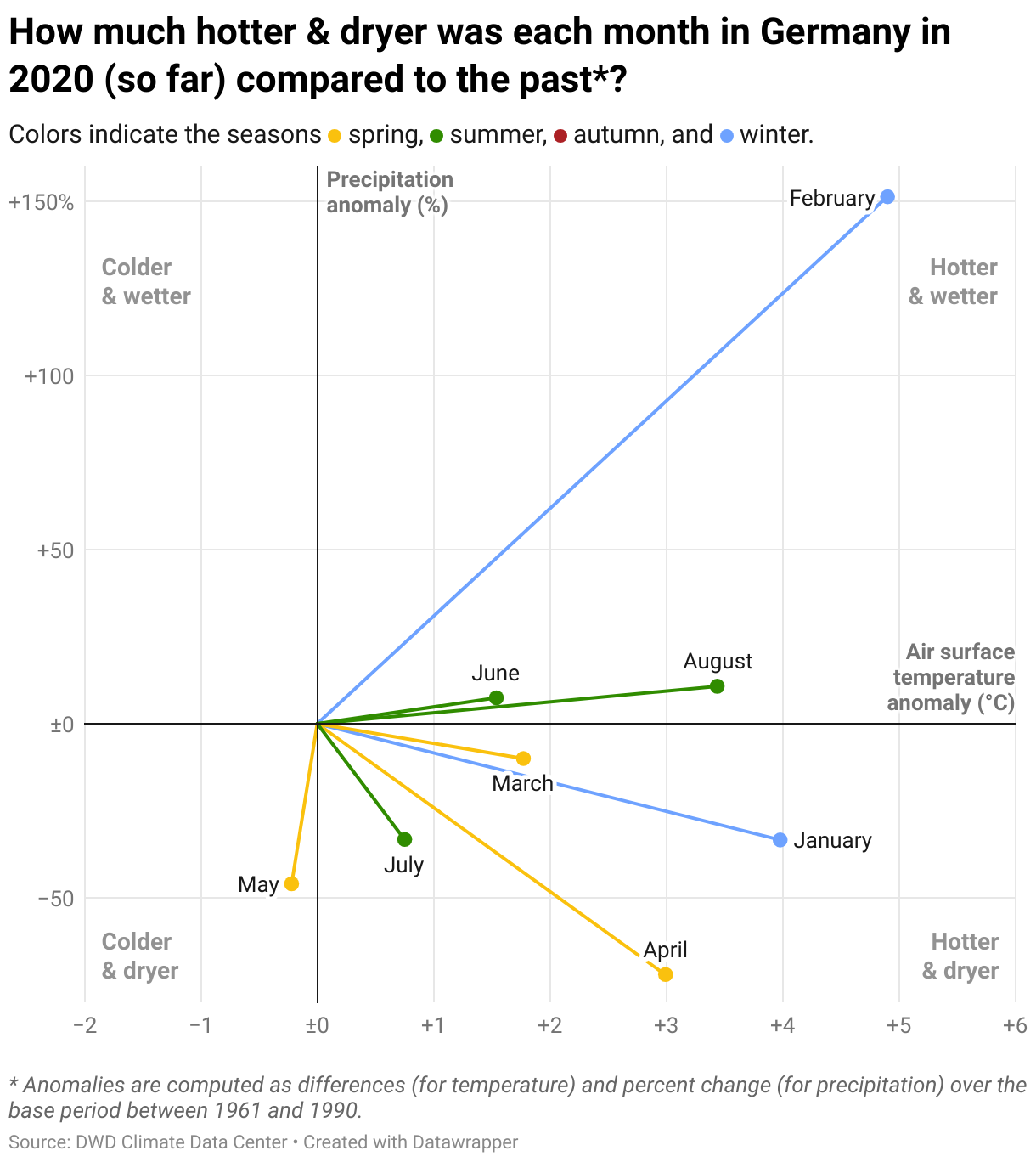
As we see, there is much variation between the years. It makes sense to “zoom-out” a little further and look at seasons instead of months. The next view allows us to look at an entire decade at once. Unsurprisingly, we see most seasons on the “hotter” side of the chart, but most seasons often appear on both sides of the dry/wet spectrum:
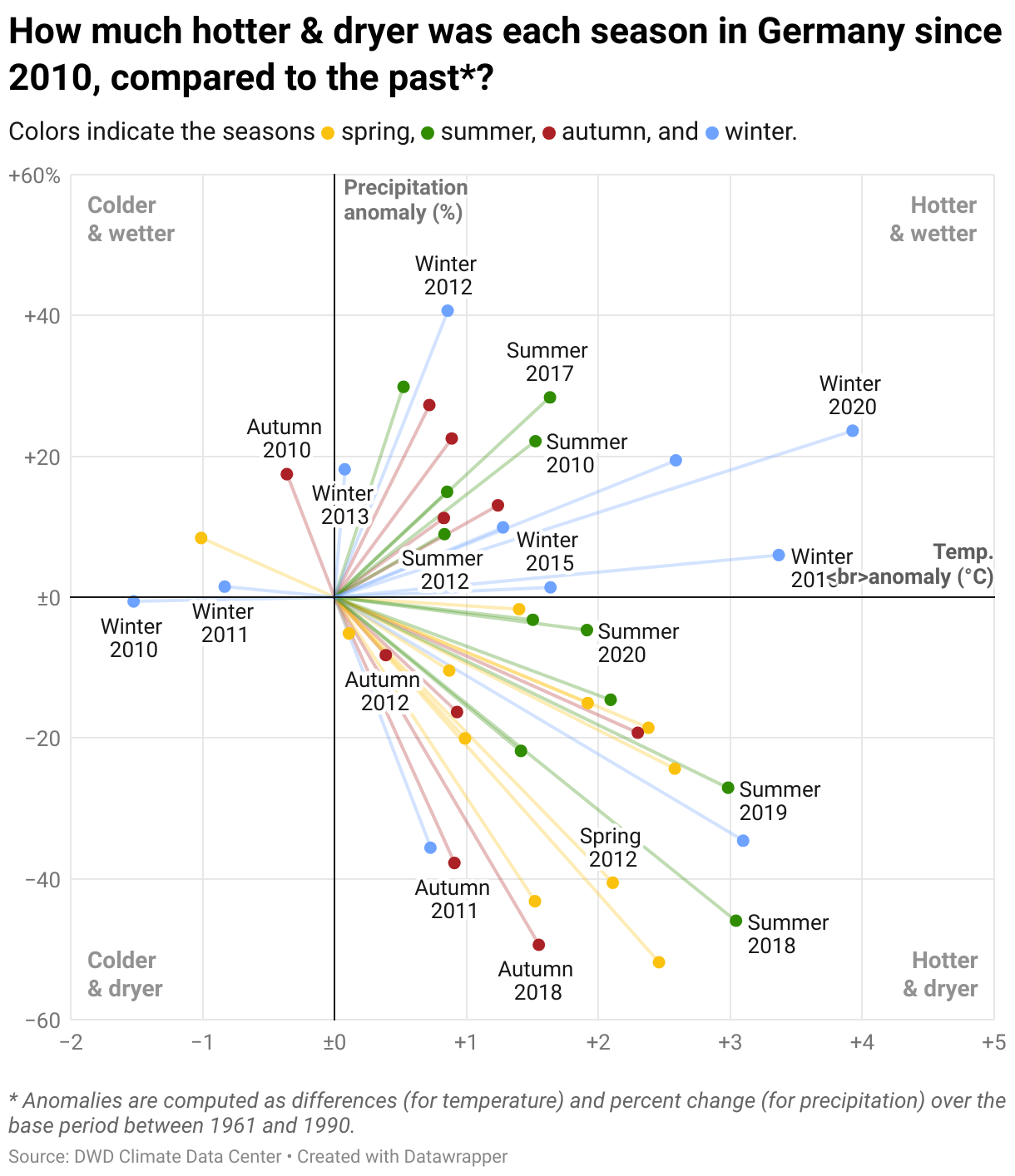
But since it’s still hard to interpret this “confetti explosion” chart, I’m ending this post with a much more simplified view of the average seasonal temperature and precipitation anomaly over the past 20 years.
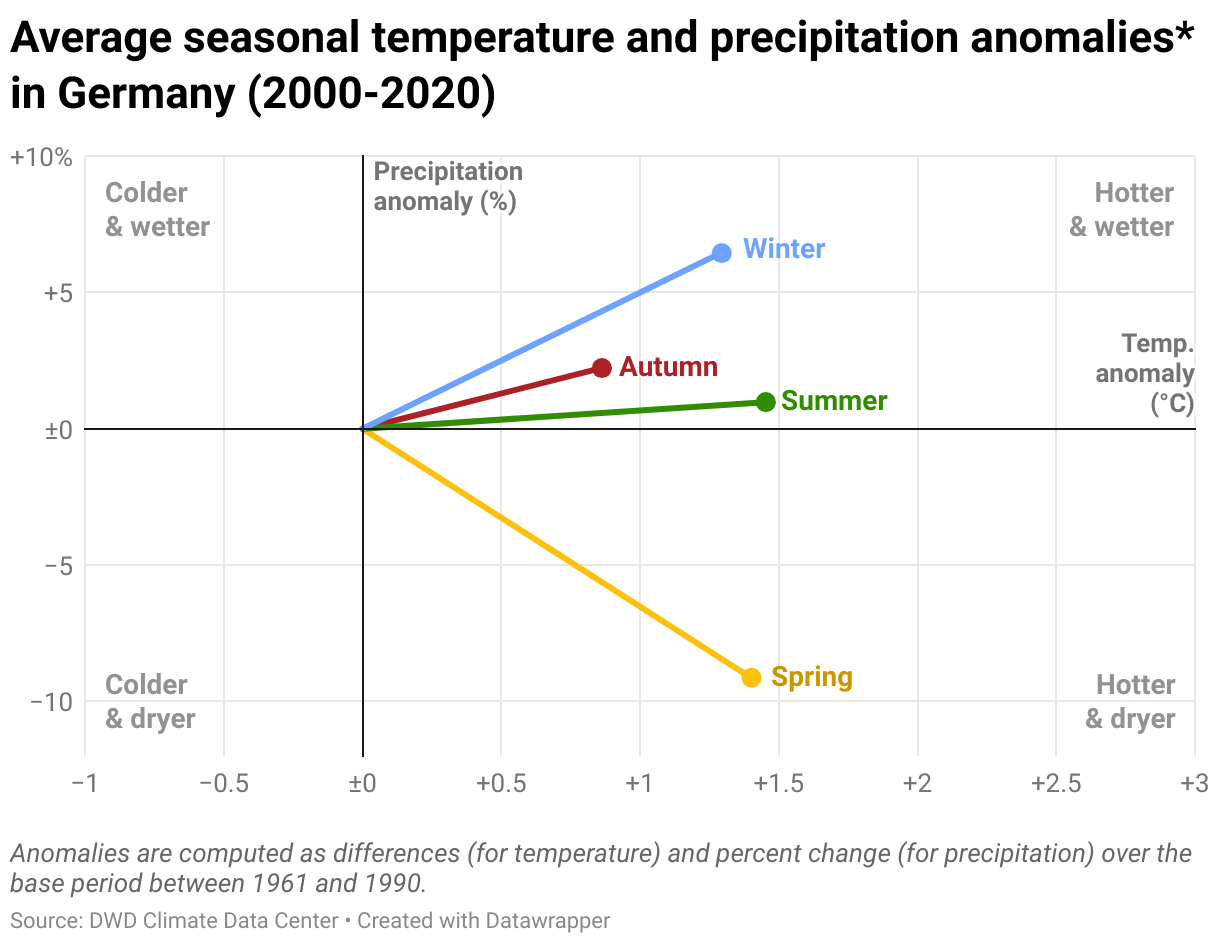
And indeed, on average, three out of four seasons have been more rainy compared to the 1961-1990 base period, especially the winter months between November and January. The typical new dry season in Germany is not the summer, but spring (from March to May).
That’s it for this week. As usual, you can find the R script for this analysis on Github if you want to play around with it (feel free to re-use it).
The DWD report says that “in the past hundred years, we’ve seen an increase in the average precipitation. In the future, there too will be a likely increase in yearly total precipitation.”. ↩︎
Found it on page 5 in the 2019 edition of the Climate Status Report for Germany (in German) by the DWD. ↩︎
The DWD defines temperature anomalies as differences between a month’s average temperature and the average temperature of the same month over the base period 1961 to 1990. Precipitation anomalies use the same base period but use percentage-change instead of absolute differences. ↩︎
I would have preferred arrows to show shifts, but that’s not possible with our Datawrapper scatterplots (yet!). ↩︎

A “virtue” is defined as a commendable quality or trait or alternatively a beneficial quality or power of a thing.
While many people are aware of code smells to describe what is bad about bad code, I have long thought that we needed a language to describe what is good about good code.
In AgileInAFlash, Jeff Langr and I presented the 7 Code Virtues in an attempt to provide a positive language to describe code goodness.
The virtues are:
The number 7 was not intentional. It was just a bit of luck that 7 Virtues riffs (or contrasts) with other famous lists of virtues, including the Bushido Code (compassion, sincerity, loyalty, honor, courage, courtesy) and the Catholic Seven Virtues (chastity, temperence, charity, diligence, patience, kindness, humility).
We didn’t base our 7 virtues on any of those lists and I don’t know that either of us were even aware of them at the time. I was, however, aware of Ben Franklin’s 13 Virtues.
This language will allow people to say what they like about one way of expressing a code idea vs other ways of saying the same thing.
Do you like it better because it’s unique? Because it’s brief? Because it’s clear (to you)?
This doesn’t replace mechanisms such as the SOLID principles or the 4 Rules of Simple Design, it merely helps us communicate clearly about the code we love.
But what do the seven virtues mean?
We provide an opposite with each virtue term for context, a graphic illustration, and a short summary.

The first and most important feature of code is that it works.
The code is assembled and integrated. If you run the code, it will get the right answer. It may not do everything that one may wish it did, but it can run and can perform some meager functions.
Without this, no other quality is remotely interesting.
This means that a program must not only have the potential of running someday in the future given the right support and care and services and environment, but that it has already been observed running and behaving as intended.
Code that works today is superior in virtue to code that may someday run.
Code that has been proven to work recently, is better than code that has not. This suggest that code that performs frequently under automated tests (such as in TDD) is more likely to have the virtue that it works.
Code that was tested at some time in the past but has since been changed without testing is less likely to have this virtue.
And code that is working in production is superior to code that has never operated in real life.
This is the first virtue.
It is not the only virtue.
For it to work, work recently, and be proven to work, is merely table stakes. Once it works, then we can talk about the other virtues.

We know the issues with code duplication. We’ve seen the horrors that come from having implicitly shared algorithms and constants.
Code can work, but still be burdensome and dangerous.
Every system of code virtues has come up with one way or another to describe unique code as a virtue:
My preference is SPOT.
The idea of Single Point of Truth is that every fact and every algorithm has a single definition within a body of code, so that every fact or algorithm has a single point of maintenance within the codebase.
The code isn’t bloated by duplication and maintenance is not hindered by finding that one module implicitly counts on another module using a specific algorithm.
One example we’ve seen is prepending punctuation to the starts of names in order to cause them to sort to the top of an alphabetical list. When the lists are modified to not be alphabetical (such as most-recent-first), the names show up as unnecessarily cryptic and can confuse users. This one is benign.
We’ve seen “magic numbers” used in a system that relied on the ID generator’s implementation never using a number greater than 100,000. By creating test IDs of 100,001 and higher they were duplicating the algorithm’s upper-limit fact. This worked fine for some time (years). When the ID generator changed, there was no clear path to also change the test’s implicit dependencies; tests began to corrupt user data (and vice-versa).
Single Point of Truth makes dependencies and assumptions explicit, which makes them maintainable.
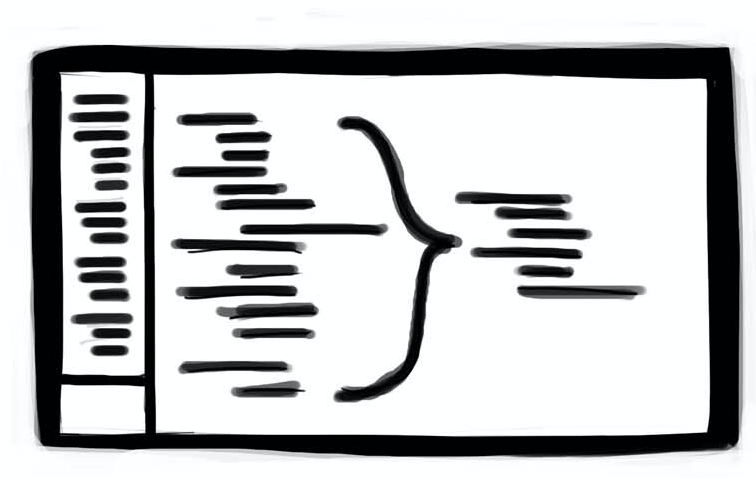
Once code works, and has no duplication, the next interesting feature is how complex the code itself is.
Simple and Complicated are words that sound rather subjective, and people tend to use them subjectively. Still, in the 7 Virtues we mean this to be an objective structural idea rather than a relationship between the reader and the material.
“Simple” means that it has few operations, few operands, and very few paths through the code.
If there are dozens of variables, it is less simple (more complicated).
If there are dozens and dozens of computations steps, it is not as simple as if there were only a handful.
The query !isEmpty(x) is one operator more complex than isPopulated(x) because of the not operator (!). It may also be less clear, as human beings have trouble with not-logic, but that is a matter of clarity not simplicity.
Note that the isPopulated method may merely call !isEmpty in its implementation, and this makes no difference. Simplicity is a local phenomenon. The code you are reading can more simple even if it invokes functions of considerable complexity.
This includes logical operators, so isFull(x) is more simple than x->lastUsed < x->lastAvailable even if both expressions produce the exact same behavior. One function call is fewer operations than two member lookups and one numeric comparison. In addition, the second expression has a number of other problems (primitive obsession, shared knowledge of a data structure, etc) which likely make it less clear as well but simplicity is only concerned with operations, operands, and paths.
Code without for, if, case, while, unless, and ternary statements will have fewer paths, and therefore be more simple than code that includes these conditionals even if the code that contains those statements is easier to understand.

This is the first subjective virtue in our list.
It is certainly true that readability and clarity are more about a relationship between the code and the programmer than about the code alone.
A passage of code may be clear to one programmer (perhaps its author) and unclear to others (perhaps its maintainers). This is often because of the context the reader has available to them.
Still, subjectivity doesn’t mean that it’s random and unworkable. For instance, food taste is subjective and yet people all over the world eat more potato chips than library paste. Much of subjective taste falls in a narrow band.
For instance, people may prefer two, three, or four character indents. Almost nobody prefers zero character indentation, and similarly it is rare to find someone who prefers 120 character indentation. Usually the range is 2-8 with some outliers. A quick survey of published code shows that 3 and 4 are the most popular, but which your teammates prefer is locally subjective.
A person who does not know how to program will likely find every expression of code essentially unreadable and puzzling, but that hardly seems important to us. Their opinion of the readability of Java, Python, or Clojure styling is not relevant to us.
Our interests fall to the people whose opinions are relevant; those who share the codebase on a day-to-day basis. These are likely people who know the stack fairly well and the domain fairly well.
Do the codebase denizens find a particular expression more or less puzzling than another expression? Is one more idiomatic, and therefore more clear to experienced developers? Is one ordered in a way that seems more logical?
Coding standards are about codifying a shared subjective sense of clear coding ideas. We negotiate them into existence, and amend or change them as needed.
Life is too busy for people to have to reverse-engineer code every time they visit a module. If we can make the code clear to people who will be maintaining and expanding it, we have done virtuous deed.

Easy is not about how easily one can read the code, but how easily one can change the code.
If one can write a new feature into the code in 15 minutes, isn’t that better than if one has to wrestle with it for days?
To a certain degree, the ease of writing is related to how clear, unique, simple, and developed the code has become. Easy is still a distinct virtue.
In some special cases code can meet all of the above virtues, but be intricate and opinionated in inconvenient ways, or it can be organized in a peculiar way that makes it hard to induce a change.
It is much better if the code is organized and expressed so that people can quickly make sense of it, quickly reshape it to meet their needs, and quickly add new functionality or remove old functionality.
This is somewhat subjective, so again we rely upon the taste and judgment of those who share our codebase.

This is a special case of “Easy” and “Simple.”
Primitive obsession is a code smell where the code lacks useful and clear abstractions. All operations are primitive operations (add, multipy, compare, concatenate) against primitive data types and structures.
The basis of good organization is that things that belong together are kept together. Date operations should belong in a date class or a date utility library. Once they are gathered, usually some abstraction is formed.
Say I have dozens of methods that each take in a parameter list consisting of integers representing a year, a month, a day of the month, an hour of the day, the minutes of the hour, the seconds of the minute, and a timezone indicator. This group of 7 primitive integers will usually give way to a structure of some sort.
At that point, the functions that operate on 7 integers become functions that operate on date structures. Perhaps the methods become member functions of the date structure (creating a class).
Users of the date class have much simpler code (and a single point of truth) by calling date.nextDay() than by duplicating the logic of calculating the date one day from now.
In this way, most software projects become their own kind of Domain-Specific Language for solving problem in that domain. This makes code simpler and easier, but also more clear in the system.
Similarly, in functional systems composed higher-order functions can take some of the pain and suffering out of manipulations.

This one sometimes surprises people, but concise code is generally better than chatty code for expressing the same concept.
For example, consider how much better it is for me to say
x=5*10instead of saying:
x=10;x=x+10;x=x+10;x=x+10;x=x+10;or
x=0;
for(int i=0;i<5;i++){
x+=10;
}The idea of code virtues is not to replace or augment any laws of software design, but to help recognize and describe the “goodness” we see in “good” code.
These virtues are placed in order to help us consider making tradeoffs. We should generally never consider making code brief at the cost of being clear, nor making it clear at the cost of actually working.

Heads up, transit nerds (or anyone curious about the literal insides of our transit system): local Vancouver blogger Mike (born and raised!) DownieLive “spent the day in Vancouver with Translink, checking out their bus simulator, an electric trolley bus, SeaBus, the West Coast Express and the SkyTrain.”
Love his enthusiasm when he’s driving a trolley. ( And totally not surprised to see trolley advocate and driver Derek Cheung in the background.)
I live in Squamish traditional territory, Skwxwú7mesh Temíxw, and I have spent the last 19 years of my residency here as an uninvited guest trying to learn a little about the land and sea, and the traditional teachings that have found a home here for tens of thousands of years.
This month I have joined dozens of others in taking a course from my friend Ta7táliya and her family and friends called Mi tel’nexw which in Squamish means “figure it out.” It’s a leadership course that is rooted in Squamish ways of knowing and being (you can join anytime at that link.)
Our first class was last week, listening to the teachings of Skwetsimeltxw, who spoke about Squamish history and teaching from the perspective of sp’ákw’us, the eagle. As part of the course, we are invited to articulate takeaways and giveaways, naming the gifts received and how we will offer gifts as a result. This cycle of reciprocity is essential.
So here are a couple of takeaways and giveaways that are sitting with me.
Everything starts with the land. As obvious as this one seems, it’s important to remember. I take away from this insight the idea that when doesn’t know what to do, stop and see where you are, what is the land or sea saying about this. It is the ultimate source of everything. The other day I was up at Rivendell Retreat Centre, where I am a Board member, and we were talking about the gardens and outdoor space there. People come to Rivendell from all over the world to experience contemplative practice through silence, hospitality, simplicity and prayer. The practice of simplicity invites us into a powerful, open and basic relationship with the natural world, and my friend and I were discussing how we could make the gardens of Rivendell embody the hosting that the land does so that visitors to our centre could practice outside of our beautiful rooms and sanctuary, attuned to the blessing of the natural world. This territory begs to be loved through every expression of the land and the sea and so my giveaway is to put that lens back on the land at Rivendell and to work with folks to help us help spiritual seekers find the simplicity in that teaching.
Ceremony strengthens you so you can stay positive. My takeaway here is how important practice is. Ceremony that ties me to the land and to the community, brings me into a relationship with the natural world, the supernatural world and community in a way that makes me accountable for the way I spend my time in this life. Skwetsimeltxw shared a teaching of revered Squamish Elder Louis Miranda: “Don’t be afraid of death – we are only here camping for a short time. Don’t waste a day while you are here.” Ceremony gives us names, helps us over the transition of life’s markers, through grieving and loss, through celebration and abundance. Daily practices helps us to live well so that we can take care of what we have. My giveaway is to a practice that shares the beauty and goodness of my life and to this end I have deleted my social media apps from my phone to manage my energy and attention.
Take care of the things in your temporary possession. Squamish culture, like most west coast traditional cultures, is heavily based on property and ownership. The myth that indigenous people don’t have concepts of land ownership is patently false everywhere. Here on the west coast where potlatching is the governance system, all of the property of the nation – including land and places, stories, names, responsibilities, and resources – are placed in the care of someone. The laws and the rules are very strict because care for these fundamental things is essential to the survival of a people. (and yes removing these systems is a form of genocide, set on destroying a people through banning potlatching and ceremony, and stealing these possessions). Skwetsimeltxw said that when a person is given a name, it is not theirs to own but theirs to carry for a while and “polish during your life.” The takeaway for me is a teaching about stewardship and how we are to care for the things that come into our possession. For me this means that names I have like “Art of Hosting steward” confer responsibility to ensure that when I no longer carry that title, it has been made better for those who pick it up. My giveaway is to examine the various names and identities I carry – Board member, Bowen Islander (Nexwlélexwm uxwimíuxw), settler, Canadian, father, husband, facilitator, – and to live them in a way that people encountering these identities in others – especially in those I teach, train and raise – will recognize them as honourable. It is my work to transform an identity like “Canadian” conferred by my birth into this colonial land, or to try to live up to the high standards of a word like “father” that has been given to me by my dad and children.
“Prayers and love, once they are put down, stay where they are put.” This is a direct quote from Skwetsimeltxw and it refers to how Squamish people, living in this territory for tens of thousands of years, have prayed and loved every inch of it from time immemorial. The love and prayers of every ancestor lie upon the rocks and mountains and waterways here and my takeaway is that this land is soaked in blessings. Everywhere you walk or sit is a place that has been stewarded since the beginning of time with care and affection and deep spiritual connection. My giveaway is gratitude and an attuned sense of this sacredness. When Skwetsimeltxw uttered this sentence, I felt a complete and overwhelming sense of gratitude for the fact that I live in a place that is literally covered in love and prayer. Open to the sacred appreciatiation of the stewards and owners of this territory, inspired to attune myself ever deeper to what is really here.
There was a time last year when I was in active communication with three people named Matthew, all of whom went by Matt casually, and who had overlapping domains. More than once I caught myself emailing Matt № 1 when I meant to email Matt № 2 or 3. And, indeed, once I did that. And because of the overlapping domains, the email kind of made sense.
This year I’ve swapped out Matts for Joshes. I’m juggling four Joshes this year. Their domains don’t overlap as much as the Matts, but I suspect that, nonetheless, I will end up emailing Josh № 4 sometime soon when I mean to email Josh № 2. Thank goodness I’m not dating any of them.
(I’ve met a new Mitch this summer, which pushes my Mitch-count to three, so it’s possible that there will be similar Mitch-problems in parallel).
All of which got me curious about first name frequency, so I exported the 1,092 contacts in my address book, extracted their first names, and then sorted and calculated frequency (if you’re a command line-user and have never explored uniq -c, you haven’t lived!).
There are 32 first names that show up 5 or more times in my contacts; in order of frequency, they are:
18 John 12 Peter 11 Paul 10 David 10 Dave 9 Steve 9 Chris 8 Mark 7 Stephen 7 Mike 7 Kelly 7 Bill 6 Robert 6 Patrick 6 Karen 6 Ian 6 Heather 6 Gary 6 Alan 5 Tom 5 Tim 5 Susan 5 Scott 5 Ron 5 Nancy 5 Kevin 5 Jeff 5 George 5 Doug 5 Don 5 Bob 5 Ben
It’s worth noting, per aforementioned first name confusion, that in that top-32 are the names of all of my brothers (John, Stephen, Mike).
And, in the number two slot, is my name. Given that nobody has been named Peter since the 1950s, this tells you something about the age of my contacts.
This blog post actually started off being a blog post not about Joshes, but about Peters. About Peter Bihr, in fact. He’s the youngest Peter in my contacts, an exception to the aged rule.
And what I wanted to mention about Peter is that he’s started to post his weekly email newsletter to his blog, which means that I can consume his weekly newsletter in my RSS reader. For which I am truly thankful.
I should really send him a thank you note. There’s a good chance that one of the Peters Bevan-Baker, Foley, Hooley, Johnston, Livingstone, Lux, Mutch, Noonan, Porteous, Richards or Whittle will get the thank you instead, but that’s a risk I’ll have to take.
Brigid Delaney writes about the new friendship for The Guardian:
You haven’t seriously thought about the concept of picking a best friend since primary school, but now Bryony has asked you to be her best friend. “Will you be in my bubble?” she asks. You’re flattered but surprised. You don’t know Bryony that well. A former colleague, you’ve only hung out a handful of times outside the office. You haven’t even put her number in your phone. You’d only ask her to be in your bubble if everyone you knew died. The asymmetrical nature of the friendship unnerves you. You get to thinking: “What if the person I asked to be in my bubble was freaked out at my request?” You start to question every friendship you’ve ever had. Are you someone’s Bryony?

One of the neatest features added in the recently released iOS 14 is the ability to set your default mail and browser.
However, users soon discovered an issue that reset the default to Mail or Safari whenever they restarted their device.
Thankfully, Apple is now rolling out a fix to this issue via an update that brings iPhone and iPad to version 14.0.1.
The update also addresses several other issues, including one that prevented camera previews from displaying on iPhone 7 and 7 Plus, and another that prevented iPhones in general from connecting to Wi-Fi.
If you don’t see the update immediately, you can manually prompt it by heading to the Settings app and choosing ‘Software Update.’
A full breakdown of the update can be found on Apple’s support website.
Via: 9to5Mac
The post Apple fixes iOS 14 default mail and browser issue appeared first on MobileSyrup.
 |
mkalus
shared this story
from |
Das Autohersteller irgendwann damit begonnen haben, Fahrräder zu bauen, ist keine Neuigkeit. Die gibt es dann meistens in Serie und für teuer Geld. Dieses Trabant-Fahrrad hingegen dürfte wohl ein echtes Unikat und so gar nicht vom Band sein.
Quite epic!
Source unknown.#PeakTraffic pic.twitter.com/Juj52kJA7v— Tamara Bozovic (@tamara_bozovic) September 20, 2020
This.
Was the time I spent writing my RSS scripts more than the time I would now spend thinking about the "best" RSS aggregator and reader? Doesn't matter. I enjoyed writing the scripts. I learned new things and got satisfaction out of seeing them run correctly. I get nothing like that out of comparing apps and services.
I concur so strongly not only because he writes about RSS, which I'm on record as supporting and using. I enjoy rolling my own simple software in almost any domain. Simple has a lot of advantages. Under my control has a lot of advantages. But the biggest advantage echoes what Dr. Drang says: Programming is often more fun than the alternative uses of my time.
I program because I like to, and because I can.
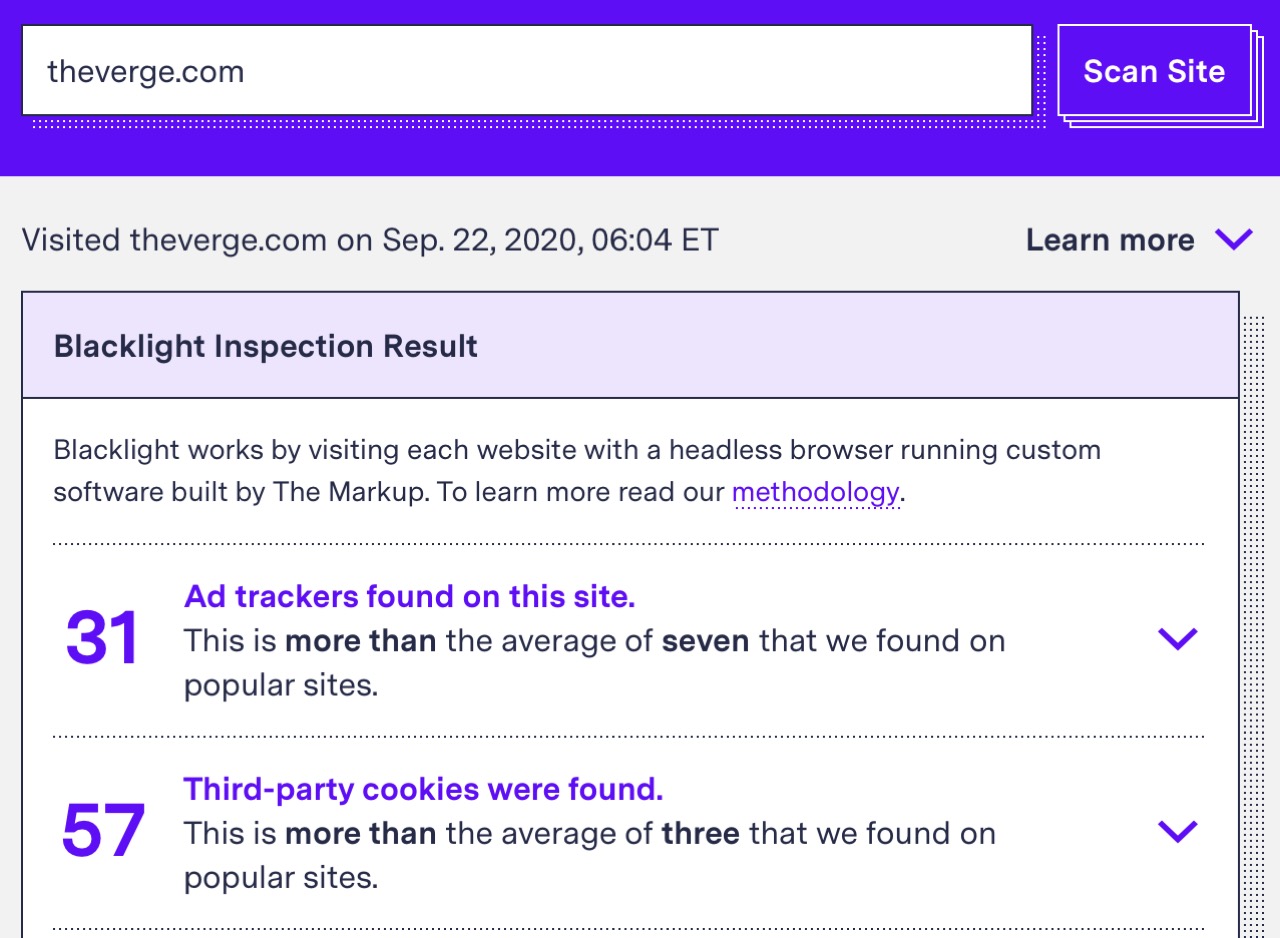
Blacklight is a great tool to scan the websites you visit for trackers that monitor your behaviour. This is the report for vowe.net: exactly one site gets information, which I cannot avoid if I want to embed Youtube videos. It is youtube-nocookie.com
Now check the other sites you visit.
Perhaps there’s life on Venus. There’s phosphine gas in the cloud decks of Venus and it should break down pretty quickly, so there’s something replenishing it. The scientists can’t think of any abiotic processes that would create phosphine in that quantity, so maybe microbes it is?
I’m sceptical. There was similar excitement in 1996 about the Martian meteorite Allan Hills 84001 – microscopic fossils! Life! Well, pseudo-fossils.
More likely explanation: planetary geology is weird. (“Geo”-logy? I’m not sure what the appropriate word is.)
Going to check out Venus will be tough.
There was a great paper in JBIS in April: Conceptual Design of a Crewed Platform in the Venusian Atmosphere (abstract only). It summarises two comprehensive studies of how to float crewed scientific missions in the clouds of Venus. The mock-ups look like a cross between dirigibles and the space station. Alien.
Because Venus is fierce.
Here are the first colour photos from the surface of Venus, taken by the Soviet lander Venura 13 in 1982. It lasted 127 minutes. And: Venera 14, a twin of Venera 13, launched five days later and also reached the surface. It lasted there for 57 minutes.
A lander dropped by Vega 2 (1985) lasted 56 minutes. There have been no landings since.
Remote observation of the Venusian surface is not possible due to its thick clouds of sulphuric acid. It has a surface atmospheric pressure 90x that of Earth, and a surface temperature averaging 464C/867F.
In terms of size and gravity, Venus is Earth’s twin.
Venus is trying to kill you. It’s dense and impenetrable – there could be a whole civilisation a mile away, and you’d never know.
Venus is Joseph Conrad’s Heart of Darkness, the hidden Africa, unknown to Europeans – the novella that was translated to Vietnam for Apocalypse Now. A journey up the Congo River and into the psyche. Both book and film highly recommended.
Contrast with Mars.
Which is empty (at least in the imagination). Tabula rasa. It’s dangerous, sure, but in a character-building, life-at-the-frontier kind of way. It’s there, waiting for Will to be imposed on it.
And Mars is so explored in fiction, and I mean this modern conception of Mars, not the old one which was criss-crossed with canals and dotted with ancient civilisations. Mars, now, is a blank canvas for the imagination.
So no wonder Elon Musk has Mars as his goal. It’s a place for pure expansion.
A city on Mars will be like a city on Earth but with better AC.
And I think it has diminished us somehow to have Mars held up in the public imagination as the ultimate frontier. Because all other problems become versions of that grand yet simple model frontier, empty spaces that we pave over.
But Venus…
Venus is far from empty. Venus has its own agenda. It has an oppressive air and acid rain. Landers are destroyed in an hour. If humans go there, we’ll be the ones who have to change, not Venus.
Which is a very 2020s metaphor.
Climate change, inequality, pandemics – these problems won’t be resolved by paving over them, no matter how much Will we exert.
They will be negotiated, worked at; they’re obdurate and incredibly complex, and require an acceptance of ground truths that are bigger and stronger than us and can’t be ignored. We won’t fix them, we’ll have to learn about them and deal with them in a million different ways and sometimes we’ll have to appease them. We’re mortal in the face of them. Through the mist and the jungle that crowds the boat, eyes look back, eyes belonging to who-know-what staring out from an unknown land which goes back who-knows-how-deep, and so we push on, we adapt.
The solutions are not straightforward. They require something from us. A price must be paid.
I think we don’t think about Venus because it’s the part of us which is animal, it’s the part which we keep hidden, the un-modern, it scares us to know it’s there; because if we really were to live on Venus, we would have to become something Other, and we can’t tolerate what that might be. Not like Mars which is manageable, already mapped and all that’s left to argue about is the collection of property taxes.
I would like to imagine more stories about Venus and how we would live there.
Because the challenges of the 2020s are Venus problems, not Mars problems.
Update 24/9: It’s an odd experience seeing one of my back-of-the-notebook posts briefly hit the top spot on Hacker News. 5,000 views later… There’s a long discussion here. Currently 186 comments, wonderfully including this one that disagrees yet sums up this whole post better than I could: The challenges of exploring Venus/searching for life are metaphorically similar to current issues here on Earth (climate change, SARS-Cov2, etc.), while Mars represents the endless expansion/frontier attitudes of 18th-20th century mercantilism/capitalism.
More than a year ago we talked about "a non-profit that leveraged good will whilst silently giving out equity for years prepping a shift to for-profit" and I had to remind people that this wasn't just fear-mongering. Today we read that OpenAI, which had previously shifted to a for-profit enterprise, announced exclusive licensing of GPT-3 technology to Microsoft. I suppose it was inevitable, but it ratchets the cynicism to see projects misuse the word 'open' to mean 'commercial'. More from Technology Review.
Web: [Direct Link] [This Post]This article discusses "a recent study by Educause, developed to examine the 'general trends' taking shape as institutions have made plans and preparations for fall education." It reports that "whereas in fall 2019 most institutions were offering one in five or fewer classes online, a year later that was flipped: A majority of schools were offering four in five or more courses online this fall." Additionally, classes in general have been 'hybridized' through the use of technology for video communication, lecture capture, and more. Some areas that could use more support include labs and co-curricular activities.
Web: [Direct Link] [This Post]Yesterday I described the new sqlite-utils transform mechanism for applying SQLite table transformations that go beyond those supported by ALTER TABLE. The other new feature in sqlite-utils 2.20 builds on that capability to allow you to refactor a database table by extracting columns into separate tables. I’ve called it sqlite-utils extract.
Much of the data I work with in Datasette starts off as a CSV file published by an organization or government. Since CSV files aren’t relational databases, they are often denormalized. It’s particularly common to see something like this:
| Organization Group Code | Organization Group | Department Code | Department | Union Code | Union |
|---|---|---|---|---|---|
| 1 | Public Protection | POL | Police | 911 | POA |
| 4 | Community Health | DPH | Public Health | 250 | SEIU, Local 1021, Misc |
| 1 | Public Protection | FIR | Fire Department | 798 | Firefighters,Local 798, Unit 1 |
| 1 | Public Protection | POL | Police | 911 | POA |
This is an extract from the San Francisco Employee Compensation dataset from DataSF.
The sqlite-utils extract command-line tool, and the table.extract() Python method that underlies it, can be used to extract these duplicated column pairs out into separate tables with foreign key relationships from the main table.
Here's how to use sqlite-utils to clean up and refactor that compensation data.
First, grab the data. It's a 150M CSV file containing over 600,000 rows:
curl -o salaries.csv 'https://data.sfgov.org/api/views/88g8-5mnd/rows.csv?accessType=DOWNLOAD'
Use sqlite-utils insert to load that into a SQLite database:
sqlite-utils insert salaries.db salaries salaries.csv --csv
Fire up Datasette to check that the data looks right:
datasette salaries.db
There's a catch here: the schema for the generated table (shown at the bottom of http://localhost:8001/salaries/salaries) reveals that because we imported from CSV every column is a text column. Since some of this data is numeric we should convert to numbers, so we can do things like sort the table by the highest salary.
We can do that using sqlite-transform:
sqlite-utils transform salaries.db salaries \
--type 'Employee Identifier' integer \
--type Salaries float \
--type Overtime float \
--type 'Other Salaries' float \
--type 'Total Salary' float \
--type 'Retirement' float \
--type 'Health and Dental' float \
--type 'Other Benefits' float \
--type 'Total Benefits' float \
--type 'Total Compensation' float
Having run that command, here's the new database schema:
$ sqlite3 salaries.db '.schema salaries'
CREATE TABLE IF NOT EXISTS "salaries" (
[rowid] INTEGER PRIMARY KEY,
[Year Type] TEXT,
[Year] TEXT,
[Organization Group Code] TEXT,
[Organization Group] TEXT,
[Department Code] TEXT,
[Department] TEXT,
[Union Code] TEXT,
[Union] TEXT,
[Job Family Code] TEXT,
[Job Family] TEXT,
[Job Code] TEXT,
[Job] TEXT,
[Employee Identifier] INTEGER,
[Salaries] FLOAT,
[Overtime] FLOAT,
[Other Salaries] FLOAT,
[Total Salary] FLOAT,
[Retirement] FLOAT,
[Health and Dental] FLOAT,
[Other Benefits] FLOAT,
[Total Benefits] FLOAT,
[Total Compensation] FLOAT
);
Now we can start extracting those columns. We do this using several rounds of the sqlite-utils extract command, one for each duplicated pairs.
For Organization Group Code and Organization Group:
sqlite-utils extract salaries.db salaries \
'Organization Group Code' 'Organization Group' \
--table 'organization_groups' \
--fk-column 'organization_group_id' \
--rename 'Organization Group Code' code \
--rename 'Organization Group' name
This took about 12 minutes on my laptop, and displayed a progress bar as it runs. (UPDATE: in issue #172 I improved the performance and knocked it down to just 4 seconds. I also removed the progress bar).
Here's the refactored database schema:
$ sqlite3 salaries.db .schema
CREATE TABLE [organization_groups] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE IF NOT EXISTS "salaries" (
[rowid] INTEGER PRIMARY KEY,
[Year Type] TEXT,
[Year] TEXT,
[organization_group_id] INTEGER,
[Department Code] TEXT,
[Department] TEXT,
[Union Code] TEXT,
[Union] TEXT,
[Job Family Code] TEXT,
[Job Family] TEXT,
[Job Code] TEXT,
[Job] TEXT,
[Employee Identifier] INTEGER,
[Salaries] FLOAT,
[Overtime] FLOAT,
[Other Salaries] FLOAT,
[Total Salary] FLOAT,
[Retirement] FLOAT,
[Health and Dental] FLOAT,
[Other Benefits] FLOAT,
[Total Benefits] FLOAT,
[Total Compensation] FLOAT,
FOREIGN KEY(organization_group_id) REFERENCES organization_groups(id)
);
CREATE UNIQUE INDEX [idx_organization_groups_code_name]
ON [organization_groups] ([code], [name]);
Now fire up Datasette to confirm it had the desired effect:
datasette salaries.db
Here's what that looks like:

Note that the new organization_group_id column still shows the name of the organization group, because Datasette automatically de-references foreign key relationships when it displays a table and uses any column called name (or title or value) as the label for a link to the record.
Let's extract the other columns. This will take a while:
sqlite-utils extract salaries.db salaries \
'Department Code' 'Department' \
--table 'departments' \
--fk-column 'department_id' \
--rename 'Department Code' code \
--rename 'Department' name
sqlite-utils extract salaries.db salaries \
'Union Code' 'Union' \
--table 'unions' \
--fk-column 'union_id' \
--rename 'Union Code' code \
--rename 'Union' name
sqlite-utils extract salaries.db salaries \
'Job Family Code' 'Job Family' \
--table 'job_families' \
--fk-column 'job_family_id' \
--rename 'Job Family Code' code \
--rename 'Job Family' name
sqlite-utils extract salaries.db salaries \
'Job Code' 'Job' \
--table 'jobs' \
--fk-column 'job_id' \
--rename 'Job Code' code \
--rename 'Job' name
Our finished schema looks like this:
$ sqlite3 salaries.db .schema
CREATE TABLE [organization_groups] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE [departments] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE [unions] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE [job_families] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE [jobs] (
[id] INTEGER PRIMARY KEY,
[code] TEXT,
[name] TEXT
);
CREATE TABLE IF NOT EXISTS "salaries" (
[rowid] INTEGER PRIMARY KEY,
[Year Type] TEXT,
[Year] TEXT,
[organization_group_id] INTEGER REFERENCES [organization_groups]([id]),
[department_id] INTEGER REFERENCES [departments]([id]),
[union_id] INTEGER REFERENCES [unions]([id]),
[job_family_id] INTEGER REFERENCES [job_families]([id]),
[job_id] INTEGER,
[Employee Identifier] INTEGER,
[Salaries] FLOAT,
[Overtime] FLOAT,
[Other Salaries] FLOAT,
[Total Salary] FLOAT,
[Retirement] FLOAT,
[Health and Dental] FLOAT,
[Other Benefits] FLOAT,
[Total Benefits] FLOAT,
[Total Compensation] FLOAT,
FOREIGN KEY(job_id) REFERENCES jobs(id)
);
CREATE UNIQUE INDEX [idx_organization_groups_code_name]
ON [organization_groups] ([code], [name]);
CREATE UNIQUE INDEX [idx_departments_code_name]
ON [departments] ([code], [name]);
CREATE UNIQUE INDEX [idx_unions_code_name]
ON [unions] ([code], [name]);
CREATE UNIQUE INDEX [idx_job_families_code_name]
ON [job_families] ([code], [name]);
CREATE UNIQUE INDEX [idx_jobs_code_name]
ON [jobs] ([code], [name]);
We've also shrunk our database file quite a bit. Before the transformations salaries.db was 159MB. It's now just 70MB - that's less than half the size!
I used datasette publish cloudrun to publish a copy of my final database here:
https://sf-employee-compensation.datasettes.com/salaries/salaries
Here's the command I used to publish it:
datasette publish cloudrun salaries.db \
--service sf-employee-compensation \
--title "San Francisco Employee Compensation (as-of 21 Sep 2020)" \
--source "DataSF" \
--source_url "https://data.sfgov.org/City-Management-and-Ethics/Employee-Compensation/88g8-5mnd" \
--about "About this project" \
--about_url "https://simonwillison.net/2020/Sep/23/sqlite-utils-extract/" \
--install datasette-block-robots \
--install datasette-vega \
--install datasette-copyable \
--install datasette-graphql
You may have noticed my datasette publish line above finished with the line --install datasette-graphql. This installs the datasette-graphql plugin as part of the deployment to Cloud Run. Which means we can query the salary data using GraphQL as an alternative to SQL!
Here's a GraphQL query that shows the ten highest paid employees, including their various expanded foreign key references:
{
salaries(sort_desc: Total_Compensation, first: 10) {
nodes {
Year_Type
Year
union_id {
id
name
}
job_id {
id
name
}
job_family_id {
id
name
}
department_id {
id
name
}
organization_group_id {
id
name
}
Salaries
Overtime
Other_Salaries
Total_Salary
Retirement
Health_and_Dental
Other_Benefits
Total_Benefits
Total_Compensation
rowid
Employee_Identifier
}
}
}You can try that query out here in the GraphiQL API explorer.
Right now, we’re in the early stages of the next phase of computing: AI. First we had the desktop. Then the internet. And smartphones. Increasingly, we’re living in a world where computing is built around vast troves of data and the algorithms that parse them. They power everything from the social platforms and smart speakers we use everyday, to the digital machinery of our governments and economies.
In parallel, we’re entering a new phase of how we think about, deploy, and regulate technology. Will the AI era be defined by individual privacy and transparency into how these systems work? Or, will the worst parts of our current internet ecosystem — invasive data collection, monopoly, opaque systems — continue to be the norm?
A year ago, a group of funders came together at Mozilla’s Berlin office to talk about just this: how we, as a collective, could help shape the direction of AI in Europe. We agreed on the importance of a landscape where European public interest and civil society organisations — and not just big tech companies — have a real say in shaping policy and technology. The next phase of computing needs input from a diversity of actors that represent society as a whole.
Over the course of several months and with dozens of organizations around the table, we came up with the idea of a European AI Fund — a project we’re excited to launch this week.
The fund is supported by the Charles Stewart Mott Foundation, King Baudouin Foundation, Luminate, Mozilla, Oak Foundation, Open Society Foundations and Stiftung Mercator. We are a group of national, regional and international foundations in Europe that are dedicated to using our resources — financial and otherwise — to strengthen civil society. We seek to deepen the pool of experts across Europe who have the tools, capacity and know-how to catalogue and monitor the social and political impact of AI and data driven interventions — and hold them to account. The European AI Fund is hosted by the Network of European Foundations. I can’t imagine a better group to be around the table with.
Over the next five years, the European Commission and national governments across Europe will forge a plan for Europe’s digital transformation, including AI. But without a strong civil society taking part in the debate, Europe — and the world — risk missing critical opportunities and could face fundamental harms.
At Mozilla, we’ve seen first-hand the expertise that civil society can provide when it comes to the intersection of AI and consumer rights, racial justice, and economic justice. We’ve collaborated closely over the years with partners like European Digital Rights, Access Now Algorithm Watch and Digital Freedom Fund. Alternatively, we’ve seen what can go wrong when diverse voices like these aren’t part of important conversations: AI systems that discriminate, surveil, radicalize.
At Mozilla, we believe that philanthropy has a key role to play in Europe’s digital transformation and in keeping AI trustworthy, as we’ve laid out in our trustworthy AI theory of change. We’re honoured to be working alongside this group of funders in an effort to strengthen civil society’s capacity to contribute to these tech policy discussions.
In its first step, the fund will launch with a 1,000,000 € open call for funding, open until November 1. Our aim is to build the capacity of those who already work on AI and Automated Decision Making (ADM). At the same time, we want to bring in new civil society actors to the debate, especially those who haven’t worked on issues relating to AI yet, but whose domain of work is affected by AI.
To learn more about the European AI Fund visit http://europeanaifund.org/
The post Launching the European AI Fund appeared first on The Mozilla Blog.

Volkswagen has finally shared all the specs and the design of its new electric crossover, the ID.4.
The car features the same compact SV design that the automaker has been teasing for years at this point and it boasts an impressive 520km of range.
Volkswagen even says that the ID.4 can accelerate from 0 to 100 km/h in eight and a half seconds and delivers a top speed of 160 km/h. These aren’t incredible stats, but combined with the low centre of gravity most EVs have, it should be very fun to drive.
The interior of the car is something that VW has done an impressive job with. The company is using modern colours and textures to bring the cockpit of the car into the future. It doesn’t look as minimal as a Tesla, but instead offers a nice mix of classic car controls and new-age digital controls.

The automaker has also packaged in its IQ.Drive driver assistance technology which includes parking and lane assists, plus much more. VW hasn’t gone too deep on what self-driving hardware the ID.4 is installed with, but it does mention that it will get over-the-air updates over time to improve it.
The car also features quick charging at DC-charging stations that support 125kw charging speeds. The company says that the ID.4 can get up to 320km of range on a single 30-minute charge.

This is a global car, but it doesn’t seem that VW is going to bring it to Canada right away. Instead, the vehicle is launching in Europe, then heading to China and the U.S. at some point after that before finally turning into a truly global car.
Source: Volkswagen
The post Volkswagen finally launches ID.4 electric crossover appeared first on MobileSyrup.
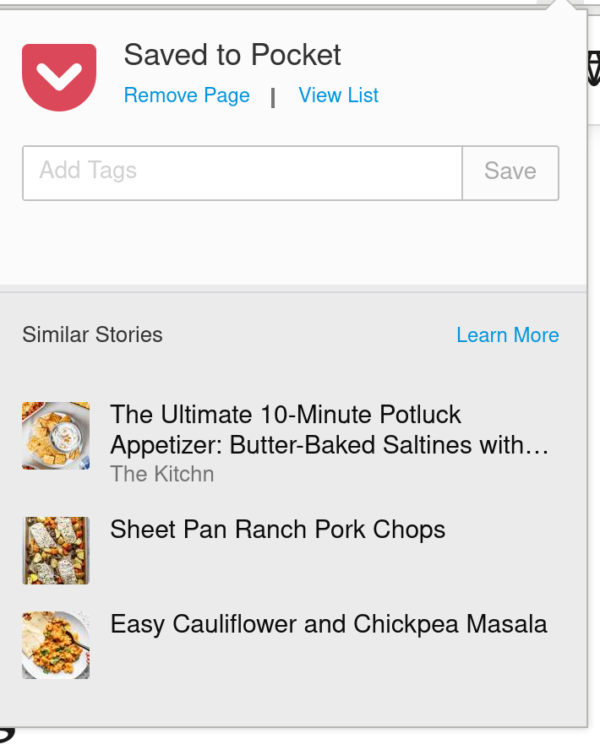
The “Saved to Pocket” doorhanger is open. A “similar stories” section is open at the bottom with articles about cooking.
James Gleick, the author of the classic book “Chaos: Making a New Science” has written a terrific review of Jill Lepore’s new book “If Then: How the Simulmatics Corporation Invented the Future.”The book covers the origin of data science as applied to democracy, and comes as conversations about social media, algorithms, and electoral manipulation are in full swing due to the US election and the release of The Social Dilemma.
Gleick’s review is worth a read. He covers some basic complexity theory when working with data. He provides a good history of the discovery of how the principles of “work at fine granularity” helps to see patterns that aren’t otherwise there. He also shows how the data companies – Facebook, Google, Amazon – has mastered the principle of “data precedes the framework” that lies at the heart of good sensemaking. For me, both of these principles learned from anthro-complexity, are essential in defining my complexity practice.
Working at fine granularity means that, if you are looking for patterns, you need lots of data points before seeing what those patterns are. You cannot simply stake the temperature in one location and make a general conclusion about what the weather is. You need not only many sites, but many kinds of data, including air pressure, wind speed and direction, humidity and so on – in order to draw a weather map that can then be used to predict what MIGHT happen. The more data you have, the more models you can run, and the closer you can come to a probable prediction of the future state. The data companies are able to work at such a fine level of granularity that they can not only reliably predict the behaviour of individuals, but they can also serve information in a way that results in probable changes to behaviour. AS a result, social media is destroying democracy, as it segments and divides people for the purpose of marketing, but also dividing them into camps that are so disconnected from one another that Facebook has already been responsible for one genocide, in Myanmar.
Data preceding the framework means that you don’t start with a framework and try to fit data to that matrix, but rather, you let the data reveal patterns that can then be used to generate activity. Once you have a ton of data, and you start querying it, you will see stable patterns. If you turn these into a framework for action, you can sometimes catalyze new behaviours or actions. This is useful if you are trying to shift dynamics in a toxic culture. But in the dystopian use of this principle, Facebook for example notices the kinds of behaviours that you demonstrate and then serves you information to get you to buy things in a pattern that is similar to others who share a particular set of connections and experiences and behaviours. Cambridge Analytica used this power in many elections, including the 2016 US election and the Brexit referendum as well as elections in Trinidad and Tobago and other places to create divisions that resulted in a particular result being achieved. You can see that story in The Great Hack. Algorithms that were designed to sell products was quickly repurposed to sell ideas, and the result has been the most perilous threat to democracy since the system was invented.
Complex systems are fundamentally unpredictable but using data you can learn about probabilities. If you have a lot of data you gain an advantage over your competitors. If you have all the data you gain an advantage over your customers, turning them from the customer to the product. “If you’re not paying, you are the product” is the adage that signals that customers are now more valuable products to companies that the stuff they are trying to sell to them.
Putting these principles to use for good.
I work with complexity, and that means that I also work with these same principles in helping organizations and communities confront the complex nature of their work. Unlike Facebook though )he says polemically) I try to operate from a moral and ethical standpoint. At any rate, the data we are able to work within our complexity work is pretty fine-grained but not fine-grained enough to provide accurate pictures of what can be manipulated. We work with small pieces of narrative data, collecting them using a variety of methods and using different tools to look for patterns. Tools include NarraFirma, Sensmaker and Spryng, all of which do this work. We work with our clients and their people to look for patterns in these stories and then generate what are called “actionable insights” using methods of complex facilitation and dialogic practice. These insights give us the inspiration to try things and see what happens. When things work, we do more and when they don’t we stop and try something else.
It’s a simple approach derived from a variety of approaches and toolsets. It allows us to sift through hundreds of stories and use them to generate new ideas and actions. It is getting to the point that all my strategic work now is actually just about making sense of data, but doing it in a human way. We don’t use algorithms to generate actions. We use the natural tools of human sensemaking to do it. But instead of starting with a blank slate and a vision statement that is disconnected from reality, we start with a picture of the stories that matter and we ask ourselves, what can we start, stop, stabilize or create to take us where we want to go.
In a world that is becoming increasingly dystopian and where our human facilities are being used against us, it’s immensely satisfying to use the ancient human capacities of telling stories and listening for patterns to create action together. I think in some ways doing work this way is an essential antidote to the way the machines are beginning to determine our next moves. You can use complexity tools like this to look at things like your own patterns of social media use and try to make some small changes to see what happens. Delete the apps from your phone, visit sites incognito, actively seek out warm connections with real humans in your community and look for people that get served very different ads and YouTube videos and recommended search results. Talk to them. They are being made to be very different from you, but away from the digital world, in the slower, warmer world of actual unmediated human interaction, they are not so different.
Postscript
Over the past few years, my work has taken shape from the following bodies of work:
SQLite's ALTER TABLE has some significant limitations: it can't drop columns, it can't alter NOT NULL status, it can't change column types. Since I spend a lot of time with SQLite these days I've written some code to fix this - both from Python and as a command-line utility.
To SQLite's credit, not only are these limitations well explained in the documentation but the explanation is accompanied by a detailed description of the recommended workaround. The short version looks something like this:
My sqlite-utils tool and Python library aims to make working with SQLite as convenient as possible. So I set out to build a utility method for performing this kind of large scale table transformation. I've called it table.transform(...).
Here are some simple examples of what it can do, lifted from the documentation:
# Convert the 'age' column to an integer, and 'weight' to a float
table.transform(types={"age": int, "weight": float})
# Rename the 'age' column to 'initial_age':
table.transform(rename={"age": "initial_age"})
# Drop the 'age' column:
table.transform(drop={"age"})
# Make `user_id` the new primary key
table.transform(pk="user_id")
# Make the 'age' and 'weight' columns NOT NULL
table.transform(not_null={"age", "weight"})
# Make age allow NULL and switch weight to being NOT NULL:
table.transform(not_null={"age": False, "weight": True})
# Set default age to 1:
table.transform(defaults={"age": 1})
# Now remove the default from that column:
table.transform(defaults={"age": None})
Each time the table.transform(...) method runs it will create a brand new table, copy the data across and then drop the old table. You can combine multiple operations together in a single call, avoiding copying the table multiple times.
The table.transform_sql(...) method returns the SQL that would be executed instead of executing it directly, useful if you want to handle even more complex requirements.
Almost every feature in sqlite-utils is available in both the Python library and as a command-line utility, and .transform() is no exception. The sqlite-utils transform command can be used to apply complex table transformations directly from the command-line.
Here's an example, starting with the fixtures.db database that powers Datasette's unit tests:
$ wget https://latest.datasette.io/fixtures.db
$ sqlite3 fixtures.db '.schema facetable'
CREATE TABLE facetable (
pk integer primary key,
created text,
planet_int integer,
on_earth integer,
state text,
city_id integer,
neighborhood text,
tags text,
complex_array text,
distinct_some_null,
FOREIGN KEY ("city_id") REFERENCES [facet_cities](id)
);
$ sqlite-utils transform fixtures.db facetable \
--type on_earth text \
--drop complex_array \
--drop state \
--rename tags the_tags
$ sqlite3 fixtures.db '.schema facetable'
CREATE TABLE IF NOT EXISTS "facetable" (
[pk] INTEGER PRIMARY KEY,
[created] TEXT,
[planet_int] INTEGER,
[on_earth] TEXT,
[city_id] INTEGER REFERENCES [facet_cities]([id]),
[neighborhood] TEXT,
[the_tags] TEXT,
[distinct_some_null] TEXT
);
You can use the --sql option to see the SQL that would be executed without actually running it:
$ wget https://latest.datasette.io/fixtures.db
$ sqlite-utils transform fixtures.db facetable \
--type on_earth text \
--drop complex_array \
--drop state \
--rename tags the_tags \
--sql
CREATE TABLE [facetable_new_442f07e26eef] (
[pk] INTEGER PRIMARY KEY,
[created] TEXT,
[planet_int] INTEGER,
[on_earth] TEXT,
[city_id] INTEGER REFERENCES [facet_cities]([id]),
[neighborhood] TEXT,
[the_tags] TEXT,
[distinct_some_null] TEXT
);
INSERT INTO [facetable_new_442f07e26eef] ([pk], [created], [planet_int], [on_earth], [city_id], [neighborhood], [the_tags], [distinct_some_null])
SELECT [pk], [created], [planet_int], [on_earth], [city_id], [neighborhood], [tags], [distinct_some_null] FROM [facetable];
DROP TABLE [facetable];
ALTER TABLE [facetable_new_442f07e26eef] RENAME TO [facetable];
sqlite-utils has plenty more tricks up its sleeve. I suggest spending some time browsing the Python library reference and the sqlite-utils CLI documentation, or taking a look through through the release notes.
