Hello. Hello everyone pleasure to be here today. This presentation will be in English. I'm going to be talking about open learning open networks and open learning.
Just a few just a few notes to begin our presentation.
- First of all, you can share and edit the links to this presentation. I've opened up a page on Google Docs for you and so you should be able to go into that page and edit that page, add links, change things. I've left it wide open for anybody to change as you want.
- As well the discussion has a Twitter feed. #Numerique 2020 is the hashtag and I'm monitoring the hashtag as well and so… here it is, we have something from Tracy Rosen, but that's from yesterday. So anything you say here - I'm not sure how much time I'll have to get to them during the talk but you can certainly have a conversation with each other while I'm talking.
- Oh yes in the slides audio video recording all of that all the recording information will be online on my website www.downes.ca/presentation/533, and I see also that the conference is recording this zoom session as well. So we've got both.
So let's launch into it.
You've probably noticed it's been a challenging year. We've got, you know, the usual crises plus a little bit of extra. Today we've got climate change, of course we've got democracy in crisis (and I do note for the record that this presentation is happening the day of the 2020 presidential election in the United States, we don't know what's going to happen yet, so we're all interested or some of us are). We have ongoing problems in Canada, the US and around the world with poverty and inequality. We have issues with social media disinformation, fake news. Oh yes and we have a global pandemic happening, which means that everybody we're not everybody but many people are working at home. I am working at home (this is my personal home office as you can see, especially cleaned up for this presentation). And of course we have the economic crisis, and we're probably just at the beginning of that. So it's a pretty interesting time in the world today.
I'm going to structure my presentation today around the current work that I'm doing, and I know you're probably not necessarily interested in the current work that I'm doing, but this work touches on many of the themes that I think are prevalent in the world of online learning and new media today. So we'll begin with some of the stuff that I've done for my Covid response and then look at some projects that I'm involved in: extended reality training, data literacy; and then some off-the-side of the desk research that I've been doing on ethics and analytics and, of course, as always, personal learning environments.
Covid Response
So we begin with the Covid response. And you know, just in case you're curious, inside NRC now, of course we've shifted to working at home like everyone else. To make this work we've had to greatly expand our virtual private network capacity, buying a bunch of extra bandwidth and seat licenses. We adopted Zoom meetings (and I'm getting kind of good at working with zoom meetings), we set up Slack for quick messaging. Longer term, we're probably going to move all of this to Microsoft Teams, but you don't migrate an enterprise like NRC to Microsoft teams on the turn of a dime, so we're using these other things. And we've faced issues, the same sorts of issues that schools are facing around the world, issues with cloud services, making sure we're secure while working at a distance, migrating our processes to an online environment, and then thinking about the long-term impact of this. And there will be a long-term impact. I, for one, don't intend to go back to the office if I can possibly avoid it.
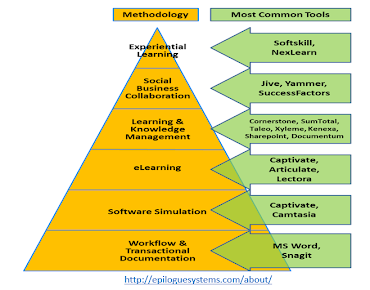
So the Covid response really is framed around the different types of educational technology that are available, everything from tools for experiential learning all the way down to tools for software simulation, workflow, transactions, and so on. And now what I did to begin with, to adapt to Covid, is I began by creating something called a ‘Quick Tech Guide’, because the idea here was that enterprise technology isn't going to change on a dime. People needed quick tools in a hurry to make things work. So, that's what I did. So if we go to that very quickly to take a look at - here it is bit.ly/quicktechguide - so here it is.
This basically on the left-hand side is a listing of pretty much all the different types of educational technology that you would ever need and what I've done in this guide is provided links for people for individuals to create any of these things using free tools. And... oh, there's a bunch of people on it already! So everything from calendar to teams to screen and video recording etc. Wow. It's nice to see that everybody's able to just zip into this like this right away. That's wonderful. When I first started it I left it open for anybody to edit, and so I had a fair amount of time that I had to spend fixing the edits.
But it became really popular in a hurry, you know, the first few days of the pandemic. The popularity is waning off a bit, but I'm still accepting submissions. There are all these options and if you don't like my guide, who says you have to right? There's a long list of other guides at the bottom, and if you send me yours, I'll add it to the list.
So, that was the first thing basically that I did for the Covid response, the Quick Tech Guide, and as I say, the tech I added needed to be web-based, free and open access, etcetera, as well. I'm looking at the longer-term impact here, you know, maybe I should expand this guide include pedagogy etc. Not really sure at this point in time.
Another part of the Covid response: thinking about MOOCs. A lot of people turned to MOOCs and, you know, it's almost like this year has become the resurgence of the MOOC. These are a few resources that I've put together on MOOCs over the years, including the True History of the MOOC, which was of course developed by us in 2008, and then Tony Bates wrote a pretty good article distinguishing between the cMOOC and the xMOOC. Now, I haven't run a MOOC over this coveted pandemic but, a lot of other people have, and so I haven't felt the need to, although I'm probably looking at running one or two. Wow, I was gonna say maybe in the fall, but it's November so... sometime. Sometime in the future.
I've also worked with some other bodies on the covered response, including a group put together by the International Science Council called CovidEA. That stands for Covid Education Alliance. We've just released something called a Covid EA Primer. That's just a rough quick draft of the sorts of things that we need to be thinking about when we're thinking about what it's going to take to get people to the point of moving to online learning, which is what we're going to have to do in this current covet environment.
So moving forward, you know, we're looking at a lot of issues that the Covid pandemic has brought to us. What kind of education are we looking at?
Providing competencies? You know, there's this whole story about the competency model of education, but there are issues with that model, issues around “are we providing the proper sort of education if we're focusing only on competencies?” And not a lot of, I won't say soft skills, but along the lines of the more social benefits that are created by an education, especially, you know, an education in an institution like Harvard, MIT, Princeton, Yale. They're not focused on competencies, they're focused on building networks, they're focused on creating social skills, giving people the practical experience they need to navigate in the academic and business world. Things like that.
Questions of the evidence for learning. There's been a controversy around an exam proctoring service called Proctorio, you know. What sort of evidence do we provide for learning? I did a presentation recently (there's a link in the slide) on open recognition networks. What about microlearning? What about course libraries? A lot of libraries during the pandemic had to, you know, change their systems on the fly in order to provide access to people who weren't on the university campus.
Extended Reality Training
So now the second type of project that I've been involved in is an immersive reality project. The name keeps changing, but right now it's XRT for TEAM. Extended reality XT for teams, I mean, in particular, for emergency response teams. Now we're looking at what immersive reality is. Is it just the VR helmet? What are the key elements of immersion? Does it include games or should it focus on serious learning? So, looking at our particular presentation, we're looking at virtual reality mostly but you know, there is the choice: extended reality or augmented reality.
Virtual reality two major platforms to consider: Unity and Unreal. Now Unity was originally released for the macOS and it's a pretty popular virtual reality platform, but there's also the Unreal Engine, and it's from Epic Games. So you might recall Epic Games is the company that is currently engaged in a lawsuit with Apple about the 30% surcharge that Apple levies on anything that is offered on the Apple or the IOS platform. This battle isn't just about app stores. This battle is about the future of virtual reality, and whether Apple gets a 30% cut basically from all of virtual reality, and it's a serious issue. So I think there's more to this battle between Epic and Apple than we're seeing in the news headlines.
Right now the big stopper for virtual reality is the cost of the hardware. Three of the major choices:
-
HTC Vive 1.3 thousand in other words thirteen hundred dollars
- the HoloLens from microsoft, super expensive
- you can get an Oculus headset for much less the problem with the oculus headset is you have to also get a Facebook account.
So, I think there's a gap still between where we are and virtual reality actually hitting education in a big way. But these prices are going to come down, I think, in fairly short order.
So anyhow, we're doing extended reality training for transportation emergencies and management. We've been doing a bit of background research on this now. We've got some people developing the actual simulations. I'm not doing the hands-on on that because I don't have a headset, but I've been doing some background research on it, and putting together the advisory group which we've put together of people in the sector from across Canada.
And here are a few links on this page to extended reality training for emergency management. Emergency management is a little outside my own area of expertise but it's so pretty interesting and I got to go to the fire building at NRC where they deliberately set things on fire, and that was pretty cool.
So, what really makes extended reality work is presence. I did a presentation on presence a month or two ago looking at models of presence, like the Community of Inquiry model from Anderson, Archer and Garrison. I also surveyed some other kinds of presence, you know, interface, learning, autonomy, etc. presence. Really is the idea that there's somebody at the other end of the system. If I'm succeeding with presence here today what you should be getting is the feeling that I'm human, I'm doing stuff, I'm doing stuff live on the fly, I'm conveying not just information but maybe a sense of my interest in the subject, my excitement about the subject etc. If we think about other kinds of presence, you know, for example, interface, learning, autonomy, cognitive social, etc, these are different aspects, different ways of me projecting myself into the environment where you are. And I've thought about it, and to me, what makes the difference in presence and what will make the difference in extended reality isn't the technology, it's belief. Does the person using the tool believe that they're there? Do they think it's real? Are they willing to engage? So it's very much a perceptual question rather than a technology question. So I found that pretty interesting.
Data Literacy
Another big project that we're working on is on data literacy. This seems like a bit of a jump from the other stuff, but it's not. I mean, if we go back to the crises that we've been looking at (fake news, democracy in crisis and all of that) plus all of the complications that have been brought to us by the pandemic and the difficulties, you know, even if things like having a meeting online, things like data literacy moved to the fore.
I've done and will be presenting in another forum a fair amount of background work here in data literacy. I would break it down into four major data literacy models (clip and save):
- data stewardship
- science and research
- information literacy, and
- analytics and decision making
These are for frames or four ways of thinking about data literacy.
For example: data stewardship. It’s: do you know how to manage your data? Do you have a source of truth for your data? Do you know how to integrate multiple sources of data into a data lake? Do you know how to organize that data into an application specific data marked stuff like that?
There are also different measurement frameworks for assessing data literacy. Most of what's out there now is self-assessment, which is not that useful. As well, there's a distinction to be drawn, a useful one, I think, between individual and collective data literacy. And then, because we're working in a practical context, data literacy isn't this thing that's abstract out there in the world; we need a mechanism for mapping what we think data literacy is to what we think the benefits are that are realized from it. You know, it might be as simple as saving money or not being fooled. In our context, we're looking at operational advantages, being better than the other people who are in the same field.
So anyhow, I've compiled a bunch of stuff and I continue to add to this. You can view that as soon as it loads here again. It's a Google doc, and so, here are all of my notes the different types of data literacy, etc. I put on the PowerPoint slide a couple of key references but you know, there's lots and lots and lots of stuff you can read on data literacy. So if you're interested in this subject this might be a starting point for you, and if you're interested in data literacy and have a resource that you haven't found please send it to me. I'll add it to this list. I'll add the summary to the summary and when I produce the overall report on what I think data illiteracy is and how to go about teaching it. You'll be able to access it there in that copy. I don't know when that'll be done but some, Time in the next few months probably maybe sooner so watch for it. It's such an important topic and it is new. I mean work began really seriously on it in, say, 2010. The earliest significant references are 2008, but 2010 is kind of when it all came together.
I do want to mention the challenges to learning providers that data literacy, the whole question, poses. Learning providers today are asking whether they should focus on content knowledge versus literacies, not just reading and writing, but what I call critical literacies, which would include critical thinking, the capacity to explain, the ability to sort real from false information, and even things like identifying value systems, identifying what you want to value, etc. They are also looking at the distinction between ‘employment skills’ versus ‘education’. That's a key issue today. People are always talking about how education should be providing job skills. The problem is the job skills that are relevant today aren't the jobs skills that'll be relevant when they graduate. We've seen in our world of crisis how society can change on a dime, and we need to be able to develop ways for people to be resilient, to be able to learn how to learn, and that means focusing on what all call here ‘education’.
We're also looking at major social change inside and outside of education. Do we rely on authority or can we look at the wisdom of crowds (properly so-called). This is the distinction between “do we learn from experts?” or “do we learn for ourselves with the support of experts?” And of course the question of credentials again comes up in this area.
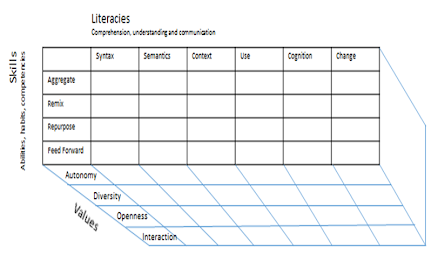
This is basically my approach to data literacy. My approach to critical literacy is generally the major critical literacies: syntax, semantics, context, use, cognition, and change; then the skills that are needed in working in a data environment: aggregate, remix, repurpose, feed forward; and then the semantic side of that, the values that make a data network work most effectively: autonomy, diversity, openness, interaction. If you've listened to or see any of my stuff at all in the past you've probably seen me hit on some of these subjects in my various talks.
Ethics, Analytics and the Duty of Care
The next major subject is ethics, analytics and the duty of care. Now one of the things that I did there is a presentation on open recognition networks. That was just a few days ago and the audio and video and all of that are available for you on the web. See how this is part of data literacy: instead of just doing a presentation and letting it disappear into the ether I collect this, the slides, the audio, the video. I use Google to make an automated transcript; I use my Google Pixel And I provide a link back to the conference. So when I said this presentation will be available at presentation/533, well here's the site right now because the presentation hasn't happened yet, but in a day or two all of this stuff will be available on this website and you'll be able to access it. That's data management, but that's also adapting how you're doing what you're doing to the online world. Okay. So also on ethics analytics and duty of care.
I've been getting involved a little bit in communities and councils related to this subject. I've joined the government-wide artificial intelligence policy community of practice and actually I'll be working on a subcommittee on best practices for AI in education. So if you have ideas on that, send them to me. This is the gcCollab link. Now gcCollab is a public facing website, but it's not wide open, so I'm not sure if you will be able to get access to it. Generally if you're an academic or if you're working in government, you can access it. But each individual case is different.
Also internally at NRC I'm on a data equity working group. I also did a thing recently. I don't have a link to it looking at ethical codes and research ethics boards and I'm looking at joining the research ethics board for the NRC. That should be a lot of fun, actually, and I know not everybody thinks of something like that is fun, but I think of something like that is fun.
The main bit about ethics, analytics and duty of care for me is a presentation, then I started writing a paper and it grew. So, here's the Google Docs version of it. This is page one.I've looked at applications of AI in education, issues, ethical codes, and then beginning with ethical approaches and through the rest of it. I have notes. This is gradually being converted into a book which I'm hosting on PressBooks. I actually have real text for, say, the first third to a half of it, and then the rest of it is my notes and progress. I think you'll find it already interesting. If you have suggestions or ideas about things that I should consider, I'm all ears, and again, of course, the results of this will be made freely and openly available as a service to the community.
I think of this as the world's most boring book. And you know, I'm not writing this for marketability or sales or anything like that. I'm writing this for comprehensiveness and accuracy. So for example when I talk about the applications of analytics and learning I'm talking about all of the applications of analytics and learning. I'm not picking and choosing. I'm capturing everything with examples, so you can get a complete picture of it. Similarly with the issues. I'm not highlighting this or that issue. I'm identifying all of them. That's what makes it so boring but I think that's also what makes it useful. At least I hope that's what makes it useful. This has been a big part of my work over the last year and it'll continue to occupy my time and my interest, because I think we need this broad-based look.
Again we go back to all of the issues in our society: the pandemic, the information issues, the democracy issues; we as a society need to get a handle nn the ethical approaches to artificial intelligence and other technologies, and especially how we talk about them and how we teach them and.
Here's my conclusion from the work that I've done so far - still tentative, but I just read a thing today from Geoffrey Hinton, the father of AI, saying eventually deep learning is going to do everything. There aren't any gaps, that is, that aren't going to be done by deep learning. There aren't any jobs, any super-creative jobs, that only humans can do. We like to think that, but deep learning works the same way brains work, which means they're eventually going to do all this work.
So what is there for us to do? Our job in the future, our only job in the future, will be to be teachers, to teach artificial intelligence. That means we have to get our acts together in the sense that we have to figure out you know, not by voting, but figure out what values, what principles, what processes we want to teach artificial intelligence. We have to instantiate them in ourselves. Because otherwise we'll never be able to teach the AI. You know, the issues that come up in AI - bias and prejudice and bad predictions and all of that - we can see those in the population as a whole, right? So we need to fix these in ourselves before we can ever fix them in AI, because we are the ones teaching AI. That will be our job. So we have to get it right.
Anyhow, I'm looking forward to finishing this even if it's a boring book it might be relevant and useful. It's certainly possible.
Personal Learning Environments
The last thing is personal learning environments. A few years ago, I ran a MOOC called e-learning 3.0 that's still available on the website. Here it is. And it covers some of the major trends in e-learning, not the ones that are happening now that other futurists like Horizon report will predict, but the stuff that's coming that will impact us really in a big way in five to ten years.
I broke them down into: data, cloud, graph, identity, resources, recognition, community, experience and agency. I wrote a little essay for each and talked about them in some presentations, especially later the big idea from each of these things. There's a lot of stuff in there. There's no way to summarize it at this point in time, but this content I'm finding is still relevant even to this day.
The other thing that I'm doing with respect to personal learning environments is continuing to work on distributed social networks, you know things like Opera Unite, Mozilla OS, Diaspora - these have passed by the wayside. SoLiD, which is Tim Berners-Lee's project, continues to be important but I noticed just yesterday Mitzi Laszlo, their manager, said that she's moving on, so I wonder about that project. I'm still interested in the Interplanetary File System. I'm still very interested in Mastodon, the federverse generally, and something called ActivityPub. If you want to learn about Fediverse, or Federated Networks, this website is a really comprehensive website. It covers everything for you.
The other thing I'm doing is something called Grasshopper in a box and what I've done is taken my gRSShopper application (and put it into a container). Anyhow, on that website is a link to a Docker container so that with just one or two commands you can actually get an instance of gRSShopper running in a virtual container on your own desktop. It should run on any desktop now. It's not perfect, I'm still working on it, but it gives it's the first real chance for people who are not programming experts to get a sense of what I'm trying to do with grasshopper and I'm going to continue to develop this idea and this concept.
Cloud infrastructures in general are pretty important for this. Like I say I'm using Docker. I've done it in the past using Vagrant. It didn't go as well as I wanted to. Vagrant and gRSShopper resulted in me never being invited back to Online Educa Berlin, so that tells you something. The thing that containerization does for you is it provides you access to a whole bunch of cloud services - Wolfram Alpha, MS Cognitive Services, basic AI services, automated translation, all of that sort of thing.
So my view of the personal learning environment is you get one of these containers, it has gRSShopper in it, gRSShopper accesses the cloud storage the distributed data networks and these cloud services that you can use in order to work with your own “data - aggregate - remix - repurpose - feed - forward”, that's what gRSShopper is intended to support.
It's your personal answer to fake news, the information crisis, the crisis in democracy, global warming and all the rest of it. Here's the concept all of this: different information comes in, you manage it and then you broadcast it to wherever you want. That's also where data literacy comes in, right? So you know, it's interesting.
This position that I'm working in, it's not about the technology all the time, hey you got another technology, but it's so often about critical literacy, about perception, sense of belief, it's so often about how people see things, what their environment is, what their ways of perceiving things are, how they're going to learn. You can't dismiss the technology, and it's a two-way kind of thing. And you don't ‘plan pedagogy then do technology’. It goes back and forth because the technology lets you do stuff you were never able to do before the technology came.
So some of the things that I've been looking at: repository networks, personal cloud, personal learning record, personal learning assistants (probably powered by AI that we have to teach) and distributed intelligence.
You know, we're facing a lot of challenges in our educational institutions with this economic crisis coming, the bottom is going to fall out of the financial support governments provide. We as a people have to adapt. So we are looking at these challenges, we're looking at what we need to go forward. We can't depend on the institutions to do this. We have to do it for ourselves.
Thank you.










 If you want certain annotations to always show up directly in your visualization, disable “Show as key on mobile” in the annotation settings. We did this here with the “2019” label.
If you want certain annotations to always show up directly in your visualization, disable “Show as key on mobile” in the annotation settings. We did this here with the “2019” label. The width of annotations is now measured in chart width, not in absolute pixels.
The width of annotations is now measured in chart width, not in absolute pixels.
 Bye bye, old interface. Hello, new one!
Bye bye, old interface. Hello, new one!


 Organizations invest enormous resources to strengthen their capabilities and capacity to innovate but are often disappointed by the results. Building an innovation capability is a systems design challenge that requires a system solution; if instead you try to build it by cobbling together isolated point solutions, each is likely to fail in entirely predictable ways.
Organizations invest enormous resources to strengthen their capabilities and capacity to innovate but are often disappointed by the results. Building an innovation capability is a systems design challenge that requires a system solution; if instead you try to build it by cobbling together isolated point solutions, each is likely to fail in entirely predictable ways.