Note: cross-posted at LinkedIn
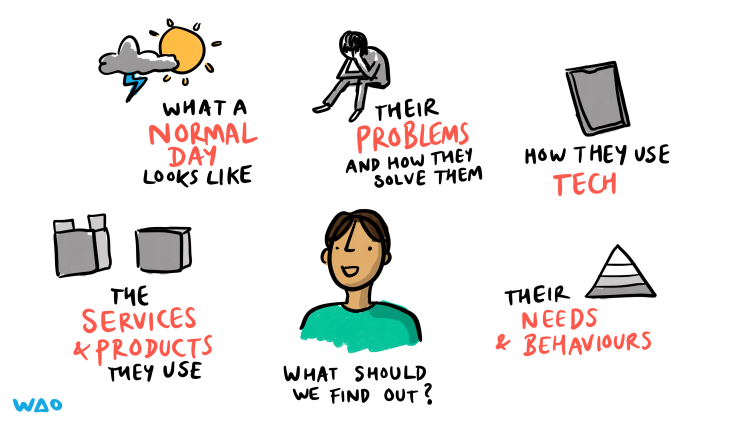
When WAO starts working with organisations, the most important thing we have to figure out is how decisions are made. After we’ve established that, the second is the organisation figures out how best to serve their audience. The latter can be done in several ways, but there’s no substitute for talking to people!
In our experience, there’s quite a few reasons why organisations might avoid user research. Let’s have a look at a few of the most common along with some arguments against (and ways around) them.
1. Inadequate understanding of its value
The world is not slowing down, and product development and service delivery are particularly fast-paced environments. That means it’s not uncommon for managers and stakeholders to overlook the vital role that user research plays in their success. This oversight may stem from a lack of comprehension regarding the tangible benefits that user research brings to the table. As a result, decision-makers might be hesitant to allocate resources towards research initiatives.
However, by shedding light on the value of user research and illustrating its impact on the effectiveness of products and services, we can help foster a deeper appreciation among stakeholders. Quantitative data is important, but gaining qualitative data from users or your audience is vital. It’s the difference between ‘having a better value proposition’ and the realisation that your core audience doesn’t think that your product or service is actually for them.
2. Overconfidence in existing knowledge
People are promoted within organisations often because of their understanding of the sector in which they work. However, it can be dangerous to think that previous lived experience or a particular view constitutes the ‘truth’ of the situation. This can lead to thinking that user research is superfluous. Such overconfidence is usually based on anecdotal evidence, personal experiences, or preconceived notions that may not accurately reflect the broader user base.
If we acknowledge the limitations of these informal insights, then we can emphasise the importance of user research in painting a more comprehensive and diverse picture of users’ needs. By doing so, organisations can make more informed decisions and avoid the pitfalls of overconfidence, which ultimately results in more successful products and services for their users or audience.
3. Fear of negative feedback
No-one particularly likes to hear that they or their organisation are doing anything other than a good job. So it’s natural for people to be wary of negative feedback. The problem is that this apprehension can sometimes give rise to resistance towards user research, as decision-makers may be reluctant to uncover potential issues or face criticism.
There is a way of reframing this mindset by embracing the notion that constructive feedback is a valuable opportunity for growth and improvement. Looked at this way, organisations can overcome hesitations and appreciate the indispensable role that user research plays in enhancing their offerings. In the end, it’s through facing these challenges head-on that organisations can truly thrive and achieve long-term success.
4. Short-term focus
As mentioned above, we live in a fast-paced world with organisations tending to focus on short-term objectives and instant outcomes. User research, on the other hand, represents a long-term investment in product development, which might not always align with the immediate ambitions of an organisation or its decision-makers.
However, when undertaking user research for the first time, or for the first time in a while, immediately-actionable insights often are forthcoming. Coupled with the long-term value that user research brings to the table, organisations can strike a balance between short-term wins and sustainable success. In doing so, they can foster a more holistic approach to product development that not only meets immediate needs but also paves the way for a future-proof, user-centric experience.

5. Limited resources
User research is a time-consuming process. I’m well aware of this as my wife (Hannah Belshaw) is a user researcher! As such, organisations might find themselves facing constraints around budgets or staff, which can make it challenging to plan and carry out research sessions. More frequently, they may opt to prioritise other initiatives over user research.
Nevertheless, by acknowledging the long-term value that user research brings to product development and service design, organisations can make a conscious effort to allocate resources effectively. User research can be weaved into the fabric of strategic planning to ensure that their products and services continually evolve to meet the needs and expectations of their users. This ultimately drives long term success.
6. Lack of expertise
Organisations often don’t know what they don’t know about user research. Sometimes they don’t have the required in-house expertise for designing, implementing, and analysing user research sessions. This gap in their knowledge can make it difficult to derive actionable insights which means that they’re hesitant to get started in the first place.
Once this challenge has been recognised, organisations can seek to bridge that gap in their expertise, either through training existing staff, hiring new ones, or partnering with external experts. By tapping into the wealth of knowledge that user research provides, organisations they can ensure that their products and services evolve in sync with the ever-changing needs of their users.
7. Resistance to change
The idea of user research is to gain insights to improve products and services. Sometimes, these insights can lead to a call for substantial alterations which, understandably, might be met with resistance. After all, if you’ve invested considerable time and effort into the existing design, then you might not be best pleased if you’re being asked to change course. In addition, there are many people and organisations who are naturally averse to change of any sort.
However, by embracing the notion that adaptability is key to long-term success, organisations can begin to adopt a growth mindset. By navigating this resistance to change they can make use of user research insights to create better, more user-centric products and services that ultimately stand the test of time.
8. Other factors
There are many other reasons barriers to performing effective user research. For example, gaining buy-in or support from leadership can be an uphill battle, making it difficult to secure the necessary resources or cooperation. Then there are sometimes privacy and legal concerns, particularly when handling sensitive information or user data. And, of course, logistical complexities in terms of co-ordinating with research participants, internal teams, and external organisations can be off-putting.
To overcome these additional obstacles, organisations can focus on ensuring proper legal guidance when dealing with sensitive data — which is something they should be doing anyway! Effective project management should help with difficulties around logistics, and it’s always a good time to start fostering a culture of research appreciation among leadership.

Conclusion
User research is a form of superpower for organisations. Doing it effectively means the difference between designing products and services that work for your users and audience, and creating a barrier between you and them. It’s no silver bullet, but if the best time to start was several years ago, the second best time to start is today!
Images CC BY-ND Visual Thinkery for WAO
The post Identifying and overcoming barriers to user research within organisations first appeared on Open Thinkering.