Overview
The Domain Name System (DNS) is often referred to as the “phonebook of the Internet.” It is responsible for translating human readable domain names–such as mozilla.org–into IP addresses, which are necessary for nearly all communication on the Internet. At a high level, clients typically resolve a name by sending a query to a recursive resolver, which is responsible for answering queries on behalf of a client. The recursive resolver answers the query by traversing the DNS hierarchy, starting from a root server, a top-level domain server (e.g. for .com), and finally the authoritative server for the domain name. Once the recursive resolver receives the answer for the query, it caches the answer and sends it back to the client.
Unfortunately, DNS was not originally designed with security in mind, leaving users vulnerable to attacks. For example, previous work has shown that recursive resolvers are susceptible to cache poisoning attacks, in which on-path attackers impersonate authoritative nameservers and send incorrect answers for queries to recursive resolvers. These incorrect answers then get cached at the recursive resolver, which may cause clients that later query the same domain names to visit malicious websites. This attack is successful because the DNS protocol typically does not provide any notion of correctness for DNS responses. When a recursive resolver receives an answer for a query, it assumes that the answer is correct.
DNSSEC is able to prevent such attacks by enabling domain name owners to provide cryptographic signatures for their DNS records. It also establishes a chain of trust between servers in the DNS hierarchy, enabling clients to validate that they received the correct answer.
Unfortunately, DNSSEC deployment has been comparatively slow: measurements show, as of November 2020, only about 1.8% of .com records are signed, and about 25% of clients worldwide use DNSSEC-validating recursive resolvers. Even worse, essentially no clients validate DNSSEC themselves, which means that they have to trust their recursive resolvers.
One potential obstacle to client-side validation is network middleboxes. Measurements have shown that some middleboxes do not properly pass all DNS records. If a middlebox were to block the RRSIG records that carry DNSSEC signatures, clients would not be able to distinguish this from an attack, making DNSSEC deployment problematic. Unfortunately, these measurements were taken long ago and were not specifically targeted at DNSSEC. To get to the bottom of things, we decided to run an experiment.
Measurement Description
There are two main questions we want to answer:
- At what rate do network middleboxes between clients and recursive resolvers interfere with DNSSEC records (e.g., DNSKEY and RRSIG)?
- How does the rate of DNSSEC interference compare to interference with other relatively new record types (e.g., SMIMEA and HTTPSSVC)?
At a high level, in collaboration with Cloudflare we will first serve the above record types from domain names that we control. We will then deploy an add-on experiment to Firefox Beta desktop clients which requests each record type for our domain names. Finally, we will check whether we got the expected responses (or any response at all). As always, users who have opted out of sending telemetry or participating in studies will not receive the add-on.
To analyze the rate of network middlebox interference with DNSSEC records, we will send DNS responses to our telemetry system, rather than performing any analysis locally within the client’s browser. This will enable us to see the different ways that DNS responses are interfered with without relying on whatever analysis logic we bake into our experiment’s add-on. In order to protect user privacy, we will only send information for the domain names in the experiment that we control—not for any other domain names for which a client issues requests when browsing the web. Furthermore, we are not collecting UDP, TCP, or IP headers. We are only collecting the payload of the DNS response, for which we know the expected format. The data we are interested in should not include identifying information about a client, unless middleboxes inject such information when they interfere with DNS requests/responses.
We are launching the experiment today to 1% of Firefox Beta desktop clients and expect to publish our initial results around the end of the year.
The post Measuring Middlebox Interference with DNS Records appeared first on Mozilla Security Blog.


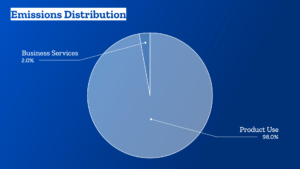
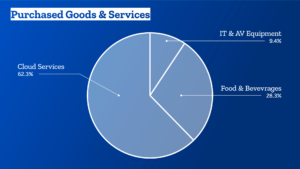
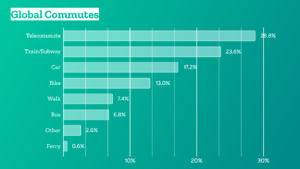
 Anjo Anjewierden passed away unexpectedly last week. We didn’t have much contact in recent years, but he has a warm place in my heart. We worked together exploring what you can learn from digital traces that people leave. Part of that work, understanding knowledge flows in weblogs and weblog conversations, became an integral part of my PhD research.
Anjo Anjewierden passed away unexpectedly last week. We didn’t have much contact in recent years, but he has a warm place in my heart. We worked together exploring what you can learn from digital traces that people leave. Part of that work, understanding knowledge flows in weblogs and weblog conversations, became an integral part of my PhD research.
 Knowing how much Anjo contributed to the research of others with developing new methods and tools I am sure he will be missed as an important piece of the puzzle. From the other side, he will also continue to be part of it with the ideas and code he developed. In that sense, his weblog tagline “the source code is the ultimate documentation” is telling.
Knowing how much Anjo contributed to the research of others with developing new methods and tools I am sure he will be missed as an important piece of the puzzle. From the other side, he will also continue to be part of it with the ideas and code he developed. In that sense, his weblog tagline “the source code is the ultimate documentation” is telling.










 The company is now legally known as "THAT COMPANY WHOSE NAME USED TO CONTAIN HTML SCRIPT TAGS LTD".
The company is now legally known as "THAT COMPANY WHOSE NAME USED TO CONTAIN HTML SCRIPT TAGS LTD".







