Change is inevitable, and this year, it has been inescapable. We’ve had to find new ways to relate, learn, and balance both work and life at home. One thing has stayed the same: developers collaborate and build a global community, no matter where they are.
Today, we are excited to announce this year’s State of the Octoverse report, which brings a new approach to sharing data and insights with our community. Similar to past reports, you will find data on GitHub’s growth and usage over the previous year. In addition, we will also share deep dives into the compelling patterns and trends we see to help developers and teams working in open source and enterprise organizations. These deep dives provide additional analyses in three areas: finding balance between work and play, empowering healthy communities, and securing the world’s software.
We share patterns about the hours we worked this year and the ways our community is growing and changing. We also touch on the state of open source security and how teams can secure their systems, plus the role that automation plays in it all.
But I don’t want to spoil it for you! Head to the report and check it out for yourself!
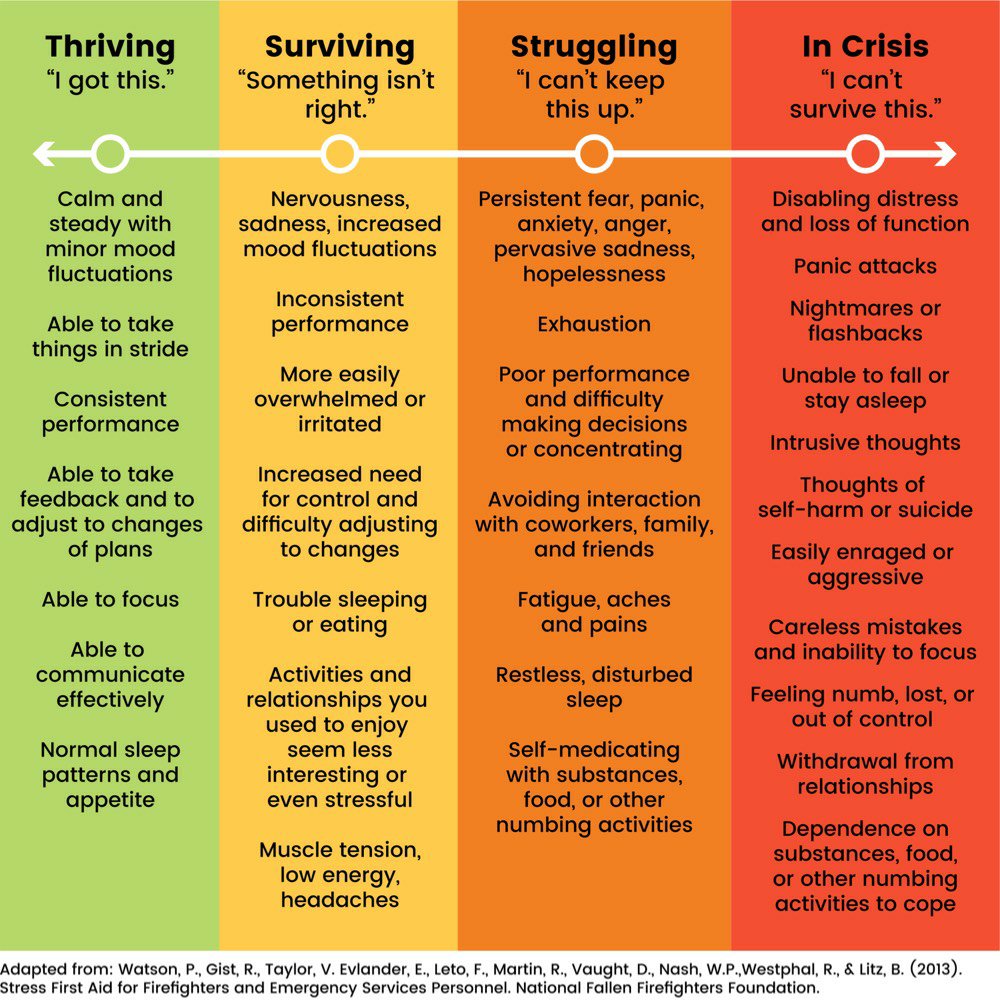
I wanted to share a couple of things that I found via Jason Kottke. The first is this infographic made for healthcare workers in Colorado:.
The reason I think this is helpful is that it’s sometimes difficult to spot in yourself and others when things start slipping from “Surviving” to “Struggling”.
She points out how difficult it can be to help others if you haven’t been thought what they’re suffering:
When we are not equipped to support loved ones through a hard time, our discomfort can compel us to point out a bright side or offer a simple solution, which may come across as dismissive. Sometimes, my patients say they walk away feeling judged or burdensome. While putting ourselves in other people’s shoes and treating people how we want to be treated are generally useful principles, they are not always the most effective ways to cultivate compassion. It is hard to imagine being in a situation that you have not actually been in, and people differ in what they find comforting.
Gordon goes on to give five pieces of advice:
Ask them how they are feeling. Then, listen non-judgmentally to their response.
Show them that you want to understand and express sympathy.
Ask how you can support them and resist jumping in to problem-solve.
Check in to see if they are suicidal.
Reassure them, realistically.
I found these resources really useful, so thanks to Kottke for sharing them. I hope by re-sharing these resources here means they reach a few people who otherwise wouldn’t have seen them.
By 'discipline' here we don't mean 'enforcement' but rather the development of good habits. Paul Bradshaw writes, "Discipline can sometimes be seen as creativity’s killjoy, but this is a myth: there are numerous books about the subject, and in education around creativity you will find exercises that involve putting limits on the creator to encourage it." The big difference, to my mind, is between limitations that you impose on yourself, and limitations that are imposed on you from outside.
Over the last week, theres been a lot of conversation about Microsoft Productivity Scorea tool that helps organizations measure and manage the adoption of Microsoft 365. Weve heard the feedback, and today were responding by making changes to the product to further bolster privacy for customers. In this post, Ill outline the changes were making to protect individual privacy, while still giving organizations the data-driven insights they need to manage their digital transformation.
This feature was probably the dumbest idea that Microsoft had in a while. And they could have learned from IBM's Social Dashboard.
SAN FRANCISCO--(BUSINESS WIRE)-- Salesforce (NYSE: CRM), the global leader in CRM, and Slack Technologies, Inc. (NYSE: WORK), the most innovative enterprise communications platform, have entered into a definitive agreement under which Salesforce will acquire Slack. Under the terms of the agreement, Slack shareholders will receive $26.79 in cash and 0.0776 shares of Salesforce common stock for each Slack share, representing an enterprise value of approximately $27.7 billion based on the closing price of Salesforces common stock on November 30, 2020.
Stewart Butterfield sold his first successful startup Flickr to Yahoo. The transition destroyed Flickr. If Butterfield is once again selling his company to a much larger enterprise, albeit a very different one, he has to. Slack should have boomed in the pandemic but it did not.
Slack spent three years migrating 99% of their MySQL query load to run against Vitess, the open source MySQL sharding system originally built by YouTube. "Today, we serve 2.3 million QPS at peak. 2M of those queries are reads and 300K are writes. Our median query latency is 2 ms, and our p99 query latency is 11 ms."
Telco regulation is usually fraught with pitfalls, but this mandate was particularly egregious and did a fair amount of damage, both inside and outside the US (with local lobbies in various countries taking advantage of the US “example” for their own nefarious purposes).
At a time when telcos and media services are one of the few things holding our civilization together, it will be great to have someone with less vested interest in charge–and that, I think, would be a much better example to the industry in general.
(Any relationship between this comment and the current ongoing fracas regarding the 5G spectrum auction in Portugal is just serendipitous coincidence, of course…)
Twitter announced Project
@bluesky back in December 2019. I
blogged about it supportively then reached out saying I was interested, and was
invited to join the conversation; thanks!
Several of us offered proposals; this is part of mine, concerned with how identity might work in a world of diverse federated
social networks.
Goal
On the Internet, there are many entities that provide online conversations, whether short-form like Twitter or
bulletin-board-esque like Reddit. Then there are a nearly infinite number of specialized communities, for photographers, dog
groomers, and the owners of particular types of boats or cameras. Let’s call these entities “Providers”.
@bluesky envisions allowing online conversations to span Providers. Which is to say, from inside Twitter I could follow not
only other Twitter accounts, but posts on my boat-owners’ forum. And vice versa. This is a straightforward and
easy-to-understand — if not necessarily easy to build — vision, and
might be worth doing by itself.
In this simple vision, there’s no linkage between Twitter Tim (“Canadian Web geek with a camera”) and boat-forum Tim
(“Jeanneau NC 795 tied up in Vancouver”). For a lot of people that’s probably OK or even desirable. But in some cases, people
would like to take their identity, and perhaps their reputation, with them. If you’re a big hot-shot on Parler, you’d maybe
like people on Twitter and your horse-dressage conversations to know that you’ve got serious alt-right credentials (shudder).
This is a proposal for a higher-level form of cross-Provider identity.
Provider Identity
Providers who participate in @bluesky have users with identities — they control user access and
behavior. Let’s call those “Provider Identities”, PIDs for short. It’s easy to imagine a syntax to express this: I would be
twitter.com@timbray.
This would open the door to using OAuth-2 techniques like
OIDC ID Tokens for Providers’ identity assertions,
which would have the
advantage of excellent library support on most programming platforms. For those who care about
decentralized identity, it
can
be represented in the OIDC framework.
Any @bluesky post has an originating Provider. This information would be valuable input to reputation and other
filtering operations. It would not make sense to apply the same set of criteria to posts from 4chan as to those from
a Pediatric Endocrinologists’ forum.
Bluesky Identity
Most users are likely content to remain associated with their home Provider, but it would be of value to @bluesky to have a
global notion of identity that is not tied to any Provider. Let’s call this a “Bluesky Identity” or BID for short.
A BID would typically be associated (“mapped” for short) with multiple PIDs, normally but not necessarily on different Providers.
The goal of the Bluesky identity protocol is that multiple parties can easily maintain databases of mappings between PIDs and BIDs
suitable for quick lookup, for example in reputation and search applications.
A BID is represented by a globally unique opaque bit string. There are multiple plausible ways to generate
them, discussed below.
This protocol assumes the existence of a reliable Ledger service, shared by all Providers, to which arbitrary messages can be
committed and which are recorded immutably with strict ordering semantics.
There are multiple plausible ways to implement the ledger, discussed below. Note that the transaction load would be read-mostly
with a low update rate.
In the following discussion, “structured”, when applied to Provider posts and ledger messages, implies the use of an
agreed-on syntax specified as part of the @bluesky protocol, to facilitate unambiguous assertion parsing.
BID Identity Protocol
I propose that Providers offer APIs to facilitate implementing this protocol, but it’s the protocol that matters so I’m
focusing on that.
The protocol assumes that the user has access to an account
on a Provider which we’ll call P1, and write access to the ledger.
Claiming a new BID
Summary: The user generates a BID, makes a Provider post claiming it, and records that post
on the ledger.
The user generates a BID.
The user makes a structured post to P1 containing the BID. Let’s call this a BID-claim post.
Once the post has been created and the user knows its URL, the user commits a structured message to the ledger
containing the URL of the BID-claim post.
Now the ledger contains a permanent immutable record of a PID-BID mapping.
Note that there is no particular relationship between a BID and the Provider where it was originally claimed. BIDs can be passed
from PID to PID even in the case where the originating Provider has ceased operation.
Grant a BID from one PID to another
The protocol assumes that the user is executing on a computer with access to accounts on two Providers, P1 and P2, and
also to the ledger.
Summary: a user creates a zero-knowledge proof that the owners of the two accounts know a shared secret, posts the proof
to both Providers, and records the URLs of the posts on the ledger.
The user creates an asymmetric keypair. Unusually, no special care need be taken to secure the private key, which only
needs to exist in one computer’s memory for a few seconds.
The user creates a nonce, signs it with the private key, and makes a structured post to P1 containing the BID, the
public key, the nonce, the signature, and the P2 PID which is to be mapped to the BID.
Let‘s call this a BID-grant post.
The user creates a different nonce, signs it with the private key, and makes a structured post to P2 containing the
BID, the public key, the nonce, the signature, and the PID on P1 which granted the BID mapping. Let’s call this a BID-accept
post.
The user forgets the private key, presumably by overwriting it in memory.
Once both posts have been made, the user commits a structured message to the ledger containing the URLs of the BID-grant
and BID-accept posts. Let’s call this a BID-grant transaction.
Now the ledger contains permanent immutable evidence backing the mapping of a BID from one PID to another.
Unmap a BID from a PID
Suppose the user’s PID at Provider P1 is bound to a particular BID.
The user makes a structured post to P1 containing the BID. Let’s call this a BID-unclaim post.
The user commits a structured message to the ledger containing the URL of the BID-unclaim post.
By processing the ledger in sequence, any software agent can build a consistent mapping between PIDs and BIDs.
Single-use keys
The protocol
asserts one more rule: No key-pair can be used more than once in BID-grant operations. That is to say, a software
agent building a BID/PID map MUST remember which keys it has seen and ignore any BID-grant transactions which re-use a
previously-used key.
Implementation notes
To be useful, Providers and other interested parties would use the ledger to generate and maintain a database of mappings
between PIDs and BIDs. Presumably it would be keyed by both PID and BID.
The protocol requires a single-use keypair. It is assumed that storing and securing private keys is difficult and
probably beyond the capabilities of many users of these APIs. Should a private key leak, it would allow an adversary to assert
PID-PID linkages.
This description of the protocol assumes User Agents writing directly to the ledger. In practice, write access would be
better limited to Providers, which would provide APIs such as ClaimBID, GrantBID, and UnclaimBID, which could take care of
enforcing protocol constraints (such as single-use key-pairs) and correct structuring of messages, while reducing ledger
spam.
A Provider might limit a PID to a single BID claim.
BID generation and ledger implementation
Ways that BIDs could be generated:
A BID could be a 128-bit integer, the first 64 bits identifying the Provider where it was claimed. Any provider joining the
@bluesky protocol would be given a 64-bit range and hand out BIDs in sequence.
Some organization could hand out BIDs as a service, for example a @bluesky nonprofit, IANA, ISOC, or the
ITU.
A BID could be a 64-bit integer, pick one at random and if there’s a collision, discover at ledger commit, give that one
up and retry with another.
If the ledger were implemented as a blockchain, the BID could be the transaction hash for the transaction recording the
BID claim.
Ways that the ledger could be generated:
An organization such as a @bluesky nonprofit, IANA, ISOC, or the ITU could offer it as a service. It would not be
particularly technically challenging.
The ledger could be operated in a decentralized fashion based on blockchain technology. Since write transactions are
rare, the poor update throughput typical of blockchain implementations shouldn’t be a problem.
Conclusion
I’m not sure this is the optimal scheme for establishing a higher-level shared-identity construct in a @bluesky-like federated
system. I might be prepared to argue that this is the simplest thing that could possibly work.
Credits
The notion of using social-media posts to establish key ownership was originated by keybase.io back in the day. Paul Hoffman
and Lauren Wood contributed comments that led to significant clarification.
The Headline is taken from a CTV Vancouver Island news story which is just wrong.
The first paragraph tries to nuance the headline a bit but doesn’t get it right either. The twenty year old retiring buses were “reportedly the first double decker buses to ever be used in a North American public transit system.”
Actually there were double deckers running on 5th Avenue in New York City in 1912 – as a Google search will confirm.
A post card scan from flickr
Paul Bateson reminds me that Brampton Transit in Ontario had a double decker Leyland Olympian that entered service in March 1989.
Victoria, of course, has had double decker sightseeing buses – most retired from the UK – for many years
Sightseeing bus in Victoria formerly used in NYC: my image
It’s once again time to celebrate an employee milestone here at Rogue Amoeba. Today, we want to honor our designer Neale Van Fleet, who recently hit the five year mark working with us. We’re beyond delighted to celebrate his tenure thus far, which includes countless contributions.
Neale’s Work
As the sole designer here at Rogue Amoeba, Neale is in charge of just about everything visual. Whether it’s artwork for our blog posts, the design of our web site, or the user interfaces of our applications, you’ve definitely been touched by Neale’s tremendous work.
Since joining us in 2015, he’s made every single one of our products better. That works has included the creation of tremendously well-received new designs for apps including Loopback:
Neale also took charge of our company rebranding, an important effort which produced a more polished logo and brand that still retains a sense of fun.
Neale has also overhauled nearly every corner of our website, added helpful introductory tours to every product we make, powered our Instagram account, and so much more.
A small sample of images from the Rogue Amoeba Instagram account
He’s even written articles for this very blog, and those posts are some of my favorites. In particular, I love his reviews whenever we unveil a major new design, such as his recent look at “The Design of SoundSource 5”.
Neale has produced stellar work while being a great teammate. What more could we ask for?
Looking to the Heavens
Speaking of stellar, let’s briefly discuss Neale’s anniversary gift. To celebrating a five year anniversary, we like to find a personalized gift that will mean something to the recipient. While working on his Everywhere School project, Neale made particular note of some astronomy streams he’d watched with his son. On top of that, Neale and his family recently acquired a small cabin out away from his home city of Montreal.
Those two things inspired us to find what we hoped would be the perfect gift: A top-notch telescope.
Happily, this gift turned out very well indeed. While Neale already had a borrowed telescope, it was low-end, and needed to go back to its owner eventually. Now, Neale has a vastly superior telescope to call his own. It even features a computerized stand, which solves one of the most annoying problems of using a telescope, aiming it at tiny objects millions upon millions of miles away. It should provide many years of stargazing delight.
Closing
Since joining Rogue Amoeba, Neale has had a dramatic influence on the appearance and feel of everything we do. Whenever I step back and look at our website or our products, I’m blown away by the level of quality and attention to detail that are a direct result of Neale’s efforts.
Speaking for both the Rogue Amoeba team, and our entire user base, thank you, Neale! We’re delighted with what you’ve done since joining us, and we hope for many more fruitful years together.
P.S. We’re Still Hiring
Once again, a celebration post is coinciding with job openings here at Rogue Amoeba. In addition to the Mac software developer we’ve had open for a bit (we’re taking our time there), we also have an open role for a new Support tech, which we’d like to fill soon.
If you’re interested in joining our team, see our Jobs page, then get in touch. We just might be celebrating you in a few years.
However, it was a bit above freezing this morning, and so by midday when I was biking in to work most of the snow had melted off the roads.
Bloor bike lanes were totally clear.
Technically there was snow on the ground, so I guess this is the first snowy commute of the year, but not really. The first snowy commute last year was November 11.
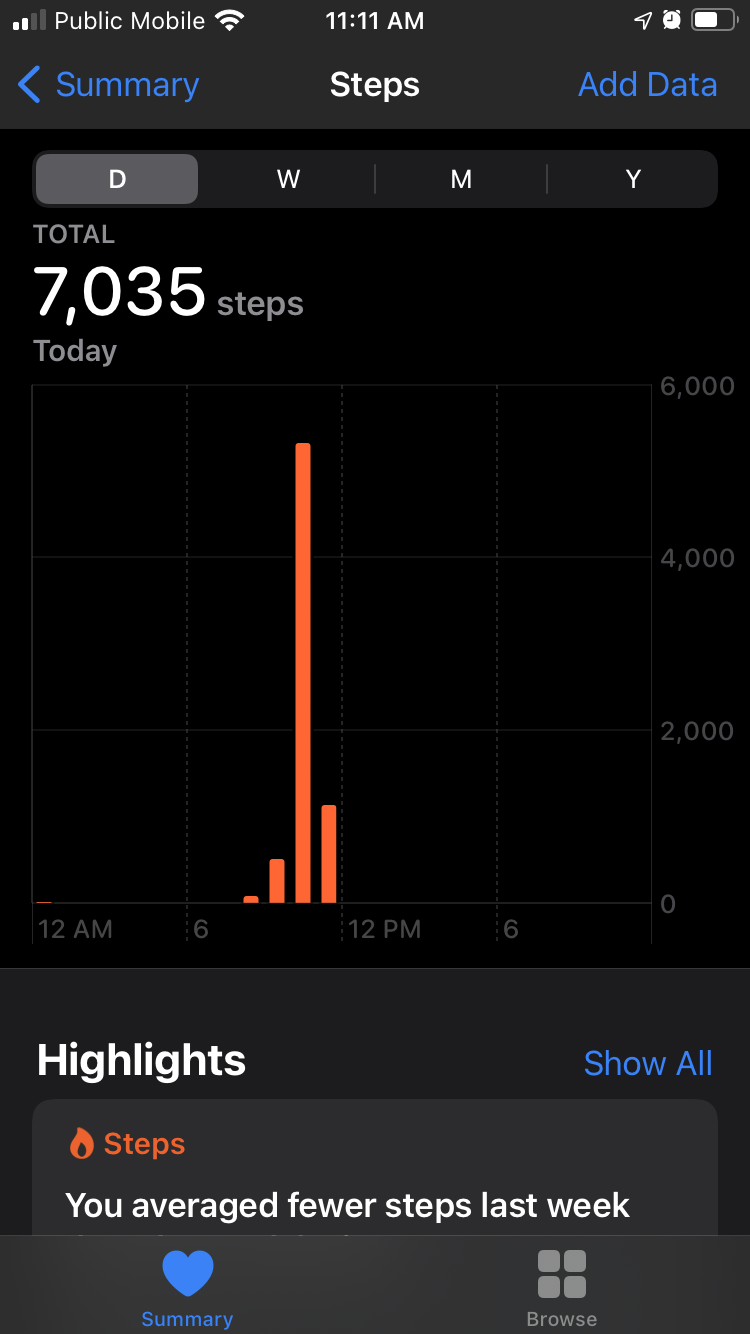
It’s a rare warm autumn today, 13ºC as I write, and so I decided to do my local Queen Square Press deliveries this morning on foot.
As a result, I walked more than 7,000 steps before noon:
Because my deliveries took me into the heart of midtown, I took the opportunity to enjoy a bánh mì from Madame Vuong on the way home, making their street food actual street food:
The forecast called for rain, but it has yet to come. A very pleasant way to start the day.
Carriers in the U.K. will officially be banned from installing Huawei 5G equipment after September 2021.
The U.K.’s Department for Digital, Culture, Media and Sport made the announcement, and the government has also released a plan to remove Huawei-built telecom gear by 2027.
“Today I am setting out a clear path for the complete removal of high-risk vendors from our 5G networks,” said Digital Secretary Oliver Dowden in the annoucement. “This will be done through new and unprecedented powers to identify and ban telecom equipment which poses a threat to our national security.”
Earlier this year in January, the U.K. granted the Chinese telecom a limited role in the deployment of its 5G networks, but later reversed its decision.
This decision comes as Canada is now the only member of the Five Eyes Alliance to not ban or restrict the use of Huawei 5G equipment. Other countries in the alliance are the United States, the United Kingdom, Australia and New Zealand.
The U.S. has been urging its allies to ban Huawei equipment from 5G deployment and has claimed that the Chinese company poses a security risk. Huawei has repeatedly rejected this accusation.
Opposition parties in Canada have passed a motion put forward by the Conservatives to call on the Liberal government to make a decision in its Huawei 5G security review.
The federal government hasn’t provided a timeline on when it may come to a decision regarding its Huawei 5G security review. A Huawei executive has said that the company is ready to honour the Canadian government’s decision, regardless of the outcome.
It has long been said that from 1973 to 1983, the American automotive industry was stuck in a rut that is now referred to as the Malaise Era. ... Looking back on this era as a car fan, most cars coming out of Detroit were incredibly depressing, underwhelming, and unmemorable.
So why would I bring this up on a blog where I normally talk about computing or technology topics? Because I believe that weve now firmly entered the PC Malaise Era. I want to highlight right now that when I say PC in this post, I mean Windows PC.
This image is another rare example of a Vancouver building published in the Journal of the Royal Architectural Institute of Canada, this time in 1953. The reason for selecting this particular building is unclear, but it was one of three industrial buildings featured in the June edition of the Journal, none likely to set the architectural world on fire.
The Vancouver warehouse for the Grinnell Company of Canada Ltd was designed by Townley and Matheson, and was filled with ‘Wrought, Cast Iron and Brass Pipe. Fittings, Valves, Pipe Hangers and Supports, Piping Supplies, Etc,’ and the company traced its history back to 1850, founded as the Providence Steam and Gas Pipe Co in Providence, Rhode Island. Among the piping they supplied and installed were early fire fighting systems. In 1869, Frederick Grinnell, a Massachusetts-born engineer, purchased a controlling interest in Providence Steam and Gas and became its president. Fire-extinguishing apparatus in factories was mainly perforated pipes connected to a water-supply system and installed along the ceilings. The water had to be turned on by hand – often too late to prevent the loss of wooden buildings. In 1874 a Connecticut inventor patented a sprinkler design and Grinnell installed it, paying a royalty to the inventor. Grinnell soon designed his own more sensitive system in 1881, and from there became one of the largest suppliers of fire systems and fire extinguishers in North America. In the year the building was photographed the company had just absorbed ADT (American District Telegraph Co), an alarm company. In 1966 they were forced to sell it, having been accused of price fixing.
The Canadian arm of the business was established in 1914, and in the 1970s became part of Tyco Industries, which in turn has been swallowed up by Johnson Controls. The company’s Lower Mainland operation is now based in Delta. This warehouse is currently vacant, and available to lease, but was most recently home to the Greater Vancouver Food Bank, who moved to a new location in Burnaby in mid 2019.
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
So you want to collect data in your project? Okay, it’s pretty straightforward.
API: You need a way to combine the name of your data with the value that data has. Ideally you want it to be ergonomic to your developers to encourage them to instrument things without asking you for help, so it should include as many compile-time checks as you can and should be friendly to the IDEs and languages in use. Note the plurals.
Persistent Storage: Keyed by the name of your data, you need some place to put the value. Ideally this will be common regardless of the instrumentation’s language or thread of execution. And since you really don’t want crashes or sudden application shutdowns or power outages to cause you to lose everything, you need to persist this storage. You can write it to a file on disk (if your platforms have such access), but be sure to write the serialization and deserialization functions with backwards-compatibility in mind because you’ll eventually need to change the format.
Networking: Data stored with the product has its uses, but chances are you want this data to be combined with more data from other installations. You don’t need to write the network code yourself, there are libraries for HTTPS after all, but you’ll need to write a protocol on top of it to serialize your data for transmission.
Scheduling: Sending data each time a new piece of instrumentation comes in might be acceptable for some products whose nature is only-online. Messaging apps and MMOs send so much low-latency data all the time that you might as well send your data as it comes in. But chances are you aren’t writing something like that, or you respect the bandwidth of your users too much to waste it, so you’ll only want to be sending data occasionally. Maybe daily. Maybe when the user isn’t in the middle of something. Maybe regularly. Maybe when the stored data reaches a certain size. This could get complicated, so spend some time here and don’t be afraid to change it as you find new corners.
Errors: Things will go wrong. Instrumentation will, despite your ergonomic API, do something wrong and write the wrong value or call stop() before start(). Your networking code will encounter the weirdness of the full Internet. Your storage will get full. You need some way to communicate the health of your data collection system to yourself (the owner who needs to adjust scheduling and persistence and other stuff to decrease errors) and to others (devs who need to fix their instrumentation, analysts who should be told if there’s a problem with the data, QA so they can write tests for these corner cases).
Ingestion: You’ll need something on the Internet listening for your data coming in. It’ll need to scale to the size of your product’s base and be resilient to Internet Attacks. It should speak the protocol you defined in #4, so you should probably have some sort of machine-readable definition of that protocol that product and ingestion can share. And you should spend some time thinking about what to do when an old product with an old version of the protocol wants to send data to your latest ingestion endpoint.
Pipeline: Not all data will go to the same place. Some is from a different product. Some adheres to a different schema. Some is wrong but ingestion (because it needs to scale) couldn’t do the verification of it, so now you need to discard it more expensively. Thus you’ll be wanting some sort of routing infrastructure to take ingested data and do some processing on it.
Warehousing: Once you receive all these raw payloads you’ll need a place to put them. You’ll want this place to be scalable, high-performance, and highly-available.
Datasets: Performing analysis to gain insight from raw payloads is possible (even I have done it), but it is far more pleasant to consolidate like payloads with like, perhaps ordered or partitioned by time and by some dimensions within the payload that’ll make analyses quicker. Maybe you’ll want to split payloads into multiple rows of a tabular dataset, or combine multiple payloads into single rows. Talk to the people doing the analyses and ask them what would make their lives easier.
Tooling: Democratizing data analysis is a good way to scale up the number of insights your organization can find at once, and it’s a good way to build data intuition. You might want to consider low-barrier data analysis tooling to encourage exploration. You might also want to consider some high-barrier data tooling for operational analyses and monitoring (good to know that the update is rolling out properly and isn’t bricking users’ devices). And some things for the middle ground of folks that know data and have questions, but don’t know SQL or Python or R.
Tests: Don’t forget that every piece of this should be testable and tested in isolation and in integration. If you can manage it, a suite of end-to-end tests does wonders for making you feel good that the whole system will continue to work as you develop it.
Documentation: You’ll need two types of documentation: User and Developer. The former is for the “user” of the piece (developers who wish to instrument back in #1, analysts who have questions that need answering in #10). The latter is for anyone going in trying to understand the “Why” and “How” of the pieces’ architecture and design choices.
You get all that? Thread safety. File formats. Networking protocols. Scheduling using real wall-clock time. Schema validation. Open ports on the Internet. At scale. User-facing tools and documentation. All tested and verified.
Look, I said it’d be straightforward, not that it’d be easy. I’m sure it’ll only take you a few years and a couple tries to get it right.
Or, y’know, if you’re a Mozilla project you could just use Glean which already has all of these things…
API: The Glean SDK API aims to be ergonomic and idiomatic in each supported language.
Persistent Storage: The Glean SDK uses rkv as a persistent store for unsubmitted data, and a documented flat file format for submitted but not yet sent data.
Networking: The Glean SDK provides an API for embedding applications to provide their own networking stack (useful when we’re embedded in a browser), and some default implementations if you don’t care to provide one. The payload protocol is built on Structured Ingestion and has a schema that generates and deploys new versions daily.
Scheduling: Each Glean SDK payload has its own schedule to respect the character of the data it contains, from as frequently as the user foregrounds the app to, at most, once a day.
Errors: The Glean SDK builds user metric and internal health metrics into the SDK itself.
Ingestion: The edge servers and schema validation are all documented and tested. We autoscale quite well and have a process for handling incidents.
Pipeline: We have a pubsub system on GCP that handles a variety of different types of data.
Warehousing: I can’t remember if we still call this the Data Lake or not.
Datasets: We have a few. They are monitored. Our workflow software for deriving the datasets is monitored as well.
Tooling: Quite a few of them are linked from the Telemetry Index.
Tests: Each piece is tested individually. Adjacent pieces sometimes have integration suites. And Raphael recently spun up end-to-end tests that we’re very appreciative of. And if you’re just a dev wondering if your new instrumentation is working? We have the debug ping viewer.
Glean takes this incredibly complex problem, breaks it into pieces, solves each piece individually, then puts the solution together in a way that makes it greater than the sum of its parts.
All you need is to follow the six steps to integrate the Glean SDK and notify the Ecosystem that your project exists, and then your responsibilities shrink to just instrumentation and analysis.
If that isn’t frictionless data collection, I don’t know what is.
:chutten
(( If you’re not a Mozilla project, and thus don’t by default get to use the Data Platform (numbers 6-10) for your project, come find us on the #glean channel on Matrix and we’ll see what help we can get you. ))
While there are not huge differences between Stratechery Weekly Articles and subscriber-only Daily Updates, I do spend more time on the Weekly Articles trying to craft an overarching narrative; Weekly Articles, by virtue of being free, are better suited to sharing, and humans like stories, not just analysis.
However, the first lesson from Dave Chappelle’s latest release on Instagram, Unforgiven, is that one best not compete with Chappelle when it comes to story-telling; the way in which the comedian weaves together multiple stories from his childhood on up to the present to make his argument about why he should be paid for the rights to stream Chappelle’s Show is truly extraordinary.
To that end, I thought a more prosaic approach might be in order: Chappelle’s 18-minute special, which I highly suggest you watch in full, is chock-full of insights about how the Internet has transformed the entertainment industry specifically, and business broadly; my goal is to, in my own clumsy way, highlight and expand on those insights. That I ought to make a simple list and not compete on story-telling is one lesson down; four to go.
Lesson Two: Talent in an Analog World
This lesson is exposed in two parts; first, Chappelle on his precociousness as a child comedian:
A few minutes later, though, Chappelle admits that fourteen years after he started as a standup comedian he signed a deal to make Chappelle’s Show under some amount of financial duress:
Chappelle may have been preternaturally gifted, but that wasn’t enough to avoid being broke in the early 2000s when he signed that contract with Comedy Central. Granted, Chappelle was almost certainly scratching out a living doing standup, but to truly make it big meant signing up with a network (or, in the case of music, a label), because they controlled distribution at scale.
That’s the big difference between stand-up and something like Chappelle’s Show: when it comes to the former your income is directly tied to your output; if you do a live show, you get paid, and if you don’t, you don’t. A TV show or record, on the other hand, only needs to be made once, at which point it can not only be shown across the country or across the world, but can also be shown again and again.
It’s the latter that is the key to getting rich as a creator, but in the analog world there were two big obstacles facing creators: first, the cost of creating a show or record was very high, and second, it was impossible to get said show or record distributed even if you managed to get it made. The networks and labels were the ones that had actual access to customers, whether that be via theaters, cable TV, record stores, or whatever physical channel existed.
Over the last two decades, though, technology has demolished both obstacles: anyone with access to a computer has access to the tools necessary to create compelling content, and, more importantly, the Internet has made distribution free. Of course the Internet did exist when Chappelle signed that contract, but there are two further differences: first, the advent of broadband, which makes far richer content accessible, and second, social networks, which provide far more reach than traditional channels, for free. Today it is far more viable for talent to not only create content and distribute it, but also promote it in a way that has tangible economic benefits.
Lesson Three: The House Wins
What is noteworthy about Chappelle’s argument is that he is quite ready to admit that everyone involved is acting legally:
From the perspective of 2020, and Chappelle’s overall point about how he feels his content was taken from him, this seems blatantly unfair. At the same time, from a network’s perspective, Chappelle’s success pays for all of the other shows that failed. It’s the same idea as the music industry: yes, record companies claim rights to your recordings forever, but for the vast majority of artists those rights are worthless. In fact, for that vast majority of artists, they represent a loss, because the money the network or label spent on making the show or record, promoting it, and distributing it, is gone forever.
There is an analogy to venture capital here, which I made five years ago in the context of Tidal:
This is why, by the way, I’m generally quite unsympathetic to artists belly-aching about how unfair their labels are. Is it unfair that all of the artists who don’t break through are not compelled to repay the labels the money that was invested in them? No one begrudges venture capitalists for profiting when a startup IPOs, because that return pays for all the other startups in the portfolio that failed.
It’s not a perfect analogy, in part because the output is very different: a founder will typically only ever have one company, so of course they retain a much more meaningful ownership stake from the beginning; an artist, on the other hand, will hopefully produce new art, which they will be in a much stronger position to monetize if their initial efforts are successful. Chappelle, for example, earns around $20 million per stand-up special on Netflix; Taylor Swift, another artist embroiled in an ongoing controversy around rights to her original work, fully owns the rights for her two most recent records.
The lesson to be learned, though, is that for many years venture capitalists, networks, and record labels could ensure that the expected value of their bets was firmly in their favor. There were more entrepreneurs that wanted to start companies, more comedians that wanted to make TV shows, and more musicians that wanted to make records than there was money to fund them, which meant the house always came out ahead: sure, money was lost on companies, comedians, and musicians that failed, but the upside earned by those that succeeded more than made up for it.
Over the last two decades venture has been flooded with new sources of capital, resulting in far more founder-friendly terms than before; comedy, meanwhile, has been a particularly notable beneficiary of the podcast boom, as more and more artists create shows that are inexpensive to produce yet extremely lucrative for the artist. Music has seen its own independent artists emerge, although the labels, thanks in part to the power of their back catalogs, have retained their power longer than many expected. Still, the inevitable outcome of Lesson Two is that Lesson Three is shakier than ever.
Lesson Four: Aggregators and the Individual
The one company that comes out looking great is Netflix:
Technically speaking, Netflix did exist when Chappelle negotiated that contract with Comedy Central, but the company was a DVD-by-mail service; the streaming iteration that Chappelle is referring to wasn’t viable back then. Indeed, the entire premise of the streaming company is that it takes advantage of the changes wrought by the Internet to achieve distribution that is not simply equivalent to a TV network, but actually superior, both in terms of reaching the entire world and also in digitizing time. On Netflix, everything is available at anytime anywhere, because of the Internet.
Netflix’s integration of distribution and production also means that they are incentivized to care more about the perspective of an individual artist than a network; that is the optimal point of modularity for the streaming company. At the same time, it is worth noting that Netflix is actually claiming even more rights for their original content than networks ever did, in exchange for larger up-front payments. This makes sense given Netflix’s model, which is even more deeply predicated on leveraging fixed cost investments in content than networks ever were, not simply to retain users but also to decrease the cost of acquiring new ones.
At the same time, Aggregators (even weak ones like Netflix), are inherently a better bet for the individual creator than middlemen like the networks ever were. On Netflix, every show is equally accessible relative to every other show; there is no fighting for prime time slots or seasons. It’s the same dynamic on Google or Facebook: all content is treated the same, which is absolutely a problem for companies that used to rule the roost when physical distribution mattered, and nothing but upside for individual creators that only exist because of the Internet.
And, by extension, a company like Netflix is far more sensitive to the needs of the creators that its audience actually care about. The fact the company has twice extended Chappelle’s stand-up special deal is all of the evidence you need that that $20/million per show is money well spent, not because Netflix made people watch, but because people sought it out, and the reality of Aggregators is that they win by making users happy in a world where competition is only a click away, not by denying them choice by virtue of controlling physical distribution.
Lesson Five: The Real Boss
Chappelle made this point explicitly in his call to action:
This is the most important lesson of the Internet: the consumer is the ultimate boss. In markets without any sort of additional friction, like website or social media, this means that power accrues almost completely to Aggregators, with creators able to connect with consumers as secondary beneficiaries. Look no further than the fact that this special was posted on Instagram: Chappelle has the platform to appeal directly to his fans that his predecessors, all of whom despised the networks and labels and their contracts just as much if not more than he does, lacked. That Chappelle’s Instagram post is no different in format from one posted by you or me is a feature, not a bug.
Of course not everything is as clear cut as the open web, or user-generated content. In other markets, with legacy friction from analog business models, or legal friction like copyright, power is more disbursed, which is why it is not certain that Chappelle’s power play will succeed; the fact of the matter is that he did sign a contract, which absolutely gives Comedy Central the rights to stream Chappelle’s Show on HBO Max, CBS All Access, and anywhere else they please, and customers may very well choose to ignore Chappelle’s plea. After all, they are the boss.
What is just as clear, though, is that networks and anyone else dependent on physical distribution are on the retreat. Contracts and copyright may secure their place for longer than seems earned, but there is a reason this fight is about content made twenty years ago, while Chappelle is very content with the status of content made today. The Internet favors creators and Aggregators, while everyone in the middle of the smiling curve — where power used to be centered — is increasingly of little value.
Going through the script for an upcoming member feedback session, I caught a line which read:
“We’re soon going to be launching some exciting new changes we think you’ll love. […] And we want your feedback!”
If you’re telling members how you want them to think and respond, you’re not gathering feedback, you’re trying to persuade them.
There’s nothing wrong with persuasion, we do it all the time. But don’t confuse it with gathering feedback.
A feedback session is about creating a neutral space where members are encouraged to be honest and happy to share the things they like and dislike. You have to tease out the key insights (both the good and bad).
If you begin by telling members how excited you are, they’re far less likely to give honest feedback for fear of upsetting you (or being seen as the ‘negative’ person in the group).
A persuasion session is where you try to get members as excited about the upcoming changes as you are. You give them a narrative, sell a vision of the future, and identify their own efficacy to help make that future happen.
Both are fine approaches, just be clear which yours is.
If you need a clearer distinction…
When you’ve made a decision about a major change, you need to persuade members.
When you’re not sure what decision to make, you need to gather feedback.
If I could get it my way, I’d probably put LineageOS or another proprietary Google and hardware manufacturer free Android version on my tablet. While this is possible with some tablets, I would however loose the pen and handwriting input which is an absolute must to use the tablet not only for media consumption but also for work. So I made the best out of the situation and here’s a short overview of my setup:
I can get most applications I need from the F-droid app store. However, there is currently no open-source PDF annotation program and Collabora’s Libreoffice for Android is also not to be found there. So I installed the Aurora Store app from F-droid that gives me access to Google’s Play store without a Google account and without entering Google account credentials into Android. It doesn’t stop Google’s privacy invading data collection completely, but at least they can’t outright tie it to a particular account.
Via the Aurora Store I then installed the Xodo PDF reader / annotation app that was recommended to me for this purpose from different people. There’s no paid version available but there is also no advertisement in the free app and there seem to be no trackers inside. I had a look at the Canadian company behind it and it seems that their business model is selling services around online PDF processing. So the PDF annotation part is covered.
For handwriting notes I use Samsung’s ‘Notes’ app that came with the tablet. It works nicely and while it asks if I want to use Samsung’s cloud store it doesn’t ask twice. Fine! Which brings me to the important point how to get files to and from the device. For this purpose I use the Nextcloud app that synchronizes with my own Nextcloud folder. As the tablet is not entirely trusted, I created a separate account with a folder that I do share with my main account. Files I want to work with on the go are put into the the shared folder and are synchronized to the device. This works well in both directions and Xodo and Samsung’s notetaking app have no problems using files there.
And for Office-like applications I use Collabora’s Libreoffice implementation for Android. They have come a long way since last year and even commenting and marking changes now work nicely. Except for the user shown for changes and comments that is called “LocalHost”. Ah well, small things…
And finally, I installed Conversations on the tablet for quickly exchanging links, text and images with the quickly. Like all other data I exchange with the device, no service in the cloud that is not controlled by me is touched.
So while it’s arguably an imperfect setup, giving the tablet only access to a shared folder in my own cloud and not using a Google account makes it trustworthy enough to be usable with most documents and information I would like to work with on a tablet.
On Wednesday, Katie Cunningham is defending her dissertation, “Purpose-First Programming: A Programming Learning Approach for Learners Who Care Most About What Code Achieves.” I’m proud of the work Katie has done with Barb and me over the years. Let me relate the story here, with links to the blog posts.
I first met Katie through through an on-line essay she wrote explaining the issues of gender and CS to her faculty (see my blog post referencing at link here). After she graduated, she worked on the CSin3 project at California State University at Monterey Bay which helped Latino and Latina students get undergraduate degrees in CS in three years. The paper she and the CSin3 team wrote won a Best Paper award at SIGCSE 2018 (see paper here).
Katie started her PhD research studying how students traced code when trying to understand and predict program behavior. She published her findings at ICER 2017 (see blog post). As you’d expect, students who traced programs line-by-line were more likely to get prediction problems (What is the output? What is this variable’s value?) correct. But not always. Most intriguing: Students who stopped mid-way through a trace were more likely to get the problems wrong than those who never traced at all.
In her next study, she replicated the original experiment and then brought into the lab those students who had stopped mid-way in order to ask them “why?” A common answer was that the students were trying to see the “pattern” of the program, and once they saw the pattern, they were able to predict the answer. The problem is that the students were novices. They didn’t know many patterns. They often guessed wrong. Katie presented this paper at ITiCSE 2019 (see blog post).
Katie did a think-aloud study where she could watch students tracing, and something unexpected and interesting happened — two participants refused to trace. These were data science students who did program successfully, but they were unwilling to trace code at the line-by-line level. She wrote an ICLS 2020 paper about their reasons (see blog post). She decided to study that population.
A 2018 CHI paper by another U-M student, April Wang, had talked about how computing education fails conversational programmers (see paper here). Katie decided to build a new kind of curriculum that addressed her data science students and April’s conversational programmers. How do you teach programming to students who (1) don’t want to become professional programmers and (2) are dissuaded from high cognitive load activities like tracing code? This is a very different problem than most of CS education at the undergraduate level where we have eager CS majors who want to get software development jobs. Katie was dealing with issues both of motivation and of cognitive load.
Katie invented purpose-first programming. I don’t want to say too much about it here — her dissertation and her future papers will go more into it. I’ll give you a sense for her process. She used Github repositories and expert interviews to identify a few programming plans (just like Elliot Soloway and Jim Spohrer studied years ago) that were in common use in a domain that her participants cared about. She then taught those plans. Students modified and combined the plans to create programs that the students found useful. Rather than start with syntax or semantics, she started with the program’s purpose. The results were very positive in terms of learning, performance, and affect. Rather than be turned away, they wanted more. One student asked if she could create a whole set of curricula like this, each for a different purpose. That’s the idea exactly. Katie may be on her way to inventing the Duolingo of programming.
Katie already has a post-doc lined up. She’ll be a CI Fellow with Nell O’Rourke at Northwestern. The defense will be on Zoom — feel free to come and cheer her on!
The School of Information is pleased to announce the oral defense of Kathryn Cunningham:
Title: Purpose-First Programming: A Programming Learning Approach for Learners Who Care Most About What Code Achieves
Date: Wednesday, December 2nd
Time: 10 am – 12 pm EST
Place: This defense will be held virtually for the public to attend. Please use this link.
Barbara Ericson and Mark Guzdial, serving as committee chairs, will preside over the oral defense.
I jumped on the radio on a whim last night to try and do some groundwork for the headlining Sunday Special featuring the great Anne-Marie Scott, Maren Deepwell, and Tannis Morgan.
I wanted to play some of the synthwave tunes I discovered one the Italians Do It Better website/youtube channel thanks to this Tweet from Paul Bond while he was broadcasting a fine needle-dropping vinylcast of Brian Eno and David Byrne on #ds106radio:
By the way, are you familiar with the @IDIB label? I think you'd appreciate their visual aesthetic, whether you like the music or not
It’s awesome that ds106radio is still delivering the goods, it is moments like this on the radio via Twitter that the web feels like friends hanging out sharing what they love, which is the best feeling of both connection and growth. And then when folks actually listen to your radishow? SWOON!
ds106radio: Synthwave with Jim Groom
This show was fun and fairly tight at 50 minutes, so I wanted to get it on the bavaradio site with the idea of sometime soon backfilling the bavaradio catalogue given I have a ton of shows just sitting in my Audio Hijack folder that have never seen the light of the web since their inception.
Microsoft is reportedly developing a way to bring Android apps to Windows devices with few or no code changes.
Windows Central detailed the effort, called ‘Project Latte,’ in a recent report. In short, app developers could package their Android apps with the MSIX Windows app package format, which “preserves the functionality of existing app packages and/or install files” according to Microsoft documentation.
Sources familiar with the project told Windows Central it could arrive as early as next year, perhaps as part of the fall 2021 Windows 10 update.
It’s worth noting that Microsoft attempted to bring Android apps to Windows Phones in the past with a project codenamed Astoria, but it never came to fruition. Although Project Latte is similar, it will likely make use of the Windows Subsystem for Linux (WSL), but Microsoft will need to provide an Android subsystem for the apps to run.
Further, it’s unlikely the project will get support for Play Services — Google typically doesn’t allow the software to be installed on anything other than native Android devices and Chrome OS. In other words, that means apps that depend on Play Services — in other words, many Android apps — will need updates to remove those dependencies so they work on Windows 10.
If Project Latte ships — and if developers get on board with it — it could open the gates for quite a few Android apps on Windows 10 and in a much better way than Microsoft’s current solution. Through the Your Phone app and a limited group of Samsung devices, some users can stream apps from their phone to their PC, but that’s not always a great experience.
It also could be an integral part of Microsoft’s Surface Neo plans. Although the folding tablet was delayed, it could be an ideal device to make use of the touch-friendly Android apps on offer while also supporting Windows 10 apps (albeit in a limited capacity).
Evidence-based software research requires access to data, and Github has become the primary source of raw material for many (most?) researchers.
Parallels are starting to emerge between today’s researchers exploring Github and biologists exploring nature centuries ago.
Centuries ago scientific expeditions undertook difficult and hazardous journeys to various parts of the world, collecting and returning with many specimens which were housed and displayed in museums and botanical gardens. Researchers could then visit the museums and botanical gardens to study these specimens, without leaving the comforts of their home country. What is missing from these studies of collected specimens is information on the habitat in which they lived.
Github is a living museum of specimens that today’s researchers can study without leaving the comforts of their research environment. What is missing from these studies of collected specimens is information on the habitat in which the software was created.
Github researchers are starting the process of identifying and classifying specimens into species types, based on their defining characteristics, much like the botanist Carl_Linnaeus identified stamens as one of the defining characteristics of flowering plants. Some of the published work reads like the authors did some measurements, spotted some differences, and then invented a plausible story around what they had found. As a sometime inhabitant of this glasshouse I will refrain from throwing stones.
Zoologists study the animal kingdom, and entomologists specialize in the insect world, e.g., studying Butterflys. What name might be given to researchers who study software source code, and will there be specialists, e.g., those who study cryptocurrency projects?
The ecological definition of a biome, as the community of plants and animals that have common characteristics for the environment they exist in, maps to the end-user use of software systems. There does not appear to be a generic name for people who study the growth of plants and animals (or at least I cannot think of one).
There is only so much useful information that can be learned from studying specimens in museums, no matter how up to date the specimens are.
Studying the development and maintenance of software systems in the wild (i.e., dealing with the people who do it), requires researchers to forsake their creature comforts and undertake difficult and hazardous journeys into industry. While they are unlikely to experience any physical harm, there is a real risk that their egos will be seriously bruised.
I want to do what I can to prevent evidence-based software engineering from just being about mining Github. So I have a new policy for dealing with PhD/MSc student email requests for data (previously I did my best to point them at the data they sought). From now on, I will tell students that they need to behave like real researchers (e.g., Charles Darwin) who study software development in the wild. Charles Darwin is a great role model who should appeal to their sense of adventure (alternative suggestions welcome).
This is a story about researching Russian music, about Italian adulterers in Hell, and
about pulp sci-fi featuring fairy-cursed princesses. To be honest, it’s also about editing Wikipedia, why that’s fun and
rewarding and maybe you should try it.
What happened was, on Friday there was a
Twitter challenge: “What's a great song that is over
10 minutes in length?” I replied “Francesca da Rimini” and without thinking too much switched over to YouTube and,
since I was about done with things and ready for bed, dialed up
this pretty good performance by Igor Manasherov and the
Moscow Philharmonic. While I was enjoying that, I had a glance at
the Wikipedia
entry (that’s a pointer to the entry as of Friday night) and was saddened — it opened with three
windy paragraphs about themes and influences which lacked even one citation, some rando injecting amateur-music-critic opinions
into Wikipedia. Obviously had to be fixed.
A word on the music
I’ve loved this piece since I stumbled into a live performance in Switzerland at the Lucerne festival while on a
business trip sometime around 1990. If you want to know more about it, I enthused about it back in 2006, and
the improved Wikipedia entry (see below) is full of
well-cited factual material, including descriptions by contemporary critics and praise from Saint-Saëns.
To the library!
We had some running around to do on Saturday so I tacked on a stop at the Vancouver Public Library’s Central Branch.
I’d already poked around and found three respectable Tchaikovsky biographies that were said to have good coverage of the
music, including one (Tchaikovsky: A Self-Portrait by Alexandra Orlova) which is an assemblage of Tchaikovsky’s own
writings.
In normal times I would have gone to the library, grabbed the books off the shelves, sat down with my computer at a quiet
table, and done my editing there and then.
But the stacks are closed because of Covid so you have to talk to a person at the Info desk to order the books you want and
somebody brings them to you after a few minutes. Which is time to walk around the main floor and look at the new books and
comics and magazines. My eyes were captured by the cheerful luridness of the September-October
Fantasy & Science Fiction cover. So on impulse I brought that home, along with
Tchaikovsky.
Editing
One of the biographies turned out to be useless, but the other three each had a good index, so I could skip through all the
mentions of Francesca. It was only an hour or two’s work to pull citations together and reorganize the entry.
Now, rather than offering opinions about Tchaikovsky’s influences, it quotes his own remarks on the
subject — yes, he was influenced by Ring of the Nibelung which he’d seen at Bayreuth,
even though he found it “very antipathatic”.
Bonus!
After I’d finished editing I picked up Fantasy & Science Fiction, feeling all nostalgic. About 300 years
ago, as an undergraduate I lived in a student house full of Sci-Fi hounds and we bought F&SF every month,
along with Asimov’s Science Fiction, and passed it from hand to hand. It’s still got unironic Space Opera covers
entirely unrelated to any stories inside. It’s still got klunky typography on cheap paper. It’s still got lots of reviews and
amusing classified ads.
What’s different is that the stories are 100% free of the egregious sexism that marred twentieth-century sci-fi and
fantasy.
I really enjoyed, and unhesitatingly recommend, Of Them All, a novella by
Leah Cypess. It’s good old-fashioned fantasy about two princesses, neither
particularly lovely, one fairy-cursed at birth: “You will be beautiful only to those who wish you harm.” What a great
premise! And nicely developed.
Downside
I’ve loved Francesca da Rimini for thirty years but it’d never occurred to me to wonder who Francesca might have
been — a
real person, it turns out.
The work is inspired by Dante Aligheri’s description, in Inferno, of the eternal punishment in
Hell of Francesca and her adulterous lover. Which was pretty gruesome, and now that I know about it, I have to grant that
Tchaikovsky did a fine job of painting the picture musically. Which is not helping my enjoyment of the music, but I’ll
probably get over it.
You can too
Edit Wikipedia, I mean. Everybody is an expert in a few things, at the very least the neighborhood they live in,
some aspects of their profession, and likely one or two extracurricular interests.
It’s this simple: Whenever you see something
wrong in Wikipedia, just fix it. It doesn’t need to be time-consuming and I never find it tedious. Plus, you’re enriching the
world that everyone lives in.
a command line tool that enables data analysts and engineers to transform data in their warehouses more effectively. Today, dbt has ~850 companies using it in production, including companies like Casper, Seatgeek, and Wistia. – What, exactly, is dbt?, Tristan Handy, Oct 2017
From the same article:
dbt code is a combination of SQL and Jinja, a common templating language used in the Python ecosystem. ref() is a function that dbt gives to users within their Jinja context to reference other data models. ref() does two things:
It interpolates itself into the raw SQL as the appropriate schema.table for the supplied model.
It automatically builds a DAG of all of the models in a given dbt project.
Both of these are core to the way that dbt operates. Because dbt is interpolating the locations of all of the models it generates, it allows users to easily create dev and prod environments and seamlessly transition between the two. And because dbt natively understands the dependencies between all models, it can do powerful things like run models in dependency order, parallelize model builds, and run arbitrary subgraphs defined in its model selection syntax.
Once again, this little device to the left has saved me $100+.
A few years ago, my Chevy Volt’s ABS warning light came on. A brief search around various forums said the most likely cause was driving through deep puddles in wet weather. That the water would muck up the ABS (automatic braking / skid avoidance sensor) and, typically, waiting until everything dried out and then resetting the trouble code would fix it (would make the warning light go out).
To reset the trouble code requires an OBDII scanner of some sort. OBDII is the on board diagnostics system and a standard connector for interacting with the system has been mandated on all new cars in the US since 1996 (but the original OBD systems date all the way back to 1969!).
When you take your car to the shop and they come back after 15-20 minutes with a printed report of various trouble codes? Most likely, a standard report produced by the OBDII system.
There are three types of codes, more or less, confirmed, pending, and permanent. Confirmed and pending are typically the “detected a problem, might go away” and “might be a problem variety”. Permanent are the “yeah, really, a problem was detected” variety. Would have been at least $150 to clear the codes at a dealer and, of course, an upsell for many hundrends of dollars to “fix” the “clearly on the verge of failing” sensor.
Yesteday, my Volt barfed up a “service high-voltage charging system” message and refused to charge the batteries. Plugging in the OBDII scanner, it showed a few error codes across all varieties. Specifically, it was claiming low coolant. But there was plenty of coolant in the battery coolant tank.
Clear the codes!
I cleared all the pending and confirmed trouble codes. Permanent codes can’t be cleared but they will also update automatically based on new sensor data.
The car has to be turned on to do this. And, because the battery was dead, the gas engine was running.
Within seconds of clearing the codes, I heard the engine rev a bit, indicating that it was charging the batteries!
Plugging the car in and it immediately started chargin.
So, once again, the OBDII scanner saved me at least $150 and a lot of inconvenience just to clear a code. An unscrupulous mechanic would have printed out the report, showed it to me, and charged $800-$1200 to replace the charging sensor wiring harness.
I highly recommend adding one to your toolkit. There are a bunch out there. The BlueDriver isn’t the cheapest, but it works over bluetooth and looks up trouble codes on the internet to provide a list of the most common fixes to any given trouble code. Not the “dealer recommends you spend $#,### replacing this thing” fixes, but fixes looked up in various online car enthusiast forums that are a treasure trove of tips and tricks!
Of course, the concern is whether clearing the codes might cover a problem.
It really won’t. Any important– about-to-cause-destruction– sort of code is of the permanent nature. It can’t be cleared and it will be updated.
The confirmed/pending codes are much more advisory. They may indicate very real problems– certainly, the ABS sensor was mucked up by water and the coolant sensor did detect low coolant because of sloshing– but if there is a real problem, then the cleared codes will just pop right back up in short order anyway.
Talking posed a challenge for me. While my Mandarin was strong
for someone who had grown up in the US, I wasn't fluent enough
to express myself in the way I wanted. This had some benefits:
I had to think before I spoke. I was more measured. I was a
better listener. But it was also frustrating, as though I'd
turned into a person who was meek and slow on the uptake. It
made me think twice about the Chinese speakers at work or school
in the US whom I'd judged as passive or retiring. Perhaps they
were also funny, assertive, flirtatious, and profane in their
native tongue, as I am in mine.
When people in the US talk about the benefits of learning a second
language, they rarely, if ever, mention the empathy one can develop
for others who speak and work in in a second language. Maybe that's
because so few of us Americans learn a foreign language well enough
to reach this level of enlightenment.
I myself learned just enough German in school to marvel at the
accomplishment of exchange students studying here in their second
language, knowing that I was nowhere near ready to live and study
in a German-speaking land. Marvel, though, is not quite as valuable
in this context as empathy.