|
mkalus shared this story . |
Oh sweet Christ not Brexit again.
Yes, you will never escape. It will never be over. Decades from now, as your wrinkled fingers grasp the remote for your 3D holo-viewer, the main news item will still be about Brexit.
At least we got a break during the coronavirus emergency.
Yep, say what you like about pandemics, but at least they take trade talks off the front pages. Still, it's back now. We leave at the end of the year. And deal or no-deal, things at the border are going to be very different.
OK lay it out for me.
For decades we have had frictionless trade with Europe in the customs union and single market. The customs union got rid of tariffs, which are taxes on goods entering a territory, and the single market harmonised regulations, which means goods are made to the same standards. Once you're outside of them, you need checks at the border to make sure people are paying the right tax and complying with the regulations.
And that's what's about to happen?
Exactly. And this will apply regardless of whether there is a deal or not. I want to issue a word of warning before we go any further: It's a horror show. The level of tediousness here is off the scale. This is like someone came up with a super-powered serum for the concept of bureaucracy and then injected it directly into your bloodstream. But you didn't turn into Chris Evans in Captain America, you turned into Jeff Goldblum in The Fly. The worst things are the acronyms. Everything has an acronym. But you need to get your head around it in order to understand what's going to happen to us next month.
I don't care. I hate this. I want this conversation to stop.
You can't, it's too late. You are trapped here with me and the acronyms. OK so here's the basic problem, the one from which all others follow. Our customs system currently processes around 55 million declarations a year. In 2021, it will process around 270 million. It needs to massively ramp up capacity.
It's just as well the government has such a good track record of implementing complex IT projects at speed then.
Quite. To be fair, the government has put a lot of effort into this, albeit belatedly. More than 35 government departments and public bodies are involved, including HM Revenue & Customs (HMRC), the Department for Environment, Food & Rural Affairs (Defra), the Home Office (HO), the Department for Transport (DfT), the Border and Protocol Delivery Group (BPDG) and the Transition Task Force (TTF).
Sweet Jesus the acronyms.
Actually, most of those are abbreviations, but let's not get caught up on details. We've barely scratched the surface. There are three key areas where the government needs to build capacity: IT systems to process the customs declarations, physical infrastructure at or near ports, and staff in government and the private sector to keep the customs system going.
That's a lot to do.
It is. But the government made things easier in one crucial respect: it delayed its own import declarations system until July next year.
What does that mean?
It means that stuff coming into Britain from Europe basically gets waved through. There are still technically customs requirements, but they've been pushed back six months. This allowed them to make sure goods would still enter the country and let them focus on trying to get the exports right.
It's hardly taking back control, is it?
No it isn't, but they're undertaking a systems-level change at an eye-watering timetable, so it was a necessary sacrifice.
Couldn't they have extended transition to prepare for this?
Yes they could, but chose not to. That's cost them. Covid seriously delayed preparations, dominated attention in business and government, paused ministerial decision-making and put communication with traders into deep-freeze over the summer.
So what are the biggest risks now?
The IT systems. There are 10 critical IT systems which are needed at the GB–EU border. Then there are the European systems which UK exporters will need to use to get access to the continent. We're not going to go into all of them here - we're going to massively simplify.
Thank heavens.
Don't worry, it'll still make your brain dribble out of your ears. We're also going to simplify by taking goods going from Britain to Northern Ireland off the table. That's its own separate hellscape. And we're going to focus on the Dover-Calais crossing. There are many others going from England to France, but this is the main route. It serves 'accompanied goods' - when a driver in a lorry takes the goods onto a ferry and then drives it off on the other side of the Channel. This is called RoRo, for roll-on-roll-off.
Acronym. Drink.
If you keep that up you'll be smashed by the end of the article and won't have any idea what I'm talking about.
I already have no idea what you're talking about.
Fair enough, drink away. The trouble with customs IT systems is this: Everyone needs to be filling in the right thing, in the right place, at the right time. If they don't, things break down. That doesn't just apply to the UK and French governments. It applies to exporters and importers, ports, hauliers and others. Customs is all or nothing. If one section is wrong, it's all wrong. Lorries are often full of lots of different consignments of goods from different exporters. Plenty of them travel with 100 individual separate consignments on them. This is called 'groupage'. So if one input of one customs form in one of those consignments is wrong, the whole lorry is delayed. And if that lorry is delayed, all the lorries behind it are delayed. The potential for breakdown is therefore very significant.
This is already making me anxious. It's like Jenga but it reaches all the way into the sky and is composed entirely of knives.
You also need to make sure that third party software used by places like the ports integrates with the government systems. And that assumes that the government IT systems actually work and have staff with the proper experience and training to operate them. And this too is interrelated. If one of the systems breaks down, it has a knock-on effect on the other systems. You keep seeing this same problem crop up. It's not one of error, exactly. It's about the consequence of the error, the knock-on effects of it.
How robust are those IT systems looking right now?
Not great. Some have been delayed indefinitely, some for a set period, some are in trials and some are online. But even when they're finished, you really want to give all the people using them time to understand them, to get used to them, so that when we leave transition there are as few mistakes as possible. All four industry representative bodies, including the Road Haulage Association (RHA) and the British International Freight Association (Bifa), have raised concerns about the government's level of preparedness, saying that they don't believe the border will be fully functioning by next month.
That's two more acronyms by my count.
I'm glad to see you sticking to the important information here. The trouble is that lack of government preparedness doesn't just affect it - it affects trader preparedness as well. If they're not getting clear communication from the government about what is happening and how it is happening, they don't know what to do. And the government has a bad record here. It has marched traders up the hill on no-deal several times over recent years, only to march them down again. Now many simply ignore it. Government communications have, until recently, centred on the "opportunities" of Brexit, which does nothing to indicate the urgency with which people need to make expensive and time-consuming changes. Even in October, just 45% of high-value traders who trade exclusively with the EU had started to invest in readiness.
Oh dear.
There are some reasons to be more optimistic. The first is that government communication has belatedly started to improve. A new campaign in October was much better, telling traders that "time is running out". There's also one really important thing to remember about all this: it's not a long term problem. Brexit has plenty of those and they are severe, but this is not one of them. This is a short, sharp, embarrassing shock. Eventually, the market will adjust. People will see what happens in January and find ways around it so they can get their goods to market. Some people think that will happen very quickly indeed - no more than a month. Some think it'll take the first quarter of next year or longer. But very few people think it will last the whole year. What we're looking at here is the most dramatic, but also ultimately the most superficial, of Brexit impacts.
Starting to feel a bit tipsy now.
Cool, then it might be a good time to start talking about the IT systems.
No. Stop.
What?
I don't want to hear it. I want to get out.
It's too late. You're trapped here in an imaginary world in which I am talking to myself and explaining customs procedures. And in fact your resistance to this conversation probably points to some kind of deep-seated psychological trauma which I'm working my way through.
Dog carcass in alley this morning. Tyre tread on burst stomach.
Very good, Rorschach. So look, there are really four forms you need to remember. First, the import/export declaration. Second, the safety and security documentation. Third, the sanitary and phytosanitary measures for agricultural goods. And fourth, the system that collects these data sets and connects them to the lorry which is transporting the good.
What's in the import/export declaration?
They basically state what the good is, its value and how much duty you have to pay on it. It's the tax bit. It's all very complex, laborious and crammed full of technical minutiae but that's the executive summary. It needs to be lodged before the good gets to the French border.
How do you lodge it?
You do it through a UK system called the Customs Handling of Import and Export Freight, or Chief.
Drink.
This is a really old system and before Brexit was even a twinkle in Boris Johnson's eye, the UK planned to turn it off and migrate all traders to a new system called the Customs Declarations Service, or CDS.
Drink.
CDS was meant to replace Chief from January 2019 and then switch off altogether by March 2021, but there were repeated delays. So instead they're keeping Chief for trade between Britain and the EU and using CDS for trade between Britain and Northern Ireland, because it has the capacity for dual tariff fields. CDS is then going to be scaled up until it can deal with all the declarations.
No acronyms there.
Actually trade between Britain and Europe is called GB-EU and trade between Britain and Northern Ireland is called GB-NI, but let's not worry about that. The government insists that Chief now has an increased capacity that can handle 400 million annual declarations - way higher than the 265 million which are expected. HMRC has paid Fujitsu £85 million to provide technical support. But others aren't convinced. They're not sure it can handle the load and nervous that there isn't enough support if something goes wrong.
Very reassuring.
Isn't it. Remember that the importer on the EU side also has to be doing all of this - at the right time, in the right place - on the European customs system.
OK so what about the safety and security thing?
It's a document outlining what the good is, so it can be assessed for potential risks. Again, it's a long complex thing with multiple data fields. Like import/export, it has to be done in advance of the goods reaching Calais. It's submitted to the UK government via a new system called S&S GB.
Drink.
It must also be submitted to the EU member state's Import Control System, which is called ICS.
Drink. OK tell me about the sanitary pad things.
Sanitary and phytosanitary measures, or SPS.
Drink.
These are there to protect people, animals and plants from disease or pests. They cover products of an animal origin, like cheese, or meat, or fish, as well as live animal exports, plants and plant products, and even the wooden crates used to transport other types of goods. It's painstaking stuff, but I think, given the pandemic we're all going through, we all understand why it's important.
Yeah, fair enough. You've sold me. I'm totally on board with this stuff.
These kinds of goods have to enter Europe through specific Border Control Posts, or BCPs.
Drink.
And there they undergo some, or all, of a variety of checks. There's a documentary check for the official certification which travels with the good. There are identity checks, which provide a visual confirmation that the consignment corresponds to the documentation. And there's a physical check to verify the goods are compliant with the rules, for instance temperature sampling, or laboratory testing. You know that whole chlorine-washed chicken thing?
Sure.
Well this is where they check whether it has been and stop it getting into Europe if it has. But it's actually the documentary check which is the hardest part in terms of UK preparedness. It includes something called an Export Health Certificate, or EHC.
Drink. Jesus Christ.
These are documents which confirm that the product meets the health requirements of the EU. So they might say that the animal was vaccinated, for instance. Some products, like a cut of lamb, will just have one EHC. But others, like a chicken pizza, will have more than one.
We've talked about this before. People shouldn't put chicken on pizza.
You are wrong, it's a perfectly legitimate pizza topping, and in fact you are so wrong that I have started using chicken pizza as my trade-good shorthand. Chicken pizza is the new widgets.
What even are widgets?
No-one knows, that's why economists love them. A chicken pizza, however, is a composite good for the purposes of SPS. The chicken and the cheese are different animal products, so they would need separate export health certificates. And all these certificates have to be verified by an official veterinarian, or OV.
You're just messing me about now.
No seriously, they use that acronym. This whole area of public life has been radicalised into extreme acronym use. Anyway, the OV goes through the details, queries the documents and signs them off. But there's assistance from a person pulling together all the paperwork. They're called a Certification Support Officer, or…
I can't believe this.
...CSO. These guys are mostly in private practices, usually farming practices. It's not a big part of their workload - maybe 20% of what they do. But if you don't have those vets, you can't send the export. That would be catastrophic for the farming, food and hospitality sectors. And that's where we have an issue. There are restrictions on getting that many OVs up and running. There's a tight labour market for vets and the UK is highly reliant on Europeans coming over to do the job, but the end of free movement makes that much more difficult and expensive, as does the covid pandemic.
So what has the government done?
It pumped £300,000 into providing free training for the role. Many vets took it up. The number of qualified vets has jumped from 600 in February 2019 to 1,200 today. But that still leaves a capacity gap of 200.
Well that doesn't sound so bad.
No it doesn't, but when you start to scratch away at the figures, they fall apart. The 200 figure is the number of 'full time equivalent' qualified vets required. And if vets only spend about 20% of their time doing this, it means we'll actually need an extra 1,000 vets training in the additional qualification.
Oh dear.
Yep. Groups representing the sector are seriously worried about this. And as with customs, the smooth functioning of the border will rely on the importer on the EU side doing all the bits they're required to do too, by creating a record in the Trade Control and Expert System, or Traces NT.
Drink. OK, what's the fourth bit of IT?
Transport. This involves wrapping all the other forms together and attaching them to a vehicle. In the UK, we'll be doing this through something called the Goods Vehicle Movement Service, or GVMS.
Drink.
It links export declaration references together into one single Goods Movement Reference, or GMR.
Drink. Bloody hell man these people are out of control.
The GMR should come out like a barcode, a one-stop shop for all the tied-together information we've been discussing. GVMS will be needed for certain movements in January, particularly for trade with Northern Ireland, but it won't be a requirement of all imports until July. It's currently being tested and there are dark murmurs about its functionality from those who have come into contact with it. Mercifully, exporters into Europe on January 1st will be using the French system, SI Brexit. This was operational a year ago and has been fully tested several times.
Those lazy French with their useless romantic dispositions.
It's almost like they're a nation that cares about shopkeepers.
Speaking of which, how're British businesses going to deal with all this additional paperwork?
Many companies will be OK. Very big corporations are well ahead and in many cases have set up a European entity so that they can sell directly from their UK entity to the EU one. Then they'll probably just reflect the customs costs in a subtly increased retail price. Smaller companies who are used to exporting to the rest of the world outside of Europe also have an advantage. They're used to these kinds of things. The people who are most at risk are the small-to-medium-sized enterprises who have traded exclusively with Europe.
Small-to-medium-sized… Oh no.
Yeah, that's right. SMEs. Which, by the way, comprise the vast majority of companies in the UK. If you send just two or three loads of your product a month to Europe, it probably won't be worth the cost in manpower and money preparing for all this stuff. They'll likely just accept a shrinkage in their business. For many of them, the whole thing is a bafflement. Honestly, you read the guidance on all these systems and it's like it's in an alien code - a garbled assault of acronyms and complex systems. Many small firms, already suffering from covid, just throw up their hands in despair.
Bleak. It's always the little guys that get it.
Yes, although paradoxically, that actually presents one of the few reasons for optimism. Well, not optimism exactly, but a hope for least-badism. Now that so many people feel January will be chaotic, they might just decide not to bother trying to send anything. Goods will get stuck at a warehouse instead of on a truck.
Seriously? That's your good news? Aren't you just displacing disruption from the ports to other parts of the supply network?
Yes precisely. But there really are no good outcomes here.
Because if that doesn't happen, the system seizes up?
Yeah exactly. Lorries head to Dover then get held up because they don't have the correct paperwork. Then lorries behind those lorries get caught up, pushing the queue out, dominating Kent, creating a huge singular blockage. The government's own Reasonable Worst Case Scenario, or RWCS…
Drink.
... estimates that between 40% and 70% of lorries may not be ready for border controls, leading to queues of up to 7,000 trucks.
But that would only be going out right? The stuff we bring in to the country would be unaffected because we're not putting in place controls.
Kind of. It's certainly true that most imports should have a clear run into the UK. You can keep those two lanes separate. But most hauliers are from Romania, Lithuania, Hungary and Poland. They pay a lease on their trucks, which means they have to keep them going if they're to make money. They can't afford to get stuck in a queue at the border. So there's a good chance they'll look at the log-jam in the UK and think: 'I'm not touching that with a barge pole'. This would mean Britain struggled to get its imports, including potentially fresh food and medicines.
Wow.
Yeah, it could be bad. But there are plans for that eventuality. The government has set up some emergency routes, for instance on the Newhaven-Dieppe crossing. There's additional ferry capacity at eight ports, with the Department for Transport acting as the referee on which vehicles get onto their crossing. But it's not a like-for-like replacement. Many of these crossings take much longer than the short gap between Dover and Calais, and they often operate for unaccompanied goods overnight. If the import is urgent, or fresh, or, like some covid vaccines, needs to be kept at a certain temperature, then you may have a problem.
What is the government doing to make sure this doesn't happen? How will they control the blockage?
There's three parts to that really. The first is controlling access to Kent, which the trucks head into to get to Dover. This project has no acronym, but instead adopted one of the least elegant names in the history of British policy-making: The Check an HGV is Ready to Cross the Border Service.
Wait but...
Yeah. HGV: Heavy Goods Vehicle.
I fully accept now that it was a mistake to adopt this drinking idea.
Before the lorry gets to Kent, the driver will fill out an online form with a bunch of information - the registration number, the destination, details of the consignments, confirmations that the import/export documents have been filled in, export health certificates, the whole lot basically. Those that are judged to have all the documentation are given a Kent Access Pass, or KAP.
Drink.
And that allows them to go into Kent. Police can hand out £300 fines to lorries found on the Kent roads without the permit.
But this is all done on trust right? It's a self-assessment form.
Yep. It'll rely on people filling it out right. It's not linked to EU customs systems. So there's no guarantee that documents they claim to have completed will be accepted by EU customs authorities. But on the plus side, the software was launched recently and most people think it'll work OK. It's better than nothing, basically.
Alright so what's next? Traffic management?
Exactly. It's uncanny how naturally your questions lead me onto the next thing I want to discuss.
That's because I am you.
Don't talk about that, it makes it weird. Alright so first up we have the traffic flow plans. The Department for Transport is taking an existing temporary system to create contraflow on the M20 and putting it on a permanent footing, allowing 2,000 lorries to be held on the motorway while traffic still flows in both directions on the London-bound side.
OK, what's next?
Well then there's the issue of actual sites. HMRC has identified seven locations outside the ports. There's prep work being done at a site in Sevington, Ashford, at a cost of £110 million, to act as a clearing house for another 2,000 lorries. Some 600 lorries can be held on the approach to Manston airport, with more at the airport itself. These two sites, along with the M20 contraflow, are for holding traffic. There are also plans for Ebbsfleet International Station, North Weald Airfield and Warrington to be used for bureaucratic checks away from the border. Other sites, potentially in the Thames Gateway and Birmingham areas, are also being considered. They insist that this should give them capacity for 9,700 lorries, which is above the 7,000 in their worst case scenario.
Assuming that scenario is correct.
Right. Covid and other unrelated events, like a fire breaking out for instance, could mean that even the worst case scenario is an underestimate. We just don't know. Plus that relies on all of this being up in time. The government has passed legislation to streamline planning processes, but the timetable is unbelievably tight. The same thing goes for staff.
These are the customs officials who check all the paperwork, right?
That's certainly part of it. They're split into two departments: HMRC and Border Force. HMRC needs 8,600 full-time equivalent staff in place for January 1st. They still need another 1,500 but seem confident they'll have them. Border Force recruited an additional 900 staff ahead of a possible no-deal last year and is trying to bring in 1,000 more. Ministers are confident they'll have enough people in place by January 1st, but trade experts are less convinced.
Recurring theme.
Indeed. It's easy to get fixated on numbers but it really matters how well you've trained people too. You can have someone helping with customs work after a day or two, but for them to have any real sense of what they're doing, you're going to want a year's training. And then there's the question of personality type. Customs is a very specific kind of work, full of extremely complex documentation which must be got right. For some people, that is unimaginably boring. For others, it's very satisfying. But you need the right ones. And that's not what typically happens when people get desperate on a recruitment drive.
What's the other part of the staffing problem?
The private sector. It's a job called 'customs broker'. They're basically people who come in and help companies with their customs forms. Like I said, this stuff is mind-meltingly complex. You really do need someone to come and help you do it. And that's what the government wants too of course, because the more people getting it right, the fewer delays at the border. But as of last September, just 53% of traders said they planned to use a customs broker, with 30% unsure and 18% saying they were going to do the work themselves. Those aren't good numbers.
Are there enough of them to meet demand?
No. This has been a long-running problem. Almost two-thirds of customs brokers do not have enough staff to handle the increased paperwork from leaving the EU. And actually capacity seems to have reduced over the year due to the covid pandemic. The UK needs thousands more.
What's the government doing about it?
It's invested £84 million since 2018 into training, recruitment and IT system development. But many customs brokers are still hesitant about taking on new salary costs to build a capacity that won't be fully required until next July and they're nervous about taking on unprepared customers. Of the £84 million on offer, just £52 million had been taken up in mid-October.
Is that… is that it? Please say that's it. I'm wasted.
It is.
OK so give me the executive summary.
We're about to experience the sudden implementation of complex customs processes in a nation which forgot they existed. This involves the introduction of numerous interrelated IT systems which have been under-tested. It's not clear that either government or traders are fully prepared for what's about to happen. In order to minimise the disruption the government is introducing various traffic management projects and trying to bulk up staff capacity. But there's just too many variables to know how it'll pan out. Maybe the systems will hold out and many traders will anyway sit out January because of concerns about queues. Or maybe the systems will fail, traders won't fill in forms right and the whole thing will blow up in our face. The most likely outcome right now is somewhere between shambles and catastrophe. We have to hope it's a shambles.
Can you do it in acronym-speak?
Amid RHA and Bifa concerns about the lack of progress, HMRC, Defra, the HO, the Dft, the BPDG and the TTF are building up IT systems for post-Brexit GB-EU trade and particularly for RoRo at Dover-Calais which will involve exporters submitting import/export declarations to Chief and the CDS, S&S information to S&S GB and ICS, and collating their SPS documentation - including an EHC filled out by an CSO under the supervision of an OV sent via a BCP - with the importer logging it on Traces NT, while generating a GMR via GVMS and SI Brexit, and then HGVs getting a KAP, all to avoid the RWCS.
D… Drink?
Yes I think so. That seems very sensible.
Ian Dunt is the Editor-at-Large at Politics.co.uk. His new book, How To Be A Liberal, is out now.
The opinions in Politics.co.uk's Comment and Analysis section are those of the author and are no reflection of the views of the website or its owners.


 DB is a ultra high-performance graph database supporting Blueprints and RDF/SPARQL APIs. It supports up to 50 Billion edges on a single machine. It is in production use for Fortune 500 customers such as EMC, Autodesk, and many others. It is supporting key Precision Medicine applications and has wide-spread usage for life science applications. It is used extensively to support Cyber anaytics in commercial and government applications. It powers the Wikimedia Foundation's Wikidata Query Service.
DB is a ultra high-performance graph database supporting Blueprints and RDF/SPARQL APIs. It supports up to 50 Billion edges on a single machine. It is in production use for Fortune 500 customers such as EMC, Autodesk, and many others. It is supporting key Precision Medicine applications and has wide-spread usage for life science applications. It is used extensively to support Cyber anaytics in commercial and government applications. It powers the Wikimedia Foundation's Wikidata Query Service.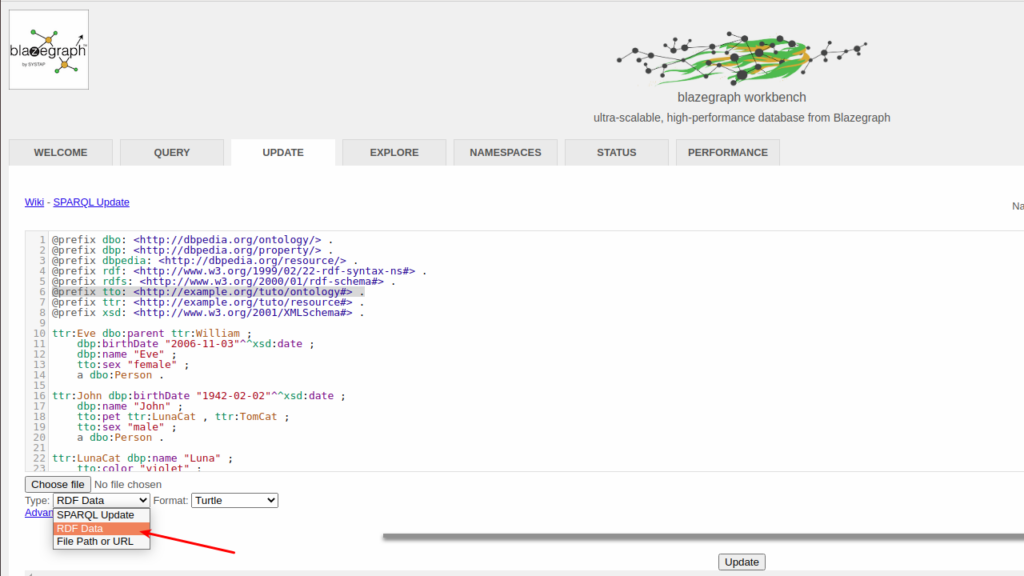
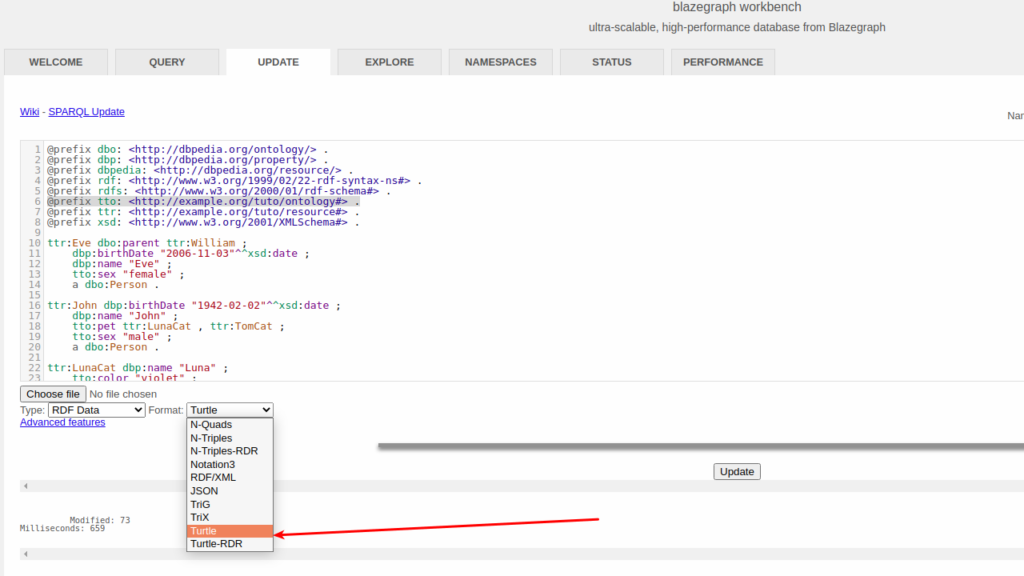



 Microsoft's System Center Configuration Manager (SCCM) seems to usually work pretty well for 95-97% of the computers at the environments I've worked in. Unfortunately for the remaining few percentage points of computers that SCCM is *not* working pretty well for when SCCM does break it does so spectacularly with style and pizzazz.
This guide will show you how to use PowerShell to remove all traces from the computer so you can perform a clean reinstall!
Microsoft's System Center Configuration Manager (SCCM) seems to usually work pretty well for 95-97% of the computers at the environments I've worked in. Unfortunately for the remaining few percentage points of computers that SCCM is *not* working pretty well for when SCCM does break it does so spectacularly with style and pizzazz.
This guide will show you how to use PowerShell to remove all traces from the computer so you can perform a clean reinstall!