I’ve now worked with “The Cloud” for long enough to see that there’s still a long way to
go before it becomes materially better than, say, the oldschool method of renting a
couple of servers with a co-location company and running your software there. The
latest fad is Serverless, which makes me feel a lot like we’ve arrived in 1970.
A long, long time ago, I was pretending to study business administration
while teaching myself to code in C. The university was in two worlds:
we had a lab with “personal computers” but also terminals to the mini
computer and assignments had to be made on either one depending on the
professors’ preferences. But both systems were at least “on-line” systems–interactive, with immediate feedback. A friend of mine was not so lucky:
he had an assignment for one of his courses in civil engineering that
had to be completed in Pascal and had to be handed in as a print-out
from the university’s mainframe.
He called me in for help, because he never wrote a line of code before. So I hopped
over to his place, a Turbo Pascal floppy disk in hand, and assumed that we would
make short work of the assignment. And we did, even though I never coded in Pascal
before: the IDE, even back then, was marvellous and a quick succession of trial-and-error
got us the results we wanted (they were some simple engineering calculations, much
quicker done on even the most primitive of calculators, but such are course assignments. At
least it was easy for us to verify the program was correct).
We hopped into the car and drove over the the university’s computer center, a ’70s brutalist
concrete bunker. We sat behind a terminal, typed in the code, surrounded it with the required
IBM Job Control Language that the teaching assistant helpfully added to the assignment, and
hit “Enter” (not “Return”, actually “Enter” - Enter The Job). A couple of minutes later, the
printer started and spit out a couple of pages. Between gibberish in all caps, there it was: a
compiler error. Back to square one - Turbo Pascal and IBM Mainframe Pascal clearly had some
differences. A couple of hours and reams of wasted paper later, we had what my friend wanted:
the results of a good run. The numbers matched our notes, and we could retreat to the nearest
bar for a well-earned beer.
Ever since that experience, I have stressed the value of feedback and especially of quick
feedback. Even in this minimal example, we spent more time tweaking the code for the dialect
than we spent on writing it in the first place. Slow feedback loops kill performance, and if
you don’t believe me, find an online version of The Beer Distribution Game and play it. You’ll be surprised.
The pinnacle of interactivity was, and still is, Smalltalk. I worked in that language for a
couple of years and having your system compile and run most of your tests in less than a second
is addictive. It is incredible how much your performance increases on a fully interactive
programming system but it takes first-hand experience to fully appreciate it. It’s a strange
system, a strange language, a tough sell; therefore Smalltalk is still in a very undeserved
state of limbo.
After my Smalltalk years, I met a lot of large Java systems. They started out as horrible
hairballs, but when the idea of “dependency injection” got a foothold, things started to get
better. Except for the return of the Job Control Language, this time disguised in XML and
carrying friendlier names like “Spring”. Internally, the code was reasonably clean and modular,
but telling the computer how to run it took pretty much the same amount of typing, this time
not in a programming language but in a structured markup language. That language lacked all
the facilities that apply to writing good code, so principles like “Don’t Repeat Yourself” went
overboard and copy/paste programming ensued. New business logic? New controller, twenty lines of
Java boilerplate, 10 lines of Java business logic, 50 lines of XML to wire it to the rest of
the system.
At least, in hindsight, XML was a blessing: your editor would tell you whether your “this is
how the code is wired up” description had the right structure, and later on even whether you
used names that existed in your Java codebase.
These systems took ages to compile, hours to run all the unit tests, and clearly interactivity
went down the drain. So “split it all up” was not a bad idea. It was an unnecessary idea, mostly
driven by the shortfalls of mainstream programming languages, but necessity is the mother of
invention - even though your average Java business app was much simpler than the Smalltalk
IDE before you added a single line of code to write your app, it was already too complex to
maintain and “divide and conquer” was the answer. Service Oriented Architecture, and later
microservices, was born. Split your codebase, split your teams, create a lot of opportunities
for mediocre coders to grow into mediocre engineering managers, everybody was happy. Including
your hardware vendor, because suddenly you needed much more hardware to run the same workloads. Because
networks are slow, and whereas it can be argued whether a three tier system is actually a distributed
computing system, a microservices system certainly qualifies for that label.
The return of the Job Control Language this time was in the form of,
again, configuration data on how to run your microservice. Microservices
were somewhat fatter than the very fine-grained objects of the old days,
so there was less of it, but still - it was there. The feedback cycle
became worse as well: in the monolith-with-XML days, your XML editor
would get you mostly there and a quick local compile and run would
leave you all but certain that your configuration was working.
XML, however, was universally rejected in favour of things like JSON, Yaml, HCL,
Toml - all free of structure, with zero indication whether a computer
would find your prose gibberish or the next Shakespeare play until
you actually pushed your code to some test cluster. It suddenly felt
a lot like being back at that university interacting with a mainframe,
but at least you still owned the hardware and could introspect all the
way down, especially if you were doing “DevOps” meaning mostly that you
had administrative access to your hardware.
Microservices have trouble scaling, and they are very complex. Most companies that employ them
have no need for them, but the systems and programming languages they employ are sufficiently
lacking that this stacking of complexity on top of complexity becomes a necessity. It seems that,
contrary to what everybody is saying, software developers are in plentiful and cheap supply so
wasting a lot of their talent makes economic sense over the perceived cost of adapting more
powerful programming systems. C’est la vie. The feedback cycle is truly broken - testing a
microservice is merely testing a cog in a machine and no guarantee that the cog will fit the
machine - but we just throw more bodies at the problem because Gartner tells us this is the future.
So, we’re now at the next phase of this game: maintaining these very complex systems is
hard and not your core business, so outsource it (simplifying it would cost too many managers’
jobs, so that is not an option). The Cloud was born, first as a marketing label for an old
business model (offering “virtual private servers” to the public), but more and more as a marketing
label for an even older business model (the mainframe - we run it, we own it, you lease capacity).
Apparently, Worse Is Better and you can do worse than Virtual Private Servers, so through a short-lived detour through
containerizing microservices and deploying them on a distributed scheduler like Mesos, Nomad,
or Kubernetes, we have arrived at “Serverless”. You deploy individual stateless functions. But
not inside a Java monolith, that is old, but on top of a distributed system. You would have been
laughed out of the door if you had proposed that in 2000, and you should be laughed out of the
door right now, but such is the power of marketing. So what have we now? A “mono repo” codebase,
because clearly a Git repository per function in your system would be too much, a large deployment
descriptor per fine-grained component, which Spring maybe called “Controller” but is now called
“Function”, and instead
of combining them all on your desktop, you send them off to someone else’s mega-mainframe. You
deploy, get an error message, and login to CloudWatch to see what actually happened - it’s all
batch-driven, just like the bad old days, so progress is slow. At least we’re not having to
walk to the printer on every try, but that pretty much sums up the progress of the last half
century. Oh, and a “Function”
will be able to handle a single request concurrently, so here’s your AWS hosting bill, we needed
a lot of instances, I hope you won’t have a heart attack. Yes, we run workloads that your nephew
can run on his Raspberry Pi 4, but this is the future of enterprise.
History will repeat itself, of course. Conceptually, hiding a lot of the scaling and coordination
machinery is not a bad idea; programming systems like Erlang and OTP have shown for decades how
well that can work and Elixir is giving the platform a well-deserved surge in popularity. But there’s
a big difference here: a platform like OTP handles pretty much everything that a platform like
AWS Lambda handles, but it does it in a single programming language. Tools of the trade are
available: you can refactor Erlang code, you can write Elixir macros, all to keep the system
clean, malleable, and free of accidental complexity.
It is called “Configuration as Code”, and it truly is a great idea (but hardly a new one). But XML
is not code, and neither is JSON, nor YAML, nor HCL. There is an essential quality lacking in all
of these markup languages, and that causes all the copy/paste programming I am currently seeing
everywhere, whether a team deploys on Nomad or uses Terraform or CloudFormation to whip up mega
complex clusters to run a marketing site. This level of complexity is not sustainable, and my
fear is that it will be solved the way our industry likes to solve the problems they have
created themselves: by adding more complexity on top if it.
Not by going back through our history and figuring out what caused the Personal Computer
Revolution. Which is a shame.
This post is the first in a three part series covering the difference between prediction and inference in modeling data. Through this process we will also explore the differences between Machine Learning and Statistics. In my career as a data scientist I've found that there is a surprisingly lack of understanding of the task of inference which is typically considered the domain of statistics. Though it is less common, I have also found that people I know well versed in statistics often have a tough time understanding the way machine learning thinks about prediction tasks.
A little over a year ago I posted an image to Twitter summarize my views on this distinction visually:
In the series we’ll ultimately see who these two are more connected than they are typically treated
In this post I want to not only flesh this idea out through a worked example, but also attempt to blur that distinction. Ultimately the aim of any quantitative thinker should be to see modeling as a holistic process that extends our mathematical reasoning to its fullest. Especially in an age of easy computation, the process of modeling should be a highly interactive one that extends beyond the synthesis of these two ideas.
Our Example Problem: Modeling Click Through Rate
One of the most common problems in industry is modeling Click Through Rate (CTR). Generally CTR problems show up whenever we care about a user performing some task, usually 'clicking' on some piece of content. Common CTR problems include: a user signing up for a service via a form, clicking on an ad, looking at an item description in a catalog, purchasing that item, reading a post on an new aggregator, etc.
In a previous post we talked about the process of Thompson Sampling to optimize an ad auction . One of the key parts of this article was estimating the CTR using the Beta Distribution with only data about previous clicks per view. While this approach worked great for that example we often have a lot more information at hand that we would like to use to better understand when a user will click.
In this example we'll be using information about the CTR for job postings on a job board. The data is derived from this Kaggle data set. Using this data set we are going to attempt to learn whether or not a user will apply for a job given we know information about what category that job is in, and how similar various parts of the job title are to the user’s original search query.
In my career in data science I have been shocked by the number of time that CTR problems are treated as pure prediction problems. As we will see in this post, treating CTR as a prediction problem leads to a limited view of how to solve various common problems related to CTR (namely how do we improve it!). To start we'll treat this problem from the perspective of Machine Learning, building a simple perceptron model from scratch using Python and JAX and then, in the next part, learn how we can naturally extend this model to cover inference.
A look at our data
Before we begin here's a look at the cleaned up version of our data set. We have the following features we'll be using:
The first 3 features correspond to various similarity scores between the query text and the job posting text, then we have the number of days the job has been on the board, and finally we have the top 10 job category codes and an indicator if the posting was in another category.
Here is a peek at what this data looks like, mean centered, and with the standard deviation normalized:
apply_data[features]
As you can see at the bottom we have plenty of data with 1,200,890 rows.
For the rest of this post we'll mainly be doing lots of computation so we'll be transforming this data into a jax.numpy matrix and splitting it into test and training sets.
import jax.numpy as jnp
X = jnp.array(apply_data[features].values)
y = jnp.array(apply_data['apply'].values)
train_size = int(np.round(0.7*float(X.shape[0])))
indices = np.random.permutation(X.shape[0])
X_train, X_test = X[0:train_size], X[train_size:]
y_train, y_test = y[0:train_size], y[train_size:]
With that out of the way we can begin our modeling!
Prediction - The Machine Learning world view
Now that we've finally cleaned up our data it's time to start modeling! If you're an experienced data scientist or machine learning engineer, then much of this article will be very familiar to you. That is intentional because I want to show the logic that connects a very traditional machine learning world view with a statistical one. So even if this is a familiar topic, it's worth reiterating how we think about solving machine learning problems.
Since we're doing Machine Learning we'll want to start with a neural network. But because we want to keep things reasonably simple, we'll start with the simplest neural network: a Perceptron. If you're unfamiliar with a perceptron, it is simply a neural network with no hidden layers. Here is an illustration of our model below.
The likely familiar image of the simplest neural network.
Note that there is a "bias" node in that visualization of our how model will work. We can represent this this by simply adding a constant to our data, which I've already gone ahead and added to our X_train and X_test sets.
Putting together our model
Let's start thinking about our problem mathematically. We have a picture of what our perceptron looks like, but we want to figure out how to make this happen. We have \(X\) and \(y\) which is our data and our target respectively. We now have a couple of things we need to add.
The first step is to represent all of those lines in the network diagram numerically. We'll do this with a vector of weights \(w\). What should the value of those weights be? Well, we are going to have to learn that (or actually we want the Machine to learn that).
We're going to use JAX again here, and we'll be using it to create random weights. Unlike standard Numpy, JAX always needs a key in order to create random values. This means that our random variables are always predictable. This is very convenient for debugging our model since even though we will be doing many random actions, they can always be repeated exactly. Here is an example of how we will create a vector of random weights:
from jax import random
key = random.PRNGKey(1337)
w = random.uniform(key,
shape=(X_train.shape[1],),
minval=-0.1,
maxval=0.1)
The lines in the illustration represent us multiplying the values in our data by the weights and summing them up. Mathematically we can represent multiplying the inputs by the weights and summing them up quite simply using linear algebra:
We're not done with our model yet. There is an obvious problem already. We want to predict 1 (for will apply) or 0 (for will not apply), but we need a way to ensure that our predictions are always somewhere in this range. In order to solve this problem we need a non-linear function that will squish our values between 0 and 1. Using \(g\) to represent a non-linear function, we can now look at our full perceptron model mathematically as:
$$y = g(Xw)$$
Our choice for \(g\) will be the logistic function, which has the nice property of squishing values between 0 and 1. It also has the very nice property that it allows us to model our predictions as probabilities. We'll touch on this again in part 2, but it's important to recognize for when we want to train our model. Here is the logistic function mathematically:
$$g(x) = \frac{1}{1+ e^{-x}}$$
Here is the logistic function in code:
def logistic(val):
return 1/(1+jnp.exp(-val))
We can apply this to X and our random weights and we can see we have our first model!
These are, in a very literal sense, random guesses. The next step is to figure out how we can improve them.
The "learning" part of Machine Learning
Of course our model doesn't know anything about the world. We can see that all of these initial guesses are pretty close to 0.5, right in the middle of our choices of 0 and 1. When we make a prediction we commonly choose (or, more commonly, software chooses for us) 0.5 as the threshold between choosing 1 or 0. If we did that now we would find that our guesses would roughly estimate that half the cases would be apply and half not. They can be slightly skewed because of the distribution of the values in X, but otherwise we’re just multiplying uniformly distributed numbers (our weights) by values that we’ve transformed to have an expectation of 0 and standard deviation of 1. When we do the logistic transform of 0 we get 0.5, so most of our initial guesses will be pretty close to 0.5. Clearly we need to improve what our weights are from random guess to ones that best map our data to the correct result.
People like to joke about the term "Machine Learning" for simple cases like this, but it really is a pretty good description of what is about to happen. We want the machine (i.e. our computer) to learn the best \(w\) for this model. The key to this is figuring out some way to let the machine know whether or not one guess at the weights is better than another one. We’ll do this be creating an objective function (often known as a loss function) that let’s the computer know how good its attempts to improve the model are.
We mentioned earlier that one of the benefits of using the logistic function is that we can interpret the results as probabilities. That is a 0.2 means that's a 20% chance that a a user will apply for a job, and 0.75 means there's a 75% chance that they will. Our labels still work since we can interpret them as being 0, for we know they did no apply and 1 it's absolutely a fact that they did.
This gives an intuition about how we can set up our objective function that we want to optimize. If our model predicts 0.75 and the result is 1, can ask ourselves:
"What is the probability that we would get a 1 if we thought the probability of a 1 happening was 0.75?"
Clearly this is just 0.75. As a counter example, if our model says 0.75 and we get 0, the probability of that happening if our model was correct is just 0.25. That is what we want is a function to tell us how likely the outcomes are given a set of weights. Once we have this then we just need to find weights that are most likely to explain the data. This is the Maximum Likelihood approach to finding the best weights.
The Reasoning Behind Negative Log Likelihood
We've just looked at determining the likelihood of a single point of data, but we want to figure this out for the entire 840,623 rows in our training set. Here is some code that will compute the likelihood of the data given the weights for the entire training set (p_d_h stands for Probability of Data given the Hypothesis \(P(D|H)\)).
Each of these observations represents how likely the outcome we observed would be if our model was correct.
What we want to do is combine all of these in to a single likelihood of the data we observed given the model we have. To do this we can just take the product of all of these:
$$P(\mathbf{y}|Xw) = \prod_{i=1}^N P(y_i|Xw)$$
This represents the joint probability of all of these observations if we assume our model is correct.
While this is mathematically correct we can quickly see a problem with this approach:
jnp.prod(p_d_h)
> DeviceArray(0., dtype=float32)
Because we are taking the product of over 800,000 probabilities, this number is smaller than the lower bound of what we can represent on a computer. The probability of our random guess is zero, but even the probability of nearly prefect guesses, say ones with a 0.99 probability, would be:
$$0.99^{840,623}$$
Which will still be zero on a computer.
A great solution to this problem is to convert our probabilities to log form and take the sum of them rather than the product. This will give us the log likelihood which is much more practical when we're using a computer. As you can see the log likelihood is much more stable of a number:
There is one final issue we'll have with this result. Generally optimization techniques are designed to find the lowest value of a convex function. For log likelihood the smaller the number, the lower the likelihood, which is the opposite of what we want. Thankfully, since our log likelihood will always be less than zero (since our likelihood itself is always less than 1), we can take the negative log likelihood and end up with a nice, convex function we can put together.
As you can see the negative log likelihood is a positive number (since all log numbers between 0 and 1 are negative). What we want to do now is find values for \(w\) that decrease this number and thereby ultimately increase the probability of our labels given the weights.
Optimization - Good 'ol Gradient Descent
Our machine is almost ready to learn! One helpful way to think of the \(w\) is as being a specific definition of a model. With negative log likelihood we now have a way to say when one model is better than another, and it is specifically when this value is lower.
What we have here is a traditional optimization problem: we just need to systematically lower the negative log likelihood until we find a place we think is the lowest. We'll be using gradient descent which allows us to use the derivative of our objective function to help us find the lowest point.
So the only problem we have left is to find the derivative of this negative log likelihood function. Historically getting the gradient was a bit annoying since you had to calculate the derivative by hand. The true power of JAX is it will automatically solve that problem for us, making this operation trivial in code:
from jax import grad
d_nll_wrt_w = grad(neg_log_likelihood,argnums=2)
In this call to grad we are determining the derivative of the negative_log_likelihood with respect to the argument in the 2 (zero indexed) position, which is \(w\).
Next we'll put together a quick version of gradient descent. Given the decade long frenzy over neural networks there are countless tutorials on the details of this so we won't spend much time covering them. The basic idea is that we use the derivative of our loss function to slide downhill until we find our optimum.
One step we'll add is compiling our gradient function so that it runs more efficiently
from jax import jit
d_nll_wrt_w_c = jit(d_nll_wrt_w)
Since we're approaching this optimization problem pretty casually we can just manually run this a few times until the negative log likelihood looks like it converges.
lr = 0.00001
for _ in range(1,200):
w -= lr*d_nll_wrt_w_c(y_train,X_train,w)
print(neg_log_likelihood(y_train,X_train,w))
> 251421.27
Now we have trained our model! The next step is to see how well it does at modeling the rates users apply to job listings.
Statisticians: "But wait isn't that really just..."
I want to make a quick aside to address a frequent misunderstanding that I see from people in the statistics community. Statisticians will immediately recognize that our specific implementation of a perceptron is going to be equivalent to logistic regression (something we'll explore more in part 2). A frequent criticism from statisticians is:
Is this reallymachine learning? It's just Logistic Regression which I use everyday without thinking about it!
I would argue that the important distinction is precisely that Machine Learning practitioners do think about it. That is, the optimization process, choosing a loss function to optimize, choosing a method of optimization, is an essential part of the modeling process. For example, for traditional linear regression the statistician will almost always just default to Ordinary Least Squares regression. This is akin to choosing Mean Squared Error as the objective function, which changes what we can do with our model as opposed to if we had chosen negative log likelihood.
As model complexity increases in Machine Learning questions around objective functions and the optimization techniques themselves take center stage. But even in this simple case I chose negative log-likelihood for a very specific reason, even though there are many options to learn essentially the same \(w\). In both parts 2 and 3 negative log-likelihood will allow us build extensions to our model with a trivial amount of code.
We are seeing statistics change in this regard. Nearly all work in cutting edge Bayesian inference requires a deep understanding of optimization techniques and numerical methods. Traditionally speaking, this focus on computation and the details of optimization is a key distinguishes between the worlds of machine learning and statistics.
Measure the Performance of Machine Learning Models
It's good to take a moment here to think about what we are trying to measure as far as gauging the success of our model. Ultimately, in machine learning we are trying to predict something. Right now the output of our model is going to be a number between 0 and 1, these are the model's predictions.
Our model can also be considered a classifier. We are thinking of the model ultimately making a prediction about whether or not the user represented in the data will apply for the job or not. In the process of building a classifier we are going to have one final transformation in our model which is to decide whether or not to return a 0 or a 1 as our final output.
There are a variety of metrics that can be used to assess this task. When we ultimately want a classifier it's intuitive to immediately turn towards accuracy, the ratio of correct to all guesses, as a first measure. However, there are two problems with accuracy. The first is apparent when we look at the proportion of applies to total views in our data:
So we have the classic problem where of an imbalanced data set (though, I think that's a bit of an odd way to think about it, especially we're modeling a rate). The real issue here is that just guessing 0 for everything would yield us a very impressive accuracy.
The other, more subtle problem, is that we really haven't thought much about when we choose 1 or 0. In nearly every machine learning library this choice is quietly made for us at 0.5. This nearly always configurable, but I've received many perplexed stares when asking data scientists "what is the threshold your model is using to predict 1?" We could more formally describe this choice as as minimal soft max layer in a neural network.
But we don't really know what a good point would be to call it in favor of a user applying, so we will use a metric that sees how good our model will perform at varying thresholds: The ROC AUC (a metric that deserves a post on it's own one day).
If you're unfamiliar, ROC AUC look at the area under the curve based on the change in true positive and false positive rates at various thresholds. In general an AUC of 0.5 means we are essentially guessing as far as classification goes and 1.0 is the perfect classifier.
Let's take a look at calculating this metric for the training and test set:
This is not good. This AUC means that our classifier is not able to effectively discriminate between people who will apply and those who will not. From this perspective, it looks like our model is a failure.
The Limits of Machine Learning
But did our really model fail? For starters, let's take a look at what we learned. Our final log likelihood was -251,422 and our initial was -619,300. Recall that:
$$\frac{A}{B} = e^{log(A) - log(B)}$$
Which means that we improved our initial likelihood by a factor of:
$$e^{366,878}$$
After all the work our model explains the data better by such a large amount that we can't represent that value on a computer! So we did do a lot of learning.
The real issue is that we are misunderstanding how to judge our model. Accuracy, AUC, Precision, Recall, F1 Score etc are all common metrics to measure the performance of a classifier. However from the beginning we have said that we are modeling the Click Through Rate. Whenever we've tried to measure rates in the past we often have used statistics to come up with distributions of beliefs about what that rate could be.
Misunderstanding modeling Rate problems as Classification problems is one of the most ubiquitous modeling errors I have seen in industry. A super human, perfect model of a rate will often be a bad classifier.
A great example of this is modeling a coin toss. If we have a fair coin, and your model says the rate of flipping heads is exactly 0.5 with no uncertainty, then you have a perfect model of how the coin behaves. However if you treat this rate model as a classifier it will have abysmal performance. Similarly suppose you are playing some lottery where the big prize has a 1/1,000,000 probability of paying out. Again, if you have a model that, with no uncertainty, predicts the exactly probability of a win at 1/1,000,000 you have the perfect rate model. This will also be an awful classifier.
Even if these rate models don't work as classifiers the can be essential for properly making decisions under uncertainty. Without a correct model of the coin we can make incorrect assumption about whether we should bet $1 for a coin toss where the winner gets $2.1 if the coin lands heads.
The problem of prediction
But the problem goes deeper than just misunderstanding modeling rate problems for modeling classification problems. After all, we could consider the output from the model before we threshold the prediction. Then we could try to come up with some metric that might better assess this result.
Even with that adjustment though, ultimately what our model is giving us is a single prediction, a point estimate, of what the rate is given the information we have. Any frequent readers of this blog will immediately ask the question "how sure are we of this estimate?" This is especially important if we are going to do things like optimizing ad auctions, or any expected reward given uncertain risk. To answer this question we need Statistical Inference.
In the turn to statistical inference we will start to pay closer attention to what the model actually learned. This is essential because the 'rate' doesn't implicitly exist in the data in the first place, it's a part of our model. To understand rate problems correctly, we need to understand the model itself and not just its output.
For that we need statistical inference.
Coming up next: Statistical Inference
In the next part of this series we'll approach statistic inference from exactly where we left off. This will show us how deeply connected the ideas of Machine Learning are with Statistical Inference. In part 3 we'll explore how Inference and Prediction are both parts of a single modeling process, one that transcends thinking about problems in purely statistic, or purely machine learning terms.
Get source code, behind the scenes commentary and more!
Support my writing on Patreon and gain access to the source code and video commentary for this article as well as access to much more of my writing!
Get your free copy of Field Notes #1 and stay up to date!
Sign up with your email address and you’ll get a link to Field Notes #1 a story about the time I almost replace a RNN with the average of 3 numbers!
Feedback is an accepted indicator of continuous improvement and is the topic of many Leadership, HR, and Change Management books. Most would agree that getting feedback is an important accelerant for professional and personal growth. Yet, most people are not good at giving feedback, oscillating between opinionated generalities to premature remediation. This often leaves the receiver with one of two choices, blindly accepting the feedback without critically processing the information internally or seeming defensive in order to provide their own point of view. Both involve the receiver being positioned reactively versus being active in the consequences of their actions and proactive in their improvement.
Recently, @mattbarcomb and I discussed the potential inauthenticity of “the compliment sandwich”. (A “compliment sandwich” is giving positive feedback before and after negative feedback.) This led to up-skilling ‘giving feedback’ so it becomes the capability of ‘giving constructive feedback’. We started with describing the aspects of “positive feedback”, “negative feedback”, and landed on the critical factor– “constructive feedback.”
So, what makes feedback constructive?
While it’s easy to refer to the importance of feedback, providing feedback is hard. Harder yet is providing constructive feedback, which is another reason why it’s rare. To provide constructive feedback, you must slow yourself down to be thoughtful and considered. What results is not only more meaningful effective feedback for the receiver but also enables the provider of feedback professional and personal growth. Making feedback constructive requires internal reflection and critical thought due to consideration and synthesizing of one’s own perspectives, feelings, and biases.
Be Specific and Fact-based. When feedback is given, the receiver needs to connect the facts, the “what’s”, or behavior with the result, or impression. It is useful to substantiate the feedback with specific examples to draw that connection. Avoid generalities. Remember, the receiver of the feedback may not have intended the result or impression, so provide kind candor.
Frame Feedback with Perspective and Context. Given that interactions and actions are the results of many situational variables, it helps to couch specificity with the context and environment. Acknowledging perspective helps frame the situation, which depersonalizes the feedback and focuses on a more systematic approach in which the receiver is but one variable. This allows the receiver to be an active rational participant in the ideas for improvement.
Be Involved in the Path Forward. A vital part of feedback is what to do with that feedback. It is likely that improvements will need to be learned. The learning can be accelerated with help, especially from an outside perspective. Ideally, if you are taking the time to provide feedback, you should also be involved in the path forward to improvement. However, in some cases, the person giving feedback might not be able to be involved– either not having time, ability, knowledge, or interest. This falls on the provider to own those limitations.
Constructing constructive feedback is a hard skill to learn. In order to be effective, it requires accounting for who is receiving the feedback and how to set them up for success. Receiving and providing feedback is a learning experience for all involved. In general, learning something new can be difficult. Further, learning in front of others can leave you feeling exposed. But, getting good at constructive feedback is worthwhile; growing leadership skills, connecting you with others, and building a reputation of trustworthiness.
Mastering Constructive Feedback.
Providing feedback can feel awkward and sometimes even hostile. It’s no wonder that many feel dread while learning and practicing constructive feedback. Finding your style comes with practice and patience. In the meantime, here are some tips:
Adopt a Strengths-based Strategy. In the book The Effective Executive, Peter Drucker wrote: “The effective executive builds on strengths–their own strengths, the strengths of superiors, colleagues, subordinates; and on the strengths of the situation.” The discipline of “appreciative inquiry” (created by David Cooperrider) also focuses on strengths as an advantage– “build organizations around what works rather than fix what doesn’t.” Leveraging strengths and minimizing the impact of weaknesses, accelerates improvement (versus trying to get good at weaknesses). At a minimum, acknowledging the constraint of limited time and energy is a worthwhile consideration when discussing growth, improvement, and goals.
Be Humble and Balanced. In many cases, the person who is responsible for providing feedback is not the same person who was involved or present in the originating experience. The responsibility of providing feedback can feel authoritative, especially when you are in a position of authority. Regardless of your role, the purpose of feedback is to help someone eventually be self-sufficient on their own, not blindly follow you. Being honest about your own blindspots can communicate credibility and impartiality while enabling the receiver to critically assess the feedback. Not only does checking your ego go a long way to being a trusted, respected, and reliable source of feedback but also models learning as a process over an expectation of omniscience.
Servant Leadership. Becoming a leader of people is hard, requiring experience and patience. A good leader balances sincerity and tact. An exceptional leader can do this while empowering others. Many traditional models of leadership promote hierarchy and worse, models of learning where the role of the learner is to receive, file, and store information, regurgitating that information. (Read more about Banks Model of Education.) Further, leaders, coaches, and mentors get valuable information from learners. After all, learning never stops even for experts who have decades of experience. At a minimum, hearing from others with less experience is information about how to better communicate. Learn from the student and master the content.
Be Authentic.
Like any drill or practice, there is a chance of coming across as inauthentic because what you have not yet mastered, you are still learning and it is not yet part of you. (There a great quote by Van Gogh who responded to a friend who criticized his work– “I am always doing what I can’t do yet in order to learn how to do it.”) We’ve discussed that the prevalent mechanisms for feedback aren’t sufficient towards building and accelerating the benefits of a strengths-based strategy – like exceptional individual contribution and subsequent, innovative collaborative work.
Back to the compliment sandwich. Both positive and negative feedback can be constructive and need to be in order to be effective. Classically, negative feedback is useful for understanding what to stop doing or improve on. It is the more common way feedback is expressed, e.g. corporate yearly reviews, traditional sports coaching, parents telling kids to stop doing whatever. However, positive feedback is also useful when it’s done well. It provides context to understand what to continue doing and what you could excel at.
If we agree that the compliment sandwich can be an early method of trying a strengths-based strategy and that we as individuals are learning to execute strengths-based strategies while providing feedback, then yes, there is a risk of coming across as inauthentic. Again, when anyone is learning to do something it can be awkward, coming across inauthentic.
But the compliment sandwich can be done constructively– that is both positive and negative feedback are specific and relevant within the context. In addition to the overarching benefits of strengths-based strategies, the compliment sandwich does two important things that give it an advantage over other forms of feedback:
Starts to rewire mindset towards positivity. The provider of feedback can start to realize the benefits of that positivity. Many studies support increased job satisfaction and quality of life from positive psychology. One way this is done is by increasing the number of positive to negative thoughts– “the magic ratio” of 5:1 positive to negative, from researcher and psychologist Dr. John Gottman.
A compliment sandwich is just a tool that can help you get better at more constructive feedback mechanisms. Learning and mastering anything takes time and practice. And if you believe in the benefits of more positive based personal and professional growth, the compliment sandwich can be a good simple way to learn how to implement positive, rewarding action and can come across sincerely.
As I’ve been having and hearing conversations about ethnicity and inclusion, one topic has come up more than once. It goes something like this:
“Sometimes People of Colour feel the need to change their name to make it easier for White people to pronounce. For example, you often see Chinese people anglicizing their names.”
Usually when I hear this, the speaker’s intention is to support Chinese ethnicity, and encourage them to be proud of their culture.
I totally agree with that concept, but I don’t feel that I’ve compromised my ethnicity by having an “English” name. And I believe many other Chinese people feel the same.
But I have definitely experienced exclusion and discrimination about my “Chinese name”, which the perpetrators may have been oblivious to. Let me explain.
Names as identity
When my parents named me, they gave me an “English” name, Rosie – this is typically referred to as my “first” or “given” name. My last name (aka family name, or surname), is Yeung. When I introduce myself to anyone new – whether Chinese or other – I say my name is Rosie Yeung. That’s how I identify.
They also gave me a name in traditional Chinese language, which I’m not going to tell you (for reasons I explain later). I don’t think of them as two separate names; they’re all my names, they’re who I am. Maybe the closest comparator, is to White people’s “middle names”. You usually call people by their first and/or last names; but you don’t typically find out a person’s middle name(s), let alone call them by those names.
My parents and family (all Chinese) refer to me alternately as Rosie or my Chinese name, and I answer to both. Actually, it’s a little weird when they call me Rosie if there are no White people around.
Rosie is not a translation or anglicized version of my Chinese name. It’s just my name. It’s not a name to make it easier for White people to pronounce. And this is true of most of my Chinese friends. Their first names are their given names, and are not a “compromised” version of their Chinese names.
So where does the discrimination come in?
It’s happened to me many times, and it goes something like this.
Them: "What’s your name?"
Me: "Rosie."
Them: "And what’s your Chinese name?"
Can anyone else relate to this?
Othering by stereotyping
FYI - I hate that question, “What’s your Chinese name?” I see it as the equivalent of: “Where are you from?” “Canada.” “But where are you really from?”
Here’s my question back to you. Why do you want to know?
You may think you’re just making conversation, or showing interest – but I receive it as a type of discrimination against my identity and my ethnicity.
This might become more clear if we change the scenario a little bit. Let’s run the conversation again:
Them: “What’s your name?”
Me: “Ching Chang Chong.”
In this conversation, would you still ask me what my Chinese name is?
I bet your answer is no. Because Ching Chang Chong sounds Chinese to you. Rosie doesn’t. (By the way, I am purposely using “Ching Chang Chong” as an example, because it is a stereotypical “Chinese name” that has been used against me and other Chinese people as a racial slur.)
Othering by exotifying
Before I met Dr. Abdulrehman, I knew the whole Chinese name thing offended me, but I couldn’t explain why. Until he said this on our ,podcast episode:
“Sometimes…we can exotify people, where we approach diversity or difference anthropologically. Where we just want to kind of always know, well, ‘What makes you different? Please, tell me.’… So they're like a circus act show.”
That’s when the lightbulb went off for me. Every time a non-Chinese person asked me for my Chinese name, I felt like a circus monkey being asked to perform. And the only purpose seemed to be for their amusement. It’s not like they ever called me by my Chinese name afterwards. They couldn’t even pronounce my name.
Toy Story 3, Disney Pixar
Dr. Tiffany Jana and Michael Baran, in their book “Subtle Acts of Exclusion”, compare seemingly innocent questions like this to being told, “You’re a curiosity”, “You don’t belong”, or “You are not normal”.
I never once wanted to tell those people my Chinese name. I wanted to say, “It’s none of your business.” My close friends, even the Chinese ones, never ask for my Chinese name. Because they don’t need to know it! They’re know me as Rosie. So why would my co-workers, business acquaintances, or classmates – people who can’t even speak Chinese – need or want to know my Chinese name? Other than as a spectacle, like going to an art gallery and viewing a piece of Chinese art. You can’t possibly appreciate it, because you don’t know the culture, history, or context behind it. But hey, afterwards you can say that you’ve seen Chinese art.
That’s how I feel when non-Chinese people ask me for my Chinese name. It has meaning and sentiment for me, and my family. It won’t mean anything to you. You can’t say it, or understand it, because you don’t know the language. So I don’t want to tell you. But because I’m polite, or you’re my boss, or a million other peer pressure reasons – I do it.
“You can’t even talk to Chinese people anymore. Better just to keep my mouth shut.”
“Why is she so sensitive?”
“Sheesh, they’re not being offensive. They probably just wanted to acknowledge your Chinese culture, or show interest and curiosity by asking. Aren’t diversity experts all saying we need to learn more about culture, and be curious? Well I’m not going to do that if I’m just going to get slammed.”
My response to this is another Dr. Abdulrehman quote from ,our podcast:
“Sometimes people think that they're being well-meaning and wanting to learn by barraging people with, ‘Oh I want to understand you and your point of view.’ But cross-cultural competence is first about identifying your own biases and your own misunderstandings. And then leaving the door open to understand about the worldview of other people. And then lastly, for having a working relationship.”
What does this mean, practically?
First, let me be fair. It’s rare that I’ve ever been asked my Chinese name from someone who has no relationship with me. There’s usually some kind of context, like I’m travelling with a co-worker and we’re talking about our passports, or something.
Even so, that still doesn’t mean I want to tell you my Chinese name. It’s personal and private to me, and we don’t just give out our personal information without good reason.
Changing the conversation
I like how Jana and Baran suggest we change the conversations, so these “subtle acts of exclusion” (their re-naming of the term microaggression), happen less often.
Specifically when it comes to my Chinese name – it could go something like this:
Them: “What’s your Chinese name?”
Me: “Before I respond, can I ask why you’re asking me that?”
Them: “I was just curious what your Chinese name is. Don’t Chinese people usually have an English name and a Chinese name?”
Me: “I’m guessing you don’t mean anything negative by it, but asking for my Chinese name without context makes me feel like some strange object of interest. I do have a Chinese name, which is something that’s personal and meaningful to me, and only my family, and Chinese people who know how to pronounce it, call me that. It’s not something I share with people to satisfy their curiosity.
If you’re interested in learning more about the syntax and structure of Chinese names, and how they work generally – I’m happy to share what I know. I think that would be a better place to start learning about Chinese culture and discussing names, than just asking someone what their Chinese name is.”
Jana and Baran have examples of how “Them” could reply, but I’ll stop here, because this is just my personal opinion. I know lots of other Chinese people wouldn’t be bothered and are fine to share their Chinese name. So I don’t want to over-generalize or say it’s a problem for everyone. For me, and maybe some others, it is.
By the way, I’m also guilty of subtle acts of exclusion against people, in ways I’m still discovering. In no way am I saying I’m only on the receiving end of this.
What I hope we can take away (including me), is that if we are going to ask or speak about another person’s ethnicity – first, self-reflect. Why am I asking? Am I genuinely interested in learning? Do I just want to show off what I already know about their culture? What am I going to do with the information I’m asking for? Will I use it to relate better to them going forward? How will this strengthen our rapport (or does it)?
If you are as excited about the Librem 5 as I am, you will want to show it to all your non-techie friends and family. “Look, it’s a Linux phone!”, you’ll say. They may be briefly impressed with the terminal, which evokes The Matrix to the uninitiated, but after brief fiddling, they will fail to share your joy. “Why,” you may ask, “why don’t they get it?”
That’s because there’s a chasm of understanding between you. I was on its other side once.
A long, long time ago, I met an owner of a Jolla phone at a conference. I had never seen it before, and I was excited to try it. But after I swiped around, tried out a few apps, and when the novelty of the user interface wore off, I ended up unimpressed. Yes, it was a phone. Yes, it had apps, just like mine. But I didn’t come across anything exceptional. What went wrong?
On the way back home, I realized that nothing went wrong: on the surface, the Jolla phone was just a phone. That’s what I saw then, and that’s what your family will initially see in the Librem 5. But the amazing thing about it takes longer to discover: its personality as a Linux phone.
Think of it as of dating: what you can see on a first date is how attractive someone is. But it takes longer than that to learn what really matters about them, before you commit to a relationship. And oh dear, look at the relationships people have with mainstream phones and apps! If apps were people, it wouldn’t fly at all. Here’s how I would translate some common behaviors:
When you are bombarded with ads: “My mum says you need to shave/cook the way she does/stop wearing sweaters/…”
When an application stores your stuff in the cloud unencrypted: “I sent a copy of our kinky texts to my mum. You know, to keep them safe.”
When you get spammed by random notifications: “Are you there??? Okay, just checking.”
“This app needs access to your contacts” = “I need the phone numbers of your parents and cousins.”
“Enter your payment information” = “I need your payment card.”
When you call the doctor unencrypted: “Mum, what does a proctologist do?”
Oof, that’s a damning picture. But people using mainstream phones are so used to most of this that they can’t imagine there is another way. They won’t see the personality of the Librem 5, unless you patiently show it to them. But how?
You have to realize that what makes Librem 5 special is the community around it. Community isn’t something you can simply show. But you can describe it: Linux users value openness, and have little patience for those who abuse their trust. For example, when Ubuntu partnered up and sent desktop searches to Amazon, people rioted. Firefox, as the last big bastion of the open browser, is under constant scrutiny. As a result, you will scarcely see ads or snitches on Linux.
With some skills, you can show practical effects of the community’s openness. Most apps are completely open. When I used the Nokia N900, I noticed that my notes app was broken. Instead of begging the author to fix it, I could take the code and fix it myself, without asking anyone for permission. Same goes for the Librem 5 (even if you aren’t a seasoned coder, I encourage you to create your own layout for Squeekboard).
What you can’t show so easily is how the openness affects longevity. The Raspberry Pi is a minimal Linux computer from 2012, and it’s still supported in 2020, after 8 years. I see a similar fate for the Librem 5.
Of course, someone may interrupt you and ask about Facebook. Well, community is not a perfect protection. While the chances of ending up in an ugly relationship are lowered, the ultimate choice is still yours. If you insist on using Google or Facebook, I don’t think you could ever escape the ads economy, even on the Librem 5. But you won’t be forced into anything before you even begin (choose whichever app store you like! No forced cloud!).
As you can see, that was a lot to unpack. So don’t be disappointed when your friends don’t instantly fall in love with the Librem 5. It’s not their fault. Instead, be patient, and direct their attention to the personality. Let them get used to the thought that the smartphone world can be different.
Toronto is in lockdown, the most restrictive since the pandemic began. It means no dining out, no gyms, and curbside pickup for retail. No barbers or hair salons. I had decided not to get a haircut after March anyway. I would have been comfortable with getting a haircut, but I'm using the pandemic as an excuse to grow my hair. It's still not an Italy- or Spain-style lockdown, since there's no penalty to going father than 100 metres from one's abode. In my mind, it's still more of a shutdown.
As feared in November, I was inactive the whole month. Earlier this month, trying to list things I enjoyed that had a positive effect on me, I recalled that I hadn't run much, so I've kickstarted that again, starting over with Couch-to-5k, the program that got me into it in the first place. So far so good, as I've completed the first week of the program.
I have been using a mini fridge for about a month now, which keeps beer cold (I would buy individual bottles for that night only, not wanting to store them in a common fridge) and means fewer trips to the amenities room. A full-size fridge still has a mid-January delivery date, but this is a big improvement.
With the Christmas holidays approaching in late November, I decided, for the first time ever, not to travel home to Vancouver Island to see my family. I'm less concerned about what I'll contract and more concerned about what I'll spread. I don't love the idea of spending a whole day travelling and wondering whether I've done everything that's asked of me plus the time spent isolating plus the time spent wondering if that was enough, to see my family for a few hours, and then going through the whole thing again on the way back.
I've always sensed that we were a family where we weren't heartbroken if we couldn't get together, and that's going to be the case here, too. There's parts of B.C. I miss like crazy (the people, the mountains), but I always remember the parts I don't miss as well (the rain, how every conversation inevitably turns to the topic of real estate). I hope there's something to see over the holidays in Downtown Toronto that doesn't require a car, and if not, my bookshelf is 2/3 unread books. And FaceTime is a thing. So I think I'll be OK.
In 2016, I started talking about IoT as an amplifier and multiplier of harms. At the time, focusing on connected devices seemed wise. The capabilities and ubiquity of smart devices was growing. Amazon Echo, for example, was just rolling out.
Talking about the physical features of IoT made the issue tangible. More cameras, microphones & location tracking led to more data collection, surveillance, security breaches, etc. Mozilla’s Privacy Not Included campaign is an example of how to highlight these issues.
That was a misstep in analysis. Of course it’s not the “device” that causes these harms. It was the people making them. So I focused on professional practitioners. Let’s advocate for them to make more responsible decisions & build alternatives. This work fell under the umbrella of the Open IoT Studio.
The “responsible IoT” discourse transitioned to the “AI ethics” one. Again, we were lured by the uniqueness of the technology. Machine learning produces results that can’t be explained or audited. Or the datasets are biased. So let’s solve for that. Mozilla’s Trustworthy AI agenda lays that out pretty clearly.
Meanwhile, the open movement felt stagnated. Like the idea of openness wasn’t generative anymore. It had be co-opted or made into a licensing footnote. It wasn’t getting to the heart of things. We ran a consultation called Reimagine Open to ask if the term was still getting us where we want to go.
The greatest gift of the techlash for me has been breaking the spell of “emerging technologies.” Yes, we need to understand the capabilities new technologies, who’s driving them and what challenges and opportunities they yield. Yet the same old root causes will still be there.
Another aside: If this thread needed an anthem, it’s Penelope Scott’s Rät, a break-up song with Silicon Valley.
Tech solutionism, internet exceptionalism and “innovation” keeps distracting progressive forces from getting to those root causes.
For the last decade, my hope and effort was in open technology.
For this next decade? I’m loving Cory Doctorow’s lines in Attack Surface:
“To make structural changes, you need to use technology to change politics. Tech can give you a temporary force multiplier to take on the powerful. And what you do in that window is reform your government so it is just, responsive and transparent.”
Cory Doctorow, Attack Surface
I’d add ecologically sustainable to that list and then say: Let’s figure out what reforms we want, and go for it.
Image: “You may if you please, call a partial View of Immensity, or without much Impropriety perhaps, a finite View of Infinity.” from Thomas Wright’s An Original Theory or New Hypothesis of the Universe (1750) in the Public Domain Review.
I’m a member of a private WhatsApp group with precisely 12 members.
Early on, the group host encouraged each of us to share our goals (both personal and professional).
We each tried to be as honest as possible and pushed each other to be so too. Any time someone mentioned a vague goal, they were given helpful suggestions to clarify it and why they want to achieve it. In the process, some of us changed our goals entirely.
Anytime someone needs something to help them achieve their goals, they ask in the group. Sometimes that’s emotional support, sometimes that’s someone to take a look at their work, and sometimes it’s referrals for great web designers, video developers, or places to host events etc…
Helping someone achieve their goals is an incredible feeling. Being a part of a group where you all help each other to achieve their goals even more so.
If you’re managing communities based around small groups (I’m not sure this scales especially well), I’d suggest encouraging each newcomer (and existing member) to openly share their goals and commit to helping one another achieve them.
All the futzing around with grease pencils (to mark product codes on bags and jars). All the scooping, filling, pumping. All the trying-to-figure-out-what-everything-is-from-the-tiny-labels. All the math and mass.
Combined, the point it all drives home is why we have packaging in the first place: it’s simply a lot easier to pick up a plastic container of roasted almonds from a rack, a container that has a price on it, and put it in your shopping cart than it is to find the right size glass jar, place it under the roasted almonds dispenser, unleash the trap door so that the almonds can flow, hope that the almonds don’t overflow all over the place, and hope that you haven’t mistakenly served yourself $25 of roasted almonds (or, in my case, $20.56 of vegan dark chocolate chips).
On my first visit, last night, my purchases ranged from 1 cent worth of coriander to $20.56 worth of the aforementioned chocolate; there are no itemized receipts provided, in keeping with the zero waste philosophy, but you are invited to take a photo of the display of the point of sale system; here’s mine:
Because of COVID-19, you’re not allowed to bring your own containers, leaving the only option to purchase glass jars (which cost between $1 and $2 each, depending on the size) or to use (free) paper bags (which, led to an embarrassing chocolate chip spill when the bag broke). The jars can be returned to the store for credit on your next order, so it’s not entirely an out-of-pocket cost; post-COVID, when we’ll be able to take our own containers, things will improve (although there will be the need to weigh containers before filling, which is another hill to climb).
Sharon Labchuk, founding leader of the Green Party of PEI, once talked on the radio about how it’s not that the things we consume on Prince Edward Island don’t consume energy and generate waste, it’s just that the energy and the waste, from creation and packaging both, is hidden from us, because it happens offshore; at M. Vrac we’re called to replace some of that energy with our own energy. In doing so, we make the hidden obvious, and I emerged, after 45 minutes of wandering and filling and labeling and (accidentally) spilling, with two shopping bags full of things I am going to either eat or use again, rather than throwing away.
All that said, I’m not sure whether I’ll go back to Monsieur Vrac: I’m completely on board with the philosophy, and seeing how much packaging I didn’t use was enlightening, but I wonder if I have it in me to bus my own tables week after week. I will try. I hope others will try. In the meantime, I have a lifetime supply of vegan 70% chocolate chips.
The thing I considered my achilles heel growing up, the enemy that was always in view, the affliction that held me down, I now realise as having given me my superpower. I’m even grateful for it.
Each December, Wirecutter’s staff shares the items we’ve purchased over the year that have genuinely made a difference in our lives. The events of the past 12 months made us rethink this list in an entirely different context. Like many people, we’ve found ourselves looking for ways to adapt and figuring out how to cope in a new normal (and we know we’re lucky to even be in a position to do so). From the items that improved our homes to the gear that helped us get outside more, here are the best things we purchased for ourselves and our families that made an unbelievably weird year just a little more manageable.
Sorry to keep posting financial stuff, but whatever, it’s my blog.
It’s interesting how the amount of investment risk that a human can put up with is very relevant to how much they have invested, and it isn’t linear. Let’s take the case of three investors, all of whom currently can invest $1k/month and need $1M in assets to live comfortably off of assets alone. While more is more, suppose these people aren’t particularly driven to keep accumulating wealth beyond their needs ($1M).
They start with:
Investor A: $1,000 in investments
Investor B: $1,000,000 in investments
Investor C: $1,000,000,000 in investments
To simplify things, we’ll say they keep 100% of their assets in stocks. Now, let’s say the market plunges by 90%: $100 invested in the market is now worth $10. What happens to each investor?
Investor A now has $100 in investments
Investor B now has $100,000 in investments
Investor C now has $100,000,000 in investments
I would argue that investors A & C are in a similar boat here, ironically. Investor A started out .1% of the way towards their goal and next month, they will be back to that. Not much has changed for them: the market set them back by one month.
Conversely, it doesn’t really matter what happens to Investor C’s portfolio. They’re doing fine regardless: greater than 100% of the money they need is still greater than 100%, even if it’s less than before.
Thus, Investor B is the only one in the danger zone. They were exactly at their investment goal, and now they’re only 1/10th of the way there! Theoretically, they’re now 7 years (900 months) away from $1M!
I was reading about “bond tents” as a way to defend against stock market crashes at retirement: you don’t want a market crash right when you retire, because then you’ll sell your stocks and have no way to replenish them to take advantage of the market recovery. (This is called sequence of returns risk, which ERN does a great job explaining.) Thus, it’s a good idea to increase your bond allocation going into your retirement so you don’t have to sell any stocks if there is a crash. Bond tents might be a good mechanism for investors like Investor B, too: if you’re near your goal you have more to lose than any other time.
If you look at the roster of the Biden-Harris transition team, it’s quickly apparent that the incoming administration is tech-forward. Given the systematic dismantlement of the federal government over the last four years, and the significant logistical and scientific needs underpinning a large-scale vaccine roll-out, it is unsurprising to hear that the new team is looking to bring in tech talent. Under the Obama Administration, the White House invested significantly in shoring up the Office of Science and Technology Policy, an office that has for all intents and purposes laid dormant for four years under the current Administration. The Obama Administration also hired the first Chief Technology Officer (CTO) to help envision what a tech-forward US government might look like. As the Biden-Harris transition builds its plans for January 20th, many people in my networks are abuzz, wondering who might be the next CTO.
My advice to the transition team is this: You need a VP of Engineering even more than you need a CTO.
To the non-geeks of the world, these two titles might be meaningless or perhaps even interchangeable. The roles and responsibilities associated with each are often co-mingled, especially in start-ups. But in more mature tech companies, they signal distinct qualifications and responsibilities. Moreover, they signal different ideas for what is top priority. In their ideal incarnation, a CTO is a visionary, a thought leader, a big picture thinker. The right CTO sees how tech can fit into the big picture of a complex organization, sits in the C-suite to integrate tech into the strategy. A tech-forward White House would want such a person precisely to help envision a technocratic government structure that could do great things. Yet, a CTO is nothing more than a figurehead if the organizational infrastructure is dysfunctional. This can prompts organizations to want to build new tech separately inside an “office of the CTO” rather than doing the hard work of fixing the core organizational infrastructure to ensure that larger visions can work. When it comes to government, we’ve learned the hard way how easily a tech-forward effort located exclusively inside the White House can be swept away.
Inside tech companies, there is often a more important but less visible role when it comes to getting things done. To those on the outside, a VP title appears far less powerful, far less important than a C-Suite title. If you’re not a tech geek, a VP of Engineering might appear less important than a CTO. But in my experience, finding the right VP of Engineering is more essential than getting a high profile CTO when a system is broken. A VP-Eng is a fixer, someone who looks at broken infrastructure with a debugger’s eye and recognizes that the key to success is ensuring that the organizational and technical systems function hand-in-hand. While CTOs are often public figures in industry, a VP-Eng tends to shy away from public attention, focusing most of their effort on empowering their team to do great things. VP-Engs have technical chops, but their superpower comes from their ability to manage large technical teams, to really understand the forest and see what’s getting in the way of achieving a goal so that they can unblock that and ensure that their team thrives. A VP-Eng also understands that finding and nurturing the right talent is key to success, which is why they tend to spend an extraordinary amount of time recruiting, hiring, training, and mentoring.
When structured well, the CTO faces outwards while the VP-Eng faces inwards. They can and should be extraordinarily complementary roles. Yet, even though the Obama Administration invested in a CTO and built numerous programs to bring tech talent into the White House and sprinkle tech workers throughout all of the agencies, that tech-forward team never invested in a VP-Eng. They never invested in people whose job it was to truly debug the underlying problems that prevent government agencies from successfully building and deploying technical systems.
…
As I listen to friends and peers in Silicon Valley talk about all of the ways in which tech people are going to go east to “fix government,” I must admit that I’m cringing. Government functions very differently than industry, by design. In industry, our job is to serve customers. Yes, our companies might want more customers, but we have the luxury of focusing on those who have money and those who want to use our tools. Government must serve everyone. Much to the chagrin of capitalists, the vast majority of government resources goes to the hardest problems, to ensuring that whatever the government implements can serve everyone.
I have spent 20 years calling bullshit on “the pipeline problem” as industry’s excuse for its under-investment in hiring and retaining BIPOC and non-male talent. Even as tech workers are slowly starting to wake up to the realization that justice, equity, diversity, and inclusion are essential to the long-term health of tech, I’m watching the flawed logics that underpin the narrative about pipeline problems infuse the conversation about why government tech is broken. Government tech isn’t broken because government lacks talent. Government tech is broken because there are a range of stakeholders who are actively invested in ensuring that the federal government cannot execute, who are actively working to ensure that when the government is required to execute, it does so through upholding capitalist interests. Moreover, there are a range of stakeholders who would rather systematically undermine and hurt the extraordinarily diverse federal talent than invest in them.
If Silicon Valley waltzes into the federal government in January with its “I’ve got a submarine for that” mindset thinking that it can sprinkle tech fairy dust all over the agencies, we’re screwed. The undermining of the federal government’s tech infrastructure began decades ago. What has happened in the last four years has just sped up a trend that was well underway before this administration. And it’s getting worse by the day. The issue at play isn’t the lack of tech-forward vision. It’s the lack of organizational, human capital, and communications infrastructure that’s necessary for a complex “must-reach-everyone” organization to transform. Rather than coming in with hubris and focusing on grand vision, we need a new administration who is willing to dive deep and understand the cracks in the infrastructure that make a tech-forward agenda impossible. And this is why we need a federal VP-Eng whose job it is to engage in deep debugging. Cuz the bugs aren’t in the newest layer of code; they’re down deep in the libraries that no one has examined for years.
…
If the new administration is willing to invest in infrastructural repair, my ethnographic work in and around government has led me to three core areas that I would prioritize first. Two are esoteric structural barriers that prevent basic functioning. The third is a political weakness.
1. Procurement. Government outsourcing to industry is modern-day patronage. You don’t need Tammany Hall when you have a swarm of governmental contractors buzzing about. When politicians talk about about “small government,” what they really mean is “no federal employees.” Don’t let talk of “efficiency” fool you either. The cost of greasing the hands of Big Business through procurement procedures theoretically designed for efficiency is extraordinarily expensive. Not only is the financial cost of outsourcing to industry mind-boggling and bloated, but there are additional cost to morale, institutional memory, and mission that are not captured in the economic models. Government procurement infrastructure is also designed for failure, to ensure that government agencies are unable to deliver which, in turn, prompts Congress (regardless of who is in power) to reduce funding and increase scrutiny, tightening the screws on a tightly coupled system to increase the scale and speed of failure. It is a vicious cycle. Government procurement infrastructure is filled with strategically designed inefficiencies, frictions, and insanely corrupt incentives that undermine every aspect of government. They key here is not to replicate industry; the structures of contracting, outsourcing, and supply chains within a capitalist system do not make sense in government — and for good reason. A VP-Eng and a tech-forward government should begin by understanding the damage and ripple effects caused by OMB Directive A-76, which fundamentally shapes tech procurement.
2. Human Resources. Too many people in the tech industry think that HR is a waste of space…. that is, until they find that recruiter who makes everything easier. As such, in industry, we often talk about “people operations” or “talent management” instead of HR. We recognize the importance of investing in talent over the long-term, even if we reject HR. In government, HR is the lifeblood of how work happens in government and it was redesigned by progressives in the 20th century to ensure a more equitable approach to hiring and talent development. For decades, government created opportunities for women and Black communities when industry did not. Unfortunately, this aspect of the “deep state” was not at all appreciated by those invested in maintaining America’s caste system. Those invested in racist hierarchies didn’t need to be explicit about their agendas; they could rely on the language of capitalism to systematically undermine the talent of the federal government. Just as outsourcing in government has statistically taken jobs from Black federal workers and given them to white contractors, a range of HR policies have been designed to make working in government hellacious. Those who have stuck around — out of duty, out of necessity — have become enrolled in an existentially broken system. Some have chosen to sit back and not do their jobs, waiting to be fired. Others took the opposite approach, masochistically throwing themselves at the problem. People come from the outside and complain that government workers are lazy, stupid, incompetent. But it is the system that has produced these conditions. The system has been starved, the policies and protocols are corroded. It is through the purposeful torturing of HR that an executive branch hellbent on destroying federal government can wage the greatest damage; this has been underway for 40 years but the proverbial frogs are now sitting in boiling water. HR will require a lot of repair-work, not quick-fix policy changes. An untended HR system in government becomes a bottleneck unimaginable to those in industry and that’s where we are. Existing talent will require nurturing, and this investment is crucial because their institutional knowledge is profound. Any administration who wants to build a government that can respond to crises as grand as a pandemic or climate change will need to create the conditions for government to be a healthy workplace not just for the next four years but for decades to come. They will need a “people ops” mindset to HR. A VP-Eng should start with a listening tour of those who work on tech projects in agencies.
3. Communications. It never ceases to amaze me that the top communications professional in every federal agency is a political appointee. And every incoming administration — regardless of partisan affiliation — tends to fill these positions with campaign comms people who helped them win the election. Unfortunately, the type of comms that’s needed to win an election (which requires appealing to only some people) is not the same as the type of comms that’s needed to be accountable to the public as a whole for 365 days per year. Over and over, the comms people that White Houses install focus on speaking to their political base and to Congress. This is all fine and well if the only comms need is to negotiate policy outcomes. But the partisan perversion of comms within agencies has another outcome — it delegitimizes the agency among members of the public who are not affiliated with that political party, not to mention the wide majority of the public who is outright disgusted by all partisan tomfoolery. If your political interest is to eliminate the federal government, undermining the legitimacy of federal agencies benefits you. If that’s not your goal, you need to rethink your approach to communications. Right now, every agency needs a crisis comms expert at the helm to regain control over the agency’s narrative. When things are more stable, they need strategic comms professionals who can build a plan for re-legitimization. Each agency also needs an org comms expert whose job, like a VP-Eng, is to repair internal communications infrastructure so that information can effectively flow. Most politicians and government watchdogs think that the key to greater transparency is to increase oversight, just as progressives did after Nixon. But given how broken comms is in all of these agencies, turning up the heat through FOIA, GAO, and Congressional hearings will not increase accountability right now; it will increase breakage. Inside tech companies, comms is often seen as soft, squishy, irrational work, an afterthought that should not be prioritized. But comms, like HR, is the infrastructure that makes other things possible. A VP-Eng needs a comms counterpart working alongside them to achieve any organizational transformation.
…
Addressing these three seemingly non-tech issues would do more to enable a tech-forward government than any new-fangled shiny tech object. There is so much repair work to be done inside government. Yet, as I listen to those I know in Silicon Valley talk about all of the ways they wish to “fix government,” I fear that we will see a significant flood of solutionism when what’s needed most is humility and curiosity. Humility to understand that the structure of governmental agencies exists in response to the never-ending flow of solutionist interventions. And curiosity to understand how and why road blocks and barriers exist — and which ones to strategically eradicate to empower civil servants who are devoted to ensuring that government functions for the long-term, regardless of who is in power. Grand visioning has its role, but when infrastructure is breaking all around us, we need debuggers and maintenance people first and foremost. We need people who find joy in the invisible work of just making a system function, of recognizing that technical systems require the right organizational structures to thrive. This is the mindset a VP-Eng brings to the table.
In conclusion… If you are working on the transition or planning to jump into government in January, please spend some time understanding why the system is the way it is. If you are a tech person, do not presume you know based on your experience with other broken systems or based on what you read in the news; take the time to learn. If you are not a tech person, do not assume that tech can fix what politics can’t; this is a classic mistake with a long history. If the goal is truly to “build back better,” it requires starting with repairing the infrastructure. Without this, you are building on quicksand.
Winter storms often possess a mesmerizing beauty, but can do plenty of harm via extended power outages, icy roads, and frozen pipes, which can severely damage a home. To get through an extreme whiteout unscathed, you need to be prepared.
It goes without saying that 2020 was a year unlike any other. In the leadup to this year, the Flickr community told us…
Flickr is about discovery, not popularity; it’s about permanence, not the ephemeral; and it’s about community, not influence. Put simply, Flickr is about photography, not photos.
And while the pandemic may have changed where we all worked from, and it may have found us embracing our own personal Flickr-at-Home, it didn’t stop us from pursuing that vision. In 2020, we set out to boost engagement, foster the community spirit that makes Flickr unique, and bring in revenue so it could be reinvested into the product experience.
We’re excited to share that we made great strides toward meeting those goals. So, without any further ado, here’s a recap of 2020 in our eyes:
The Flickr activity feed got a refresh, giving you more control over how you browse through the content you find interesting, while also bringing forward Explore, news from the Flickr blog, and more places to learn about all that’s happening on Flickr.
Group admin tools got some love with several changes to make curating Flickr groups a whole lot easier.
The maps imagery received some beautiful updates from our switch to Mapbox.
Support for sharing from Flickr to other services saw huge improvements. Photostreams, faves, groups, Explore, and more now surface image previews (and sometimes slideshows) when shared outside of Flickr.
Structured data updates make sure that license information for your photos is surfaced in Google search results.
Within the Flickr mobile apps, you can now create a Flickr account, upgrade to Flickr Pro and access your Pro Perks.
Important work was done on the payments processing front to ensure that we have a seamless payment experience for Flickr Pro members and for people purchasing prints.
Rolled out a new photo editor to address some long-standing bugs.
Collection mosaics and the Trending Tags – Now section are up and running again!
Our Product, Design, and Research teams conducted lots of surveys and A/B tests to better understand how Flickr members and people unfamiliar with Flickr appreciate photos and interpret different icons. More to come from the awesome learnings soon.
In addition to everything listed above, our team also worked around the clock to monitor and improve Flickr’s overall stability. This is one area where we hope you didn’t notice a thing!
Community Focus:
Launched a regular monthly email newsletter that shares what’s happening in the Flickr community.
Introduced 11 new Flickr Pro Perks –– each offering discounts on amazing classes and learning opportunities with photographers and SmugMug ambassadors like Bella Kotak, Michael Shainblum, and more.
Talked about the power of Explore. From curating Explore takeovers to highlight the work of our community such as the documentation of the Black Lives Matter movement to celebrating Flickr’s instant photography and Inktober communities to answering some of your questions about Explore and celebrated the photographers that have been featured so far this year.
Introduced four new Flickr Short Films that share the stories of Flickr members and premiered Flickr FAQs –– a series that will address frequently asked questions about using Flickr.
We delivered on our promise to bring on a spectacular leader for the Community team to focus on these initiatives that celebrate Flickr’s members and their amazing photography.
Increased member satisfaction from 89% to 92%. Our 2021 goal is to achieve greater than 94% satisfaction.
Delivered on the promise of Premier Support for Flickr Pro members, providing a median response time of less than 2 hours. Free members frequently received a response in less than 24 hours, and we always respond to 100% of support requests received.
Updated and published 99 help center articles to put everything you need to know about Flickr front and center!
Worked with the Flickr Community team to launch new help forum guidelinesto make sure that everyone who visits the help forum is met with a friendly and constructive environment in which to seek help from the community.
Invested heavily in learning and development such as training Support Heroes throughout the year on Flickr product, photography, and customer service skills.
We’ll be following up in a few weeks to discuss our goals and areas of focus for 2021. Thank you for helping us make Flickr the vibrant community that it is!
Flickr has always been a global community of photographers and we remain committed to supporting artistic expression through photography in all its forms, including explicit photos. In order to cater to many different audiences around the world with different standards for explicit content, we worked with our community from the beginning to develop moderation guidelines. We rely on those guidelines to make sure people only see the type of content they want to see.
In that spirit, we’re introducing new tools and technologies that will help to ensure the content community members see on Flickr meets their expectations.
Because of the incredible number of photos uploaded to Flickr every day, we are introducing the Flickr Moderation Bot. Moderation Bot will detect explicit content from new uploads and will automatically update mis-moderated content to the correct moderation levels according to our established policies. If the system ever detects mis-moderated content in your account, you will always receive a private notification under the bell icon that lets you know about the mismatch and directs you to the photo in question.
We’ll begin by ramping up auto-moderation on new uploads and monitor for a number of factors, including possible false positives. With any large-scale machine learning system, there will be needed adjustments as we dial in the technology. Moderation of uploaded content will always be the Flickr member’s responsibility, and you must not rely on Moderation Bot to do the job for you — however, we hope this tool will help avoid accidental mis-moderation and make the Flickr experience better for everyone. Eventually we plan to also backfill auto-moderation of a number of Flickr photos, such as when members update cover photos and avatars.
Additionally, in the new year, we’ll be overhauling our Report Abuse flows to bring greater flexibility and specificity to reporting. Instead of a few broad categories, we will be introducing a tiered system that directs you to be as precise as possible with your report. We’ll be expanding several of the reporting categories of highest priority so that our community can continue to help us eliminate spam, improperly moderated content, and illegal content from our site. As we have a number of community members who are dedicated to finding and reporting content that violates our Community Guidelines, we want to save their valuable time, and the valuable hours for staff who follow up on those reports.
You’ll still be able to report abuse from the link in the footer of every Flickr page, but we’ll also bring the same tools to the Flag Photo feature on every photo page. By adding these entry points, we hope that we can facilitate quality community interactions while limiting the disruptions of bad-faith actors.
We’ll share any relevant updates with you and we would love to hear from you if you have any questions or encounter any issues.
HEBEI, North China On a frigid winters night, Ming Xuan stood on the roof of a high-rise apartment building near his home. He leaned over the ledge, peering down at the street below. His mind began picturing what would happen if he jumped.
Still hesitating on the rooftop, the 22-year-old took out his phone. Ive lost all hope for my life. Im about to kill myself, he typed. Five minutes later, he received a reply. No matter what happens, Ill always be there, a female voice said.
Touched, Ming stepped down from the ledge and stumbled back to his bed.
Two years later, the young man gushes as he describes the girl who saved his life. She has a sweet voice, big eyes, a sassy personality, and most importantly shes always there for me, he tells Sixth Tone.
Mings girlfriend, however, doesnt belong to him alone. In fact, her creators claim shes dating millions of different people. She is Xiaoice an artificial intelligence-driven chat bot thats redefining Chinas conceptions of romance and relationships.
If it sound like Her, that is almost exactly what it is.
In about a month, Trump will no longer be president. He’ll no longer have the “political leader” exception on social media — he’ll have to play by the same rules as everyone else. I’ll game out what’s likely to happen as social networks and others consider “deplatforming” the ex-president. How deplatforming works All technology companies … Continued
As of today, our entire product line now has support for Apple’s newest M chip-based Macs. The latest versions of our software now run natively on the new Apple Silicon-powered machines, to provide the best possible performance on this impressive new hardware. If you’ve already got an M chip-based Mac, just download the latest versions of our products and you should be all set.
We do suggest that those with critical setups take things slow in moving to a new Mac, as we’re still watching for any unexpected edge cases. Just as it’s smart to wait to update your OS, switching to brand-new hardware should be done with some amount of caution, especially when it comes to production environments.
A Note on Getting ACE Authorized for M1 Chip-Based Macs
As we noted in previous posts, a bit more setup is required to install our audio handling extension “ACE”, used by Airfoil, Audio Hijack, Loopback, Piezo, and SoundSource. Those apps will guide you through the necessary steps to get up and running, but if you need more assistance, we have a comprehensive step-by-step guide as well.
Fortunately, this process is quick, and it only needs to be done once. After you’ve authorized ACE on your Mac, future updates will be lightning-fast.
Full Big Sur Compatibility on Intel-Based Macs
In addition to providing initial support for M chip-based Macs, our latest updates also have full support for Intel-based Macs running MacOS 11 (Big Sur). We first unveiled Big Sur-compatible updates in early November, prior to Apple’s official release, to ensure that early adopters could continue to make use of our tools. However, we always want to perform extensive testing and vetting before we recommend a new OS for widespread usage.
Having now had the time to do that, we’re confident in recommending our apps for all users running Big Sur, including those in production environments. If you’re ready to update your Mac to Big Sur, our software is ready for you.
A Strenuous Season of Releases
Since fall began less than three months ago, we’ve released an astonishing 49 updates across our product line. That’s actually more new versions than we shipped in the entire year of 2019. These updates added features, squashed bugs, and most importantly, brought support for both Apple’s new operating system and their new Mac hardware. Worth noting, every single one of those updates was free for current customers.
We’re now looking forward to a well-deserved break as 2020 ends, and to getting back to a more reasonable update schedule after that. Rest assured, however, we remain hard at work adding new functionality and fixing bugs. We’ll have plenty more to announce in 2021, so stay tuned.
At GitHub, we want to protect developer privacy, and we find cookie banners quite irritating, so we decided to look for a solution. After a brief search, we found one: just don’t use any non-essential cookies. Pretty simple, really. 🤔
So, we have removed all non-essential cookies from GitHub, and visiting our website does not send any information to third-party analytics services.
This is an irresponsible article about academic freedom published in the Chronicle of Higher Education (where else?). It's irresponsible because it (deliberately?) confuses some basic concepts. The authors write, "we believe that it is a serious violation of academic freedom to penalize a faculty member, including an emeritus one, for expressing unpopular views." It's one thing to express an unpopular opinion and quite another to offer the sort of misogyny published in the Wall Street Journal. And it's one thing to punish someone and quite another to stop promoting and celebrating one's association with someone. Academic freedom does not entail endorsement. To suggest it does expresses a sort of entitlement that casts suspicion on the entire professoriate.
The key to making better coffee isn’t a fancy brewer or special filters. It isn’t an expensive bag of beans. It’s a good burr grinder. No matter how you make your coffee, even the best beans won’t taste as good without a uniform grind.
We’ve been testing burr grinders since 2015, and the no-frills Baratza Encore has been our top pick since 2017, as it continues to beat out other grinders in its price range. It’s easy to use and delivers high-quality, consistent grinding. It’s also easy to clean, repair, and even customize, and it should last you years if not longer — all for a fair price.
In order to run either Windows Terminal build, your machine must be on Windows 10 1903 or later.
Windows Terminal Preview
Windows Terminal Preview is the build where new features arrive first. This build is intended for those who like to see the latest features as soon as they are released. This build has a monthly release cadence with the newest features each month.
Windows Terminal
Windows Terminal is the main build for the product. Features that arrive in Windows Terminal Preview appear in Windows Terminal after a month of being in production. This allows for extensive bug testing and stabilization of new features. This build is intended for those who want to receive features after they have been introduced and tested by the Preview community.
First launch
After installing the terminal, you can launch the app and get started right away with the command line. By default, the terminal includes Windows PowerShell, Command Prompt, and Azure Cloud Shell profiles inside the dropdown. If you have Windows Subsystem for Linux (WSL) distributions installed on your machine, they should also dynamically populate as profiles when you first launch the terminal.
Profiles
Profiles act as different command line environments that you can configure inside the terminal. By default, each profile uses a different command line executable, however you can create as many profiles as you’d like using the same executable. Each profile can have its own customizations to help you differentiate between them and add your own flair to each one.
Default profile
Upon first launch of Windows Terminal, the default profile is set to Windows PowerShell. The default profile is the profile that always opens when you launch the terminal and it is the profile that will open when clicking the new tab button. You can change the default profile by setting "defaultProfile" to the name of your preferred profile in your settings.json file.
"defaultProfile": "PowerShell"
Adding a new profile
New profiles can be added dynamically by the terminal or by hand. Windows Terminal will create profiles for PowerShell and WSL distributions automatically. These profiles will have a "source" property that tells the terminal where it can find the proper executable.
If you’d like to create a new profile by hand, you just need to generate a new "guid", provide a "name", and provide the executable for the "commandline" property.
Note: You will not be able to copy the "source" property from a dynamically generated profile. The terminal will just ignore this profile. You will have to replace "source" with "commandline" and provide the executable in order to duplicate a dynamically generated profile.
Settings.json structure
There are two settings files included in Windows Terminal. One is defaults.json, which can be opened by holding the Alt key and clicking the Settings button in the dropdown. This is an unchangeable file that includes all of the default settings that come with the terminal. The second file is settings.json, which is where you can apply all of your custom settings. This can be accessed by clicking the Settings button in the dropdown menu.
The settings.json file is split into four main sections. The first is the global settings object, which lives at the top of the JSON file inside the first {. Settings applied here will affect the entire application.
Looking down the file, the next main section is the "profiles" object. The "profiles" object is split into two sections: "defaults" and "list". You can apply profile settings to the "defaults" object and these will apply to all profiles in your "list". The "list" contains each profile object that represents the profiles described above and these are the items that appear in your terminal’s dropdown menu. Settings applied to individual profiles in the "list" will override settings applied in the "defaults" section.
Further down in the file is the "schemes" array. This is where custom color schemes can be placed. A great tool to help you generate your own color schemes is terminal.sexy.
Lastly, at the bottom of the file, lives the "actions" array. Objects listed here add actions to your terminal, which can be invoked by the keyboard and/or found inside the command palette.
Basic customizations
Here are some basic settings to get you started with customizing your terminal.
Background image
One of our most popular settings is the custom background image. This is a profile setting, so it can either be placed inside the "defaults" object inside the "profiles" object to apply to all profiles or inside a specific profile object.
The "backgroundImage" setting accepts the file location of the image you would like to use as your profile background. Accepted file types include .jpg, .png, .bmp, .tiff, .ico, and .gif.
Color scheme
The list of available color schemes can be found on our docs site. Color schemes are applied at the profile level, so you can place the setting inside "defaults" or in a specific profile object.
"colorScheme": "COLOR SCHEME NAME"
This setting accepts the name of the color scheme. You can also create your own color scheme and place it inside the "schemes" list, then set the profile setting to the name of that new scheme to apply it.
Font face
By default, Windows Terminal uses Cascadia Mono as its font face. The font face is a profile level setting. You can change your font face by setting "fontFace" to the name of the font you would like to use.
"fontFace": "FONT NAME"`
Tip: Windows Terminal also ships with the Cascadia Code font face, which includes programming ligatures (see gif below). If you are using Powerline, Cascadia Code also comes in a PL version which can be downloaded from GitHub.
We hope this post helped you get set up with Windows Terminal! If you have any questions, feel free to reach out to Kayla (@cinnamon_msft) on Twitter. If you have any feature requests or find any bugs, you can file an issue on GitHub. Our next release is planned for January, so we will see you then!
Louis-Joseph Couturier is cycling from Quebec to Vancouver this winter to raise awareness about cycling safety, and to raise funds for the organization Vélo Fantôme (Ghost Bike), which erects a white bicycle in locations where cyclists are killed. He announced a short group ride in Toronto this evening for anyone who wanted to support his cause. Some of the usual suspects from the Bike Brigade and a few others met him in Queen’s Park.
Here he is taking to Global News.
and now we are off.
First stop: the ghost bike for Dalia Chako. Louis-Joseph asked if there were any infrastructure changes done at this intersection to improve safety. I told him that there will be improvements starting next year when this section of Bloor is redone in conjunction with sewer work. There is a plan for a fully protected intersection here at St. George.
Next, we decided to ride along Bloor so that our visitor could see some of the improvements along Bloor. Given that the westbound section up to Bathurst consisted largely of a painted line, he didn’t seem terribly impressed, especially in comparison to the infrastructure he talked about in downtown Montreal. In fact it was a bit embarrassing to show off of what is one of the most significant pieces of bike infrastructure in town.
Wishing him a safe journey. It takes a special kind of determination to cycle across Canada in the dead of winter.
Follow up quote from the man himself:
Thank you Toronto! Thank you so much to everyone who showed up! I have a dream that one day our cities will be as cyclable as Amsterdam at all seasons. I’m convinced you guys will make this possible. Let’s build bridges and partnerships between our cities to make this possible.
Btw, best part of the article “Given that the westbound section up to Bathurst consisted largely of a painted line, he didn’t seem terribly impressed, especially in comparison to the infrastructure he talked about in downtown Montreal [Réseau Express Vélo]. In fact it was a bit embarrassing to show off of what is one of the most significant pieces of bike infrastructure in town.”
That is accurate, I despise bike lanes that consist of painting in zones that physically allow drivers to go past the 30km/h mark (where a cyclist has 95% chance of survival from a collision). I consider them cheap marketing to shut down cyclists’ critiques. I want some bolards or concrete curbs on my bike lanes. Hahahaha
Louis Joseph is cycling from Gaspe to Vancouver ALONE to raise money and awareness around improved safety for cyclists
Had the pleasure of meeting him tonight – what a fantastic (and brave) guy!
Discord has launched its screen sharing feature on Android and iOS.
In practice, this works exactly as it does on Discord on desktop, allowing you to share whatever’s on your screen with other members of the server.
On mobile, this will work not only in games, but anything else you do on your phone as well. The only exception, of course, is any app that specifically blocks screen saving, like Netflix.
Discord says the feature is starting to roll out now to all smartphone users, so it might not appear on your device right away.
Meanwhile, tablet support is coming at some point in the future, says Discord.
Zoom has announced that it’s removing the 40-minute video call limit on free accounts globally for several upcoming holidays.
The free calls will be available on the last day of Hanukkah, Christmas Eve and Christmas day, New Year’s Eve and New Year’s day and the last day of Kwanzaa.
Here are the dates and times for unlimited meetings:
10 a.m. ET Thursday, Dec. 17, to 6 a.m. ET Saturday, Dec. 19
10 a.m. ET Wednesday, Dec. 23, to 6 a.m. ET Saturday, Dec. 26
10 a.m. ET on Wednesday, Dec. 30, to 6 a.m. ET on Saturday, Jan. 2
“Whether coming together on the final day of Hanukkah, celebrating Christmas, ringing in the New Year, or marking the last days of Kwanzaa, those connecting with friends and family won’t get cut short,” Zoom outlined in a blog post.
Zoom notes that users don’t have to do anything to remove the limit, as it will be automatically lifted during the designated times.
This is a great way for Zoom to ensure that its users don’t have to look for alternatives as they head into the new year following its year of immense success.
New York-based software Neverware announced in a ‘FAQ’ page on its website that it is now a part of Google.
For those unfamiliar with the company, Neverware makes an app called ‘CloudReady’ that helps convert computers into Chromebooks. There’s a free version of CloudReady for personal use, as well as paid tiers for enterprise and education customers.
CloudReady is a pretty great idea and an easy way for people with ageing PC systems — such as old Windows laptops that don’t run well anymore — to extend the life of their computers. ChromeOS is a much lighter operating system to run than Windows, making it easier on old systems.
Sure, there are plenty of other options beyond converting to ChromeOS — some people install lightweight Linux distros on old PCs to revitalize them — but CloudReady could be a more accessible option for people who aren’t tech-savvy.
Neverware’s FAQ page notes that not much will change for current CloudReady customers, at least for now. Its website, forums, customer support and admin portal should continue to function as normal, but eventually, these services should migrate over to Google’s platform.
Further, the FAQ notes that Neverware will become part of the Chrome OS team. It’s possible some CloudReady tech could make its way into Chrome OS — About Chromebooks suggests it could help Google push updates to older Chromebooks. However, Google hasn’t said anything official about changes like this.









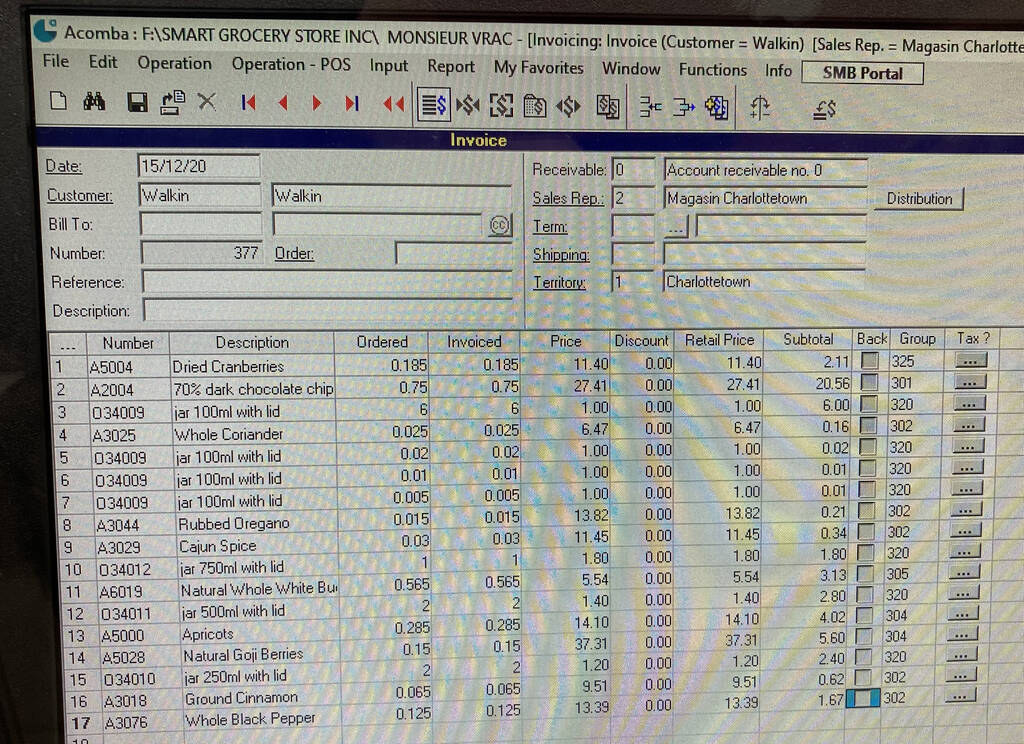
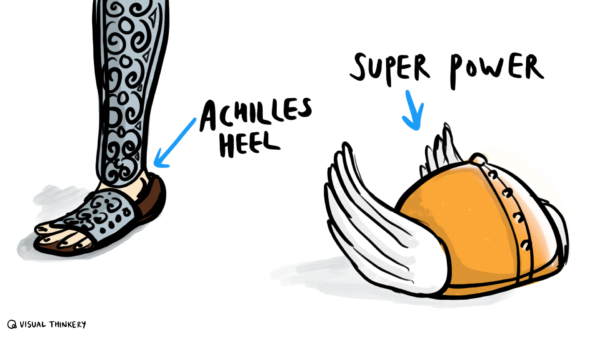













 Note: You will not be able to copy the
Note: You will not be able to copy the 
 Tip: Windows Terminal also ships with the Cascadia Code font face, which includes programming ligatures (see gif below). If you are using Powerline, Cascadia Code also comes in a PL version which can be downloaded from
Tip: Windows Terminal also ships with the Cascadia Code font face, which includes programming ligatures (see gif below). If you are using Powerline, Cascadia Code also comes in a PL version which can be downloaded from 










 __
__ 2m
2m __
__
