Some day I’ll blog about the tools I built to create Software Design by Example,
but if you’re interested in that kind of thing,
check out Bob Nystrom’s articles ([1], [2])
about how he built Crafting Interpreters,
which is the most beautiful book about programming I’ve seen in years.
(It’s worth buying a copy of the book just to admire the production values.)
This book uses a static site generator called Ivy,
which in turn relies on a page templating tool called Ibis.
Thousands of these have been written in the last thirty years;
most use one of three designs:
Mix commands in a language such as JavaScript with the HTML or Markdown
using some kind of marker to indicate which parts are commands
and which parts are to be taken as-is.
Create a mini-language with its own commands.
Mini-languages are appealing because they are smaller and safer than general-purpose languages,
but experience shows that they eventually grow
most of the features of a general-purpose language.
Again, some kind of marker must be used to show
which parts of the page are code and which are ordinary text.
Put directives in specially-named attributes in the HTML.
This approach has been the least popular,
but since pages are valid HTML,
it eliminates the need for a special parser.
This chapter used the third strategy,
partly for novelty’s sake and partly because it saved us writing a parser.
What the chapter shows is that even an apparently simple task of filling in strings
requires the implementation of variables and scope—in short,
a programming language.
There are lots of ways to get this wrong;
hopefully,
this chapter will help readers get it right if it’s ever their turn.
Figure 9.1: Three different ways to implement page templating.
Terms defined: bare object, dynamic scoping, environment, lexical scoping, stack frame, static site generator, Visitor pattern.
A Note on Open Source Etiquette
While using Ivy and Ibis on another project,
I ran into a problem that I’d never encountered before.
Ibis is hosted on PyPI at https://pypi.org/project/ibis/,
installed with pip install ibis,
and imported with import ibis.
There is another project called the Ibis Framework
that is hosted on PyPI at https://pypi.org/project/ibis-framework/,
installed with pip install ibis-framework,
but which is also imported with import ibis.
That naming conflict makes it impossible to use the two together
without manually renaming one or the other.
Ibis-the-templating-engine was created first,
which I presume is why Ibis-the-framework uses a two-part name.
I recognize that Ibis-the-framework is a bigger project
than Ibis-the-templating-engine,
and that the space of package names is getting pretty crowded,
but I still think the authors of the latter should have chosen a different name
to avoid the import conflict.
Tim Stahmer points to "two interesting stories about some in the 'younger generations' who are pulling back on their use of high tech in favor of older ways of doing thing." The stories are in the New York Times and therefore behind a paywall. Just as well. I can't imagine these stories reflect what young people are actually doing. As Stahmer says, "How many of these kids will continue embracing low tech after they graduate and move into new peer groups?" I would say close to none.
Or if you enjoy #webDevelopment and want to build (option three^3), use developer services to more rapidly add IndieWeb building blocks^4 to your site so you too can focus on creating & owning your content^5.
Using a developer service to support IndieWeb protocols saves you time. You can also contribute to the community by filing suggestions for improvements, or participating on their GitHub repositories.
If you prefer that your site not depend on any external services, you can do that too.
Another option is to use one of many open source libraries to more rapidly implement support for IndieWeb standards^7. The wiki pages for each standard list libraries in a variety of programming languages, e.g.: * https://indieweb.org/Webmention-developer#Libraries
If you choose the path of installing or building something new with libraries or by directly implementing an IndieWeb standard, be sure to test your implementation with its test suite, e.g.: * https://webmention.rocks/
As a web developer, you can choose how much of your #IndieWeb support you want to implement yourself (and time to invest) vs build on the services, libraries, and other open source that the community has produced and is actively supporting.
This student describes the process of making homemade silicon chips in his parents' garage. "Now we know that it's possible to make really good transistors with impure chemicals, no cleanroom, and homemade equipment... A major theme of this DIY silicon process is to circumvent expensive, difficult, or dangerous steps." When I was a kid my parents' garage contained a car (and a snowblower) and was a shed. Still, this is a great glimpse at what high school projects of the future could look like. Via Ars Technica and Wesley Fryer.
This is quite a nice summary from Contact North of what we've learned about chatGPT over the last month or so. The 'ten facts' in the article are, from my perspective, undeniably facts, which means we don't have the hyperbole of claims that chatGPT will replace everything or that it shouldn't be used for anything. Some of the items describe what the program does, some of them describe some of the reaction to it, and one - arguably the most speculative - describes what can be done to prevent academic misconduct.
Nicht nur bei Softwareproblemen kann man nichts machen. Auch sauberes Projektmanagement geht offenbar schlicht nicht.
Aktuelles Beispiel: Norwegens neue Schnellbahnstrecke von Oslo nach Ski, die Follo-Bahn. Da wurde gerade ein Prestigeprojekt eröffnet, ein 20-km-Tunnel mit zwei Röhren für Züge mit 200 km/h. Alles ganz frisch, zur Eröffnung fuhr der König mit dem Ministerpräsidenten durch den Tunnel.
Stellt sich raus: Die Elektrik war unterdimensioniert für die beim Bremsen ins Netz zurückgespeiste Energie. Daraufhin überhitzten da Komponenten bis hin zur Rauchentwicklung.
Ja aber Fefe, fragt ihr jetzt, kann man sowas nicht vorher wissen? Klar kann man! Wusste man auch.
Laut Medienberichten hatte im Verlauf der Bauarbeiten eine externe Beratungsfirma gegenüber Bane Nor entsprechende Vorbehalte geäussert. Dennoch habe sich die Zulieferfirma mit ihrer Variante durchgesetzt, wohl auch mit Blick auf die termingerechte Eröffnung der Neubaustrecke Mitte Dezember.
Klar ist es lebensgefährlich, aber schaut nur wie schön termingerecht es fertig wurde!1!!
The t-digest construction algorithm uses a variant of 1-dimensional
k-means clustering to produce a very compact data structure that
allows accurate estimation of quantiles.
Daniel Christian points to this LinkedIn post (may be behind a spamwall) by Santiago Valdarrama. All his examples refer to software development, but of course AI has many more applications. Not counting things like adaptive cruise control, where AI may be built into the products I buy, I use AI explicitly in the following ways:
Automated translation, to read content from around the world
Automated transcription, to create text out of my talks
Content organization using an AI in my feed reader
Removing noise from my photos
If you're not using AI, as compared to me, then you're reading less diverse sources, have to pay for audio transcription (or worse, not do it al all), take longer to sift through relevant resources, and have lower quality photos at low light. Maybe you can still out-compete me, but it gets harder.
Apologies, dear reader, it has been far too long since my last post. I did mean to post before the end of 2022 but, well none of the dozen or so half written posts really seemed to have the need to be finished and published. The mass exodus from Twitter to Mastadon seems to have now happened. I couldn’t really think of anything else about the whole white, middle aged billionaire buys twitter and f***’* it up being a classic exemplar of everything that our neoliberal age supports that hadn’t already been said.
Whilst I and many of my peers have been lamenting the end of twitter in terms of our networking and sharing of practice, this post by @ImaniBarbarin did make me give myself a good talking too. I just lost one place of instant connection and comfort, so many disabled /chronically ill people are facing a much great loss around connection and losing their voices.
As the new year starts, I’m looking forward to some f2f learning design workshops and continuing to work with Helen Beetham on a follow up project to the review we did of approaches to curriculum and learning design last year. There will be more to share on that in the coming months, but for now I’m just trying to ease myself back into things in this part of my life whilst balancing the other, artistic part of my life which is actually getting quite busy now.
I always appreciate, enjoy and find inspiration from Sherri Spelic’s Bending the Ark newsletter, and the one that dropped early this week was no exception. In this edition, Sherri shared how she left her laptop behind and reconnecting with friends and did “other stuff” over the holidays. I loved this phrase in particular:
I had a chance to remind myself that I am so much more than the words I put out for others to find.
Yes, Sherri you are so much more than that. And thank you for reminding me and other that many of us are. I always have a nagging feeling in my head that over the last few years I haven’t shared as much as I used to. So I’m going to try and get more comfortable with the realities of my working life and sharing only when I have something useful to share. Not quite a new year’s resolution, maybe more of a reminder. And hopefully that won’t be too long.
You gotta have a gimmick, and to my mind the best gimmick is jazz-infused smoked salmon.
There used to be a salmon smokery in north London. Aside from the juniper and beech wood, Ole Hansen (proprietor) would, once a day, sit down and play piano to the hanging fish – live jazz and occasional singing.
"I argue that the sound waves penetrate the flesh of the fish and it goes in and it just gives and it enriches," he says.
I found out about jazz-infused smoked salmon a few years back from a TV show about the world’s most expensive foods.
It’s such a good gimmick! The story was everywhere for a few years with Hansen playing his jazz. It would be a great story to tell your dinner guests.
And that’s fine, right? Taste is some % psychological. Red wine tastes better if you know it’s an expensive bottle. Same same, I’m ok with that.
But I don’t suppose the bebop energies actually live in the memory of the fish molecules and transmit to your boogie-woogie taste bugs or whatever. Or maybe?
(Btw another of the world’s most expensive foods is a kind of barnacle which is so hard to gather that a number of the people gathering it… die? Every year? And this is part of how it’s marketed? For avoidance of doubt this is a terrible, terrible gimmick.)
Anyway, Swiss cheese tastes better when aged with hip-hop.
Last September, Swiss cheesemaker Beat Wampfler and a team of researchers from the Bern University of Arts placed nine 22-pound wheels of Emmental cheese in individual wooden crates in Wampfler’s cheese cellar. Then, for the next six months each cheese was exposed to an endless, 24-hour loop of one song using a mini-transducer, which directed the sound waves directly into the cheese wheels.
Cheez-It has teamed up with streaming music site Pandora to create what they are billing as “the first-ever sonically-aged cheese snack” in the form of limited-edition Cheez-It x Pandora Aged by Audio crackers.
The cheese used to make the crackers was aged for six and a half months using a whole hip-hop playlist. Congrats to whichever agency pitched that. Food & Wine, May 2022.
It is easy to mock.
BUT, rather than lazily disbelieve,
it almost feels truer to say that vibe propagates in a multimodal fashion through the world by mechanisms yet unknown. And I am kinda down with it? It is a more accurate description of the universe that I inhabit than a claim that vibe does not propagate?
Let’s just be open to all of the above.
And then let’s consumerise the emerging science of vibe gastroacoustics and take it to CES 2024.
Because it seems like there is a new fad oven every year or two… George Foreman grill. Instant Pot. Air fryers. And we can get in on that.
So let me propose a new Samsung oven with integrated proving drawer and Spotify built right in.
And a recipe book, just like microwaves used to ship with microwave-specific recipes. For example:
For a long time, members of our fantastic photo community have only been able to buy prints of their own photos. Today, we’re rolling out a new feature on Flickr that lets anyone—Flickr members and visitors alike—order professional quality prints from a select group of photographers who’ve made their work available for sale.
How does it work?
Whether you’re looking for a print to decorate your living space or searching for a piece to give to someone special, you can now shop prints and wall art with just a few clicks. Start by clicking “Prints” in the upper nav, then select our brand new storefront: “The Print Shop”. When searching, photos that are available for print will also appear in the first row of your search results.
Once you’ve located the photo you want to print, click the shopping cart icon in the right-hand corner below the image, select the product style, size, etc., and proceed to check out.
Flickr Prints
Flickr Prints is backed by years of photography sales success on our sister site, SmugMug. Your prints will come from Bay Photo, a professional lab located in Santa Cruz, California, and they ship all over the world! We offer paper prints, wall art, and desk art of photos in a wide range of sizes and finishes.
Who are the approved sellers?
This feature is part of a pilot program, so you can expect to hear about more improvements, tweaks, and featured photographers in the future. For launch, these are the talented photographers whose work you can buy for your home, office, or wherever you could use some inspiring photography:
How can I become an approved seller?
For now, selling photos is limited to a small pool of photographers who all fit criteria for testing this exciting new opportunity. If you’re interested in becoming a future seller, please fill out this form. Please note: At this time, Flickr members who are outside of the United States or don’t have a Pro account are currently not eligible.
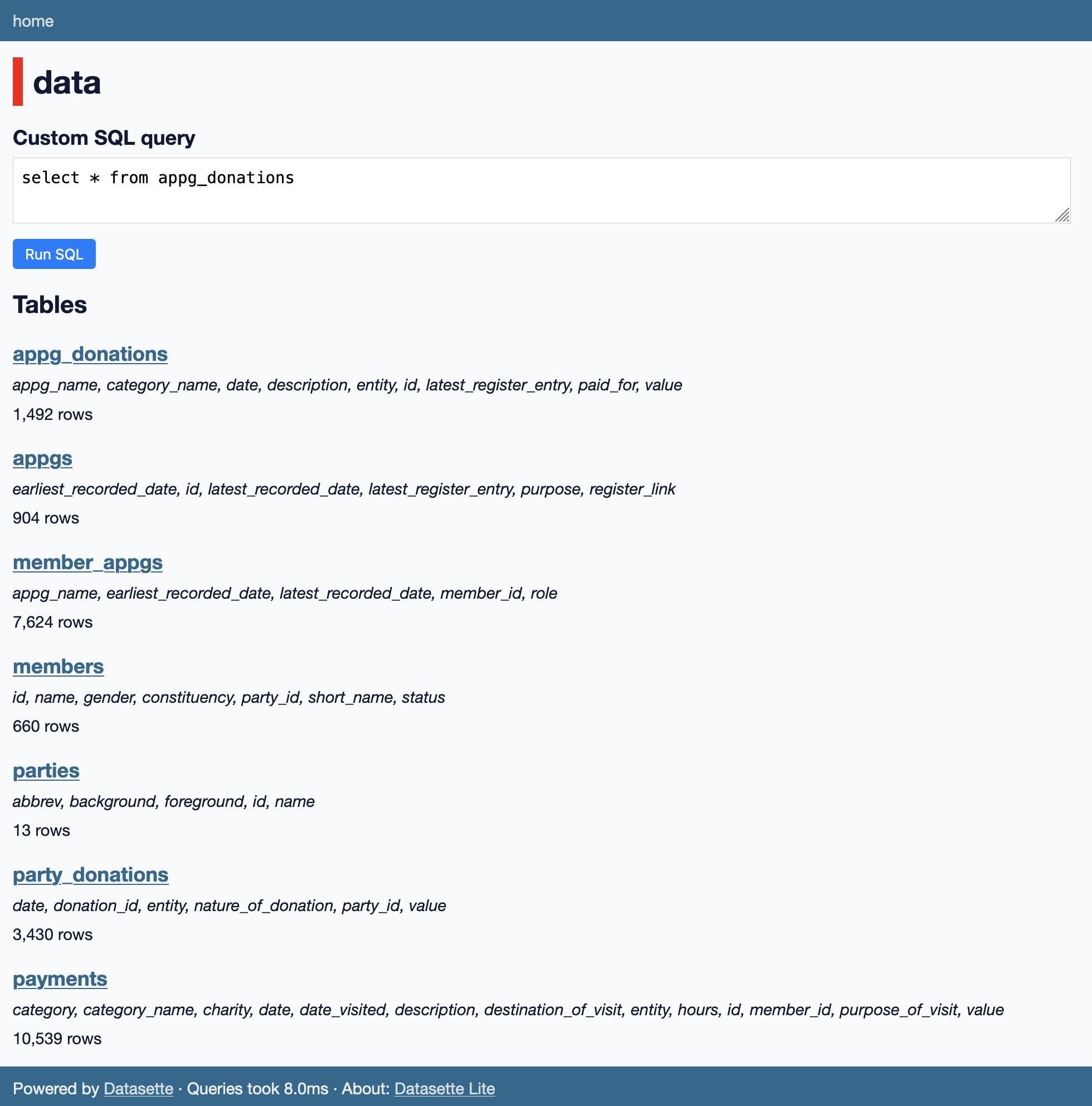
Sky News in partnership with Tortoise published a fantastic piece of investigative data reporting: the Westminster Accounts, a database of money in UK politics that brought together data from three different sources and make it explorable.
I now had JSON files for each of the seven tables that made up the data.
I used the following commands to import them into a SQLite database using sqlite-utils:
sqlite-utils insert sky-westminster-files.db appg_donations appg_donations.json --pk id
sqlite-utils insert sky-westminster-files.db appgs appgs.json --pk id
sqlite-utils insert sky-westminster-files.db members members.json --pk id
sqlite-utils insert sky-westminster-files.db parties parties.json --pk id
sqlite-utils insert sky-westminster-files.db party_donations party_donations.json --pk donation_id
sqlite-utils insert sky-westminster-files.db payments payments.json --pk id
sqlite-utils insert sky-westminster-files.db member_appgs member_appgs.json
I ran this a couple of times to figure out the primary keys so I could specify them with --pk id.
When I explored the resulting database using Datasette it became clear that some columns were foreign keys to other tables. I figured out what those were and used the following commands to add those to the database:
sqlite-utils add-foreign-key sky-westminster-files.db \
appg_donations appg_name appgs id
sqlite-utils add-foreign-key sky-westminster-files.db \
member_appgs appg_name appgs id
sqlite-utils add-foreign-key sky-westminster-files.db \
member_appgs member_id members id
sqlite-utils add-foreign-key sky-westminster-files.db \
members party_id parties id
sqlite-utils add-foreign-key sky-westminster-files.db \
party_donations party_id parties id
sqlite-utils add-foreign-key sky-westminster-files.db \
payments member_id members id
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
Kwakwaka’wakw artist Richard Hunt has enjoyed an illustrious career. Now a member of the Order of Canada and the Order of B.C., Hunt began as a teenage apprentice carver at the Royal B.C. Museum, working under the direction of his legendary artist father, Henry.
As a young man, Hunt became chief carver at Thunderbird Park, which is adjacent to the museum.
In a Zoom interview with Pancouver, the 71-year-old Hunt has lots to say about growing up in the James Bay area of Victoria. His family moved there when he was just two years old. In those days, he says, the Royal B.C. Museum site was a giant parking lot.
He started hanging out in Thunderbird Park in childhood with his father and another master Kwakwaka’wakw painter and carver, Mungo Martin.
“The first building was a horse shed,” Hunt recalls. “We had to go to the bus depot to go to the washroom. There were no facilities.”
Despite this, visitors to Victoria would gather in the park to watch the Indigenous artists.
“I thought of myself as a working exhibit,” Hunt quips. “I was in front of the public all day.”
He remembers the day when a couple of politicians were watching Martin carving—and it dawned upon these elected officials that Thunderbird Park was a great tourist attraction. As a result, the government constructed a bigger building on-site. Sadly, according to Hunt, it burned down a couple years later with four totem poles inside.
“We had to re-carve them,” Hunt says. “They built us a new carving shed. That was a great place to work.”
Thunderbird Park. Photo by Tourism Victoria.
Hunt plays hide-and-go-seek in legislature
His first solo totem pole, completed in 1979, stands in the centre of Thunderbird Park. Hunt went on to carve many other totem poles, including ones erected in Liverpool, Edinburgh, and Brisbane, as well as in in the City of Duncan and on the Camosun College Interurban campus.
In addition, Hunt created a 10.6-metre pole with artist Tim Paul that stood outside the CBC building in Vancouver for almost 25 years. In 2006, CBC returned it to Hunt’s hometown of Fort Rupert on northern Vancouver Island.
His parents had 14 kids. As a child, he remembers playing war games with his siblings on the grounds of the B.C. legislature. They climbed what’s now a very large tree by the Parliament Buildings.
Hunt also played hide-and-go-seek inside the legislature when it was still home to the museum and the provincial archives.
“Commissionaires, Mungo, and my dad used to look for us,” Hunt says with a laugh. “We would be small enough that we could hide in the little corners and they couldn’t find us.”
Those early memories of the area around the legislature are central to artwork that will be included in Vancouver’s upcoming LunarFest celebrations. Hunt’s painting, Victoria 2018, features various animals, including two riding in a canoe with an Indigenous oarsman. It will be on a large lantern on public display at Granville Island.
Hunt’s design is part of a collection of artistic lanterns; artists Jessie Sohpaul and Rachel Smith, and Arts Umbrella students created the others, which will be at Ocean Artworks outdoor pavilion from January 20 to February 20.
Richard Hunt’s painting, Victoria 2018, will be on a Lunar New Year lantern at Granville Island.
Lantern inspired by Victoria
Entitled the Cycle of Life, the Granville Island display is part of the Lantern City exhibition. It will also feature artistic lanterns at Jack Poole Plaza and šxʷƛ̓ənəq Xwtl’e7énḵ Square on the north side of the Vancouver Art Gallery.
“We are connected to our past and our future all at once,” the Lantern City exhibition states on its website. “Like salmon that returns up-river every year for new springs, like the animals in this land that watch over us like family, like the young dancers that spin under the sun with endless hope, we pass on our legacies to curious hands, gifts freely given for the next generation to explore freely in their wildest imaginations.”
Hunt says that his lantern design reflects Victoria in several ways.
“I kind of used the domes of the Parliament Buildings at the top of the picture with the Olympic Mountains in the background,” he reveals. “It looks like an octopus stretched out.”
The legislature’s cone appears below the octopus’s head. There’s a bear totem pole on the right, similar to the one carved by his father near Inner Harbour. The killer whale on the left represents a carved orca-shaped tree on the north end of the Empress Hotel grounds near Humboldt Street.
On his website, Hunt states that the killer whale represents the spirits of his deceased family members.
“The canoe at the bottom represents the boats in the Inner Harbour,” he adds. “Our people travelled by canoe and we still do today. On board is a wolf, an eagle, and a man steering the canoe. Finally, there is a raven dancing on the lawn of the legislature.”
In 1991, Richard Hunt received the Order of B.C.
A career filled with highlights
One of his memorable moments was receiving the Order of Canada at Rideau Hall in 1994 with hockey stars Frank Mahovlich and Serge Savard. Hunt recalls striking up an enduring friendship with Mahovlich that day.
“Frank ended up coming to Victoria and playing a round of golf at Bear Mountain,” Hunt says. “They asked this politician who he’d like to play with. He said ‘Richard Hunt’, so I got to play with him. We went for dinner a few times.”
This came three years after Hunt had been awarded the Order of B.C.
Hunt’s career includes many artistic highlights, including collaborating with Tim Paul on a totem pole in the Southwest Museum in Los Angeles. In addition, Hunt, Paul, and artist Eugene Arima carved an 11-metre Nuu-chah-nulth whaling canoe, which was displayed at Expo 86 in Vancouver. And Hunt created a five-metre orca and three-metre thunderbird at the Vancouver International Airport domestic terminal
Hunt attended Victoria High School, where he’s now commemorated on its “Wall of Fame”.
Nowadays, one of his greatest concerns is halting the forging of Northwest Coast Indigenous art in other countries. He says a lot of it is created in Indonesia with mahogany. He’s even seen forgeries of his deceased brother Tony’s art being sold on T-shirts.
“They’ve copied all different styles,” Hunt says. “To me, I don’t care how bad it is or how good it is. You’re taking away from my culture. It’s intellectual property.”
He and other artists are trying to persuade the federal government to address this issue.
Richard Hunt is not ready to retire. Photo by Sandra Hunt.
Father taught Hunt all he needed to know
Hunt reveals that he once spent a summer up island with a recently deceased uncle who was a tremendous fisherman.
“I was supposed to go up there and learn how to fish,” Hunt says. “After one week of fishing, I realized I’m a landlubber.”
He describes his father as a great teacher who taught him everything he needed to know when they worked together at Thunderbird Park.
“One of the things my dad promised Mungo is there would always be one of us from Fort Rupert there,” Hunt states. “After I got there, my dad realized that he didn’t have to be there and went out on his own. He was a great carver. I mean, he could carve a mask in two days and that would be his two-week’s salary.”
Martin and Hunt’s father were so talented that they carved various Indigenous styles, including Salish, Haida, and Tsimshian. Hunt also learned to do this, but now that he’s on his own, he sticks with Kwakwaka’wakw art.
His Kwakwaka’wakw name is Gwe-la-yo-gwe-la-gya-lis. According to his website, it means “a man that travels and wherever he goes, he potlatches.”
Hunt describes himself as a traditional carver, even though he generates ideas from a multitude of sources, including Mayan and Egyptian art. At the end of the day, he wants everything that he carves to be acceptable in his First Nation’s ceremonies.
“I don’t deviate too much, other than drawing,” Hunt says. “Because you know, I’d hate to have something go to the Big House and have people laugh at it—and say ‘you tried to do something too different.’ I stick to traditional.”
Someone on Mastodon posted a link to
a 2021 survey
of how the parsers for major languages are implemented. Are they
written by hand, or automated by a parser generator? The answer
was mixed: a few are generated by yacc-like tools (some of which
were custom built), but many are written by hand, often for speed.
My two favorite notes:
Julia's parser is handwritten but not in Julia. It's in Scheme!
Good for the Julia team. Scheme is a fine language in which to
write -- and maintain -- a parser.
Not only [is Clang's parser] handwritten but the same file handles
parsing C, Objective-C and C++.
I haven't clicked through to the source code for Clang yet but,
wow, that must be some file.
Finally, this closing comment in the paper hit close to the heart:
Although parser generators are still used in major language
implementations, maybe it's time for universities to start
teaching handwritten parsing?
I have persisted in having my compiler students write table-driven
parsers by hand for over fifteen years. As I noted in
this post at the beginning of the 2021 semester,
my course is compilers for everyone in our major, or potentially
so. Most of our students will not write another compiler in their
careers, and traditional skills like implementing recursive descent
and building a table-driven program are valuable to them more
generally than knowing yacc or bison. Any of my compiler students
who do eventually want to use a parser generator are well prepared
to learn how, and they'll understand what's going on when they do,
to boot.
My course is so old school that it's back to the forefront. I just
had to be patient.
(I posted the seeds of this entry
on Mastodon.
Feel free to comment there!)
Part 1 of this series looks at the state of the climate emergency we’re in, and how we can still get our governments to do something about it. Part 2 looks at collapse scenarios we’re likely to face if we fail in those efforts, and part 3 is about concrete things we could work towards to make our software more resilient in those scenarios. In this final part we’re looking at obstacles and contradictions on the path to resilience.
Part 3 of this series was, in large parts, a pretty random list of ideas for how to make software resilient against various effects of collapse. Some of those ideas are potentially contradictory, so in this part I want to explore these contradictions, and hopefully start a discussion towards a realistic path forward in these areas.
Efficient vs. Repairable
The goals of wanting software to be frugal with resources but also easy to repair are often hard to square. Efficiency is generally achieved by using lower-level technology and having developers do more work to optimize resource use. However, for repairability you want something high-level with short feedback loops and introspection, i.e. the opposite.
An app written and distributed as a single Python file with no external dependencies is probably as good as it gets in terms of repairability, but there are serious limitations to what you can do with such an app and the stack is not known for being resource-efficient. The same applies to other types of accessible programming environments, such as scripts or spreadsheets. When it comes to data, plain text is very flexible and easy to work with (i.e. good for repairability), but it’s less efficient than binary data formats, can’t be queried as easily as a database, etc.
My feeling is that in many cases it’s a matter of choosing the right tradeoffs for a given situation, and knowing which side of the spectrum is more important. However, there are definitely examples where this is not a tradeoff: Electron is both inefficient and not very repairable due to its complexity.
What I’m more interested in is how we could bring both sides of the spectrum closer together: Can we make the repair experience for a Rust app feel more like a single-file Python script? Can we store data as plain text files, but still have the flexibility to arbitrarily query them like a database?
As with all degrowth discussions, there’s also the question whether reducing the scope of what we’re trying to achieve could make it much easier to square both goals. Similar to how we can’t keep using energy at the current rate and just swap fossil fuels out for renewables, we might have to cut some features in the interest of making things both performant and repairable. This is of course easier said than done, especially for well-established software where you can’t easily remove things, but I think it’s important to keep this perspective in mind.
File System vs. Collaboration
If you want to store data in files while also doing local-first sync and collaboration, you have a choice to make: You can either have a global sync system (per-app or system wide), or a per-file one.
Global sync: Files can use standard formats because history, permissions for collaboration, etc. are managed globally for all files. This has the advantage that files can be opened with any editor, but the downside is that copying them elsewhere means losing this metadata, so you can no longer collaborate on the file. This is basically what file sync services à la Nextcloud do (though I’m not sure to what degree these support real-time collaboration).
Per-file sync: The alternative is having a custom file format that includes all the metadata for history, sync, and collaboration in addition to the content of the file. The advantage of this model is that it’s more flexible for moving files around, backing them up, etc. because they are self-contained. The downside is that you lose access to the existing ecosystem of editors for the file type. In some cases that may be fine because it’s a novel type of content anyway, but it’s still not great because you want to ensure there are lots of apps that can read your content, across all platforms. The Fullscreen whiteboard app is an example of this model.
Of course ideally what you’d want is a combination of both: Metadata embedded in each file, but done in such a way that at least the latest version of the content can still be opened with any generic editor. No idea how feasible that’d be in general, but for text-based formats I could imagine this being a possibility, perhaps using some kind of front-matter with a bunch of binary data?
More generally, there’s a real question where this kind of real-time collaboration is needed in the first place. For which use cases is the the ability to collaborate in real time worth the added complexity (and hence reduced repairability)? Perhaps in many cases simple file sync is enough? Maybe the cases where collaboration is needed are rare enough that it doesn’t make sense to invest in the tech to begin with?
Bandwidth vs. Storage
In thinking about building software for a world with limited connectivity, it’s generally good to cache as much as possible on disk and hit the network as little as possible. But of course that also means using more disk space, which can itself become a resource problem, especially in the case of older computers or mobile devices. This would be accelerated if you had local-first versions of all kinds of data-heavy apps that currently only work with a network connection (e.g. having your entire photo and music libraries stored locally on disk).
One potential approach could be to also design for situations with limited storage. For example, could we prioritize different kinds of offline content in case something has to be deleted/offloaded? Could we offload large, but rarely used content or apps to external drives?
For example, I could imagine moving extra Flatpak SDKs you only need for development to a separate drive, which you only plug in when coding. Gaming could be another example: Your games would be grayed-out in the app grid unless you plug in the hard drive they’re on.
Having properly designed and supported workflows and failure states for low-storage cases like these could go a long way here.
Why GNOME?
Perhaps you’re wondering why I’m writing about this topic in the context of free software, and GNOME in particular. Beyond the personal need to contextualize my own work in the reality of the climate crisis, I think there are two important reasons: First, free software may have an important role to play in keeping computers useful in coming crisis scenarios, so we should make sure it’s good at filling that role. GNOME’s position in the GNU/Linux space and our close relationships and personnel overlap with projects up and down the stack make it a good forum to discuss these questions and experiment with solutions.
But secondly, and perhaps more importantly, I think this community has the right kinds of people for the problems at hand. There aren’t very many places where low-level engineering and principled UX design are done together at this scale, in the commons.
Some resilience-focused projects are built on the very un-resilient web stack because that’s what the authors know. Others have a tiny community of volunteer developers, making it difficult to build something that has impact beyond isolated experiments. Conversely, GNOME has a large community of people with expertise all across the stack, making it an interesting place to potentially put some of these ideas into practice.
People to Learn From?
While it’s still quite rare in tech circles overall, there are some other people thinking about computing from a climate collapse point of view, and/or working on adjacent problems. While most of this work is not directly relevant to GNOME in terms of technology, I find some of the ideas and perspectives very valuable, and maybe you do as well. I definitely recommend following some of these people and projects on Mastodon :)
Permacomputing is a philosophy trying to apply permaculture-like principles to computing. The term was coined by Ville-Matias “Viznut” Heikkilä in a 2020 essay. Permaculture aims to establish natural systems that can work sustainably in the long term, and the goal with permacomputing is to do something similar for computing, by rethinking its relationship to resource and energy use, and the kinds of things we use it for. As further reading, I recommend this interview with Heikkilä and Marloes de Valk.
100 Rabbits is a two-person art collective living on a sailboat and experimenting with ideas around resilience, wherein their boat studio setup is a kind of test case for the kinds of resource constraints collapse might bring. One of their projects is uxn, a tiny, portable emulator, which serves as a super-constrained platform to build apps and games for in a custom Assembly language. I think their projects are especially interesting because they show that you don’t need fancy hardware to build fun, attractive things – what’s far more important is the creativity of the people doing it.
Collapse OS is an operating system written in Forth by Virgil Dupras for a further-away future, where industrial society has not only collapsed, but when people stop having access to any working modern computers. For that kind of scenario it aims to provide a simple OS that can run on micro-controllers that are easy to find in all kinds of electronics, in order to build or repair custom electronics and simple computers.
Low Tech is an approach to technology that tries to keep things simple and resilient, often by re-discovering older technologies and recombining them in new ways. An interesting example of this philosophy in both form and content is Low Tech Magazine (founded in 2007 by Kris De Decker). Their website uses a dithered aesthetic for images that allows them to be just a few Kilobytes each, and their server is solar-powered, so it can go down when there’s not enough sunlight.
Screenshot of the Low Tech Magazine website with its battery meter background
p2panda is a protocol for building local-first apps. It aims to make it easy enough to build p2p applications that developers can spend their time thinking about interesting user experiences rather than focus on the basics of making p2p work. It comes with reference implementations in Rust and Typescript.
Earthstar is a local-first sync system developed by Sam Gwilym with the specific goal to be “like a bicycle“, i.e. simple, reliable, and easy enough to understand top-to-bottom to be repairable.
Funding Sources
Unfortunately, as with all the most important work, it’s hard to get funding for projects in this area. It’ll take tons of work by very skilled people to make serious progress on things like power profiling, local-first sync, or mainlining Android phones. And of course, the direction is one where we’re not only not enabling new opportunities for commerce, but rather eliminating them. The goal is to replace subscription cloud services with (free) local-first ones, and make software so efficient that there’s no need to buy new hardware. Not an easy sell to investors :)
However, while it’s difficult to find funding for this work it’s not impossible either. There are a number of public grant programs that fund projects like these regularly, and where resilience projects around GNOME would fit in well.
If you’re based in the the European Union, there are a number of EU funds under the umbrella of the Next Generation Internet initiative. Many of them are managed by dutch nonprofit NLNet, and have funded a number of different projects with a focus on peer-to-peer technology, and other relevant topics. NLNet has also funded other GNOME-adjacent projects in the past, most recently Julian’s work on the Fractal Matrix client.
If you’re based in Germany, the German Ministry of Education’s Prototype Fund is another great option. They provide 6 month grants to individuals or small teams working on free software in a variety of areas including privacy, social impact, peer-to-peer, and others. They’ve also funded GNOME projects before, most recently the GNOME Shell mobile port.
The Sovereign Tech Fund is a new grant program by the German Ministry of Economic Affairs, which will fund work on software infrasctucture starting in 2023. The focus on lower-level infrastructure means that user-facing projects would probably not be a good fit, but I could imagine, for example, low-level work for local-first technology being relevant.
These are some grant programs I’m personally familiar with, but there are definitely others (don’t hesitate to reach out if you know some, I’d be happy to add them here). If you need help with grant applications for projects making GNOME more resilient don’t hesitate to reach out, I’d be happy to help :)
What’s Next?
One of my hopes with this series was to open a space for a community-wide discussion on topics like degrowth and resilience, as applied to our development practice. While this has happened to some degree, especially at in-person gatherings, it hasn’t been reflected in our online discourse and actual day-to-day work as much as I’d hoped. Finding better ways to do that is definitely something I want to explore in 2023.
On the more practical side, we’ve had sporadic discussions about various resilience-related initiatives, but nothing too concrete yet. As a next step I’ve opened a Gitlab issue for discussion around practical ideas and initiatives. To accelerate and focus this work I’d like to do a hackfest with this specific focus sometime soon, so stay tuned! If you’d be interested in attending, let me know :)
Closing Thoughts
It feels surreal to be writing this. There’s something profoundly weird about discussing climate collapse… on my GNOME development blog. Believe me, I’d much rather be writing about fancy animations and porting apps to phones. But such are the times. The climate crisis affects, or will affect, every aspect of our lives. It’d be more surreal not to think about how it will affect my work, to ignore or compartmentalize it as a separate thing.
But no matter how bad things get, there’s always hope in action. Whether you glue yourself to the road to force the government to enact emergency measures, directly stop emissions by blocking the expansion of coal mines, seize the discourse with symbolic actions in public places, or disincentivize luxury emissions by deflating SUV tires, there’s a wing of this movement for everyone. It’s not too late to avoid the worst outcomes – If you, too, come and join the fight.
The connection between language and meaning has been well established. The language we use is directly related to the way we view and treat others. Inclusive language is imperative to achieve equitable change, grounded in human rights and social justice.
Many countries today have laws protecting against the use of any language that incites or wilfully promotes hatred against an identifiable group.
These preferences are distilled over time through an ebb and flow of factors including advocacy and allyship, grassroots activism, legal and legislative proceedings and empirical research.
Internationally, the United Nations Convention on the Rights of Persons with Disabilities (UNCRPD), of which Canada is a primary signatory, aims to protect the rights and dignity of persons with disabilities without discrimination and on an equal basis with others. Parties to the UNCPRD are required to promote and ensure the full enjoyment of human rights for people with disabilities, including full equality under the law.
Terminology about any community must reflect their autonomy, preference and ideals.
The disabled community has been subjected not only to paternalism but also eugenics. Policymakers across society have ignored their inherent expertise.
Systemic ableism in schools
In a recent study involving adults with disabilities reflecting on their experiences in kindergarten to Grade 12 education in the United States, researcher Carlyn O. Mueller found schools continue to lag behind in terms of:
a lack of disability representation in K-12 curriculum;
Kindergarten to Grade 12 schooling is often stigmatizing for students with disabilities. Ableist slurs continue, and segregationist practices abound while disability representation in staff, programming and curriculum remains limited at best.
A community
The disability community is the largest diversity-equity group globally. It’s also one that many of us will join throughout our lifetime.
It is important to remember disability is not synonymous with notions of lacking, charity or pity.
Moving away from derogatory terms, such as “special” and “exceptional” is important. This promotes positive representation for people within the disability community, and respects their human rights.
Human rights perspectives stress that our society recognizes and names disability as the consequence of a person interacting with an environment that does not accommodate their differences.
This lack of accommodation impedes participation in society. Inequality is due to the inability of society to eliminate barriers challenging persons with disabilities.
Some terminology
The following is some terminology that schools and communities can use to promote inclusivity:
Neurodiversity and neurodivergence:Neurodiversity, originating in the autism community, reflects the notion that all “bodyminds” work in diverse ways. As noted by the Critical Disability Studies Collective at University of Minnesota, the terms neurodiversity and neurodivergence “come from autistic communities, who have welcomed folks with other marginalized brain/bodyminds to use them, including but not limited to people with cognitive, brain injury, epilepsy, learning and mental health disabilities.”
Ableism advances the belief that “typical” abilities are normal and superior. Ableism assumes disabled people need to be fixed and an ableist attitude defines people as lesser while including harmful stereotypes about disabilities. Ableism often leads to discriminatory beliefs, attitudes and actions often resulting in segregationist and exclusionary measures.
The medical model of disability says people are disabled by their impairments or differences. Under the medical model, impairment is equated with being broken and in need of a fix. Even when the impairment or difference does not cause pain or illness, the individual is considered lesser. The medical model lens can lead to stigma and may be considered a prelude to ableism.
The social model of disability: Created by disabled people, the social model argues humans naturally come in a variety of bodyminds, which are changed and shaped by our environment. Disability is part of the human experience. The social model argues that nothing is wrong with the disabled bodymind but that inaccessible structures, systems and attitudes of society are the issue that need fixing. The social model sets the foundation for equitable approaches for inclusion.
Pancouver is primarily focused on underrepresented artists, but it also publishes David Suzuki’s weekly column to advance education about critical environmental issues. Without a habitable planet that relies on biodiversity, there will be no arts and culture.
By David Suzuki
Despite Canada’s important commitments at the December UN COP15 in Montreal, we’re not halting, let alone reversing, biodiversity loss. More than 5,000 wild species face some risk of extinction, according to the recently released report “The Wild Species 2020: The General Status of Species in Canada.”
The main driver is habitat loss. Yet, the Ontario government plans to run a major highway through the valuable greenbelt around Canada’s largest city. In British Columbia, fracking and clearcut logging continue to decimate lands and waters. And the federal government is supporting offshore oil projects and pipelines—all while climate change fuels wildfires, droughts, floods and other habitat-destroying events.
We’re still chasing symptoms rather than causes. We’ve been so indoctrinated into growth-based economic and societal paradigms that we fail to notice those outdated systems are themselves at the root of many problems—so we race along, extracting and consuming what we can without considering consequences or giving much back.
Take forestry. You’d think research by scientists like Suzanne Simard at the University of British Columbia would have shifted the way we “manage” forests.
Healthy forests include biodiversity
In her book Finding the Mother Tree, Simard describes working for the B.C. Forest Service when she realized practices ignored processes that keep forests healthy. Most of her colleagues only considered how best to “harvest” the most valuable old growth and promote commercially desirable species using fertilizers and eliminating competition from “weed” species with clearing and pesticides. The result: more than half of B.C.’s old-growth forests have been replaced by mostly single-species tree plantations, many of which aren’t biodiverse or flourishing.
To show how little has changed, in recently resigning from the Association of B.C. Forest Professionals, eminent ecological forester Herb Hammond delivered a damning indictment of ongoing practices that maximize profits and destroy forests.
Simard started looking below ground, studying the mycorrhizal (from Greek for “fungi” and “root”) networks through which plants, especially trees, and fungi connect—and communicate. What she discovered was profound, but it didn’t sit well with some industry-focused colleagues.
A mushroom is only a small part of the organism—the fruiting body where spores are produced. It’s attached to an underground network of fine tubular structures called hyphae “that branch, fuse, and tangle into the anarchic filigree of mycelium,” says biologist Merlin Sheldrake in his book Entangled Life, adding this is “better thought of not as a thing but as a process.”
These connect with plant root structures, forming symbiotic circuits to exchange nutrients, water and information. Simard writes, “I learned that this network is pervasive through the entire forest floor, connecting all the trees in a constellation of tree hubs and fungal links. A crude map revealed, stunningly, that the biggest, oldest timbers are the sources of fungal connections to regenerating seedlings.”
Natural system intricately connected
She found these networks even have “similarities with our own human brains,” using chemicals “identical to our own neurotransmitters” to perceive, communicate and respond to one another.
So much plundering has been and is being carried out in a state of ignorance—wilful or otherwise—about the intricately connected natural systems that ensure our well-being and survival.
Old growth and natural forests are critical. They produce oxygen, sequester atmospheric carbon, keep temperatures cooler and provide habitat for plants, animals and fungi—and much more.
Western colonial expansion and the industrial interests it’s facilitated have long been rooted in a sense of superiority. Colonizers often considered those they colonized as “primitives” or “savages.”
But extractivist-consumer capitalism has always been the “primitive” way of thinking and doing. Yes, we need continued advances in science, technology, beneficial industries and food production, but they should be directed at improving well-being within the limits of what the planet can provide.
Indigenous Peoples worldwide have learned over millennia of observation, experience and storytelling that we’re part of nature, utterly dependent on biodiversity and intricately connected not only with living things but with rocks, water and air. What we do to nature we do to ourselves.
Global conferences and agreements are necessary, but we need far more ambition and action—and humility. To fulfil our potential as a species, we need a paradigm shift, from an archaic consumer mindset to a wider vision that encompasses nature and recognizes the values and connections that will help us live well.
David Suzuki is a scientist, broadcaster, author and co-founder of the David Suzuki Foundation. Written with contributions from David Suzuki Foundation Senior Writer and Editor Ian Hanington.
So I have 30% more subscribers now than I did when I did the last newsletter, which is fun! Welcome to all the new folks. A few things to note/know:
Beginner’s mind: I’m trying very hard to approach AI with humility—and encourage everyone from “traditional” open to do the same. That’s particularly relevant this week because I’m seeing lots of AI-space writers start the year with 2023 predictions, and I won’t be doing that—there’s still too much I don’t know. (My long-term prediction, though, is here. tldr: as big as the printing press?)
Open(ish): If you’re new here, you might want to read my essay on open(ish)—where I talk about what traditional open has meant to me and what of that might (or might not) transfer to what I’ve been calling open(ish) machine learning. The most important thing to know is that I find the question “is some-ML-thing OSI-open” to be a nearly completely-uninteresting question.
Ghost: I use Ghost (an AGPL newsletter/blog tool), but TBH my experience with it has been mediocre so that’ll probably only until I can find the time to switch. So please forgive me if some time in the next few weeks you get a re-subscribe request from another platform.
Smaller, Better, Cheaper, Faster
One of the things that prompted me to start writing this was the change in what tech we thought was necessary to do ML. Two recent notes on that front:
"Cramming": A paper on training a language model on a single GPU in a single day, and a good Twitter summary of the paper. Results: can reach 2018 state-of-the-art this way. 2018 state of the art is no longer great, and there are reasons to think there are natural limits to this approach, but doing it in one day on one card represents massive progress—especially since they do not enable most hardware speedups, so these wins are mostly because of more efficient techniques and software.
NanoGPT: Where the previous example used a lot of complexity to save on training time, this MIT-licensed repo goes the other way: training a medium-size language model in a mere 300 lines of code. Like many “small”, “simple” tools, of course, much of the simplicity is because underlying tools (here, PyTorch) provide a lot of power.
I think it’s safe to say that we’re going to continue to see both announcements about high-end training becoming very high-end (vast numbers of expensive GPUs, running continuously) but also increased experimentation at the low end.
Should you use ML tools?
In this newsletter, so far, I've focused less on what “should” happen and more on what the possibilities are: is meaningfully open ML feasible? What would that mean? What impact would that have? Two recent good pieces do touch on that "should" question:
Friend-of-the-newsletter Sumana has a succinct, practical summary of “should” questions in a post on her use of Whisper, an openly-licensed speech-to-text model. I particularly like Sumana’s use of “reverence” to describe her respect for artists—and her admission that gut feel is a factor (here, in favor of transcription but perhaps against use in art).
This essay on “ChatGPT should not exist” is more acute than most, getting to the root of a critical question: what does this tooling mean for our humanity? I think ultimately I disagree with the author's conclusion, because I think tool-using is (or at least can be) a critical part of what it means to be human. But I respect the question, and think we'll all have to grapple with real modern Luddism (in the most serious, thoughtful sense of that word) soon.
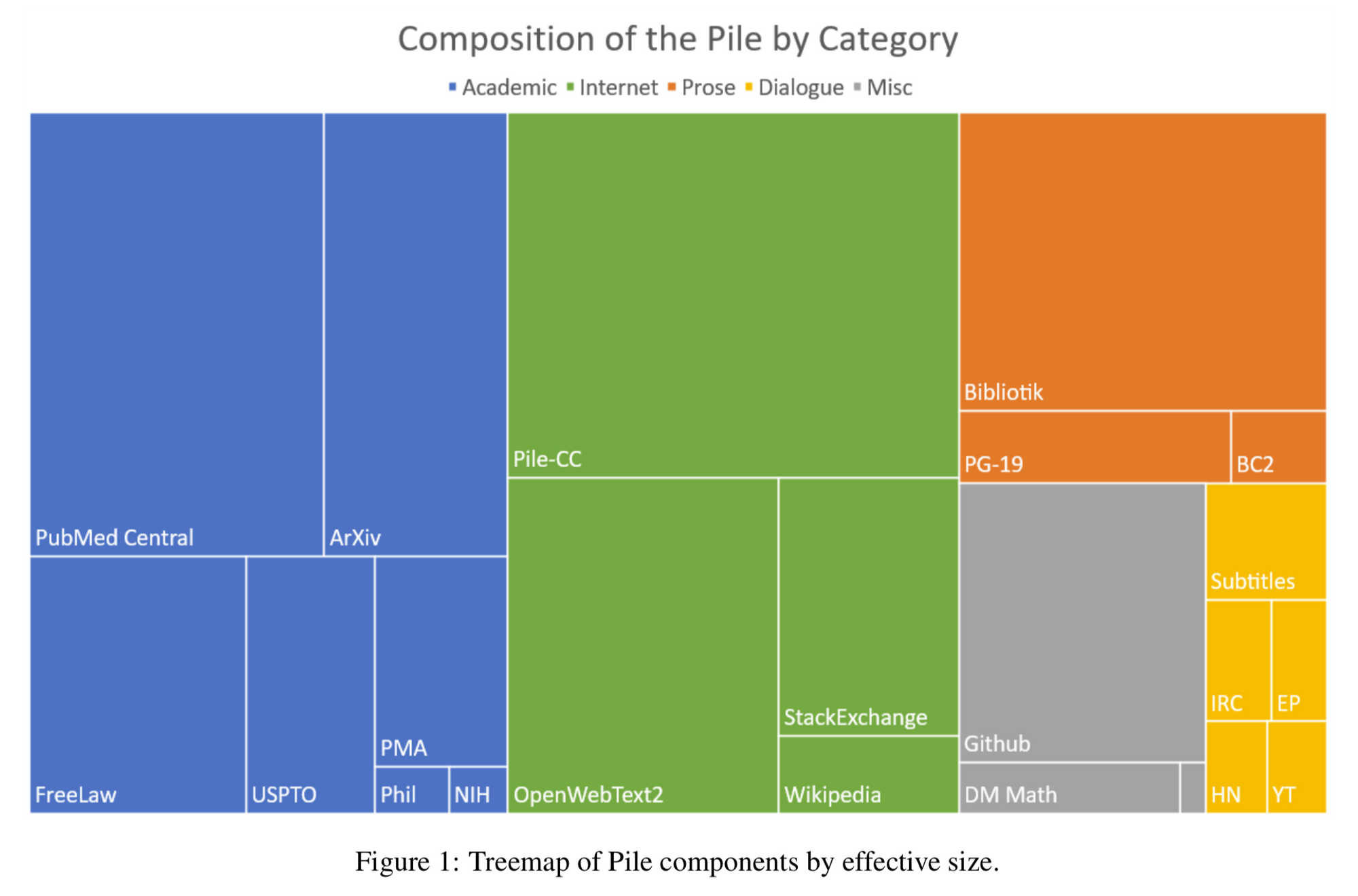
5-7 years ago, ML techniques relied heavily on well-structured data like Wikipedia. That’s no longer the case, because the techniques for dealing with unstructured data have become much better, and the volume of training data used has gone way up.
One publicly-documented ML data project—The Pile—can give us a sense of the state of the art. In early 2021, Wikipedia was already a small component:
I’ve seen similar numbers in other recent papers. That’s not to say Wikipedia isn’t important (eg this 2022 paper from Facebook relies on it quite heavily), but it’s not essential as it once was, so it now approaches the problem with less leverage than it had even a few years ago.
Good enough?
One discussant pointed out that Wikipedia “thrived because our readers find us ‘good enough’”. This is critical! It’s an easy and common mistake to measure machine learning only against the best of humanity and humanity’s outputs—to understand where ML will have impact, it also has to be compared against mediocre and bad human outputs. (Early Wikipedia, as a reminder, was very bad!) Wikipedia has a better chance than most victims of the innovator's dilemma to collaborate with the new tools—we'll see if that actually happens in practice or not.
Trust shortage as opportunity?
Early Wikipedia benefited a lot from the shortage of simple, credible, fact-centric text on the early internet. It seems likely that soon we'll have a glut of text, while having an even greater shortage of trustworthy text. If Wikipedia can cross that gap, it could be potentially even more influential than it already is.
Creative Commons
I’ve mentioned before that Creative Commons is investigating machine learning, and Creative Common’s most famous user—Wikipedia—is going to be where that rubber meets the road. I don't anticipate a CC5, but it wouldn't surprise me to see a joint announcement of some sort.
An under-appreciated fact about Creative Commons is that it was the first open license, to the best of my knowledge, to explicitly endorse fair use—something since adopted by GPL v3, MPL v2, and other open licenses. In some sense, this is redundant—a license, by definition, can’t take away your fair use rights. But it’s still an important reminder when asking “what does Wikipedia’s license allow” that CC endorses a world where licenses are not all-powerful.
Self-fact-checking?
In the discussion, one Wikimedian claimed that “AI simply can’t discriminate between good research and bad research”. I think that’s probably correct—with two important caveats.
First, humans aren’t actually that good at this problem either—here’s a great article on the shortcomings of peer review. Wikipedia also once happily ingested all of the 1913 Encyclopedia Brittanica, whose commitment to "good research" would be disputed by women, Africans, Asians, etc.
Second, there’s interesting research going on on how to marry LLMs with reliable datasets to reduce “hallucination”. (Google paper, Facebook paper) I’d expect we’ll see a lot more creativity in this area soon, because Wikipedians aren’t the only ones who want more reliability. Wikipedia can engage with this, or (likely) get steamrolled by it.
Misc.
Stable Diffusion posted a (half)year-in-review thread that’s pretty wild. SD is not traditionally open, but the velocity and variety of deployment and use are verrrry reminiscent of the path of early “real” open techs like Linux, Apache, and MySQL.
Algorithmic power: In talking about ML regulation recently, it’s been very useful for me to revisit Lessig’s “modalities of regulation”. In this talk by Seth Lazar (notes) he expands on Lessig's “code is law” by going deep on algorithms as power. Given that part of what’s important about “open” is its impact on power, this will be something I'd like to explore more.
Legal training data? By the nature of the profession, legal data sets for ML training are hard to get at. I was pointed at this one recently, so sharing here, but it’s quite small. I have to wonder if, ironically, ML will be good only at the stuff we do “for fun” because that’s, primarily, what’s on the internet—boring professional work may be more difficult for ML because good data will be harder to find.
Professional exams: Very related to professional data sets: can GPT pass the bar exam? Not yet. Can it pass medical exams? Not yet. I suspect this particular problem may look a lot like the self-driving car: getting 80% of the way there is doable, but getting further is going to be very hard, in part because of data and in part because of the nuance necessary for professions. But that doesn’t mean they won’t be very useful tools—and potentially replace some specific use-cases—but they won't replace general-purpose lawyers or doctors for a while.
New art from long-dead artists I’m enchanted by this use of generative ML to re-imagine/extend the career of an artist who died young, 170+ years ago.
What professors did on their holiday break: I’m seeing many, many examples of professors who spent the break playing with ChatGPT and, in the new semester, experimenting with how to incorporate chatbots into their teaching. One example, of many.
And on a joyful note…
This README is good nerd humor:
My functions were written by humans. … How can I make them more dangerously unpredictable?
Using AI to make arrays of data infinitely long. By filling them with what, you may ask? (The answer, of course, is … filling them with AI! So slow, and probably garbage, and… nevertheless a fun, hopefully harmless, thought experiment…)
ccg@ccg
Dear Berlin. I’m glad we’ve agreed that Vietnamese and Mexican are the best foods. Your versions confuse me and I m… twitter.com/i/web/status/1…
TL;DR: ChatGPT killer use case is mental unblocking.
I participated in a number of discussions with “knowledge workers” about their experiences using ChatGPT in the workplace via the OpenAI UI.
Many non-technical users are finding it sufficiently useful as a writing aid that they imagine continuing its use, especially as it gets better. Use cases varied, from outlining video scripts to helping with product descriptions to generating job descriptions to general re-writes of documents. Many found it useful as an ideation tool due to its content diversity, having been trained on a truly super-massive set of examples.
The primary use case for ChatGPT is accelerating writing tasks where it’s easier to hack a prompt than think of what to write — or do — from scratch. It is a useful mental unblocking tool. The knack is learning how to write productive prompts as a kind of “programmatic writing” vs. “chatting”.
All those I spoke with encountered issues, such as hallucination. But this did not seem to present enough of a barrier to prevent usage.
Those competent at writing often did not rate the outputs as good enough to wholesale replace entire writing tasks, such as writing finished blog posts. It often has a tendency to produce unappealing unoriginal prose unless manipulated via an excess of prompt hacks. However, some claimed that such outputs still provided a better-than-nothing starting point.
Introduction
There’s much hype about ChatGPT, so I asked various folks what they have found it good at. Mostly I spoke with “knowledge workers”, including quite a few in creative professions (e.g. digital agencies). I did not speak to any who struggled to write to begin with.
What is ChatGPT?
For those unfamiliar, ChatGPT is a specially trained version of another AI model built by OpenAI, called GPT-3, which is a class of model called a Transformer. If you are a coder and want to know more, I provided a detailed code-level annotation on Github. For the rest of us, a Transformer is a giant computer program that spends a mind-blowing amount of time trying to guess how to complete sentences that it finds online.
This guessing game is a brute force attempt to learn language structure. It turns out that if done long enough over a big enough corpus, the program gets stupendously good at guessing which words go with which over very long spans of text, or long enough to subsequently generate quite productive prose. This is known as self-supervised learning because the program doesn’t need to be told (supervised) how to complete the task because the words it is trying to guess were already there: it simply masked them out in order to guess them.
What has surprised seemingly everybody, including AI experts and linguists, is how good this brute force method is when carried out a super-massive scale. And scale is seemingly what matters most, not any particular architectural sophistication.
The scale of the model allows it to learn a tremendous number of structural patterns over large spans of text. Once it has finished guessing, the trained model can be used to carry out other language-related tasks.
One such fine-tuned task is language generation. As you can imagine, a program that knows so much about which words go with which can complete entire sentences just by “guessing” the next most probable word, one at a time, over and over. This isn’t just a testament to the model’s scale, but a feature of language, namely that longer sequences are composed from smaller ones, which are composed from smallers ones (and so on), sometimes called recursion.
Language has this amazing creative aspect: take any starting word and there will be dozens, sometimes hundreds, or more, of potential next words. Over the span of a sentence, this gives rise to a mind-boggling number of novel combinations of words. Indeed, perhaps we don’t realize that many of the sentences we utter in our lifetime are entirely novel in the history of language. This creative aspect of language is considered by experts to be one of the great mysteries of the mind that is very hard to explain with a scientifically tractable theory. This is perhaps why it has surprised so many that a brute-force computer program has been able to detect enough structure in its training data to allow it to complete various language tasks with human or beyond-human performance.
The truly surprising aspect of pre-trained transformers is that not only can they generate a passage of text, but they can interpret an initial seeding sequence, called a prompt, such that it can be used as a kind of instruction as to how to generate the text. This makes the AI a kind of “programmatic writing” machine. (We shall return to this perspective.)
This seems like magic and has led many users to feel an illusory sense that the model “understands” what’s being requested. Here’s an example:
What’s happening here? It looks as if the program has understood the sentence and looked up the answer, like it might a database of questions. But that is not what’s happening. The program is generating the green text as a highly probable follow-on text to the prompt — highly probably in the sense of all the vast swathes of text it has seen whilst training and which of those in which combinations might plausibly follow from the prompt. Think of it this way: if we were to look at all the text on the web and find that prompt, or something similar, then most likely we would see a list of sales methods afterwards.
Let me be clear: it is generating that green text. It is not trying to look it up from the training corpus. It doesn’t know that this is the correct answer — there is no “correctness” or “truth” inherent in the program. Indeed, it does not understand any of the words in the prompt either. It is blindly performing a function: given the input sequence, what is a highly probable output sequence. The output is only plausible, and potentially truthful, because the words it saw (in relation to the prompt) during training are plausible and contain truths, facts (or not) and useful explanations and descriptions.
And this is where scale comes into the picture. If the program sees enough examples of text, as in a truly super-massive corpus, then it will have seen enough examples of this question, or what it represents, such that its answers are so probable as to overlap with common experience or useful information as available on the web and in various books.
Representation is key, as this is what the model learns. For example, the model will learn the pattern “What…[plural nouns]…?” has a high probability of being followed by a numerical list. We can tell this by repeating the pattern and swapping out the meaning:
What is it good for? Unblocking.
Now we know what it is and how it works, what is it good for? Here I participated in a number of discussions, in-person and via forums, with various knowledge workers who had tried to use the tool in earnest to do useful work. I only asked about uses of the raw OpenAI interface, not any specialist application like the AI Copywriter tools built using GPT.
Everyone I spoke to found it useful for something. This is not surprising given its super-massive scale. It is hard to stump it, even, apparently with very esoteric questions of the kind that philosopher and quantum physicist David Deutsch has been posting on his twitter account.
Many folks were surprised by how good the tool was in getting a response that proved useful. A senior content manager at a high-end digital agency told me how he had experimented with generating script outlines for corporate videos. Having recently done some consulting related to online retail in the Metaverse, I tried something similar with a prompt: Write me a corporate video script outline for a person whose shopping experience is enhanced by shopping in the metaverse. The output followed a coherent structure with a meaningful narrative. For someone unrehearsed in script writing, it provided a useful starting point. For professional script writers, it probably isn’t so useful, except, perhaps, for ideation of scenes.
A consultant friend of mine tried to write blog posts about innovation, his area of expertise. He found the outputs coherent as a blog post, but a bit flat, lacking any originality. Indeed, it looked trite. This is to be expected if the tool is basically trying to find the most probable text.
But, like all probabilities, they can be constrained, or made conditional. This is the art of refining the prompt. In that same conversation, another innovation consultant reworded the prompt to generate something more convincing. We all concluded that it was still not good enough to warrant publication (in the name of the original consultant) but some of the participants believed that it was far enough along to get there via editing, even using ChatGPT to suggest new edits on a paragraph or sentence basis.
Despite some believing that this prompt-manipulation will become unnecessary with new versions of the tool, this seems an unlikely prospect. This is because language is, no matter how it is generated, ambiguous and able to convey many different voices, tones and ideas with even subtle rewording.
It was interesting to watch a live session of a Gen-Z user “hack” the prompts back and forth to generate a LinkedIn bio for a friend. It was interesting to watch this younger user take to the tool like it was how writing had always been done. Of those involved in the process, we all agreed that the final version was better worded than the author’s original bio. This hacking on a theme to get a final result seems like it could be skill, but one that is more powerful in the hands of someone with a good command of language to begin with, but nonetheless unaware of what a good LinkedIn bio might look like until they saw it, versus thinking of it entirely from scratch.
And this seemed to be the killer use case: hacking on a prompt to converge upon productive content without the pain of filling the void of blank paper — a kind of mental unblocker, as it were. Indeed, a professional writer friend of mine told me how some of his fellow fiction writers were using it often to “fill the gaps” with hard to find narrative turns or adjectives or scene ideas.
Using ChatGPT: Programming words with words
I am not going to offer a long list of tips and instructions, but rather an insight into how to use ChatGPT productively. And it’s an insight that all of the correspondees discovered for themselves, also widely discussed on the Web — e.g. see this article by Wharton Professor Ethan Mollick.
The trick is to understand what I explained above about how ChatGPT works, as in it is able to consult a truly super-massive corpus to understand how to construct plausible, or highly probable, sequences. This means it is capable of detail and nuance, but only if you instruct it with specific detail and nuance to begin with.
Users learn that ChatGPT is a kind of “programming words using words” versus a mind-reading “Oracle” — and yes, some folks use it in that latter way and get disappointing results. Part of the programming can be the inclusion of lots of specific detail, even as bullet points, without attempting to construct a prompt that another human might find meaningful, per se.
Consider a generic prompt like: Write me an AI strategy. This will likely produce the kind of generic or trite response expected, like identify a problem, find the data, select a model, train it and use it etc. But something more elaborate might produce more interesting responses, like: Why should a CEO of a mature company that is struggling in the marketplace care about the manifold hypothesis?
You’d have to know that the manifold hypothesis is related to AI, but this is a more nuanced prompt that generates a more nuanced response related to the nature of high-dimensionality data.
The best way to discover this “programming words with words” is to experiment. Take you baseline prompt and mix-in a lot of details, perhaps quirky and tangential ones, just to understand how the machine works.
Issues
Unsurprisingly, given that we know how Transformers work (brute force probability machines), we expect some of the outputs not to meet the mark. To recap, the model does not attempt to “make sense” of the prompt, but rather looks at the sequence and, based upon patterns found it it, at many levels (morphologically, syntactically, semantically) computes the most probable follow-on sequence based upon a super-massive scale of prior examples (of the morphological representations, not necessarily the exact wording of the prompt).
The model can easily produce incoherent output, which has been documented by many. They can also hallucinate facts or fail to generate prompts that are well reasoned based upon the prompt.
However, I didn’t find anyone who was attempting to use it as a general knowledge bot, like a Siri. Indeed, it was well understood that this wasn’t a wise use case, nor anything that would involve having to subsequently check all factual claims in the generated text.
Also, that friend of mine who tried to write an innovation post, also used another AI model to detect if the text had been generated. It detected with high confidence that the text had been generated. Whilst it’s not clear how these detection scripts work, the potential for having content detected as fake could be worrying, especially if it gets dinged by Google Search.
Nonetheless, as said, most of the users I spoke to were not attempting to generate wholesale content for publication online, but these various writer’s companion tasks to accelerate production of content, knowledge, ideas and format etc.
Where Next
Of course, pre-trained Transformers can do lots of other things, like summarize text or answer questions from a text. They can be used to analyze different document types, like invoices or business contracts, or even generate them. Perhaps they can find clauses in contracts that are likely to lead to poor value or lack of compliance, and so on. When it comes to the technical use of the underlying technology, suddenly many business processes become amenable to automation. However, this wasn’t the subject of my inquiry, but the use of ChatGPT as a writer’s companion. For that, it appears to have sufficient value that it might be expected to enhance knowledge-worker productivity over time.
And no — none of this article was written using ChatGPT (except the indicated examples).
If you’d like to know more about how to use GPT-like technology in your company to uniquely add value, feel free to reach out.
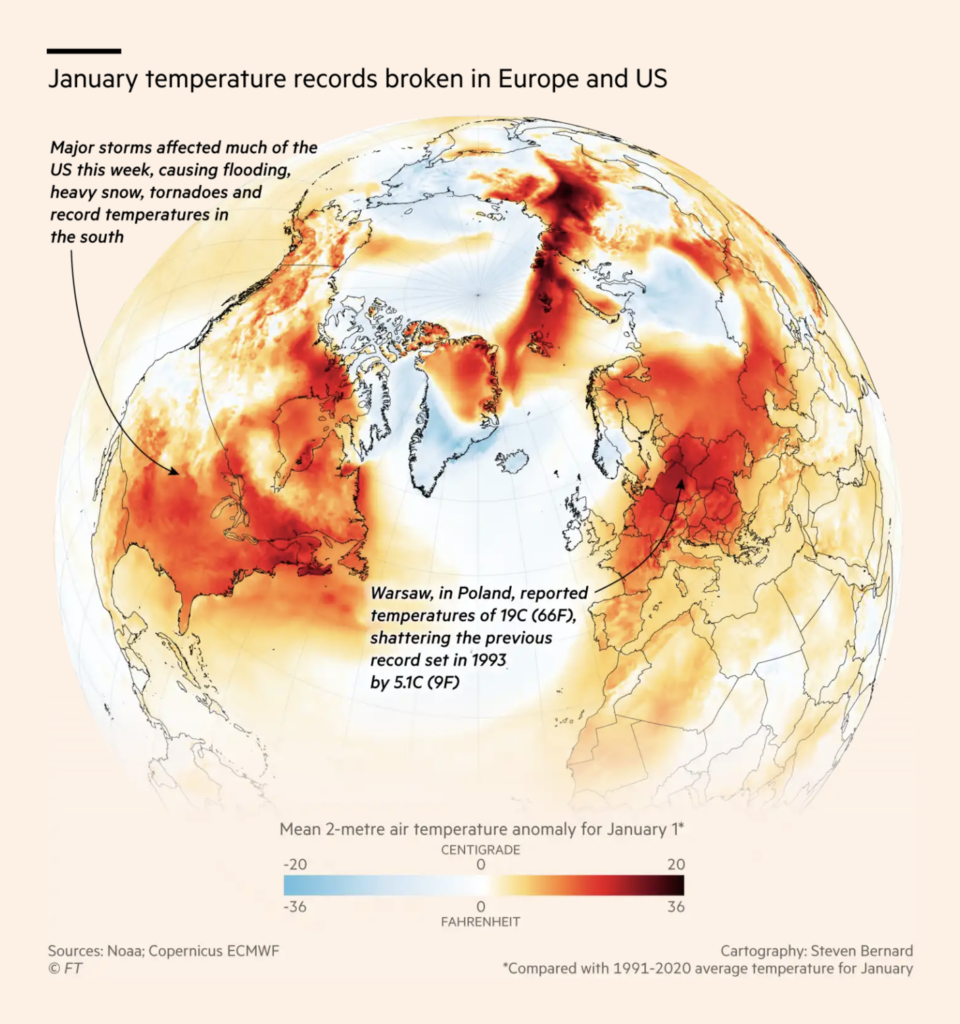
Welcome back to the 76th edition of Data Vis Dispatch! Every week, we’ll be publishing a collection of the best small and large data visualizations we find, especially from news organizations — to celebrate data journalism, data visualization, simple charts, elaborate maps, and their creators.
Recurring topics this week include the U.S. House Speaker election, extreme weather, and space travel.
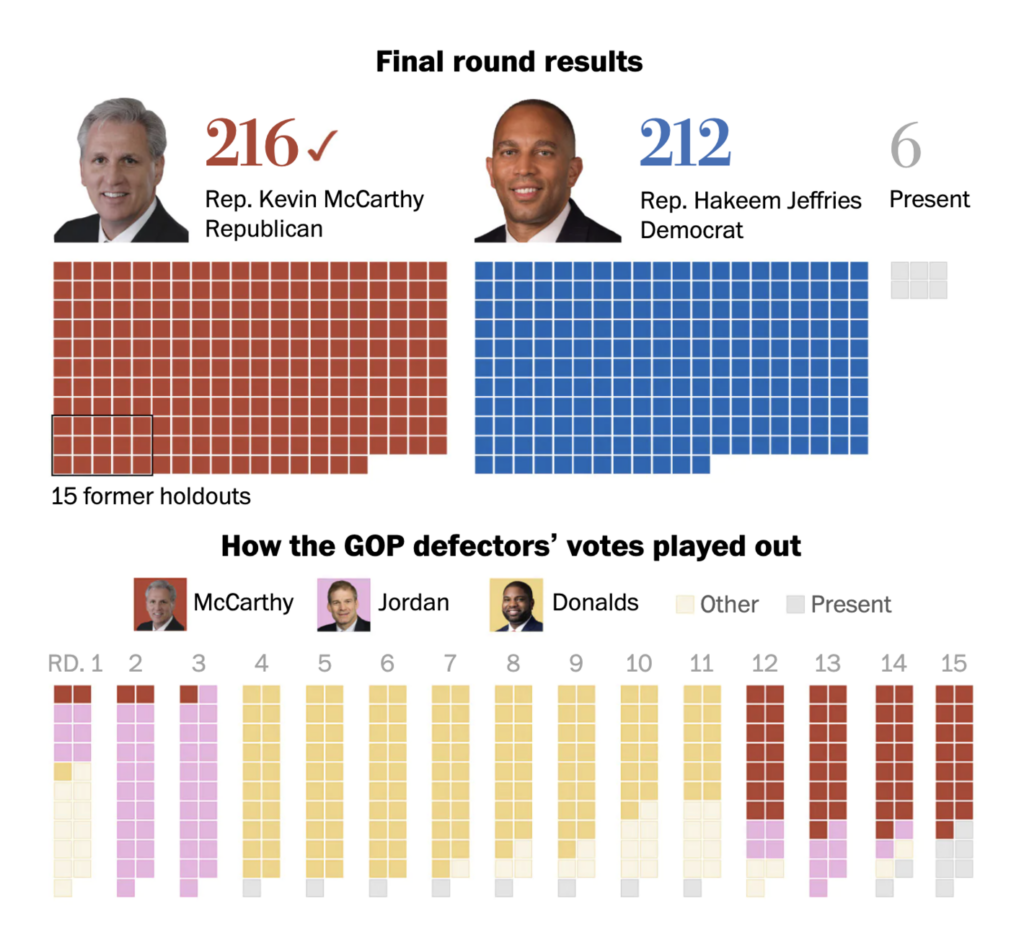
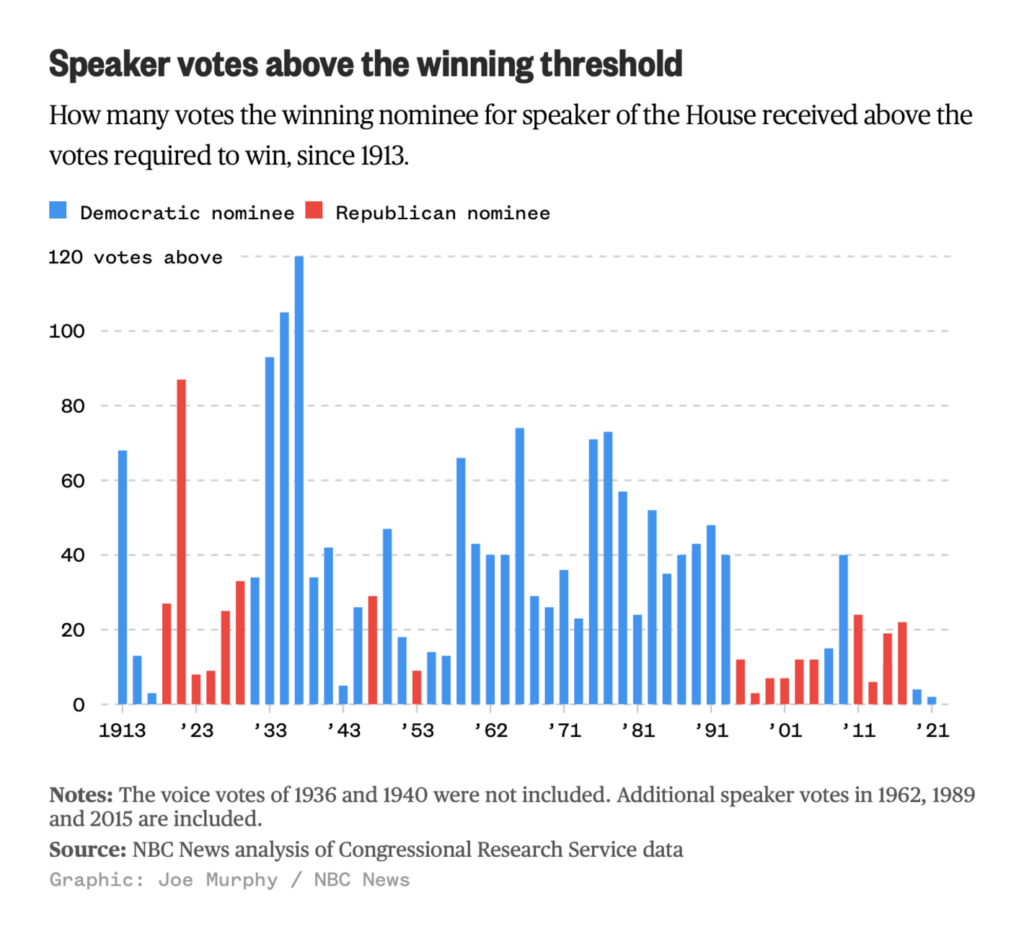
The U.S. House of Representatives elected its speaker, Kevin McCarthy, on Saturday — after 15 rounds of voting.
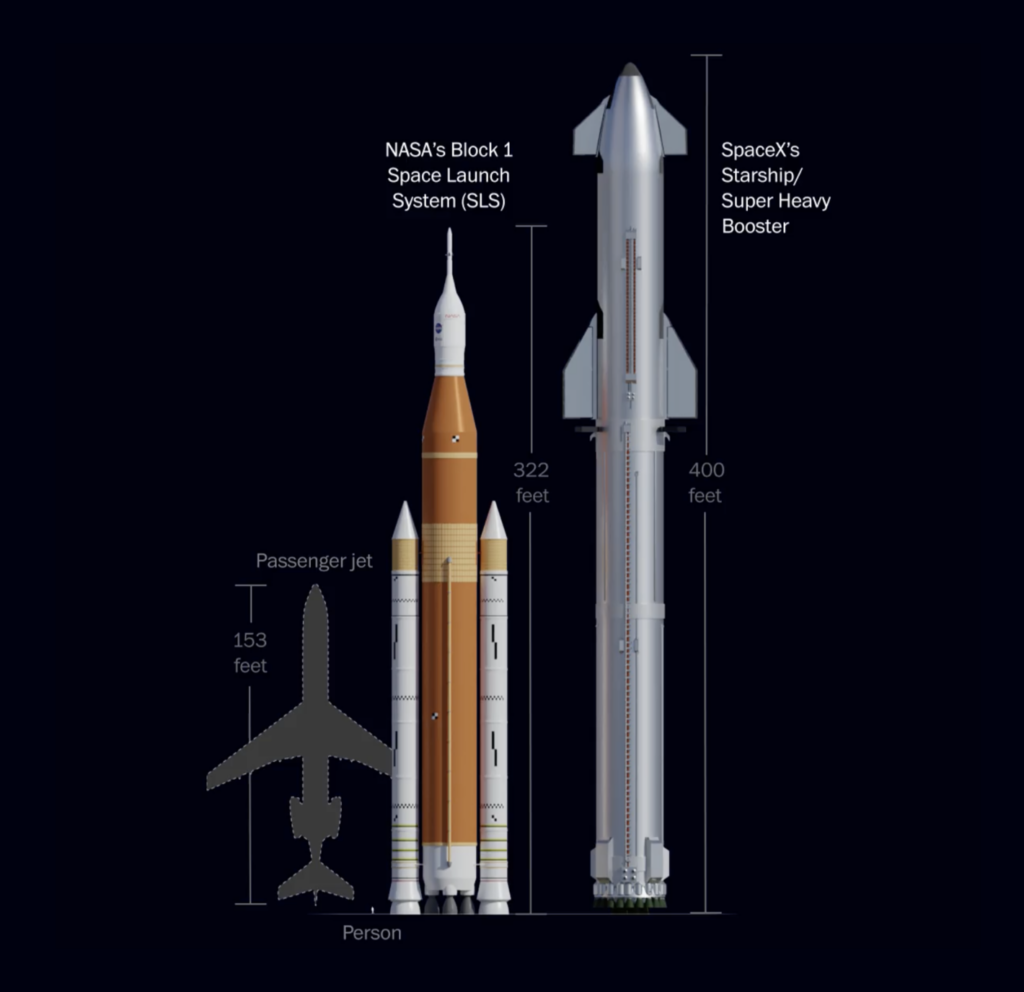
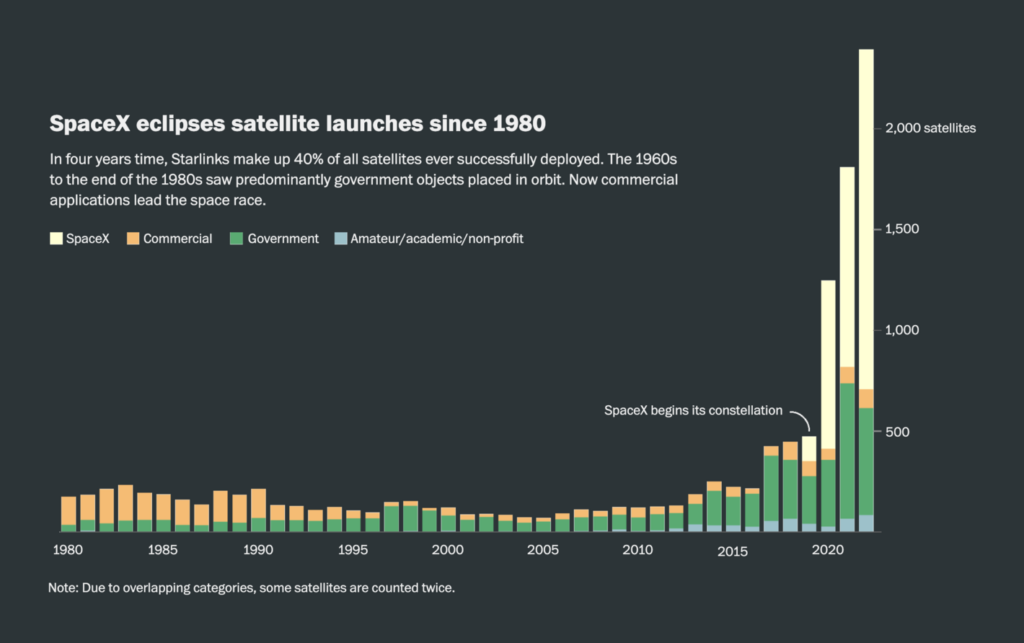
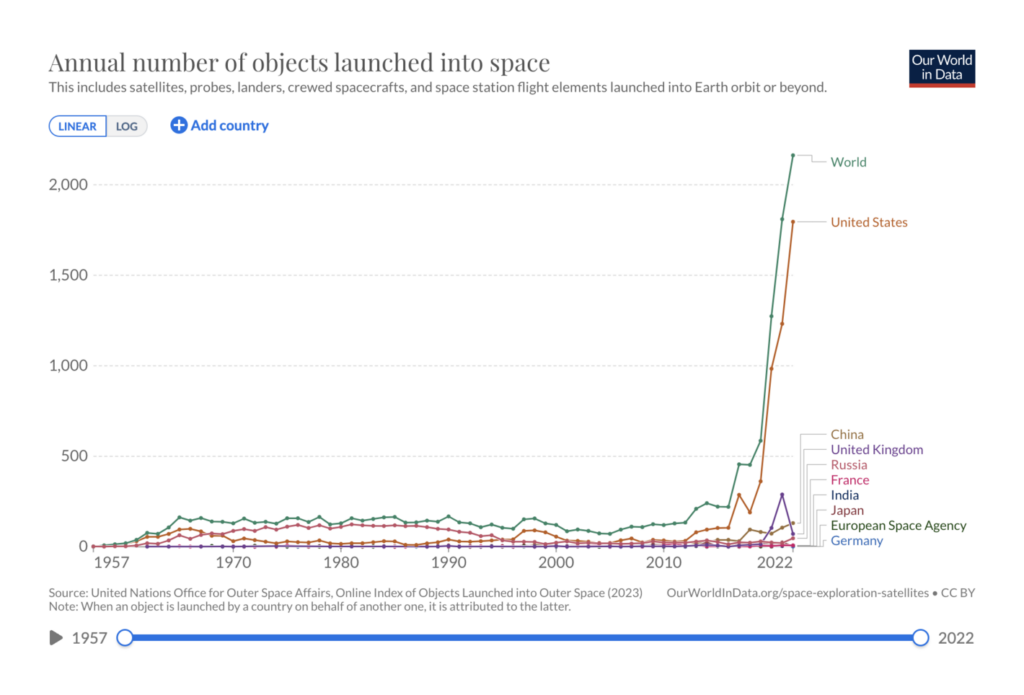
NASA and SpaceX are both reaching for the Moon, with flights planned for this and the following years. What does an increase in space exploration mean for the night sky and the Earth’s orbit?
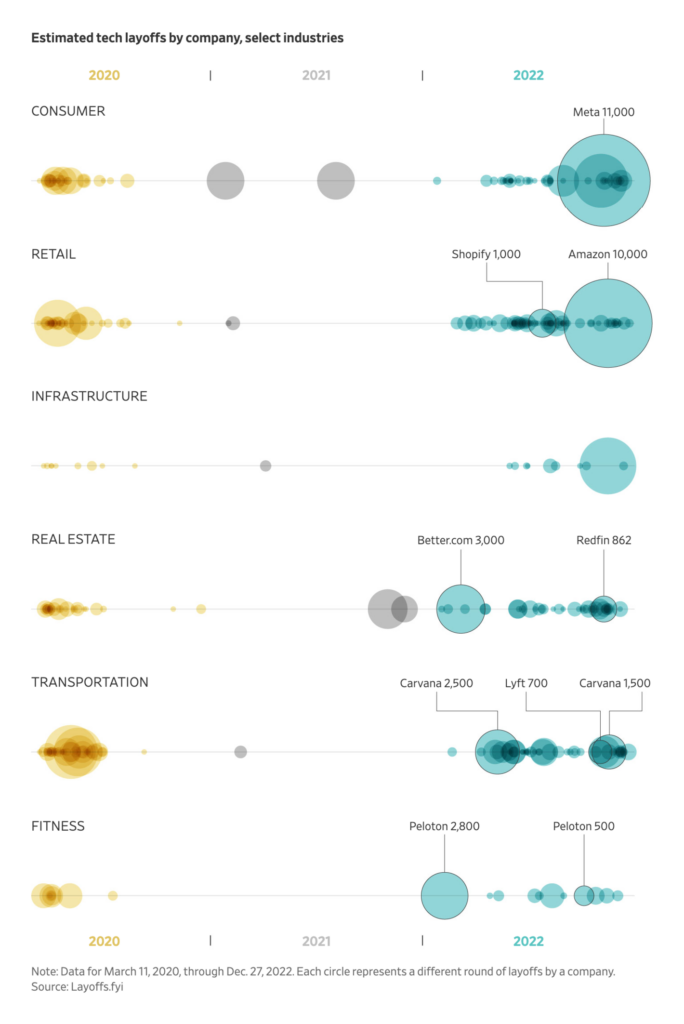
Tech companies continue to lay off employees in large numbers. After layoffs at Twitter two months ago, users turned to a competing platform, Mastodon, but not all of them stayed.
Help us make this dispatch better! We’d love to hear which newsletters, blogs, or social media accounts we need to follow to learn about interesting projects, especially from less-covered parts of the world (Asia, South America, Africa). Write us at hello@datawrapper.de or leave a comment below.
There are two good ways to get people to believe in your book. First, show them all the good things in the book. Publish excerpts. Write bylined articles. Preview the content. Second, have other people tell the world how good the book is. Collect blurb quotes from prominent people. Get people to write reviews on … Continued
Mark Brown takes apart this sloppy opinion piece in the Times higher education supplement. "In sum, short opinion pieces that imply face-to-face teaching is the 'Gold Standard' for promoting good learning and the 'art of conversation' might go unchallenged in the real time debates. However, the good news is that such critiques do not stand up as well to wider public scrutiny when published online and subject to further analysis." (The debate reminds me of the same sloppy and superficially reasoned arguments we employees have been given to force us back into 'real' offices). Via Marcus Green.
I followed a prompt from Miguel Guhlin to this article. The article was unclear and didn't directly link to the Pear Deck home page, but I found it and tried it out. I think it's quite a good idea - it's an add-on to Google Slides that creates versions of the slides students can access to interact by typing messages, drawing faces, answering polls, and more. The teacher can see and optionally share the results. But the marketing feels, well, skeevy, and does not fill me with confidence. You can't really learn about it from the website; you need to watch this video. I tried to set up an account and got Google's famous 'something went wrong' error message. Same when I tried to add it as an add-on in Slides. So it doesn't work in Firefox; it did, however, work in Chrome. So I went to set it up, but before it would allow me access to the free account I had to enter my school name and postal code to 'get started' on the premium account. I tried it, and found it added an unasked-for 'How do you feel' question at the start of the presentation. All of this feels wrong to me. So while it seems like a great product, my own experience is unsettling.
Whether a tweet or Instagram photo, the answer is no.^1
Blogs and websites have had editing capabilities since the start.
However, no site is an island, it’s a *web* site. Interlinked.
We expect edits on one site to show up when embedded or syndicated on other sites.
#Webmention provides the ability for cross-site comments, and unlike the "one-off" prior protocols of Trackbacks & Pingbacks^2, when you update a cross-site comment, by resending a Webmention, the other post updates its copy of your reply: https://www.w3.org/TR/webmention/#sending-webmentions-for-updated-posts
Thanks to these update protocols in Webmention & ActivityPub, and BridgyFed connecting them, after adding “forward-in-time” links (https://tantek.com/2023/006/t1/forward-in-time-links) I was able to resend webmentions for my previous #100DaysOfIndieWeb posts, and have those forward links show up wherever my posts were already displayed on Mastodon.
Posts interlinked with replies interlinked with protocols interlinked.
^2 Pingbacks were originally (and for many years) only implemented as one-off cross-blog interactions. One-time, uneditable. Pingbacks (and Trackbacks before them) were notoriously ugly when they showed up on blogs, listed & displayed as a separate thing (never tie presentation to the name of a protocol) with cryptically elided summaries: https://indieweb.org/pingback#Poor_display.
Over 10 years after Pingback was specified (2002), the then nascent (founded 2011) IndieWeb community re-used pingbacks for actual comments across sites in 2013: https://tantek.com/2013/113/b1/first-federated-indieweb-comment-thread separating presentation & UI from the protocol.
This separation of concerns approach evolved into the Webmention specification, separating the protocol from the display of comments, likes, reposts, and other social web https://indieweb.org/responses.
At the beginning of each year, I publish a retrospective that looks back on the prior year at Acquia. I write these both to reflect on the year, and to keep a record of things that happen at the company. I've been doing this for the past 14 years.
As Acquia has grown, it has become increasingly challenging for me to share updates on the company's progress in a way that feels authentic and meaningful.
First, I sometimes feel there are fewer exciting milestones to report on. When a company is small and in startup mode, each year tends to bring significant changes and important milestones. As a company transitions to steady growth and stability, the rate of change tends to slow down, or at least, feel less newsworthy. I believe this to be a natural evolution in the lifecycle of a company and not a negative development.
Second, while it was once exciting to share revenue and headcount milestones, it now feels somewhat self-indulgent and potentially off-putting. In light of the current global challenges, I want to be more mindful of the difficulties that others may be experiencing.
I've also been surprised and humbled by the thorough reading of my retrospectives by a wide range of audiences, including customers, partners, investors, bankers, competitors, former Acquians, and industry analysts.
Because of that I have come to realize that my retrospectives have gradually transformed from a celebration of rapid business milestones to something more akin to a shareholder letter — a way for a company to provide insight into its operations, progress, and future plans. As a business student, I have always enjoyed reading the annual shareholder letters of great companies. Some of my favorite shareholder letters offer a glimpse into the leadership's thinking and priorities.
As I continue to share my thoughts and progress through these annual retrospectives, I aim to strike a balance between transparency, enthusiasm, and sensitivity to the current environment. It is my hope that my updates provide valuable insights and serve as historical markers on the state of Acquia each year. Thank you for taking the time to read them.
Acquia business momentum
When writing my 2022 update, it's impossible to ignore the macroeconomic situation.
The year 2022 was marked by inflation, tighter monetary conditions, and conflict in Europe. This caused asset price bubbles to deflate. While this led to lower valuations and earnings multiples for technology companies, corporate earnings generally held up relatively well in comparison.
Looking ahead to 2023, Jerome Powell and the Federal Reserve are expected to keep their foot on the brake. They will keep interest rates high to tame inflation. Higher interest rates translate to slower growth and margin compression.
In anticipation of lower growth and margin compression, many companies reduced their forecasts for 2023 and adjusted their spending. This has resulted in layoffs across the technology sector.
I have great empathy for those who have lost their jobs or businesses as a result. It is a difficult and unsettling time, and my thoughts are with those affected.
I share these basic macroeconomic trends because they played out at Acquia as well. Like many companies, we adjusted our spending throughout the year. This allowed us to exit 2022 with the highest gross margins and EBITDA margins in our history. If the economy slows down in 2023, Acquia is well-positioned to weather the storm.
That said, we did continue our 16-year, unbroken revenue growth streak in 2022. We saw a healthy increase in our annual recurring revenue (ARR). We signed up many new customers, but also renewed existing customers at record-high rates.
I attribute Acquia's growth to the fact that demand for our products hasn't slowed. Digital is an essential part of most organizations' business strategies. Acquia's products are a "must have" investment even in a tough economy, rather than a "nice to have".
In short, we ended the year in our strongest financial position yet – both at the top line and the bottom line. It feels good to be a growing, profitable company in the current economic climate. I'm grateful that Acquia is thriving.
Can you clarify exactly what Acquia does?
Acquia's vision and mission statement has been unchanged the last 8+ years.
Frequently, I am asked: Can you clarify exactly what Acquia does?. Often, people only have a general understanding of our business. They vaguely know it has something to do with Drupal.
In this retrospective, I thought it would be helpful to illustrate what we do through examples of our work with customers in 2022.
Our core business is assisting organizations in building, designing, and maintaining their online presence. We specialize in serving customers with high-traffic websites, many websites, or demanding security and compliance requirements. Our platform scales to hundreds of millions of page views and has the best security of any Drupal hosting platform in the world (e.g. ISO-27001, PCI-DSS, SOC1, SOC2, IRAP, CSA STAR, FedRAMP, etc).
For example, we worked closely with Bayer throughout 2022. Bayer Consumer Health had 400+ sites on a proprietary platform coming to the end of its life, and needed to replatform those sites in a very tight timeframe. Bayer rebuilt these sites in Drupal and migrated its operations to Acquia Cloud in the span of 1.5 years. At the peak of the project, Bayer migrated 100 sites a month. Bayer reduced time to market by 40%, with new sites taking two to three weeks to launch. Organic traffic increased from 4% to 57%. Visit durations have increased 13% and the bounce rate has dropped 19%. As a result of the replatform, Bayer has realized a $15 million efficiency in IT and third-party costs over three years.
For many organizations, the true challenge in 2023 is not redesigning or replatforming their websites (using the latest JavaScript framework), or even maintaining their websites. The more impactful business challenge is to create better, more personalized customer experiences. Organizations want to deliver highly relevant customer experiences not only on their websites, but across other channels such as mobile, email, and social.
The issue that organizations face is that they don't have a deep enough understanding of their customers to make experiences highly relevant. While they may collect a large amount of data, they struggle to use it. Customer data is often scattered across various systems: websites, commerce platforms, email marketing tools, in-store point of sale systems, call center software, and more. These systems are often siloed and do not allow for a comprehensive understanding of the customer.
This is a second area of focus for Acquia, and one that has been growing in importance. Acquia helps these organizations integrate all of these systems and create a unified profile for each customer. By breaking down the data silos and establishing a single, reliable source of information about each customer, we can better understand a customer's unique needs and preferences, leading to significantly improved customer experiences.
In 2022, outdoor retailer Sun & Ski Sports used Acquia's Customer Data Platform (CDP) to drive personalized customer experiences across a variety of digital channels. Acquia CDP unified their customer data into a single source of truth, and helped Sun & Ski Sports recognize subtle but impactful trends in their customer data that they couldn't identify before. The result is a 1,500% increase in response rate for direct mail efforts, a 1,100% improvement in incremental net profit on direct mail pieces, a 200% increase in paid social clickthrough rates, and a 25% reduction in cost per click for paid social efforts.
A third area of focus for Acquia is helping our customers manage their digital content more broadly, beyond just their website content. For example, Autodesk undertook a global rebrand. Their goal was to go from a house of brands to a branded house. This meant Autodesk had to update many digital assets such as images and videos across websites, newsletters, presentations, and even printed materials. Using Acquia DAM, Autodesk redesigned the process of packaging, uploading, and releasing their digital assets to their 14,000 global employees, partners, and the public.
Experiences need to be personalized and orchestrated across all digital channels. To deliver the best digital experiences, user profile data needs to be unified across all systems. To make experience delivery easy, all content and digital assets need to be reusable across channels. Last but not least, digital experiences need to be delivered fast, securely, and reliably across all digital touchpoints.
When people ask me what Acquia does, they usually know we do something with Drupal. But they often don't realize how much more we do. Initially known exclusively for our Drupal-in-the-cloud offering, we have since expanded to provide a comprehensive Open Digital Experience Platform. This shift has allowed us to offer a more comprehensive solution to help our customers be digital winners.
Customer validation
At our customer and partner conference, Acquia Engage, we shared the stage with some of our customers, including ABInBev, Academy Mortgage, the American Medical Association, Autodesk, Bayer, Burn Boot Camp, Japan Airlines, Johnson Outdoors, MARS, McCormick, Novavax, Omron, Pearl Musical Instruments, Phillips 66, Sony Pictures, Stanley Black & Decker, and Sun & Ski Sports. Listening to their success stories was a highlight of the year for me.
Some of Acquia's customers in 2022: Cigna, Novartis, Lowe's, Barnes & Noble, Best Buy, Panasonic and more.
I'm also particularly proud of the fact that in 2022, our customers recognized us across two of the most popular B2B software review sites, TrustRadius and G2. Acquia earned Top Rated designation on TrustRadius four times over, and was named a Leader by G2 users in 20 areas.
Customers and partners rated our products very highly on G2 and TrustRadius.
The results prove that customers want what we're building, which is a great feeling. I'm proud of what our team has accomplished.
Analyst reports are important to our customers and prospects because these firms take into account customer feedback, a deep understanding of the market, and each vendor's product strategy and roadmap.
In this manifesto, I outline the growing demand for agility, flexibility, and speed in the enterprise sector and propose a solution in the form of Composable Digital Experience Platforms (DXPs).
Composable DXPs allow organizations to quickly assemble solutions from pre-existing building blocks, often using low-code or no-code interfaces. This enables organizations to adapt to changing business needs.
In my manifesto, I outline six principles that are essential for a DXP to be considered "composable", and I explain how Acquia is actively investing in research and development in alignment with these principles.
A summary of Acquia's current R&D investments in relation to these principles includes:
Component discovery and management tools. This includes tools to bundle components in pre-packaged business capabilities, CI/CD pipelines for continuous integration of components, and more.
Low-code / no-code tooling to speed up experience building. No-code tools also enable all business stakeholders to participate in experience creation and delivery.
Headless and hybrid content management so content can be delivered across many channels.
A unified data layer on which content personalization and journey orchestration tools operate.
Machine learning-based automation tools to tailor and orchestrate experiences to people's preferences.
Services that streamline the management and sharing of content across an organization.
Services to manage a global portfolio of diverse sites and deliver experiences at scale.
While there are six principles, there are four fundamental blocks to creating and delivering exceptional digital customer experiences: (1) managing content and digital assets, (2) managing user data, (3) personalized experience orchestration using machine learning, and (4) multi-experience composition and delivery across digital touchpoints. In the next sections, I'll talk a bit more about each of these four.
Managing content and digital assets
Given the central role of content in any digital experience, content management is a core capability of any DXP. Our content management capabilities are centered around Drupal and Acquia DAM.
Drupal has long been known for its ability to effectively manage and deliver content across various channels and customer touchpoints. In 2022, Drupal made significant strides with the release of Drupal 10, a major milestone that has taken 22 years to achieve.
The Drupal 10 release was covered by numerous articles on the web so I won't repeat the main Drupal 10 advancements or features in my retrospective. I do want to highlight Acquia's contributions to its success. Acquia was founded with the goal of supporting Drupal and, 16 years later, we continue to fulfill that mission as the largest corporate contributor to Drupal 10. I am proud of the work we have done to support the Drupal community and the release of Drupal 10.
I also wanted to provide an update on Acquia DAM. In 2021, Acquia acquired Widen, a digital asset management platform (DAM), and rebranded it as Acquia DAM. In 2022, we integrated it into both Drupal and Acquia's products.
Providing our customers with strong content management capabilities is essential to help them create great digital experiences. The integration of Widen marks an important step towards achieving our vision and implementing our strategy.
The combination of Drupal and Acquia DAM allows us to assist our customers in managing a wide range of digital content, including website content, images, videos, PDFs, and product information.
Managing user data
We have been investing in experience personalization since 2013, and over the past eight years, the market has continued to move toward data-driven, personalized experiences. IDC predicts that the Customer Data Platform (CDP) market will grow about 20% per year, reaching $3.2 billion by 2025.
This growth is driven by significant market changes, such the end of browser support for third-party cookies and the necessity for marketers to create personal customer experiences that are compliant with privacy regulations. The use of first-party data has become increasingly crucial. Acquia CDP is helping our customers with exactly this, and it's the perfect tool for this moment in time.
In order to deliver great customer experiences, it is essential that our customers have a single, accurate source of truth for customer data and complete user profiles. To achieve this, we made the decision to replatform our marketing products on Snowflake throughout 2022, a major architectural undertaking.
With Snowflake serving as our shared data layer, our customers now have easy and direct access to all of their customer data. This allows them to leverage that data across multiple applications within the Acquia product portfolio and connect to other relevant applications as part of their complete digital experience platform (DXP) solutions. I believe that our shared data layer sets us apart in the market and gives us a competitive advantage.
Personalized experience orchestration using machine learning
Our machine learning models allow our customers to use predictive marketing to improve and automate their marketing and customer engagement efforts. In 2022, we delivered over 1 trillion machine learning predictions. These predictions help our customers identify the best time and channel for engagement, as well as the most effective content to use, and more.
One of the primary reasons that companies purchase CDPs is to respect their customers' privacy preferences. A major benefit of a CDP is that it helps customers comply with regulations such as GDPR and CCPA. In June, we enhanced Acquia CDP to make it even easier for our customers to comply with subject data requests and privacy laws.
Multi-experience composition and delivery across digital touchpoints
According to a Gartner report from Q4 2022, global end-user spending on public cloud services is expected to increase by 20.7% in 2023, reaching a total of $591.8 billion.
The growth of Open Source software has paralleled the adoption of cloud technology. In 2022, developers initiated 52 million new Open Source projects on GitHub and made over 413 million contributions to existing Open Source projects. 90% of companies report using Open Source code in some manner.
Drupal is one of the most widely used Open Source projects globally and Acquia operates a large cloud platform. Acquia has been a pioneer in promoting both Open Source software and cloud technology. The combination of Open Source and cloud has proven to be particularly powerful in enabling innovation and digital transformation.
At Acquia, we strongly believe that experience creation and delivery will continue to move to Open Source and the cloud for many more years. The three largest public cloud vendors — Amazon, Microsoft, and Google — all reported annual growth between 25% and 40% in Q3 of 2022 (Q4 results are not public yet).
The past few years, our cloud platform has undergone a major technical upgrade called Acquia Cloud Next, modernizing Acquia Cloud using a cloud-native, Kubernetes-based architecture. In 2022, we made significant progress on Acquia Cloud Next, with many customers transitioning to the platform. They have experienced exceptional levels of performance, self-healing, and dynamic scaling for their large websites thanks to Acquia Cloud Next.
In 2022, we also introduced a new product called Acquia Code Studio. In partnership with GitLab, we offer a fully managed continuous integration/continuous delivery (CI/CD) pipeline optimized for Drupal. I have been using Acquia Code Studio myself and have documented my experience in deploying Drupal sites with Acquia Code Studio. In my more than 20 years of working with Drupal, I believe that Acquia Code Studio offers the best Drupal development and deployment workflow I have encountered.
Acquisitions
A key part of delivering on our vision is acquisitions. One disappointment for me was that we were unable to complete any acquisitions in 2022, despite our eagerness to do so. We looked at various potential acquisition targets, but ultimately didn't move forward with any. We remain open to and enthusiastic about acquiring other companies to become part of the Acquia family. This will continue to be a key focus for me in 2023.
The number one trend to watch: AI tools
The ever-growing amount of content on the internet shows no signs of slowing down. With the advent of "AI creation tools" like ChatGPT (for text creation) and DALL·E 2 (for image creation), the volume of content will only increase at an accelerated rate.
It is clear that generative AI will be increasingly adopted by marketers, developers, and other creative professionals. It will transform the way we work, conduct research, and create content and code. The impact of this technology on various industries and fields is likely to be significant.
Initially, AI tools like ChatGPT and DALL·E may present opportunities for Drupal and Acquia DAM. As the volume of content continues to increase, the ability to effectively manage and leverage that content becomes even more important. Drupal and Acquia DAM specialize in the management of content after it has been created, rather than in the creation process itself. As such, these tools may complement our offerings and help our customers better handle the growing volume of content. Those in the business of creating content, rather than managing content, are likely to face some disruption in the years ahead.
In the future, ChatGPT and similar AI tools may pose a threat to traditional websites as they are able to summarize information from various websites, rather than directing users to those websites. This shift could alter the relative importance of search engines, websites, SEO optimization, and more.
At Acquia, we will need to consider how these AI tools fit into our product strategy and be mindful of the ethical implications of their use. I will be closely monitoring this trend and plan to write more about it in the future.
Acquia also launched its own Environmental, Social, and Governance (ESG) stewardship as a company and joined the Vista Climate Pledge. This is important, not just for me personally, but also for many of our customers, as it aligns with their values and expectations for socially responsible companies.
Conclusion
In some respects, 2022 was more "normal" than the previous few years, as I had the opportunity to reconnect with colleagues, Open Source contributors, and customers at various in-person events and meetings.
However, in other ways, 2022 was difficult due to the state of the economy and global conflict.
While 2022 was not without its challenges, Acquia had a very successful year. I'm grateful to be in the position that we are in.
Of course, none of our results would be possible without the hard work of the Acquia team, our customers, our partners, the Drupal and Mautic communities, and more. Thank you!
I am not sure what 2023 will bring but I wish you success and happiness in the new year.
If you need an object lesson to demonstrate how inextricably linked technology is to the basic functioning of government, just look at the municipal governments that have been hit with cyber attacks recently and forced to shut down their digital systems.
For these governments it’s like a bumpy trip back to the way they used to operate decades ago. I wrote about this not long ago after Suffolk County New York was hit with a ransomware attack that forced them to rely on fax machines and other antiquated technology.
We are going to revert to 1990. We are going to teach millennials what a fax machine was.
Lisa Black, Chief Deputy Suffolk County Executive
Some trends in the local government technology ecosystem are making this issue more acute. Over the past ten years, there has been a trend toward consolidation in the market for local government software, with a shrinking number of firms providing service to an increasing number of local government customers. In addition, local governments often eschew managing their own infrastructure and solutions, favoring instead solutions that are built on a SaaS model.
At the confluence of these trends is a company like Cott Systems, a SaaS provider of municipal record keeping and court systems solutions. The company was hit with a cyber attack recently which forced it to shut down its service, bringing business in local governments across the country to a standstill. Cott reportedly has 400 local government customers across 21 states.
This feels like it should be a bigger story. I became aware of this particular incident because it affected my home county. If the trends toward more consolidation in the local government technology market, and local governments pushing everything out to the cloud via a SaaS provider continue this problem will get worse.
There has to be some ways to mitigate this. Certainly awareness is one issue. It seems like more mainstream coverage of this issue is warranted, as is more awareness on the part of local officials of the risks they take on when they put all their eggs in one basket with a SaaS provider in this way.
Maybe the effort to create a FedRAMP-style program for state (and hopefully local) governments will help officials vet their technology partners more thoroughly. It’s encouraging to see cybersecurity at the top of the priority list for state and local government officials, but this is an area that definitely needs more good ideas.
The link between the job of government, and the technology solutions governments use to do that job is too strong. As much as I loved the 90’s, we can’t go back.
This is an archived version of a Fortune article, the original of which is behind a paywall (adding confirmation to my theory that a primary intent of paywalls is to make sure critics don't read the content). "2023 will center on skills-based hiring rather than degree requirements—at least at successful companies, predicts research advisory and consulting firm Gartner in its list of top nine workplace predictions." No, it won't, and no, it doesn't. Once you get beyond the fast food sector, the vast majority of hiring will still require a traditional degree or diploma. And Gartner didn't say it wouldn't - it said "organizations will need to become more comfortable assessing candidates solely on their ability to perform in the role, rather than their credentials and prior experience." Which is true, but it doesn't mean they will. And even if they do adopt non-traditional hiring practices, says Gartner, they won't necessarily be focusing on skills. "They will deploy current employees to the highest priorities, which may necessitate reskilling and stretch assignments." The Gartner report isn't especially convincing, and the Fortune coverage is a joke. So just as well the content is behind a paywall. Via Apostolos.