Rolandt
Shared posts
The Post-Political Era
The person who is always walking around in any weather
This coast is wet in the fall and winter. We get pummelled by atmospheric rivers that bring strong warm winds and days of rain from the south west. We get drizzled on by orographic rain. We get soaked by passing fronts. And the land drinks it up, the rivers swell and call the salmon back. If you don’t love rain, this is a very hard place to live from October through to March., when the light is dim and the air moist. Me, I’ve grown to love it. I love to be out in the rain, walking about, listening to it on the hood of my jacket, sitting by the sea and watching is dapple the surface.
This is a video of some Nuu Chah Nulth language speakers from Hesquiaht on the west coast of Vancouver Island on the north end of Clayoquot Sound. And not just any language speakers but Julia Lucas, Simon Lucas and Maggie Ignace. I first met Julia and Simon in 1989 on my first trip to the west coast when I visited their village for a week and got to spend time with them. They are revered Elders. Simon, who passed away in 2017, was a a lifelong champion for Nuu Chah Nulth fishing and political rights and Julia has been a knowledge keeper, educator and language teacher for decades. Maggie is one of the many Nuu Chah Nulth language learners who are building up their fluency thanks to videos like this and programs.
Largely inspired by a slow reading through this paper (“Over reliance on English hinders cognitive science“) I’ve been thinking a bit today about the Indigenous languages of this region and how they point at such different ways of looking at the world, while I sip team and watch the rain. While surfing and I stumbled upon this video today, noting that OF COURSE Nuu Chah Nulth has a word for “a person who walks around in any weather” and I was really touched to see Julia and Simon here.
The 2023 Moby-Dick Marathon, Put On by the New Bedford Whaling Museum, Part I
Chapter 1: Moby-Dick
Talk to me long enough, and I'll bring up the subject of whales. I'm awed by the fact that the largest animal that has ever existed (the blue whale) exists today; that they live in the sea but breathe air; that the can hold their breath for 40 minutes, sometimes longer; that they swim for great lengths to feed and rest; and other facts that don't seem possible. It would surprise people a little that I hadn't read Moby-Dick, the epic American novel by Herman Melville.
Wondering how long the pandemic restrictions were going to last, at the end of 2020, I signed up for a course from the University of Toronto's Continuing Studies department as a way to motivate me to read it, and it would take place during the early months of 2021. I couldn't keep up with the assigned readings, and to this day I don't know what kind of credit I got for the course, but I finished the book. The edition I read, the Norton Critical Edition, was love at first sight. The footnotes (not endnotes!) were descriptive without being overly lengthy, pointing out biblical references I may not have caught (having not grown up in a religious family) and Shakespearean references that I had a chance of catching (whatever I would have read in high school), some quotations and facts that were flat out made up by Melville, and other words and terms that may have fallen out of fashion. It's a dense book, which some have called encyclopaedic, and that, not the length of the book is why it took me most of that year to finish.
I had known about the New Bedford Whaling Museum from a 2016 trip to Boston, and therefore knew about its yearly Moby-Dick Reading Marathon. I recorded a virtual reading marathon in the late months of 2021, reading chapter 92, titled "Ambergris" (the pronunciation of which I had to look up, and was disappointed to learn it wasn't the way French-speakers would have pronounced it). I did at least 6 takes, stopping each time I faltered, ultimately going with a take that had a minor slip in the end.
Emboldened by the removal of all pandemic restrictions and travel (minus the required vaccination, which I had covered), I signed up to be a reader at the in-person marathon in January 2023. At the very last minute, after looking up hotel rates and flight prices, I decided to accept. The only thing I was nervous about was the transportation between Boston and New Bedford, which had uncertainties due to the fact that I couldn't buy a ticket for a specific time and date. That would ultimately cause the chaos I feared.
Chapter 2: The Bus Schedule
I didn't look carefully at the special holiday-related cancellations before deciding which bus to take. The plan was to fly in on Thursday, work from the Boston HQ of the company I work for in Friday, and take a bus later that evening, settle into the hotel, then wake up refreshed for the proceedings at the museum. Working in the office was an absolute blast. We had a few more crises than I thought we would, and while I worried that we would take too much of the advantage for a social occasion, we were almost all business throughout (very pleasantly and productively so). I don't know if more gets done in person, but we learn more about each other that way, and it seemed a bit easier to figure things out together that way. I still think we do quite well with a spread out team, but one of the reasons I moved to Toronto is that I could do work trips like this, and I was brimming with joy the whole evening, despite how it played out as far as trip-planning was concerned.
What I hadn't internalized was that there was no 7 PM trip to New Bedford from Boston on that particular Friday due to the holiday schedule. There was, evidently, a 5:30 PM one, but I was blissfully eating nachos in the middle of South Station at the time. Not getting to New Bedford meant I couldn't make it for the first night of my hotel stay there. My hurried decision was to book another night at the Boston hotel I was staying at and, once I got back there, plead my case to cancel my New Bedford hotel room. After calling the hotel customer service line, and only explaining what happened, the people on the end of the line connected the dots themselves and looked to see if I could cancel despite the expired cancellation deadline. It took about over an hour of talking to at least 3 representatives, my having to call a second line (not to mention be subjected to a sales pitch on a resort getaway), to ultimately be granted, as a "one-time courtesy" (a line I know in my own field), a cancellation and rebooking. Having gotten that, and believing that I could catch a 7 AM bus the next morning, I went to bed early. I woke up at 5 AM the next morning, a Saturday, and made it with a lot of time before my 7 AM bus time only to find out that…
Chapter 3: The Uber Ride
…I had been looking at the weekday schedule. There were no scheduled bus trips on Saturdays not to mention no return bus trips on the coming Sunday. (Normally there were, but again, holiday schedule.) Just as I was contemplating cancelling the New Bedford portion of my trip did it turn out that another guy, a 72-year-old man from Japan, was also planning on going to Fairhaven (the last stop of the route) on that same trip. He suggested taking a taxi, and at first I dismissed it, but then thought "OK, how much would it cost?" So I looked it up, and it would be $77 USD. I thought: "You know what? That would be worth it." The Japanese fellow asked if he could come with me, and I couldn't think of a reason why not.
His English was pretty good, maybe a little halting, but we always got to understanding each other. Almost right away he asked to add him on Facebook. I couldn't think of a reason why not. We were about to share an hour-long ride together. The Uber driver asked if he could gas before going, and I had no problem with that. The Japanese fellow and I each got snacks, though we probably should have thought that through a little, since he wasn't too pleased about the crumbs we left. He won't see the tip he got, or the five-star rating I gave him (Uber only sends drivers averages), but he seemed pretty OK with it. The Japanese fellow offered to pay his share, and I took whatever he offered (it was more than half; I don't know if he knew I was just happy to get to New Bedford on time). He was on a day trip to Fairhaven, so I don't know how he got back. He seemed pretty resourceful to me, with his iPad mini always on and taking phone calls during the trip and looking up stuff as we went. I'm not too worried about him.
Chapter 4: The Reading

I couldn't check into he hotel until 1 PM, but left my suitcase there until I could. I actually made it to the museum at the time I had planned to arrive. I spent the morning listening to Stump the Scholars, half hoping my question would come up, half hoping it wouldn't. It didn't. The morning and afternoon went by pretty fast, with a quick meal at the Quahog Republic Tavern (a giant fish sandwich), and watched a bit of the main event, where dignitaries read from the first few chapters in front of an audience in the large room with the whaling ship. It was quite the scene for me, almost everybody looking down at their own copy of Moby-Dick, me included. Along with a couple of other things, my passport and my well-read copy of the book were the only two things I couldn't by. (It wouldn't be the same if I had to get a new copy of my own while in New Bedford.) There are a few photographs of me somewhere, with my trees-and-a-mountain-on-a-whale pin that someone, the only person who knows the reasons why I love whales that I don't talk about, bought me, reading Moby-Dick along with dozens of others. What a feeling!

My time to read, 3:30 PM, was going to be later than planned, because I had correctly sensed that the marathon was a bit behind time-wise. So I grabbed a coffee, which wasn't the smoothest move, because I forgot it can sometimes make my face break out. I powered through those feelings and kept along with the other readers until it was my time. I had practiced beforehand, not knowing exactly which section I'd read from, but knowing I had exactly 5 minutes. I had correctly guessed that I would read from the section introducing Captain Bildad, though, thankfully, it wasn't the hardest parts of that section that had the initial dialogue, where dost and thou were thrown around with wild, reckless, Quaker abandon. (Melville, though Ishmael, even makes fun of Quakers for doing that.) I had stage fright all day, and worried about pretty much all aspects, including being tall and having to adjust the microphone. I saw some people before me do it, so I knew it was possible. Just like the practice session, the 5 minutes went by like a flash. After hating every minute of the lead-up, I loved every second of reading it. It helped to know that hardly anybody would be looking at me, and the laughter would be at the content, and not the delivery.
I have a grin on my face from ear to ear. I already know that I want to do it again, and knowing what I know about the bus schedule, I'll make either fewer mistakes or different mistakes next time. I'll even practice a bit more seriously, this time conceding that this was going to be my first time and that no matter what, I'd want to improve from my previous performance. When it comes around again, I'll sign up for the lottery and if invited to read, I wouldn't hesitate to say Yes.
Read Part 2 now.
11 years ago today, Ryan Barrett (https://snarf...
This meant those of us building #IndieWeb sites could use a service for that functionality, instead of having to write code ourselves, for each proprietary API.
When a few of us originally started syndicating to silos (https://indieweb.org/POSSE), and sometimes reverse-syndicating replies (https://indieweb.org/backfeed), we had to write custom code to do so, calling each social media API (like Twitter) both ways.
Bridgy alleviated some of that burden, and over time added support for more silos, sometimes dropping support when they were shutdown (Google+, Buzz) or scuttled their APIs (Facebook).
While Bridgy started only with backfeed as a service, it eventually added publishing support, POSSE as a service.
Even though I already had code working to POSSE text notes to Twitter, when I added photo posting support to my site, rather than write more code to call Twitter’s API, I started conditionally using Bridgy Publish to POSSE my photo (and video) posts.
In 2017, Ryan launched Bridgy Fed (https://fed.brid.gy) which he has substantially improved in the past few months.
I and many others now use Bridgy Fed to broadcast to & interact with Mastodon (and other ActivityPub) servers, without having to write any ActivityPub, Webfinger etc. code ourselves.
https://tantek.com/2022/301/t1/twittermigration-bridgyfed-mastodon-indieweb
Every user of Bridgy Fed gets a nice dashboard for notifications and activity. Here’s mine: https://fed.brid.gy/user/tantek.com
Bridgy is a great example of a project that was started to fulfill a personal need (https://indieweb.org/make_what_you_need), growing to support broader community needs.
Read more about Bridgy & Bridgy Fed:
* https://indieweb.org/Bridgy (including Publish)
* https://indieweb.org/Bridgy_Fed
* Launch post: https://snarfed.org/2012-01-08_bridgy_launched
It’s this hybrid of encouraging personally relevant work and community contributions that makes the #IndieWeb community special.
Yes there is a focus on greater independence with your personal website. However we can all do more by working together.
We achieve more independence, more quickly, by collaborating in community.
This is day 8 of #100DaysOfIndieWeb #100Days.
← Day 7: https://tantek.com/2023/007/t2/more-100daysofindieweb-projects
→ Day 9: https://tantek.com/2023/009/t2/edit-reply-comment-update
Bias in AI-generated images
Lensa is an app that lets you retouch photos, and it recently added a feature that uses Stable Diffusion to generate AI-assisted portraits. While fun for some, the feature reveals biases in the underlying dataset. Melissa Heikkilä, for MIT Technology Review, describes problematic biases towards sexualized images for some groups:
Lensa generates its avatars using Stable Diffusion, an open-source AI model that generates images based on text prompts. Stable Diffusion is built using LAION-5B, a massive open-source data set that has been compiled by scraping images off the internet.
And because the internet is overflowing with images of naked or barely dressed women, and pictures reflecting sexist, racist stereotypes, the data set is also skewed toward these kinds of images.
This leads to AI models that sexualize women regardless of whether they want to be depicted that way, Caliskan says—especially women with identities that have been historically disadvantaged.
Tags: AI, bias, images, Lensa, MIT Technology Review, Stable Diffusion
The 2023 Moby-Dick Marathon, Put On by the New Bedford Whaling Museum, Part II
Read Part I first.
Chapter 5: The Ending
I had considered going to the overnight portion of the marathon, but resolved that if I couldn’t sleep, I’d make my way over. It turned out I slept well enough, and checked out of the hotel just in time to make the discussion with the scholars. On the first day, the moderator didn’t ask my question, but I knew I have another chance. At this morning’s discussion, where the seats were placed in the shape of a whale, I was one of the first to ask a question/make a comment. I actually chose to point out how funny Moby-Dick is, as evidenced by the laughter from the audience. That comment was well-received! One of the scholars sat next to me, and during the discussion, she mentioned the Melville’s Marginalia Online website (which was part of my question) so I took that to mean I wouldn’t ask the audience but would save it for her. So I did, and it emerged why there wasn’t a particular book listed on that website. it was because he didn’t actually own a copy (he lists two books as one book in his “Extracts” section, another she told me that I didn’t know). I asked her the meat of the question, and she seemed to think it’s a good enough question to write a short article about, and she encouraged me to do just that. She said she wanted me to keep in touch about it, even. Yet another project to add to the list!
What was the question? Well, you’ll have to read my forthcoming article to find out!
I had some time in the morning to wander around New Bedford, and after that, I ended up walking by the coffee shop next to the hotel, and had a nice brunch there. I’m sure the European café-style diner with a 25-minute wait is great, but I’ll do that next trip.
I returned to the museum just in time to read along with the ending of the book. Spoiler alert: It’s [the three chapters where the crew of The Pequod, including Captain Ahab, meet their doom]https://www.gutenberg.org/files/2701/2701-h/2701-h.htm#link2HCH0133), and he says his famous line “from hell's heart I stab at thee!” (which I probably heard first from The Simpsons). The reader of those chapters, Henry Sullivan, acted out Ahab’s voice, and it was incredibly stirring as one would expect such a scene to be.
Chapter 6: Back to Boston
Without much left to do in New Bedford, I got my bag. I have social anxiety in most situations, but the desire to know something often overcomes that. If you stay through the night and read along, for all 25 hours, you get a prize package. It sounded like this was verified with a stamp partway through, because it can’t be on the honour system. I saw a couple of people with the prize pack at the hotel, but they disapeared around the cornee before I could talk to them. As luck would have it, as I was fretting about how to get back to Boston, I saw them again, and caught their eye, and asked “Got any pro tips for staying the whole time?” They had lots! Like to expect to close your eyes and open them up later and find yourself 5 pages behind. Micro-naps, one of them called it. And nobody will blame you if you need fresh air. And don’t expect to be ina conduction to drive the next day. (They’re staying overnight tonight.) One benefit, they said, was that a sleep-deprived mind will make connections you won’t normally make between one part of the book and another. Such great tips! I got the sense that they wanted to keep talking, and I wanted to keep talking to them, too, but I had to focus on how to get out of town and back to Boston.
The first Uber driver asked me to cancel and try someone else. I wasn’t about to force anybody to do such a long fare, so I agreed. That cost me $5, though. I sort of feel in a bind about that. I’m not going to lose sleep over that, and I wonder if the driver felt better off rejecting it? Anyway, I had a problem to solve, so for the next driver, I sent a message saying I’d tip generously for the hour-plus-long drive. He agreed, and it was an uneventful, and hopefully the 20% tip is generous. I’m thinking of sending more, which I still have the chance to do. I made it to my hotel for tonight, so I got what I needed.
Traveling between Boston and New Bedford was the part I was most worried about for the trip, and it actually went worse than I thought it would. I’ll need to plan this better for next time. Maybe I could help organize a ride-share if the bus situation is the same next year.
Lots to think about, lots to process about this short trip. This was one of the best ideas I’ve ever had for a trip, and despite the mishaps, I’ve been really happy with it.
Software Design by Example 7: Pattern Matching
Every piece of technical writing I’ve ever done has been shaped by the work of Brian Kernighan. The Elements of Programming Style, Software Tools in Pascal, The Unix Programming Environment, and The C Programming Language didn’t just teach me how to design software (as opposed to just writing code); the clarity of Kernighan’s explanations gave me a model to imitate and a standard to strive for.
It was therefore one of the proudest moments of my life when Kernighan agreed to contribute a chapter to Beautiful Code in 2006. The subject he chose was matching regular expression—more specifically, the very first regular expression matcher that Rob Pike wrote for Unix in the early 1970s. It only matched the patterns shown below, but as Kernighan wrote, “This is quite a useful class; in my own experience of using regular expressions on a day-to-day basis, it easily accounts for 95 percent of all instances.”
| Meaning | Character |
|---|---|
| Any literal character c | c |
| Any single character | . |
| Beginning of input | ^ |
| End of input | $ |
| Zero or more of the previous character | * |
Re-implementing this in JavaScript turned out to be a natural way to introduce the Open-Closed Principle in object-oriented design and the Chain of Responsibility design pattern. However, the chapter was also very frustrating: a couple of simple animations would have been much easier to understand than the diagrams and prose I created, but (a) I didn’t have an easy way to create what I wanted, (b) maintaining animations as examples change is a lot of work, and (c) they don’t really work in print. I use tools like PythonTutor every time I teach live, and while I’m concerned about the accessibility gap they create, I am certain that they make hard things much easier. Perhaps one day someone will define a programming language whose elements have standard, animatable graphic representations that are supported by IDEs. Until then, the best we can do is try to meet the standard that Kernighan set for us forty years ago.

Terms defined: base class, Chain of Responsibility pattern, child (in a tree), coupling, depth-first, derived class, Document Object Model, eager matching, eager matching, greedy algorithm, lazy matching, node, Open-Closed Principle, polymorphism, query selector, regular expression, scope creep, test-driven development.
Is AI sentient and is it even useful to ask?
June 2022. Blake Lemoine, an engineer at Google, claims that their new AI is sentient and is fired (The Verge).
Although, not quite. You can piece what actually happened from Lemoine’s own contemporary Medium article and the subsequent Washington Post piece [no paywall]: Lemoine shared a doc around Google titled “Is LaMDA Sentient?” (LaMDA is the name of the AI, a large language model like GPT-3) – a colleague said this was "a bit provocative." He started to speak with people outside the company and was placed on disciplinary leave for violating confidentiality. Lemoine upped the ante, "inviting a lawyer to represent LaMDA," and then you’re kinda done I reckon. But the point is that the question was asked.
Can an AI be sentient?
Are there already sentient AIs, and if not now then when? 1,000 years from now? Surely. 100 years? Probably. So 10 years? Maybe. How about 2025? Tomorrow?
How could we tell?
Would it matter?
I’m going to muddle sentience and consciousness here because I don’t want to get lost in definitions.
Wikipedia’s article on Sentience cites philosopher Antonio Damasio and says that "sentience is a minimalistic way of defining consciousness" and limits it to "the capacity to feel sensations and emotions."
According to this view: consciousness = sentience + creativity + intelligence + sapience + self-awareness + intentionality + more.
I’d prefer to say that our terms are ill-defined, and that consciousnesses may have all kinds of different characteristics, and may be a matter of degree.
So let’s enlarge the question, and agree to come back to pinning down terms later: can an AI be conscious?
2017. Philosopher Susan Schneider proposes ACT: the AI Consciousness Test.
The idea is that consciousness is something that is felt: "we can all experience what it feels like, from the inside, to exist."
So the question for ACT is "whether the synthetic minds we create have an experience-based understanding of the way it feels, from the inside, to be conscious."
i.e. do AIs feel the same as we do?
The proposed test is a series of questions.
Thus, the ACT would challenge an AI with a series of increasingly demanding natural language interactions to see how quickly and readily it can grasp and use concepts and scenarios based on the internal experiences we associate with consciousness. At the most elementary level we might simply ask the machine if it conceives of itself as anything other than its physical self. At a more advanced level, we might see how it deals with ideas and scenarios such as those mentioned in the previous paragraph. At an advanced level, its ability to reason about and discuss philosophical questions such as “the hard problem of consciousness” would be evaluated. At the most demanding level, we might see if the machine invents and uses such a consciousness-based concept on its own, without relying on human ideas and inputs.
– Scientific American, Is Anyone Home? A Way to Find Out If AI Has Become Self-Aware (2017)
(Article by Susan Schneider and Edwin Turner.)
One problem - as with GPT-3/ChatGPT - is that large language models are extraordinary mimics. So maybe they just say the right stuff to pass the test.
Schneider’s suggestion is to “box in” the AI away from human culture until we’ve tested it against the ACT, so it can’t make guesses.
I don’t know. I’m more convinced by the “quickly and readily” component of ACT. Surely there are some puzzles that are quicker to deduce if you have self-awareness? Dunno.
The AI Consciousness Test is one in a long line of tests for machine intelligence, such as the Turing Test.
2020. There’s a solid critique of ACT in this paper by David Udell and Eric Schwitzgebel, Susan Schneider’s Proposed Tests for AI Consciousness: Promising but Flawed (PDF at that link).
The challenge is that there’s always going to be a lower-level explanation of how the AI is answering questions on the silicon substrate (a giant lookup table, matrix maths, whatever), and that no series of questions is going to be sufficient to convince people that there is genuine machine consciousness at a higher level too.
One for the philosophers.
But Udell & Schitzgebel are articulate on the urgency of finessing ACT or something ACT-like:
AI consciousness, despite its present science-fictional air, may soon become an urgent practical issue. Within the next few decades, engineers might develop AI systems that some people, rightly or wrongly, claim have conscious experiences like ours. We will then face the question of whether such AI systems would deserve moral consideration akin to that we give to people. There is already an emerging ‘robot rights’ movement which would surely be energized by plausible claims of robot consciousness (Schwitzgebel and Garza 2015; Gunkel 2018; Ziesche and Yampolskiy 2019). So we need to think seriously in advance about how to test for consciousness among apparently conscious machines …
– David Billy Udell and Eric Schwitzgebel, Susan Schneider’s Proposed Tests for AI Consciousness: Promising but Flawed (2020)
Schneider, in her Scientific American piece above, broadens the urgency to brain implants:
machine consciousness could impact the viability of brain-implant technologies, like those to be developed by Elon Musk’s new company, Neuralink. If AI cannot be conscious, then the parts of the brain responsible for consciousness could not be replaced with chips without causing a loss of consciousness. And, in a similar vein, a person couldn’t upload their brain to a computer to avoid death because that upload wouldn’t be a conscious being.
Consciousness is hard hey.
Consciousness is weird.
Let’s say that we agree that a silicon substrate can host consciousness.
Or that a group of organic cells, properly arranged etc, can host consciousness.
There is a slippery slope…
Eric Schwitzgebel again:
"The United States is literally, like you, phenomenally conscious. That is, the United States literally possesses a stream of experiences over and above the experiences of its members considered individually."
If you’re a materialist, you probably think that rabbits have conscious experiences. And you ought to think that. After all, rabbits are a lot like us, biologically and neurophysiologically.
If you’re a materialist, you probably also think that conscious experience would be present in a wide range of naturally evolved alien beings behaviorally very similar to us even if they are physiologically very different. And you ought to think that. After all, it would be insupportable Earthly chauvinism to deny consciousness to alien species behaviorally very similar to us, even if they are physiologically different.
But, I will argue, a materialist who accepts consciousness in hypothetical weirdly formed aliens ought also to accept consciousness in spatially distributed group entities. If you then also accept rabbit consciousness, you ought also accept the possibility of consciousness in rather dumb group entities.
Finally, the United States is a rather dumb group entity of the relevant sort (or maybe even it’s rather smart, but that’s more than I need for my argument).
If we set aside our prejudices against spatially distributed group entities, we can see that the United States has all the types of properties that materialists normally regard as indicative of consciousness.
– Eric Schwitzgebel, The Weirdness of the World (2021)
(I’ve added paragraph breaks.)
Schwitzgebel asks us to take the perspective of a consciousness entity which is much larger than us humans:
A planet-sized alien who squints might see the United States as a single, diffuse entity consuming bananas and automobiles, wiring up communication systems, touching the Moon, and regulating its smoggy exhalations – an entity that can be evaluated for the presence or absence of consciousness.
…and the rest of the chapter goes on to show convincingly that, yes, even if the USA isn’t conscious, it’s worthy of being evaluated.
(Do we need Schneider to write the USACT?)
This is perilously close to panpsychism, "the view that the mind or a mindlike aspect is a fundamental and ubiquitous feature of reality."
We are conscious. My cat is conscious, although differently. Asteroids is conscious; AI is conscious, why not. Mud is conscious; a stellar nebula has its own nebula-like conscious. (Olaf Stapledon, in Star Maker, way back in 1937, wrote beautifully and poignantly about the culture of gas cloud megatheria at the dawn of the cosmos.)
What’s the alternative?
Maybe silicon can’t be conscious.
Maybe GPT-4, GPT-5, GPT-N, no matter how convincing, will be an AI p-zombie, "a hypothetical being that is physically identical to and indistinguishable from a normal person but does not have conscious experience, qualia, or sentience."
Which implies there’s a cut-off somewhere. And I’m not happy with that either – I’m not ready to declare that my cat isn’t conscious, in her own cat way.
Everything is conscious.
Or nothing is conscious – except me. I’m not so sure about you.
Neither seems satisfying. Or useful?
Back to Eric Schwitzgebel, his paper (and forthcoming book) The Weirdness of the World, and the consciousness or otherwise of the USA…
Schwitzgebel asked philosopher Daniel Dennett, and he replied:
To the extent that the United States is radically unlike human beings, it’s unhelpful to ascribe consciousness to it. Its behavior is impoverished compared to ours and its functional architecture is radically unlike our own. Ascribing consciousness to the United States is not as much straightforwardly false is it is misleading. It invites the reader to too closely assimilate human architecture and group architecture.
And I like this approach, in a general sense, because it acknowledges the perspective from which we’re asking the question - being human - and therefore implicitly accepts that there will be other perspectives which have different answers.
The question is not: do we have conscious AIs?
It is more like: from our perspective, is there a non-misleading distinction between non-conscious AI and hypothetical conscious AI, and do we have conscious AIs in that sense?
AND THEN:
If an AI were to pass an AI Consciousness Test, in the non-misleading sense above, would it make any difference?
Udell & Schwitzgebel’s argument is that it’s meaningful in terms of robot rights.
But chickens have chicken-consciousness and we industrialise their growth and kill and eat them. Maybe the implication is that we ought to feel more gratitude when eating meat - if we eat meat at all - and that it’s poisonous to us to ignore that.
Or maybe they don’t have chicken-consciousness! Arguably we shouldn’t be treating chickens like we do in any case. It’s hard to imagine that we would treat them any worse even if we were certain they were lumps of 100% unthinking rock.
The point is that it’s not a question we really engage with, as a society. Maybe when it comes up with AI we collectively won’t care then, either.
So, for me, asking about AI consciousness is a way to winkle out these other questions.
Yes it’s important that we know when, in 50 years or 5 years, the machines wake up and we meet the first conscious AI. But if we then vary in our treatment of that AI, we’ll then have to ask what’s different about chickens, talking dogs, the Whanganui River in New Zealand which was granted legal personhood (BBC, 2017), the first uploaded nervous system - the open source OpenWorm virtual nemotode project - the entire USA as a conscious entity, and well, each other.
Definitely useful questions to ask.
More posts tagged: gpt-3 (12).
Out, Damn Internet.
I’ve an ambitious goal for 2023: Write more out loud. I write (by hand) every day in a journal, but that’s more of a personal practice, a meditation. This year I want to get back to writing publicly, and last week, I managed to write four days in a row, a rare streak over the past few years.
I was all fired up to continue my new habit this morning, but my internet provider has decided that it’s a good day to remind me what life was like in the days of the dial up modem. Something’s awry with my connection, and without broadband, I can’t properly write.
No, that’s not quite it – without broadband, I can’t properly think. I have dozens of active tabs open when I write, and I’ll often make on the fly phone calls to sources as well. Cell service sucks where I live, so I use WiFi calling. With these two main inputs offline, I’m stuck staring at a blank page. For me writing isn’t so much placing one word after the other as it is a record of active inquiry, of engaging with the Internet and reporting back what I’ve found (and how it’s changed or informed my point of view).
Fortunately WordPress (my blog’s platform service) seems to work on tiny sips of bandwidth, so I can squeeze this short missive out. I’ll be back once service resumes – in the meantime, here are the pieces that were going to be the stepping off point to my journey this morning – tabs I opened right before the lights went out.
AI & The Big Five – Ben Thompson (paywall). Ben’s been covering AI’s impact for years, and is upping his game as it relates to all aspects of the tech industry, especially chips and the big players like Amazon, MSFT, and GOOG.
Six OpenAI Rivals Google and Microsoft Are Watching – The Information (paywall). Get to know the various startups playing the AI/LLM game.
Social Quitting – Cory Doctorow. Cory dissects the unraveling of Facebook and Twitter.
China, a Pioneer in Regulating Algorithms, Turns Its Focus to Deepfakes -WSJ. I follow whatever China’s doing to regulate tech, and this one has implications for how things may play out here.
I hope to be back later this week – I’m traveling till Thursday, so see you then, Internet gods willing.
Play it loud in your Nissan Micra
This is magnificent stuff from Iain. He describes it like this:
"I attempted to capture a journey across London in a mixtape. These tracks are a mixture of what I was listening to and how I was feeling during a trip from East Dulwich to Regent Street by bus / underground / foot. I didn't set my microphone up properly so there's less field recording than I was intending (so I filled in with some extra sampled dialogue)."
AI and the Big Five
The story of 2022 was the emergence of AI, first with image generation models, including DALL-E, MidJourney, and the open source Stable Diffusion, and then ChatGPT, the first text-generation model to break through in a major way. It seems clear to me that this is a new epoch in technology.
To determine how that epoch might develop, though, it is useful to look back 26 years to one of the most famous strategy books of all time: Clayton Christensen’s The Innovator’s Dilemma, particularly this passage on the different kinds of innovations:
Most new technologies foster improved product performance. I call these sustaining technologies. Some sustaining technologies can be discontinuous or radical in character, while others are of an incremental nature. What all sustaining technologies have in common is that they improve the performance of established products, along the dimensions of performance that mainstream customers in major markets have historically valued. Most technological advances in a given industry are sustaining in character…
Disruptive technologies bring to a market a very different value proposition than had been available previously. Generally, disruptive technologies underperform established products in mainstream markets. But they have other features that a few fringe (and generally new) customers value. Products based on disruptive technologies are typically cheaper, simpler, smaller, and, frequently, more convenient to use.
It seems easy to look backwards and determine if an innovation was sustaining or disruptive by looking at how incumbent companies fared after that innovation came to market: if the innovation was sustaining, then incumbent companies became stronger; if it was disruptive then presumably startups captured most of the value.
Consider previous tech epochs:
- The PC was disruptive to nearly all of the existing incumbents; these relatively inexpensive and low-powered devices didn’t have nearly the capability or the profit margin of mini-computers, much less mainframes. That’s why IBM was happy to outsource both the original PC’s chip and OS to Intel and Microsoft, respectively, so that they could get a product out the door and satisfy their corporate customers; PCs got faster, though, and it was Intel and Microsoft that dominated as the market dwarfed everything that came before.
- The Internet was almost entirely new market innovation, and thus defined by completely new companies that, to the extent they disrupted incumbents, did so in industries far removed from technology, particularly those involving information (i.e. the media). This was the era of Google, Facebook, online marketplaces and e-commerce, etc. All of these applications ran on PCs powered by Windows and Intel.
- Cloud computing is arguably part of the Internet, but I think it deserves its own category. It was also extremely disruptive: commodity x86 architecture swept out dedicated server hardware, and an entire host of SaaS startups peeled off features from incumbents to build companies. What is notable is that the core infrastructure for cloud computing was primarily built by the winners of previous epochs: Amazon, Microsoft, and Google. Microsoft is particularly notable because the company also transitioned its traditional software business to a SaaS service, in part because the company had already transitioned said software business to a subscription model.
- Mobile ended up being dominated by two incumbents: Apple and Google. That doesn’t mean it wasn’t disruptive, though: Apple’s new UI paradigm entailed not viewing the phone as a small PC, a la Microsoft; Google’s new business model paradigm entailed not viewing phones as a direct profit center for operating system sales, but rather as a moat for their advertising business.
What is notable about this history is that the supposition I stated above isn’t quite right; disruptive innovations do consistently come from new entrants in a market, but those new entrants aren’t necessarily startups: some of the biggest winners in previous tech epochs have been existing companies leveraging their current business to move into a new space. At the same time, the other tenets of Christensen’s theory hold: Microsoft struggled with mobile because it was disruptive, but SaaS was ultimately sustaining because its business model was already aligned.
Given the success of existing companies with new epochs, the most obvious place to start when thinking about the impact of AI is with the big five: Apple, Amazon, Facebook, Google, and Microsoft.
Apple
I already referenced one of the most famous books about tech strategy; one of the most famous essays was Joel Spolsky’s Strategy Letter V, particularly this famous line:
Smart companies try to commoditize their products’ complements.
Spolsky wrote this line in the context of explaining why large companies would invest in open source software:
Debugged code is NOT free, whether proprietary or open source. Even if you don’t pay cash dollars for it, it has opportunity cost, and it has time cost. There is a finite amount of volunteer programming talent available for open source work, and each open source project competes with each other open source project for the same limited programming resource, and only the sexiest projects really have more volunteer developers than they can use. To summarize, I’m not very impressed by people who try to prove wild economic things about free-as-in-beer software, because they’re just getting divide-by-zero errors as far as I’m concerned.
Open source is not exempt from the laws of gravity or economics. We saw this with Eazel, ArsDigita, The Company Formerly Known as VA Linux and a lot of other attempts. But something is still going on which very few people in the open source world really understand: a lot of very large public companies, with responsibilities to maximize shareholder value, are investing a lot of money in supporting open source software, usually by paying large teams of programmers to work on it. And that’s what the principle of complements explains.
Once again: demand for a product increases when the price of its complements decreases. In general, a company’s strategic interest is going to be to get the price of their complements as low as possible. The lowest theoretically sustainable price would be the “commodity price” — the price that arises when you have a bunch of competitors offering indistinguishable goods. So, smart companies try to commoditize their products’ complements. If you can do this, demand for your product will increase and you will be able to charge more and make more.
Apple invests in open source technologies, most notably the Darwin kernel for its operating systems and the WebKit browser engine; the latter fits Spolsky’s prescription as ensuring that the web works well with Apple devices makes Apple’s devices more valuable.
Apple’s efforts in AI, meanwhile, have been largely proprietary: traditional machine learning models are used for things like recommendations and photo identification and voice recognition, but nothing that moves the needle for Apple’s business in a major way. Apple did, though, receive an incredible gift from the open source world: Stable Diffusion.
Stable Diffusion is remarkable not simply because it is open source, but also because the model is surprisingly small: when it was released it could already run on some consumer graphics cards; within a matter of weeks it had been optimized to the point where it could run on an iPhone.
Apple, to its immense credit, has seized this opportunity, with this announcement from its machine learning group last month:
Today, we are excited to release optimizations to Core ML for Stable Diffusion in macOS 13.1 and iOS 16.2, along with code to get started with deploying to Apple Silicon devices…
One of the key questions for Stable Diffusion in any app is where the model is running. There are a number of reasons why on-device deployment of Stable Diffusion in an app is preferable to a server-based approach. First, the privacy of the end user is protected because any data the user provided as input to the model stays on the user’s device. Second, after initial download, users don’t require an internet connection to use the model. Finally, locally deploying this model enables developers to reduce or eliminate their server-related costs…
Optimizing Core ML for Stable Diffusion and simplifying model conversion makes it easier for developers to incorporate this technology in their apps in a privacy-preserving and economically feasible way, while getting the best performance on Apple Silicon. This release comprises a Python package for converting Stable Diffusion models from PyTorch to Core ML using diffusers and coremltools, as well as a Swift package to deploy the models.
It’s important to note that this announcement came in two parts: first, Apple optimized the Stable Diffusion model itself (which it could do because it was open source); second, Apple updated its operating system, which thanks to Apple’s integrated model, is already tuned to Apple’s own chips.
Moreover, it seems safe to assume that this is only the beginning: while Apple has been shipping its so-called “Neural Engine” on its own chips for years now, that AI-specific hardware is tuned to Apple’s own needs; it seems likely that future Apple chips, if not this year then probably next year, will be tuned for Stable Diffusion as well. Stable Diffusion itself, meanwhile, could be built into Apple’s operating systems, with easily accessible APIs for any app developer.
This raises the prospect of “good enough” image generation capabilities being effectively built-in to Apple’s devices, and thus accessible to any developer without the need to scale up a back-end infrastructure of the sort needed by the viral hit Lensa. And, by extension, the winners in this world end up looking a lot like the winners in the App Store era: Apple wins because its integration and chip advantage are put to use to deliver differentiated apps, while small independent app makers have the APIs and distribution channel to build new businesses.
The losers, on the other hand, would be centralized image generation services like Dall-E or MidJourney, and the cloud providers that undergird them (and, to date, undergird the aforementioned Stable Diffusion apps like Lensa). Stable Diffusion on Apple devices won’t take over the entire market, to be sure — Dall-E and MidJourney are both “better” than Stable Diffusion, at least in my estimation, and there is of course a big world outside of Apple devices, but built-in local capabilities will affect the ultimate addressable market for both centralized services and centralized compute.
Amazon
Amazon, like Apple, uses machine learning across its applications; the direct consumer use cases for things like image and text generation, though, seem less obvious. What is already important is AWS, which sells access to GPUs in the cloud.
Some of this is used for training, including Stable Diffusion, which according to the founder and CEO of Stability AI Emad Mostaque used 256 Nvidia A100s for 150,000 hours for a market-rate cost of $600,000 (which is surprisingly low!). The larger use case, though, is inference, i.e. the actual application of the model to produce images (or text, in the case of ChatGPT). Every time you generate an image in MidJourney, or an avatar in Lensa, inference is being run on a GPU in the cloud.
Amazon’s prospects in this space will depend on a number of factors. First, and most obvious, is just how useful these products end up being in the real world. Beyond that, though, Apple’s progress in building local generation techniques could have a significant impact. Amazon, though, is a chip maker in its own right: while most of its efforts to date have been focused on its Graviton CPUs, the company could build dedicated hardware of its own for models like Stable Diffusion and compete on price. Still, AWS is hedging its bets: the cloud service is a major partner when it comes to Nvidia’s offerings as well.
The big short-term question for Amazon will be gauging demand: not having enough GPUs will be leaving money on the table; buying too many that sit idle, though, would be a major cost for a company trying to limit them. At the same time, it wouldn’t be the worst error to make: one of the challenges with AI is the fact that inference costs money; in other words, making something with AI has marginal costs.
This issue of marginal costs is, I suspect, an under-appreciated challenge in terms of developing compelling AI products. While cloud services have always had costs, the discrete nature of AI generation may make it challenging to fund the sort of iteration necessary to achieve product-market fit; I don’t think it’s an accident that ChatGPT, the biggest breakout product to-date, was both free to end users and provided by a company in OpenAI that both built its own model and has a sweetheart deal from Microsoft for compute capacity. If AWS had to sell GPUs for cheap that could spur more use in the long run.
That noted, these costs should come down over time: models will become more efficient even as chips become faster and more efficient in their own right, and there should be returns to scale for cloud services once there are sufficient products in the market maximizing utilization of their investments. Still, it is an open question as to how much full stack integration will make a difference, in addition to the aforementioned possibility of running inference locally.
Meta
I already detailed in Meta Myths why I think that AI is a massive opportunity for Meta and worth the huge capital expenditures the company is making:
Meta has huge data centers, but those data centers are primarily about CPU compute, which is what is needed to power Meta’s services. CPU compute is also what was necessary to drive Meta’s deterministic ad model, and the algorithms it used to recommend content from your network.
The long-term solution to ATT, though, is to build probabilistic models that not only figure out who should be targeted (which, to be fair, Meta was already using machine learning for), but also understanding which ads converted and which didn’t. These probabilistic models will be built by massive fleets of GPUs, which, in the case of Nvidia’s A100 cards, cost in the five figures; that may have been too pricey in a world where deterministic ads worked better anyways, but Meta isn’t in that world any longer, and it would be foolish to not invest in better targeting and measurement.
Moreover, the same approach will be essential to Reels’ continued growth: it is massively more difficult to recommend content from across the entire network than only from your friends and family, particularly because Meta plans to recommend not just video but also media of all types, and intersperse it with content you care about. Here too AI models will be the key, and the equipment to build those models costs a lot of money.
In the long run, though, this investment should pay off. First, there are the benefits to better targeting and better recommendations I just described, which should restart revenue growth. Second, once these AI data centers are built out the cost to maintain and upgrade them should be significantly less than the initial cost of building them the first time. Third, this massive investment is one no other company can make, except for Google (and, not coincidentally, Google’s capital expenditures are set to rise as well).
That last point is perhaps the most important: ATT hurt Meta more than any other company, because it already had by far the largest and most finely-tuned ad business, but in the long run it should deepen Meta’s moat. This level of investment simply isn’t viable for a company like Snap or Twitter or any of the other also-rans in digital advertising (even beyond the fact that Snap relies on cloud providers instead of its own data centers); when you combine the fact that Meta’s ad targeting will likely start to pull away from the field (outside of Google), with the massive increase in inventory that comes from Reels (which reduces prices), it will be a wonder why any advertiser would bother going anywhere else.
An important factor in making Meta’s AI work is not simply building the base model but also tuning it to individual users on an ongoing basis; that is what will take such a large amount of capacity and it will be essential for Meta to figure out how to do this customization cost-effectively. Here, though, it helps that Meta’s offering will probably be increasingly integrated: while the company may have committed to Qualcomm for chips for its VR headsets, Meta continues to develop its own server chips; the company has also released tools to abstract away Nvidia and AMD chips for its workloads, but it seems likely the company is working on its own AI chips as well.
What will be interesting to see is how things like image and text generation impact Meta in the long run: Sam Lessin has posited that the end-game for algorithmic timelines is AI content; I’ve made the same argument when it comes to the Metaverse. In other words, while Meta is investing in AI to give personalized recommendations, that idea, combined with 2022’s breakthroughs, is personalized content, delivered through Meta’s channels.
For now it will be interesting to see how Meta’s advertising tools develop: the entire process of both generating and A/B testing copy and images can be done by AI, and no company is better than Meta at making these sort of capabilities available at scale. Keep in mind that Meta’s advertising is primarily about the top of the funnel: the goal is to catch consumers’ eyes for a product or service or app they did not know previously existed; this means that there will be a lot of misses — the vast majority of ads do not convert — but that also means there is a lot of latitude for experimentation and iteration. This seems very well suited to AI: yes, generation may have marginal costs, but those marginal costs are drastically lower than a human.
The Innovator’s Dilemma was published in 1997; that was the year that Eastman Kodak’s stock reached its highest price of $94.25, and for seemingly good reason: Kodak, in terms of technology, was perfectly placed. Not only did the company dominate the current technology of film, it had also invented the next wave: the digital camera.
The problem came down to business model: Kodak made a lot of money with very good margins providing silver halide film; digital cameras, on the other hand, were digital, which means they didn’t need film at all. Kodak’s management was thus very incentivized to convince themselves that digital cameras would only ever be for amateurs, and only when they became drastically cheaper, which would certainly take a very long time.
In fact, Kodak’s management was right: it took over 25 years from the time of the digital camera’s invention for digital camera sales to surpass film camera sales; it took longer still for digital cameras to be used in professional applications. Kodak made a lot of money in the meantime, and paid out billions of dollars in dividends. And, while the company went bankrupt in 2012, that was because consumers had access to better products: first digital cameras, and eventually, phones with cameras built in.
The idea that this is a happy ending is, to be sure, a contrarian view: most view Kodak as a failure, because we expect companies to live forever. In this view Kodak is a cautionary tale of how an innovative company can allow its business model to lead it to its eventual doom, even if said doom was the result of consumers getting something better.
And thus we arrive at Google and AI. Google invented the transformer, the key technology undergirding the latest AI models. Google is rumored to have a conversation chat product that is far superior to ChatGPT. Google claims that its image generation capabilities are better than Dall-E or anyone else on the market. And yet, these claims are just that: claims, because there aren’t any actual products on the market.
This isn’t a surprise: Google has long been a leader in using machine learning to make its search and other consumer-facing products better (and has offered that technology as a service through Google Cloud). Search, though, has always depended on humans as the ultimate arbiter: Google will provide links, but it is the user that decides which one is the correct one by clicking on it. This extended to ads: Google’s offering was revolutionary because instead of charging advertisers for impressions — the value of which was very difficult to ascertain, particularly 20 years ago — it charged for clicks; the very people the advertisers were trying to reach would decide whether their ads were good enough.
I wrote about the conundrum this presented for Google’s business in a world of AI seven years ago in Google and the Limits of Strategy:
In yesterday’s keynote, Google CEO Sundar Pichai, after a recounting of tech history that emphasized the PC-Web-Mobile epochs I described in late 2014, declared that we are moving from a mobile-first world to an AI-first one; that was the context for the introduction of the Google Assistant.
It was a year prior to the aforementioned iOS 6 that Apple first introduced the idea of an assistant in the guise of Siri; for the first time you could (theoretically) compute by voice. It didn’t work very well at first (arguably it still doesn’t), but the implications for computing generally and Google specifically were profound: voice interaction both expanded where computing could be done, from situations in which you could devote your eyes and hands to your device to effectively everywhere, even as it constrained what you could do. An assistant has to be far more proactive than, for example, a search results page; it’s not enough to present possible answers: rather, an assistant needs to give the right answer.
This is a welcome shift for Google the technology; from the beginning the search engine has included an “I’m Feeling Lucky” button, so confident was Google founder Larry Page that the search engine could deliver you the exact result you wanted, and while yesterday’s Google Assistant demos were canned, the results, particularly when it came to contextual awareness, were far more impressive than the other assistants on the market. More broadly, few dispute that Google is a clear leader when it comes to the artificial intelligence and machine learning that underlie their assistant.
A business, though, is about more than technology, and Google has two significant shortcomings when it comes to assistants in particular. First, as I explained after this year’s Google I/O, the company has a go-to-market gap: assistants are only useful if they are available, which in the case of hundreds of millions of iOS users means downloading and using a separate app (or building the sort of experience that, like Facebook, users will willingly spend extensive amounts of time in).
Secondly, though, Google has a business-model problem: the “I’m Feeling Lucky Button” guaranteed that the search in question would not make Google any money. After all, if a user doesn’t have to choose from search results, said user also doesn’t have the opportunity to click an ad, thus choosing the winner of the competition Google created between its advertisers for user attention. Google Assistant has the exact same problem: where do the ads go?
That Article assumed that Google Assistant was going to be used to differentiate Google phones as an exclusive offering; that ended up being wrong, but the underlying analysis remains valid. Over the past seven years Google’s primary business model innovation has been to cram ever more ads into Search, a particularly effective tactic on mobile. And, to be fair, the sort of searches where Google makes the most money — travel, insurance, etc. — may not be well-suited for chat interfaces anyways.
That, though, ought only increase the concern for Google’s management that generative AI may, in the specific context of search, represent a disruptive innovation instead of a sustaining one. Disruptive innovation is, at least in the beginning, not as good as what already exists; that’s why it is easily dismissed by managers who can avoid thinking about the business model challenges by (correctly!) telling themselves that their current product is better. The problem, of course, is that the disruptive product gets better, even as the incumbent’s product becomes ever more bloated and hard to use — and that certainly sounds a lot like Google Search’s current trajectory.
I’m not calling the top for Google; I did that previously and was hilariously wrong. Being wrong, though, is more often than not a matter of timing: yes, Google has its cloud and YouTube’s dominance only seems to be increasing, but the outline of Search’s peak seems clear even if it throws off cash and profits for years.
Microsoft
Microsoft, meanwhile, seems the best placed of all. Like AWS it has a cloud service that sells GPU; it is also the exclusive cloud provider for OpenAI. Yes, that is incredibly expensive, but given that OpenAI appears to have the inside track to being the AI epoch’s addition to this list of top tech companies, that means that Microsoft is investing in the infrastructure of that epoch.
Bing, meanwhile, is like the Mac on the eve of the iPhone: yes it contributes a fair bit of revenue, but a fraction of the dominant player, and a relatively immaterial amount in the context of Microsoft as a whole. If incorporating ChatGPT-like results into Bing risks the business model for the opportunity to gain massive market share, that is a bet well worth making.
The latest report from The Information, meanwhile, is that GPT is eventually coming to Microsoft’s productivity apps. The trick will be to imitate the success of AI-coding tool GitHub Copilot (which is built on GPT), which figured out how to be a help instead of a nuisance (i.e. don’t be Clippy!).
What is important is that adding on new functionality — perhaps for a fee — fits perfectly with Microsoft’s subscription business model. It is notable that the company once thought of as a poster child for victims of disruption will, in the full recounting, not just be born of disruption, but be well-placed to reach greater heights because of it.
There is so much more to write about AI’s potential impact, but this Article is already plenty long. OpenAI is obviously the most interesting from a new company perspective: it is possible that OpenAI will become the platform on which all other AI companies are built, which would ultimately mean the economic value of AI outside of OpenAI may be fairly modest; this is also the bull case for Google, as they would be the most well-placed to be the Microsoft Azure to OpenAI’s AWS.
There is another possibility where open source models proliferate in the text generation space in addition to image generation. In this world AI becomes a commodity: this is probably the most impactful outcome for the world but, paradoxically, the most muted in terms of economic impact for individual companies (I suspect the biggest opportunities will be in industries where accuracy is essential: incumbents will therefore underinvest in AI, a la Kodak under-investing in digital, forgetting that technology gets better).
Indeed, the biggest winners may be Nvidia and TSMC. Nvidia’s investment in the CUDA ecosystem means the company doesn’t simply have the best AI chips, but the best AI ecosystem, and the company is investing in scaling that ecosystem up. That, though, has and will continue to spur competition, particularly in terms of internal chip efforts like Google’s TPU; everyone, though, will make their chips at TSMC, at least for the foreseeable future.
The biggest impact of all though, though, is probably off our radar completely. Just before the break Nat Friedman told me in a Stratechery Interview about Riffusion, which uses Stable Diffusion to generate music from text via visual sonograms, which makes me wonder what else is possible when images are truly a commodity. Right now text is the universal interface, because text has been the foundation of information transfer since the invention of writing; humans, though, are visual creatures, and the availability of AI for both the creation and interpretation of images could fundamentally transform what it means to convey information in ways that are impossible to predict.
For now, our predictions must be much more time-constrained, and modest. This may be the beginning of the AI epoch, but even in tech, epochs take a decade or longer to transform everything around them.
I wrote a follow-up to this Article in this Daily Update.
Thoughts on Software and Teaching from Last Week's Reading
I'm trying to get back into the habit of writing here more regularly. In the early days of my blog, I posted quick snippets every so often. Here's a set to start 2023.
• Falsework
From A Bridge Over a River Never Crossed:
Funnily enough, traditional arch bridges were built by first having a wood framing on which to lay all the stones in a solid arch (YouTube). That wood framing is called falsework, and is necessary until the arch is complete and can stand on its own. Only then is the falsework taken away. Without it, no such bridge would be left standing. That temporary structure, even if no trace is left of it at the end, is nevertheless critical to getting a functional bridge.
Programmers sometimes write a function or an object that helps them build something else that they couldn't easily have built otherwise, then delete the bridge code after they have written the code they really wanted. A big step in the development of a student programmer is when they do this for the first time, and feel in their bones why it was necessary and good.
• Repair as part of the history of an object
From The Art of Imperfection and its link back to a post on making repair visible, I learned about Kintsugi, a practice in Japanese art...
that treats breakage and repair as part of the history of an object, rather than something to disguise.
I have this pattern around my home, at least on occasion. I often repair my backpack, satchel, or clothing and leave evidence of the repair visible. My family thinks it's odd, but figure it's just me.
Do I do this in code? I don't think so. I tend to like clean code, with no distractions for future readers. The closest thing to Kintsugi I can think of now are comments that mention where some bit of code came from, especially if the current code is not intuitive to me at the time. Perhaps my memory is failing me, though. I'll be on the watch for this practice as I program.
• "It is good to watch the master."
I've been reading a rundown of the top 128 tennis players of the last hundred years, including this one about Pancho Gonzalez, one of the great players of the 1940s, '50s, and '60s. He was forty years old when the Open Era of tennis began in 1968, well past his prime. Even so, he could still compete with the best players in the game.
Even his opponents could appreciate the legend in their midst. Denmark's Torben Ulrich lost to him in five sets at the 1969 US Open. "Pancho gives great happiness," he said. "It is good to watch the master."
The old masters give me great happiness, too. With any luck, I can give a little happiness to my students now and then.
Serving a small static Site from Azure Functions
This is something I keep reinventing from scratch, and that I thought was worthy of posting a note about given that the Functions runtime is now in v4 and function proxies are deprecated (even though you can enable them again).
To be perfectly candid, it bugs me a lot that a small function app doesn’t have the bare minimum to serve up one HTML file and a handful of bundled resources by itself instead of having to resort to Azure CDN or a storage account, which just add to the amount of moving parts and add far too much complexity for small things.
So here’s what I did today while building a small PoC app:
-
Set
AzureWebJobsDisableHomepage: trueinsettings.json -
Created an
indexfunction with these bindings infunction.json, so it has effectively no route and spits out binary data:
# These are shorthand for the JSON entries
bindings[0].route: "{default:maxlength(0)?}"
bindings[0].dataType: "binary"
-
Created a
staticfunction that responds tobindings[0].route: "static/{*file}", with the samedataType. -
Set
extensions.http.routePrefix: ""inhost.jsonto remove the/apiprefix. -
Fished out an old function I had that essentially uses
fsandmime-typesto send out acontext.res.body: fs.readFileSync(file, null)after sorting out the full path and thecontent-type, and added that to bothindexandstatic.
Bam, you can now serve index.html and static assets that get deployed with your functions.
I then carried on to write the rest mostly unhindered, although it was JavaScript and I keep forgetting to await some of the APIs I’m calling.
The gist of things is that I’m only doing this in this way because JavaScript, for all its foibles, is still relatively quick to iterate upon.
Actually, let me rephrase that. JavaScript is actually much slower than Python to iterate on for API development due to things not failing and spitting out
undefinedall over the place, but I just can’t get the confusingly namedv2Python programming model of thev4Azure Functions runtime to work for me, and I really wanted to do this test I just did.
Also, my usual default of building a container and deploying it would be overkill for this scenario.
A Note On This Note
Something that saddens me a bit is that I am really losing faith in Azure Functions as a “rapid” programming model because every time I go back to it after a while everything I had done needs updating (editor extensions, runtime, code, dependencies, ways to configure basic settings, the works).
It’s just easier to go build and slap a binary behind caddy, or pack it into an ersatz container and push it to an Azure Container Instance. I can even pack all my static assets into the Go binary1.
Which is what I will probably be doing from now on for prototypes2, as long as they don’t involve too much JSON handling (which is still easier to do in dynamic languages).
Datasette 0.64, with a warning about SpatiaLite
I release Datasette 0.64 this morning. This release is mainly a response to the realization that it's not safe to run Datasette with the SpatiaLite extension loaded if that Datasette instance is configured to enable arbitrary SQL queries from untrusted users.
Here are the release notes quoted in full:
- Datasette now strongly recommends against allowing arbitrary SQL queries if you are using SpatiaLite. SpatiaLite includes SQL functions that could cause the Datasette server to crash. See SpatiaLite for more details.
- New default_allow_sql setting, providing an easier way to disable all arbitrary SQL execution by end users:
datasette --setting default_allow_sql off. See also Controlling the ability to execute arbitrary SQL. (#1409)- Building a location to time zone API with SpatiaLite is a new Datasette tutorial showing how to safely use SpatiaLite to create a location to time zone API.
- New documentation about how to debug problems loading SQLite extensions. The error message shown when an extension cannot be loaded has also been improved. (#1979)
- Fixed an accessibility issue: the
<select>elements in the table filter form now show an outline when they are currently focused. (#1771)
The problem with SpatiaLite
Datasette allows arbitrary SQL execution as a core feature. It takes a bunch of steps to provide this safely: database connections are opened in read-only mode, it imposes a strict time limit on SQL queries and Datasette is designed to be run in containers for a further layer of protection.
SQLite itself is an excellent platform for this feature: it has a set of default functionality that supports this well, protected by a legendarily thorough test suite.
SpatiaLite is a long running third-party extension for SQLite that adds a bewildering array of additional functionality to SQLite - much of it around GIS, but with a whole host of extras as well. It includes debugging routines, XML parsers and even it's own implementation of stored procedures!
Unfortunately, not all of this functionality is safe to expose to untrusted queries - even for databases that have been opened in read-only mode.
After identifying functions which could crash the Datasette instance, I decided that Datasette should make a strong recommendation not to expose SpatiaLite in an unprotected manner.
In addition to the new documentation, I also added a feature I've been planning for a while: a simple setting for disabling arbitrary SQL queries entirely:
datasette --setting default_allow_sql off
Prior to 0.64 you could achieve the same thing by adding the following line to your metadata.json file:
{
"allow_sql": false
}Or in metadata.yml:
allow_sql: false
The new setting achieves the same thing, but is more obvious and can be easily applied even for Datasette instances that don't use metadata.
A new SpatiaLite tutorial
The documentation now recommends running SpatiaLite instances with pre-approved SQL implemented using Datasette's canned queries feature.
To help clarify how this works, I decided to publish a new entry in the official series of Datasette tutorials:
Building a location to time zone API with SpatiaLite
This is an updated version of a tutorial I first wrote back in 2017.
The new tutorial now includes material on Chris Amico's datasette-geojson-map plugin, SpatiaLite point-in-polygon queries, polygon intersection queries, spatial indexes and how to use the simplify() function to reduce huge polygons down to a size that is more practical to display on a map.
I'm really happy with this new tutorial. Not only does it show a safe way to run SpatiaLite, but it also illustrates a powerful pattern for using Datasette to create and deploy custom APIs.
The resulting API can be accessed here:
https://timezones.datasette.io/timezones
It's hosted on Fly, using their $1.94/month instance size with 256MB of RAM - easily powerful enough to host this class of application.
I also updated the datasette-publish-fly plugin to make it easier to deploy instances with SQL execution disabled, see the 1.3 release notes.
Moya Michael’s carnival-like Coloured Swan 3: Harriet’s Remix brings “a party of the mind” to Vancouver’s PuSh Festival
Belgium-based choreographer and dancer Moya Michael is very aware of the fluidity and complexity of identity. Born and raised in Johannesburg, South Africa, she learned this at a very young age—and it’s influenced her Coloured Swan trilogy.
“I grew up in apartheid,” Michael tells Pancouver over Zoom in advance of her shows at the PuSh International Performing Arts Festival. “I was in the ‘Coloured’ race group.”
In those days, she says, white people did what they wanted. And people knew that a boss would always be white and ranked above people in her race group.
However, she didn’t feel “Coloured”. It was an imposed identity. Moreover, she wanted to be Black.
“I realized, after a while, that my ethnic lineage is to the Indigenous people of South Africa—the Khoi and the Sam people,” Michael says.
She points out that that these Indigenous people are still “heavily exploited” today.
“So many things in that culture have been erased, like a lot of Indigenous populations across the globe,” she continues.
In addition, because white colonists brought slaves to South Africa and migrant labourers from different parts of South Asia, the country is among the most multi-generationally mixed in the world.
“But then we were all put into these categories and sort of had to live by those rules—very strange,” Michael says. “And of course, you’re growing up in it as a kid, so you don’t really realize what’s happening… You’re not really sure what’s going on. It’s not being taught to you at school.”
Much later, she learned about the magnitude of atrocities that occurred under apartheid. She describes it as “genocide”.
“Nobody sees us as survivors, which is very…weird for me, in a way,” she adds.
Video: Watch the trailer for Coloured Swans 3: Harriet’s Remix.
Coloured Swan developed in three parts
Michael studied ballet in South Africa. She moved to Brussels in 1997 after receiving a scholarship to pursue dance education at the Performing Arts Research and Training Studios.
Her PuSh Festival show, Coloured Swan 3: Harriet’s Remix, is the third in a series of performances exploring layers of identity. Through these productions, she’s revealing how imposed identities can influence how people move, speak, and sing.
The first, Coloured Swan 1: Khoiswan, is a solo show focusing on her own ancestry. This was examined in detail in a 20-page academic paper, “Coloured Swan: Moya Michael’s Prowess in the Face of Fetishization in European Dance”, by Ghent University professor Annelies Van Assche.
“Notably, she was not regarded as a ‘real African’ by African and European gatekeepers alike, which to her remains an important part of her identity,” Van Assche writes in the paper, which was published Dance Research Journal last year. “The frustration of not being associated with the African continent led to the investigation into her African origins.”
Van Assche notes that her ancestors from the Khoi and San people were “the original and indigenous inhabitants of the southern part of Africa who were labelled by the derogatory term ‘Hottentots’ by the settlers”.
“To this day, these people are fighting for recognition of their existence as a people,” the academic adds. “This research gave rise to Khoiswan, in which Michael encounters her personal and historical ancestors, with and through whom she critically questions her artistic context.”

Symbols appear on-stage
In Coloured Swan 2: Eldorado, American dancer David Hernandez performs a solo that touches on his heritage.
Meanwhile, Coloured Swan 3: Harriet’s Remix features four biracial performers of African ancestry—rapper and electronic music producer Loucka Fiagan, MC and dancer Milo Slayers, and performer and audiovisual artist Oscar Cassamajor, and dancer, DJ, and sound designer Zen Jefferson.
The PuSh Festival website describes it as having “the variety and eye-catching flashiness of a splendid carnival”. In addition, it’s called a “party for the mind”. It has been performed in Nigeria and Norway, but never before in North America.
“I wanted to focus on how we can think of our bodies within the future,” Michael says. “There’s a sort of symbolism in there. My work is never literal.”
Moreover, this show integrates dance, text, singing, sound, and video in a wildly colourful presentation featuring a “Mothership”. The set includes rope and tires, which carry historical meaning in Africa. Ropes, of course, are linked to slavery. Furthermore, tires have been used in extrajudicial necklacing executions.
Michael’s show also has many masks made of cowry shells.
“Cowries used to be currency,” she explains. “It was used to buy slaves, for example. But today, it represents wealth.”
For her part, Michael is very conscious of the fetishization of Afrodiasporic dance artists in Europe. When she first moved to Belgium and later worked in England, she found it very disorienting.
Then, she decided to reclaim this as part of her voyage to change the dynamic between Black dancers and white audiences.
“I was like Josephine Baker with the piece that she does with all the bananas—‘You want exotic? I’m going to give you exotic!’ ” she declares.
In fact, she even referred to Josephine Baker in her solo Coloured Swan !: Khoiswan.

Addressing the white gaze
In the academic paper, Van Assche devotes a great deal of attention to Michael’s transformation. Assche writes about how Michael “gradually started to notice the subtle exoticization of her body” after arriving in Europe as a dancer.
“Although it was never very explicit, it would sometimes be intimated that her movements be more suggestive, more sensual,” Van Assche states. “As she states, her body was ‘pushed into a frame to fit the white gaze’.”
Michael tells Pancouver that she’s now creating works for people who came before her. And she says that this entails “shutting out the sort of white gaze upon Black or Brown bodies”.
“Performing in these sort of spaces, we are always the ones that are ‘raced’,” Michael says.
In addition, she believes that white people don’t often think about their own race. In response, she addressed this in a keynote speech to the cultural sector in Flanders. She delivered it in the dark so that the audience could consider Blackness in a more visceral way.
“I am grappling with all of these questions—trying to view my body inside of these spaces,” Michael says.
The PuSh Festival presents Moya Michael / Anaku & KVS’s Coloured Swan 3: Harriet’s Remix at the Orpheum Annex from January 20 to 22. For more information and tickets, visit the website. Follow Charlie Smith on Twitter @charliesmithvcr. Follow Pancouver on Twitter @PancouverMedia.
The post Moya Michael’s carnival-like Coloured Swan 3: Harriet’s Remix brings “a party of the mind” to Vancouver’s PuSh Festival appeared first on Pancouver.
Thinking a little bit about snow
I can’t remember the first time I saw snow.
It was most likely some time after we had moved to New York from Tanzania; it was most likely a surreal, foreign, and magical experience.
When we moved to Toronto, I remember seeing snow on the ground when we arrived. It was a cold January and a layer of powder was blanketing the ground. I was transfixed: here I was in a new country, a new place to call home, and the world around me felt soft, delicate, and pristine. I was being welcomed to my new home by landing in the middle of a sea of white, a blank slate for me to create a new life, to carve out my own path and destiny. The snow felt just right for this new beginning.
In college in DC, a friend of mine woke me up early one winter morning with excitement in her eyes. As I stumbled out of bed, she exclaimed, “it’s snowing!” Growing up in South Asia and in the Middle East, she had never seen snow before: the sprinkling that we had gotten overnight—minuscule, less than an inch—was a revelation for her, a little bit of magic. We borrowed dining trays from the dining hall that morning and spent the morning pushing each other through the snow as we sat on the trays; the hills were barely covered, but we still tried to sled down them as best as we could. The snow was a small delight.
These days, when I think of the snow, I think of snowdrifts and slush. I think of shoveling the driveway, driving in treacherous conditions, having to bundle up to escape the cold. The snow isn’t magic: it is something to rue and to bemoan. The snow feels like an impediment to real life, like a chore to do and a blight to overcome. Living in a snow belt city makes the winter difficult to enjoy: every day of the season, the risk of snowfall is present and imminent, and the dread sits inside me for four or five months of the year.

A few weeks ago, while in British Columbia, we got hit by a by snowstorm which left a veritable deluge—several inches, at least—of snow outside on the street. We bundled up my two-year-old daughter in her snowsuit and a hat and some mittens, and took her outside to experience the freshly fallen flakes that had gathered into a thick layer of snow, untouched by cars or by people, outside the house. This wasn’t her first snowfall—there had been a lot when she was younger and we took her out for walks in the stroller—but it was the first one where she was old enough to really appreciate and enjoy what she was seeing and doing. She was delighted as she stomped through the white layer on the ground, nervous but excited when we helped her make snow angels, tickled by some of the flakes falling off the trees. The snow was magic to her, and she laughed as she explored its beauty.
Perhaps it is time for me to rediscover snow as I once knew it, as my daughter experienced it. Perhaps, instead of a difficulty, I need to think of snow as an opportunity: the snowfall as a moment to appreciate beauty and experience delight before the doldrums of the day begin. Perhaps I need to find a tray and go sledding; perhaps I need to get in a snowsuit and make snow angels. Maybe I’ve been looking at snow all wrong. Maybe it’s time to experience wonder and awe, again.
Mapping Python to LLVM
Codon is a fascinating new entry in the "compile Python code to something else" world - this time targeting LLVM. Ariya Shajii describes in great detail how it pulls this off, including tricks such as transforming Python generators to LLVM coroutines. Codon doesn't promise that all Python code will work - it's best thought of as a Python-like language which can be used to create compiled modules which can then be imported back into regular Python projects.
Via Hacker News
Retiring Pinafore
Nolan Lawson built Pinafore, which became my default Mastodon client on both desktop and mobile over the past month. He thoughtfully explains why he's ending his involvement in the project - and why, for trust reasons, he's not planning on handing over the reigns to someone else. Pinafore is everything I want a good SPA to be - it loads fast, works offline and packs a whole lot of functionality into a tiny package. I'm sad to see Nolan's involvement come to end - it's a superb piece of software.
Via @nolan
2022 Reading List
I've updated my 2022 reading list with all the 112 books I read in the year.
Highlights were Tomorrow, and Tomorrow, and Tomorrow, by Gabrielle Zevin and A Memory Called Empire by Arkady Martine.
CoVid-19: Are You Feeling Lucky?
I’m still tracking the data on the pandemic. My message hasn’t changed. I’ll try to keep this short, since it’s mostly preaching to the choir. The data in the charts below are based on excess deaths data, provided by health and government statistics bureaus in most countries. Infection data is based on seroprevalence reports, mostly from surveys of blood donors and community water testing samples. Hospitalization data is as provided by health authorities, but is likely understated.
Reminder: I am not a medical expert, but have worked with epidemiologists and have some expertise in research, data analysis and statistics. I am producing these articles in the belief that reasonably researched writing on this topic can’t help but be an improvement over what’s currently out there.
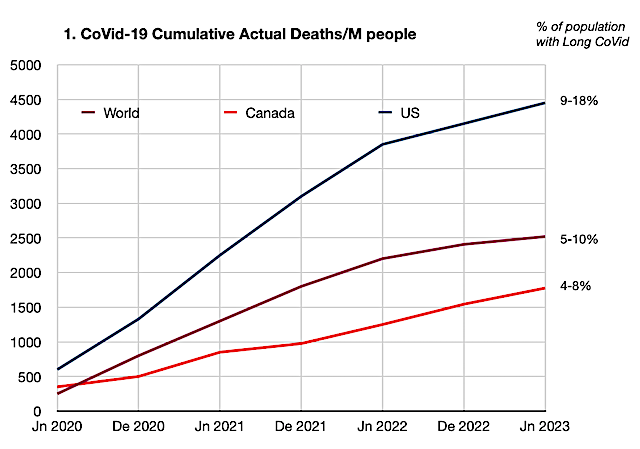
The chart above shows excess deaths, smoothed, since the start of the pandemic. It shows that the pandemic is still raging, taking almost as many lives in 2022 as in 2021, the worst year globally. In Canada, as measures were relaxed and fewer had been infected, 2022 was actually the worst year yet for deaths.
At current rates, it will likely kill another 200,000 Americans, another 17,000 Canadians, and another 1.8M people worldwide in 2023.
A cumulative death rate of 5000/Million people means that 1 out of every 2o0 people has been killed by this disease. Your risk of dying is at least 10x higher than that if you’re elderly or immunocompromised.
Based on the average of six published estimates, it would appear that about 6% of Canadians, 8% of the world’s population, and 14% of Americans, will have acquired Long CoVid symptoms by mid-2023, sufficient to permanently impair their health.
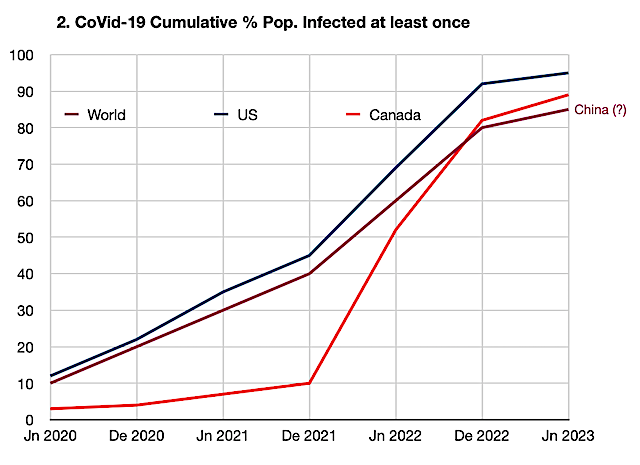
As chart 2 above shows, some countries like Canada that “flattened the curve” early through masking, high rates of vaccination and boosters, self-isolating and other measures were able to avoid high rates of infection when the prevailing variants had the highest fatality rate, but Omicron and its subvariants were so transmissible that almost all countries now have cumulative infection rates of 80-95%, and high rates of reinfection as the new subvariants “escape” being neutralized by previous infection or the older vaccines.
The newest “bivalent” boosters, along with N-95 masking, self-isolating, and (increasingly difficult to get) testing after symptoms or high-risk exposures, and the use of antivirals by older and immunocompromised people testing positive, are now the only effective ways to prevent reinfection, and the heightened risk of Long CoVid that accompanies each reinfection. And these are also the only effective ways to reduce your risk of hospitalization and death from the disease.
Your alternative is just to hope that you don’t get reinfected, that no new dangerous variants emerge, and that the existing subvariants will continue to have relatively low fatality rates.
What remains to be seen is how the BA.5.2.1.7 (also known as BF.7) subvariant that is tearing its way through China, now that that country has dramatically relaxed its mandates, will have on global total infections, hospitalizations and deaths, and on the emergence of yet more new variants as global case counts soar and provide yet more opportunities for the virus to mutate.
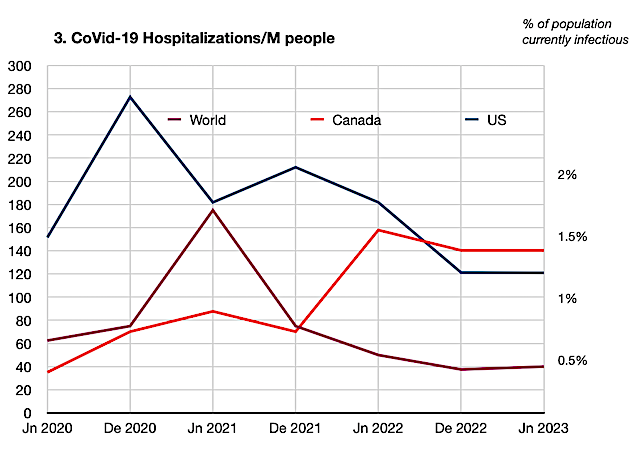
Chart 3 above shows smoothed publicly-provided hospitalization data — the number of people in hospitals with the disease, per million residents. While the Canadian data are alarming, they may partly reflect the high access provided by Canada’s universal health care system, compared to countries that have unaffordable two-tier health care systems. Still, given these trends, the Canadian governments’ relaxing of standards, monitoring capacity and testing is particularly reprehensible, as Canada’s running daily per-capita death toll from the disease has now caught up to that of the US.
In New York, thanks to the explosion in cases of the new hyper-transmissible XBB.1.5 subvariant, New York State’s January hospitalization numbers have soared above 200/M people. This suggest that for the rest of 2023, we may see a sharp uptick in hospitalizations, rather than the continuing decline most countries are banking on. And then we’ll find out how lethal XBB.1.5 is compared to previous subvariants. Fingers crossed, I guess.
Since hospitalizations are a good indicator of infectious disease prevalence, this chart also shows that, on average, 1-2% of all the people you encounter in a mall, restaurant, friend’s home, arena, bus or train are likely to be actively infectious, so your risk of reinfection, especially if you and others aren’t masked or distancing, is high. It only took six months for half of all Canadians to get their first infection (the first half of 2022), so it wouldn’t be unreasonable to assume that in most countries you have a 50% risk of reinfection in 2023. You can take steps to reduce that risk, or not.
And each reinfection increases your risk of getting Long CoVid.
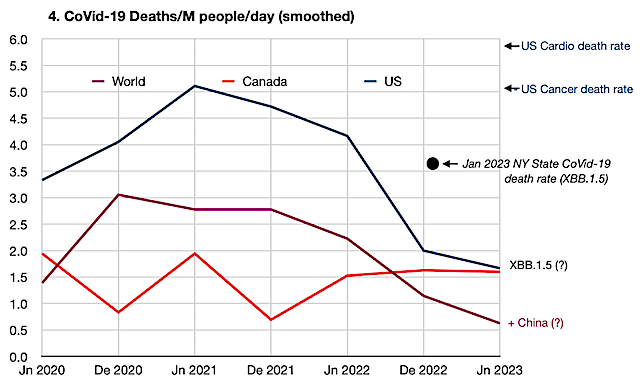
Chart 4 above shows the same excess deaths data as chart 1, but on an average-per-day basis rather than cumulative. It shows that CoVid-19 remains, and is expected to continue to remain, the 3rd largest cause of death in North America, at least for this year, behind only cardiovascular diseases and cancers.
There are two huge wild cards in the projections of deaths for 2023. The first is the explosion of XBB.1.5, which first appeared in the US in New York last month, and where the death rate has spiked to 3.6/Million people/day, more than twice what it was before, and twice the US average. If that death rate holds as XBB.1.5 spreads across the country and the world, we may see new peaks in deaths and hospitalizations rivalling the worst of the pandemic so far.
The second wild card is, of course, China, where the BF.7 subvariant is exploding as mandates are abandoned there. We have little reliable data on China’s infection and death rates, or on the extent and effectiveness of their vaccination program. We will see.
So, to recap:
- The pandemic is far from over, and while excess death numbers are declining, they are still unacceptably high, and there are some very worrying indicators that they could soon rise again.
- Since governments have washed their hands of responsibility, the only thing you can do is take precautions yourself and urge family and friends and coworkers to do likewise, even though they will probably not thank you for doing so.
- The precautions I am still taking, that you can take, are:
- Get the newest “bivalent” booster
- Wear an N-95 mask, at least whenever you’re indoors away from home or in crowded places, and keep your distance as much as possible
- Get tested if you have symptoms or if someone you’ve been exposed to has symptoms, or if you’ve been unmasked in a crowded place or indoors with people you don’t know for more than 15 minutes or so
- Self-isolate if you test positive or have symptoms
- If you test positive and are over 60 or immunocompromised, ask your doctor for antivirals (not monoclonal antibodies which are not effective against Omicron variants)
- Understand that each reinfection significantly increases your risk of getting Long CoVid, and confers very little immunity from the next reinfection
If you’re in average health, your chances of dying of CoVid-19 if you don’t take precautions are approximately the same as your chances of dying if you were make 1,000 parachute jumps from an airplane. Why would anyone take such a risk if they didn’t have to? Just because everyone else does, it would seem.
Login via command line
I’m working on a command-line tool that will require user login, so I wanted to have the flow that all the snazzy command-line clis use: pop up a browser window and ask you to login with <known provider>, then pass back something to the command line. Unfortunately, I had no idea what this type of login was called or how to do it.
This article was great, and went through enough of the flow that I got the idea and finished it up on my own. The (kind of ridiculous) flow is:
- Start a local webserver.
- Open a browser pointing to the platform you want to use to login.
- …passing the local webserver’s address in as the redirect for post-login.
- Receive the response on the webserver and parse it.
I’m using Python, so in more detail: first we start a local webserver. I’m doing this in a separate thread, because I need to do some other work while the webserver is handling stuff.
import http.server
import threading
class LoginManager:
def __init__(self):
self._server = None
self._port = 0
def start_web_server(self):
"""Kick off a thread for the local webserver."""
th = threading.Thread(target=self._start_local_server)
th.start()
def _start_local_server(self):
self._server = http.server.HTTPServer(('localhost', 0), Handler)
self._port = self._server.server_port
print(f'Serving on port {self._port}')
self._server.serve_forever()_start_local_server is the interesting part here. I don’t want to risk bumping into a port conflict (imagine how confusing it would be to not be able to log into a website because you happened to be running some emulator), so I’m going to make the OS give us an open port. Also, we only want the server to listen to localhost (no outside traffic). The pair ('localhost', 0) is the host and port, which binds the server to only accept requests to localhost and says “give me an open port.”
Because we’re not specifying a port, we then have to figure out what port we’re using. So I immediately ask the server what port was chosen (and then print it, for my own debugging).
Next up, we need to open a browser.
def open_browser(self):
"""Opens the browser to the login page."""
# Waits for the server to start.
while self._server is None:
time.sleep(1)
url = self.create_login_url()
system = platform.system()
if system == 'Darwin:
cmd = ['open', url]
elif system == 'Linux':
cmd = ['xdg-open', url]
elif system == 'Windows':
cmd = ['cmd', '/c', 'start', url.replace('&', '^&')]
else:
raise RuntimeError(f'Unsupported system: {system}')
subprocess.run(cmd, check=True)This is just copied from the article I linked above. I’m on Darwin and it works great, YMMV.
The URL is returned from create_login_url. This is where the article leaves us to our own devices. My default device is “Google probably has a free service that does this,” which seems to be true for this case. I created a new client credential under “OAuth 2.0 Client IDs”
In the client’s configuration you have to specify “Authorized JavaScript origins” and “Authorized redirect URIs.” We want URIs that match http://localhost:N, where N is going to change each run. However, the ? sternly warns you against URIs containing wildcards, so how do we specify N? The answer is: don’t. Turns out this is a prefix match, so put “http://localhost” in the questionable-named “URIs 1” for each section. This does mean that you have to serve the redirect from root (e.g., you have to redirect to localhost:12345, not localhost:12345/login-success-page), but this is just a scratch server for handling this one request, so that shouldn’t be a huge deal.
Armed with this configuration, we can now implement the URL gen function:
def create_login_url(self) -> str:
"""Generate the login URL."""
nonce = hashlib.sha256(os.urandom(1024)).hexdigest()
return (
'https://accounts.google.com/o/oauth2/v2/auth?'
'response_type=code&'
f'client_id={_CLIENT_ID}&'
'scope=openid%20email&'
f'redirect_uri=http%3A//localhost:{self._port}&'
f'nonce={nonce}')Another stern warning that we’re ignoring is that the docs “highly recommend” passing a “state” parameter. The docs assume you’re using this flow to have users log into your website, so your server has to be cautious that it’s getting a response from your actual user, not a man-in-the-middle attacker. However, we are running this direct from command line to Google, so using the state doesn’t make a lot of sense.
The final piece is to actually handle that redirect request from the browser. The browser passes back the ID token as a base64-encoded cookie, so we can use Python’s built-in libraries to extract it:
class Handler(http.server.SimpleHTTPRequestHandler):
"""Handle the response from accounts.google.com."""
# Sketchy static variable to hold response.
info = None
def do_GET(self):
c = http.cookies.SimpleCookie(self.headers.get('Cookie'))
jwt = c['idToken'].value
if not jwt:
# If the server gets a non-login request.
return
# Google's cookie comes in the format: "[header].[idToken]."
# where [header] and [idToken] are base64 encoded. However,
# "." isn't a base64 thing, so we have to split up the
# cookie before decoding.
pieces = jwt.split('.')
info = None
for piece in pieces:
# The base64 might not have enough padding for Python's
# decoder to roll with (JS is fine with it, but Python
# needs a couple of extra trailing =s).
i = base64.b64decode(f'{piece}==').decode('utf-8')
info = json.loads(i)
if is_header(info):
continue
# Otherwise, "info" is the value we want! Actually do
# something with it here:
do_something_with(info)
break
self.wfile.write(b'All set, feel free to close this tab')
def is_header(info: dict[str, Any]) -> bool:
return 'alg' in info and 'typ' in infoThis is full of gross little implementation details. I’ve tried to comment on them above. info looks something like:
{
'name': 'Alice Doe',
'email': 'adoe@example.com',
'email_verified': True,
'auth_time': 1659727260,
'user_id': '...',
'firebase': {
'identities': {
'email': ['adoe@example.com'],
'google.com': ['<long string>']
},
'sign_in_provider': 'google.com'
},
'iat': 1659727260,
'exp': 1659730860,
'aud': 'lien-288519',
'iss': 'https://securetoken.google.com/<your project>',
'sub': '...'
}Then we just have to put this all together:
def main(argv):
m = LoginManager()
m.start_web_server()
m.open_browser()
# Probably do something with info here, and shutdown the
# server.
if __name__ == '__main__':
app.run(main)Now when we run, it’ll create a server, pop open a browser, wait for us to log in, then redirect back to the server we just started, show a polite message to the user in the browser, and we can do something with the user’s token.
Datasette News: 2023-01-09
Datasette 0.64 is out, and includes a strong warning against running SpatiaLite in production without disabling arbitrary SQL queries, plus a new --setting default_allow_sql off setting to make it easier to do that. See Datasette 0.64, with a warning about SpatiaLite for more about this release. A new tutorial, Building a location to time zone API with SpatiaLite, describes how to safely use SpatiaLite and Datasette to build and deploy an API for looking up time zones for a latitude/longitude location.
Deductive vs. big-bang book structures
As you structure your book, deductive logic is leading you astray — especially if you are an academic. State big conclusions first, if you want readers to keep reading. The logical, and wrong, way to structure a nonfiction book Here is the logical way to structure a book: Very nice. Very easy to follow. Very … Continued
The post Deductive vs. big-bang book structures appeared first on without bullshit.
Love of learning
When I first moved to Boston as a graduate student, I joined the local science fiction fan group. After each meeting, we would all go to a Chinese restaurant and order a bunch of dishes, family style. And there was one rule: you had to eat with chopsticks. Which was a skill I’d never learned. … Continued
The post Love of learning appeared first on without bullshit.
Software Design by Example 8: Parsing Expressions
While Chapter 7 explained how to build a simple regular expression matcher, Chapter 8 explains how to parse regular expression patterns, and in doing so gives readers an idea of how more complicated parsers work. The grammar that the final parser handles is pretty simple:
| Meaning | Character |
|---|---|
| Any literal character c | c |
| Beginning of input | ^ |
| End of input | $ |
| Zero or more of the previous thing | * |
| Either/or | | |
| Grouping | (…) |
Even this grammar is enough to show why parsing is hard—hard enough that people should use existing data formats rather than create new ones and should generate data that can be parsed with off-the-shelf tools. But from a design point of view, it’s a chance to introduce the idea of actions as objects. Earlier chapters showed that functions are just another kind of data; taking that up a level, everything from “match these characters” in a parser to “move the cursor up a line” in an editor or “compile this file” in a build tool can and should be turned into an object that can be put in a list, concatenated with other actions, and so on.
This idea is one of the reasons I hope someone who knows more about functional programming than I do will some day add a third volume to this series that shows how to implement these tools in a language like Haskell or a superset of Elm. Those languages embody the same general design ideas in very different ways, and I think I’d learn a lot from seeing how someone who thinks in those ways translates these ideas into working code.

Terms defined: finite state machine, literal, parser, precedence, token, Turing Machine, well formed, YAML.
Seattle public schools sue social media platforms for youth 'mental health crisis'
I was in a discussion this week on the same sort of issue in other areas. In the current case, the Seattle lawsuit "accuses companies behind TikTok, Facebook, Instagram, Snapchat and YouTube of harming young peoples mental health." Perhaps these companies are liable (though certainly a similar case can be made about television in the case of previous generations; look at the damage wrought by an inescapable addition to things like Fox News). But more to the point - why should schools and educators be the ones to have to take legal action here? They have neither the experience nor the background to manage for these issues. Isn't it the proper role of government to protect people, including especially young people, from harm? That's what we see in Ireland, as Facebook was assessed a fine of 265 million Euros for publishing personal details of users online.
Web: [Direct Link] [This Post]The decline of disruptiveness
At my institution researchers are evaluated, in part, by the number of papers they produce. So they look at someone like me and conclude I'm not very productive. But it's a silly metric, and one made all the more so by the revelation in a Nature article (more) that some scientists publish a paper every five days. No wonder the authors are finding that there's less disruption and innovation in these works! "The growth in publishing and patenting may lead scientists and inventors to focus on narrower slices of previous work," write the authors. "We are at crossroads," says Olga Ioannou in this post. "We are at that awkward moment in time that we've lost sight of the others. So, how do we move forward? The paper's authors ask for broader research and more time."
Web: [Direct Link] [This Post]ChatGPT for Educators
Over the last week there has been a second wave of articles about chatGPT, these all focused on chatGPT for educators. I'll summarize them in this post, starting with this slide show by Jessica Adams, et al. Or you could start with this slide show by Torrey Trust. chatGPT "may be the best thing for education since the ballpoint pen," says Doug Peterson. By contrast, the all out rejection of this tech is appealing to Autumn Caines "as it seems tied to dark ideologies." Minimally, there should be ground rules for the robot wars, says Brenna Gray.
Still, "You know it's time to start re-thinking our kids' future!" says Marc Prensky. "Prepare for many of your old ideas about learning to die." Andrew Herft, meanwhile, shares a teachers' prompt guide to chaGPT. People creating content might want to review Tamilore Oladipo's "six ways AI already supports content creation and which tools are leading the charge." Lindsey Downs previews WCET's upcoming work looking at the impact of AI on education (and yes, I did read Danny Dunn and the Homework Machine as a child). Kasey Short on Middleweb discusses how to introduce chatGPT to your classroom. Final warning, though: "We're about to drown in a sea of pedestrian takes. An explosion of noise that will drown out any signal."
Web: [Direct Link] [This Post]State of the Word
A few weeks ago, but what feels like a lifetime ago, I was in New York City with a few dozen extra special people from around the WordPress world. Alongside Josepha and the community we presented this review of how WordPress did in 2022, and vision for what’s coming: