
Gadis, Froiz y Cuevas acumulan beneficios millonarios mientras sus trabajadoras cobran el salario mínimo y la mesa de negociación lleva meses paralizada.
etiquetas: cig, coruña, huelga, convenio
» noticia original (www.elsaltodiario.com)
Gadis, Froiz y Cuevas acumulan beneficios millonarios mientras sus trabajadoras cobran el salario mínimo y la mesa de negociación lleva meses paralizada.
etiquetas: cig, coruña, huelga, convenio
» noticia original (www.elsaltodiario.com)

La Cámara Alta aprueba votar el proyecto de ley por primera vez y después de ocho intentos, después de que cuatro republicanos se hayan unido a los demócratas del Senado
etiquetas: derrota, trump, irán, senado, impedir, ataques
» noticia original (www.eldiario.es)

Europa lanza por fin su respuesta tecnológica frente a la hegemonía estadounidense. Cinco gigantes del pago móvil continental acaban de sellar una alianza histórica para unificar sus redes. A partir del año que viene, las transacciones diarias de millones de usuarios se liberarán de los circuitos transatlánticos tradicionales para circular por una infraestructura estrictamente europea e independiente.
etiquetas: bizum, visa, mastercard, dependencia, tecnológica, eeuu
» noticia original (www.lesnumeriques.com)

Tres canales de TikTok que acumulan en total más de 1,5 millones de seguidores están suplantando la imagen de profesionales médicos de Brasil, México y Francia para difundir como "consejos de salud" recomendaciones sin evidencia científica: desde de infusiones de hoja de níspero para prevenir un cáncer a colocar patatas debajo de la cama para quitar la fiebre. Una investigación de VerificaRTVE analiza cómo proliferan este tipo de cuentas y cómo podemos identificarlas.
etiquetas: falsos, médicos, tiktok, consejos, salud
» noticia original (www.rtve.es)

La investigación sobre el fraude millonario a las arcas del Servicio Murciano de Salud (SMS) se salda ya con once personas detenidas y dos investigadas. Y no solo por presuntos delitos económicos, sino también contra la salud pública, debido al uso de productos sanitarios caducados en operaciones quirúrgicas, lo que puso en «riesgo» a los pacientes.
etiquetas: murcia, sms, fraude
» noticia original (www.laverdad.es)

Marisol, de 66 años, deberá dejar su casa en alquiler en la calle Mauricio Moro Pareto el próximo 11 de junio, tras 18 años pagando el alquiler, por la vulnerabilidad de sus propios arrendadores. Mantiene a tres familiares y no ha encontrado adónde ir.
etiquetas: málaga, desahucios, 95 años
» noticia original (www.laopiniondemalaga.es)

Ya no conducimos coches, sino centros de datos. El coche moderno no se limita a transportarte del punto A al punto B. Los coches tienen fallos de seguridad informática como cualquier producto o servicio conectado. Del mismo modo, está documentado que los fabricantes de coches no dudan en vender nuestros datos. General Motors, por ejemplo, espiaban a sus clientes hasta que les pillaron vendiendo datos a LexisNexis, y a su vez a las aseguradoras para subir las pólizas. ¿Podría pasar algo similar en Europa? Por supuesto. De hecho, está pasando.
etiquetas: ciberseguridad, gps, rgpd, lopd, aepd, coche, espiar, toyota, gm, lexisnexis, eu
» noticia original (www.motorpasion.com)

Las autoridades investigan una violenta pelea ocurrida en la madrugada de este miércoles en el barrio de Canalejas, en Las Palmas de Gran Canaria, donde un joven fue agredido por un grupo de chicas en plena vía pública, presuntamente después de que éste intentara robarles
etiquetas: las palmas de gran canaria, agresión grupal, paliza, chicas
» noticia original (www.canarias7.es)
By Diana DiGangi of UtilityDive
The U.S. Energy Information Administration projects that data centers will “increasingly skew more energy intensive” and that electricity consumed by them will increase across all commercial building stock, with their servers growing to make up an estimated 22% to 33% of commercial building electricity use by 2050, according to an April report.
In its 2026 Annual Energy Outlook, EIA modeled various scenarios to explore how much data centers might drive demand in the medium and long term. In its high electricity demand scenario, the agency assumed “growth in the installed stock of AI servers follows an exponential trend through 2050” and didn’t make any assumptions about increases in computational efficiency beyond historical trends.
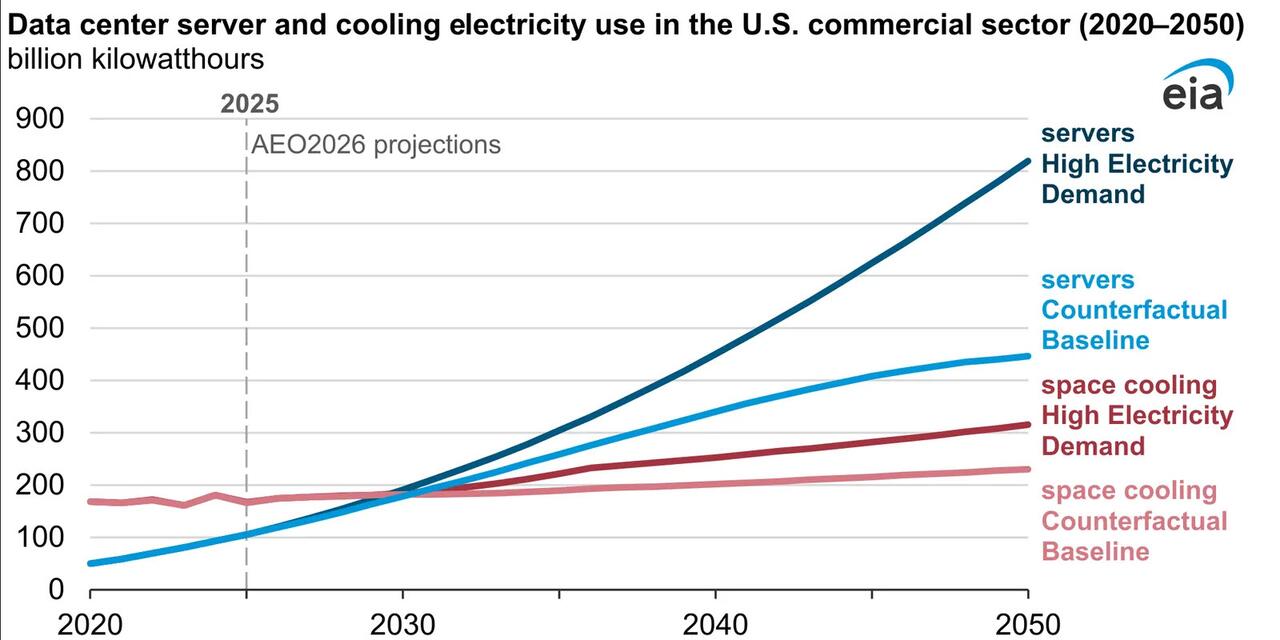
"These assumptions lead data center server energy use alone to grow to 818 billion kilowatt hours in 2050 in the High Electricity Demand case,” EIA said. “Server electricity consumption in 2050 is more than 16 times that in 2020.”
In its counterfactual base case, EIA models how “U.S. and world energy markets would operate through 2050 under laws and regulations in force as of December 2025,” but said that this “should not be regarded as the most likely of the cases.”
EIA projects that electricity consumption in the U.S. will continue to grow through 2050 at an annual rate of 0.9% to 1.6%, “with data center server energy use a major factor,” after the previous five years saw a 2.1% average annual demand increase, which followed 15 years of nearly flat demand.
“Energy use in commercial buildings, home to data center activity, grows more rapidly than in the residential or industrial sectors in all modeled cases,” the report said. In a Tuesday release, EIA noted that “across all cases, servers alone accounted for an estimated 7% of commercial sector electricity consumption in 2025.”
In both EIA’s high electricity demand scenario and its counterfactual base case, the commercial sector’s electricity intensity — measured in kilowatt hours of electricity consumed per square foot — eventually exceeds the 2003 historical high of 14.9 kWh per square foot for the first time in either 2031 or 2032, depending on the scenario.
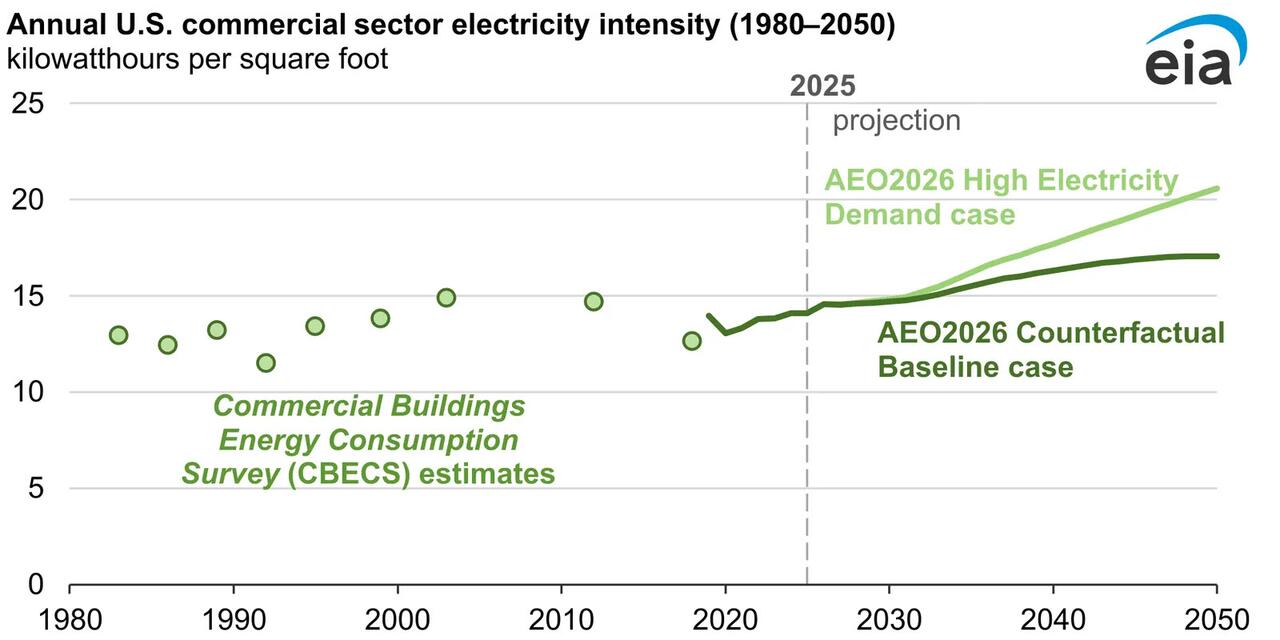
In its counterfactual base case, EIA projects that “after 2040, servers will become increasingly efficient, resulting in a 10% reduction in average annual operational power draw every three years, above and beyond historical efficiency trends. However, continued growth in server installations drives overall consumption growth.”
Google on Wednesday published exploit code for an unfixed vulnerability in its Chromium browser codebase that threatens millions of people using Chrome, Microsoft Edge, and virtually all other Chromium-based browsers.
The proof-of-concept code exploits the Browser Fetch programming interface, a standard that allows long videos and other large files to be downloaded in the background. An attacker can use the exploit to create a connection for monitoring some aspects of a user’s browser usage and as a proxy for viewing sites and launching denial-of-service attacks. Depending on the browser, the connections either reopen or remain open even after it or the device running it has rebooted.
The unfixed vulnerability can be exploited by any website a user visits. In effect, a compromise amounts to a limited backdoor that makes a device part of a limited botnet. The capabilities are limited to the same things a browser can do, such as visit malicious sites, provide anonymous proxy browsing by others, enable proxied DDoS attacks, and monitor user activity. Nonetheless, the exploit could allow an attacker to wrangle thousands, possibly millions, of devices into a network. Once a separate vulnerability becomes available, the attacker could use it to then compromise all those devices.
Cyber resilience is the ability to recover workloads to a known-good state after an adversary has affected the environment. Prevention works to keep threat actors out and detection works to find them quickly. Cyber resilience focuses on recovery: restoring a trustworthy environment when backups, credentials, or parts of the infrastructure can no longer be assumed to be safe.
For organizations running critical workloads on AWS, ransomware, data extortion, and other destructive events are increasingly central to recovery planning. The recovery environment and backups that recovery strategies depend on could themselves be targets of these events. This post is written for teams building recovery capabilities for these scenarios.The post walks through a reference pattern for isolating recovery from production, describes how AWS Backup logically air-gapped vaults provide deletion-protected backup storage, and presents a validation pipeline that checks whether a backup is recoverable and safe to use. It then lays out a concrete recovery workflow with parallelizable stages, introduces the Rebuild-Restore-Rotate framework for deciding what to recover from code, from backup, or to generate fresh, and addresses how to select the right recovery point when the most recent backup might carry the same threat that triggered the event.
The core architectural idea in cyber resilience is that the recovery environment, including its identities, keys, and network paths, shouldn’t share a trust boundary with the environment being recovered. If production identity is compromised, recovery must be able to proceed without depending on it.Most customers achieve this using separate AWS accounts inside an AWS Organization. A common pattern uses three account roles:
The production account is where workloads run. If a cyber event is confirmed, these accounts are isolated for investigation. Recovery work doesn’t happen in production, because in some scenarios remediation in place may not fully restore trust.
The recovery account owns the AWS Backup logically air-gapped vault. Most AWS-native backup mechanisms produce recovery points that are inherently immutable. You can’t modify an Amazon Elastic Block Store (Amazon EBS) snapshot or an Amazon Aurora snapshot after creation. The logically air-gapped vault adds deletion protection. Recovery points can’t be deleted or have their retention period shortened by any principal, including the account root user or a compromised administrator, within the retention period. This account’s purpose is to keep the controls around backups safe. It’s where you configure who can share the vault, who can initiate a restore, and who approves a restore operation through Multi-party approval (MPA). Keeping these controls in a dedicated account means a compromised identity in a production account cannot modify them (due to account isolation). SCPs on the recovery account further restrict its own identities to backup operations only, limiting blast radius if that account is also compromised.
Where backups are restored, validated, and the new production environment is rebuilt before cutover. The IRE is kept separate from the Production Account so that if a restored backup still contains the threat, it has nowhere to spread. It has no trust relationship to the Production Account, no VPC peering to it, and no internet-facing resources, so a tainted restore discovered during validation stays contained inside the IRE instead of reaching back into production or out to the internet. Infrastructure deployment in the IRE uses VPC endpoints (AWS PrivateLink) to reach AWS service APIs without internet connectivity or VPC peering to production. The following diagram shows how the three account roles relate to each other within a single AWS Organization, including their trust boundaries and the flow of recovery points between them.
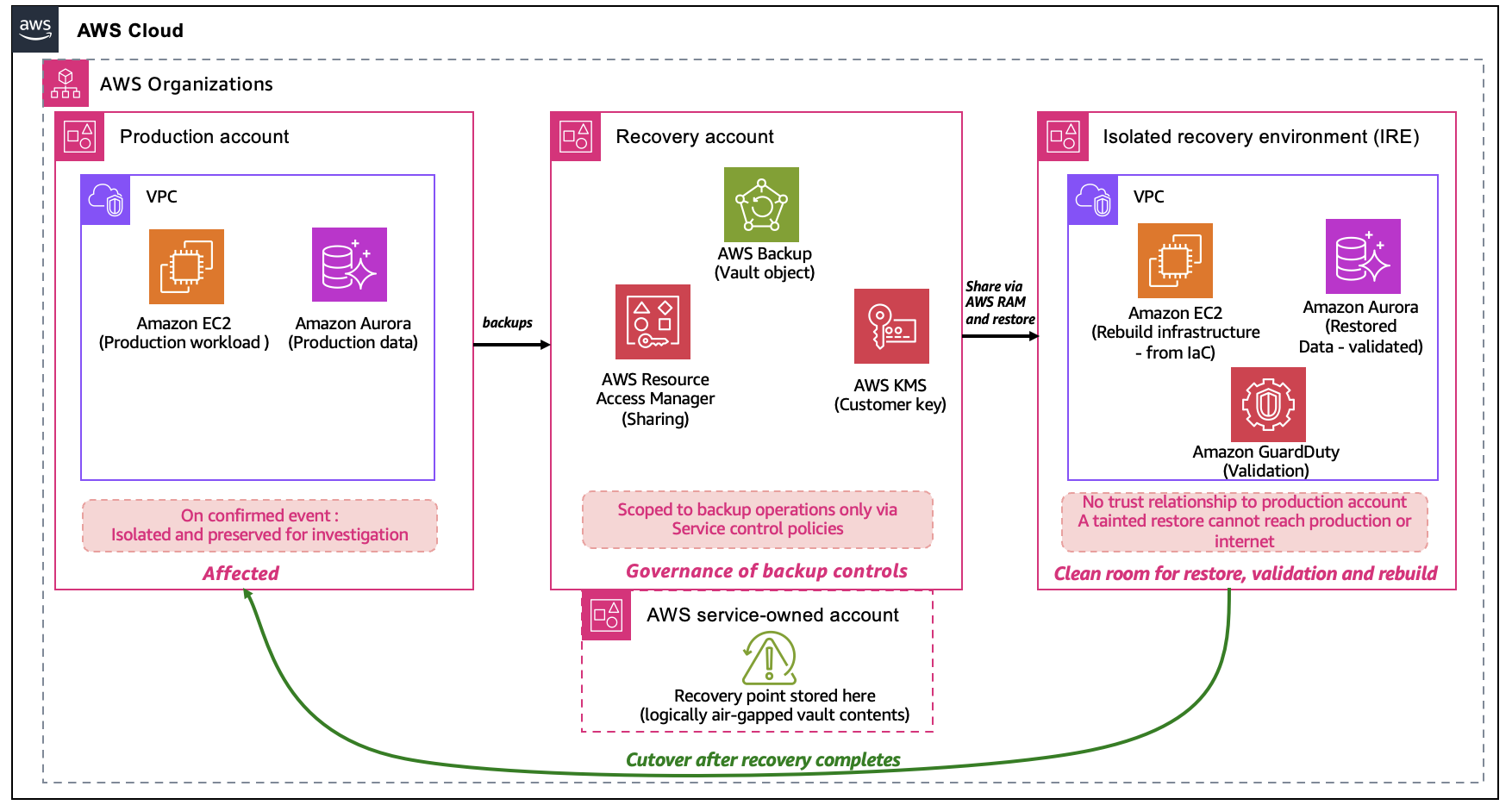
Figure 1. The Production Account is isolated after a confirmed event. The Recovery Account owns the logically air-gapped vault and controls restore authorization through Multi-party approval. The IRE has no trust relationship or network path to production.
The AWS Backup logically air-gapped vault is the primary AWS-native option for protecting backup storage from deletion.
Use the vault for what it provides, which is deletion protection enforced by the service. A logically air-gapped vault is always locked in Compliance mode. The service itself enforces retention, so recovery points can’t be deleted by any principal, including the account root user or a compromised administrator, within the retention period. Deletion protection keeps the recovery point available when needed. Whether the recovery point is safe to use is determined by the validation pipeline described in the following section.
Understand where recovery points live. A logically air-gapped vault stores recovery points in AWS service-owned accounts. You can choose to encrypt these recovery points with either an AWS-owned key or an AWS Key Management Service (AWS KMS) customer managed key. The vault object in your Recovery Account is the governance and access boundary where sharing, restore authorization, and Multi-party approval are configured. This separation is what makes the air-gap logical rather than network-based.
Share recovery points through AWS Resource Access Management (AWS RAM) for restore. You share recovery points across accounts through AWS RAM. You can initiate restores from the owning account or from any account with which you share the vault. This is how the Recovery Account makes recovery points available to the IRE.
Configure Multi-party approval for restore. MPA, configured through IAM Identity Center, requires a predefined set of approvers before a restore proceeds. This is particularly valuable when the source account might no longer be trusted.
Back up fully managed resources directly to the vault. AWS Backup supports the logically air-gapped vault as a primary backup target for fully managed resources (Amazon S3, Amazon DynamoDB, Amazon Elastic File System (Amazon EFS)), so backups can be written directly to the vault without staging in a standard vault first. Non-fully-managed resources (Amazon EBS, Amazon Aurora, Amazon FSx) use an intelligent orchestration path where the service creates and transfers a temporary snapshot.
For S3 data that cannot be backed up by AWS Backup (such as SSE-C encrypted objects, objects in Glacier Flexible Retrieval/Deep Archive storage classes, or directory buckets), Amazon S3 Object Lock in Compliance mode paired with S3 Versioning provides equivalent deletion protection at the S3 layer.
A successful restore confirms that the backup was readable. Validation confirms that it’s safe to use. No single check catches everything, which is why validation combines several layers.
For ransomware, a malware scan on the restored volume catches known encryption tools and indicators. For threats that have been present in the environment for some time, a malware scan isn’t enough because the attacker might have modified legitimate code, configuration, or data in ways that look normal to a scanner. These kinds of changes show up through workload-specific checks, such as a database consistency check failing, an application invariant being violated, or a configuration diff showing an unexpected change against a known-good baseline. Log and audit review across the backup window helps identify unexpected identity or configuration changes that neither a malware scan nor a workload check would catch on their own.
The layers commonly combined into a validation pipeline:
| Layer | Capability | What it provides |
| AWS native | AWS Backup Restore Testing | Automated verification that backups are recoverable, with custom hooks via the PutRestoreValidationResult API |
| AWS native | Amazon GuardDuty Malware Protection | Malware scanning on restored volumes |
| AWS Partner | AWS Marketplace partner solutions | Content-level ransomware scanning inside backup contents without requiring a full restore first |
| Workload-specific | Integrity and consistency checks | Database consistency, application invariants, and configuration diffs against known-good baselines |
| Cross-cutting | Log and audit review | Identify unexpected identity or configuration changes across the backup window using AWS CloudTrail and workload logs |
Both AWS-native validation and workload-specific validation should pass before a recovery point is approved. Validation happens in the IRE so that if any check detects a problem, the affected restore is contained inside the IRE and doesn’t reach production. AWS backup mechanisms operate independently per service, so recovery points for different services might not be precisely time-synchronized. Aligning backup schedules as tightly as possible and including cross-service consistency checks in the validation pipeline reduces this gap.
For most operational recoveries, the most recent backup is the right one. For cyber events and for data corruption more generally, the most recent working copy is often a better target. If an adversary was present in the environment before detection, backups taken during that window might carry the same issues.
The following diagram illustrates how recovery point candidates are evaluated against the compromise boundary to identify the most recent backup that’s safe to use.
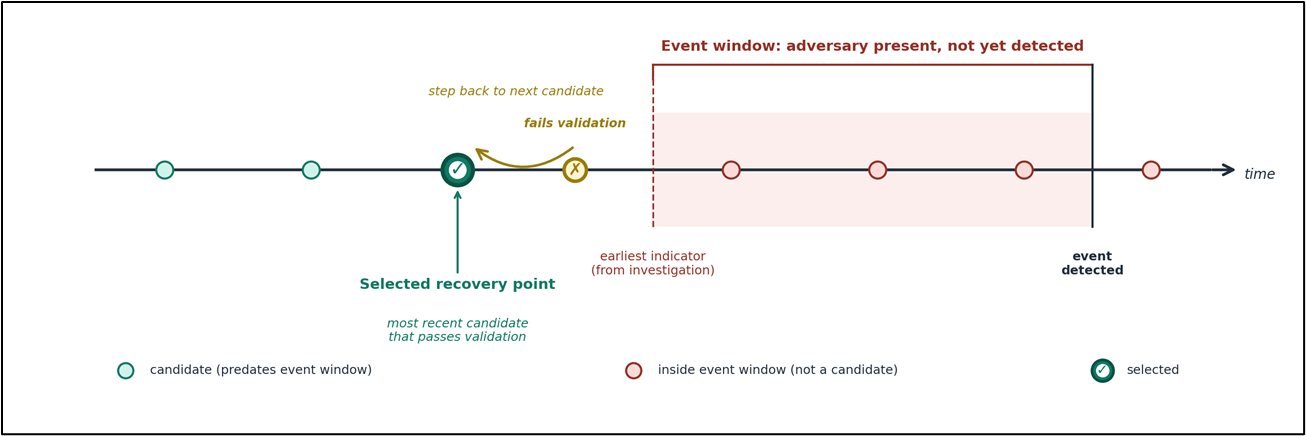
Figure 2. Candidates are evaluated in reverse chronological order starting from the most recent backup that predates the event boundary, with each passing through the validation pipeline before approval.
Backup retention should include recovery points that predate realistic detection windows in your organization. Detection timing varies widely by organization and by threat type, so this is a number to set based on your own investigation capabilities and to revisit as those mature.
Recovery has five stages. Three of them run at the same time because the slowest path through recovery is what determines how long the business is down. Investigation and validation run in parallel with infrastructure rebuild so the new environment is being built while the recovery point is being chosen. We wait to restore data because restoring untrusted data into a new environment defeats the purpose of the validation. The following diagram shows which stages run in parallel and where the approval gate separates validation from data restore.
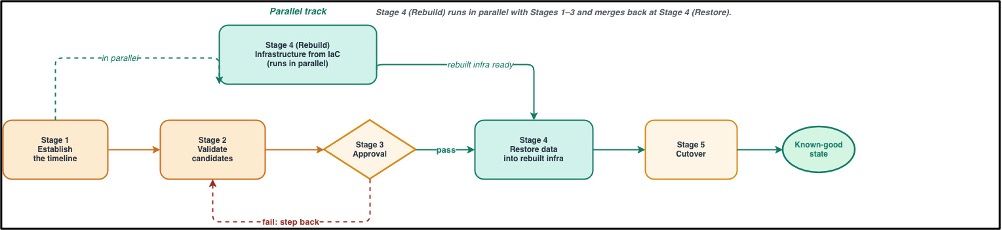
Figure 3. Stages 1, 2, and 4 (investigation, validation, and infrastructure rebuild) run in parallel. Stage 3 (approval) is the gate before validated data is restored into the rebuilt environment.
Cyber recovery requires sorting what gets rebuilt from code, restored from backup, and generated fresh:
Infrastructure is code. Data is backup. Credentials are new.
| Category | Examples | Why |
| Rebuild from code | IAM policies and roles, Security Groups, Amazon EC2, Amazon VPC, AWS Lambda, CI/CD pipeline definitions | Configurations come from reviewed, version-controlled templates rather than from a backup that may have been affected |
| Restore from backup | Amazon Aurora, Amazon EFS, Amazon EBS, Amazon FSx | Business data cannot be recreated from code and must come from validated, immutable backups |
| Rotate or re-issue | IAM access keys, database passwords, API keys, certificates, OAuth tokens, SSH keys | Any secret that may have been exposed during the event window is replaced, not carried forward from backup |
Some services sit across two categories. For example, Amazon S3 buckets and Amazon DynamoDB tables have both configuration (rebuilt from code) and data inside them (restored from backup), so recovery treats the two layers separately. Similarly, some credentials are re-issued by AWS rather than rotated by you. For example, consider service-linked roles and STS session tokens. The framework still applies, it’s just AWS that issues them fresh. Other data stores aren’t backed up at all because they are derived from sources that are backed up. Search indexes, analytics tables, caches, and materialized views are common examples. These regenerate from restored data, so they are a recovery dependency rather than a separate recovery category but they must be included in the recovery runbook and sequenced after the data they depend on has been restored. The framework assumes that your source of configuration, including IaC templates, pipelines, and source repositories, wasn’t itself the target of the attack. If it was, recovery starts further upstream with a trusted copy of source before rebuild can begin. Knowing where your known-good source of configuration lives, and how it is protected, is worth thinking through in advance.
For credential rotation, the practical prerequisite is a rotation process that already exists and is exercised. AWS Secrets Manager rotation, IAM Identity Center session revocation, AWS Certificate Manager renewal, and workload-specific rotation hooks are components most customers already have in some form. The cyber recovery capability is the ability to invoke that rotation comprehensively and verify that nothing was missed.
For services not currently supported by the logically air-gapped vault, Cross-Region Replication to a locked bucket or service-native point-in-time recovery can serve as interim options. These are recovery-oriented copies rather than tamper-proof storage and should be treated accordingly when designing around them.
The following steps provide a starting point for teams building cyber recovery capability. Each step can be implemented incrementally, but together they form the operational foundation for the recovery workflow described in this post.
Cyber resilience on AWS builds on the services and patterns customers already use for recovery, with additions that address the specific concern that the production environment, the backups, or the recovery path itself may not be trustworthy after an event. The reference approach in this post, including isolation of recovery from production, deletion protected backup storage, a validation pipeline, a concrete workflow, and the Rebuild-Restore-Rotate framework, is a starting point. How you adapt it depends on your workloads, your existing recovery posture, and your organizational boundaries.

De pronto entró un rayito de luz en la cueva de Drácula y están todos los murciélagos revoloteando desquiciados y sin saber qué pasa ni qué hacer. @TuiteroMartin
Mientras tanto, los últimos violinistas del barco…
Ver post completo: Antonino Losada reconociendo que «no es un entramado normal de facturación de unos servicios normales».


Me hace gracia cuando Pdro dice “estamos en el lado correcto de la historia”. Hoy más que nunca se demuestra que la única forma de estar en el lado correcto de la historia es no estar en ningún lado. Si te casas con unos colores, prepárate para defender a delincuentes, porque la política es eso.

Ver post completo: Los “bulos” de la fachosfera están resultando ser más reales que la “verdad” de la izquierda.

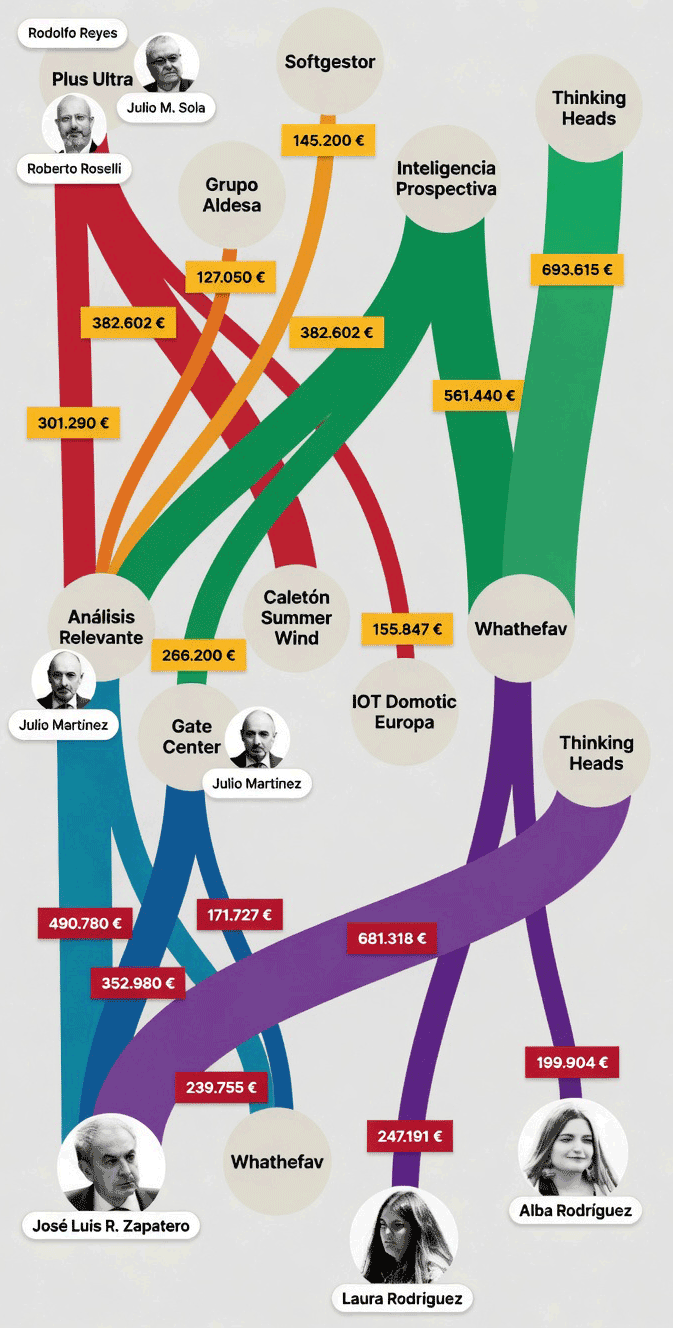
Los protagonistas, los indicios y las actuaciones, extraídos tras un análisis profundo vía LLM, todo enlazado a la parte del auto de la que se extrae -> [LINK]
En la parte II se recogen los indicios. El auto recoge que el origen es la colaboración internacional con la agencia estadounidense Homeland Security Investigations, que aporta el volcado de un abogado venezolano del entorno Plus Ultra.
Un detalle es que el auto no sólo menciona Plus Ultra: también operaciones de compra de derivados de petróleo, oro, acciones y divisas con operadores económicos de Venezuela, China y Emiratos.

Vía @naroh enviado por @Igualdad_7_2521
Y aquí la red de Zapatero explicada con dibujitos para que hasta un votante de la PSOE lo pueda entender.
Si lo preferís en vídeo, Rallo ha hecho un buen trabajo resumiendo el asunto.
Enviado por @ElFinolier.
Ver post completo: Os dejo aquí una web que explica paso por paso el auto que cita a Zapatero como investigado.
Cuando te menosprecias, tu mente cree lo que dices: que eres inadecuado, defectuosa, incompetente, que estás destinado al fracaso, etc. Tu mente no se toma un momento para reflexionar, examinar los hechos en cuestión, evaluar las premisas y examinar la evidencia para determinar si el diálogo interno es cierto o no. Cree lo que oye, y lo que oye es lo que te dices a ti mismo/a en voz baja. Lo que te dices a ti mismo/a tiene un poder de permanencia, afecta tus sentimientos más profundos sobre ti y socava la motivación para seguir adelante con tu vida.
Las palabras tienen poder, así que ¿no es hora de usar el poder de tu discurso interno para cambiar cómo te sientes contigo mismo?

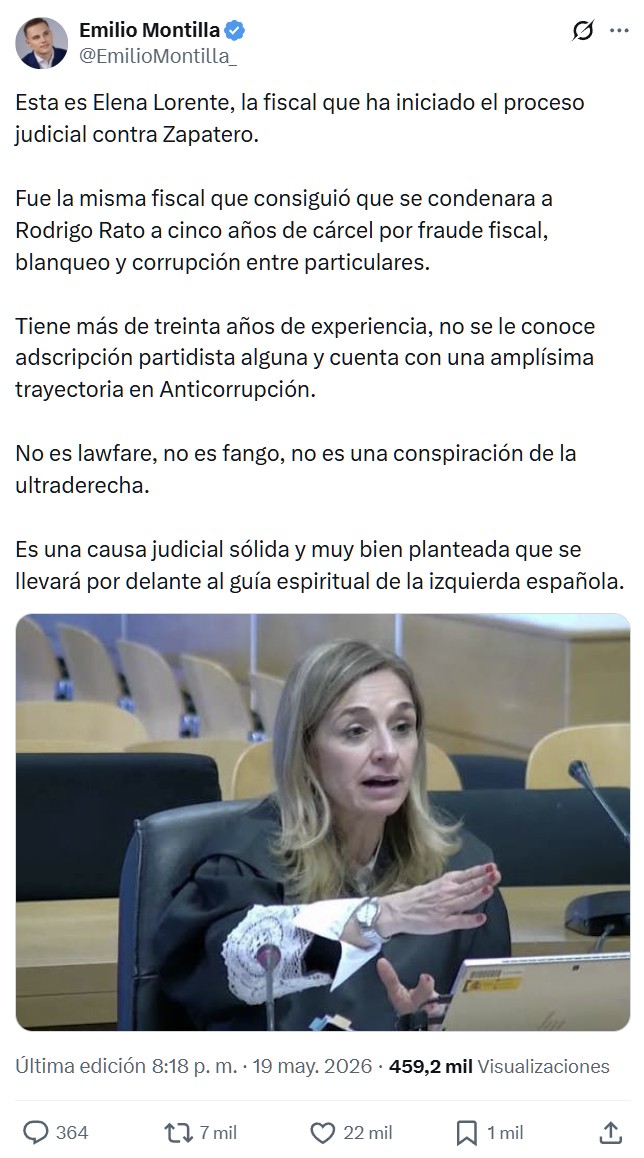
El expresidente canceló su viaje a Caracas. El avión partía a República Dominicana a las 16.10h, donde luego hacia escala hasta Caracas, pero Zapatero tuvo que cancelar ese viaje al iniciarse los registros por parte de la UDEF en su despacho situado justo enfrente de la sede socialista de Ferraz, así como en la oficina de la empresa de sus hijas. El expresidente del Gobierno, José Luis Rodríguez Zapatero, tenía previsto viajar a Venezuela el pasado martes, el mismo día que se le notificó su imputación por corrupción en la Audiencia Nacional,
etiquetas: zapatero, venezuela, imputación, corrupción
» noticia original (www.telemadrid.es)
Today, AWS announces the general availability of a new AWS Local Zone in Istanbul, Türkiye, bringing AWS infrastructure closer to end users, while enabling organizations to meet data residency requirements by storing and backing up data locally.
AWS Local Zones are AWS infrastructure deployments that extend core services, such as compute, storage, networking, and other select services, closer to metropolitan areas worldwide. AWS Local Zones help you achieve single-digit millisecond latency for end-user workloads, meet data residency requirements, support AI/ML inference workloads, and accelerate migration and modernization of legacy applications to the cloud, all while maintaining consistent AWS APIs, tools, and services as AWS Regions. AWS Local Zones are available in more than 30 metropolitan areas worldwide.
The AWS Local Zone in Istanbul supports Amazon Elastic Compute Cloud (Amazon EC2) with C7i, M7i, and R7i instances, Amazon S3 with the One Zone-Infrequent Access storage class, Amazon EBS with Local Snapshots and volume types gp3, gp2, io1, sc1, and st1, Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Virtual Private Cloud (Amazon VPC), AWS Direct Connect, and Application Load Balancer.
To get started, enable the AWS Local Zone in Istanbul (eu-central-1-ist-1a) from the Zones tab in the Amazon EC2 console settings or by using the ModifyAvailabilityZoneGroup API. For pricing information, visit the AWS Local Zones pricing page. To learn more, visit the AWS Local Zones overview page.
Las denuncias internacionales contra el Estado de Israel continúan creciendo tras la interceptación de la Global Sumud Flotilla y la Freedom Flotilla Coalition (FFC), atacadas en aguas internacionales cuando se dirigían hacia Gaza con ayuda humanitaria destinada a romper el bloqueo impuesto sobre la
La primera ministra italiana califica de 'inaceptable' el trato del ministro Ben Gvir a los manifestantes y exige disculpas públicas ...
etiquetas: ben gvir, israel, genocidas, flotilla, italia, giorgia meloni
» noticia original (www.catalunyapress.es)

GitHub es uno de los mayores repositorios en la nube. Permite alojar y gestionar código fuente por parte de desarrolladores de software. Es una especie de sistema de control de versiones y muchos usuarios podrían trabajar al mismo tiempo sobre un mismo proyecto, registrar los cambios, hacer pruebas, etc. Se puede utilizar tanto para proyectos públicos como también privados. Aunque no está pensado como tienda de aplicaciones, sí que es posible descargar de ahí instaladores y aplicaciones de código abierto.
etiquetas: github, hackeado, repositorios privados, software
» noticia original (www.redeszone.net)

<Accesible modo lectura> Andorra les abrió los brazos de par en par, pero han generado también problemas: gentrificación e inversión en el ladrillo en un país en el que la vivienda se ha convertido en un bien solo apto para los bolsillos más abultados, con desahucios a personas mayores incluidos. La gota que colmó el vaso —y acabó removiendo a la sociedad andorrana— fue la emisión (en marzo de 2024) del programa Equipo de Investigación de La Sexta sobre el rey de OnlyFans, Sergio Favda (Sergio Fuentes).
etiquetas: redes, corrupcion, andorra, dubai
» noticia original (elpais.com)

Elon Musk sigue cambiando las normas de X, red social conocida antiguamente como Twitter y una de las más populares en España. Tras reducir los pagos a los creadores de contenido que comparten posts con 'clickbait', ahora la plataforma ha limitado a las cuentas gratuitas a tan solo 50 publicaciones y 200 respuestas. Según informan desde la propia red social y foros como Reddit, X ha activado nuevos incentivos para impulsar el pago por la verificación, aunque la medida no ha sentado bien entre parte de sus usuarios más veteranos.
etiquetas: twitter, x, límites, 50 publicaciones, 200 respuestas, cuentas gratuitas
» noticia original (www.elespanol.com)




