En el episodio 105 del podcast de Entre Dev y Ops hablaremos de kubernetes e IA con Rael Garcia.
En el episodio 105 del podcast de Entre Dev y Ops hablaremos de kubernetes e IA con Rael Garcia.

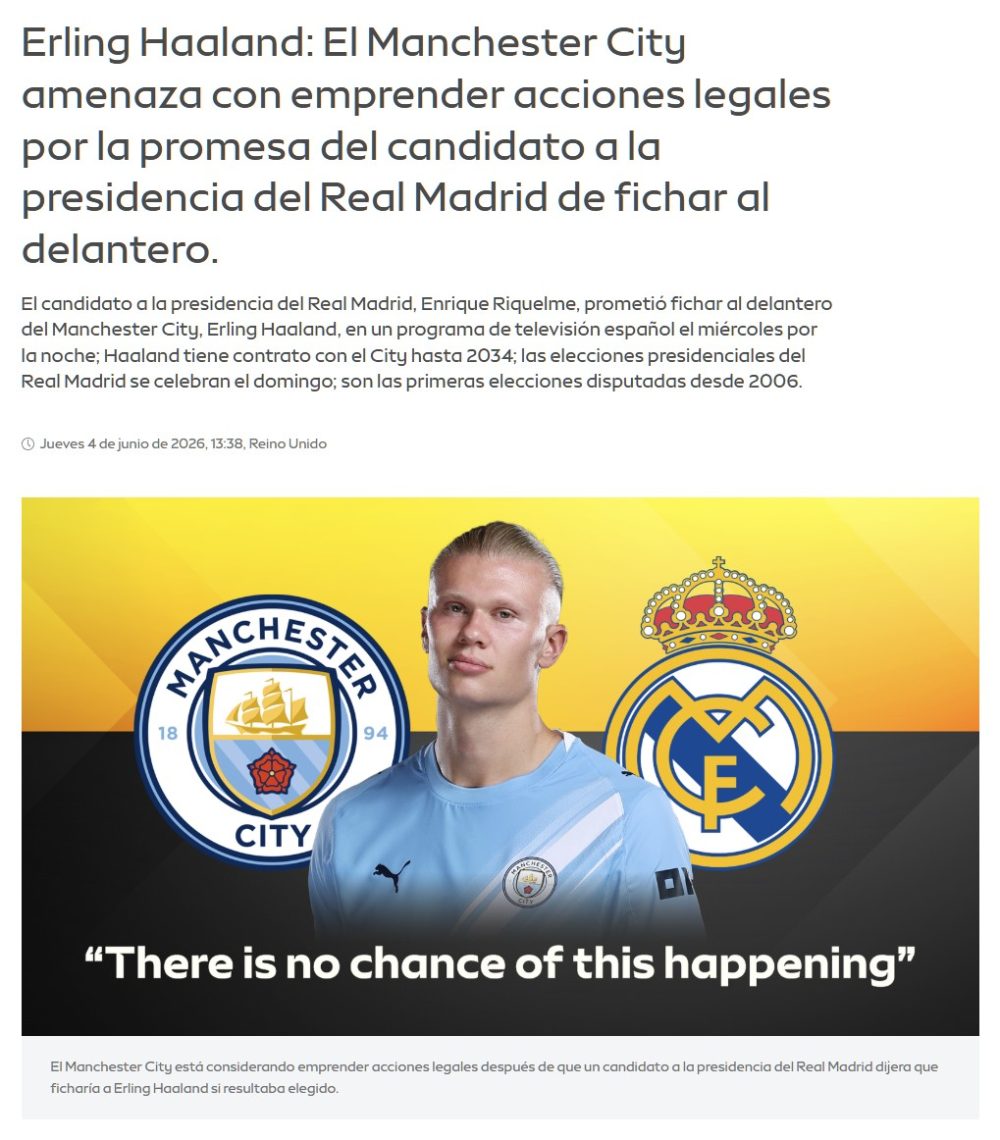
Se le ve nerviosísimo.
Por su parte el el entorno de Haaland lo desmiente.

Y el City plantea acciones legales.
Sea como sea, hay varios antecedentes de desmentidos similares (totalmente previsibles) que acabaron en agua de borrajas…

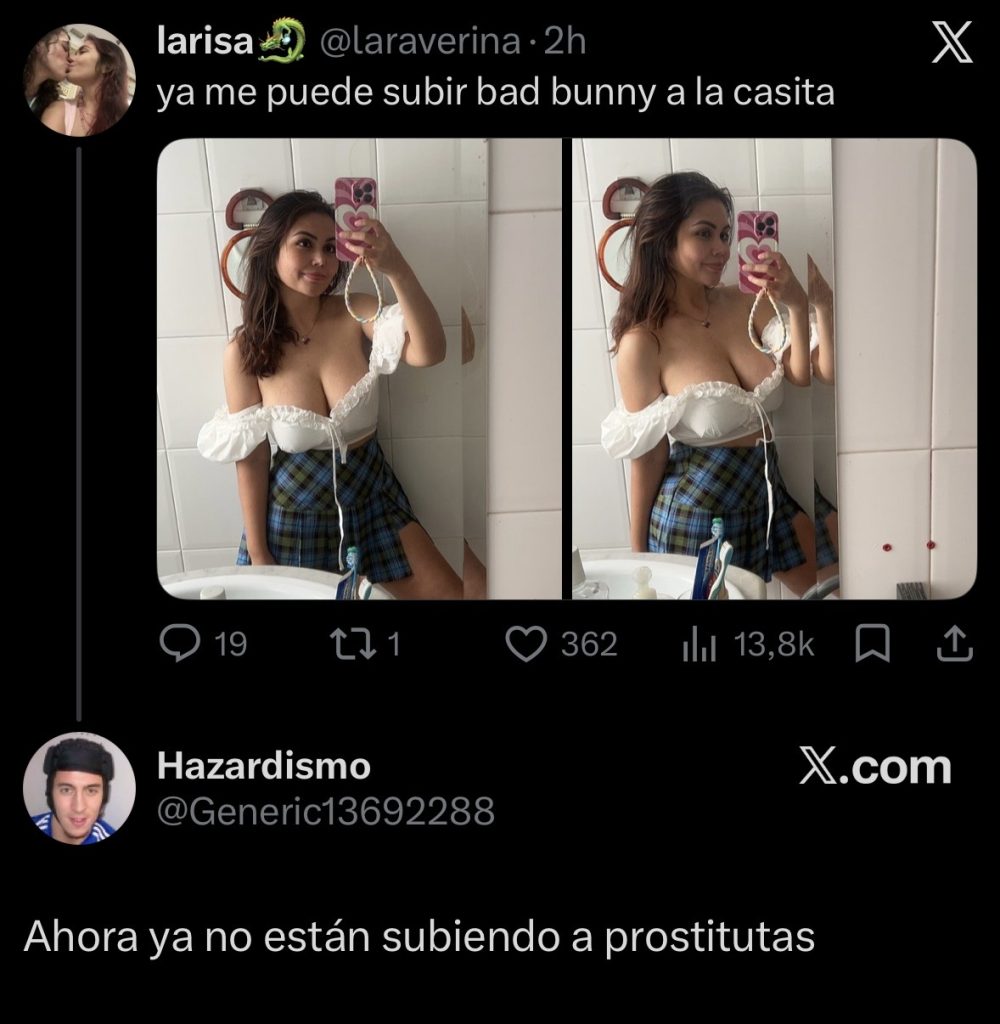
Ver post completo: Riquelme promete que si no cumple su promesa de fichar a Haaland, pagará el 100% de la cuota de los 100.000 socios del Real Madrid la próxima temporada.

By: Bo Teng, Cosmo Qiu, Siyuan Zhou, Ankur Soni, Xin Huang, Willis Harvey
In our previous post, we explored Airbnb’s dynamic configuration system, Sitar, with a focus on service architecture and configuration change safety. Now for the harder question: once a config change is committed, which happens several times each minute, how does it actually reach the thousands of Airbnb’s service instances reliably, quickly, and without redeploying the services?
This post describes sitar agent: a lightweight Kubernetes sidecar that runs alongside every subscribed service pod, continuously synchronizing the latest configurations from the service backend and making them available on the local filesystem for reads. In this post, we will first go through the configuration delivery life cycle, and then discuss some key design choices for the sitar-agent sidecar.
The diagram below illustrates the end-to-end journey of a configuration change, from the developer-facing layer to the production service fleet.
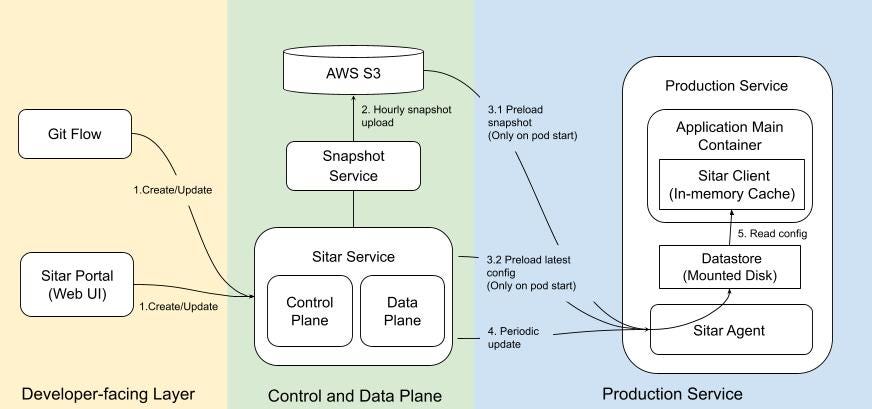
Step 1 — Config creation/update
Developers create or update configuration values through either Git flow or the web UI. These changes are committed to the Sitar Service, where they are stored with full versioning, change logs, and ACL enforcement.
Step 2 — Hourly snapshot upload
The Snapshot Service periodically packages the full state of all config groups and uploads compressed snapshots to AWS S3.
Step 3.1 — Preload snapshot from S3 (on pod startup)
When a production service pod starts, the sitar-agent sidecar runs first. It downloads the latest snapshot for each subscribed tenant’s configs from S3 to the mounted disk (shared between sitar-agent and the main container). This allows the agent to bootstrap from a known-good state without fetching every config from the Sitar Service from scratch on every restart. Preloading the snapshots from S3 enables faster restarts, makes the service resilient to transient Sitar Service unavailability, and avoids load spikes during deployments.
Step 3.2 — Preload latest config from Sitar Service (on pod startup)
After loading the S3 snapshot, the agent performs an initial sync with the Sitar Service to catch up on any changes published since the last snapshot. Once this step succeeds, the agent signals readiness, unblocking the application main container from starting.
Step 4 — Periodic update
After startup, the agent enters a continuous polling loop (order of seconds with jitter). On each cycle, the sitar agent queries the Sitar Service for changes across all subscribed groups.
Step 5 — Read config
The application main container reads configurations from the mounted disk through the Sitar client library, which maintains an in-memory cache. The client detects file changes and refreshes its cache transparently.
With the delivery lifecycle in mind, the following sections walk through the major architectural choices that shaped the sidecar’s design.
In 2024, the sitar-agent underwent a full rewrite from Ruby to Java, Airbnb’s mainstream JVM language, giving the team an opportunity to modernize the architecture alongside the language migration. The snapshot-based S3 preload introduced in the previous section is one outcome of this effort: it dramatically reduces cold start time for the pod and decouples startup reliability from Sitar Service availability. The rewrite also led to several other deliberate design decisions around reliability, performance, and operational safety. The sections below walk through each of these choices.
Before diving into specific design choices, it helps to understand the constraints that shaped every decision. At Airbnb, dynamic configuration delivery isn’t just a convenience: it controls critical features across thousands of services. That means configs must always be available, even when the Sitar Service itself is down; a slightly stale value is tolerable, but an unreadable config is not. At the same time, when an engineer pushes a change, it needs to reach every subscribed service within tens of seconds, not minutes. Making that work at scale is non-trivial: with tens of thousands of pods fetching updates simultaneously, the system has to absorb that load without degrading. And since Airbnb’s service fleet spans Java, Python, Go, Typescript, and Ruby, the solution needs to serve all of them, ideally minimizing the effort of maintaining separate per-language implementations.
The above requirements for reliability, performance, scalability, and multi-language support aren’t independent. As you’ll see, most of our design decisions, described below, come back to balancing one against another.
The question of whether sitar-agent should run as a sidecar container or a process in the main container surfaced as a key architectural decision during the Java rewrite. We evaluated the pros and cons of each option as follows:
Pros of moving to the main container:
Cons of moving to the main container:
Decision:
Despite the cost savings and reduced operational surface which would result from moving the sitar-agent logic to the main container, the projected savings were insufficient to justify the tradeoffs in reliability and operational overhead, and the development overhead of supporting the sidecar logic in multiple languages. We therefore decided to maintain the sitar-agent as an isolated sidecar container.
Sitar-agent fetches configuration updates by polling the Sitar service every 10 seconds. This is a pull model: the agent drives the update cycle by periodically asking the server for changes. This pull-based architecture, while being simple and easy to maintain, generates unnecessary load on the server when there is no update needed.
A push-based architecture change can greatly reduce the server-side load and change propagation time, at the expense of a more complicated architecture. In order to keep the current simple architecture while reducing the service-side load, the sitar system implements the following optimizations:
Given the above optimizations, the sitar-service can scale and perform quite well in handling the pull request from all service pods at Airbnb, and we can preserve the simple, stateless server-with-pull architecture.
Decision:
For sitar’s use case, polling latency on the order of seconds is acceptable; dynamic config is not a real-time signaling mechanism, and most config changes are manual, making a few seconds of propagation delay inconsequential. The pull model’s stateless simplicity is a strong operational advantage at Airbnb’s scale. The team elected to keep the pull model and invest instead in reducing per-poll cost.
Sitar-agent maintains a local on-disk key-value store that the main container reads from. The legacy datastore is a Sparkey-backed internal implementation, with a thin layer around the Sparkey datastore for concurrent coordination. As the usage of Sitar continues to grow and evolve, the mismatch of the Sparkey-backed datastore and sitar’s needs have become evident:
The team evaluated and benchmarked two candidates to replace the legacy Sparkey-based datastore: SQLite and RocksDB. A matrix of experiments were run across varying dataset sizes, read QPS, and memory allocations, fixing two of the three dimensions and varying the third in each run. We also researched community support, open source activity, supported languages, and adoption breadth of both. The following summarizes our findings:
SQLite:
Pros:
Cons:
RocksDB:
Pros:
Cons:
Decision:
In our tests, both RocksDB and SQLite significantly outperform Sparkey-backed datastores for our workload across all three test dimensions: data size, memory allocation, and read QPS. While RocksDB delivers better raw performance, sitar-agent’s workload operates comfortably within SQLite’s envelope. SQLite’s first-class multi-language library support, native WAL-based concurrent access model, and simpler operational footprint made it the better overall fit for a team supporting multiple language runtimes. The team selected SQLite as the replacement for the Sparkey-backed datastore.
Safe migration from Sparkey to SQLite
Operational safety was a top priority. Beyond extensive testing, we also we relied on two mechanisms to keep the rollout safe:
Sitar-agent sits at the core of Airbnb’s dynamic configuration delivery system. This post walked through how it works and the key tradeoffs we navigated during the Java rewrite: between cost and isolation, simplicity and push-based efficiency, and raw performance and operational practicality. Every decision came back to the same constraints: configs must always be available, changes must propagate quickly across a fleet of tens of thousands of pods, and the solution must work across Airbnb’s polyglot service stack without compounding the maintenance burden.
If this type of work interests you, check out some of our related positions!
Our progress with Sitar would not have been possible without the support and contributions of many people. We’d like to thank Craig Sosin, Nikolaj Nielsen, Daniel Fagnan, Alex Edwards, Nick Morgan, Carolina Calderon, Hanfei Lin, Yunong Liu, Lucas Rosa Galego, Yann Ramin, Denis Sheahan, Richa Khandelwal, Swetha Vaidy, Adam Kocoloski, Adam Miskiewicz, and all the other engineers and teams at Airbnb who joined design reviews and offered valuable feedback, as this work would not have been possible without them.
All product names, logos, and brands are property of their respective owners. All company, product, and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Sitar-agent: Building a reliable dynamic configuration sidecar at scale was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
It’s four answers to four questions. Here we go…
1. My employee doesn’t know how long their work takes
I have managed people for a handful of years, so not brand new but still green. I have recently have been stymied by one of my direct reports in general, particularly a series of questions about how to navigate their work. It is as if they are born anew on a regular basis. A recurring issue is that they don’t know how long various projects or project components will take. The work just … takes as long as it takes.
I understand no one can draw up a precisely accurate timeline, but part of work is figuring out how to get work done in a timely manner or on deadline. Our projects here are all variations rather than exact repetition, but the steps repeat. I simply do not know how to manage someone with this issue. It seems similar to the inability to recognize faces, or a lack of spatial awareness. Is this fixable? So far I have encouraged attending time management workshops and building in swing time to schedules. What is my role in helping them set and meet accurate deadlines?
There are other serious issues with their work too (unclear communicator, unable to work independently, don’t meet annual goals, and don’t complete day to day responsibilities). I am working on being very clear about what’s unacceptable but because of our employer’s policies, it will be some time before I can move them toward a PIP or firing, and meanwhile I want to make sure that I am providing an appropriate amount of support.
Well … if it were just an inability to estimate how long their work would take, that could be coachable. But combined with all the other issues you mentioned, this person just isn’t doing their job, and this is only one small piece of that — to the point that I doubt it’s a good investment of your time to do the sort of intensive coaching that I’d suggest if they were otherwise a decent employee. Instead, it sounds more likely that you’re going to need to let this person go, after following whatever policies your organization has in that regard.
If you wanted to try anyway, you could sit with them and walk through how you’d estimate the work involved, explaining your process out loud, and then ask prompting questions to help them go through that process on their own, and maybe dig into a completed project to draw out timelines for various components, and also explain that if they don’t know how long any given piece of work will take, they have no ability to plan out the interim milestones that need to be met to keep the work on track … but I’m really skeptical that it will solve whatever is going on here or that it would be a good use of your time.
2. My coworker is addicted to their phone
I have a coworker who appears to be addicted to their phone, and I’m not sure if/how to address it. When we work in the office together, we’ll be in the middle of a conversation, and (I think without them even realizing they’re doing it) they’ll pick up their phone and start scrolling Instagram, checking message apps, etc. — yes, while I’m in the middle of a sentence! We are frequently on Zoom calls where I see them begin to look down and very obviously check their phone. We’ll be in team meetings in person where they will clearly be scrolling Instagram in their lap, etc.
This person is a peer to me and we have the same supervisor. Otherwise they appear to be on top of their work. I am struggling, however, as I find it pretty rude to look at your phone for something non-work related while in a meeting while others are talking, and find it incredibly rude to start scrolling on your phone while in a 1:1 conversation with someone! Is this a “let it go” situation or perhaps a different approach whether in a 1:1 or group setting? Do I just let them continue to act like the rude, checked-out coworker they are appearing to me and let their supervisor address it if it’s a problem?
You don’t have the standing to address it when they’re doing it in group conversations that your manager is present for, but if they start looking at their phone while you’re talking one-on-one, you absolutely do! And it’s rude in either situation, but it’s far ruder when it’s just the two of you.
If they start scrolling their phone while you’re one-on-one, I’m a fan of pausing what you’re saying and asking, “Do you need a minute?” Sometimes that will be enough to jolt the person back into politer behavior, but if it keeps happening after that, you can also just stop talking and wait for them to realize that you’re waiting for their attention. Or you can just say directly, “If there’s something you need to deal with I’ll come back, but otherwise do you mind putting your phone down so we can finish up here?”
Also, for group situations, if it’s just a few of you (and not a huge meeting) and your manager isn’t around, since you’re peers you have standing to say, “Jane, do you mind not being on your phone while we’re hashing this out? It’ll be faster if we’re all paying attention.”
And if it ever happens at a meeting you’re running, feel free to ask everyone at the start to keep their phones put away.
3. Can “hurt feelings” be a performance measure?
My friend works for state government. Their boss said that if an employee says something that hurts another’s feelings, and it impacts their work, then “action will be taken.”
How realistic are hurt feelings as a performance/disciplinary measure? If you were a middle manager, how would you implement this? I have so many questions.
There’s probably more to it than that. Most likely the manager meant that your relationships with colleagues matter and if you talk to people in a way that harms those relationships, there will be repercussions to that. That’s a reasonable stance! It’s a way of saying, “Your performance is based on more than your literal work and includes how you interact with people; your colleagues need to be willing to approach you and work with you. If you manage those relationships in a way that decreases people’s willingness to do that, that’s a work problem.” (Think, for example, of a perfectly competent colleague who everyone tries to work around and not deal with because the person is a jerk.)
As for how you implement it, you make good working relationships with colleagues an explicit part of the role expectations and address it like any other performance issue when someone is falling short in that area. More here.
4. A bananas interview
Last, please enjoy this dispatch from a reader:
I’ve done a couple interviews with a company that’s based elsewhere in the country but has a satellite office where I live. It’s pretty small in manpower but does hundreds of millions in sales. I spoke with an external recruiter first and then the (fully remote) CMO last week, and the CMO conversation was really encouraging. Then he set me up yesterday to meet a same-level coworker at the office rather than on Zoom. From the get-go, it was just bananas. The highlight reel:
— I showed up at the address and it’s a condo. Not an office in a condo complex, a condo.
— The interviewer lets me in and tells me the CEO lived in the building and liked it there so much that he bought the unit below his and converted it into an office. (It was not converted, it’s a bunch of desks in the living room and bedrooms.)
— The 60-year-old CEO was on the patio in a T-shirt, sweats, and flip flops and, I come to find out later, was smoking a joint. He exclaimed that I “dressed up all nice for them!” I was wearing a business shirt, khakis, and sneakers. One of the other staff was wearing a black sleeveless undershirt.
— The interviewer offered me something to drink. I said I’d love a glass of water. CEO calls out, “Give him a beer!” The interviewer legit offers me a beer. I decline.
— The interviewer later tells me that the CEO starts drinking around 2:30 and often makes cocktails for the staff, who decline because they’re working.
— Remote work is not an option unless it’s “absolutely necessary” but they also hired a remote CMO and a remote contributor who lives in Tennessee. Not so strange per se, but it immediately clashed with what the CMO had told me about hybrid arrangements being possible.
— I’m told the CEO’s ethos is “planners stay poor, doers get rich.” Not great when he’s hiring for a strategy role!
— After the interview, we go back out to the patio to wrap up and the CEO, clearly under the influence at least a little, talks for five solid minutes about how great he and the company are and how he hires all-stars and whatever.
— The CEO said the two junior staff (one of whom is his son) often sleep in the beds at the office if they go out partying or whatever and don’t want to go all the way home. Like what? I show up at 8 am and my coworker is walking around hungover?
— Then he says, “Next steps, we’re going to circle the wagons and share some feedback, but I want to get some time on the calendar with you so I can give you the whole background on the company and my vision for the future. I’m going to the mountains tomorrow but we can probably do a Zoom meeting tomorrow or on the weekend more likely.” Uh … on my weekend? No.Obviously I emailed the CMO this morning and diplomatically withdrew from the process citing a “culture fit at this stage in my career,” but I really hope he replies and asks me to elaborate because I have a feeling he doesn’t actually know.
Thanks for the years of advice and guidance and sheer morbid curiosity!
The post employee doesn’t know how long their work takes, coworker is addicted to their phone, and more appeared first on Ask a Manager.
Author: Phin Walton

Railway has technically ran an “edge” network for over 3 years, although it didn’t really live up to the “edge” name - it ran on our 4 Railway regions across the world, nowhere near 100+ POPs you expect when thinking about edge computing.
However, starting this week, the CDN we built (which served you this very page!) is becoming available to all Railway customers at the click of a button.
This is the story of how we built a modern CDN: why we had to build it ourselves, how BGP anycast gets messy at global scale, and how we leverage WASM to ship dataplane changes without dropping a single packet.
Note from the author: The 30M RPS in the title is real and we've absorbed DDoS attacks at that rate with zero service disruption. However, day-to-day, the network serves ~1M RPS at peak traffic. Benchmarked end-to-end under ideal conditions, it tops out around 150M RPS.
You may be reading this, asking yourself why we’d go through all the effort of building out such a large system that we could just buy off the shelf from another provider. The reality is, we initially did just that and tried to integrate it with our product, but quickly realized a few things:
But the thing I actually care about is what owning the stack lets us build into the product. If you look at our support threads, network related issues made up around 20 percent of all ticket volume. CDN configuration and nameservers and the like.
During the initial scoping of what a CDN may look like if we built it ourself, we had a realization:
We’re a cloud computing platform, not just a CDN - and that unlocks some unique benefits that traditional CDNs find very hard to execute correctly;
We operate both the edge AND the origins - which means we can send traffic through the internet and backbone links directly to your workload, rather than trying to guess where the origin is located. Traditional CDNs find this very hard, and the datapoints they use to try to make this guess are very muddy - for example, even if an “origin” is 10ms away on layer 3, the origin may proxy an asset that lives 200ms away. Luckily for us, we already know exactly where your app runs - to the longitude, latitude and altitude. This give us a unique routing superpower.
We can offer performant defaults that other CDNs are too scared to offer - for example, did you know that Cloudflare doesn’t cache HTML or JSON by default, even if your website’s Cache-Control header says to do so?
I believe this is because they’re too scared of confusing the developer: the developer expects website updates to appear when they refresh, and Cloudflare doesn’t know when you make updates to your website. However, with the Railway CDN, we respect HTML cache control and automatically purge HTML cache when you deploy - best of both worlds!
Sorry, I forgot to mention - we call this new edge network and CDN Hikari, the Japanese word for “light” or “fiber optics”, also the name of the second-fastest Tokaido Shinkansen (bullet train), and that one Blue Archive train conductor.
Since I dive into internals, it’s easier if I use the internal name for the blog.
I won’t get too much into the specifics of the server configuration or datacenter & provider lease agreements - that could be an entire post itself! But, to give you the rundown, we started procuring these a few months before we started building Hikari, and now have 60 POPs (we are still waiting for the delivery of ~40% of these locations), over 180 CDN nodes and tens of terabits of network capacity. Each node is a 16 core EPYC with 256G of memory, 8TB of NVME storage and 100G networking.

Usually when building a huge project like this, you think about the implementation, system and business logic first, and deployment later. But, with over 180 nodes, handling ~1 million RPS at peak hours, we knew we had to design this differently. To put it straight, we have been scared to perform upgrades to our existing origin proxies because of the blast radius - we use Ansible and have been burned in the past by the lossy, brittle, hard to audit behaviors that Ansible exposes - it’s also a slow tool to work with when working with hundreds of servers.
When scoping the initial project work with the team in Kyoto, we aligned on the fact that the entire deployment experience had to be first class. We need to be able to quickly iterate on the product at Railway speed, without the anxiety of potentially impacting 1M RPS at once.
Server-side WASM (WASI) and wasmtime quickly came to mind for the core request path. Our thought was - if we can expose core business logic to an extremely efficient sandboxing engine like WASI, we could invoke that binary per request. One node could serve requests under many versions of that binary, so we could easily apply rolling updates fleet-wide without effecting any existing connections. More on this later.
We effectively ended up splitting up this entire project into 4 services:

edge-cp - The edge control plane which all nodes connect to; handles rollouts, node health, configuration syncing, and exposes controls used by our internal toolinghikari-keeper - The sidecar service which sits on every node, handles BGP, dataplane upgrades and reports node status to edge-cp
hikari - The core dataplane service which terminates TLS/HTTP2, invokes WASI per request, and manages cachehikari-guest - The actual WASM guest binary invoked per request, which handles business logic like “should this asset be cached”, enforces limits based on the domain’s configuration, WAF rules, and more
hikari-keeper
When we want to onboard a new node, we just click a button on our internal tooling, which gives us an authenticated curl to run on the node, which installs hikari-keeper - that says hello to our edge-cp control plane, and starts bootstrapping. The bootstrap process is effectively a bit of Rust that defines a version and a list of Steps to reconcile against.
pub enum StepState {
InSync,
NeedsChange { reason: String },
}
#[async_trait]
pub trait Step: Send + Sync {
fn name(&self) -> &str;
async fn check(&self) -> Result<StepState, StepError>;
async fn apply(&self) -> Result<(), StepError>;
}
// The list of steps we should run when the node starts up
// or receives an upgrade signal
pub fn steps(state: &State, dynamic_config: &Arc<DynamicConfigStore>) -> Vec<Box<dyn Step>> {
let mut s: Vec<Box<dyn Step>> = vec![
b(steps::DisableUnattendedUpgrades),
b(steps::InstallAptPackage { name: "bird2" }),
b(steps::InstallAptPackage { name: "parted" }),
// -- networking: forwarding + listen backlog --
b(steps::SetSysctl { key: "net.ipv4.tcp_syncookies", value: "1" }),
b(steps::SetSysctl { key: "net.ipv4.ip_forward", value: "1" }),
b(steps::InstallHikari),
// ...etc
];
}When we want to make an update to the Linux state, we just change this file, push to git, and the fleet reconverges within a 30 minute time period, gated on any errors that occur. hikari-keeper calls itself to update every minute. The entire upgrade process, and any errors are synced with our edge-cp control plane so we can see it happen live on our internal dashboards, and automatically stop the upgrade if necessary.
hikari-keeper also handles upgrades to the dataplane binary (hikari) - once it receives an upgrade signal from the control plane, it sets up a socket for the old binary to hand over file descriptors to the new binary, so that connections stay active during a (rare) upgrade to the hikari binary itself.
Once a node is up and ready, hikari-keeper constantly healthchecks the local hikari dataplane service - and as long as it’s in an expected state, keeper will install the anycast route on the loopback lo interface, which gets picked up by our local BGP daemon - BIRD, and propagated to the internet.
To be clear, most of these systems I’m describing are solid reconciliation loop state machines that are very easy to audit and understand, both for us and our agents. This means that even if a message is lost between a system or process, the reconciliation loop picks it up on the next run and aligns the system state with the expected state. (We are an orchestration platform after all).
All of our BGP configuration, including communities for traffic engineering, is dynamically configurable from our internal tooling. It all propagates when hikari-keeper reconciles with edge-cp, every 5 seconds.

Ah, there’s another fun hint in that screenshot about the reality of operating a large anycast network, too: Operating anycast at global scale is hard.
BGP was never really designed for anycast, it’s a side effect of the protocol. BGP does not understand geography or latency. It sees the internet as a graph of networks (”autonomous systems”). The “best network path” is whatever can be reached in less autonomous systems. But, a lot of these networks and autonomous systems span the entire globe, like our own network AS400940 and larger transit providers like NTT.
That distinction matters. As a CDN operator, you want user traffic to terminate at the closest CDN node to them by latency, which is usually the geographically closest node, thanks to the speed of light (modern switches can forward packets in nanoseconds).
But, an end user’s ISP may peer with a global transit network, and from the BGP perspective, that transit network is only one ASN (autonomous system) away from our CDN prefix (e.g. 69.46.46.0/24) - but we may only peer with that large transit network in only one location on the other side the globe. This means the user’s ISP takes the traffic on a world tour before it reaches our network! Not ideal.

Luckily, there is a slight knob that BGP exposes to operators called Communities. This allows you to “tag” IP announcements with behaviors such as “Do not export this route outside of Japan”. We’ve built automatic support for BGP community tagging right into Hikari, so we can optimize our network for both major and smaller ISPs in realtime. There are some outlier ISPs that make it very hard for us to engineer traffic - for example Liberty Global, a major European transit network, exposes no communities, likely because they want content networks like us to pay for transit with them.
You can see how internet networks see each other using tools called Looking Glasses. The bgp.tools looking glass lets you query a lot of internet routers at once, check it out!
As hinted earlier in the post, we chose to take a bet on WASI and wasmtime - an extremely fast server runtime for WASM bytecode, which (importantly) is extremely cheap to invoke - so cheap that we do it on every request. It’s a battle tested technology, used by products like Fastly Compute in production.
If you're not familiar with WASM/WASI, to summarize briefly: WASM is a portable bytecode format - you can compile a program in almost any language to it, and run it inside another process. It's sandboxed by default; the guest can't see the host's memory, files, or network, only a set of imports and functions you explicitly hand it.
WASI is the standardized version of those imports for server-side use. The property we cared about most: a single host process can have many versions of a guest loaded at the same time, and pick which one to call per-request. That maps cleanly to what we wanted - hikari (the long-lived dataplane) terminates TLS and holds connections open forever; hikari-guest (the per-request brain) is a versioned blob we can swap underneath it without disturbing a single byte of in-flight traffic.
We can make updates to the hikari-guest Rust binary and have it live on the edge in seconds - which gives us the ability to write WAF rules, DDoS mitigations and request/response behavior dynamically - we expose well defined callbacks which hand actual IO work back up to the host.
To be honest, we'll probably write more in-depth blog posts about how we operate WASI at scale - but we were surprised by how performant wasmtime was straight out of the box. To cold instantiate a WASM guest VM, it's about ~10μs - cheap, but at our request rate we'd rather not pay it on the hot path, so we pool warm guest instances and hand them out per-request.
The instinct here is to reach for a shared concurrent pool - one big pile of warm guests sitting behind a lock-free queue (crossbeam::ArrayQueue, flume, whatever), and every worker dips into it. That works, but it means an atomic op on every acquire and release, and worse, the pool's cache lines bounce between CPU cores as workers fight over them. At a few hundred thousand requests per second per node, that adds up.
We sidestep all of it with a thread-per-core model: Each Hikari worker is a single-threaded tokio runtime pinned to one CPU core, with no work-stealing between them. A task spawned on that worker stays on that core for its entire lifetime - including across the .await inside the guest call. Which means each worker can keep its pool entirely thread-local: a HashMap<VersionId, VecDeque<GuestInstance>> sitting in a thread_local!, one queue per live guest version (we may be running several at once mid-rollout). Acquire and release are a pop_front and a push_back on a deque only one thread ever sees.

The 10μs cold-instantiate cost only shows up when a worker's local queue for the version it's about to call happens to be empty. The kernel pins each connection to one worker (SO_REUSEPORT + NIC RSS), each version's queue is capped at a PER_WORKER_POOL_CAP, and the pool warms up in the first few seconds after a deploy - so in steady state, it's pop/push from then on.

You may be asking then, after all this work… how can I use it?
It’s been live for everyone since 7 days ago from writing this. It now serves 100% of all Railway traffic. This plus the network flow visualizations means I think Railway has one of the most developer friendly networking experiences out there.
That said, ~40% of the PoPs are still in transit, so the map that you saw will expand over the next few weeks. While we add more sites, our tiered caching and BGP traffic engineering get tuned basically every day, and the big one on the roadmap is domains and the CDN becoming a single thing in the product.
We're also nowhere near done optimizing.
If you're seeing latency that feels off, or there's a city or region where you wish we had a PoP closer to your users, tell us. New PoP suggestions, weird edge cases, optimizations we haven't thought of yet, we're all ears.
The CDN is live now. Read the docs here [secret debugging endpoint]
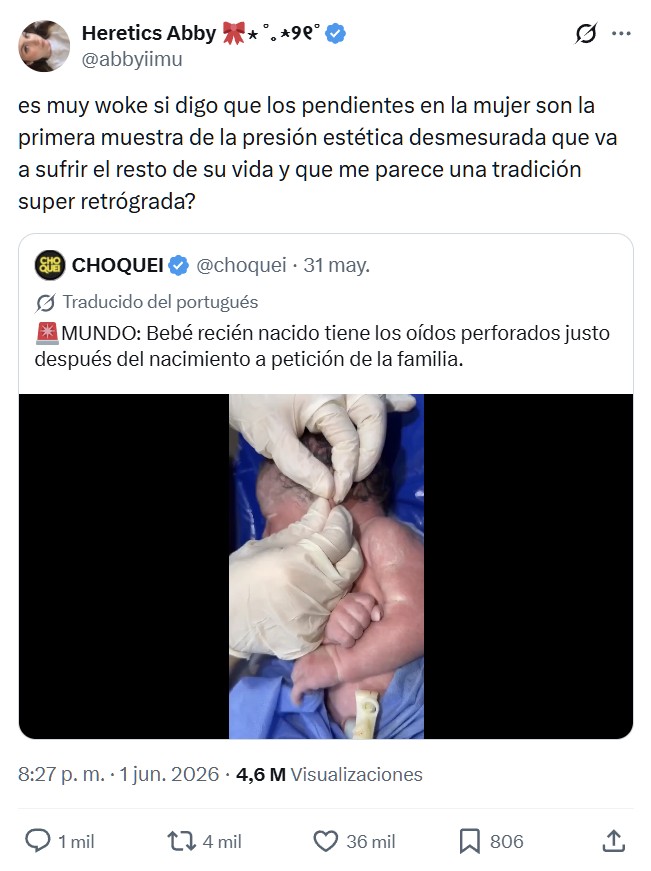
El dictador Francisco Franco aún tiene un lugar destacado en los archivos del Vaticano. A las puertas de la visita del Papa León XIV a España, la Santa Sede mantiene al jefe del régimen como uno de los premiados con el Gran Collar de la Suprema Orden de Cristo, una distinción otorgada por Pío XII en 1953 con el objetivo de reconocer su papel en la "cruzada" española.
El último boletín de la Fundación Nacional Francisco Franco (FNFF) está repleto de fotos sobre la vida y obra del dictador. Entre esas imágenes en blanco y negro hay una que alude a las complicidades entre el régimen y el Vaticano, con premio incluido.
Que Jorge Riechmann tenga que sentarse en el banquillo por participar en protestas climáticas pacíficas resulta profundamente revelador del tiempo que vivimos. No porque sea un caso aislado, sino precisamente porque no lo es. El filósofo, poeta y ecologista que lleva décadas advirtiendo con rigor, serenidad y lucidez sobre el colapso ecosocial se enfrenta ahora a procesos penales por acciones de desobediencia civil no violenta. En uno de ellos, junto con Marina Martínez y Francisco del Pozo, ya celebrado el 26 de mayo de 2026 y pendiente de sentencia, la Fiscalía ha mantenido su petición de diez meses de prisión por el bloqueo del puente de la calle Raimundo Fernández Villaverde, sobre la Castellana, en Madrid, durante una protesta climática de octubre de 2019 dentro de una movilización de 2020 Rebelión por el Clima y Extinction Rebellion en la que participaron unas 300 personas para reclamar políticas urgentes frente a la emergencia climática. En otro procedimiento, Riechmann afronta una petición de 21 meses de prisión por la acción de Rebelión Científica ante el Congreso en 2022, en la que se vertió un líquido biodegradable para simbolizar la sangre derramada por la inacción climática.
El concepto de “Ciudad de 15 Minutos” se ha consolidado como un modelo popular de planificación urbana centrado en la creación de comunidades donde los residentes puedan acceder a los servicios básicos diarios a poca distancia a pie, en bicicleta o en transporte público. Para analizar su funcionamiento práctico, investigadores de la Universidad Atlántica de Florida analizaron cerca de 200 barrios con estaciones de transporte público en las áreas metropolitanas de Portland y Washington. Mediante datos de movilidad a gran escala de StreetLight Data y técnicas de aprendizaje automático, el equipo evaluó cómo factores como la densidad de empleos, el diseño de las calles, los ingresos y el acceso al transporte público influyen en la “captura de viajes internos”, es decir, el porcentaje de viajes que se realizan dentro del barrio.
Una de las realidades más difíciles de las relaciones adultas es reconocer que no todos los que nos quieren son capaces de celebrar nuestro crecimiento. A menudo damos por sentado que quienes nos son más cercanos, como familiares, amigos de toda la vida o pareja, serán los primeros en reconocer nuestros esfuerzos y logros. Sin embargo, muchas personas experimentan lo contrario. Un ascenso se recibe con indiferencia, un título universitario con críticas y el crecimiento personal con incomodidad en lugar de aliento. Para algunas personas, la crítica más dolorosa no proviene de desconocidos, sino de aquellas personas cuya aprobación alguna vez fue la más importante.

Finolis, de aquí saldrá la base para otra temporada más de “tramar en tiempos revueltos”. @SujetoAtónico
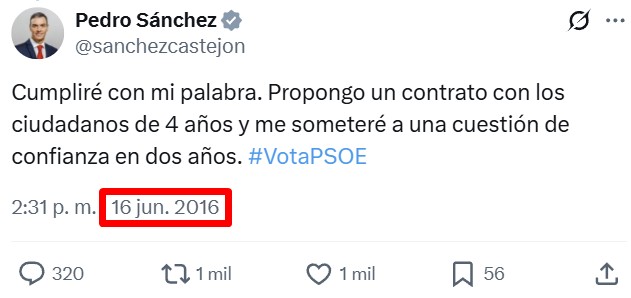
Los agentes de la UCO que llegaron a la sede del PSOE el pasado 27 de mayo tenían el mandato del juez de requerir, de “manera voluntaria”, pero con la amenaza de acometer el registro por la fuerza, toda la información y posibles pruebas sobre las cloacas del partido, esa ‘unidad’ que se reunió en Ferraz al mismo tiempo que el presidente del Gobierno se tomaba cinco días de reflexión tras la imputación de su mujer y que, desde entonces, en abril de 2024, comenzó una campaña de ocupación de las instituciones, desde la Fiscalía General del Estado a la Dirección de la Guardia Civil, para “ayudar al presidente” -según certifica el propio sumario conocido este miércoles- y atacar a jueces, fiscales, mandos de la UCO y periodistas molestos “para el entorno del presidente y de algunos miembros del Gobierno”. @elconfidencial
Extra:
Hay que tener mucha capacidad mental para conocer de cada Lore y su universo expandido. @chofas



La fobia social no se limita solo a lo social. No es solo evitar hablar en público o sentir vergüenza en ciertas situaciones. Se cuela en lo cotidiano, en lo profundo, y cambia la manera en que construyo mi día a día. Me ha ido quitando muchas cosas, pero lo que más me duele es que ha ido reduciendo mi calidad de vida, a veces sin que me diera cuenta.

También frena mi crecimiento y desarrollo, porque la inseguridad me hace rechazar retos que podrían ayudarme a avanzar. Me cuesta crear y mantener relaciones significativas, no solo evito lo social, sino que se hace difícil conectar de verdad con otros. Los hobbies y actividades que antes disfrutaba quedan en segundo plano, porque el miedo a ser juzgada o sentirme incómoda es demasiado fuerte.
Mi confianza en mí misma se va erosionando poco a poco, y la autoestima se resiente. Incluso las oportunidades laborales o educativas se ven limitadas porque la idea de interactuar me paraliza. Y todo esto afecta no solo mi salud mental, sino también la física: la ansiedad constante pasa factura, el cuerpo se cansa, la mente se agota.
Con el tiempo, esta situación puede llevar a un aislamiento profundo, a una soledad que pesa más de lo que imaginaba. Me he encontrado renunciando a metas importantes, posponiendo sueños, dejando que la vida pase mientras intento mantener el equilibrio. Y la verdad, sin ayuda, la fobia social puede minar poco a poco mi felicidad y bienestar, generando un desgaste emocional que pesa cada día más.
Lo más duro es que, cuando todo esto dura tanto, empieza a parecer normal. Me he acostumbrado a vivir en alerta constante y casi olvido lo que es la calma. Me he adaptado tanto al malestar que casi no lo reconozco como tal. Pero está ahí, siempre, como una capa invisible que envuelve todo lo que hago, lo que siento, y también lo que dejo de vivir.
No es una vida en pausa. Es una vida con el freno de mano echado. Y cada día que pasa, ese peso se hace un poco más pesado.
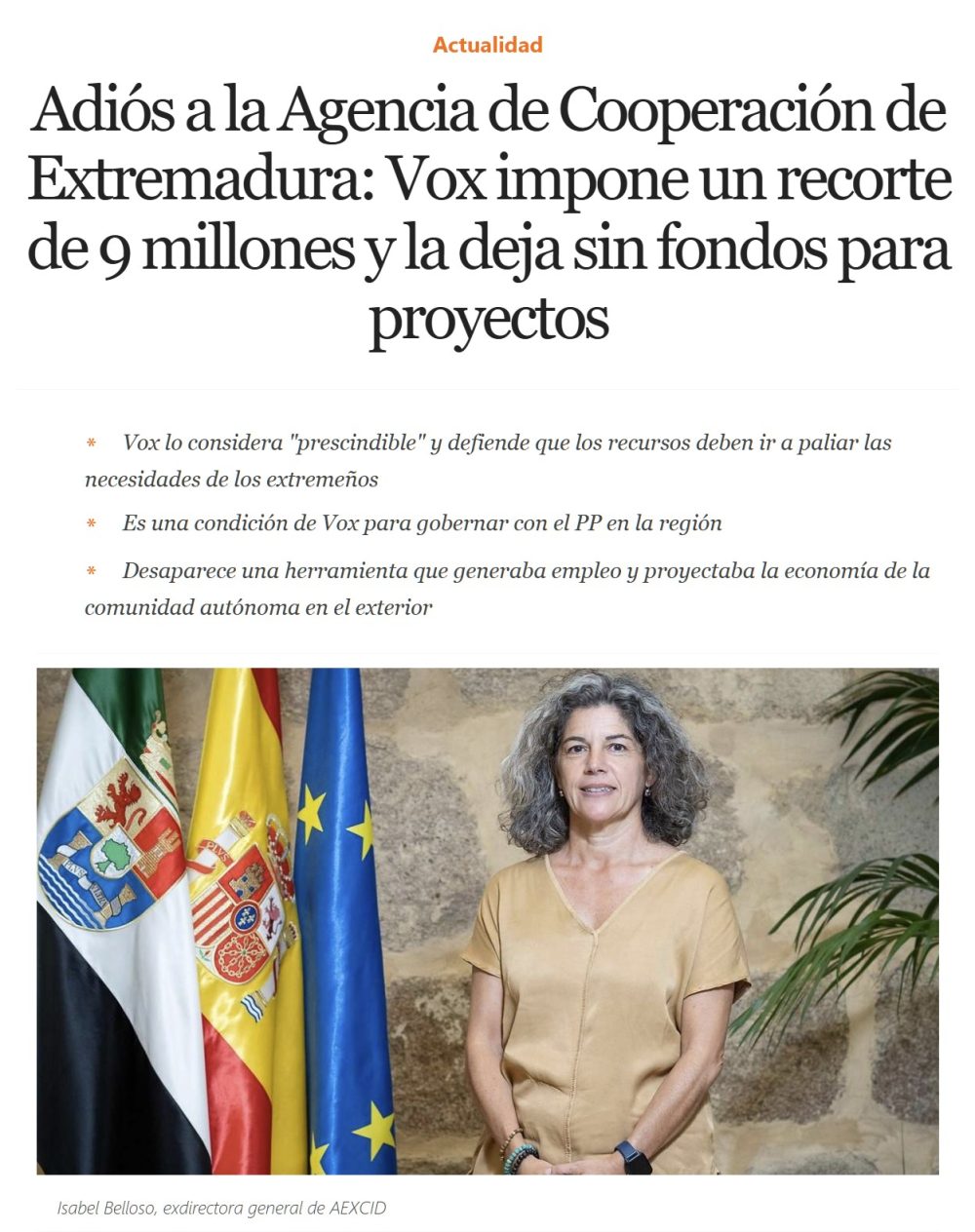
Vox a ha enterrado la Agencia Extremeña de Cooperación Internacional tras la reducción de su presupuesto de 11 a 2 millones de euros, la directora general, Isabel Belloso, ha presentado su dimisión y la Junta de Extremadura, a través de la Consejería de Desregulación, Servicios Sociales y Familia, ha decidido poner fin a esta Dirección General y la AEXCID quedaría integrada en una estructura más reducida dentro de la Junta.
La reducción del presupuesto de la AEXCID en los próximos presupuestos extremeños ha sido determinante para el futuro de la Cooperación Internacional, el Ejecutivo ha reducido de 11 a 2 millones de euros, una de las condiciones de Vox para formar gobierno en Extremadura e investir a la popular María Guardiola. @eleconomista


Pues como Cruz Roja… salarios 
Ver post completo: Vox ha enterrado la Agencia Extremeña de Cooperación Internacional tras la reducción de su presupuesto de 11 a 2 millones de euros
“No estamos en un momento para titubear. ¿Qué voy a ser, feminista de lunes a miércoles, y luego los jueves, pues ya veré? ¿O estoy en contra del genocidio en Gaza solo los lunes?” El presentador ha analizado su primer mes en La Sexta con ‘Cara al show’, su nuevo ‘late night’. (Visible en modo lectura).
etiquetas: marc giró, equidistancias, izquierdas, antifascista
» noticia original (elpais.com)