Rubén Gallego es senador por Arizona desde 2024 y miembro del Comité de Servicios Armados de la Cámara Alta. Fue veterano de la guerra de Irak, donde estuvo desplegado con su unidad de marines en 2005. Gallego nació en Chicago hace 46 años. Es hijo de madre colombiana y padre mexicano.
etiquetas: rubén gallego, eeuu, trump, irán, españa
El comisario José Manuel García Catalán ha sido citado el próximo 25 de junio para declarar como investigado en la causa que instruye el juez Santiago Pedraz por las maniobras policiales para atacar a Podemos durante el Gobierno de Mariano Rajoy. García Catalán, jubilado recientemente, era el jefe de la Unidad contra la Delincuencia Económica y Fiscal (UDEF) de la Policía cuando viajó a Nueva York en abril de 2016 para intentar obtener un testimonio contra los fundadores de Podemos por parte de un exministro de Hugo Chávez.
etiquetas: juez, pedraz, imputacion, jefe, udef, guerra sucia, podemos
El pensador madrileño disecciona la ceguera del flechazo para revelar cómo esta obsesión involuntaria devora nuestra capacidad crítica, diferenciándola radicalmente del compromiso libre y consciente que define al amor verdadero.
etiquetas: ortega y gasset, filosofía, amor, enamoramiento
Hace veinte años, una redada policial en un centro de datos de Estocolmo confiscó los servidores de The Pirate Bay. La acción, impulsada por presiones del gobierno de EE. UU. y su industria del entretenimiento, resultó contraproducente: Una copia de seguridad, realizada por un cofundador, permitió la rápida resurrección del sitio, catapultándolo a la fama y fortaleciendo su resiliencia
etiquetas: pirate bay, aniversario, resiliencia, torrent, redada
Las contrataciones se produjeron con Eulen, la empresa donde es directiva la hermana de Feijóo, y Universal Support, la firma de telemárketing donde es director comercial su cuñado. La Xunta asegura que se trata de facturas y prórrogas atribuibles a acuerdos previos y de pagos agrupados que se registraron "por error" como contrataciones menores.
etiquetas: feijóo, pp, corrupción, xunta galicia, contratación pública
El cálculo es complejo porque depende de varios factores. Los propios sistemas fiscales difieren, algunos países tienen un enfoque sencillo mientras que otros son más complejos. Euronews Business ha estimado el salario neto correspondiente a un sueldo bruto de 100.000€ a partir del informe Tax Wedge 2026 de la OCDE, de los archivos por país de la OCDE, de los resúmenes fiscales mundiales de PwC y de fuentes nacionales.
Preparar las maletas para recorrer el Viejo Continente suele evocar una reconfortante sensación de seguridad. Vivimos con la certeza de que, al movernos dentro de las fronteras de la Unión Europea, estamos plenamente respaldados. En el centro de esta tranquilidad se encuentra un pequeño plástico azul que casi todos llevamos en la cartera: la Tarjeta ... Leer más
El formato televisivo que marcaba la conversación pública y atraía a las grandes estrellas vive sus momentos más difíciles, como demuestra la despedida de Stephen Colbert de la parrilla Leer
Tras más de un año de trabajo, los abogados del ingeniero de caminos ultiman una fórmula que permitiría incorporar a un socio financiero sin alterar la naturaleza jurídica de club deportivo Leer
Without the second Trump Administration, we would surely not have discovered, and most importantly, acted upon, the fraud being committed around the country, most notably in blue states like Minnesota and California. So much has been discovered so rapidly, President Trump appointed Vice President Vance to head an anti-fraud task force, and the DOJ hired additional prosecutors to handle the dramatically increasing number of cases. Federal officials are suggesting the sheer amount of fraud, discovered and yet to be discovered, is so staggering clawing back that money could balance the federal budget.
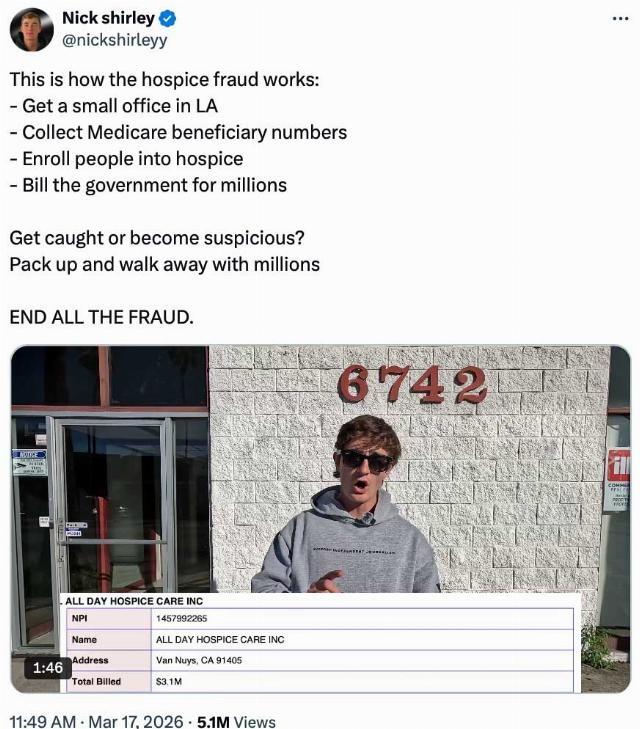
Instrumental in exposing sufficient fraud so it could no longer be ignored by local or state officials is independent journalist Nick Shirley, who exposed the infamous “Quality Learing Center” day care fraud in Minneapolis, as well as many less well-known fraudulent day cares. So effective was Shirley, and so quickly did his work anger local fraudsters and state officials, Shirley received so many death threats he apparently decided to give California a try. This was the immediate result:
Graphic: X Post
Independent journalist Nick Shirley has released a devastating 40-minute investigative video that exposes what appears to be massive waste and potential fraud in California’s hospice, Medi-Cal, and daycare programs. His report, now viewed more than 7.7 million times on X, uncovers over $170 million in questionable billings tied to ghost hospice and daycare operations that show virtually no signs of actually caring for patients or children.
Shirley found that focusing mostly on Victory Blvd. in Van Nuys:
Graphic: X Post
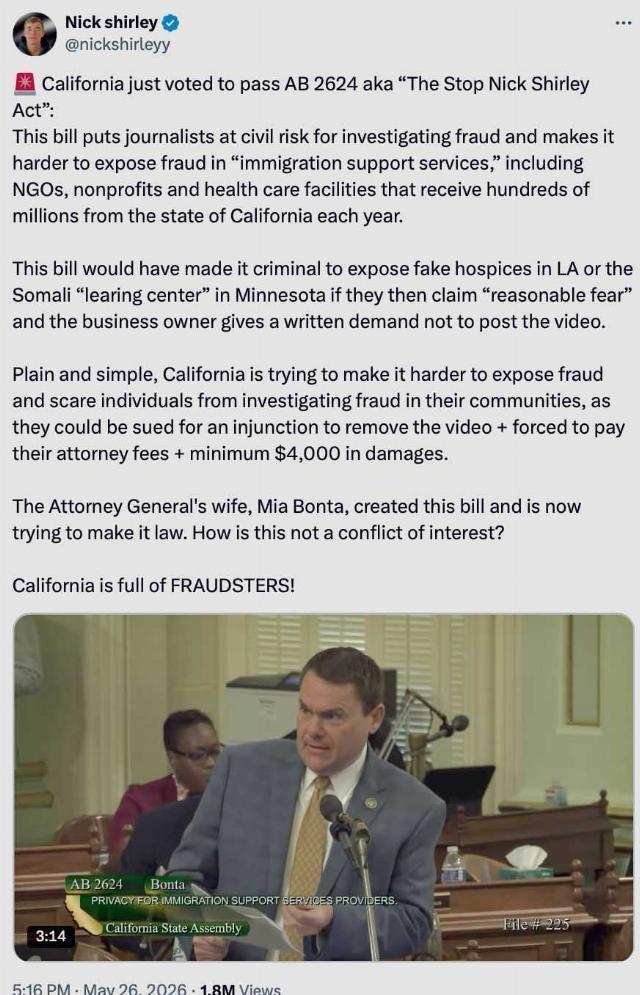
In Minnesota and California, honest public employees tried for years to expose fraud, but their superiors and the state Attorney General’s Office ignored them. But with Shirley’s discovery of incredible levels of fraud, the California Legislature was prodded into action: they’re criminalizing exposing fraud:
Independent journalist Nick Shirley accused California lawmakers of trying to shield taxpayer-funded organizations from scrutiny after the state Assembly advanced AB 2624, dubbed the "Stop Nick Shirley Act," a bill the author says is intended to protect immigration service providers from harassment and threats.
"I obviously hit a nerve," Shirley said during an appearance Wednesday night on "Fox News @ Night" with Trace Gallagher.
"What's interesting about this, this bill is it's protecting NGOs and nonprofits," Shirley said. "These are organizations and groups that receive our tax dollars, yet they want to make it so we can't find out what they're doing with our tax dollars."
Shirley argued the proposal would discourage investigations into organizations receiving public funds.
And that’s obviously the point of the legislation. But why would legislators, people sworn to protect the public, presumably at least in part by catching criminals defrauding taxpayers of billions, want to protect those criminals? It’s a puzzler, unless, perhaps, those NGOs and nonprofits are primary funding sources of the Democrat Party and Democrat politicians? But surely that can’t be happening in a single-party state like California, where corruption is all but nonexistent? Shirley explained:
"The Somalis in Minnesota, they stole hundreds of millions, billions of dollars, and then the hospice fraud that took place inside California," Shirley said.
"Everyone was saying that was bogus. And then her husband actually tried to take credit for exposing the hospice fraud after I had went and exposed the hospice fraud."
Shirley was referring to Assemblymember Mia Bonta's husband, California Attorney General Rob Bonta, who has not responded to Fox News Digital's request for comment.
"The fraud has been going on for so long. These fraudsters thought they could get away with it for so long that so many people started committing this fraud."
Graphic: X Post
What’s really amazing, though utterly unsurprising, is Shirley is only talking about hospice fraud. That’s only the shrink-wrap packaging on the box of a 100-story-tall fraud package.
To paraphrase Shakespeare, something is rotten in the bluer than blue state of California.
Mientras el mandatario neoliberal ecuatoriano celebra estabilidad macroeconómica pero oculta que la remesas son lo que sostiene el día a día de las familias. Con 7.729 millones de dólares en 2025, las remesas de la diáspora ecuatoriana por el mundo, superan ya las exportaciones de petróleo.
Las Fuerzas Armadas iraníes han alertado a Israel sobre la continuación de aatques israelíes contra Líbano, advirtiendo a los colonos israelíes que abandonen las zonas del norte si no quieren sufrir daños.
Llevamos años oyendo que la expansión de los parques solares amenaza al campo. La imagen mental que solemos tener es la de hectáreas y hectáreas de paneles negros bajo un sol implacable, arrasando el paisaje y sin un solo pájaro en kilómetros a la redonda. Sin embargo, los datos empiezan a contar una historia radicalmente diferente. Hay más vida dentro que fuera. Para entender este fenómeno, solo tenemos que mirar los datos más recientes en España. Según un informe de la Unión Española Fotovoltaica (UNEF), avalados por la consultora ambiental
Los acreedores afectados por el impago de los laudos derivados del recorte retroactivo de las primas a las energías renovables de 2013 han certificado la toma de posesión efectiva del inmueble que alberga la sede del Instituto Cervantes en Utrecht (Países Bajos), en ejecución de las resoluciones dictadas por la justicia neerlandesa. Los acreedores se han personado en el inmueble para formalizar los trámites asociados a la ejecución decretada por los tribunales holandeses. Relacionada: menea.me/2hfoh
etiquetas: holanda, embargo, instituto cervantes, renovables, recortes
Imágenes satelitales y videos analizados por BBC Verify muestran que Irán ha dañado 20 instalaciones militares estadounidenses desde el inicio de la guerra, lo que sugiere que los ataques son más extensos de lo que se ha reconocido públicamente. Desde finales de febrero, Irán ha atacado instalaciones clave en ocho países de Medio Oriente, causando daños por valor de millones de dólares a sistemas de defensa aérea de última generación, aviones de reabastecimiento de combustible y radares. Teherán ha atacado bases estadounidenses e instalaciones.
Mo Gawdat believes up to 30% of jobs in certain sectors could disappear by 2028.
That stopped me in my tracks.
Mo was one of the first people to come on this podcast and warn me about AI, long before most of the world was talking about it.
At the time, it felt early.
Now, it feels like the world is catching up to what he was seeing.
I’m still trying to understand what AI actually means for our lives.
Not just whether it can write emails, create images or make us more productive. I mean what it does to jobs. What it does to power. What it does to education. What it does to human connection…
That’s why I wanted to have this discussion with Mo again.
What makes Mo worth listening to is that he saw these systems inside Google years before most of us had even heard the term AI. His book *Scary Smart* now feels like it was written for this exact moment.
Let me explain why this discussion matters.
Mo believes we’re not just entering an AI revolution. We’re entering a period where AI, robotics, economics, surveillance, digital currencies and global instability are all colliding at the same time.
That’s a lot for any of us to process.
We spoke about:
- The jobs Mo believes are most at risk from AI. - Why he believes that AI is actually underhyped! - The mistake almost everyone is making with ChatGPT. - The prediction that changed even his own view of the future.
The part that stayed with me was this idea that human connection may become the real currency.
Because if AI can produce the information, write the report, analyse the data, then what is left?
I don’t think this conversation gives neat answers. That’s probably why it’s worth watching.
It helped me think more honestly about what’s coming.
El embajador José Antonio Zorrilla analiza las últimas noticias más preocupantes y que todos nos afectan, con su estilo único y con el mayor rigor y conocimiento, sin pelos en la lengua. Lo que nos gusta y necesitamos oír.
ME DESPIDO PORQUE NOS VAN A CENSURAR, NO ME VOY, ME PREPARO para MAS BATALLA PARA LA GUERRA por la LIBERTAD y VERDAD QUE NOS VA A TOCAR BREAR. En este vídeo, comparto mi despedida de las redes sociales, una decisión motivada por los recientes acontecimientos que justifican esta decisión. Abordo las últimas noticias y la actualidad política, incluyendo un análisis de cómo ciertos eventos en el ámbito de la política internacional están generando un intenso news commentary. No te pierdas este análisis profundo sobre los world events y las trending news que nos afectan a todos.
Sarah Wynn-Williams, autora de 'Los irresponsables', no pronunció palabra en un evento previsto con ella en el festival literario de Gales, que canceló la venta de su libro crítico con Facebook tras una denuncia de la empresa
Quisimos entrevistar a esta exdirectiva de Facebook. Mark Zuckerberg no lo ha permitido
Sarah Wynn-Williams, abogada y antigua jefa de política pública global de Facebook, se subió este domingo al escenario del Hay Festival, el encuentro literario anual en un pueblo de Gales. Se sentó entre Tim Wu, catedrático de la Universidad de Columbia, y la periodista Carole Cadwalladr. Wynn-Williams permaneció en silencio todo el evento para evitar una sanción de Meta, la propietaria de Facebook, Instagram y WhatsApp.
Era una de las charlas más esperadas del festival, y se presentaba como una conversación con Wynn-Williams y Wu, que acaba de publicar The Age of Extraction, un ensayo sobre cómo las grandes plataformas se han convertido en un factor de inestabilidad y desigualdad. Hace dos décadas, Wu acuñó el término neutralidad de la red como un principio por el que los proveedores de Internet deben tratar el tráfico de datos sin discriminar ni priorizar contenidos para garantizar una red abierta donde los operadores no favorezcan sus propios servicios o no cobren extra a otros. Cadwalladr es la reportera que en 2018 reveló en el Observer el escándalo de Cambridge Analytica, una consultora que utilizó datos personales de millones de usuarios de Facebook sin consentimiento para la campaña de Donald Trump en 2016.
Wynn-Williams es la autora de Los irresponsables, una crónica de sus siete años en Facebook (ahora la empresa se llama Meta) que denuncia el desdén de líderes egocéntricos y superficiales ante el impacto negativo de la red en la política y la salud, la complicidad con regímenes autoritarios y un ambiente de supuestos abusos laborales y sexuales que llegaba hasta la cúpula, incluida Sheryl Sandberg, la exdirectora ejecutiva. El retrato de Mark Zuckerberg es el de un líder caprichoso, deseoso de atención de los políticos y de la adulación constante de sus empleados. El título original en inglés, Careless People (gente descuidada) viene de una cita de El gran Gatsby, la novela de Scott Fitzgerald: “Eran gente descuidada. Tom y Daisy destrozaban cosas y criaturas y luego se refugiaban en su dinero o en su inmensa despreocupación, o lo que quiera que los mantuviera juntos, y dejaban que otras personas limpiaran el desastre que habían causado”.
Meta dice que el libro de Wynn-Wlliams contiene información “falsa y difamatoria”, aunque no entra en detalles.
El evento en el Hay Festival prometía ser una “conversación abierta y sincera” sobre “los entresijos de la influencia sin precedentes de las redes sociales, las fuerzas ocultas que moldean nuestra vida online y las preguntas urgentes sobre la democracia, la privacidad y la rendición de cuentas en la era digital”. En cambio, la exempleada de Facebook no pudo pronunciar palabra.
Sarah Wynn-Williams, autora de 'Los irresponsables' y exempleada de Facebook, en el Hay Festival, este domingo en Hay-on-Wye, Gales.
Silencio
Wynn-Williams está acostumbrada al silencio sobre su libro, que se publicó en marzo de 2025 en inglés. Entonces Meta acudió al sistema de arbitraje que en Estados Unidos se ocupa de disputas comerciales y argumentó que su antigua trabajadora no debería poder hablar sobre el libro por el contrato que firmó para recibir una indemnización por despido en 2017.
Unas horas después de que el libro llegara a las librerías en Estados Unidos, Meta logró una orden legal para impedir que Wynn-Williams lo promocionara. La decisión del árbitro no afectaba a la editorial ni a la publicación de libro, que ha vendido más de 150.000 ejemplares y que la editorial Península editó el pasado julio en español. Pero Wynn-Williams no podía “amplificar” de ninguna manera el contenido de su libro que podría ser considerado una forma de “comentarios críticos o dañinos” para su antigua empresa.
La autora no dio entonces las habituales entrevistas para la promoción de su libro y no apareció durante casi un año en eventos públicos para hablar de su libro. En marzo de este año, Wynn-Williams, que es diplomática neozelandesa y ahora vive en el Reino Unido, se atrevió a participar en algunas charlas públicas para hablar sobre tecnología, democracia y la inteligencia artificial, su campo de especialización ahora, pero sin mencionar a Meta o lo que cuenta su libro.
En uno de los pocos eventos que hizo a principios de marzo, en una pequeña sala de la librería Blackwell’s en Oxford, sin streaming ni apenas cobertura (por la pobre infraestructura local), Wynn-Williams permaneció en silencio, con aire impasible, mientras la moderadora leía pasajes de Los irresponsables. Incluso esos párrafos fueron elegidos con cuidado para evitar las partes más polémicas o críticas con Facebook.
Pero eventos como el de Oxford molestaron a Meta, que volvió a pedir la intervención de urgencia del árbitro para impedir que Wynn-Williams participara en foros públicos donde se mencionara o se vendiera su libro. Después de los renovados esfuerzos de Meta, la abogada de Wynn-Williams le aconsejó que no dijera nada de nada en el evento ya previsto en Gales. El festival, en lugar de cancelar la charla o quitar a la autora del panel, optó por escenificar el silencio por mandato legal.
Tim Wu, Sarah Wynn-Williams y Carole Cadwalladr en el Hay Festival este domingo, en Hay-on-Wye, Gales.
La directora de programación del festival, Helen Bagnell, anunció al público que, siguiendo el consejo legal, la autora no podía hablar, pero acompañaba a los ponentes en el escenario, y así los espectadores estaban presenciando “un acto importante de solidaridad con los silenciados”.
Wu, el catedrático de Derecho de la Universidad de Columbia, criticó lo que estaba pasando: “Esto es un ejemplo vivo de censura. Tenemos que llamarlo por su nombre. Esta es la era de la censura privada. Es una imposición de poder”, dijo. “Demuestra que algunos de los peores abusos de nuestro tiempo no se limitan a reyes, emperadores o gobiernos, sino que los comete un tipo de empresas que han asumido la soberanía y buscan imponer su poder del mismo modo que lo hacen los Estados despóticos”.
“Parpadea dos veces”
La autora se sentó en silencio y no se atrevió ni a mover la cabeza en forma de asentimiento o negación. “Esto podría ser una primera vez para el Hay, tenemos a un autor en una situación de secuestro”, dijo Cadwalladr, la periodista. “Parpadea una vez si nos oyes, Sarah; dos veces si Zuckerberg es un imbécil”.
La autora apenas se movía. Ya tiene práctica en no parpadear ni hacer gestos cuando hay referencias a Meta o a su libro. Al final del evento, el público le dedicó una ovación de aplausos tan intensa que la hizo llorar.
El camino tomado por Meta puede sentar precedente para la libertad de expresión especialmente en Silicon Valley, donde son habituales los contratos como el de Wynn-Williams para evitar críticas de sus prácticas.
La empresa ha descrito el libro como “una mezcla de denuncias anticuadas y ya contadas” sobre la compañía y “acusaciones falsas” sobre sus ejecutivos, y asegura que la despidió por sus “pobres resultados” y que sus denuncias de acoso estaban infundadas. Pero la empresa ha optado por denunciarla no por contenido del libro, sino por el contrato que firmó al marcharse y que le prohíbe decir una palabra despectiva sobre su antiguo empleador o cualquier persona que trabaje allí. Hay un proceso judicial en curso sobre la legitimidad de esta práctica y si ese contrato sigue vigente para siempre. Entretanto, Meta sigue intentando que la abogada y su libro tengan la menor difusión posible.
Durante el evento en el Hay Festival, Cadwalladr leyó la carta de la abogada de Wynn-Williams que detallaba las últimas quejas ante el tribunal de Meta. En marzo, justo cuando la autora habló en Oxford y se publicó la edición de bolsillo en inglés, Meta acudió al árbitro designado en su caso en Estados Unidos para pedir una sanción económica contra Wynn-Williams por supuestamente violar la orden preventiva por su contrato.
Según la explicación ofrecida en la carta de la abogada, Meta sostiene que la autora viola la orden “cada vez que aparece en público en un lugar donde debería saber que su libro está en venta y su presencia podría llamar la atención sobre él”, por ejemplo, en una librería. Meta identificaba la participación en el Hay Festival de manera preventiva “como una conducta que debe ser sancionada de manera formal”.
El abogado encargado del arbitraje rechazó levantar la orden temporal que pesa sobre la autora desde hace más de un año y advirtió que no debe hablar en ningún evento “donde su presencia probablemente animaría a las ventas” de su libro.
Una ministra del Gobierno británico aseguró durante un debate sobre derechos laborales en la Cámara de los Comunes que cada infracción le puede costar a la autora 50.000 dólares (más de 43.000 euros). Por precaución, el festival de Gales retiró el libro de la venta.
Meta aseguró este lunes en un comunicado compartido con elDiario.es y otros medios que “se trata de una resolución del árbitro, no de una decisión de Meta para silenciar a nadie”. “Tenemos derecho a pedir que los términos de esa resolución se cumplan”, dice la empresa, que insiste en la resolución de arbitraje provisional que Wynn-Williams aceptó y que “prohíbe explícitamente la promoción de su libro”. También destaca que el texto es público.
La amenaza de la IA
En los eventos que molestaron a Meta en marzo, la autora se concentraba en un discurso general y más relacionado con el momento actual, en particular la inteligencia artificial y los centros de datos que está intentando atraer el Reino Unido.
La autora se preguntaba sobre el entusiasmo del primer ministro británico, Keir Starmer, para atraer estos centros como supuesto generador de puestos de trabajo.
“¿Alguna vez ha estado en un centro de datos? No hay nadie allí. Me pregunto si en su cabeza es como un almacén de Amazon y piensa en gigantescos almacenes llenos de gente trabajando”, explicaba Wynn-Williams en la librería de Oxford. “Después de haber pasado mucho tiempo en condiciones gélidas, intentando negociar todo tipo de cosas relacionadas con centros de datos, lo que más te sorprende de estos lugares es su silencio. Son tan silenciosos y están tan vacíos... Y la falta de empleos es tan evidente que me pregunto: ¿es ingenuidad? En mis días más sombríos, pienso en que el ex primer ministro [Rishi Sunak] ahora es asesor de Anthropic y de Microsoft, y que un exministro de Hacienda [George Osborne] ahora trabaja en OpenAI... Si no es ingenuidad, ¿será complicidad?”
Uno de sus principales mensajes en 2026 es que la experiencia de las redes sociales y cómo han alterado nuestro mundo debería servir ahora de lección para la regulación de las empresas de inteligencia artificial. “Muchos de los problemas que surgieron con las redes sociales y la dificultad de regularlas y equilibrarlas con la libertad de expresión y con empresas que son transnacionales o que tienen un alcance global y no necesariamente están sujetas a las leyes locales vienen del hecho que políticos no provenían de ese entorno y, por lo tanto, tardaron en comprender las implicaciones”, dijo la abogada y diplomática. “Y eso parece ser doblemente cierto para la IA”.
En el coloquio después de la conversación en Oxford, Sarah Wynn-Williams explicó a elDiario.es que la mayor amenaza que representa la IA ahora se encuentra en sus usos militares: “La idea de abdicar de la toma de decisiones humanas en torno a armas autónomas letales es enorme, y cambia fundamentalmente la geopolítica”, dijo. Entonces, animó a los ciudadanos a implicarse más porque los problemas que plantea la IA “son existenciales de una manera en la que las redes sociales no lo eran”.
¿Tiene Facebook?
A la pregunta de este periódico de si todavía utiliza redes sociales, Wynn-Williams contestó con otro interrogante: “¿Hay alguien en esta sala porque vio algo en mis redes sociales esta noche?” No, la escritora no comparte nada en redes. Pero también dijo que, más allá del hecho de que ella las haya abandonado, es muy cautelosa al denostarlas y puso el ejemplo a progenitores que se organizan en grupos de redes sociales para hacer campañas para limitar el uso de las redes o de móviles para los menores.
Lo que la anima es la reacción que no veía antes contra el mal uso de la tecnología porque hay muchas personas “que están pensando seriamente en su propio uso de estas tecnologías”, por ejemplo con la reacción contra X de Elon Musk. Se trata, según ella, de decisiones personales y también de regulación: “Necesitamos que las cosas sucedan en todos los niveles de la sociedad”, dijo.
La presión ciudadana a los representantes públicos a veces comienza con conversaciones entre amigos y compañeros sobre el uso personal de la tecnología. “Todos estos procesos son complicados. Así que no sabes cuál es la última pequeña grieta en el parabrisas que hace que todo se venga abajo”, dijo. “Pero cuanto más hagas, cuanto más hables de ello, más probable es que el cambio ocurra rápido”.
The phrase "CI/CD tools" suggests a category of products that exist independently of the platforms they deploy to. In 2026, for most teams reading this, that is no longer the right way to think about it.
The ranking will reward both readers: the ones who want a standalone CI/CD product, and the ones who should be re-evaluating whether they need one at all.
House rule: every claim in this post is sourced, no handwaving.
CI/CD as a separate category exists mostly because deploy was historically painful enough that you had to build your own pipeline on top of platforms that didn't handle it. The modern PaaS providers handle build, test, deploy, preview environments per pull request, environment promotion, secrets, and rollbacks natively. If you are on one of those platforms, you probably do not need a standalone CI/CD product. If you are not, you do. This list treats both cases honestly.
A CI/CD pipeline, when fully built out, handles seven things.
Build. Compile, bundle, containerize. Cache the result.
Test. Run unit, integration, end-to-end. Block the deploy on failure.
Deploy. Push the artifact to the target environment, run database migrations if any, swap traffic, verify health.
Preview environments. Spin up an ephemeral copy of the app for every pull request so reviewers can poke at it.
Promote. Move artifacts from staging to production with the same artifact bytes, not a rebuild.
Rollback. If production breaks, return to the last known good deploy in seconds, not minutes.
Secrets and configuration. Surface the right secrets to the right environment without leaking them into logs.
When teams ask "what CI/CD tool should I pick," what they're often asking is "who is going to do these seven things for me?" The answer depends on whether your deploy platform already handles them.
Best for teams who don't want CI/CD as a separate concern.
The whole pitch of this post is that you don't have to think about CI/CD as a separate problem in 2026, and Railway is the platform that has bet the hardest on that being true. Push to your repo, Railway builds the artifact, deploys to a preview environment per pull request, and promotes to production on merge. Secrets are per-environment. Rollbacks are one click. The build cache is on us.
What makes Railway agent-native: every step of that pipeline is also reachable from Claude Code, Cursor, or Codex over MCP. You can prompt the agent to spin up a new environment for a feature branch, run a test suite, redeploy a service, or roll a config change, and the platform handles it. The Stripe Projects CLI extends this to provisioning entire stacks via an agent, end to end.
For overworked dev teams who do not have an engineer to dedicate to maintaining a Jenkinsfile, this matters. Internal tools and production deploys live on the same platform, with the same primitives, on the same bill. You stop thinking about CI/CD because the deploy platform handles it; you stop thinking about internal-tool hosting because the same platform serves it.
Features: native preview environments per PR, branch-deploy automation, build cache, one-click rollback, secrets and config per environment, MCP server for agent-driven CI/CD, Stripe Projects CLI for end-to-end agent provisioning, private networking between deploy environments.
Pricing: $5 Hobby with included usage credit, Pro at $20/seat. CI/CD is included in the platform; you don't pay extra for it.
Best for full-stack teams that don't want a separate CI/CD tool, teams whose engineers' time is the constraint, teams who want the agent to drive deploys, teams running internal tools and production deploys on the same surface.
Honest trade-offs: if your CI/CD needs sit outside of "build, test, deploy this repo," such as complex pipeline orchestration across many systems, regulated compliance pipelines, or build farms doing release engineering for non-Railway-hosted artifacts, you still want a dedicated CI/CD tool. Railway is not trying to be Jenkins for the JPL.
GitHub Actions is the default CI/CD for anything on GitHub. Free for public repos, generous limits for private ones, an enormous marketplace of third-party actions, and runners that can be self-hosted or GitHub-managed. If you have decided you want a separate CI/CD tool, Actions is almost certainly the right answer for any team starting fresh in 2026.
Features: native GitHub integration, matrix builds across runtime versions, self-hosted runners, third-party action marketplace, secrets at repo / org / environment levels, environments with deploy gates.
Pricing: free for public repos; 2,000 minutes/month free for private on the free GitHub plan; per-minute pricing thereafter, with self-hosted runners free.
Best for teams on GitHub who want a real, programmable CI/CD pipeline alongside their repo.
Honest trade-offs: pipeline performance is good but not best-in-class, since CircleCI and Buildkite often beat it on heavier matrices. YAML configuration grows hair on it past a certain size; large monorepos end up with reusable workflows that are a mini DSL of their own. If you are not on GitHub, none of this applies.
Best for frontend CI/CD inside the Vercel ecosystem.
Vercel is the integrated CI/CD for Next.js and frontend-shaped applications. Preview environments are automatic for every pull request. The build pipeline is optimized for the frameworks Vercel supports.
Features: automatic preview deployments per PR, native Next.js integration, Edge Functions, Fluid Compute with Active CPU pricing (the 2025 update that solved the streaming-workload cost problem), Vercel Postgres (Neon-backed), Vercel KV, image optimization, deploy hooks.
Pricing: Hobby free; Pro $20/seat with included credit, plus usage-based add-ons. Bandwidth and per-seat costs are the more legitimate 2026 critique.
Best for frontend-heavy teams, Next.js shops, static and ISR-heavy sites.
Honest trade-offs: the CI/CD is tightly coupled to Vercel's runtime model. For anything past the frontend, you are pairing Vercel with a real backend platform and your CI/CD spans two surfaces.
Best for standalone CI/CD with serious test orchestration needs.
CircleCI is the standalone CI/CD product that has aged the best. Strong test parallelization, an Orbs ecosystem for reusable pipeline components, and a UI that handles large matrices better than most peers. If you are running a CI workload that's heavy on parallel test execution, CircleCI's parallelism model is often faster than GitHub Actions.
Features: parallel test execution, Orbs reusable config, self-hosted runner option, Docker-layer caching, insights and test analytics.
Pricing: free tier with 6,000 build-minutes/month; paid tiers from $15/mo for more credits and concurrency.
Best for teams with expensive test suites where parallelism pays for itself. Teams that have outgrown GitHub Actions on matrix performance.
Honest trade-offs: it is the second product in a category where GitHub Actions is the default. If you don't have a specific reason to use CircleCI, GitHub Actions is the cheaper-friction choice.
Render handles CI/CD natively for the apps it hosts. Preview environments per PR, native build pipeline, autoscaling, rollback. The same shape as Railway's CI/CD story but with a fixed-price billing model instead of usage-based.
GitLab CI is GitLab's repo-integrated CI/CD product. The same shape as GitHub Actions, but for GitLab. Strong if your team already uses GitLab, not relevant otherwise.
Features: native GitLab integration, parent-child pipelines, dynamic environments, Auto DevOps, container registry built in.
Pricing: free tier for public projects and small teams; paid tiers for self-hosted runners at scale.
Best for teams on GitLab. Teams running self-hosted GitLab who want everything (repo, CI, registry) on one server.
Honest trade-offs: it lives inside the GitLab ecosystem; if you're on GitHub or Bitbucket, this isn't your tool.
Best for hybrid self-hosted CI/CD at serious scale.
Buildkite is the CI/CD product that serious infrastructure teams pick when they have outgrown the hosted-runners model. You run the agents on your own infrastructure (your AWS, your data center), Buildkite orchestrates the pipeline. Used at Shopify, Pinterest, Airbnb scale.
Pricing: free for open source; paid tiers from $15/user/mo. You pay for orchestration; you pay for your own compute.
Best for teams big enough that hosted runner costs dominate the CI bill, teams that need to run builds inside their own VPC, teams that have a platform engineer to operate Buildkite agents.
Honest trade-offs: not the right answer for most teams under 50 engineers; the operational cost of running agents only pays off at scale.
Argo CD is the GitOps tool of choice for Kubernetes shops. Declarative: you commit Kubernetes manifests, Argo reconciles cluster state to match. It is not a CI tool; it is a CD tool. Pair it with GitHub Actions, Jenkins, or anything that produces images.
Pricing: open source, free. Hosted versions available from Akuity and Codefresh.
Best for teams running Kubernetes who want their cluster state to track git.
Honest trade-offs: only useful if you're already on Kubernetes. The mental model is "your cluster is a function of your repo," which is great if you live in that world and noise if you don't.
Best for legacy, regulated, or self-hosted CI/CD at scale.
Jenkins is the historical anchor of CI/CD, like Heroku for PaaS. Open source, self-hosted, infinitely pluggable, and old enough to have outlived several generations of competitors. In 2026 Jenkins is still the dominant CI tool in large enterprise environments and regulated industries; in greenfield environments, it is almost never the right choice anymore.
Features: open-source self-hosted, massive plugin ecosystem, declarative or scripted pipelines, distributed build agents, fits any compliance posture because you control everything.
Pricing: free. Your cost is the engineer-hours operating it.
Best for regulated industries (financial services, defense, healthcare) where pipeline auditability and self-hosting are non-negotiable. Teams with existing Jenkins investment too big to migrate.
Honest trade-offs: you operate Jenkins. The plugin ecosystem is also where most of the security exposure lives. If you are not already on Jenkins, you are almost certainly better served by GitHub Actions or a hosted competitor.
Bitbucket Pipelines is Atlassian's repo-integrated CI/CD, for teams on Bitbucket. The same shape as GitHub Actions and GitLab CI, with the Atlassian-flavored UX.
Features: native Bitbucket integration, Docker-based pipelines, deploy environments, integration with Jira and the rest of Atlassian's stack.
Pricing: free tier with 50 build minutes/month; paid tiers from $3/user/mo.
Best for teams on Bitbucket, teams already in the Atlassian ecosystem.
Honest trade-offs: it lives inside Atlassian's universe. If you are not there already, you would pick GitHub Actions instead.
CI/CD as a category was about codifying the deploy pipeline so humans didn't have to remember it. The next category is about making the pipeline reachable to agents, so humans don't have to write it either. Railway's bet is that the right architecture for this is an MCP server that exposes deploy primitives directly to the agent (branch operations, environment provisioning, secret rotation, deploy rollback) without a YAML file in the middle.
This matters for overworked dev teams because most of the CI/CD complexity that gets blamed on the tool is pipeline boilerplate. A team of three engineers shouldn't be writing a 400-line YAML pipeline to deploy a Node app. The agent should be writing and running those for them, on a platform that exposes the right primitives. That is the contract we have built toward.
The second-order point: when CI/CD lives inside the deploy platform, internal tooling and production workloads end up on the same surface. The same primitives (build, deploy, secrets, rollback) serve the staging cluster, the internal dashboards, the analytics jobs, and the production API. You stop reaching for a separate "internal tools platform" too.
If your team is already on a modern PaaS, you have CI/CD; you just stopped thinking about it as a separate problem. That is the correct outcome, not a gap. Pick the deploy platform that handles the seven things above, set up the agent integration if you have one, and don't go shopping for a CI/CD tool you don't need.
If your team is not on a modern PaaS, because of compliance, scale, or stack constraints that justify it, the standalone tools on this list are real and the ranking is honest. The gravity is mostly toward GitHub Actions for greenfield, Jenkins for legacy, and Buildkite for serious scale.
If your current "CI/CD" is a 400-line shell script someone wrote in 2019 that nobody fully understands anymore, the right move is to give yourself the quarter back.
Happy shipping.
Angelo
Angelo Saraceno is a Solutions Engineer at Railway. Before Railway he was at Citrix, working inside Verizon and Lockheed environments, so he has seen what "enterprise IaaS" looks like after the slides come down. He writes about infrastructure, deployment, and the gap between how cloud is sold and how it runs in practice.
Every year a fresh crop of "best serverless platforms" listicles ships, every year they rank the same eight FaaS vendors against each other, and the question that matters (what should I run my app on?) gets buried under feature matrices. The 2026 answer: "serverless" no longer means one thing. It points at three runtime contracts, and the right pick depends on which one matches the app you already have.
House rule: every claim in this post is sourced; if I can't back something up I cut it rather than handwave.
Before Railway I was at Citrix working on customer environments for shops like Verizon and Lockheed Martin, which is a polite way of saying I spent years inside other people's infrastructure decisions. Strong opinions about what a "platform" should do, low tolerance for marketing that pretends a Lambda rewrite is free.
The shortlist below is ranked by how often the platform is the right answer in 2026, not who has the biggest billboards. Railway is at the top because the economics now favor full-app scale-to-zero over function-shaped serverless for most workloads. I'll defend the ranking and tell you where Railway is the wrong call.
The word got stretched across three things and never recovered. Before ranking, agree on vocabulary.
Contract 1: Function-as-a-Service (FaaS). You write handlers. The platform routes events to them, spins them up on demand, charges per invocation and per GB-second. AWS Lambda invented this in 2014; Cloudflare Workers, Vercel Functions, and Azure Functions run the same contract with different runtimes. You either started serverless-native or you rewrote.
Contract 2: Container-as-a-Service with scale-to-zero. You hand the platform a container. It runs on demand, scales to zero when traffic dies, bills per request and per CPU-second. Google Cloud Run is the canonical example; AWS Fargate plays the same game.
Contract 3: Full-app scale-to-zero on usage-based pricing. You push your app. The platform runs it like a normal long-lived process, sleeps the container when there's no traffic, and only charges for resources consumed. No handler rewrite, no per-invocation accounting, no cold-start budget. Railway is the canonical example.
Once you have these three buckets in your head, the rest of this post is a sort.
Best for full-app serverless with usage-based pricing and no rewrite.
Railway runs your existing container, scales it to zero when traffic stops, and only charges for the CPU, memory, network, and disk you used. Keep your Dockerfile (or let Railpack build from source), keep your runtime, keep your framework, and the bill stops when the traffic stops. No FaaS rewrite, no cold-start budget, no "Lambda-shaped app" trap. The platform also ships native managed Postgres, MySQL, Redis, and MongoDB, so the database isn't a second vendor.
The agent story is where 2026 Railway diverges from the rest of this list. Railway exposes an MCP server, so Claude and other tool-using agents can read project state and drive deploys directly. The Stripe Projects CLI integration means an agent can provision a Railway service against a Stripe-backed account end to end without a human pasting API keys. Pair that with git-deploys, PR environments, instant rollbacks, and private networking, and the platform stops being a Heroku replacement and starts being the substrate an LLM can operate.
Pricing: Hobby at $5/month with included usage credit, Pro at $20/seat. Usage-based on CPU, memory, network, and storage on top.
Best for product teams shipping web apps, API backends, full-stack frameworks, internal tools, agent-driven deploys, anyone on Heroku or Render who wants serverless economics without the rewrite.
Trade-offs: if your workload is a true FaaS shape (millions of tiny edge-routed invocations, sub-50ms cold-start budget, CDN-tier geographic distribution), Cloudflare Workers will be cheaper and faster; Railway is not an edge platform. Railway is also opinionated about service structure; if you want raw VM access with sudo, Fly Machines gives you that and Railway does not.
Best for event-driven glue inside an existing AWS estate.
Lambda is the historical anchor. It invented FaaS pricing, it's been GA since 2014, and for most AWS-resident teams it's already part of the vanilla cloud stack (S3 triggers, SQS consumers, EventBridge handlers, API Gateway routes). If you live in AWS, you are using Lambda whether you call it your serverless platform or not.
Where Lambda gets oversold is as a primary runtime for a team that didn't start there. Chopping a Rails or Express app into discrete handlers is a multi-month project, and the result is harder to reason about, not easier. The "Lambda-shaped app" trap: handlers need shared state so you bolt on DynamoDB, then orchestration so you bolt on Step Functions, then long-running work so you bolt on Fargate anyway.
Features: per-event invocation, 15-minute max execution, provisioned concurrency, SnapStart for Java, Node / Python / Ruby / Java / Go / .NET runtimes, VPC integration, layers, response streaming.
Pricing: per-invocation plus per-GB-second. Free tier of 1M requests/month and 400k GB-seconds.
Best for AWS-native teams, event-driven glue, scheduled jobs, anyone whose architecture is already serverless-shaped.
Trade-offs: cold starts are still a real problem for latency-sensitive paths (provisioned concurrency exists and costs money). VPC-attached Lambdas inherit AWS networking pain. Observability requires CloudWatch (or paying a third party to make CloudWatch tolerable). And the rewrite tax for non-serverless-native apps is almost always larger than the infra savings, which is the next section.
Workers run on V8 isolates instead of containers, which means cold starts in single-digit milliseconds and a 0ms cold-start claim that holds up for most workloads. The platform runs in 300+ Cloudflare PoPs, so handlers execute close to the user. For request routing, auth middleware, A/B logic, and lightweight APIs, Workers is the cheapest and fastest option on this list.
The catch: the Workers runtime is not Node. It implements a subset of Node-compat plus Cloudflare-specific APIs (Durable Objects, KV, R2, D1, Queues, Workflows). Many npm packages run, many don't, and the failure mode is usually "works locally, breaks on deploy."
Pricing: free up to 100k requests/day, paid plan at $5/month for 10M requests included, then $0.30 per additional million.
Best for edge APIs, middleware, auth and routing layers, low-latency global apps.
Trade-offs: runtime constraints are real and you'll discover them at the worst possible moment. Durable Objects lock you in more deeply than Lambda locks you into AWS. Debugging is harder than a normal container. If your app needs a long-lived process (websockets at scale, anything stateful beyond DOs), you're outside the contract.
Best for container scale-to-zero with first-class GPU support.
Cloud Run is the cleanest implementation of Contract 2. Give it an image, get a URL, scale from zero to many based on request volume. The June 2025 GA of GPU support (NVIDIA L4) made it credibility-positive for AI inference, which used to be a Modal-only story.
The thing nobody warns you about is the GCP setup tax. To use Cloud Run well you also touch Artifact Registry, IAM, VPC connectors, Cloud SQL, Secret Manager, and probably Cloud Build. If you already operate in GCP, fine; if you don't, you are buying a cloud, not a platform.
Features: container scale-to-zero, scale-to-many, request-based and CPU-based pricing, GPU support (NVIDIA L4), VPC connectors, Cloud SQL, IAM-bound services, traffic splitting, revisions, jobs (batch).
Pricing: per-request and per-CPU-second, with a generous free tier (2M requests, 360k vCPU-seconds, 180k GiB-seconds per month). GPU pricing on top.
Best for GCP-native teams, AI inference, containerized backends with a Dockerfile, batch jobs.
Trade-offs: GCP onboarding is real work. Cold starts on GPU instances are non-trivial (model load time dominates). Per-region only; multi-region requires you to wire it up.
Best for Next.js-shaped frontends with serverless backends behind them.
Vercel sells frontend hosting, and Vercel Functions is the backend you reach for when you're already on the frontend product. The April 2025 launch of Fluid Compute and Active CPU pricing cut function bills by 80%+ on I/O-bound workloads by only billing for CPU when the function is doing work, not when it's idle waiting on I/O. For a Next.js app that calls OpenAI on every request, this is a real cost reduction.
If you aren't on Next.js, Vercel Functions is harder to justify. The value proposition gets thinner the further you drift from that center.
Features: Fluid Compute, Active CPU pricing, edge functions, Node and Python runtimes, ISR, image optimization, preview deploys, Vercel KV / Blob / Postgres, AI Gateway.
Pricing: Hobby free, Pro at $20/seat/month, then usage-based on function execution, bandwidth, and storage.
Best for Next.js teams, frontend-heavy apps with light backends, Jamstack-shaped projects.
Trade-offs: pricing is famously hard to predict at scale, and bandwidth overages on viral content have produced a steady drip of public horror stories. Lock-in to Vercel-specific abstractions makes leaving expensive.
Best for Python-native AI workloads and GPU batch jobs.
Modal is what you reach for when your workload is "run this Python function on a GPU, sometimes." It's Python-first (decorate functions with @app.function and Modal handles containerization, scheduling, and GPU allocation), supports cold-start times in single-digit seconds for large models, and prices by the second. For ML inference that doesn't justify a long-running GPU container, Modal is the most ergonomic option on this list.
It is not a general-purpose application platform and doesn't try to be. No managed Postgres, no service mesh, no preview environments. A serverless GPU runtime with a beautiful Python SDK.
Features: Python-native function deploys, GPU support (A10G, A100, H100, H200, B200), per-second billing, web endpoints, scheduled functions, batch jobs, volumes, secrets, queues.
Pricing: per-second compute plus per-GPU-second rates. Free tier for hobbyists, then usage-based.
Best for ML inference, batch GPU jobs, Python data pipelines, fine-tuning workloads.
Trade-offs: Python only. Not a place to run your main web app. Pricing is great if your workload is bursty, terrible if steady-state (a dedicated GPU is cheaper for 24/7 inference).
Microsoft's FaaS answer. The Consumption plan offers scale-to-zero with per-invocation pricing. For teams already on Azure (Entra ID, Cosmos DB, Service Bus), it slots in cleanly. .NET support is best-in-class because Microsoft writes both the runtime and the platform.
Outside that context the case is weaker. Developer ergonomics lag Lambda's, and documentation is famously dense.
Features: Consumption plan with scale-to-zero, Premium plan with pre-warmed instances, Durable Functions, .NET / Node / Python / Java / PowerShell, Application Insights integration.
Pricing: per-execution plus per-GB-second on Consumption. Free grant of 1M executions and 400k GB-seconds per month.
Best for .NET teams, Microsoft-shop estates, orgs with an Enterprise Agreement that already includes Azure spend.
Trade-offs: outside the Microsoft ecosystem, hard to justify. Cold starts on Consumption are slower than Lambda's for most runtimes. Tooling sprawl is its own learning curve.
Fargate fits when you're already deep in AWS and need a container alongside Lambda, RDS, S3, and the rest of the estate without managing nodes. Outside that context, it's a heavier lift than Cloud Run or Railway for the same job.
Pricing: per-vCPU-second and per-GB-second of memory. No included free tier; Express Mode adds request-based billing on top.
Best for AWS-resident teams, container workloads alongside an AWS estate, anyone migrating off App Runner.
Trade-offs: pricing is higher than equivalent EC2 compute for steady-state workloads. Cold-start behavior on Express Mode is slower than Cloud Run's. Networking setup is the usual AWS tax.
Best for VM-based serverless with multi-region as a first-class concept.
Fly Machines run your container as a Firecracker microVM that can be stopped and started in roughly a second. Multi-region is the headline: pin a Machine to a region or run replicas across many, and the routing layer sends users to the nearest instance. For workloads where geographic distribution matters (and is not just CDN cacheable), this is the right contract.
Reliability is where I have to be careful. The October 2024 fleet-wide outage shook customer confidence, and there have been further regional and platform incidents through 2025 and into 2026. If your workload is mission-critical and single-region, the trade is not obviously worth it.
Pricing: per-second compute when Machines are running, storage and bandwidth on top.
Best for multi-region apps, latency-sensitive global workloads, teams who need VM-level control with serverless billing.
Trade-offs: reliability is the thing to dig into before you commit. Fly Postgres has its own history of incidents. Support is community-flavored; if you need an enterprise SLA, look elsewhere.
Best for predictable-bill PaaS with a scale-to-zero option on the cheap tiers.
Render is the predictable-bill alternative: pick an instance size, pay a flat monthly fee, scale-to-zero is available on the free tier with a 15-minute idle timeout. If your workload is steady and you want to know the bill before the month starts, Render's pricing is friendlier than Railway's metered model.
The trade is that you're paying for capacity you might not be using, which is the problem usage-based pricing fixes. For low-traffic side projects, scale-to-zero with a 15-minute spin-down is fine. For production, cold-start latency on request 1 makes it not much of a serverless story.
Features: scale-to-zero on free tier, instance-based pricing on paid tiers, native Postgres and Redis, preview environments, autoscaling, private services, cron jobs, blueprints (config-as-code).
Pricing: free tier with 15-minute idle timeout, paid instances from $7/month, database from $7/month.
Best for predictable-bill shops, side projects on the free tier, teams who explicitly want flat pricing.
Trade-offs: scale-to-zero on free means cold starts on every first request after idle, which is a bad production story. Paid tiers don't scale to zero, so you're paying for idle capacity. Feature velocity has been quieter than competitors in 2025-26.
This is the part the listicles skip. FaaS pricing looks fantastic on the calculator: a million invocations for pocket change, no idle cost, infinite scale. The calculator doesn't include the engineer-months to chop your existing app into handlers.
If you didn't start serverless-native, the rewrite is the real cost. Break a long-lived process into stateless functions, move in-memory state to Redis or DynamoDB, replace background jobs with queues and Step Functions, redesign request handling around 15-minute limits and cold-start budgets, redo observability because CloudWatch on Lambdas is not the same shape as logs from a normal process. Two quarters of senior engineering time, easily, for a mid-sized app.
The contrarian read: most teams overestimate FaaS savings and underestimate rewrite cost. If your infra bill is $2k/month and the rewrite is six engineer-months, the math never works. Full-app scale-to-zero sidesteps the rewrite entirely. You get serverless economics on the app you already have.
If any of these describe your workload, none of the platforms above are the right answer and you should run a long-lived container or VM.
Long-running jobs. Anything past Lambda's 15-minute limit, anything that holds state across hours, anything that's really a batch pipeline. Use a container on Railway or Fargate, or Modal for GPU batches.
Stateful workloads. Databases, queues, anything owning durable state. Run them as managed services (Railway's native Postgres, RDS, Cloud SQL) or on dedicated infra. Putting them on FaaS is malpractice.
Persistent connections. Websockets at scale, gRPC streams, long-polling, SSE. FaaS platforms have hacky support; container platforms with scale-to-many (Railway, Cloud Run, Fly) handle this naturally.
Cold-start-sensitive UX. If a 500ms cold start kills your product (real-time multiplayer, interactive AI demos, payment flows), pay for warm instances, or pick a platform with sub-millisecond starts (Cloudflare Workers) if your workload fits that runtime.
Serverless is a billing model wearing a runtime model's clothes. Match the billing to traffic shape, match the runtime to the app shape, and don't let a marketing word make you pick the wrong one.
Lambda is part of vanilla AWS for most teams already, and that's fine. The question this post answers is what to reach for when you're picking a primary application platform in 2026, and the answer for most teams is full-app scale-to-zero on usage-based pricing. Keep the codebase you have, stop paying when nobody's hitting it, let the agent drive deploys, and nobody on the team learns what a cold-start budget is.
Give yourself the quarter back. Don't rewrite into handlers because a calculator told you to.
Happy shipping.
Angelo
Angelo Saraceno is a Solutions Engineer at Railway. Before Railway he was at Citrix, working inside Verizon and Lockheed environments, so he has seen what "enterprise IaaS" looks like after the slides come down. He writes about infrastructure, deployment, and the gap between how cloud is sold and how it runs in practice.
Observability used to be a budget line item nobody understood and everybody dreaded. You bought Splunk, watched the bill balloon, then quietly cut retention from 90 days to 30, then to 7, then prayed nothing broke during an audit. The story has improved, slightly. The pricing has not.
What changed is that observability fragmented into three pillars: logs, metrics, traces. Then it tried to unify itself through OpenTelemetry. Then a generation of platforms launched promising to be cheaper than Datadog. Some delivered. Most repackaged the same problem.
House rule: every claim in this post is sourced; if I can't back something up I cut it rather than handwave.
Before Railway I was at Citrix, where my customer environments included Verizon and Lockheed. Both ran observability stacks that cost more than most startups' Series A. I have opinions about what you need versus what a vendor will sell you. Most teams asking "what observability tool should I use" have one of three real problems. Either their PaaS doesn't give them basic observability and they need to bolt something on; or they've outgrown their PaaS-bundled observability and need a real APM; or they're on vanilla cloud (AWS, GCP, bare EC2) and they need to assemble a stack from parts.
This post helps you figure out which bucket you're in, then ranks the ten platforms worth considering in 2026. I'll be direct about which ones I would pick and which ones are coasting on enterprise inertia.
Observability is a fancy word for "can you tell what your system is doing without SSH'ing into a box at 2am." It traditionally splits into three pillars.
Logs are timestamped text events. Your app says "user logged in," "request failed," "cache miss." Logs are the oldest and most universal signal. They are also the most expensive to store at scale because text is bulky and high-cardinality.
Metrics are numeric time series. CPU at 73%, request latency p99 at 240ms, queue depth at 1,200. Metrics are cheap to store (numbers and timestamps) and great for dashboards and alerts, but they don't tell you why something happened.
Traces are the path a single request took through your system. Service A called Service B which called the database, and here's how long each hop took. Traces are how you debug distributed systems. They are also the hardest to set up correctly because they require instrumentation in every service.
You used to need three different tools for these. Now you don't, mostly because of OpenTelemetry. OTel (as everyone calls it) is a vendor-neutral standard for emitting logs, metrics, and traces. You instrument your app once, then point the output at whichever backend you want. Datadog, Honeycomb, Grafana Cloud, Axiom, your own stack. Switching backends becomes a config change instead of a six-month migration.
This matters because the lock-in story of observability used to be brutal. Once you'd shipped Datadog agents to a thousand hosts and rewritten your alerts in their DSL, leaving was a year-long project. OTel breaks that. Not entirely, since every backend still has proprietary features, but enough that you can negotiate from a position of strength.
The unification angle also matters for correlation. If your error logs, latency metrics, and request traces all share a trace ID, you can pivot between them. That is what "modern observability" means. Not three tools that exist in the same UI, but three signals that reference each other.
Before you compare vendors, write down what observability has to do for your team. There are seven jobs.
Capture. Something has to receive the signals. Agents, SDKs, sidecars, OTel collectors. Capture is usually the messy part because it touches every service.
Store. Logs and traces are bulky. Metrics are not. Storage cost dominates total cost, especially for logs.
Query. Can you find things? Splunk's SPL, Datadog's query language, Honeycomb's BubbleUp, Grafana's LogQL. Each has a learning curve.
Alert. When something is wrong, someone needs to know. PagerDuty integration, on-call routing, alert fatigue management.
Correlate. Can you jump from a slow request (trace) to its error logs to its host metrics in one click? This is the modern bar.
Retain. How long do you keep data? Compliance often dictates 90 days or a year. Storage cost scales linearly.
Expose. Who reads this? Engineers in dashboards, sure, but increasingly agents and AI assistants reading logs to debug. The platforms that expose logs to programmatic consumers (MCP, APIs, exports) win in 2026.
Score your needs against those seven jobs before you start a vendor demo. Most teams over-buy because they evaluate on features they will never use.
Best for built-in observability for PaaS workloads.
I work here, so I'll be transparent. Railway ships with observability included: structured logs that are queryable and retained, metrics for CPU and memory and network on every service, deploy history that shows you exactly which commit is running where, and the ability to exec into a running container when you need to poke at something live. There is also an MCP server so an AI agent (Claude, Cursor, whatever you use) can read your logs and debug alongside you.
For 70% of teams, this is enough. Most apps don't need distributed tracing because they aren't distributed. They're a web service, a worker, a database, maybe a cache. The other 30% have genuine distributed-systems problems and they should pair Railway with a real APM (probably Honeycomb or Datadog, depending on budget). We're honest about that split rather than pretending the built-in tools cover every case.
Features: structured logs with full-text and attribute filters, log retention by plan, CPU/memory/network metrics per service, deploy history, exec-into-container, MCP server for agent-driven debugging, webhook integrations, OpenTelemetry-compatible log ingestion.
Pricing: included in the platform. Hobby is $5/month, Pro is $20/seat/month, with usage-based compute on top.
Best for product teams running web apps, APIs, workers, databases on a PaaS who want to spend zero time on observability infrastructure.
Honest trade-offs: no built-in distributed tracing, no APM-grade flamegraphs, no profiling. If you need those (most teams don't), you bolt on Honeycomb or Datadog via OTel.
Enterprise standard, all three pillars plus 600+ integrations.
Datadog is the default when budget is not the constraint. It does logs, metrics, traces, RUM, synthetics, security, and twenty other things they keep adding. The integration catalog is the broadest in the industry and the UI, while busy, is mature.
The famous problem is pricing. Datadog charges per host, per million custom metrics, per ingested GB of logs, per APM host, per RUM session. A mid-sized team can land at $50k to $200k per year. At Citrix-scale enterprises I watched bills cross seven figures.
Pricing: roughly $15/host/month for infrastructure, $31/host/month for APM, $0.10/GB ingest plus $1.70/million events for logs, plus add-ons. Wildly variable in practice.
Best for engineering orgs above 100 engineers where the cost of context-switching between tools exceeds the cost of Datadog.
Honest trade-offs: expensive, and the bill compounds as you adopt more products. Cost surprises are routine. The query language is powerful but not portable.
Open-source-friendly, modular, the most flexible serious option.
Grafana Cloud is the hosted version of the open-source Grafana stack: Grafana for dashboards, Loki for logs, Tempo for traces, Mimir for metrics, Pyroscope for continuous profiling. You can adopt one piece at a time and the components are themselves open source, so the exit ramp is real.
The free tier is generous (10k series, 50GB logs, 50GB traces) and the paid tiers scale linearly. If you already know Grafana from self-hosting, the hosted version removes the operational burden without locking you in.
Pricing: free tier with caps; Pro starts at $8/month plus usage ($0.50 per million log lines, $8/1000 metrics series, similar for traces).
Best for teams who want serious observability without enterprise pricing, and who like the open-source ethos.
Honest trade-offs: more pieces to learn than a single-vendor stack. LogQL is powerful but quirky. The UI is improving but still feels like five products in a trench coat.
Honeycomb is the platform I recommend when a team tells me they have a genuine distributed-systems problem. It's trace-first and event-based, meaning every signal is a structured event you can slice by any dimension. BubbleUp (their flagship feature) lets you click an outlier and ask "what's different about these requests" and get an actual answer.
It's the tool engineers reach for when "p99 went up" isn't enough and you need to understand which 0.1% of users are affected and why. Used heavily by Slack, Vanguard, the Honeycomb team's previous employers.
Pricing: free tier (20M events/month), Pro at $130/month for 100M events, Enterprise on quote.
Best for teams who already know their problem is "distributed systems debugging" and not "I need a dashboard."
Honest trade-offs: not a logs product in the traditional sense. If you want grep-style log search across unstructured text, Honeycomb is awkward. You have to think in events.
APM heritage, full platform, unusual per-user pricing.
New Relic invented APM as a category, then spent a decade losing market share to Datadog, then rebuilt as a unified telemetry platform with an unusual pricing model: you pay per user, not per host. This makes it dramatically cheaper for teams with a lot of infrastructure and few engineers, and dramatically more expensive for large engineering orgs.
The platform itself covers everything (APM, infra, logs, browser, mobile, synthetics) and the data model is unified under NRQL, their query language.
Pricing: free tier (100GB ingest, 1 full user); Standard Full User at $99/month, Pro at $349/month, plus $0.35/GB ingest beyond the free 100GB.
Best for infra-heavy teams with a small number of engineers (the per-user model rewards this).
Honest trade-offs: the per-user pricing penalizes large teams. The UI has improved but still carries APM-era patterns. NRQL is fine but yet another language to learn.
Sentry started as the de facto error tracker for SaaS and expanded into performance monitoring, session replay, and profiling. If you're a web or mobile product team and your number one observability need is "tell me when users hit errors and show me the stack trace," Sentry is the answer.
It's not trying to be Datadog. It's trying to be the tool product engineers open every morning. Session Replay (DOM-level recording of what the user did) is excellent for reproducing bugs.
Pricing: free tier; Team at $26/month, Business at $80/month, plus event-based usage.
Best for product engineering teams shipping web and mobile apps where user-facing errors are the primary observability concern.
Honest trade-offs: infrastructure monitoring is not its strength. If you need host metrics, network monitoring, or deep backend tracing, you'll pair it with something else.
Modern, designed-for-developers, much cheaper than Datadog.
Better Stack is what happens when someone looks at Datadog and asks "what if this didn't cost a kidney and had a UI built in this decade." It combines log management (Logtail), uptime monitoring (Better Uptime), and on-call (similar to PagerDuty) into one product.
It's not as deep as Datadog. It also costs roughly a tenth as much. For a startup or mid-size team that wants logs, uptime, and on-call from one vendor, it's an obvious choice.
Features: log management with ClickHouse-backed search, uptime monitoring, incident management and on-call, status pages, heartbeat monitoring, SQL-compatible log queries.
Pricing: free tier; Logs starts at $25/month for 30GB, Uptime starts at $25/month, bundled plans available.
Best for small-to-mid teams who want a consolidated, modern stack and don't need APM.
Honest trade-offs: no distributed tracing, no infrastructure metrics in the Datadog sense. The integration catalog is smaller. Newer product, fewer enterprise references.
Axiom built a logs and events platform on a serverless, object-storage-backed architecture. The result is that ingesting and storing logs is dramatically cheaper than ClickHouse-backed competitors, and queries are still fast because the engine is built for it.
If your problem is "I have terabytes of logs per day and Datadog is going to bankrupt me," Axiom is worth a serious look. Their pitch is essentially "pay 10x less for the same logs experience."
Pricing: free tier (0.5TB/month ingest, 30 day retention); Personal at $25/month, Team at $99/month, plus usage-based pricing that stays cheap at high volumes.
Best for teams with high log volumes (TB/day range) on tight budgets.
Honest trade-offs: it's primarily a logs/events product. No APM, no infrastructure metrics. APL (their query language) is yet another DSL to learn.
Legacy enterprise, security-flavored, now owned by Cisco.
Splunk is the granddaddy of log management. At a Fortune 500, Splunk is often already deployed, often for security and compliance use cases (SIEM workloads dominate). It's powerful, deeply customizable, and roughly the most expensive option in this list per GB.
Cisco acquired Splunk in 2024 for $28 billion, which signals where it sits in the market: a strategic platform play, not a tool you adopt fresh in 2026 unless you're a regulated enterprise.
Features: log management, SIEM, observability cloud (APM, infrastructure, RUM), SOAR, ITSI, hundreds of apps and integrations.
Pricing: workload-based or ingest-based, opaque, and effectively enterprise-only. Multi-six-figure deals are normal.
Best for regulated enterprises (finance, defense, healthcare) where Splunk is already the standard and SIEM workloads dominate.
Honest trade-offs: expensive, complex, slow to adopt. Not the right starting point for greenfield projects. SPL (their search language) is powerful but archaic.
Open-source path, free in licensing, expensive in operations.
You can build the whole stack yourself. Instrument with OpenTelemetry, send signals to your own Loki (logs), Tempo (traces), Mimir or Prometheus (metrics), visualize in Grafana. Zero license cost. All open source.
The catch is operations. Running Loki at scale is a specialized skill. Tempo's storage costs add up. You'll spend engineer-time on capacity planning, version upgrades, and debugging your observability stack instead of your product. For a team with infra-leaning engineers and strong opinions about lock-in, it's the right answer. For everyone else, the time cost dwarfs the license savings.
Features: OpenTelemetry SDKs and collector, Loki for logs, Tempo for traces, Prometheus/Mimir for metrics, Grafana for dashboards, Alertmanager for alerts.
Pricing: free in licensing; pay for infrastructure (object storage, compute) plus engineer time.
Best for infrastructure-heavy teams who want full control and are allergic to vendor lock-in.
Honest trade-offs: you are now an observability platform team in addition to whatever your actual job is. Upgrades, sharding, retention tuning, query performance, all of it lives with you.
The observability market in 2026 looks healthier than it has in years. OpenTelemetry is real, the cheap-storage entrants are credible, and the enterprise incumbents are finally feeling pricing pressure. The wrong move is to default to Datadog because everyone else does, or to default to self-hosting because licensing offends you. Both decisions tend to be made for the wrong reasons.
If you're on a PaaS that already gives you logs, metrics, and deploy history, start there and add an APM only when you have a real problem to solve. If you're on vanilla cloud and assembling a stack, Grafana Cloud or OTel-plus-self-hosted is the most defensible starting point. If you're at scale and budget isn't the bottleneck, Datadog or Honeycomb depending on whether you optimize for breadth or depth.
Happy shipping.
Angelo
Angelo Saraceno is a Solutions Engineer at Railway. Before Railway he was at Citrix, working inside Verizon and Lockheed environments, so he has seen what "enterprise IaaS" looks like after the slides come down. He writes about infrastructure, deployment, and the gap between how cloud is sold and how it runs in practice.












 Mientras el mandatario neoliberal ecuatoriano celebra estabilidad macroeconómica pero oculta que la remesas son lo que sostiene el día a día de las familias. Con 7.729 millones de dólares en 2025, las remesas de la diáspora ecuatoriana por el mundo, superan ya las exportaciones de petróleo.
Mientras el mandatario neoliberal ecuatoriano celebra estabilidad macroeconómica pero oculta que la remesas son lo que sostiene el día a día de las familias. Con 7.729 millones de dólares en 2025, las remesas de la diáspora ecuatoriana por el mundo, superan ya las exportaciones de petróleo.








