Over the past month I have been involved in the optimization of a Spatial Index creation/rebuild. Microsoft has several fixes included in the SQL Server 2012 SP1 CU7 Release
I have been asked by several people to tell the story of how I was able to determine the problem code lines that allowed the Spatial Index build/rebuild to go from taking 4+ days to only 4 hours on the same machine.
Environment
- 1.6 billion rows of data containing Spatial, geography polygon regions
- Data stored on SSD drives, ~100GB
- Memory on machine 256GB
- 64 schedulers across 4 NUMA nodes
Customer was on an 8 scheduler system that took 22 hours to build the index and expected to move to an 80 scheduler system and get at least 50% improvement (11 hours.) Instead it took 4.5 days!
Use of various settings (max dop, max memory percentage) only showed limited improvement. For example 16 schedulers took 28 hours, 8 scheduler took 22 hours, 80 too 4.5 days.
Just from the summary of the problem I was skeptical of a hot spot that required the threads to convoy and that is exactly what I found.
Started with DMVs and XEvents (CMemThread)
I started with the common DMVs (dm_exec_requests, dm_os_tasks, dm_os_wait_stats and dm_os_spinlock_stats.)
CMEMThread quickly jumped to the top of the list, taking an average of 3.8 days of wait time, per CPU over the life of the run. If I could address this I get back most of my wall clock time.
Using XEvent I setup a capture, bucketed by the waits on the CMemThread and looked at the stacks closely. This can be some with public symbols.
-- Create a session to capture the call stack when these waits occur. Send events to the async bucketizer target "grouping" on the callstack.
-- To clarify what we're doing/why this works I will also dump the same data in a ring buffer target
CREATE EVENT SESSION wait_stacks
ON SERVER
ADD EVENT sqlos.wait_info
(
action(package0.callstack)
where opcode = 1 -- wait completed
and wait_type = 190 -- CMEMTHREAD on SQL 2012
)
add target package0.asynchronous_bucketizer (SET source_type = 1, source = 'package0.callstack'),
add target package0.ring_buffer (SET max_memory = 4096)
With (MAX_DISPATCH_LATENCY = 1 SECONDS)
go
-- Start the XEvent session so we can capture some data
alter event session wait_stacks on server state = start
go
Run the repro script to create a couple of tables and cause some brief blocking so that the XEvent fires.
select event_session_address, target_name, execution_count, cast (target_data as XML)
from sys.dm_xe_session_targets xst
inner join sys.dm_xe_sessions xs on (xst.event_session_address = xs.address)
where xs.name = 'wait_stacks'
What I uncovered was the memory object used by spatial is created as a thread safe, global memory object (PMO) but it was not partitioned. I PMO is like a private HEAP and the spatial, object is marked thread safe for multi-threaded access. Reference: http://blogs.msdn.com/b/psssql/archive/2012/12/20/how-it-works-cmemthread-and-debugging-them.aspx
A parameter to the creation of the memory object is the partitioning schema (by NUMA node, CPU or none.) Under the debugger I forced the scheme to be, partitioned by NUMA Node and the runtime came down to ~25 hours on 80 schedulers. I then forced the partitioning by scheduler (CPU) and achieved an 18 hour completion.
Issue #1 was identified and filed with the SQL Server development team. When creating the memory object used for ANY spatial activity partition it by NUMA Node. Partitioning adds a bit more memory overhead so we don’t target per CPU unless we know it is really required. We also provide startup, trace flag –T8048 that upgrades any NUMA partitioned memory object to CPU partitioned.
Why is –T8048 important? Heavily used synchronization objects tend to get very hot at around 8 CPUs. You may have read about the MAX DOP targets for SQL that recommend 8 as an example. If the NUMA node, CPU density if 8 or less node partitioning may suffice but if the density (like on this system with 16 CPUs per node) increases the trace flag can be used to further partition the memory object.
In general we avoid use of –T8048 because in many instances partitioning by CPU starts to approach a design of scheduler local memory. Once we get into this state we always consider the design to see if a private memory object is a better long term, design solution.
Memory Descriptor
Now that I had the CMemThread out of the way I went back to the DMVs and XEvents and looked for the next target. This time I found a spinlock object encountering millions of back-offs and trillions of spins in just a 5 minutes. Using a similar technique as shown above I bucketed the spinlock back-off stacks.
The spinlock was the SOS_ACTIVEDESCRIPTOR. The descriptor, spinlock is used to protect aspects of the memory manager and how it is able to track and hand out memory. Each scheduler can have an active descriptor, pointing to hot, free memory to be used. Your question at this juncture might be, why, if you have a CPU partitioned memory object would this be a factor.
Issue #2 is uncovered but to understand it you have to understand the spatial index build flow first. The SQL Server spatial data type is exposed in the Microsoft.SqlServer.Types.dll (managed assembly) but much of the logic is implemented in the SqlServerSpatial110.dll (native).
Sqlserver Process (native) –> sqlaccess.dll (managed) –> Microsoft.SqlServer.Types.dll(managed) –> SqlServerSpatial110.dll (native) –> sqlos.dll (native)
Shown here is part of the index build plan. The nested loops in native SQL engine, doing a native clustered index scan and then calling the 'GetGergraphyTessellation_VarBinary' managed implementation for each row.

CREATE SPATIAL INDEX [idxTeset] ON [dbo].[tblTest]
( [GEOG] )USING GEOGRAPHY_GRID
WITH (GRIDS =(LEVEL_1 = MEDIUM,LEVEL_2 = MEDIUM,LEVEL_3 = MEDIUM,LEVEL_4 = MEDIUM),
CELLS_PER_OBJECT = 16, PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
The implementation of the tessellation is in the SqlServerSpatial110.dll (native) code that understands it is hosted in the SQL Server process when used from SQL Server. When in the SQL Server process space the SQL Server (SOS) memory objects are used. When used in a process outside the SQL Server the MSVCRT memory allocators are used.
What is the bug? Without going into a specifics, when looping back to the SQLOS, memory allocators, didn’t properly honor the scheduler id hint and the active partition ended up always being partition 0 making the spinlock hot.
To prove I could gain some speed by fixing this issue I used the debugger to make SqlServerSpatial110.dll think it was running outside of the SQL Server process and use the MSVCRT memory allocators. The MSVC allocators allowed me to dip near the 17 hour mark.
A fix for the SOS_ACTIVEDESCRIPTIOR issue dropped the index creation/rebuild to 16 hours on the 80 scheduler system.
First set of (2) fixes released: http://support.microsoft.com/kb/2887888
Geometry vs Geography
Before I continued on I wanted to understand the plan execution a bit better. Found out that the Table Valued Function (TVF) is called for each row to help build the spatial, index grid accepting 3 parameters and a return value. You can read about these at: http://technet.microsoft.com/en-us/library/bb964712(v=SQL.105).aspx
Changing the design of TVF execution is not something I would be able to achieve in a hot fix so I set off to learn more about the execution and if I could streamline it. In my learning I found out that the logic to build the grid is highly tied to the data stored in the spatial data type, and the type used. For example, LineString requires less mathematical computations than a Polygon.
Geometry is a flat map and Geography is a map of the round earth. My customer could not move to a flat map as they are tracking polygons down to 120th of a degree of latitude and longitude. The distance of Longitude 0 degrees and 30 degrees as the equator is different than the distance 2000 miles north of the equator, for example.
The geography calculations are often more CPU intense because of the additional logic to use cos, radius, diameter, and so forth. I am unlikely able to make the MSVC runtime, cos function faster and the customer requires Polygons.
Index Options
I was able to adjust the ALTER/CREATE index grid levels and shave some time off the index creation/rebuild. The problem with that is going to a LOW grid or limiting the number of grid entries for a row can force me to do additional filtering for runtime queries (residual where clause activities.) In this case going to LOW was trading index build speed for increased query durations. This was a non-goal for the customer and the savings in time was not significant in my testing.
P/Invokes
Those familiar with managed and native code development may have asked the same question I did. How many P/Invokes are occurring to execute the TVF as the function is being called and we are going in and out of native?
This was something I could not change in a hot fix but I broken the reproduction down to 500,000 rows and filed a work item with the SQL Server development team, who is investigating, to see if we can go directly to the native, SqlServerSpatial110.dll and skip the managed logic to avoid the P/Invokes.
SOS_CACHESTORE, SOS_SELIST_SIZED_SLOCK, and SOS_RW
Still trying to reach the 11 hour mark I went back to looking at the DMVs and XEvent information for hot spots. I noticed a few more spinlocks that were hot (SOS_CACHESTORE, SOS_SELIST_SIZED_SLOCK, and SOS_RW.)
Found the cache and selist was related to the CLR Procedure Cache. The CLR procedure, execution plans are stored in a cache. Each parallel thread (80 in this test) uncached, used, cached the TVF. As you can imagine the same hash bucket is used for all 80 copies of the execution plan (same object id) and the CLR Procedure Cache is not partitioned as much as the SQL Server, TSQL, procedure cache.
Issue #3 - The bucket and list was getting hot as each execution uncached and cached the CLR, TVF plan. The SQL Server dev team was able to update this behavior to the additional overhead. Reduced the execution by ~45 minutes.
The SOS_RW was found to protect the application domain for the database. Each time the CLR procedure was executed the application domain (AppDomain) had a basic validation step and the spinlock for the reader, writer lock in the SOS_RW object was hot.
Issue #4 – SQL Server development was able to hold a better reference to the application domain across the entire query execution. Reducing the execution by ~25 minutes.
Array Of Pages
The Polygon can contain 1000s of points and is supported in the SqlServerSpatial110.dll with an array of page allocations. Think of it a bit like laying down pairs of doubles in a memory location. This is supported by –>AllocPage logic inside a template class that allows ordinal access to the array but hide the physical allocation layout from the template user. As the polygon requires more pages they are added to an internal list as needed.
Using the Windows Performance Analyzer and queries against the data (<<Column>>.ToString(), datalength, …) we determined a full SQL Server page was generally not needed. A better target than 8K is something like 1024 bytes.
Issue #5 - By reducing the target size used by each TVF invocation SQL Server can better utilize the partitioned memory object. This reduces the number of times pages need to be allocated and freed all the way to the memory manager. The per scheduler or NUMA node memory objects hold a bit a memory in a cache. This allows better utilization of the memory manager, less memory usage overall and gained us another ~35 minutes of runtime reduction.
What Next Is Big - CLR_CRST?
As you can see I am quickly running out of big targets to get me under the 11 hour mark. I am slowly getting to 13 hours but running out of hot spots to attack.
I am running all CPUs at 100% on the system, taking captures of DMVs, XEvents and Windows Performance Analyzer. Hot spots like scheduler switch, cos and most of the function captures are less than 1% of the overall runtime. At this rate I am looking at trying to optimize 20+ more functions to get approach the 11 hours.
That is, except for one wait type I was able to catch, CLR_CRST. Using XEvent I was able to see that CLR_CRST is associated with GC activities as SQL Server hosts the CLR process.
Oh great, how am I going to reduce GC activity? This is way outside of the SQL Server code path. Yet, I knew most, if not all the core memory allocations were occurring in SqlServerSpatial110.dll using the SQLOS hosting interfaces. Why so much GC activity.
What I found was the majority of the GC was being triggered from interop calls. When you traverse from managed to native the parameters have to be pinned to prevent GC from moving the object while referenced in native code.
The Microsoft.SqlServer.Types.dll used a pinner class that performed a GCHandle::Alloc to pin the object and when the function was complete GCHandle::Free. Turns out this had to be used for 12 parameters to the tessellation calls. When I calculated the number of calls, 16. billion per row, add in the number of grid calculations per row, etc.. the math lands me at 7,200 GCHandle::Alloc/GCHandle::Free calls, per millisecond, per CPU for the a run on 80 schedulers over a 16 hour window.
Working with the .NET development team they pointed out the fixed/__pin keywords that are used to create, stack local references (pin) objects in the .NET heap without requiring the overhead of GCHandle::Alloc and ::Free. http://msdn.microsoft.com/en-us/library/f58wzh21.aspx
Issue #6 – Change the Geographic, grid method in the Microsoft.SqlServer.Types.dll to use the stack, local object pin references. BIG WIN – The entire index build now takes 3 hours 50 minutes on the 80 scheduler system.
The following is the new CPU usage with all the bug fixes. The valley is the actual .NET Garbage collection activity. The performance analysis now shows the CPUs are pegged doing mathematical calculations and the index build will scale, reasonably as more schedulers are available.

In order to maximize the schedulers for the CPU bound index activity I utilized a resource pool/group – MAX DOP setting. http://blogs.msdn.com/b/psssql/archive/2013/09/27/how-it-works-maximizing-max-degree-of-parallelism-maxdop.aspx
create workload group IndexBuilder
with
(
MAX_DOP = 80,
REQUEST_MAX_MEMORY_GRANT_PERCENT = 66
)
Why was this important to customer?
Like any endeavor, getting the best result for your money is always a goal. However, some of the current Spatial limiations fueled the endeavor.
- Spatial indexes must be built offline. They are not online aware a lock down the core table access during the index creation/rebuild.
- Spatial data is not allowed as part of a partitioning function. This means a divide and scale out type of approach using partitioned tables is not a clear option. (Note you can use separate tables and a partitioned view, using a constraint on a different column to achieve a scale out like design where smaller indexes can be maintained on each base table.)
- We looked at a Performance Data Warehouse (PDW) approach but PDW does not currently support Spatial data types.
- HDInsight has Spatial libraries but the nature of the interactive work the customers application was doing required a more interactive approach. However, for batch and analysis activities HDInsight may be a great, scale out, compute intensive solution.
- SQL Server handles and provides a full featured, Spatial library for Polygon storage, manipulation and query activities. Other products may only support points or are not as feature rich.
Fix References
The following Microsoft Knowledge Base articles contain the appropriate links to these fixes.
Fixes are included in SQL Server 2012 SP1 CU7 - http://support.microsoft.com/kb/2894115/en-us
Note: Don’t forget you have to enabled the proper trace flags to enable the fixes.
|
2887888 (http://support.microsoft.com/kb/2887888/ ) | FIX: Slow performance in SQL Server when you build an index on a spatial data type of a large table in a SQL Server 2012 instance |
|
2887899 (http://support.microsoft.com/kb/2887899/ ) | FIX: Slow performance in SQL Server 2012 when you build an index on a spatial data type of a large table |
|
2896720 (http://support.microsoft.com/kb/2896720/ ) | FIX: Slow performance in SQL Server 2012 when you build an index on a spatial data type of a large table |
Recap
I realize this was a bit of a crash course in Spatial and internals. It was a bit like this for me as well. This was my first, in depth experience with tuning Spatial activities in SQL Server. As you have read SQL Server, with the fixes, is very effective with Spatial data and can scale to large numbers.
The DMVs and XEvents are perfect tools to help narrow down the hot spot and possible problems. Understanding the hot spot and then building a plan to avoid it could provide you with significant performance gains.
If you are using spatial you should consider applying the newer build(s), enabling trace flags and creating a specific workload group to assign maintenance activities to.
Additional Tuning
The following is an excellent document discussing the ins and outs of spatial query tuning.
http://social.technet.microsoft.com/wiki/contents/articles/9694.tuning-spatial-point-data-queries-in-sql-server-2012.aspx
Bob Dorr - Principal SQL Server Escalation Engineer


 As I said, this isn’t something I have much experience with as a SQL Server professional. The systems that I support for my employer are bound by various government rules and regulations, both U.S. and abroad, not to mention PCI compliance and all of the other compliances that we have to comply with. Plus, some of our customers simply don’t want their data in the cloud. All of these things will change eventually I’m sure, but for the time being, no cloud for me. Our corporate email, calendar and things of that nature are all “in the cloud”, but not our databases.
As I said, this isn’t something I have much experience with as a SQL Server professional. The systems that I support for my employer are bound by various government rules and regulations, both U.S. and abroad, not to mention PCI compliance and all of the other compliances that we have to comply with. Plus, some of our customers simply don’t want their data in the cloud. All of these things will change eventually I’m sure, but for the time being, no cloud for me. Our corporate email, calendar and things of that nature are all “in the cloud”, but not our databases.



















 Over the last couple of months I’ve been busy phasing out an old EMC CLARiiON CX3 system and migrating all the data to either newer
Over the last couple of months I’ve been busy phasing out an old EMC CLARiiON CX3 system and migrating all the data to either newer 










 The masochists in the crowd might enjoy running server-side traces around the clock to capture every SQL statement – free and built-in to SQL Server, but cumbersome to work with and store, especially on a busy system. Plus, they’re being phased out in favor of Extended Events – more powerful and flexible, but yet another complicated thing to learn. Personally, I’ve found capturing trace logs around the clock to be extreme overkill for most needs. My busy OLTP system generates hundreds of gigabytes of trace log files every day. Mining through them to find “that problem” is impossible.
The masochists in the crowd might enjoy running server-side traces around the clock to capture every SQL statement – free and built-in to SQL Server, but cumbersome to work with and store, especially on a busy system. Plus, they’re being phased out in favor of Extended Events – more powerful and flexible, but yet another complicated thing to learn. Personally, I’ve found capturing trace logs around the clock to be extreme overkill for most needs. My busy OLTP system generates hundreds of gigabytes of trace log files every day. Mining through them to find “that problem” is impossible.



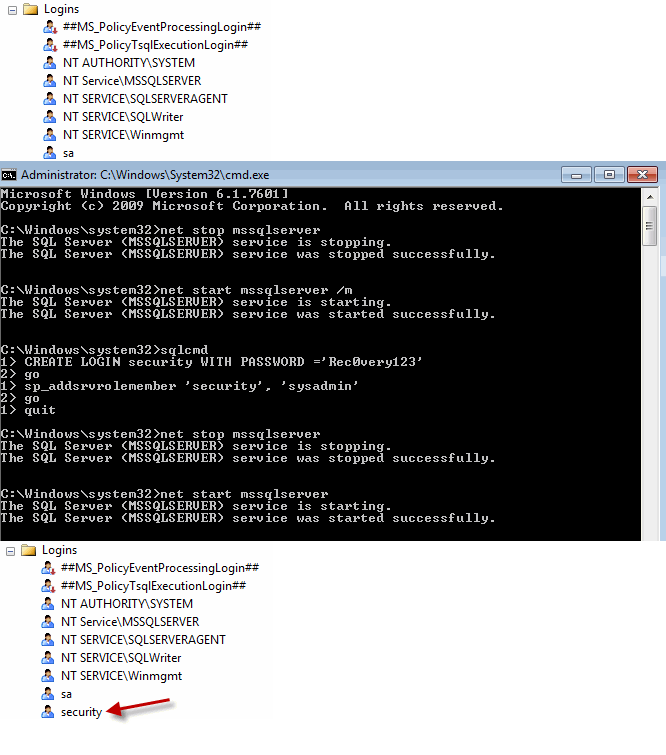
 Like a ninja in the night, Hanz M., AKA Hanzo, stalks across Hesse University’s Dresden campus. The go-to man in the IT department, he fixes the messes that others leave behind. This is one of his stories.
Like a ninja in the night, Hanz M., AKA Hanzo, stalks across Hesse University’s Dresden campus. The go-to man in the IT department, he fixes the messes that others leave behind. This is one of his stories. [Advertisement] Make your team a DevOps team with
[Advertisement] Make your team a DevOps team with 


