[NOTE: Update 12 Nov 2014. The most recent bug (KB article KB2965069) is THANKFULLY very unlikely for most environments (mentioned below). As a result, I’m glad to say that we can use OPTION (RECOMPILE) as a much easier (and safer) solution. So, while I’ll still leave solution 3 as an option if you run into troubles with OPTION (RECOMPILE), I can luckily say that if you’re on the latest SP/CU – the problems are incredibly unlikely. The BEST hybrid solution is shown below as solution 2.]
In my SQL PASS Summit 2014 session last week, I spoke about building high performance stored procedures and properly dealing with parameter sniffing problems… if you’re interested, the session was recorded for PASStv and you can watch it here.
It all ties to something incredibly common in development – I call it the multipurpose procedure. Simply put, it’s one application dialog with many possible options and then sitting behind it – ONE stored procedure. This one stored procedure is supposed to handle every possible case of execution with multiple parameters. For example, imagine a dialog to search for a customer.
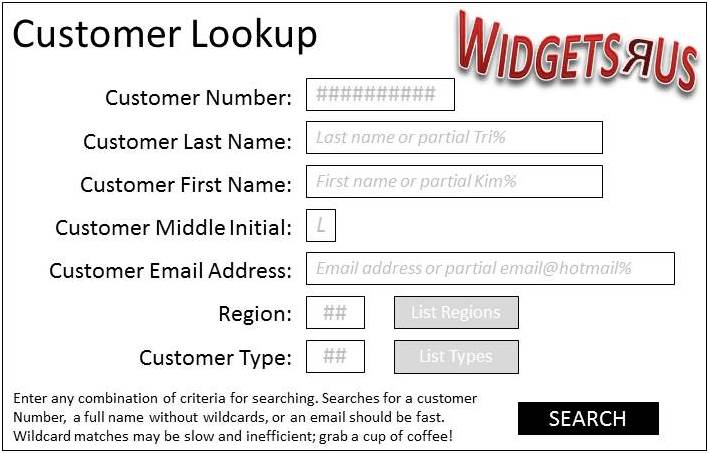
The user can enter in any combination of these elements and the procedure’s header looks like this:
CREATE PROC [dbo].[GetCustomerInformation]
(
@CustomerID INT = NULL
, @LastName VARCHAR (30) = NULL
, @FirstName VARCHAR (30) = NULL
, @MiddleInitial CHAR(1) = NULL
, @EmailAddress VARCHAR(128) = NULL
, @Region_no TINYINT = NULL
, @Cust_code TINYINT = NULL
)
...
And then the procedure’s main WHERE clause looks like this:
WHERE ([C].[CustomerID] = @CustomerID OR @CustomerID IS NULL)
AND ([C].[lastname] LIKE @LastName OR @LastName IS NULL)
AND ([C].[firstname] LIKE @FirstName OR @FirstName IS NULL)
AND ([C].[middleinitial] = @MiddleInitial OR @MiddleInitial IS NULL)
AND ([C].[EmailAddress] LIKE @EmailAddress OR @EmailAddress IS NULL)
AND ([C].[region_no] = @Region_no OR @Region_no IS NULL)
AND ([C].[cust_code] = @Cust_code OR @Cust_code IS NULL)GO
Or, possibly like this:
WHERE [C].[CustomerID] = COALESCE(@CustomerID, [C].[CustomerID])
AND [C].[lastname] LIKE COALESCE(@lastname, [C].[lastname])
AND [C].[firstname] LIKE COALESCE(@firstname, [C].[firstname])
AND [C].[middleinitial] = COALESCE(@MiddleInitial, [C].[middleinitial])
AND [C].[Email] LIKE COALESCE(@EmailAddress, [C].[Email])
AND [C].[region_no] = COALESCE(@Region_no, [C].[region_no])
AND [C].[cust_code] = COALESCE(@Cust_code, [C].[Cust_code]);
Or, maybe even like this:
WHERE [C].[CustomerID] = CASE WHEN @CustomerID IS NULL THEN [C].[CustomerID] ELSE @CustomerID END
AND [C].[lastname] LIKE CASE WHEN @lastname IS NULL THEN [C].[lastname] ELSE @lastname END
AND [C].[firstname] LIKE CASE WHEN @firstname IS NULL THEN [C].[firstname] ELSE @firstname END
AND [C].[middleinitial] = CASE WHEN @MiddleInitial IS NULL THEN [C].[middleinitial] ELSE @MiddleInitial END
AND [C].[Email] LIKE CASE WHEN @EmailAddress IS NULL THEN [C].[Email] ELSE @EmailAddress END
AND [C].[region_no] = CASE WHEN @Region_no IS NULL THEN [C].[region_no] ELSE @Region_no END
AND [C].[cust_code] = CASE WHEN @Cust_code IS NULL THEN [C].[cust_code] ELSE @Cust_code END
But, no matter which of these it looks like – they’re all going to perform horribly. An OSFA procedure does not optimize well and the end result is that you’ll get one plan in cache. If that was generated from a different combination of parameters than the ones you’re executing, you might get an absolutely abysmal plan. The concept is fairly simple – when a procedure executes and there isn’t already a plan in cache (for that procedure), then SQL Server has to generate one. To do so it “sniffs” the input parameters and optimizes based on the parameters sniffed. This is the plan that gets stored with the procedure and saved for subsequent executions. Depending on your workload characteristics, you might end up with a very common plan in cache and other users also executing the common parameters might see reasonable performance (especially if the WHERE does NOT use LIKE and has nothing but equality-based criteria [those aren’t quite as bad as this one]). But, there will still be cases where an atypical execution performs horribly.
And, unfortunately, sometimes the worst combination happens – a very atypical execution is the one that gets sniffed and then everyone suffers.
So, the admin might update statistics or force a recompile (or, even restart SQL Server) to try and get around this problem. These things “fix” the immediate problem by kicking the plan out of cache but they are NOT A SOLUTION.
Solution 1: The Simple Solution – OPTION (RECOMPILE)
Since SQL Server 2005, we’ve had an option to add OPTION (RECOMPILE) to the offending statement. When OPTION (RECOMPILE) works – it works incredibly well. However, there have been bugs and you’ll want to make sure that you’re on the latest SP or CU. It’s definitely had a bit of a checkered past. Here’s a list of issues and links to KB articles / bugs around this problem:
-
KB2965069 FIX: Incorrect result when you execute a query that uses WITH RECOMPILE option in SQL Server 2012 or SQL Server 2014. Fixed in:
- Cumulative Update 4 for SQL Server 2014
- Cumulative Update 2 for SQL Server 2012 SP2
- Cumulative Update 11 for SQL Server 2012 SP1
-
KB968693 FIX: A query that uses parameters and the RECOMPILE option returns incorrect results when you run the query in multiple connections concurrently in SQL Server 2008. Fixed in:
- SQL Server 2008 CU4
- SQL Server 2008 R2 CU1
- I don’t have a KB article link for this one but in both SQL Server 2008 and SQL Server 2008 R2 there are versions where some performance related features were unable. For example, filtered indexes could not be used inside of stored procedures even if you used OPTION (RECOMPILE) because of changes with the behavior or bugs. So, I’d fall back on using DSE (shown by solution 3).
Anyway, despite these issues (the first one listed above – is INCREDIBLY unlikely), I LOVE the simplicity of OPTION(RECOMPILE) because all you have to do is change the offending statement like this:
SELECT ...
FROM ...
WHERE ...
OPTION (RECOMPILE);
The reason I love this is for the simplicity of the statement. The reason that I have an issue with just doing this as a standard is two-fold:
- First, if you do this too often (or, for extremely frequently executed procedures), you might end up using too much CPU.
- Second, I’ve seen some environments where this is used to fix ONE problem and then it becomes a standard for ALL problems. This DEFINITELY should NOT become a standard coding practice. You only want to use this if your testing shows parameter sniffing problems and plan unstability. Stored procedures that have stable plans should be compiled, saved, and reused.
A better solution is one where you recompile for unstable plans but for stable plans – you place those in cache for reuse.
A Hybrid Solution – recompile when unstable, cache when stable
My main problem with adding OPTION (RECOMPILE) to many statements is that it can be costly to do when you’re executing thousands of procedures over and over again. And, if you really think about it, not all combinations really need to be recompiled.
For example, take an easier combination of just 3 parameters: CustomerID, Lastname, and Firstname. The possible combinations for execution will be:
- CustomerID alone
- Lastname alone
- Firstname alone
- CustomerID and Lastname together
- CustomerID and Firstname together
- Firstname and Lastname together
- Or, all three – CustomerID, Lastname, and Firstname
My questions for you to consider are:
- Are all of those going to want the same execution plan?
- And, what if they supply wildcards?
The most important consideration is that ANY query that submits CustomerID should NOT be recompiled, right? Think about it – if someone says I want to search for all of the people that have an ‘e’ in their last name (Lastname LIKE ‘%e%’) AND that have an ‘a’ in their first name (Firstname LIKE ‘%a%’) AND that have a CustomerID of 123456789 then all of a sudden this becomes an incredibly simple query. We’re going to go an lookup CustomerID 123456789 and then check to see if they have an ‘a’ in their first name and an ‘e’ in their last name. But, the lookup is incredibly simple. So, ANY execution where CustomerID is supplied should NOT be recompiled; the plan for those executions is STABLE. However, Lastname and Firstname searches might be highly unstable – especially if there’s a leading wildcard. So, if wildcard is present then let’s recompile if they don’t supply at least 3 characters for BOTH the first name and last name – preceding the wildcard character. And, it’s also OK if they don’t supply a wildcard at all. Then, the overall number of recompilations will be much lower – we’ll save CPU and we’ll get better performance by using a lot of STABLE, precompiled plans.
To do this, there are TWO versions. Solution 2 uses OPTION (RECOMPILE) strategically. Solution 3 using dynamic string execution instead.
Solution 2 – recompile when unstable [by adding OPTION (RECOMPILE)], cache when stable (using sp_executesql)
There are absolutely some criteria when plan stability can be predicted. For these, we will build the statement to concatenate only the non-NULL parameters and then execute normally using sp_executesql. For where it’s unknown or unstable, we’ll recompile by OPTION (RECOMPILE) to the statement. For all executions, use sp_executesql. And, of course, this is ONLY substitution for parameters. And, this should only be done for the most frequently executed procedures. You don’t have to do this for every procedure but it’s extremely beneficial for things that are heavily executed.
----------------------------------------------
-- Solution 2
----------------------------------------------
CREATE PROC [dbo].[GetCustomerInformation]
(
@CustomerID BIGINT = NULL
, @LastName VARCHAR (30) = NULL
, @FirstName VARCHAR (30) = NULL
, @MiddleInitial CHAR(1) = NULL
, @EmailAddress VARCHAR(128) = NULL
, @Region_no TINYINT = NULL
, @Member_code TINYINT = NULL
)
AS
IF (@CustomerID IS NULL
AND @LastName IS NULL
AND @FirstName IS NULL
AND @MiddleInitial IS NULL
AND @EmailAddress IS NULL
AND @Region_no IS NULL
AND @Member_code IS NULL)
BEGIN
RAISERROR ('You must supply at least one parameter.', 16, -1);
RETURN;
END;
DECLARE @ExecStr NVARCHAR (4000),
@Recompile BIT = 1;
SELECT @ExecStr =
N'SELECT COUNT(*) FROM [dbo].[Customers] AS [C] WHERE 1=1';
IF @CustomerID IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[CustomerID] = @CustID';
IF @LastName IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[LastName] LIKE @LName';
IF @FirstName IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[Firstname] LIKE @FName';
IF @MiddleInitial IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[MiddleInitial] = @MI';
IF @EmailAddress IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[EmailAddress] LIKE @Email';
IF @Region_no IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[Region_no] = @RegionNo';
IF @Member_code IS NOT NULL
SELECT @ExecStr = @ExecStr
+ N' AND [C].[Member_code] = @MemberCode';
-- These are highly limited sets
IF (@CustomerID IS NOT NULL)
SET @Recompile = 0
IF (PATINDEX('%[%_?]%', @LastName) >= 4
OR PATINDEX('%[%_?]%', @LastName) = 0)
AND (PATINDEX('%[%_?]%', @FirstName) >= 4
OR PATINDEX('%[%_?]%', @FirstName) = 0)
SET @Recompile = 0
IF (PATINDEX('%[%_?]%', @EmailAddress) >= 4
OR PATINDEX('%[%_?]%', @EmailAddress) = 0)
SET @Recompile = 0
IF @Recompile = 1
BEGIN
--SELECT @ExecStr, @Lastname, @Firstname, @CustomerID;
SELECT @ExecStr = @ExecStr + N' OPTION(RECOMPILE)';
END;
EXEC [sp_executesql] @ExecStr
, N'@CustID bigint, @LName varchar(30), @FName varchar(30)
, @MI char(1), @Email varchar(128), @RegionNo tinyint
, @MemberCode tinyint'
, @CustID = @CustomerID
, @LName = @LastName
, @FName = @FirstName
, @MI = @MiddleInitial
, @Email = @EmailAddress
, @RegionNo = @Region_no
, @MemberCode = @Member_code;
GO
Solution 2 is the preferred and best method to create a balance where you don’t just recompile every time. This will give you better long-term scalability.
Solution 3 – recompile when unstable [by using DSE], cache when stable (using sp_executesql)
In the past, if I’ve ever run into problems with OPTION (RECOMPILE), I always consider (albeit, not lightly) rewriting the statement using a dynamic string instead; this always works! But, yes, it’s a pain to write. It’s a pain to troubleshoot. And, above all, yes, you have to be careful of SQL injection. There are ways to reduce and even eliminate the potential for problems (and, not all DSE can). Above all, you do need to make sure you have clean input (limiting only to valid input for the type of column such as characters for names and emails, etc.). Check out this blog post if you want more information Little Bobby Tables, SQL Injection and EXECUTE AS.
Based on that blog post, the solution to this problem is the following code.
-- To reduce the potential for SQL injection, use loginless
-- users. Check out the "Little Bobby Tables" blog post for
-- more information on what I'm doing in this code / execution
-- to reduce the potential surface area of the DSE here.
CREATE USER [User_GetCustomerInformation]
WITHOUT LOGIN;
GO
GRANT SELECT ON [dbo].[Customers]
TO [User_GetCustomerInformation];
GO
-- You'll need this if you want to review the showplan
-- for these executions.
GRANT SHOWPLAN TO [User_GetCustomerInformation];
GO
----------------------------------------------
-- Solution 3
----------------------------------------------
CREATE PROC [dbo].[GetCustomerInformation]
(
@CustomerID BIGINT = NULL
, @LastName VARCHAR (30) = NULL
, @FirstName VARCHAR (30) = NULL
, @MiddleInitial CHAR(1) = NULL
, @EmailAddress VARCHAR(128) = NULL
, @Region_no TINYINT = NULL
, @Cust_code TINYINT = NULL
)
WITH EXECUTE AS N'User_GetCustomerInformation'
AS
IF (@CustomerID IS NULL
AND @LastName IS NULL
AND @FirstName IS NULL
AND @MiddleInitial IS NULL
AND @EmailAddress IS NULL
AND @Region_no IS NULL
AND @Cust_code IS NULL)
BEGIN
RAISERROR ('You must supply at least one parameter.', 16, -1);
RETURN;
END;
DECLARE @spexecutesqlStr NVARCHAR (4000),
@ExecStr NVARCHAR (4000),
@Recompile BIT = 1;
SELECT @spexecutesqlStr =
N'SELECT * FROM [dbo].[Customers] AS [C] WHERE 1=1';
SELECT @ExecStr =
N'SELECT * FROM [dbo].[Customers] AS [C] WHERE 1=1';
IF @CustomerID IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[CustomerID] = @CustID';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[CustomerID] = CONVERT(BIGINT, ' + CONVERT(NVARCHAR(30),@CustomerID) + N')';
END
IF @LastName IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[LastName] LIKE @LName';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[LastName] LIKE CONVERT(VARCHAR(30),' + QUOTENAME(@LastName, '''''') + N')';
END
IF @FirstName IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[Firstname] LIKE @FName';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[FirstName] LIKE CONVERT(VARCHAR(30),' + QUOTENAME(@FirstName, '''''') + N')';
END
IF @MiddleInitial IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[MiddleInitial] = @MI';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[MiddleInitial] = CONVERT(CHAR(1), ' + QUOTENAME(@MiddleInitial, '''''') + N')';
END
IF @EmailAddress IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[EmailAddress] LIKE @Email';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[EmailAddress] LIKE CONVERT(VARCHAR(128), ' + QUOTENAME(@EmailAddress, '''''') + N')';
END
IF @Region_no IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[Region_no] = @RegionNo';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[Region_no] = CONVERT(TINYINT, ' + CONVERT(NVARCHAR(5),@Region_no) + N')';
END
IF @Cust_code IS NOT NULL
BEGIN
SELECT @spexecutesqlStr = @spexecutesqlStr
+ N' AND [C].[Cust_code] = @MemberCode';
SELECT @ExecStr = @ExecStr
+ N' AND [C].[Cust_code] = CONVERT(TINYINT, ' + CONVERT(NVARCHAR(5), @Cust_code) + N')';
END
-- These are highly limited sets
IF (@CustomerID IS NOT NULL)
SET @Recompile = 0
IF (PATINDEX('%[%_?]%', @LastName) >= 4
OR PATINDEX('%[%_?]%', @LastName) = 0)
AND (PATINDEX('%[%_?]%', @FirstName) >= 4
OR PATINDEX('%[%_?]%', @FirstName) = 0)
SET @Recompile = 0
IF (PATINDEX('%[%_?]%', @EmailAddress) >= 4
OR PATINDEX('%[%_?]%', @EmailAddress) = 0)
SET @Recompile = 0
IF @Recompile = 1
BEGIN
-- Use this next line for testing
-- SELECT @ExecStr -- For testing
EXEC (@ExecStr);
END
ELSE
BEGIN
-- Use this next line for testing
-- SELECT @spexecutesqlStr, @Lastname, @Firstname, @CustomerID;
EXEC [sp_executesql] @spexecutesqlStr
, N'@CustID bigint, @LName varchar(30), @FName varchar(30)
, @MI char(1), @Email varchar(128), @RegionNo tinyint
, @CustomerCode tinyint'
, @CustID = @CustomerID
, @LName = @LastName
, @FName = @FirstName
, @MI = @MiddleInitial
, @Email = @EmailAddress
, @RegionNo = @Region_no
, @CustomerCode = @Cust_code;
END;
GO
This solution should NOT be used as a standard. But, it is an option for handling some cases where OPTION (RECOMPILE) isn’t giving you the plans / performance that you need. This solution is more complicated for developers to code. But, I’m not saying you have to do this for absolutely everything. Just work through the most critical procedures that are causing you the most grief.
The RIGHT way to handle multipurpose procedures
The hybrid solution (solution 2) is more complicated for developers to code. Remember, I’m not saying you have to do this for absolutely everything. Just work through the most critical procedures that are causing you the most grief (because they’re the most heavily executed procedures). The hybrid solution really gives you the best of all worlds here:
- It reduces CPU by only recompiling for unstable combinations
- It allows every combination executed with sp_executesql to get its own plan (rather than one per procedure)
- It allows stable plans to be put in cache and reused for subsequent executions (which reduces your impact to CPU and gives you long-term scalability)
Above all, you need to test that this works as expected but not only will you get better plans but you’ll also scale better!
Cheers,
kt
For more information
- Check out my PASS presentation DBA-313 here.
- Check out my Pluralsight course: SQL Server: Optimizing Ad Hoc Statement Performance here.
- Check out my Pluralsight course: SQL Server: Optimizing Stored Procedure Performance here.
- Check out our Immersion Event: IEPTO2: Immersion Event on Performance Tuning and Optimization – Part 2 here.
The post Building High Performance Stored Procedures appeared first on Kimberly L. Tripp.


 .
.















 Simon worked in a small shop that supported a sales system. One of the features of the system was that sales commissions were stored in the database. For the sake of simplicity, the sales commissions were stored as the multiplier factor needed to compute the total sale. For example, a 5% commission on $100 would be $5, so the factor would be 1.05 so you could just multiply: 100 * 1.05 -> 105.
Simon worked in a small shop that supported a sales system. One of the features of the system was that sales commissions were stored in the database. For the sake of simplicity, the sales commissions were stored as the multiplier factor needed to compute the total sale. For example, a 5% commission on $100 would be $5, so the factor would be 1.05 so you could just multiply: 100 * 1.05 -> 105.























{kind=link}