Reviewed By: Denzil Ribeiro, Dimitri Furman, Mike Weiner, Rajesh Setlem, Murshed Zaman
Background
SQLCAT often works with early adopter customers, bring them into our lab, and run their workloads. With SQL Server now available on Linux, we needed a way to visualize performance and PerfMon, being a Windows only tool, was no longer an option. After a lot of research on ways to monitor performance in Linux, we didn’t find a de facto standard. However, we did learn that in the open source community there are many ways of accomplishing a goal and that there is no one “right way”, rather choose the way that works best for you.
The following solutions were tested:
- Graphing with Grafana and Graphite
- Collection with collectd and Telegraf
- Storage with Graphite/Whisper and InfluxDB
We landed on a solution which uses InfluxDB, collectd and Grafana. InfluxDB gave us the performance and flexibility we needed, collectd is a light weight tool to collect system performance information, and Grafana is a rich and interactive tool for visualizing the data.
In the sections below, we will provide you with all the steps necessary to setup this same solution in your environment quickly and easily. Details include step-by-step setup and configuration instructions, along with a pointer to the complete GitHub project.
Solution Diagram
Here is the high-level architecture of how this solution works. Collectd continuously runs in a container on your SQL Server on Linux environment and pushes metrics to InfluxDB. The data is then visualized via the Grafana dashboard, which reads data from InfluxDB when Grafana requests it.

Setup
When we found a set of tools that let us easily visualize the performance for troubleshooting purposes , we wanted to provide an easy, repeatable method for deployment using Docker. The directions below will walk you through setting this up using our Docker images. The complete mssql-monitoring GitHub project can be found here. Give it a try, we welcome feedback on your experience.
Prerequisites
- Access to docker.io and GitHub for pulling Docker images and accessing the GitHub repository.
- 1 – 2 Linux machines for running InfluxDB and Grafana, depending on how large your deployment is.
- If using 2 machines, 1 machine will be used for hosting the InfluxDB container and the second machine will be used for hosting the Grafana container
- If using 1 machine, it will be used for hosting both the InfluxDB and Grafana containers.
InfluxDB opened ports: 25826 (default inbound data to InfluxDB), 8086 (default outbound queries from Grafana)
Grafana opened port: 3000 (default web port for inbound connections)
A SQL Server on Linux machine or VM that you would like to monitor.
Setting up InfluxDB
For sizing InfluxDB, you can refer to the InfluxDB documentation. Also, note that it is recommended to provision SSD volumes for the InfluxDB data and wal directories. In our experience this has not been necessary when monitoring just a few machines.
- Install Docker Engine (if not already installed)
- Install Git for your distro (if not already installed)
- For RHEL:
yum install git -y
- For Ubuntu:
apt-get install git -y
- Clone the mssql-monitoring GitHub repository
git clone https://github.com/Microsoft/mssql-monitoring.git
- Browse to mssql-monitoring/influxdb
cd mssql-monitoring/influxdb
- Edit run.sh and change the variables to match your environment
# By default, this will run without modification, but if you want to change where the data directory gets mapped, you can do that here
# Make sure this folder exists on the host.
# This directory from the host gets passed through to the docker container.
INFLUXDB_HOST_DIRECTORY="/mnt/influxdb"
# This is where the mapped host directory get mapped to in the docker container.
INFLUXDB_GUEST_DIRECTORY="/host/influxdb"
- Execute run.sh. This will pull down the mssql-monitoring-InfluxDB image and create and run the container
Setting up collectd on the Linux SQL Server you want to monitor
Note: These commands have to be run on the SQL Server on Linux VM/box that you want to monitor
- Using SSMS or SQLCMD, create a SQL account to be used with collectd.
USE master;
GO
CREATE LOGIN [collectd] WITH PASSWORD = N'mystrongpassword';
GO
GRANT VIEW SERVER STATE TO [collectd];
GO
GRANT VIEW ANY DEFINITION TO [collectd];
GO
- Install Docker Engine (if not already installed)
- Install Git for your distro (if not already installed)
- For RHEL:
yum install git -y
- For Ubuntu:
apt-get install git -y
- Clone the mssql-monitoring GitHub repository
git clone https://github.com/Microsoft/mssql-monitoring.git
- Browse to mssql-monitoring/collectd
cd mssql-monitoring/collectd
- Edit run.sh and change the variables to match your environment
#The ip address of the InfluxDB server collecting collectd metrics
INFLUX_DB_SERVER="localhost"
#The port that your InfluxDB is listening for collectd traffic
INFLUX_DB_PORT="25826"
#The host name of the server you are monitoring. This is the value that shows up under hosts on the Grafana dashboard
SQL_HOSTNAME="MyHostName"
#The username you created from step 1
SQL_USERNAME="sqluser"
#The password you created from step 1
SQL_PASSWORD="strongsqlpassword"
- Execute run.sh. This will pull down the mssql-monitoring-collectd image, set it to start on reboot and create and run the container
Setting up Grafana
If you are doing a small scale setup (monitoring a few machines), you should be fine running this on the same host as your InfluxDB container. We use the image created by Grafana Labs with an addition of a run.sh file that you can use to create and run the container.
- Install Docker Engine (if not already installed)
- Install Git for your distro (if not already installed)
- For RHEL:
yum install git -y
- For Ubuntu:
apt-get install git -y
- Clone the mssql-monitoring GitHub repository
git clone https://github.com/Microsoft/mssql-monitoring.git
- Browse to mssql-monitoring/grafana
cd mssql-monitoring/grafana
- Edit run.sh and change the variables to match your environment
# We use the grafana image that Grafana Labs provides http://docs.grafana.org/installation/docker/
# If you wish to modify the port that Grafana runs on, you can do that here.
sudo docker run -d -p 3000:3000 --name grafana grafana/grafana
- Run run.sh. This will pull down the mssql-monitoring-grafana image and create and run the container
Configuring the InfluxDB data source in Grafana
In order for Grafana to pull data from InfluxDB, we will need to setup the data source in Grafana.
- Browse to your Grafana instance
- http://[GRAFANA_IP_ADDRESS]:3000
- Login with default user admin and password admin
Click “Add data source”
- Name: influxdb
- Type: InfluxDB
- Url: http://[INFLUXDB_IP_ADDRESS]:8086
- Database: collectd_db
Click “Save & Test”
Importing Grafana dashboards
We have a set of dashboards that we use and have made available to the community. These dashboards are included in the GitHub repository: mssql-monitoring. Just download them and import them in Grafana. Once the dashboards are imported, you will see metrics that collectd, running on your SQL Server, is pushing to InfluxDB.
How the data gets loaded
In this solution, we leverage collectd and several plugins to get data from the system(s) we are monitoring. Specifically, on the SQL Server side, we leverage the collectd DBI plugin with the FreeTDS driver, and execute the following queries every 5 seconds, using sys.dm_os_performance_counters and sys.dm_wait_stats DMVs. You can view the complete collectd.conf file here. These specific counters and waits provided a good starting point for us, but you can experiment and change as you see fit.
sys.dm_os_performance_counters query
For this query, we needed to replace spaces with underscores in counter and instance names to make them friendly for InfluxDB. We also do not need to reference the counter type field (cntr_type) since the logic to do the delta calculation is done in Grafana with the non-negative derivative function. To find out more about counter types and implementation, please see: Querying Performance Counters in SQL Server by Jason Strate and Collecting performance counter values from a SQL Azure database by Dimitri Furman
SELECT Replace(Rtrim(counter_name), ' ', '_') AS counter_name,
Replace(Rtrim(instance_name), ' ', '_') AS instance_name,
cntr_value
FROM sys.dm_os_performance_counters
WHERE ( counter_name IN ( 'SQL Compilations/sec',
'SQL Re-Compilations/sec',
'User Connections',
'Batch Requests/sec',
'Logouts/sec',
'Logins/sec',
'Processes blocked',
'Latch Waits/sec',
'Full Scans/sec',
'Index Searches/sec',
'Page Splits/sec',
'Page Lookups/sec',
'Page Reads/sec',
'Page Writes/sec',
'Readahead Pages/sec',
'Lazy Writes/sec',
'Checkpoint Pages/sec',
'Database Cache Memory (KB)',
'Log Pool Memory (KB)',
'Optimizer Memory (KB)',
'SQL Cache Memory (KB)',
'Connection Memory (KB)',
'Lock Memory (KB)',
'Memory broker clerk size',
'Page life expectancy' ) )
OR ( instance_name IN ( '_Total',
'Column store object pool' )
AND counter_name IN ( 'Transactions/sec',
'Write Transactions/sec',
'Log Flushes/sec',
'Log Flush Wait Time',
'Lock Timeouts/sec',
'Number of Deadlocks/sec',
'Lock Waits/sec',
'Latch Waits/sec',
'Memory broker clerk size',
'Log Bytes Flushed/sec',
'Bytes Sent to Replica/sec',
'Log Send Queue',
'Bytes Sent to Transport/sec',
'Sends to Replica/sec',
'Bytes Sent to Transport/sec',
'Sends to Transport/sec',
'Bytes Received from Replica/sec',
'Receives from Replica/sec',
'Flow Control Time (ms/sec)',
'Flow Control/sec',
'Resent Messages/sec',
'Redone Bytes/sec')
OR ( object_name = 'SQLServer:Database Replica'
AND counter_name IN ( 'Log Bytes Received/sec',
'Log Apply Pending Queue',
'Redone Bytes/sec',
'Recovery Queue',
'Log Apply Ready Queue')
AND instance_name = '_Total' ) )
OR ( object_name = 'SQLServer:Database Replica'
AND counter_name IN ( 'Transaction Delay' ) )
sys.dm_os_wait_stats query
WITH waitcategorystats ( wait_category,
wait_type,
wait_time_ms,
waiting_tasks_count,
max_wait_time_ms)
AS (SELECT CASE
WHEN wait_type LIKE 'LCK%' THEN 'LOCKS'
WHEN wait_type LIKE 'PAGEIO%' THEN 'PAGE I/O LATCH'
WHEN wait_type LIKE 'PAGELATCH%' THEN 'PAGE LATCH (non-I/O)'
WHEN wait_type LIKE 'LATCH%' THEN 'LATCH (non-buffer)'
ELSE wait_type
END AS wait_category,
wait_type,
wait_time_ms,
waiting_tasks_count,
max_wait_time_ms
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN ( 'LAZYWRITER_SLEEP',
'CLR_AUTO_EVENT',
'CLR_MANUAL_EVENT',
'REQUEST_FOR_DEADLOCK_SEARCH',
'BACKUPTHREAD',
'CHECKPOINT_QUEUE',
'EXECSYNC',
'FFT_RECOVERY',
'SNI_CRITICAL_SECTION',
'SOS_PHYS_PAGE_CACHE',
'CXROWSET_SYNC',
'DAC_INIT',
'DIRTY_PAGE_POLL',
'PWAIT_ALL_COMPONENTS_INITIALIZED',
'MSQL_XP',
'WAIT_FOR_RESULTS',
'DBMIRRORING_CMD',
'DBMIRROR_DBM_EVENT',
'DBMIRROR_EVENTS_QUEUE',
'DBMIRROR_WORKER_QUEUE',
'XE_TIMER_EVENT',
'XE_DISPATCHER_WAIT',
'WAITFOR_TASKSHUTDOWN',
'WAIT_FOR_RESULTS',
'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
'WAITFOR',
'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
'LOGMGR_QUEUE',
'FSAGENT' )
AND wait_type NOT LIKE 'PREEMPTIVE%'
AND wait_type NOT LIKE 'SQLTRACE%'
AND wait_type NOT LIKE 'SLEEP%'
AND wait_type NOT LIKE 'FT_%'
AND wait_type NOT LIKE 'XE%'
AND wait_type NOT LIKE 'BROKER%'
AND wait_type NOT LIKE 'DISPATCHER%'
AND wait_type NOT LIKE 'PWAIT%'
AND wait_type NOT LIKE 'SP_SERVER%')
SELECT wait_category,
Sum(wait_time_ms) AS wait_time_ms,
Sum(waiting_tasks_count) AS waiting_tasks_count,
Max(max_wait_time_ms) AS max_wait_time_ms
FROM waitcategorystats
WHERE wait_time_ms > 100
GROUP BY wait_category
Dashboard Overview
With the metrics that we collect from the collectd system plugins and the DBI plugin, we are able to chart the following metrics over time and in near real time, with up to 5 second data latency. The following are a snapshot of metrics that we graph in Grafana (Clicking the images will enlarge them).
Core Server Metrics

Core SQL Metrics

 .
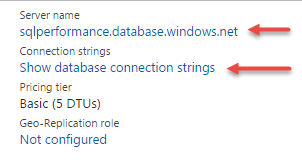
.
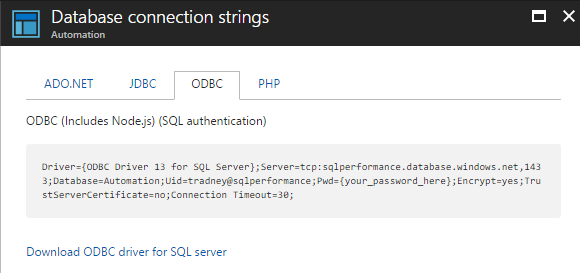
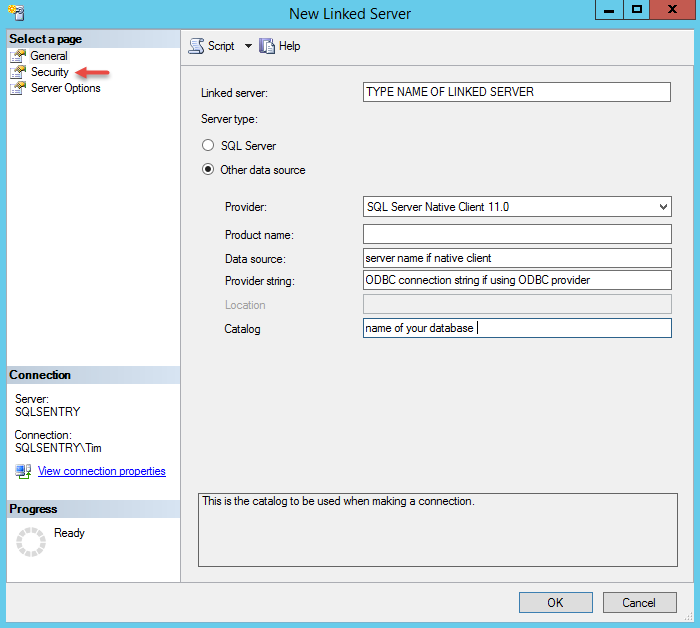
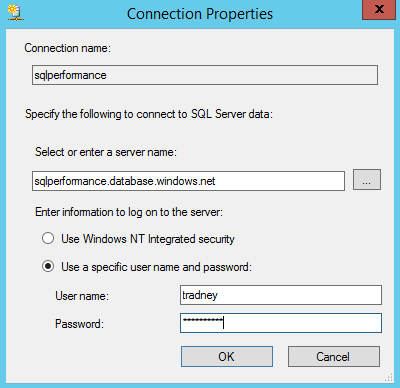












![DML Performance by Test and Workload [Modified scale]](https://sqlperformance.com/wp-content/uploads/2017/06/graph2new.jpg)









