There is a lot of information within the Windows registry. Sometimes, it would sure be nice to work with the registry within your T-SQL scripts. As it turns out, there are a bunch of undocumented extended stored procedures that do just this. A listing of these procedures are:
| Regular |
Instance-Aware |
| sys.xp_regread |
sys.xp_instance_regread |
| sys.xp_regenumvalues |
sys.xp_instance_regenumvalues |
| sys.xp_regenumkeys |
sys.xp_instance_regenumkeys |
| sys.xp_regwrite |
sys.xp_instance_regwrite |
| sys.xp_regdeletevalue |
sys.xp_instance_regdeletevalue |
| sys.xp_regdeletekey |
sys.xp_instance_regdeletekey |
| sys.xp_regaddmultistring |
sys.xp_instance_regaddmultistring |
| sys.xp_regremovemultistring |
sys.xp_instance_regremovemultistring |
As you can see, there are two categories of extended stored procedures that we can use, with complimentary procedures between them. The “Instance-Aware” category procedures utilizes key word substitution in order to navigate to the appropriate registry keys for the SQL Server instance that is running. I’ll show you an example shortly.
Registry Basics
Before we go too much further, lets explain a few key phrases when dealing with the registry:
Registry: The registry is a hierarchical database used by Windows. It is organized in a tree view manner.
Registry Hive: A hive is a logical group of keys, subkeys, and values in the registry that has a set of supporting files containing backups of its data.
Examples of Registry Hives are:
| Registry Hive |
| HKEY_CURRENT_CONFIG< |
| HKEY_CURRENT_USER |
| HKEY_LOCAL_MACHINE\SAM |
| HKEY_LOCAL_MACHINE\Security |
| HKEY_LOCAL_MACHINE\Software |
| HKEY_LOCAL_MACHINE\System |
| HKEY_USERS\.DEFAULT |
Of all of these hives, you will probably use HKEY_LOCAL_MACHINE and HKEY_CURRENT_USER the most.
Registry Key: A node within a registry hive is called a key. A key can contain both sub-keys and values. Sometimes an application will only be looking for the presence of a key; at other times it will need to look at the value.
Registry Value: A registry value is simply a piece of data, of any data type.
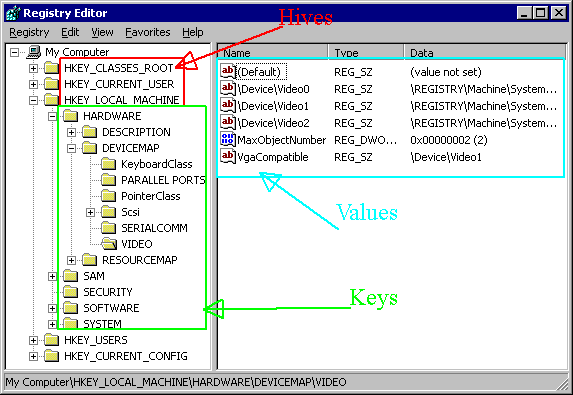
The following image shows the tree view layout of the registry, and identifies the various items within it:
Querying the registry from SQL Server
Using xp_regread / xp_instance_regread
Let’s start off by querying some data within SQL Server. I have an instance of SQL Server named “SQL2014” (would you care to take a guess as to what version of SQL Server this is?). One of the items stored in the registry is the location of the SQL Agent working directory. These procedures can query the registry and return the specified values. For example:
EXECUTE master.sys.xp_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\Microsoft SQL Server\MSSQL12.SQL2014\SQLServerAgent',
'WorkingDirectory';When I execute this statement, SQL returns the following result:
Value Data
---------------- -----------------------------------
WorkingDirectory D:\MSSQL\MSSQL12.SQL2014\MSSQL\JOBS
In order for you to run this, you may need to change the key as appropriate for the version and instance on your server. The result includes both the value, and the data for the specified path.
xp_instance_regread
In this example, I used xp_regread to read the direct registry path. If you remember from earlier, there are SQL Server instance-aware versions of each registry procedure. A comparable statement using the instance-aware procedure would be:
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent',
'WorkingDirectory';This statement returns the exact same information. Let’s look at the difference between these – in the first query, the registry path is the exact registry path needed, and it includes “\Microsoft SQL Server\MSSQL12.SQL2014\”. In the latter query, this string is replaced with “\MSSQLSERVER\”. Since the latter function is instance aware, it replaces the “MSSQLSERVER” with the exact registry path necessary for this instance of SQL Server. Pretty neat, isn’t it? This allows you to have a script that will run properly regardless of the instance that it is being run on. The rest of the examples in this post will utilize the instance-aware procedures to make it easier for you to follow along and run these yourself.
Syntax
The syntax for these procedures is:
EXECUTE xp_regread
[@rootkey=]’rootkey’,
[@key=]’key’
[, [@value_name=]’value_name’]
[, [@value=]@value OUTPUT]The first parameter is the registry hive that you want to query, the second parameter is the key path, and the third is the value name. The third parameter is optional – if it is provided, then the procedure will return the data from the specified value item; if it is not provided, then the procedure only returns whether the specified key exists. There is also an optional fourth parameter, which is an output parameter, and the data output will go into that. The parameters are positional, and while you can specify a name for the parameter, any name will work. Since the parameters are positional, my recommendation is to not use the parameter names. The following example utilizes the optional fourth parameter, and it will return just the specified path into the variable:
DECLARE @SQLAgentDirectory VARCHAR(255);
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent',
'WorkingDirectory',
@SQLAgentDirectory OUTPUT;
SELECT @SQLAgentDirectory;You would think that if you specify either NULL or an empty string for the third parameter, that you could send whether the key exists to an output variable – however, I have not been able to figure out a way to accomplish this. Specifying either of these values results in an error when running this statement. If you know how to do this, please leave a remark so that this post can be updated with that information.
Using xp_regenumvalues / xp_instance_regenumvalues
These procedures will enumerate through all of the values of the specified key, returning a separate result set for each value. For instance, the following statement will return all of the values in the above SQLServerAgent key:
EXECUTE master.sys.xp_instance_regenumvalues
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent';Having all of these result sets makes it difficult to work with this procedure. Thankfully, you can put these all into one result set – just create a temporary table (or table variable) to hold the output, and then use INSERT / EXECUTE to fill it, like the following example does:
DECLARE @Registry TABLE (Value VARCHAR(255), Data VARCHAR(255));
INSERT INTO @Registry
EXECUTE master.sys.xp_instance_regenumvalues
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent';
SELECT * FROM @Registry;Now that all of the results are in one result set, you can work with it a bit easier.
Syntax
The syntax for these procedures is:
EXECUTE xp_regenumvalues
[@rootkey=]’rootkey’,
[@key=]’key’
Using xp_regenumkeys / xp_instance_regenumkeys
These procedures will enumerate through all of the keys in a specified path, and return all of the keys in that path. Unlike xp_instance_regenumvalues, all of the keys are returned in one result set, though you will probably want to use INSERT / EXECUTE to put this into temporary storage so that you can work with it. An example of using these procedures is:
EXECUTE master.sys.xp_instance_regenumkeys
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER';The syntax for these procedures is:
EXECUTE xp_regenumkeys
[@rootkey=]’rootkey’,
[@key=]’key’
Modifying the registry from within SQL Server
Up to this point, we have focused on retrieving data from the registry. What if you want to modify the registry? Read on… be forewarned that the following procedures are modifying the registry, which means that they can also damage the registry, possibly rendering the server unusable. Use at your own risk!
xp_regwrite / xp_instance_regwrite
These procedures are used to create keys and write data into the registry. You can create up to 32 sub-keys at a time. In the following example, a new key “MyNewKey” will be added to the SQLServerAgent key, and the value “MyNewValue” will be added to this new key with the data “Now you see me!”. It will then read this value from the registry.
EXECUTE master.sys.xp_instance_regwrite
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue',
'REG_SZ',
'Now you see me!';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue';
Syntax
The syntax for these procedures is:
EXECUTE xp_regwrite
[@rootkey=]’rootkey’,
[@key=]’key’,
[@value_name=]’value_name’,
[@type=]’type’,
[@value=]’value’
xp_regdeletevalue / xp_instance_regdeletevalue
These procedures are used to delete a specified value from the registry. In this example, the “MyNewValue” value will be deleted. The example first enumerates through all of the values in this key (just the one), deletes the value, enumerates through them again (since there are no values, there will be no result set), and then finally shows that the key is still present.
EXECUTE master.sys.xp_instance_regenumvalues
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
EXECUTE master.sys.xp_instance_regdeletevalue
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue';
EXECUTE master.sys.xp_instance_regenumvalues
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
Syntax
The syntax for these procedures is:
EXECUTE xp_regdeletevalue
[@rootkey=]’rootkey’,
[@key=]’key’,
[@value_name=]’value_name’
xp_regdeletekey / xp_instance_regdeletekey
These procedures are used to delete an entire key from the registry. In this example, the script will first add another new key under “MyNewKey”, and a value in that new key. The script then deletes both the “AnotherNewKey” (which deletes the value just added also) and “MyNewKey” keys and finally shows that both keys have been deleted. Note that in order to delete a key, it cannot have any sub-keys, which is why the script deletes “AnotherNewKey” first (try running the script first by commenting out the first xp_instance_regdeletekey to see that it must be empty).
EXECUTE master.sys.xp_instance_regwrite
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey\AnotherNewKey',
'MyNewValue',
'REG_SZ',
'Another new value!';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey\AnotherNewKey';
EXECUTE master.sys.xp_instance_regdeletekey
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey\AnotherNewKey';
EXECUTE master.sys.xp_instance_regdeletekey
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey\AnotherNewKey';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
Syntax
The syntax for these procedures is:
EXECUTE xp_regdeletekey
[@rootkey=]’rootkey’,
[@key=]’key’
xp_regaddmultistring / xp_instance_regaddmultistring
These procedures are used to add a string to a multi-string entry in the registry, or to create a multi-string registry entry. In this example, I’ll call the procedure twice. The first time will create the entry with one string in it, and the second time will add a second string to it. Then the example will show the results of this value.
EXECUTE master.sys.xp_instance_regaddmultistring
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue',
'A multi-string value!';
EXECUTE master.sys.xp_instance_regaddmultistring
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue',
'Yet Another new string added to this multi-string value!';
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue'Did you notice that the regread procedure got a little confused here? It has two value columns (which is the name of the value), but the second one has the data for the first one. Then the data column is null. If a third string is added, it still returns just these three columns. To see that we actually added these strings, we’ll have to use regedit.exe:
-- add a third string
EXECUTE master.sys.xp_instance_regaddmultistring
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue',
'How about a third string?';
-- only shows the first string
EXECUTE master.sys.xp_instance_regread
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue'
Syntax
The syntax for these procedures is:
EXECUTE xp_regaddmultistring
[@rootkey=]’rootkey’,
[@key=]’key’,
[@value_name=]’value_name’,
[@value=]’value’
xp_regremovemultistring / xp_instance_regremovemultistring
These procedures are used to remove a string from a multi-string entry. This example will remove the middle string.
EXECUTE master.sys.xp_instance_regremovemultistring
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey',
'MyNewValue',
'Yet Another new string added to this multi-string value!';Examining the string now in regedit.exe, it can be seen that it removed all of the strings starting with the specified string… in other words, it removed the second and third strings. If we add the strings back in, and then remove the third string, we can see that it also removes the second and third string. In testing with a fourth string, it appears that if you are deleting a string that is not the first string, then all of the remainder of the strings after the first string are removed. Deleting the first string deletes all of the strings. Well, these are undocumented procedures, so it’s not likely that this bug will ever be fixed.
Syntax
The syntax for these procedures is:
EXECUTE xp_regremovemultistring
[@rootkey=]’rootkey’,
[@key=]’key’,
[@value_name=]’value_name’,
[@value=]’value’And finally, let’s ensure that things are cleaned up:
EXECUTE master.sys.xp_instance_regdeletekey
'HKEY_LOCAL_MACHINE',
'Software\Microsoft\MSSQLSERVER\SQLServerAgent\MyNewKey';
Conclusion
With the exception of removing and reading the multi-string values, these extended stored procedures all work pretty well. We’ve been able to read registry values, and to enumerate through a list of keys and values. Keys and values can be created and deleted.
If you try to use the procedures in sections outside of SQL Server keys, you may run into registry security problems where the SQL Server service account doesn’t have permissions to accomplish the task. On the internet, you will find articles telling you to add the service account to the local administrators group (and to restart the service). This is a VERY BAD IDEA – by doing this, the server can be completely compromised – you will be allowed to do anything that you desire on the server. Instead, use regedt32.exe, which will allow you to modify the permissions on the key that where you are having access issues.
I close by repeating my warning from above – be very careful when modifying the registry. It is possible to corrupt the registry to the point where the server will no longer function. To recover, an operating system reinstall will be necessary.
As a footnote on working with the instance-aware installation. I recall seeing on the internet other keywords that could be substituted instead of MSSQLSERVER. One of them is SQLServerAgent. However, I can’t find any others right now. If you happen to know of other keywords that work, please reply to this post so that it can be added to this post.

The post Working with the registry from within SQL Server appeared first on Wayne Sheffield.
















 Andy Mallon is a SQL Server DBA and
Andy Mallon is a SQL Server DBA and 

 Figure 2: Logical processor display in Windows Server 2016 Task Manager
Figure 2: Logical processor display in Windows Server 2016 Task Manager