IMPORTANT NOTE: Be sure to read the ENTIRE post as there’s a workaround that QUERYTRACEON is ALLOWED inside of stored procedures… just NOT in an adHoc statement. Not documented but I think this is excellent! There are still some uses of what I’ve written but this specific use is much easier because of this undoc’ed “feature.” :-)
While the new cardinality estimator can offer benefits for some queries, it might not be perfect for ALL queries. Having said that, there is an OPTION clause that allows you to set the CE for that query. The setting to use depends on the CE that you’re running under currently. And, as of SQL Server 2016, even determining this can be difficult. At any given time, there are multiple settings that might affect your CE.
In SQL Server 2014, your CE was set by the database compatibility model. If you’re running with compatibility mode 120 or higher, then you’re using the new CE. If you’re running with compatibility mode 110 or lower, then you’re using the Legacy CE. In SQL Server 2016, the database compatibility mode is not the only setting that can affect the CE that you’re using. In SQL Server 2016, they added ‘database scoped configuations’ and introduced:
ALTER DATABASE SCOPED CONFIGURATION LEGACY_CARDINALITY_ESTIMATION = { ON | OFF | PRIMARY}
Having said that, an administrator can always override this setting by setting one of the CE trace flags globally [using DBCC TRACEON (TF, -1) – but I don’t recommend this!].
To use the LegacyCE when the database is set to the new CE, use Trace Flag 9481.
To use the New CE when the database is set to the LegacyCE, use Trace Flag 2312.
Generally, I recommend that most people STAY with the LegacyCE until they’ve thoroughly tested the new CE. Then, and only then, change the compatibility mode. But, even with extensive testing, you might still want some queries to run with the LegacyCE while most run with the new CE (or, potentially the opposite). What I like most about the addition of the new CE is that we have the ability to set EITHER!
But, before setting this (or, overriding how the database is set), let’s make sure we know how it’s set currently… If you’re wondering which CE you’re running under, you can see it within the graphical showplan (in the Properties [F4] window, use: CardinalityEstimationModelVersion OR search for that within the showplan XML).
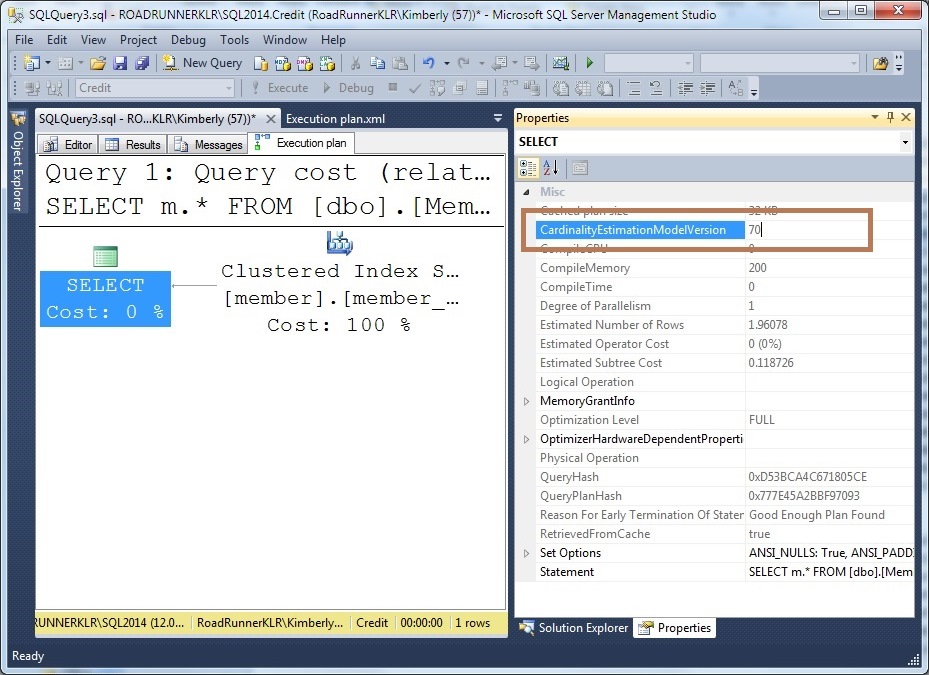
Above all, what I like most is – CHOICE. I can even set this for a specific query:
SELECT m.* FROM [dbo].[Member] AS [m] WHERE [m].[firstname] LIKE 'Kim%' OPTION (QUERYTRACEON 9481);
However, the bad news is the QUERYTRACEON is limited to SysAdmin only (be sure to read the UPDATEs at the end of this post). Jack Li (Microsoft CSS) wrote a great article about a problem they solved by using a logon trigger to change the CE for an entire session: Wanting your non-sysadmin users to enable certain trace flags without changing your app? Now, I do want to caution you that setting master to trustworthy is not something you should take lightly. But, you should NOT let anyone other than SysAdmin have any other rights in master (other than the occasional EXEC on an added user-defined SP). Here are a couple of posts to help warn you of the danger:
A warning about the TRUSTWORTHY database option
Guidelines for using the TRUSTWORTHY database setting in SQL Server
Having said that, what I really want is to set this on a query by query basis AND I don’t want to elevate the rights of an entire stored procedure (in order to execute DBCC TRACEON). So, I decided that I could create a procedure in master, set master to trustworthy (with the caution and understanding of the above references/articles), and then I can reference it within my stored procedures NOT having to use use 3-part naming (for the sp_ version of the procedure):
ALTER DATABASE master
SET TRUSTWORTHY ON;
GO
USE master;
GO
ALTER PROCEDURE sp_SetTraceFlag
(@TraceFlag int,
@OnOff bit = 0)
WITH EXECUTE AS OWNER
AS
DECLARE @OnOffStr char(1) = @OnOff;
-- Sysadmins can add supported trace flags and then use this
-- from their applications
IF @TraceFlag NOT IN (
9481 -- LegacyCE if database is compat mode 120 or higher
, 2312 -- NewCE if database compat mode 110 or lower
)
BEGIN
RAISERROR('The Trace Flag supplied is not supported. Please contact your system administrator to determine inclusion of this trace flag: %i.', 16, 1, @TraceFlag);
RETURN
END
ELSE
BEGIN
DECLARE @ExecStr nvarchar(100);
IF @OnOff = 1
SELECT @ExecStr = N'DBCC TRACEON(' + CONVERT(nvarchar(4), @TraceFlag) + N')';
ELSE
SELECT @ExecStr = N'DBCC TRACEOFF(' + CONVERT(nvarchar(4), @TraceFlag) + N')';
-- SELECT (@ExecStr)
EXEC(@ExecStr)
-- RAISERROR (N'TraceFlag: %i has been set to:%s (1 = ON, 0 = OFF).', 10, 1, @TraceFlag, @OnOffStr);
END;
GO
GRANT EXECUTE ON sp_SetTraceFlag TO PUBLIC;
GO
As for using this procedure, you have TWO options. If you can modify the stored procedure then you can wrap a single statement with the change in trace flag. But, to make it take effect, you’ll need to recompile that statement. So, if your stored procedure looks like the following:
CREATE PROCEDURE procedure ( params ) AS statement; statement; <<<--- problematic statement statement; statement; GO
Then you can change this to:
CREATE PROCEDURE procedure ( params ) AS statement; EXEC sp_SetTraceFlag 2312, 1 statement OPTION (RECOMPILE); <<<--- MODIFIED problematic statement EXEC sp_SetTraceFlag 2312, 0 statement; statement; GO
If you don’t want to set master to trustworthy then you can add a similar procedure to msdb (which is already set to TRUSTWORTHY) and then use 3-part naming to reference it.
USE msdb;
GO
CREATE PROCEDURE msdbSetTraceFlag
(@TraceFlag int,
@OnOff bit = 0)
WITH EXECUTE AS OWNER
AS
DECLARE @OnOffStr char(1) = @OnOff;
-- Sysadmins can add supported trace flags and then use this
-- from their applications
IF @TraceFlag NOT IN (
9481 -- LegacyCE if database is compat mode 120 or higher
, 2312 -- NewCE if database compat mode 110 or lower
)
BEGIN
RAISERROR('The Trace Flag supplied is not supported. Please contact your system administrator to determine inclusion of this trace flag: %i.', 16, 1, @TraceFlag);
RETURN
END
ELSE
BEGIN
DECLARE @ExecStr nvarchar(100);
IF @OnOff = 1
SELECT @ExecStr = N'DBCC TRACEON(' + CONVERT(nvarchar(4), @TraceFlag) + N')';
ELSE
SELECT @ExecStr = N'DBCC TRACEOFF(' + CONVERT(nvarchar(4), @TraceFlag) + N')';
-- SELECT (@ExecStr)
EXEC(@ExecStr)
-- RAISERROR (N'TraceFlag: %i has been set to:%s (1 = ON, 0 = OFF).', 10, 1, @TraceFlag, @OnOffStr);
END;
GO
GRANT EXECUTE ON msdbSetTraceFlag TO PUBLIC;
GO
To use this, you’ll need to use 3-part naming:
CREATE PROCEDURE procedure ( params ) AS statement; EXEC msdb.dbo.msdbSetTraceFlag 2312, 1 statement OPTION (RECOMPILE); <<<--- MODIFIED problematic statement EXEC msdb.dbo.msdbSetTraceFlag 2312, 0 statement; statement; GO
Finally, another option is to wrap a statement with the change in trace flag.
EXEC sp_SetTraceFlag 2312, 1; GO STATEMENT or PROCEDURE GO EXEC sp_SetTraceFlag 2312, 0; -- don't remember to turn it back off! GO
Now, you have strategic access to EITHER CE and you don’t have to elevate anyone’s specific rights to SysAdmin. You can even let developers use the changes to the new CE or the LegacyCE in their code which is incredibly useful!
UPDATE: If you can’t change the code then another excellent option would be use to a plan guide (permissions are only at the object/database level: To create a plan guide of type OBJECT, requires ALTER permission on the referenced object. To create a plan guide of type SQL or TEMPLATE, requires ALTER permission on the current database.). Here’s a good post on how to add QUERYTRACEON into a plan guide: Using QUERYTRACEON in plan guides by Gianluca Sartori.
UPDATE #2: Wow! A bit of digging and I stumbled on this ConnectItem: QUERYTRACEON with no additional permissions and after I up-voted it, I noticed the workaround by Dan Guzman: There is currently undocumented behavior in SQL 2014 that allows use of QUERYTRACEON in a stored procedure without sysadmin permissions regardless of module signing or EXECUTE AS. This is a workaround in situations where the query is already in a stored procedure or when a problem ad-hoc query needing the trace flag can be encapsulated in a proc. However, until it’s documented, this workaround is at-your-own-risk. I did NOT know this… So, QUERYTRACEON CAN be used in a stored procedure even without SysAdmin permissions (I actually like this!). And, I tested this in BOTH 2014 AND 2016 and it works! It’s not documented nor is it recommended but I’m happy to see that you do NOT need to do this for QUERYTRACEON. It looks like it evens works in earlier versions. Most of us ran into problems with the clause erroring on adhoc statements so we just didn’t expect it to work INSIDE of a proc. Well… better late than never!
Thanks for reading,
Kimberly
The post Setting CE TraceFlags on a query-by-query (or session) basis appeared first on Kimberly L. Tripp.




![a-data-scientist-is-a-business-analyst-that-lives-in-california[1]](http://datasciencedojo.com/wp-content/uploads/2014/07/a-data-scientist-is-a-business-analyst-that-lives-in-california1.jpg)


















 I've been a Type 1 Diabetic now for nearly 25 years. The first thing that every techie does once they've been diagnosed with Diabetes is they try to solve the problem with software or hardware. Whatever tool they have, they use that too to "solve their Diabetes." Sometimes it's Excel, sometimes it's writing a whole new system. We can't help ourselves. We see the charts and graphs, we start to understand that this is a solvable problem.
I've been a Type 1 Diabetic now for nearly 25 years. The first thing that every techie does once they've been diagnosed with Diabetes is they try to solve the problem with software or hardware. Whatever tool they have, they use that too to "solve their Diabetes." Sometimes it's Excel, sometimes it's writing a whole new system. We can't help ourselves. We see the charts and graphs, we start to understand that this is a solvable problem.


















