So you have a multi-tenant SaaS application that is using PostgreSQL as a Database of choice. As you are serving multiple customers, how do you protect each customer’s data? How do you provide full data isolation (logical and physical) between different customers? How do you minimize impact of attack vectors such as SQL Injection? How do you retain the flexibility to potentially move the customer to a higher hosting tier or higher SLAs?
1. One DB per customer
Instead of putting every customer’s data in one database, simply create one database per customer. This allows for physical isolation of data within your Postgres cluster. So, for every new customer that registers, do this as part of the workflow:
CREATE DATABASE customer_A WITH TEMPLATE customer_template_v1;
In the example above customer_template_v1 is a custom database template with all the tables, schemas, procedures pre-created.
Note: You can use Schema or Row Level Security (v9.5) to effect isolation. However, Schema and Row Level Security would only allow for logical isolation. You could go the other extreme and use a DB cluster (as opposed to a database) per customer to effect complete data isolation. But the management overhead makes it a less than ideal option in most cases.
2. Separate DB user(s) per customer
After the Database is created as mentioned above, create a unique Database user as well. This user only would have permission to one (and only one) database: customer_A.
CREATE ROLE customer_A_user with option NOSUPERUSER NOCREATEDB LOGIN ENCRYPTED PASSWORD ''
REVOKE ALL ON DATABASE customer_A FROM PUBLIC;
GRANT CONNECT ON DATABASE customer_A TO customer_A_user;
GRANT ALL ON SCHEMA public TO customer_A_user WITH GRANT OPTION;
Now, in your middleware code, make sure to connect to customer_A database only using customer_A_user. In other words, when a user from customer_A organization logs into your SaaS application, use appropriate database and database user name.
If you wish, you can even create separate READ and WRITE users. So, to create a read user for database: customer_A
CREATE ROLE customer_A_read_user with option NOSUPERUSER NOCREATEDB LOGIN ENCRYPTED PASSWORD ''
GRANT USAGE ON SCHEMA public TO customer_A_read_user;
GRANT CONNECT, TEMPORARY ON DATABASE customer_A TO customer_A_read_user;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO customer_A_read_user;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO customer_A_read_user;
With the above you have fine grained control in terms of database access privileges and every activity from the middleware needs to decide carefully as to which role (read or read/write) needs to be used for access.
So, what DB User/Role do you use to create the new customer database in the first place? Create a special DB User (say create_db_user) just for this purpose. Audit and monitor this user’s activity closely. Don’t use this DB User for anything else. Or you can create a new user for each new database and simply specify that at database creation time. Whatever happens, don’t use the Postgres root user for your web connections!
CREATE ROLE customer_B_user with option NOSUPERUSER NOCREATEDB NOCREATEROLE LOGIN ENCRYPTED PASSWORD 'ABGF$%##89';
CREATE DATABASE customer_B WITH TEMPLATE customer_template_v1 OWNER=customer_B_user;
As you may have noticed, a number of SaaS applications give vanity URLs (example: https://customerA.example.com) to their customers. Some other SaaS applications have a concept of ‘customerId’ which is a required field for authentication into SaaS application. The benefit is two fold:
As the user logs into the SaaS application, the middleware code knows exactly which database to connect to.
This also helps to keep the URL space isolated, allowing the SaaS application to start isolation at the web server level itself.
3. Separate crypto keys per customer
If you are doing any encryption within the database (say with pgcrypto), make sure to use separate encryption keys for each customer. This adds cryptographic isolation between your customer data. Finally, when it comes to encryption and key management, avoid these common encryption errors developers keep making.
Comment and do let us know what other best practices make sense for multi-tenant SaaS access with PostgreSQL.
Antes de me tornar cristã, eu depositava minha confiança em uma divindade que oscilava entre o Deus cristão e o “deus interior” (ou força impessoal), um híbrido mal-ajambrado dominante no meio em que circulava (espírita e esotérico) — alguém a quem eu orava vez ou outra enquanto conservava a certeza de que eu mesma era meu próprio Deus.
Isso começou a ser quebrado através de uma música de David Bowie chamada Quicksand (“areia movediça”). O refrão era anunciado pelas palavras “Não tenho mais o poder”, para arrematar: “Não acredite em si mesmo”. A cada vez em que ouvia essa música belíssima (e um tanto depressiva), sentia um tiro no coração que espatifava o tal deus interior. Mostrei-a para minha melhor amiga na época — que partilhava resolutamente de meus conceitos religiosos — e observei: “Mas não é um orgulho imenso esse negócio de acreditar em si mesmo?” Era o prenúncio de que em breve eu conheceria o verdadeiro Deus.
Semana passada, eu e André fomos ver um "filme cristão" - categoria que vem ganhando os espaços do cinema. Eis aqui minhas impressões. War Room (em português, Quarto de Guerra) não é um mau filme. Não é uma obra-prima artística, mas também não é perda de tempo. De forma geral, o Evangelho está presente, bem como a centralidade em Jesus. A história é interessante, os atores não fazem feio, as tiradas de humor - peculiarmente focadas em maus cheiros corporais - são eficazes e se integram bem ao todo. Há algumas pentequices, mas, como não sou uma reformada antipenteca, isso não me incomodou. No entanto, saí do cinema um tanto fustigada, como se a experiência tivesse sido negativa em algum nível que não consegui imediatamente compreender.
Esse artigo (em inglês) me ajudou a entender um pouco o porquê. Richard Brody aplica ao filme o termo "sanitizado" para referir-se à ausência total de balizas culturais na história. É algo que sempre me chateou, por exemplo, na série Friends, em que os personagens vivem em um vácuo inexplicável de leituras e arte. O mesmo ocorre em Quarto de Guerra. No contexto protestante, essa falta adquire um tom mais macabro, por causa do fenômeno descrito por Francis Schaeffer em O grande desastre evangélico e que eu costumo chamar, em minhas palestras, de "alienação": o cristianismo que se pensa ortodoxo (em contraposição ao sintético) meteu-se em um gueto cultural autodefensivo cuja crítica está apenas esboçada. No Brasil, muitas denominações ainda mantêm seus membros afastados de músicas, filmes, livros etc. considerados "do mundo". Quarto de Guerra não defende essa postura, mas também não desafia as fronteiras do gueto - e uma das consequências desse alheamento é apontada pelo autor do artigo muito acertadamente: a descrição pobre do mal, com seus atrativos e suas profundidades. Sim, Jesus salva - mas do quê? No que consiste a luta cristã? Quarto de Guerra faz parecer tudo muito simples e rápido, e a isso reagi mal emocionalmente, pois nada foi simples e rápido na minha vida cristã; muito pelo contrário. Assim, saí da sala sentindo o desconforto de um filme que representa pouco minha vivência e a de incontáveis outros cristãos.
Daí minha ênfase na descrição mais acurada do mal - no caso, da idolatria -, que em breve espero começar a trazer de modo consistente para o blog.
Antes de me tornar cristã, eu depositava minha confiança em uma divindade que oscilava entre o Deus cristão e o “deus interior” (ou força impessoal), um híbrido mal-ajambrado dominante no meio em que circulava (espírita e esotérico) — alguém a quem eu orava vez ou outra enquanto conservava a certeza de que eu mesma era meu próprio Deus.
Isso começou a ser quebrado através de uma música de David Bowie chamada Quicksand (“areia movediça”). O refrão era anunciado pelas palavras “Não tenho mais o poder”, para arrematar: “Não acredite em si mesmo”. A cada vez em que ouvia essa música belíssima (e um tanto depressiva), sentia um tiro no coração que espatifava o tal deus interior. Mostrei-a para minha melhor amiga na época — que partilhava resolutamente de meus conceitos religiosos — e observei: “Mas não é um orgulho imenso esse negócio de acreditar em si mesmo?” Era o prenúncio de que em breve eu conheceria o verdadeiro Deus.
As such, there’s really no “standard” benchmark that will inform you about the best technology to use for your application. Only your requirements, your data, and your infrastructure can tell you what you need to know.
NoSql is everywhere and we can't escape from it (although I can't say we want to escape). Let's leave the question about reasons outside this text,
and just note one thing - this trend isn't related only to new or existing NoSql solutions. It has another side, namely the schema-less data support in
traditional relational databases. It's amazing how many possibilities hiding at the edge of the relational model and everything else. But of course there is
a balance that you should find for your specific data. It can't be easy, first of all because it's required to compare incomparable things,
e.g. performance of a NoSql solution and traditional database. Here in this post I'll make such attempt and show the comparison of jsonb in PostgreSQL,
json in Mysql and bson in Mongodb.
What the hell is going on here?
Breaking news:
PostgreSQL 9.4 - a new data type jsonb with slightly extended support in the upcoming release PostgreSQL 9.5
and several other examples (I'll talk about them later). Of course these data types supposed to be binary, which means great performance.
Base functionality is equal across the implementations because it's just obvious CRUD. And what is the oldest and almost cave desire in this situation?
Right, performance benchmarks! PostgreSQL and Mysql were choosen because they have quite similar implementation of json support, Mongodb - as a veteran of NoSql. An EnterpriseDB research is slightly outdated, but we can use it as a first step for the road of a thousand li. A final goal is not to display the performance in artificial environment, but to give a neutral evaluation and to get a feedback.
Some details and configurations
The pg_nosql_benchmark from EnterpriseDB suggests an obvious approach - first of all the required amount of records must be generated using different kinds of
data and some random fluctuations. This amount of data will be saved into the database, and we will perform several kinds of queries over it.
pg_nosql_benchmark doesn't have any functional to work with Mysql, so I had to implement it similar to PostgreSQL.
There is only one tricky thing with Mysql - it doesn't support json indexing directly, it's required to create virtual columns and create index on them.
Speaking of details, there was one strange thing in pg_nosql_benchmark. I figured out that few types of generated records
were beyond the 4096 bytes limit for mongo shell, which means these records were
just dropped out. As a dirty hack for that we can perform the inserts from a js file (and btw, that file must be splitted into the series of chunks
less than 2GB).
Besides, there are some unnecessary time expenses, related to shell client, authentication and so on. To estimate and exclude them I have to perform corresponding amount of "no-op" queries for all databases (but they're actually pretty small).
After all modifications above I've performed measurements for the following cases:
PostgreSQL 9.5 beta1, gin
PostgreSQL 9.5 beta1, jsonb_path_ops
PostgreSQL 9.5 beta1, jsquery
Mysql 5.7.9
Mongodb 3.2.0 storage engine WiredTiger
Mongodb 3.2.0 storage engie MMAPv1
Each of them was tested on a separate m4.xlarge amazon instance with the ubuntu 14.04 x64 and default configurations,
all tests were performed for 1000000 records. And you shouldn't forget about the instructions for the jsquery -
bison, flex, libpq-dev and postgresql-server-dev-9.5 must be installed. All results were saved in json file,
we can visualize them easily using matplotlib (see here).
Besides that there was a concern about durability. To take this into account I made few specific configurations
(imho some of them are real, but some of them are quite theoretical, because I don't think someone will use them for production systems):
Mysql 5.7.9, no fsync (innodb_flush_method=nosync)
Results
All charts presented in seconds (if they related to the time of query execution) or mb (if they related to the size of relation/index).
Thus, for all charts the smaller value is better.
Select
Insert
Insert with configurations
Update
Update is another difference between my benchmarks and pg_nosql_benchmark. It can bee seen, that Mongodb is an obvious
leader here - mostly because of PostgreSQL and Mysql restrictions, I guess, when to update one value you must override an entire field.
Update with configurations
As you can guess from documentation and this answer,
writeConcern j:true is the highest possible transaction durability level (on a single server),
that should be equal to configuration with fsync.
I'm not sure about durability, but fsync is definitely slower for update operations here.
Table/index size
I have a bad feeling about this
Performance measurement is a dangerous field especially in this case. Everything described above can't be a completed benchmark, it's just
a first step to understand current situation. We're working now on ycsb tests to make more
finished measurements, and if we'll get lucky we'll compare the performance of cluster configurations.
PgConf.Russia 2016
It looks like I'll participate in the PgConf.Russia this year, so if you're interested
in this subject - welcome.
Ring is multi-media communication platform with secured multi-media
channels, that doesn't require centralized servers to work. It is
developed by Savoir-faire Linux, a Canadian company located in
Montréal, Québec. It is a potential free-software replacement for
Skype, and possibly more.
What inspired the creation of Ring?
The way everyone perceives the world changed when Edward Snowden,
Wikileaks and others started to massively warn the public about global
surveillance made by our states, network control companies and so
on. The need of software solutions that give back the control to user
has never been as urgent as before. As citizens of democracies and
professionals of free software, we are worried about how frequently
this concentration of our private data is controlled by monolithic
internet giants. This is a real problem for the real global economy
and makes a serious roadblock to innovation. These are our main
reasons to make something different.
In conjunction with these concerns, Savoir-faire Linux developed
another project just before: SFLPhone. It was only usable in a
centralized concept (SIP or IAX servers was necessary), and
communication wasn't secured by encryption/authentication. This first
experience was a good starting point to propose something more
evolved. Even though Ring is currently in alpha version, it allows
decentralization and secure communication, whatever the media
exchanged.
All these matters are our guiding rules and we invite developers who
want to join this project to contribute.
How are people using it?
Within Savoir-faire Linux, we use it as our main phone, some even only
use Ring to make calls. We also use it as a video conferencing tool
for our daily communications with our different branches over the
world.
In our team, one of us has even built an Arduino based circuit to
connect Ring to the lights of his house: he can turn them on/off from
distance.
Our great beta-testers (that can be even our mum, dad, friends, ...)
use Ring to make calls and they mostly use the instant message feature
that they like a lot. It's fantastic to hear when someone outside of
our daily job environment gives Ring a try and judges it awesome, even
in the current stage alpha stage. The instant messaging is
particularly used by such users.
As we're also active in local meetups (here at Montreal), where some
free-software enthusiasts are present, to demonstrate our
technology. First impressions make us confident in our decisions.
What features do you think really sets Ring apart from similar software?
Ring is a particular piece of software for at least three reasons:
The interoperability over communication protocols and the goal to
make it available for anyone, not just a group of crypto-savvy
enthusiasts. We target the universality concept into Ring: as an
example, we don't support XMPP yet, but there is nothing in the
design that could block it's implementation. Developers are welcome!
The fact we intend to support decentralization (DHT) and industrial
standards like SIP in the same application.
Our layered design permits the use of its low-level core to make
something completely different from our current clients. Ring allows
prospects with the Internet of Things.
Why was the GPLv3 chosen as Ring's license?
Ring comes from SFLPhone, already under GPLv3 license. It was always
obvious to use it for Savoir-faire Linux, especially when we are
looking at the goals of the Ring software. So it has always be evident
to use GLPv3 if we think about the goals of the software itself:
To be "hackable": re-use for your needs, provides seeds of our near
future.
To let people see what we do at SFL: we provide skills; software is
just a tool or an artefact of that.
Only GPL can give the necessary guarantees to achieve that.
How can users (technical or otherwise) help contribute to Ring?
The most important is to use our available front-ends for your daily
usage. Replace non-free solutions and grow the mesh: it's so important
due to the distributed nature of Ring. We need to grow to securise
(secure) the DHT mesh.
Immediately after this, comes the translation of Ring: better
accessibility is a key of the wide usage success. Then we're free
software, so the code is ready for «happy-hacking» . We're waiting for
security analysis, enhancements, patchsets, ... pick up the code and
let us know what you think about it. For sure we try to do that
everyday, but we're a relatively small team to realize all these
tasks.
As Ring is in alpha development stage, we always have ideas to improve
or enhance it, so the list is long. In the immediate future we want to
deliver an Android version of our front-end. After that we have
discussion channels (chat) in a generic way (during a call, a
conference, "out-of-call", ...). Then fast and secure file sharing
(that comes after a way to propose a warranted generic data stream
channel). Right after, we are working on a way to provide a
"distributed services" framework: DNS, routing or whatever anyone is
able to dream about the final usage, we want to provide a solid
solution to make it real. We plan to enter in beta stage in the early
of part 2016 sprint.
PostgreSQL 9.5 has been released
with lots of new features for the database management system, including
UPSERT, row-level security, and several "big data" features. We previewed
some of these features back in July and August. "A most-requested feature by application developers for several years,
'UPSERT' is shorthand for 'INSERT, ON CONFLICT UPDATE', allowing new
and updated rows to be treated the same. UPSERT simplifies web and
mobile application development by enabling the database to handle
conflicts between concurrent data changes. This feature also removes
the last significant barrier to migrating legacy MySQL applications to
PostgreSQL."
Saiu hoje no Globo uma denúncia aterradora do historiador Marco Antonio Villa. Afirma ele que mudanças propostas pelo Ministério da Educação - a serem aprovadas até junho deste ano - equivalem a "culto à ignorância" e "crime de lesa-pátria". As novas diretrizes levam às últimas consequências os postulados do politicamente correto: "histórias ameríndias, africanas e afro-brasileiras" são o foco atual. A ênfase na raça e na geografia não é nova, mas sim um prolongamento lógico de uma tradição já descrita e criticada por Mario Vieira de Mello em Desenvolvimento e cultura, o desenvolvimentismo. Ao consolidar-se nesse currículo, tal tradição, que buscou em Marx as bases para uma identidade nacional, aprofunda agora o problema antigo para o qual apontou Mello: o abandono de considerações das ideias europeias. Agora, com a Europa devidamente apagada dos estudos históricos, efetua-se por canetadas o triunfo final de toda uma linha de pensamento cuja única preocupação é marcar uma orgulhosa diferença, racial e geográfica, em relação ao Velho Continente. Ou seja, um antieuropeísmo que nos situa em uma periferia mais distante ainda da cultura ocidental, ao lado de um brasileirismo que quer triunfar na marra, não por seus próprios méritos, mas por decretos ressentidos.
Homeschoolers serão ainda mais necessários, caso isso se torne realidade. E nós, educadores e críticos sociais, precisaremos mais que nunca de Vieira de Mello e seus continuadores para compreender os rumos do país, alertando e ensinando direito as novas gerações.
I'm sitting on a train traveling from Illinois to California, the
long stretch of a journey from Madison to San Francisco.
Morgan sits next to me.
We are staring out the windows of the observation deck of this train
as we watch the snow covered mountains pass by.
I am feeling more relaxed and at peace than I have in years.
2016 is opening in a big way for me.
As you may have heard (I mentioned it in the last
State of the Goblin post)
MediaGoblin was accepted into the Stripe Open Source Retreat program.
Basically, Stripe gives us no-strings-attached funding for me to advance
our work on MediaGoblin, but they wanted me to work from their office
during that time.
Seems like quite a deal to me!
Unfortunately it does mean leaving Morgan behind in Madison for that time
period.
But that's why we splurged on a fancy train car and why she's joining me
in San Francisco for the first week, so we can spend some quality
time together.
(Plus, Morgan has a conference that first week in San Francisco
anyway; double plus, Amtrak has an extremely generous baggage
policy so I'm able to get all of the belongings I need for that
period shipped along with me fairly easily.)
Morgan and I have been talking about but not really taking a
vacation for a while, so we decided the moving-scenery approach
would be a nice way to do things.
It's great... we're mostly reading and drinking tea and staring out
the window at the beautiful passings-by.
I could hardly imagine a nicer send-off.
(So yeah, if you're considering taking such a journey with your
loved ones, I recommend it.)
The passage of scenery leads to reflection on the passage of time.
Now seems a good time to write a bit about 2015 and what it meant.
It was a very eventful year for me.
I have come recently to explain to people that "I live a magical and
high-stress life"; 2015 evoked that well.
From a personal standpoint, Morgan and I's relationship runs strong,
maybe stronger than ever, and I am thankful for that.
From the broader family standpoint, the graph advances steady at
times with strong peaks and valleys, perhaps more pronounced than
usual.
Love, gain, success, loss... it feels that everything has happened this
year.
Our lives have also been rearranged dramatically in an attempt to help a
family member in a time of need, and that has its own set of peaks and
valleys, as is to be expected.
But that is the stuff of life, and you do what you can when you can,
and you try your best, and you hope that others will try their best,
what happens from there happens, and you use it to plan the next
round of doing the best you can.
That's all very vague I suppose, but many things feel too private to
discuss so publicly.
Nonetheless, I wanted to record the texture of the year.
So what in the way of, you know, that thing we call a "career"?
Well, it has continued to be magical, in the way that I have had a lot
of freedom to explore things and address issues I really care about.
Receiving an award (particularly
since I did not know I had even been a candidate ahead of being
notified that I received it) has also been gratifying and
reassuring in some ways; I regularly fear that I am not doing well
enough at advancing the issues I care about, but clearly some
people do, and that's nice.
It has also continued to be high stress, in that the things I worry about
feel very high stakes on a global level, and that the difficulty of
accomplishing them also feels very strong, and of course many are not
there yet.
Nonetheless, there has been a lot of progress this year, though it
has come with a worrying increase of scope in the number of things
I am attempting to accomplish.
We're much nearer to 1.0 on MediaGoblin, which is a huge relief.
Of course, this is mostly due to Jessica Tallon's hard work on
getting federation in MediaGoblin working, and other MediaGoblin
community memebers doing many other interesting things.
Embarassingly, I have done a lot less on MediaGoblin than in
the last few years.
In a sense, this is okay, because the money from the campaign has
been going to pay Jessica Tallon, and not myself.
I still feel bad about it though.
The good news is that the focus time from the Stripe retreat should
allow me the space and focus to hopefully get 1.0 actually out the
door.
So that leads to strong optimism.
The reduced time spent coding on MediaGoblin proper has been deceptive,
since most of the projects I've worked on have spun out of work I
believe is essential for MediaGoblin's long-term success.
I took a sabbatical from MediaGoblin proper mid-year to focus on two
goals: advancing federation standards (and my own understanding of
them), and advancing the state of free software deployment.
(I'm aware of a whiff of yak fumes here, though for each I can't see
how MediaGoblin can succeed in their present state.)
I believe I have made a lot of progress in both areas.
As for federation, I've worked hard in participating in the
W3C Social Working Group,
I have done some test implementations, and recently I became
co-editor on
ActivityPump.
On deployment, much work has been done on the
UserOps
side, both in speaking and in actual work.
After initially starting to try to use Salt/Ansible as a base and
hitting limitations, then trying to build my own Salt/Ansible'esque
system in Hy and then Guile and hitting limitations there too,
I eventually came to look into (after much prodding)
Guix.
At the moment, I think it's the only foundation solid enough on which
to build the tooling to get us out of this mess.
I've made some contributions, albeit mostly minor, have begun promoting
the project more heavily, and am trying to work towards getting
more deployment tooling done for it (so little time though!).
I'm also now dual booting between GuixSD and Debian, and that's nice.
(Speaking of, towards the end of the year I switched to a
Minifree x200 on which I'm
dual booting Debian and Guix.
I believe this puts me much deeper into the "free software vegan"
territory.)
I also believe that over the last year I have changed
dramatically as a programmer.
For nearly ten years I identified as a "python web developer",
but I believe that identity no longer feels like an ideal
description.
One thing I have always been self conscious of is how little
I've known about deeper computer science fundamentals.
This has changed a lot, and I believe much of it has been
spending so much time in the Guile and Scheme communities,
and reading the copious interesting literature that is available
there.
My brother Steve and I also now often meet together and watch
various programming lectures and discuss them, which has been both
illuminating and also a great way to understand a side of my
brother I never knew.
It's a nice mix; I'm a very get-things-done person, he's a very
theoretical person, and we're meeting partway in the middle
and I think both of us are stretching our brains in ways
we hadn't before.
I feel like a different programmer than I was.
A year and a half ago, I remember being on a bike ride with
Steve and I remember complaining to him that I didn't
understand why functional programmers are so obsessed
with immutability... mutation is so useful,
I exclaimed!
Steve paused and said very carefully,
"Well... mutation brings a lot of problems..."
but I just didn't understand what he was getting at.
Now I look back on that bike ride and wonder at the former-me
taking that position.
(All that said though, I'm glad that I've had the background I have
of being a "python web developer" first, for a matter of
perspective...)
I do feel that much has changed in my life in this last year.
There were hard things, but overall, life has been good to me,
and I still am doing what I believe in and care about.
Not everyone has that opportunity.
And this train ride already points the way to a year that
should be productive, and will certainly be eventful.
Anyway, that's enough navel-gazing-reflection, I suppose.
One more navel-gaze: here's to the changed person on the other end
of 2016.
I hope I can do them justice.
And I hope you can do yourself justice in 2016 too.
The Olympus 300mm ƒ/4 Pro is one heck of a lens. Simply put. After a long time in development — it was announced as “in-development” back at CP+ in 2014 — the biggest, brightest supertelephoto lens of the Micro Four Thirds system is, well, not so “big” after all, physically at least. An impressive feat of engineering, the folks at Olympus have managed to shrink down a 600mm-equivalent supertelephoto lens, with a constant, relatively bright ƒ/4 aperture and image stabilization into a remarkably small, comfortable, hand-holdable, weather-sealed lens.
Like Olympus’ other Zuiko Pro lenses, image quality from the 300mm ƒ/4 is thoroughly impressive on all fronts: excellent sharpness and all-around wonderful optical qualities with little to no distortion, aberrations or vignetting. What’s even more impressive is the lens’ stunning image stabilization. Combining lens-based and body-based I.S., the Olympus 300mm ƒ/4 Pro lets you capture handheld images down to shockingly slow shutter speeds. All this, plus impressive close-focusing capabilities, make the Olympus 300mm ƒ/4 Pro a stunning lens for the professional and advanced photographer looking for a top-notch wildlife, sports, stage performance and close-up lens no matter the weather or lighting conditions. It may be pricey, but this is one of the best lenses Olympus has made thus far.
In the early 70's E. F. Codd provided a very precise, formal definition of a table in its normal form. Any table not normalized was in violation of the RDM and not considered a R-table. But you are unlikely to have encountered that definition. Instead you probably heard about "repeating groups", "simple domains" and "atomic values", neither of which are formal relational concepts. C. J. Date provided a 1NF definition different than Codd's. And you probably think that the same design principle underlies all normal forms, but 1NF is somewhat distinct.
This presentation introduces order and makes sense of all this, including the practical implications for SQL database practice. It is first in THE REAL DATA SCIENCE series (that includes papers and seminars) expounding the Codd-McGoveran relational model, distinct from Date-Darwen's.You will learn:
I'll be at the University of Ferrara Saturday 9th of January for a PostgreSQL afternoon.
This is the confirmed schedule.
15:00 - Federico Campoli: PostgreSQL, the big the fast and the (NOSQL on) Acid 15:40 - Michele Finelli: The PostgreSQL's transactional system 16:20 - Coffee break / general chat 16:40 - Federico Campoli: Streaming replication 17:30 - Federico Campoli: Query tuning in PostgreSQL 18:00 - Michele Finelli: An horror fairy tale: how we have lost a database 18:20 - Wrap up and general chat
All talks are in Italian language. The conference is free. All times are European time zone (GMT +1).
The venue's address is: CenTec Via Guercino, 47 44042 Cento Ferrara Italy
The headline of Postgres 9.5 is undoubtedly: Insert… on conflict do nothing/update or more commonly known as Upsert or Merge. This removes one of the last remaining features which other databases had over Postgres. Sure we’ll take a look at it, but first let’s browse through some of the other features you can look forward to when Postgres 9.5 lands:
Grouping sets, cube, rollup
Pivoting in Postgres has sort of been possible as has rolling up data, but it required you to know what those values and what you were projecting to, to be known. With the new functionality to allow you to group various sets together rollups as you’d normally expect to do in something like Excel become trivial.
So now instead you simply add the grouping type just as you would on a normal group by:
SELECT department, role, gender, count(*)
FROM employees
GROUP BY your_grouping_type_here;
By simply selecting the type of rollup you want to do Postgres will do the hard work for you. Let’s take a look at the given example of department, role, gender:
grouping sets will project out the count for each specific key. As a result you’d get each department key, with other keys as null, and the count for each that met that department.
cube will give you the same values as above, but also the rollups of every individual combination. So in addition to the total for each department, you’d get breakups by the department and gender, and department and role, and department and role and gender.
rollup will give you a slightly similar version to cube but only give you the detailed groupings in the order they’re presented. So if you specified roll (department, role, gender) you’d have no rollup for department and gender alone.
I only use foreign tables about once a month, but when I do use them they’ve inevitably saved many hours of creating a one off ETL process. Even still the effort to setup new foreign tables has shown a bit of their infancy in Postgres. Now once you’ve setup your foreign database, you can import the schema, either all of it or specific tables you prefer.
It’s as simple as:
IMPORT FOREIGN SCHEMA public
FROM SERVER some_other_db INTO reference_to_other_db;
pg_rewind
If you’re managing your own Postgres instance for some reason and running HA, pg_rewind could become especially handy. Typically to spin up replication you have to first download the physical, also known as base, backup. Then you have to replay the Write-Ahead-Log or WAL–so it’s up to date then you actually flip on replication.
Typically with databases when you fail over you shoot the other node in the head or STONITH. This means just get rid of it, completely throw it out. This is still a good practice, so bring it offline, make it inactive, but from there now you could then flip it into a mode and us pg_rewind. This could save you pulling down lots and lots of data to get a replica back up once you have failed over.
Upsert
Upsert of course will be the highlight of Postgres 9.5. I already talked about it some when it initially landed. The short of it is, if you’re inserting a record and there’s a conflict, you can choose to:
Do nothing
Do some form of update
Essentially this will let you have the typically experience of create or update that most frameworks provide but without a potential race condition of incorrect data.
JSONB pretty
There’s a few updates to JSONB. The one I’m most excited about is making JSONB output in psql read much more legibly.
If you’ve got a JSONB field just give it a try with:
SELECT jsonb_pretty(jsonb_column)
FROM foo;
Give it a try
Just in time for the new year the RC is ready and you can get hands on with it. Give it a try, and if there’s more you’d like to hear about Postgres please feel free to drop me a note craig.kerstiens@gmail.com.
Those of you who follow me on Twitter may be aware of my recent
travails with a bogeyman I've named only as "XML". Having banged my
head against this abomination of software for several days, it's
venting time so buckle in for the ride.
The Hell Am I Building
The summer I was working at Calxeda, my friends
@frozenfoxx and
@Sweet_Grrl got me hooked on a
tabletop game, Warmachine by
the Privateer Press aka PP. At a high level since PP's digital
presence is pretty last decade, Warmachine is a tabletop miniature
army game in the 2.5cm to 12cm base diameter size range. Models and
units of models have statistics in the classical D&D style, and
players engage in deathmatch and king of the hill style games.
Compared to Warhammer 40k which is probably better known, Warmachine
features a much more steampunk theme & universe, simpler rules of
play, lower entry price point and a greater focus on balance of play
rather than on army construction and model specialization.
In short, Warmachine is a player's game while Warhammer is a modeler's
game.
Unfortunately, a few realities of this game genre assert themselves.
Games are slow and take up a lot of space
Games are only possible at the other player's convenience
Exploring game balance questions is difficult b/c play is time-hard
You've got to buy before you try much of the time
As a student with homework, I simply haven't been able to attend
Austin's various weekly Warmachine evenings in about a year which
means it's a long time since I've gotten to play a game I enjoy a
lot. Unlike Starcraft or Dota I can't just drop into a game at my
convenience. But what if I could?
I've previously messed with AIs for Magic: the Gathering, so the idea
at some point asserted itself that I could (or even should) try to
build a full up simulator for Warmachine IP issues be damned.
The What
There are two "moving pieces" to this project. Or maybe prior art is
the better term. Sebastien Laforet, here and after referred to as the
Frenchman, built
an Android app
which is capable of rendering data files encoding the rules of play
and model statistics for the game. Great! Someone else already typed
all that in for me. In English, but typed it in. These files are
available
on github
and are "just" XML. More on this in a bit.
Two other people, "Hobo" and "PG_Corwin" build
a tile set for
the VASSAL tabletop simulation
engine. Unfortunately VASSAL is just a sprite engine with no
understanding of the rules or this whole project would be
moot. Treating the module as a JAR yields a whole bunch of sprites in
the /images/ tree, so there's "free" art to work with as well.
The Devils in the Data
In theory this should be dead easy. The rules files are a full
enumeration of every known piece in the game, and the sprites package
has an image for most of them, so just wire them together into a data
store of some sort and I'd be done from an assets point of view. I'd
just need to well build the graphics engine and figure out how to
simulate the ruleset.
Unfortunately this isn't so simple for a couple reasons.
First of all, the XML files Sebastien put together are designed to do
one thing and one thing only: encode the rule text on the playing
cards associated with each model and unit. Cards are generally
formatted with an image, some fluff and statistics on the front and
rules on the back. So for instance this recently released model,
Coleman Stryker v3 has a model and stat card face as such:
So we can slap all this in XML and it works just fine (with serious
elisions for length)
So we have some meaning for a <warcaster> which is a title and a
specialization of <model>, we have <basestats> which is common to
pretty much everything, we have a <weapons> block with a list of
<weapon> entries each of which has some attributes (rules) named
<capacity> and this is all pretty sane. Writing a set of functions
which can walk this tag tree using clojure.xml was really simple,
and worked great, and all you have to do is reduce over all this tag
soup with some bindings and a state object to build a representation
of a given model.
That code has been working for about 12 months, because shortly
thereafter batteries of special cases appeared from the woodwork and
fouled my initial efforts on this up.
See as in Magic: the Gathering, Warmachine derives a lot of well value
from novelty and from mixing things up in the ruleset. This means that
it's not uncommon to find things which aren't what they appear to
be. The newest faction in the game has this awesome model:
The text at the bottom "Battle engine and solos" is the important
bit. The TEP itself is what is called a Battle Engine and has a
whole battery of rules associated with that concept. However it comes
in a box with three other models which aren't part of this Battle
Engine entity, they are independent during play hence the use of the
word Solo. So... what the hell is this thing and how do we represent it?
Well this is our Frenchman's answer, again with omissions:
Did you catch that? <battleEngine> NESTS another <model>! From the
WHAC app, which seeks to duplicate the cards that come in the box this
makes sense. There's a card which represents the TEM, and there's
another card which gives the statistics for each of the spawnable
Servitors. Also, <battleEngine> as a tag is implicitly dealt with as
<model>, same as <warcaster> was earlier.
Rendering in the app this looks just fine, because you render the
"top" model being the big ol' TEM anyone reading the cards cares about
and the Servitors are secondary and so don't occur as a primary
listing.
Unfortunately this is nonsense from my point of view as a consumer
trying to extract structured information. The TEM is a <model> in
and of itself, as are the Servitors, and they come together in a
package that PP calls PIP 36028.
A similar problem applies to units. It turns out that the Frenchman
encodes units by using this implicit <model> behavior. So a unit
will be named "Foo, Leader & Grunts", use the implicit <model> tag,
just have <basestats>, some weapons and capacities and that'll be
all. Which sorta works.
Unfortunately it falls apart in units with models that aren't all the
same. I've wasted enough length on images and listings here, but go
check out the encoding of the
Black 13th
if you care. The Black 13th is composed of three characters, being
Lynch, Watts and Ryan each of whom is unique. They are encoded using
the implicit <model> on their shared <unit> to describe Lynch, the
leader, and the other two have their own nested <model>s.
Again from a rendering standpoint this makes sense, but really what I
want is something like this:
The even more degenerate case of this is unfortunately the common case
of an infantry unit: "Foo, Leader & Grunts" where the leader will get
the implicit <model> and there'll be a <model name="grunts"> or
something in its body. This is really a problem because usually the
officer has a different sprite than the grunts, and the grunts need to
have an ID in order to have a sprite permanently associated with
them. Guess what attribute they may not have.
And don't get me started on the spelling errors and qualification
mistakes and soforth I've found in these files as a result of trying
to automate parsing them.
The Devils in the Sprites
The sprites are their own little shitshow. There isn't a naming
convention to all of the files as they were done by several artists
over the course of years. Most of the time they're named with
substrings or abbreviations for a model's name, so some regex voodoo
is able to recover about a third of the model to file associations but
for most of it pfft I got to spend last night hand matching data file
model IDs to sprite names.
I'm down to about 250 entities which aren't associated with a sprite,
and I built a three page webapp to speed up building these
associations, so it could be worse but it's still painful.
Why do this? Well because the XML file that's in the root of the
VASSAL module and describes all the sprite to model associations isn't
actually valid XML, it's some VASSAL specific nonsense that I can't
seem to parse.
So yeah. XML and other people's data can go burn.
The question now before me is whether I try to do awful things to my
XML file parser so I can continue consuming Sebastien's data file
format non-deal as it is in the hope that as he maintains it I can
"just" import changes or whether I want to for my own sanity just
refactor these files and walk away from any future work of Sebastien's
in the interest of quality and sanity of parsed results.
Olympus Air Review: The Future of iPhone Cameras? (Wall Street Journal).
sign up to receive the 12 visionary tips of christmas (GetOlympus).
Canon Explorer of Light copies Lumix Luminary (Giulio Sciorio).
Ted: “Finally checking in with my first bit of news I can show! I’ll soon have news for the MFT DEC PRO coming out soon too. Could we get a quick news/blog posting on our new monitor? Was just released today. I’m certain there will be a lot of positive feedback and viewership from this announcement. I’ll send you a model if you’d like to take a look at it. The products are the VS-1 and VS-2 FINEHD. They’re basically 1920 x 1200 resolution versions of our very popular 7 inch monitors. The VS-2 comes with additional monitoring functions like histogram, false color and volume bar. This is the higher resolution than monitors five times the price. VS-1 FineHD: http://aputure.com/vs-1-FineHD VS-2 FineHD: http://aputure.com/vs-2-FineHD”
Dslava: “Commercial for KM Novosibirsk. In this project I was DOP and the operator in some shots. Shot with the gh4, DJI Ronin, set of cine lenses Samyang and nikkor 50 1.2 ais, benro tripod, crane, 3x Dedolight Felloni. Сuts in Premiere, colorgrading Magic Bullit, Davinci. https://youtu.be/szTiJLZgRLY”
The E-M5II has been selected twice at Imaging Resource best 2015 camera reward:
Once because of the best “Camera of Distinction”:
Overall, the Olympus E-M5 II takes what we loved about the E-M5 and polishes it to perfection. Combined with the ever-growing lineup of fantastic Olympus lenses, the E-M5 Mark II is a top-notch system camera for the enthusiast photographer.
And also because it has the best “Technology of Distinction”:
We’ve tested the E-M5 II’s 40-megapixel mode, and the results are very impressive. While medium-format cameras with high resolution sensors will still win on the resolution front, the level of detail the E-M5 II can deliver in its 40 megapixel mode with a good lens (and Olympus makes many such) is truly impressive. When you consider the price point, it’s a tough act to follow.
If you do enough work in any sort of free software environment, you get used
to doing lots of writing of documentation or all sorts of other things in
some plaintext system which exports to some non-plaintext system.
One way or another you have to decide: are you going to wrap your lines with
newlines?
And of course the answer should be "yes" because lines that trail all the way
off the edge of your terminal is a sin against the plaintext gods, who are
deceptively mighty, and whose wrath is to be feared (and blessings to be
embraced).
So okay, of course one line per paragraph is off the table.
So what do you do?
For years I've taken the lazy way out.
I'm an emacs user, and emacs comes with the `fill-paragraph' command,
so conveniently mapped to M-q.
So day in and day out I'm either whacking M-q now and then, or
I'm being lazy and letting something like `auto-fill-mode' do the job.
Overall this results in something rather pleasing to the plaintext-loving
eye.
If we take our first paragraph as an example, it would look like this:
If you do enough work in any sort of free software environment, you get used to
doing lots of writing of documentation or all sorts of other things in some
plaintext system which exports to some non-plaintext system. One way or
another you have to decide: are you going to wrap your lines with newlines?
And of course the answer should be "yes" because lines that trail all the way
off the edge of your terminal is a sin against the plaintext gods, who are
deceptively mighty, and whose wrath is to be feared (and blessings to be
embraced). So okay, of course one line per paragraph is off the table. So
what do you do?
But my friends, you know as well as I do: this isn't actually good.
And we know it's not good because one of the primary benefits of plaintext
is that we have nice tools to diff it and patch it and check it into
version control systems and so on.
And the sad reality is, if you make a change at the start of a paragraph
and then you re-fill (or re-wrap for you non-emacs folks) it,
you are going to have a bad time!
Why?
Because imagine you and your friends are working on this document together,
and you're working in some branch of your document, and then your friend
Sarah or whoever sends you a patch and you're so excited to merge it,
and she does a nice job and edits a bunch of paragraphs and re-wraps it or
re-fills them because why wouldn't she do that, it's the best
convention you have, so you happily merge it in and say thanks, you look
forward to future edits, and then you go to merge in your own branch you've
been working on privately, but oh god oh no you were working on your own
overhaul which re-wrapped many of the same paragraphs
and now there are merge conflicts everywhere.
That's not an imaginary possibility; if you've worked on a documentation
project big enough, I suspect you've hit it.
And hey, look, maybe you haven't hit it, because maybe most of your writing
projects aren't so fast paced.
But have you ever looked at your version control log?
Ever done a `git/svn/foo blame', `git/svn/foo praise', or whatever
convention?
Eventually you can't figure out what commit anything came from, and my
friends, that is a bad time.
In trying to please the plaintext gods, we have defiled their temple.
Can we do better?
One interesting suggestion I've heard, but just can't get on board with,
is to keep each sentence on its own line.
It's a nice idea, and I want to like it, because the core idea is good:
each sentence doesn't interfere with the one before or after it,
so if you change a sentence, it's easy for both you and the computer
to tell which one.
This means you can check things in and out of version control,
send and receive patches, and from that whole angle, things are great.
But it's a sin to the eye to have stuff scrolling off the edge of
your terminal like that, and each sentence on its own line, well...
it just confuses me.
Let's re-look at that first paragraph again in this style:
If you do enough work in any sort of free software environment, you get used to doing lots of writing of documentation or all sorts of other things in some plaintext system which exports to some non-plaintext system.
One way or another you have to decide: are you going to wrap your lines with newlines?
And of course the answer should be "yes" because lines that trail all the way off the edge of your terminal is a sin against the plaintext gods, who are deceptively mighty, and whose wrath is to be feared (and blessings to be embraced).
So okay, of course one line per paragraph is off the table.
So what do you do?
Ugh, it's hard to put into words why this is so offensive to me.
I guess it's because each sentence can get so long that it looks like
the separation between sentence is a bigger break than the separation
between paragraphs.
And I just hate things scrolling off to the right like that. I don't want
to be halfway through reading a word on my terminal and then have to jump
back so I can keep reading it.
So no, this is not good either.
But it is on the right track.
Is there a way to get the best of both worlds?
Recently, when talking about this problem with my good friend
David Thompson, I came to realize
that there is a potentially great solution that makes a hybrid of the
technical merits of the one-sentence-per-line approach and the visually
pleasing merits of the wrap/fill-your-paragraph approach.
And the answer is: put each sentence on its own line, and wrap each
sentence!
This is best seen to be believed, so let's take a look at that first
paragraph again... this time, as I typed it into my blogging system:
If you do enough work in any sort of free software environment, you get used
to doing lots of writing of documentation or all sorts of other things in
some plaintext system which exports to some non-plaintext system.
One way or another you have to decide: are you going to wrap your lines with
newlines?
And of course the answer should be "yes" because lines that trail all the way
off the edge of your terminal is a sin against the plaintext gods, who are
deceptively mighty, and whose wrath is to be feared (and blessings to be
embraced).
So okay, of course one line per paragraph is off the table.
So what do you do?
Yes, yes, yes!
This is what we want!
Now it looks good, and it merges good.
And we still can preserve the multi-line separation between paragraphs.
Also, you might notice that I continue each sentence by giving two spaces
before its wrapped continuation, and I think that's an extra nice touch
(but you don't have to do it).
This is how I'm writing all my documentation, and the style in which I will
request all documentation for projects I start be written in, from now
on.
Now if you're writing an email, or something else that's meant to be read
in plaintext as-is (you do read/write your email in plaintext, right?),
then maybe you should just do the traditional fill paragraph approach.
After all, you want that to look nice, and in many of those cases,
the text doesn't change too much.
But if you're writing something where the plaintext version is just
intermediate, and you have some other export which is what people
mostly will read, I think this is a rather dandy approach.
I hope you find it useful as well!
Happy documentation hacking!
The GH4-GX8-E-M5II are among the Top 10 Compact Cameras for Travelers from National Geographic. This is the camera they mention and why they are so good:
Olympus OM-D E-M5 Mark II
Pick for Travelers: This is a new version of an Olympus OM camera that dates back to the 1970s. Here, Olympus revisits its “smaller is better” philosophy and packs in the latest high-tech features. If you like technical features, particularly when shooting cities at twilight, you’ll like the multishot 40-megapixel mode. Like the Fuji, a complete setup fits in a smaller bag.
Pro Tip: Try the articulated screen with touch-screen focusing for video and stills. The option to touch-focus and shoot is set right on the screen. This works particularly well when shooting from a low angle. After framing up the shot, you can wait for someone to walk into the frame, touch their image on the screen, and the camera will focus and immediately take the picture. —Jim Richardson, contributing photographer for National Geographic magazine and National Geographic Traveler
Panasonic Lumix DMC-GX8
Pick for Travelers: The Panasonic G series has been a photographer favorite for a few years. The cameras are loved for their small size and excellent image quality, as well as for the huge range of lenses available from Panasonic, Olympus, and Leica. An added advantage is that the micro 4/3 cameras in this series all share a common lens mount and functionality. This is a good choice if you want a higher megapixel count than the Olympus cameras offer.
Pro Tip: David Alan Harvey used an earlier version of this surprisingly tiny camera to capture many of the pictures featured in a National Geographic magazine story on North Carolina’s Outer Banks.
Panasonic Lumix DMC-GH4
Pick for Travelers: If you like a modern-looking, great-shooting still camera, this is a great choice. It has all the advantages of using the micro 4/3 format with a huge selection of lenses that don’t lock you into a particular manufacturer’s camera. But it’s a video-shooting powerhouse. The Lumix DMC-GH4 takes still-camera video into an entirely new class by shooting in ultrahigh definition, a resolution that is commonly referred to as 4K. This camera is the least expensive way to shoot ultra-HD video.
Pro Tip: To see what this camera is capable of, watch “Light of the Yucatan” by Bryan Harvey, an award-winning commercial and documentary director of photography.
Olympus TG-3
Pick for Travelers: Although this camera has the very small point-and-shoot-size sensor, its other attributes more than make up for that slight handicap. It’s pocket-size and completely shockproof, freezeproof, and dustproof, as well as waterproof to 50 feet without a housing. Sometimes the best photos come from the sketchiest circumstances, and you won’t be afraid to bring this camera along—it’s one you don’t have to worry about. Olympus has added a new Tough camera, the TG-860, which incorporates a selfie-friendly, 180-degree flip screen.
Pro Tip: [I took] this camera on my first diving trip to the Great Barrier Reef. I was very impressed by the clarity of the images I got below the surface. All of my dive mates were jealous, especially the one who paid extra for housings and whose pictures weren’t as clear. —Carolyn Fox, former director of digital, Nat Geo Travel
At that point, I had zero doubt: the production version of the BI connector, to be shipped with MongoDB 3.2, was, in fact, the PostgreSQL database in disguise!
To be fair, MongoDB and others in the NoSQL space are facing a difficult problem: duplicate the massive amount of BI infrastructure that exists for SQL databases. That’s an unenviable uphill battle. It’s even more difficult because BI tools are as complex as databases themselves, which means it’s difficult for companies to adopt a BI tool that’s not already well established.
De Goes is approaching this from the standpoint that traditional BI tools don’t work well with NoSQL. I think that depends on just how unstructured your data is. If you really don’t know what you’ll be pulling analytics on then trying to handle that with a traditional BI tool that’s pulling data through a relational database won’t be very satisfying. But I think a lot of NoSQL users actually do know the structure that they’re dealing with, and that structure is fairly fixed. That makes it a lot more reasonable to map your “unstructured” data (which in reality is structured) into a relational schema. From that context, utilizing Postgres to be a relational interface and query planner to Mongo storage is actually a very astute (and gutsy!) choice. Why try and re-invent all those wheels when you can have them for free?
The danger here for MongoDB is that Postgres equals or exceeds MongoDB performance on many workloads, at which point you start wondering why you’re using Mongo to begin with. For further reading, check out De Goes’ whitepaper “Characteristics of NoSQL Analytics Systems” which makes some really good points. It would be interesting to see what Slam Data‘s tool on top of Postgres using a mix of relational and JSON would look like.
There are a diverse range of free software solutions for accounting.
Personally, I have been tracking my personal and business accounts using a double-entry accounting system since I started doing freelance work about the same time I started university. Once you become familiar with double-entry accounting (which doesn't require much more than basic arithmetic skills and remembering the distinction between a debit and a credit) it is unlikely you would ever want to go back to a spreadsheet.
Accounting software promoted for personal/home users often provides a very basic ledger where you can distinguish how much cash goes to rent, how much to food and how much to the tax man. Software promoted for business goes beyond the core ledger functionality and provides helpful ways to keep track of which bills you already paid, which are due imminently and which customers haven't paid you. Even for a one-mand-band, freelancer or contractor, using a solution like this is hugely more productive than trying to track bills in a spreadsheet.
Factors to consider when choosing a solution
Changing accounting software can be a time consuming process and require all the users to learn a lot of new things. Therefore, it is generally recommended to start with something a little more powerful than what you need in the hope that you will be able to stick with it for a long time. With proprietary software this can be difficult because the more advanced solutions cost more money than you might be willing to pay right now. With free software, there is no such limitation and you can start with an enterprise grade solution from day one and just turn off or ignore the features you don't need yet.
If you are working as an IT consultant or freelancer and advising other businesses then it is also worthwhile to choose a solution for yourself that you can potentially recommend to your clients and customize for them.
The comparison
Here is a quick comparison of some of the free software accounting solutions that are packaged on popular Linux distributions like Debian, Ubuntu and Fedora:
While the above list gives a basic summary of features, it is necessary to look more closely at how they are implemented.
For example, if you need to report on VAT or GST, there are two methods of reporting: cash or accrual. Some products only support accruals because that is easier to implement. Even in commercial products that support cash-based VAT reporting, the reports are not always accurate (I've seen that problem with the proprietary Quickbooks software) and a tax auditor will be quick to spot such errors.
The only real way to get to know one of these products is to test it for a couple of hours. Postbooks, for example, provides the Demo database so you can test it with dummy data without making any real commitment.
User interface choices
If you need to support users on multiple platforms or remote users such as an accountant or book-keeper, it is tempting to choose a solution with a web interface. The solutions with desktop interfaces can be provisioned to remote users using a terminal-server setup.
The full GUI solutions tend to offer a richer user interface and reporting experience. It can frequently be useful to have multiple windows or reports open at the same time, doing this with browser tabs can be painful.
File or database storage
There are many good reasons to use database storage and my personal preference is for PostgreSQL.
Using a database allows you to run a variety of third-party reporting tools and write your own scripts for data import and migration.
Community and commercial support
When dealing with business software, it is important to look at both the community and the commercial support offerings that are available.
My personal choice at the moment is Postbooks from xTuple. This is because of a range of factors, including the availability of both web and desktop clients, true multi-user support, the multi-currency support and the PostgreSQL back-end.
Now this get's interesting. Apparently MongoDB will get a BI connector - which seems to be a Multicorn foreign data wrapper for PostgreSQL!
While the step is logical in some way given MongoDBs limited built-in analytical capabilities vs. what PostgreSQL can do by declaration, e.g. CTEs, window functions or TABLESAMPLE, this also could backfire badly. Well, I'm almost convinced it will backfire.
PostgreSQL already has 'NoSQL' capabilities like native JSON and HSTORE k/v, there is ToroDB, emulating a wire protocol compatible MongoDB on top of PostgreSQL. There is already work on Views (Slide 34) in ToroDB, which will enable Users to query documents stored in ToroDB not only with the MongoDB query language but also with SQL, thus seamlessly integrating ToroDB document data with plain PostgreSQL relational data.
Then, there is no reason to use MongoDB at all, except maybe data ingestion speed. Data ingestion in ToroDB is way slower than with a 'real' MongoDB, but this is being worked on.
And from my experience in a current project, with a bit of anticipatory thinking, PostgreSQL data ingestion speed can at least challenge MongoDB, with security, integrity, transactions and all - on a server with 1/4 the CPU cores than the Mongo-Server has.
So, the wolf and the lamb will feed together, and the lion will eat straw like the ox... - there are truly interesting times ahead. :-)
I got more feedback from different sources that Olympus will indeed announce a new roadmap of f/1.2 prime lenses in early Spring. I have been told they will announce the specs of multiple(!) f/1.2 prime lenses. The lenses shipment will then be spread during the upcoming 12 months.
— For sources: Sources can send me anonymous info at 43rumors@gmail.com (create a fake gmail account) or via contact form you see on the right sidebar. Thanks!
Rumors classification explained (FT= FourThirds): FT1=1-20% chance the rumor is correct FT2=21-40% chance the rumor is correct FT3=41-60% chance the rumor is correct FT4=61-80% chance the rumor is correct
For a far-outside view, it's hard to beat this
VentureBeat article, wherein a venture capitalist talks about how
"open-source companies" are taking over. "The OSS companies that
will be pillars of IT in the future are the companies that leverage a
successful OSS project for sales, marketing, and engineering prioritization
but have a product and business strategy that includes some proprietary
enhancements. They’ve figured out that customers are more than happy to pay
for an enterprise-grade version of the complete product, which may have
security, management, or integration enhancements and come with
support. And they also understand that keeping this type of functionality
proprietary won’t alienate the community supporting the project the way
something such as a performance enhancement would."
These proposed regulations are meant to facilitate public reuse
of works funded by Department of Education grants. Currently, as
explained in the NPRM, grantees are allowed to make their
federally-funded works proprietary. The Department of Education
receives a special license to share the works with the public, but in
practice it rarely does so. Worse, teachers and students absolutely
cannot use them in freedom (except for those few that happen to be
made free).
Since the course materials are works of practical use, they should
carry the four freedoms of free software,
just as programs and manuals should.
The proposal would require grantees to publish the works under an
"open" license. In the case of software, they may be thinking of
"open source", which is not quite as strong as free; in the case of
courseware, many "open" courses are not free. The flaw in the
proposed specific rules is that they don't require that the license
permit redistribution of modified versions. Without that freedom, the
works will be nonfree.
With a small change, this proposal will more clearly do what is
needed. The small change is to add "redistribution of modified
versions" to the list of uses these works must permit users to do.
If you are a US citizen or you are living in the US, then you can help
make that change happen by submitting a comment advocating it.
If you are not a US citizen, then we hope you will use this as an
opportunity to reach out to the department of education or the
appropriate government rule makers in your own country and encourage
them to adopt similar rules -- ones that require grant funded works of
a functional nature be distributed under free licenses. If you do
contact your own government with such a request, please, email
licensing@fsf.org and let us know!
Unfortunately, submitting a comment digitally requires the user
to run nonfree JavaScript (JS) code. We are taking a stand
against that by submitting the FSF's comment another way. We are going
to submit it by post so that it gets to the Dept. of Ed. by Friday, December
18th (the date comments are due).
To help you submit a comment without running the US government's
nonfree JS, we offer to print and send your comment along with ours.
To do that, we need to receive your comment by email sent to
licensing@fsf.org with the subject "Dept. of Ed. comment" by 12:00PM EST on
December 15th. We can print PDF files, ODF files and plain text. You
need to follow the rules for submissions 100%, because we don't have
staff to correct even minor errors. The eRulemaking Initiative has
some guidance on how to write a good comment. But in the very
least: your comment should clearly cite the above referenced NPRM (Docket ID ED-2015-OS-0105), it should express your support for these proposed regulations, and it should cite the exact section (§3474.20 (a)) that you believe should
be updated and why you think it should, including any relevant personal or professional experience or knowledge. See our NPRM Basics guide for citing and formatting your comment.
We may skip comments that are too long or that are inconsistent with
the goal. Please say in your email message whether you give permission
for us to publish your comment.
While we would like to deliver a large packet of comments to the
Department of Education, you can also mail your own: address them to
Sharon Leu, U.S. Department of Education, 400 Maryland Avenue SW.,
Room 6W252, Washington, DC 20202-5900.
In addition, if you are interested in becoming a cosigner to the
comment the FSF is going to write and submit, then please email us at
licensing@fsf.org with the subject "Dept. of Ed. comment cosigner." In your
email please provide your full name, city and state, and be aware that
we will be making that information public as part of publishing our
comment.
Lastly, there should be no doubt in your mind that the FSF's work in
free licensing, licensing education, and advocacy has played a
meaningful part in the circumstances that have lead to the US
Department of Education reforming its policy from promoting
proprietary works to one that requires the development of only free
works. We know that the GNU GPL and the FSF's work in free licensing
education serves as a guiding light to policy makers everywhere. But,
in order for us to continue positively influencing public policy, we
need your help: please,
become an associate member or make a donation today.
My colleagues and I are often asked “when will you (2ndQuadrant) contribute BDR to PostgreSQL”.
This makes an interesting assumption: that we have not already done so. We have. Much of BDR has already been contributed to core PostgreSQL, with more to come. All of BDR is under the PostgreSQL license and could be merged into PostgreSQL at any time if the community wished it (but it doesn’t and shouldn’t; see below).
It’s now quite trivial to implement an extension to add simple multi-master on top of the facilities built-in to PostgreSQL 9.5 if you want to. See the work Konstantin Knizhnik and colleagues have been doing, for example. Many if not most of the facilties that make this possible were added for and as part of the BDR project.
There seems to be some widespread misunderstanding about how contributing large pieces of work to PostgreSQL works.
PostgreSQL is a complex piece of software and it’s developed quite conservatively, focusing on correctness and maintainability over pace of development. This means that big “code drops” are not welcome. That’s where multiple features are added at once in changes that affect large parts of many different files across the server. Merging BDR in one go would be just such a code drop. As a result, even though BDR is released under the PostgreSQL license and could simply be merged into PostgreSQL tomorrow that isn’t going to happen – and it shouldn’t.
That doesn’t mean we’re sitting idle, though.
Instead we’ve progressively worked with the rest of the community (including our competitors in the services and consulting space) to get the changes to the core server that BDR needs merged into PostgreSQL over the 9.3, 9.4 and 9.5 development series. The considerable majority of those features are now in place in 9.5, with more being worked on for 9.6. BDR on 9.4 requires quite a big patch to the core PostgreSQL server, wheras on 9.5 it would require very little as a result of all the work that’s been merged.
Now that most of the core server patches are merged we’re working on getting some of the upper layers of the technology into PostgreSQL. Petr and I submitted the pglogical_output plugin to the November commitfest for 9.6 and the team is working to get the downstream/client ready for general availability and submission. The reason we’re doing this is to get it in core and into the hands of users who don’t want to rely on patched servers and big extensions, which BDR undeniably is.
A partial list of patches created for or as part of BDR and merged to core includes:
Background workers (9.3)
Event Triggers (9.3 and 9.4)
Replication slots (9.4)
Logical decoding (9.4)
Enhanced DROP event triggers (9.4)
REPLICA IDENTITY (9.4)
Commit Timestamps (9.5)
Replication Origins (9.5)
DDL Deparse hooks (9.5)
Meanwhile we continue to work on getting further core enhancements into place to improve logical replication and multimaster capabilities, with work on sequence access methods, wal messaging, logical decoding enhancements, and more. At the same time we’re contributing extensions that use that work now that the foundations are strong enough to support them.
In other words: we have contributed BDR, and continue to contribute it. Not only have we contributed the code, but we’ve contributed countless hours extracting pieces for submission then revising and editing and changing them to meet community standards.
The latest part of that effort is pglogical, which I’ll discuss in more detail in a follow-up post.
Lembro-me que, quando era adolescente, havia uma grande expectativa sobre o que a minha geração poderia fazer para o Senhor. A Mocidade Para Cristo fez o desafio da Geração Compromisso, que se consagraria ao Senhor para a obra missionária. Eu imaginava que a minha geração seria um marco na História da Igreja brasileira, uma espécie de antes e depois, que teria o poder de transformar o Brasil em um país verdadeiramente evangélico. Seríamos a geração que superou os debates entre o pentecostalismo e o tradicionalismo, que incorporou uma linguagem contemporânea à comunicação do Evangelho, educados e com acesso às elites do país e com o ardor de coração necessário para trazer o avivamento ao Brasil.
Hoje, quase vinte anos depois, não há um marco visível do que a “Geração Compromisso” tenha produzido. A divisão entre tradicionais e pentecostais recrudesceu, agora no debate cessacionistas vs. carismáticos ou reformados e arminianos. O neopentecostalismo e a Teologia da Prosperidade continuam sendo os motores da igreja evangélica e aparecem no noticiário político, envolvidos nos escândalos de corrupção que envolvem o presidente da Câmara. É alarmante constatar o número de pessoas com idade entre 30 e 45 anos (minha geração) que passaram por divórcios. A maioria possui uma visão de mundo muito mais influenciada pela esquerda do que pelo Evangelho…e o resultado é que os ídolos da Geração Compromisso são Caio Fábio, Ricardo Gondim e Ed René Kivitz, cuja teologia aproxima-se da neo-ortodoxia, do liberalismo teológico e comportamental e pregam uma visão alternativa da Igreja. Aliás, a Geração Compromisso é desencantada tanto com a Igreja como com a Bíblia. Busca tanto uma igreja não institucional como uma interpretação mais livre das Escrituras.
O que aconteceu? Talvez a resposta esteja nos dois primeiros capítulos do livro de Juízes, que você pode ler aqui.
A miscigenação ideológica no passado
Quando o povo de Israel saiu do Egito e foi para Canaã, a “Terra Prometida”, Deus deu ordem para que os israelitas não se aliassem aos cananeus e os destruíssem da terra. Embora pareça uma ordem dura, os cananeus eram violentos, queimavam os filhos a ídolos (consagrar a Moloque) e cometiam imoralidades sexuais que fariam um pedófilo corar de vergonha, a tal ponto que a Bíblia diz que a terra vomitava os cananeus.
O motivo era simples: se os cananeus convivessem com Israel, os hebreus aprenderiam os costumes de Canaã e os seguiriam. Entretanto, ao invés de obedecer, o que fez Israel?
Porém os filhos de Benjamim não expulsaram os jebuseus que habitavam em Jerusalém; antes, os jebuseus habitam com os filhos de Benjamim em Jerusalém, até ao dia de hoje. (Juízes 1:21)
Manassés não expulsou os habitantes de Bete-Seã, nem os de Taanaque, nem os de Dor, nem os de Ibleão, nem os de Megido, todas com suas respectivas aldeias; pelo que os cananeus lograram permanecer na mesma terra. Quando, porém, Israel se tornou mais forte, sujeitou os cananeus a trabalhos forçados e não os expulsou de todo. Efraim não expulsou os cananeus, habitantes de Gezer; antes, continuaram com ele em Gezer.
Zebulom não expulsou os habitantes de Quitrom, nem os de Naalol; porém os cananeus continuaram com ele, sujeitos a trabalhos forçados. Aser não expulsou os habitantes de Aco, nem os de Sidom, os de Alabe, os de Aczibe, os de Helba, os de Afeca e os de Reobe; porém os aseritas continuaram no meio dos cananeus que habitavam na terra, porquanto os não expulsaram. Naftali não expulsou os habitantes de Bete-Semes, nem os de Bete-Anate; mas continuou no meio dos cananeus que habitavam na terra; porém os de Bete-Semes e Bete-Anate lhe foram sujeitos a trabalhos forçados. Os amorreus arredaram os filhos de Dã até às montanhas e não os deixavam descer ao vale. Porém os amorreus lograram habitar nas montanhas de Heres, em Aijalom e em Saalabim; contudo, a mão da casa de José prevaleceu, e foram sujeitos a trabalhos forçados. (Juízes 1:27-35)
Reparem nas diferentes situações:
– Trabalhos forçados: os cananeus não foram destruídos, mas se tornaram escravos de Israel. A convivência continuava;
– Coexistência: nos casos das tribos de Manassés e Efraim, os cananeus continuaram em sua terra, junto com os hebreus. Cada um em seu território, mas como inimigos de força semelhante;
– Minoria: algumas tribos continuavam “no meio”. Os cananeus eram dominantes.
– Opressão: no caso de Dã, os israelitas foram oprimidos e confinados nas montanhas. Os cananeus dominavam e oprimiam.
Tudo isso aconteceu porque o povo de Israel desobedeceu a ordem divina. De perto, os cananeus não pareciam tão horríveis assim. Israel amou a Canaã e não quis destruí-la. No máximo, eles poderiam sobreviver como escravos. Após algum tempo, o Senhor desistiu de destruir os cananeus. Israel falhou em sua missão:
Subiu o Anjo do SENHOR de Gilgal a Boquim e disse: Do Egito vos fiz subir e vos trouxe à terra que, sob juramento, havia prometido a vossos pais. Eu disse: nunca invalidarei a minha aliança convosco. Vós, porém, não fareis aliança com os moradores desta terra; antes, derribareis os seus altares; contudo, não obedecestes à minha voz. Que é isso que fizestes? Pelo que também eu disse: não os expulsarei de diante de vós; antes, vos serão por adversários, e os seus deuses vos serão laços. Sucedeu que, falando o Anjo do SENHOR estas palavras a todos os filhos de Israel, levantou o povo a sua voz e chorou. (Juízes 2:1-4)
“Mulher Chorando”, de Pablo Picasso
A miscigenação ideológica do presente
No Novo Testamento, não há mais uma ordem para que a Igreja destrúa os que não acreditam em Cristo. Os cristãos devem viver no que a Bíblia chama de “mundo”, pregando o Evangelho e vivendo segundo Cristo, de modo a trazer outras pessoas para Jesus. Todavia, isso não significa que a separação tenha deixado de existir.
Se o mundo vos odeia, sabei que, primeiro do que a vós outros, me odiou a mim. Se vós fôsseis do mundo, o mundo amaria o que era seu; como, todavia, não sois do mundo, pelo contrário, dele vos escolhi, por isso, o mundo vos odeia. Lembrai-vos da palavra que eu vos disse: não é o servo maior do que seu senhor. Se me perseguiram a mim, também perseguirão a vós outros; se guardaram a minha palavra, também guardarão a vossa. (João 15:18-20)
Reparem no que diz Jesus: os discípulos d’Ele não pertencem mais ao mundo! Estamos vivendo no meio do mundo, mas não somos mais dele. Na verdade, os cristãos são odiados.
A Bíblia volta a reforçar isso em 1 João, de modo inverso. Os cristãos devem amar as pessoas que não são cristãs. Mas eles não devem amar aquilo que a Bíblia chama de “mundo”:
Não ameis o mundo nem as coisas que há no mundo. Se alguém amar o mundo, o amor do Pai não está nele; porque tudo que há no mundo, a concupiscência da carne, a concupiscência dos olhos e a soberba da vida, não procede do Pai, mas procede do mundo. Ora, o mundo passa, bem como a sua concupiscência; aquele, porém, que faz a vontade de Deus permanece eternamente. (1 João 2:15-17)
Os cananeus do Antigo Testamento são um tipo do mundo do Novo Testamento. Assim como os cananeus deveriam “passar”, o mundo passará. Como era impossível obedecer a Deus e conviver com os cananeus, também não há como amar o Pai e o mundo ao mesmo tempo.
Por que a “Geração Compromisso” fracassou em sua missão de mudar a Igreja no Brasil? Pelo mesmo motivo que os israelitas fracassaram nos dias dos juízes: amamos e preservamos os “cananeus”.
Amamos a Deus, mas também amamos o mundo. Não consideramos que a Bíblia ou o Evangelho são suficientes. Nós os complementamos com o mundo e sua sabedoria. Trouxemos a psicologia, a sociologia, o marketing, a filosofia e outras coisas para dentro da Igreja, do culto e até do discipulado. Na hora de educar os filhos, o Espírito Santo precisou disputar espaço com os valores pregados pelos educadores da televisão e o ensino guiado pelo Estado. A Bíblia não é suficiente, ela precisa da validação de algum erudito secular para ser aceita em seus termos.
Trocamos o amor sacrificial da Bíblia pela visão de amor das novelas, dos filmes, das séries…e, pior, dos sites de pornografia. Abandonamos o ensino bíblico sobre marido e mulher, sobre pais e filhos e fizemos pior do que nossos pais, que tanto condenávamos! Há mais efeminação, má educação e egoísmo em nossos filhos do que havia antes. E muito mais poderia ser dito sobre dinheiro, trabalho, sexualidade, relacionamentos…o amor ao mundo está impregnado em cada centímetro da nossa vida.
A solução: o libertador
A “Geração Compromisso” merece o juízo de Deus tanto como os hebreus que preservaram os cananeus. Merecemos a confusão, a crise existencial, a falta de bênçãos em nossas famílias, a desolação do Brasil…assim como eles. Mas, felizmente, Deus é bom e misericordioso.
Nos dias dos Juízes, após os cananeus se levantarem contra Israel e oprimirem os israelitas, Deus levantava juízes para livrar o Seu povo:
Quando o SENHOR lhes suscitava juízes, o SENHOR era com o juiz e os livrava da mão dos seus inimigos, todos os dias daquele juiz; porquanto o SENHOR se compadecia deles ante os seus gemidos, por causa dos que os apertavam e oprimiam. (Juízes 2:18)
Isso nos ensina que o poder de se livrar de nossos próprios erros não está em nós, mas no Senhor. Dependemos que Ele levante alguém para nos salvar. A “Geração Compromisso” precisa entender que ela não pode se resgatar de seus erros e fracassos. Contudo, nem mesmo juízes comuns eram capazes de manter Israel fiel ao Senhor:
Sucedia, porém, que, falecendo o juiz, reincidiam e se tornavam piores do que seus pais, seguindo após outros deuses, servindo-os e adorando-os eles; nada deixavam das suas obras, nem da obstinação dos seus caminhos. (Juízes 2:19)
Precisamos de um novo juiz. Um que viva para sempre e cujos dias nunca tenham fim. Um que seja Eterno e Perfeito. Um que possa nos livrar não apenas de inimigos externos, mas dos nossos próprios afetos e sentimentos enganosos e do nosso amor desesperado pelo mundo e suas coisas. Precisamos de Jesus:
A este ressuscitou Deus no terceiro dia e concedeu que fosse manifesto, não a todo o povo, mas às testemunhas que foram anteriormente escolhidas por Deus, isto é, a nós que comemos e bebemos com ele, depois que ressurgiu dentre os mortos; e nos mandou pregar ao povo e testificar que ele é quem foi constituído por Deus Juiz de vivos e de mortos. Dele todos os profetas dão testemunho de que, por meio de seu nome, todo aquele que nele crê recebe remissão de pecados. (Atos 10:40-43)
Pense bem: onde está o seu coração? O que vale mais: ser feliz em relacionamentos românticos condenados pelo Senhor ou desfrutar do amor do Pai? Prosperar como funcionário público e medir sua felicidade pelo sucesso material atingido ou prosperar espiritualmente, gastando tempo com Jesus e crescendo em santificação? Ser aprovado pelos colegas do trabalho e pelos amigos que vieram da época do colégio ou por Cristo?
Não espero que eu e a minha geração mudem coisa alguma na história da Igreja brasileira. Apenas suplico que nós, eu e eles, nos voltemos para os apóstolos que testemunharam na Bíblia sobre Jesus, que creiamos neles e nos profetas, e sejamos todos resgatados (redimidos) de nossos pecados por meio de Cristo Jesus.

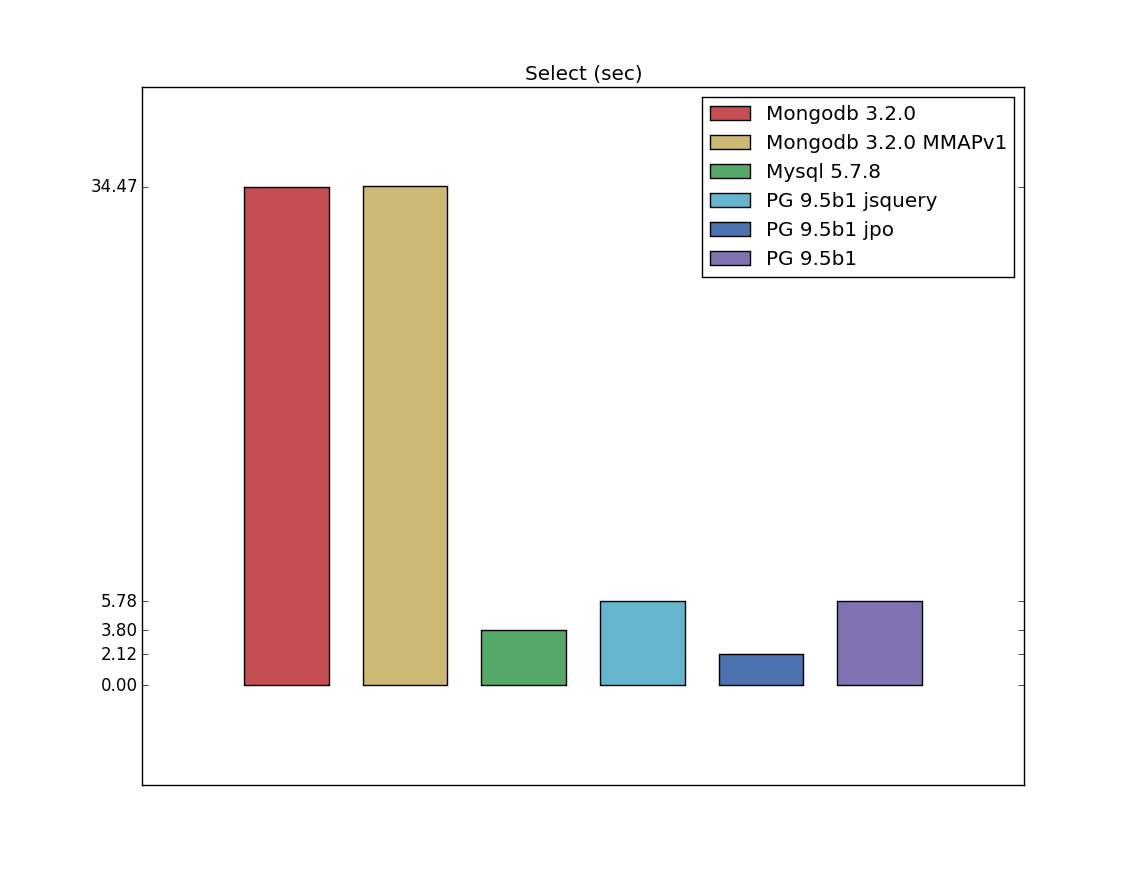
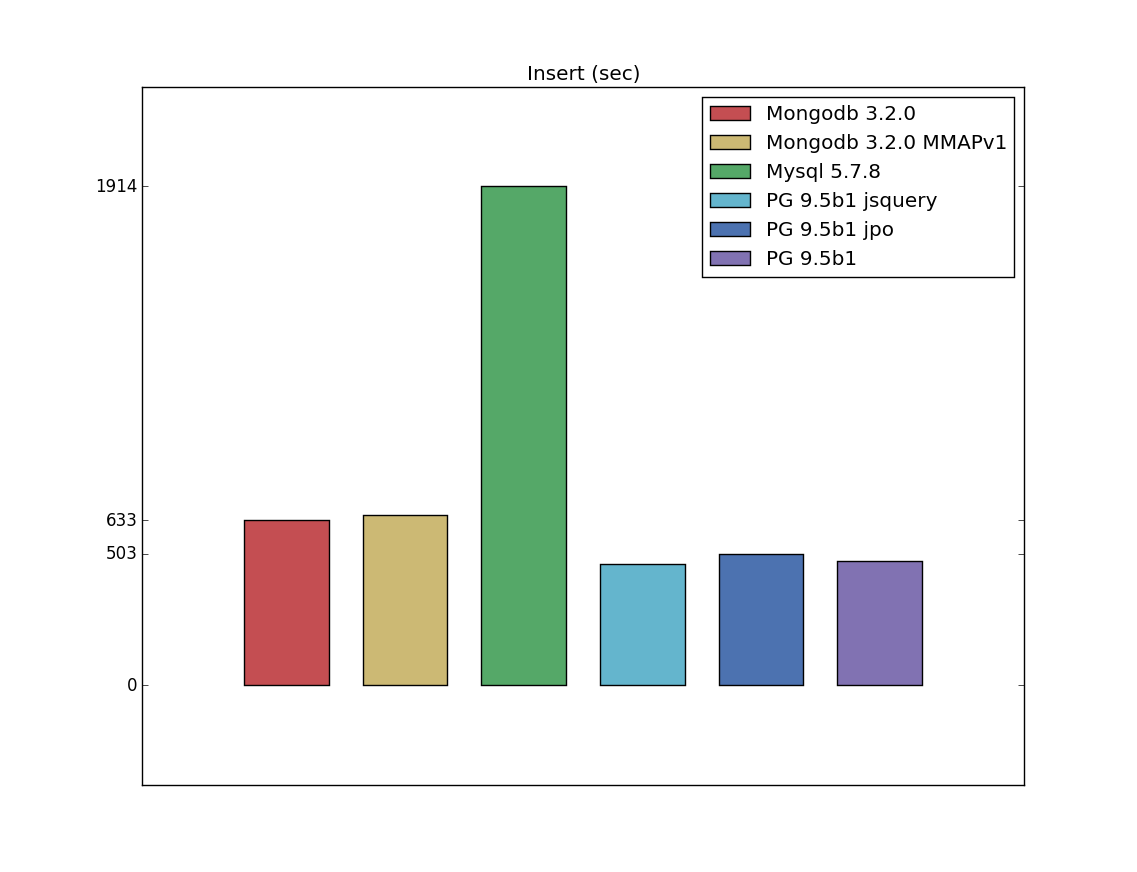
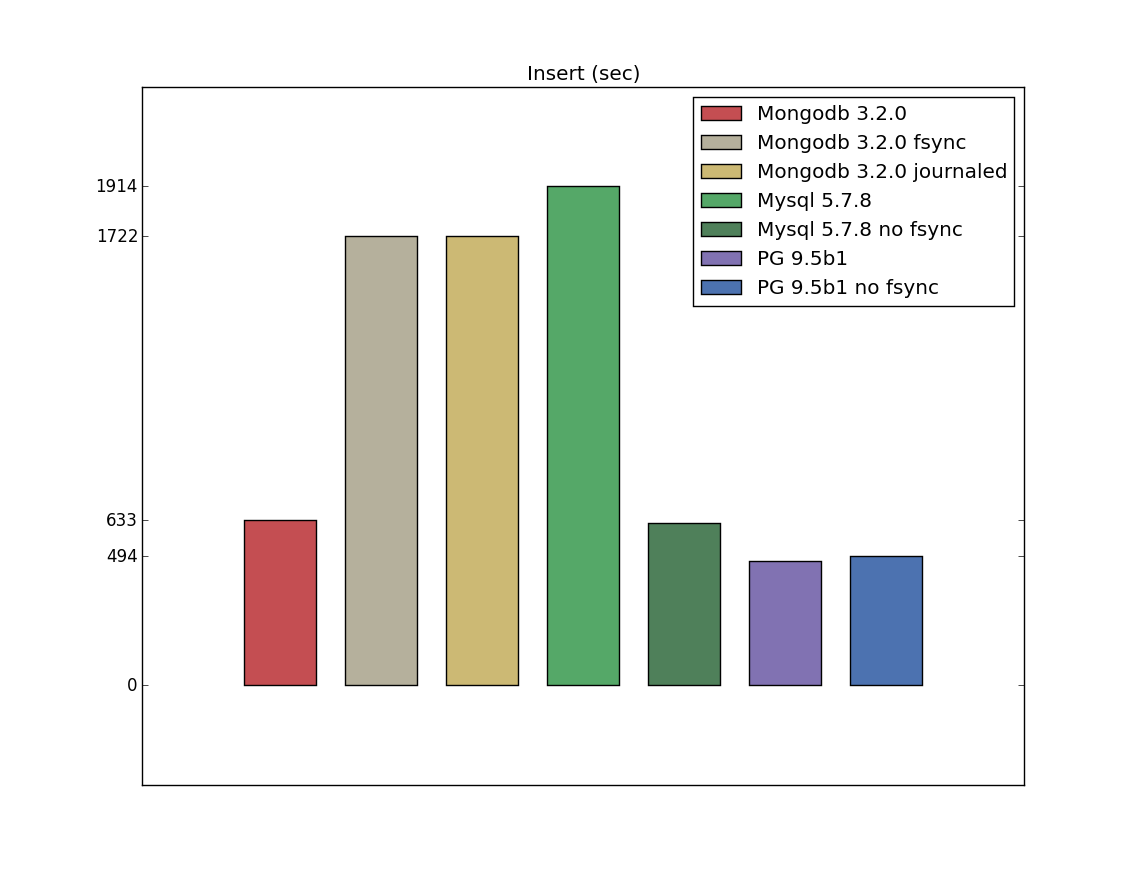
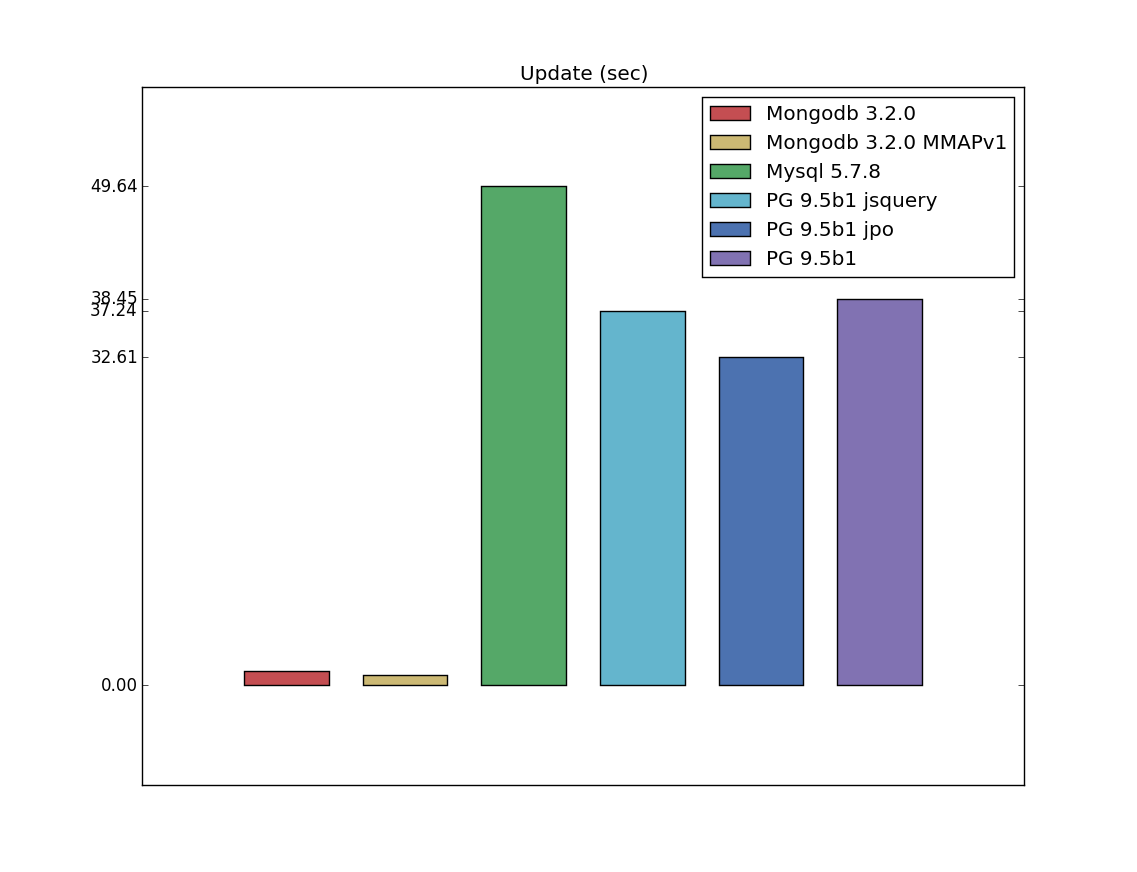
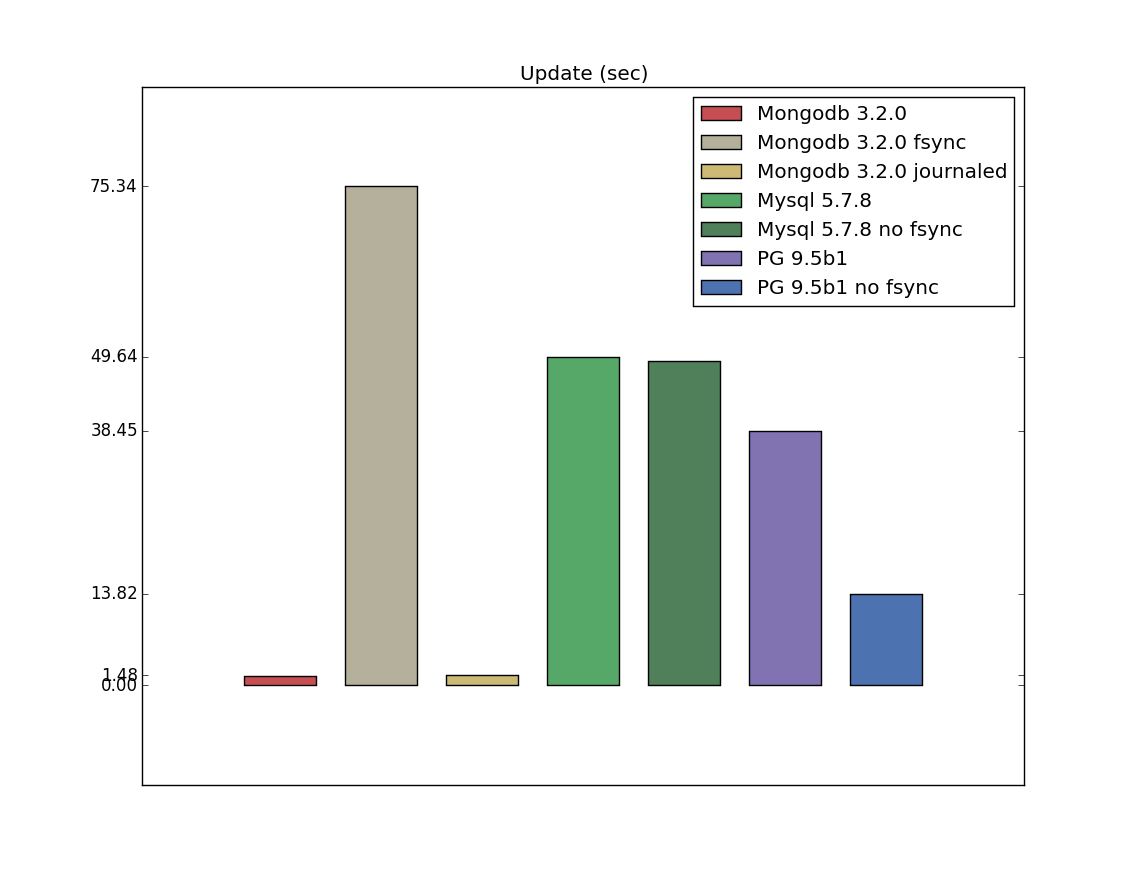
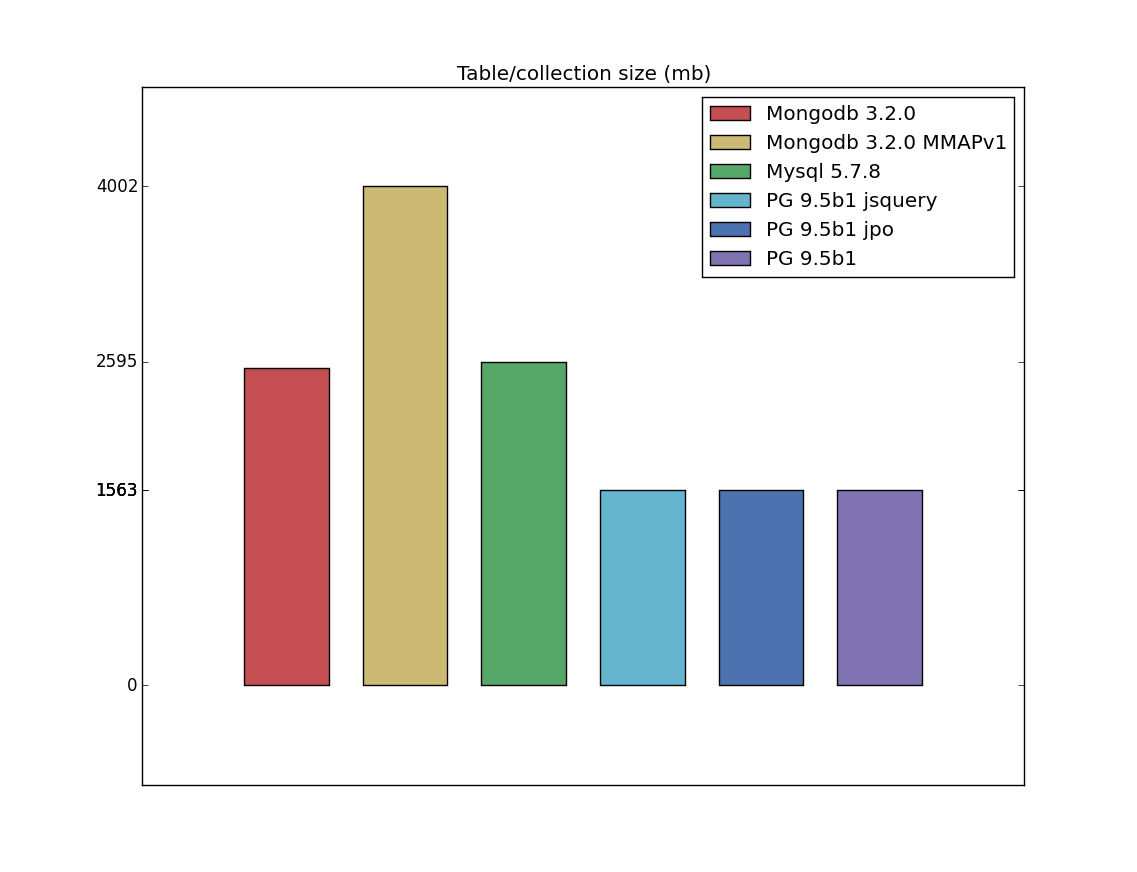
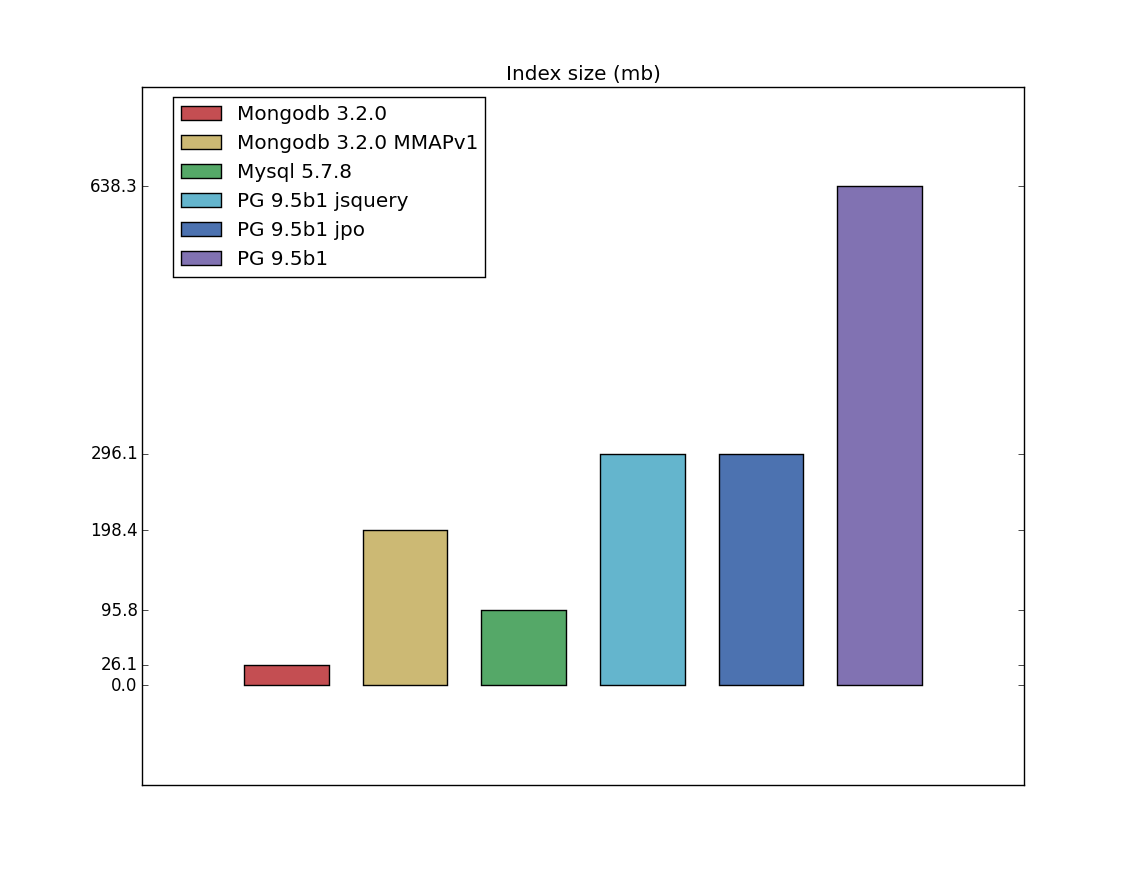


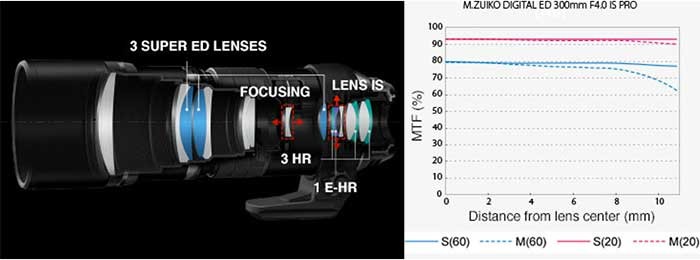








{kind=link}