Edit 21 Jan 2013: added “Example 3″ to the title.
Introduction
I’m going to jump right in and imagine that we have a known plant which we wish to control using P, PI, or PID. I’m going to assume that you have some idea what those are. We’ve seen proportional (P) control, where the control signal is proportional to the error. Integral control has a signal which is proportional to the integral of the error, and derivative control a signal which is proportional to the rate of change (the derivative) of the error. Proportional control is always used in conjunction with integral, hence PI. Although derivative control can be used with only proportional, in process control we generally use both integral and proportional with it, hence PID. We’ll talk more about them in subsequent posts, but for now I want to show you two ways to get the required parameters. They may not always be very good values, but they’ll be better than in the ballpark. At the very least, they are good starting values for further investigation.
Oh, I am aware that Mathematica® version 9 has new capabilities for tuning controllers – but let me write about what I know, using version 8.
My plant is a 3rd-order transfer function… as usual, rules are a convenient way to specify things:

Bequette – this is Example 5.3 (p. 174) and Example 6.1 (p. 199) from Bequette’s “Process Control: Modeling, Design, and Simulation”, Prentice Hall 2003. He used the Routh criterion to decide that the ultimate gain was 10: that’s on the verge of instability. Let’s take a look – that is, I’m about to show you what the ultimate gain means.
I set a new parameter value for K, namely K = 10, the alleged ultimate gain.

The closed loop transfer function (y) is…. and the time-domain response to a unit step function is…

Let’s get the control effort transfer function u, too… and the time-domain behavior:

Here’s my usual first plot: step function in silver (or whatever it is), system response in black, scaled control effort (c1/K) in gold:

OK, we see steady-state oscillations in response to a unit step input. Make K slightly greater, and the oscillations will grow; make K slightly smaller and the oscillations will get smaller. We are on the edge of instability, just as advertised.
I should also show you the actual control effort:

We would like to know the period of these output oscillations. It looks like it is slightly above 6… there’s a minimum just before 7, and the next one is just after 13 – look at the previous graph… that’s why I scale the control effort, so the output is not compressed.
We could use calculus to find them…. If we were looking at a paper recording, we might be able to measure them, but in this case we have an explicit equation for the solution, so let’s go ahead and do calculus. Here’s the first derivative of the output… set it to zero.

Let’s find solutions near 7 and 13…

We could also back up, and instead of finding the ultimate gain by the Routh criterion, we could have found it by simulation. I’ve shown you simulation before, so I won’t do it this time. If, instead of having a math model, you were in the control room playing with parameters, you’d be using the system itself to do a simulation… and the operators would be planning to kill you for bringing the system to the edge of instability.
The bottom line, however, is that we now have two parameters, called the ultimate gain and the ultimate period. There are some simple tuning rules – choices of P, PI, and PID settings – which are based on these two parameters.
But first let me show you the right way to get the ultimate gain and ultimate period, if you have a quantitative model. Everything else in this post is straight-forward, I hope, but this trick is not, at least to me.
We return to our initial system (K = 1):

And here’s the open loop Bode plot:
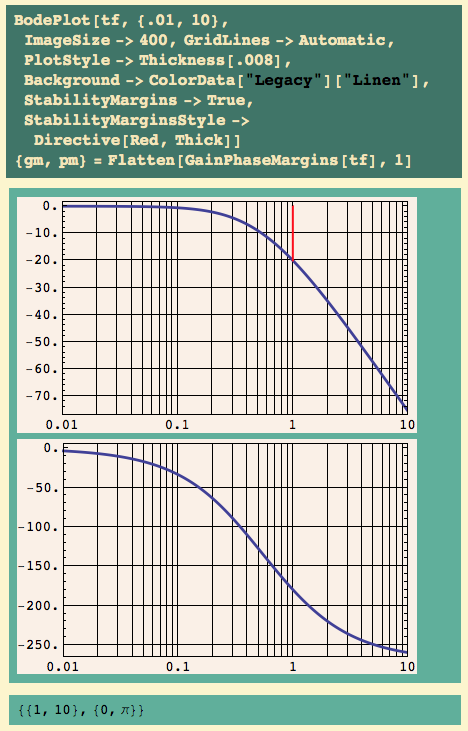
The gain margin is 10 – gee, that’s the ultimate gain Bequette found! It occurs at a frequency of 1 radian/second.
Given a frequency f in radians/second, we find the period from P f = 2 pi. This crossover frequency is 1, so the corresponding period is

… and that is the ultimate period we computed by finding two consecutive minima.
Don’t ask me why it works, I don’t understand it yet. But I have more than one book telling me it’s not an accident. This, as far as I’m concerned at this point, is the main use of the gain margin. There’s absolutely no reason to simulate the math model and estimate these numbers: they can read off the gain margin. If you have a math model.
Now save these:

Now that we have Pu and ku, there are some rules for setting the parameters of P, PI, and PID controllers. But while I have the default K = 1, let’s see how the uncontrolled plant responds to a unit step. I get the closed loop transfer function and then the inverse Laplace transform:
Here’s the output and the input (black and silver resp.)

Well, except that it’s nowhere near 1 – i.e. we have offset – it had a pretty gentle response, without wild swings.
With a PID controller, we have plant… and controller…

We see three parameters: an overall gain kc, and two time constants,  and
and  . The is multiplied by s – which says that’s the Laplace transform of a derivative… and the is coupled with a 1/s – which says that’s the Laplace transform of an integral. What I’m going to show you is two sets of rules for getting from the ultimate gain and the ultimate period to values of kc, , and .
. The is multiplied by s – which says that’s the Laplace transform of a derivative… and the is coupled with a 1/s – which says that’s the Laplace transform of an integral. What I’m going to show you is two sets of rules for getting from the ultimate gain and the ultimate period to values of kc, , and .
The first set of rules is called Ziegler-Nichols; the second is called Tyreus-Luyben.
Let’s go.
Ziegler-Nichols with P, PI, PID
First, let’s try the Ziegler-Nichols rules.
P-only control
To get P-only control, we set ->0 and ->  .
.

Here are the closed loop transfer functions for output and for control… and, since I will want it later, the open loop transfer function, too:

The Z-N rule for P-only control is to set kc = .5 ku. (Parts of the following rule are redundant, because I’ve already set and , but I like having a complete rule anyway.)

and the closed loop for control becomes

We get the time-domain responses by taking inverse Laplace transforms…

And we plot the input (step function in “silver”), output (black), and scaled control effort (gold):

Not only does it take a long time to settle, but there is offset. As for the long settling time… K = 1 got there quickly, K = 10 was on the edge of instability, so K = 5 should have decaying oscillations. OK?
(And if you’re not used to seeing offset with P-only control… remember that the use of transfer functions requires that we use deviation variables: all our initial conditions are zero, in these variables. That is, for example, we’re not using the actual liquid level in a tank – we’re using the deviation from the set point. To hold the system at a value other than zero requires a constant nonzero control effort… so the response is nonzero, but not necessarily 1.)
For the record, here’s the unscaled control effort (gold):

Lastly, I want to see the open loop Bode plot, and compute the phase margin:

The phase margin is 25° – a little too jittery, as we saw.
PI control
To get PI control, we set ->0.

Here are the closed loop transfer functions for output and for control… and the open loop transfer function for later:

Note that kc has changed a little: instead of .5 we have .45 . What this says is that the control modes interact: they should not be set independently of each other…once we add integral control to proportional control, we change the value of the proportional control… and we’ll change both of them again when we add derivative control.
The closed loop transfer function for output becomes.. and we know the ultimate gain ku and ultimate period Pu:

The closed loop for control becomes

The open loop transfer function becomes

The time-domain responses become:

And here’s the usual plot, including scaled control effort:

It still takes a long time to settle, but the offset is gone.
After all, that’s one of things integral control does for us: it eliminates offset. I should point out that we don’t always care about offset: level control for surge tanks is the best example where we do not care to hold the level at exactly 50%. In fact, to do so would defeat the purpose of a surge tank, and we might as well replace it by a pipe – what goes out is exactly what comes in.
Here’s the unscaled control effort:

And here’s the open loop Bode plot:

This quantifies what we saw: that the output is more jittery than P-only control.
PID control
To get PID control, we keep all three PID parameters:

Here are the closed loop transfer functions for output and for control… and, as usual, the open loop transfer function for later:

This time kc is greater than .5, is smaller than for PI.
The closed loop transfer function for output becomes.. and we know the ultimate gain ku and the ultimate period Pu:

and the closed loop transfer function for control becomes

The open loop transfer function becomes

The time domain responses…

… and the usual plot:

As usual, here is the unscaled control effort:

The open loop Bode plot is

That phase margin of 29 is… marginal, at best – go ahead, grimace and hate me; still too jittery.
Let’s take a look at the three output responses:

I used panels 3-5 from the following, so orange is P, brown is PI, and yellow is PID. Alternatively, the orange must be P because it has offset, so PID should be yellow.

Anyway, we see that P has offset… PI does not, but it takes longer to settle down than P did… PID settles down much faster than the other two, and has no offset, but it still swings wildly at first (that overshoot is just over 40%.)
Tyreus-Luyben with PI, PID
Now I try the Tyreus-Luyben rules. Like the Ziegler–Nichols, they use ultimate gain ku and ultimate period Pu. For P-only control, they are the same.
PI control
To get PI control, we set ->0.

Here are the closed loops for output and for control… and, of course, the open loop transfer function:

The T-L rule for PI control is

The closed loop for control becomes

The open loop becomes

The time-domain responses are…

Here is the usual plot showing input, output (black), and scaled controller effort:

Settles faster, and the offset is gone.
Here’s the unscaled control effort:

Here’s the open loop Bode plot:

OK, we finally have a phase margin (39°) which is greater than 30°: this choice of parameters is OK by that criterion.
PID control
To get PID control, we need all three PID parameters:

The T-L rule for PID control is

and the closed loop transfer function for control becomes

The open loop transfer function becomes

Here are the time-domain responses:

Here is the usual plot…

Here’s the unscaled controlled effort:

Here, as usual, is the open loop Bode plot:

Even better than the PI control: a not-too-large phase margin.
Now let’s compare things. Here are the two PI controls:

The T-L has significantly less wildness than the Z-N: the overshoot is less and the settling time is less.
Here are the two PID controls:

The T-L has significantly less overshoot, but it does take a little longer to get close to its final value. That probably corresponds to a phase margin close to 60°.
I shouldn’t even think of putting all 5 controllers on one graph….

…though they look better if I shorten the time, except that it is no longer clear that P-only has offset:

Recall the colors in order, orange (3) thru dark gray (7): so, orange, brown, and yellow are Z-N P, PI, and PID; light and dark gray are T-L PI and PID.

Summary
Here are the Ziegler-Nichols rules:

Here are the alternative Tyreus-Luyben rules:

These rules require that we determine the ultimate gain and the ultimate period… and we saw how to get them from the open loop Bode plot, specifically from the gain margin and the frequency at which it occurs.
We saw the effect of these rules on a particular plant, and we also checked the phase margin for each choice of control method and parameters.
As you might expect, I would tend to go with the Tyreus-Luyben rules.





























 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from









































































 :
:






 / 1 = 2
/ 1 = 2 








 .) Here’s the resulting PID controller:
.) Here’s the resulting PID controller:





















 . Periodically, we order more of this product, to replenish our inventory I(t). Further, there is a known constant lead time L – between when we place an order and when we receive it (actually, when we can sell or use it, so this includes unloading and storing). If our inventory will go to zero at t = T, then, at the very latest, we must place an order at T – L:
. Periodically, we order more of this product, to replenish our inventory I(t). Further, there is a known constant lead time L – between when we place an order and when we receive it (actually, when we can sell or use it, so this includes unloading and storing). If our inventory will go to zero at t = T, then, at the very latest, we must place an order at T – L:
 .
. , so the frequency of orders (the order frequency OF) is the inverse.)
, so the frequency of orders (the order frequency OF) is the inverse.) .
. = (k + c\ q) OF + h\ \bar{I}\")
 = (k + c\ q) \frac{\lambda}{q} + h \ \frac{q}{2}\")






















 . Now save these:
. Now save these:





 and
and  . I have a rule for that:
. I have a rule for that:


 , but I like having a complete rule anyway.)
, but I like having a complete rule anyway.)

































 as the variable of integration:
as the variable of integration:













