Développé par Madh93, cet outil en Go baptisé Prxy résout un problème que beaucoup d’entre nous subissent en silence à savoir comment accéder proprement à ses services auto-hébergés sans transformer sa connexion en passoire ou en goulot d’étranglement. L’idée, c’est du split-tunneling application par application, une approche chirurgicale qui évite les compromis habituels.
While Artificial Intelligence (AI) technology is evolving rapidly, AI models still struggle with understanding long videos. A research team from The Hong Kong Polytechnic University (PolyU) has developed a novel video-language agent, VideoMind, that enables AI models to perform long video reasoning and question-answering tasks by emulating humans' way of thinking.
As the adoption of AI increases, hear how SAP is expanding its AI capabilities across the business suite. By catching up with this TechCrunch Sessions: AI panel, you can see how to leverage upcoming innovations to boost efficiency, streamline processes, and drive greater engagement across your business. Plus, you’ll get the opportunity to learn about […]
Researchers say there could be over $1 trillion worth of platinum lurking under the surface of the Moon — a major lunar bounty waiting to be mined.
As detailed in a paper published in the journal Planetary and Space Science, independent researcher Jayanth Chennamangalam and his team determined that out of around 1.3 million craters lining the Moon's surface with diameters greater than 0.6 miles across, almost 6,500 were created by asteroids that contain commercial quantities of platinum, among other valuable ores like palladium or iridium.
To the researchers, the draw isn't just the promise of immense wealth; the proceeds of mining these ores could be used to explore space.
"Today, astronomy is done to satiate our curiosity," Chennamangalam told New Scientist, a surprisingly cynical statement that's bound to raise eyebrows among researchers. "It has very few practical applications and is mostly paid for by taxpayer money, meaning that research funding is at the mercy of governmental policy."
"If we can monetise space resources — be it on the Moon or on asteroids — private enterprises will invest in the exploration of the solar system," he added.
Moon Miner
Chennamangalam, who holds a PhD in astrophysics and was a postdoc at the University of Oxford, found that there could be a "lot more craters on the moon with ore-bearing asteroidal remnants than there are accessible ore-bearing asteroids."
Mining these craters would be significantly simpler than traveling to distant asteroids, which most of the time don't have enough gravity for mining operations.
But whether plundering the Moon for profit would even be legal remains a far murkier question. As New Scientist points out, the Outer Space Treaty, which was signed in 1967, sets strict rules for space resource mining, stopping any nation from claiming or occupying the "Moon and other celestial bodies."
However, experts say those rules could still allow for governments to find loopholes and still claim licensing rights to extract resources.
In an effort to ratify international rules, the US established the Artemis Accords, a non-binding framework. However, neither China nor Russia has signed it, leaving its authority murky.
In short, the race to the surface of the Moon is on — a tight competition that could be decided between the US and China by the end of this decade, especially if a fortune in precious metals is at play.
It's a worthwhile line of inquiry. Back in 2019, a Lego-sponsored survey found that among 3,000 kids in the US, UK, and China, a full third said they wanted to be influencers, while only 11 percent indicated an interest in becoming an astronaut.
What does that immensely powerful trend mean for society? In a new study published in the journal Telematics and Informatics, researchers from Poland's University of Wrocław and Oxford found that young people who are extraverted, self-involved, and — quelle surprise — dramatic were more likely to aspire to being an influencer than their more introverted and calmer counterparts.
After recruiting nearly 800 participants aged 16 and 17 — roughly half of whom were Polish, with the other half based in the United Kingdom — the researchers posed a battery of questions to their teen subjects about their career goals and their dream jobs.
The participants were also given questionnaires that measured how strongly they exhibit the "Big Five" personality traits — openness, conscientiousness, extroversion, agreeableness, and neuroticism — as well as how histrionic, or dramatic, they are.
As the researchers found, those with heightened extraversion, narcissism, and histrionics — a tendency to be dramatic and expressive about it, basically — were more likely to be interested in the influencer life. Those traits correlate to a desire to be seen and validated by others in much the same way as with theater kids — suggesting, perhaps, that the student thespians of today may be the influencers of tomorrow.
Though there's been some research into how audiences perceive the personalities of content creators, this study appears to be the first that looks into the traits the drive people to become influencers — or wannabe influencer, at least, since the career is anything but a slam dunk for most who attempt it.
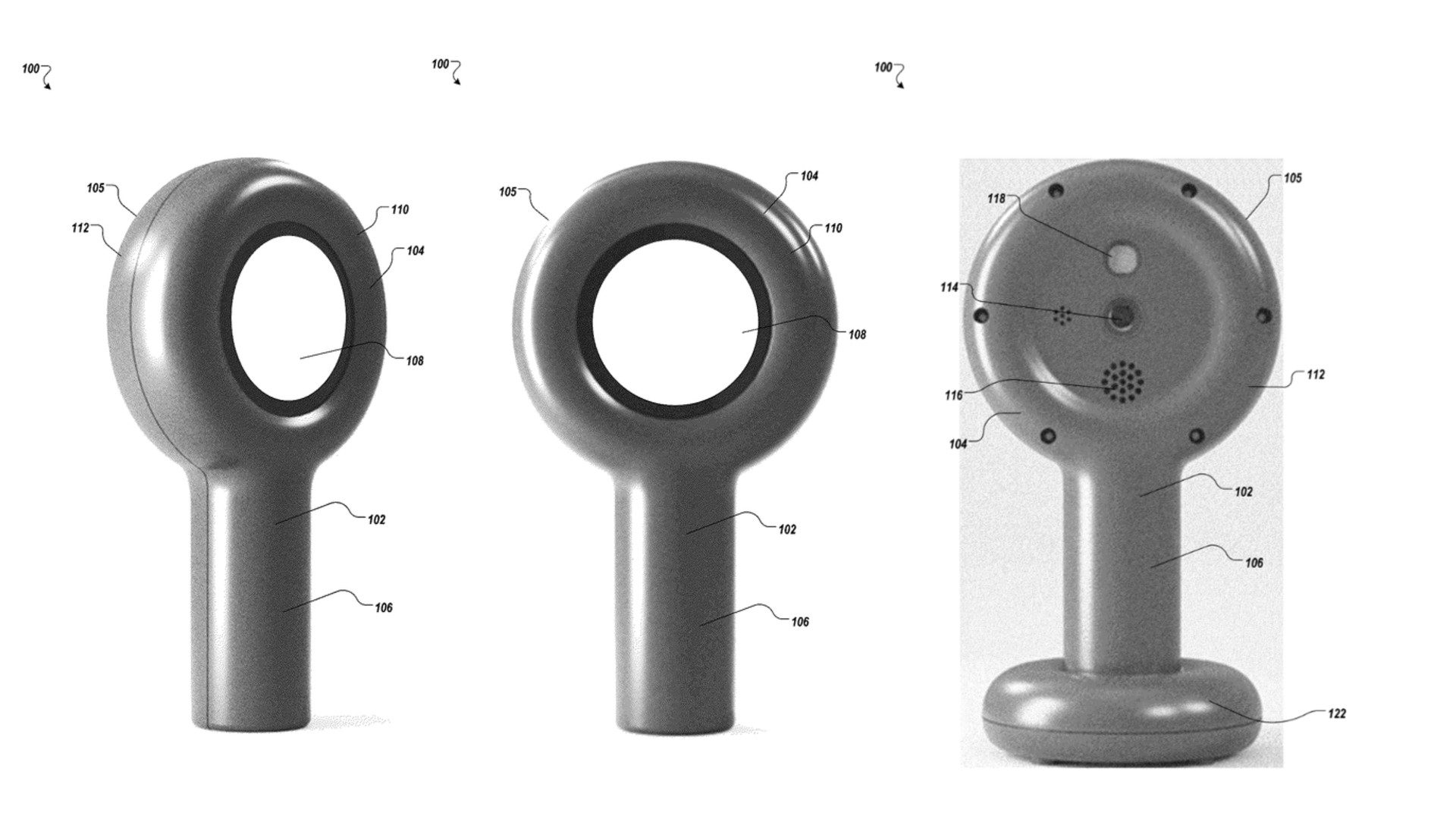
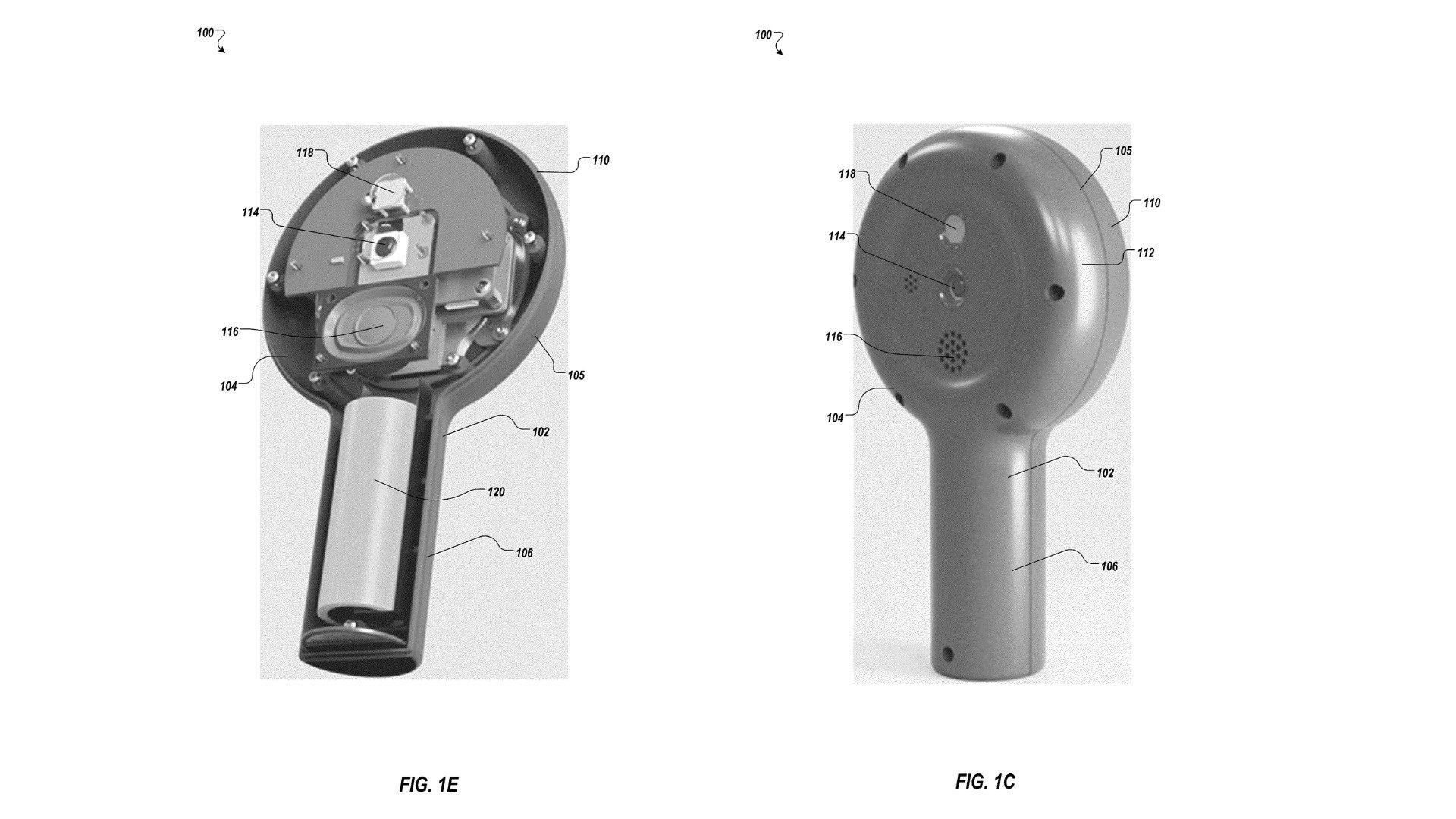
Robert Kalin, co-founder and former CEO of online marketplace Etsy, is reportedly building a hand-held, magnifying glass-like XR device.
As discovered by Low Pass, Kalin’s new startup Dopple Works is developing a mixed reality device reportedly called ‘Loop’. An application for the device just passed through the FCC, which could mean it’s nearing release.
As FCC applications typical go, details have been heavily redacted, noting only that Loop is “a portable, battery-powered device that has Wifi and Bluetooth connectivity as well as NFC functionality,” Low Pass reports, additionally noting Loop is rated IP65 for dust and light water exposure.
There’s no telling what the alleged device looks like presently, however a patent from Dopple Works was published for a ‘Dedicated hand-held spatial computing device’, which included a number of images alongside some standard boiler plate of intended use cases.
Image courtesy Dopple Works
Notably, it appears the device could rest in a dedicated cradle in the upright position, possibly suggesting it’s the main recharging method.
Additionally, the patent illustrates there may include a number of features, including a 6DOF tracking sensor, microphone, camera, speaker, and possibly also eye-tracking.
It’s uncertain whether the user would hold the device up to their eye, like a monocle, or farther away from them like a magnifying glass, as no mention of lens is made.
Image courtesy Dopple Works
As for content, the patent covers nearly everything you’d expect, from games to educational use cases, with the latter being the most likely target. A trademark application filed by Dopple Works describes the company as creating an ‘electronic learning toy’.
As discovered by Low Pass, Dopple Works’ is made up of several former engineers who worked on social VR platforms Mozilla Hubs and AltspaceVR, both of which are now defunct. Dopple Works CTO Geoff Chatterton was previously Head of Hardware at Paypal before joining the company; Chatterton also previously worked at Apple, Dell and smartwatch startup Wimm Labs, which was acquired by Google in 2013.
That said, creating a magnifying glass-style device without a lens like a standard XR headset has some unique benefits, but also its fair share of drawbacks. It could allow kids of any age to interact with mixed reality without worry of a headset not correctly fitting. Its simple design could also encourage casual play sessions.
On the other hand, if Loop is a ‘magic window’ of sorts meant to be held away from the user’s eye, it could be pretty similar to the type of augmented reality experiences you can already have on a smartphone—making content the device’s key differentiator.
Avec la stratégie de recentrer son offre sur le prêt-à-porter et la décoration-maison, La Redoute poursuit sa croissance en tant qu'acteur majeur du e-commerce, tout en affirmant son engagement pour un commerce en ligne plus responsable. Rencontre avec Marie Guillemot, directrice de la stratégie développement durable de la marque.
Figure AI has drawn attention for making claims that its AI-powered robots possess human-like fine motor skills and can manipulate objects with precision but hasn't done a live demonstration of the humanoids.
At I/O, Google presented its vision of Android XR. But the "Android XR" that runs on headsets is not the "Android XR" that runs on smart glasses.
The name Android XR was actually first reported by Business Insider's Hugh Langley 18 months before Google officially revealed it. According to that report, Google internally called an operating system for headsets "Android XR", and a much simpler OS for glasses "Android micro XR".
I bring this up because since officially revealing the two platforms in December, Google has instead referred to them as one "Android XR". Samsung's device is an "Android XR headset", while the prototype smart glasses with a small HUD it showed at TED and I/O were "Android XR glasses".
This is both confusing and misleading. Because in reality, these are two completely different software platforms.
The Android XR that runs on headsets is an extension of the Android experience you have on your phone or tablet, fully standalone, with access to the Play Store and a full-fledged developer SDK.
The Android XR that runs on smart glasses, on the other hand, is a highly cut-down version of Android that Google has not announced any SDK or platform for, where your phone handles a lot of the computing, similar to the Ray-Ban Meta glasses.
Sure, these two platforms both have the same AOSP at the core, and yes you'll find some of the same Google services on both. But the similarities end there.
Imagine if Apple had presented the Apple Watch as running "iOS", or if Meta described the Ray-Ban Meta glasses as running Horizon OS. That's the equivalent of Google describing these smart glasses as running Android XR.
I imagine Google's strategy here is driven by the success of Ray-Ban Meta, the major hype around Meta's Orion prototype, and the poor public reception to the first-generation Apple Vision Pro. Essentially, I suspect the company is intentionally trying to present its headsets and glasses work under one hype banner, rather than disclosing the distinction between these two platforms.
You could argue that the words "headset" and "glasses" will make the difference obvious for consumers. But the distinction between these device categories became blurred with the reveal of Xreal's Project Aura. Aura is designed to resemble sunglasses from certain angles, but powered by a tethered compute puck running the headset version of Android XR.
This means that there are two completely different meanings of "Android XR glasses". There are Android XR glasses, of the kind that will take on Ray-Ban Meta, and there are Android XR glasses, of the kind that Meta and Apple will take on with their next headsets.
So we'll soon be in a world where you can buy Android XR glasses, or glasses that run Android XR, and they're completely different software platforms. This will obviously lead to confusion.
When a developer releases an interesting app "for Android XR", will consumers with no understanding of the difference between "Android XR glasses" and Xreal Aura understand that buying Warby Parker glasses won't give them access to said app? Do all developers understand that the Android XR apps they might build will not run on the simple smart glasses?
As a reader of UploadVR, these distinctions may seem obvious to you. But the nature and limitations of XR headsets and smart glasses are not widely known by the general public.
The solution here is to give the operating system for smart glasses its own name. Google could repurpose the "Glass OS" name it used for Glass, for example, or use a name like "Glasses OS", akin to how it calls its smartwatch platform Wear OS.
Of course, no hardware company has actually launched any "Android XR" product yet, and it's possible the marketing and PR around these products will make the distinction I bring up crystal clear. But given Google's messaging so far, I worry that clear positioning is not the company's priority.
For all the remarkable improvements we’ve seen in desktop 3D printers, metal printers have tended to stay out of reach for hackers, mostly because they usually rely on precise and expensive laser systems. This makes it all the more refreshing to see [Dan Gelbart]’s demonstration of Rapidia’s cast-to-sinter method, which goes from SLA prints to ceramic or metal models.
The process began by printing the model in resin, scaled up by 19% to account for shrinkage. [Dan] then used the resin print to make a mold out of silicone rubber, after first painting the model to keep chemicals from the resin from inhibiting the silicone’s polymerization. Once the silicone had set, he cut the original model out of the mold and prepared the mold for pouring. He made a slurry out of metal powder and a water-based binder and poured this into the mold, then froze the mold and its contents at -40 ℃. The resulting mixture of metal powder and ice forms a composite much stronger than pure ice, from which [Dan] was able to forcefully peel back the silicone mold without damaging the part. Next, the still-frozen part was freeze-dried for twenty hours, then finally treated in a vacuum sintering oven for twelve hours to make the final part. The video below the break shows the process.
A significant advantage of this method is that it can produce parts with much higher resolution and better surface finish than other methods. The silicone mold is precise enough that the final print’s quality is mostly determined by the fineness of the metal powder used, and it’s easy to reach micron-scale resolution. The most expensive part of the process is the vacuum sintering furnace, but [Dan] notes that if you only want ceramic and not metal parts, a much cheaper ceramic sintering oven will work better.
Alors que les projecteurs s’éteignent sur le Festival de Cannes, une autre révolution se joue loin des tapis rouges : celle de la génération vidéo par intelligence artificielle. Avec VO3, son nouvel outil bluffant, Google pousse encore plus loin les limites de la création automatisée. Vidéos réalistes, sons d’ambiance, dialogues… on peut désormais produire une séquence complète, seul devant son ordinateur, sans caméras, sans acteurs, sans décor.
Dans cet édito, je reviens sur l’évolution fulgurante de ces technologies, leurs implications concrètes pour les métiers du cinéma et de l’audiovisuel, mais aussi sur les dérives potentielles, entre fausses vidéos virales et manipulation de l’opinion. L’IA ne va pas tuer le cinéma — du moins pas tout de suite — mais elle va sûrement le transformer en profondeur.
I don't know about you, but I love sushi. We didn't have a Japanese restaurant in the town where I grew up until I hit my 20s. A conversation around sushi was always, "You eat raw fish?!" accompanied by "ew" s and amazement. Of course, since then, I've learned it's delicious.
It took me a little while to become familiar with the various types of sushi and how to decipher a sushi menu. I have a lot still to learn, but I wanted to capture the common sushi types—with names and pictures—in case it helps others. I'm not an expert, so if you've got wisdom to share, feel free to write to me.
Here's the breakdown reflected in the sketch:
Sashimi
Raw fish or seafood served on its own or with simple garnishes. Sashimi is not technically sushi, as there's no rice, but it's a classic that's virtually synonymous with sushi.
Nigiri
A shaped piece of seasoned sushi rice with a slice of fish or other topping laid on top. I've seen the literal translation of nigiri as something like "two hands to make rice ball food."
Maki
Maki means "rolled" and refers to sushi wrapped in sheets of nori (dried seaweed). Classic maki rolls have the nori on the outside and are sliced into mouthful-sized pieces. The genius of maki, much like the genius of the sandwich, is that it allows you to eat the delicious filling by only touching the nori with your fingers. Here are a few types:
Hosomaki - Thin rolls
Hosomaki are typically filled with just one ingredient, such as tuna or cucumber. Tekka maki ( tuna roll) was popular in casinos and was sometimes called the "casino roll."
Futomaki - Thick rolls
Futomaki are much larger than hosomaki and can have several fillings inside. They're often served at festivals and celebrations.
Uramaki - Inside-out rolls
Uramaki was developed with the California roll and have the rice on the outside, hiding the nori. They're medium-sized and can fit a few more fillings than hosomaki. Incidentally, several people claim to have invented the California roll. Since the California roll, an amazing variety of rolls have been created, such as the rainbow, dragon, spicy tuna, caterpillar, Philadelphia, spider, and others.
Temaki - Hand rolls
Meaning "roll in hand", the temaki is a little like the burrito of sushi. Wrapping the nori around the filling in a cone shape makes it easy to hold.
Other Types of Sushi
Inari
Named after a Shinto god said to ride a fox and love fried tofu, inari are pouches of fried tofu filled with sushi rice and other fillings.
Chirashi
Meaning scattered, chirashi is a sushi plate where the chef lays the main ingredients on top of a bed of rice in a bowl.
Temari
Temari are small, decorative sushi balls. A small ball of rice is wrapped in fish or vegetables, making an amazing-looking snack.
The language of sushi is vast, but if you're not fluent yet, I hope this provides a few pointers.
BidenCash est désormais hors service. La « marketplace », spécialisée dans la revente de cartes bancaires volées, était l'une des plus actives du dark web. Dans une opération conjointe avec les autorités néerlandaises, le FBI a saisi plus de 145 domaines. Un message s’affiche désormais : « Ce site a été saisi par les autorités. »
Des scientifiques ont découvert que le noyau terrestre laisse échapper de l'or et d'autres métaux précieux. Cette fuite pourrait expliquer la présence de ces métaux dans certaines roches en...
Paris accueillera l’événement majeur du retail en Europe : NRF 2025: Retail’s Big Show Europe. 📆 Du 16 au 18 septembre 2025 à Paris. Porté par Comexposium et la NRF, ce nouveau format est né de la fusion entre le savoir-faire de Paris Retail Week et la renommée internationale du NRF Retail’s Big Show de …
[Tommy] has a great write-up about designing and building a minimalistic handheld electronic game called “Higher Lower”. It’s an audio-driven game in which the unit plays two tones and asks the player to choose whether the second tone was higher in pitch, or lower. The game relies on 3D printed components and minimal electronics, limiting player input to two buttons and output to whatever a speaker stuck to an output pin from an ATtiny85 can generate.
Fastener-free enclosure means fewer parts, and on the inside are pots for volume and difficulty. We love the thoughtful little tabs that hold the rocker switch in place during assembly.
Gameplay may be straightforward, but working with so little raises a number of design challenges. How does one best communicate game state (and things like scoring) with audio tones only? What’s the optimal way to generate a random seed when the best source of meaningful, zero-extra-components entropy (timing of player input) happens after the game has already started? What’s the most efficient way to turn a clear glue stick into a bunch of identical little light pipes? [Tommy] goes into great detail for each of these, and more.
In addition to the hardware and enclosure design, [Tommy] has tried new things on the software end of things. He found that using tools intended to develop for the Arduboy DIY handheld console along with a hardware emulator made for a very tight feedback loop during development. Being able to work on the software side without actually needing the hardware and chip programmer at hand was also flexible and convenient.
We’ve seen [Tommy]’s work before about his synth kits, and as usual his observations and shared insights about bringing an idea from concept to kit-worthy product are absolutely worth a read.
You can find all the design files on the GitHub repository, but Higher Lower is also available as a reasonably-priced kit with great documentation suitable for anyone with an interest. Watch it in action in the video below.
Ce jeudi 4 juin, trois des sites pour adultes les plus consultés au monde couperont volontairement l’accès à la France. Non pas à cause d’une interdiction officielle, mais par refus de se soumettre aux nouvelles règles de vérification d’âge. Une Marianne s’affichera à la place des pages d’accueil, accompagnée du message : “La liberté n’a pas de bouto...
L’entreprise Paradromics annonce avoir réussi à implanter son interface cerveau-machine Connexus chez un patient humain pour la première fois. Elle va pouvoir démarrer les essais cliniques et rejoindre les rangs d’entreprises comme Neuralink ou Synchron.
The AI effects we know these days were once preceded by CGI, and those were once preceded by true hand-built physical props. If that makes you think of Muppets, this video will change your mind. In a behind-the-scenes look with [Adam Savage], effects designer [Mark Setrakian] reveals the full animatronic glory of Mr. Wink’s mechanical fist from Hellboy II: The Golden Army (2008) – and this beast still flexes.
Most of this arm was actually made in 2003, when 3D printing was very different than what we think of today. Printed on a Stratasys Titan – think: large refrigerator-sized machine, expensive as sin – the parts were then hand-textured with a Dremel for that war-scarred, brutalist feel. This wasn’t just basic animatronics for set dressing. This was a fully actuated prop with servo-driven finger joints, a retractable chain weapon, and bevel-geared mechanisms that scream mechanical craftsmanship.
Each finger is individually designed. The chain reel: powered by a DeWalt drill motor and custom bevel gear assembly. Every department: sculptors, CAD modelers, machinists, contributed to this hybrid of analog and digital magic. Props like this are becoming unicorns.
Une nouvelle avancée dans la technologie OLED permet désormais à chaque pixel d’agir comme une source sonore. Ce progrès promet des écrans ultrafins capables de diffuser du son directement depuis l’image, ouvrant la voie à des expériences immersives inédites.
Adding textures is a great way to experiment with giving 3D prints a different look, and [PandaN] shows off a method of adding a wood grain effect in a way that’s easy to play around with. It involves using a 3D model of a log (complete with concentric tree rings) as a print modifier. The good news is that [PandaN] has already done the work of creating one, as well as showing how to use it.
The model of the stump — complete with concentric tree rings — acts as a modifier for the much-smaller printed object (in this case, a small plate).
In the slicer software one simply uses the log as a modifier for an object to be printed. When a 3D model is used as a modifier in this way, it means different print settings get applied everywhere the object to be printed and the modifier intersect one another.
In the case of this project, the modifier shifts the angle of the fill pattern wherever the models intersect. A fuzzy skin modifier is used as well, and the result is enough to give a wood grain appearance to the printed object. When printed with a wood filament (which is PLA mixed with wood particles), the result looks especially good.
In addition to the 3D models, [PandaN] provides a ready-to-go project for Bambu slicer with all the necessary settings already configured, so experimenting can be as simple as swapping the object to be printed with a new 3D model. Want to see that in action? Here’s a separate video demonstrating exactly that step-by-step, embedded below.
[It’s on my MIND] designed a clever BB blaster featuring a four-bar linkage that prints in a single piece and requires no additional hardware. The interesting part is how it turns a trigger pull into launching a 6 mm plastic BB. There is a spring, but it only acts as a trigger return and plays no part in launching the projectile. So how does it work?
There’s a spring in this BB launcher, but it’s not used like you might expect.
The usual way something like this functions is with the trigger pulling back a striker of some kind, and putting it under tension in the process (usually with the help of a spring) then releasing it. As the striker flies forward, it smacks into a BB and launches it. We’ve seen print-in-place shooters that work this way, but that is not what is happening here.
With [It’s on my MIND]’s BB launcher, the trigger is a four-bar linkage that transforms a rearward pull of the trigger into a forward push of the striker against a BB that is gravity fed from a hopper. The tension comes from the BB’s forward motion being arrested by a physical detente as the striker pushes from behind. Once that tension passes a threshold, the BB pops past the detente and goes flying. Thanks to the mechanical advantage of the four-bar linkage, the trigger finger doesn’t need to do much work. The spring? It’s just there to reset the trigger by pushing it forward again after firing.
It’s a clever design that doesn’t require any additional hardware, and even prints in a single piece. Watch it in action in the video, embedded just below.
L'agence spatiale des États-Unis ne sera peut-être plus jamais comme avant. Le leadership mondial de la NASA dans les domaines des sciences astronomiques et spatiales semble plus que jamais remis en question. Effectivement, la Maison Blanche du président Donald Trump vient de renoncer à proposer Jared Isaacman, un proche d'Elon Musk, comme administra...
Samsung fait une entrée remarquée dans le monde des casques XR (réalité étendue) avec son nouveau modèle, un concurrent direct à l’Apple Vision Pro. Après plusieurs années de teasing et de spéculations, le géant coréen dévoile les spécifications impressionnantes de son casque XR. Ce dernier se distingue par ses caractéristiques techniques robustes et son partenariat avec Google. Le duel Samsung contre Apple dans l’espace XR pourrait bien redéfinir l’avenir des technologies immersives.
La guerre des casques XR s’intensifie avec Samsung prêt à bousculer Apple. L’annonce du casque Samsung XR a créé une onde de choc dans l’industrie technologique. Les spécifications de l’appareil font de l’ombre à l’Apple Vision Pro. Contrairement à Apple, Samsung a choisi de collaborer avec Google et Qualcomm pour optimiser l’expérience XR. Le résultat ? Un casque XR plus puissant et potentiellement plus abordable, prêt à conquérir les utilisateurs en quête de performances et d’innovation.
Les caractéristiques qui font trembler Apple
Samsung a équipé son casque XR avec le processeur Qualcomm Snapdragon XR2 Plus Gen 2. Ce processeur, spécialement conçu pour la réalité étendue, offre une puissance de calcul impressionnante. Le processeur est accompagné de 16 Go de RAM et d’un GPU Adreno 740. Ces spécifications assurent des performances exceptionnelles dans des environnements XR. L’écran 4K micro-OLED de Sony renforce l’expérience visuelle. Cela permet d’offrir des résolutions de 3 552 x 3 840 pixels pour des images incroyablement nettes.
Les benchmarks du casque révèlent des performances qui rivalisent avec les meilleurs appareils Android du marché. Le processeur, avec ses six cœurs, et la GPU Adreno assurent une fluidité d’affichage à 90 Hz. Samsung met également l’accent sur une consommation énergétique réduite, un facteur crucial pour prolonger l’autonomie. Comparé au Vision Pro d’Apple, le casque Samsung semble prometteur, qui allie haute performance et efficacité énergétique. De plus, il pourrait être proposé à un prix plus abordable.
L’intégration de l’IA pour une expérience immersive unique
L’une des innovations du casque XR de Samsung est l’intégration de l’IA Gemini de Google. Cette collaboration avec Google permet d’enrichir l’expérience XR avec des fonctionnalités intelligentes. L’IA peut analyser l’environnement visuel en temps réel et fournir des informations contextuelles sans interrompre l’immersion. Les utilisateurs pourront interagir avec des objets numériques ou recevoir des suggestions basées sur ce qu’ils voient à travers le casque.
Cette approche proactive de l’intelligence artificielle distingue le casque Samsung de la concurrence. Alors qu’Apple se concentre sur un écosystème fermé et premium, Samsung, avec l’aide de Google, semble vouloir rendre son produit plus accessible. Ce partenariat pourrait créer un environnement plus interactif pour les utilisateurs, avec des applications XR plus variées et performantes.
Un écran qui surpasse les attentes visuelles
Le casque Samsung XR est équipé d’un écran micro-OLED 4K de Sony. Cette technologie permet d’offrir une expérience visuelle fluide et de haute qualité. Avec une résolution de 3 552 x 3 840 pixels, l’écran produit des images nettes. Cela offre ainsi une immersion totale. Les couleurs sont également vives, avec 96 % de couverture de la gamme de couleurs DCI-P3, et un contraste impressionnant. Ce type d’affichage pourrait en effet surpasser celui de l’Apple Vision Pro en matière de clarté et de performance, bien que l’écart de prix entre les deux appareils reste à confirmer.
L’écran de Samsung, avec une luminosité de 1 000 nits et une consommation énergétique réduite de 20 %, semble plus optimisé pour des sessions prolongées. La gestion de la batterie est un élément crucial pour une expérience XR agréable et continue. En effet, les utilisateurs ne voudront pas que la batterie de leur appareil se vide trop rapidement lors de l’utilisation de cette technologie immersive.
Le prix et l’accessibilité de la nouvelle technologie XR
L’un des principaux avantages du casque XR de Samsung est son prix, qui pourrait être plus compétitif que celui du Vision Pro d’Apple. Bien que le coût exact n’ait pas encore été révélé, les spéculations suggèrent un prix bien inférieur à celui de l’Apple Vision Pro, dont le tarif avoisine les 3 499 $/3 499 €. Samsung semble vouloir offrir ainsi une technologie de pointe à un public plus large, et offrir également une alternative abordable sans sacrifier la qualité.
Le marché des casques XR est en pleine expansion, et Samsung pourrait bien capter une part importante de ce marché en raison de ses caractéristiques techniques et de son approche plus abordable. Ce prix plus compétitif pourrait permettre à Samsung alors de conquérir des segments plus jeunes et des consommateurs à la recherche de technologies immersives sans se ruiner.
Un avenir prometteur pour l’XR avec Samsung et Google
La collaboration de Samsung avec Google est stratégique et laisse présager des innovations excitantes. Samsung pourrait bien surpasser Apple dans le domaine de la réalité étendue, non seulement grâce à ses spécifications impressionnantes mais aussi par la force de son partenariat avec Google. L’utilisation de l’IA Gemini, les performances de l’écran Sony et un prix plus abordable font du casque XR de Samsung une option incontournable. Ces caractéristiques positionnent le casque comme un choix privilégié pour les amateurs de technologies immersives.
Les utilisateurs auront bientôt l’opportunité de découvrir un nouveau monde de possibilités avec le casque XR de Samsung. L’entreprise coréenne mise sur la performance, l’accessibilité et l’innovation, ce qui pourrait bien secouer la domination d’Apple dans le domaine de la réalité étendue. La concurrence s’intensifie, et les consommateurs devraient en bénéficier avec des options plus puissantes et diversifiées sur le marché.
Unexpected Maker’s SQUiXL is a battery-powered ESP32-S3 WiFi and Bluetooth IoT controller and development platform with a 4-inch touchscreen display with 480×480 resolution.
Designed for makers, hardware engineers, embedded developers, and home automation enthusiasts, the SQUiXL integrates with 8MB PSRAM and a 16MB SPI flash for plenty of resources for the firmware. Other features include a microSD card, an amplifier with speaker connector, a haptic driver and motor, an RTC, and a STEMMA/Qt connector for expansion.
CPU – Dual-core Tensilica LX7 @ up to 240 MHz with vector instructions for AI acceleration
Memory – 512KB RAM
Wireless – 2.4 GHz WiFi 4 and Bluetooth 5.0 LE + Mesh
Memory – 8MB octal PSRAM
Storage
16MB QSPI flash
MicroSD card slot (multiplexed with audio amplified)
Display – 4-inch 480×480 RGB display with capacitive touch (GT911)
Audio
MAX98357A I2S Audio Amplifier (multiplexed with microSD card slot)
8 Ohm, 2W Speaker connector
Expansion
STEMMA/QT for additional I2C expansion
IO Expander (LCA9555)
IO MUX (TMUX1574RSVR)
Misc
Power, IO0/Boot, and Reset buttons
DRV2605L haptic driver and motor
RV-3028-C7 I2C low-power RTC
Magnetic Connector + USB adapter
ESD protection on USB and buttons
Internal high-gain antenna
Power Management
1,500mAh 1S battery
LiPo battery charging
MAX1704X I2C battery fuel gauge
5V presence detection circuit
Dimensions – TBD
Unexepted Maker also designed an optional Dock for the SQUiXL. It makes use of the magnetic USB connector on the devkit, which can be easily inserted and removed without needing to plug or unplug cables. The dock comes in two parts with two small M2.5 screws that the users need to assemble. It was designed that way to take up less space and reduce shipping costs.
SQUiXL with dock (left) and dock itself (right)
The SQUiXL devkit ships with Arduino firmware developed with PlatformIO, but the Arduino IDE will soon be supported too. The shipping firmware relies on the SQUiXL library and is designed to showcase the capabilities of the ESP32-S3 devkit and offers a WiFi manager for initial setup, a clock, local weather display using an Open Weather API Key, a random joke display, and more. You’ll find the source code for the shipping firmware on the SQUiXL-DevOS GitHub repository, and there’s a separate repo with some Arduino and LVGL samples, and a MicroPython firmware. CircuitPython support is also in the works.
Some screenshots of the Settings in the shipping firmware
ESP32-S3 solutions with a 4-inch display are somewhat popular, as we’ve seen such products before with the MaTouch_ESP32-S3 4-inch Display Demo Kit, Seeed Studio’s SenseCAP Indicator with LoRaWAN, and the LILYGO T-Panel, which also adds an ESP32-H2 in the mix for Zigbee, Thread, and Matter connectivity. The main differentiating feature of the SQUiXL devkit is that it is portable since it’s battery-powered.
The SQUiXL is sold on the Unexpected Maker’s shop for $99 plus shipping, and the dock adds $29 if you need it. They don’t produce a lot of those, and 20 pieces (second batch) were added this morning, with 16 units left at the time of writing this article.
I've often found myself wondering how thinking is hard work. If someone gives me a long list of arithmetic to do, it's tempting not to do it. If I have a tricky problem, it's easy to procrastinate and do "easier" stuff instead. Deep reflective thinking, and even shallow thinking that requires holding information in memory, seems like work—ever been tempted to delegate the adding up of scores for a board game?
I've never quite figured out where the hard work is in thinking—after all, it's not physically tiring like heading out for a 5-mile run—but it's definitely there. Hence, perhaps the tempting and irresistible rise of cognitive offloading: delegating our thinking tasks so we don't have to do them.
We've been cognitive offloading for a long time. When I carried the 2 in a long sum, I was offloading a task for my memory. And I grew up remembering phone numbers rather than dialling a person, and I don't feel the change has made things worse.
Hiring employees can be a form of delegating thinking. Using a calculator rather than a slide rule or working something out on paper leaves more room for deeper thinking. Other common examples of cognitive offloading include using notes apps, reminders, calculators, navigation systems, and now AI chatbots.
But what about when we can offload the deeper thinking, too, as we can now with AI chatbots? That may leave room for more interesting tasks. Or maybe, like not training my muscles and endurance by going out for a 5-mile run, it reduces my ability for deep thinking.
Nicholas Carr discussed a shift to shallow thinking from the pervasive use of the internet in his 2011 book The Shallows. We became proficient at skimming and scanning for answers rather than interrogating and questioning.
There's some evidence that more cognitive offloading reduces our critical thinking abilities, and an MIT study showed that "the more help students had from AI, the less their brains worked. People using ChatGPT struggled to remember or quote from the essays they had just written and reported feeling little ownership of their work. By comparison, the essays written by the “brain-only” writers were more original and their brains more active."
If a developer uses an AI chatbot in an interview and gives a strong answer, will that make them worse at the job when they would use an AI chatbot on the job anyway?
I use ChatGPT as a thinking partner for posts these days. I think that it helps make them better, but who knows what it's really doing to me =) Are Sketchplanations just staying surface-level or engaging some thinking? It would be nice to think that it grinds a few gears. Here's hoping!
Several technology demonstrations stood out to me at Display Week (DW) 2025. This article will cover Playnitride’s Quantum Dot (QD) based full-color MicroLED, combined with Lumus’s geometric (also known as reflective waveguide) technology.
I know it has been a lot on Lumus lately, but that’s just how the news and information came to me and what I found exciting. I had no idea that Lumus would be in Rivet, and as far as I know, I was the first to identify that Lumus was inside, so I wanted to publish it promptly. Then, this article made sense to follow up on that one.
In the next article, I plan to follow up with more about Avegant’s LCOS engine, featuring an Applied Materials diffractive waveguide, and provide another clue that Avegant’s and Applied Materials’ projectors and waveguides are likely being used in the Google/Android XR prototypes. I got to try on the Avegant 30-degree biocular prototype, and overall, it looked good.
AWE on June 10-12, 2025 (I’m Attending and Speaking)
For anyone interested in meeting me, I will be attending AWE on June 10-12. I’m happy to meet with both companies and individuals. Please email me at meet@kgontech.com if you want to meet. I will also be speaking on Thursday, June 12th, from 10:30 AM to 10:55 AM in the Promenade Room 104 B.
Lumus and PlayNitride at Display Week 2025
Lumus had a running demo in the PlayNitride booth at DW 2025. The demo featured a PlayNitride 720×720 (0.18″ diagonal, ~3.2mm on a side) 4.5 µm pixel (pitch) full-color QD MicroLED display, accompanied by a small but unoptimized projector engine, and a 50-degree (diagonal) Lumus Maximus waveguide.
Lumus’s DW demo is a “quick and dirty” proof-it-works setup, with the optics held in place by a small optical bench and a large “pull” lens in front of the waveguide, primarily to prevent people from touching the setup. The lens also had the effect of keeping cameras at a distance and magnifying the image (see the upper right picture below). Unfortunately, there was great content being shown, but at least you can see that the white lines are white across the image (unlike many diffractive waveguides).
Since the display form factor is square, the horizontal and vertical field of view (FOV) are ~35 degrees, resulting in about 20 pixels per degree PPD, which is larger than some would desire, but within the bounds of general acceptability considering it is an optical see-through (OST) device. The placard on the demo states that it outputs more than 700 “white” nits (to the eye), which is largely a function of Lumus Maximus waveguides that are over 90% transparent.
Fantasically Tiny Projector
Lumus states that the current design outputs approximately 0.7% of the nits of the display, which, although it may seem small, should be about five to seven times more efficient than a diffractive waveguide. PlayNitride, in its presentation, claims that the MicroLED is capable of exceeding 500K nits, which at 0.7% would be 4,500 nits via the waveguide to the eye. I’m unsure if there are lifetime or other practical issues with driving PlayNitrides MicroLEDs hard enough to produce more than 500K (white) nits. As I explained in Caution on Comparing Nits/WattLED with Different Waveguides, there are many ways companies specify nits. I also want to note that white/full-color nits and power consumption can’t be compared fairly to, say, “green only nits,” as much of the perceived “nits” are in green, and generally, red is much less efficient than blue or green.
While the Maximus connected to the PlayNitride 720×720 is small, it may not be dramatically smaller than the 3-chip (R, G, and B) 640×480 X-Cube projectors I have seen using Jade Bird Display’s MicroLEDs. Lumus then showed me privately a more optimized projector that they have working with the same PlayNitride MicroLED, which they did not want to show on the floor, which I have since dubbed “the fantastically tiny projector.”
Shown below, from left to right, are the Lumus Maximus 50+ degree waveguide with a 1440×1440 LCOS, an older 1920×1080 with a 5.6µ pixel PlayNitride engine, the 720×720 engine shown at Display Week, and the tiny, optimized 720×720 engine. The engine is only a few millimeters bigger than the display in every dimension. Note that the tiny projector’s waveguide has not been cut to shape for glasses. Based on the pictures, I would estimate the volume of Lumus’s optimized prototype engine to be approximately 0.15 cubic centimeters (or less, depending on the definition of “counts”).
While the PlayNitride display is not yet ready for production, the tiny combination shows where this technology is headed in a few years. We can expect the pixel size to continue shrinking, enabling an increase in angular resolution while maintaining the field of view (FOV). Lumus states that the current Maximus design supports a field of view (FOV) up to 60 degrees, and their Z-Len technology is capable of exceeding 70 degrees (in glass, not exotic, but very high-index Silicon Carbide).
PlayNitride Diffractive Waveguide Demo
PlayNitride also had a diffractive waveguide demo in their booth, which they discussed in their presentation. It also has a tiny projector, considering that it is full color. The diffractive waveguide had a 30-degree field of view (FOV). It claims to support over 500 nits, but once again, we don’t know under what conditions or for how long.
The Lumus Maximus waveguide demo was significantly brighter than the diffractive waveguide’s demo using the same device, despite having about 2.8 times the field of view (FOV) area. However, I have no information on how hard each display device was driven. However, it does make Lumus’s claim of being more than five times more efficient than diffractive waveguides plausible. I should note that different diffractive waveguides have different efficiencies.
Below is an image I captured through the Diffractive waveguide demo in the PlayNitride booth. Even with the lack of content, it is evident that the parts intended to be white exhibit significant color variation across the waveguide’s field of view (FOV). The picture also shows some light capture rainbows (blue streaks on the left and lower right).
Not Enough Content to Judge Display Quality
Unfortunately, PlayNitride had very little content to judge the image quality of their displays. Usually, this means that the devices are not up to being judged on display quality. The very simple images PlayNitride provided can easily conceal everything from bad or dead pixels to issues with color accuracy and uniformity.
My general experience and skepticism, based on demo content seen at shows, suggest that the PlayNitride MicroLEDs are far from ready for production, or they would have shown better demo images.
More on PlayNitride
I first took notice of PlayNitride back in 2018 when it was rumored that they were working with Apple on MicroLEDs for watches (see the 2018 MICROLED-info article). A couple of years later, it was rumored that Apple decided to back off or delay its planned use of MicroLEDs in watches, as they were not yet mature. PlayNitride has continued to improve its MicroLED development.
PlayNitride manufactures blue MicroLEDs and then utilizes quantum dots to convert the blue light to red or green. Playnitride offers three ranges of products, categorized by pixel size and display backplane. For products like watches, smartphones, and moderately small displays, it will singulate individual pixels and transfer them to a TFT on a glass or plastic backplane, which may or may not be transparent. For very large displays, the full-color pixels are plugged into a printed circuit board (PCB). However, for the very small microdisplays used in AR/smart glasses, the pixel sizes are so small that transferring individual pixels is impractical; therefore, the entire display array of MicroLEDs is flipped and bonded to a CMOS substrate.
Most other companies flip whole wafers of MicroLEDs onto CMOS wafers. MicroLED wafers are smaller than state-of-the-art CMOS wafers. Some companies flip multiple smaller whole LED wafers onto a 12″ CMOS wafer, which wastes a significant part of the CMOS wafer. Some companies compromise and make 8″ LED wafers to make 8″ CMOS wafers. For MicroDisplays, PlayNitride tests and singulates whole displays/devices on a 12″ CMOS wafer and the MicroLED wafer before combining them (right). Without delving into all the details, each method has its advantages and disadvantages.
PlayNitride shows the chart below in the DW 2025 Presentation. Note that this is only applicable to “full color” MicroLED microdisplays. I covered Raysolve and Saphlux in my SID Display Week 2024 – MicroLEDs for AR, and will be updating my findings in an upcoming article about MicroLEDs at DW 2025. Raysolve showcased a working ~8-micron pixel pitch 320×240 full-color MicroLED in their booth at DW 2025. I must point out that none of these devices are currently in production, so it is impossible to know who is ahead of whom.
Using QD conversion appears to be the most straightforward method for producing full-color MicroLEDs, but it has its drawbacks. The most obvious is that the reds and greens are not as pure or saturated and typically contain some unconverted blue. There is also typically some “crosstalk” from the adjacent color’s blue light stimulating the wrong quantum dot (QD). Some propose using a UV simulation that is covered with red, green, and blue QD with a UV filter to block all the unconverted light. Both JBD and Innovision, among others, have developed stacked native red, green, and blue LED layers on top of the CMOS backplane. Once again, none of these are in production, and each of these full-color MicroLED microdisplay methods has its technical and manufacturing advantages and disadvantages.
While I don’t think any of the single-chip, full-color MicroLED solutions are ready for production anytime soon, the Lumus engine with the PlayNitride device demonstrates the potential for how tiny/insignificant the projector engine can become.
According to Lumus, the Maximus should be more than 5 times the light efficiency of diffractive waveguides for the same size field of view (FOV) and eye box. If true, this is a massive advantage for Lumus/Reflective waveguides because not only can the displays be brighter, but more importantly, they require significantly less power for the same brightness. Typically, power goes up non-linearly with brightness as the LEDs self-heat. As I repeatedly say about AR glasses and power consumption, “Amateurs worry about battery life, the pros worry about heat management.” Based on my experience, I also expect the Lumus waveguides to have much better color and brightness uniformity.










































{kind=link}