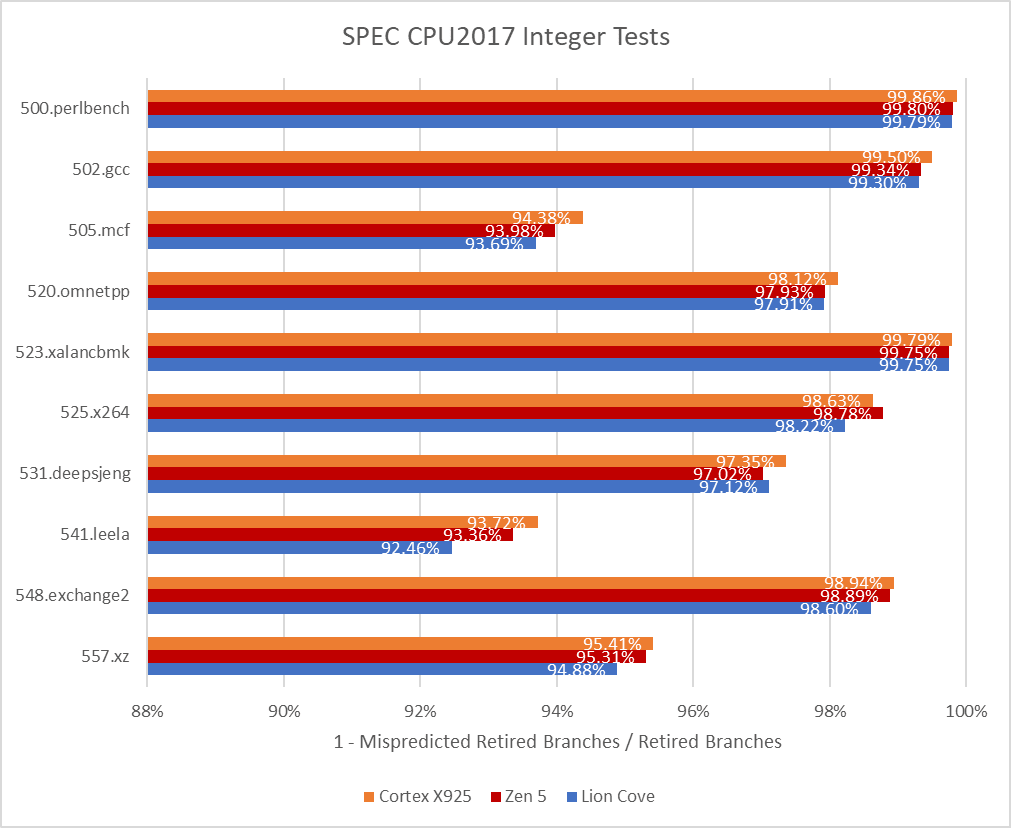This Week in Schadenfreude: Maybe Utah Republicans Can't Count
These days, this strikes us as a Politics 101-level lesson: If you're mounting a petition drive, get
considerably more signatures than the minimum required. You never know what could happen, from signatures being
duplicated, to signatures being invalidated, to signatures being... withdrawn, apparently.
It would seem that Utahns For Representative Government (UFRG), an extremely ironic name adopted by a bunch of
Republican operatives who most certainly do NOT value representative government, did not get the memo. They are cranky
that those infernal liberals in and around Salt Lake City might actually have a voice in Congress, due to recent
political and legal maneuvers that slayed Utah's 4R, 0D House delegation gerrymander, and turned it into a (likely) 3R,
1D. So, UFRG launched a petition drive for an initiative that would have put the drawing of House districts back in the
hands of "the people," by which they mean "the Utah legislature." Since the Utah legislature has 61 Republicans versus
14 Democrats in the state House, and 22 Republicans vs. 6 Democrats in the state Senate, it's pretty clear what would
have happened if "the people" regained control of the process.
Anyhow, UFRG thought they had cleared the bar, signature-wise, albeit with a relatively small margin of error. But
then an information campaign warned Utah voters what UFRG really stood for, and what the ballot measure was really
about. Since people often sign petitions without knowing the contents (outside, say, the grocery store), it is plausible
that many people did not know. And Utah law allows people to withdraw their signatures up to the point that the
initiative is certified. And just enough people
chose to exercise that right
that the initiative fell below the minimum threshold. The overall total was actually enough, but there also has to be a
certain minimum in at least 26 of 29 state Senate districts, and the efforts of state Sen. Kathleen Riebe (D) caused her
district (SD-15) to drop below the minimum, leaving UFRG with the necessary number of signatures in 25 districts, which
is close, but no cigar.
It is now too late for UFRG to fix the problem, though the group's leaders say they will try again next cycle. Maybe
so, but they spent more than $4 million this time, and they also enlisted the assistance of Donald Trump, J.D. Vance,
Gov. Spencer Cox (R-UT) and other heavy hitters, yet came up short. In the future, people asked to sign petitions might
just look a bit more closely before bestowing their John Hancock. Also, in a presidential year, it may not be as easy to
come up with $4 million to chase just one House seat. So, the good people of Salt Lake City might actually be able to
keep the pinko commie lib'rul they're likely to elect in November of this year.
Oh, and thanks to reader B.P. in Salt Lake City for sending this along. He's one of those
pinko commie lib'ruls, of course. (Z)
The International Olympic Committee will require all athletes who want to participate in women's events to undergo genetic testing. The policy takes effect for the 2028 Summer Games in Los Angeles.
Chinese eTail giant Alibaba has removed listings and suspended the accounts of sellers that were found to be advertising 'cruise missiles' and 'suicide attack drones.'
Well, I guess this means things are going to really kick up another notch monday night between trump's 48 hour threat and the saudi's kicking out whatever diplomats were left.
Iran launched missiles at two southern Israeli cities that lie close to the country's main nuclear research center, while President Trump gave Iran 48 hours to reopen the Strait of Hormuz.
I guess I didn't realize they still had nearly 100 'legacy admissions' to their parliament.
Government minister Nick Thomas-Symonds said the change put an end to "an archaic and undemocratic principle." The removed aristocrats are 92 of the House of Lords' 800 members.
NVIDIA today unveiled NVIDIA DLSS 5, the company's most significant breakthrough in computer graphics since the debut of real-time ray tracing in 2018. DLSS 5 introduces a real-time neural rendering model that infuses pixels with photoreal lighting and materials. Bridging the divide between rendering and reality, DLSS 5 empowers game developers to deliver a new level of photoreal computer graphics previously only achieved in Hollywood visual effects.
"Twenty-five years after NVIDIA invented the programmable shader, we are reinventing computer graphics once again," said Jensen Huang, founder and CEO of NVIDIA. "DLSS 5 is the GPT moment for graphics—blending hand-crafted rendering with generative AI to deliver a dramatic leap in visual realism while preserving the control artists need for creative expression."
Several games on Steam that were secretly carrying malware now seem to be under active investigation by the FBI. The department is looking for victim information tied to these games; anyone who installed and played an infected game and was harmed is being urged to step forward and share more info to help with the investigation.
Microsoft has updated Windows 11 Insider Preview builds 26100.8106 and 26200.8106 in the Release Preview Channel, and one of the more unusual additions is support for monitor refresh rates above 1,000 Hz.
Google is rolling out a substantial Maps update that focuses on making in-car navigation easier to interpret, especially in situations where traditional map guidance can feel too abstract.
Australian biotech company Cortical Labs has partnered with data center firm DayOne to establish two new data centers using its CL1 biological computers.
First vibe coding, now vibe reviewing ... but the buzz is good as it finds worthy issues
Anthropic has introduced a more extensive – and expensive – way to review source code in hosted repositories, many of which already contain large swaths of AI-generated code.…
Seems like the first few cracks are starting to appear in the AI deployments.
Financing terms and swinging OpenAI capacity forecast collapse a major expansion of a Stargate data center. Yet, Meta could take the yet-to-be-expanded space.
The US economy shed 92,000 jobs in February, a dramatic downturn from analyst expectations that it would add about 50,000 jobs. The shortfall stoked growing fears that AI could be contributing to higher unemployment.…
The FreeDOS situation with this seems the most funny. No user accounts, no app stores, etc. How exactly are they supposed to get and store user age information to control access to an app store?
Bad legislation, but an especially big headache for FOSS
Many web sites, social media services, and other platforms require age verification on the theory that it will protect kids from seeing inappropriate content. But now some US states want to require the operating system itself to check your age and that could cause big headaches for FOSS vendors.…
"Our only concerns have been our exceptions on fully autonomous weapons and mass domestic surveillance, which relate to high-level usage areas, and not operational decision-making."
I mean that second one is illegal, right?
Brands Trump administration decision 'legally unsound' and has 'no choice but to challenge it in court'
AI giant Anthropic says that it has "no choice" but to sue the US government after being officially designated a supply chain risk to national security.…
I don't understand how this is different from the Biden era rule. Seems largely the same with a few details tweaked and costs possibly raised. It also still allows for the classic "make up 200 shell companies to buy 1000 cards each" approach to just fully bypass the rules. Seems trivial to get around this.
The U.S. Commerce confirms work on new export regulations for AI accelerators, but implies they will not resemble the ill-fated AI Diffusion Rule.
Seems like the most promising ARM core yet for high performance with a few caveats. This thing looks really bad with vector workloads compared to AMD and Intel options and that will really hurt on a number of consumer applications. Also it's made on TSMC's 3nm process instead of the 4nm process that Zen 5 is built on, so that's somewhat artificially making it look better just by being designed later. Curious to see how the nvidia desktop systems work when they come out later this year (this quarter?).
Desktop and laptop use cases demand high single threaded performance across a large variety of workloads. Creating CPU cores to meet those demands is no easy task. AMD and Intel traditionally dominated this high performance segment using high clocked, high throughput cores with large out-of-order engines to absorb latency. Arm traditionally optimized for low power and low area, and not necessarily maximum performance. Over the years though, Arm steadily built more complex cores and looked for opportunities to expand into higher performance segments. Matching the best from Intel and AMD must have been a distant dream in 2012, when Arm launched their first 64-bit core, the Cortex A57. Today, that dream is a reality.
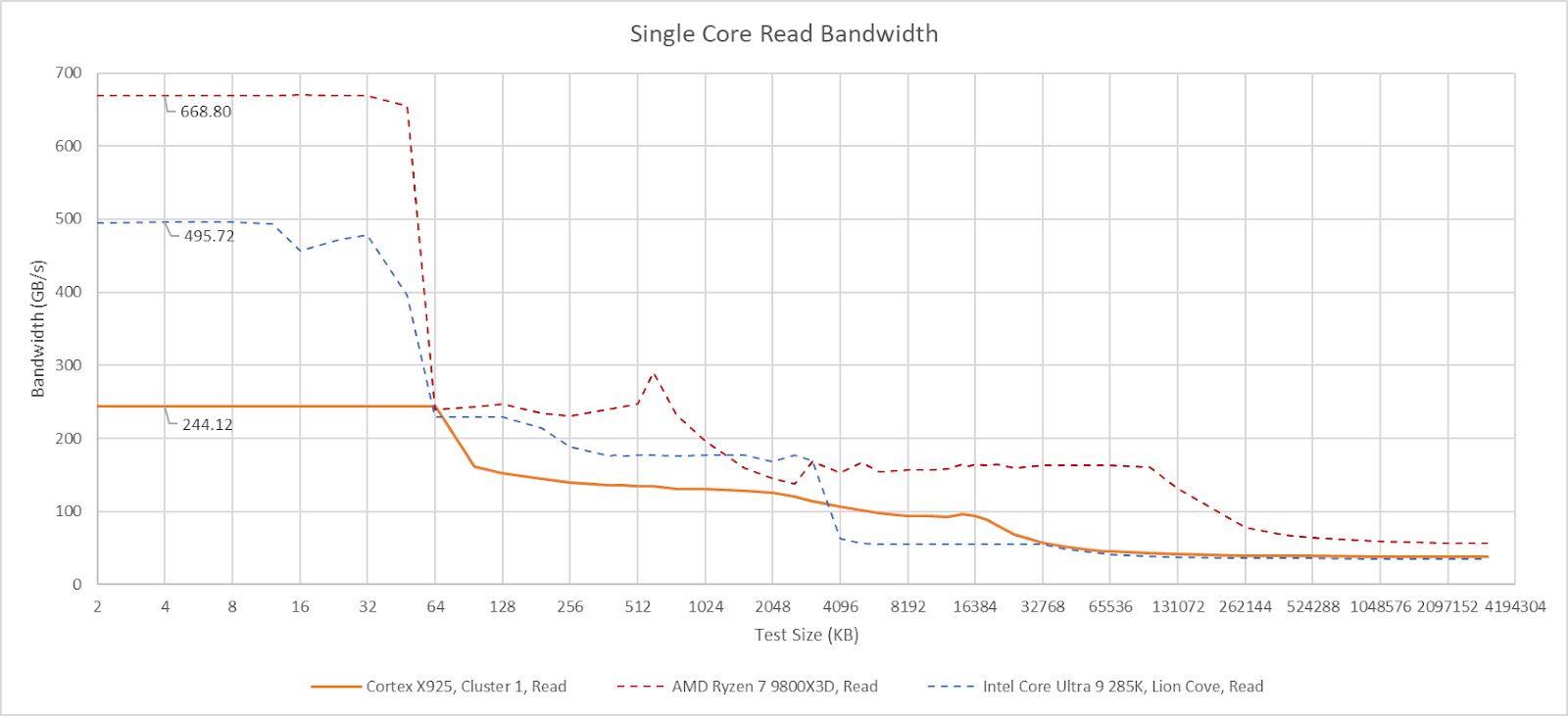
Cortex X925 in Nvidia’s GB10 achieves performance parity with AMD’s Zen 5 and Intel’s Lion Cove in their fastest desktop implementations. That gives Arm a core fast enough to not just play in laptop segments, but potentially in the most performance sensitive desktop applications too. Nvidia’s GB10 uses ten X925 cores, split across two clusters. One of those X925 cores reaches 4 GHz, while the others are not far behind at 3.9 GHz. Dell uses the GB10 chip in their Pro Max series, and we’re grateful to Dell for letting us test that product.
Overview
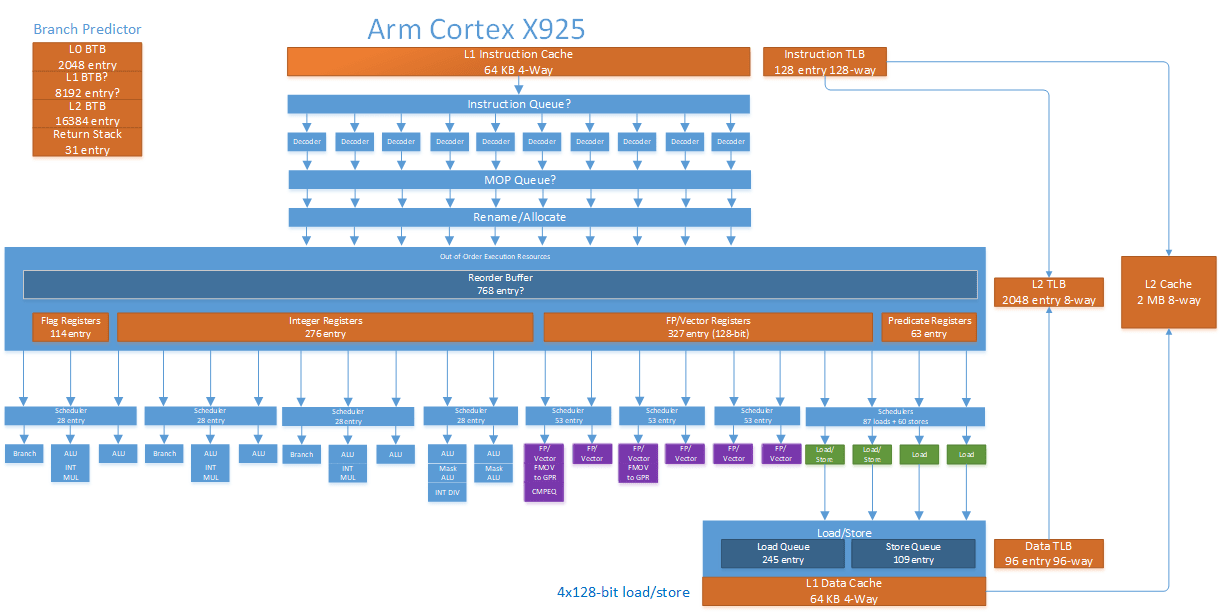
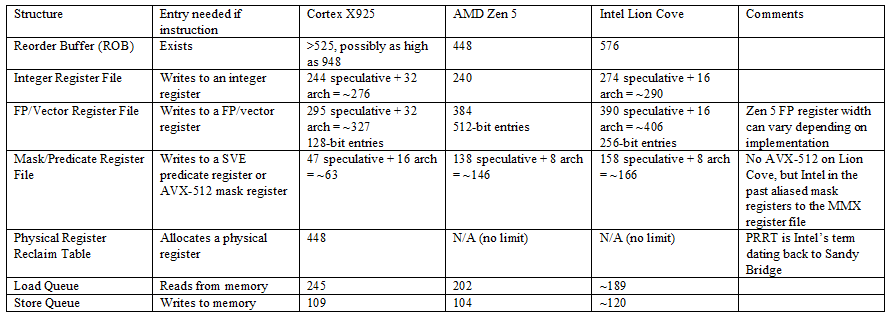
Arm’s Cortex X925 is a massive 10-wide core with a lot of everything. It has more reordering capacity than AMD’s Zen 5, and L2 capacity comparable to that of Intel’s recent P-Cores. Unlike Arm’s 7-series cores, X925 makes few concessions to reduce power and area. It’s a core designed through and through to maximize performance.
Rough block diagram of the Cortex X925’s microarchitecture
In Arm tradition, X925 has a number of configuration options. However, X925 omits the shoestring budget options present for A725. X925’s caches are all either parity or ECC protected, dropping A725’s option to do without error detection or correction. L1 caches on X925 are fixed at 64 KB, removing the 32 KB options on A725. X925’s most significant configuration options happen at L2, where implementers can pick between 2 MB or 3 MB of capacity. They can also choose either a 128-bit or 256-bit ECC granule to make area and reliability tradeoffs.
X925 interfaces with the rest of the system via Arm’s DSU-120, which acts as a cluster-level interconnect and hosts a L3 cache with up to 32 MB of capacity. X925 and its DSU support 40-bit physical addresses, which is adequate for consumer systems. However, it’s clearly not designed for server applications, where larger 48-bit or even 52-bit physical address spaces are common.
Branch Prediction
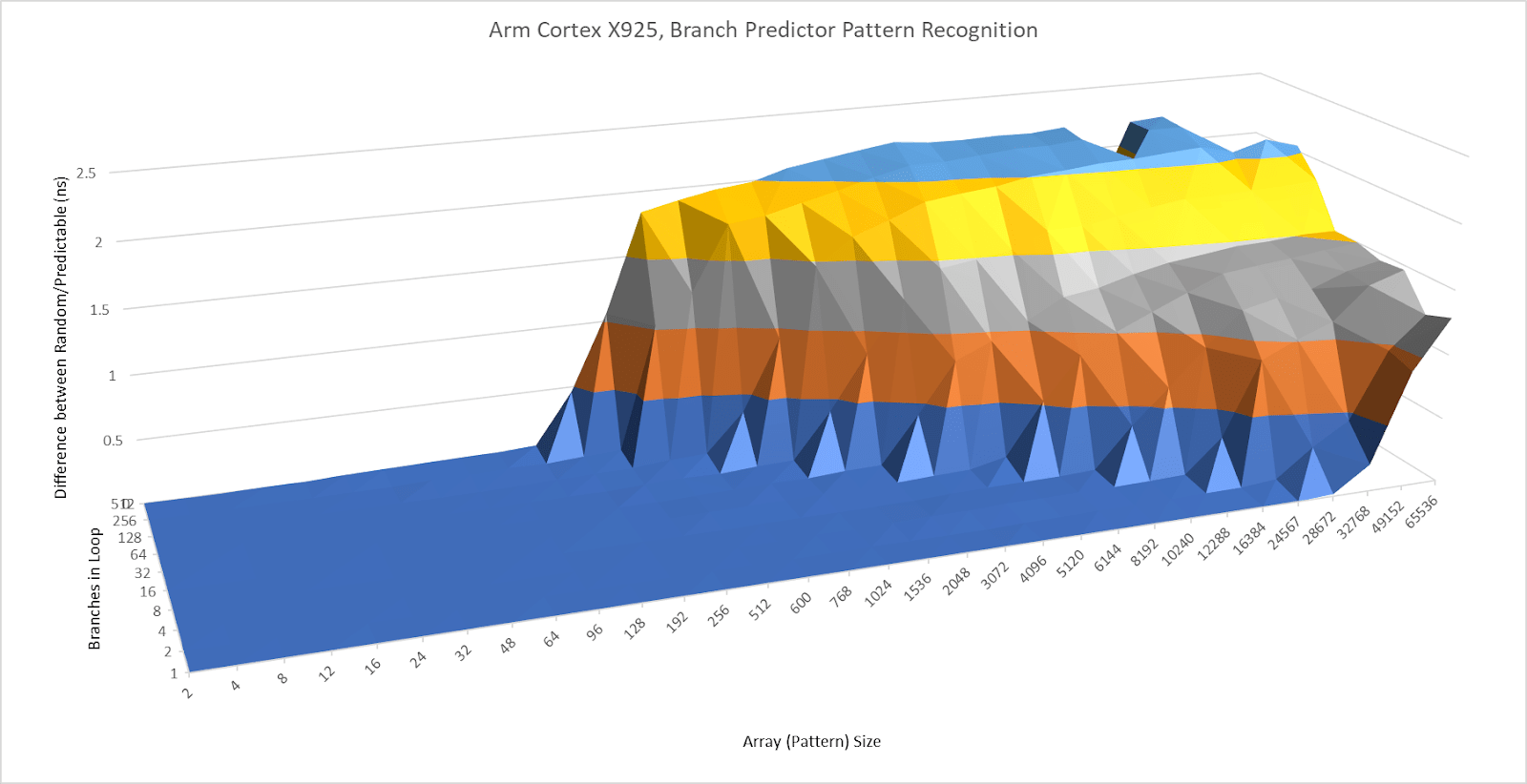
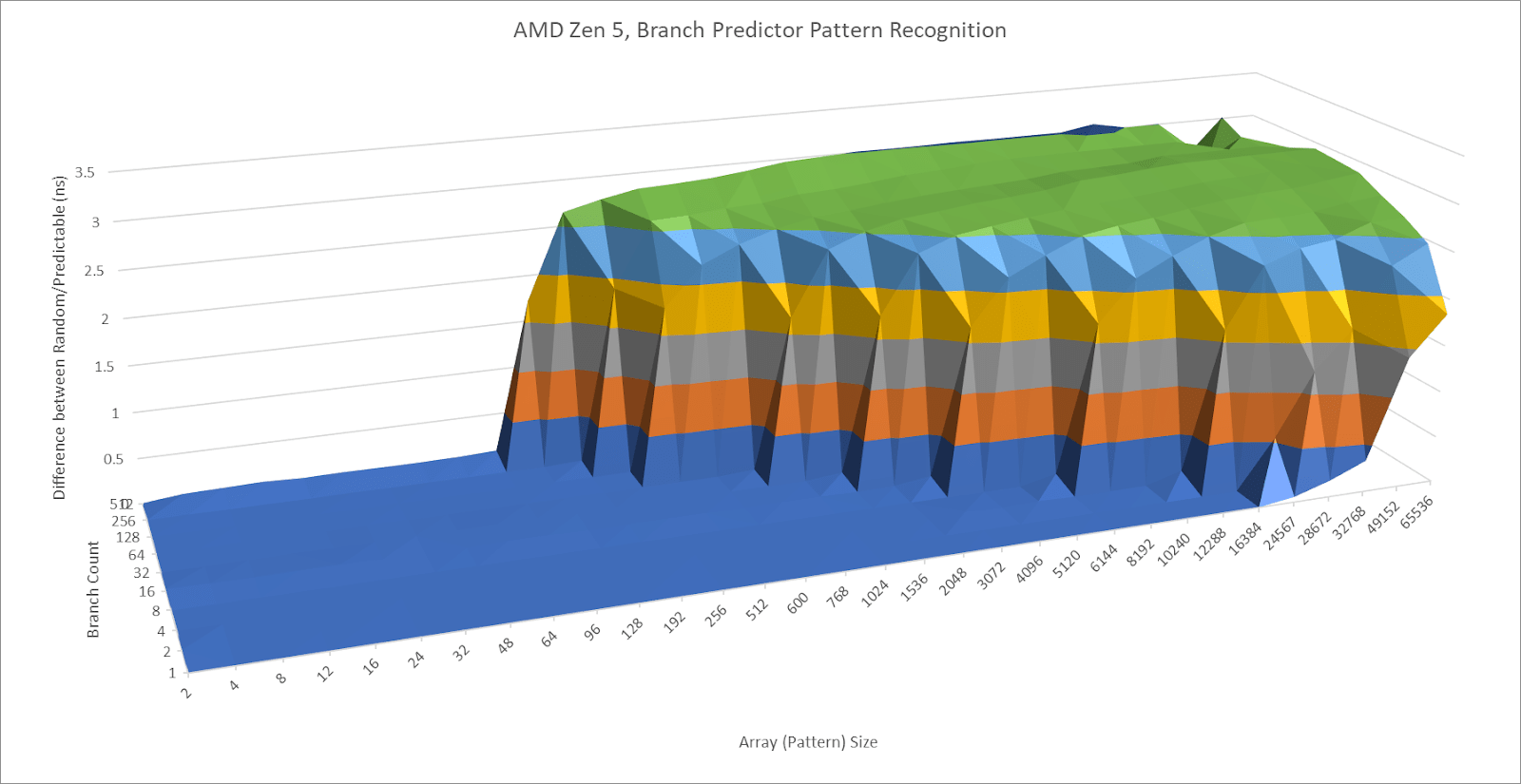
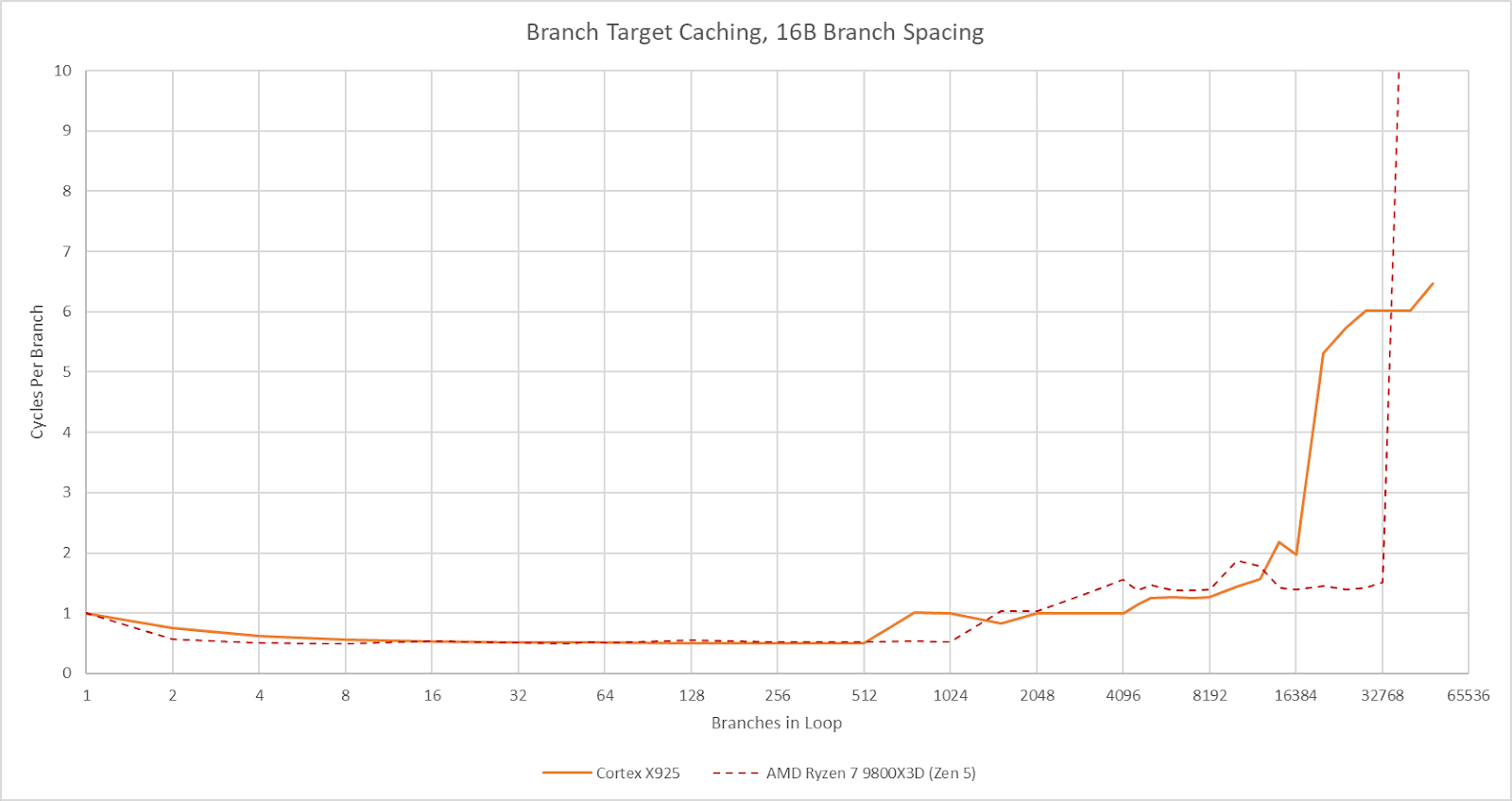
Performance and power efficiency starts with good branch prediction. Arm knows this, and X925 doesn’t disappoint. Its branch predictor can recognize extremely long repeating patterns. In a test with branches that are taken or not-taken in random patterns of increasing lengths, X925 behaves a lot like AMD’s Zen 5. AMD’s cores have featured very strong branch predictors since Zen 2, so X925’s results are impressive.
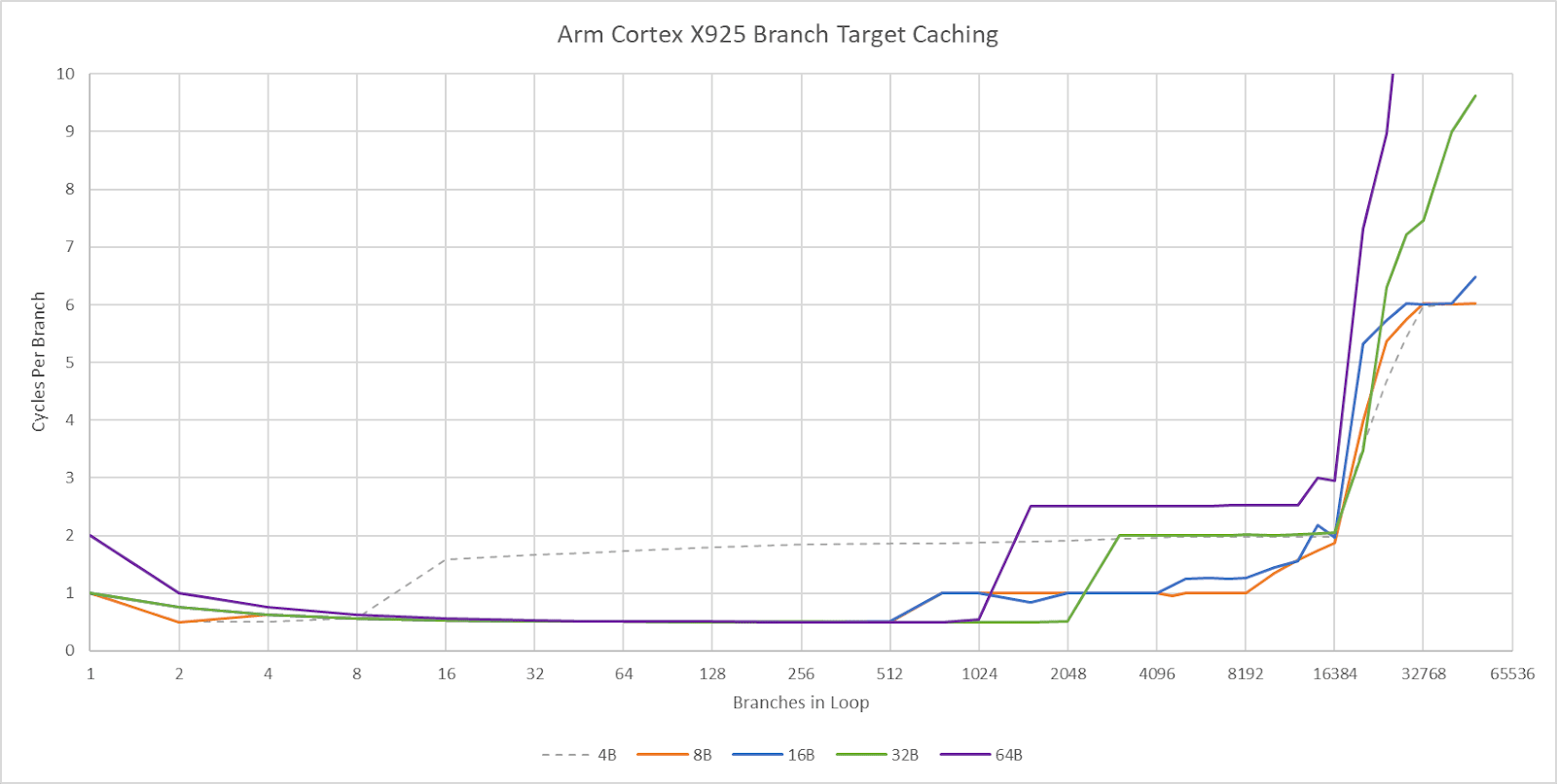
Cortex X925’s branch target caching compares well too. Arm has a large first level BTB capable of handling two taken branches per cycle. Capacity for this first level BTB varies with branch spacing, but it seems capable of tracking up to 2048 branches. This large capacity brings X925’s branch target caching strategy closer to Zen 5’s, rather than prior Arm cores that used small micro-BTBs with 32 to 64 entries. For larger branch footprints, X925 has slower BTB levels that can track up to 16384 branches and deliver targets with 2-3 cycle latency. There may be a mid-level BTB with 4096 to 8192 entries, though it’s hard to tell.
Compared to AMD’s Zen 5, X925 has roughly comparable capacity in its fastest BTB level depending on branch spacing. Zen 5 has more maximum branch target caching capacity, especially when it can use a single BTB entry to track two branches. Still, X925 has more branch target storage than Arm cores from a few years ago. Cortex X2 for example topped out at about 10K branch targets.
A 29 entry return stack helps predict returns from function calls, or branch-with-link in Arm instruction terms. Like Intel’s Sunny Cove and later cores, the return stack doesn’t work if return sites aren’t spaced far enough apart. I spaced the test “function” by 128 bytes to get clear results.
In SPEC CPU2017, Cortex X925 achieves branch prediction accuracy roughly on par with AMD’s Zen 5 across most tests, and may even be slightly ahead. 505.mcf and 541.leela consistently challenge branch predictors, and X925 pulls ahead in both. Intel’s Lion Cove is a bit behind both Zen 5 and X925.
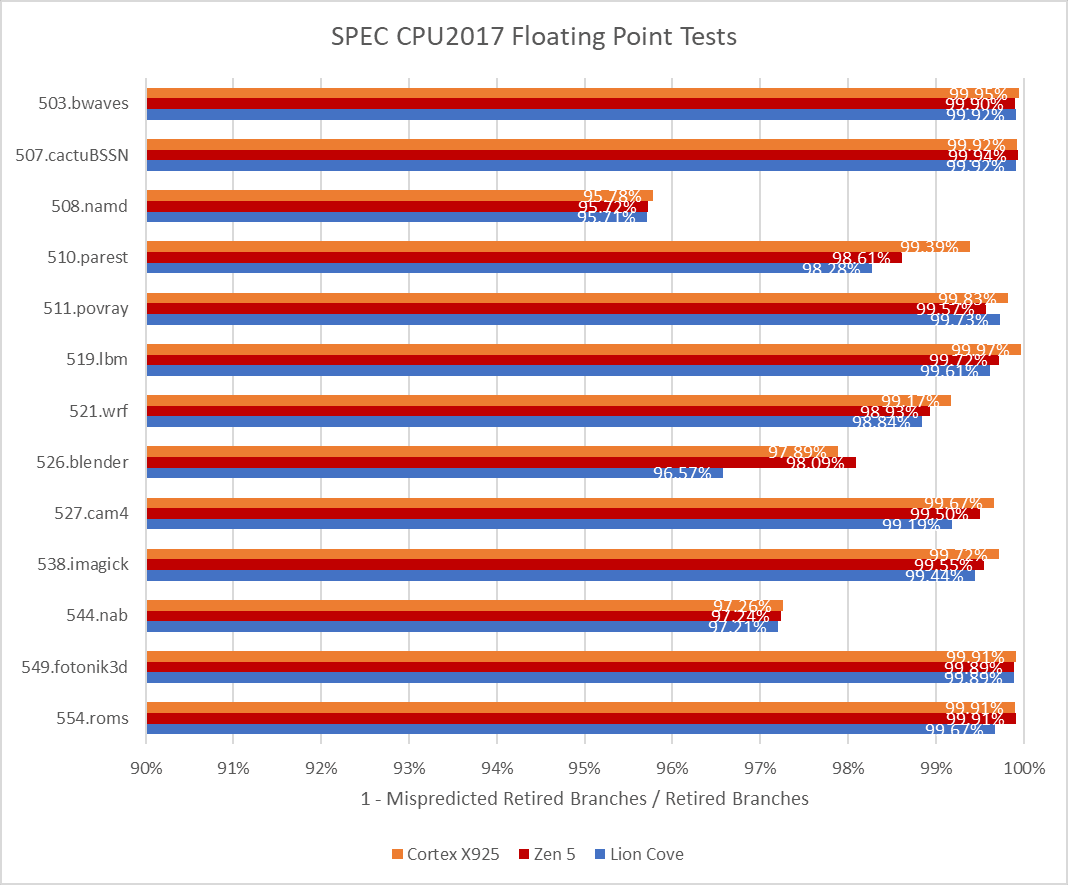
SPEC’s floating point workloads are gentler on the branch predictor, but X925 still shows its strength. It’s again on par or slightly better than Zen 5.
Instruction Fetch and Decode
Cortex X925 ditches the MOP cache from prior Arm generations, much like mid-core companion (A725). While Cortex X925 doesn’t have the same tight power and area restrictions as A725, many of the same justifications apply. Arm already tackles decode costs through a variety of measures like predecode and running at lower clock speeds. A MOP cache would be excessive.
On the predecode side, X925’s TRM suggests the L1I stores data at 76-bit granularity. Arm instructions are 32-bits, so 76 bits would store two instructions and 12 bits of overhead. Unlike A725, Arm doesn’t indicate that any subset of bits correspond to an aarch64 opcode. They may have neglected to document it, or X925’s L1I may store instructions in an intermediate format that doesn’t preserve the original opcodes.
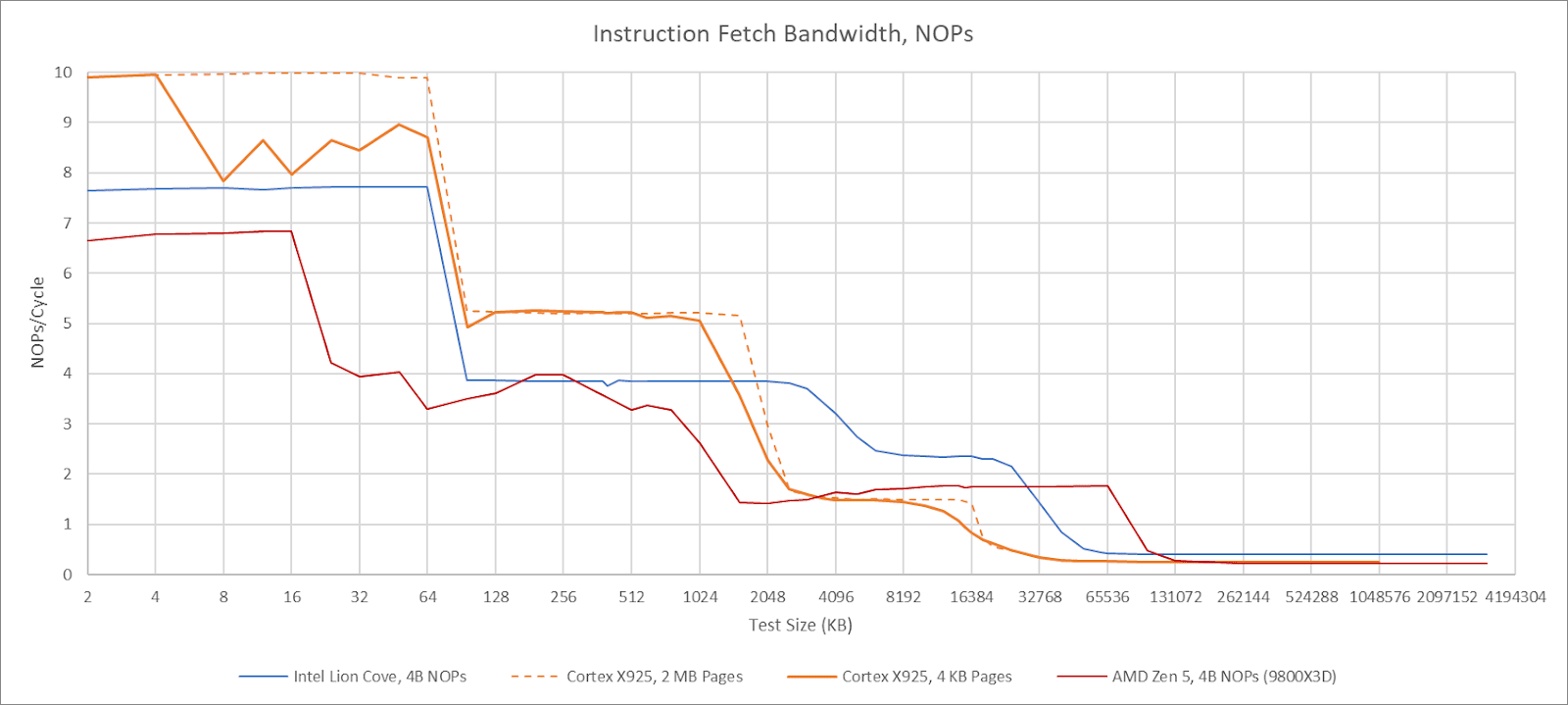
Zen 5 can achieve 8 instructions per cycle with 8B NOPs. There seems to be a strange limitation with 4B NOPs, but I’m using the same NOP size for all cores for consistency
X925’s frontend can sustain 10 instructions per cycle, but strangely has lower throughput when using 4 KB pages. Using 2 MB pages lets it achieve 10 instructions per cycle as long as the test fits within the 64 KB instruction cache. Cortex X925 can fuse NOP pairs into a single MOP, but that fusion doesn’t bring throughput above 10 instructions per cycle. Details aside, X925 has high per-cycle frontend throughput compared to its x86-64 peer, but slightly lower actual throughput when considering Zen 5 and Lion Cove’s much higher clock speed. With larger code footprints, Cortex X925 continues to perform well until test sizes exceed L2 capacity. Compared to X925, AMD’s Zen 5 relies on its op cache to deliver high throughput for a single thread.
Rename and Allocate
MOPs from the frontend go through register renaming and have various bookkeeping resources allocated for them, letting the backend carry out out-of-order execution while ensuring results are consistent with in-order execution. While allocating resources, the core can carry out various optimizations to expose additional parallelism. X925 can do move elimination like prior Arm cores, and has special handling for moving an immediate value of zero into a register. Like on A725, the move elimination mechanism tends to fail if there are enough register-to-register MOVs close by. Neither optimization can be carried out at full renamer width, though that’s typical as cores get very wide.
Unlike A725, X925 does not have special handling for PTRUE, which sets a SVE predicate register to enable all lanes. A725 could eliminate PTRUE like a zeroing idiom, and process it without allocating a physical register. While this is a minor detail, it does show divergence between Arm’s mid-core and big-core lines.
Out-of-Order Execution
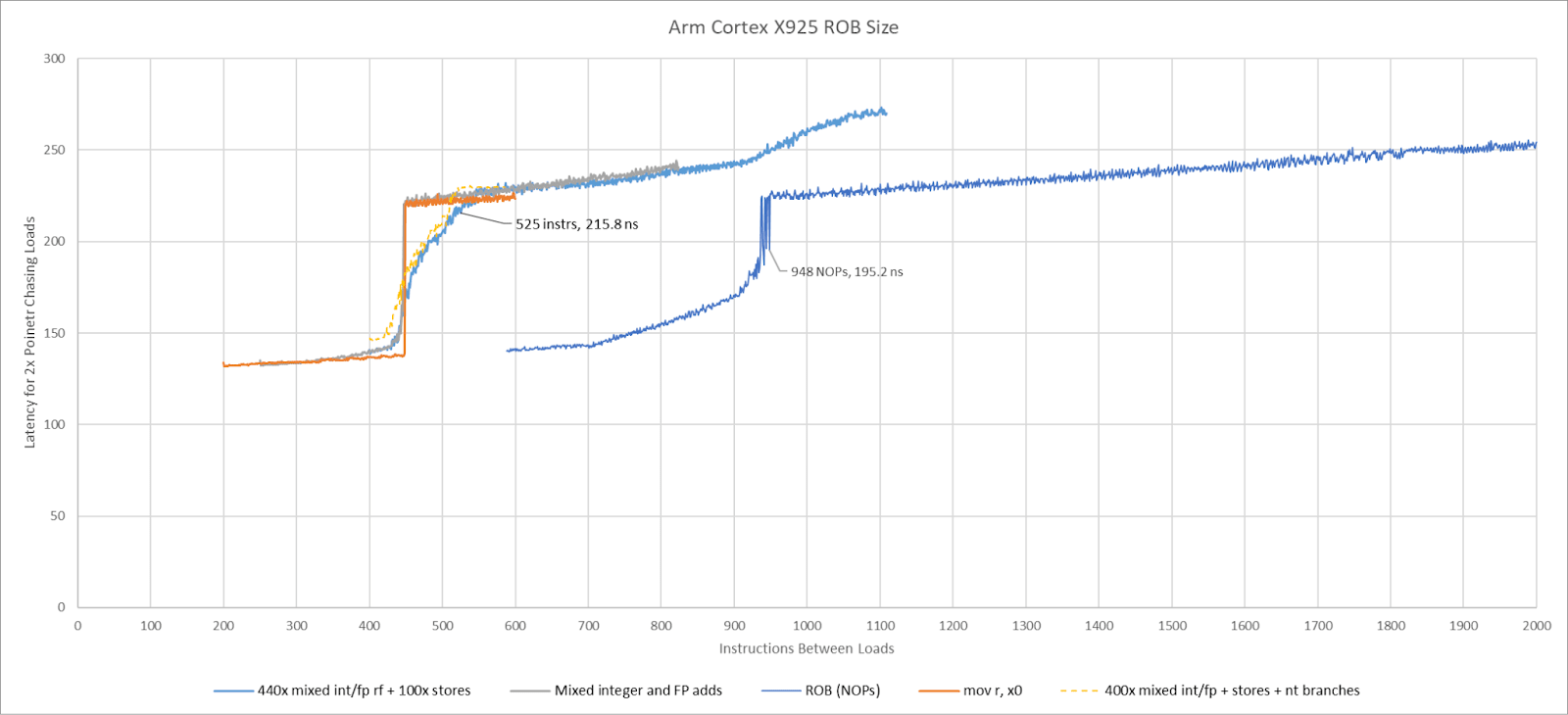
A CPU’s out-of-order backend executes operations as their inputs become ready, letting the core keep its execution units fed while waiting for long latency instructions to complete. Different sources give conflicting information about Cortex X925’s reordering window. Android Authority claims 750 MOPs. Wikichip believes it’s 768 instructions, based off an Arm slide that states Cortex X925 doubled reordering capacity over Cortex X4. Testing shows X925 can keep 948 NOPs in flight, which doesn’t correspond with either figure unless NOP fusion only worked some of the time.
Because results with NOPs were inconclusive, I tried testing with combinations of various instructions designed to dodge other resource limits. Mixing instructions that write to the integer and floating point registers showed X925 could have a maximum of 448 renamed registers allocated across its register files. Recognized zeroing idioms like MOV r,0 do not allocate an integer register, but also run up against the 448 instruction limit. I tried mixing in predicate register writes, but those also share the 448 instruction limit. Adding in stores showed the core could have slightly more than 525 instructions in flight. Adding in not-taken branches did not increase reordering capacity further. Putting an exact number on X925’s reorder buffer capacity is therefore difficult, but it’s safe to say there’s a practical limitation of around 525 instructions in flight. That puts it in the same neighborhood as Intel’s Lion Cove (576) and ahead of AMD’s Zen 5 (448).
X925’s register files, memory ordering queues, and other resources have comparable capacity to those in Zen 5 and Lion Cove. The only weakness is 128-bit vector execution, with correspondingly wide register file entries. AMD and Intel’s big cores have wider vector registers, and more of them available for renaming.
Execution Units and Schedulers
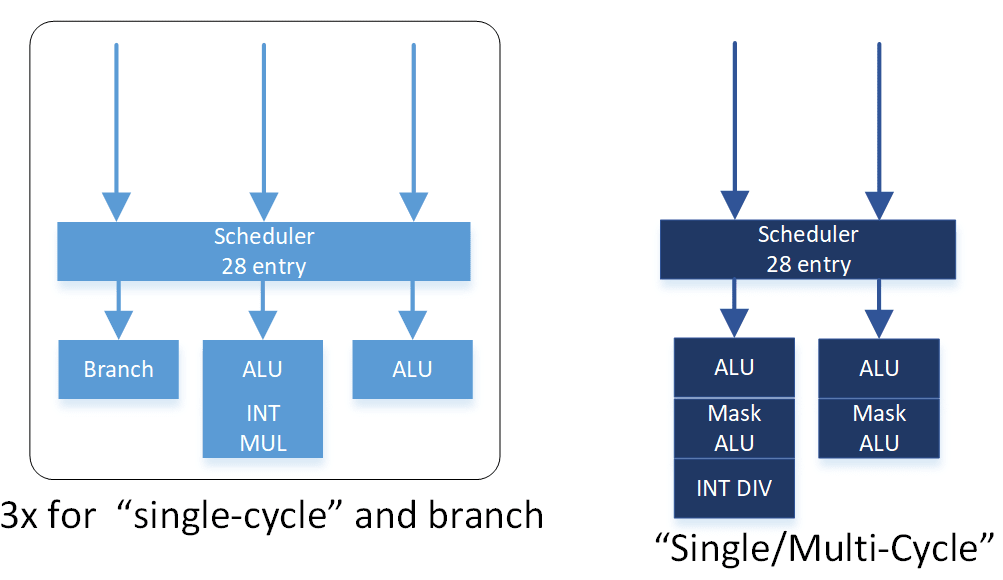
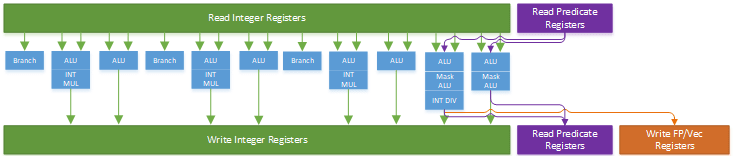
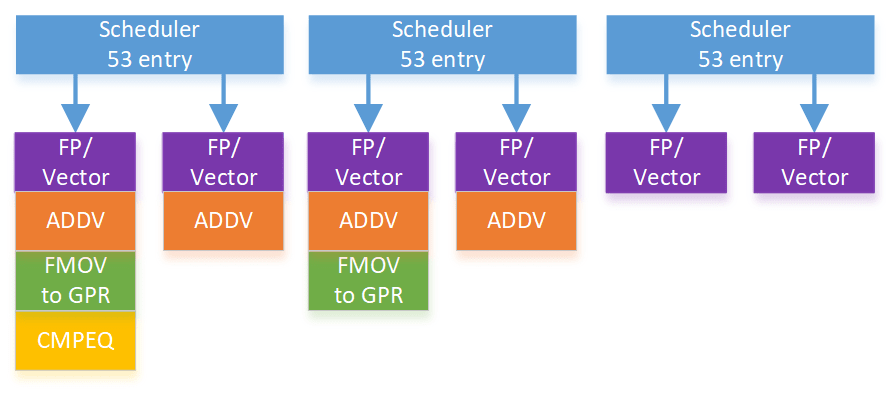
Arm laid out Cortex X925’s integer side to deliver high throughput while controlling port count for both the integer register file and scheduling queues. Eight ALU ports and three branch units are distributed across four schedulers in a layout that maximizes symmetry for common ALU operations. All four schedulers have two ALU ports and 28 entries. Similarly, each scheduler has one multiply-capable ALU pipe. Branches and special integer operations see a split, with the first three schedulers getting a branch pipe and the fourth scheduler getting support for pointer authentication and SVE predicate operations.
The aarch64 instruction set has a madd instruction that performs integer multiply-adds. Cortex A725 and older Arm cores had dedicated integer multi-cycle pipes that could handle madd along with other complex integer instructions. Cortex X925 instead breaks madd into two micro-ops, and handles it with any of its four multiply-capable integer pipes. Likely, Arm wanted to increase throughput for that instruction without the cost of implementing three register file read ports for each multiply-capable pipe. Curiously, Arm’s optimization guide refers to the fourth scheduler’s pipes as “single/multi-cycle” pipes. “Multi-cycle” is now a misnomer though, because the core’s “single-cycle” integer pipes can handle multiplies, which have two cycle latency. On Cortex X925, “multi-cycle” pipes distinguish themselves by handling special operations and being able to access FP/vector related registers.
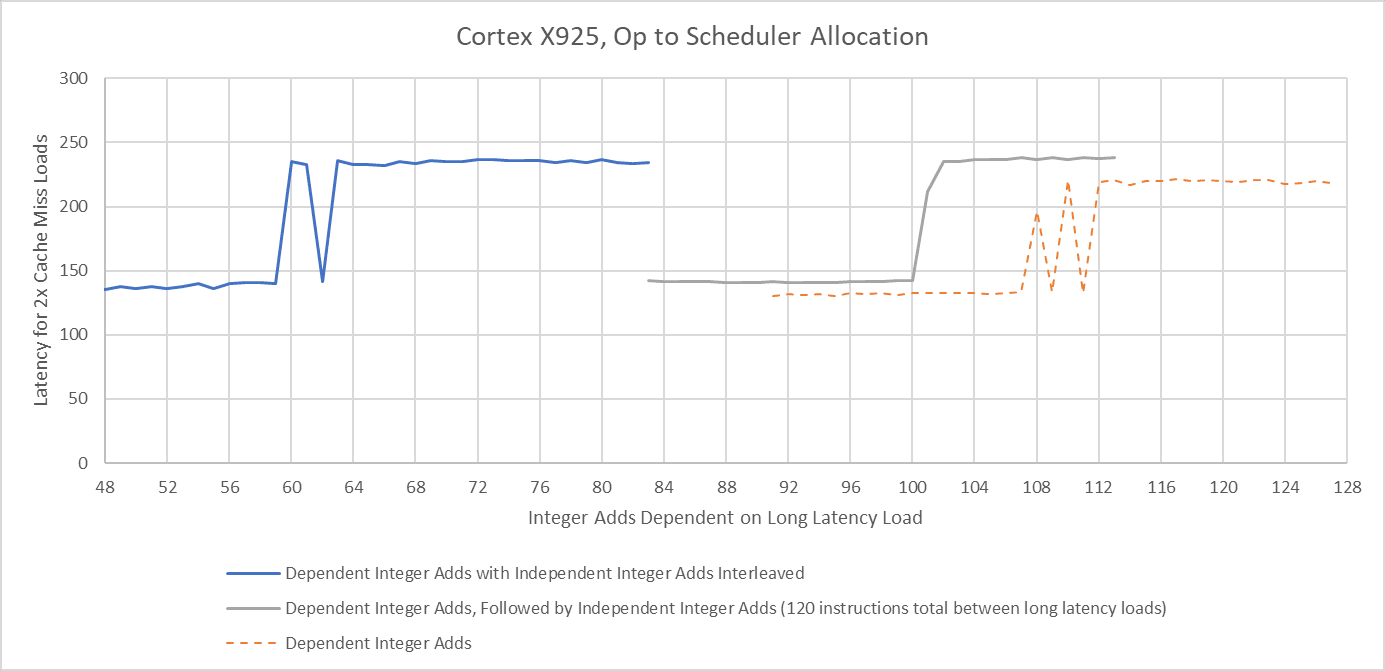
The two multi-cycle pipes on the right can take three inputs each from predicate registers (two inputs, and a predicate as a mask), so treat the purple input arrow as three. Drawing more arrows is hard.
Thanks to symmetry across the integer schedulers, X925’s renamer likely uses a simple round-robin allocation scheme for operations that can go to multiple schedulers. If I test scheduler capacity by interleaving dependent and independent integer adds, X925 can only keep half as many dependent adds in flight. Following dependent adds by independent ones only slightly reduces measured scheduling capacity. That suggests the renamer assigns a scheduler for each pending operation, and stalls if the targeted scheduling queue is full without scanning other eligible schedulers for free entries.
Cortex X925’s FPU has six pipes, all of which can handle vector floating point adds, multiplies, and multiply-adds. All six pipes also support vector integer adds and multiplies. Less common instructions like addv are still serviced by four pipes. X925’s FP schedulers are impressively large with approximately 53 entries each. For perspective, each of X925’s three FP schedulers has nearly as much capacity as Bulldozer’s 60 entry unified FP scheduler. Bulldozer used that scheduler to service two threads, while X925 uses its three FP schedulers to service a single thread.
High scheduler capacity and high pipe count should give X925 good performance in vectorized applications despite its 128-bit vector width.
Load/Store
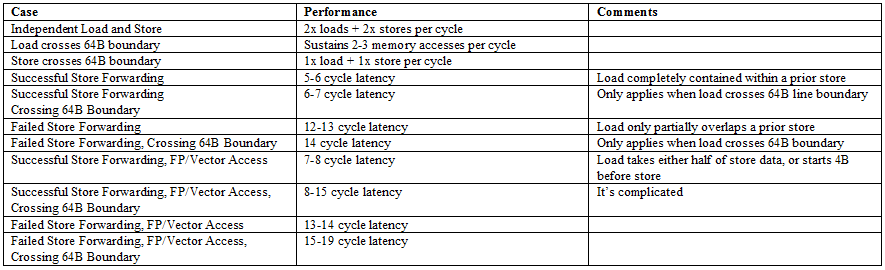
Memory accesses are among the most complicated and performance critical operations on a modern CPU. For each memory access, the load/store unit has to translate program-visible virtual addresses into physical addresses. It also has to determine whether loads should get data from an older store, or from the cache hierarchy. Cortex X925 has four address generation units that calculate virtual addresses. Two of those can handle stores.
Address translations are cached in a standard two-level TLB setup. The L1 DTLB has 96 entries and is fully associative. A 2048 entry 8-way L2 TLB handles larger data footprints, and adds 6 cycles of latency. Zen 5 for comparison has the same L1 DTLB capacity and associativity, but a larger 4096 entry L2 DTLB that adds 7 cycles of latency. Another difference is that Zen 5 has a separate L2 ITLB for instruction-side translations, while Cortex X925 uses a unified L2 TLB for both instructions and data. AMD’s approach could further increase TLB reach, because data and instructions often reside on different pages.
And adapting it to use vector registers with 128-bit stores and 64-bit loads
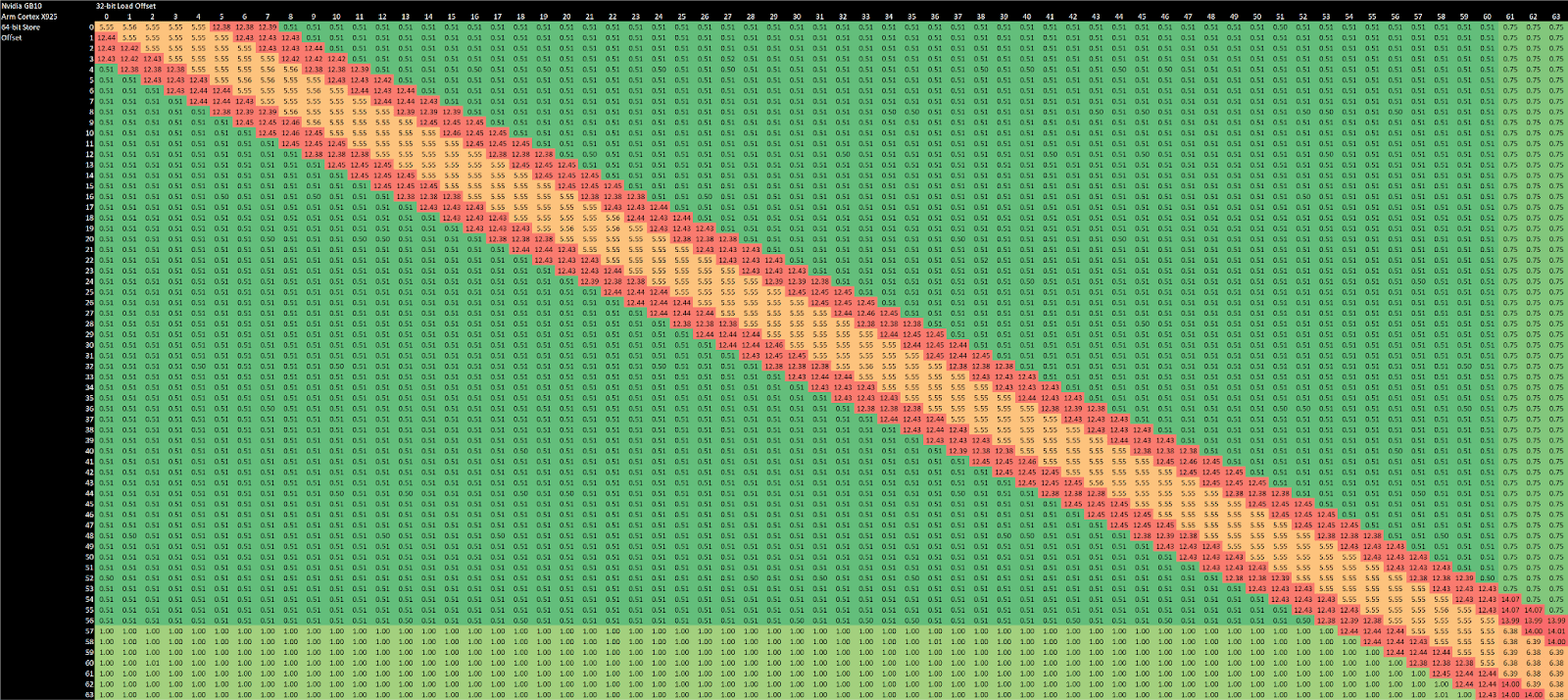
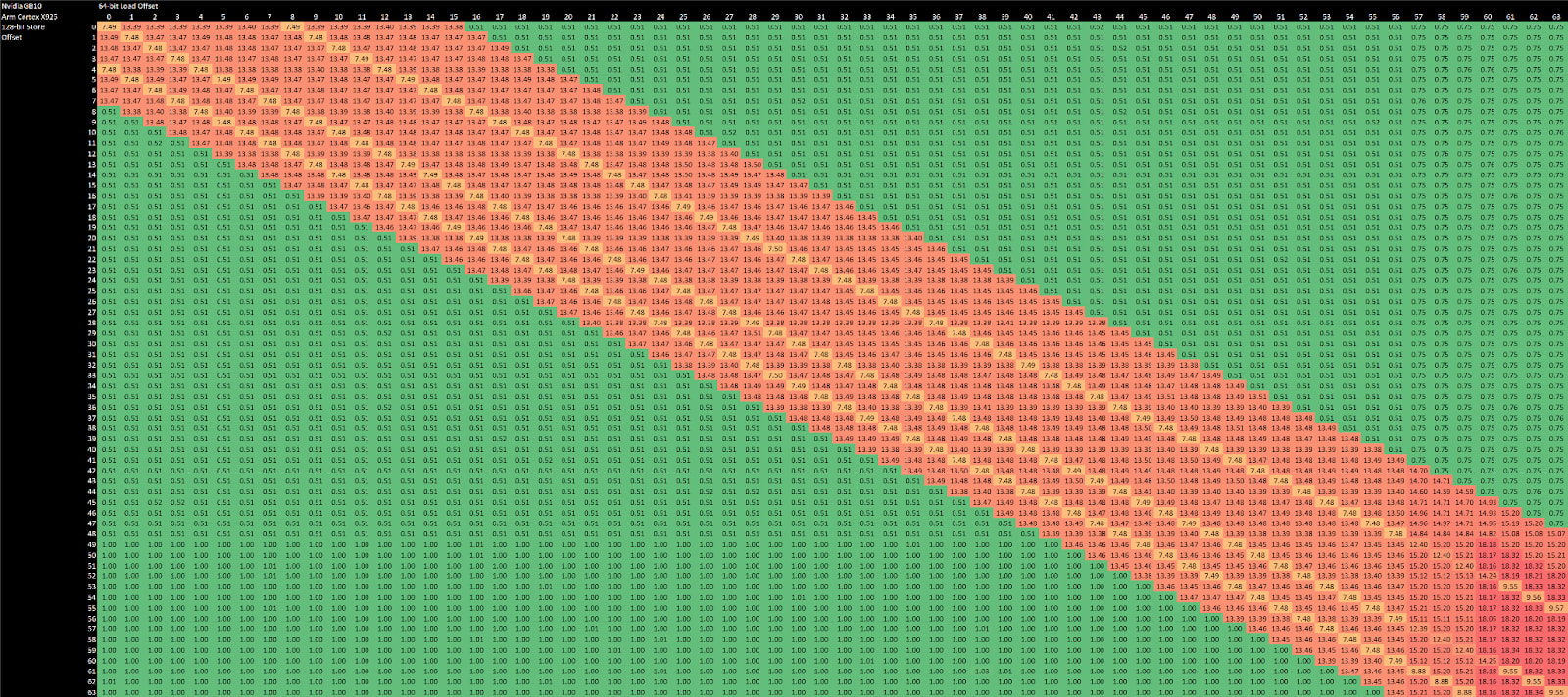
Store forwarding on the integer side works for all loads contained within a prior store. It’s an improvement over prior arm cores like the Cortex X2, which could only forward either half of a 64-bit store to a 32-bit load. Forwarding on the FP/vector side still works like older Arm cores, and only works for specific load alignments with respect to the store address. Unlike recent Intel and AMD cores, Cortex X925 can’t do zero latency forwarding when store and load addresses match exactly. To summarize store forwarding behavior:
Memory dependencies can’t be definitively determined until address translation finishes. Some cores do an early check before address translation completes, using bits of the address that represent an offset into a page. Cortex X925 might be doing that because it takes a barely measurable penalty when loads and stores appear to overlap in the low 12 bits.
Core-Private Caches
Cortex X925 has a 64 KB L1 data cache with 4 cycle latency like A725 companions in GB10, but takes advantage of its larger power and area budget to make that capacity go further. It uses a more sophisticated re-reference interval prediction (RRIP) replacement policy rather than the pseudo-LRU policy used on A725. Bandwidth is higher too. Arm’s technical reference manual says the L1D has “4x128-bit read paths and 4x128-bit write paths”. Sustaining more than two stores per cycle is impossible because the core only has two store-capable AGUs. Loads can use all four AGUs, and can achieve 64B/cycle from the L1 data cache. That’s competitive against many AVX2-capable x86-64 CPUs from a few generations ago. However, more recent Intel and AMD cores can use their wider vector width and faster clocks to achieve much higher L1D bandwidth, even if they also have four AGUs.
Injected liver cells stayed viable and functional for eight weeks in mice
Can’t keep waiting on the transplant list? How about an injectable “satellite liver” instead? After an MIT research project showed early success, the idea of a mini organ that could be injected into the body to take over for a failing liver doesn’t sound so far-fetched.…
The law's broad definition of an "operating system provider" pulls in not just Windows, macOS, Android, and iOS, but Linux distributions and Valve's SteamOS.
Microsoft recently updated its Agility SDK to version 1.619, bringing DirectX Shader Model 6.9 alongside some new DirectX 12 improvements. However, Microsoft's latest product demo about Shader Execution Reordering (SER) now confirms a massive performance uplift across several GPUs, with up to a 90% improvement on Intel Arc B-Series and more than 80% from independent sources' benchmarks on NVIDIA "Blackwell." With SER, the API gives applications the ability to dynamically sort rays for highly optimized parallel execution, improving performance by a large margin. In Microsoft's own testing, Intel's Arc B-Series GPUs, which include "Battlemage" discrete GPUs and Xe3-based integrated GPUs in "Panther Lake," managed to achieve a 90% framerate increase in the technology demonstration, suggesting that ray tracing performance still has some tricks up its sleeve for optimization.
Meanwhile, the company also tested the NVIDIA GeForce RTX 4090 with SER, scoring a 40% improvement over the default ray sorting in the previous execution model. Independent testing from Osvaldo Pinali Doederlein on X showed that the GeForce RTX 5080 "Blackwell" GPU scored about an 80% improvement running this demo, which gives confidence that games implementing this technology will provide gamers with a massive performance boost once implemented. Microsoft has built this D3D12RaytracingHelloShaderExecutionReordering demo with a minimum demonstration of the SER technology, so anyone can test their own hardware and the performance improvement.
Shortly following the recent announcement that Phil Spencer would be leaving as the head of Xbox Gaming, the division's new CEO, Asha Sharma, released a long statement expressing her distaste for AI slop and her belief that, although "AI has long been part of gaming and will continue to be," games "are and always will be art, crafted by humans and created with the most innovative technology provided by us." Many gamers have been skeptical of these and similar statements now and in the past, but it seems as though industry veteran and founder of Xbox, Seamus Blackley, seems to be convinced that those are empty words, whether Sharma believes it or not. In a recent interview with GamesBeat, Blackley said about Sharma that he believes "her job is going to be as a palliative care doctor who slides Xbox gently into the night," going on to say that assurances like the aforementioned one by Sharma are "just what occurs to people to say when they bring in someone from an outside business into games."
In Blackley's view, Microsoft's bet on AI will result in a lot of the non-AI businesses being sunsetted, and that is what is happening to Xbox under the new CEO. He says that, just like AI has taken over "everything else," it will take over gaming as well, at least at Microsoft, going on to say that "Asha's background is entirely in software as a service and AI. The implicit thing here is that games is going to be AI-driven software as a service." Part of his justification for this belief is that, despite gaming industry veteran, Matt Booty, acting as Executive Vice President and Chief Content Officer, Sharma is an outsider to the gaming industry and doesn't necessarily understand the industry. His concern is that such an outsider, especially one coming from an AI background, can only see gaming in an abstract way. That said, he does admit that there have been outsiders that have succeeded in gaming, but those that have understood that gaming is a content business. He also jokingly says that her statement about the future of Xbox "reminded me of that meme 'Hello, fellow kids!'" and that she would have to figure out what's interesting about gaming.
An NPR investigation finds the public database of Epstein files is missing dozens of pages related to sexual abuse accusations against President Trump.
(Image credit: Department of Justice and Getty Images/Collage by Danielle A. Scruggs/NPR)
Canadian startup Taalas claims nothing less than to rewrite the economics of AI inference. The HC1 is not just another GPU clone, not a TPU knockoff, not a “me too” accelerator with HBM towers and 700-watt TDP. It is a hardwired model. Specifically: Llama 3.1 8B, physically cast in silicon. 17,000 tokens per second – […]
Last week I found out that epstein got rich by just straight up transferring money from wexner's accounts to his own in a blatant stealing scheme. It was on another podcast. It would make a lot of sense as to why wexner didn't raise this issue with the authorities if epstein already had compromising photos and videos on wexner with children.
Epstein Buddy Leslie Wexner Testified before a House Committee in Camera Yesterday
Retail billionaire and friend-of-Epstein Leslie Wexner testified before the House Oversight Committee yesterday. At
one time, Wexner controlled the Limited, Victoria's Secret, Abercrombie & Fitch, PINK, and Bath & Body works. He
had an intimate and complicated relationship with Jeffrey Epstein. His name appears hundreds of times in the Epstein
files, once as a co-conspirator. He has admitted
traveling
to Epstein's private island. Virginia Giuffre said that she was trafficked to Wexner. Unfortunately, she is no longer
around to testify under oath about this. Wexner, not surprisingly, denies it. However, this undated
photo
suggests that he was very friendly with some woman and Epstein at one point.
Wexner issued a statement before his testimony admitting that he was "naive, foolish, and gullible to put any trust
in Jeffrey Epstein." Boy, is that ever true. He trusted Epstein so much that he allowed Epstein to manage his vast
fortune. Epstein grabbed the chance and helped himself to hundreds of millions of dollars of it. When Wexner found out
that he had been fleeced, why didn't he go to the FBI? Epstein was known to be an avid photographer and videographer.
Could it be that Epstein had a wee bit of kompromat on Wexner that might just leak out if Wexner sued him? We
have no idea.
The deposition took place in new Albany, OH, where Wexner lives. The panel's chairman, Rep. James Comer (R-KY), was
absent due to major oral surgery that had been previously scheduled. One can only hope the procedure involved sewing his
mouth shut. Afterwards, Democrats on the panel began
telling
what they heard from Wexner. It wasn't much. The ranking member, Rep. Robert Garcia (D-CA), said that Wexner denied
everything and showed no remorse. No doubt his lawyers suggested that approach. Wexner also denied that he and Epstein
were close friends, despite the fact that Ghislaine Maxwell once described Wexner as Epstein's closest friend. Maxwell's
version makes sense, as Wexner is a multibillionaire, the kind of person Epstein loved being around. Garcia didn't
believe anything Wexner said. Garcia: "There is no single person that was more involved with providing Jeffrey Epstein
with the financial support to commit his crimes than Les Wexner."
What is noteworthy is that Wexner said he had not been interviewed by the DoJ or FBI, despite his name being present
in the Epstein files hundreds of times. Seems odd to us. He also said that he was only present on Epstein's island once
and Epstein never presented him with women. He didn't mention anything about girls, though.
Fox News (!) is
reporting
that Robert Morosky, a former executive at Wexner's company, said he had information about the use of Wexner's private
jet being used to transport young girls from Mexico to the U.S. This information appears in an
FBI memo
that was part of the most recent Epstein dump. But the FBI never followed up and so never asked Morosky what
he knew, even though the memo said Morosky was prepared to talk if the FBI simply called him, which
it didn't.
Incompetence or cover-up? Inquring minds want to know.
Wexner is 88 now.
There is probably a lot of evidence against him in the unredacted files and Maxwell is surely a witness against him, albeit
unreliable but maybe enough to convince a jury.
Giuffre's parents and friends might remember what Virginia told them years ago.
He probably does not want to spend his remaining years in prison with $10 billion in the bank.
That doesn't buy him a business-class cell and he can't take it with him.
If the government really wants to get the truth out, it could offer him a plea deal: Spill all the beans and you get
a mind-boggling fine but no prison time.
He might take it and the money could go to the victims.
Does it really matter to him if each of
four kids inherits a mere $500 million instead of $1 billion? They are not going to be eating dog food either way. He probably
knows some of the other people who were on the island when he was there. We doubt the government will make him an offer,
though, because Trump is in the business of protecting the perps, not the victims. (V)