Jean-Philippe Encausse
Shared posts
Neuralink est peut-être déjà dépassé : un nouvel implant cérébral testé puis retiré en 20 minutes !
17 Year Old Hellboy II Prop Still Amazes

The AI effects we know these days were once preceded by CGI, and those were once preceded by true hand-built physical props. If that makes you think of Muppets, this video will change your mind. In a behind-the-scenes look with [Adam Savage], effects designer [Mark Setrakian] reveals the full animatronic glory of Mr. Wink’s mechanical fist from Hellboy II: The Golden Army (2008) – and this beast still flexes.
Most of this arm was actually made in 2003, when 3D printing was very different than what we think of today. Printed on a Stratasys Titan – think: large refrigerator-sized machine, expensive as sin – the parts were then hand-textured with a Dremel for that war-scarred, brutalist feel. This wasn’t just basic animatronics for set dressing. This was a fully actuated prop with servo-driven finger joints, a retractable chain weapon, and bevel-geared mechanisms that scream mechanical craftsmanship.
Each finger is individually designed. The chain reel: powered by a DeWalt drill motor and custom bevel gear assembly. Every department: sculptors, CAD modelers, machinists, contributed to this hybrid of analog and digital magic. Props like this are becoming unicorns.

Révolution OLED : un écran où chaque pixel diffuse non seulement l’image, mais aussi le son

Une nouvelle avancée dans la technologie OLED permet désormais à chaque pixel d’agir comme une source sonore. Ce progrès promet des écrans ultrafins capables de diffuser du son directement depuis l’image, ouvrant la voie à des expériences immersives inédites.

Add Wood Grain Texture to 3D Prints – With a Model of a Log

Adding textures is a great way to experiment with giving 3D prints a different look, and [PandaN] shows off a method of adding a wood grain effect in a way that’s easy to play around with. It involves using a 3D model of a log (complete with concentric tree rings) as a print modifier. The good news is that [PandaN] has already done the work of creating one, as well as showing how to use it.
In the slicer software one simply uses the log as a modifier for an object to be printed. When a 3D model is used as a modifier in this way, it means different print settings get applied everywhere the object to be printed and the modifier intersect one another.
In the case of this project, the modifier shifts the angle of the fill pattern wherever the models intersect. A fuzzy skin modifier is used as well, and the result is enough to give a wood grain appearance to the printed object. When printed with a wood filament (which is PLA mixed with wood particles), the result looks especially good.
We’ve seen a few different ways to add textures to 3D prints, including using Blender to modify model surfaces. Textures can enhance the look of a model, and are also a good way to hide layer lines.
In addition to the 3D models, [PandaN] provides a ready-to-go project for Bambu slicer with all the necessary settings already configured, so experimenting can be as simple as swapping the object to be printed with a new 3D model. Want to see that in action? Here’s a separate video demonstrating exactly that step-by-step, embedded below.

This BB Shooter Has a Spring, But Not For What You Think

[It’s on my MIND] designed a clever BB blaster featuring a four-bar linkage that prints in a single piece and requires no additional hardware. The interesting part is how it turns a trigger pull into launching a 6 mm plastic BB. There is a spring, but it only acts as a trigger return and plays no part in launching the projectile. So how does it work?

The usual way something like this functions is with the trigger pulling back a striker of some kind, and putting it under tension in the process (usually with the help of a spring) then releasing it. As the striker flies forward, it smacks into a BB and launches it. We’ve seen print-in-place shooters that work this way, but that is not what is happening here.
With [It’s on my MIND]’s BB launcher, the trigger is a four-bar linkage that transforms a rearward pull of the trigger into a forward push of the striker against a BB that is gravity fed from a hopper. The tension comes from the BB’s forward motion being arrested by a physical detente as the striker pushes from behind. Once that tension passes a threshold, the BB pops past the detente and goes flying. Thanks to the mechanical advantage of the four-bar linkage, the trigger finger doesn’t need to do much work. The spring? It’s just there to reset the trigger by pushing it forward again after firing.
It’s a clever design that doesn’t require any additional hardware, and even prints in a single piece. Watch it in action in the video, embedded just below.

Actualité : La NASA en crise : jamais son budget n'avait été aussi bas, beaucoup de missions à l'abandon

XR : Pourquoi ce nouveau casque Samsung fait trembler Apple ?
Samsung fait une entrée remarquée dans le monde des casques XR (réalité étendue) avec son nouveau modèle, un concurrent direct à l’Apple Vision Pro. Après plusieurs années de teasing et de spéculations, le géant coréen dévoile les spécifications impressionnantes de son casque XR. Ce dernier se distingue par ses caractéristiques techniques robustes et son partenariat avec Google. Le duel Samsung contre Apple dans l’espace XR pourrait bien redéfinir l’avenir des technologies immersives.
La guerre des casques XR s’intensifie avec Samsung prêt à bousculer Apple. L’annonce du casque Samsung XR a créé une onde de choc dans l’industrie technologique. Les spécifications de l’appareil font de l’ombre à l’Apple Vision Pro. Contrairement à Apple, Samsung a choisi de collaborer avec Google et Qualcomm pour optimiser l’expérience XR. Le résultat ? Un casque XR plus puissant et potentiellement plus abordable, prêt à conquérir les utilisateurs en quête de performances et d’innovation.
Les caractéristiques qui font trembler Apple
Samsung a équipé son casque XR avec le processeur Qualcomm Snapdragon XR2 Plus Gen 2. Ce processeur, spécialement conçu pour la réalité étendue, offre une puissance de calcul impressionnante. Le processeur est accompagné de 16 Go de RAM et d’un GPU Adreno 740. Ces spécifications assurent des performances exceptionnelles dans des environnements XR. L’écran 4K micro-OLED de Sony renforce l’expérience visuelle. Cela permet d’offrir des résolutions de 3 552 x 3 840 pixels pour des images incroyablement nettes.
Les benchmarks du casque révèlent des performances qui rivalisent avec les meilleurs appareils Android du marché. Le processeur, avec ses six cœurs, et la GPU Adreno assurent une fluidité d’affichage à 90 Hz. Samsung met également l’accent sur une consommation énergétique réduite, un facteur crucial pour prolonger l’autonomie. Comparé au Vision Pro d’Apple, le casque Samsung semble prometteur, qui allie haute performance et efficacité énergétique. De plus, il pourrait être proposé à un prix plus abordable.
L’intégration de l’IA pour une expérience immersive unique
L’une des innovations du casque XR de Samsung est l’intégration de l’IA Gemini de Google. Cette collaboration avec Google permet d’enrichir l’expérience XR avec des fonctionnalités intelligentes. L’IA peut analyser l’environnement visuel en temps réel et fournir des informations contextuelles sans interrompre l’immersion. Les utilisateurs pourront interagir avec des objets numériques ou recevoir des suggestions basées sur ce qu’ils voient à travers le casque.
Cette approche proactive de l’intelligence artificielle distingue le casque Samsung de la concurrence. Alors qu’Apple se concentre sur un écosystème fermé et premium, Samsung, avec l’aide de Google, semble vouloir rendre son produit plus accessible. Ce partenariat pourrait créer un environnement plus interactif pour les utilisateurs, avec des applications XR plus variées et performantes.
Un écran qui surpasse les attentes visuelles
Le casque Samsung XR est équipé d’un écran micro-OLED 4K de Sony. Cette technologie permet d’offrir une expérience visuelle fluide et de haute qualité. Avec une résolution de 3 552 x 3 840 pixels, l’écran produit des images nettes. Cela offre ainsi une immersion totale. Les couleurs sont également vives, avec 96 % de couverture de la gamme de couleurs DCI-P3, et un contraste impressionnant. Ce type d’affichage pourrait en effet surpasser celui de l’Apple Vision Pro en matière de clarté et de performance, bien que l’écart de prix entre les deux appareils reste à confirmer.
L’écran de Samsung, avec une luminosité de 1 000 nits et une consommation énergétique réduite de 20 %, semble plus optimisé pour des sessions prolongées. La gestion de la batterie est un élément crucial pour une expérience XR agréable et continue. En effet, les utilisateurs ne voudront pas que la batterie de leur appareil se vide trop rapidement lors de l’utilisation de cette technologie immersive.
Le prix et l’accessibilité de la nouvelle technologie XR
L’un des principaux avantages du casque XR de Samsung est son prix, qui pourrait être plus compétitif que celui du Vision Pro d’Apple. Bien que le coût exact n’ait pas encore été révélé, les spéculations suggèrent un prix bien inférieur à celui de l’Apple Vision Pro, dont le tarif avoisine les 3 499 $/3 499 €. Samsung semble vouloir offrir ainsi une technologie de pointe à un public plus large, et offrir également une alternative abordable sans sacrifier la qualité.
Le marché des casques XR est en pleine expansion, et Samsung pourrait bien capter une part importante de ce marché en raison de ses caractéristiques techniques et de son approche plus abordable. Ce prix plus compétitif pourrait permettre à Samsung alors de conquérir des segments plus jeunes et des consommateurs à la recherche de technologies immersives sans se ruiner.
Un avenir prometteur pour l’XR avec Samsung et Google
La collaboration de Samsung avec Google est stratégique et laisse présager des innovations excitantes. Samsung pourrait bien surpasser Apple dans le domaine de la réalité étendue, non seulement grâce à ses spécifications impressionnantes mais aussi par la force de son partenariat avec Google. L’utilisation de l’IA Gemini, les performances de l’écran Sony et un prix plus abordable font du casque XR de Samsung une option incontournable. Ces caractéristiques positionnent le casque comme un choix privilégié pour les amateurs de technologies immersives.
Les utilisateurs auront bientôt l’opportunité de découvrir un nouveau monde de possibilités avec le casque XR de Samsung. L’entreprise coréenne mise sur la performance, l’accessibilité et l’innovation, ce qui pourrait bien secouer la domination d’Apple dans le domaine de la réalité étendue. La concurrence s’intensifie, et les consommateurs devraient en bénéficier avec des options plus puissantes et diversifiées sur le marché.
Cet article XR : Pourquoi ce nouveau casque Samsung fait trembler Apple ? est apparu en premier sur OBJETCONNECTE.COM.
Battery-powered SQUiXL devkit pairs 4-inch touchscreen display with ESP32-S3 WiFi and Bluetooth SoC


Unexpected Maker’s SQUiXL is a battery-powered ESP32-S3 WiFi and Bluetooth IoT controller and development platform with a 4-inch touchscreen display with 480×480 resolution.
Designed for makers, hardware engineers, embedded developers, and home automation enthusiasts, the SQUiXL integrates with 8MB PSRAM and a 16MB SPI flash for plenty of resources for the firmware. Other features include a microSD card, an amplifier with speaker connector, a haptic driver and motor, an RTC, and a STEMMA/Qt connector for expansion.
SQUiXL specifications:
- WiSoC – Espressif Systems ESP32-S3
- CPU – Dual-core Tensilica LX7 @ up to 240 MHz with vector instructions for AI acceleration
- Memory – 512KB RAM
- Wireless – 2.4 GHz WiFi 4 and Bluetooth 5.0 LE + Mesh
- Memory – 8MB octal PSRAM
- Storage
- 16MB QSPI flash
- MicroSD card slot (multiplexed with audio amplified)
- Display – 4-inch 480×480 RGB display with capacitive touch (GT911)
- Audio
- MAX98357A I2S Audio Amplifier (multiplexed with microSD card slot)
- 8 Ohm, 2W Speaker connector
- Expansion
- STEMMA/QT for additional I2C expansion
- IO Expander (LCA9555)
- IO MUX (TMUX1574RSVR)
- Misc
- Power, IO0/Boot, and Reset buttons
- DRV2605L haptic driver and motor
- RV-3028-C7 I2C low-power RTC
- Magnetic Connector + USB adapter
- ESD protection on USB and buttons
- Internal high-gain antenna
- Power Management
- 1,500mAh 1S battery
- LiPo battery charging
- MAX1704X I2C battery fuel gauge
- 5V presence detection circuit
- Dimensions – TBD

Unexepted Maker also designed an optional Dock for the SQUiXL. It makes use of the magnetic USB connector on the devkit, which can be easily inserted and removed without needing to plug or unplug cables. The dock comes in two parts with two small M2.5 screws that the users need to assemble. It was designed that way to take up less space and reduce shipping costs.

The SQUiXL devkit ships with Arduino firmware developed with PlatformIO, but the Arduino IDE will soon be supported too. The shipping firmware relies on the SQUiXL library and is designed to showcase the capabilities of the ESP32-S3 devkit and offers a WiFi manager for initial setup, a clock, local weather display using an Open Weather API Key, a random joke display, and more. You’ll find the source code for the shipping firmware on the SQUiXL-DevOS GitHub repository, and there’s a separate repo with some Arduino and LVGL samples, and a MicroPython firmware. CircuitPython support is also in the works.

ESP32-S3 solutions with a 4-inch display are somewhat popular, as we’ve seen such products before with the MaTouch_ESP32-S3 4-inch Display Demo Kit, Seeed Studio’s SenseCAP Indicator with LoRaWAN, and the LILYGO T-Panel, which also adds an ESP32-H2 in the mix for Zigbee, Thread, and Matter connectivity. The main differentiating feature of the SQUiXL devkit is that it is portable since it’s battery-powered.
The SQUiXL is sold on the Unexpected Maker’s shop for $99 plus shipping, and the dock adds $29 if you need it. They don’t produce a lot of those, and 20 pieces (second batch) were added this morning, with 16 units left at the time of writing this article.
The post Battery-powered SQUiXL devkit pairs 4-inch touchscreen display with ESP32-S3 WiFi and Bluetooth SoC appeared first on CNX Software - Embedded Systems News.
Cognitive Offloading: Delegating Our Thinking

I've often found myself wondering how thinking is hard work. If someone gives me a long list of arithmetic to do, it's tempting not to do it. If I have a tricky problem, it's easy to procrastinate and do "easier" stuff instead. Deep reflective thinking, and even shallow thinking that requires holding information in memory, seems like work—ever been tempted to delegate the adding up of scores for a board game?
I've never quite figured out where the hard work is in thinking—after all, it's not physically tiring like heading out for a 5-mile run—but it's definitely there. Hence, perhaps the tempting and irresistible rise of cognitive offloading: delegating our thinking tasks so we don't have to do them.
We've been cognitive offloading for a long time. When I carried the 2 in a long sum, I was offloading a task for my memory. And I grew up remembering phone numbers rather than dialling a person, and I don't feel the change has made things worse.
Hiring employees can be a form of delegating thinking. Using a calculator rather than a slide rule or working something out on paper leaves more room for deeper thinking. Other common examples of cognitive offloading include using notes apps, reminders, calculators, navigation systems, and now AI chatbots.
But what about when we can offload the deeper thinking, too, as we can now with AI chatbots? That may leave room for more interesting tasks. Or maybe, like not training my muscles and endurance by going out for a 5-mile run, it reduces my ability for deep thinking.
Nicholas Carr discussed a shift to shallow thinking from the pervasive use of the internet in his 2011 book The Shallows. We became proficient at skimming and scanning for answers rather than interrogating and questioning.
There's some evidence that more cognitive offloading reduces our critical thinking abilities, and an MIT study showed that "the more help students had from AI, the less their brains worked. People using ChatGPT struggled to remember or quote from the essays they had just written and reported feeling little ownership of their work. By comparison, the essays written by the “brain-only” writers were more original and their brains more active."
If a developer uses an AI chatbot in an interview and gives a strong answer, will that make them worse at the job when they would use an AI chatbot on the job anyway?
I use ChatGPT as a thinking partner for posts these days. I think that it helps make them better, but who knows what it's really doing to me =) Are Sketchplanations just staying surface-level or engaging some thinking? It would be nice to think that it grinds a few gears. Here's hoping!
Related Ideas to Cognitive Offloading
Exclusive – Playnitride Single Chip Full Color MicroLED & Lumus Waveguide with a “Fantasically Tiny Projector”
Introduction

Several technology demonstrations stood out to me at Display Week (DW) 2025. This article will cover Playnitride’s Quantum Dot (QD) based full-color MicroLED, combined with Lumus’s geometric (also known as reflective waveguide) technology.

As I hinted in my last article, “Rivet Industries Using Lumus Waveguides for Military & Industrial AR, Lumus showed me in private a “fantastically tiny MicroLED projector.” This development came on the heels of rumors that a 30-degree Lumus Z-Lens is included in Meta’s Hypernova glasses, as discussed in Meta Hypernova and Google AR/AI Glasses – Lumus & Avegant Inside, both of Which Utilize LCOS MicroDisplays. I also wrote about a PlayNitride and Lumus waveguide demo at AR/VR/MR 2023 (see: PlayNitride (Blue with QD Conversion Spatial Color)) and about PlayNitride at Display Week 2024 using a diffractive waveguide with a lower resolution display (see: PlayNitride).
I know it has been a lot on Lumus lately, but that’s just how the news and information came to me and what I found exciting. I had no idea that Lumus would be in Rivet, and as far as I know, I was the first to identify that Lumus was inside, so I wanted to publish it promptly. Then, this article made sense to follow up on that one.
In the next article, I plan to follow up with more about Avegant’s LCOS engine, featuring an Applied Materials diffractive waveguide, and provide another clue that Avegant’s and Applied Materials’ projectors and waveguides are likely being used in the Google/Android XR prototypes. I got to try on the Avegant 30-degree biocular prototype, and overall, it looked good.
AWE on June 10-12, 2025 (I’m Attending and Speaking)
For anyone interested in meeting me, I will be attending AWE on June 10-12. I’m happy to meet with both companies and individuals. Please email me at meet@kgontech.com if you want to meet. I will also be speaking on Thursday, June 12th, from 10:30 AM to 10:55 AM in the Promenade Room 104 B.
Lumus and PlayNitride at Display Week 2025
Lumus had a running demo in the PlayNitride booth at DW 2025. The demo featured a PlayNitride 720×720 (0.18″ diagonal, ~3.2mm on a side) 4.5 µm pixel (pitch) full-color QD MicroLED display, accompanied by a small but unoptimized projector engine, and a 50-degree (diagonal) Lumus Maximus waveguide.
I’ve been impressed with Lumus Maximus’s waveguide compared to diffractive waveguides since I first saw it (see: Exclusive: Lumus Maximus 2K x 2K Per Eye, >3000 Nits, 50° FOV with Through-the-Optics Pictures). The engine in that article utilized a Compound Photonics 2048×2048 LCOS device with a 3-micron pixel pitch. Lumus switched to RAONTECH’s 1440×1440 with a 4.3-micron pixel after Snap acquired Compound Photonics (see: Exclusive: Snap Buying Compound Photonics (LCOS and MicroLED)). RAONTECH recently announced that its new 1440×1440 device features a 3-micron pixel and a 0.24″ diagonal display.
Lumus’s DW demo is a “quick and dirty” proof-it-works setup, with the optics held in place by a small optical bench and a large “pull” lens in front of the waveguide, primarily to prevent people from touching the setup. The lens also had the effect of keeping cameras at a distance and magnifying the image (see the upper right picture below). Unfortunately, there was great content being shown, but at least you can see that the white lines are white across the image (unlike many diffractive waveguides).

Since the display form factor is square, the horizontal and vertical field of view (FOV) are ~35 degrees, resulting in about 20 pixels per degree PPD, which is larger than some would desire, but within the bounds of general acceptability considering it is an optical see-through (OST) device. The placard on the demo states that it outputs more than 700 “white” nits (to the eye), which is largely a function of Lumus Maximus waveguides that are over 90% transparent.
Fantasically Tiny Projector
Lumus states that the current design outputs approximately 0.7% of the nits of the display, which, although it may seem small, should be about five to seven times more efficient than a diffractive waveguide. PlayNitride, in its presentation, claims that the MicroLED is capable of exceeding 500K nits, which at 0.7% would be 4,500 nits via the waveguide to the eye. I’m unsure if there are lifetime or other practical issues with driving PlayNitrides MicroLEDs hard enough to produce more than 500K (white) nits. As I explained in Caution on Comparing Nits/WattLED with Different Waveguides, there are many ways companies specify nits. I also want to note that white/full-color nits and power consumption can’t be compared fairly to, say, “green only nits,” as much of the perceived “nits” are in green, and generally, red is much less efficient than blue or green.
While the Maximus connected to the PlayNitride 720×720 is small, it may not be dramatically smaller than the 3-chip (R, G, and B) 640×480 X-Cube projectors I have seen using Jade Bird Display’s MicroLEDs. Lumus then showed me privately a more optimized projector that they have working with the same PlayNitride MicroLED, which they did not want to show on the floor, which I have since dubbed “the fantastically tiny projector.”
Shown below, from left to right, are the Lumus Maximus 50+ degree waveguide with a 1440×1440 LCOS, an older 1920×1080 with a 5.6µ pixel PlayNitride engine, the 720×720 engine shown at Display Week, and the tiny, optimized 720×720 engine. The engine is only a few millimeters bigger than the display in every dimension. Note that the tiny projector’s waveguide has not been cut to shape for glasses. Based on the pictures, I would estimate the volume of Lumus’s optimized prototype engine to be approximately 0.15 cubic centimeters (or less, depending on the definition of “counts”).

While the PlayNitride display is not yet ready for production, the tiny combination shows where this technology is headed in a few years. We can expect the pixel size to continue shrinking, enabling an increase in angular resolution while maintaining the field of view (FOV). Lumus states that the current Maximus design supports a field of view (FOV) up to 60 degrees, and their Z-Len technology is capable of exceeding 70 degrees (in glass, not exotic, but very high-index Silicon Carbide).
PlayNitride Diffractive Waveguide Demo

PlayNitride also had a diffractive waveguide demo in their booth, which they discussed in their presentation. It also has a tiny projector, considering that it is full color. The diffractive waveguide had a 30-degree field of view (FOV). It claims to support over 500 nits, but once again, we don’t know under what conditions or for how long.
The Lumus Maximus waveguide demo was significantly brighter than the diffractive waveguide’s demo using the same device, despite having about 2.8 times the field of view (FOV) area. However, I have no information on how hard each display device was driven. However, it does make Lumus’s claim of being more than five times more efficient than diffractive waveguides plausible. I should note that different diffractive waveguides have different efficiencies.
Below is an image I captured through the Diffractive waveguide demo in the PlayNitride booth. Even with the lack of content, it is evident that the parts intended to be white exhibit significant color variation across the waveguide’s field of view (FOV). The picture also shows some light capture rainbows (blue streaks on the left and lower right).

Not Enough Content to Judge Display Quality
Unfortunately, PlayNitride had very little content to judge the image quality of their displays. Usually, this means that the devices are not up to being judged on display quality. The very simple images PlayNitride provided can easily conceal everything from bad or dead pixels to issues with color accuracy and uniformity.
My general experience and skepticism, based on demo content seen at shows, suggest that the PlayNitride MicroLEDs are far from ready for production, or they would have shown better demo images.
More on PlayNitride
I first took notice of PlayNitride back in 2018 when it was rumored that they were working with Apple on MicroLEDs for watches (see the 2018 MICROLED-info article). A couple of years later, it was rumored that Apple decided to back off or delay its planned use of MicroLEDs in watches, as they were not yet mature. PlayNitride has continued to improve its MicroLED development.
PlayNitride manufactures blue MicroLEDs and then utilizes quantum dots to convert the blue light to red or green. Playnitride offers three ranges of products, categorized by pixel size and display backplane. For products like watches, smartphones, and moderately small displays, it will singulate individual pixels and transfer them to a TFT on a glass or plastic backplane, which may or may not be transparent. For very large displays, the full-color pixels are plugged into a printed circuit board (PCB). However, for the very small microdisplays used in AR/smart glasses, the pixel sizes are so small that transferring individual pixels is impractical; therefore, the entire display array of MicroLEDs is flipped and bonded to a CMOS substrate.


Most other companies flip whole wafers of MicroLEDs onto CMOS wafers. MicroLED wafers are smaller than state-of-the-art CMOS wafers. Some companies flip multiple smaller whole LED wafers onto a 12″ CMOS wafer, which wastes a significant part of the CMOS wafer. Some companies compromise and make 8″ LED wafers to make 8″ CMOS wafers. For MicroDisplays, PlayNitride tests and singulates whole displays/devices on a 12″ CMOS wafer and the MicroLED wafer before combining them (right). Without delving into all the details, each method has its advantages and disadvantages.
PlayNitride shows the chart below in the DW 2025 Presentation. Note that this is only applicable to “full color” MicroLED microdisplays. I covered Raysolve and Saphlux in my SID Display Week 2024 – MicroLEDs for AR, and will be updating my findings in an upcoming article about MicroLEDs at DW 2025. Raysolve showcased a working ~8-micron pixel pitch 320×240 full-color MicroLED in their booth at DW 2025. I must point out that none of these devices are currently in production, so it is impossible to know who is ahead of whom.

Using QD conversion appears to be the most straightforward method for producing full-color MicroLEDs, but it has its drawbacks. The most obvious is that the reds and greens are not as pure or saturated and typically contain some unconverted blue. There is also typically some “crosstalk” from the adjacent color’s blue light stimulating the wrong quantum dot (QD). Some propose using a UV simulation that is covered with red, green, and blue QD with a UV filter to block all the unconverted light. Both JBD and Innovision, among others, have developed stacked native red, green, and blue LED layers on top of the CMOS backplane. Once again, none of these are in production, and each of these full-color MicroLED microdisplay methods has its technical and manufacturing advantages and disadvantages.
Many of the pros and cons of various approaches to making full-color MicroLED microdisplays were discussed in “SID Display Week 2024 – MicroLEDs for AR.”
I also want to note that TCL just “launched” their RayNeo X3 Pro glasses with dual 640×480 X-Cube three displays that are X-Cube combined. These glasses were supposed to have applied Materials waveguides. Applied Materials waveguides are also likely in the Google/Android XR smartglasses (but which uses LCOS displays) shown at Google I/O and their TED talk (see Meta’s Hypernova glasses, as discussed in Meta Hypernova and Google AR/AI Glasses – Lumus & Avegant Inside, both of Which Utilize LCOS MicroDisplays)
Conclusion
While I don’t think any of the single-chip, full-color MicroLED solutions are ready for production anytime soon, the Lumus engine with the PlayNitride device demonstrates the potential for how tiny/insignificant the projector engine can become.
According to Lumus, the Maximus should be more than 5 times the light efficiency of diffractive waveguides for the same size field of view (FOV) and eye box. If true, this is a massive advantage for Lumus/Reflective waveguides because not only can the displays be brighter, but more importantly, they require significantly less power for the same brightness. Typically, power goes up non-linearly with brightness as the LEDs self-heat. As I repeatedly say about AR glasses and power consumption, “Amateurs worry about battery life, the pros worry about heat management.” Based on my experience, I also expect the Lumus waveguides to have much better color and brightness uniformity.
A Simple Tip for Gluing Those LED Filaments

[Boylei] shows that those little LED filament strips make great freeze-frame blaster shots in a space battle diorama. That’s neat and all, but what we really want to highlight is a simple tip [Boylei] shares about working with these filament strips: how to glue them.

The silicone (or silicone-like) coating on these LED filament strips means glue simply doesn’t stick. To work around this, [Boylei] puts a piece of clear heat shrink around the filament, and glues to that instead. If you want a visual, you can see him demonstrate at 6:11. It’s a simple and effective tip that’s certainly worth keeping in mind, especially since filament strips invite so many project ideas.
When LED filament strips first hit the hobbyist market they were attractive, but required high operating voltages. Nowadays they are not only cheaper, but work at battery-level voltages and come in a variety of colors.
These filaments have only gotten easier to work with over the years. Just remember to be gentle about bending them, and as [Boylei] demonstrates, a little piece of clear shrink tubing is all it takes to provide a versatile glue anchor. So if you had a project idea involving them that didn’t quite work out in the past, maybe it’s time to give it another go?

Ils cherchent l'origine de la vie, et synthétisent... un nouveau biocarburant ⚗️
La République tchèque accuse ouvertement la Chine d’une vaste campagne de cyberespionnage

Prague a officiellement attribué à la Chine une cyberattaque visant son ministère des Affaires étrangères. L’Union européenne et l’OTAN affichent leur solidarité, tandis que Pékin reste silencieux.
Amazon and Stellantis abandon project to create a digital “SmartCockpit”
Automaker Stellantis and retail and web services behemoth Amazon have decided to put an end to a collaboration on new in-car software. The partnership dates back to 2022, part of a wide-ranging agreement that also saw Stellantis pick Amazon Web Services as its cloud platform for new vehicles and Amazon sign on as the first customer for Ram's fully electric ProMaster EV van.
A key aspect of the Amazon-Stellantis partnership was to be a software platform for new Stellantis vehicles called STLA SmartCockpit. Meant to debut last year, SmartCockpit was supposed to "seamlessly integrate with customers’ digital lives to create personalized, intuitive in-vehicle experiences," using Alexa and other AI agents to provide better in-car entertainment but also navigation, vehicle maintenance, and in-car payments as well.
But 2024 came and went without the launch of SmartCockpit, and now the joint work has wound down, according to Reuters, although not for any particular reason the news organization could discern. Rather, the companies said in a statement that they "will allow each team to focus on solutions that provide value to our shared customers and better align with our evolving strategies."

Invisible PC Doubles As Heated Seat

Some people really want a minimalist setup for their computing. In spite of his potentially worrisome housing situation, this was a priority for the man behind [Basically Homeless]: clean lines on the desk. Where does the PC go? You could get an all-in-one, sure, but those use laptop hardware and he wanted the good stuff. So he decided to hide the PC in the one place no one would ever think to look: inside his chair. (Youtube video, embedded below.)
This chair has very respectable specs: a Ryzen 7 9800XD, 64GB of ram and a RTX 4060 GPU, but you’d never know it. The secret is using 50 mm aluminum standoffs between the wooden base of the seat and the chair hardware to create room for low-profile everything. (The GPU is obviously lying sideways and connected with a PCIe riser cable, but even still, it needed a low-profile GPU.) This assemblage is further hidden 3D printed case that makes the fancy chair donated from [Basically Homeless]’s sponsor look basically stock, except for the cables coming out of it. It’s a very niche project, but if you happen to have the right chair, he does provide STLs on the free tier of his Patreon.
This is the first time we’ve seen a chair PC, but desk PCs are something we’ve covered more than once, so there’s obviously a demand to hide the electronics. It remains to be seen if hiding a PC in a chair will catch on, but if nothing else [Basically Homeless] will have a nice heated seat for winter. To bring this project to the next level of minimalism, we might suggest chording keyboards in the armrests, and perhaps a VR headset instead of a monitor.

XIAO Vision AI Camera combines ESP32-C3 and WiseEye2 HX6538 AI MCU with 5MP camera, supports SenseCraft no-code platform


Seeed Studio has recently released the XIAO Vision AI Camera, a compact, open-source smart ESP32-C3 AI Camera that integrates the Grove Vision AI Module V2, a XIAO ESP32C3 module, and an OV5647 5MP camera in a custom 3D-printed PLA case.
One of the key components of the camera module is the WiseEye2 HX6538 chip, which features dual-core Arm Cortex-M55 processors and an Ethos-U55 NPU for edge AI computing. It also comes with Wi-Fi connectivity, turning it into an intelligent IP camera that easily integrates with Home Assistant for closed-loop automation (e.g., object detection triggering lights or alerts). Its 5MP OV5647 camera can record 1080p@30fps video and has adjustable focus. These features make this camera useful for industrial automation, smart cities, transportation monitoring, intelligent agriculture, and mobile IoT devices.
XIAO Vision AI Camera Specifications
- Main MCU module – XIAO ESP32C3
- SoC – Expressif Systems ESP32-C3
- CPU – Single-core RISC-V microcontroller @ 160 MHz
- Memory – 400KB SRAM
- Storage – 384KB ROM
- Wireless Wi-Fi 4 & Bluetooth LE 5.0 connectivity
- Storage – 4MB flash
- USB – 1x USB Type-C port for power and firmware flashing (via CH343)
- Antenna – External u.FL antenna
- SoC – Expressif Systems ESP32-C3
- Vision AI Processor – Grove Vision AI Module V2
- Himax WiseEye2 HX6538 SoC
- Arm Cortex-M55 @ 400 MHz
- Arm Cortex-M55 @ 150 MHz
- AI accelerator – Arm Ethos-U55 microNPU @ 400 MHz
- Memory – Up to 2432KB SRAM
- Storage – 64KB boot ROM
- CSI camera connector
- Grove interfaces: I²C, UART, SPI
- PDM microphone
- Himax WiseEye2 HX6538 SoC
- Storage
- 16MB flash for firmware
- MicroSD card slot supporting DS mode up to 25 MHz(on the Grove Vision AI Module V2)
- Camera Module – OV5647
- 5MP CMOS image sensor
- Resolution – 2592 × 1944
- Video output
- 1080p @ 30 fps
- 720p @ 60 fps
- Field of View – 62°
- Pixel size – 1.4 µm × 1.4 µm
- Focal length – 3.4 mm (adjustable)
- Aperture – f/2.8
- CMOS size – 1/4″
- Expansion – Grove I2C connector
- Power Supply – 5V via USB Type-C ports on XIAO ESP32C3
- Dimensions – 49 x 32 x 31 mm (3D printed housing)
- Operating temperature – -20°C to +70°C
To simplify AI model development, this camera module supports no-code/low-code AI model deployment through the SenseCraft AI platform, so that users can quickly and easily train and deploy models without writing a single line of code. Users can select from a wide range of built-in models, including MobileNet V1/V2, EfficientNet-Lite, and YOLO v5/v8, or upload their datasets for training using either “Quick Training” or “Image Collection Training” methods. Once trained, the models can be deployed to the device with a single click, and inference results are visualized in real time through a web interface.

You also have the option to integrate this camera with Home Assistant for building Smart Home automation solutions. After flashing ESPHome firmware onto the XIAO ESP32C3 and deploying a model via SenseCraft AI, you can link the camera to Home Assistant. Within its automation editor, various actions, such as triggering smart devices or sending alerts, can be programmed based on detection events like object recognition or fall detection, enabling a fully local, closed-loop smart system.

While reviewing the documentation, I also noticed support for TensorFlow Lite and PyTorch, ensuring compatibility with a broader range of machine learning frameworks, and the Arduino IDE is also supported for more flexibility.
The software is completely open source, with all code, schematics, and design files available on the company’s GitHub repository. Additional documentation, like the 3D-printed foldable holder and datasheet for HX6538, is also available on the products page.

Previously, we have written about various MCU-class edge AI camera boards, including the ultra-low-power OpenMV N6 and AE3 AI camera boards, which can run on battery for years, Seeed Studio’s Modbus Vision RS485 and SenseCAP A1102 (with LoRaWAN) ESP32-based outdoor Edge AI cameras built around the Himax WiseEye2 HX6538 microcontroller, and Sipeed’s MaixCAM-Pro AI camera devkit equipped with the SOPHGO SG2002 RISC-V SoC with a 1 TOPS NPU.

At the time of writing, the XIAO Vision AI Camera is available for pre-order from the Seeed Studio’s store for $24.90, with a discount of $23.50 for 10 units or more. Shipping from the Chinese Warehouse is expected to start from June 3, 2025. It should also soon be listed on the company’s AliExpress store.

The post XIAO Vision AI Camera combines ESP32-C3 and WiseEye2 HX6538 AI MCU with 5MP camera, supports SenseCraft no-code platform appeared first on CNX Software - Embedded Systems News.
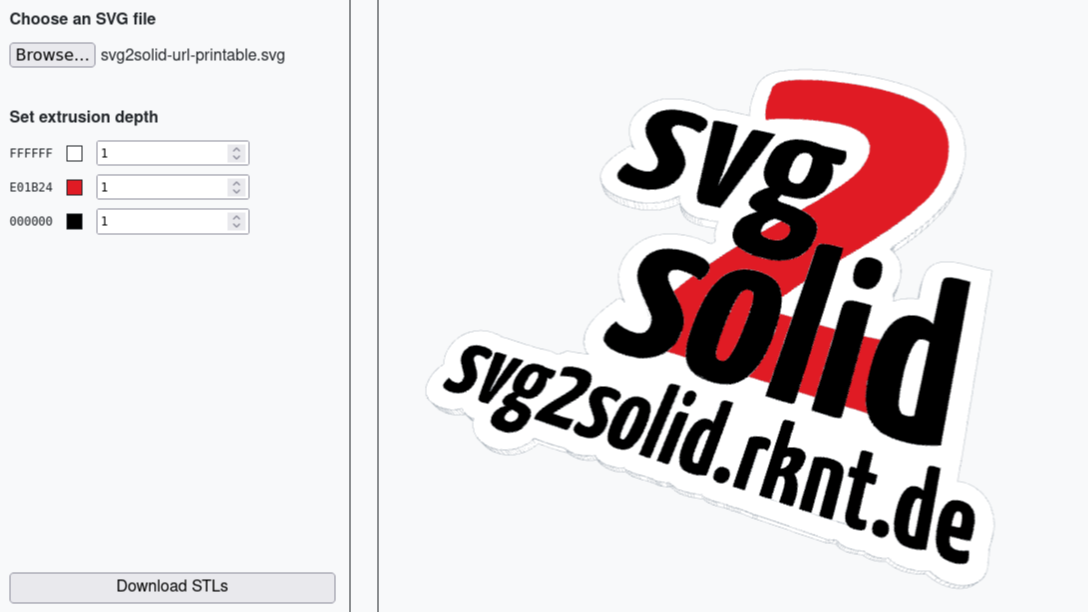
Tool Turns SVGs into Multicolor 3D Prints
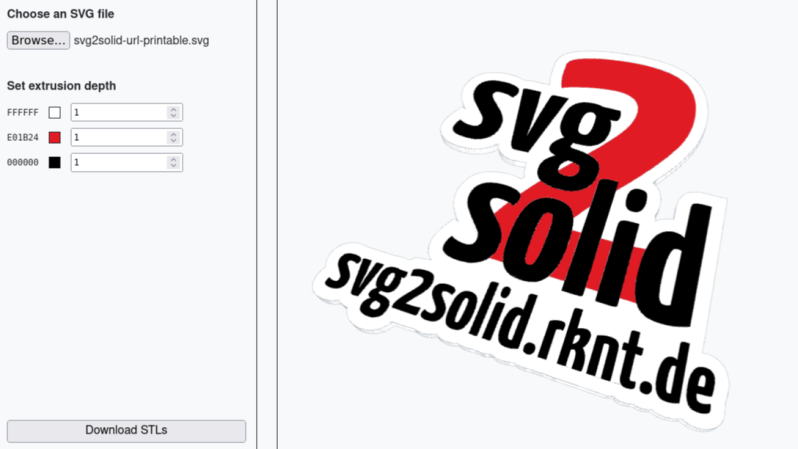
Want to turn a scaled vector graphic into a multicolor 3D print, like a sign? You’ll want to check out [erkannt]’s svg2solid, a web-based tool that reads an SVG and breaks the shapes up by color into individual STL files. Drag those into your slicer (treating them as a single object with multiple parts) and you’re off to the races.

This is especially handy for making 3D printed versions of things like signs, and shown here is an example of exactly that.
It’s true that most 3D printer software supports the .svg format natively nowadays, but that doesn’t mean a tool like this is obsolete. SVG is a 2D format with no depth information, so upon import the slicer assigns a arbitrary height to all imported elements and the user must make any desired adjustments manually. For example, a handy tip for making signs is to make the “background” as thick as desired but limit colored elements to just a few layers deep. Doing so minimizes filament switching while having no impact on final visual appearance.
Being able to drag SVGs directly into the slicer is very handy, but working with 3D models has a certain “what you see is what you get” element to it that can make experimentation or alternate applications a little easier. Since svg2solid turns an SVG into discrete 3D models (separated by color) and each with user-defined heights, if you find yourself needing that then this straightforward tool is worth having in your bookmarks. Or just go straight to the GitHub repository and grab your own copy.
On the other hand, if you prefer your 3D-printed signs to be lit up in a faux-neon style then here’s how to do that in no time at all. Maybe there’s a way to mix the two approaches? If you do, be sure to use our tips line to let us know!
Virtual models enable real-time decision making for next-generation nuclear reactors
Hidden AI instructions reveal how Anthropic controls Claude 4
On Sunday, independent AI researcher Simon Willison published a detailed analysis of Anthropic's newly released system prompts for Claude 4's Opus 4 and Sonnet 4 models, offering insights into how Anthropic controls the models' "behavior" through their outputs. Willison examined both the published prompts and leaked internal tool instructions to reveal what he calls "a sort of unofficial manual for how best to use these tools."
To understand what Willison is talking about, we'll need to explain what system prompts are. Large language models (LLMs) like the AI models that run Claude and ChatGPT process an input called a "prompt" and return an output that is the most likely continuation of that prompt. System prompts are instructions that AI companies feed to the models before each conversation to establish how they should respond.
Unlike the messages users see from the chatbot, system prompts typically remain hidden from the user and tell the model its identity, behavioral guidelines, and specific rules to follow. Each time a user sends a message, the AI model receives the full conversation history along with the system prompt, allowing it to maintain context while following its instructions.

Ultra-thin display technology shows dozens of images hidden in a single screen
Scientists Puzzled by Mysterious Motion in Atmosphere of Saturn's Moon

Researchers have found that the thick and hazy atmosphere enveloping Saturn's largest moon, Titan, behaves in a very peculiar way.
As detailed in a new paper published in The Planetary Science Journal, a team of scientists analyzed 13 years' worth of thermal infrared observations recorded by NASA and the European Space Agency's Cassini-Huygens mission.
Their finding: that Titan's atmosphere wobbles like a gyroscope as it shifts with the seasons of its nearly 30 Earth-year cycle, instead of spinning in line with its surface.
"The behavior of Titan's atmospheric tilt is very strange," said lead author and University of Bristol postdoctoral researcher Lucy Wright in a statement about the work. "Titan's atmosphere appears to be acting like a gyroscope, stabilizing itself in space."
The discovery makes the moon, which has already captured the attention of astronomers for its suspected bodies of liquid and planet-like dimensions — it's larger in diameter than Mercury — an even more intriguing candidate for a closer look, since it appears to have its own, independent climate system.
Given the latest discovery, though, scientists are now facing even more riddles about the unusual celestial body.
"We think some event in the past may have knocked the atmosphere off its spin axis, causing it to wobble," Wright posited. "Even more intriguingly, we've found that the size of this tilt changes with Titan's seasons."
"What's puzzling is how the tilt direction remains fixed in space, rather than being influenced by the Sun or Saturn," coauthor and University of Bristol planetary scientist Nick Teanby added. "That would've given us clues to the cause. Instead, we've got a new mystery on our hands."
The findings could influence NASA's upcoming Dragonfly mission, which is tentatively scheduled to launch no sooner than 2028, and will see a massive rotorcraft attempt to descend through Titan's extremely dense atmosphere to explore its surface.
It won't be a walk in the park, as it will have to endure temperatures around -300 Fahrenheit while keeping itself airborne with a surface pressure one and a half times that on Earth and winds of up to 20 times faster than the moon's rotation.
How the atmosphere "wobbles" on its own could allow scientists to get a better idea of how to keep Dragonfly operational, and where to touch down.
The new findings could also have far-reaching implications, forcing us to reevaluate our understanding of the Earth's atmosphere.
"The fact that Titan's atmosphere behaves like a spinning top disconnected from its surface raises fascinating questions — not just for Titan, but for understanding atmospheric physics more broadly, including on Earth," said coauthor and NASA Goddard planetary scientist Conor Nixon in the statement.
As for the chances that we'll encounter extraterrestrial life on the surface of Titan, astronomers aren't exactly hopeful. In a recent study, scientists concluded that Titan's rivers and lakes of liquid methane make it quite inhospitable to life as we know it. However, they found that a tiny amount of glycine-consuming microbes could, in theory, survive in its oceans.
More on Titan: Titan Covered With Fragments of Obliterated Moons, Scientists Say
The post Scientists Puzzled by Mysterious Motion in Atmosphere of Saturn's Moon appeared first on Futurism.
F1 in Monaco: No one has ever gone faster than that
The principality of Monaco is perhaps the least suitable place on the Formula 1 calendar to hold a Grand Prix. A pirate cove turned tax haven nestled between France and Italy at the foot of the Alps-Maritimes, it has also been home to Grand Prix racing since 1929, predating the actual Formula 1 world championship by two decades. The track is short, tight, and perhaps best described as riding a bicycle around your living room. It doesn’t even race well, for the barrier-lined streets are too narrow for the too-big, too-heavy cars of the 21st century. And yet, it’s F1’s crown jewel.
Despite the location's many drawbacks, there’s something magical about racing in Monaco that almost defies explanation. The real magic happens on Saturday, when the drivers compete against each other to set the fastest lap. With overtaking as difficult as it is here, qualifying is everything, determining the order everyone lines up in, and more than likely, finishes.
Coverage of the Monaco Grand Prix is now filmed in vivid 4K, and it has never looked better. I’m a big fan of the static top-down camera that’s like a real-time Apple TV screensaver.

2025 Pet Hacks Contest: Fytó – Turn Your Plant Into a Pet

This entry into the 2025 Pet Hacks Contest is about bringing some fun feedback to normally silent plants. Fytó integrates sensors and displays into a 3D printed planter. The sensors read the various environmental and soil conditions that the plant is experiencing, and give you feedback about them via a series of playful expressive faces that are displayed on the screen embedded in the planter.
At the core of the Fytó is a Raspberry Pi Zero 2 W, which has plenty of power to display the animations while also being small enough to easily fit inside the planter without it growing in size much more than a normal planter would be. The sensors include a capacitive soil moisture sensor, a temperature sensor, and a light-dependent resistor. These sensors all provide analog outputs to relay their measurements and so there was an ADS1115 analog-to-digital converter board also included as the Raspberry Pi doesn’t have the required analog pins to communicate with them.
The fun animated faces are displayed with a 2-inch LCD display embedded in the planter. A small acrylic cover is placed in front of the LCD to help ease the transition from the printed planter to the internally mounted screen. The temperature and light sensors were also placed in openings around the planter to ensure they could get good environmental readings. There are six expressions the Fytó can express based on its sensor readings, ranging from happy when all the readings are in a good zone, to thirsty if it needs water or freezing when it’s too cold. Be sure to check out the other entries in the 2025 Pet Hacks Contest.

New Supermaterial: As Strong as Steel and as Light as Styrofoam

Today in material science news we have a report from [German Science Guy] about a new supermaterial which is as strong as steel and as light as Styrofoam!
A supermaterial is a type of material that possesses remarkable physical properties, often surpassing traditional materials in strength, conductivity, or other characteristics. Graphene, for example, is considered a supermaterial because it is extremely strong, lightweight, and has excellent electrical conductivity.
This new supermaterial is a carbon nanolattice which has been developed by researchers from Canada and South Korea, and it has remarkably high strength and remarkably low weight. Indeed this new material achieved the compressive strength of carbon steels (180-360 MPa) with the density of Styrofoam (125-215 kg m-3).
One very important implication of the existence of such material is that it might lead to a reduction in transport costs if the material can be used to build vehicles such as airplanes and automobiles. For airplanes we could save up to 10 gallons per pound (80 liters per kilogram) per year, where an airplane like the Airbus A380-800 weighs in at more than one million pounds.
To engineer the new material the researchers employed two methods: the Finite Element Method (FEM) and Bayesian optimization. Technically these optimized lattices are manufactured using two-photon polymerization (2PP) nanoscale additive manufacturing with pyrolysis to produce carbon nanolattices with an average strut diameter of 300 and 600 nm.
If you have an interest in material science, you might also like to read about categorizing steel or the science of coating steel.
Thanks to [Stephen Walters] for letting us know about this one on the tips line.

Beauty and fashion technology specialist Perfect Corp. takes wraps off new AI Clothes Try-On solution
Perfect Corp. has announced the launch of AI Clothes Try-on, a generative AI powered experience for virtual fashion shopping.
This lets shoppers see exactly how any look complements their unique body shape, complexion and style. They can mix and match separate pieces, preview full outfit swaps, and experiment with fabrics, prints and colourways, all rendered in photorealistic detail.
AI Clothes Try-on is available through both the YouCam Makeup mobile app and the YouCam Online Editor, Perfect Corp.’s web-based editing platform. For brands and developers, the solution is also accessible through the YouCam Online Editor AI Clothes Try-on API.

“With the AI Clothes Try-on feature, we’re not just visualising clothes, we’re rethinking how people connect with style,” says Alice Chang, CEO and Founder at Perfect Corp. “It gives users the freedom and power to explore, customise, and express their fashion choices instantly. For brands and retailers, it’s a smarter way to deliver personalisation at scale, where inspiration becomes interaction in just one click.”
RTIH AI in Retail Awards
RTIH, organiser of the industry leading RTIH Innovation Awards, proudly brings you the first edition of the RTIH AI in Retail Awards, which is now open for entries.
As we witness a digital transformation revolution across all channels, AI tools are reshaping the omnichannel game, from personalising customer experiences to optimising inventory, uncovering insights into consumer behaviour, and enhancing the human element of retailers' businesses.
With 2025 set to be the year when AI and especially gen AI shake off the ‘heavily hyped’ tag and become embedded in retail business processes, our newly launched awards celebrate global technology innovation in a fast moving omnichannel world and the resulting benefits for retailers, shoppers and employees.
Our 2025 winners will be those companies who not only recognise the potential of AI, but also make it usable in everyday work - resulting in more efficiency and innovation in all areas.
Winners will be announced at an evening event at The Barbican in Central London on Wednesday, 3rd September.
This will kick off with a drinks reception in the stunning Conservatory, followed by a three course meal, and awards ceremony in the Garden Room.
Please email our Editor, Scott Thompson, if you have any questions or need further information: scott.thompson@retailtechinnovationhub.com
Key 2025 dates
Friday, 18th July: Award entry deadline
Tuesday, 22nd July: 2025 finalists revealed
Wednesday, 23rd July - Friday, 8th August: Judging days
Wednesday, 3rd September: Winners announced at the 2025 RTIH AI in Retail Awards Ceremony, to be held at The Barbican in Central London.

IA générative : une bulle, un krach ou un virage ?

En mars dernier je me posais la question de savoir si l’IA générative relevait d’une révolution durable ou d’une bulle spéculative (L’IA vers une impasse économique ?). J’y faisais part d’un optimisme prudent mais toutefois confiant. Je voyais bien les zones d’ombre et les premières dérives mais m’interrogeais surtout sur la capacité des acteurs du marcher à démontrer assez de valeur pour passer leurs coûts à leurs clients pour devenir rentables. Mais j’étais assez confiant qu’au fil du temps on allait trouver des usages solides et bâtir des modèles économiques qui tenaient la route.
Mais quelques mois plus tard, le paysage a changé. Pas beaucoup mais assez, en tendance, pour que je jette un nouveau regard sur le sujet.
Non, l’IA générative n’a pas échoué. Elle progresse même, les modèles s’améliorent, le champ des usages s’élargit mais quelque chose s’est cassé dans le réci et le doute s’installe. Sur les promesses, sur l’impact réel, sur la capacité du secteur à tenir ses engagements notamment techniques et économiques. Et il ne s’agit plus seulement de prudence naturelle face à une technologie encore jeune mais de constater qu’un certain seuil d’insoutenabilité est peut-être déjà franchi.
Ce que l’on nous présentait comme une trajectoire de croissance linéaire semble désormais plus proche d’une surchauffe nourrie moins par les résultats que par l’anticipation de résultats futurs. Un emballement dû non pas à la valeur delivrée mis à l’espérance de valeur future. On mise massivement sur une technologie sans s’assurer qu’elle dispose des conditions minimales de soutenabilité et, faute de modèle clair, la croyance en devient le principal carburant (AGI, emploi, productivité : le grand bluff des prédictions IA).
Aujourd’hui, l’écart entre ce que coûte l’IA générative, ce qu’elle promet, et ce qu’elle produit réellement s’accroit et tout l’écosystème semble avancer, comme ça a toujours été le cas dans ces circonstances similaires, en espérant que quelqu’un d’autre trouvera la réponse avant d’être confronté au principe de réalité.
Ce n’est pas une prédiction catastrophiste car au fond de moi je me refuse à penser que cela ne va pas marcher mais une lecture rationnelle des signaux faibles qui, mis bout à bout, devraient nous apprendre à tempérer nos attentes et que même si, espérons le, le secteur ne s’effondre pas il ne pourra pas faire l’économie d’une reconfiguration.
En bref :
- L’IA générative progresse techniquement mais rencontre des limites économiques structurelles : coûts élevés d’entraînement et d’usage, difficulté à monétiser, faible fidélisation des utilisateurs et dépendance aux géants de la tech pour la distribution.
- Le modèle économique repose davantage sur des anticipations et des effets d’annonce que sur une valeur réellement captée, créant une dynamique spéculative semblable à la bulle internet des années 2000.
- Les acteurs historiques (Microsoft, Google, Amazon) intègrent l’IA dans leurs écosystèmes existants sans modèle de rentabilité clair, tandis que les pure players comme OpenAI ou Anthropic peinent à équilibrer leurs finances.
- Un réalignement progressif est en cours : rationalisation des projets, réduction des budgets, concentration sur des usages ciblés et industriels, au détriment des ambitions de transformation globale.
- L’IA générative entre dans une phase de banalisation et d’intégration, devenant un outil d’optimisation métier plutôt qu’un moteur de rupture économique ou technologique.
Et avant toute chose je tiens à préciser une fois encore qu’ici on parle bien d’IA générative. Il y a une tonne de types d’IA qui fonctionnent très bien (L’IA pour les nuls qui veulent y voir un peu plus clair), avec un ROI avéré, qui sont rentables pour toute la chaine de valeur et que l’on utilise, pour certaines d’entre elles, depuis des années sans même le savoir et qui ne soulèvent aucune question sauf, éventuellement, de savoir si un jour on ne risque pas de jeter le bébé avec l’eau du bain.
Des fondations plus fragiles qu’on ne voulait le croire
En dépit des projections enthousiastes mais qui ne reposent sur aucune méthodologie solide (voir ci-dessus) et des démonstrations à couper le souffle dont les éditeurs ont le secret il devient devient de plus en plus évident que le modèle économique de l’IA générative est bancal. Pas seulement parce qu’il est jeune et et immature mais parce qu’il repose sur des hypothèses ou coûts, valeur et revenus ne s’alignent pas. Un déséquilibre pointé par de plus en plus d’observateurs qui est, malheureusement, structurel.
Commençons par les coûts. L’entraînement d’un modèle comme GPT-4 aurait coûté plus de 100 millions de dollars (The Extreme Cost Of Training AI Models) mais c’est surtout l’inférence, c’est à dire chaque requête d’un utilisateur qui reste couteuse, de $0,01 à $0,1 (How much does GPT-4 cost?) en fonction de lasacomplexité. Contrairement au modèle Saas ou aux services financés par la publicité en ligne, ici, plus on utilise le service plus il coûte cher au fournisseur sans qu’il n’y ait d’effet d’échelle automatique.
En face de cela, la capacité à faire payer les utilisateurs et donc de leur passer les couts est plus que limitée. Le grand public se limite à des offres à $20 par mois comme ChatGPT plus et les entreprises, de leur côté, ont du mal de justifier des des coûts élevés pour des gains souvent difficiles à mesurer. D’après une étude IBM seuls de 25% des projets IA atteignent aujourd’hui les objectifs de rentabilité (Will genAI businesses crash and burn?). L’essentiel des gains, quand il y en a, relève de la réduction des coûts et d’automatisations très ciblées ce qui explique également que les secteurs à faible marge ne peuvent se payer le luxe d’investir massivement dans l’IA (The disconnect between AI spend and potential).
A cela s’ajoute une pression déflationniste venue du monde open source avec des modèles comme Mistral, LLaMA ou Phi peuvent être déployés localement, à moindres coûts, avec des performances très compétitives. Un mouvement qui est, peut être, encore minoritaire mais est en train de tirer les prix vers le bas. L’entreprise qui peut internaliser un modèle open source n’a aucune raison de payer cher une API à coût variable. Le résultat est prévisible :le prix unitaire d’un token baisse, sans que les coûts d’infrastructure des acteurs privés ne suivent la même tendance.
Le rapport de force est donc en train de se renverser. Alors qu’on pensait l’IA générative capable de désintermédier les géants de la tech elle est en train d’être elle-même absorbée dans des plateformes qui détiennent alors sa distribution. Google intègre Gemini à Search, Gmail et Android, Microsoft impose Copilot dans Windows et Office 365, Amazon inclut ses briques IA dans AWS. En face de cela les nouveaux acteurs ne possèdent ni l’interface, ni la plateforme, ni la base installée et dépendent de ceux qui contrôlent les points d’entrée.
On le voit très bien avec OpenAI qui bien qu’ayant popularisé le concept d’agent conversationnel avec ChatGPT dépend presque totalement de Microsoft pour son cloud (Azure), pour sa distribution (Copilot), et même pour son support technique dans les entreprises. C’est Microsoft qui facture, Microsoft qui embarque, Microsoft qui encadre et dans ce schéma OpenAI n’est qu’un moteur.
Un moteur qui n’est même pas captif. Les utilisateurs peuvent facilement aller voir ailleurs. D’un modèle à l’autre, la friction est faible, l’usage interchangeable et contrairement aux grandes plateformes historiques, l’IA générative n’a pas de verrouillage structurel. Pas de réseau social, pas d’écosystème fermé, pas de dépendance croisée.
De plus la « fidélité cognitive » est très faible : les statistiques d’usage montrent que la plupart des utilisateurs exploitent ces IA pour des tâches comme la rédaction de messages, la gestion de calendriers, ou la génération de contenus (mémos, emails), qui relèvent d’une assistance ponctuelle ou d’une optimisation de tâches individuelles plutôt que d’une transformation structurelle des workflows (AI Assistant Statistics 2025: How AI is Transforming Workflows and Productivity). De plus les particuliers passent d’une IA à l’autre pour essayer, souscrivent et annulent leurs abonnements à chaque expérimentation ce qui signifie que les prévisions de revenu ne veulent plus dire grand chose (L’ARR ne dit plus grand-chose sur la santé d’une startup).
Résultat : les modèles supportent les coûts, mais ne captent ni d’usage durable, ni de revenu récurrent. De la même manière que durant la ruée vers l’or les seuls à avoir gagné de l’argent sont les marchands de pioches, la seule à gagner quoi que ce soit dans cette histoire est Nvidia, dont les marges records (supérieures à 75 % sur les GPU dédiés à l’IA) sont aujourd’hui financées par une économie encore incapable de prouver sa viabilité (Big Tech’s AI spending boom increases risk of a bust).
Un modèle structurellement non rentable
On présente les pertes financières des acteurs de l’IA comme une question de cycle en laissant entendre qu’il faut laisser le temps au marché de maturer, aux usages de s’ancrer et aux investissements de se transformer en chiffre d’affaire. Et c’est vrai que c’est ainsi que les choses ont toujours fonctionné dans le monde de la tech mais dans le cas de l’IA on peut avoir des doutes car le problème n’est pas conjoncturel mais structurel.
Encore une fois on nous cite souvent l’exemple de Google ou d’Amazon mais ces entreprises ne voyaient pas leur couts augmenter proportionnellement aux usages et c’était même plutôt l’inverse.
Ca n’est pas parce que cela a fonctionné pour un type d’entreprise et de technologie que cela fonctionnera donc pour tous.
Les modèles de langage de grande taille (LLM) ne sont pas des plateformes. Ce sont des infrastructures computationnelles intensives, qui consomment énormément à l’entraînement comme à l’usage. GPT-4, Claude 3 ou Gemini 1.5 ne sont pas comparables à un moteur de recherche ou un logiciel cloud : leur coût marginal ne diminue pas avec le volume, pire, il augmente. Chaque utilisateur supplémentaire, chaque requête, chaque millier de tokens a un coût énergétique et matériel significatif (There Is No AI Revolution).
Le problème c’est que les revenus ne suivent pas. OpenAI aurait généré environ 4 milliards de dollars en 2025, mais dans le même temps, la société aurait vu ses dépenses croitre à environ 9 milliards de dollars sans parvenir à équilibrer son modèle (Will genAI businesses crash and burn?). Et pour ce qui est du futur les analystes s’inquiètent qu’en dépit d’une croissance du revenu l’entreprise continue à voir ses dépenses croitre proportionnellement, sachant de plus que la grande majorité des utilisateurs ne paient rien (OpenAI’s profit trajectory is an open question).
Anthropic, soutenue par Amazon et Google, connaît une situation similaire. Valorisation autour de 15 milliards de dollars pour, selon les sources, moins de 150 millions de chiffre d’affaires annuel. Là encore, les multiples sont typiques d’un pari spéculatif et pas d’une entreprise structurellement viable.
Qu’on soit clairs : chaque utilisateur nouveau, chaque requête, ne rapproche pas ces entreprises de la rentabilité mais contribue à creuser leurs pertes.
En parallèle, les revenus sont largement captés par les wrappers dont je vous ai parlé dernièrement (Wrappers, deeptechs et IA générative : un château de cartes rentable mais fragile). La majorité des revenus d’OpenAI provient des abonnements directs à ChatGPT (Plus, Teams, Business…), représentant plus de 70 % du chiffre d’affaires, tandis que la vente d’accès API (utilisée par les intégrateurs comme Notion, Canva, Copilot, Salesforce, etc.) ne représente qu’environ 15 à 20 % du total alors que c’est la grande majorité des usages. Cela signifie que la valeur générée par les usages intégrés dans d’autres outils remonte principalement à ces plateformes finales, et non à OpenAI elle-même (OpenAI Is A Bad Business) et ce d’autant plus que l’accès aux APIs est souvent vendu à perte (The Subprime AI Crisis) pour en stimuler l’usage qui malgré tout peine à décoller.
Même lorsque les acteurs IA sont présents dans les produits finaux, ils ne maîtrisent ni le pricing, ni la distribution, ni la relation client. OpenAI dans Copilot, Claude dans Notion, Gemini dans Gmail : à chaque fois, l’IA est intégrée mais invisible. C’est Microsoft, Google, Amazon qui commercialisent, qui facturent, qui fidélisent, captent la valeur ajoutée et peuvent de plus changer de fournisseurs d’IA comme bon leur semble.
Et ce que ces mêmes wrappers découvrent aujourd’hui, c’est que la rentabilité n’est pas plus évidente de leur côté. Copilot, qui devait être la démonstration de force de Microsoft dans la productivité augmentée, peine à s’imposer : 60% des entreprises ont testé Copilot, 16% seulement sont passées en phase de déploiement (How to get Microsoft 365 Copilot beyond the pilot stage). Beaucoup d’organisations commencent par acheter un nombre limité de licences, souvent pour tester Copilot sur quelques équipes pilotes, puis hésitent à généraliser, faute de retour d’expérience convaincant.
Que ce soit du côté de Microsoft comme de Salesforce, les revenus générés par l’IA sont faibles et les projections peu engageantes (Reality Check). Mais Microsoft et ses semblables ont un avantage considérable par rapport à OpenAi et consorts : en plus d’être en frontal face au client et de contrôler la distribution d’une partie des pure players ils ne sont pas monoproduits : ils ont des vaches à lait qui peut leur permettre de financer leurs efforts dans l’IA pendant des années le temps que marché devienne mature, un temps que les autre n’auront pas.
Aujourd’hui 66% des pilotes ne passent pas en production pour des raisons d’immaturité et de ROI (88% of AI pilots fail to reach production — but that’s not all on IT) et seulement 25 % des initiatives en matière d’IA ont généré le retour sur investissement escompté au cours des dernières années, avec seulement 16 % qui ont été déployées à l’échelle de l’entreprise (IBM Study: CEOs Double Down on AI While Navigating Enterprise Hurdles).
Dans ce contexte, les coûts continuent d’augmenter, et les entreprises clientes, elles, commencent à se lasser de tester des outils dont elles peinent à démontrer l’impact économique car la productivité promise n’est pas au rendez-vous (Workday CEO: ‘For all the dollars that’s been invested so far, we have yet to realize the full promise of AI’) avec des investissements qui croissent, mais sans que la production nette par travailleur n’augmente proportionnellement (AI’s productivity paradox: how it might unfold more slowly than we think).
Résultat : les modèles sont coûteux, la valeur perçue reste nébuleuse, la fidélité utilisateur est faible, la rentabilité industrielle est incertaine… et les seuls à dégager des marges nettes dans ce système sont les vendeurs d’infrastructure à savoir Nvidia, évidemment, mais aussi Microsoft, Amazon, Google, non pas grâce à l’IA, mais grâce au cloud, à la bande passante, aux GPU. C’est une logique de rente sur la dépendance matérielle, pas sur la valeur logicielle.
Soyons clairs : je ne dis pas que l’IA n’a pas de valeur, n’apporte rien, je suis même intimement convaincu du contraire. Je me borne simplement à constater que vu les bénéfice perçus les entreprises et les utilisateurs individuels ne sont pas prêts à payer le prix qui permettrait aux fournisseurs d’IA de devenir rentables un jour, quand une partie de ce prix n’est d’ailleurs pas capté par des intermédiaires.
Il y a une indéniable asymétrie entre les bénéfices de l’IA et les investissements nécessaires à leur obtention et le caractère structurel de cette dernière pourrait bien mener à une impasse.
Une bulle entretenue par des croyances mais pas par des faits
Ce n’est pas la première fois que la tech fonctionne davantage sur la croyance que sur les résultats. Ce n’est pas non plus la première fois qu’un secteur entier parie sur une promesse, sans vérifier si les conditions économiques sont réunies pour la tenir mais dans le cas de l’IA générative, l’écart entre les attentes et la réalité (AGI, emploi, productivité : le grand bluff des prédictions IA) commence à devenir difficile à ignorer.
Les chiffres parlent : multiples de valorisation sans lien avec les revenus, tours de table massifs sur des projections invérifiables, pression continue pour alimenter une croissance encore théorique.
Anthropic en est un excellent exemple : une valorisation estimée à 15 milliards de dollars pour à peine 100 à 150 millions de chiffre d’affaires annuel. Une structure ultra-financée, mais dont le modèle repose encore essentiellement sur des financements conditionnés et des accords d’intégration avec des géants comme Amazon, Google, Salesforce ou Zoom.
OpenAI, de son côté, fait figure de vitrine mondiale… mais continue de perdre plusieurs milliards de dollars par an, malgré une adoption spectaculaire de ChatGPT. Quant à ses agents dont elle espère tirer $3 milliards de revenus en 2025 il semble qu’ils proviendront d’un seul client, à savoir Softbank, qui se trouve être actionnaire d’OpenAI (Reality Check). Un peu comme si votre banque vous achetait vos produits pour faire croire au monde que vous allez bien et en plus cette activité sera probablement déficitaire elle aussi.
Le parallèle avec la bulle Internet du début des années 2000 n’est pas abusif. L’IA générative est financée sur des promesses d’avenir, pas sur des actifs solides (The Dot-Com Bubble vs. The AI Boom: Lessons for Today’s Market), l’effet de réseau y est faible, la fidélisation client incertaine, et la dépendance au capital externe extrême même si je vois des différences notables comme « des cas d’usage clairs et souvent très B2B, les modèles économiques sont connus et éprouvés avec une manière claire de faire du revenu (même si insuffisants) et, surtout, les gouvernements supportent le secteur. » (L’IA vers une impasse économique ?).
Ce qui alimente cette dynamique, c’est un mécanisme bien connu du capital-risque : le FOMO (fear of missing out). Personne ne veut rater le prochain Google. Le résultat, c’est une course à la valorisation où les modèles de revenus importent peu, pourvu que la trajectoire apparente soit exponentielle.
Ce qui soutient aujourd’hui la bulle IA, ce n’est pas la valeur livrée par les produits mais le narratif d’une rupture inévitable (Is the AI Revolution Already Losing Steam?), d’un basculement technologique auquel il faudrait croire avant même qu’il ne se concrétise.
Cette dynamique est renforcée par le fait que les grands acteurs ont tout intérêt à entretenir cette illusion du passage obligé. Microsoft, Amazon, Google, tous intègrent massivement des fonctions IA dans leurs produits sans hausse de prix toujours visible. Non pas parce qu’elles sont immédiatement rentables, mais parce qu’elles renforcent leur emprise sur les écosystèmes et laissent penser que tout se jouera chez eux.
On vend l’idée d’une transformation en cours, alors qu’il s’agit, le plus souvent, d’un packaging cosmétique ou d’un rebranding intelligent.
Et même chez les acteurs qui s’étaient engagés dans des usages IA concrets avec des cas d’usage bien pensées, les limites apparaissent. Le cas de Klarna est sur ce point intéressant : après avoir annoncé en fanfare l’automatisation d’une partie de son support client grâce à des agents IA, la société a dû reconnaître que les résultats n’étaient ni aussi réplicables, ni aussi transformateurs qu’escomptés et que si ils avaient calculé les gains ils avaient sous estimé ce qu’ils avaient à perdre (Klarna nous montre les limites des agents IA).
On voit peu à peu le vent tourner. Des projets sont gelés, des roadmaps sont revues et les plans de déploiement se ralentissent. Selon The Times, plusieurs projets de data centers géants prévus pour absorber la vague IA auraient été suspendus ou redimensionnés dès le premier trimestre 2025 (Big Tech’s $340bn AI spending boom increases risk of a bust) comme par exemple chez Amazon (Amazon has halted some data center leasing talks, Wells Fargo analysts say) et il semble que ce soit une tendance générale dans le secteur.
Enfin, même côté des utilisateurs finaux, le phénomène de fatigue cognitive commence à se faire sentir. L’effet « wow » des débuts s’estompe. ChatGPT, Claude ou Copilot sont certes encore utilisés, mais moins pour transformer que pour assister. Ce sont devenus des outils ponctuels, pas des agents de transformation.
L’IA semble donc avoir atteint le pic de ses promesses, sans que la réalité ne suive (AI’s productivity paradox: how it might unfold more slowly than we think)
Autrement dit : tout le monde continue à jouer mais plus personne ne regarde vraiment le tableau de score.
Et après ? Explosion ou atterrissage ?
Les bulles technologiques ne finissent pas toujours par une explosion. Parfois elles se dégonflent lentement, sans bruit, l’emballement se tasse, les promesses diminuent, les projets se redimensionnent et à la fin, il reste c’est une infrastructure plus modeste mais parfois plus saine.
Puisqu le scénario d’un krach n’est pas difficile à comprendre ni à expliquer, regardons celui, plus crédible, d’un
2025-2026: un retournement très discret
Rien d’alarmant mais devant les doutes, les critiques, et l’effet « magique » qui s’estompe le marché commence à tout doucement se rétracter. Les budgets IA sont peu à peu réduits, les DSI cessent de multiplier des pilotes qui ne mènent à rien (88% of AI pilots fail to reach production — but that’s not all on IT )mais en tirent des leçons et les directions financières commencent à être strictes sur les ROI.
Côté utilisateurs, la magie s’émousse. L’usage grand public de ChatGPT et consorts plafonne. On commence à parler de fatigue, de banalisation voire saturation cognitive. l’IA lasse et déçoit un peu et au final son marketing envahissant joue contre elle.
Le ralentissement des projets de construction de datacenters est la nouvelle qui fait changer l’IA d’époque : si le marketing des acteurs dit que tout est et sera formidable, leurs propres décisions d’investissement disent qu’ils ne voient pas la demande suivre.
2026-2027 : une purge silencieuse
C’est l’année du réalignement. Des startups disparaissent ou son rachetées mais rien à voir avec le krach des dot-com. C’est discret et d’ailleurs on dit même que les « exits » sont plutôt bonnes. A des années lumières des attentes de 2024 mais finalement très convenables. Preuve que ça n’est pas l’IA qui ne fonctionne pas mais qu’on attendait trop et trop vite.
Les survivantes se réorganisent et rationalisent leur investissements.
Parallèlement les grandes plateformes reprennent le contrôle. OpenAi est de plus en plus intégrée à Microsoft et oublie son rêve de devenir le nouveau Google (OpenAI veut-elle, doit-elle et peut-elle devenir le nouveau Google ?) et Anthropic se fond dans les offres cloud Amazon.
Les grandes plateformes reprennent le contrôl. Les modèles deviennent invisibles : ils tournent en arrière-plan, intégrés à des produits déjà existants, sans plus porter leur nom et. Invisibles, interchangeables, ils sont des commodités.
Encore une fois, avoir plusieurs lignes de produit permet de vivre dans le temps long. OpenAI et les autres étaient, elles, condamnées à vivre dans le temps court et les premières hésitations des investisseurs ont eu raison de leur indépendance mais leur survie était à ce prix.
Dans les entreprises on ne parle plus de transformation IA. On parle d’amélioration incrémentale, d’aide à la productivité, d’assistance documentaire. L’IA devient une brique parmi d’autres.
Côté financement, le ton change aussi : les investisseurs ferment les vannes et c’est un peu ce qui a d’ailleurs accéléré ce phénomène
2027–2028 : reconstruction dans la sobriété
Progressivement, les lignes se stabilisent.
Ceux qui survivent repartent sur des bases différentes.
Des modèles plus petits, plus sobres, open source et spécialisés, comme ceux développés par Mistral ou la série Phi de Microsoft, des intégrations verticales, avec une IA enfouie dans les process métiers, et des business models nouveaux, non plus à l’usage tokenisé, mais à la valeur métier créée : par exemple, génération d’une réponse client qualifiée, d’un contrat structuré, d’un rapport de synthèse validé.
On paie à l’action, voire au résultat et le modèle tenté par Salesforce par quelques années plus tôt devient la norme (Agentforce Pricing Update: Salesforce Announces Major Changes).
L’IA n’est plus une rupture mais un outil et c’est là que commence sa seconde vie.
Ceux qui n’ont jamais venu du rêves mais des composants continuent, eux, à prospérer : Nvidia, bien sûr, mais aussi les fournisseurs de cloud, les éditeurs de middleware, les intégrateurs spécialisés
L’IA générative n’aura peut-être été qu’une transition technologique vers autre chose.
Conclusion
Le problème de l’IA générative ça n’est ni son potentiel ni les bénéfices qu’elle apporte mais le fait que personne n’est prêt à payer pour, d’autant que les fournisseurs de technologie ne sont pas ceux qui captent l’essentiel du revenu du marché.
Le problème n’est donc pas la technologie mais le récit qui l’entoure. Un récit qui la présente comme inévitable, repose sur l’idée que l’IA allait tout changer et la croyance que tout cela créerait un marché et des rentes nouvelles.
Le prix à payer sera trop fort pour beaucoup de clients et la rente ne viendra probablement pas, en tout cas pour les pure players.
Le discours sur l’IA est juste sur la tendance mais ne repose, comme on l’a vu, sur rien en termes de chiffrage (AGI, emploi, productivité : le grand bluff des prédictions IA) et c’est ce qui a provoqué des attentes exagérées qui finissent par saper peu à peu la confiance envers le secteur.
Les bénéfices tardent à arriver et n’arriveront peut être jamais, les couts augmentent et au final le récit lasse. Ca n’est pas propre à l’IA, c’est l’histoire du monde de la tech sauf qu’avec l’IA tout est plus rapide et plus amplifié.
Et comme toujours on rebondira vers quelque chose de moins clinquant mais de plus sain et de plus impactant à très long terme. On est pas à la fin de l’IA mais on atteint la fin de la période d’expérimentation et d’apprentissage.
Il en restera des modèles plus sobres, des usages plus ciblés, des intégrations métier plus profondes mais le tout de manière quasi invisible. L’IA ne se donnera plus en spectacle mais va délivrer dans la plus grande discrétion.
Crédit visuel : Image générée par intelligence artificielle via ChatGPT (OpenAI)
L’article IA générative : une bulle, un krach ou un virage ? est apparu en premier sur Bloc-Notes de Bertrand Duperrin.
Découverte: les êtres vivants émettent une lumière qui s'éteint à leur mort 💡

Delta Air Lines Is Ditching Basic Economy. Here’s Why
Delta Air Lines is one of the most popular airlines in the United States and, indeed, the world. Recently, however, the global airline announced that it is getting rid of one of its most popular offerings. Let’s take a look at what they’re getting rid of and why.
Delta Air Lines Is Getting Rid of Basic Economy
According to Time Out, starting Oct. 1, Delta Air Lines will discontinue its Basic Economy class — at least in name. The no-frills fare is not going away, but it will be given a new name as part of a rebranding of Delta’s fare classes.
According to the airline, the rebrand provides greater flexibility and customization, allowing passengers to select the desired experience.
“As we listen and learn about what our customers want when it comes to their travel, we know that clarity and choice are paramount,” SVP and Chief Digital Officer Eric Phillips said in a press release. “Our reimagined shopping experience gives customers more options and flexibility to pick the travel experience that works best for them, and a full picture of all the benefits of flying with Delta.”
So, what will take Basic Economy’s place?
The airline is combining Basic Economy with a new Delta Main category (previously Main Cabin), which now has three tiers: Basic, Classic, and Extra. Delta Main Basic is effectively the same stripped-down experience: no seat selection until check-in, and the final boarding location is in Zone 8. However. Delta hopes the new moniker will indicate a more expansive and adaptable ticketing system.
Other categories are also being renamed. Comfort+ will become Delta Comfort, and First Class will become Delta First, but the in-flight experience remains unchanged. Premium Select and Delta One maintain their current names.
New Routes, Including One to Aspen
Whatever you want to call these new fare rates, you can take Delta Air Lines to any of its three new routes, including one from the greater New York City area to Vail, Colorado, beginning in December 2025 and extending indefinitely thereafter.
As previously reported in Cirium schedules and confirmed by an airline spokesman, the Atlanta-based carrier will begin service between the following airports on Dec. 20:
- New York City’s John F. Kennedy International Airport (JFK) — Eagle County Regional Airport (EGE) near Vail, Colorado
- New York City’s LaGuardia Airport (LGA) — Bozeman Yellowstone International Airport (BZN) in Montana
- Salt Lake City International Airport (SLC) — Southwest Florida International Airport (RSW) in Fort Myers, Florida
During the heaviest winter months, all new flights will operate once per week on Saturdays. Seats on these new flights are currently available for purchase through Delta Air Lines’ booking systems. As expected, these new flights do not provide saver awards; consequently, if you want to spend miles, you must pay Delta’s dynamic SkyMiles redemption rates.
An Airbus A319 will operate the next two flights, while Delta will use a Boeing 757-200 on the JFK to EGE route.
Flyers looking for a premium winter ski trip without a stopover can consider the 1,746-mile route from New York to Vail. On this route, Delta Air Lines will compete with American Airlines’ daily service. The flight from Salt Lake City to Fort Myers should appeal to individuals in Utah’s capital and other nearby areas looking to dodge the cold.
Finally, with service from New York to Bozeman, tourists will have a new route to visit Big Sky and other nearby ski resorts without flying through JFK or Newark Liberty International Airport (EWR). United Airlines flies there from EWR, while JetBlue flies from JFK.
Novo Nordisk Offering Large Discount on Wegovy in Bid to Recapture Market

It's been a tough year for Novo Nordisk, the Danish pharmaceutical company behind the GLP-1 drugs Ozempic and Wegovy. Competitors are nipping at its heels, cheaper knockoffs have been eating into its sales, and it just gave the boot to its former CEO.
Now, hoping its worst days are behind it, Novo says it's offering customers a massive discount on Wegovy, the weight-loss variant of its flagship drug semaglutide.
For your first month of treatment, Reuters reports, you can nab a batch of Wegovy injections for $199 until June 30, Novo said. After that, it'll set you back $499 per month — which is still a lot of money, but the drug used to cost an outrageous $1,000 per month without insurance, so at least it's a step toward broader access.
Don't mistake this for benevolence, though, or even necessarily a sign of growing desperation, though there may be a component of that as well. Instead, Novo is looking to capitalize on a massive victory it was handed last month, when the Food and Drug Administration instituted a crackdown on pharmacies offering compounded forms of semaglutide. The ban took effect this week, following a lengthy grace period.
Compounded drugs are created by a pharmacy, sometimes by using alternative ingredients, to tailor a drug to a patient's specific needs, typically at a much lower cost than buying it straight from a manufacturer.
On the one hand, this gives patients access to medications they normally wouldn't be able to afford. But the lack of regulation has raised concerns over the drugs' safety, which have only grown in volume as compounding pharmacies have shot up — and shut down — across the country.
Following the FDA decision, hundreds of thousands of Americans will lose access to their knockoff semaglutide, the New York Times reported, providing a huge windfall for Novo. With the discounts, it's eagerly poised to sweep up a huge amount of new customers, who are desperate not to derail their weight loss journey.
"We are doubling down on our commitment to accessibility, availability, and affordability of authentic, FDA-approved Wegovy," Dave Moore, executive vice president of Novo's US operations, said in a statement.
The once most valuable company in Europe still faces increasingly stiff competition, however.
Eli Lilly overtook US prescriptions for Wegovy with its Zepbound weight loss shot last year. Inflaming the rivalry, a just-published head-to-head trial showed that Zepbound users lost 50 percent more weight than those who took Novo's drug. Eli Lilly also has a pill version waiting in the wings that promises to be just as effective as semaglutide, precipitating a drop in the Danish company's stock, which has never rebounded to its $615 billion peak in market capitalization nearly two years ago.
More on drugs: Eli Lilly's New Weight Loss Drug May Have the Worst Name in Pharmaceutical History
The post Novo Nordisk Offering Large Discount on Wegovy in Bid to Recapture Market appeared first on Futurism.