I’ve been working on a little project recently that involves handling hundreds of millions of email addresses from various sources. More on that in a later post, but for now let’s just assume that I want to have a reasonable degree of confidence that each of these addresses from an untrusted source is valid. Indeed many of them are just rubbish – beyond the obvious “does it have an @ symbol”, a bunch of them don’t have dots in the domains or contain illegal characters in places where they just shouldn’t be. Clearly it’s time for a regex because you can fix anything with a regex, right? Guys…?
I thought the easiest way to get this right straight off the bat would be to just grab a regex validator from an ASP.NET web forms project and copy the pattern into my project. It looks like this:
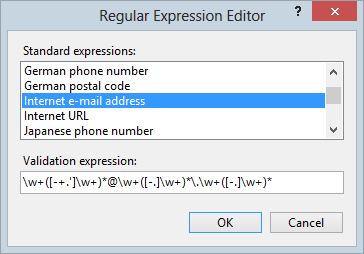
Regexes are never much fun to read but on the surface of it, this doesn’t look too bad. So I drop the pattern into the project and start parsing addresses and a heap of them come back as invalid. Stuff like foo.foo@bar and foo@bar get binned and that’s just great. But then foo-@bar.com gets binned too. Hang on – has .NET got it wrong?! (In fairness it’s not .NET as in the framework itself that has it wrong, rather it’s the default value Visual Studio provides when selecting the expression above)
Now you can read the spec and get a headache or you can take a look at Wikipedia’s description of the “local part” of an email address:
The local-part of the email address may use any of these ASCII characters RFC 5322 Section 3.2.3, RFC 6531 permits Unicode beyond the ASCII range:
- Uppercase and lowercase English letters (a–z, A–Z) (ASCII: 65–90, 97–122)
- Digits
0 to 9 (ASCII: 48–57)
- Characters
!#$%&'*+-/=?^_`{|}~ (ASCII: 33, 35–39, 42, 43, 45, 47, 61, 63, 94–96, 123–126)
- Character
. (dot, period, full stop) (ASCII: 46) provided that it is not the first or last character, and provided also that it does not appear two or more times consecutively (e.g. John..Doe@example.com is not allowed.).
- Special characters are allowed with restrictions. They are:
- Space and
"(),:;<>@[\] (ASCII: 32, 34, 40, 41, 44, 58, 59, 60, 62, 64, 91–93)
- The restrictions for special characters are that they must only be used when contained between quotation marks, and that 2 of them (the backslash
\ and quotation mark " (ASCII: 92, 34)) must also be preceded by a backslash \ (e.g. "\\\"").
- Comments are allowed with parentheses at either end of the local part; e.g. "john.smith(comment)@example.com" and "(comment)john.smith@example.com" are both equivalent to "john.smith@example.com".
- International characters above U+007F are permitted by RFC 6531, though mail systems may restrict which characters to use when assigning local parts.
The third bullet says dashes are good – what gives?! Going back to the regex, the problem is that whilst is allows dashes in the local part of the address, it won’t allow them immediately before the @ symbol. This is incorrect.
Screwy regexes are nothing new and much has been written about them for many years, including this great one by Phil Haack. Certainly when asking around on Twitter there was a lot of ire at the inconsistency of email regexes and as some said, it’s actually not even possible, at least not without excluding various valid patterns.
The point of all this is firstly to say “Don’t trust the default validator in the regex control of ASP.NET”. It’s a fair assumption to make – that Microsoft will give you a validator that actually works – but it’s an incorrect assumption.
Secondly, clearly we need something more decent and obviously it’s easy to replace the one in the validator or drop it into your C# as required. I grabbed Phil’s from the post above which looks like this:
^(?!\.)("([^"\r\\]|\\["\r\\])*"|([-a-z0-9!#$%&'*+/=?^_`{|}~] |(?@[a-z0-9][\w\.-]*[a-z0-9]\.[a-z][a-z\.]*[a-z]$
Yeah, um, that looks good?
More importantly though, here are the stats from the analysis I did on a bunch of user-provided email addresses:
-
Total “addresses” (including invalid ones): 859,248
-
Rejected with ASP.NET validator: 1,864
-
Rejected with Phil’s validator: 3,423
Huh? Why is Phil rejecting nearly twice as many? Because ASP.NET’s validator is also too liberal in many cases. For example, it believes foo@bar.c0m. is valid which is just wrong. It also reckons foo..foo@bar.com is good which is also not the case:
Character . (dot, period, full stop) (ASCII: 46) provided that it is not the first or last character, and provided also that it does not appear two or more times consecutively (e.g. John..Doe@example.com is not allowed.).
The ASP.NET validator also allows foo@f.com which is an invalid host name as is foo@foo.c0m. There are many similar examples of various flavours that show in many cases the “native” validator is just too liberal.
Edit: foo@f.com is a valid address – sorry Phil! There are a number of single char names such as t.co and x.co. The part of the regex immediately after the last @ symbol was expecting an alphanumeric character and a word character before the next dot. Here’s a revision that fixes that case:
^(?!\.)("([^"\r\\]|\\["\r\\])*"|([-a-z0-9!#$%&'*+/=?^_`{|}~] |(?@[\w\.-]*[a-z0-9]\.[a-z][a-z\.]*[a-z]$
At the end of the day, being too liberal is probably not a bad thing – is it really so bad if someone registers with an invalid address? Probably not. On the other hand, being too stringent can mean losing a customer which is probably a whole lot worse. But then again, any half-reasonable validator is probably only going to find false positives in addresses that people have plenty of problems getting into sites with anyway!
Email address validation is an absolute quagmire. Phil’s solution is more accurate than the others I’ve seen but if it doesn’t have flaws I’ll be massively surprised and that’s not to cast a dispersion on Phil, it’s just that this game is a very, very imprecise science. He does go on to point out a very poignant comment in his subsequent post:
The only way to validate an email address is to deliver a message to it!
Now of course that’s very context-sensitive statement too; yes, this would work well at the point of registration on a website but no, it doesn’t work well when you’re parsing hundreds of millions of addresses in a data dump! My case is special and again, I’ll detail it more later, but my particular priorities are on having a higher degree of confidence in the integrity data I have rather than ensuring obscure edge-case addresses are allowed through.
Oh – and just in case anyone is interested, here’s a dump of those 3,423 rejected email addresses (alpha chars substituted with “x’ for the sake of anonymity then distilled to a distinct list of 1,905 records). If, for argument’s sake, 10% of those are false positives (and I highly doubt it’s that high), we’re looking at 0.04% of the original dataset being invalid. If you applied Phil’s regex on a live site that means one in every 2,500 emails would be spat back out. That may be too high for some people (but again, I think the reality is much lower), but I thought it was good context for people debating the virtues of less validation and more junk versus the alternative.
Edit: After the revision above in the previous edit, the number rejected email addresses came down to 2,378 so a 31% reduction – so much for my 10% theory! That said, many of those single char domain examples look like junk but they do now pass the pattern. The list below still includes these. Oh – and there are other legit patterns that get rejected even by the revised regex but I’ll touch on those in a follow-up post shortly.
If you see any reckon are actually legal per the spec, yell out:
!@1.xxx, $xxxxxxx@47, .x.xxxxx@xxx.xxx, .x.xxxxx@xxxxxxx.xxx, .x.xxxxxx2@xxxxxxxxxx.xxx, .xxx51896@xxxxxxx.xxx, .xxxxx.xxxxx@xxxxx.xxx, .xxxxx@xxxxx.xxx, .xxxxx1@xxxxxxxxx.xxx, .xxxxx313@xxxxxx.xx, .xxxxxx@xxxxx.xxx, .xxxxxx44@xxxxx.xxx, .xxxxxxx@xxxx-xxxxxxxx-xx.xxx, .xxxxxxxx@xxxx.xxxxxxx.xxx, .xxxxxxxxx@xxxxxxxxxxxxxx, .xxxxxxxxxx@xxxxxxxxxxxxxxx.xxx, .xxxxxxxxxx22@xx.xx, .xxxxxxxxxxxx@xxxxxxx.xxx, .xxxxxxxxxxxx@xxxxxxxxx, .xxxxxxxxxxxxx@xxxxx.xxx, .xxxxxxxxxxxxxxx@xxxxx.xxx, _xxxxxxxx@xxxxxx, 0@2, 000xxxx@000xxxx.xxx0, 001xxxx@001xxxx.xxx0, 04%2x81.51744@xxxxx.xxx, 1@1, 1@1.1, 1@1.2, 1@1.xxx, 1@2.3, 1@2.31, 1@2.xxx, 11@1.xxx, 11xxx%2xx2@xxxxx.xx.xxx, 123@123.x0x, 123@x.xxx, 12xxxxxxx@x.xx, 13_xxxxxxx@x.xx, 138@xx, 14xxxxxxx@x.xx, 1996@xxx, 1xxxx1@1xxxxxxx1.1xxx, 1xxxxxxx@xxxxx, 2@2.xxx, 2@3.xxx, 2@x.xxx, 200xxxx@x.xx, 21559879xx@xxxxxxxx, 22@22, 27_xxx_2505@x.xxx, 27_xxx2_505@x.xxx, 2x_@9.xx, 2xxx.@xxxx.xxx, 300xxx@x.xx, 34@x.xx, 357xx@xxxxxxxxxxxx, 3xx%2xx9x@xxxxxxxx.xx.xxx, 400xxx@x.xx, 44x@x.xxx, 5.5xxxxx@x.xxx, 500xxx@x.xx, 500xxxx@x.xx, 51072905022@xxxx, 555xxxx@555xxxx.xxx4, 5xxx%2xx2@xxxxx.xx.xxx, 600xxxx@x.xx, 60xxxxxxxxxxxxx@xxxxx, 6xxxxx@xxxxx, 7xxxx@xxxxxxx, 822xxxxxxx@x.xxx, 84@xxxxx.xxxxxxx84, x%2xx@xx.xx, x%2xxxxxxx@xxxxxxx.xxx, x%2xxxxxxx@xxxxxxxxx.xxx, x..x.x.xxxxxx@xx4xxx.xx, x..x.xxxxx@xxxxxxxxxx.xxx, x..xxxx@xxxx.xxx, x.x%2xxxxxxxxx@xxxxx.xx.xx, x.x.@xxxxx.xxx, x.x.@xxxxxxx.xx, x.x.xxxx@x.xx, x.x.xxxxx@x, x.x.xxxxx@xxxxx, x.x.xxxxxxx.xxxxxxxxxxxx@x, x.x.xxxxxxxxx@xxxxxxxx, x.x@x.x, x.x@x.xxx, x.x@xxx, x.xx@x.xxx, x.xxxxx.@xxxxxxx.xxx, x.xxxxx.xxxxxxx@xxxxxxxxxxx.x0x, x.xxxxx@x.xxx, x.xxxxx@xxxx.x, x.xxxxx@xxxxxxx.x123xx, x.xxxxx@xxxxxxxx, x.xxxxxx@x.xxx, x.xxxxxx@xxxx, x.xxxxxx@xxxxxx, x.xxxxxx@xxxxxxxxx, x.xxxxxx@xxxxxxxxxx.x0x, x.xxxxxx@xxxxxxxxxx.x123xx, x.xxxxxx@xxxxxxxxxxxx, x.xxxxxx@xxxxxxxxxxxxxxxxxx, x.xxxxxxx@x.xx, x.xxxxxxx@xxxxxxx, x.xxxxxxx@xxxxxxx.x3x, x.xxxxxxx@xxxxxxxxxx.xx., x.xxxxxxx01@xxxxx.xx9x, x.xxxxxxxx@xxxxxxx, x.xxxxxxxx@xxxxxxxxxx, x.xxxxxxxx5@xxxxx, x.xxxxxxxx80@xxxxx, x.xxxxxxxxx@x.xxx, x.xxxxxxxxx@xx.x0x, x.xxxxxxxxx1@xxxxxxx, x.xxxxxxxxxxx@xx, x.xxxxxxxxxxx@xxxxxxxxxx, x.xxxxxxxxxxxxx@x, x@1.xxx, x@x, x@x.x, x@x.xx, x@x.xxx, x@x.xxxx, x@xx.x, x@xxx, x@xxx7, x_@x.xxx, x_xxxx@xxxxxx, x_xxxxx@xxxxxxxxxx, x_xxxxxx@xxx.x123xx, x_xxxxxx@xxxxx.x, x_xxxxxxx@xxxxxxx, x_xxxxxxx@xxxxxxxxx, x_xxxxxxxx@xxx.x, x11@x.xxx, x1234567@x.xx, x2@x., x2@x.xxx, x212521@xxxxx., x2xxxxxxx@xxxxxxxxx, x3@xxxxxxxx, x3142323@x.xxx, x321@x.xx, x4xxxxx@xxxxx, x4xxxxxxx@xxxxx.xxx., x51xxxx@xxxxxxx.xxx., x6745@xxx.x132xx, x6x5x3x1962@x6x0x53.x60, x700x@xxx.x123xx, x851864@xxxxxx, x99@xxxxxxx.xxx., xx%3x54@xxxxxxx.xxx, xx..xx.xxxx@xxxxx.xxx, xx..xxxxxx@xxxxx.xxx, xx.1025@xxxxxx, xx.xxx@x.xxx, xx.xxx1@x, xx.xxxx.xxxxxxx@xxx.xxxx.x1x, xx.xxxx@xxxxxx, xx.xxxxx@x.xxx, xx.xxxxx1@x.xxx, xx.xxxxxx@xxx.x0x, xx.xxxxxx@xxxxx.x, xx.xxxxxx@xxxxxxxx, xx.xxxxxxxx@xxx, xx.xxxxxxxx@xxxxxxxxxxxxxxx, xx.xxxxxxxxx@xxxx., xx.xxxxxxxxxxxxx@xxxxxxxx, xx.xxxxxxxxxxxxxx@xxxxx, xx@x, xx@x.x, xx@x.xx, xx@x.xxx, xx@xx, xx@xxx.x3x, xx@xxxx, xx@xxxx.xxx1, xx@xxxxxx, xx@xxxxxxx, xx@xxxxxxxxx, xx@xxxxxxxxxx.x0x, xx@xxxxxxxxxxx, xx@xxxxxxxxxxx.x0x, xx@xxxxxxxxxxxx, xx@xxxxxxxxxxxxxxx, xx@xxxxxxxxxxxxxxxx, xx@xxxxxxxxxxxxxxxxx.xxx., xx_xxxxx.@xxx.xxx, xx_xxxxx@xxxxxxxxxx, xx_xxxxxx@xxxxxxxxxx, xx_xxxxxxxxx@xxxx.x, xx1035@xxxxxxxx.x0x, xx106600@xxxxx, xx1095@xxxxxxx, xx1115.xx@xxxxx, xx123@x.xxx, xx14xxx@xxxxxx, xx1877@xxxxx, xx1944@x.xxx, xx1964@xxxxx, xx2@x.xxx, xx2@xxxxxxx.x12xx, xx290@xxxxxx, xx3xxxx@xxxxxx, xx3xxxxx@xxxxxxxxx.x3x, xx4715x@xxxxx.x123xx, xx4xxxx@x.xxx, xx5664@x.xxx, xx599341@xxxxxx, xx5xx@xxx, xx761@x.xxx, xx7xxx@x.xxx, xx8x@xxxxxxxxxx, xx92733@xxx, xxx%2394299@xxx44, xxx.........xxxx@xxxxx.xxx, xxx..x1.xxxxx@xxxx.xxx, xxx..xxxx3@xxxxxxx.xxx, xxx..xxxxxxxx.xx@xxxxx.xxx, xxx.@xxx.xxx, xxx.38@x.xxx, xxx.x...x.xx@xxxxx.xxx, xxx.x.x@x.xx, xxx.xx@x.xxx, xxx.xx73@xxxxx, xxx.xxx.@xxxx.xx, xxx.xxx@xxx, xxx.xxx@xxxxxxxx, xxx.xxxx.@xxxxxxxxx.xxx, xxx.xxxx.xxxxxxxxx@xxxx, xxx.xxxx@xxxxx.x123xx, xxx.xxxx@xxxxxxxx.x0x, xxx.xxxxx.@xxx.xxx.xx, xxx.xxxxx@x, xxx.xxxxx@xxxxx, xxx.xxxxx@xxxxxxxxxxxxxx, xxx.xxxxxx@xxxxx.xxxx.x123xx, xxx.xxxxxx@xxxxxxx.x0x, xxx.xxxxxx@xx-xxxx-xxx, xxx.xxxxxx@xxxxxxxxxxxxxx., xxx.xxxxxx10@xxxxx, xxx.xxxxxx546@xxxxxxx, xxx.xxxxxxx.xxxxxxx@x, xxx.xxxxxxx@x.xx, xxx.xxxxxxx@xxx.xxx., xxx.xxxxxxx@xxxxx, xxx.xxxxxxx@xxx-xxx, xxx.xxxxxxx@xxxxxxxxxx., xxx.xxxxxxx@xxxxxxxxxxxxx.x0x, xxx.xxxxxxx77@xxxxx, xxx.xxxxxxxx@x.xxx, xxx.xxxxxxxx@xxxxxxxxx, xxx.xxxxxxxx243@xxxxx, xxx.xxxxxxxxx@xxx, xxx.xxxxxxxxx@xxxx, xxx.xxxxxxxxx@xxxxx.x0x, xxx.xxxxxxxxx@xxxxxxxxx, xxx.xxxxxxxxx@xxxxxxxxxxx.x0000xx, xxx.xxxxxxxxxx@xxxxxxxx, xxx.xxxxxxxxxxx@xxxxxx., xxx.xxxxxxxxxxxx@xx, xxx.xxxxxxxxxxxxx@xxxxx, xxx@1982, xxx@245, xxx@x.x, xxx@x.xx, xxx@x.xxx, xxx@x.xxxx, xxx@xx, xxx@xx3.x3x, xxx@xxx, xxx@xxx.xxx.1, xxx@xxx.xxx123, xxx@xxxx, xxx@xxxx.x, xxx@xxxxx, xxx@xxxxx.x213xx, xxx@xxxxxx, xxx@xxxxxx.x, xxx@xxxxxx.x123xx, xxx@xxxxxx78745, xxx@xxxxxxx, xxx@xxxxxxx.x123xx, xxx@xxxxxxxx, xxx@xxxxxxxx.x3x, xxx@xxxxxxxxx, xxx@xxxxxxxxx.0xx, xxx@xxxxxxxxx.x, xxx@xxxxxxxxxx, xxx@xxxxxxx-xxx, xxx@xxxxxxxxxxx3, xxx@xxxxxxxxxxxx, xxx@xxxxx-xxxxxxx, xxx@xxxxxxxxxxxxx, xxx@xxxxxxxxxxxxxxx, xxx@xxxxxxxxxxxxxxxx.x123xx, xxx@xxxxxxxxxxxxxxxxxxx, xxx@xxxxxxxxxxxxxxxxxxxx, xxx_15432@x.xxx, xxx_1991@xxxxxx, xxx_22xxxxxxxxx.@xxx.xx, xxx_447_@xxxxxxxxxx, xxx_77@x.xx, xxx_xx@xxxxx, xxx_xxx@x.xx, xxx_xxx@xxxxx.xxx., xxx_xxx@xxxxxxxxx, xxx_xxxxx@x.xxx, xxx_xxxxx@xxxxxxxx, xxx_xxxxx67@xxxxxxxxxx, xxx_xxxxxx@xxxxxxx., xxx_xxxxxxx@xxxxx.x0x, xxx_xxxxxxx@xxxxxxxx, xxx0006@xxxxxx.xxx., xxx001@xxxx.xxxxx.xxxx., xxx0123@xxxxxxxxxxxxxx.x213xx, xxx05@x.xxx, xxx1@x.xx, xxx1@x.xxx, xxx1@xxx, xxx1072@x.xxx, xxx111@xxx.x123xx, xxx1121@xxxxx, xxx1126@xxx, xxx123@x.xxx, xxx1291@xx2000, xxx1429@xxxxxxxxxxxx, xxx14x@xxxxxxxx, xxx150967@xxxxx.xxx., xxx168x@x, xxx1778@xxxxxxxxxx, xxx1919@xx.x0x, xxx1939@x.xxx, xxx1966@xxxxxxxx, xxx19762009@xxxxxxx, xxx1977xx@xxxxx, xxx19890527@xxxxxxx, xxx210@xxxxxx, xxx21xxx@xxxxx, xxx2323@xxx, xxx252@x.xxx, xxx2706@x.xxx, xxx2708@x.xxx, xxx279@xxxxx.x213xx, xxx2839@x.xxx, xxx28409@xxxxxxxxx.x123xx, xxx29@x.xxx, xxx2xxxx@x.xxx, xxx3@xxxxxxx.234xxx, xxx3006@x.xxx, xxx31@xxxxx., xxx333@x.xxx, xxx35@x, xxx37312@xxxxxxxx, xxx38%2x5@xxxx.xxx, xxx46xxx@xxxxxxx, xxx49@xxxxxxx, xxx4xxx@xxx, xxx5@xxxxxxxxx.x, xxx50@xxxxxxx, xxx6313@xxxxx, xxx661@xxxxx, xxx67@xxx, xxx7@x.xxx, xxx7@xxxxxxx, xxx7_xxx_xxxxx@xxxx, xxx702@xxxxxx, xxx72@xxx, xxx74502@xxx, xxx7554@xxxxxxxx, xxx765xxxxxxxx@xxx, xxx76xxxxx@x.xxx, xxx7xx%2x@xxx.xxx, xxx818254@xxxxx.xxx.xx., xxx86@xxxxxxx.x123xx, xxx9@9.xx, xxx9026@9026, xxx97334@xxxxx.xxx., xxx983@xx, xxx99@xxxxxx, xxx9999999@xx, xxxx%2xxxxxxxx@xxxxxxxxx.xxx, xxxx...2@xxxxx.xxx, xxxx..x.xxxxxx@xxx.xxxx.xxx, xxxx..x0722@xxx.xxxxx.xxx, xxxx..xxx1991@xxxxx.xxx, xxxx..xxxxxx@xxxxx.xxx, xxxx.@xxx.xxx, xxxx.x.xxxxx@xxxx.xxx., xxxx.x.xxxxxx@xxxxx.x0x, xxxx.x.xxxxxxx@xxxxx, xxxx.x.xxxxxxxx@xxxxxxxx, xxxx.x.xxxxxxxx@xxxxxxxxxx, xxxx.x@x.xxx, xxxx.xxx.@xxxxx.xxx, xxxx.xxx@xxxxx, xxxx.xxx@xxxxxxxx, xxxx.xxxx.@xxxxxx.xxx, xxxx.xxxx@x.xxx, xxxx.xxxx@xxx, xxxx.xxxx@xxxxx., xxxx.xxxx@xxxxxxx, xxxx.xxxx@x-xxxxxx.x0x, xxxx.xxxx@xxxxxxxx.x3, xxxx.xxxx@xxxxxxxxxx, xxxx.xxxx@xxxxxxxxxx.x, xxxx.xxxx_xxxxxxx@xxxxx, xxxx.xxxx01@xxxxx.x0x, xxxx.xxxxx@x.xxx, xxxx.xxxxx@xxx.x0x, xxxx.xxxxx@xxxx.x0x, xxxx.xxxxx@xxxx.xxxxx.x0x, xxxx.xxxxx@xxxxx.x123xx, xxxx.xxxxx@xxxxxx, xxxx.xxxxx@xxxxxxxx, xxxx.xxxxx@xxxxxxxxxx.x0x, xxxx.xxxxx@xxxxxxxxxxxxxxxx, xxxx.xxxxx1@xx.xxxx.x213xx, xxxx.xxxxxx.@xxxxx.xx.xx, xxxx.xxxxxx.@xxxxxxx.xxx, xxxx.xxxxxx.06@xxxxxxxx, xxxx.xxxxxx@x, xxxx.xxxxxx@x.xxx, xxxx.xxxxxx@xxx, xxxx.xxxxxx@xxx.xx.x0x, xxxx.xxxxxx@xxxx, xxxx.xxxxxx@xxxx.x123xx, xxxx.xxxxxx@xxxxx, xxxx.xxxxxx@xxxxxxx, xxxx.xxxxxx@xxxxxxxx, xxxx.xxxxxx@xxxxxxxxx, xxxx.xxxxxx@xxxxxxxxx.x0x, xxxx.xxxxxx@xxxxxxxxx.x3x, xxxx.xxxxxxx@xx.xxxx.x123xx, xxxx.xxxxxxx@xxx, xxxx.xxxxxxx@xxx.x0x, xxxx.xxxxxxx@xxx.x234xx, xxxx.xxxxxxx@xxx.xxxxx.xx.123xx, xxxx.xxxxxxx@xxxx.x0x, xxxx.xxxxxxx@xxxxx, xxxx.x'xxxxxx@xxxxx., xxxx.xxxxxxx@xxxxx.x0x, xxxx.xxxxxxx@xxxxxxxx, xxxx.xxxxxxxx.xx@xxxxxxx.x123xx, xxxx.xxxxxxxx@xx.xxxx.x123xx, xxxx.xxxxxxxx@xxx.x123xx, xxxx.xxxxxxxx@xxxx, xxxx.xxxxxxxx@xxxx.x1x, xxxx.xxxxxxxx@xxxxx, xxxx.xxxxxxxx@xxxxxxx, xxxx.xxxxxxxx@xxxxxxxx.x0x, xxxx.xxxxxxxxx@x, xxxx.xxxxxxxxx@x.xxx, xxxx.xxxxxxxxx@xxxxxxxxx, xxxx.xxxxxxxxx@xxxxxxxxxxxx, xxxx.xxxxxxxxxxx@x, xxxx.xxxxxxxxxxx@xxxxxxxx, xxxx.xxxxxxxxxxxxxx353@xxx, xxxx@127.0.0.1, xxxx@1321.0xx, xxxx@x.xx, xxxx@x.xx.x, xxxx@x.xxx, xxxx@xx, xxxx@xx2009, xxxx@xxx, xxxx@xxx.x, xxxx@xxx.x123xx, xxxx@xxx.xx.x213xx, xxxx@xxxx, xxxx@xxxx.xxx.x2, xxxx@xxxx194672946, xxxx@xxxxx, xxxx@xxxxx.x0x, xxxx@xxxxx31, xxxx@xxxxxx, xxxx@xxx-xxx, xxxx@xxxxxx.x123xx, xxxx@xxxxxxx, xxxx@xxxxxxx.3x, xxxx@xxxxxxx.x0x, xxxx@xxxxxxx.x21xx, xxxx@xxxxxxxx, xxxx@xxxxxxxx.x, xxxx@xxxxxxxx.x00000xx, xxxx@xxxxxxxxx, xxxx@xxxxxxxxx.x123xx, xxxx@xxxxxxxxx.x3x.xx., xxxx@xxxxxxxxxx, xxxx@xxxxxxx-xxx, xxxx@xxxxxxxxxxx, xxxx@xxxxxxxxxxxx, xxxx@xxxxxxxxxxxx.x, xxxx@xxxxxxxxxxxx.x0x, xxxx@xxxxxxxxxxxxx.x123xx, xxxx@xxxxxxxxxxxxxx, xxxx@xxxxxxxxxxxxxxx, xxxx@xxxxxxxxxxxxxxxxx, xxxx@xxxxxxxxxxxxxxxxxx, xxxx@xxxxxxxxxxxxxxxxxxx.x0x, xxxx@xxxxxxxxxxxxxxxxxxx-xxx, xxxx__xxxxxxxx@xxxxxxx.xxx., xxxx_21@xxxxx.x, xxxx_281@xxxxxxx, xxxx_9230@xxxxxxx.xx9x, xxxx_x@x.xx, xxxx_x3@xxxxxxxxxx, xxxx_xx3@xxxxxxxx, xxxx_xxxx104@xxxxxxxxx, xxxx_xxxx47@xxxxx, xxxx_xxxxx.xx.xxxxxx@xx, xxxx_xxxxx@xxx.xx123x, xxxx_xxxxx@xxxxx, xxxx_xxxxxx@xxxxx, xxxx_xxxxxx@xxxxx.x0x, xxxx_xxxxxx@xxxxxxxxxx, xxxx_xxxxxxx@x.xxx, xxxx_xxxxxxx@xxxxx, xxxx_xxxxxxx@xxxxxxx.x0x, xxxx_xxxxxxx_@xxxxxxx, xxxx_xxxxxxxx%3x@xxxxxx.xxx, xxxx_xxxxxxxx@xxxxx.x123xx, xxxx0@x.xxx, xxxx007@xxxxxxxx, xxxx00723@xxxxxxx, xxxx0146@xxxxx, xxxx07@xxxxx, xxxx077@xxxxx, xxxx1@x.xx, xxxx1@xxx, xxxx1@xxxxxxx, xxxx111@x.xxx, xxxx1111@xxxxxxxxxx, xxxx13@xxxxx, xxxx13@xxxxxxxx, xxxx1820@x.xxx, xxxx1958@xxx, xxxx1979@xxxx.x, xxxx1989@x.xxx, xxxx2@xxxxxxx, xxxx21@xxxxx, xxxx22@x.xxx, xxxx29@x.xx, xxxx2x@xxxxxxx.x123xx, xxxx2xxx@x.xxx, xxxx3@x.xxx, xxxx3000xx@xxxxx., xxxx316@xxx3, xxxx32605@xxxxx, xxxx32xx@xxx, xxxx36@xxxxx., xxxx39@xxxxxxxxx.x123xx, xxxx3x@xxxx.x, xxxx4@xxxxxxxx, xxxx42@xxx, xxxx45xxxxx@x.xxx, xxxx48@xxxxxxxx, xxxx480000%3x@xxxxx.xxx, xxxx5@xxxxx, xxxx51@x.xxx, xxxx52@xxxxxxxx, xxxx5201@xxxx, xxxx526@x.xxx, xxxx55@x.xxx, xxxx59@x.xxx, xxxx621@xxxxxxxxxxx, xxxx64@xxxxx, xxxx70@xxxxxxx, xxxx714@x.xxx, xxxx77@xxx.x123xx, xxxx8%2x5@xxxxx.xxx, xxxx-801@x, xxxx812@xxx, xxxx84@xxxxxxxxxx, xxxx8xxx@xxx, xxxxx%2xxxxx@xxxxxxxxx.xxx, xxxxx..x.xxxxxx@xxxxx.xxxx.xxx, xxxxx..xxxx@xxxxxxx.xxx, xxxxx..xxxxxxxx@xxxxxxxxxx.xxx, xxxxx..xxxxxxxxx@xxxxx.xxx, xxxxx..xxxxxxxxxx@xxx.xxx, xxxxx.@xxx.xxx, xx-xxx.@xxxx.xx, xxxxx.@xxxxx.xxx, xxxxx.@xxxxxx.xx, xxxxx.@xxxxxx.xxx, xxxxx.@xxxxxxx.xxx, xxxxx.@xxxxxxxx.xxx, xxxxx.x.xx.x...xxx10@xxxxx.xxx, xxxxx.x.xxx.@xxxxxxxxx.xxx, xxxxx.x.xxxx@xxxxx, xxxxx.x.xxxxx@x, xxxxx.x.xxxxx@xxxx.x0x, xxxxx.x.xxxxxxx@xxxx.x123xx, xxxxx.x.xxxxxxxxx@xxx, xxxxx.x.xxxxxxxxx@xxxx.x1x, xxxxx.x@x.xxx, xxxxx.xx.xxxxxx@2, xxxxx.xx@xxxxx., xxxxx.xx@xxxxxxxx, xxxxx.xxx@xxxxxxxx, xxxxx.xxxx.@xxxx.xxx.xx, xxxxx.xxxx.xxxxx@xxxxx.x, xxxxx.xxxx@x.xxx, xxxxx.xxxx@xxxx.x0x, xxxxx.xxxx@xxxxx., xxxxx.xxxx@xxxxx.x0x, xxxxx.xxxx@xxxxx.xxx., xxxxx.xxxx@xxxxxxxx, xxxxx.xxxx@xxxxxxxx.xxx.x3x, xxxxx.xxxx@xxx-xxxxxxxxxx, xxxxx.xxxx@xxxxxxxxxxxxxxxxxxx, xxxxx.xxxxx%2xxxx@xxxx.xxx, xxxxx.xxxxx.@xxxxx.xxx., xxxxx.xxxxx.xxxxxx@xxx.xx., xxxxx.xxxxx@x, xxxxx.xxxxx@x.xxx, xxxxx.xxxxx@xxx, xxxxx.xxxxx@xxxx, xxxxx.xxxxx@xxxxx, xxxxx.xxxxx@xxxxx.x0x, xxxxx.xxxxx@xxxxx.xxx., xxxxx.xxxxx@xxxxxx, xxxxx.xxxxx@xxxxxxx, xxxxx.xxxxx@xxxxxxxx, xxxxx.xxxxx@xxxxxxxxx-xxxxxxxx, xxxxx.xxxxxx..@xxx.xxx, xxxxx.xxxxxx@x.xxx, xxxxx.xxxxxx@xxxx.x1x, xxxxx.xxxxxx@xxxxx, xxxxx.xxxxxx@xxxxxx.x0x, xxxxx.xxxxxx@xxxxxxx, xxxxx.xxxxxx@xxxxxxxx, xxxxx.xxxxxx@xxxxxxxx.xxx.xx., xxxxx.xxxxxx@xxxxxxxxx.x3x, xxxxx.xxxxxx@xxxxxxxxxx.xxx., xxxxx.xxxxxx@xxxxxxxxxxxxxxxx.xx., xxxxx.xxxxxx21@xxxxx, xxxxx.xxxxxxx.@xxxxx.xxx.xxx, xxxxx.xxxxxxx@x.xxx, xxxxx.xxxxxxx@xxxx.xxxxxxx., xxxxx.xxxxxxx@xxxxx, xxxxx.xxxxxxx@xxxxx.x123xx, xxxxx.xxxxxxx@xxxxxx.xxxã‚â, xxxxx.xxxxxxx52@xxxxxxxx, xxxxx.xxxxxxxx.@xxxxx.xxx, xxxxx.xxxxxxxx.@xxxxx.xxx., xxxxx.xxxxxxxx@x, xxxxx.xxxxxxxx@x.xxx, xxxxx.xxxxxxxx@xxx., xxxxx.xxxxxxxx@xxxxx, xxxxx.xxxxxxxx@xxxxx.xxx., xxxxx.xxxxxxxx@xxxxxxx, xxxxx.xxxxxxxx@xxxxxxx.0xx, xxxxx.xxxxxxxx@xxxxxxxxxx.x0x, xxxxx.xxxxxxxxx.xxx@xxxxxxxxxxx, xxxxx.xxxxxxxxx@xx, xxxxx.xxxxxxxxx@xxxxx, xxxxx.xxxxxxxxx@xxxxx., xxxxx.xxxxxxxxx@xxxxxx, xxxxx.xxxxxxxxx@xxxxxxxxx.xxx0., xxxxx.xxxxxxxxx@xxxxxxxxxx, xxxxx.xxxxxxxxx@xxxxxxxxxxxx, xxxxx.xxxxxxxxx3@xxxxx.x0x, xxxxx.xxxxxxxxxx@xxxx, xxxxx.xxxxxxxxxxx.@xxxx.xxx, xxxxx.xxxxxxxxxxx@x, xxxxx.xxxxxxxxxxxxxx@xx, xxxxx@127.0.0.1, xxxxx@20, xxxxx@3.xxx, xxxxx@x, xxxxx@x.xx, xxxxx@x.xxx, xxxxx@xx, xxxxx@xx.x, xxxxx@xx.x0x, xxxxx@xx.x123xx, xxxxx@xx.xxx., xxxxx@xx2009, xxxxx@xx4xxxx, xxxxx@xxx, xxxxx@xxx.x, xxxxx@xxx.x0x, xxxxx@xxx.x10x, xxxxx@xxx.xx3, xxxxx@xxx.xxx., xxxxx@xxxx, xxxxx@xxxx.x123xx, xxxxx@xxxx.xxx.x5x, xxxxx@xxxx2, xxxxx@xxxxx, xxxx-x@xxxxx, xxxxx@xxxxx., xxxxx@xx-xxx.x0x, xxxxx@xxxxxx, xxxxx@xxxxxx.x0x, xxxxx@xxxxxxx, xxxxx@xxxxxxx.x0x, xxxxx@xxxxxxxx, xxxxx@xxx-xxx-xx, xxxxx@xxxxxxxx., xxxxx@xxxxxxxxx, xxxxx@xxxxx-xxxx, xxxxx@xxxxxxxxx.x, xxxxx@xxxxxxxxx.x3x, xxxxx@xxxxxxxxxx, xxxxx@xxxxxxxxxx.x0x, xxxxx@xxxxxxxxxx.xxx.xx., xxxxx@xxxxxxxxxxx, xxxxx@xxxxxxxxxxxx, xxxxx@xxxxx-xxxx-xxx, xxxxx@xxxxx-xxxxxxx.x1212xx, xxxxx@xxxxxxxxxxxxx, xxxxx@xxxxxxxxxxxxxx, xxxxx@xxxxxxxxxxxxxx2xx, xxxxx@xxxxxxxxxxxxxxxx, xxxxx@xxxxxxx-xxxxxxxxx, xxxxx@xxxxxxxxxxxxxxxx9xx, xxxxx@xxxxxxxxxxxxxxxxxxx, xxxxx_81@xxxxx.xx., xxxxx_9@x.xxx, xxxxx_9@xxxxx.xxx6, xxxxx_x_xxxxxxxx@x.xxx, xxxxx_xxxx@x.xx, xxxxx_xxxx@xxxxx.x0x, xxxxx_xxxx@xxxxxxxxxxxx, xxxxx_xxxx007@xxxxx., xxxxx_xxxx1969@xxxxxxx, xxxxx_xxxxx_x@xxx.x123xx, xxxxx_xxxxxx@xxxxx, xxxxx_xxxxxx@xxxxxxx, xxxxx_xxxxxx@xxxxxxx.x123xx, xxxxx_xxxxxx@xxxxxxxxxx, xxxxx_xxxxxxx@xxxx, xxxxx_xxxxxxx@xxxxx28, xxxxx_xxxxxxx@xxxxxx, xxxxx_xxxxxxx@xxxxxxx, xxxxx_xxxxxxxx@x.xxx, xxxxx_xxxxxxxxx@xxxxxxx, xxxxx_xxxxxxxxxxx@xxxxxxxx, xxxxx0@xxxxx, xxxxx001@xx, xxxxx007@x.xxx, xxxxx008@x.xx, xxxxx013@xxx, xxxxx0215@xxxxxxxxxx, xxxxx05@xxxxxxxx, xxxxx0513@xxxxxxxx, xxxxx06@xxxxx, xxxxx07@xxxxxxx, xxxxx1@x.xxx, xxxxx1@xx, xxxxx1@xxx, xxxxx1@xxxx, xxxxx1@xxxxxx, xxxxx1@xxxxxxx, xxxxx1@xxxxxxxxx.x123xx, xxxxx100@xxx, xxxxx1061@x.xxx, xxxxx1123@x.xxx, xxxxx114@xxxxx, xxxxx12@xxx.x123xx, xxxxx1206@xxxxxxxx, xxxxx126@x.xxx, xxxxx150@xxxxxxx, xxxxx16@x.xxx, xxxxx16@xxx, xxxxx1633@xxxxxxx., xxxxx1961@xxx, xxxxx1968@x.xxx, xxxxx1983@xxxxx, xxxxx2@x.xxx, xxxxx2@xxxxx, xxxxx2000@x.xxx, xxxxx2000@xxx.x123xx, xxxxx2002@xxxxxxxx, xxxxx2008@x.xx, xxxxx2009@xxxxx, xxxxx22@xxx, xxxxx240@xxxxx, xxxxx28@xxxxxx, xxxxx2x@xxxxx.x0x, xxxxx2xx@xxx., xxxxx2xxxxxxxxxxx@xxxxxxxxxxxxxxxxxxx, xxxxx3.xxxxx@xxxxx, xxxxx3@xxx, xxxxx3@xxxxxxx., xxxxx30@xxxxx.x0x, xxxxx3000@xxxxxxx., xxxxx302@xxx, xxxxx31@xxxxxxx.x3x, xxxxx34@xxxxxxx, xxxxx346@x.xxx, xxxxx44@xxxxxx, xxxxx453.@xxxxx.xxx, xxxxx47.02@xxxxx, xxxxx4xxxx@xxxxx, xxxxx53@xxxx, xxxxx54@xxxxx.x0x, xxxxx55@xxxxxxx, xxxxx58750@x.xxx, xxxxx590@xxx.x0x, xxxxx5901@xxxxx, xxxxx6@x.xxx, xxxxx63@xxxxx, xxxxx63@xxxxxx, xxxxx64@xxx, xxxxx6862@xxxxxxxx, xxxxx6x@xxxxxxx, xxxxx7@xxxxxx, xxxxx7@xxxxxxxx, xxxxx713@x.xxx, xxxxx728@xxxxxxxxx.xxx., xxxxx75@xx.xxx., xxxxx777@x.xx, xxxxx777@xxxxx.xxx., xxxxx8@x.xxx, xxxxx80@xxxxxxx.x0x, xxxxx901@xxxxxx, xxxxx925@xxxxxxxxxx, xxxxx99@xxxxxxxxxx, xxxxx9903@xxxxx.x9x, xxxxx99xxx@xxxxx.xxx.xx., xxxxxx%2x@xxxxxxxxxxxxx.xxx, xxxxxx%3x@xxxxxxx.xxx, xxxxxx..x.xxxxxx@xxxxx.xxx, xxxxxx..x@xxxxx.xxx, xxxxxx..xxxxxxxx@xxx69.xxxx.xxx, xxxxxx..xxxxxxxx@xxxxxxxx.xxx, xxxxxx.@xx, xxxxxx.@xxxxx.xxx, xxxxxx.@xxxxxx.xxx.xxx, xxxxxx.x.%2xxxxxx2@xxxx.xxx, xxxxxx.x..xxxx@xxxxx.xxx, xxxxxx.x.@xxxxxxxxxxxx.xxx, xxxxxx.x.xxx@xxxx, xxxxxx.x.xxxx@xxxxxxxx, xxxxxx.x.xxxxx@xxxx, xxxxxx.x.xxxxxx@xx.xxx.xxxx.x123xx, xxxxxx.x.xxxxxx@xxxx.x0x, xxxxxx.x.xxxxxxx.@xxxx.xxx, xxxxxx.x.xxxxxxx@xxxx.x0x, xxxxxx.x.xxxxxxxx@xx.xxxx.xxx., xxxxxx.x.xxxxxxxx@xxxx.x0x, xxxxxx.x.xxxxxxxx@xxxxx, xxxxxx.x@x, xxxxxx.x@x.xxx, xxxxxx.xx.55@xxxxxxxx, xxxxxx.xx@xxxxxxx.xxx., xxxxxx.xxx@xxx.xxx.xx., xxxxxx.xxx@xxxxx, xxxxxx.xxx83@xxxxx, xxxxxx.xxxx.@xxxxx.xxx, xxxxxx.xxxx.xxx@xxxxxxxxxxxx, xxxxxx.xxxx@xxxx, xxxxxx.xxxx@xxxx.x0x, xxxxxx.xxxx@xxxx.x1x, xxxxxx.xxxx@xxxxxxxx, xxxxxx.xxxx@xxxxxxxxxx.x, xxxxxx.xxxx@xxxxxxxxxx.x123xx, xxxxxx.xxxx313@xxxx, xxxxxx.xxxxx@x.xxx, xxxxxx.xxxxx@xxx.x0x, xxxxxx.xxxxx@xxxxxxxx, xxxxxx.xxxxx@xxxxxxxx.xx., xxxxxx.xxxxx@xxxxxxxxxx, xxxxxx.xxxxx@xxxxxxxxxxxxxxx.xxxx2, xxxxxx.xxxxxx@xx, xxxxxx.xxxxxx@xx.xxx.xxx., xxxxxx.xxxxxx@xx.xxxx.x1x, xxxxxx.xxxxxx@xxx.x0x, xxxxxx.xxxxxx@xxx.x123xx, xxxxxx.xxxxxx@xxxxx, xxxxxx.xxxxxx@xxxxx., xxxxxx.xxxxxx@xxxxxx.xxx.xx.x123xx, xxxxxx.xxxxxx@xxxxxxx.x0x, xxxxxx.xxxxxx@xxxxxxxxx, xxxxxx.xxxxxxx.@xxxxxxxx.xxx, xxxxxx.xxxxxxx.@xxxxxxxxxxxxx.xxx, xxxxxx.xxxxxxx@x.xx, xxxxxx.xxxxxxx@x.xxx, xxxxxx.xxxxxxx@x-3xxx, xxxxxx.xxxxxxx@xx, xxxxxx.xxxxxxx@xxxx, xxxxxx.xxxxxxx@xxxx.x0x, xxxxxx.xxxxxxx@xxxx.xxxx.x123xx, xxxxxx.xxxxxxx@xxxxxx.xxx.xx.x123xx, xxxxxx.xxxxxxx@xxxxxxxx.x, xxxxxx.xxxxxxx@xxxxxxxx.x0x, xxxxxx.xxxxxxx@xxxxxxxxx.x, xxxxxx.xxxxxxx@xxxxxxxxxx, xxxxxx.xxxxxxx@xxxxxxxx-xx, xxxxxx.xxxxxxx4@xxxxxxxx, xxxxxx.xxxxxxxx@x.xxx, xxxxxx.xxxxxxxx@xx, xxxxxx.xxxxxxxx@xxx, xxxxxx.xxxxxxxx@xxx.x, xxxxxx.xxxxxxxx@xxxxx, xxxxxx.xxxxxxxx@xxxxx.xxx., xxxxxx.xxxxxxxx@xxxxxxx.x123xx, xxxxxx.xxxxxxxx@xxxxxxxx, xxxxxx.xxxxxxxx@xxxxxxxxxx, xxxxxx.xxxxxxxx@xxxxxxxxxxx, xxxxxx.xxxxxxxxx@x, xxxxxx.xxxxxxxxx@xxxxx-xxxxxxx.x0x, xxxxxx.xxxxxxxxx@xxxxxxxxxxx-xxx.x0, xxxxxx.xxxxxxxxxx@xxx, xxxxxx.xxxxxxxxxx@xxxx.xxx-xxxxx, xxxxxx.xxxxxxxxxx@xxxxx, xxxxxx.xxxxxxxxxx@xxxxx., xxxxxx.xxxxxxxxxx@xxxxx.x, xxxxxx.xxxxxxxxxxxxxx@xxx, xxxxxx@1.xxx, xxxxxx@306, xxxxxx@x, xxx-xxx@x, xxxxxx@x.x, xxxxxx@x.xx, xxx-xxx@x.xx, xxxxxx@x.xxx, xxxxxx@xx, xxxxxx@xx51xx, xxxxxx@xxx, xxxxxx@xxx., xxxxxx@xxx.x, xxxxxx@xxx.x0x, xxxxxx@xxx.x123xx, xxxxxx@xxx.xxx., xxxxxx@xxx.xxx.xxx., xxxxxx@xxx5.x12, xxxxxx@xxxx, xxxxxx@xxxx.x, xxxxxx@xxxx21xxx, xxxxxx@xxxxx, xxxxxx@xxxxx., xxxxxx@xxxxx.x0x, xxxxxx@xxxxx.x123xx, xxxxxx@xxxxx.x132xx, xxxxxx@xxxxx.x5465xx, xxxxxx@xxxxx.xxx., xxxxxx@xxxxx.xxx.xx., xxxxxx@xxxxx.xxx2, xxxxxx@xxxxxx, xxxxxx@xxxxxx., xxxxxx@xxxxxx.x0x, xxxxxx@xxxxxx.xx.x123xx, xxxxxx@xxxxxx123.x00xx, xxxxxx@xxxxxx2, xxxxxx@xxxxxx5, xxxxxx@xxxxxxx, x-xxxxx@xxxxxxx, xxxxxx@xxxxxxx.x, xxxxxx@x-xxxxxx.x, xxxxxx@xxxxxxx.x123xx, xxxxxx@xxxxxxx.x3x, xxxxxx@xxxxxxx.xxx5, xxxxxx@xxxxxxxx, xxxxxx@xxxxx-xxx, xxxxxx@xxxx-xxxx, xxxxxx@xxxxxxxx., xxxxxx@xxxxxxxxx, xxxxxx@xxxxx-xxxx, xxxxxx@xxxxxxxxxx, xxxxxx@xxxxxxxxxxx, xxxxxx@xxxx-xxxxxxx, xxxxxx@xxxxxxxxxxx.x45xx, xxxxxx@xxxxxxxxxxxx, xxxxxx@xxxxxxxxxxxx.x0x, xxxxxx@xxxxxxxxxxxxx, xxxxxx@xxxxxxxxxxxxxx, xxxxxx@xxxxxxxxxxxxxx.x, xxxxxx@xxxxxxxxxxxxxx.x0x, xxxxxx@xxxxxxxxxxxxxx.xxx., xxxxxx@xxxxxxxxxxxxxxx, xxxxxx@xxxxxxxxxxxxxxx.x123xx, xxxxxx@xxxxxxxxxxxxxxxxx, xxxxxx@xxxxxxxxxxxxxxxxxx, xxxxxx_23@xxxxxxxxxxx, xxxxxx_234@xxxxx, xxxxxx_75%2x@xxxxxxx.xxx, xxxxxx_x@xxx, xxxxxx_x_xxxxxxx@x.xxx, xxxxxx_xx@271956, xxxxxx_xx@xxxxxxx, xxxxxx_xx@xxxxxxxx, xxxxxx_xxx@xxxxx, xxxxxx_xxxx@x, xxxxxx_xxxx@xxxxxx, xxxxxx_xxxxxx.xxxx@x, xxxxxx_xxxxxx@xx.xxx1, xxxxxx_xxxxxx@xxx, xxxxxx_xxxxxx@xxxxx, xxxxxx_xxxxxx@xxxxxxxxx, xxxxxx_xxxxxx@xxxxxxxxxx, xxxxxx_xxxxxx_2@xxxxxxxxxx, xxxxxx_xxxxxxx@xxxxx.xxx., xxxxxx_xxxxxxx20@xxxxxxx, xxxxxx001@x.xxx, xxxxxx001@xxxxx., xxxxxx01@x.xxx, xxxxxx0329@xxx.x0x, xxxxxx048@xxxxxx., xxxxxx09@xxxxx, xxxxxx1@x.xx, xxxxxx1@x.xxx, xxxxxx1@xxx.x0x, xxxxxx1@xxxxx, xxxxxx1@xxxxxxx, xxxxxx1@xxxxxxx.xxx., xxxxxx1@xxxxxxxxxx, xxxxxx10@xxxxxxx, xxxxxx100@xxxx, xxxxxx1000@xxxxx.x, xxxxxx101@xxxxx., xxxxxx102@xxxxx, xxxxxx1030@xxx, xxxxxx121@xxxxxxx, xxxxxx1218@x.xxx, xxxxxx123@xxxxx, xxxxxx123@xxxxxxx.xxx., xxxxxx12xxxx@xxxx, xxxxxx1769@xxxxxxxxx.x, xxxxxx180@x.xxx, xxxxxx1974@x.xxx, xxxxxx19840920@126., xxxxxx1xxxxx@x.xxx, xxxxxx2@x.xx, xxxxxx2@x.xxx, xxxxxx2@xxxxx, xxxxxx2@xxxxxx, xx-xxxx2@xxxxxx-xx, xxxxxx2003@xxxxxxxxxx, xxxxxx2007@xxxxxxxx, xxxxxx215@xxxxxxx, xxxxxx21xxx@xxxxx, xxxxxx22@x.xxx, xxxxxx22@xxxxxxx, xxxxxx222@xx., xxxxxx23@xxx, xxxxxx234@xxxxxxx, xxxxxx24002003@x, xxxxxx248@xxxx, xxxxxx24x@x.xxx, xxxxxx25@xxxxx, xxxxxx260@x.xxx, xxxxxx27@xxxxxxx, xxxxxx27@xxxxxxxx., xxxxxx27@xxxxxxxxxxx, xxxxxx3@x, xxxxxx3@x.xx, xxxxxx3@xxxxxx, xxxxxx312@x.xxx, xxxxxx33@xxxxx.xxx., xxxxxx35@xxxxxxxx, xxxxxx35@xxxxxxxxxx.x, xxxxxx359@x.xxx, xxxxxx365@xxxxx, xxxxxx40x@xxxxxxx, xxxxxx411@xxxxxxxx, xxxxxx4176@xxx.x123xx, xxxxxx420@xxxxxxxx, xxxxxx44@xxxxx, xxxxxx45@xxx, xxxxxx4823@xxxxxxx.x3x, xxxxxx5@x.xxx, xxxxxx51943@xxxxxxx, xxxxxx55@xxxxx, xxxxxx56@x.xxx, xxxxxx61001@xxxxxxx, xxxxxx64@x, xxxxxx65@xxxxxxxx, xxxxxx69@x, xxxxxx7@x.xxx, xxxxxx7000@x.xxx, xxxxxx7104@xxxxx, xxxxxx75@x.xxx, xxxxxx77@xxx.xxx., xxxxxx77@xxxxxx, xxxxxx77@xxxxxxx, xxxxxx77@xxxxxxxx, xxxxxx784@xxxxx, xxxxxx8@x.xxx, xxxxxx8@xxxxx.x0x, xxxxxx807@x.xxx, xxxxxx808@x.xxx, xxxxxx82@xxxxxxxxxx, xxxxxx88%2x@xxxxx.xxx, xxxxxx88@x.xxx, xxxxxx88@xxxxx, xxxxxx888@xxxxxxxx, xxxxxx9@x.xxx, xxxxxx922@xxxxxxx, xxxxxx93@xxxxxxx., xxxxxx93561@xxxxxx, xxxxxx95@x.xxx, xxxxxx98@xxxxxx, xxxxxx9x@x.xxx, xxxxxxx%3x%3x%3x%3x%3x@xxxxx.xxx, xxxxxxx..@xxxxxx.xxx, xxxxxxx..xxxxxx@xxxxxxx.xx, xxxxxxx.@xxx.xxx, xxxxxxx.@xxxxxxx.xxx, xxxxxxx.x.xxxxx@xxx.x0x, xxxxxxx.x.xxxxx@xxxxx, xxxxxxx.x.xxxxx@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx, xxxxxxx.x.xxxxxx@xxxxxxxxxx.x0x, xxxxxxx.x.xxxxxx@xxxxxxxxxxx.x0x, xxxxxxx.x.xxxxxxxx@xxxx.x0x, xxxxxxx.x@xxxxx, xxxxxxx.xx.@xxxxx.xxx, xxxxxxx.xx.xxxxxx@xxxxx, xxxxxxx.xxx.xxxxx.@xxxxxxx.xxx, xxxxxxx.xxx@xxxxx, xxxxxxx.xxxx@xxxxx, xxxxxxx.xxxx@xxxxx.xxx., xxxxxxx.xxxx@xxxxxxxx, xxxxxxx.xxxxx.xxxxx@xx.xxx.xxxx.x123xx, xxxxxxx.xxxxx@xxxxx, xxxxxxx.xxxxx@xxxxxxx, xxxxxxx.xxxxx@xxxxxxx.x0x, xxxxxxx.xxxxx@xxxxxxxx, xxxxxxx.xxxxxx@xxxxxx, xxxxxxx.xxxxxx@xxxxxxx, xxxxxxx.xxxxxx@xxxxxxx., xxxxxxx.xxxxxx@xxxxxxxx.x0x, xxxxxxx.xxxxxx@xxxxxxxxxx, xxxxxxx.xxxxxx@xxxxxxxxxxxxx, xxxxxxx.xxxxxx79@xxxxx, xxxxxxx.xxxxxxx@xx.xxxx.x123xx, xxxxxxx.xxxxxxx@xxx, xxxxxxx.xxxxxxx@xxxx.x1x, xxxxxxx.xxxxxxx@xxxxx.x123xx, xxxxxxx.xxxxxxx@xxxxxxx.x123xx, xxxxxxx.xxxxxxx@xxxxxxxx, xxxxxxx.xxxxxxx@xxxxxxxx.x0x, xxxxxxx.xxxxxxx12@xxxxxxxx, xxxxxxx.xxxxxxxx@xxxx.x0x, xxxxxxx.xxxxxxxx@xxxxxxxx, xxxxxxx.xxxxxxxx@xxxxxxxxxx, xxxxxxx.xxxxxxxxx@xxx, xxxxxxx.xxxxxxxxx@xxxx.x, xxxxxxx.xxxxxxxxx@xxxxx.x0x, xxxxxxx.xxxxxxxxxx@xxx, xxxxxxx.xxxxxxxxxx@xxxxx, xxxxxxx.xxxxxxxxxx@xxxxx.x, xxxxxxx.xxxxxxxxxxx@xxxxxxx, xxxxxxx@x, xxxxxxx@x.xx, xxxxxxx@x.xxx, xxxxxxx@xx, xxxxxxx@xx.xxx.xx., xxxxxxx@xxx, xxxxxxx@xxx., xxxxxxx@xxx.234xxx, xxxxxxx@xxx.x0x, xxxxxxx@xxx.x1234xx, xxxxxxx@xxx.x123xx, xxxxxxx@xxx.x213xx, xxxxxxx@xxx.xx., xxxxxxx@xxx.xx1, xxxxxxx@xxxx, xxxxxxx@xxxx.x, xxxxxxx@xxxx.x123xx, xxxxxxx@xxxx.xx.x0x, xxxxxxx@xxxx.xx0x, xxxxxxx@xxxx123, xxxxxxx@xxxxx, xxxxxxx@xx-xxx, xxxxxxx@xxxxx., xxxxxxx@xxxxx.x, xxxxxxx@xxxxx.x0x, xxxxxxx@xxxxx.x123xx, xxxxxxx@xxxxx.x3x, xxxxxxx@xxxxx.xxx., xxxxxxx@xxxxx.xxx.xx., xxxxxxx@xxxxx.xxxxxxx.3xx, xxxxxxx@xxxxxx, xxxxxxx@xxx-xxx, xxxxxxx@xxxxxx.x0x, xxxxxxx@xxxxxx.x123xx, xxxxxxx@xxxxxx.xx.x234xx, xxxxxxx@xxxxxx.xxx., xxxxxxx@xxxxxxx, xxxxxxx@xxxxxxx.x, xxxxxxx@xxxxxxx.x123xx, xxxxxxx@xxxxxxx.x3x, xxxxxxx@xxxxxxx.xxx., xxxxxxx@xxxxxxxx, xxxxxxx@xxxxxxxx.90., xxxxxxx@xxxxxxxx.x123xx, xxxxxxx@xxxxxxxx.x213xx, xxxxxxx@xxxxxxxxx, xxxxxxx@xxxxxxxxx.x0x, xxxxxxx@xxxxxxxxx.x123xx, xxxxxxx@xxxxxxxxx.x3x, xxxxxxx@xxxxxxxxx.xx123x, xxxxxxx@xxxxxxxxx.xxx.8xx, xxxxxxx@xxxxxxxxxx, xxxxxxx@xxxxxxxxxx.x0x, xxxxxxx@xxxxxxxxxx.xxx1, xxxxxxx@xxxxxxxxxxx, xxxxxxx@xxxxxxxxxxx.x3x, xxxxxxx@xxxxxxxxxxxx, xxxxxxx@xxxxxxxxxxxxx, xxxxxxx@xxxxxxxxxxxxxx, xxxxxxx@xxx-xxxxxxxxxxx, xxxxxxx@xxxxxxxxxxxxxxxx, xxxxxxx@xxxxxxxxxxxxxxxxx, xxxxxxx_1@x.xxx, xxxxxxx_2000@xxxxxxx, xxxxxxx_29@xxxxxxx, xxxxxxx_3000@x.xx, xxxxxxx_76@xxxxx, xxxxxxx_x@xxxx.xxx.x2, xxxxxxx_xxx@x.xxx, xxxxxxx_xxxx_@xxx.x, xxxxxxx_xxxxx@xxxxx, xxxxxxx_xxxxx@xxxxxxx, xxxxxxx_xxxxxxx@x.xxx, xxxxxxx_xxxxxxx@xxxxxxx.x, xxxxxxx007@x.xxx, xxxxxxx1@9697xx, xxxxxxx1@x.xx, xxxxxxx1@x.xxx, xxxxxxx1@xxxx, xxxxxxx1@xxxxxxx, xxxxxxx1@xxxxxxx., xxxxxxx1@xxxxxxxx.xx.xxx., xxxxxxx1@xxxxxxxxxx, xxxxxxx1@xxxxxxxxxxxx, xxxxxxx10@x.xxx, xxxxxxx12@xxx, xxxxxxx12@xxxxxxxx, xxxxxxx1238@x.xxx, xxxxxxx15@xxxxxxxxxx, xxxxxxx16@xxxxx, xxxxxxx18@x.xxx, xxxxxxx184@xxxxxxxx, xxxxxxx1956@xxxxxxxx, xxxxxxx2@193.17.41.103, xxxxxxx2@193.17.41.85, xxxxxxx2@x.xxx, xxxxxxx2@xxx, xxxxxxx2@xxxx, xxxxxxx2@xxxxxxx.x0x, xxxxxxx2@xxxxxxxx, xxxxxxx20@x.xx, xxxxxxx20@xxxxxxx, xxxxxxx2001@xxxxx, xxxxxxx2003@xxxxx.x0x, xxxxxxx2007@x.xx, xxxxxxx217@xxxxx, xxxxxxx222@xxxxxxx, xxxxxxx25@xxxxx, xxxxxxx254@xxxxxxx, xxxxxxx266@xxxxx.xx., xxxxxxx3@x.xxx, xxxxxxx3@xxxxx, xxxxxxx3@xxxxxxxx, xxxxxxx32@x.xxx, xxxxxxx33@xxxxx, xxxxxxx33@xxxxxxx, xxxxxxx34@x.xxx, xxxxxxx39@x.xxx, xxxxxxx3xxxxx@xxxxxxxx, xxxxxxx4@xxx.x3x, xxxxxxx40@x.xxx, xxxxxxx44xxxx@xxxxx.x123xx, xxxxxxx46@xxxx, xxxxxxx478@xxx, xxxxxxx482..5@xxxxx.xxx, xxxxxxx49@xxxxxxxxxx, xxxxxxx5@xxxxx., xxxxxxx5040@xxxxxxx, xxxxxxx5071@xxxxx.xx0x, xxxxxxx55@xxxxxxx, xxxxxxx57@xxxxx.x, xxxxxxx583@x.xxx, xxxxxxx65@xxxxx.x0x, xxxxxxx69@xxxxx, xxxxxxx7@x.xxx, xxx-xxxx-76@x.xxx, xxx-xxxx-76@x.xxxx, xxxxxxx76@xxxxx, xxxxxxx76@xxxxxxx, xxxxxxx768@xxxxx.x123xx, xxxxxxx777@xxx., xxxxxxx777@xxxxx, xxxxxxx8@xxxxxxx., xxxxxxx82@xxxxxxx, xxxxxxx90@xxxxx.x, xxxxxxx927@xxxxx, xxxxxxx94@xxxxxxxx, xxxxxxx974@xxx.x231xx, xxxxxxx99@xxxxxxx.xxx., xxxxxxxx%2x@xxxxxx.xxx.xx, xxxxxxxx%2xxxxx@xxx.xx, xxxxxxxx.@xxxx.xx, xxxxxxxx.@xxxxx.xxx, xxxxxxxx.@xxxxxx.xxx, xxxxxxxx.@xxxxxxx.xxx, xxxxxxxx.x.xxxxx@xxxxxxxx.x0x, xxxxxxxx.xx@xxxxxxx.x0x, xxxxxxxx.xxx@xxx.x123xx, xxxxxxxx.xxxx.xx@xx, xxxxxxxx.xxxx@xx, xxxxxxxx.xxxx@xxxxx, xxxxxxxx.xxxx@xxxxxxxxxx.x123xx, xxxxxxxx.xxxxx.@xxx.xx, xxxxxxxx.xxxxx@xxx., xxxxxxxx.xxxxx@xxxx.x0x, xxxxxxxx.xxxxx@xxxxx.xxx., xxxxxxxx.xxxxx@xxxxxxxxx., xxxxxxxx.xxxxxx@xx.xxxx.x123xx, xxxxxxxx.xxxxxx@xxx, xxxxxxxx.xxxxxx@xxxx., xxxxxxxx.xxxxxx@xxxxx, xxxxxxxx.xxxxxx@xxxxxxxxxx.xxxxx., xxxxxxxx.xxxxxx@xxxxx-xxxxxx, xxxxxxxx.xxxxxx15@xxxxx.x, xxxxxxxx.xxxxxxx.@xxxxx.xxxx.xxx, xxxxxxxx.xxxxxxxx.@xx.xxxx.xxx, xxxxxxxx.xxxxxxxx@x, xxxxxxxx.xxxxxxxx@xxx, xxxxxxxx.xxxxxxxx4@xxxx, xxxxxxxx.xxxxxxxxx@xxxxx, xxxxxxxx@1.xxx, xxxxxxxx@123, xxxxxxxx@2xxxxx, xxxxxxxx@x, xxxxxxxx@x.xx, xxxxxxxx@x.xxx, xxxxxxxx@x.xxxx, xxxxxxxx@xx, xxxxxxxx@xx.x, xxxxxxxx@xx.xxxx.x0x, xxxxxxxx@xx.xxxxx.3xx, xxxxxxxx@xx.xxxxx.x123xx, xxxxxx-xx@xx74xx, xxxxxxxx@xxx, xxxxxxxx@xxx., xxxxxxxx@xxx.x, xxxxxxxx@xxx.x0x, xxxxxxxx@xxx.x123xx, xxxxxxxx@xxx.x234xx, xxxxxxxx@xxx.xxx., xxxxxxxx@xxx.xxxx.x123xx, xxxxxxxx@xxx69.xxxx.x132xx, xxxxxxxx@xxxx, xxxxxxxx@xxxx.0xx, xxxxxxxx@xxxx.x, xxxxxxxx@xxxx.xx.xx., xxxxxxxx@xxxx.xxxx.x0x, xxxxxxxx@xxxxx, xxxxxxxx@xxxxx., xxxxxxxx@xxxxx.9xx, xxxxxxxx@xxxxx.x, xxxxxxxx@xxxxx.x0x, xxxxxxxx@xxxxx.x123xx, xxxxxxxx@xxxxx.x45xx, xxxxxxxx@xxxxx.xxx., xxxxxxxx@xxxxx.xxx1234, xxxxxxxx@xxxxx.xxxxxxx1234, xxxxxxxx@xxxxxx, xxxxxxxx@xxxxxx.x, xxxxxxxx@xxxxxx.xxxx.x123xx, xxxxxxxx@xxxxxxx, xxxxxxxx@xxxxx-xx, xxx-xxxxx@xxxxxxx.x, xxxxxxxx@xxxxxxx.x123xx, xxxxxxxx@xxxxxxx.x3x, xxxxxxxx@xxxxxxx.x45xx, xxxxxxxx@xxxxxxx.xxx., xxxxxxxx@xxxxxxxx, xxxxxxxx@xxxxx-xxx, xxxxxxxx@xxxxxxxx.x123xx, xxxxxxxx@xxxxxxxxx, xxxxxxxx@xxxxxxxxx.0xx, xxxxxxxx@xxxxxxxxx.x3x, xxxxxxxx@xxxxxxxxxx, xxxxxxxx@xxx-xxxxxxx, xxxxxxxx@xxxxxxxxxx.x123xx, xxxxxxxx@xxxxxxxxxxx, xxxxxxxx@xxx-xxxxxxxx, xxxxxxxx@xxxxxxxxxxx.x123xx, xxxxxxxx@xxxxxxxxxxxx, xxxxxxxx@xxx-xxxxxxx-xx, xxxxxxxx@xxxxxxxxxxxx., xxxxxxxx@xxxxxxxxxxxx.x123xx, xxxxxxxx@xxxxxxxxxxxxx, xxxxxxxx@xxxxxxxxxxxxxx, xxxxxxxx@xxxxxxxx-xxxxxx, xxxxxxxx@xxxxxxxxxxxxxx@xxx.xxx, xxxxxxxx@xxxxxxxxxxxxxxx, xxxxxxxx@xxxxxxxxxxxxxxxx.x0x, xxxxxxxx@xxxxxxxxxxxxxxxxxxx, xxxxxxxx@xxxxxxxxxxxxxxxxxxxx, xxxxxxxx_121@xxxxxxxxxx, xxxxxxxx_1980@xxxxxxx, xxxxxxxx_2@x.xxx, xxxxxxxx_xxxx95@xxxxx, xxxxxxxx_xxxxx@xxxxxxxxxx, xxxxxxxx_xxxxxx@xxxxx.x123xx, xxxxxxxx_xxxxxxx@xxxxx-xxx, xxxxxxxx_xxxxxxxx@xxxxx.xxx., xxxxxxxx_xxxxxxxx2009@xxxxx, xxxxxxxx001@xxxxxxx.x123xx, xxxxxxxx001@xxxxxxxxxx-xxx, xxxxxxxx03@xxxxx.xxx., xxxxxxxx06@xxxxxxxxxx, xxxxxxxx07@x.xxx, xxxxxxxx07@xxxxxxxxxx, xxxxxxxx08@x.xxx, xxxxxxxx1@x.xx, xxxxxxxx1@x.xxx, xxxxxxxx1@xxxxx, xxxxxxxx1@xxxxxxx.9xx, xxxxxxxx1@xxxxxxxx, xxxxxxxx1@xxxxxxxxxxx, xxxxxxxx11@xx, xxxxxxxx11@xxxxx.xxx-123456, xxxxxxxx12@xxxxx, xxxxxxxx12@xxxxxxx., xxxxxxxx13@xxx.x123xx, xxxxxxxx13@xxxxx, xxxxxxxx133@xxxxx, xxxxxxxx14@xxx, xxxxxxxx14@xxxxx, xxxxxxxx16@x.xxx, xxxxxxxx1738@xxxxxxx.x123xx, xxxxxxxx18@xxx, xxxxxxxx1953@xxxxxxx, xxxxxxxx2@xxxxxxxx, xxxxxxxx2000@xx, xxxxxxxx2000@xxxxx, xxxxxxxx2002@xxxxxxxx, xxxxxxxx2007@x.xx, xxxxxxxx2008@xxxxxxxx, xxxxxxxx2011@x.xxx, xxxxxxxx234@xxxxx.x0x, xxxxxxxx24x@x.xxx, xxxxxxxx28@xxx, xxxxxxxx28@xxxxx, xxxxxxxx3@x.xxx, xxxxxxxx3@xxxxx.x, xxxxxxxx32@xxxxxxxxxx.x123xx, xxxxxxxx33@xxx.x123xx, xxxxxxxx37@xx, xxxxxxxx38@xxxxx, xxxxxxxx38@xxxxx.x0x, xxxxxxxx4@x.xxx, xxxxxxxx422@x.xxx, xxxxxxxx44@x.xxx, xxxxxxxx45@xxxxx.x0x, xxxxxxxx47@x.xxx, xxxxxxxx4xx@xxxxx, xxxxxxxx50@xxx.xxx., xxxxxxxx56@xxxxx, xxxxxxxx57@x.xxx, xxxxxxxx6.@xxxxx.xxx, xxxxxxxx6@xxx.x123xx, xxxxxxxx60@x.xxx, xxxxxxxx60@xxx, xxxxxxxx61@x, xxxxxxxx616@xxx, xxxxxxxx63@xxxxxxxx, xxxxxxxx635@xxxxx, xxxxxxxx643@xxxxx.x123xx, xxxxxxxx66@xxxxx, xxxxxxxx70@x.xx, xxxxxxxx70@xxxxxxx.x3x, xxxxxxxx71@x.xxx, xxxxxxxx757@xxxxxxxxxx, xxxxxxxx76@x.xxx, xxxxxxxx76@xxxxxxxx, xxxxxxxx777@xxxxxxx, xxxxxxxx78@xxxxxxxxx.x12xx, xxxxxxxx79@xxxxx, xxxxxxxx84@xxxxxxxxxxxx, xxxxxxxx908@x.xxx, xxxxxxxx92@x.xxx, xxxxxxxx99@xxxxx.x0x, xxxxxxxxx%3x_x22@xxxxxxx.xxx, xxxxxxxxx.@xxxx.xxx, xxxxxxxxx.@xxxx.xxxxxx.xxx, xxxxxxxxx.x@xxxxx, xxxxxxxxx.xx@xxxxxxxxxxx, xxxxxxxxx.xxxx@xx, xxxxxxxxx.xxxx@xxxxxxxxxx, xxxxxxxxx.xxxxxx@x.xx, xxxxxxxxx.xxxxxx@xxxx, xxxxxxxxx.xxxxxx@xxxxxxx, xxxxxxxxx.xxxxxxx@xxxxx.x, xxxxxxxxx.xxxxxxx@xxxxxxxxxxxxxxxxx.x, xxxxxxxxx.xxxxxxxx@xxxxxx, xxxxxxxxx.xxxxxxxxx@xxx.x0x, xxxxxxxxx.xxxxxxxxxxxxxxx@x, xxxxxxxxx@0410, xxxxxxxxx@200xxxxxxxxxxx, xxxxxxxxx@x, xxxxxxxxx@x.xx, xxxxxxxxx@x.xxx, xxxxxxxxx@xx, xxxxxxxxx@xxx, xxxxxxxxx@xxx.123xxx, xxxxxxxxx@xxx.x, xxxxxxxxx@xxx.x123xx, xxxxxxxxx@xxx.xx.x123xx, xxxxxxxxx@xxx.xxx., xxxxxxxxx@xxx123, xxxxxxxxx@xxxx, xxxxxxxxx@xxxx.xxxxxx.xxx.xx., xxxxxxxxx@xxxxx, xxxxxxxxx@xxxxx., xxxxxxxxx@xxxxx.x, xxxxxxxxx@xxxxx.x0x, xxxxxxxxx@xxxxx.x123xx, xxxxxxxxx@xxxxx.xxx., xxxxxxxxx@xxxxx.xxx.xx., xxxxxxxxx@xxxxx.xxx.xxxx1234, xxxxxxxxx@xxxxxx, xxxxxxxxx@xxxxxxx, xxxxxxxxx@xxxxxxx.x0x, xxxxxxxxx@xxxxxxx.x123xx, xxxxxxxxx@xxxxxxx.x213xx, xxxxxxxxx@xxxxxxx.x3x, xxxxxxxxx@xxxxxxx.xx., xxxxxxxxx@xxxxxxx.xxx., xxxxxxxxx@xxxxxxx.xxx-xx, xxxxxxxxx@xxxxxxx7xx, xxxxxxxxx@xxxxxxxx, xxxxxxxxx@xxxxx-xxx, xxxxxxxxx@xxxxxxxx.x, xxxxxxxxx@xxxxxxxx.x123xx, xxxxxxxxx@xxxxxxxx.x3x, xxxxxxxxx@xxxxxxxx.xx.x0x, xxxxxxxxx@xxxxxxxx.xxx.x123xx, xxxxxxxxx@xxxxxxxxx, xxxxxxxxx@xxxxxxxxx.x123xx, xxxxxxxxx@xxxxxxxxx.x3x, xxxxxxxxx@xxxxxxxxx.xxx6, xxxxxxxxx@xxxxxxxxxx, xxxxxxxxx@xxxxxxxxxx., xxxxxxxxx@xxxxxxxxxx.x1232xx, xxxxxxxxx@xxxxxxxxxxx, xxxxxxxxx@xxxxxxxxxxx.0xx, xxxxxxxxx@xxxxxxxxxxx.x0x, xxxxxxxxx@xxxxxxxxxxx.xxx., xxxxxxxxx@xxxxxxxxxxxx, xxxxxxxxx@xxxxxxxxxxxxx, xxxxxxxxx@xxxxxxxxxxxxx.1x, xxxxxxxxx@xxxxxxxxxxxxxx, xxxxxxxxx@xxxxxxxxxxxxxxx, xxxxxxxxx@xxxxxxxxxxxxxxxx54, xxxxxxxxx@xxxxxxxxxxxxxxxxxxxx, xxxxxxxxx_89@xxxxxxx., xxxxxxxxx_xxxxxx@xxxxx, xxxxxxxxx03@xxxxx, xxxxxxxxx04@x.xxx, xxxxxxxxx05@xxxxx, xxxxxxxxx08@x.xxx, xxxxxxxxx1@x, xxxxxxxxx1@x.xx, xxxxxxxxx1@xxxxx, xxxxxxxxx1@xxxxxxx.x123xx, xxxxxxxxx1@xxxxxxxxxx, xxxxxxxxx103@xxx, xxxxxxxxx1031@xxxxxxx, xxxxxxxxx107@xxxxxxxx, xxxxxxxxx11@x.xxx, xxxxxxxxx12@xxxxxxxx, xxxxxxxxx122203@xxxxxxx., xxxxxxxxx13387@xxxxxxx.x123xx, xxxxxxxxx17@xxxxxxxxxx, xxxxxxxxx179@xxxxxxxx, xxxxxxxxx1966@xxxxxxxxxx, xxxxxxxxx1979@x.xx, xxxxxxxxx1998@xxxxx.x0x, xxxxxxxxx2@x.xxx, xxxxxxxxx2000@xxxxx, xxxxxxxxx2570@xxxx., xxxxxxxxx3@xxxxx.xxx., xxxxxxxxx3@xxxxxxxx, xxxxxxxxx30@xxxxxxx, xxxxxxxxx35@x, xxxxxxxxx4@x.xxx, xxxxxxxxx4@xxxx, xxxxxxxxx41@xxxxx, xxxxxxxxx45@x.xxx, xxxxxxxxx50@x, xxxxxxxxx547@xxxxxxx, xxxxxxxxx57@xxxxxxx, xxxxxxxxx58@xxxxx, xxxxxxxxx61@x.xxx, xxxxxxxxx64@x.xxx, xxxxxxxxx649@xxxxx., xxxxxxxxx696@xxxxxx, xxxxxxxxx7@xxx, xxxxxxxxx710.@xxx.xxx, xxxxxxxxx78@xxxxxxx, xxxxxxxxx83@xxxxxxxx, xxxxxxxxx8609@x.xxx, xxxxxxxxx88@xxxxx, xxxxxxxxx99@xxx, xxxxxxxxx99@xxxxx, xxxxxxxxx999@x.xxx, xxxxxxxxxx%2x1@xxxx.xxx, xxxxxxxxxx.@xxx.xxx, xxxxxxxxxx.@xxxxx.xxx, xxxxxxxxxx.@xxxxxx.xx.xxx, xxxxxxxxxx.x.xxxxx@xxxxx., xxxxxxxxxx.x@xxxxxxx, xxxxxxxxxx.xx.xx@xx, xxxxxxxxxx.xxx@xxxx, xxxxxxxxxx.xxxxxx@x.xxx, xxxxxxxxxx.xxxxxxxx@x, xxxxxxxxxx@19659, xxxxxxxxxx@x, xxxxxxxxxx@x.xx, xxxxxxxxxx@x.xxx, xxxxx-xxxxx@x.xxx, xxxxxxxxxx@x.xxxxxxx, xxxxxxxxxx@xx, xxxxxxxxxx@xx.xxxxxxxx.xxx., xxxxxxxxxx@xxx, xxxxxxxxxx@xxx., xxxxxxxxxx@xxx.x0x, xxxxxxxxxx@xxx.x123xx, xxxxxxxxxx@xxx.x132xx, xxxxxxxxxx@xxx.x13xx, xxxxxxxxxx@xxx.x3x, xxxxxxxxxx@xxx.xx9x, xxxxxxxxxx@xxx.xxx., xxxxxxxxxx@xxxx, xxxxxxxxxx@xxxx.xxx.3xx, xxxxxxxxxx@xxxxx, xxxxxxxxxx@xxxxx., xxxxxxxxxx@xxxxx.x0x, xxxxxxxxxx@xxxxx.xxx., xxxxxxxxxx@xxxxx1948, xxxxxxxxxx@xxxxxx, xxxxxxxxxx@xxx-xxx, xxxxxxxxxx@xxxxxx.xxx.x12, xxxxxxxxxx@xxxxxxx, xxxxxxxxxx@xxxxxxx., xxxxxxxxxx@xxxxxxx.x, xxxxxxxxxx@xxxxxxx.x0x, xxxxxxxxxx@xxxxxxx.x3x, xxxxxxxxxx@xxxxxxxx, xxxxxxxxxx@xxxxxxxx.x123xx, xxxxxxxxxx@xxxxxxxxx, xxxxxxxxxx@xxxxxxxxx.x, xxxxxxxxxx@xxxxxxxxx.x213xx, xxxxxxxxxx@xxxxxxxxx.x3x, xxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxx@xxxxxxxxxx.xxx2, xxxxxxxxxx@xxxxxxxxxxx, xxxxxxxxxx@xxxxxxxxxxxxx, xxxxxxxxxx@xxxxxxxxxxxxxx.x123xx, xxxxxxxxxx@xxxxxxxxxxxxxxxxxxx.x, xxxxxxxxxx_xxx@xxxxx.xxx.3x, xxxxxxxxxx_xxxx@xxxxxxxxxx, xxxxxxxxxx_xxxxxxx@xxxxxxx, xxxxxxxxxx05@xxx, xxxxxxxxxx05@xxxx, xxxxxxxxxx1@x.xx, xxxxxxxxxx1@xxxxxxx, xxxxxxxxxx13@x.xxx, xxxxxxxxxx14@xxxxx, xxxxxxxxxx2233@x.xxx, xxxxxxxxxx26@xxxxxxxxxx, xxxxxxxxxx28@xxxxxxxx, xxxxxxxxxx3_xxxxxx@xxxxx, xxxxxxxxxx34@xxxxx, xxxxxxxxxx38@xxxxx, xxxxxxxxxx44.@xxxxx.xx, xxxxxxxxxx4xxx@xxxxxxxxx, xxxxxxxxxx518@xxxxx, xxxxxxxxxx60@x.xxx, xxxxxxxxxx726@xxxxx, xxxxxxxxxx76@xxxxx.xxx-xx, xxxxxxxxxx78@xxxxx, xxxxxxxxxx80@xxxxx.x0x, xxxxxxxxxx86@xxxxxx, xxxxxxxxxx88@x.xxx, xxxxxxxxxxx%2x@xxxxx.xxx, xxxxxxxxxxx..x.xxxxxxx@xxxxxxxxxxx.xxx, xxxxxxxxxxx.xxx_xxxxxxxx@x, xxxxxxxxxxx.xxxxx.x@xxxxx.x, xxxxxxxxxxx.xxxxx@xxxxxxx.xxx., xxxxxxxxxxx.xxxxx@xxxxxxxx, xxxxxxxxxxx.xxxxxxxxx@xxxxx, xxxxxxxxxxx.xxxxxxxxx1@xx, xxxxxxxxxxx@x, xxxxxxxxxxx@x.xx, xxxxxxxxxxx@x.xxx, xxxx-xxxxxxx@x.xxx, xxxxxxxxxxx@xx4xxx, xxxxxxxxxxx@xxx, xxxxxxxxxxx@xxxx, xxxxxxxxxxx@xxxxx, xxxxxxxxxxx@xxxxx., xxxxxxxxxxx@xxxxx.x, xxxxxxxxxxx@xxxxx.x0x, xxxxxxxxxxx@xxxxx.x123xx, xxxxxxxxxxx@xxxxx.xx6, xxxxxxxxxxx@xxxxx.xxx., xxxxxxxxxxx@xxxxxx, xxxxxxxxxxx@xxxxxxx, xxxx-xxxxxxx@xxxxxxx, xx-xxxxxxxxx@xxxxxxx., xxxxxxxxxxx@xxxxxxx.x2x, xxxxxxxxxxx@xxxxxxx.x3x, xxxxxx-xxxxx@x-xxxxxx.xx-xxxxxx, xxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxx@xxxxxxxxx.x123xx, xxxxxxxxxxx@xxxxxxxxx.x3x, xxxxxxxxxxx@xxxxxxxxx.xxx3, xxxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxxx@xxxxxxxxxx.xx12x, xxxxxxxxxxx@xxxxxxxxxx.xxx., xxxxxxxxxxx@xxxxxxxxxxx, xxxxxxxxxxx@xxxxxxxxxxxx, xxxxxxxxxxx@xxxxxxxxxxxxx, xxxxxxxxxxx@xxxxxxxxxxxxxxx, xxxxxxxxxxx07@xxxxxxxx, xxxxxxxxxxx1@xxxxx, xxxxxxxxxxx1@xxxxx.x123xx, xxxxxxxxxxx1@xxxxxxxx, xxxxxxxxxxx12@xxxxx, xxxxxxxxxxx151@xxxxx., xxxxxxxxxxx1946@xxxxxxxxxx, xxxxxxxxxxx2@x.xxx, xxxxxxxxxxx2001@xxxxx.x123xx, xxxxxxxxxxx2002@xxx, xxxxxxxxxxx2002@xxxxx, xxxxxxxxxxx21@xxx., xxxxxxxxxxx44@xxxxx., xxxxxxxxxxx45@xxxxxxx, xxxxxxxxxxx69@xxxxx, xxxxxxxxxxx7@xxxxx, xxxxxxxxxxx711@xxxxxxxxxxx, xxxxxxxxxxx8@x.xxx, xxxxxxxxxxx900@x.xxx, xxxxxxxxxxx92@x.xxx, xxxxxxxxxxx96@xxxxxx, xxxxxxxxxxx99@xxxxx, xxxxxx-xxxxxx.@xx.xxx, xxxxxxxxxxxx.@xxxxx.xxx, xxxxxxxxxxxx.x.x@xx, xxxxxxxxxxxx.xxx@xxx, xxxxxxxxxxxx.xxx@xxxx, xxxxxxxxxxxx.xxxxxxx@xxxxxxxxxx, xxxxxxxxxxxx@x.xx, xxxxxxxxxxxx@x.xxx, xxxxxxxxxxxx@x4xxx, xxxxxxxxxxxx@xxx, xxxxxxxx-xxxx@xxx, xxxxxxxxxxxx@xxx., xxxxxxxxxxxx@xxx.xx., xxxxxxxxxxxx@xxxx, xxxxxxxxxxxx@xxxxx, xxxxxxxxxxxx@xxxxx.x0x, xxxxxxxxxxxx@xxxxx.x3, xxxxxxxxxxxx@xxxxx.xx.x123x, xxxxxxxxxxxx@xxxxx.xx04, xxxxxxxxxxxx@xxxxx.xxx., xxxxxxxxxxxx@xxxxx.xxxx., xxxxxxxxxxxx@xxxxxx, xxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxx@xxxxxxx., xxxxxxxxxxxx@xxxxxxx.x, xxxxxxxxxxxx@xxxxxxx.x123xx, xxxxxxxxxxxx@xxxxxxx.xx0x, xxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxx@xxxxx-xxx, xxxxxxxxxxxx@xxxxxxxx.x123xx, xxxxxxxxxxxx@xxxxxxxx.xxx., xxxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxxx@xxxxxxxxxx, xxx-xxxxxxx-xx@xxxxxxxxxx, xxxxxxxxxxxx@xxxxxxxxxxx, xxxxxxxxxxxx@xxxxxxxxxxxx.x, xxxxxxxxxxxx_23@xxxxxxxxxx, xxxxxxxxxxxx1@xxx.x0x, xxxxxxx-xxxxx1@xxx.xx9x, xxxxxxxxxxxx1@xxxxxxx, xxxxxxxxxxxx1@xxxxxxxx, xxxxxxxxxxxx100@xxxxx.x0x, xxxxxxxxxxxx123@xxxxxxx, xxxxxxxxxxxx14@xxxxx., xxxxxxxxxxxx1970@xxxxx-xxx, xxxxxxxxxxxx1975@xxxxx, xxxxxxxxxxxx20@xxxxxxx.x9x, xxxxxxxxxxxx2000.@xxxxxxx.xxx, xxxxxxxxxxxx3@xxxxx, xxxxxxxxxxxx7@xxxxx, xxxxxxxxxxxx88.@xxxxx.xxx, xxxxxxxxxxxx88@xxxxx., xxxxxxxxxxxx9@x.xxx, xxxxxxxxxxxxx.@xxx.xxx, xxxxxxxxxxxxx@12xxxxxxxx, xxxxxxxxxxxxx@x.xxx, xxxxxxxxxxxxx@xx, xxxxxxxxxxxxx@xxx, xxxxxxxxxxxxx@xxx.x0x, xxxxxxxxxxxxx@xxx.x213xx, xxxxxxxxxxxxx@xxxx, xxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxx@xxxxx., xxxxxxxxxxxxx@xxxxx.x123xx, xxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxx@xxxxxxx.x, xxxxxxxxxxxxx@xxxxxxx.x123xx, xxxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxxxxx@xxxxxxxxxx.x123xx, xxxxxxxxxxxxx_1@x.xxx, xxxxxxxxxxxxx1@xxxxxxxxx.x123xx, xxxxxxxxxxxxx100@xxxxxxxxxx, xxxxxxxxxxxxx2@x.xxx, xxxxxxxxxxxxx4x697xxxx9x25xx8..7@xxxxx.xxx, xxxxxxxxxxxxx6699@xxxxxxx, xxxxxxxxxxxxx8@xxx, xxxxxxxxxxxxxx.@xxxxx.xxx, xxxxxxxxxxxxxx@x.xxx, xxxxxxxxxxxxxx@xxx, xxxxxxxxxxxxxx@xxx.123xx, xxxxxxxxxxxxxx@xxx.x234xx, xxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxx@xxxxx.x, xxxxxxxxxxxxxx@xxxxx.x0x, xxxxxxxxxxxxxx@xxxxx.x123xx, xxxxxxxxxxxxxx@xxxxx.xxx., xxxxxxxxxxxxxx@xxxxx.xxx.xx., xxxxxxxxxxxxxx@xxxxxx, xxxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxxx@xxxxxxx.x123xx, xxxxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxxxxx@xxxxxxxxx.x132xx, xxxxxxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxxxxxx@xxxxxxxxxxxxxxx.x123xx, xxxxxxxxxxxxxx@xxxxxxxxxxxxxxxx.x0x, xxxxxxxxxxxxxx05@x, xxxxxxxxxxxxxx2003@xxxxx.xx., xxxxxxxxxxxxxx2008@xxxxxxxxxx, xxxxxxxxxxxxxx3@xxxxxxxx, xxxxxxxxxxxxxx55@xxx, xxxxxxxxxxxxxxx%2xxxx@xxxx, xxxxxxxxxxxxxxx.@xxxxxxxxx.xxx, xxxxxxxxxxxxxxx@x, xxxxxxxxxxxxxxx@x.xxx, xxxxxxx-xxxxxxxx@x.xxx, xxxxxxxxxxxxxxx@xx.x, xxxxxxxxxxxxxxx@xxx, xxxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxxx@xxxxx.x123xx, xxxxxxxxxxxxxxx@xxxxx.xxx., xxxxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxxxxxx@xxxxxxxxx.x3x, xxxxxxxxxxxxxxx@xxxxxxxxxxxx, xxxxxx-xxxx-xxxxx2%2xxxxxxx@xxxxxx, xxxxxxxxxxxxxxx2@xxxxx.x0x, xxxxxxxxxxxxxxx85@xxxxx, xxxxxxxxxxxxxxxx%2xxxxx%2xxxxx@xxxx02, xxxxxxxxxxxxxxxx.@xxx.xxx, xxxxxxxxxxxxxxxx.x@x, xxxxxxxxxxxxxxxx@x.xxx, xxxxxxxxxxxxxxxx@xx, xxxxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxxxxxxxx@xxxxxxxxxxx.x, xxxxxxxxxxxxxxxxx.xxxx2007@x, xxxxxxxxxxxxxxxxx@x.xxx, xxxxxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxxxxx@xxxxxx, xxxxxxxxxxxxxxxxx@xxxxxxx.x0, xxxxxxxxxxxxxxxxx@xxxxxxxx, xxxxxxxxxxxxxxxxx@xxxxxxxxx, xxxxxxxxxxxxxxxxxx@x.xxx, xxxxxxxxxxxxxxxxxx@xx, xxxxxxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxxxxxx@xxxxx.xx., xxxxxxxxxxxxxxxxxx2@xxxxxxxxxx, xxxxxxxxxxxxxxxxxx62@xxxxxxxx, xxxxxxxxxxxxxxxxxxx.@xxxxx.xxx, xxxxxxxxxxxxxxxxxxx@xxxxx, xxxxxxxxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxxxxxxxxx@786, xxxxxxxxxxxxxxxxxxxx@xxxxx, xxxxxxxxx-xxxxxxxxxxx@xxxxxxx.x3x, xxxxxxxxxxxxxxxxxxxxx@xxxxxxx, xxxxxxxxxxxxxxxxxxxxx@xxxxxxxxxx, xxxxxxxxxxxxxxxxxxxxxxx.@xxxxx.xxx, xxxxxxxxxxxxxxxxxxxxxxxxxxx3xxxxxxxxx@xxxxxxxxxxxxxxxxxxxxxxxxxx,









-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)
-600.png)


















 Bogdan Condurache is one of the co-founders and a designer at
Bogdan Condurache is one of the co-founders and a designer at