O Spring Security tem recursos avançados e de simples configuração para lhe ajudar com a segurança da sua aplicação.
Falando nisso, e a sua aplicação web? Está segura!? Hoje vamos conversar sobre como você pode aplicar segurança profissional nela.
Veremos algumas coisas bem legais agora. Fique comigo nos próximos minutos que você irá aprender sobre:
- O que é Spring Security
- Como configurar o Spring Security
- Configurar autenticação em memória
- Como fazer autenticação via JDBC
- Como fazer autenticação via JPA utilizando a interface
UserDetailsService - Criar uma página de login customizada
- A função “lembrar-me”
- Criar a funcionalidade de logout
- Como adicionar permissões (autorização) em nossas páginas
Vamos lá?
O que é Spring Security?
Spring Security tem o foco em tornar a parte de autenticação e autorização uma coisa simples de fazer. Ele tem uma variedade muito grande de opções e ainda é bastante extensível.
Com algumas poucas configurações já podemos ter uma autenticação via banco de dados, LDAP ou mesmo por memória. Sem falar nas várias integrações que ele já suporta e na possibilidade de criar as suas próprias.
Quanto a autorização, ele é bem flexível também. Através das permissões que atribuímos aos usuários autenticados, podemos proteger as requisições web (como as telas do nosso sistema, por exemplo), a simples invocação de um método e até a instância de um objeto.
Sem contar que, por tabela, nós já protegemos as nossas aplicações de diversos ataques como o session fixation (link em inglês) e o cross site request forgery (link em inglês).
Como configurar o Spring Security
Para começar, já estou considerando que você tem um projeto com Spring MVC configurado. Caso você não tenha, pode ficar tranquilo que irei disponibilizar o código-fonte dos exemplos desse artigo aqui.
Falando especificamente das configurações do Spring Security, para começar você vai precisar criar uma classe que estenda AbstractSecurityWebApplicationInitializer.
Ela vai servir para adicionar o filtro do Spring Security.
import org.springframework.security.web.context.AbstractSecurityWebApplicationInitializer;
public class SpringWebSecurityInitializer extends AbstractSecurityWebApplicationInitializer {
}
Agora nós vamos começar a fazer configurações mais específicas. A primeira forma de autenticação será HTTP Basic e, por ora, o sistema não exigirá permissões de acesso. Vai ser necessária somente a autenticação.
Faremos isso com a criação de uma classe qualquer que estenda SecurityWebConfigAdapter. Depois sobrescrevemos o método configure para alterarmos a instância de HttpSecurity conforme nossa necessidade.
@EnableWebSecurity
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
// Para qualquer requisição (anyRequest) é preciso estar
// autenticado (authenticated).
.anyRequest().authenticated()
.and()
.httpBasic();
}
}
Importante não esquecer da anotação @EnableWebSecurity. Como o próprio nome diz, é ela que habilita os recursos de segurança em nossa aplicação.
Podemos dizer que temos 50% configurado. Ainda faltam os usuários. Vamos começar buscando eles em memória.
Autenticação em memória
A configuração de usuários em memória, geralmente, não é utilizada em produção, mas pode ser muito útil no início do desenvolvimento.
Continuando a alteração na nossa classe SecurityWebConfig, agora vamos sobrescrever o método configure que recebe a instância de AuthenticationManagerBuilder. Utilizaremos esse objeto para criar nossos usuários.
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
...
@Override
public void configure(AuthenticationManagerBuilder builder) throws Exception {
builder
.inMemoryAuthentication()
.withUser("garrincha").password("123")
.roles("USER")
.and()
.withUser("zico").password("123")
.roles("USER");
}
}
Veja que agora temos dois usuário configurados: o garrincha e o zico.
Já podemos fazer um teste em nossa aplicação.
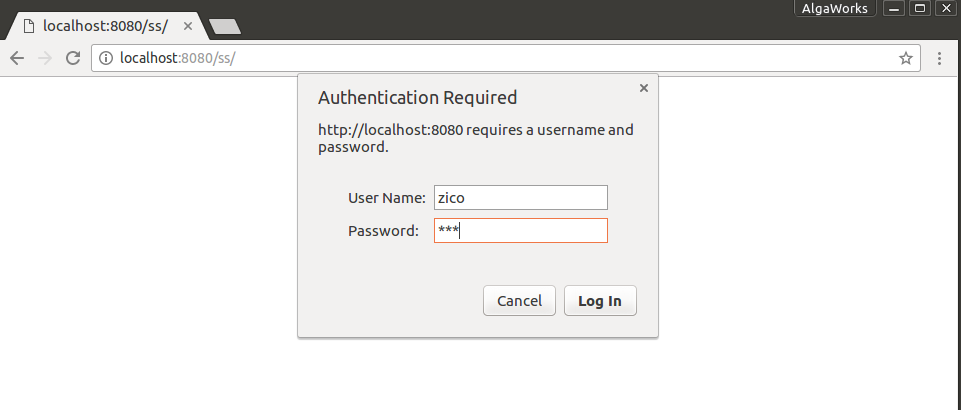
Autenticação via JDBC
Essa já é uma boa alternativa até mesmo para o projeto em produção. Para utilizar essa opção do Spring Security vamos precisar apenas de uma fonte de dados e do SQL referente as consultas que buscam o usuário no banco.
Provavelmente, você já foi alertado de que não é seguro deixar as senhas serem gravadas limpas na base de dados. Por isso vou aproveitar também para utilizar um PasswordEncoder que irá resolver esse problema.
Dessa forma poderemos salvar nossos usuários com senhas criptografadas que a implementação de PasswordEncoder irá ajudar o Spring Security a comparar a senha submetida na hora do login.
Veja aqui como fica nosso método configure(AuthenticationManagerBuilder):
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
private static final String USUARIO_POR_LOGIN = "SELECT login, senha, ativo, nome FROM Usuario"
+ " WHERE login = ?";
private static final String PERMISSOES_POR_USUARIO = "SELECT u.login, p.nome FROM usuario_permissao up"
+ " JOIN usuario u ON u.id = up.usuarios_id"
+ " JOIN permissao p ON p.id = up.permissoes_id"
+ " WHERE u.login = ?";
private static final String PERMISSOES_POR_GRUPO = "SELECT g.id, g.nome, p.nome FROM grupo_permissao gp"
+ " JOIN grupo g ON g.id = gp.grupos_id"
+ " JOIN permissao p ON p.id = gp.permissoes_id"
+ " JOIN usuario_grupo ug ON ug.grupos_id = g.id"
+ " JOIN usuario u ON u.id = ug.usuarios_id"
+ " WHERE u.login = ?";
@Autowired
private DataSource dataSource;
...
@Override
protected void configure(AuthenticationManagerBuilder builder) throws Exception {
builder
.jdbcAuthentication()
.dataSource(dataSource)
.passwordEncoder(new BCryptPasswordEncoder())
.usersByUsernameQuery(USUARIO_POR_LOGIN)
.authoritiesByUsernameQuery(PERMISSOES_POR_USUARIO)
.groupAuthoritiesByUsername(PERMISSOES_POR_GRUPO)
.rolePrefix("ROLE_");
}
}
Feita a alteração acima, agora você já pode fazer o login na aplicação via JDBC.
Para aqueles que quiserem saber como a senha deve ser salva na base de dados, eu deixei um método main na classe que vai ajudar com isso. Veja:
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
public static void main(String[] args) {
System.out.println(new BCryptPasswordEncoder().encode("123"));
}
}
Com o resultado do método encode você consegue fazer um insert para um usuário de teste:
insert into Usuario (id, nome, login, senha, ativo) values
(1, 'Alexandre Afonso', 'alexandre', '$2a$10$ARppQC0FRWaGP4pnZqYbpuVyYOWIp4q1r2ViT3PGYK6BafD5PXFiS', true);
No projeto de exemplo, que irei disponibilizar no final do artigo, tem um arquivo chamado import.sql que é executado automaticamente e já faz as inserções iniciais para os nossos testes aqui.
Autenticação via JPA com a interface UserDetailsService
Como disse, a configuração via JDBC, mostrada anteriormente, já é uma boa opção para se utilizar em produção, mas muitas vezes é necessária uma configuração mais personalizada utilizando a interface UserDetailsService.
Iremos utilizá-la para poder fazer a consulta na base de dados com JPA.
Para o nosso exemplo eu criei três entidades que participarão do processo de autenticação. São elas: a entidade Usuario, Grupo e Permissao. Como o código delas é bem simples, eu não irei mostrar aqui, mas você vai poder baixar o fonte e dar uma olhada nelas depois.
Além das entidades, cheguei a criar também a classe UsuarioSistema, que é uma implementação de UserDetails. Precisamos dela para conseguir dar um retorno para o método loadUserByUsername, que vamos implementar.
public class ComercialUserDetailsService implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
return null;
}
}
A única responsabilidade desse método é buscar o usuário pelo username. Não devemos fazer a validação da senha nele, pois quem vai fazer isso é o próprio Spring Security.
Vou utilizar JPA para buscar o usuário do banco de dados, mas é importante destacar que não importa de onde ele vem – banco de dados, memória, etc – o que importa é devolver uma implementação de UserDetails. Poderíamos utilizar aqui uma consulta JDBC com queries personalizadas, se quiséssemos.
Veja agora a implementação completa:
@Component
public class ComercialUserDetailsService implements UserDetailsService {
@Autowired
private Usuarios usuarios;
@Autowired
private Grupos grupos;
@Autowired
private Permissoes permissoes;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
Usuario usuario = usuarios.findByLogin(username);
if (usuario == null) {
throw new UsernameNotFoundException("Usuário não encontrado!");
}
return new UsuarioSistema(usuario.getNome(), usuario.getLogin(), usuario.getSenha(), authorities(usuario));
}
public Collection<? extends GrantedAuthority> authorities(Usuario usuario) {
return authorities(grupos.findByUsuariosIn(usuario));
}
public Collection<? extends GrantedAuthority> authorities(List<Grupo> grupos) {
Collection<GrantedAuthority> auths = new ArrayList<>();
for (Grupo grupo: grupos) {
List<Permissao> lista = permissoes.findByGruposIn(grupo);
for (Permissao permissao: lista) {
auths.add(new SimpleGrantedAuthority("ROLE_" + permissao.getNome()));
}
}
return auths;
}
}
Com o nosso UserDetailsService em mãos, podemos voltar na classe SecurityWebConfig e terminar a configuração:
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
@Autowired
private ComercialUserDetailsService comercialUserDetailsService;
...
@Override
protected void configure(AuthenticationManagerBuilder builder) throws Exception {
builder
.userDetailsService(comercialUserDetailsService)
.passwordEncoder(new BCryptPasswordEncoder());
}
}
Ficou simples também, não é mesmo?
Dessa forma você já pode subir a aplicação para fazer mais esse teste.
Página de login customizada
Até o momento estamos fazendo o login via HTTP Basic. Vamos mudar isso agora.
Porém, antes de criarmos uma página de login customizada por nós, gostaria de mostrar pra você a página de login que existe dentro do próprio Spring Security. Para certos tipos de caso, pode ser uma boa opção.
Para utilizarmos ela vamos precisar alterar somente uma linha. Só que agora é no método configure que recebe um objeto do tipo HttpSecurity. Veja:
@EnableWebSecurity
public class SecurityWebConfig extends WebSecurityConfigurerAdapter {
...
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin(); // <<< de HTTP Basic para formulário
}
...
}
Iniciando a aplicação novamente, a tela de login que você irá ver será esta:

É uma página bem simples, mas ela não foi feita para ser uma solução geral e sim para aqueles casos em que precisamos economizar tempo.
Bom… Agora vamos fazer a configuração para utilizarmos a nossa própria página de login.
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin()
// Aqui dizemos que temos uma página customizada.
.loginPage("/login")
// Mesmo sendo a página de login, precisamos avisar
// ao Spring Security para liberar o acesso a ela.
.permitAll();
}
Agora vamos para o HTML do formulário de login. Ele precisa estar de acordo com as configurações explicitas e implícitas acima. Veja uma versão simplificada do nosso formulário:
<form th:action="@{/login}" method="post">
<input name="username" class="form-control" placeholder="Usuário"/>
<input type="password" name="password" class="form-control" placeholder="Senha"/>
<button class="btn btn-primary btn-block">Entrar</button>
</form>
Temos 3 coisas a reparar nesse formulário: a ação, o nome do campo de usuário e o nome do campo de senha.
A ação é /login e o método HTTP que será usado é o POST. Isso é porque a ação tem o mesmo path da URL que abre a página de login. Só que a requisição para página é feita com um GET para /login e a submissão do formulário é feita com um POST.
O campo “Usuário” precisa ter o nome username. Ele pode ser configurado explicitamente, mas eu preferi utilizar o padrão. Da mesma forma é o campo “Senha” de nome password.
Com as alterações acima já é possível fazer o login através da nossa página. Só que ainda temos um problema com os arquivos JS e CSS utilizados para montar o layout dela:
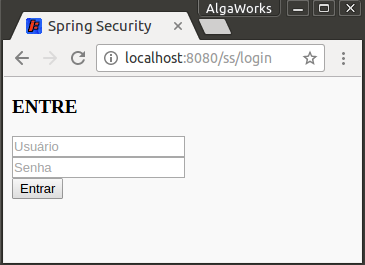
Ela ficou bem parecida com a própria página do Spring Security, mesmo tendo alguns estilos já – aplicados pelo Bootstrap. Isso acontece porque ele restringiu o acesso aos recursos JS e CSS também. Afinal, em momento algum avisamos pra ele liberar.
Esse aviso é feito com a adição da linha:
antMatchers("/resources/**", "/webjars/**").permitAll()
Veja como ficou o método completo até aqui:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/resources/**", "/webjars/**").permitAll()
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login").permitAll();
}
Agora nossa página abre como esperado:

Um detalhe que não pode escapar é que foi preciso criar uma action que fosse responsável por devolver nossa página de login.
Criei um controlador bem simples para isso, que chamei de HomeController. Veja como ficou a action para /login, que devolve a nossa página customizada:
@Controller
public class HomeController {
@GetMapping("/login")
public String login() {
return "login"; // <<< Retorna a página de login
}
@GetMapping("/")
public String index() {
return "inicio";
}
}
Função “lembrar-me”
Uma função muito usada nos sistemas web e que os usuários gostam muito é a “lembrar-me”. Mais uma vez, o Spring Security vai ser uma mão na roda pra nós.
Pra que isso funcione na nossa aplicação é preciso acrescentar somente duas coisas dentro do que já temos.
Uma é o checkbox “lembrar-me” dentro do nosso formulário:
<form th:action="@{/login}" method="post">
...
<button class="btn btn-primary btn-block">Entrar</button>
<input type="checkbox" id="remember-me" name="remember-me" />
<label for="remember-me">Lembrar?</label>
</form>
Repare que o nome do checkbox precisa ser remember-me. Como no caso do input de nome username, esse nome pode ser alterado, mas vou ficar com o padrão mesmo.
Nossa tela vai ficar assim:
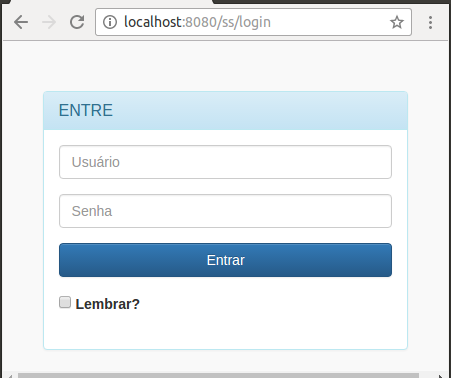
A outra coisa que precisamos é a chamada do método rememberMe, que vai habilitar essa função pra gente:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/resources/**", "/webjars/**").permitAll()
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login").permitAll()
.and()
.rememberMe(); // <<< Habilita a função de "lembrar-me".
}
Depois dessa configuração você já pode reiniciar o servidor e testar o formulário. Faça o login com o campo “lembrar-me” marcado, depois feche todas as instâncias do navegador e entre novamente. O sistema não deve pedir que você se autentique.
Funcionalidade de logout
Do jeito que o sistema está até aqui, a única forma de sair é fechando o navegador. Vamos melhorar isso agora acrescentando um botão para sair.
É bem simples, pois, o Spring Security já tem essa funcionalidade implementada. Basta colocar esse formulário em qualquer lugar do seu sistema:
<form method="post" class="navbar-form navbar-right"
th:action="@{/logout}">
<button type="submit" class="btn btn-default">
<span class="glyphicon glyphicon-log-out"></span>
Sair
</button>
</form>
O mais importante nele é a ação do formulário – ele está fazendo um POST para /logout. Como quase tudo no Spring Security, esse path pode ser customizado, mas estou utilizando o padrão.
Na aplicação de exemplo, deixei o botão na barra superior:

Autorização – permissões para acessar URLs
Como já temos a autenticação configurada – inclusive com login customizado -, podemos pensar um pouco em autorização. Vamos colocar permissões específicas para as nossas páginas.
Na verdade, no Spring Security nós colocamos permissões nas URLs, e não nas páginas. É quase a mesma coisa, mas com essa ideia podemos incluir permissões, por exemplo, em imagens, pois uma imagem tem uma URL e o Spring Security, como eu disse, protege URLs.
Para isso vou criar mais três ações no controlador que irão devolver as páginas que terão restrições.
public class HomeController {
...
@GetMapping("/vendas")
public String vendasLista() {
return "vendas";
}
@GetMapping("/vendas/relatorios/custos")
public String vendasRelatorioMensal() {
return "vendas-relatorio-custos";
}
@GetMapping("/vendas/relatorios/equipe")
public String vendasRelatorioEquipe() {
return "vendas-relatorio-equipe";
}
}
A página /vendas vai exigir somente a autenticação. Já as páginas /vendas/relatorios/custos e /vendas/relatorios/equipe exigirão as permissões VISUALIZAR_RELATORIO_CUSTOS e VISUALIZAR_RELATORIO_EQUIPE, respectivamente.
Esse tipo de configuração nós fazemos também no método configure, que recebe uma instância de HttpSecurity.
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/resources/**", "/webjars/**").permitAll()
.antMatchers("/vendas/relatorios/equipe").hasRole("VISUALIZAR_RELATORIO_EQUIPE")
.antMatchers("/vendas/relatorios/custos").hasRole("VISUALIZAR_RELATORIO_CUSTOS")
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login").permitAll()
.and()
.rememberMe();
}
Olha agora o que acontece quando você entrar no sistema com um usuário que não tem a permissão VISUALIZAR_RELATORIO_EQUIPE e tentar acessar a URL (ou página) /vendas/relatorios/equipe:
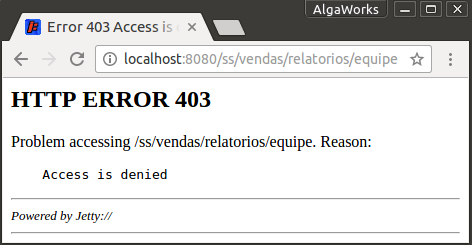
O acesso será negado, claro.
Conclusão
Como mostrei pra você agora, o Spring Security é uma solução profissional para proteção em nível de aplicação.
Mostrei como fazer a configuração do mesmo e depois trabalhamos com autenticação via memória, JDBC e JPA (com o UserDetailsService).
Utilizamos também 3 tipos de login: com HTTP Basic, com o formulário HTML do próprio Spring Security e, por último, fizemos um formulário personalizado.
No final do artigo mostrei como incluir permissões para diferentes URLs do sistema.
Espero que tenha gostado. :)
Gostaria de aprender sobre a integração de Spring Security com o Spring Boot? Então baixe agora o nosso e-book Produtividade no Desenvolvimento de Aplicações Web com Spring Boot:

Um abraço pra você e até uma próxima!
PS: você pode baixar o código-fonte de exemplo em nosso GitHub: http://github.com/algaworks/artigo-spring-security















 . Pode haver mais modificações? Claro, sempre há e com certeza as novidades que trouxemos hoje serão melhor explicadas após o lançamento oficial, então o jeito é ficar ligado
. Pode haver mais modificações? Claro, sempre há e com certeza as novidades que trouxemos hoje serão melhor explicadas após o lançamento oficial, então o jeito é ficar ligado