
Ever wondered how device drivers are reverse engineered? We’ll show you with a simple yet complete example

Fun to play and also simple: this is the device for which we will write a driver.
Ever been enticed into a Windows versus Linux flame war? If not, you are lucky. Otherwise, you probably know that Windows fanboys often talk as though support for peripherals in Linux is non-existant. While this argument loses ground every year (the situation is incomparably better than it was in around 2005), you can still occasionally come across a device that is not recognised by your favourite distribution. Most of the time, this will be some sort of a USB peripheral.
The beauty of free software is that you can fix this situation yourself. The effort required is obviously dependent on how sophisticated the peripheral is, and with a shiny new 3D web camera you may be out of luck. However, some USB devices are quite simple, and with Linux, you don’t even need to delve into the kernel and C to write a working driver program for it. In this tutorial, we’ll show you how it’s done step by step, using a high-level interpreted language (Python, you guessed it) and a toy USB radio controlled car we happen to have lying around.
What we are going to do is a basic variant of a process generally known as reverse engineering. You start examining the device with common tools (USB is quite descriptive itself). Then you capture the data that the device exchanges with its existing (Windows) driver, and try to guess what it means. This is the toughest part, and you’ll need some experience and a bit of luck to reverse engineer a non-trivial protocol. This is legal under most jurisdictions, but as usual, contact a lawyer if in doubt.
Get to know USB
Before you start reversing, you’ll need to know what exactly USB is. First, USB is a host-controlled bus. This means that the host (your PC) decides which device sends data over the wire, and when it happens. Even an asynchronous event (like a user pressing a button on a USB keyboard) is not sent to the host immediately. Given that each bus may have up to 127 USB devices connected (and even more if hubs are concerned), this design simplifies the management.
USB is also a layered set of protocols somewhat like the internet. Its lowest layer (an Ethernet counterpart) is usually implemented in silicon, and you don’t have to think about it. The USB transport layer (occupied by TCP and UDP in the internet – see page 64 for Dr Brown’s exploration of the UDP protocol) is represented by ‘pipes’. There are stream pipes that convey arbitrary data, and message pipes for well-defined messages used to control USB devices. Each device supports at least one message pipe. At the highest layer there are the application-level (or class-level, in USB terms) protocols, like the ubiquitous USB Mass Storage (pen drives) or Human Interface Devices (HID).
Inside a wire
A USB device can be seen as a set of endpoints; or, simply put, input/output buffers. Each endpoint has an associated direction (in or out) and a transfer type. The USB specification defines several transfer types: interrupt, isochronous, bulk, and control, which differ in characteristics and purpose.
Interrupt transfers are for short periodic real-time data exchanges. Remember that a host, not the USB device, decides when to send data, so if (say) a user presses the button, the device must wait until the host asks: “Were there any buttons pressed?”. You certainly don’t want the host to keep silent for too long (to preserve an illusion that the device has notified the host as soon as you pressed a button), and you don’t want these events to be lost. Isochronous transfers are somewhat similar but less strict; they allow for larger data blocks and are used by web cameras and similar devices, where delays or even losses of a single frame are not crucial.
Bulk transfers are for large amounts of data. Since they can easily hog the bus, they are not allocated the bandwidth, but rather given what’s left after other transfers. Finally, the control transfer type is the only one that has a standardised request (and response) format, and is used to manage devices, as we’ll see in a second. A set of endpoints with associated metadata is also known as an interface.
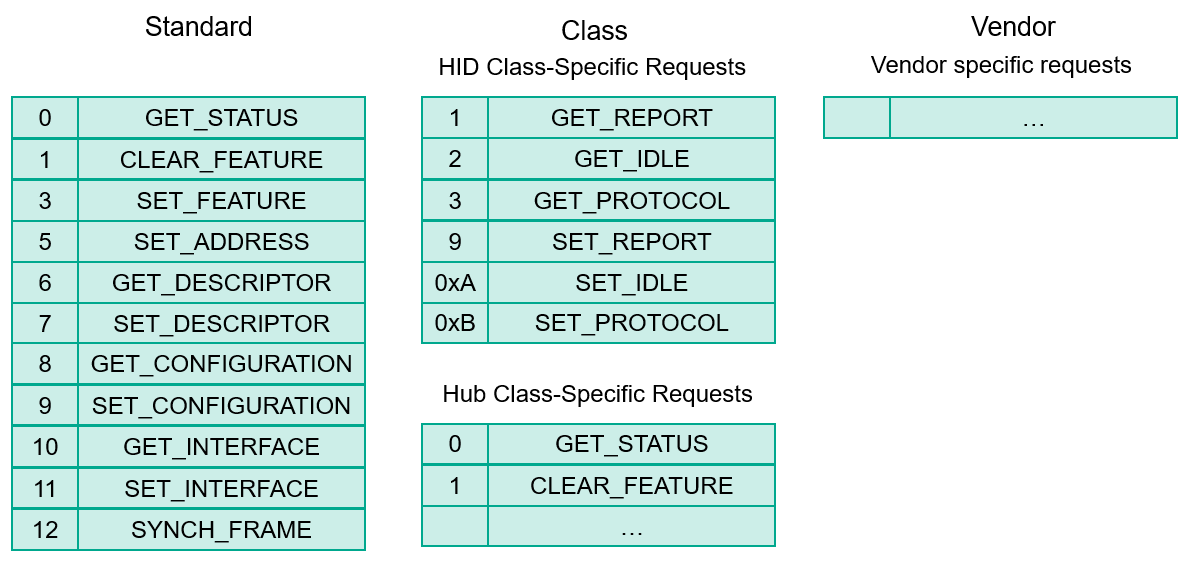
Any USB device has at least one endpoint (number zero) that is the end for the default pipe and is used for control transfers. But how does the host know how many other endpoints the device has, and which type they are? It uses various descriptors available on specific requests sent over the default pipe. They can be standard (and available for all USB devices), class-specific (available only for HID, Mass Storage or other devices), or vendor-specific (read “proprietary”).
Descriptors form a hierarchy that you can view with tools like lsusb. On top of it is a Device descriptor, which contains information like device Vendor ID (VID) and Product ID (PID). This pair of numbers uniquely identifies the device, so a system can find and load the appropriate driver for it. USB devices are often rebranded, but a VID:PID pair quickly reveals their origin. A USB device may have many configurations (a typical example is a printer, scanner or both for a multifunction device), each with several interfaces. However, a single configuration with a single interface is usually defined. These are represented by Configuration and Interface descriptors. Each endpoint also has an Endpoint descriptor that contains its address (a number), direction (in or out), and a transfer type, among other things.
Finally, USB class specifications define their own descriptor types. For example, the USB HID (human interface device) specification, which is implemented by keyboards, mice and similar devices, expects all data to be exchanged in the form of ‘reports’ that are sent/received to and from the control or interrupt endpoint. Class-level HID descriptors define the report format (such as “1 field 8 bits long”) and the intended usage (“offset in the X direction”). This way, a HID device is self-descriptive, and can be supported by a generic driver (usbhid on Linux). Without this, we would need a custom driver for each individual USB mouse we buy.
It’s not too easy to summarise several hundred pages of specifications in a few passages of the tutorial text, but I hope you didn’t get bored. For a more complete overview of how USB operates, I highly recommend O’Reilly’s USB in a Nutshell, available freely at www.beyondlogic.org/usbnutshell. And now, let’s do some real work.
Fixing permissions
By default, only root is able to work with USB devices in Linux. It’s not a good idea to run our example program as a superuser, so add a following udev rule to fix the permissions:
SUBSYSTEM=="usb", ATTRS{idVendor}=="0a81", ATTRS{idProduct}=="0702", GROUP="INSERT_HERE", MODE="0660"
Just insert the name of a group your user belongs to and put this in /lib/udev/rules.d/99-usbcar.rules.
Under the hood
For starters, let’s take a look at how the car looks as a USB device. lsusb is a common Linux tool to enumerate USB devices, and (optionally) decode and print their descriptors. It usually comes as part of the usbutils package.
[val@y550p ~]$ lsusb
Bus 002 Device 036: ID 0a81:0702 Chesen Electronics Corp.
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
...
The car is the Device 036 here (unplug it and run lsusb again to be sure). The ID field is a VID:PID pair. To read the descriptors, run lsusb -v for the device in question:
[val@y550p ~]$ lsusb -vd 0a81:0702
Bus 002 Device 036: ID 0a81:0702 Chesen Electronics Corp.
Device Descriptor:
idVendor 0x0a81 Chesen Electronics Corp.
idProduct 0x0702
...
bNumConfigurations 1
Configuration Descriptor:
...
Interface Descriptor:
...
bInterfaceClass 3 Human Interface Device
...
iInterface 0
HID Device Descriptor:
...
Report Descriptors:
** UNAVAILABLE **
Endpoint Descriptor:
...
bEndpointAddress 0x81 EP 1 IN
bmAttributes 3
Transfer Type Interrupt
...
Here you can see a standard descriptors hierarchy; as with the majority of USB devices, the car has only one configuration and interface. You can also spot a single interrupt-in endpoint (besides the default endpoint zero that is always present and thus not shown). The bInterfaceClass field suggests that the car is a HID device. This is a good sign, since the HID communication protocol is open. You might think that we just need to read the Report descriptor to understand report format and usage, and we are done. However, this is marked ** UNAVAILABLE **. What’s the matter? Since the car is a HID device, the usbhid driver has claimed ownership over it (although it doesn’t know how to handle it). We need to ‘unbind’ the driver to control the device ourselves.
First, we need to find a bus address for the device. Unplug the car and plug it again, run dmesg | grep usb, and look for the last line that starts with usb X-Y.Z:. X, Y and Z are integers that uniquely identify USB ports on a host. Then run:
[root@y550p ~]# echo -n X-Y.Z:1.0 > /sys/bus/usb/drivers/usbhid/unbind
1.0 is the configuration and the interface that we want the usbhid driver to release. To bind the driver again, simply write the same into /sys/bus/usb/drivers/usbhid/bind.
Now, Report descriptor becomes readable:
Report Descriptor: (length is 52)
Item(Global): Usage Page, data= [ 0xa0 0xff ] 65440
(null)
Item(Local ): Usage, data= [ 0x01 ] 1
(null)
...
Item(Global): Report Size, data= [ 0x08 ] 8
Item(Global): Report Count, data= [ 0x01 ] 1
Item(Main ): Input, data= [ 0x02 ] 2
...
Item(Global): Report Size, data= [ 0x08 ] 8
Item(Global): Report Count, data= [ 0x01 ] 1
Item(Main ): Output, data= [ 0x02 ] 2
...
Here, two reports are defined; one that is read from the device (Input), and the other that can be written back to it (Output). Both are one byte long. However, their intended usage is unclear (Usage Page is in the vendor-specific region), and it is probably why the usbhid driver can’t do anything useful with the device. For comparison, this is how a USB mouse Report descriptor looks (with some lines removed):
Report Descriptor: (length is 75)
Item(Global): Usage Page, data= [ 0x01 ] 1
Generic Desktop Controls
Item(Local ): Usage, data= [ 0x02 ] 2
Mouse
Item(Local ): Usage, data= [ 0x01 ] 1
Pointer
Item(Global): Usage Page, data= [ 0x09 ] 9
Buttons
Item(Local ): Usage Minimum, data= [ 0x01 ] 1
Button 1 (Primary)
Item(Local ): Usage Maximum, data= [ 0x05 ] 5
Button 5
Item(Global): Report Count, data= [ 0x05 ] 5
Item(Global): Report Size, data= [ 0x01 ] 1
Item(Main ): Input, data= [ 0x02 ] 2
This is crystal clear both for us and for the OS. With the car, it’s not the case, and we need to deduce the meaning of the bits in the reports ourselves by looking at raw USB traffic.
A bonus value
Most RC toys are quite simple and use stock receivers and other circuits that operate at the same frequencies. This means our car driver program can be used to control toys other than the car that comes bundled. I’ve just discovered that I can play with my son’s tractor from my laptop. With some background in amateur radio, you’ll certainly find more interesting applications for this.
Detective work
If you were to analyse network traffic, you’d use a sniffer. Given that USB is somewhat similar, it comes as no surprise that you can use a sniffer to monitor USB traffic as well. There are dedicated commercial USB monitors that may come in handy if you are doing reverse engineering professionally, but for our purposes, the venerable Wireshark will do just fine.
Here’s how to set up USB capture with Wireshark (you can find more instructions at). First, we’ll need to enable USB monitoring in the kernel. The usbmon module is responsible for that, so load it now:
[root@y550p ~]# modprobe usbmon
Then, mount the special debugfs filesystem, if it’s not already mounted:
[root@y550p ~]# mount -t debugfs none /sys/kernel/debug
This will create a /sys/kernel/debug/usb/usbmon directory that you can already use to capture USB traffic with nothing more than standard shell tools:
[root@y550p ~]# ls /sys/kernel/debug/usb/usbmon
0s 0u 1s 1t 1u 2s 2t 2u
There are some files here with cryptic names. An integer is the bus number (the first part of the USB bus address); 0 means all buses on the host. s stands for ‘statistics’ t is for ‘transfers’ (ie what’s going over the wire) and u means URBs (USB Request Blocks, logical entities that represents a USB transaction). So, to capture all transfers on Bus 2, just run:
[root@y550p ~]# cat /sys/kernel/debug/usb/usbmon/2t
ffff88007d57cb40 296194404 S Ii:036:01 -115 1 <
ffff88007d57cb40 296195649 C Ii:036:01 0 1 = 05
ffff8800446d4840 298081925 S Co:036:00 s 21 09 0200 0000 0001 1 = 01
ffff8800446d4840 298082240 C Co:036:00 0 1 >
ffff880114fd1780 298214432 S Co:036:00 s 21 09 0200 0000 0001 1 = 00
Unless you have a trained eye, this feedback is unreadable. Luckily, Wireshark will decode many protocol fields for us.
Now, we’ll need a Windows instance that runs the original driver for our device. The recommended way is to install everything in VirtualBox (theOracle Extension Pack is required, since we need USB support). Make sure VirtualBox can use the device, and run the Windows program (KeUsbCar) that controls the car. Now, start Wireshark to see what commands the driver sends over the wire. At the intial screen, select the ‘usbmonX’ interface, where X is the bus that the car is attached to. If you plan to run Wireshark as a non-root user (which is recommended), make sure that the /dev/usbmon* device nodes have the appropriate permissions.
Suppose we pressed a “Forward” button in KeUsbCar. Wireshark will catch several output control transfers, as shown on the screenshot above. The one we are interested in is highlighted. The parameters indicate it is a SET_REPORT HID class-specific request (bmRequestType = 0x21, bRequest = 0x09) conventionally used to set a device status such as keyboard LEDs. According to the Report Descriptor we saw earlier, the data length is 1 byte, and the data (which is the report itself) is 0x01 (also highlighted).
Pressing another button (say, “Right”) results in similar request; however, the report will be 0x02 this time. One can easily deduce that the report value encodes a movement direction. Pressing the remaining buttons in turn, we discover that 0x04 is reverse right, 0x08 is reverse, and so on. The rule is simple: the direction code is a binary 1 shifted left by the button position in KeUsbCar interface (if you count them clockwise).
We can also spot periodic interrupt input requests for Endpoint 1 (0x81, 0x80 means it’s an input endpoint; 0x01 is its address). What are they for? Except buttons, KeUsbCar has a battery level indicator, so these requests are probably charge level reads. However, their values remain the same (0x05) unless the car is out of the garage. In this case, there are no interrupt requests, but they resume if we put the car back. We can suppose that 0x05 means “charging” (the toy is simple, and no charge level is really returned, only a flag). If we give the car enough time, the battery will fully charge, and interrupt reads will start to return 0x85 (0x05 with bit 7 set). It looks like the bit 7 is a “charged” flag; however, the exact meaning of other two flags (bit 0 and bit 2 that form 0x05) remains unclear. Nevertheless, what we have figured out so far is already enough to recreate a functional driver.

Wireshark captures Windows driver-originated commands.
No more toys: writing a real driver (almost)
Having a custom program to work with a previously unsupported device is certainly a step forward, but sometimes you also need it to integrate with the rest of the system. Generally it implies writing a driver, which requires coding at kernel level (see our tutorial from LV002 at www.linuxvoice.com/be-a-kernel-hacker/) and is probably not what you want. However, with USB the chances are that you can stay in userspace.
If you have a USB network card, you can use TUN/TAP to hook your PyUSB program into Linux networking stack. TUN/TAP interfaces look like regular network interfaces (with names like tun0 or tap1) in Linux, but they make all packets received or transmitted available through the /dev/net/tun device node. The pytun module makes working with TUN/TAP devices in Python a breeze. Performance may suffer in this case, but you can rewrite your program in C with libusb and see if this helps.
Other good candidates are USB displays. Linux comes with the vfb module, which makes a framebuffer accessible as /dev/fbX device. Then you can use ioctls to redirect Linux console to that framebuffer, and continuously pump the contents of /dev/fbX into a USB device using the protocol you reversed. This won’t be very speedy either, but unless you are going to play 3D shooters over USB, it could be a viable solution.
Get to code
The program we are going to create is quite similar to its Windows counterpart, as you can easily see from the screenshot above. It has six arrow buttons and a charge level indicator that bounces when the car is in the garage (charging). You can download the code from GitHub (https://github.com/vsinitsyn/usbcar.py); the steering wheel image comes from
www.openclipart.org.
The main question is, how do we work with USB in Linux? It is possible to do it from userspace (subject to permission checks, of course; see the boxout below), and the libusb library facilates this process. This library is written for use with the C language and requires the user to have a solid knowledge of USB. A simpler alternative would be PyUSB, which is a simpler alternative: it strives to “guess” sensible defaults to hide the details from you, and it is pure Python, not C. Internally, PyUSB can use libusb or some other backend, but you generally don’t need to think about it. You could argue that libusb is more capable and flexible, but PyUSB is a good fit for cases like ours, when you need a working prototype with minimum effort. We also use PyGame for the user interface, but won’t discuss this code here – though we’ll briefly visit it at the end of this section.
Download the PyUSB sources from https://github.com/walac/pyusb, unpack them and install with python setup.py install (possibly in a virtualenv). You will also need the libusb library, which should be available in your package manager. Now, let’s wrap the functionality we need to control a car in a class imaginatively named USBCar.
import usb.core
import usb.util
class USBCar(object):
VID = 0x0a81
PID = 0x0702
FORWARD = 1
RIGHT = 2
REVERSE_RIGHT = 4
REVERSE = 8
REVERSE_LEFT = 16
LEFT = 32
STOP = 0
We import two main PyUSB modules and define the direction values we’ve deduced from the USB traffic. VID and PID are the car ID taken from the output of lsusb.
def __init__(self):
self._had_driver = False
self._dev = usb.core.find(idVendor=USBCar.VID, idProduct=USBCar.PID)
if self._dev is None:
raise ValueError("Device not found")
In the constructor, we use the usb.core.find() function to look up the device by ID. If it is not found, we raise an error. The usb.core.find() function is very powerful and can locate or enumerate USB devices by other properties as well; consult https://github.com/walac/pyusb/blob/master/docs/tutorial.rst for the full details.
if self._dev.is_kernel_driver_active(0):
self._dev.detach_kernel_driver(0)
self._had_driver = True
Next, we detach (unbind) the kernel driver, as we did previously for lsusb. Zero is the interface number. We should re-attach the driver on program exit (see the release() method below) if it was active, so we remember the initial state in self._had_driver.
self._dev.set_configuration()
Finally, we activate the configuration. This call is one of a few nifty shortcuts PyUSB has for us. The code above is equivalent to the following, however it doesn’t require you to know the interface number and the configuration value:
self._dev.set_configuration(1)
usb.util.claim_interface(0)
def release(self):
usb.util.release_interface(self._dev, 0)
if self._had_driver:
self._dev.attach_kernel_driver(0)
This method should be called before the program exits. Here, we release the interface we claimed and attach the kernel driver back.
Moving the car is also simple:
def move(self, direction):
ret = self._dev.ctrl_transfer(0x21, 0x09, 0x0200, 0, [direction])
return ret == 1
The direction is supposed to be one of the values defined at the beginning of the class. The ctrl_transfer() method does control transfer, and you can easily recognise bmRequestType (0x21, a class-specific out request targeted at the endpoint), bRequest (0x09, Set_Report() as defined in the USB HID specification), report type (0x0200, Output) and the interface (0) we saw in Wireshark. The data to be sent is passed to ctrl_transfer() as a string or a list; the method returns the number of bytes written. Since we expect it to write one byte, we return True in this case and False otherwise.
The method that determines battery status spans a few more lines:
def battery_status(self):
try:
ret = self._dev.read(0x81, 1, timeout=self.READ_TIMEOUT)
if ret:
res = ret.tolist()
if res[0] == 0x05:
return 'charging'
elif res[0] == 0x85:
return 'charged'
return 'unknown'
except usb.core.USBError:
return 'out of the garage'
At its core is the read() method, which accepts an endpoint address and the number of bytes to read. A transfer type is determined by the endpoint and is stored in its descriptor. We also use a non-default (smaller) timeout value to make the application more responsive (you won’t do it in a real program: a non-blocking call or a separate thread should be used instead). Device.read() returns an array (see the ‘array’ module) which we convert to list with the tolist() method. Then we check its first (and the only) byte to determine charge status. Remember that this it is not reported when the car is out of the garage. In this case, the read() call will run out of time and throw a usb.core.USBError exception, as most PyUSB methods do. We (fondly) assume that the timeout is the only possible reason for the exception here. In all other cases we report the status as ‘unknown’.
Another class, creatively named UI, encapsulates the user interface – let’s do a short overview of the most important bits. The main loop is encapsulated in the UI.main_loop() method. Here, we set up a background (steering wheel image taken from OpenClipart.org), display the battery level indicator if the car is in the garage, and draw arrow buttons (UI.generate_arrows() is responsible for calculating their vertices’ coordinates). Then we wait for the event, and if it is a mouse click, move the car in the specified direction with the USBCar.move() method described earlier.
One tricky part is how we associate directions with arrow buttons. There is more than one way to do it, but in this program we draw two sets of arrows with identical shapes. A first one, with red buttons you see on the screenshot, is shown to the user, while the second one is kept off-screen. Each arrow in that hidden set has a different colour, whose R component is set to a direction value. Outside the arrows, the background is filled with 0 (the USBCar.STOP command). When a user clicks somewhere in the window, we just check the R component of the pixel underneath the cursor in that hidden canvas, and action appropriately.
The complete program with a GUI takes little more than 200 lines. Not bad for the device we didn’t even had the documentation for!
That’s all folks!
This concludes our short journey into the world of reverse engineering and USB protocols. The device for which we’ve developed a driver (or more accurately, a support program) was intentionally simple. However, there are many devices similar to this USB car out there, and many of them use a protocol that is close to the one we’ve reversed (USB missile launchers are good example). Reversing a sophisticated device isn’t easy, but now you can already add Linux support for something like a desktop mail notifier. While it may not seem immediately useful, it’s a lot of fun.

























































































{kind=link}