This is a really keen observation by Evan Puschak about the camera movement in David Fincher’s films: it mimics your eyes in paying attention to the behavior in a scene. The effect is sometimes subtle. When a character shifts even slightly, the camera keeps that person’s eyes and face in the same place in the frame, just as you would if you were in the room with them.
Today, Mozilla is announcing a plan that grows collaboration with Microsoft, Google, and other industry leaders on MDN Web Docs. The goal is to consolidate information about web development for multiple browsers – not just Firefox. To support this collaboration, we’re forming a Product Advisory Board that will formalize existing relationships and guide our progress in the years to come.
Why are we doing this? To make web development just a little easier.
“One common thread we hear from web developers is that documentation on how to build for the cross-browser web is too fragmented,” said Daniel Appelquist, Director of Developer Advocacy at Samsung Internet and Co-Chair of W3C’s Technical Architecture Group. “I’m excited to be part of the efforts being made with MDN Web Docs to address this issue and to bring better and more comprehensive documentation to developers worldwide.”
More than six million web developers and designers currently visit MDN Web Docs each month – and readership is growing at a spectacular rate of 40 percent, year over year. Popular content includes articles and tutorials on JavaScript, CSS and HTML, as well as detailed, comprehensive documentation of new technologies like Web APIs.
Community contributions are at the core of MDN’s success. Thousands of volunteers have helped build and refine MDN over the past 12 years. In this year alone, 8,021 users made 76,203 edits, greatly increasing the scope and quality of the content. Cross-browser documentation contributions include input from writers at Google and Microsoft; Microsoft writers have made more than 5,000 edits so far in 2017. This cross-browser collaboration adds valuable content on browser compatibility and new features of the web platform. Going forward, Microsoft writers will focus their Web API documentation efforts on MDN and will redirect relevant pages from Microsoft Developer Network to MDN.
A Broader Focus
Now, the new Product Advisory Board for MDN is creating a more formal way to absorb all that’s going on across browsers and standards groups. Initial board members include representatives from Microsoft, Google, Samsung, and the W3C, with additional members possible in the future. By strengthening our relationships with experts across the industry, the Product Advisory Board will ensure MDN documentation stays relevant, is browser-agnostic, and helps developers keep up with the most important aspects of the web platform.
“The reach of the web across devices and platforms is what makes it unique, and Microsoft is committed to helping it continue to thrive,” said Jason Weber, Partner Director of Program Management, Microsoft Edge. “We’re thrilled to team up with Mozilla, Google, and Samsung to create a single, great web standards documentation set on MDN for web developers everywhere.”
Mozilla’s vision for the MDN Product Advisory Board is to build collaboration that helps the MDN community, collectively, maintain MDN as the most comprehensive, complete, and trusted reference documenting the most important aspects of modern browsers and web standards.
The board’s charter is to provide advice and feedback on MDN content strategy, strategic direction, and platform/site features. Mozilla remains committed to MDN as an open source reference for web developers, and Mozilla’s team of technical writers will continue to work on MDN and collaborate with volunteers and corporate contributors.
“Google is committed to building a better web for both users and developers,” said Meggin Kearney, Lead Technical Writer, Web Developer Relations at Google. “We’re excited to work with Mozilla, Microsoft, and Samsung to help guide MDN towards becoming the best source of up-to-date, comprehensive documentation for developers on the web.”
MDN directly supports Mozilla’s overarching mission. We strive to ensure the Internet is a global public resource that is open and accessible to all. We believe that our award-winning documentation helps web developers build better web experiences – which also adhere to established standards and work across platforms and devices.
The head of America's telly watchdog, the FCC, said he cannot follow up on Donald Trump's threat to revoke the broadcast licenses of TV networks that run unflattering news coverage of the US president.…
We spent the majority of last month prototyping a new graphical interface for Eve. We’re exploring new ways to interact with Eve that enable us to more quickly express the programs Eve is targeting. Such workflows should have the property that building a simple application (like the incrementer or bouncing balls examples) should require very little coding, and you should be able to build them within a few minutes. Here are some example videos that demonstrate the prototype interface at work:
We started a thread on the mailing list where we will be posting more of these videos as the interface becomes more robust. We’re going to hold this prototype back from release until the end of October, just to get it a little further along; but in the meantime, we’d like to hear any feedback you have!
One of the things we’re trying to do with this prototype is to make sure the programs we want to build are easily expressible. Therefore, we are also mocking up how various programs might be built in this interface. We’ll be making our examples more complex over time, so we can be sure certain programs can be easily expressed in this interface. If you have any ideas about programs that might be hard to build in the prototype interface as demonstrated, let us know and we’ll mock-up a solution that will guide our development.
If you’re interested in the reasons we’re currently moving in this direction, Chris goes into more detail in this post on the mailing list.
Community
Eve Around The Web
The Atlantic magazine published an article titled “The Coming Software Apocalypse” at the end of September, which features some thoughts from Chris on the future of programming. If you follow us, his words will likely be familiar to you, but the whole article focuses on more than just Eve, covering various projects attempting to shape the future of programming.
Eve Around the World
Coming up this month, Chris is giving a keynote presentation at SPLASH 2017 titled: “Eve: tackling a giant with a change in perspective”. If you’re attending SPLASH this year, his talk will be on October 25th at 08:45 AM. We look forward to meeting you there!
At The New York Times we have a number of different systems that are used for producing content. We have several Content Management Systems, and we use third-party data and wire stories. Furthermore, given 161 years of journalism and 21 years of publishing content online, we have huge archives of content that still need to be available online, that need to be searchable, and that generally need to be available to different services and applications.
These are all sources of what we call published content. This is content that has been written, edited, and that is considered ready for public consumption.
On the other side we have a wide range of services and applications that need access to this published content — there are search engines, personalization services, feed generators, as well as all the different front-end applications, like the website and the native apps. Whenever an asset is published, it should be made available to all these systems with very low latency — this is news, after all — and without data loss.
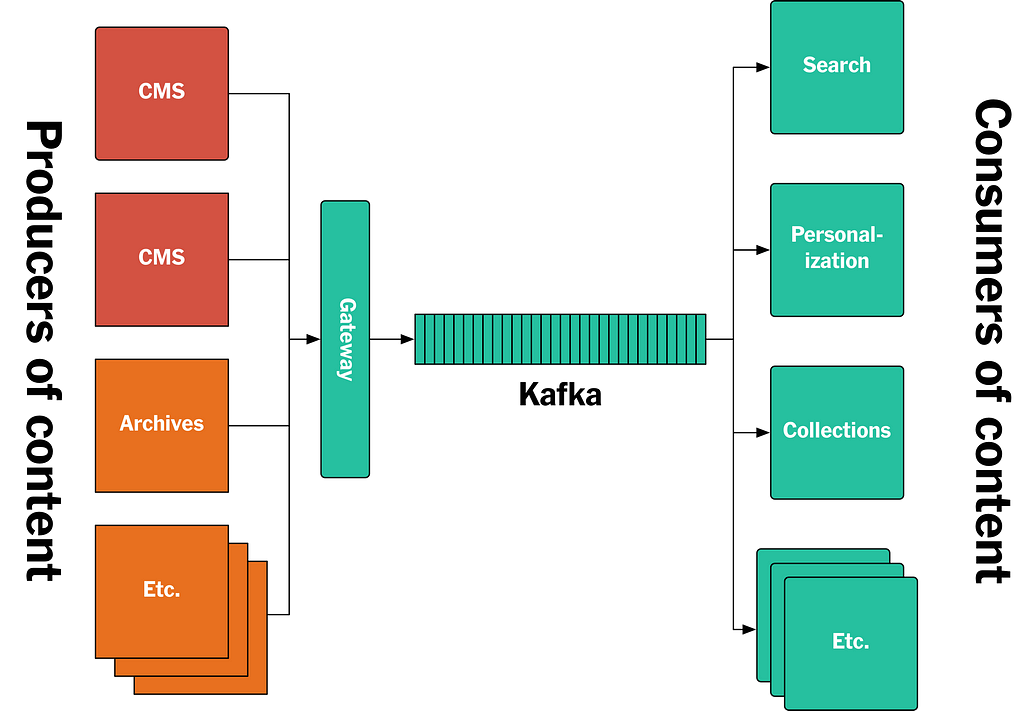
This article describes a new approach we developed to solving this problem, based on a log-based architecture powered by Apache Kafka®. We call it the Publishing Pipeline. The focus of the article will be on back-end systems. Specifically, we will cover how Kafka is used for storing all the articles ever published by The New York Times, and how Kafka and the Streams API is used to feed published content in real-time to the various applications and systems that make it available to our readers. The new architecture is summarized in the diagram below, and we will deep-dive into the architecture in the remainder of this article.
Figure 1: The new New York Times log/Kafka-based publishing architecture.
The problem with API-based approaches
The different back-end systems that need access to published content have very different requirements:
We have a service that provides live content for the web site and the native applications. This service needs to make assets available immediately after they are published, but it only ever needs the latest version of each asset.
We have different services that provide lists of content. Some of these lists are manually curated, some are query-based. For the query-based lists, whenever an asset is published that matches the query, requests for that list need to include the new asset. Similarly, if an update is published causing the asset no longer to match the query, it should be removed from the list. We also have to support changes to the query itself, and the creation of new lists, which requires accessing previously published content to (re)generate the lists.
We have an Elasticsearch cluster powering site search. Here the latency requirements are less severe — if it takes a minute or two after an asset is published before it can be found by a search it is usually not a big deal. However, the search engine needs easy access to previously published content, since we need to reindex everything whenever the Elasticsearch schema definition changes, or when we alter the search ingestion pipeline.
We have personalization systems that only care about recent content, but that need to reprocess this content whenever the personalization algorithms change.
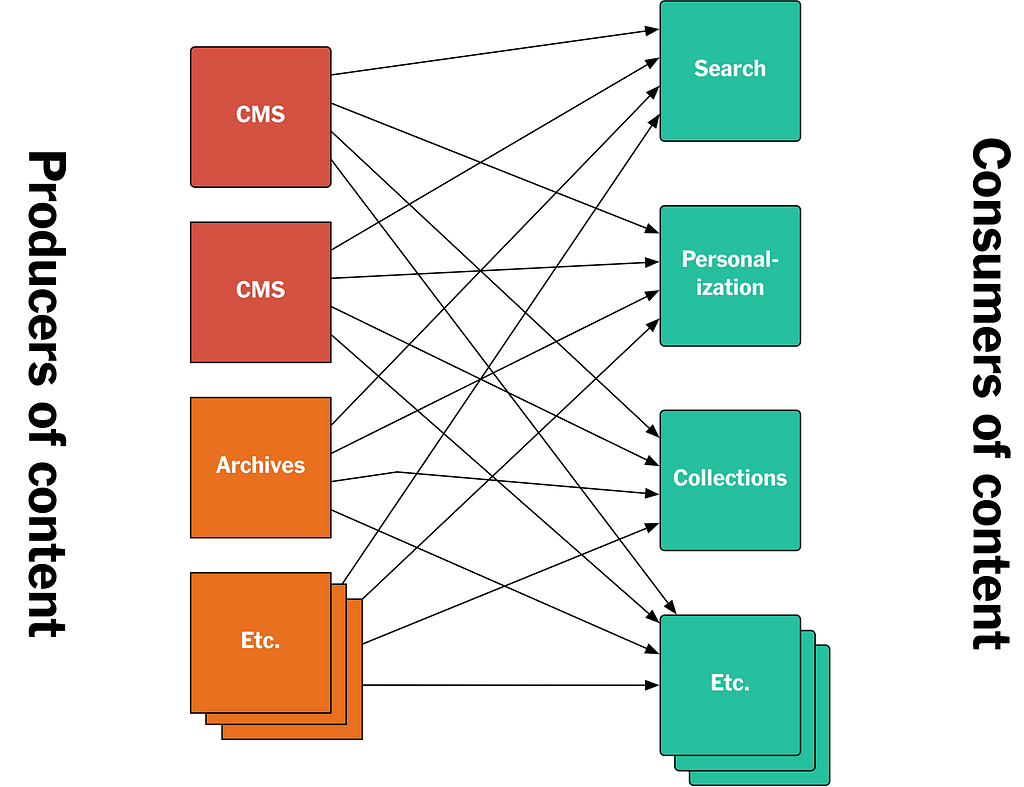
Our previous approach to giving all those different consumers access to published content involved building APIs. The producers of content would provide APIs for accessing that content, and also feeds you could subscribe to for notifications for new assets being published. Other back-end systems, the consumers of content, would then call those APIs to get the content they needed.
Figure 2: A sketch of our previous API-based architecture that has since been replaced by the new log/Kafka-based architecture described in this article.
This approach, a fairly typical API-based architecture, had a number of issues.
Since the different APIs had been developed at different times by different teams, they typically worked in drastically different ways. The actual endpoints made available were different, they had different semantics, and they took different parameters. That could be fixed, of course, but it would require coordination between a number of teams.
More importantly, they all had their own, implicitly defined schemas. The names of fields in one CMS were different than the same fields in another CMS, and the same field name could mean different things in different systems.
This meant that every system that needed access to content had to know all these different APIs and their idiosyncrasies, and they would then need to handle normalization between the different schemas.
An additional problem was that it was difficult to get access to previously published content. Most systems did not provide a way to efficiently stream content archives, and the databases they were using for storage wouldn’t have supported it (more about this in the next section). Even if you have a list of all published assets, making an individual API call to retrieve each individual asset would take a very long time and put a lot of unpredictable load on the APIs.
Log-based architectures
The solution described in this article uses a log-based architecture. This is an idea that was first covered by Martin Kleppmann in Turning the database inside-out with Apache Samza[1], and is described in more detail in Designing Data-Intensive Applications[2]. The log as a generic data structure is covered in The Log: What every software engineer should know about real-time data’s unifying abstraction[3]. In our case the log is Kafka, and all published content is appended to a Kafka topic in chronological order. Other services access it by consuming the log.
Traditionally, databases have been used as the source of truth for many systems. Despite having a lot of obvious benefits, databases can be difficult to manage in the long run. First, it’s often tricky to change the schema of a database. Adding and removing fields is not too hard, but more fundamental schema changes can be difficult to organize without downtime. A deeper problem is that databases become hard to replace. Most database systems don’t have good APIs for streaming changes; you can take snapshots, but they will immediately become outdated. This means that it’s also hard to create derived stores, like the search indexes we use to power site search on nytimes.com and in the native apps — these indexes need to contain every article ever published, while also being up to date with new content as it is being published. The workaround often ends up being clients writing to multiple stores at the same time, leading to consistency issues when one of these writes succeeds and the other fails.
Because of this, databases, as long-term maintainers as state, tend to end up being complex monoliths that try to be everything to everyone.
Log-based architectures solve this problem by making the log the source of truth. Whereas a database typically stores the result of some event, the log stores the event itself — the log therefore becomes an ordered representation of all events that happened in the system. Using this log, you can then create any number of custom data stores. These stores becomes materialized views of the log — they contain derived, not original, content. If you want to change the schema in such a data store, you can just create a new one, have it consume the log from the beginning until it catches up, and then just throw away the old one.
With the log as the source of truth, there is no longer any need for a single database that all systems have to use. Instead, every system can create its own data store (database) — its own materialized view — representing only the data it needs, in the form that is the most useful for that system. This massively simplifies the role of databases in an architecture, and makes them more suited to the need of each application.
Furthermore, a log-based architecture simplifies accessing streams of content. In a traditional data store, accessing a full dump (i.e., as a snapshot) and accessing “live” data (i.e., as a feed) are distinct ways of operating. An important facet of consuming a log is that this distinction goes away. You start consuming the log at some specific offset — this can be the beginning, the end, or any point in-between — and then just keep going. This means that if you want to recreate a data store, you simply start consuming the log at the beginning of time. At some point you will catch up with live traffic, but this is transparent to the consumer of the log.
A log consumer is therefore “always replaying”.
Log-based architectures also provide a lot of benefits when it comes to deploying systems. Immutable deployments of stateless services have long been a common practice when deploying to VMs. By always redeploying a new instance from scratch instead of modifying a running one, a whole category of problems go away. With the log as the source of truth, we can now do immutable deployments of stateful systems. Since any data store can be recreated from the log, we can create them from scratch every time we deploy changes, instead of changing things in-place — a practical example of this is given later in the article.
Why Google PubSub or AWS SNS/SQS/Kinesis don’t work for this problem
Apache Kafka is typically used to solve two very distinct use cases.
The most common one by far is where Apache Kafka is used as a message broker. This can cover both analytics and data integration cases. Kafka arguably has a lot of advantages in this area, but services like Google Pub/Sub, AWS SNS/AWS SQS, and AWS Kinesis have other approaches to solving the same problem. These services all let multiple consumers subscribe to messages published by multiple producers, keep of track of which messages they have and haven’t seen, and gracefully handle consumer downtime without data loss. For these use cases, the fact that Kafka is a log is an implementation detail.
Log-based architectures, like the one described in this article, are different. In these cases, the log is not an implementation detail, it is the central feature. The requirements are very different from what the other services offer:
We need the log to retain all events forever, otherwise it is not possible to recreate a data store from scratch.
We need log consumption to be ordered. If events with causal relationships are processed out of order, the result will be wrong.
Only Kafka supports both of these requirements.
The Monolog
The Monolog is our new source of truth for published content. Every system that creates content, when it’s ready to be published, will write it to the Monolog, where it is appended to the end. The actual write happens through a gateway service, which validates that the published asset is compliant with our schema.
Figure 3: The Monolog, containing all assets ever published by The New York Times.
The Monolog contains every asset published since 1851. They are totally ordered according to publication time. This means that a consumer can pick the point in time when it wants to start consuming. Consumers that need all of the content can start at the beginning of time (i.e., in 1851), other consumers may want only future updates, or at some time in-between.
As an example, we have a service that provides lists of content — all assets published by specific authors, everything that should go on the science section, etc. This service starts consuming the Monolog at the beginning of time, and builds up its internal representation of these lists, ready to serve on request. We have another service that just provides a list of the latest published assets. This service does not need its own permanent store: instead it just goes a few hours back in time on the log when it starts up, and begins consuming there, while maintaining a list in memory.
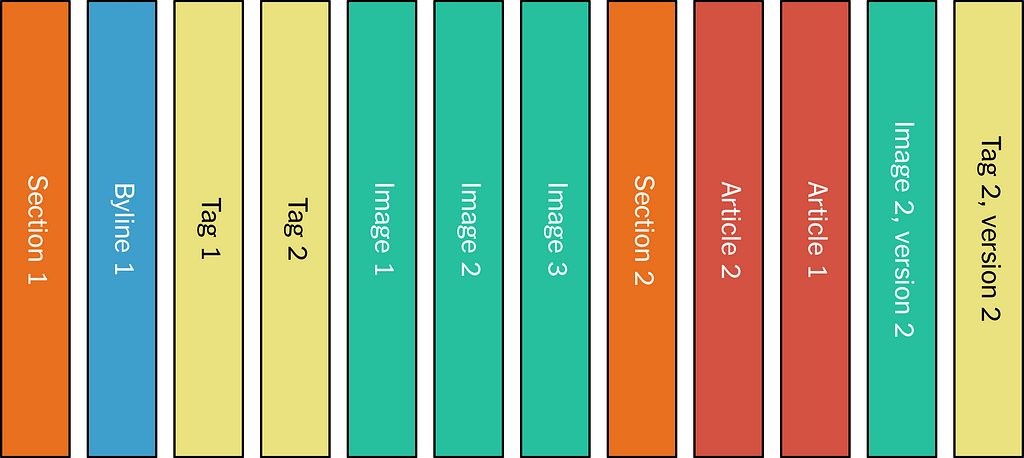
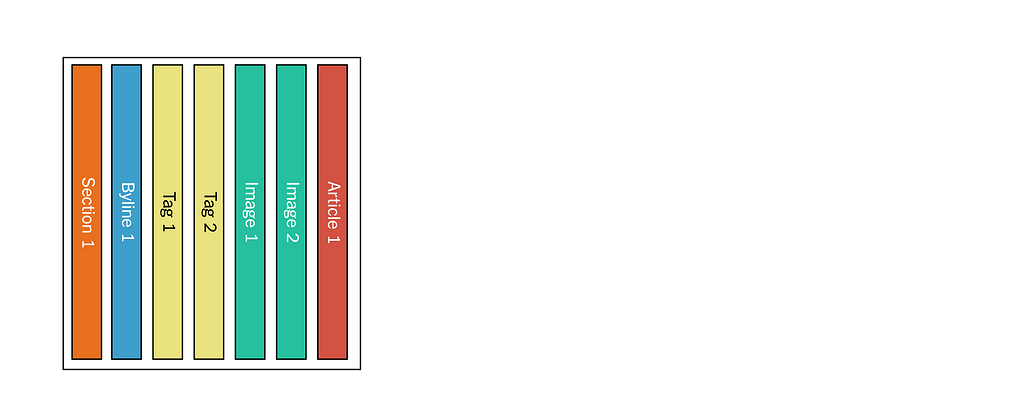
Assets are published to the Monolog in normalized form, that is, each independent piece of content is written to Kafka as a separate message. For example, an image is independent from an article, because several articles may include the same image.
The figure gives an example:
Figure 4: Normalized assets.
This is very similar to a normalized model in a relational database, with many-to-many relationships between the assets.
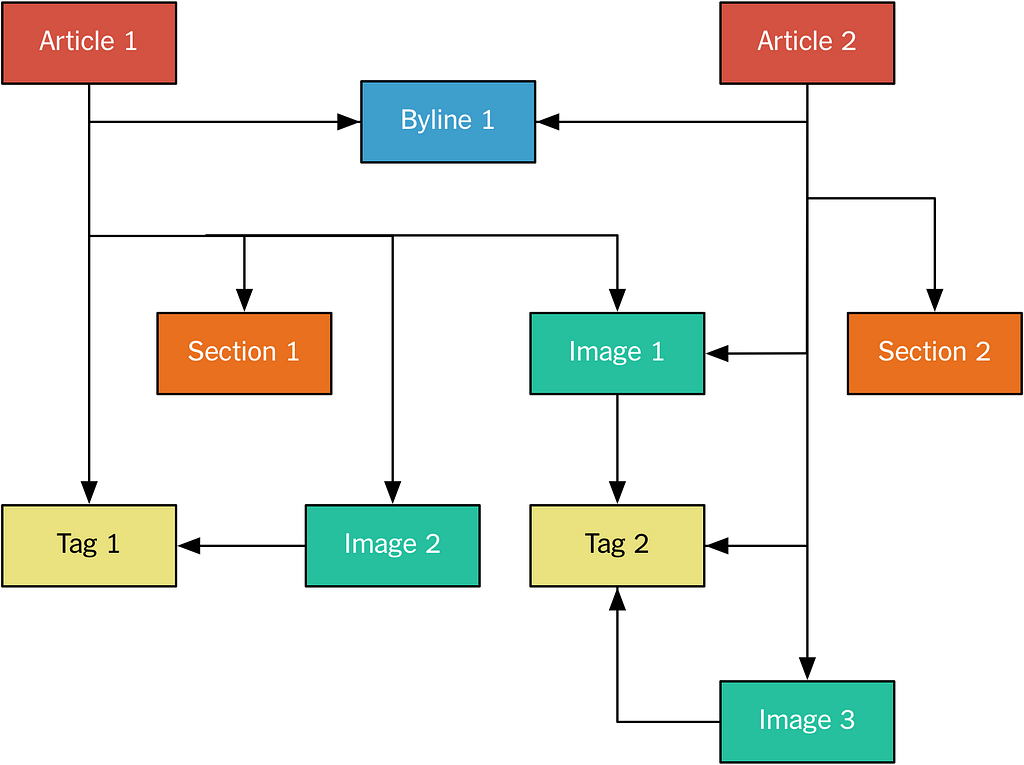
In the example we have two articles that reference other assets. For instance, the byline is published separately, and then referenced by the two articles. All assets are identified using URIs of the form nyt://article/577d0341–9a0a-46df-b454-ea0718026d30. We have a native asset browser that (using an OS-level scheme handler) lets us click on these URIs, see the asset in a JSON form, and follow references. The assets themselves are published to the Monolog as protobuf binaries.
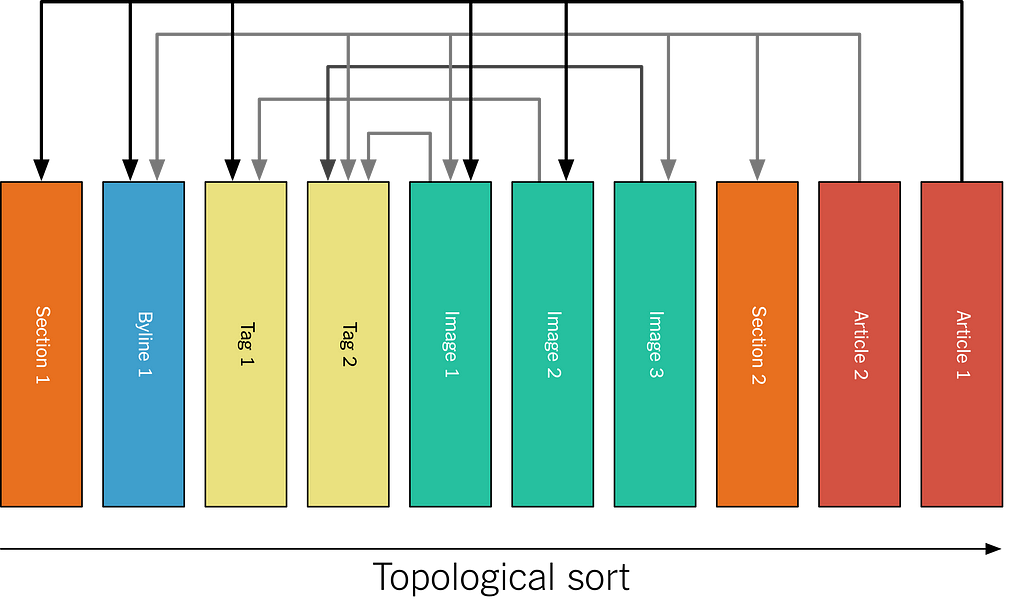
In Apache Kafka, the Monolog is implemented as a single-partition topic. It’s single-partition because we want to maintain the total ordering — specifically, we want to ensure that when you are consuming the log, you always see a referenced asset before the asset doing the referencing. This ensures internal consistency for a top-level asset — if we add an image to an article while adding text referencing the image, we do not want the change to the article to be visible before the image is.
The above means that the assets are actually published to the log topologically sorted. For the example above, it looks like this:
Figure 5: Normalized assets in publishing order.
As a log consumer you can then easily build your materialized view of log, since you know that the version of an asset referenced is always the last version of that asset that you saw on the log.
Because the topic is single-partition, it needs to be stored on a single disk, due to the way Kafka stores partitions. This is not a problem for us in practice, since all our content is text produced by humans — our total corpus right now is less than 100GB, and disks are growing bigger faster than our journalists can write.
The denormalized log and Kafka’s Streams API
The Monolog is great for consumers that want a normalized view of the data. For some consumers that is not the case. For instance, in order to index data in Elasticsearch you need a denormalized view of the data, since Elasticsearch does not support many-to-many relationships between objects. If you want to be able to search for articles by matching image captions, those image captions will have to be represented inside the article object.
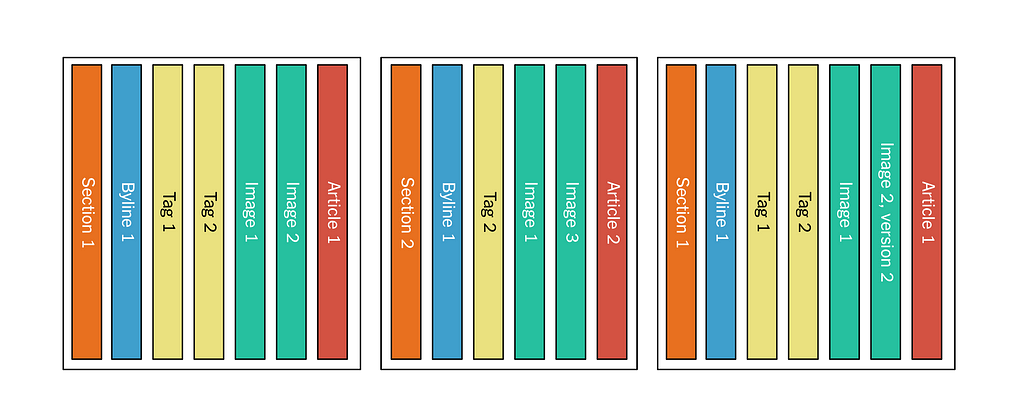
In order to support this kind of view of the data, we also have a denormalized log. In the denormalized log, all the components making up a top-level asset are published together. For the example above, when Article 1 is published, we write a message to the denormalized log, containing the article and all its dependencies along with it in a single message:
Figure 6: The denormalized log after publishing Article 1.
The Kafka consumer that feeds Elasticsearch can just pick this message off the log, reorganize the assets into the desired shape, and push to the index. When Article 2 is published, again all the dependencies are bundled, including the ones that were already published for Article 1:
Figure 7: The denormalized log after publishing Article 2.
If a dependency is updated, the whole asset is republished. For instance, if Image 2 is updated, all of Article 1 goes on the log again:
Figure 8: The denormalized log after updating Image 2, used by Article 1.
A component called the Denormalizer actually creates the denormalized log.
The Denormalizer is a Java application that uses Kafka’s Streams API. It consumes the Monolog, and maintains a local store of the latest version of every asset, along with the references to that asset. This store is continuously updated when assets are published. When a top-level asset is published, the Denormalizer collects all the dependencies for this asset from local storage, and writes it as a bundle to the denormalized log. If an asset referenced by a top-level asset is published, the Denormalizer republishes all the top-level assets that reference it as a dependency.
Since this log is denormalized, it no longer needs total ordering. We now only need to make sure that the different versions of the same top-level asset come in the correct order. This means that we can use a partitioned log, and have multiple clients consume the log in parallel. We do this using Kafka Streams, and the ability to scale up the number of application instances reading from the denormalized log allows us to do a very fast replay of our entire publication history — the next section will show an example of this.
Elasticsearch example
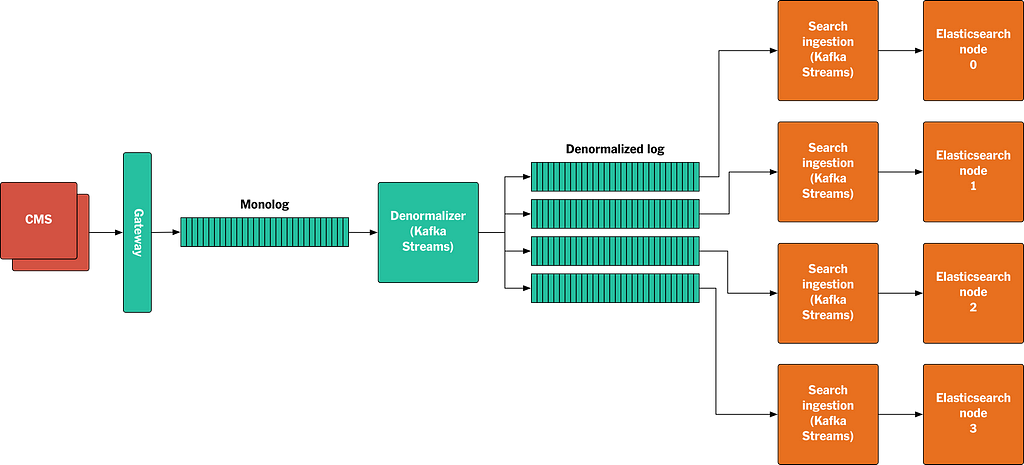
The following sketch shows an example of how this setup works end-to-end for a backend search service. As mentioned above, we use Elasticsearch to power the site search on NYTimes.com:
Figure 9: A sketch showing how published assets flow through the system from the CMS to Elasticsearch.
The data flow is as follows:
An asset is published or updated by the CMS.
The asset is written to the Gateway as a protobuf binary.
The Gateway validates the asset, and writes it to the Monolog.
The Denormalizer consumes the asset from the Monolog. If this is a top-level asset, it collects all its dependencies from its local store and writes them together to the denormalized log. If this asset is a dependency of other top-level assets, all of those top-level assets are written to the denormalized log.
The Kafka partitioner assigns assets to partitions based on the URI of the top-level asset.
The search ingestion nodes all run an application that uses Kafka Streams to access the denormalized log. Each node reads a partition, creates the JSON objects we want to index in Elasticsearch, and writes them to specific Elasticsearch nodes. During replay we do this with Elasticsearch replication turned off, to make indexing faster. We turn replication back on when we catch up with live traffic before the new index goes live.
Implementation
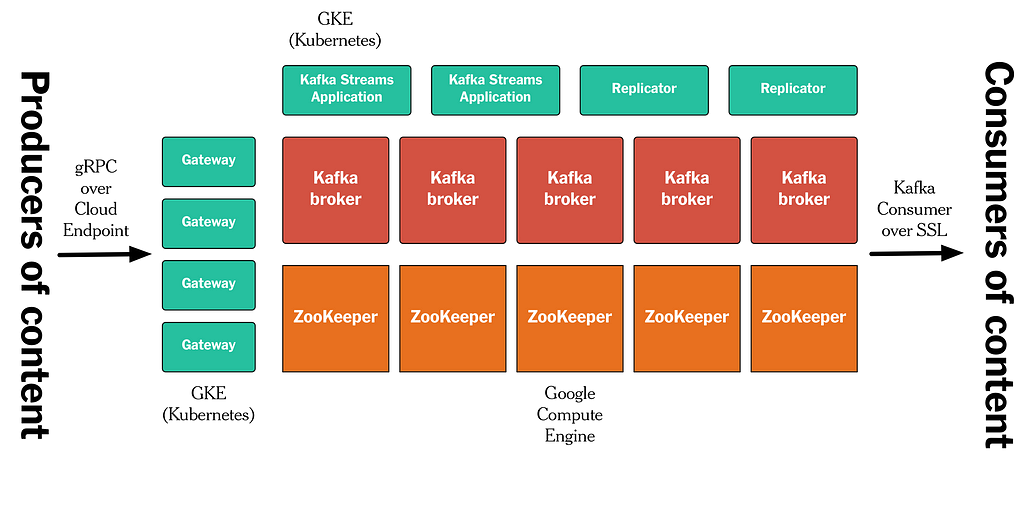
This Publishing Pipeline runs on Google Cloud Platform/GCP. The details of our setup are beyond the scope of this article, but the high-level architecture looks like the sketch below. We run Kafka and ZooKeeper on GCP Compute instances. All other processes the Gateway, all Kafka replicators, the Denormalizer application built with Kafka’s Streams API, etc. — run in containers on GKE/Kubernetes. We use gRPC/Cloud Endpoint for our APIs, and mutual SSL authentication/authorization for keeping Kafka itself secure.
Figure 10: Implementation on Google Cloud Platform.
Conclusion
We have been working on this new publishing architecture for a little over a year. We are now in production, but it’s still early days, and we have a good number of systems we still have to move over to the Publishing Pipeline.
We are already seeing a lot of advantages. The fact that all content is coming through the same pipeline is simplifying our software development processes, both for front-end applications and back-end systems. Deployments have also become simpler — for instance, we are now starting to do full replays into new Elasticsearch indexes when we make changes to analyzers or the schema, instead of trying to make in-place changes to the live index, which we have found to be error-prone. Furthermore, we are also in the process of building out a better system for monitoring how published assets progress through the stack. All assets published through the Gateway are assigned a unique message ID, and this ID is provided back to the publisher as well as passed along through Kafka and to the consuming applications, allowing us to track and monitor when each individual update is processed in each system, all the way out to the end-user applications. This is useful both for tracking performance and for pinpointing problems when something goes wrong.
Finally, this is a new way of building applications, and it requires a mental shift for developers who are used to working with databases and traditional pub/sub-models. In order to take full advantage of this setup, we need to build applications in such a way that it is easy to deploy new instances that use replay to recreate their materialized view of the log, and we are putting a lot of effort into providing tools and infrastructure that makes this easy.
I want to thank Martin Kleppmann, Michael Noll and Mike Kaminski for reviewing this article.
This presentation looks at the quantum mechanics of learning theory, drilling down from the idea of a subject or a piece of knowledge to the elements constituting a personal learning framework. Unfortunately the last 7 minutes of the video is clipped.
ICDE2017 World Conference on Online Learning, Toronto, Canada (Lecture) Oct 18, 2017 [Comment]
Occasional Price Tags contributor Michael Mortensen provided a detailed response to the post: What is the simple answer to this question? – on whether more supply is sufficient to address housing affordability.
Here’s a revised and expanded version that’s worth posting on its own:
Any discussion about unit prices needs to address the absolutely skyrocketing price of RESIDENTIAL LAND and various taxes, commissions and exactions on the same. Follow the money.
Developers are still operating on a Return on Cost margin of about 15% (to 20% if they are lucky). Internal Rates of Return – factoring in the interest costs and cash outflows needed over 4 to 5 years needed to realize that profit – are c.12% (not MASSIVE by any stretch given some of the risk involved. These benchmark ratios have not changed so it is not so much “developer greed” driving prices upwards as many might suggest. Development management fees are calculated as 2% to 4% of total costs EXCLUDING land, so there are no huge windfalls there.
Construction costs have escalated somewhat. Extended timelines for rezoning, development and building permits are also a factor in many municipalities. However, land supply and cost are the real issues.
When I left Vancouver in 2013 to work in London, land was $250/ buildable square foot in the downtown core; when I moved back to Vancouver in 2016, it was over $500 / buildable square foot – a 100% increase in 3 years! Land is now more expensive than construction on a square foot buildable basis – and remember that land costs have to be paid at the beginning of the development period … that’s an expensive financial “carry” on a project that will take 3 to 5 years to complete.
I think that most people in the development industry would agree we are seeing the influx of more global capital which takes a more speculative view of our market – witness some irrational purchases as various syndicates buy and flip land on to other syndicates Peter Wall’s flip of a Nelson Street site near Burrard – purchased for $16.8M sold less than a year later for $60M – and resold again months later for $68M is illustrative). The only thing changing in their sequential pro formas – other than escalating land costs – is an escalation in their anticipated selling prices … what will the market bear? Apparently a LOT! Down the housing production chain, a similar game exists with condo flippers who secure and assign pre-sale contracts.
Nelson Street Property Flip
The land flippers are not advancing new development rights, producing anything or, or creating any new value – they are simply inflating the price of land and housing.
The “heat map” of racing land prices has radiated outwards as developers struggle and compete to secure developable sites. Most EVERYTHING out there has some complexity and risk to it – be it environmental contamination, or political/planning risk, or assembly risk. Transit Oriented sites along the Skytrain routes are trending up to and over $200/sf buildable as these assemblies will be substitutes for the convenience of inner city living.
On the supply side, in the face of strong demand there are virtually no completed units available for sale in our region of 2.4 million people. Don’t believe me? Check CMHC’s reliable statistics.
There are really very few “greenfield” sites – most development prospects entail destroying existing value in return for the opportunity to create more intense land uses on a given parcel of land. We are so land constrained – Montreal has 80,000 square kilometres of land in a circle with a 50km radius from the city centre; Toronto has 40,000 because of Lake Ontario; Greater Vancouver has only 18,000 square kilometres once you take away mountain slopes, the Fraser river, the US border, the ALR (a regional planning success story) and the Pacific ocean.
Now, more and more, we have to RECYCLE and REPLAN developed land – witness the new Strata Dissolution legislation that allows the demise and sale of older buildings nearing the end of their service lives. More and more older stratas (remember the leaky condo crisis!) are being targeted.
Strata Dissolution
Who are the winners in all of this? …. anyone selling property is selling into a very constrained land market. For example, Homeowners along the Cambie corridor are organizing and selling their single family lots for $3 to $5 to $6 million (one seeking $11M below). That’s all capital gains free provided they were primary residences. Any business selling larger sites will trigger capital gains taxes, so they really need to see big bumps in value in order to justify redevelopment. Governments selling land also win (witness any recent large land plays and you’ll see big numbers on sales revenue for any provincial, crown, or municipal sale of land). For example, watch the City of North Vancouver’s sale of the 5 acre Harry Jerome site – it will be c.$300+/sf buildable.
Also add the brokers who guide these deals – they are making their cut on hefty commissions.
Governments are winners in other ways: Provincial Property Transfer tax fills BC’s coffers. The province collects tax on the purchase of development sites AND on the sale of the new units created on the same site – a double dip! And as land and property prices double, so too does the Province’s cut – to the point where the value of real estate property transfer taxes now eclipse natural resource royalties on an annual basis. Municipalities across BC also take their cut as they try to capture 75% of the “Land Lift” as properties are up-zoned.
Property Transfer Tax Double Dip
By virtue of their land use powers, Cities can create “land” (buildable area) for free – so this is one tool we have at our disposal to create some degree of affordability. Take Vancouver’s suburbs for example, which account for 85% of the City’s land base but houses only 75% of the population.
Time to think about a new Vancouver Special (below), about how we re-use land, and how we plan growth in our other close-in neighbourhoods to accommodate more people at greater intensity with commensurate (and reasonable) levels of new amenity. The subject of the relative fairness of compulsory city Community Amenity Contributions is rife with debate, but the truism these are exacted at the rate the market can bear – coming out of the land price, or added to the purchase price of units.
A New “Vancouver Special”
The question of who benefits from the uplift as land is rezoned is really one of equity: a classic planning problem. I think we’ll be hearing more and more about inclusionary zoning as a planning tool to share the uplift, but this still raises the question of access and fairness in the distribution of the benefits of rezoned development potential. Who wins the lottery for the next affordable home?
Ultimately supply and demand and government policies all shape the market for land and housing. We need to look at land, tax and housing policies at federal, provincial, regional and municipal levels in a holistic manner to create the conditions needed for more balanced markets.
I’m interested in other people’s perspectives on this.
A lot of folks have been asking about the future of my Keyword Search extension with the switch to WebExtensions coming with Firefox 57. Unfortunately, because Keyword Search relies on the internals of browser search as well as access to privileged pages, it can’t be simply ported to a WebExtension.
What I’ve done instead is created a WebExtension that uses the omnibox API. In order to execute a keyword search, you simply type the letter “k” followed by a space and then the search. That search will be sent to the Keyword Search WebExtension.
Because I don’t have access to the list of search engines in the browser, I’ve just created a basic set based on the US version of Firefox. You can also set a custom search URL. If you’d like your favorite search engine added to Keyword Search, please let me know.
I’ve also decided to make this a completely different extension on AMO so that existing users are not migrated. You can get the new extension here.
Apple's product strategy has been receiving more attention lately as voice-first and AI-first become buzzwords in Silicon Valley. Questions regarding whether Apple even has a coherent product vision are on the rise. While Apple is no stranger to receiving skepticism and cynicism, the degree to which people are discounting Apple's product strategy is noteworthy. There is mounting evidence that Apple's industrial designers are following a product vision based on using design to make technology more personal. It is becoming clear that such a vision extends well beyond just selling personal gadgets.
Product Strategy
Apple's financials paint a picture of a company following an iPhone as Hub product strategy in which iPhone is the sun and every other product revolves around iPhone. Apple generated $140B of revenue and approximately $60B of gross profit from iPhone over the past year. These totals amounted to 60% and 70% of Apple's overall revenue and gross profit, respectively. As seen in Exhibit 1, over the past year, Apple sold 2.5x more iPhones than iPads, Macs, Apple Watches, Apple TVs, and AirPods combined.
Exhibit 1: Apple Product Unit Sales
Upon closer examination, Apple is not following an iPhone as Hub strategy. In fact, the company has never followed such a product strategy. Apple is instead following a strategy based on selling a range of tools containing varying levels of personal technology. Management is placing big bets on four product categories: Mac, iPad, iPhone, and Apple Watch.
Apple leaves it up to the consumer to determine the amount of personal technology that fits best in his or her life. For hundreds of millions of people, iPhone is the device that has just the right mix of power and functionality in a convenient form factor. This plays a major role in explaining the iPhone's oversized impact on Apple's financials. When looking at the number of new users entering each product category, it becomes clear that iPhone is Apple's best tool for gaining new customers. (The math behind Exhibit 2 is available for Above Avalon members here, here, and here.)
Exhibit 2: Growth in Installed Base
In addition to the four primary product categories, Apple also sells a line of accessories. HomePod, AirPods, Beats, and Apple TV are positioned to add value to Apple's primary computing platforms. The bulk of these accessories are designed to control sound. AirPods and Beats handle sound on the go while HomePod is tasked with controlling sound in the home. Apple TV is unique because it is given the job of controlling both sound and video on the largest piece of glass in the home. This uniqueness is also evident with Apple launching the tvOS platform for third-party developers.
The Grand Unified Theory of Apple Products
While Apple's four primary product categories share a few obvious attributes such as possessing screens, there is a more important connection. Each is designed to be an alternative to the next most powerful device as detailed in The Grand Unified Theory of Apple Products (shown below).
Apple's quest to make technology more personal involves using design to remove barriers preventing people from getting the most out of technology. Instead of positioning new products as replacements for older ones, Apple is focused on coming up with alternatives. One way to accomplish this goal is to take complicated tasks and break them down into more granular tasks, which can then be handled by smaller and simpler devices.
iPad is given the job of being powerful and capable enough to serve as a Mac alternative.
iPhone is given the job of handling tasks that may have otherwise gone to iPad.
Apple Watch is tasked with doing enough things on the wrist that it can serve as an iPhone alternative.
Multitouch computing represented a giant leap in Apple's quest to make technology more personal. Based on unit sales, it's fair to say hundreds of millions of people think iPhone and iPad are adequate Mac alternatives. In a similar vein, Apple Watch isn't designed to replace iPhone. Instead, Apple Watch is given the job at handling some of the tasks given to iPhone. The ability to put digital voice assistants on the wrist represents Apple's latest personal technology breakthrough.
Evolving Product Priorities
While Apple designers and engineers have shown the willingness to push Apple's four primary product categories forward, change is in the air. Apple Watch and the broader wearables category represent Apple's best chance to make technology more personal. One of the highlights from Apple's inaugural event last month at Steve Jobs Theater was a cellular Apple Watch. In fact, the Apple Watch portion of the event was the strongest part of Apple's presentation. After spending the past two years refining its Apple Watch messaging, Apple now has a more appealing and convincing Watch sales pitch for consumers.
It's becoming clear that Apple's product priorities are shifting.
Release an Apple Watch that is fully independent of iPhone.
Position Apple Watch to handle more tasks currently given to iPhone.
Release accessories that complement Apple's expanding wearables strategy.
Position iPhone as an AR navigation device.
Position iPad as a genuine Mac alternative.
Position Mac as a VR/AR content creation machine.
Combining the six preceding priorities into one cohesive product strategy leads to the following diagram.
Resources and attention are flowing to the devices at the right end of the spectrum, the products most capable of making technology more personal. A cellular Apple Watch Series 3 is the latest step in Apple's journey to an Apple Watch that is completely independent from iPhone. Such a product will represent a watershed moment for Apple Watch as it would more than triple the product's addressable market. When it comes to Apple Watch serving as a genuine iPhone alternative, the addition of a selfie camera one day and an increased role played by Siri intelligence will go a long way in allowing Apple Watch to handle additional tasks formerly given to iPhone.
Grand Vision
There is a grand vision behind Apple's product strategy of selling a range of personal devices. Apple believes design is the ingredient that allows people to get the most out of technology. Even though Apple's industrial designers oversee this vision, the entire company ranging from engineers and product designers, to Apple retail specalists believe in focusing on the user experience. Apple views core technologies not as products in of themselves, but as ingredients for something else. Instead of copying other companies and chasing after technology's raw capability, Apple is more interested in technology's functionality as it relates to the user experience.
It is easy to look at Apple's current product line of personal devices and wonder where the company will turn next. Additional wearable devices like AR glasses are inevitable and fit within a product line of personal gadgets. On the other hand, Apple's growing interest in transportation has been a head scratcher for many observers as a car doesn't seem to fit within Apple's product strategy. This has led some to wonder if Apple is getting away from its mission or vision in an attempt to chase revenue or users.
Instead of assuming a self-driving car would be tacked onto the end of Apple's product line next to Apple Watch, the much more likely scenario is that transportation would represent a brand new product paradigm for Apple. The same idea applies to Apple's growing interest in architecture and construction.
As shown below, Apple would have multiple product paradigms, each comprised of a range of products. This is the primary reason why Project Titan shouldn't be thought of as just a self-driving car initiative, but rather Apple building a foundation for its transportation ambition.
In essence, Apple's transportation strategy would begin with a self-driving car but then eventually lead to the company developing more personal modes of transportation based on new user interfaces, fewer wheels, and different seating arrangements. This process would be equivalent to Apple starting with Mac and then using new user interfaces, technology, design, and manufacturing techniques to create products capable of making technology more personal. Apple would take a self-driving car and strip away capabilities in order to improve functionality. The same goal can occur with architecture and the broader concept of smart homes. It's difficult to see homes becoming truly smart until Silicon Valley begins building housing. The major takeaway is that Apple's quest to make technology more personal doesn't just apply to personal devices. Instead, there is a role for design to play in entirely new industries such as transportation and construction.
Issues
Apple has run into its fair share of issues and roadblocks following its grand vision. As resources and attention flow to devices most capable of making technology more personal, Apple has made some questionable design decisions. The Mac Pro and Apple's overall approach to pro Mac users has not fared well in recent years. This serves as the basis for my "The Mac is Turning into Apple's Achilles' Heel" article earlier this year. Management was forced to back track in order to stem growing backlash within the pro Mac community. Even today, the amount of criticism pointed at the Mac, some of which is genuine, is trending at multi-year highs.
The Mac debacle also ends up revealing some of the downsides associated with Apple's functional organizational structure. The company practices a focus mantra when it comes to product development, which may result in certain products getting left behind or not getting as much attention as they may need. This may make the jump into new product paradigms like transportation that much harder for Apple.
While Apple's product line is still incredibly focused for a $825B company, there is no denying that additional models and SKUs have led to an expanding product line over the years. Apple's entire product line is shown below. Apple relies on a consumer segmentation strategy to target as broad of a market as possible for each of its four primary product categories. Apple has learned a lesson or two from the dark days in the 1990s. A byproduct of this strategy has been complexity being added to the product mix in recent years.
Inevitable Path
Apple puts much effort, care, and deliberation into marketing. This makes one of the animated videos found on Apple's website so intriguing. As shown in the screenshots below, the animated video is meant to highlight HomePod's spatial awareness capability. The only two Apple products shown in the room are HomePod on a table and the two individuals wearing Apple Watches. There is no iPhone, iPad, or Mac in sight. For some companies, this can be brushed off as a simple oversight, but not for Apple. It's intentional.
Apple looks at Apple Watch as the natural evolution of personal computing. Having Siri intelligence on the wrist throughout the day, in addition to receiving and consuming information via a screen, is powerful. Meanwhile, HomePod is positioned as an Apple Watch accessory capable of delivering sound in a way that just isn't feasible for a device worn on the wrist. While some companies are advocating new product strategies such as voice-first or AI-first, Apple is taking a different path with a product strategy evolving into one based on wearables. Voice and AI are then positioned as core technologies powering these wearable devices. To a certain degree, this is the inevitable path Apple has been on for the past 40 years. Going forward, the largest opportunity for Apple will be found in using its product vision to create personal technology paths in new industries.
Receive my analysis and perspective on Apple throughout the week via exclusive daily emails (2-3 stories a day, 10-12 stories a week). To sign up, visit the membership page.
Everyone has a story to tell. But not everyone knows how to tell it. Some of us get so tongue tied by stage fright, we can’t get our best ideas out of our head and into the world. But public speaking doesn’t have to be a nerve-racking chore. In fact, it can be fun when you know how to get out of your own way and get into a creative flow. Today, we’ll show you 15 tips for chipping away at anxiety so you can bring your brilliant work to the people who need to hear it.
Establish your story
If the fear of public speaking has you seriously considering the advice of 1970s sitcom dads, don’t freak out. We’re gonna get through this. Don’t worry about wowing the crowd with charm and charisma. Instead, start by asking, “What message do I want them to remember?” Let that be the foundation of your presentation. Then, create content that flows from that foundation by following these five steps:
1. Set a clear goal: Why are you giving this presentation? Do you want to establish yourself as an expert on a particular topic? Expand your network of industry contacts? Even if you just want to improve your presentation skills, it helps to define your goal at the outset.
2. Determine your key takeaway. Once you’ve identified the most important point you want to make, don’t be shy about weaving it into your presentation several times as a sort of “tagline.” Studies show that “spaced repetition” can improve our ability to recall information later.
3. Choose a theme that ties your ideas together. Remember how Seinfeld used callbacks to thread a comedic theme throughout an entire episode? This technique has a way of making the audience feel more engaged as they begin to anticipate the recurring idea. Though your theme is typically a broad idea or a phrase, you could also use a recurring visual as a theme.
4. Focus on story. There’s no rule that says you have to follow a logical or chronological order. If using flashbacks or time jumps makes your story more impactful, feel free to follow that instinct. As long as you let your key takeaway be the lodestar that helps you steer your story, you’ll be heading in the right direction.
5. Create a framework for ideas. If you’re nervous about getting tongue tied, you might be tempted to write out a script you can lean on like a crutch. But that will bore the audience to sleep because you’re giving all your attention to your own words. Instead, focus on an outline of ideas that prompt you to stay present and conversational.
Next comes the fun part. After you’ve created your content, you get to dress it up and style it out. Play with visual ways to bring your message to life. Ask yourself, “How should I tell this story?”
6. Use impactful imagery. Did you know your brain can identify images you’ve seen for only 13 milliseconds? Should that make you mull over the idea of subliminal slides with your Twitter handle on them? No, it should not. But images do make your message more powerful. If words are the roots of your presentation, let simple, conceptual images be the bloom.
7. Lean toward clean. Experts like David Phillips advise using only one message per slide. That gives your audience a chance to absorb the idea, and prevents the slide from becoming a distraction as you’re speaking.
8. Use slides as visual support. Be careful not to create slides that repeat the words of your speech. They should play a complementary role to the words you’re speaking.
9. Work on your stage presence. Though you might not think of yourself as a visual aid in your presentation, your body language and movement on stage add a lot to the way your message is received. So be sure to practice your presence by rehearsing in front of other people.
10. Remember that it’s a performance. Why doesn’t it feel natural to stand on a lighted stage and talk to a crowd of strangers? Because it’s not. It’s actually better that it doesn’t feel as comfortable as a conversation at home, because you can use nervous energy to your advantage. Use it to create an onstage persona: act like an extrovert, if only for 20 minutes.
Connect with your audience
Showtime! Ready to put those first 10 tips to the test? Though you’ve already created your content and prepared your delivery with your audience in mind, it’s time to face them for real. Let’s take a good, long look at the crowd. Who are these people and why are they here?
11. Focus on the needs of the audience. When the spotlight’s on you, it’s easy to forget the simple truth every presenter should remember: it’s not about you. You’re just the messenger. Remember that the message is what matters most to your audience.
12. Build the presentation with the whole audience in mind. If you’re speaking at a conference, chances are, some VIPs will be in attendance. Yes, they’re Very Important—but they’re not the most important. So play to the average person in the crowd, not the “bigwig” outliers.
13. Be conversational. Remember, you’re not there to read a script, and that includes the one you’re filing in your mind. Choose your words in the moment. Don’t memorize your speech.
14. Go deeper than data. Numbers are helpful for substantiating your claims. But if you want the data to be meaningful and memorable, studies show it helps to elicit emotion.
15. Invite participation. Close with a call to action. Let people know how to keep in touch with you. Ask them for feedback on which ideas resonated and which parts need improvement. Make accessibility and receptivity be part of your personal brand.
Adobe announced some big changes to Lightroom today, including a new cloud-native version (Lightroom CC) as well as a re-branding of the familiar desktop version (Lightroom Classic). Additionally, they have discontinued development of a “perpetual” version and all new versions will be licensed on a subscription basis. What gives?
The Innovator’s Dilemma Clayton Christensen’s 1997 book, The Innovator’s Dilemma helps to shed some light on Adobe’s behavior. In the book, Christensen tracks the rise and fall of disruptive innovation, which includes rapid growth of successful applications, and an eventual leveling off of growth as the market becomes saturated. Eventually, changes in the market landscape allow for new competitors to arise, and the company becomes vulnerable to disruptive innovation and the loss of market dominance. If you don’t innovate on an equally aggressive basis, the company faces real danger. In this circumstance, your market dominance may prevent you from creating new software as you focus on maintaining the success of the old product.
The digital photography revolution Lightroom was, in large part, an earlier response to the innovator’s dilemma. Photoshop was the clear leader in imaging software, but it was developed before the advent of digital cameras. Camera Raw was developed as companion application to Photoshop to deal with raw files, but ultimately the very structure of Photoshop was incompatible with the needs of busy digital photographers. It had a one-at-a-time file handling structure that was insufficient for many workflows.
Lightroom was developed in response to this new market reality. Adobe took the Camera Raw engine from Photoshop and grafted it on to a database, creating one of the most successful applications in the company’s history. Lightroom was developed by a small team working inside Adobe, essentially functioning as competition to the flagship product. If Adobe had put all their effort into shoring up Photoshop, they would be in very serious trouble right now as a preferred tool for digital photographers.
Mobile>digital We are now at another inflection point, and this one, I believe, is even more transformational. The use of photography as a language, created on and consumed on smartphones has changed the way we communicate. One of the primary needs in this new world is continuous access and connectivity. Dependence on desktop software is incompatible with many of the important uses of photography. Often, we simply can’t wait until we get back to the home or office to send photos. And a great collection of images is frustratingly out of reach if you are away from your computer.
In order to serve the needs of mobile photographic communication, the Lightroom team has spent years working on ways to create an integrated cloud component to Lightroom. Publish Services allow the extension of Lightroom to integrate with a wide variety of other applications, including many cloud offerings. And the introduction of Lightroom Mobile, along with some integration with traditional Lightroom catalogs, offered some seamless interchange.
But the architecture of Lightroom as a desktop application simply cannot be stretched enough to create a great mobile application. The desktop flexibility that has powers such a wide array of workflows can’t be shoehorned in to full cloud compatibility. The freedom to set up your drives, files and folders as you wish makes a nightmare for seamless access. And the flexibility to create massive keyword and collection taxonomies does not work with small mobile screens. After years of experimentation, the only good answer was the creation of a new cloud native architecture. As with the creation of the original Lightroom, this was done by taking the existing Camera Raw imaging engine and bolting it on to a new chassis – this time a cloud native architecture.
Managed file storage In order to have “my stuff everywhere” the new application has to be cloud native. The primary storage of your images and videos is now in the cloud. This allows Lightroom to have seamless access on multiple devices. And in order to allow Lightroom to push these files around, you need to give up control over the configuration of folders. By giving the control over to Lightroom, the application itself can help to manage the transfer of files between devices, using downsized versions when storage space is not adequate for full size copies. (and, yes, you can have a complete full-sized archive on your own drives, which is something I would suggest).
Computational Tagging Lightroom has also made a major break with the metadata methods of the past, opting for a computational tagging system. Some of this is familiar – the use of date-time stamps and GPS tags to organize photos. Some is new, like the Machine Learning and Artificial Intelligence tagging that can automagically find images according to content. While these tools and techniques are pretty rudimentary now, we can expect them to mature quickly and continually. (Google Photos, for instance, just announced that they can now identify photos of your pets, and, voila, the tags simply appear.)
Not the end of desktop Lightroom
Just as the advent of Lightroom did not kill Photoshop, the introduction of Lightroom CC will not kill Lightroom Classic. It’s a hugely popular program for an important part of their customer base. And creating a cloud-native version of the software, instead of trying to shoehorn the program into a workflow it did not fit, frees up resources to make Lightroom a better desktop application. The Camera Raw development team can continue to make improvements to the engine, and each of the chassis builders – Camera Raw + Bridge, Lightroom Classic and Lightroom CC can focus on building workflows for their customer’s needs.
There are a number of important uses of Lightroom that are pretty far off for Lightroom CC. Many power users depend on custom keyword taxonomies and deep collection hierarchies and these may never appear in Lightroom CC. And there are lots of existing integrating of Lightroom through Publish Services that won’t be easy to migrate. There are also a ton of clever and useful Lightroom plugins that may be impossible to add to the cloud version.
For my own workflow, I’ll be sticking to Lightroom Classic as far as the eye can see. But I expect that my wife and kids will be happier with Lightroom CC.
The end of Perpetual Lightroom
There is certain to be some unhappiness with the discontinuation of the perpetual versions of Lightroom. For those who don’t want cloud connectivity or who don’t use smart phones, this change forces them into a subscription service that may be unwanted. I feel your pain.
But the world is changing, and photography is becoming a more important part of it. I’ve spent the last four months working on The DAM Book 3, writing about these tectonic changes, and I’m convinced that mobile imaging (and image consumption) is a driving force. Adobe is in a position to help us take advantage of that change and make the most of it. If they did not accept the evolution of the imaging landscape, they could be in real trouble. As it is, it will still be a challenge to maintain their leadership in such a fast-moving market.
Although Lightroom CC does introduce some black box functionality, Adobe is still a clear leader in “you own your stuff, and you can take it wth you.” I think this attitude, central to Adobe’s products since Geschke and Warnock left Xerox PARC to found the company, remains one of the strongest reasons to use their tools. Mobile and cloud computing has changed the landscape, but this attitude remains intact.
Note – If you want a more granular description of the changes to Lightroom, check out the ever-comprehensive Victoria Bampton’s post here.
As reported in the Toronto Star a federal-provincial-city agency overseeing Toronto’s Quayside 12 acre project site announced that Sidewalk Labs a sister company of Google has won a competition to build a new high-tech neighbourhood on that city’s east downtown waterfront. Once confirmed by the Waterfront Toronto board, “the choice of a firm owned by Google holding company Alphabet Inc. would be a big high-tech feather in the cap of the city currently chasing the second headquarters of Amazon and other innovation opportunities.”
Sidewalk Labs is committed to reimagine cities from the Internet up. The new Quayside neighbourhood will be “a testbed for cutting-edge technology as well as a bustling, functioning neighbourhood, with homes, offices, retail and cultural space, near Queens Quay East. and Parliament Street.”
As Alphabet’s urban innovation unit, Sidewalk Labs has been searching for a larger scale area to act as its “smart city test bed…The community would be universally connected by broadband and could have prefabricated modular housing, sensors to constantly monitor building performance, and robotic delivery services to cut residential storage space, The Architects’ Newspaper reported in May.”
The winning bid was to “foster sustainability, resiliency and urban innovation; complete communities with a range of housing types for families of all sizes and income levels; economic development and prosperity driving innovation that will be rolled out to the rest of the world; and partnership and investment ensuring a solid financial foundation that secures revenue and manages financial risk.” Toronto also perceives that Google’s presence in Toronto as well as the decision by Uber to make Toronto a driverless car research hub as the first step towards a massive technology boom that will shape the city.
In the “you just can’t make this stuff up” department, double salary dipping Provincial MLA Ian Paton thought he had a very good idea. A newly minted Liberal MLA and also happily continuing the strange conflict of interest of being on Delta City Council, Mr. Paton still is representing Delta’s one hand clapping for the new Massey Bridge. Instead of productively working with the new Provincial government which is overseeing an evaluation of the Massey crossing options, Mr. Paton had the time to go the Massey Tunnel and hammer in some political billboards. Seriously.
Instead of those billboards saying something constructive, those billboards contain one-sided tired 20th century political rhetoric. Those billboards don’t say that a multi-billion dollar overbuilt bridge on the sensitive Fraser River delta is being re-evaluated, that the lack of public process and the lack of buy-in of the Mayor’s Council on the size and the location was a concern. Oh no. They embarrassingly tell drivers that they are stuck in traffic because of the current government. The signs are also placed on property not surprisingly owned by Ron Toigo of White Spot fame, who of course would greatly benefit if his farmland was rezoned industrial due to the location of a ten lane bridge. It’s all so transparent.
As Mike Smyth in The Province observes Andrew Weaver of the Green Party notes what many others are thinking of these billboards: “It’s hilarious. I’ve had dozens of people contacting me to say, ‘Thank you for stopping the reckless path of an unreviewed bridge that was promised out of nowhere by the Liberals.’”
It’s really time to stop thinking of the Massey crossing as a political boondoggle and evaluate it for what it truly is. No one is disputing the need for better, more efficient access across the Fraser River. Bullying tactics don’t work~and future generations living in Metro Vancouver may inherit a prudent crossing that is respectful to the existing Agricultural Land Reserve and sensitive delta conditions, or a ten lane crossing that will speed up the industrialization of the banks of the Fraser River. It’s our choice and we need to take the time to make the right decision for future generations.
Today, Mozilla is announcing a plan that grows collaboration with Microsoft, Google, and other industry leaders on MDN Web Docs. The goal is to consolidate information about web development for multiple browsers – not just Firefox. To support this collaboration, we’re forming a Product Advisory Board that will formalize existing relationships and guide our progress in the years to come.
Why are we doing this? To make web development just a little easier.
“One common thread we hear from web developers is that documentation on how to build for the cross-browser web is too fragmented,” said Daniel Appelquist, Director of Developer Advocacy at Samsung Internet and Co-Chair of W3C’s Technical Architecture Group. “I’m excited to be part of the efforts being made with MDN Web Docs to address this issue and to bring better and more comprehensive documentation to developers worldwide.”
More than six million web developers and designers currently visit MDN Web Docs each month – and readership is growing at a spectacular rate of 40 percent, year over year. Popular content includes articles and tutorials on JavaScript, CSS and HTML, as well as detailed, comprehensive documentation of new technologies like Web APIs.
Community contributions are at the core of MDN’s success. Thousands of volunteers have helped build and refine MDN over the past 12 years. In this year alone, 8,021 users made 76,203 edits, greatly increasing the scope and quality of the content. Cross-browser documentation contributions include input from writers at Google and Microsoft; Microsoft writers have made more than 5,000 edits so far in 2017. This cross-browser collaboration adds valuable content on browser compatibility and new features of the web platform. Going forward, Microsoft writers will focus their Web API documentation efforts on MDN and will redirect relevant pages from Microsoft Developer Network to MDN.
A Broader Focus
Now, the new Product Advisory Board for MDN is creating a more formal way to absorb all that’s going on across browsers and standards groups. Initial board members include representatives from Microsoft, Google, Samsung, and the W3C, with additional members possible in the future. By strengthening our relationships with experts across the industry, the Product Advisory Board will ensure MDN documentation stays relevant, is browser-agnostic, and helps developers keep up with the most important aspects of the web platform.
“The reach of the web across devices and platforms is what makes it unique, and Microsoft is committed to helping it continue to thrive,” said Jason Weber, Partner Director of Program Management, Microsoft Edge. “We’re thrilled to team up with Mozilla, Google, and Samsung to create a single, great web standards documentation set on MDN for web developers everywhere.”
Mozilla’s vision for the MDN Product Advisory Board is to build collaboration that helps the MDN community, collectively, maintain MDN as the most comprehensive, complete, and trusted reference documenting the most important aspects of modern browsers and web standards.
The board’s charter is to provide advice and feedback on MDN content strategy, strategic direction, and platform/site features. Mozilla remains committed to MDN as an open source reference for web developers, and Mozilla’s team of technical writers will continue to work on MDN and collaborate with volunteers and corporate contributors.
“Google is committed to building a better web for both users and developers,” said Meggin Kearney, Lead Technical Writer, Web Developer Relations at Google. “We’re excited to work with Mozilla, Microsoft, and Samsung to help guide MDN towards becoming the best source of up-to-date, comprehensive documentation for developers on the web.”
MDN directly supports Mozilla’s overarching mission. We strive to ensure the Internet is a global public resource that is open and accessible to all. We believe that our award-winning documentation helps web developers build better web experiences – which also adhere to established standards and work across platforms and devices.
“We’re not in the business of keeping the media companies alive,” Mr. Edwards says he tells many media executives. “We’re in the business of connecting with consumers.”
I used that a lot in presentations over the following few years, trying to make the point that a company had been historically very good at advertising was very willing to walk away from it. It's the moment that really convinced me that smart corporate attention would eventually but inevitably move from a relationship via marketing to a relationship via services.
This is not happening quickly. I suspect it's happening in the way that Hemingway describes how one goes bankrupt: "Gradually, then suddenly".
Five years ago this week GOV.UK launched.
My only real contribution was to make sure we didn't spend any money on advertising it. That seems to be going OK.
(I am also quietly proud that they're still saying Simpler, Clearer, Faster)
Kevin Nguyen@knguyen
Hey, please DM me about the racist thing I said to you. Please feel safe DMing with me, the person who said a racist thing to you.
Google’s Twitter account says iOS users interested in signing up for the beta can do so using an online form. In order to register, users must already have the Gmail iOS app, as well as a non-Gmail email account, and be running at least iOS 10.
Google did not mention when support for non-Gmail accounts may be added to the iOS Gmail app.
After a difficult first year, Samsung’s Bixby voice assistant is getting a “bold reinvention,” the company announced at its annual develop conference.
Samsung’s head of service intelligence for mobile, Eui-Suk Chung, promised in his follow-up blog post that Bixby 2.0 will be “ubiquitous, available on any and all devices,” acting as the control hub of a user’s network of smart devices, from home speakers to refrigerators. He also noted Bixby 2.0 has enhanced natural language capabilities.
Perhaps most significantly, however, Chung announced a private beta program for the Bixby software development kit (SDK), in order to let developers build apps for the service, a key component of Amazon Alexa’s early success as an AI. Samsung says it will gradually broaden its SDK program and eventually make it publicly available.
“We know Samsung cannot deliver on this paradigm shift by ourselves — it can only happen if we all, across all industries, work together, in partnership,” said Chung.
“We know Samsung cannot deliver on this paradigm shift by ourselves.”
Bixby debuted in March 2017 and made it to Canadian users in late August. So far, it’s received lukewarm reviews, with our own Sameer Chhabra commenting on how poorly the AI responded to contextual cues. In fact, the dedicated Bixby button on the Galaxy S8 and S8+ was received so poorly (partially because of the potential for easy triggering) that Samsung had to allow users to disable the button altogether.
With the second generation of Bixby, Samsung is attempting to right that situation, a task the company is taking seriously.
Chung underlines just how important the company believes AI is to the future of consumer technology by comparing it to the advent of touch screen smartphones.
“I believe that we are now on the cusp of the next major tectonic shift,” said Chung.
Bixby 2.0 is integrated with Viv technologies, the startup founded by Siri vets that Samsung acquired last year. The exact timing of the roll-out across global markets is as yet unclear.
Google’s Pixel 2 has a hidden feature that eases the frustration of manually finding an app’s menu.
The feature, discovered by Android Police, is an invisible button located to the far right of the virtual navigation buttons that, in some apps, automatically pops up the menu.
The function does not appear to be available on other devices running Android 8.0 Oreo, or even on previous generation Pixel devices — making it, at least for now, an exclusive similar to the previous generation Pixel’s ability to swipe down on the fingerprint sensor in order to pull down the notification shade.
Through MobileSyrup‘s own testing, we found a number apps supported the hidden menu button, from Google apps like Chrome, Settings, Clock, Calculator, Downloads, Docs and Drive, as well as several third-party apps like Twitter, Waze, Messenger, Pocket and even the somewhat more obscure battery tracker, HD Battery. There were many apps that didn’t offer respond to the hidden button, however, including Google Photos, Netflix and Google Maps.
The concept of a menu button isn’t new — it was a component of Android in the earlier days of the operating system, but Google left it behind with the Galaxy Nexus in 2011 and Samsung ditched it with Galaxy Note III in 2013.
It’s unclear exactly why Google decided to re-integrate the feature into its latest devices, but while it may be from another era, it still serves a useful purpose when it comes to making apps easy to navigate.
Apple’s self-driving car technology is looking a little top-heavy in a newly posted video on Twitter.
The video is from MacCallister Higgins, co-founder of self-driving startup Voyage, and shows a bulky top-mounted array of six LIDAR sensors along with multiple radar units and cameras. The setup was further confirmed by another Twitter user who revealed a picture taken at an Apple shuttle stop.
Going to need more than 140 characters to go over ????'s Project Titan. I call it "The Thing" pic.twitter.com/sLDJd7iYSa
The hardware is more polished than what was spotted on the roads this spring, adhering to the classic all-white Apple aesthetic, but it’s not much more compact.
Comparatively, Alphabet’s fleet of Waymo self-driving Chrysler-Pacifica minivans look quite different, featuring smaller, more streamlined rooftop protrusions and a variety of other small hardware pieces placed unobtrusively around the sides and front of the vehicle.
If, like me, you’ve heard of the Canadian-developed storytelling platform Wattpad but have never ventured onto its soft orange-yellow shores to explore it yourself, you’d probably be surprised to learn that it’s much more than a modern version of Fanfiction.net.
Wattpad presents itself as a place for writers, poets, essayists and literary aficionados to experiment with literature, engage with an active audience and, quite possibly, discover burgeoning talent before they make it big.
The service is free, but Wattpad is launching a premium-tier subscription plan — priced at $5.99 CAD per month or $59.99 annually — for those looking “to enjoy an uninterrupted, ad-free Wattpad experience.”
The subscription service, dubbed ‘Wattpadd Premium’ is designed to give “people more control over their Wattpad experience, and allows us to continue to offer Wattpad as a free platform that anyone can enjoy,” according to Allen Lau, Wattpad’s CEO and founder, in an October 18th, 2017, media release.
As of right now, Wattpad Premium simply removes ads and provides a new theme within the mobile version of the platform. However, the company promises that additional features will launch in the coming months.
Wattpad Premium carries over across the platform’s desktop and mobile apps, and is available now.











































 The Province Images
The Province Images











![[link]](https://i.redd.it/hvb445eqvfsz.jpg){kind=link}
{kind=link}