We've reached a point where it is obvious that spatial user interfaces no longer work for file management. Our files are scattered over too many different places and services, and we have too many of them.
For application launchers, though, a spatial view is still the preferred approach. This is why Windows 11's Start menu is so confusing to me.
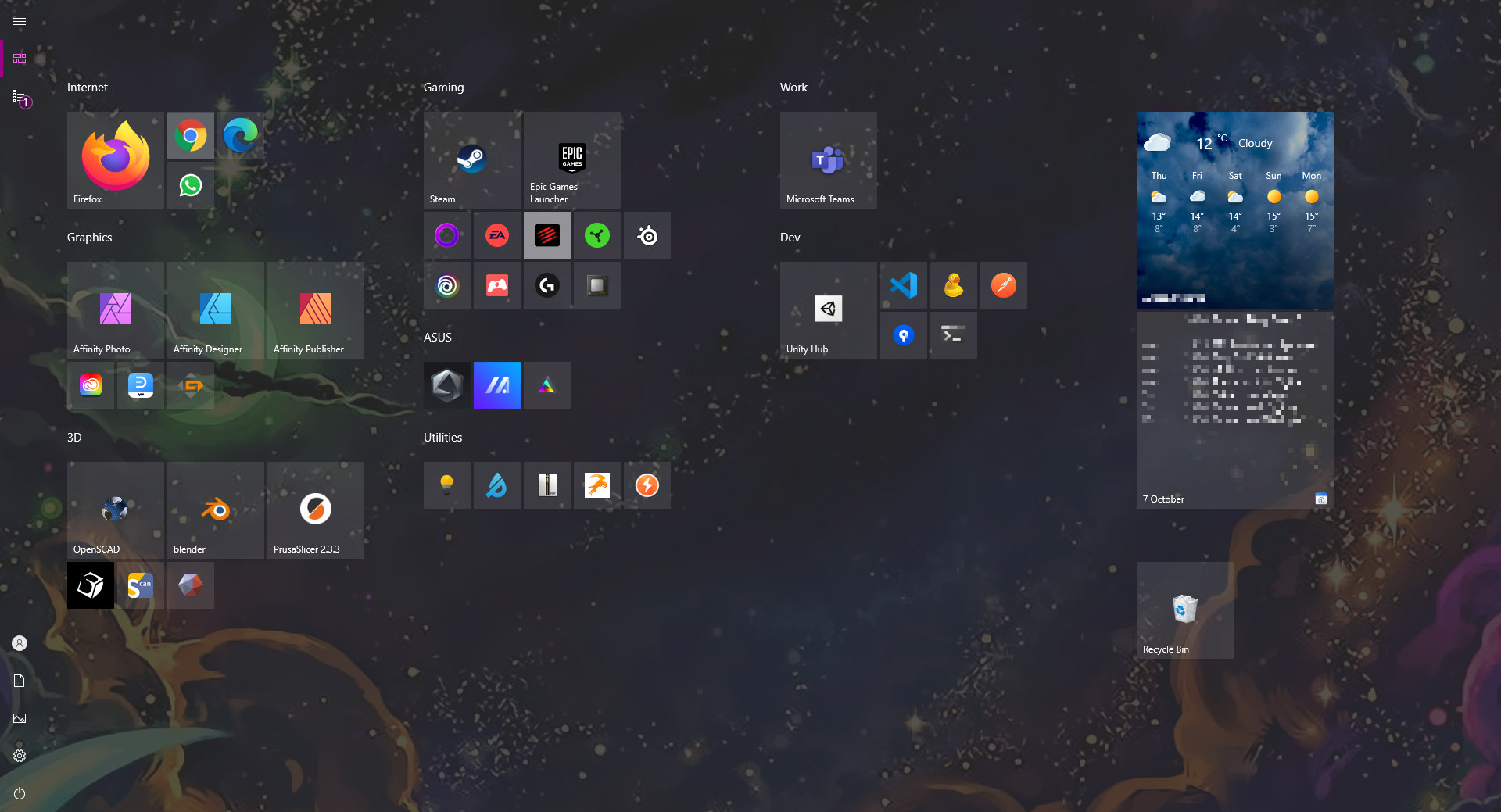
This is what my Start menu looked like in Windows 10:
This is by far the best home screen experience any operating system currently offers. Better than the app launcher on OS X, better than Android, better than iOS, better than any Linux distro I've seen.
I guess I'm not really angry. I'm not even disappointed. I'm a bit sad, but mostly I'm confused, because I truly do not understand what the purpose of this change is.
I like a lot of the changes in Windows 11. I think the visual design is nice. I love the improvements for WSL. Snap Layouts are great, and the way Windows 11 supports restoring windows on multiple screens is a welcome improvement.
But the Start menu, and everything related to it, including the way the Start icon itself dances around the screen and is always in a different place, never allowing you to develop a habit for clicking it, is just odd.
If you require a short url to link to this article, please use http://ignco.de/786
But wait, there's more!
Want to read more like this? Buy my book's second edition! Designed for Use: Create Usable Interfaces for Applications and the Web is now available DRM-free directly from The Pragmatic Programmers. Or you can get it on Amazon, where it's also available in Chinese and Japanese.
Today is my fourth day in the first full-time programming job I've had in ten years.
Some things have stayed the same (meetings, t-shirts, and package management problems),
but others have changed:
I'm finally going to have to learn how to use Docker and cloud-based microservices,
and where pre- and post-commit hooks were a rarity a decade ago,
almost every step of development is now supported by automated checks.
Kinsman2021 looks at how teams use GitHub Actions
to implement those checks and support development workflows in other ways.
They found that the most common operations are (in order)
continuous integration,
miscellaneous utilities (such as reading configuration files),
deployment,
publishing,
and code quality/code review,
with a long tail of other kinds of actions.
(Almost 40% of the actions they found fell into the "Uncategorized" bucket.)
As for impact,
they found that after adopting GitHub Actions,
projects had more rejected pull requests and fewer commits on merged pull requests;
adopting Actions didn't affect the number of merged pull requests,
the rate of comments on PRs,
or several other variables.
Actions were still fairly new when the study was done,
so I hope the authors will do a follow-up.
Better yet,
I hope they will automate their data collection and analysis to provide continuous updates,
which would be in the spirit of what they are studying.
Automated tools are frequently used in social coding repositories to
perform repetitive activities that are part of the distributed
software development process. Recently, GitHub introduced GitHub
Actions, a feature providing automated work-flows for repository
maintainers. Although several Actions have been built and used by
practitioners, relatively little has been done to evaluate
them. Understanding and anticipating the effects of adopting such
kind of technology is important for planning and management. Our
research is the first to investigate how developers use Actions and
how several activity indicators change after their adoption. Our
results indicate that, although only a small subset of repositories
adopted GitHub Actions to date, there is a positive perception of
the technology. Our findings also indicate that the adoption of
GitHub Actions increases the number of monthly rejected pull
requests and decreases the monthly number of commits on merged pull
requests. These results are especially relevant for practitioners to
understand and prevent undesirable effects on their
projects.
I'd like to propose a modest Tinderbox puzzle. If you’d like to play on the forum, you can respond there. I hope people will share their solutions. Or you can just Email me. Or follow along at home.
The Problem: Build a “journal” or “daily notes” facility that will make it easy to record notes about your progress on a project. The general structure might be something like this:
2021
September
1
..
30
October
1
2
5
Things that would be nice:
When you make a new daily note, initialize it with some template text, or display some important attributes, to remind you of things you ought to record.
Don’t require that the note for October 5 be written on October 5; make it easy to write on October 8 if that’s when you have time.
Don’t leave lots of empty notes lying around with nothing inside (e.g. notes for the future).
When you add a new note, make sensible assumptions for its name. (For example, if you add the first child to November 2021, it might default to November 1.)
Use $StartDate and $EndDate sensibly.
Think about what we might record in the notes for each month, and for each year.
Low Kickers have been a very popular frame offering and we've seen them built up in so many different styles ranging from commuter to gravelleur to tourer and everything in between. Well, they're back in stock and ready to go out!
If you're interested in build ideas for the LK (or for any other VO frame in general) check out our build ideas page.
We also got a restock of several parts and accessories you've been patiently waiting on. A lot of these items will go fast, so don't snooze on them! Highlights include:
This past Wednesday, October 6, HUB Cycling put on a webinar: E-bikes: Harnessing their potential to get more people biking. About a hundred people attended the free webinar where panelists discussed how municipalities can benefit from creating conditions favourable to e-bikes, spoke about the North Shore's e-bike share roll out, & highlighted the importance of e-bikes in getting more people of all ages & abilities biking more often.
Speakers were:
Todd Litman, Executive Director, Victoria Transport Policy Institute and author of New Mobilities: Smart Planning for Emerging Transportation Technologies
Zachary Mathurin, North Shore Mobility Options Coordinator
& me! Lisa Corriveau, bike blogger & e-bike advocate for people with mobility issues
During a member research interview this week, a member noted ‘I don’t really know the difference between groups and categories’.
That’s not a surprise. Most of the time there isn’t much of a difference. In fact, most of the time the group should simply be a category. It attracts more participation and is easier for members to use.
Groups typically serve one of three purposes:
1) Keep most discussions relevant. A group might be created to prevent the main discussion area from being overwhelmed by a topic which a small group of members are really eager to discuss but the majority aren’t. This is important when a homepage pulls in all the latest discussions. Groups also often serve as places to support different languages without replicating the entire community experience.
2) Provide a place for private, intimate, discussions to happen. A group of members want to be able to share details about themselves or their challenges where only trusted others can see. In this case, groups are typically smaller (often 8 to 12 people).
3) Coordinating actions. Provide a place for coordinating action amongst a small group of members (i.e. superuser groups). People can coordinate activities about what to work on next and it’s an easy means for the community manager to distribute news to all superusers at once.
There are some exceptions. In Salesforce communities, for example, groups serve as a place to post announcements that all subscribed members can see. But this isn’t the best medium to do it.
If your group doesn’t obviously fit into one of these molds, I’d suggest starting a category instead.
While most folks will never have an issue with setting up an account, there are however those that for inexplicable reasons find that the process fails and the message they receive as to why is less than helpful. Offering support to those people is difficult to say the least, however having access to a complete log makes it much simpler.
How to actually capture a log of what happened in the account setup process. I have never seen it mentioned outside the Bugzilla bug management system.
So here goes my attempt to document these things.
First you need to change some hidden preferences in Thunderbird to get a complete log. So go to the config editor and make the following preference changes.
mail.wizard.logging.dump to all mail.wizard.logging.console to all
Now access the error console (ctrl+Shift+J) or via the developer tools on the tool menu and clear it by clicking the trash bin icon
Once you have done the setup you can now attempt to set up your mail account and the entire operation will be logged to the console.
Once you have the output, right click in the console and select export all messages to a file.
Once done with the logging change the preferences back to default as writing to the log is a somewhat expensive process and could slow Thunderbird at critical times.
The short answer to the question posed by McIntosh2021's title is "probably not".
They analyzed the GitHub repositories of almost twelve thousand hackathon projects from 2018–19
and found that:
…approximately 85% of commits were made within the first month,
and approximately 77% of the total commits occurred within the first week.
Only 7% of projects had any activity 6 months after the event ended.
Evaluated projects had an average of only 3.097 distinct commit dates…
That said,
this paper doesn't look at the long-term impact of hackathons on the participants themselves.
In my experience,
many people participate in hackathons to build new social connections
and to learn how to create, review, and merge changes.
Those impacts don't show up directly in the hackathons' own repositories;
pointers to studies would be very welcome.
Hackathons, the increasingly popular collaborative technology
challenge events, are praised for producing modern solutions to real
world problems. They have, however, recently been criticized for
positing that serious real world problems can be solved in 24-48
hours of undergraduate coding. Projects created at hackathons are
typically demos or proof-of-concepts, and little is known about the
fate of them after the hackathon ends. Do they receive continued
development in preparation for real world use and maintenance as
part of actually being used, or are they abandoned? Since
participants often use GitHub (Microsoft's popular version control
system), it is possible to check. This quantitative, empirical study
uses a series of Python scripts to complete a robust analysis of
development patterns for all 11,889 of the U.S. based 2018-2019
Major League Hacking (MLH) affiliated hackathon projects which had
GitHub repositories. Of these projects, approximately 85% of commits
were made within the first month, and approximately 77% of the total
commits occurred within the first week. Only 7% of projects had any
activity 6 months after the event ended. Evaluated projects had an
average of only 3.097 distinct commit dates, and the average of
commits divided by the length of the development period was only
0.1. This indicates that few projects receive the post-event
attention expected of an actively developed project. Finally, this
study offers a dialogue of possible ways to reformat hackathons to
help increase the average longevity of the development period for
projects.
At the outset of a conference call with securities analysts in July to discuss Twitter’s second-quarter earnings, CEO Jack Dorsey laid out his company’s strategy: “We intend to build an ecosystem of connected features and services focused on serving three core jobs: news, which is what’s happening; discussion, conversation; and helping people get paid,” he said.
The language Dorsey used — “three core jobs” — refers to a concept called “jobs to be done,” which is an approach to defining a business from the perspective of what really matters to its customers.
For Dorsey, jobs to be done provided a tool for strategic clarity at a critical time. “It cleared something up that was missing for me, which was how do we plan and build around a customer-centric framework that would focus the organization on why our customers are coming to us in the first place,” he said. Upon his 2015 return to Twitter, Dorsey launched an effort to identify the jobs that people hired Twitter for and, importantly, which jobs it would focus on going forward.
The framework was also applied at Dorsey’s other company, Square, to help the financial services and mobile payments company redefine its business and figure out where it might look for growth. The initial approach it took was similar to that of Twitter: The company gleaned insights into the jobs to be done from customer interviews and observations of how business owners used Square solutions. For instance, Square’s managers realized that its technology, which enabled small businesses to process credit cards, was a means to solving the broader job of “grow my business.”
Many decades ago, my mother bought my father a Tissot Seastar Seven. A very simple watch, which also has its own pendulum to keep it wound as the wearer moves about. I used to use it a lot. And it had an activity tracker sort of vibe: if I spent most of the day sitting around, the watch would eventually stop.
Alas, the crown was damaged and I didn’t use it for many years. But after my father passed away, late last year, I thought I’d get it fixed, in his honor. I knew the watch would have to compete with my daily wearing of my Apple Watch, so I knew I’d want to get some sort of watch winder, so that it would keep time and be ready to wear when needed.
This wouldn’t be my first watch winder, nor the last. I had built a watch winder for my For All Time project. And my father left another, fancy, watch, also a self-winder, for my kids, so I felt that there would be yet another watch that would need a watch winder.
Spinning in a fancy way I didn’t want some boring spinner like I had to use in my For All Time project. I had seen some gyro watch winders that were really cool. After some research, I found this one by Bruno Esgulian. And I’d seen many versions to get some thoughts on the color pattern.
So I bought the model from Bruno and the parts on the list that I didn’t have and got printing the whole set up in black and transparent blue PETG.
No so fast The buttons I got didn’t fit into the hole in the original model, leading to some funny attempts by me to fit it and ruining one of the two buttons that came (I had bought a 2-pack because I eventually was going to build a second winder, right?).
I had to modify the model to enlarge the hole a tad and print it again. And that worked.
An aside: I don’t know about you, but I regularly do test prints of specific sections of my models so I don’t print a whole model and potentially waste time and materials. On the right, I printed just the section of the base that had the modified button hole.
The second modification was the code. I wasn’t too enthused with the code that the maker was offering, so I made my own from scratch (well, not from scratch, I was reusing some code from the For All Time project, so I knew what I wanted and what to do).
A third modification was the power cable. I wanted to be able to power it, switch it off from the button on front for when I’m using the watch, and still be able to program the winder in case I had to change a parameter.
For that, I did some careful surgery on a USB cable, breaking out the power to be controlled by the button and keeping the data wires intact. Worked really well.
Drifting One thing with winders is that you need to find the right amount of rotations so as to not overwind or underwind, which show up as the watch getting ahead or behind the time, respectively.
But as I was tweaking how many rotations per hour, I noticed that the stepper, not so accurate (there’s a reason the library is call “Cheap Stepper”), was slowly drifting out of true at the end of the rotations (that is, not returning to home, off by a bit each rotation).
Not aesthetically pleasing. So I needed to design a homing mechanism.
I made a modified spinning arm with a place for a magnet (image right), and used a reed switch to sense homing (and borrowed the homing code from my For All Time project). Worked like a charm, and the gyro is now always spot on.
With that, I was able to tweak the rotations, and now the watch is always wound and keeping time, ready for me to wear.
In the end, what I thought was going to be a straightforward build, turned out to require a bit of ingenuity and modification to get it to work just how I wanted.
The image to the right shows lots of the parts that went into the base. The heart is an Arduino Nano. Then there’s a cheap stepper motor and driver, you can see the blue wires of the reed switch go between the button and the motor. And there’s a nifty power button that is on-off and glows blue when on. One other thing: as the blue covers were translucent, I pointed the Nano and the stepper driver downwards, so as not to shine their LEDs up through the top cover.
[BTW, the sharp-eyed might notice that I have the USB cable coming out the top of the base instead of the bottom. Yes, for some reason, I usually end up assembling things backwards or having to repeatedly disassemble for some stupid reason. Rest assured, all is good in the final version.]
All that jazz One of the great things about making is not just all the projects out there that you can download and build. The great thing is that there is always room for tweaking, re-purposing, or modifying to fit your needs. Indeed, many of my projects are exactly that – just look at some of the projects from this challenge.
The process feels like one big jazz jam session – everyone riffing off others, weaving in their own voice, making something new and surprising.
You don’t need to follow the project to the letter, nor do you have to do it all yourself. Just go out there, find something you like, build from there, and join the jam.
The PDP-11/70 was a 16-bit minicomputer built by Digital Equipment Corporation in the 1970s. Amongst other things it is well-known for its front panel designs, with color-coded (and color-coordinated) switches and associated blinkenlights. I have an interest in vintage computers, mostly focused on Macs from the late 1980s, that I ended up indulging a little during the pandemic. I’ve fixed up a couple of SE/30s and a Quadra 700) over the past year. However, restoring a real PDP-11 is rather beyond my technical capabilities, not to mention my storage capacity and my ability to justify its acquisition financially. However, Oscar Vermeulen makes a fabulous little kit called the PiDP-11. It is a 6:10 scale replica of the PDP-11/70’s front panel. You assemble the board connect it to a Raspberry Pi via the Pi’s GPIO port. It runs some software that emulates the PDP’s operating system. The switches and LEDs and so on all function just as they would on the real machine. Oscar’s attention to detail is very high, both inside the machine and out, so when he started selling a new batch of his kits I bought one. Here are some pictures of the process of assembling it.
The kit.
We start with the kit. It has a PCB, front panel, case, and many, many switches, diodes, LEDs, resistors, and so on.
Getting ready to solder.
Since I started working on the old Macs, I learned how to solder things. Old 68k Macs, especially SE/30s have capacitors that always end up leaking, so you have to replace them with better ones. I am not very good at soldering.
Blinkengredients.
Hold me closer, tiny diode.
So many LEDs, so many diodes. Not enough diodes, as it turned out. The kit was short five. Oscar offered to ship me them, but as it happened I had a bunch of the required 1N4148 diodes on hand from a practice kit, so I was OK.
On go the first batch of diodes.
LEDs on.
I will quietly skip the part where I soldered the GPIO connector to the wrong side of the board and had to desolder it and attach it to the correct side. You will be unsurprised to learn that, having done this, I was not in the right state of mind to cheerfully take pictures.
Switches get stichez.
Getting the switches aligned before and during soldering was slightly fiddly, but Oscar’s instructions are very clear.
Lots of attention to detail.
Board assembled into the case. Now let’s see if it works …
It’s alive!
I stained the wood stand that it came with. While that dries, let’s test all the switches and mess around with the OS. Because it’s a Pi, I can SSH to the console.
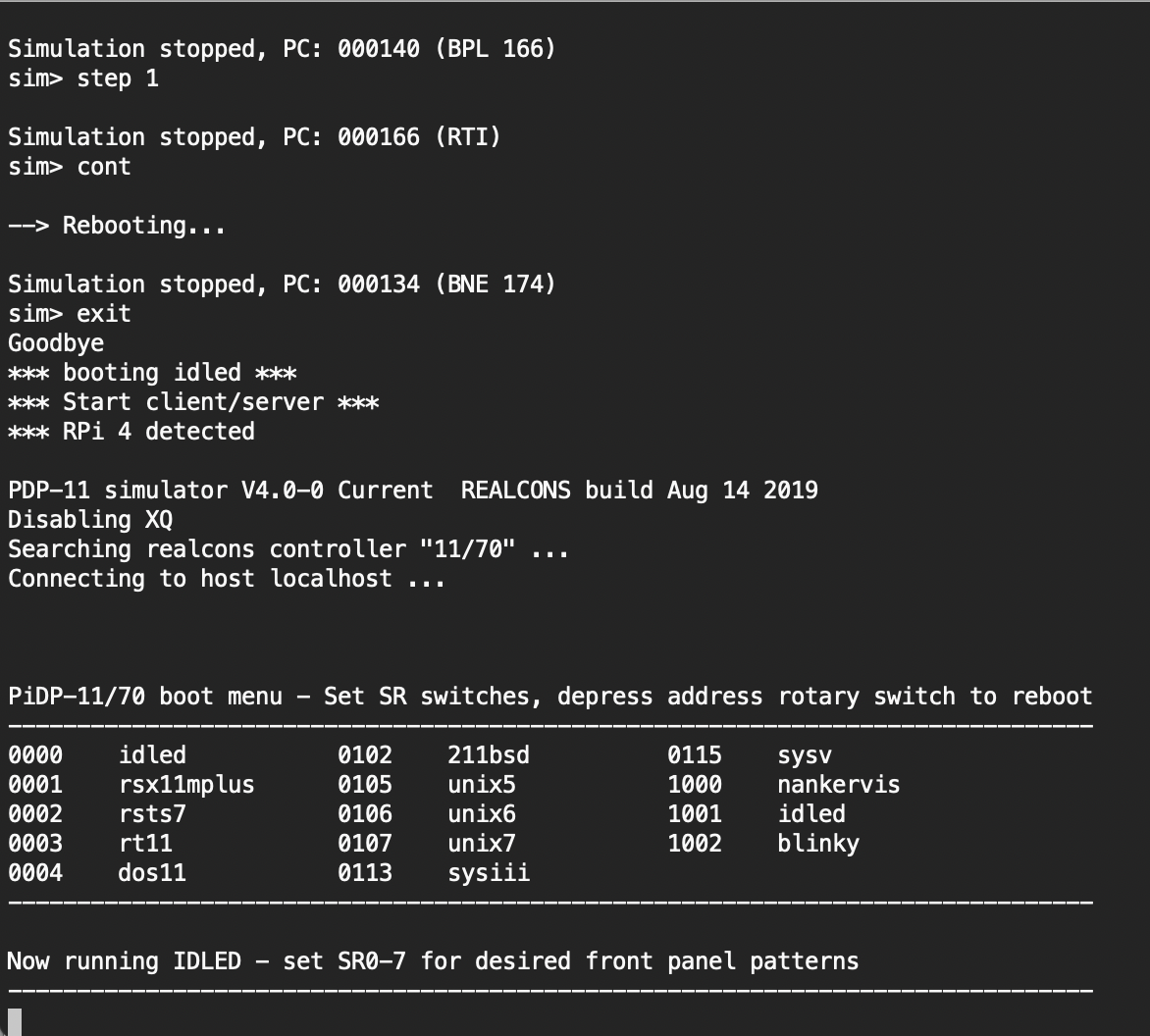
The console.
It runs an emulator of the PDP’s OS, with various disk images to play with. It’s fully-functional. It’s also possible to attach a VT terminal to the PiDP and talk to it that way.
On the shelf.
I moved it up to my office. Appropriately, it sits on the shelf next to some ancient history.
And finally the moment you’ve been waiting for. Time to relaxen and watschen der blinkenlights.
If anyone needs me, I’ll be running the inventory and payroll of a medium-sized business in 1974.
How we did this before civilization culture (30,000 years ago)
How we do it now under civilization culture
Learning and staying informed
self-directed, with self-selected mentors
dependent on massive hierarchical education systems and dumbed-down mainstream media
Making a living
simple and instinctive (we gathered what we needed from nature’s abundant wild resources)
dependent on large corporate employers “offering” us jobs
Staying healthy
preventive (exercise and healthy diet), self-diagnosis and self-treatment
dependent on massive, ineffective, cumbersome medical systems
Getting around
on foot
dependent on complex, fragile transportation systems and cheap oil
Dealing with antisocial behaviour
self-managed in community, rehabilitative
dependent on punitive, coercive, invasive, ineffectual, incarcerating centralized security systems
Eating well
simple and instinctive (we gathered what we needed from nature’s abundant wild resources)
dependent on huge, cruel, toxic agribusiness and factory farms
Clothing ourselves
self-made and/or unnecessary (self-adornment is craft, art and fun)
dependent on globalized, exploitative trade in shoddily-made clothing
Sheltering ourselves, keeping warm
unnecessary (the tropical forest provided all the shelter and warmth we needed)
dependent on globalized, exploitative trade in materials for constructing shoddily-made buildings, and on cheap oil
Entertaining ourselves
self-developed and self-performed in community (art, music, performance arts)
dependent on massively over-hyped, overpriced ‘entertainment industry’ products
Coping with retirement
not applicable (there was no arduous ‘work’ to retire from)
dependent on inflated real estate valuations and ever-increasing stock market prices to provide retirement income
A recent article by Indi Samarajiva gave me a bit of an epiphany about the schism in political thinking in many western nations, and why so many conservatives are so angry and ready to embrace fascism, or any system that they think might be less oppressive than the one we live under today.
Indi cites a 1991 report written by Wang Huning, a member of the 6-man Chinese politburo that rules under that country’s leader Xi Jingping, discussing US style democracy:
I asked a senior professor of American politics “What exactly is the difference between the Republican Party and the Democratic Party”? After a moment’s contemplation he replied: “There are different views of freedom and equality, with the Republican Party focusing on freedom and the Democratic Party focusing on equality”… In the hearts of Americans, most of them are inclined towards freedom. This is because equality under the western system is only formal political equality, not social or economic equality.
In other words, most of us in the western world are resigned to equality only of voting rights, and not equality of power, social privileges, or wealth. And since elected officials respond primarily to those with wealth, social privileges, and power (who overwhelmingly fund their electoral campaigns, and own the media covering them), voting rights per se are pretty much meaningless for most of us.
So, given the choice between a party that stresses (untrammelled) freedom and a party that stresses (formal political) equality, it’s not surprising that disgruntled citizens opt for the former, and hence why we’ve seen an apparent surge to the right over the past fifty years. We have bred a distrust and loathing of government into every aspect of our society.
So why are conservatives so passionate about “freedom”, which sounds more disruptive and perturbing and even anarchic than the “law and order” they are also passionate about?
My epiphany is that what we are witnessing is a massive resentment against our utter dependence — political, social and economic — on others”outside our control (and often beyond our comprehension), including large institutions, governments, and corporations. That massive resentment has arisen because that dependence so constricts us, belittles us, and incapacitates us, that we naturally long for “freedom” from it. We don’t really know, or care, who or what we are dependent on, or why; for most of us it’s too complex to fathom. We just know we don’t like it, and so, extreme libertarianism is taking over — left and right! — from both progressivism and conservatism.
If we don’t trust anyone else to do things for us, we want the ‘freedom’ to do everything for ourselves, from raising our children and looking after our own health, to Texas-style vigilantism as a means of punishing perceived wrong-doers.
But we have this gnawing realization that, as much as we would ideally like that, we are currently, utterly, and hopelessly dependent on others outside our control and influence for everything that is important to us. The table above, from my earlier article on dependence, lists the extent to which, I think, this is now so.
This is a scary list of dependencies, enough to be unnerving no matter where in the political spectrum your beliefs lie. We’re dependent, mostly on massive national and global bureaucracies we don’t understand, respect or trust, for almost every facet of a healthy human life.
No wonder so many of us are angry, and perhaps a bit ashamed. How did we get to this point anyway; who allowed it to happen? We are a bit like teenaged children, suddenly aware of how dependent we are on our parents, and wanting to do all kinds of things we can’t do because of that dependence. So we complain, act up, and act out — putting antlers on our heads. We can’t run away from “home” though, because we have no place to go, and because we’re dependent on what that despised, constraining “home” affords us.
There is no answer to “How did it get this way?” The collective actions of billions of people will often (perhaps always) lead to situations that no one is happy with and which benefit only a tiny few. No one is in control, and knowing that only makes our dependence on the current systems even scarier. We know the world is fucked, and yet we are helpless to do anything about it. The only thing that prevents our anger and fear from boiling over is our cultivated (both by ourselves — since we really don’t want to know — and by others) ignorance of just how awful and unfixable it really is.
Conservatives in particular (but not exclusively) are therefore conflating their understandable desire for freedom from dependence from those they don’t know or trust, with untrammelled ‘freedom’ to do whatever they, and those who think like them, want to do. What do they do with these ‘freedoms’ when they get them? Well, they accidentally or deliberately kill and injure many, many innocent victims with their righteously-possessed guns (or with their cars when they drive drunk). They infect millions of people unnecessarily with a lethal and debilitating virus. They destroy the natural wealth of the planet to the point it can no longer sustain life. What price ‘freedom’?
So when we say we want ‘freedom’, what I think we really mean is that we want freedom from our humiliating dependence. We want to do the things humans took for granted and did effortlessly for our first million years on the planet. We want a level of control over our lives that we naively or nostalgically thought we once had — though we never really did.
But in a massively complex and interconnected world of 7.8B people, in a horrifically overcrowded, prosthetic world whose biodiversity is in free fall, whose climate is in an accelerating stage of collapse, and whose economy is massively overextended and teetering on the edge of a ghastly disintegration, freedom from dependence is impossible. We will be dependent on the systems that we have cobbled together to try to support us all until they fall apart, and then we will get our wish. We will relearn how to do things locally, with people we know and trust, or we’ll die in the attempt.
I am sure if I were to say all this to conservatives or libertarians I would be told I was sanctimonious and condescending. After all, it’s hard to defend systems and institutions that have fundamentally failed and are beyond reform, even though things will only get harder when they fall apart.
But I’m content to just file this epiphany away, and the next time I hear ravings from conservatives or libertarians about the need for ‘freedom’, I’ll at least begin to understand the pain and terror that underlie their misconceptions about what ‘freedom’ they really long for. We all share that ancient longing.
It’s awful being dependent on those you don’t know or trust or control. But as I suspect many teenagers who’ve been thrown out into the streets could tell you, it could be even worse.
Over and over again, the tech industry asks ‘what’s the next cycle?’ Smartphones were the locomotive that drove the industry and all the innovation for 15 years, but now 4.5-5bn people have a smartphone and the market is mature, so what’s the next fundamental trend? Crypto people don’t ask - they know it’s crypto! - but everyone else in tech thinks that crypto is almost certainly a thing but not necessarily the thing, and wonders what else might come together.
In parallel, there’s always a hunt for a new movement or a new word - some way to describe a set of apparently unrelated trends and conceptualise and bundle them into a single narrative. ‘Digital transformation’ sounds like a parody of marketing bullshit but describes some important trends in enterprise computing. In the mid-2000s ‘Web 2.0’ gave us a useful way to think about all the different things that were emerging from the wreckage of the Dotcom bubble, and when terms like this work best, they can as much create as describe the trend. Crypto people are now trying ‘Web3’ as a conscious reference to Web 2.0, and as a way to describe and perhaps create the direction of travel for actual real products on top of the raw tech. There are plenty of other terms floating round at the moment as well - ‘creator economy’ has bubbled up this year.
But the one term that’s exploded beyond others, and broken out of tech twitter into pitch decks at IT outsourcing companies with amazing speed, is ‘Metaverse’, which I hear so often now that it reminds me of the ‘Malkovich! Malkovich? Malkovich!’ scene in ‘Being John Malkovich’. Microsoft even has ‘enterprise metaverse’ slideware. Like all the best buzzwords, ‘metaverse’ tries to link together lots of interesting things - in this case, VR, AR, games and crypto, and a few other things besides. But, all of these are questions.
Facebook has bet big on AR and VR as the next smartphone (and as potential liberation from Apple's control), so Mark Zuckerberg has naturally started saying metaverse a lot. But VR today seems to be at risk of stalling out as no more than a subset of hardcore games. We have a great consumer device but we don’t have any other use cases, and indeed some games people would argue that VR isn’t even working in games. More Moore’s Law might solve that, but this is not self-evident. AR, on the other hand, is still science rather than tech - a pair of glasses that can put things into the world that look as though they’re really there sounds like a pretty good idea, but there are serious unsolved optics questions and we don’t know when or if Apple or anyone else can solve them. But either way, in the metaverse, you wear the display and it shows you things, and a lot of that might be games, and very new kinds of games.
Hence, the second thesis, quite widespread in tech today, is that games will, so to speak, break out of games. Hardcore, rich, immersive games have always been a big business, but more people use Snapchat than games consoles - games are not universal. Now people wonder if some combination of the ideas behind Roblox and Fortnite, with their open worlds, open creativity and cross-over with other kinds of pop culture, might lead to a fundamental change. (It might also create more VC-investible companies.) In the metaverse, this also merges with VR and AR - VR, AR and games break out together, into the real world and into popular culture much more broadly than before.
The final pixie dust to tie all of this together is NFTs - this year’s set of ideas for how crypto can get from pipes and rails to applications - to a Netscape moment. Can NFTs, money, creators, collectibles, games, tokens and skins provide a new economic, incentive and experience layer that ties together games, VR, place, identity and broader popular culture? Do you buy an NFT of the new Rihanna outfit as an skin for your AR avatar? Do people see it hovering over you as you walk into the room? Is this the future of one-upmanship?
That’s a lot of buzzwords in one place, and meanwhile games people, like art people, don’t necessarily see any problem in their world that NFTs solve (Jordan Belfort, on the other hand...), neither games nor VR actually have broken out in this sense, and you can’t buy AR glasses yet. Indeed, you can’t buy ‘metaverse’ at all today.
So, all of this is rather like standing in front of a whiteboard in the early 1990s and writing words like interactive TV, hypertext, broadband, fibre optics, AOL, multimedia, and maybe video and games, and then drawing a box around them all and labelling the box ‘information superhighway’. That vision of everyone everywhere being connected to something was correct, but not like that, and many of those components were blind alleys. ‘Metaverse’ today is again a label for a bunch of words on a whiteboard, some of which are more real than others, and which might well all end up combined, but not necessarily like that. It can also mean whatever you want it to mean - I’m sure other people have definitions that don’t entirely overlap with mine.
But the nature of our interactions with software, entertainment, experiences, displays and, yes, money, is still very early. The iPhone is only 14 years old and we’re all still growing up with ubiquitous computing. Deterministically, there must be new forms of entertainment, new kinds of screens, and new ways to break down and recombine ideas of what ‘games’, ‘media’ and ‘software’ mean and how they relate to identity, self-expression and popular culture. This might all end up like the information superhighway, but, as Lord Dacre said, ‘history teaches us nothing except that something will happen.’
I’ve been collecting pictures like this for a while now, partly because they’re hilarious, but mostly because I think they say something interesting about how we find room for digital in our lives. The internet is a firehose. I don’t, myself, have 351 thousand unread emails, but when anyone can publish and connecting and sharing is free and frictionless, then there is always far more than we can possibly read. So how do we engage with that?
The first generation of internet services tried to help with filters and settings, but most normal people ignore the settings and don’t want to write filters, and so we very quickly went to systems that tried to help automatically. Gmail has its priority inbox, and social networks build recommendation engines and algorithmic feeds. Given that the average Facebook user is apparently eligible to see over a thousand items a day, it seems (or seemed) to make sense to try to show the video of your niece before the special offer from a restaurant you ate at five years ago. So your feed becomes a sample - an informed guess of the posts you might like most. This has always been a paradox of Facebook product - half the engineers work on adding stuff to your feed and the other half on taking stuff out.
Snap proposed a different model - that if everything disappears after 24 hours then there’s less pressure to be great but also less pressure to read everything. You can let go. Tiktok takes this a step further - the feed is infinite, and there’s no pressure to get to the end, but also no signal to stop swiping. You replace pressure with addiction.
Another approach is to try to move the messages. Slack took emails from robots (support tickets, Salesforce updates) and moved them into channels, but now you have 50 channels full of unread messages instead of one inbox full of unread messages. Google Docs, Figma or frame.io turn the messages into structure, so at least they’re connected to the workflow; Zawinski’s Law said that all software grows until it can do messaging, but now every document tries to absorb email, and turn threads into chat and version control.
Conversely, one of the early desire paths on the iPhone was the screenshot, and I think we take screenshots because otherwise whatever we’re looking at will be lost in the firehose and we’ll never find it again. Yes, you could search, but search where, and for what? Screenshots are the PDFs of the smartphone. You pull something into physical space, sever all its links and metadata, and own it yourself.
Email newsletters look a little like this as well. I think a big part of the reason that people seem readier to pay for a blog post by email than a blog post on a web page is that somehow an email feels like a tangible, almost physical object - it might be part of that vast compost heap of unread emails, but at least it’s something that you have, and can come back to. This is also part of the resurgence of vinyl, and even audio cassettes.
I wrote earlier this year about Morioka Shoten, a bookshop in Tokyo that only sells one book, and you could see this as an extreme reaction to a problem of infinite choice. Of course, like all these solutions it really only relocates the problem, because now you have to know about the shop instead of having to know about the book. Channeling that, a few years ago there was a hipster denim shop in Tokyo called ‘Not Found’, that hoped it would disappear from search engines and only be discoverable by word of mouth.
These kinds of reactions remind me a little of the Arts and Crafts movement in late 19th century Britain. In 1800, if you’d said that you wanted something ‘made by hand’, that would be meaningless - everything was hand-made. But half a century later, it could be a reaction against the age of the machine - of steam and coal-smoke and ‘dark satanic mills.’ The Arts and Crafts movement proposed slow, hand-made, imperfect craft in reaction to mass-produced ‘perfection’ (and a lot of other things besides). A century later this is one reason I’m fascinated by the new luxury goods platforms LVMH and Kering, or indeed Supreme. How do you mass-manufacture, mass-market and mass-retail things whose entire nature is supposedly that they’re individual, or convince people that a piece of mass-manufactured nylon and plastic is unique?
A lot of the digital firehose is photos. The film-camera industry peaked at 80bn consumer photos a year, but today that number is well into the trillions, as I wrote here. That’s probably why people keep making camera apps with built-in constraints, but it also prompts a comparison with this summer’s NFT frenzy. Can digital objects have value, and can a signature add scarcity to a JPEG - can it make it individual? Certainly it can, though it doesn’t follow that’s what people are actually doing. But the more interesting aspect of ‘crypto’ (or whatever you want to call it) is the idea of a decentralised computing network with incentives (money!) built into the core - as part of the mechanism itself. That ripples out to all sorts of ideas about how all those trillions of pieces of ‘content’ are created, and by whom, and how they’re distributed, selected, filtered and displayed. I don’t think that’s a solution, though, just another and sometimes better algorithm.
To come back to those 351 thousand unread emails, in some senses this is a product problem that can be solved, or at least improved, whether it’s with Slack, Figma, Snap, or just letting go and turning off the number. But really, it reflects that there are now close to 5bn people with a smartphone, and all of us are online and saying and doing things, and you will never be able to read everything ever again. There’s an old line that Erasmus, in the 15th century, was the last person to have read everything - every book that there was - which might not have been literally possible but which was at least conceivable. Yahoo tried to read everything too - it tried to build a manually curated index of the entire internet that reached 3.2m sites before the absurdity of the project became overwhelming. This was Borges’s 1:1 scale map made real. So, we keep building tools, but also we let go. That’s part of the progression - Arts and Crafts was a reaction against what became the machine age, but Bauhaus and Futurism embraced it. If the ‘metaverse’ means anything, it reflects that we have all grown up with this now, and we’re looking at ways to absorb it, internalise it and reflect it in our lives and in popular culture - to take ownership of it. When software eats the world, it’s not software anymore.
It feels as if we're at the tail end of the first era of social media in the West. Looking back at the companies that have survived, certain application architectural choices are ubiquitous. By now, we're all familiar with the infinite vertical scrolling feed of content units, the likes, the follows, the comments, the profile photos and usernames, all those signature design tropes of this Palaeozoic era of social.
But just as there are reasons why these design patterns won out, we shouldn't let survivor bias blind us to their inherent tradeoffs. The next wave of social startups should learn from the weaknesses of some of these choices of our current social incumbentsIt's easy to point out where our incumbent social networks went wrong. Of course, to be where they are today, they had to do a hell of a lot right, too. A lot of mistakes are understandable in hindsight given that online networks of this scale hadn't been built in history before. Still, it's easier to learn from where they went wrong if we're to head towards greener pastures.. It's never smart to tackle powerful incumbents head on anyway. The converged surface area in the design of all these apps suggest oblique vectors of attack.
While many of these flaws have already been pointed out and discussed in various places, one critical design mistake keeps rearing its head in many of the social media Testflights sent my way. I've mentioned it in various passing conversations online before. I refer to this as the problem of graph design:
When designing an app that shapes its user experience off of a social graph, how do you ensure the user ends up with the optimal graph to get the most value out of your product/service?
The fundamental attribution error has always been one of my cautionary mental models. The social media version of this is over-attributing how people behave on a social app to their innate nature and under-attributing it to the social context the app places them in. Perhaps the single most important contextual influence in social media is one's social graph. Who they follow and who follows them.
Just as some sharks that stop moving dieSome sharks rely on ram ventilation must swim in order to push water over their gills to breathe. But many shark species do not. Maybe we should refer to social apps that rely on a graph to work as "graph ventilated.", most Western social media apps must build a graph or die. This is because most of the most well-known Western social apps chose to interlace two things: the social graph and the content feed. That is, the most social media apps serve up an infinite vertical scrolling feed populated by content posted by the accounts the user follows. In my essay series on TikTok (in order, they are TikTok and the Sorting Hat, Seeing Like an Algorithm, and American Idle), I refer to this as approximating an interest graph using a social graph.
You can see this time-tested design, for example, in Facebook, Twitter, and Instagram. It is particularly suited to mobile phones, which dominate internet usage today, and which offer a vertical viewport when held in portrait orientation, as they most often are.
We'll return, in a second, to whether this choice makes sense. For now, just note that this architecture behooves these apps to prioritize scaling of the social graph. It's imperative to get users to follow people from the jump. Otherwise, by definition, their feeds will be empty.
This is the classic social media chicken-and-egg cold start problem. Every Silicon Valley PM has likely heard the stories about how Twitter and Facebook's critical keystone metrics were similar: get a user to follow some minimum number of accounts. Achieve that and those users turn into WAUs, or even better, DAUs. Users failing to follow enough accounts were the most likely to churn. Many legendary growth teams built their entire reputations inducing tens or hundreds of millions users to follow as many other users as possible.
But, again, this obligation derives entirely from the choice to build the feed directly off of the social graph. In TikTok and the Sorting Hat, I wrote:
But what if there was a way to build an interest graph for you without you having to follow anyone? What if you could skip the long and painstaking intermediate step of assembling a social graph and just jump directly to the interest graph? And what if that could be done really quickly and cheaply at scale, across millions of users? And what if the algorithm that pulled this off could also adjust to your evolving tastes in near real-time, without you having to actively tune it?
The problem with approximating an interest graph with a social graph is that social graphs have negative network effects that kick in at scale. Take a social network like Twitter: the one-way follow graph structure is well-suited to interest graph construction, but the problem is that you’re rarely interested in everything from any single person you follow. You may enjoy Gruber’s thoughts on Apple but not his Yankees tweets. Or my tweets on tech but not on film. And so on. You can try to use Twitter Lists, or mute or block certain people or topics, but it’s all a big hassle that few have the energy or will to tackle.
Almost all feeds end up vying with each other in the zero sum attention landscape, and as such, they all end up getting pulled into competing on the same axis of interest or entertainment. Head of Instagram Adam Mosseri recently announced a series of priorities for the app in the coming year, one of them being an increased focus on video. “People are looking to Instagram to be entertained, there’s stiff competition and there’s more to do,” Mosseri said. “We have to embrace that, and that means change.”
In my post Status as a Service, I noted that social networks tend to compete on three axes: social capital, entertainment, and utility. Focusing just on entertainment, the problem with building a content feed off of a person's social graph is that, to be blunt, we don't always find the people we know to be that entertaining. I love my friends and family. That doesn't mean I want to see them dancing the nae nae. Or vice versaEDITOR'S NOTE: It's not just people who know him. No one wants to see Eugene dance the nae nae.. Who we follow has a disproportionate effect on the relevance and quality of what we see on much of Western social media because the apps were designed that way.
At the same time, who follows us may be just as consequential. We tend to neglect that in our discussions of social experiences, perhaps because it's a decision over which users have even less control than who they choose to follow. Yet it shouldn't come as a surprise that what we are willing to post on social media depends a lot on who we believe might see it. Our followers are our implied audience.
To take the most famous example, the root of Facebook's churn issues began when their graph burgeoned to encompass everyone in one's life. As noted above, just because we are friends with someone doesn't mean we want to see everything they post about in our News Feed. In the other direction, having many more people from all spheres of our lives follow us created a massive context collapse. It wasn't just that everyone and their mother had joined Facebook, it was specifically that everyone's mother had joined Facebook.There's some generalizable form of Groucho's Marx quip about not refusing to join any club that would have him as a member. Namely, that most people don't want to belong to a club where they're the highest status member. Because, by definition, the median status of a member of the club is lowering their own. That's not to say it can't be a stable configuration. Networks based more around utility, like WeChat, aren't driven as much by status dynamics. Not surprisingly, they are less focused on a singular feed.
It's difficult, when you're starting out on a social network, to imagine that having more followers could be a bad thing. Yet many Twitter users complain after they surpass 20K, then 50K, then 100K followers or more. Suddenly, a lot of your hot takes attract equally hot pushback. Suddenly, it isn't so fun yeeting your ideas out into the ether. I know. Boo hoo on the smallest violin. But regardless of whether you think this is a first world problem, it's indicative of how phase shifts in the experience of social media are difficult to detect until long after they've occurred.
To put it even stronger, graph design problems are particularly dangerous to social companies because they fall into that class of mistakes that are difficult to reverse. Jeff Bezos wrote, in his 1997 Amazon letters to shareholders, about two types of decisions.
Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions. But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.
Graph design problems are one-way mistakes in large part because users make them so. Most social media users don't unfollow people after following them. Much of this comes down to social conformity. It's awkward and uncomfortable to do so, especially if you'll run into them. Anytime I unfollow someone I might run into, I imagine them cornering me like Larry David at the water cooler, eyebrows raised, with that signature tone of voice he mastered on Curb Your Enthusiasm, an equal mix of indignation at being slighted and glee at having caught you in an act of hypocrisy. "So, Eugene, I notice you unfollowed me. Pret-tay, pret-tay interesting."
If people tend to add to their social graphs more than they prune them, the social graph you help your users design should be treated as a one-way decision. And as Bezos noted, one-way decisions should be treated with care.Once Twitter started posting tweets to my timeline simply because people I followed had liked them, even if they were tweets from people I didn't follow myself, I started getting very confused. If you're angry I don't follow you, it may be that I think I already follow you.
Many social apps, because of how they're configured, undergo phase shifts as the graph scales. The user experience at the start, when you have few friends and followers, changes as those figures rise. At first, it's more lively with more people. Now the party's getting started. But beyond some scale, negative network effects creep in. And if you don't change how you handle it, before you know it, you find yourself pronouncing that you're taking a break from social media for your mental health.
Not only do users not notice it happening, like the proverbial slow boiling frog, the people operating the apps may be oblivious to the phase shifts until it's too late. Social graphs are path dependent.
A classic example, though I don't know if this still persists, is how Pinterest skewed heavily towards female users at launch, losing lots of potential male users in the process. This was a function of building their feed off of each user's social graph. Men would see a flood of pins from the females in their network as women were some of the strongest earlier adopters of pinning. This created a reflexive loop in which Pinterest was perceived as a female-centric social app, which chased off some male users, thus becoming self-fulfilling stereotype. An alternate content selection heuristic for the feed could have corrected for this skew.
But again, this is a problem unique to Western social media design. In conflating the social graph and the interest graph, we've introduced a content matching problem that needn't exist. I don't get upset that my friends don't follow me on TikTok or Reddit or what I think of as purer interest and/or entertainment networks. It's very clear in those products that each person should follow their own interests.
The way China has built out its social infrastructure is, in at least this respect, more logical. WeChat owns the dominant social graph, and it acts as an underlying social infrastructure to the rest of the Chinese internetThough not always a reliable one. If you're a WeChat competitor in any category, they may block links to your apps, as they've done with Douyin and Taobao in the past. This is always the danger of a private company owning the dominant social graph, and where regulators need to step in.. Rather than duplicate the social graph of everyone, which WeChat owns, other apps can focus on what they do best, which might or might not require an alternate graph.
Western social apps also rely much more heavily on advertising revenue. The lifeblood of their income statement is traffic to the feed. This means feed relevance is paramount. Anywhere one's social graph drifts from one's interests, boring content invades the feed. The signal to noise ratio shifts the wrong direction. Instead of pruning and tuning their social graphs to fix their feeds, most users do the next easiest thing: they churn.
As a product manager or designer on social app, you might object. The user chooses who to follow, and other users choose to follow them. It's out of your control. But this ignores all the ways in which apps put their hands on the scale to nudge each user towards a specific type of graph.
Take initial user sign-up flows. Every week, I seem to encounter this modal dialog on a new social app Testflight:
What I look for is where this request appears and how the app frames it. Most times, users are asked to grant access to their contact book and to follow any matching users (or even worse, to spam their contact list with invites) before they have any idea of what the app is even about. In pushing people to duplicate their contact book, these apps are explicitly choosing to build off of people's real-world social graphs.
It's not surprising that social apps prioritize this permission as a critical one in the sign-up flow. The iOS contact book is now the only "open-source" social graph that a new app can work from to jumpstart their own. In The Network's the Thing, I argued that the network itself provides the lion's share of the value for a social network, that arguments about what types of content to allow in feeds, how those were formatted, were of much less importance. For a brief window, massive social graphs like Facebook or Twitter allowed third-party apps to tap into those graphs, even to duplicate them wholesale.
Instagram famously got a nice head start on building out their own social graph by siphoning off of Twitter's. It didn't take long for those companies to realize that they were arming their future competition. They clamped down on graph access hard. You can still offer Facebook or Twitter auth as an option for your app, but if you want a social graph of your own, the mobile contact book is the easiest to tap into nowadays.
Another way apps really influence the shape of their social graph is with suggested follow lists. These often appear in the first-time user walkthrough, interspersed in the feed, and sometimes alongside the feed.
Early Twitter users fortunate enough to be on the first versions of Twitter's suggested follow list today have hundreds of thousands or even millions of followers because they were paraded in front of every new user.
It was a massive social capital subsidy, but I find a lot of selections on that list puzzling. A few years ago, a friend set up a Twitter account for the first time and showed me the list of accounts Twitter suggested to them during sign up. It included Donald Trump. Which, regardless of your political leanings, is a dubious choice. Let's just shove every new user in the direction of politics Twitter (I'd be skeptical of a suggestion of Biden, too), one of the worst Twitters there is. Cool, cool.
For some people, like those who frequent fight clubs on weekends, politics Twitter might be the perfect dopamine fix, but when a user is signing up for the first time and Twitter knows nothing about them, that's a bizarre gamble to take.
For years, people marveled at Facebook's Suggested Friends widget. Wow, how did they know that I knew that person, yes, of course I'll friend them. And yet, as noted earlier, that may have been a graph design mistake given the way the News Feed was being constructed.
In the other direction, it's also important to help a users acquire the right types of followers. Cults are held together by a bi-directional influence. Cult leaders use their charisma to grow a following, then those followers shape the cult leader in return. It's a symbiotic feedback loop, not always a healthy one.
Besides being one-way mistakes, graph design errors are also pernicious because the tend to manifest only after an app has achieved some level of product-market fit. By that point, not only is it difficult to undo the social graph that has crystallized, to do so would violate the expectations of the users who've embraced the app as it is. It's a double bind, you're damned if you do and damned if you don't. Apps that achieve some level of product-market fit, even if it's a local maximum, require real courage to revert.
This doesn't stop social apps from trying to fix the problem. Reduced traffic to the feed is existential for many social apps. Instead of fixing the root problem of the graph design, however, most apps opt instead to patch the problem. The most popular method is to switch to an algorithmic, rather than chronological, feed. The algorithm is tasked with filtering the content from the accounts you've chosen to follow. It tries to restore signal over noise. To determine what to keep and what to toss, feed algorithms look at a variety of signals, but at a basic level they are all trying to guess what will engage you.
Still, this is a band-aid on an upstream error. Look at Facebook oscillating every few years between news content and more personal content from people you know. Until they acknowledge that the root problem lies in sourcing stories for News Feed from their monolithic social graph, they'll never truly solve their churn. And yet, to walk away from this fundamental architecture of their News Feed would be the boldest decision they've made in their long historyIronically, shifting to the News Feed itself was perhaps their previous boldest decision.. Not just because almost all their revenue comes from News Feed as it works now, but also since assembling a monolithic graph might be their strongest architectural defense against government antitrust action.
Twitter, unlike Facebook with its predominant two-way friending, is built on a graph assembled from one-way follows. In theory, this should reduce its exposure to graph design problems. However, it suffers from the same flaw that any interest graph has when built on a social graph. You may be interested in some of a person's interests but not their others. Twitter favors pure play Twitter accounts that focus on one niche. But most people don't opt to operate multiple Twitter accounts to cleanly separate the topics they like to tweet about.
One of my favorite heuristics for spotting flaws in a system is to look at those trying to break it. Advanced social media users have long tried to hack their away around graph design problems. Users who create finsta's or alt Twitter accounts are doing so, in part, to create alternative graphs more suited to particular purposes. One can imagine alternative social architectures that wouldn't require users to create multiple accounts to implement these tactics. But in this world where each social media account can only be associated with one identity, users are locked into a single graph per account.
One clever way an app might help solve the graph design problem is by removing the burden of unfollowing accounts that no longer interest users. Just as our social graphs change throughout our lives, so could our online social graphs. Our set of friends in kindergarten tend not to be the same friends we have in grade school, high school, college, and beyond.
A higher fidelity social product would automatically nip and tuck our social graphs over time as they observed our interaction patterns. Imagine Twitter or Instagram just silently unfollowing accounts you haven't engaged with in a while, accounts that have gone dormant, and so on. Twitter and Facebook offer methods like muting to reduce what we see from people without unfriending or unfollowing, but it's a lot of work, and frankly I feel like a coward using any of those.
Messaging apps, by virtue of focusing on direct communication between two people or among groups, naturally achieve this by pushing the threads with the latest messages to the top of their application windows. People who fall out of our lives just fall off the bottom of the screen. LIFO has always been a reasonably effective general purpose relevance heuristic.
Another possible solution to the graph design problem is to decouple a users content feed from their social graph. In my three pieces on TikTok, I wrote about how that app's architecture is fundamentally different from that of most Western social media. TikTok doesn't need you to follow any accounts to construct a relevant feed for you. Instead, it does two things.
First, it tries to understand what interests you by observing how you react to everything it shows you. It tries to learn your taste, and it does a damn good job of it. TikTok is an interest graph built as an interest graph.
Secondly, TikTok runs every candidate video through a two-stage screening process. First, it runs videos through one of the most terrifying, vicious quality filters known to man: a panel of a few hundred largely Gen Z users.Okay, yes, that's not quite right. Anyone can be on this test audience for a video. It just happens, however, that TikTok's user base skews younger, so most of the people on that panel will be Gen Z. Also, it's a known fact that a pack of Gen Z users muttering "OK Boomer" is the most terrifying pack hunter in the animal kingdom after hyenas and murder hornets. If those test viewers don't show any interest, the video is yeeted into the dustbin of TikTok, never to be seen again except if someone seeks it out directly on someone's profile.
Secondly, it then uses its algorithm to decide whether that video would interest each user based on their taste profile. Even if you don't follow the creator of a video, if TikTok's algorithm thinks you'll enjoy it, you'll see it in your For You Page.
Recently, Instagram announced it would start showing its users posts from accounts they don't follow. In many ways, this is as close to a concession as we'll see from Instagram to the superiority of TikTok's architecture for pure entertainment.
Some apps use some sort of topic or content picker. Tell us what music or film genres you like. What news topics interest you. Then they try to use machine learning and signals from their entire user base to serve you a relevant feed.
The effectiveness of this approach varies widely. Why does a playlist generated off a single song on Spotify work so well and yet its podcast recommendations feel generic? Why, after spending years and millions of dollars on research, including the fabled Netflix prize, do Netflix's recommendations still feel generic, and why doesn't it really matter? Why are book recommendations on Amazon solid while article recommendations on news sites feel random? It would take an entire separate piece just to dig into why some content recommendations work so much better than others, so complex is the topic.
In this piece focused on graph design, what matters is that things like content pickers explicitly veer away from the social graph. Twitter allowing you to follow topics in addition to accounts can be seen as one attempt to move a half step towards being a pure interest graph.
It's not that apps can't be more fun when social, or that people don't share some overlapping interests with people they know. We all care both our interests and the people in our lives. When they overlap, even better. It's just that after more than a decade of living with our current social apps, we have ample case studies illustrating the downsides of assuming they are perfectly correlated.
A secondary consideration is what type of interaction an application is building towards in the long run. Is is about one-to-one interactions or broadcasting to large audiences? What percentage of your users do you want creating as opposed to just consuming? Is your app best served by a graph of people who know each other in real life or by a graph that connects strangers who share common interests? Or some mix of both? Is your app for people from the same company or organization? Will the interactions cut across cultures and national borders, or is it best if various geographies are segregated into their own graphs?
The next generation of social product teams can and should be more proactive about thinking through what type of social graph will offer the best user experience in the long run.
I'm not certain, but it doesn't feel, based on the histories I've heard, that many social networks built their graphs with a particular design in mind. This makes graph design an exercise with more open questions than answers. In some ways, Facebook being built for just Harvard students in the beginning may have imposed some helpful graph design constraints by chance.
Unlike some types of design, graph design doesn't lend itself easily to prototyping. Social networks are at least in part complex adaptive systems, making it difficult to prototype what types of interactions will occur if and when the graph achieves scale.
But whereas traditional complex adaptive systems are so complex that predictions are futile, social networks are different in two ways. One is that human nature is consistent. The second is that we have numerous super scaled social networks to study. They're massive real world test cases for what happens when you make certain choices in graph design.
They also exist in multiple markets around the world. This makes it possible to study distinct path dependencies, especially when comparing across cultures and market conditions as unique as China versus the U.S. Despite all the variations in context, issues like trolling seem universal, suggesting that some potent underlying mechanisms are at work.
Once you tug on the threads surrounding graph design, you can burrow deep down many rabbit holes. If the people connected are going to be complete strangers, how will you establish sufficient trust (e.g. through a reputation system)? If the trunk of the app is a content feed, does that feed have to draw exclusively from stories posted by accounts followed by the user? Does it have to pluck candidates from those accounts at all? Is a feed even the right architecture for healthy interactions among your users?
Whose job is it to consider the problem of graph design? And when? To take one example, growth team strategies should be informed by your graph design. Growth shouldn't be treated as a rogue team whose only job is to extend the graph in every possible direction. They need to know what both good and harmful graph growth looks like so they can craft strategies more aligned with the long term vision.
Recently, TikTok started pushing me to connect more with people I know IRL. I've gotten prompts asking me to follow people I may know, and now when I share videos with people, I often get a notification telling me they've watched the video I've shared. Often these notifications are the only way I know they even have a TikTok account and what their username is.
To date, I've enjoyed TikTok without really following any people I know IRL. Perhaps TikTok is trying to make sharing of its videos endogenous to the app itself. But by this point in my piece, it should be obvious that I consider any changes to the graph of any social product to be moves that should be treated with greater caution. Most people I know don't make any TikToks (I know, I know, this is how you can tell I'm old), so following them won't impact my FYP much. For a younger cohort, where users make TikToks at a much higher rate, following each other may make more sense.
On the other hand, any app with a default public graph structure plays into the innate human impulse to judge. Wait, this person I know follows which accounts on TikTok?! Tsk tsk.
The answer to whether TikTok should push its users to replicate their real world social graphs isn't cut and dried. I bring it up only to illustrate that graph design is a discipline that requires deeper consideration. It could use, as its name implies, some design.
The term "follow" is fitting. Who we follow can become a self-fulfilling prophecy. First you build your graph, then your graph builds you. Plenty of research shows that humans tend to oscillate at the same frequency as the people they spend the most time with. Silicon Valley sage Naval Ravikant popularized the 5 Chimp Theory from zoology, which says you can deduce the mood and behavior of any single chimp by observing by which five chimps they hang out with the most.
The social media version of this is that we can predict how any user will behave on an app by the people they follow, the people who follow them, and the "space" they're forced to interact with those people in, be it a Facebook News Feed or Twitter Timeline or other architecture. We all know people who are the worst versions of themselves on social media. The fundamental attribution error predicts we'll think they're terrible by nature when they may just be responding to their environment and incentives.
Humans aren't chimps, we tend to juggle membership in dozens of different social groups at a time. Reed's Law predicts that the utility of networks scales exponentially because not only can each person in a network connect with every other node, but the number of possible subgroups is 2^N-N-1 where N is the number of people in that network.
But whether a social app allows such subgroups to form easily is a design problem. Monolithic feeds tend to force people into larger subgroups than is optimal for healthy interaction. While every user sees a different Twitter Timeline or Facebook News Feed, the illusion is still of a large public commons. Because anyone might see something you post, you should operate as if everyone will.
Messaging apps, in contrast, tend to allow users themselves to form the subgroups most relevant to them. Facebook Groups is a more flexible architecture than News Feed. Humans contain multitudes, and social apps should flex to their various communication privacy needs.
It's no surprise that many tech companies install Slack and then suddenly find themselves, shortly thereafter, dealing with employee uprisings. When you rewire the communications topology of any group, you alter the dynamic among the members. Slack's public channels act as public squares within companies, exposing more employees to each other's thoughts. This can lead to an employee finding others who share what they thought were minority opinions, like reservations about specific company policies. We're only now seeing how many companies operated in relative peace in the past in large part because of the privacy inherent in e-mail as a communications technology.
In many ways, graph design was always bound to be more important in Western social media now, in the year 2021, than in the early days of social media. In the early days of the internet, the public social graph was sparse to non-existent. For the most part, our graphs were limited to the email addresses we knew and the occasional username of someone in our favorite news groups. It's hard to explain to a generation that grew up with the internet what a secret thrill every new connection online was in the early days of the internet. How hard it was to track down someone online if all you knew was their name.
Today, we have more than enough ways to connect to just about anybody in the world. Adding someone to my address book feels almost unnecessary when I can likely reach any person with a smartphone and internet access any of a dozen ways.
In a world where finding someone online is a commodityOne sign that it is a commodity is that messaging apps, while massive, are for the most part lousy businesses that generate little in revenue. That's the financial profile you'd expect of a commodity business., the niftier trick is connecting to the right people in the right context. I have over a dozen messaging apps installed on my phone, they all look roughly the same. While I've discussed graph design largely defensively here—how to avoid mistakes in graph design—the positive view is to use graph design offensively. How do you craft a unique graph whose very structure encodes valuable, and more importantly, unique intelligence?
LinkedIn may be the social app Silicon Valley product people like to grouse about the most, but while many of the complaints are valid, its sizable market cap is testament to the value of its graph. It turns out if you map out the professional graph, not just today but also across long temporal and organizational dimensions, recruiters will pay a lot of money to traverse it.
For all the debate over whether our current social networks are good for society, I prefer to focus on the potential we've yet to realize. We have the miracle of Wikipedia, yes, but aren't there more types of mass scale collaboration to be enabled?
Every other week or so, I am introduced to someone amazing, or an account I've never heard of before that blows me away. That social networks themselves aren't facilitating these introductions leaves me less sad than hopeful. In a decade, today's social graphs will look like blunt instruments, so primitive were their configurations.
We'll also look back over that decade, see how many more amazing people we finally met at the right time and the right context, and realize that indeed, the real treasure was the friends we made along the way.
When submitting a bid, to be awarded the contract to develop a software system, companies have to provide information on costs and delivery dates. If the costs are significantly underestimated, and/or the delivery dates woefully optimistic, one or more of the companies involved may resort to legal action.
The estimation and implementation activities described in the judgements for these two cases could apply to many software projects, both successful and unsuccessful. Claiming that the system will be ready by the go-live date specified by the customer is an essential component of winning a bid, the huge uncertainties in the likely effort required comes as standard in the software industry environment, and discovering lots of unforeseen work after signing the contract (because the minimum was spent on the bid estimate) is not software specific.
What can be learned from the judgement for this case (the letter of Intent was subsequently signed on 9 August 2000, and the High Court decision was handed down on 26 January 2010)?
If you have not been involved in putting together a bid for a large project, paragraphs 58-92 provides a good description of the kinds of activities involved. Paragraphs 697-755 discuss costing details, and paragraphs 773-804 manpower and timing details,
if you have never seen a software development contract, paragraphs 93-105 illustrate some of the ways in which delivery/payments milestones are broken down and connected. Paragraph 803 will sound familiar to developers who have worked on large projects: “… I conclude that much of Joe Galloway’s evidence in relation to planning at the bid stage was false and was created to cover up the inadequacies of this aspect of the bidding process in which he took the central role.” The difference here is that the money involved was large enough to make it worthwhile investing in a court case, and Sky obviously believed that they could only be blamed for minor implementation problems,
successfully completing an implementation plan requires people with the necessary skills to do the work, and good people are a scarce resource. Projects fail if they cannot attract and keep the right people; see paragraphs 1262-1267.
The only way to estimate, with any degree of confidence, the likely cost of implementing the required CRM system is to use a conventional estimation process, i.e., a group of people with the relevant domain knowledge work together for some months to figure out an implementation plan, and then cost it. This approach costs a lot of money, and ties up scarce expertise for long periods of time; is there a cheaper method?
Management at the claimant/defence companies will have appreciated that the original cost estimate is likely to be as good as any, apart from being tainted by the perjury of the lead manager. So they all signed up to using Tasseography, e.g., they get their respective experts to estimate the amount of code that needs to be produce to implement the system, calculate how long it would take to write this code and multiply by the hourly rate for a developer. I would loved to have been a fly on the wall when the respective IT experts, all experienced in provided expert testimony, were briefed. Surely the experts all knew that the ballpark figure was that of the original EDS estimate, and that their job was to come up with a lower/high figure?
What other interpretation could there be for such a bone headed approach to cost estimation?
The Sky expert based his calculation on the use of function points, i.e., estimation function points rather than lines of code, and then multiply by average cost per function point.
The legal teams point out the flaws in the opposing team’s approach, and the judge does a good job of understanding the issues and reaching a compromise.
There may be interesting points tucked away in the many paragraphs covering various legal issues. I barely skimmed these.
Again there is lots to learn about how projects are planned, estimated and payments/deliveries structured. There are staffing issues; paragraph 104 highlights how the client’s subject matter experts are stuck in their ways, e.g., configuring the new system for how things used to work and not attending workshops to learn about the new way of doing things.
Every IT case needs claimant/defendant experts and their collection of magic spells. The IBM expert calculated that the software contained technical debt to the tune of 4,000 man hours of work (paragraph 154).
If you find any other legal software development cases with the text of the judgement publicly available, please let me know (two other interesting cases with decisions on the British and Irish Legal Information Institute).
Real writers have wit. AI doesn’t. And that is unlikely to change. Christopher S Penn did a fascinating comparison of how an advanced AI tool, GPT-J-6B, completes writing content based on patterns it has digested from massive amounts of source material. His conclusion: I am bullish on AI creating content at scale. I am bearish … Continued
The Green Web Foundation is convening a new fellowship program to explore how to advance climate justice among internet practitioners.
The fellows and the program are aligned in the beliefs that:
The internet is a global, public resource that should serve our collective liberation and ecological sustainability.
We must go beyond tech solutionism and towards intersectional climate justice work.
There is no “right way” to learn about and address these issues. Instead, we embrace vulnerability and care while committing to transforming ourselves and our field.
Openness is a strategy to shift power.
We will learn better by learning together and from a wide, diverse set of voices.
We are embarking on this program so that we and other Internet practitioners can better connect sustainability to root causes and inequities experienced at different intersections—gender, race, class, ability, and so on. We acknowledge that these issues require many voices, and that our work will inevitably be incomplete, yet we believe it is an essential first step.
With this transformation in our practice, we hope to take more effective and collective action towards climate justice and a more sustainable and just internet.
Goals: Year 1
A. Explore the narratives. We want to explore compelling narratives that link responsible Internet practice with climate justice. This narrative is an important step to better defining the issues, identifying the most impactful interventions and galvanizing partners. The narrative could include ideas such as:
transparency and accountability
openness as a method and practice
intersectional approaches to climate justice as a core competency for practitioners
climate responsibility and climate response
shifting aesthetics and technical ideals
B. Understand the skills and characteristics. Building on our own experience and learning arcs, as well as in conversation with our communities and each other, we will map the skills and characteristics that might describe climate justice as a core competency. This may include:
self-assessment tools for internet practitioners to understand their climate journeys
learning activities that transform internet practitioners’ understanding and behavior
reflecting on our own transformations
C. Teach it forward. We will begin by transforming our own practices and behaviors with the aspiration to connect with others who also dream of a sustainable & just internet.We may pursue this by:
cultivating networks of trainers and learners who are building, teaching and testing these activities along with us
establishing shared vocabulary and concepts that resonate beyond our circles
creating & openly publishing resources or syllabi so others can build on and use these approaches.
We, the fellows and the program team, set out to work in good faith and in the spirit of open partnership as equal stakeholders. Supports for the program include: stipends and project budget, peer support, and collaborative communications about what we’re learning and doing.
Thank you to the Internet Society Foundation and their support for this work through their research program.
Learning More
Over the coming weeks, fellows will post updates on their projects and reflections as we develop these narratives and resources together.
For years many Brexiters – and some remainers for that matter – have been saying that the vote to leave was little or nothing to do with economics, but all to do with a desire for sovereignty and ‘liberation’. I’ve consistently argued that this was a myth, and that the Vote Leave campaign was to a large extent fought on ‘bread and butter’ issues such as wages, public services and housing, usually falsely linking them to reducing immigration and to the supposed EU budget contribution.
So it’s both surprising and unsurprising that as the interlinked fuel, supply and labour crisis drags on, ‘economic Brexit’ is now back in fashion, with Boris Johnson saying that “when people voted for change in 2016 and when people voted for change in 2019, they voted for the end of a broken model of the UK economy that relied on low wages and low skills and chronic low productivity. We're moving away from that”. On this account, the crisis is just a necessary part of this transition, with wage growth as the key metric of its success.
In this sense it shows the government realizing that the public narrative about the crisis – which, as charted in my last few posts, has been under contestation in recent weeks - has now pretty much settled on viewing it as in part a consequence of Brexit, and responding by trying to re-appropriate it as Brexit working as it was meant to.
This isn’t just doublethink ….
However it’s more complicated than a shift in messaging. Listening to government ministers you can still hear that the supply and labour crisis is a global event that is beyond government control as well as that it is part of a considered national plan and, even, good news. So it’s not that one message is being replaced by another but that they are being run simultaneously.
Johnson, inevitably, is the master of this illogic, managing to suggest within the course of one interview that the crisis doesn’t exist, and that it exists but is nothing to do with Brexit, and that it exists but is part of what delivering Brexit means. It’s like the three-card Monte scam in reverse: rather than the gullible punter never turning up the winning card, Johnson’s trick is to present whatever card he picks as being the winner.
Many commentators, such as John Crace of the Guardian, have been struck by the inconsistency or, as LBC’s James O’Brien put it, the ‘doublethink’ entailed in simultaneously deploying these contradictory rationales. Actually, it is no surprise at all, and it hasn’t just emerged this week, although Johnson’s statements have given it much higher profile. For example, earlier on in the crisis, at the end of August, I discussed how the statement of a government spokesperson explicitly tied it to the successful delivery of Brexit employment policy: “The British people repeatedly voted to end free movement and take back control of our immigration system and employers should invest in our domestic workforce instead of relying on labour from abroad”. So throughout the crisis this and the contradictory claim that it’s nothing to do with Brexit have been in play.
… it’s Brexit doublethink
However, the more important point is that this is just the latest example of something inherent to the entire Brexit project. Always it has relied upon, and been permeated with, inconsistent claims produced at the same time and often by the same person. This also wrongfoots (and exhausts) opponents, who carefully chase down the flaws in one claim only to be confronted with a different, and diametrically opposite, one.
The ‘sovereignty at any cost’ and ‘all costs are Project Fear’ dyad is perhaps the most obvious example, and the constant slippage between and conflation of ‘Norway’ and ‘Canada’ models of Brexit during and after the campaign is another. Further examples include:
· The UK is a big economy, so is bound to get a good Brexit trade deal AND the EU is useless at making trade deals with big economies
· The EU needs us more than we need them AND the EU is bound to punish us for leaving
· Because the EU will give us a great deal, that proves it’s right to leave AND because the EU didn’t give us a great deal that proves it’s right to leave
· The UK-EU negotiations will be quick and easy AND the EU is slow and lumbering
· Germany always tells the EU what to do AND the EU can never decide what to do because it has to get the agreement of all its members
· We will threaten the EU with ‘no deal’ to get what we want AND a ‘no-deal Brexit’ would have no adverse consequences
· We don’t need a trade agreement with the EU, WTO terms are fine AND we must make trade deals with other countries rather than trade on WTO terms
· The EU is a bully AND the EU is weak and on the point of collapse
· Brexit will make us more global AND Brexit will protect local traditions and businesses
· Brexit will lead to a glorious future AND Brexit will reclaim the past
· Brexit will change everything AND most things will go on as usual
There are undoubtedly many other examples of the same thing, and at one level they could just be seen as normal political opportunism and, certainly, as one of the reasons Brexit was supported, since the very contradictions in the case meant it could mean all things to all people. But I think that the opportunism wasn’t just a tactic to win Brexit but was inherent to the intellectual and strategic incoherence of Brexit itself: it wasn’t a coherent project which was sold in contradictory ways, but its very incoherence lent itself to being expressed in such ways.
This matters hugely, now, because it explains why delivering Brexit is proving to be such a mess. The government oscillates between totally contradictory economic and geo-political strategies because the only guiding thread of its formation was to ‘get Brexit done’ (the ‘levelling up’ agenda is a sub-theme of this, in that it is presented as being what getting Brexit done enables), and that thread pulls in contradictory directions, for example as between free trade and protectionism. Moreover, whilst Brexit could mean all things to all people as a proposal, by definition it cannot do so in delivery, since its various aims and claims were incompatible.
The object of power is power
But that is only part of the picture, in that whilst it would have made delivering Brexit an incoherent mess under any Prime Minister and government it also interacts with the particular and peculiar nature of Johnson and his government. In C.P. Snow’s classic 1964 political novel Corridors of Power, the government minister at the centre of the story remarks that “the first thing is to get the power. The next – is to do something with it”. It’s almost a truism, and it’s easy to imagine almost any leading politician saying something similar.
But it very obvious that only the first part, and not the second, applies to Johnson. He may, perhaps, be interested in his ‘historical legacy’, but seems almost completely uninterested in what has to be done to secure a legacy worthy of the name. He is certainly totally bored with Brexit (“we’ve sucked that lemon dry”, as he put it recently).
Instead, and whilst there may be individual exceptions amongst his ministers it seems to set the tone for his government as a whole, his interest is solely in having power. As one anonymous former minister reportedly put it, “the trouble with Boris is that he’s not very interested in governing. He’s only interested in two things. Being world king and shagging”.
Such a political rationality – if such it can be called – does drive a certain kind of political agenda, albeit a deeply pernicious one. First, to retain power by rigging the system in his favour and by providing his voter base with the culture war forays that energise it. And second, as ‘world king’, to dole out courtly favours in the form of jobs and contracts for cronies and vengeful banishments for the disloyal.
But when it comes to serious questions of government, his only response is to try to get through the next few minutes, or hours or days by presenting whatever bogus argument suits the moment. Thus the response to the present Brexit-related crisis, as to the delivery of Brexit in general, is of this sort. He probably knows, and many of his MPs certainly know, that his response is economic nonsense but, for now, it is an answer to why the country has to endure this crisis. Next week or month, it’s easy to imagine a completely different line being taken. For example, the already growing fears of inflation could lead him to say that wage control is the new imperative and, no doubt, that Brexit provides us with the opportunity to achieve it.
Northern Ireland: more of the same
Nowhere is the meeting of the inherent incoherence of Brexit and the depravity of Johnson’s approach to politics clearer than Northern Ireland. At the most general level, it’s here that the contradiction between leaving the institutions that removed borders and insisting that doing so won’t recreate borders has the most dangerous and destabilising effects.
More narrowly, it’s never been clear whether Johnson agreed the Northern Ireland Protocol (NIP) without understanding what it meant, or whether he understood what it meant and never intended to honour it. Either way, it was another example of his lazily or dishonestly grabbing at a supposed solution to an immediate problem. This week David Frost, Johnson’s Brexit subbie, continued to make aggressive sounds about making major changes to the NIP under threat of invoking Article 16.
However, it is worth noting that on this issue there is also contradiction, with Johnson saying this week the problems were those of implementation and that it could work “in principle”, whilst Frost has said that not only the implementation but the actual construction of the NIP is flawed.
So again incoherent justifications are advanced simultaneously. If criticised for having agreed it, the response is that it is implementation that is the problem. If criticised for not having implemented it, the response is that the agreement is flawed. So back to why agree it? Because the remainer parliament constrained our options. So why sign it after you’d won the election? Because we didn’t expect it to be implemented so inflexibly. Pick a card, any card. Thus whilst the UK’s approach to the NIP row has been described this week as playing poker (£), its intellectual basis is the same old Brexit three-card trick.
There is also the contradiction, discussed in my last post, between the fact that it is in Northern Ireland that the supply and labour crisis is least acute, yet only here where the government insists the Brexit arrangements aren’t working and must be changed. Perhaps under the new messaging, in which the crisis is depicted as showing Brexit doing its necessary work of restructuring, we will now be told that the NIP must be changed in order to allow Northern Ireland to have its fair share of this beneficial crisis. For it now seems that success is defined as failure and failure as success.
The public verdict: Brexit has failed
As regards the wider Brexit situation, the public have a more straightforward grasp on all this, with a new poll showing that, overall, 36% think it has been a success and 52% think it has been a failure. Within that, there are significant variations between the four nations – in Northern Ireland just 18% think it has been a success and a stonking 74% think it a failure – but even in England the figures are 37% (success) to 50% (failure).
The variation in results amongst remain and leave voters is much as would be expected but intriguingly, given that the referendum vote showed no significant gender difference, they vary sharply between men (44% success, 49% failure) and women (29% success, 55% failure). I think this is the first time any opinion poll has shown anything much in the way of a gender divide over Brexit (for example, the latest poll on opinions about the main cause of the HGV driver shortage shows the single commonest explanation to be Brexit, at 35% amongst all respondents, but with no gender difference at all).
It is worth dwelling on these results. We already knew that the referendum was almost the only moment when there was a majority for Brexit, and then only in England and Wales, and that for almost the entire time since then there has been a small majority for remain. This latest poll (which of course may not be sustained) shows the majority in each constituent nation and in the nation as a whole, as well as the majority of women, think it is a failure. That is hardly surprising, considering the scale the Brexit damage catalogued in the remarkable Kelemen archive, now closed at an astonishing 1000 reputably-sourced examples. So for all the ‘will of the people’ rhetoric, Brexit is a huge national project which is being done without sustained national support or acclaim.
In the face of that it is really quite grotesque for David Frost to talk, as he did at this week, of “the long bad dream of EU membership” being over. Of course, that was in the context of the Tory Party conference, though it’s of note that 32% of 2019 Conservative voters, a not inconsiderable minority, also think that Brexit is a failure. That, too, is not surprising considering that Brexit damage now reaches deep into some of the traditional heartlands of the Tory Party in farming and business in a way that would have been unthinkable in the past.
Indeed the party now seems decidedly anti-business in its latest stance on the labour and supply crisis (and interestingly is now even at odds with pro-Brexit business leaders). One Conservative MP, Chris Loder, who is apparently a member of the ‘Common Sense Group’, even suggested that the collapse of supermarket supply chains would be a good thing as it would mean “the farmer down the street will be able to sell their milk in the village shop like they did decades ago”. If the Tories are the party of business, then it’s business circa 1890.
Brexiters should be wary of hubris
Whatever the context of Frost’s words, there’s a serious problem in gloating over something which is so widely seen as having failed. Although this has not much dented the Tories in the polls (though that may be in flux), I continue to think that the disconnect between public opinion and what is a major and ongoing shift in national direction is going to play out in complex, unpredictable and far-reaching ways.
Frost also showed remarkable stupidity in suggesting that the New York Times report that the referendum result had “stunned the world” was some kind of endorsement for Brexit or for Britain. The reality, of course, is that Brexit has shredded Britain’s reputation and made us a laughing stock. That is obvious from a resumé of this week’s foreign press coverage of Brexit, and in cartoons as diverse as that in Germany, suggesting people visit British supermarkets to experience what life in Communist East Germany was like, to one in the Bangkok Post depicting the British lion leaping through a door marked Brexit and emerging as a dopey-looking pussycat. Indeed if Labour was really canny in attempting to tap into the fabled patriotism of ‘red wall’ voters, it could do worse than to circulate these images of what Brexit’s plastic patriots have done to us.
Frost’s remarks reveal a hubris amongst Brexiters which they’d be wise to be wary of. That was one of the thoughts prompted by watching the fascinating new BBC documentary series Blair & Brown: the New Labour Revolution, in that in its heyday New Labour, like Thatcher’s New Right before it, thought, as the Brexiters do, that they had redefined politics forever. In fact, not only does the ‘wheel always turn’ but, more importantly, each supposed triumph provokes and incubates surprising counter-reactions.
The other thought was a more melancholic one. Whatever one thinks of them and what they did, Brown, Blair and those around them were serious, committed, competent politicians who knew what they wanted to do and why, and, to an extent, how. For that matter, the same could be said of Thatcher and many of her ministers. It is a dispiriting contrast with the squalid and mediocre three-card tricksters, the architects and progeny of Brexit, who now govern us.
These two buildings were demolished many years ago, and for the time being are the location of one of the City’s temporary modular housing buildings. The building on the left pre-dated the 20th Century (and looked like it in our 1978 image), while the one on the right was developed in 1912 as an apartment building. It cost $9,000 and was designed and built by W J Prout for E McPherson.
We’ve noted Mr. Prout’s history in relation to a West Pender building. He was originally from Cornwall, and he was a builder who could design the project too; presumably shaving cost and time. His client was variously Ewen, or Ewan, McPherson or MacPherson. Probably the accurate version was Ewen MacPherson, born in Blair Athol in Scotland in 1851. His family ran the Tarbet Hotel on the banks of Loch Lomond. After travelling to Argentina and Australia, Ewen arrived in Canada in 1887 and settled in Harrison Hot Springs. He had a small farm that supplied eggs and milk to the Saint Alice Hotel, a significant property run by the Brown Brothers. In 1888 Jack Brown married Luella Agassiz, and two years later Ewen married her sister, Jane Vaudine Caroline Agassiz. The 1895 directory shows him as ‘E McPherson, gentleman.’ Jane was shown to have been born in Ontario.
In the 1891 census the McPhersons were shown living in New Westminster, where Ewen was listed as a hotel keeper, although the BC Directory shows him in Harrison Hot Springs. In the 1901 census the family were still in New Westminster, but Ewen was shown as a farmer, and there were three daughters aged 8, 7 and 5. (The street directory in 1900 still had him as a gentleman, and still in Harrison Hot Springs.) In 1908 he was in Agassiz, and farming. In the 1911 census all three daughters were still at home, and Ewen’s profession was described as ‘income’
All three daughters married; Florence was 23, shown born in Vancouver when she got married in 1914 in Vancouver to Hesketh St. John Biggs, an Australian. (Despite his impressive name, his work was as a meter reader and clerk with the British Columbia Electric Railway). The family moved to California in the 1920s. In 1920 Constance McPherson, aged 27, and shown born in Vancouver was married to James Hermon in Agassiz. In 1922 Edith was 26, born in Harrison Hot Springs, and was married in Vancouver to Ernest Baker.
Mr. McPherson was briefly proprietor of the Bodega Hotel on Carrall in the 1890s, although shown still living in Agassiz. The street directory for 1891 shows the proprietor to be Alexander McPherson, who was Ewen’s brother. Alexander also farmed in Agassiz later in the 1890s, so it appears the two brothers co-operated on their business activities.
Ewen first moved to Vancouver in 1910, living on Denman Street. His wife, Jane, passed away in 1916 after a short illness. Her obituary recorded the family traveling over the Panama peninsula in 1862 to join their father, who had settled in the area that would subsequently be named after him, after he had been to the gold fields in 1859. Ewen was 82 when he died in 1932.
Given it’s location in the heart of the Japanese community in the city, it’s not surprising that the buildings had Japanese tenants. In 1920 523 was the Kawachi Rooms, with M J Nishimura’s grocery store on the street. 519 however shows a different ethnicity, with Kashi Ram’s confectionery store. The census recorded him as Kanshi, and he was 35, single, and had arrived from India in 1911. Twenty years later Y Hayashi had his confectionery business at 519, and there were four residential units upstairs, and Mrs Taniguichi was living at the rear of the property. 523 had become the Calm Rooms, run by Mrs K Kawabata, and Tomejiro Isogai ran his ‘tranf’ business here – we assume a goods transfer firm.
By the end of the war all the Japanese had been forced into camps in the interior. 519 was ‘occupied’, and 523 was vacant, although the Calm Rooms were still in operation upstairs, run by Nils Engkvlst. In 1948 a new business took over the retail space under the Calm Rooms, the Three Vets Warehouse. They moved on very quickly, replaced by Aquapel Cement Paint manufacturers in 1950, with the Calm Rooms run by E W Haggstrom. That was the last reference to the Calm Rooms – there were no residences shown here after 1951, just a Scaffolding company, and later a construction company, suggesting a vacant building. 519 was still listed, but remained vacant through the mid 1950s. Our 1978 image shows 519 in use, but with no business name, and 523 with Downtown Glass Sales on the main floor, but no sign that the rooms above were in use.
A recent holiday aerial, posted five weeks ago, showed False Creek looking westwards in 1981, when the mills along False Creek were closed and the idea for organizing a World Fair in Vancouver was being discussed. That became Expo ’86, and put the city on the world map in ways that some loved, and others think was the start of a different and (to them) less attractive city.
Here’s a similar view, but from earlier. This was photographed in 1954, when the Granville Bridge in the distance was shiny and very new, (and the old 1909 bridge was still in place at a much lower level). The Cambie Bridge in the middle of the picture was the old Connaught Bridge, with the pivoting section to allow shipping to reach the eastern end of False Creek. (The new bridge was built alongside on a slightly different alignment).
Expo ’86, and then Concord Pacific Place, replace the railyards and train repair facilities developed by Canadian Pacific in the late 1880s and 1890s. The semi circular engine roundhouse was initially built in 1888, and expanded in 1911. Located almost exactly half way between the Granville and Cambie bridges, since 1997 it’s been the Community Centre for the new residential neighbourhood (and is almost completely lost in the sea of towers in this view).
The BC Place stadium sits on more former railyards, the site of a box factory, and an asphalt plant. The gasholder and plant were on the north eastern side of the Creek, generating the polluted land that remains to this day, that has been partly capped with Andy Livingstone Park. A new Creekside Park will serve a similar role for contaminated land where the coal gas plant once stood, when the area around the viaducts is redeveloped. As there were still lumber mills and a barrel manufacturer on False Creek in the 1950s, it was filled with rafts of logs. Rolling them into the ocean, tying them together into rafts, and towing them to the water beside the mill was the easiest way to transport the logs. The remaining mills on the Fraser River use the same methods today, and there are still booming yards where the log booms are temporarily stored until the mill can process the logs.
Image source: City of Vancouver Archives CVA 228-383 and Trish Jewison in the Global BC traffic helicopter, on her twitter feed on 12 March 2021
I’m excited to share some great news. We’re releasing Windows Package Manager 1.1. We’ve squashed some annoying bugs and added some highly anticipated features. The Windows Package Manager is being released to Windows 10 (build 1809 and newer) and Windows 11 as an automatic update via the Microsoft Store. The moment we’ve been waiting for has finally arrived. Grab yourself a cup of coffee (or any other favorite beverage). Don’t worry; I’ll wait. Cheers!
Client
The team has been busy over the last few months making improvements and adding new features. The most notable new feature is access to apps in the Microsoft Store. The client now ships with two sources configured. One of them is the Windows Package Manager app repository, and the other is the Microsoft Store.
You might already have it from an automatic update via the Microsoft Store. Launch your favorite terminal (I prefer Windows Terminal ) and run winget. If you see the help menu , you’re ready to go (that’s the image above). You can also confirm the version in the first line of output from the help menu (Windows Package Manager v1.1.12653 on Windows 10 or v1.1.12663 on Windows 11). If not, the Windows Package Manager is distributed with the App Installer from the Microsoft Store. You can also download and install the Windows Package Manager from our GitHub release, or just directly install the latest available released version.
If you want to continue receiving development builds, we will continue to publish those to Windows Insiders Dev Channel builds and Windows Package Manager Insiders. Instructions are available at GitHub describing your options for installing the Windows Package Manager and signing up for our insider program.
Windows Package Manager App Repository
More than 2,600 packages are available in the Windows Package Manager app repository. Just run winget search <SomePackage> to see if the package you are looking for has already been submitted. You might see what you’re looking for in the new Microsoft Store source as well (customization tips below). If you don’t see what you’re looking for, feel free to submit it. I suggest using the Windows Package Manager Manifest Creator.
Windows Package Manager Manifest Creator Preview
If you are a software publisher or an ISV, you might want to skip this part and get registered so you will be able to submit your application to the Microsoft Store. If you want to add an application to the Windows Package Manager app repository, you’re going to want to winget install wingetcreate. The tool is currently in preview and details can be found at the Windows Package Manager Manifest Creator GitHub repository.
Private App Repositories
We announced support for private app repositories with the Windows Package Manager 1.0 release. We have continued to extend capabilities like establishing a source agreement users must accept to use your source and supporting an arbitrary value the client can pass to a server so you can build custom behaviors.
Customization Tips
We built the Windows Package Manager with developers in mind. Several customizations are possible from configuring your progress bar to working with multiple sources. Just run winget settings and you will be able to customize the experience to match your preferences or requirements. Everything you need to know for settings is well documented.
Working with multiple sources is another area you may want to customize. If you want to narrow results down to a specific source, just pass the --source or -s parameter and specify what you want. For example, you might want to see if Visual Studio Code is in the store by running winget search “Visual Studio Code” -s msstore. This search is using the name for a package.
Or you might want to get the latest insider build from the Windows Package Manager app repository by running winget install vscode-insiders -s winget. This install command is using the moniker for the Visual Studio Code Insider package. One note to call out here is we don’t have monikers for packages in the Microsoft Store.
In the next example, you will see search results spanning across multiple sources, and using the “Id” from the entry in the Microsoft Store source to install Visual Studio Code. Note the agreement can be accepted via the command line using --accept-package-agreements.
Our default behavior is to search across all configured sources. If you want to remove a source, use an administrative prompt and run winget source remove <source>. If you want the default sources added back, use an administrative prompt and run winget source reset --force. When more than one source has a strong match, you will be asked to disambiguate the results. The image below shows what would happen in this case.
IT Professionals
As an enterprise administrator you may want to manage Windows Package Manager using Group Policy. I’ve written an article to help you. Your users are also able to see any configured policies using winget --info.
Open Source
We’ve been developing the Windows Package Manager, the Windows Package Manager app repository, the Windows Package Manager Manifest Creator, and the reference implementation for private repositories at GitHub. Feel free to submit feature requests and bugs via GitHub Issues. If you have questions, feel free to start a GitHub Discussion. We look forward to your feedback.
Alkhabaz2021 tries to determine what concepts are difficult for students when learning MongoDB,
and what common errors students make when first learning to query a MongoDB database.
I came away not quite understanding the authors' conclusions,
but I did encounter two observations that surprised me:
3.5% of student submissions
"were omitted from this study,
because they had a common error where students copied JavaScript code from online sources,
causing the interpreter to fail due to an unexpected unicode character."
That seems like a lot to me, and highlights the prevalence of "copy-and-paste" programming
even in early computing education.
47% of all submissions resulted in "incorrect result set"
(versus "mongodb error", "javascript error", or "correct"),
that is a "silent" error.
In retrospect, this should not have surprised me as much as it did.
Others such as Rich Hickey
([talk](https://www.youtube.com/watch?v=2V1FtfBDsLU),
[transcript](https://github.com/matthiasn/talk-transcripts/blob/9f33e07ac392106bccc6206d5d69efe3380c306a/Hickey_Rich/EffectivePrograms.md),
[slides](https://github.com/matthiasn/talk-transcripts/blob/9f33e07ac392106bccc6206d5d69efe3380c306a/Hickey_Rich/EffectivePrograms/00.27.19.png))
have insisted that most of problems in the practice of programming
are above the "language model complexity" level,
such as dealing with misconceptions.
We analyze submissions for homework assignments of 527 students in
an upper-level database course offered at the University of Illinois
at Urbana-Champaign. The ability to query databases is becoming a
crucial skill for technology professionals and academics. Although
we observe a large demand for teaching database skills, there is
little research on database education. Also, despite the industry's
continued demand for NoSQL databases, we have virtually no research
on the matter of how students learn NoSQL databases, such as
MongoDB. In this paper, we offer an in-depth analysis of errors
committed by students working on MongoDB homework assignments over
the course of two semesters. We show that as students use more
advanced MongoDB operators, they make more Reference
errors. Additionally, when students face a new functionality of
MongoDB operators, such as \texttt{\$group} operator, they usually
take time to understand it but do not make the same errors again in
later problems. Finally, our analysis suggests that students
struggle with advanced concepts for a comparable amount of time. Our
results suggest that instructors should allocate more time and
effort for the discussed topics in our paper.
I grew up reading second-hand copies of books by Asimov, Clarke, and Heinlein,
and bought every novel Larry Niven wrote in the 1970s the day it came out in paperback.
I daydreamed about a world run by scientists,
or at least by people who were as excited by science as I was.
It never occurred to me that other people might legitimately be excited about other things:
as far as I was concerned,
if they didn't think space travel and plate tectonics were the coolest things ever,
it was only because they didn't understand them yet.
When I started programming in my late teens,
I transferred all of that proselytizing enthusiasm to computing.
I was in my early thirties when I finally accepted that for most people,
programming was and always would be a tax they had to pay in order to do
whatever they actually cared about.
Recursion, parallelism, and design patterns weren't somehow worthier
than gardening, brewing, or running marathons;
by acting and speaking as though they were,
I was alienating people and making computing less accessible.
A lot of people have either never had that realization or have never accepted it.
Most computer science departments still have faculty who sincerely believe that
everyone should learn Scheme as a first language
because gosh darn it,
if we just show kids how beautiful programming can be,
they'll fall in love with it just like we did.
You will also find a lot of faculty (and even more entrepreneurs)
who believe that "education" is part of the problem,
rather than part of the solution.
Some of these beliefs can be traced back to Seymour Papert's influential work on Logo,
which was a direct ancestor of Scratch, One Laptop per Child,
and many other projects I've enthused about over the years.
But as Ames2018 carefully shows:
…this foundational CSCL project—one of the first, and certainly one of the best-known—still
frames assumptions about the universal allure and importance of learning to program computers,
which undergirds projects like Scratch, FabLabs, the Hour of Code, One Laptop per Child, and more.
Moreover,
these individualistic assumptions about learning and computer use
continue to have purchase within CSCW as well as HCI.
They promote an atomized and often oppositional understanding of not just learners,
but workers and technology 'users,'
and make it more difficult to envision alternatives for computer-supported collaboration
that account for power, are built around collectivity, or encode forms of social reciprocity.
As the consequences of this individualized approach become clear—in antisocial practices online,
in stress among family and friends regarding technology use,
in ongoing problems with discrimination in the technology industry,
in technology-assisted weakening of social institutions like public education,
in algorithmic tracking of individuals,
and in the technology industry's ongoing inability to imagine collective responses to these issues—it
becomes useful to examine some of the assumptions that brought us here…
As the author writes:
Papert's disdain for school and his conflicting vision of the role of teachers
point to a deeper problem in constructionism:
it tends to present learning (especially learning motivation)
as largely and implicitly individualistic
when it is actually a deeply social process—and, in particular,
that teachers, parents, and other adults play crucial roles.
While Papert occasionally discusses the value of learning from peers—which
Scratch, the Maker Movement, and other informal learning approaches also valorize—he often portrays adults
as a hindrance to learning
and the learning process itself as ultimately individualistic in both practice and motivation.
Further:
In dismissing the value of educational research more broadly,
these responses sidestepped one of the most important critiques of Logo:
that it was primarily the researchers' presence and scaffolding
that accounted for children's positive experiences with the program.
They also avoided addressing Papert's own 'technocentric' thinking in Mindstorms
in assuming that computers would hold universal appeal for children—an assumption
that still undergirds constructionist-inspired projects today.
I believe very strongly that
we will only get through the next fifty years
if we start to care about each other and our collective future
more than we do right now.
I also believe that in order to do that,
we need to figure out why we haven't cared in the past.
The Internet and modern computing culture
aren't solely responsible for today's woes,
but they're responsible for enough of them
to be worth looking at much more critically than Silicon Valley chooses to.
Papers like Ames2018 are a good place to start.
This paper examines the history of the learning theory
"constructionism" and its most well-known implementation, Logo, to
examine beliefs involving both "C's" in CSCW: computers and
cooperation. Tracing the tumultuous history of one of the first
examples of computer-supported cooperative learning (CSCL) allows us
to question some present-day assumptions regarding the universal
appeal of learning to program computers that undergirds popular CSCL
initiatives today, including the Scratch programming environment and
the "FabLab" makerspace movement. Furthermore, teasing out the
individualistic and anti-authority threads in this project and its
links to present day narratives of technology development exposes
the deeply atomized and even oppositional notions of collaboration
in these projects and others under the auspices of CSCW today that
draw on early notions of 'hacker culture'. These notions tend to
favor a limited view of work, learning, and practice—an invisible
constraint that continues to inform how we build and evaluate CSCW
technologies.
The way I’m using the dashboard is to run queries against the SQLite datasource, which contains some preprocessed telemetry data. The data source includes time into stage, lat/lon co-ordinates, distance into stage (-ish!), and various telemetry channels, such as speed, throttle, brake, etc.
Here’s a quick view of a simple dashboard:
At the top of the dashboard are controls for selecting particular fields. These are defined using dashboard variables and can be used to set parameter values used by other queries in the dashboard.
Changing one of the selector fields updates all queries that call on the variable.
Variables can also be used in the definition of other variables, which means that selector fields will up date responsively to changes in other fields.
In the dataset I am using, telemetry is not available on all stages for all drivers, so we can limit which stages can be selected for each driver based on the selected driver.
The timeseries chart display panels are also defined against a query. A time field is required. In the ata I am using, the time is just a delta, starting at zero and then counting in seconds (and milliseconds). This time seems to be parsed as a timedelta from from Unix basetime, which is okay, although it does mean you have to be careful selecting the period you want to display the chart for…
SELECT displacementTime as time, throttle, brk FROM full_telem2 WHERE driver="${driver}" AND stage="${stage}"
One thing I didn’t explore was dual axis charts, but these do appear to be available.
I appreciate that grafana is intended for displaying real time streaming data, but for analysing this sort of historical data it would be so much easier if you could not only specify the input time as a delta, but also set the display window to automatically display the full width of the data to fit the display window.
If you have multiple time series charts, clicking and dragging over a horizontal region of one of the time series charts allows you to zoom in on that chart and automatically zoom the other time series chart displays. This is great for zooming in, but I didn’t find a way to reset the zoom level other than by trying to use the browser back button. This really sucks.
The map display uses another plugin, pr0ps-trackmap-panel. Shift-clicking and dragging to select a particualr area of the map also zooms the other displays, which means you can check the telemetry for a particular part of the stage (it helps if you can remember which way it flows! It would be hand to be able to put additional specific coloured marker points onto the map, for example to indicate the start and end of the route with different coloured markers.
The map definition is a bit odd: you have specify to separate queries:
SELECT displacementTime as time, lat from full_telem2 where driver="${driver}" and stage="${stage}";
SELECT displacementTime as time, lon from full_telem2 where driver="${driver}" and stage="${stage}";
You also need to disable the autozoom in to prevent the view zooming back to show the whole route after shift-click-dragging to zoom to a particular area of it. (That said, disabling autozoom seems to break the display of the map for me when you open the dashboard?)
SELECT DISTINCT(stage) FROM full_telem2 WHERE driver="$driver" ORDER BY stage
The final chart on my demo dashboard tries to capture the stage time for a particular distance into the stage. The time series chart requires a time for the x-coordinate, so I pretend that my stage distance is a time delta, then map the time into stage at that distance onto the y-axis.
This isn’t ideal because the x-axis units are converted to times (minutes and seconds) and I could see how to force the display of raw “time” in seconds to better indicate the actual value (of distance in meters). The y-axis is a simple seconds count, but that would be handy if it were given as a time!
What would be useful would be the ability to at least transpose the x and y-axis of the time series chart, although a more general chart where you can plot what you like on the x-and y-axes would be even nicer.
Which makes me think… is there a plugin for that? Or perhaps a scatter plot plugin with a line facility?
At first sense, a scatter plot may not seem that useful for this dataset. But a couple of the telemetry traces capture the lateral and longitudinal accelerations… So let’s see how they look using the michaeldmoore-scatter-panel.
This is okay insofar as it goes, but it doesn’t appear to be responsive to selection of particular areas of the other charts, nor does it appear to let you click and drag to highlight areas and then automatically set a similar time scope in the other charts. It would also be handy if you could set colour thresholds. Taking a hint from the map plugin, which required mutliple queires, I did try using multiple queries to give me positive and negative accelerations that I thought I could then colour separately, but only ata from the first query appeared to be displayed.
The scatter plot also gives us a route to a time versus distance chart, but again there’s no zooming or linking.
It’s possible to create you extensions, so maybe at some point I could have a look at creating my own extensions.
PS I did also wonder whether there would be a route to using pyodide (WASM powered Python) in a grafana extensions, which would then potentially give you access to a full scipy stack when creating widgets…
Carlota Perez documents technological revolutions, and thinks we're in the middle of the current one; what, though, if we are nearing its maturation? Is crypto next?
What was especially remarkable about Carlota Perez’s Technological Revolutions and Financial Capital was its timing: 2002 was the middle of the cold winter that followed the Dotcom Bubble, and here was Perez arguing that the IT revolution and the Internet were not in fact dead ideas, but in the middle of a natural transition to a new Golden Age.
Note: the following is a woefully incomplete summary of what is a brilliant — and very readable — book. Jerry Neumann has written an excellent overview of Perez’s theory at Reaction Wheel; I highly recommend reading that first if you are unfamiliar with Perez’s work.
Perez’s thesis was based on over 200 years of history and the patterns she identified in four previous technological revolutions:1
The Industrial Revolution began in Great Britain in 1771, with the opening of Arkwright’s mill in Cromford
The Age of Steam and Railways began in the United Kingdom in 1829, with the test of the ‘Rocket’ steam engine for the Liverpool-Manchester railway
The Age of Steel, Electricity and Heavy Engineering began in the United States in 1875, with the opening of the Carnegie Bessemer steel plant in Pittsburgh, Pennsylvania
The Age of Oil, the Automobile, and Mass Production began in the United States in 1908, with the production of the first Ford Model-T in Detroit, Michigan
The Age of Information and Telecommunications began in the United States in 1971, with the announcement of the Intel microprocessor in Santa Clara, California
Perez’s argument was that the four technological revolutions that proceeded the Age of Information and Telecommunications followed a similar cycle:
However, this process is usually disjointed; Perez writes:
In real life, the trajectory of a technological revolution is not as smooth and continuous as the stylized curve presented in Figure 3.1. The process of installation of each new techno-economic paradigm in society begins with a battle against the power of the old, which is ingrained in the established production structure and embedded in the socio-cultural environment and in the institutional framework. Only when that battle has been practically won can the paradigm really diffuse across the whole economy of the core nations and later across the world…
In very broad terms, each surge goes through two periods of a very different nature, each lasting about three decades.
As shown in Figure 4.1, the first half can be termed the installation period. It is the time when the new technologies irrupt in a maturing economy and advance like a bulldozer disrupting the established fabric and articulating new industrial networks, setting up new infrastructures and spreading new and superior ways of doing things. At the beginning of that period, the revolution is a small fact and a big promise; at the end, the new paradigm is a significant force, having overcome the resistance of the old paradigm and being ready to serve as propeller of widespread growth.
The second half is the deployment period, when the fabric of the whole economy is rewoven and reshaped by the modernizing power of the triumphant paradigm, which then becomes normal best practice, enabling the full unfolding of its wealth generating potential.
What made Perez’s observation so trenchant in 2002 is that part in the middle: the turning point.
The Post-Dotcom Era
While the Installation Period begins with irruption as new technology emerges in pursuit of real world applications, it eventual transitions into a full-blown frenzy as speculative capital pursues increasingly fantastical commercial applications.
Reality, though, catches up, and the bubble pops.
This financial frenzy is a powerful force in propagating the technological revolution, in particular its infrastructure, and enhancing – even exaggerating – the superiority of the new products, industries and generic technologies. The ostentation of success pushes the logic of the new paradigm to the fore and makes it into the contemporary ideal of vitality and dynamism. It also contributes to institutional change, at least concerning the ‘destruction’ half of creative destruction.
At the same time, as mentioned before, all this excitement divides society, widening the gap between rich and poor and making it less and less tenable in social terms. The economy also becomes unsustainable, due to the appearance of two growing imbalances. One is the mismatch between the profile of demand and that of potential supply. The very process by which intense investment was made possible by concentrating income at the upper end of the spectrum becomes an obstacle for the expansion of production of any particular product and for the attainment of full economies of scale. The other is the rift between paper values and real values. So the system is structurally unstable and cannot grow indefinitely along that path.
With the collapse comes recession – sometimes depression – bringing financial capital back to reality. This, together with mounting social pressure, creates the conditions for institutional restructuring. In this atmosphere of urgency many of the social innovations, which gradually emerged during the period of installation, are likely to be brought together with new regulation in the financial and other spheres, to create a favorable context for recoupling and full unfolding of the growth potential. This crucial recomposition happens at the turning point which leaves behind the turbulent times of installation and paradigm transition to enter the ‘golden age’ that can follow, depending on the institutional and social choices made.
This certainly seems to describe the Dotcom Bubble, which was not only destructive to speculators directly but the economy broadly, even as its excesses, particularly in terms of broadband build-up, funded the infrastructure that would fuel the Internet over the next two decades. And, by extension, those two decades would seem to be the Golden Age of the “Deployment Period.” That certainly seems to be the case with technological dispersion: today over four billion people have access to the Internet, and thanks to the global nature of the web, those in developing countries can consume and create on the same platforms as the most well off.
Moreover, the “Capital” part of Perez’s theory seems to fit as well: some of the best returns over the last fifteen years have been in established public companies like Apple, Microsoft, Google, Amazon, and Microsoft — “Production Capital”, in Perez’s nomenclature. Venture capital, meanwhile, which is theoretically speculative “Financial Capital”, has increasingly become professionalized and standardized, thanks in part to the rise of cloud platforms like AWS; building a new SaaS company to take on another old-world vertical certainly takes hard work, but the playbook is fairly well-known.
This was my thinking behind 2020’s The End of the Beginning; I wasn’t thinking of Perez when I wrote that, to be honest, even though I reached for the automobile example. It just seemed clear to me that the post Dotcom Bubble era had reached its natural endpoint as far as market structure was concerned; whatever came next would look significantly different.
Perez disagrees.
The Imminent Golden Age
While the introduction to Technological Revolutions and Financial Capital makes the case that the Dotcom Bubble was the Turning Point, Perez now thinks we are still waiting for the Golden Age — and that there may be another crash in the future (Perez now includes the Great Recession as part of the current revolution’s Turning Point).
I respect your view. Theories belong to the public. But I see the present as the 1930s, the turning point of the IT surge. We have had 2 frenzies and we have not yet had a golden age. The power of AI, IoT, 3D, robots, blockchain is there to be shaped https://t.co/FybfqgLJLM
The important thing is that the previous revolutions had the Golden Age after the recession that follows the crash. And we could now perhaps have a global sustainable Golden Age. I think it is perfectly possible with the current technologies.
What would be necessary to bring that Golden Age about? How do we need to tilt the playing field to make that happen?
Well “tilt the playing field” is the word. The first thing we have to understand is that every Golden Age has had to do with social-political choices made by governments, because capitalism really only becomes legitimate when the greed of some is for the benefit of the many.
I think in order to tell you what needs to happen next time I have to give you an example from the past, because otherwise we don’t learn anything from history, and that’s why it’s important to understand how revolutions happen before. The mass production revolution brought the post-War boom. Now what happened then? If we look at the 1930s, we have some similarities with today. We see xenophobia, we see a lot of people angry and following at that time fascism and communism, now all sorts of extremisms right and left, leaders that really offer heaven even though they cannot delivery, but the whole thing is that people are angry and disappointed.
But you also have something else which is very important, which is that there is an enormous technological potential which is not being used. Not enough investment is going in the possible innovations because there is not enough demand, and demand is normally created by some policies. But it has to be policies that are adequate for that particular revolution. So what was the previous revolution? It was about mass production. So what was the direction in which it was tilted?
Well, first of all it was the World War. And with the World War it was obvious that producing a lot of weapons made a lot of good business sense. They became cheaper and better and so on. But then at the end of the war, governments did something very important: they created a set of policies that favored suburbanization. Before the automobile you had railways, so you only had stations, and the land in-between was very cheap, it had no way of being used. But once you have the automobile you can build cheap mass-produced houses to put lots of electrical appliances inside and the car at the door. And at the same time governments made the welfare state so that workers could buy those houses. So you have home ownership and consumerism, that’s one of the directions, and the other direction was the Cold War of course, so that you had innovation going in the two directions.
If we had stayed in what was visible in the 30s, it was very difficult to imagine this Golden Age that came after the war. The same thing is happening to us now. In order to get the technologies to go in the right direction, you’ve got to tilt the playing field, and I hold that the most effective way of doing that today is tilting it towards ‘Green’.
Perez’s view on how a focus on “Green” policies could fuel a Golden Age are well fleshed-out in papers like A Smart Green ‘European Way of Life’: the Path for Growth, Jobs and Wellbeing; one insight that I find very compelling is that the demand that drives job growth is less about the technology itself and more about the new lifestyle that the technology enables (just like suburbanization drove the previous revolution).
It’s worth noting, though, that Perez has a somewhat darker interpretation of the 1930’s in Technological Revolutions and Financial Capital (emphasis mine):
Regarding recovery in the 1930s, one cannot look at the USA only. In Germany, with Hitler’s rise to power, the institutional framework was reoriented to facilitate the development of mass production (and later of mass destruction and genocide). The war economy that began after 1933 in Germany could be seen as a synergy phase of a sort. Fortunately, the Nazis failed to conquer Europe and lost the war; otherwise, National Socialist Germany might have been the center of a longer-lasting fascist world. At that same time, the Soviet economy too was developing very fast with another mode of growth that was also capable of intensively deploying mass production. This wide range of options for the deployment of that particular paradigm — including the Keynesian democracies that will have the USA as their core — is an indication of how much is at stake and how much is decided about the future of each country and of the world at the turning point of each surge.
This isn’t a throwaway observation; Perez’s chart of technological revolutions is clear that the U.S. and Europe were on different timelines:
The implication of this observation is that the “Synergy” phase is amoral; it is not guaranteed that the alignment of government with the new technological revolution and its resultant impact on people leads to a “better” outcome as far as liberal democracy is concerned. Perez noted in a footnote:
The mass-production revolution, which marked most of the institutions of the twentieth century, underlay the centralized governments and massive consumption patterns of the four great modes of growth that were set up to take advantage of those technologies: the Keynesian democracies, Nazi-fascism, Soviet socialism and State developmentalism in the so-called ‘Third World,’ each with very wide-ranging specificities.
Synergies are not always golden.
The China Model
Another observation from Perez is that new technological revolutions create the conditions for newcomers to “leapfrog”:
In periods of paradigm shift there is a window of opportunity for real catching up as well as for forging ahead. Belgium, France and the USA caught up in the installation period of the second surge; Germany and the USA forged ahead in that of the third. Most of Europe, Japan and the Soviet Union, caught up in the fourth (though the latter fell dramatically behind with the fifth).
This is where the absence of China from Technological Revolutions and Financial Capital is notable. The only mention is in the postscript:
Yet, in the globalized world of the present paradigm, demand is also global. The best promise of massive market expansion would seem to be in the incorporation of more and more countries to global growth, investment, production and consumption. Growth in the larger countries of the developing world, together with China, Russia and the ex-socialist group of Eastern Europe, could serve as a first tier to pull the others forward. It is quite obvious that these potentially huge markets are a very long way from saturation.
This was a view reflective of the era in which it was written, in which it was assumed that the Internet, in conjunction with globalization, would liberalize and ultimately democratize China. In 2000, President Bill Clinton, upon the occasion of the establishment of Permanent Normal Relations with China said in a speech:
When China joins the W.T.O., by 2005 it will eliminate tariffs on information technology products, making the tools of communication even cheaper, better, and more widely available. We know how much the Internet has changed America, and we are already an open society. Imagine how much it could change China.
Now there’s no question China has been trying to crack down on the Internet. (Chuckles.) Good luck! (Laughter.) That’s sort of like trying to nail jello to the wall. (Laughter.) But I would argue to you that their effort to do that just proves how real these changes are and how much they threaten the status quo. It’s not an argument for slowing down the effort to bring China into the world, it’s an argument for accelerating that effort. In the knowledge economy, economic innovation and political empowerment, whether anyone likes it or not, will inevitably go hand in hand.
Things obviously didn’t work out that way; if anything the Internet has allowed China to push its values onto Americans. What is worth noting, though, is that you can make the case that China has entered the Synergy phase in which government has aligned with technology to profoundly impact China’s citizens. That this entails mass surveillance, censorship, and propaganda doesn’t undo Perez’s thesis; it perhaps punctures her optimism.
There are signs a weaker, yet in some ways similar, form of synergy has happened in the U.S. as well; soon after the Dotcom Bubble came the Patriot Act, and while the political motivations were the 9/11 terrorist attacks, the implementation was very much about leveraging technology for government ends. The extent of this synergy only became clear in 2013 when the Snowden revelations exposed a vast web of surveillance conducted by tech and telecommunications companies in partnership with the NSA.
Then, over the last several years, there has been a concerted effort to push tech companies to increasingly limit misinformation on their networks, and post corrective information instead; it doesn’t take much squinting to re-label both efforts as censorship and propaganda. This is not, I would note, to pass judgment as to whether those efforts are right or wrong (although I am skeptical); merely to note that there may be more evidence of synergy between the government and tech than it seems. It’s all a bit dystopian, to be sure, but revolutions by their nature are unpredictable; it wasn’t a certainty that liberal democracy would triumph in the fourth revolution, much less the current one.
A Crypto Revolution?
As the tweet above makes clear, Perez relishes debate about her theories; I am one of many writers on the Internet who have had the distinct pleasure of getting an email out of the blue from Perez, and having a conversation where she pushes and prods to understand the other’s point of view, confident it will make her theses stronger.
And, in that spirit, I have to confess I’m not sure if this rebuttal to Perez’s current position — my sense that we are in the maturation phase of the technological revolution, complete with government synergy — is correct or not. Perez has noted that COVID-19 could end what she thinks is the elongated turning point era, much like World War II ended the elongated turning point era of the previous revolution (at least in the U.S.). It is notable, for example, that the tech industry has also been an essential element in various government lockdown strategies during the COVID pandemic, most obviously by making it possible for the economy to continue to function while people work from home, and also in enabling a work-from-home lifestyle via e-commerce and food delivery services, with all of the commensurate jobs entailed in providing these services. That is a fundamental change to society that is only getting started — perhaps a new Golden Era is in fact imminent.
At the same time, it is notable that crypto, the most obvious candidate for the next technological revolution is not — contra Perez — an obvious extension of the current era. The overarching story of Stratechery has been the rise and consolidation of the aforementioned Big 5 tech companies, and the entire premise of Aggregation Theory is the inevitability of centralization in a world of frictionless abundance. Crypto, though, is about the introduction of scarcity; its payoff is decentralization, at the cost, at least for now, of convenience and speed.
Perez writes in Technological Revolutions and Financial Capital about what the Maturity phase looks like:
This is the twilight of the golden age, though it shines with false splendor. It is the drive to maturity of the paradigm and to the gradual saturation of markets. The last technology systems and the last products in each of them have very short life cycles, since accumulated experience leads to very rapid learning and saturation curves. Gradually the paradigm is taken to its ultimate consequences until it shows up its limitations.
Yet, all the signs of prosperity and success are still around. Those who reaped the full benefits of the ‘golden age’ (or of the gilded one) continue to hold on to their belief in the virtues of the system and to proclaim eternal and unstoppable progress, in a complacent blindness, which could be called the ‘Great Society syndrome’. But the unfulfilled promises had been piling up, while most people nurtured the expectation of personal and social advance. The result is an increasing socio-political split…this is a time when deep questions about the system are being asked in many quarters; the climate is favorable for politics and ideological confrontations to come to the fore. The social ferment can become intense and is sometimes quelled with social reforms.
Meanwhile, in the world of big business, markets are saturating and technologies maturing, therefore profits begin to feel the productivity constriction. Ways are being sought for propping them up, which often involve concentration through mergers or acquisitions, as well as export drives and migration of activities to less-saturated markets abroad. Their relative success makes firms amass even more money without profitable investment outlets. The search for technological solutions lifts the implicit ban on truly new technologies outside the logic of the now exhausted paradigm. The stage is set for the decline of the whole mode of growth and for the next technological revolution.
That seems awfully descriptive of the current era, no? Products that break through reach saturation in record time (see TikTok reaching a billion users in three years, or DTC companies that seem to max out in only a couple of years), while the future of established companies seems to be quagmire in legislators and the courts, even as profits continue to pile up without obvious places to invest. And if the government’s response to the revolution has been disappointing, that also may be because of the revolution itself.
Moreover, to the extent the dystopian picture above is correct — that the real synergy has been between centralized governments and centralized tech companies, to the alarm of both those abroad and in the U.S. — the greater the motivation there is to make the speculative investments that drive the next paradigm, especially if that paradigm operates in direct opposition to the current one. To be sure this framework does imply that crypto is full of scams and on its way to inflating a spectacular bubble, the aftermath of which will be painful for many, but that is both expected and increasingly borne out by the facts as well. What will matter for the future is how much infrastructure — particularly wallet installation — can be built-out in the meantime.
For what it’s worth my suspicion is that the current Installation period for crypto — if that is indeed where we are — has a long ways to run, which is another way of saying most of the economy will remain in the current paradigm for a while longer. The time from the Intel microprocessor to the Dotcom Bubble bursting was 30 years (and, it should be noted, there were a lot of smaller, more localized bubbles along the way); Satoshi Nakamoto only published his paper in 2008. Thirteen years after 1971 was 1984, the year the Mac was introduced; the browser was another 9 years away. It’s one thing to see the future coming; it’s something else entirely to know the timing. On that Perez and I can certainly agree.
This list is transcribed from the second Table 2.1 — there are two — on page 11 of 2014 paperback edition of Technological Revolutions and Financial Capital↩
The other day I was mulling a particularly boring chore I had just finished (one of the many mundane tasks associated with my industry consulting role) and started musing about what I would really like to be doing with my time.
Don’t get me wrong, I love the management (business, people and processes) stuff–within reason–but I soon started thinking only about engineering stuff, which is what I have been missing the most.
It took no time at all to come up with a bullet list of the points I expand upon below, together with the realization that a fair amount of it is (unsurprisingly) in direct opposition to what I am doing.
But it was still a fun thing to consider, since the kind of stuff I really enjoy doing is actually on two opposite ends of the computing universe:
This is the stuff I did on a daily basis a couple of years ago and miss diving deeper into, because even though the technology involved is still a part of my role, I’m now managing how it’s done for customers, and that is definitely not as much fun as owning the outcomes:
Building (and automating) massive compute-intensive deployments, typically high-throughput, highly available data munging solutions. This can be anything from off-the shelf Kafka, plain Spark, etc., to custom ML or media conversion pipelines.
I enjoy the networking and pure compute/infrastructure stuff, which can be engrossing enough when you get down to the details of what each workload needs–and how fast it needs it, not to mention where it needs it. High-throughput, low latency stuff is my jam.
At a higher level, I love building the data munging logic to build clean datasets–especially in Spark, but I’m no stranger to doing it by hand, especially since there’s often a sweet spot between concurrency approach, compute resources and data representation that just makes it fun.
As an aside, I’m still trying to reason out why it’s so hard to do “proper” knowledge management with modern techniques. Search and indexing (which I’ve worked in a lot) is just glorified bit stuffing, topic extraction is a bit limited and Latent Semantic Mapping has been commoditised for years but seems to have fallen out of favor, etc.
As to how to build these things today, and the current industry hype–I see containers as mere scaffolding, and Kubernetes as something you need to be absolutely sure you need. I’m becoming hesitant to recommend it wholeheartedly as it’s “solved” many deployment and orchestration problems1, but, worryingly enough, created a bunch of ceremony and overhead that is on par with peak OpenStack2.
Still, for enterprise application workloads, my money is typically on OpenShift, if only because I like to think about it as “Kubernetes for grown-ups” and it’s been quietly making inroads on-premises.
But I digress. There are other things I love dealing with, which lie eat the other end of the spectrum:
I feel a constant need to build tangible stuff, so anything that involves “small computing” or what passes for IoT these days takes up a lot of the time I spend reading about and tinkering with:
I really enjoy dealing with tiny systems–MCUs, development boards, anything you’d ordinarily classify as IoT or embedded hardware.
That enjoyment comes partly from the fact that they are constrained systems, and fine-tuning things to run smoothly on tiny machines can be much more enjoyable a challenge than throwing more cores at a problem (and is a skill that scales up).
There is an entire universe of application deployment and connectivity models to explore there, which also means more interesting problems to solve.
On the flip side, edge hardware can also be embarrassingly powerful–even an ESP32 can do OCR and face detection these days.
The common theme here, I think, is attention to detail. Yes, you need to marshal the time, people and processes to address each end of the scale properly, and each of those is an extra dimension in its own right.
But since this is solely about technology, I think the best summary (and common ground) regarding what I like doing is hashing out how anything can be done better and simpler–a key question that is unfortunately seldom asked in many places.
I still think about this Calvin and Hobbes strip, though:
Calvin might come across as being a tad too entitled, but I do wish I could say the same.
That some people will never have, but don’t let the truth get in the way of a good sale. ↩︎
When I worked at the Apple store more than a decade ago, hundreds of customers asked me to put screen protectors on their brand new iPhones. “Listen, I’m pretty good at it, but I’m not responsible if I screw it up,” I’d tell them. Back then you could manually line up the protector, using the home button and earpiece as your guides. So with some practice it wasn’t too hard—and I had plenty of practice.
It’s with great pleasure that I introduce Abby Parise, who is the latest addition to the Customer Experience team. Abby is taking the role of Support Content Manager, so you’ll definitely see more of her in SUMO. If you were with us or have watched September’s community call, you might’ve seen her there.
Here’s a brief introduction from Abby:
Hi there! My name is Abby and I’m the new Support Content Manager for Mozilla. I’m a longtime Firefox user with a passion for writing compelling content to help users achieve their goals. I’m looking forward to getting to know our contributors and would love to hear form you on ideas to make our content more helpful and user-friendly!
Suppose you’re running your organization’s crucial apps in the cloud. Specifically, suppose you’re running them them
on AWS, and in particular in the “us-east-1” region? Could us-east-1 go away? What might you do about it? Let’s catastrophize!
Acks & disclaimers
First, thanks to Corey Quinn for
this Twitter thread, which got me thinking.
Second, while I worked for AWS for 5½ years, I’ve never been near a data center, nor do I have any inside information about
the buildings, servers, or networking. On the other hand, I do have a decent understanding of AWS culture and capabilities
in software engineering and operations. Bear those facts in mind as you read this.
Finally, since this blog fragment concerns itself entirely with catastrophic scenarios, I’ll try to be cheerful about it.
[Those of you who know what us-east-1 is can skip over the next section to the first entertaining disaster.]
“us-east-1”?
AWS means “Amazon Web Services”, Amazon’s insanely huge ($60B/year revenue) and profitable (~30% margin) collection of cloud-computing
services. Basically, AWS will rent you computers and databases and the use of many other software services. So more or less everything your
IT department owns can be rented by the hour (or second) rather than installed in your own data center.
If you’re using AWS, you have to pick one (or more) of its (24, as I write) “regions” to host your systems. They have boring names like
“us-west-2” (Portland) and “ap-northeast-1” (Tokyo).
“us-east-1” (N. Virginia) is generally thought to be the biggest region, by a huge margin. There have been estimates that
30% of all Internet traffic flows through it. Here’s
AWS’s official write-up and here’s a
nice
Atlantic story by a person
who drove around Northern Virginia looking for the actual buildings.
Before we leave the subject, I should say that each AWS region is divided into multiple “availability zones” (AZ’s),
data centers that are independently operated and geographically separated, so to really lose a whole region, you”d have to
take all of them out.
If us-east-1 went off the air, it would be Really Bad. How could that happen?
Threatening clouds.
Terrestrial disaster
This is the first one anybody thinks of.
Suppose a big late-summer hurricane somehow misses Florida and Texas, cruises north
offshore picking up energy from an anomalously-warm western Atlantic, turns left just south of DC, and savages
anywhere that’s easy driving distance from Dulles airport. We’re talking about inches of rain in a few hours so every waterway
floods;
also, high winds and
lightning are playing hell with the electrical and network infrastructure.
The other obvious candidate would be an earthquake, which can ravage infrastructure to a degree unequaled by any
other flavor of natural catastrophe. Among other thing, the Potomac bridges and lots of freeway overpasses would be rubble,
so your ability to bring help in would be severely reduced.
If you’re the unlucky proprietor of systems hosted at us-east-1, they’d be off the air, and while AWS would probably arrange
to answer your distress call, there’s really not much that could be done. How would your business do if it were off the air for,
uh, nobody really knows how long?
How much should you worry?
This one worries me less than a lot of the other scenarios here. First off, the hurricane scenario is so utterly
predictable that I bet anyone with a significant data-center presence in the region has been planning and wargaming around this
one for at least a decade.
Modern data centers all come with self-contained backup generators and some sort of power-bridging
gear, so assuming the water doesn’t actually get in and flood the equipment rooms, things should be fine. You’d expect
Internet-provider outages as well, but once again, modern data centers strive for redundant connections and are built in places
where there are multiple providers, so they’d all have to go down to go completely off the air.
Having said that, the climate is changing and possibly, everything we know about that storm system will turn out to have been wrong.
The earthquake scenario is tougher, but fortunately that’s not a seismically active zone.
Also bear in mind that the availability-zone architecture is going to help you. You can imagine one data centre’s backup
power failing to operate, but it’d be really unlikely for that to happen in all the AZ’s.
I’m not sure this is much consolation, but: If an event of this scale occurs, you’re not going to be the only operation who’s
off the air. Probably, quite a lot of the United States government would be in the same boat. So while your customers and
employees are going to be mad, they’re also going to be distracted from worrying about your downtime.
Extraterrestrial disaster
What about devastation raining down from space?
Sophie Schmieg is a high-level cryptography/security Googler, and Knows What She’s Talking About. She refers to the
Carrington Event, a major solar storm (“Coronal Mass Ejection” they
say) that happened in 1859, and severely disrupted the world’s telegraph system
for about eight hours.
This is an example of a
Solar proton event. If/when one happens, it’s going to
seriously suck for astronauts and for anyone who depends on aerial radio-frequency communications. How hard will it hit
modern data-center and Internet infrastructure? The deepest dive on the subject seems to be
Solar Superstorms: Planning for an Internet Apocalypse
(PDF) by
Sangeetha Abdu Jyothi.
Physicists I’ve talked to say “Yeah, that’s gonna happen someday.” Bear in mind that since the duration is measured in
hours, we might get lucky and find us-east-1 facing away from the sun.
How much should you worry?
I figure that this is actually a more likely disaster scenario for us-east-1 then either the hurricane or the earthquake.
But I’ve got no special insights into how much it will hurt. In Abdu Jyothi’s paper, she offers lots of specific recommendations
about how to solar-storm-proof the infrastructure. How much have the operators of us-east-1 tried,
and how well will their efforts work? We don’t know.
However, as with the terrestrial disasters, your personal pain may not matter that much. After all, as Abdu Jyothi points
out, “A recent study … which analyzed the risks posed by a Carrington-scale event to the US power grid today found that 20 - 40
million people could be without power for up to 2 years, and the total economic cost will be 0.6 - 2.6 trillion USD.”
So… there’s not going to be much leftover attention for your little outage.
Labor unrest
It’s increasing around the globe as multiple decades of increasing inequality in wealth and power bite down harder and
harder.
Also, it may turn out that Covid has disturbed the balance of power between the working and owning classes. A wave of
Big Tech unionization would be surprising, but not that surprising.
So here’s the scenario: Some group of employees whose services are essential for the operation of us-east-1 wins a
unionization vote and starts trying to negotiate a contract with AWS, because they’re looking at that
30% margin on the tens of billions in revenue.
Unsurprisingly, Amazon goes all hard-ass, explains that unionization is
incompatible with Day One
thinking and Amazon Leadership Principles, and refuses to talk. So they take a strike vote, and on one fine spring day, don’t
come to work. Nobody’s watching the graphs, whether those are graphs of electrical-supply stability, fiber-repeater failures, or
data-storage latencies. How long does us-east-1 stay operative? I have no idea. But it’s a terrifying scenario.
It’s going to be difficult to explain to your customers that you can’t service them because of a labor dispute between a
company they’re not dealing with and a union that doesn’t contain any of your employees.
How much should you worry?
Not at all. This will never happen.
Let’s ignore the passion and fury with which Amazon will resist unionization, and suppose
hypothetically that
things proceed as described, the strike vote passes, and it’s becoming apparent that several thousand essential workers are
absolutely not going to show up on a near-future morning. What happens? Amazon caves instantly and does whatever it takes to come
to a settlement with the workers.
The company is always talking customer obsession and that’s no BS, they really mean it. Failing
to provide services that customers pay for and rely on because of internal management failure (and this is one of those) is
violently antipathetic to Amazon culture. So they just won’t let it happen.
AWS software or operational failure
I’m talking about something like what happened to Facebook this month: For reasons that nobody who’s not a serious software geek
can understand, us-east-1 suddenly vanishes from the network. Or is still on the network but is refusing all requests. Or is
accepting requests but timing them out. Or is accepting requests but returning empty answers.
Once again, you’re in a bad spot when you have to explain to your customers that you’re off the air because you made a bet on a
provider who couldn’t deliver the goods.
How much should you worry?
I’m not going to say this could never happen. But I’d be shocked. AWS has been doing cloud at scale for longer than
anyone, they have the most experience, and they’ve seen everything imaginable that could go wrong, most things multiple times,
and are really good at learning from errors.
Also, AWS has a powerful and consciously-constructed culture of operational excellence based on extreme paranoia. To be
honest, I’m just the tiniest bit concerned over the recent departure of Charlie Bell, because he, more than anyone else,
deserves credit for building and maintaining that culture. But it runs very deep.
War
It doesn’t seem likely that foreign attackers are going to swarm ashore on the Virginia beaches and send tank battalions
through the industrial parks to blow up us-east-1. So maybe you don’t need to worry?
But wait; how about civil war? Let’s see; suppose Trump wins the Republican nomination for 2024, and runs on a
rabble-rousing campaign of Revenge For The Steal, and explicitly rallies the Proud Boys, Oath Keepers, Sovereign Citizens, Three
Percenters, Groypers, and police unions, telling them, “We can’t lose in a fair election, so if we do, let’s not let them steal
it again.”
His
election rallies are stuffed with Second-Amendment fanatics brandishing assault weapons. Every debate and campaign
interview features questions along the lines of “If you lose, will there be an insurrection?” The majority of voters are out
of patience with Trump and vote in Kamala Harris by a decent popular margin, but once again it’s a squeaker in the Electoral
College.
The Trump supporters scream “Steal!” and launch a march on Washington; it
turns out they have support from significant factions in the police forces and the US armed forces.
Northern Virginia becomes a key strategic battleground, and both sides deploy heavy artillery…
OK, that’s a little far-fetched (I hope). Here’s another scenario: Beijing launches an invasion of Taiwan and the US
comes to its defence. China’s
cyberwar apparatus turns out to have discovered multiple
zero-day attacks against
Internet exchanges, poison pills that knock BGP off the air
and keep it from coming back up. In this scenario, us-east-1 may be up and running, but nobody can reach it.
How much should you worry?
Probably not very much. Like the hurricane or solar storm, your problems are going to vanish in the static.
Enemy action
In this scenario, the Bad Guys (who knows, maybe those Chinese cyberwarfighters I just mentioned) figure out some
combination of poison pills and DDOS and Linux kernel zero-days to knock over us-east-1 and keep it that way.
Once again, there you are explaining to your customers why AWS’s incompetence is screwing up their lives.
How much should you worry?
Not at all; I just can’t see this happening. I remember an AWS meeting with a customer looking at moving to the
cloud, who asked “What about DDOS attacks?” The Amazon executive in the room said “Yeah, there’s probably three or four of those
going on right now, they’re a cost of doing business for us.” There’s nobody in the world with more experience than AWS in
dealing with this kind of crap.
But there’s a bigger reason. The vast majority of hackers are in it for the money, and they know
perfectly well that AWS has one of the best-defended attack surfaces on the planet. So it’s in their interest to go after
softer targets; big companies with juicy customer lists and password files and so on who aren’t minding their perimeters.
Note: You might be one of those big companies; while AWS is generally secure, it’s possible to run insecurely on it. So
while the Bad Guys might come after you, they’re almost certainly not going to go after us-east-1 as a whole.
Public legal risk
It seems quite unlikely that any force of nature or criminal action could wipe out us-east-1. How about the US Government?
Bear in mind that Republicans hate Amazon because of Bezos’s Washington Post and because the whole tech industry is
(somewhat correctly) perceived as progressive.
Suppose Trump or some guttersnipe like Cruz or DeSantis wins the Presidency in
2024, and the Republicans control congress. Could AWS survive a US Federal legal move that forced a us-east-1 shutdown? Could
it even survive a continuous credible threat of such a thing happening? The temptation might be too much for the GOP goons.
How much should you worry?
I would. But in a more general way; the existential peril to the USA following on the exercise of power by the Trumpist
faction seems to me very severe, not something that can be ignored. So I would be watching which PACs I donated money to, and
encouraging grassroots political activism to stave off the wreckage before it happens.
But then, I’m on the respectable left of the Canadian political spectrum, which makes me a raving Commie by US standards.
Surviving
Let’s assume you’re not going to wait for us-east-1 to come back, you want to resume operations elsewhere. So, you need to
pick another region. Depending on which scenario worries you the most, you might want to be (as Sophie Schmieg suggested) in a
different hemisphere, or if you’re worried about political/legal risks, at least a different jurisdiction.
The best thing you could possibly do is, don’t wait: Run “active-active”, which is to say have your application live in both
regions all the time. Netflix kind of wrote the book on this, for example consider
this 2013 write-up.
I’ll be honest: I don’t know if Netflix has ever actually failed over in the face of an actual region outage. But their thinking
is correct: The only way you can be sure that your backup region will run in production is by running it in production.
But let’s suppose you’re less ambitious; you’re not going to try to keep operations running continuously in the case of a failed
region, you just need to be able to get back on the air in a reasonable amount of time, probably accepting that some
transactions happening just as disaster struck might get lost.
Your app inventory, if it’s typical, probably includes virts running your code, along with
load-balancing and fire-walling gear, and your code accesses a variety of services such as messaging systems and databases and
serverless stuff. Let’s assume you’ve got your configurations all stored as code with Terraform or
CloudFormation or whatever, so that if you needed to rebuild the system from scratch, you could. You do, right? Seriously,
given that, if us-east-1 got blown to hell and you have a copy of the config code, revivifying your app is plausible.
Then there’s your data, which lives in some combination of databases, filesystems, and S3.
If it were me in my ideal world, I’d have copies of everything stored in S3 because of its exceptional durability; I
sincerely believe there is no safer place on the planet to save data. Then I’d have a series of scripts that would rehydrate all
my databases and config from S3, reconfigure all my code, and fire up my applications. I’d test this script regularly; any more than a few
weeks untested and I’d lose confidence that it’d work.
Anyhow…
We probably won’t lose us-east-1. I’m not absolutely 100% sure that these scenarios are even worth thinking about,
in a strictly economic sense. But if I were running a big important app, I wouldn’t be able to not think about it.