It is now just over six years since the start of the official campaign for the 2016 referendum, years which have transformed and polarized British politics, economics and culture. What wasted years these have been. For whilst Brexit is mainly discussed, including by Brexiters, in terms of whether or not it has been as damaging as the most dire predictions, it has also had a huge, if incalculable, opportunity cost.
Perhaps these years would have been squandered in some different way, but in principle so much might have been achieved but for all the energy and resources Brexit has soaked up. And it is surely the case that, but for
hard Brexit fealty being the sole criterion for appointment, many current ministers would never have got anywhere near holding government office. For example, does anyone really think that, without Brexit, we would have Jacob Rees-Mogg
lounging affectedly on the front benches and in a position to write
his spiteful little notes in the name of ‘government efficiency’? Would we be saddled with a government which, judged overall, a
mere 18% of people now think is ‘competent’?
They have certainly been years of failure, and whilst that failure may not all be down to Brexit it is inseparable from it so that,
as I’ve argued before, we need to think in terms of the ‘post-Brexit condition’. That’s not because nothing else has happened or will ever happen apart from Brexit, but because Brexit marked a decisive, historic break in national strategy (according to Brexiters, especially) for the better (according to Brexiters, uniquely) and so it is legitimate to define and judge this period, which we are only at the beginning of, in those terms.
In this (even) longer than usual post I’ll look at some aspects of where these years have now led us. It’s a good time to do so, partly because the contrast is so great with all the pre-referendum leave campaign claims, and partly because the last week or so has seen some really quite significant developments in both the economics and politics of Brexit. Anyway, it’s a Bank Holiday weekend ….
A failing national strategyI
wrote recently of the many ways in which the country the Brexiters are creating is going rotten, with so many basic services not working properly, and each week brings fresh reports of what is now in danger of becoming a national calamity. Agriculture
faces a growing crisis, with implications for the availability and price of basic foodstuffs, and there is a
widespread shortage of both basic and vital medicines leading to
a spate of abusive behaviour towards pharmacists. In both cases Brexit is explicitly reported as one significant factor. It’s the aggregate effect of these multiple Brexit harms that defines the post-Brexit condition. To get a sense of their scope, it is as always worth checking the regularly updated
Yorkshire Bylines’ Davis Downside Dossier.
At the more macro-level, consumer confidence
is at a 50-year low, not least because of inflation and the cost-of-living crisis, whilst
the Office for Budget Responsibility expects this year to see the biggest fall in living standards since records began in the 1950s. Brexit is certainly in the mix of this, too, because from the moment it happened the vote to leave, largely because of the drop in the value of sterling it caused, had an impact on inflation. So, by June 2018,
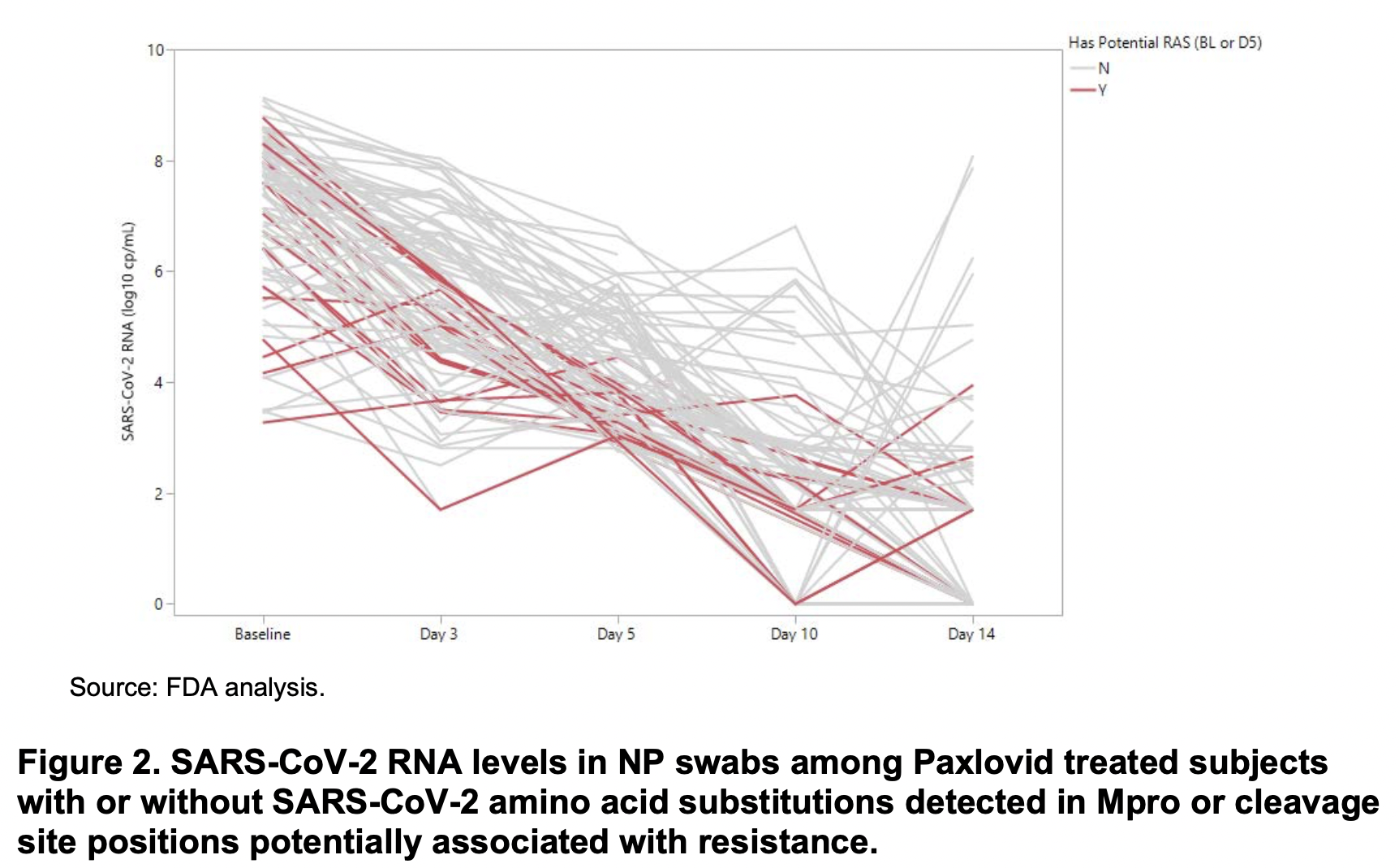
the vote to leave had already raised consumer prices by 2.9%, costing the average household £870, with a related
sharp decline in real incomes (figure 2 of link). Once Brexit actually happened, it introduced further inflationary pressures in terms of labour shortages and higher costs of trading with the EU. The eminent economist Adam Posen
this week estimated that 80% of UK inflation is attributable to Brexit.
This week also saw the publication of
a major study showing that Brexit has caused a 6% increase in food prices, and
of another study which confirms a dramatic fall in the number of trade, especially export, relationships with the EU (what this means in practice is that large numbers of small firms have dropped out). As Posen
pungently expressed it, the UK is “running a natural experiment in what happens when you run a trade war on yourself”. The results so far,
his data also suggest, show just how damaging it is.
Overall, the
latest IMF World Economic Outlook published this month has the UK set to be
the slowest-growing G7 economy in 2023 at 1.2% (compared with 2.4% average for advanced economies and 2.3% average for Euro area) and
to have higher inflation, at an average of 6.3% over the next two years, than Germany (4.2%), France (2.9%) and Italy (3.9%) as well as the non-EU G7, and higher than the advanced economies average (4.1%) and the Euro area average (3.8%).* In other words, it’s not just Covid, Ukraine, and global energy and supply chain factors, which have affected all countries. Something particular has happened to the UK and it has a name: Brexit. Indeed
the IMF’s 2022 country report for the UK identifies Brexit, along with the pandemic, as having “magnified structural challenges” facing the economy. This is why, as other major economies ‘bounce back’ from Covid, the UK does so more slowly.
Brexiters like, notoriously, Michael Gove poured scorn on the IMF and similar bodies during the referendum. However, it’s reasonable to make use of their figures if only because, for months now, Boris Johnson has been
trumpeting (and cherry-picking) OECD data to claim that the UK was the fastest-growing G7 economy last year. And whilst I don’t know whether he has explicitly tied this to Brexit (though I wouldn’t be surprised if he has at some point), he most certainly
has linked it to the speed of the Covid vaccine roll-out, which he and other ministers have repeatedly, and
entirely dishonestly, attributed to Brexit. So if such global economic comparisons are to be made then, with more justification than the government, it’s fair to claim that post-Brexit Britain is failing to deliver its promises.
The Brexiters have no new ideasWhat’s most striking about that claim is that it isn’t ‘remainer moaning’. It is pretty much what every Brexiter, from Nigel Farage to David Frost to Iain Duncan Smith
has been saying for several months now. They, inevitably, ascribe it to a lack of deregulatory zeal and to the need to press ahead with ambitious trade deals. The problem, to their minds, is not Brexit but that Brexit hasn’t been done properly. But the scope for de-regulation remains elusive.
In some cases, like
Solvency II reforms or
gene editing regulation, it is complex, time-consuming and, actually, likely to end up in a similar place as would have been the case without Brexit. In many areas, like conformity assessment, regional aid and, most obviously, trade, Brexit actually means whole new swathes of regulation and red tape, sometimes duplicating that of the EU, sometimes restoring that which EU membership had abolished. All of this reflects Brexiters near-complete ignorance of how regulation actually works and why it is necessary. Bluntly, they simply
had no idea what they were doing.
In still other cases, like the dismantling of employment rights which the Thatcherite Brexiters undoubtedly hunger for, it may be that Brexit makes deregulation possible, but there is no political mandate for it and little political appeal in it. In that respect, such Brexiters are reaping the consequences of having sold Brexit and won the election with the aid of nativist and, literally, conservative votes. Nor, since it will cost some of them their lives, is it likely to prove popular with voters
if the government decides to diverge from new EU standards on road vehicle safety in order to prove an ideological point about ‘freedom from Brussels’.
As for trade deals, they also encounter
opposition from the public and, anyway, even the dullest-minded Brexiter (a title for which there is considerable competition, even if the field were restricted solely to those whose surnames begin with ‘B’) must be starting to grasp that
they offer no economic salvation.
Thus, faced with a burgeoning economic crisis, this post-Brexit government is bereft of workable ideas. Its flagship policy has proved an economic dud, but it is inherent in the government’s very formation to be unable to admit that, or to produce any policies that might ameliorate it. Having smashed up the old order, all they can do is stare in slack-jawed bemusement at the rubble around them, like a convention of peculiarly vandalistic village idiots who accidentally got control of a wrecking-ball.
To the extent they have any ideas of how to proceed, these go in two contradictory directions. One is just to not implement Brexit so far as possible. This has happened with much of the Northern Ireland Protocol and, most strikingly, in the
confirmation this week of the long-trailed fourth postponement of import controls. It’s a remarkable and
explicit admission that Britain simply can’t afford the Brexit trade deal that Johnson pronounced a triumph, albeit one carrying its own costs and risks, as I’ve discussed at length in previous posts (e.g.
here and
here).
Their other idea it is to do the same thing all over again but ‘this time properly’, the latest manifestation being suggestions this week that
the government is considering unilaterally abolishing several import tariffs, perhaps especially on food. It’s an idea that goes back to
Patrick Minford’s extreme version of ‘true’ Brexit, with horrendous consequences for UK farmers and manufacturers, whilst also giving away one of the main bargaining chips for striking free trade agreements.
And it's no good Brexiters saying that leaving the EU was never about economics. First, both during the referendum and since they repeatedly made claims that
it would be economically beneficial, and at the very least not harmful, hence all the effort put into the Project Fear rebuttal line. Second, although at one level describable (and dismissible) as ‘just economics’, when people can’t feed their families and are fighting to get medicines it is more than that.
Dangerous political trickeryMeanwhile, the astonishingly dangerous political trick the government used to ‘get Brexit done’ has blown up in its face. That, of course, was agreeing to the Northern Ireland Protocol (NIP) which it is clear the government never intended to honour, and which it sold to its MPs
as a supposedly temporary measure. Yet, at the very same time, it was sold to the electorate as part of the ’oven-ready deal’ which would put an end to all the boring Brexit wrangling. Worse still, it was signed as an international treaty with the EU, which certainly didn’t regard it as temporary, any more than does the US.
This was done quite knowingly and entirely cynically, and it’s very difficult to think of any equivalent trickery in modern British political history in terms of that combination of national and international dishonesty. Not only was it dishonest, it was actually – I don’t use this word casually – wicked in that the patsy in this trick was, and is, the people of Northern Ireland and the fragile politics of their hard-won peace. This makes David Frost’s handwringing about that fragility in
a repellently self-serving and disgracefully misleading speech about the Protocol this week all the more nauseating (alas, no space here to pull it apart, but see
some thoughts from me and from Gavin Barwell, formerly Theresa May’s Chief of Staff, and the highly revealing and unusual comments
from a former senior civil servant which clearly contradict some of Frost’s key claims).
What Frost and Johnson so wickedly did in 2019 created a carbuncle that has suppurated ever since. If there has so far been little domestic political price to pay for this, it is only because relatively few British voters outside Northern Ireland really understand or care about it. That’s especially so of English voters,
who are the Tory Party’s main concern (£). It has also created less international drama than it might have done because the EU, perhaps partly because it is less careless than Johnson and the Brexiters about Northern Ireland’s peace, perhaps from uncertainty about how to proceed with its new ‘
neighbour from hell’, has trodden a very soft path so far. Just how soft can be seen via the thought experiment of imagining the outrage with which the UK, and especially Brexiters, would have reacted if the EU had announced immediately after signing the Withdrawal Agreement that it had never had any intention of being bound by one of its key provisions.
Thus of the three audiences for this confidence trick – apathetic voters, a cautious EU, and Brexiter Tory MPs – it is the latter who have been most vocal in insisting that the government keep to its promise to them, that of treating the NIP as temporary. Northern Irish unionist politicians have also done so, of course, but, unlike Tory MPs, they never pretended to support the deal. Despite his large majority, Johnson has been vulnerable from the outset to ERG obduracy, and as his hold on office gets ever more shaky that increases. And under any conceivable replacement their power will persist. “So,” as RTE’s Tony Connelly concludes
his review of the current situation, “nearly six years after the Brexit referendum, the EU and Northern Ireland remain hostage to Tory Party machinations”.
Northern Ireland: a litany of failureThe essence of this current, or at least emerging, situation is, as Connelly explains, the widespread report that the British government is devising a new way to renege on the NIP, or at least the threat of doing so in order to blackmail the EU into allowing it to renege. Rather than continue with the repeated threats to ‘invoke Article 16’, this new approach would amend UK law so as to disapply the NIP. In particular, it is reported by Connelly and others that the government is considering repealing Section 7a of the EU Withdrawal Act, the legislation that enshrines the Protocol into domestic law, a course of action which is also being urged
by the Brexit Ultra commentariat (£).
The roots of this go all the way back to the total failure of Brexiters to understand or accept the implications for Northern Ireland of, at least, hard Brexit. I’ve written about that many times, and summarized some of the main issues on
a standalone page on this blog. But its more proximate root – and this is an important point – is that the new approach demonstrates the abject
failure of the old one. That is to say, all the threats of using Article 16, which
started in January 2021, only weeks after the NIP came into operation (and before the aborted EU threat to do so, since used as a justification), have now been exposed as nonsensical. Having treated Article 16 as if it were some kind of route to disapplying or unilaterally rewriting the Protocol, something all
credible experts agreed was untrue, the government seems to finally have understood this basic fact.
Along the lines of
my previous post, this could be called a ‘we told you so’ moment although, also in line with that post, the government is not learning from its mistakes but compounding them by proposing an even more absurd policy. In fact, in its essence, this new approach relies upon the idea which also informed the eventually aborted illegal clauses in the Internal Market Bill as well as one of the suggestions about how
Article 16 could be used for the specific purpose (£) of ending ECJ involvement in the Protocol.
As
discussed at that time at length by Mark Elliott, Professor of Public Law at Cambridge University, this
underlying idea is the “facile” one, endorsed by the Attorney General and arch-Brexiter Suella Braverman, that the sovereignty of the UK parliament means that it can pass laws that somehow trump international law and treaty obligations. (Elliott also explained this at the time of the Internal Market Bill proposals, in
an elegant essay which eviscerates the Brexiters’ entire concept of sovereignty.)
It’s not necessary to be an eminent lawyer, or even a lawyer, to see that this is nonsense: if it were true, no international agreement would have any legal standing at all. However, it seems clear that it is what informs the government’s thinking because when the new approach was first hinted at, by Jacob Rees-Mogg at the EU Scrutiny Committee a couple of weeks ago, he made exactly the point that
the UK had the “sovereign right” to override the Protocol (£). (In passing, it is shocking that literally
none of the Labour members of the committee turned up to this meeting, nor did the official SNP member, which is part of the wider story, for which I’ve no space here, of Labour’s near silence about the damage of Brexit.)
In any case, apart from its legal fatuity, it’s politically naïve. Domestically, there is bound to be substantial opposition from the House of Lords, and perhaps some Tory MPs, as
there was to the Internal Market Bill clauses. Even more importantly,
the international repercussions will be huge. It’s not only a matter of the non-trivial damage to the UK’s reputation. There is also the potential, at least eventually, to
end up with a trade war with the EU (£) and diplomatic rupture with the US. Already the UK’s conduct over the NIP is costing it dear in terms of the continuing
refusal of the EU to ratify UK membership of the Horizon Europe science funding programme in retaliation.
It is especially irresponsible in the context of the Ukraine War,
playing into Putin’s hands by undermining the Western alliance against him. The government’s thinking seems to be that the war will actually make the EU more likely to yield to this new threat. It’s a shabby idea in itself, relying on others to put up with our behaviour because, unlike us, they are too responsible to give succour to Putin. And it may not be realistic, anyway. It seems to rely on the government’s illusion that it is somehow the leader of the Western alliance, whereas from an EU perspective the UK is an important, but secondary, player to the primary EU-US-NATO. Keeping the UK sweet by indulging a new tantrum probably won’t be a priority, especially after all the years of British antagonism and dishonesty. Moreover, it’s entirely inconsistent with
Johnson’s reported desire (£) to “re-set” relations with France following Macron’s election victory this week.
Trapped in lies and denialIt remains to be seen whether the government is going to push ahead with this new approach – the consensus of knowledgeable commentators seems to be that it will, but that nothing will happen until after the Northern Ireland Assembly elections. But, as with the latest postponement of import controls and the possible continuation of accepting the CE conformity assessment mark (ludicrously
described in the Express this week as a ‘Brexit masterstroke’), the continuing ructions over implementing the NIP show the depths of the folly of Brexit in general, and the Brexit the government chose to agree to in particular.
What all three, and much else in the Brexit saga, share is a bull-headed denial of what hard Brexit means for customs and regulatory borders, and what they in turn mean for Northern Ireland, allied to a bone-headed concept of sovereignty. And so it goes on, year after year after wretched year. All the fantasies, lies and denials that permeated the dreadful referendum campaign six long years ago are still running into the rock of the realities of international trade and international relations. The government has no solutions because it has never been a government in any real sense of the term, just a vehicle for precisely the fantasies and denials of that campaign.
In consequence, its responses to the multiple and growing crises it has created veer between the ludicrous and the contemptible, dragging a bitterly divided country,
the clear majority of which thinks Brexit was a mistake, ever deeper into poverty, decline, misery and disrepute.
*Barely, if at all, reported, perhaps because balance of payments scarcely features in UK political discourse any more, are the IMF’s latest projections
for the current account balance (Table A10, p.153). Expressed as a percentage of GDP the UK deficit in 2021 was -2.6% with a forecast of -5.5% in 2022, then -4.8% in 2023 (advanced economy averages -0.7%, -0.1% and 0% respectively). It’s worth recalling the furore caused before the referendum when the then Governor of the Bank of England, Mark Carney, warned of his concern that
Brexit could test the UK’s reliance on “the kindness of strangers” to fund its current account deficit. At that time, the UK deficit was understood to be -3.7% (now adjusted to -3.6%) considered high by international standards (the advanced economy average was a surplus of +1%).