And that's great. It's also the return of Google Reader!
Mastodon is really confusing for newcomers. There are memes about it.
If you're an internet user of a certain age, you may find an analogy that's been working for me really useful:
Mastodon is just blogs.
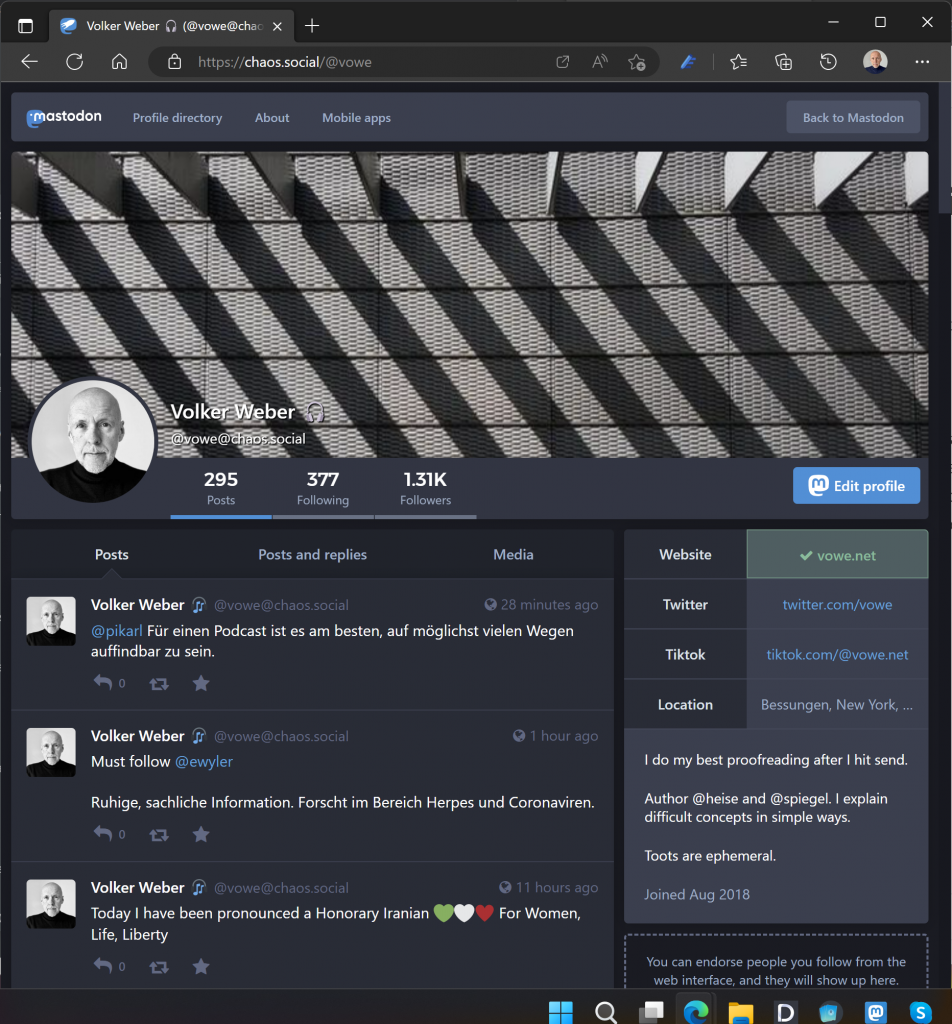
Every Mastodon account is a little blog. Mine is at https://fedi.simonwillison.net/@simon.
You can post text and images to it. You can link to things. It's a blog.
You can also subscribe to other people's blogs - either by "following" them (a subscribe in disguise) or - fun trick - you can add .rss to their page and subscribe in a regular news reader (here's my feed).
A Mastodon server (often called an instance) is just a shared blog host. Kind of like putting your personal blog in a folder on a domain on shared hosting with some of your friends.
Want to go it alone? You can do that: run your own dedicated Mastodon instance on your own domain (or pay someone to do that for you - I'm using masto.host).
Feeling really nerdy? You can build your own instance from scratch, by implementing the ActivityPub specification and a few others, plus matching some Mastodon conventions.
Differences from regular blogs
Mastodon (actually mostly ActivityPub - Mastodon is just the most popular open source implementation) does add some extra features that you won't get with a regular blog:
- Follows: you can follow other blogs, and see who you are following and who is following you
- Likes: you can like a post - people will see that you liked it
- Retweets: these are called "boosts". They duplicate someone's post on your blog too, promoting it to your followers
- Replies: you can reply to other people's posts with your own
- Privacy levels: you can make a post public, visible only to your followers, or visible only to specific people (effectively a group direct message)
These features are what makes it interesting, and also what makes it significantly more complicated - both to understand and to operate.
Add all of these features to a blog and you get a blog that's lightly disguised as a Twitter account. It's still a blog though!
It doesn't have to be a shared host
This shared hosting aspect is the root of many of the common complaints about Mastodon: "The server admins can read your private messages! They can ban you for no reason! They can delete your account! If they lose interest the entire server could go away one day!"
All of this is true.
This is why I like the shared blog hosting analogy: the same is true there too.
In both cases, the ultimate solution is to host it yourself. Mastodon has more moving pieces than a regular static blog, so this is harder - but it's not impossibly hard.
I'm paying to host my own server for exactly this reason.
It's also a shared feed reader
This is where things get a little bit more complicated.
Do you still miss Google Reader, almost a decade after it was shut down? It's back!
A Mastodon server is a feed reader, shared by everyone who uses that server.
Users on one server can follow users on any other server - and see their posts in their feed in near-enough real time.
This works because each Mastodon server implements a flurry of background activity. My personal server, serving just me, already tells me it has processed 586,934 Sidekiq jobs since I started using it.
Blogs and feed readers work by polling for changes every few hours. ActivityPub is more ambitious: any time you post something, your server actively sends your new post out to every server that your followers are on.
Every time someone followed by you (or any other user on your server) posts, your server receives that post, stores a copy and adds it to your feed.
Servers offer a "federated" timeline. That's effectively a combined feed of all of the public posts from every account on Mastodon that's followed by at least one user on your server.
It's like you're running a little standalone copy of the Google Reader server application and sharing it with a few dozen/hundred/thousand of your friends.
May a thousand servers bloom
If you're reading this with a web engineering background, you may be thinking that this sounds pretty alarming! Half a million Sidekiq jobs to support a single user? Huge amounts of webhooks firing every time someone posts?
Somehow it seems to work. But can it scale?
The key to scaling Mastodon is spreading the cost of all of that background activity across a large number of servers.
And unlike something like Twitter, where you need to host all of those yourself, Mastodon scales by encouraging people to run their own servers.
On November 2nd Mastodon founder Eugen Rochko posted the following:
199,430 is the number of new users across different Mastodon servers since October 27, along with 437 new servers. This bring last day's total to 608,837 active users, which is without precedent the highest it's ever been for Mastodon and the fediverse.
That's 457 new users for each new server.
Any time anyone builds something decentralized like this, the natural pressure is to centralize it again.
In Mastodon's case though, decentralization is key to getting it to scale. And the organization behind mastodon.social, the largest server, is a German non-profit with an incentive to encourage new servers to help spread the load.
Will it break? I don't think so. Regular blogs never had to worry about scaling, because that's like worrying that the internet will run out of space for new content.
Mastodon servers are a lot chattier and expensive to run, but they don't need to talk to everything else on the network - they only have to cover the social graph of the people using them.
It may prove unsustainable to run a single Mastodon server with a million users - but if you split that up into ten servers covering 100,000 users each I feel like it should probably work.
Running on multiple, independently governed servers is also Mastodon's answer to the incredibly hard problem of scaling moderation. There's a lot more to be said about this and I'm not going to try and do it justice here, but I recommend reading this Time interview with Mastodon founder Eugen for a good introduction.
How does this all get paid for?
One of the really refreshing things about Mastodon is the business model. There are no ads. There's no VC investment, burning early money to grow market share for later.
There are just servers, and people paying to run them and volunteering their time to maintain them.
Elon did us all a favour here by setting $8/month as the intended price for Twitter Blue. That's now my benchmark for how much I should be contributing to my Mastodon server. If everyone who can afford to do so does that, I think we'll be OK.
And it's very clear what you're getting for the money. How much each server costs to run can be a matter of public record.
The oldest cliche about online business models is "if you're not paying for the product, you are the product being sold".
Mastodon is our chance to show that we've learned that lesson and we're finally ready to pay up!
Is it actually going to work?
Mastodon has been around for six years now - and the various standards it is built on have been in development I believe since 2008.
A whole generation of early adopters have been kicking the tyres on this thing for years. It is not a new, untested piece of software. A lot of smart people have put a lot of work into this for a long time.
No-one could have predicted that Elon would drive it into hockeystick growth mode in under a week. Despite the fact that it's run by volunteers with no profit motive anywhere to be found, it's holding together impressively well.
My hunch is that this is going to work out just fine.
Don't judge a website by its mobile app
Just like blogs, Mastodon is very much a creature of the Web.
There's an official Mastodon app, and it's decent, but it suffers the classic problem of so many mobile apps in that it doesn't quite keep up with the web version in terms of features.
More importantly, its onboarding process for creating a new account is pretty confusing!
I'm seeing a lot of people get frustrated and write-off Mastodon as completely impenetrable. I have a hunch that many of these are people who's only experience has come from downloading the official app.
So don't judge a federated web ecosystem exclusively by its mobile app! If you begin your initial Mastodon exploration on a regular computer you may find it easier to get started.
Other apps exist - in fact the official app is a relatively recent addition to the scene, just over a year old. I'm personally a fan of Toot! for iOS, which includes some delightful elephant animations.
The expanded analogy
Here's my expanded version of that initial analogy:
Mastodon is just blogs and Google Reader, skinned to look like Twitter.


 Libre Computers is a company making single board computers that are much more open-sourced than the Raspberry Pi (especially when it comes to hardware). They are offering a USB 2.0 model (the "Le Potato") for $40 and a USB 3.0 model (the "Renegade") for $50. Those are not theoretical MSRP prices that are impossible to find either. Those are the listed prices available today!
When I first covered these boards the Libre reddit account let me know about a utility they had available that could enable most Raspberry Pi images to boot on Libre Computers boards such as the "Le Potato" and "Renegade". I tried out the tool and it worked great! In this guide I will show you where to get the tool and how to use it.
Let's begin!
Libre Computers is a company making single board computers that are much more open-sourced than the Raspberry Pi (especially when it comes to hardware). They are offering a USB 2.0 model (the "Le Potato") for $40 and a USB 3.0 model (the "Renegade") for $50. Those are not theoretical MSRP prices that are impossible to find either. Those are the listed prices available today!
When I first covered these boards the Libre reddit account let me know about a utility they had available that could enable most Raspberry Pi images to boot on Libre Computers boards such as the "Le Potato" and "Renegade". I tried out the tool and it worked great! In this guide I will show you where to get the tool and how to use it.
Let's begin!