An interesting (but quite expensive) piece of kit I’d love to have.
E-ink is one of those things I wish had become far more commonplace, but small production runs (and yields for large sizes) still make it prohibitively expensive, and the hefty price tag on this is ample proof of that.
I don’t really relate to arbitrary calendar milestones like “the new decade” that was supposed to have started January 1st (spoiler–it’s going to start on 2021), but there is a specific date I like to keep track of.
Ten years ago I wrote a bit about the first day we effectively started college (amidst the usual turmoil of those analog, fuzzy times), and all of it still holds true.
A lot has changed (there is now an actual Department of Computer Science and Engineering in place, for starters, and we’ve taken to WhatsApp instead of mailing-lists), but we still get together now and then.
And if I have any regrets or melancholy, they are most about how much local academia is removed from the reality of what I do on a daily basis and their awkward, indrawn take on things.
I’d love to “go back” and instill some fresh viewpoints into both coursework and academic life, but that is extremely unlikely at this point.
Still, who knows–there are a few decades to go yet, I hope.
Bluetooth drives wireless headphones and portable speakers and lets you wirelessly connect your stereo system or soundbar to your smartphone and its myriad streaming services. Yet despite Bluetooth’s ubiquity, it’s still the most misunderstood audio technology. Audio companies offer numerous variants—or codecs—of Bluetooth, and some people claim that a certain codec will improve Bluetooth sound quality. But those differences are hard to quantify and harder to hear. Read on if you’re confused about how (or if) different Bluetooth codecs should factor into your headphone or speaker choice.
^do(image,Borderlands3.jpg)
I’ve been working on some ideas about computation and character recently, and that’s led me to consider the role of stock characters in literary machines.
Why do we see the same characters all the time? Part, of course, is laziness. Part, I suspect, is that people who are willing to study games and other literary machines, or who choose to work in its dysfunctional industry, simply love those old familiar characters. Part, too, is that two of the most risk-averse people out there are
# a pre-teen boy risking his savings on a game, and
# a marketing executive whose future depends on convincing that boy to spend money now now now.
The upshot is that we see lots of warriors with a tragic backstory, lots of noble elves, lots of funny dwarfs, lots of tanks. We instantly recognize the characters wherever we meet them:
^do(quote,"She was a Tree Elf named Riyah. He was a Water Elf, Tildor. They came from different realms, but for the past three nights they’d qwested, traded and killed together. They had hunted basilisks, slain dragons, and retrieved two diamonds, which Riyah carried in the bag hanging at her waist. She was an amazing marksman, and beautiful, even for an Elf, her eyes huge, her body supple. Her breasts swayed as she ran, her quiver bouncing behind her. — Allegra Goodman, The Chalk Artist")
You know this is a game, and you know what sort of game it is, and you know its designers played too much Final Fantasy IV and Tomb Raider and have spent way too much time with obscure Japanese media.
But there’s more, too. Back when I started going to the American Repertory, its founding artistic director Robert Brustein was making an extended and important argument in support of theater as spectacle, in contrast to the Arthur Miller school of theater as a window into the neighbors’ living room. Part of that argument was the virtue of commedia dell'arte and its stock cast: because they are exaggerated and familiar, we have time to get to the point before everyone has to go home. And, because people miss stuff and sometimes misunderstand, characters need to be able to stand up to some degree of abuse.
This is even truer where the character is a joint creation of the author and the player.
Still, what is going on in Borderlands? It’s a AAA shooter franchise. I’ve always enjoyed it. There’s a new installment out now.
But what’s it about? Borderlands inhabits a reimagined American South — not the dreamland that has Gone With The Wind but the post-industrial wreckage left behind. (There’s no border in Borderlands: it has no Mexico and no Indian Territory.) Its people speak broad Kentucky with occasional mixtures of Arkansas; its major villains emulate “coastal” fashions like soul patches while its cannon-fodder look and speak just like the good guys. Everyone has a gun, just like in Texas. The women are either spectacularly sexy or spectacularly otherwise. There’s a good deal of talk about incest.
Is this an angry world? I’m not sure. It’s a lot of fun, but I do not understand what’s driving this.
Great audio in a video game can draw you into a digital world with bold effects, realistic details, and moving soundtracks. A great gaming headset can make that possible while you chat with your friends and teammates, too. But even the best sound quality won’t do you any good in a headset too uncomfortable to wear for long stretches. After testing more than 50 headsets for this update, we found that the HyperX Cloud Alpha is still the most comfortable, best-sounding gaming headset for the price.
Many moons ago, I was working at the New York Times and created a library called Store, which was “a Java library for effortless, reactive data loading.” We built Store using RxJava and patterns adopted from Guava’s Cache implementation. Today’s app users expect data updates to flow in and out of the UI without having to do things like pulling to refresh or navigating back and forth between screens. Reactive front ends led me to think of how we can have declarative data stores with simple APIs that abstract complex features like multi-request throttling and disk caching that are needed in modern mobile applications. Fast forward three years, Store has 45 contributors and more than 3,500 stars on Github. Today, I am delighted to announce Dropbox will be taking over active development of Store and releasing it in 100% Kotlin backed by Coroutines and Flow. Store 4 is an opportunity to take what we learned while rethinking the api and current needs of the Android ecosystem.
Android has come a long way in the last few years. The pattern of putting networking code in Activities and Fragments is a thing of the past. Instead, the community is increasingly converging on new, useful libraries from Google. These libraries, combined with architecture documentation and suggestions, now form the foundation of modern Android development. As an example, here’s Android Jetpack’s guide to Android architecture:
It’s one thing to provide docs for patterns but the Android Jetpack team has gone further and actually provided implementations for us:
Fragments and Activities: These have always been around, but now have AndroidX versions with things like Lifecycle and Scopes for coroutines. Fragments and Activities give us what we need to build the view layer of our app.
View Model and Live Data: These help us transmit data that we get from repositories without needing to manage rotation and lifecycle ourselves (Wow, we’ve come a long way!)
Room: Takes the complexities out of working with SQLite by providing us a full-fledged ORM with RxJava and coroutines support.
Remote Data Source: While not a part of Jetpack, Square’s Retrofit and Okhttp have solved network access in two different levels of abstraction.
Careful readers may have noticed that I skipped over Repository (not just me, it seems like Jetpack team also skipped it ). Repository currently only has a few code samples and no reusable abstractions that work across different implementations. That’s one of the big reasons why Dropbox is investing in Store—to solve this gap in the architecture model above.
Before diving into Store’s implementation, let’s review the definition of a repository. Microsoft offers a nice definition, describing repositories as
“classes or components that encapsulate the logic required to access data sources. They centralize common data access functionality, providing better maintainability and decoupling the infrastructure or technology used to access databases from the domain model layer.”
Repositories allow us to work with data in a declarative way. When you declare a repository, you define how to fetch data, how to cache it, and what you will use to transmit it. Clients can then declare request objects for the pieces of data they care about, and the repository handles the rest.
What problem is Store trying to solve?
Four years ago, when we before we began working on Store, preventing complex Android apps from using large amounts of data was a struggle. It was a significant engineering challenge to figure out how to keep network usage low while maintaining always-on connectivity. Most companies opted for always-on connectivity to ensure the best user experience. Unfortunately, most users’ cell phone bills scale with the amount of data used, so this approach was more expensive for users. With that in mind, it was important for apps to find ways to keep data usage to a minimum. We created Store in part, to address this problem and make it easy for engineers to keep data usage low.
A major contributor to this problem of large data usage was duplicate requests for the same data. A common example…
Here’s how the original version of Store solved the problem:
Sharing with Store
As you can see above, having a repository abstraction like Store gives you a centralized place to manage your requests and responses, allowing you to multicast both loading, error, and data responses rather than doing the same work many times.
Fast forward 4 years and the world of Android has changed at breakneck speed. Previously, we were working with network and databases that returned scalar values. Now, with the release of Room and SQLDelight, applications can subscribe for changes to data that they require. Similarly, websockets, push libraries like Firebase, and other “live” network sources are becoming more prevalent. Originally, Store was not written to handle these new observable data sources, but given their new prevalence we decided it was time for a rewrite. After much collaboration and many late nights, we’re pleased to introduce the fourth version of Store: github.com/dropbox/Store.
Store 4 is completely written in Kotlin. We also replaced RxJava with Kotlin’s newly-stable, reactive streams implementation called Flow.
You might be asking, Why ditch an industry leader like RxJava? First and most importantly is the concept of structured concurrency. Structured concurrency means defining the scope or context where background operations will run before making a request rather than after. This matters because the way scoping of background work is handled has a huge impact on avoiding memory leaks. Requiring scope to be defined at the beginning of the background work ensures that when that work is complete or no longer needed, the resources are guaranteed to be cleaned up.
Structured concurrency is not the only way to define the scope of background work. RxJava solves the same problem in a different way. Let’s look at RxJava’s core API for defining the scope of background work:
// Observable.java
@CheckReturnValue
public final Disposable subscribe(Consumer onNext) {}
Notice in the method signature above, RxJava Observable will return a disposable as the handle of the subscription. The disposable has a function dispose which tells the upstream observable to detach the consumer from itself. The scope background operation is defined between the start of the subscription and the call to this dispose method. Recently, RxJava2 added @CheckReturnValue, an annotation to denote that a call to flowable.subscribe will return a value and a user should retain it to use for future cancellation. Unfortunately, this is only a lint warning and will not prevent compilation. Think of it as RxJava warning you not to leak.
The big problem with RxJava’s approach to scoping background operations is that it’s too easy for engineers to forget to call dispose . Failing to dispose of active subscriptions directly leads to memory leaks. Unlike RxJava, which lets you first start an observable and then reminds you to handle the cancellation or detachment later, Kotlin Flow forces you to define when observables should be disposed right when you create the data source. This is because Flow is implemented to respect structured concurrency. Let’s take a look at Flow and how it prevents leaks
suspend fun Flow.collect(...)
Collect is similar to subscribe in RxJava, it takes a consumer that gets called with each emissions from the flow. Unlike RxJava, Flow's collect function is marked with suspend. This means that it is a suspending function (think async/await) which can only be called inside a coroutine. This forces Flow.collect to be called inside a coroutine guaranteeing that Flows will have a well-defined scope.
While this seems like a small distinction, in the world of Android (an embedded system with limited memory resources) having better contracts for scoping async work leads directly to fewer memory leaks, improving performance and reducing risk of crashes. Now, with structured concurrency from Kotlin coroutines, we can use things like Jetpack’s viewModelScope, which auto-cancels our running flow when the view model is cleared. This cleanly solves a core problem faced by all Android applications: how to determine when resources from background tasks are no longer needed.
public fun CoroutineScope.launch(...)
viewModelScope.launch {
flow.collect{ handle(it) }
}
Structured concurrency was the biggest reason why we switched to Flow. Our next biggest reason to switch was to align ourselves with the direction of the broader Android community. We’ve already seen that AndroidX loves Kotlin and Coroutines. Many libraries like ViewModel already support coroutine scopes, Room has first-class Flow support. There is even talk of new libraries that are being converted to use coroutines as an async primitive (Paging). It was important to us to rewrite Store in a manner that aligns with the Android ecosytem, for not just today but many years to come.
Lastly, while we do not have current plans to use Store for anything but Android, we felt that the future may include Kotlin multi-platform as a target and wanted to have as few dependencies as possible. RxJava is not compatible with Kotlin native/js and pulls in 6,000+ functions).
What is a Store?
A Store is responsible for managing a particular data request. When you create an implementation of a Store, you provide it with a Fetcher which is a function that defines how data will be fetched over the network. Optionally, you declare how your Store will cache data in-memory and on-disk. Since Store returns your data as a Flow, threading is a breeze! Once a Store is built, it handles the logic around your data fetching/sharing/caching, allowing your views to use the most up-to-date data source and ensuring that data is always available for offline use.
Fully Configured Store
Let’s start by looking at what a fully configured Store looks like. We will then walk through simpler examples showing each piece:
Rich API to ask for data whether you want cached, new, or a stream of future data updates.
Store additionally leverages duplicate request throttling to prevent excessive calls to the network and allows the disk-cache to be used as a source of truth. The disk-cache implementation is passed through the persister() builder function and can be used to modify the disk directly without going through Store. Source of truth implementations work best with databases that can provide observable sources like Jetpack Room, SQLDelight, or Realm.
And now for the details:
Creating a Store
You create a Store using a builder. The only requirement is to include a function that returns a Flow or a suspend function that returns a ReturnType.
val store = StoreBuilder.from {
articleId -> api.getArticle(articleId) //Flow<Article>
}
.build()
Store uses generic keys as identifiers for data. A key can be any value object that properly implements toString(), equals() and hashCode(). It will be passed to your Fetcher function when it is called. Similarly, the key will be used as a primary identifier within caches. We highly recommend using built-in types that implement equals and hashcode or Kotlin data classes for complex keys.
Public Interface: Stream
The primary public API provided by a Store instance is the stream function which has the signature:
fun stream(request: StoreRequest<Key>): Flow<StoreResponse>Output>>
Each stream call receives a StoreRequest object, which defines which key to fetch and which data sources to utilize. The response is a Flow of StoreResponse. StoreResponse is a Kotlin sealed class that can be either a Loading, Data, or Error instance. Each StoreResponse includes a ResponseOrigin field which specifies where the event is coming from.
The Loading class only has an origin field. This can be a good signal to activate the loading spinner in your UI.
The Data class has a value field which includes an instance of the type returned by Store.
The Error class includes an error field that contain the exception thrown by the given origin.
When an error occurs, Store does not throw an exception, instead, it wraps it in a StoreResponse.Error type which allows Flow to not break the stream and still receive updates that might be triggered by either changes in your data source or subsequent fetch operations. This allows you to have truly reactive UIs where your render/updateUI function is a sink for your flow without ever having to restart the flow after an error is thrown. See example below:
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(key = key, refresh=true)).collect { response ->
when(response) {
is StoreResponse.Loading -> showLoadingSpinner()
is StoreResponse.Data -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
updateUI(response.value)
}
is StoreResponse.Error -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
showError(response.error)
}
}
}
}
For convenience, there are Store.get(key), Store.stream(key) and Store.fetch(key) extension functions.
suspend fun Store.get(key: Key): Value
This method returns a single value for the given key. If available, it will be returned from the in-memory or disk cache
suspend fun Store.fresh(key: Key): Value
This method returns a single value for the given key that is obtained by querying the fetcher.
suspend fun Store.stream(key: Key): Flow
This method returns a Flow of the values for the given key.
Here’s an example using get() which is a single shot function:
lifecycleScope.launchWhenStarted {
val article = store.get(key)
updateUI(article)
}
On a fresh install when you call store.get(key), the network response will be stored first in the disk-cache (if provided) and in an in-memory cache afterwards. All subsequent calls to store.get(key) with the same key will retrieve the cached version of the data, minimizing unnecessary data calls. This prevents your app from fetching fresh data over the network (or from another external data source) in situations when doing so would unnecessarily waste bandwidth and battery. A great use case is any time your views are recreated after a rotation, they will be able to request the cached data from your Store. Having this data always available within a Store will help you avoid the need to retain copies of large objects in the view layer. With Store, your UI only needs to retain identifiers to use as keys while declaring whether it is ok to return the first value from cache or not.
Busting through the cache
Alternatively you can call store.fetch(key) to get a suspended result that skips the memory (and optional disk cache). A good use case is overnight background updates which use fetch() to make sure that calls to store.get()/stream() will not have to hit the network during normal usage. Another good use case for fetch() is when a user wants to pull to refresh.
Calls to both fetch() and get() emit one value or throw an error.
Stream
For real-time updates, you may also call store.stream(key) which creates a Flow that emits each time the disk-cache emits or when there are loading/error events from network. You can think of stream() as a way to create reactive streams that update when your db or memory cache updates.
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(3, refresh = false))
.collect{ }
store.stream(StoreRequest.get(3)) //skip cache, go directly to fetcher
.collect{ }
Get on Cold Start and Restart
Inflight multicasting
To prevent duplicate requests for the same data, Store has a built-in inflight debouncer. If a call is made that is identical to a previous request that has yet to complete, the same response for the original request will be returned. This is useful for situations when your app needs to make many async calls for the same data at startup or when users are obsessively pulling to refresh. As an example, you can asynchronously call Store.get() from 12 different places on startup. The first call blocks while all others wait for the data to arrive. We saw a dramatic decrease in data usage after implementing this inflight logic in NYT.
Disk as cache
Store can enable disk caching by passing an implementation to the persister() function of the builder. Whenever a new network request is made, the Store will first write to the disk cache and then read from the disk cache to emit the value.
Disk as single source of truth
Providing a persister whose read function can return a Flow allows you to make Store treat your disk as the source of truth. Any changes made on disk, even if it is not made by Store, will update the active Store streams.
This feature, combined with persistence libraries that provide observable queries (Jetpack Room, SQLDelight, or Realm) allows you to create offline first applications that can be used without an active network connection while still providing a great user experience.
Stores don’t care how you’re storing or retrieving your data from disk. As a result, you can use Stores with object storage or any database (Realm, SQLite, Firebase, etc). If using SQLite we recommend working with Room developed by our friends on the Jetpack team.
The above builder and Store stream API is our recommendation for how modern apps should be working with data. A fully configured store will give you the following capabilities:
Memory caching with TTL and Size policies
Disk caching including simple integration with Room
Multicasting of responses to identical requestors
Ability to get cached data or bust through your caches (StoreRequest)
Ability to listen for any new emissions from network (stream)
Structured concurrency through APIs build on Coroutines and Kotlin Flow
Wrapping Up
We hope you enjoyed learning about Store. We can’t wait to hear about all the wonderful things the Android community will build with it and welcome any and all feedback. If you want to be even more involved, we are currently hiring) all levels of mobile engineers in our NY, SF, and SEA offices. Come help us continue build great products both for our users and the developer community.
This information was presented at KotlinConf, if you would rather watch a presentation.
The Canada Revenue Agency has issued a warning about scammers posing as the agency, and has provided tips on how to avoid getting scammed.
The CRA has outlined the reasons that it may call you. It says it would only try to reach you if you’re in any of these circumstances:
If you owe tax or money to a government program – a collections officer may call you to discuss your file and ask you to make a payment. In this case, you may need to provide some information about your financial situation.
If you did not file your income tax and benefit return – we may call you to ask for the missing return.
If you did not file your GST/HST return.
If we have questions about the tax and benefit documents you sent.
If you operate a small business, we may call to offer free tax help through our Liaison Officer program.
If we have questions about your new business registration.
If we have questions regarding a limited review of your Corporate Return.
Further, the CRA says you should make sure that the person calling you is an actual CRA employee before you hand over any money or information over the phone. You can do this by asking for the caller’s name and office location and tell them that you first want to verify their identity.
The agency also suggests that you check the status of your tax account, and make sure the CRA has your current address and email.
Lastly, it suggests that you look for warning signs such as the caller pressuring you to act immediately. You may also want check if you received a notice about the subject of the call.
The CRTC recently implemented a rule that requires Canadian carriers to implement universal network-level blocking of calls with blatantly illegitimate caller identification to address spam calls.
Rogers has started to roll out Canada’s first 5G network in downtown Vancouver, Toronto, Ottawa and Montreal so it is ready when 5G devices become available.
The 5G network will initially use 2.5 GHz spectrum in the downtown cores, and will expand to use 600 MHz 5G spectrum later this year. 600 MHz is best suited for wireless data across long distances and through urban areas, creating higher quality coverage in remote areas and smart cities.
Rogers says that in the future, it will also deploy 3.5 GHz spectrum and dynamic spectrum sharing, which will allow 4G spectrum to be used for 5G.
It’s important to note that no one will be able to use the network yet, as there aren’t any phones authorized to the network. The carrier hasn’t provided any information regarding coverage.
“5G is the biggest technological evolution since the launch of wireless in Canada. We are making the right investments, building the right partnerships and deploying the right technology to bring Canadians the very best of 5G,” said Joe Natale, president and CEO of Rogers Communications in a press release.
The Rogers 5G network will expand to over 20 more markets by the end of the year.
The carrier says it will turn on 5G in the Rogers Centre, Scotiabank Arena and Rogers Arena to enhance how fans watch the game in the future.
Rogers says it partnered with Ericsson for its 4.5G and 5G technology. The two companies have worked together on wireless services since 1985.
The carrier says its 5G services will only be available on Rogers Infinite plans with unlimited data. Rogers launched those plans in the summer of 2019.
Rogers’ CTO Jorge Fernandes stated, “5G is not just another G. It is a global technology that requires local development to deliver the best social and economic benefits to Canadians. Through our multi-year program we will invest in our wireless network and partner with leaders to drive innovative use cases for Canadian consumers and businesses.”
Update 15/01/20 4:10pm ET:MobileSyrup has reached out to Bell and Telus regarding their status on 5G networks. Bell said that it “is ready to launch similar Early 5G service in these and other centres this year as capable smartphones become available.”
Google’s awesome Live Caption feature, which debuted alongside the Pixel 4 last year, is now available for Pixel 2 and 2 XL devices.
Live Caption, for the unfamiliar, is able to generate captions for all video and audio content on your phone. The crazy part is that it can do so entirely on-device, and doesn’t require an internet or data connection to do it.
Some Redditors were able to activate it on their Pixel 2 devices by manually installing the latest Device Personalization Services APK update. Several users have chimed in on the Reddit post confirming that Live Caption now works on their Pixel 2 or 2 XL phones. Further, Android Policeconfirmed reports that the APK enables Live Caption.
Live Caption’s arrival on the Pixel 2 shouldn’t come as much of a surprise. XDA Developers was able to get it running on a Pixel 2 before the Pixel 4 launch. Knowing that the Pixel 2 was cable of running Live Caption made it a given that Google would eventually launch the feature. That said, Google hasn’t officially said anything about Live Caption’s arrival on the older Pixel phone. It’s possible that Google’s waiting for the rollout to near completion before it makes an announcement.
Regardless, Live Caption is here. If you use a Pixel 2 and want to try it out but haven’t received the update yet, you can always install it manually through an APK. You can find the needed files on the Reddit post here.
The ‘Beastie Boys Story‘ documentary is set to make its way to Apple TV+ in April following a limited IMAX theatrical release.
The documentary, which is based on the Beastie Boys Book, follows the story of the iconic hip-hop group from the perspective of Mike Diamond and Adam Horovitz, the Beastie Boys’ two surviving members. Spike Jonze is the music documentary’s director.
“Beastie Boys Mike Diamond and Adam Horovitz tell you an intimate, personal story of their band and 40 years of friendship in this live documentary experience directed by their longtime friend and collaborator, and their former grandfather, filmmaker Spike Jonze.
The film is set to premiere on the heels of the 26th anniversary of the release of Beastie Boys’ No. 1 charting 1994 album, “Ill Communication,” and reunites Beastie Boys with director Spike Jonze over 25 years after directing the music video for the album’s immortal hit single, “Sabotage.”
The Beastie Boys Story will launch on Apple TV+ in April. This isn’t the first time Apple planned to release original content in theatres prior to it hitting the tech giant’s streaming service.
Adam ‘MCA’ Yauch, The Beastie Boys’ third member, passed away back in 2012 following a battle with cancer.
An Apple TV+ documentary produced by Oprah Winfrey was recently cancelled due to creative differences, and Samuel L. Jackson’s The Banker was supposed to hit theatres this past Christmas but was pulled following sexual abuse allegations from someone in the family depicted in the film.
Other original content, including Little America, Mythic Quest and Visible, is set to launch on Apple TV+ in January and February.
Apple has acquired Xnor.ai, the Seattle-based artificial intelligence company behind Wyze’s on-device people detection.
As a result, person detection has been removed from Wyze’s cameras. Below is a statement from the company, which says that it plans to create its own in-house version of the functionality.
Person Detection will be temporarily removed from Wyze Cam beginning with a new firmware release planned for mid-January 2020, due to the unexpected termination of our agreement with our AI provider. We are preparing to roll out our own in-house version of Person Detection this year, which will remain free for our users.
Apple likely purchased Xnor.ai to improve the current smart camera people detection that is part of its HomeKit Secure Video platform.
Neither Apple nor Xnor.ai have confirmed the deal, but GeekWire’s report indicates that the tech giant paid in the range of $200 million USD (about $260 million CAD) for the startup. Apple issued a standard PR response to CNBC when it asked about the acquisition.
“Apple buys smaller technology companies from time to time and we generally do not discuss our purpose or plans,” said Apple in a statement to CNBC.
Apple acquiring a smaller company to bolster its technology isn’t anything new. Back in May of 2019, Tim Cook, Apple’s CEO, stated that the tech giant has acquired between 20 and 25 companies over the past six months.
Wyze’s cameras are sold both on Amazon at Best Buy in Canada.
Mozilla must do two things in this era: Continue to excel at our current work, while we innovate in the areas most likely to impact the state of the internet and internet life. From security and privacy network architecture to the surveillance economy, artificial intelligence, identity systems, control over our data, decentralized web and content discovery and disinformation — Mozilla has a critical role to play in helping to create product solutions that address the challenges in these spaces.
Creating the new products we need to change the future requires us to do things differently, including allocating resources for this purpose. We’re making a significant investment to fund innovation. In order to do that responsibly, we’ve also had to make some difficult choices which led to the elimination of roles at Mozilla which we announced internally today.
Mozilla has a strong line of sight on future revenue generation from our core business. In some ways, this makes this action harder, and we are deeply distressed about the effect on our colleagues. However, to responsibly make additional investments in innovation to improve the internet, we can and must work within the limits of our core finances.
We make these hard choices because online life must be better than it is today. We must improve the impact of today’s technology. We must ensure that the tech of tomorrow is built in ways that respect people and their privacy, and give them real independence and meaningful control. Mozilla exists to meet these challenges.
Adrianna Tan@skinnylatte
My quality of life in the US has improved since I went home and bought all this sambal and pastes. Eating really sp… twitter.com/i/web/status/1…
The new Microsoft Edge browser - the first built on the Chromium browser engine - has been released and is available for general download. Features include "AAD support, Internet Explorer mode, 4K streaming, Dolby audio, inking in PDF, Microsoft Search in Bing integration, support for Chrome-based extensions, and more." What I want to know is how well ad-blocking works. Because it doesn't matter what the browser can do if I can't turn off the ads. Here's how to upgrade.
The release of the Windows Terminal preview v0.8 has arrived! You can download the Terminal from the Microsoft Store or from the GitHub releases page. Let’s jump into what’s new!
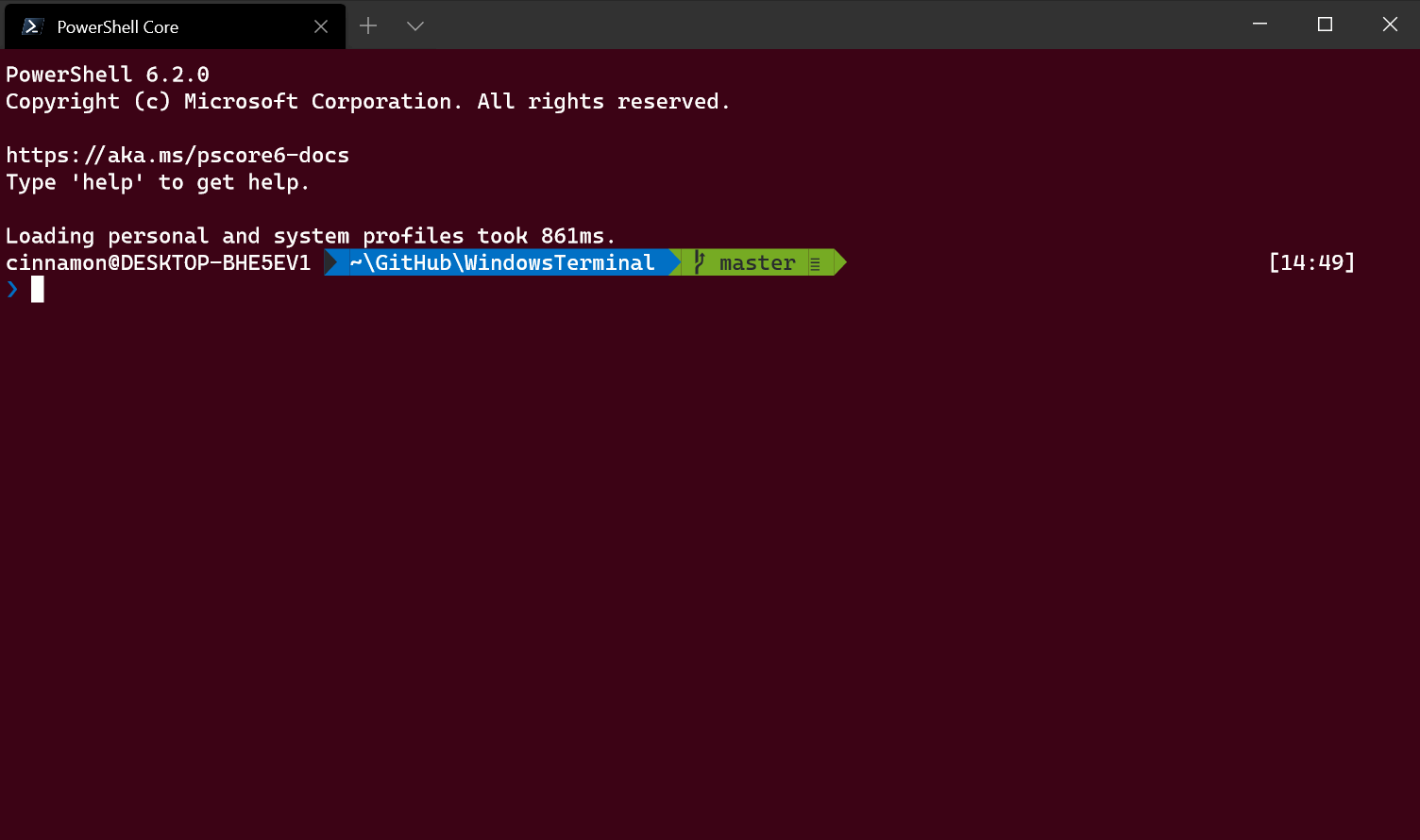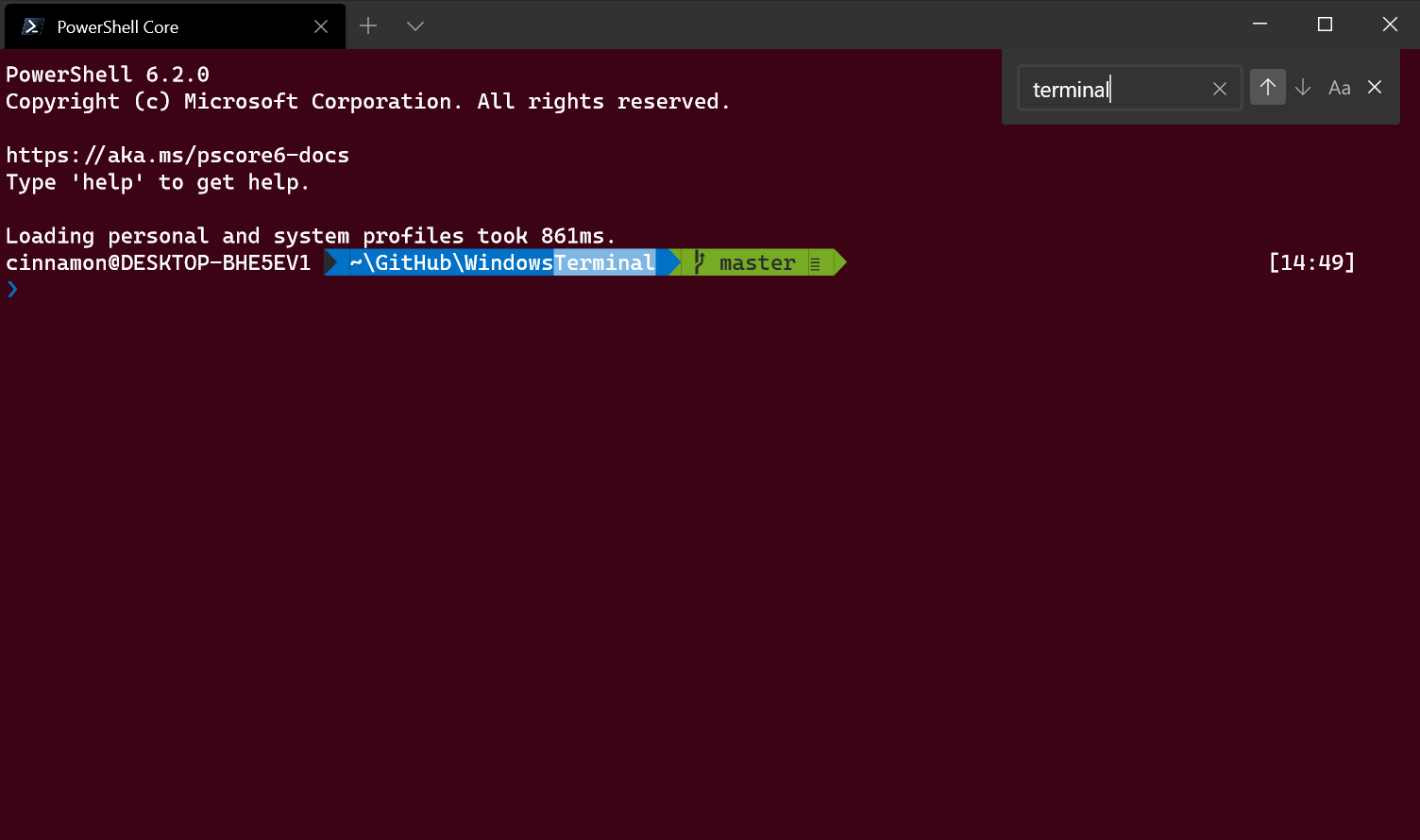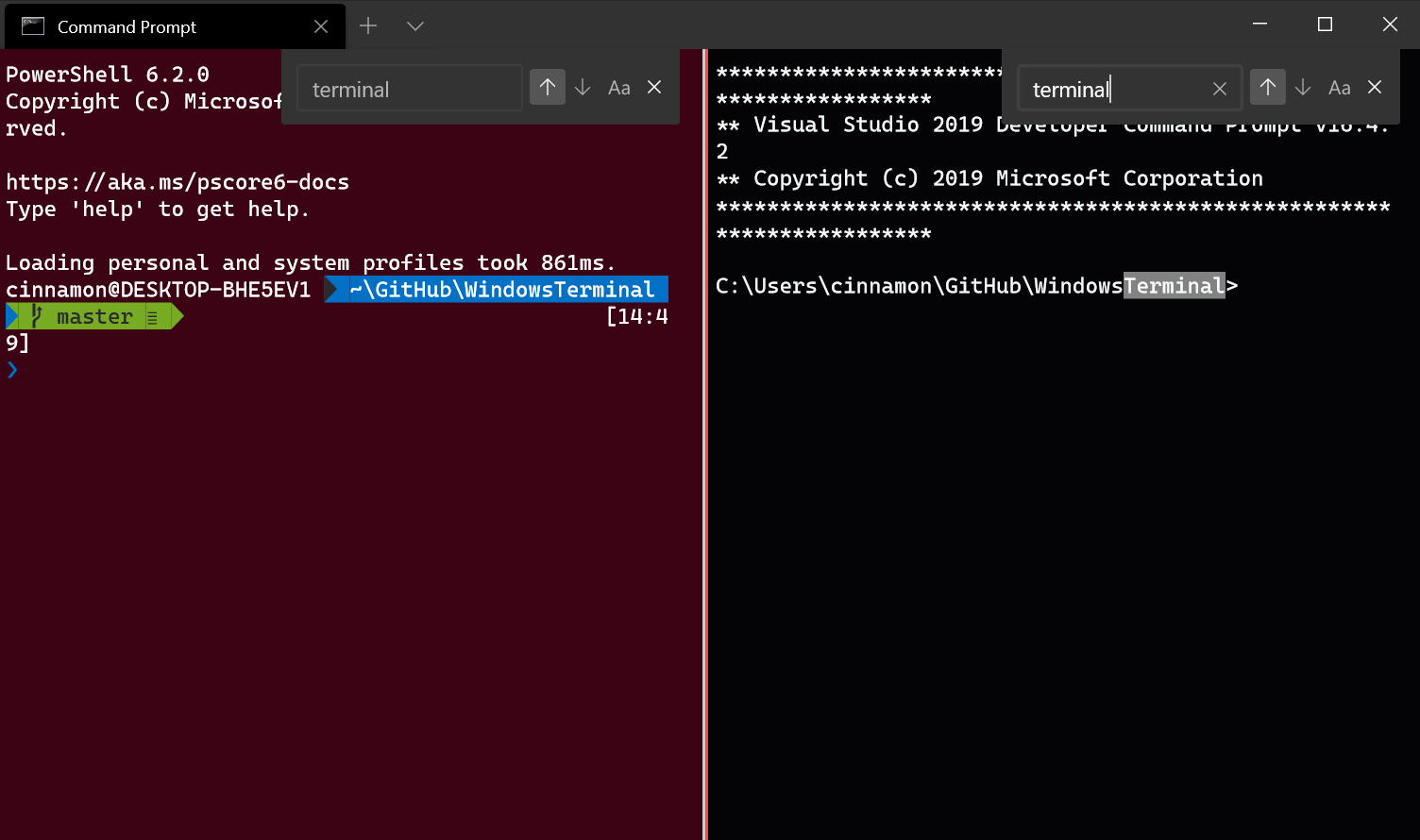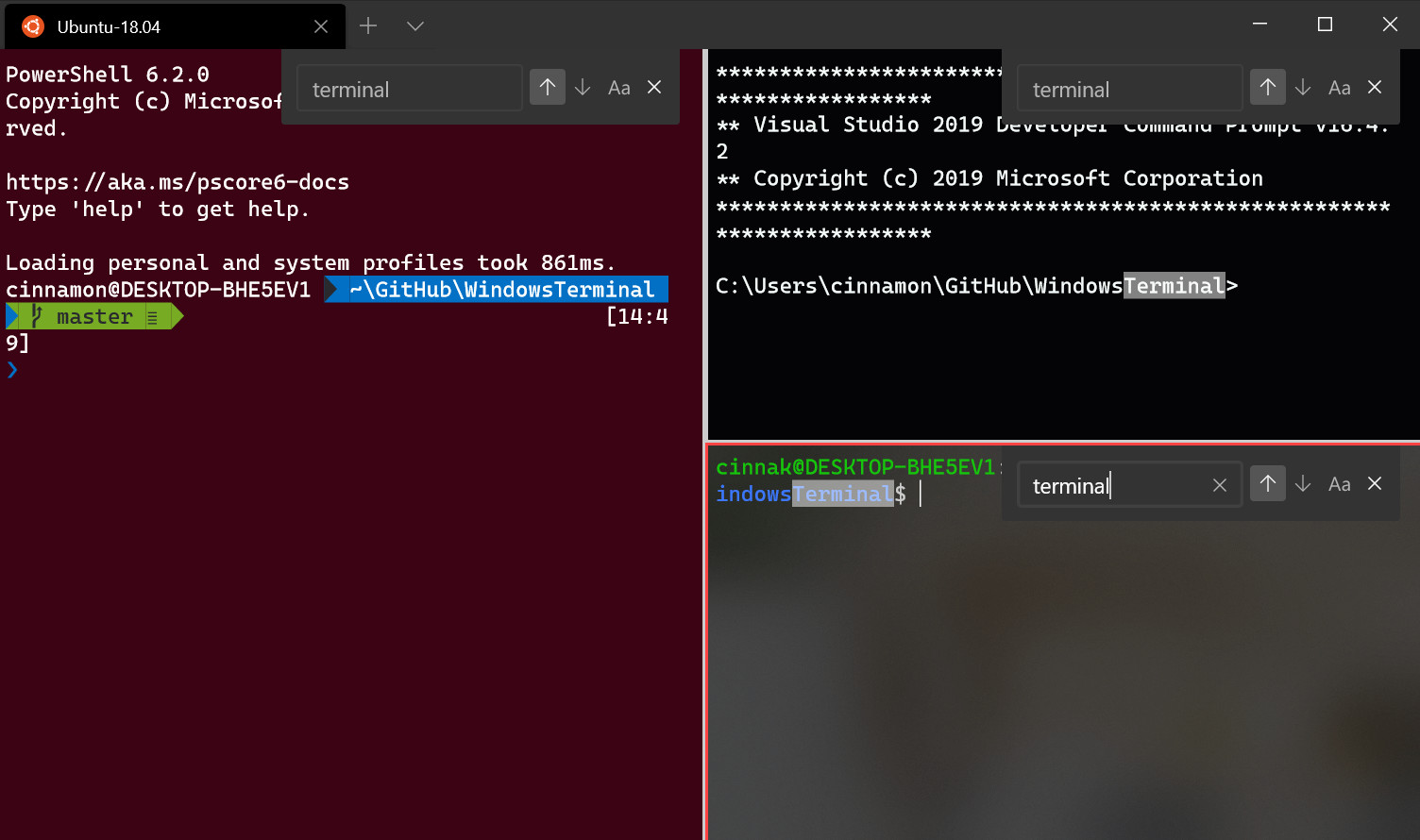
Search
Search functionality has been added to the Terminal! The default key binding to invoke the search dropdown is {"command": "find", "keys": ["ctrl+shift+f"]}. Feel free to customize this key binding in your profiles.json if you prefer different key presses! The dropdown allows you to search up and down through the buffer as well as with letter case matching.
Retro Terminal Effects (Experimental)
Do you miss the days of scanlines and glowing text? Well this is the Terminal release for you! Thanks to community member @ironyman, you can now have CRT retro effects inside the Windows Terminal! This is an experimental feature, but to enable it you can add the following code snippet to any of your profiles:
"experimental.retroTerminalEffect": true
Settings Updates
Enhanced Panes and Tabs Key Bindings
When opening a new pane or tab with a key binding, you can now specify which profile by using the profile’s name "profile": "profile-name", guid "profile": "profile-guid", or index "index": profile-index. If none are specified, the default profile is used.
Additionally, you can override certain aspects of the profile such as the profile’s command line executable "commandline": "path/to/my.exe", starting directory "startingDirectory": "my/path", or tab title "tabTitle": "new-title".
Here are a few examples of how to implement this new feature:
{"keys": ["ctrl+a"], "command": {"action": "splitPane", "split": "vertical"}}Opens the default profile in a new vertical pane.
{"keys": ["ctrl+b"], "command": {"action": "splitPane", "split": "vertical", "index": 0}}Opens the first profile in the dropdown in a new vertical pane.
{"keys": ["ctrl+c"], "command": {"action": "splitPane", "split": "horizontal", "profile": "{00000000-0000-0000-0000-000000000000}", "commandline": "foo.exe"}}Opens the profile with the guid 00000000-0000-0000-0000-000000000000 using the command line executable of foo.exe in a new horizontal pane.
{"keys": ["ctrl+d"], "command": {"action": "newTab", "profile": "profile1", "startingDirectory": "c:\\foo"}}Opens the profile with the name profile1 starting in the c:\foo directory in a new tab.
{"keys": ["ctrl+e"], "command": {"action": "newTab", "index": 1, "tabTitle": "bar", "startingDirectory": "c:\\foo", "commandline":"foo.exe"}}Opens the second profile in the dropdown using the command line executable of foo.exe with a tab title of bar starting in the c:\foo directory in a new tab. *catches breath*
Custom Default Settings
You can now modify your profiles.json to have your own default profile settings. With this new architecture, you can set a property once and have it apply to all of your profiles. This new setting helps minimize redundant settings between profiles. To add this feature, you can modify the profiles object in your profiles.json to have the "defaults" and "list" properties in the following format:
With the above code snippet, all of the profiles will use the Cascadia Code font and have the Vintage color scheme.
Note: All of the profile settings can be found here. All can be applied to "defaults" except "guid".
UI Improvements
Tab Sizing
You now have the ability to modify the behavior of your tab widths. A new setting has been added called "tabWidthMode". This setting provides two different tab width behaviors: "equal" and "titleLength". "equal" will make all of your tabs equal width and shrink as additional tabs are added, similar to a traditional browser experience. "titleLength" will size each tab to the length of the tab title.
The Terminal originally had the default tab width behavior set to "titleLength". This release changes the default behavior to "equal". If you’d like to change your tab width behavior back to the "titleLength" mode, you can add the following code snippet to the "globals" property of your profiles.json file:
"tabWidthMode": "titleLength"
Here’s an example of how both tab width modes behave:
Bug Fixes
The tab row will now get larger when the window does!
Full screen mode now works more reliably!
Moving focus between grouped panes should act in the way you expect!
Windows Subsystem for Linux (WSL) users will now see the WT_SESSION environment variable!
Heaps of crash fixes!
Top Contributors
Our community has contributed immensely to the Terminal project and we’d like to recognize those who have especially made an impact on this release!
Contributors Who Opened the Most Non-Duplicate Issues
If you have any questions or comments, feel free to reach out to Kayla (@cinnamon_msft) on Twitter. If you find any bugs or would like to request new features, you can file an issue on GitHub! We hope you like our latest release!
Marco Arment on marco.org, outlining his self-created Low Power Mode-like system which relies on a third-party app, and making the case for Apple to add something similar as an official macOS feature:
The vast majority of the time I’m using it, the 16-inch MacBook Pro is a much better laptop with Turbo Boost disabled.
It’s still fast enough to do everything I need (including significant development with Xcode), while remaining silent and cool, with incredible battery life.
But soon, I bet I won’t be able to do this anymore.
Turbo Boost Switcher Pro relies on a kernel extension that’s grandfathered into Apple’s latest security requirements, but it can never be updated — and when macOS Catalina loads it for the first time, it warns that it’ll be “incompatible with a future version of macOS.” I suspect that this is the last year I’ll get to run the latest OS and be able to turn off Turbo Boost at will, making all of my future laptop usage significantly worse.
Low Power Mode is one of many useful features that iOS has had for years but that Mac users have been forced to live without. The feature’s popularity on iOS makes it a no-brainer addition for portable Macs, where battery life is already worse than what’s found in the iPhone and iPad.
Update: Former MacStories contributor TJ Luoma helpfully pointed out something that genuinely surprised me: Low Power Mode isn’t on the iPad either. Here’s hoping Apple brings it not only to the Mac, but the iPad as well.
At the beginning of every year, I like to publish a retrospective to look back and take stock of how far Acquia has come over the past 12 months. I take the time to write these retrospectives because I want to keep a record of the changes we've gone through as a company and how my personal thinking is evolving from year to year.
If you'd like to read my previous retrospectives, they can be found here: 2018, 2017, 2016, 2015, 2014, 2013, 2012, 2011, 2010, 2009. This year marks the publishing of my eleventh retrospective. When read together, these posts provide a comprehensive overview of Acquia's growth and trajectory.
Our product strategy remained steady in 2019. We continued to invest heavily in (1) our Web Content Management solutions, while (2) accelerating our move into the broader Digital Experience Platform market. Let's talk about both.
Acquia's continued focus on Web Content Management
We continued to invest heavily in Acquia Cloud in 2019. As a result, Acquia Cloud remains the most secure, scalable and compliant cloud for Drupal. An example and highlight was the successful delivery of Special Counsel Robert Mueller's long-awaited report. According to Federal Computer Week, by 5pm on the day of the report's release, there had already been 587 million site visits, with 247 million happening within the first hour — a 7,000% increase in traffic. I'm proud of Acquia's ability to deliver at a very critical moment.
Time-to-value and costs are big drivers for our customers; people don't want to spend a lot of time installing, building or upgrading their websites. Throughout 2019, this trend has been the primary driver for our investments in Acquia Cloud and Drupal.
In September, we announced that Acquia acquired Cohesion, a Software-as-a-Service visual Drupal website builder. Cohesion empowers marketers, content authors and designers to build Drupal websites faster and cheaper than ever before.
We launched a multitude of new features for Acquia Cloud which enabled our customers to make their sites faster and more secure. To make our customer's sites faster, we added a free CDN for all Cloud customers. All our customers also got a New Relic Pro subscription for application performance management (APM). We released Acquia Cloud API v2 with double the number of endpoints to maximize customer productivity, added single-sign on capabilities, obtained FIPS compliance, and much more.
We rolled out many "under the hood" improvements; for example, thanks to various infrastructure improvements our customers' sites saw performance improvements anywhere from 30% to 60% at no cost to them.
Making Acquia Cloud easier to buy and use by enhancing our self-service capabilities has been a major focus throughout all of 2019. The fruits of these efforts will start to become more publicly visible in 2020. I'm excited to share more with you in future blog posts.
At the end of 2019, Gartner announced it is ending their Magic Quadrant for Web Content Management. We're proud of our six year leadership streak, right up to this Magic Quadrant's end. Instead, Gartner is going to focus on the broader scope of Digital Experience Platforms, leaving stand-alone Web Content Management platforms behind.
Gartner's decision to drop the Web Content Management Magic Quadrant is consistent with the second part of our product strategy; a transition from Web Content Management to Digital Experience Management.
Acquia's expansion into Digital Experience Management
We started our expansion from Web Content Management to the Digital Experience Platform market five years ago, in 2014. We believed, and still believe, that just having a website is no longer sufficient: customers expect to interact with brands through their websites, email, chat and more. The real challenge for most organizations is to drive personalized customer experiences across all these different channels and to make those customer experiences highly relevant.
For five years now, we've been patient investors and builders, delivering products like Acquia Lift, our web personalization tool. In June, we released a completely new version of Acquia Lift. We redesigned the user interface and workflows from scratch, added various new capabilities to make it easier for marketers to run website personalization campaigns, added multi-lingual support and much more. Hands down, the new Acquia Lift offers the best web personalization for Drupal.
In addition to organic growth, we also made two strategic acquisitions to accelerate our investment in becoming a full-blown Digital Experience Platform:
In May, Acquia acquired Mautic, an open marketing automation platform. Mautic helps open up more channels for Acquia: email, push notifications, and more. Like Drupal, Mautic is Open Source, which helps us deliver the only Open Digital Experience Platform as an alternative to the expensive, closed, and stagnant marketing clouds.
In December, we announced that Acquia acquired AgilOne, a leading Customer Data Platform (CDP). To make customer experiences more relevant, organizations need to better understand their customers: what they are interested in, what they purchased, when they last interacted with the support organization, how they prefer to consume information, etc. Without a doubt, organizations want to better understand their customers and use data-driven decisions to accelerate growth.
We have a clear vision for how to redefine a Digital Experience Platform such that it is free of any silos.
In 2020, expect us to integrate the data and experience layers of Lift, Mautic and AgilOne, but still offer each capability on its own aligned with our best-of-breed approach. We believe that this will benefit not only our customers, but also our agency partners.
Momentum
Demand for our Open Digital Experience Platform continued to grow among the world's most well-known brands. New customers include Liverpool Football Club, NEC Corporation, TDK Corporation, L'Oreal Group, Jewelers Mutual Insurance, Chevron Phillips Chemical, Lonely Planet, and GOL Airlines among hundreds of others.
We ended the year with more than 1,050 Acquians working around the globe with offices in 14 locations. The three acquisitions we made during the year added an additional 150 new Acquians to the team. We celebrated the move to our new and bigger India office in Pune, and ended the year with 80 employees in India. We celebrated over 200 promotions or role changes showing great development and progression within our team.
We continued to introduce Acquia to more people in 2019. Our takeover of the Kendall Square subway station near MIT in Cambridge, Massachusetts, in April, for instance, helped introduce more than 272,000 daily commuters to our company. In addition to posters on every wall of the station, the campaign — in which photographs of fellow Acquians were prominently featured — included Acquia branding on entry turnstiles, 75 digital live boards, and geo-targeted mobile ads.
Last but not least, we continued our tradition of "Giving back more", a core part of our DNA or values. We sponsored 250 kids in the Wonderfund Gift Drive (an increase of 50 from 2018), raised money to help 1,000 kids in India to get back to school after the floods in Kolhapur, raised more than $10,000 for Girls Who Code, $10,000 for Cancer Research UK, and more.
Some personal reflections
With such a strong focus on product and engineering, 2019 was one of the busiest years for me personally. We grew our R&D organization by about 100 employees in 2019. This meant I spent a lot of time restructuring, improving and scaling the R&D organization to make sure we could handle the increased capacity, and to help make sure all our different initiatives remain on track.
It feels a bit surreal that we crossed 1,000 employees in 2019.
There were also some low-lights in 2019. On Christmas, Acquia's SVP of Engineering Mike Aeschliman, unexpectedly passed away. Mike was one of the three people I worked most closely with and his passing is a big loss for Acquia. I miss Mike greatly.
If I have one regret for 2019, it is that I was almost entirely internally focused. I missed hitting the road — either to visit employees, customers or Drupal and Mautic community members around the world. I hope to find a better balance in 2020.
Thank you
2019 was a busy year, but also a very rewarding year. I remain very excited about Acquia's long-term opportunity, and believe we've steered the company to be positioned at the right place at the right time. All of this is not to say 2020 will be easy. Quite the contrary, as we have a lot of work ahead of us in 2020, including the release of Drupal 9. 2020 should be another exciting year for us!
More than 40 hours of research and tests of 17 ice scrapers—including on 28 windshields in a -3 °F cold-chamber at Ford’s vehicle test facility in Detroit—prove the Hopkins SubZero 80037 is a far better tool to clear snow and ice off your car than those cheap handheld scrapers we’ve all had to use in a pinch.
I’m often asked to discuss one of my most popular techniques, the Everything Notebook. I have considered making YouTube videos explaining how to make one, how it operates, etc. But I end up running out of time. But over the winter break (this past one, December 2019-January 2020), I was asked what kind of stuff do I write in the Everything Notebook. I was planning my 2020, so I took the opportunity to showcase the kinds of things that I post to my Everything Notebook.
I am also experimenting with something in 2020: I am starting my new Everything Notebook WITHIN my 2019 one. Normally, I devote at least 1 Everything Notebook to a specific year. Some years I have run out of space and therefore I have to start another one, but this year, I had enough space (mostly I believe as a result of my being in Paris for the Spring term) to start the 2020 one right there and then.
So here are a few things that I write in my Everything Notebook:
1) My Weekly To-Do List.
This is perhaps the one component that is similar to the Bullet Journal and one of the major reasons why people confuse both systems. The Everything Notebook, however, has both project notes AND To-Do lists in it. That’s perhaps the one thing that differentiates both systems. I am writing a blog post explaining the (rather substantial) differences, which I’ll publish soon.
2) Project Notes
When I refer to project notes, I mean notes about a particular project I am developing or commentaries about scholarship I have read. So within the “Bottled Water” section of my Everything Notebook, I may have summarized an article and dropped a few notes regarding its content, or written a few ideas about stuff I am thinking about.
1) staple these pages into my Everything Notebook in my 2020 section “Discards and Waste Studies”
2) transcribe my abstracts and notes (instead of stapling)
In this case I find it’s better for me to finish drafting my papers and their linkages and THEN transcribe onto EN. pic.twitter.com/iGWpGc3cRL
I also copy suggestions on to my Everything Notebook, which I obtain from tweets answering my tweeted research-related questions online.
I find writing by hand helps me clarify my thinking. I could, if I wanted to, store this tweet as a thread (compiled w/ Threader App) and then save it into Evernote. BUT I find that copying and writing advice I’m given by hand into my Everything Notebook helps me learn better.
One of the ways in which I keep track of what I am supposed to be writing is by virtue of keeping my yearly plan in my Everything Notebook. This includes my writing commitments. Within each project tab/section, I make a note regarding which projects I am supposed to be tackling related to that specific research area (in this case, discards and waste).
Once I have mapped out my writing commitments on waste and discards for the year, I start mapping a sub-Publications Planner (specific to the topic).
This is important because the cells I fill out in this draft in my Everything Notebook land in the digital version. pic.twitter.com/2sFqdc7WQz
In one of my previous tweest, I explained that I write a sub-Publications Planner (per topic) that I integrate into my global one. Here’s how I write the latter.
Obviously, the power of the Everything Notebook resides in having EVERYTHING in one place instead of scattered notes all over the place. That’s why I encourage folks to adapt my method (or if they so choose, the Bullet Journal idea!) the way they prefer. Because for me, having the To-Do lists with my yearly plan and my writing commitments and project notes, field notes, etc. is much more efficient than dedicating different notebooks to each one of these items.
I’ve always fantasized about climbing something big, and would love—like most of us—to top out El Capitan. But I’ve focused on sport climbing the past few years, and I’ve also had a difficult time progressing into higher grades. However, I’m solid on moderates. With 18 bolted pitches, none harder than 5.9, Flyboys was a route where I could have a real adventure at my current level—and top out something big.
I've yet to climb Flyboys, but I have done some of the others mentioned in the article. Not when wet though, that sounds horrible.
Because of the similarity of both concepts (one notebook to organize your life), a lot of people online confuse my idea of the Everything Notebook with the Bullet Journal. I’ve tweeted about the differences between both systems quite a few times, but on this occasion I want to keep these tweets in more permanent form.
My tweets explain in a bit more detail how the Bullet Journal and the Everything Notebook differ.
Personally, I find the BuJo system quite convoluted. Ironically enough, its alleged simplicity is what drives me bonkers.
There is a fundamental difference between a Bullet Journal and my #EverythingNotebook – BuJo is primarily for task control and progress monitoring.
Don’t get me wrong. I have seen BuJos that make me super jealous. People add colour and stickers and grand goals and motivational phrases and they make them so pretty.
Personally, I wish I had learned about the Bullet Journal before I developed my idea of the Everything Notebook, because I am sure that there are ways to make both of them work (below see an example of a Bullet Journal).
Bullet Journal (photo credit: John Uri on Flickr, Creative Commons Licensed)
I already had devised the idea of an Everything Notebook BEFORE Bullet Journal came about. Last year I learned of the Passion Planner.
— Dr Raul Pacheco-Vega (@raulpacheco) June 1, 2017
At the core, an Everything Notebook functions under the premise of having just ONE notebook for To-Do’s, task management, note-keeping.
— Dr Raul Pacheco-Vega (@raulpacheco) June 1, 2017
FUNDAMENTAL DIFFERENCES BETWEEN A BULLET JOURNAL AND AN EVERYTHING NOTEBOOK
The way I see them, the below are the major differences between an Everything Notebook and a Bullet Journal.
The Bullet Journal serves more as a planner. The Everything Notebook includes planning and project notes/field notes/random ideas.
The Bullet Journal has numbered pages and an index (pre-made). The Everything Notebook has rigid plastic tabs (1″) that mark different sections. Once you run out of pages with the Everything Notebook, THEN you write an index/table of contents.
The Bullet Journal method is very well suited for creativity/colours/etc. The Everything Notebook has colours, but mostly for writing and for differentiating sections (various rigid plastic tab colours)
In the end, you can use the Everything Notebook, or the Bullet Journal, or a commercial planner like the Passion Planner, or a combination of the first two (as many people have done, see below).
I do a modified bullet journal similar to what @raulpacheco calls an everything notebook. Am lost without it.
I am starting the new year by creating a hybrid bullet journal/everything notebook (the latter a la @raulpacheco). I will soon be either wildly productive or too disorganized to make it out of bed in the morning.
When social media first came into being, pundits like Michael Wesch and dana boyd talked of "context collapse" - you would no longer have a work identity, home identity, party identity, whatever; they would all collapse into a single public identity. But eventually people rebelled, and social media began to help us respect boundaries. But now we're entering the real on "content collapse". All content is the same. "A presidential candidate's policy announcement is given equal weight to a snapshot of your niece's hamster and a video of the latest Kardashian contouring." The danger here - as with context collapse - is that "content collapse consolidates power over information, and conversation, into the hands of the small number of companies that own the platforms and write the algorithms.





 ). Repository currently only has a few code samples and no reusable abstractions that work across different implementations. That’s one of the big reasons why Dropbox is investing in Store—to solve this gap in the architecture model above.
). Repository currently only has a few code samples and no reusable abstractions that work across different implementations. That’s one of the big reasons why Dropbox is investing in Store—to solve this gap in the architecture model above.














 Note: All of the profile settings can be found
Note: All of the profile settings can be found 
 The tab row will now get larger when the window does!
The tab row will now get larger when the window does!