What Elon Musk got wrong about Twitter, journalists and VCs got wrong about FTX, and Peter Thiel got wrong about crypto and AI — and why I made many of the same mistakes along the way.
Listen to this Update in your podcast player
Two pieces of news dominated the tech industry last week: Elon Musk and Twitter, and Sam Bankman-Fried and FTX. Both showed how narratives can lead people astray. Another piece of news, though, flew under the radar: yet another development in AI, which is a reminder that the only narratives that last are rooted in product.
Twitter and the Wrong Narrative
I did give Elon Musk the benefit of the doubt.
Back in 2016 I wrote It’s a Tesla, marveling at the way Musk had built a brand that transcended far beyond a mere car company; what was remarkable about Musk’s approach is that said brand was a prerequisite to Tesla, in contrast to a company like Apple, the obvious analog as far as customer devotion goes. From 2021’s Mistakes and Memes:
This comparison works as far as it goes, but it doesn’t tell the entire story: after all, Apple’s brand was derived from decades building products, which had made it the most profitable company in the world. Tesla, meanwhile, always seemed to be weeks from going bankrupt, at least until it issued ever more stock, strengthening the conviction of Tesla skeptics and shorts. That, though, was the crazy thing: you would think that issuing stock would lead to Tesla’s stock price slumping; after all, existing shares were being diluted. Time after time, though, Tesla announcements about stock issuances would lead to the stock going up. It didn’t make any sense, at least if you thought about the stock as representing a company.
It turned out, though, that TSLA was itself a meme, one about a car company, but also sustainability, and most of all, about Elon Musk himself. Issuing more stock was not diluting existing shareholders; it was extending the opportunity to propagate the TSLA meme to that many more people, and while Musk’s haters multiplied, so did his fans. The Internet, after all, is about abundance, not scarcity. The end result is that instead of infrastructure leading to a movement, a movement, via the stock market, funded the building out of infrastructure.
TSLA is not at the level it was during the heights of the bull market, but Tesla is a real company, with real cars, and real profits; last quarter the electric car company made more money than Toyota (thanks in part to a special charge for Toyota; Toyota’s operating profit was still greater). SpaceX is a real company, with real rockets that land on real rafts, and while the company is not yet profitable, there is certainly a viable path to making money; the company’s impact on both humanity’s long-term potential and the U.S.’s national security is already profound.
Twitter, meanwhile, is a real product that has largely failed as company; I wrote earlier this year when Musk first made a bid:
Twitter has, over 19 different funding rounds (including pre-IPO, IPO, and post-IPO), raised $4.4 billion in funding; meanwhile the company has lost a cumulative $861 million in its lifetime as a public company (i.e. excluding pre-IPO losses). During that time the company has held 33 earnings calls; the company reported a profit in only 14 of them.
Given this financial performance it is kind of amazing that the company was valued at $30 billion the day before Musk’s investment was revealed; such is the value of Twitter’s social graph and its cultural impact: despite there being no evidence that Twitter can even be sustainably profitable, much less return billions of dollars to shareholders, hope springs eternal that the company is on the verge of unlocking its potential. At the same time, these three factors — Twitter’s financials, its social graph, and its cultural impact — get at why Musk’s offer to take Twitter private is so intriguing.
Stop right there: can you see where I opened the door for an error of omission as far as my analysis is concerned? Yes, Musk has successfully built two companies, and yes, Twitter is not a successful company; what followed in that Article, though, was my own vision of what Twitter might become. I should have taken the time to think more critically about Musk’s vision…which doesn’t appear to exist.
Oh sure, Musk and his coterie of advisors have narratives: bots are bad and blue checks are about status. And, to be fair, both are true as far as it goes. The problem with bots is self-explanatory, while those who actually need blue checks — brands, celebrities, and reliable news breakers — likely care about about them the least; the rest of us were happy to get our checkmark despite the fact there was no real risk of anyone impersonating us in any damaging way just because it made us feel special (speaking for myself anyway: I don’t much care about it now, but I was pretty delighted when I got it back in 2014 or so).
Of course Musk felt these problems more acutely than most: his high profile, active usage of Twitter, and popularity in crypto communities meant Musk tweets were the most likely place to encounter bots on the service; meanwhile Musk’s own grievances with journalists generally could, one imagine, engender a certain antipathy for “Bluechecks”, given that the easiest way to get one was to work for a media organization. The problem, though, is that Musk’s Twitter experience — thought to be an asset, including by yours truly — isn’t really relevant to the actual day-to-day reality of the site as experience by Twitter’s actual users.
And so we got last week’s verified disaster, where Musk could have his revenge on bluechecks by selling them to everyone, with the most eager buyers being those eager to impersonate brands, celebrities, and Musk himself. It was certainly funny, and I believe Musk that Twitter usage was off the charts, but it wasn’t a particularly prudent move for a company reliant on brand advertising in the middle of an economic slowdown.
This is not, to be clear, to criticize Musk for acting, or even for acting quickly: Twitter needed a kick in the pants (and, even had the company not been sold, was almost certainly in line for significant layoffs), and it’s understandable that mistakes will be made; the point of rapid iteration is to learn more quickly, which is to say that Twitter has, for years, not been learning very much at all. Rather, what was concerning about this mistake in particular is the degree to which it was so clearly rooted in Musk’s personal grievances, which (1) were knowable before he acted and (2) were not the biggest problems facing Twitter. That was knowable by me as an analyst, and I regret not pointing them out.
Indeed, these aren’t the only Musk narratives that have bothered me; here is his letter to advertisers posted on his first day on the job:
I wanted to reach out personally to share my motivation in acquiring Twitter. There has been much speculation about why I bought Twitter and what I think about advertising. Most of it has been wrong.
The reason I acquired Twitter is because it is important to the future of civilization to have a common digital town square, where a wide range of beliefs can be debated in a healthy manner, without resorting to violence. There is currently great danger that social media will splinter into far right wing and far left wing echo chambers that generate more hate and divide our society.
In the relentless pursuit of clicks, much of traditional media has fueled and catered to those polarized extremes, as they believe that is what brings in the money, but, in doing so, the opportunity for dialogue is lost.
This is why I bought Twitter. I didn’t do it because it would be easy. I didn’t do it to make more money. I did it to try to help humanity, whom I love. And I do so with humility, recognizing that failure in pursuing this goal, despite our best efforts, is a very real possibility.
That said, Twitter obviously cannnot become a free-for-all hellscape, where anything can be said with no consequences! In addition to adhering to the laws of the land, our platform must be warm and welcoming to all, where you can choose your desired experience according to your preferences, just as you can choose, for example, to see movies or play video games ranging from all ages to mature.
I also very much believe that advertising, when done right, can delight, entertain and inform you; it can show you a service or product or medical treatment that you never knew existed, but is right for you. For this to be true, it is essential to show Twitter users advertising that is as relevant as possible to their needs. Low relevancy ads are spam, but highly relevant ads are actually content!
Fundamentally, Twitter aspires to be the most respected advertising platform in the world that strengthens your brand and grows your enterprise. To everyone who has partnered with us, I thank you. Let us build something extraordinary together.
All of this sounds good, and on closer examination is mostly wrong. Obviously relevant ads are better, but Twitter’s problem is not just poor execution in terms of its ad product but also that it’s a terrible place for ads. I do agree that giving users more control is a better approach to content moderation, but the obsession with the doing-it-for-the-clicks narrative ignores the nichification of the media. And, when it comes to the good of humanity, I think the biggest learning from Twitter is that putting together people who disagree with each other is actually a terrible idea; yes, it is why Twitter will never be replicated, but also why it has likely been a net negative for society. The digital town square is the Internet broadly; Twitter is more akin to a digital cage match, perhaps best monetized on a pay-per-view basis.
In short, it seems clear that Musk has the wrong narrative, and that’s going to mean more mistakes. And, for my part, I should have noted that sooner.
FTX and the Diversionary Narrative
Eric Newcomer wrote on Twitter with regards to the FTX blow-up:
There are a few different ways to interpret Sam Bankman-Fried’s political activism:1
- That he believed in the causes he supported sincerely and made a mistake with his business.
- That he supported the causes cynically as a way to curry favor and hide his fraud.
- That he believed he was some sort of savior gripped with an ends-justify-the-means mindset that led him to believe fraud was actually the right course of action.
In the end, whichever explanation is true doesn’t really matter: the real world impact was that customers lost around $10 billion in assets, and counting. What is interesting is that all of the explanations are an outgrowth of the view that business ought to be about more than business: to simply want to make money is somehow wrong; business is only good insofar as it is dedicated to furthering goals that don’t have anything to do with the business in question.
To put it another way, there tends to be cynicism about the idea of changing the world by building a business; entrepreneurs are judged by whether their intentions beyond business are sufficiently large and politically correct. That, though, is precisely why Bankman-Fried was viewed with such credulousness: he had the “right” ambitions and the “right” politics, so of course he was running the “right” business; he wasn’t one of those “true believers” who simply wanted to get rich off of blockchains.
In the end, though, the person who arguably comes out of this disaster looking the best is Changpeng Zhao (CZ), the founder and CEO of Binance, and the person whose tweet started the run that revealed FTX’s insolvency.2 No one, as far as I know, holds up CZ as any sort of activist or political actor for anything outside of crypto; isn’t that better? Perhaps had Bankman-Fried done nothing but run Alameda Research and FTX there would have been more focus on his actual business; too many folks, though, including journalists and venture capitalists, were too busy looking at things everyone claims are important but which were, in the end, a diversion from massive fraud.
Crypto and the Theory Narrative
I never wrote about Bankman-Fried; for what it’s worth, I always found his narrative suspect (this isn’t a brag, as I will explain in a moment). More broadly, I never wrote much about crypto-currency based financial applications either, beyond this article which was mostly about Bitcoin,3 and this article that argued that digital currencies didn’t make sense in the physical world but had utility in a virtual one.4 This was mostly a matter of uncertainty: yes, many of the financial instruments on exchanges like FTX were modeled on products that were first created on Wall Street, but at the end of the day Wall Street is undergirded by actual companies building actual products (and even then, things can quite obviously go sideways). Crypto-currency financial applications were undergirded by electricity and collective belief, and nothing more, and yet so many smart people seemed on-board.
What I did write about was Technological Revolutions and the possibility that crypto was the birth of something new; why Aggregation Theory would apply to crypto not despite, but because, of its decentralization; and Internet 3.0 and the theory that political considerations would drive decentralization. That last Article was explicitly not about cryptocurrencies, but it certainly fit the general crypto narrative of decentralization being an important response to the increased centralization of the Web 2.0 era.
What was weird in retrospect is that the Internet 3.0 Article was written a week after the article about Aggregation Theory and OpenSea, where I wrote:
One of the reasons that crypto is so interesting, at least in a theoretical sense, is that it seems like a natural antidote to Aggregators; I’ve suggested as such. After all, Aggregators are a product of abundance; scarcity is the opposite. The OpenSea example, though, is a reminder that I have forgotten one of my own arguments about Aggregators: demand matters more than supply…What is striking is that the primary way that most users interact with Web 3 are via centralized companies like Coinbase and FTX on the exchange side, Discord for communication and community, and OpenSea for NFTs. It is also not a surprise: centralized companies deliver a better user experience, which encompasses everything from UI to security to at least knocking down the value of your stolen assets on your behalf; a better user experience leads to more users, which increases power over supply, further enhancing the user experience, in the virtuous cycle described by Aggregation Theory.
That Aggregation Theory applies to Web 3 is not some sort of condemnation of the idea; it is, perhaps, a challenge to the insistence that crypto is something fundamentally different than the web. That’s fine — as I wrote before the break, the Internet is already pretty great, and its full value is only just starting to be exploited. And, as I argued in The Great Bifurcation, the most likely outcome is that crypto provides a useful layer on what already exists, as opposed to replacing it.
Of the three Articles I listed, this one seems to be the most correct, and I think the reason is obvious: that was the only Article written about an actual product — OpenSea — while the other ones were about theory and narrative. When that narrative was likely wrong — that crypto is the foundation of a new technological revolution, for example — then the output that resulted was wrong, not unlike Musk’s wrong narrative leading to major mistakes at Twitter.
What I regret more, though, was keeping quiet about my uncertainty about what exactly all of these folks were creating these complex financial products out of: here I suffered from my own diversionary narrative, paying too much heed to the reputation and viewpoint of people certain that there was a there there, instead of being honest that while I could see the utility of a blockchain as a distributed-but-very-slow database, all of these financial instruments seemed to be based on, well, nothing.
The FTX case is not, technically speaking, about cryptocurrency utility; it is a pretty straight-forward case of fraud. Moreover, it was, as I noted in passing in that OpenSea article, a problem of centralization, as opposed to true DeFi. Such disclaimers do, though, have a whiff of “communism just hasn’t been done properly”: I already made the case that centralization is an inevitability at scale, and in terms of utility, that’s the entire problem. An entire financial ecosystem with a void in terms of underlying assets may not be fraud in a legal sense, but it sure seems fraudulent in terms of intrinsic value. I am disappointed in myself for not saying so before.
AI and the Product Narrative
Peter Thiel said in a 2018 debate with Reid Hoffman:
One axis that I am struck by is the centralization versus decentralization axis…for example, two of the areas of tech that people are very excited about in Silicon Valley today are crypto on the one hand and AI on the other. Even though I think these things are under-determined, I do think these two map in a way politically very tightly on this centralization-decentralization thing. Crypto is decentralizing, AI is centralizing, or if you want to frame in a more ideologically, you could say crypto is libertarian, and AI is communist…
AI is communist in the sense it’s about big data, it’s about big governments controlling all the data, knowing more about you than you know about yourself, so a bureaucrat in Moscow could in fact set the prices of potatoes in Leningrad and hold the whole system together. If you look at the Chinese Communist Party, it loves AI and it hates crypto, so it actually fits pretty closely on that level, and I think that’s a purely technological version of this debate. There probably are ways that AI could be libertarian and there are ways that crypto could be communist, but I think that’s harder to do.
This is a narrative that makes all kind of sense in theory; I just noted, though, that my crypto Article that holds up the best is based on a realized product, and my takeaway was the opposite: crypto in practice and at scale tends towards centralization. What has been an even bigger surprise, though, is the degree to which it is AI that appears to have the potential for far more decentralization than anyone thought. I wrote earlier this fall in The AI Unbundling:
This, by extension, hints at an even more surprising takeaway: the widespread assumption — including by yours truly — that AI is fundamentally centralizing may be mistaken. If not just data but clean data was presumed to be a prerequisite, then it seemed obvious that massively centralized platforms with the resources to both harvest and clean data — Google, Facebook, etc. — would have a big advantage. This, I would admit, was also a conclusion I was particularly susceptible to, given my focus on Aggregation Theory and its description of how the Internet, contrary to initial assumptions, leads to centralization.
The initial roll-out of large language models seemed to confirm this point of view: the two most prominent large language models have come from OpenAI and Google; while both describe how their text (GPT and GLaM, respectively) and image (DALL-E and Imagen, respectively) generation models work, you either access them through OpenAI’s controlled API, or in the case of Google don’t access them at all. But then came this summer’s unveiling of the aforementioned Midjourney, which is free to anyone via its Discord bot. An even bigger surprise was the release of Stable Diffusion, which is not only free, but also open source — and the resultant models can be run on your own computer…
What is important to note, though, is the direction of each project’s path, not where they are in the journey. To the extent that large language models (and I should note that while I’m focusing on image generation, there are a whole host of companies working on text output as well) are dependent not on carefully curated data, but rather on the Internet itself, is the extent to which AI will be democratized, for better or worse.
Just as the theory of crypto was decentralization but the product manifestation tended towards centralization, the theory of AI was centralization but a huge amount of the product excitement over the last few months has been decentralized and open source. This does, in retrospect, make sense: the malleability of software, combined with the free corpus of data that is the Internet, is much more accessible and flexible than blockchains that require network effects to be valuable, and where a single coding error results in the loss of money.
The relevance to this Article and introspection, though, is that this realization about AI is rooted in a product-based narrative, not theory. To that end, the third piece of news that happened last week was the release of Midjourney V4; the jump in quality and coherence is remarkable, even if the Midjourney aesthetic that was a hallmark of V3 is less distinct. Here is the image I used in The AI Unbundling, and a new version made with V4:

One of the things I found striking about my interview with MidJourney founder and CEO David Holz was how Midjourney came out of a process of exploration and uncertainty:
I had this goal, which was we needed to somehow create a more imaginative world. I mean, one of the biggest risks in the world I think is a collapse in belief, a belief in ourselves, a belief in the future. And part of that I think comes from a lack of imagination, a lack of imagination of what we can be, lack of imagination of what the future can be. And so this imagination thing I think is an important pillar of something that we need in the world. And I was thinking about this and I saw this, I’m like, “I can turn this into a force that can expand the imagination of the human species.” It was what we put on our company thing now. And that felt realistic. So that was really exciting.
Well, your prompt is, “/Imagine”, which is perfect.
So that was kind of the vision. But I mean, there is a lot of stuff we didn’t know. We didn’t know, how do people interact with this? What do they actually want out of it? What is the social thing? What is that? And there’s a lot of things. What are the mechanisms? What are the interfaces? What are the components that you build this experiences through? And so we kind of just have to go into that without too many opinions and just try things. And I kind of used a lot of lessons from Leap here, which was that instead of trying to go in and design a whole experience out of nothing, presupposing that you can somehow see 10 steps into the future, just make a bunch of things and see what’s cool and what people like. And then take a few of those and put them together.
It’s amazing how you try 10 things and you find the three coolest pieces, and you put them together, it feels like a lot more than three things. It kind of multiplies out in complexity and detail and it feels like it has depth, even though it doesn’t seem like a lot. And so yeah, there’s something magic about finding three cool things and then starting to build a product out of that.
In the end, the best way of knowing is starting by consciously not-knowing. Narratives are tempting but too often they are wrong, a diversion, or based on theory without any tether to reality. Narratives that are right, on the other hand, follow from products, which means that if you want to control the narrative in the long run, you have to build the product first, whether that be a software product, a publication, or a company.
That does leave open the question of Musk, and the way he seemed to meme Tesla into existence, while building a rocket ship on the side. I suspect the distinction is that both companies are rooted in the physical world: physics has a wonderful grounding effect on the most fantastical of narratives. Digital services like Twitter, though, built as they are on infinitely malleable software, are ultimately about people and how they interact with each other. The paradox is that this makes narratives that much more alluring, even — especially! — if they are wrong.
Beyond the conspiracy theories that he was actually some sort of secret agent sent to destroy crypto, a close cousin of the conspiracy theory that Musk’s goal is to actually destroy Twitter; I mean, you can make a case for both! ↩
Past performance is no guarantee of future results! ↩
Given Bitcoin’s performance in a high inflationary environment the argument that it is a legitimate store of value looks quite poor ↩
TBD ↩
Add to your podcast player: Stratechery | Sharp Tech | Dithering | Sharp China | GOAT
Subscription Information
Member: Roland Tanglao
Email: rolandt@gmail.com
Manage your account










 index
index-P(B vert D)=A/{A+B}-C/{C+D}") (sorry about the double,
(sorry about the double,  , rather than single, vertical lines).
, rather than single, vertical lines).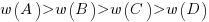 , e.g., that subjects have a
, e.g., that subjects have a 

















