
Feeling cute, idk, might become Vice President later. pic.twitter.com/bfPNb4H8f7


I’m just back from the dentist right now, so here’s a story about another time going to the dentist and an epiphany I had while I was in the chair.
I had a whole bunch of dental work a few years ago.
Three sessions in the chair, each 3 or 4 hours long. My dentist was from Iraq and he had a sideline representing the new government installed by the Allies so he would crop up in the media from time to time and occasionally disappear for a few months to Baghdad to lend a hand. He was also a neurolinguistic programming adept, so I enjoyed quizzing him about that, and his professional claim was that he employed hypnosis to take the sting out of dental work, using a process of visualisation to descend a series of steps into a beautiful garden of lakes and trees, etc, though actually I think he just had a heavy hand on the nitrous.
I don’t know if you’ve ever had nitrous oxide but it’s mildly euphoric and very relaxing. Sensation is reduced and your body feels heavy, floating somehow. Together with the headphones (the aforementioned hypnosis playing on a tape) and my eyes closed, I would pretty quickly descend back inside myself, and spend the hours in a semi-observant, semi-dreaming state.
So that was really the story of the first session, inhabiting this odd kind of dentist dream, idly exploring my altered mental state, dissociated, yet able to think and reason.
What I noticed was that my mind felt smaller somehow, like a cat’s brain (I remember thinking), but also closer to the fabric of reality itself. Without my preconceptions getting in the way, stripped back to my animal brain, I was able to perceive more clearly, and therefore had access to deeper truths about myself and the cosmos – both the same thing really.
And just before I resurfaced, I discovered a huge truth, a startling revelation.
Not that I could remember it.
All I could recall was its import.
So in the second of my three sessions, I went back to re-discover whatever it was.
The way I ended up thinking about the nitrous state wasn’t that it wasn’t that I was reduced, like this simplified mind idea I had, or transcendent even, a layer above or below my regular mind somehow.
Rather it was as if my mind had rotated about itself into a new configuration so that all the sensory apparatus was now pointing inwards at itself, the full power of sense-making lensed inward, and by looking into my own mind and contemplating its form, I could then make deductions from its shape about the nature of the cosmos outside.
What’s more, I was able to maintain ideas and follow trains of thought, in this configuration, that wouldn’t be possible or sustainable in the other, regular configuration, the configuration of mundane reality. Both states were valid, independently, but they couldn’t exist simultaneously.
But what was interesting was that there was an isomorphism between ideas in the two configurations. So while I was able to run impossible chains of thought in the nitrous configuration that I couldn’t run in the regular configuration, the destination concepts that I reached could be transferred between configurations.
That was why it was possible to reach some kind of epiphany. In mundane reality, such a concept would be inaccessible. By in the altered configuration, I could reach this new idea, and then, having reached it, bring it back.
My mental model for this was two worlds, two bubbles, linked with a tunnel.
One bubble, large, outward facing and well-lit: the regular configuration of mundane reality. The second bubble, dark, inward facing, contemplative, possibly small but possibly infinite: the altered nitrous configuration. I inhabit either one configuration or the other. Between them, a narrow tunnel, along which my consciousness moves as it transforms from one to the other.
Did I re-discover the revelation? Yes. I know that I did. I know that it was important. Did I remember what it was?
That second session, no, I did not.
When I came out of the dentist, all I could remember was the image of these two bubbles for the two psychic configurations, and the tunnel.
And mainly, this idea: you can bring one thing through the tunnel.
What I had figured out was that when my mind moved between the configurations, what I thought was urgent and desirable in one configuration wouldn’t necessarily translate to the other.
In particular, what felt like a rare revelation about the nature of self and the cosmos, etc, from the perspective of the regular configuration was, yes, important when viewed from the nitrous configuration, but actually it felt pretty natural and commonsensical there too, and so, in that altered state, I felt no necessity to work hard to remember it.
But what I also figured out what that, as I moved between these two worlds, if I concentrated on holding one thought in mind, I could deliberately carry it through the tunnel and it would be the seed for my thoughts on the other side.
So what I decided to do, ahead of the third session in the dentist chair, was to carry this vow with me:
When I encountered the revelation, I must carry it back, no matter what.
I would entered the altered state configuration, and hand this vow to altered state me.
It didn’t work entirely as planned.
The third session began. They gave me the gas, I went through the tunnel repeating to myself this vow to re-discover the big truth and bring it back, I entered the altered state, and so on, and as before I had this same revelation - this epiphany - but this time I also remembered my goal to bring it back with me to the surface.
But while the plan was to carry it through the tunnel, back to everyday reality, I realised that this idea, discovered in the alternate configuration, was too large to come back with me that way.
Instead the only way was to burst between the realms of consciousness by force and bring the new truth into the light via a new route.
Which is what I did, and it must have been disconcerting to see.
My mouth was being held open. There were a lot of broken teeth at that point, it was right in the middle, and they were cutting back my gums too, so there was a fair amount of blood I believe, and a couple of suction tubes in my mouth.
Coming up was like swimming hard towards the sun from deep under the ocean, and breaking the through the water’s surface took huge effort.
Forcing my eyes open was a slow battle.
Eventually I triumphed, and the dentist and two nurses in the room were there as I managed to open my eyes, halfway through that day’s procedure, and gestured that I needed to speak – I remember knowing that was my chance to vocalise and concretise my epiphany before it evaporated in the light. So they took the tubes out of my mouth and the clamps off my lips, and moved the equipment away, and pulled the cotton wool out, and all of that stuff, and gestured to let me know I could speak, and listened as I was able to get out the words that had taken me 10 hours over three weeks of deep internal exploration, and strategic planning let’s not forget, to bring back from the depths of altered psychic states to our everyday reality; and I said these words, and no words will ever be truer than the truth contained in these words at that moment, and I said this: Can I Have More Nitrous Please.
And they laughed and nodded and turned the nitrous oxide up, and put the tubes back in my mouth, and I closed my eyes, and they carried on with their work, and I lay there happy.
I guess the lesson is that what is vitally important in one state of mind is not necessarily vital or important in another.
Truth is contextual?
Something like that.
Nitrous is great? Or at least it was at that particular time for that particular me. That’s another lesson I suppose.
They offered me nitrous today and I declined. Instead I was amazed when they scanned my teeth with a handheld scanner that automatically stitched the images into a 3D model, and even more amazed that it took only 7 minutes to print the new crown. Colouring and firing the crown took 15 minutes. I was in and out in an hour and a half, including having the old crown knocked out, watching the dentist adjust the 3D geometry on the big screen next to the chair, and having a nice chat about photogrammetry and also the history of milling machines. So there we go.
A couple of days ago, I noticed a new release from the Raspberry Pi folks, a "$70 computer" bundling a Raspberry Pi 4 inside a keyboard, with a mouse, power supply and HDMI cable all as part of the under a hundred quid "personal computer kit". Just add screen and network connection (ethernet cable, as well as screen, NOT provided).
Mine arrived today:

So… over the last few months, I’ve been working on some revised material for a level 1 course. The practical computing environment, which is to be made available to students any time now for scheduled use from mid-December, is being shipped via a Docker image. Unlike the TM351 Docker environment (repo), which is just the computing environment, the TM129 Docker container (repo) also contains the instructional activity notebooks.
One of the issues with providing materials this way is that students need a computer that can run Docker. Laptops and desktop computers running Windows or MacOS are fine, but if you have a tablet, cheap Chromebook, or just a phone, you’re stuck. Whilst the software shipped in the Docker image is all accessed through a browser, you still need a "proper" computer to run the server…
For a long time, several of us have muttered about the possibility of distributing software to students that can run on a Raspberry Pi, shipping the software on a custom programmed SD card. This is fine, but there are several hurdles to overcome, and the target user (eg someone whose only computer is a phone or a tablet) is likely to be the least confident sort of computer user at a "system" level. For example, to use the Raspberry Pi from a standing start, you really need access to:
You might also try to get your Raspberry Pi to speak to you if you can connect it to your local network, for example to tell you what IP address it’s on, but then you need an audio output device (the HDMI’d screen may do it, or you need a headset/speaker/set of earphones with an appropriate connector).
Considering these hurdles, the new RPi-containing keyboard, makes it easier to "just get started", particularly if purchased as part of the Personal Computer Kit: all you need is a screen if the SD card has all the software you need.
So I’m wondering again if this is a bit closer to the sort of thing we might give to students when they sign up with the OU: a branded RPi keyboard, with a custom SD card for each module or perhaps a single custom SD card and then a branded USB memory stick with additional software applications required for each module.
All the student needs to provide is a screen. And if we can ship a screensharing or collaborative editing environment (think: Google docs collaborative editing) as part of the software environment, then if a student can connect their phone or tablet to a server running from their keyboard, we could even get away without a phone.
The main challenges are still setting up a connection to a screen or setting up a network connection to a device with a screen.
> Notes from setting up my RPi 4000: don’t admit to having a black border on your screen: I did and lost the the desktop upper toolbar off the top of my TV and had to dive into a config file to reset it, eg as per instructions here: run sudo nano /boot/config.txt then comment out line: #disable_overscan=1
As far as going software environments to work with the RPi, I had a quick poke around and there are several possible tools that could help.
One approach I am keen on is using Docker containers to distribute images, particularly if we can build images for different platfroms from the same build scripts.
Installing Docker on the RPi looks simple enough, eg this post suggests the following is enough:
sudo apt update -y curl -fsSL get.docker.com -o get-docker.sh && sh get-docker.sh
although if that doesn’t work, a more complete recipe can be found here: Installing Docker on the Raspberry Pi .
A quick look for arm32 images on DockerHub turns up a few handy looking images, particulalry if you work with a docker-compose architecture to wire different containers together to provide the student computing environment, and there are examples out there of building Jupyter server RPi Docker images from these base containers (that repo includes some prevbuilt arm python package wheels; other pre-built packages can be found on piwheels.org). See also: jupyter-lab-docker-rpi (h/t @dpmcdade) for a Docker container route and kleinee/jns for a desktop install route.
The Docker buildx cross-builder offers another route. This is available via Docker Desktop if uou enable experimental CLI features and should support cross-building of images targeted to the RPi Arm processor, as described here.
Alternatively, it looks like there is at least one possible Github Action out there that will build an Arm7 targeted image and push it to a Docker image hub? (I’m not sure if the official Docker Github Action supports cross-builds?)
There’s also a Github Action for building pip wheels, but I’m not convinced this will build for RPi/Arm too? This repo — Ben-Faessler/Python3-Wheels — may be more informative?
For building full SD card images, this Dockerised pi-builder should do the trick?
So, for my to do list, I think I’ll have a go at seeing whether I can build an RPi runnable docker-compose version of the TM351 environment (partitioning the services into separate containers that can then be composed back together has been on my to do list for some time, so this way I can explore two things at once…) and also have a go at building an RPi Docker image for the TM129 software. The TM129 release might also be interesting to try in the context of an SD Card image with the software installed on the desktop and, following the suggestion of a couple f colleagues, accessed via an xfce4 desktop in kiosk mode perhaps via a minimal o/s such as DietPi.
PS also wonders – anyone know of a jupyter-rpi-repodocker that will do the repo2docker thing on Raspberry Pi platforms…?!
I never understood the desire to launch a new community on a top-tier platform.
You invest hundreds of thousands of dollars and have to wait months to get started.
For a massive customer support community with clear demand, it might make sense. You’re simply redirecting traffic from one place to another.
For almost any other type of community, it simply doesn’t. It’s too slow, too risky, and too costly to make changes as you go.
Start with a platform that costs less than $5k to get started. Test the waters first.
Check your concept draws interested members. Make sure you can engage them and keep them engaged. Build up some momentum and get a sense of what features members do and don’t use. Use this time to learn everything you can about what does and doesn’t work.
When you’re ready and feel the clear need, move on to something that offers features your members are screaming for.
Wednesday it was 18 years ago that I first posted in this space. The pace of writing has varied over the years, obviously intensively at the start, and in the past 3 years I have been blogging much more frequently again (with a correlated drop off in my Facebook activity to 0), more than at the start even.
This year is of course different, with most of the people I know globally living much more hyper local lives due to pandemic lockdowns. This past year of blogging turned out more introspective as a consequence. In the past few years I took the anniversary of this blog to reflect on how to raise awareness for grasping your own agency and autonomy online, and reading last year‘s it’s so full of activity from our current perspective, organising events, going places. None of that was possible really this year. I returned home from the French Alps late February and since then haven’t seen much more than my work space at home, and the changing of the seasons in the park around the corner, punctuated only with a half dozen brief visits to Amsterdam and two or three to Utrecht in the past 8 months. A habit of travel has morphed into having the world expedited to our doorstep, in cardboard packaging in the back of delivery vans.
Likewise my ongoing efforts and thinking concerning networked agency, distributed digital transformation and ethics as a practice has had a more inward looking character.
Early in the year we completed the shift of my company’s internal systems to self-hosted Nextcloud and Rocket.chat. When the pandemic started we added our own Jitsi server for video conferencing, although in practice with larger groups we use Zoom mostly, next to the systems our clients rolled out (MS Teams mostly). Similarly I will soon have completed the move of the Dutch Creative Commons chapter, where I’m a board member, to Nextcloud as well. That way the tools we use align better with our stated mission and values.
I spent considerable time renovating my PKM system, and the tools supporting it, with Obsidian the biggest change in tooling underneath that system since a decade or so. It means I am now finally getting away from using Evernote. Although I haven’t figured out yet what to do, if anything, with what I stored in Evernote in the 10 years I’ve been using it daily.
This spring I left Facebook and Whatsapp completely (I’ve never used Instagram), not wanting to have anything to do anymore with the Facebook company. I departed from my original FB account 3 years ago, which led to me blogging much more again, but created a new account after a while to maintain a link to some. That new account slowly but steadily crept back into the ‘dull’ moments of the day, and when the pandemic increased the noise and hysterics levels aided by FB’s algorithmic amplification outrage machine, I decided enough was enough. A 2.5 year process! It more or less shows how high the, mostly misplaced, sense of cost of leaving can be. And it was also surprising how some take such a step as an act of personal rejection.
I also see my Twitter usage reducing, in favour of interacting more on my personal Mastodon instance, through e-mail (yay for e-mail) and LinkedIn (where your interaction is tied to your professional reputation so much less of a ragefest). Even though I never dip into the actual Twitter stream, as I only check Twitter using Tweetdeck to keep track of specific topics, groups and interests. This summer I from close-up saw how the trolls came for a colleague that moved to a position in national media. Even if the trolling and vitriol was perhaps mild by e.g. US standards, it made me realise again how there was an ocean of toxic interaction just a single click away from where I usually am on Twitter.
On the IndieWeb side of things, I of course did not get to organise new IndieWebCamps like last year in Amsterdam and Utrecht. I’ve thought about doing some online events, but my energy flowed elsewhere. I’ve looked more inwardly here as well. I’ve been bringing my presentation slides ‘home’, closing my Slideshare account, and removing my company from Scribd as well. This is a still ongoing process. The solution is now clear and functional, but moving over the few hundred documents is something that will take a bit of time. I don’t want to move over the bulk of 14 years of shared slide decks, but want to curate the collection down to those that are relevant still, and those that were published in my blog posts at the time.
I am tinkering with a version of this site that isn’t ‘stream’ (blogposts in reverse chronological order), and isn’t predominantly ‘garden’ (wiki-style pseudo-static content), but a mix of it. I’ve been treating different types of content here differently for some time already. A lot never is shown on the front page. Some posts are never distributed through RSS, while some others are only distributed through RSS and unlisted on the site (my week notes for instance). Now I am working on removing what is so clearly a weblog interface from the front page. The content will still be there of course, the RSS feeds will keep feeding, all the URLs will keep working, but the front of this site I think should morph into something that is much more a mix of daily changes and highlighted fixtures. Reflecting my current spectrum of interests more broadly, and providing a sense of exploration, as well as the daily observations and occurrences.
Making such a change to the site is also to introduce a bit of friction, of a need to spend time to be able to get to know the perspectives I share here if you newly arrive here. I think that there should be increased friction with increased social distance. You’ll know me better if you spend time here. The Twitter trolling example above is a case of unwanted assymmetry in my eyes: it’s incredibly easy for total strangers to lob emotion-grenades at someone, low cost for them, potentially high-impact for the receiver. Getting within ‘striking distance’ of someone should carry a cost and risk for the other party as well. A mutuality, to phrase it more constructively.
Here’s to another year of blogging and such mutuality. My feed reader brings me daily input from so many of you, around the world, and I’m looking forward to many more distributed conversations based on that. Thank you for reading!
Brilliant application of git scraping by Alex Gaynor and a growing team of contributors. Takes a JSON snapshot of the NYT's latest election poll figures every five minutes, then runs a Python script to iterate through the history and build an HTML page showing the trends, including what percentage of the remaining votes each candidate needs to win each state. This is the perfect case study in why it can be useful to take a "snapshot if the world right now" data source and turn it into a git revision history over time.
Today I read a Guardian article about the iconic bookshop Shakespeare and Company, across the Seine from the Notre Dame in Paris. It made me remember our own trips to Paris, and Elmine browsing the mentioned bookstore. I thought about having a box of nice books sent to our home, as a souvenir now that we can’t visit other cities for inspiration ourselves. The website was clearly not equipped to deal with the Guardian readership taking the article as a cue to order something the same way I did, so it took all day to get through and place an order. (Peter, they also suggested ‘Ma vie à Paris‘ en francais, not in English though)

The Shakespeare and Company bookstore, photo by Zoetnet, license CC BY
While trying to order I thought about how there are other cities we love to visit. Could I order a box of interesting and beautiful things from several cities, and present them as gifts to E to travel in our mind? Cities such as Copenhagen. Maybe I thought, I can have something shipped from a Danish ceramics artisan we appreciate, Inge Vincents. We have several things she made in our home, mementos from different trips.

Inge Vincents’ store on Jægersborggade, when we visited in 2012
But I cannot order with her, because Inge Vincents uses Instagram as her only sales channel online. Instagram doesn’t allow me to scroll past the first few images without an account, let alone interact with the poster to request a quote. It’s something E and I have seen with a wider variety of artisans. Do they realise their shops are within walled gardens where not all are able to visit? How many missed sales will they never notice?


You have seen it in Vancouver~long lines of vehicles in the drive-in lanes at McDonald’s in Kerrisdale when there’s no one inside the quick serve restaurant. You may have wondered why there were so many people idling in a queue, and just assumed it was an anomaly. But apparently it is not, and as News 1130’s Monica Gul reports Dr. Sylvain Charlebois who is the director of Agri-Food Analytics Lab at Dalhousie University is studying this phenomena. Dr. Charlebois has called it “the fake commute”.
It does make sense in that Tim Hortons and McDonalds have been reporting a doubling or tripling of business at some drive-in locations, and the locations that expected a 30 percent drop in revenue quickly gained ground. Sadly the drive-in quick service chains have been able to adapt well to the pandemic and will emerge with healthy profit margins unlike the independent retailers and restaurants that are not set up for quick serve window accessed meals.
There is a psychological reason that people are leaving home to pick up a coffee whether by foot, bike or vehicle. As Dr. Charlebois notes, people don’t just get up in the morning and sit to work at the home office station, and leaving to get coffee elsewhere creates a regularity and a “commute” to the home office.
“Which means that even though people aren’t necessarily going to work, physically, or going to some place, people are still basically driving around or busing around to get their morning fix…A lot of people are struggling to physically distance themselves from their work.
If they’re working from home, it’s very difficult to create that physical division between your personal life and professional life.”
Dr. Charlebois thinks this trend will intensify in the winter months as people set up a regularity and pattern to their work day, and that includes a cup of coffee from somewhere else than the home office.
You can hear some of the research in this YouTube video belo

Several years ago when I was visiting family in Prince Edward Island I saw a Vancouver postcard in a rummage sale. It seemed completely out of context and it was encased in a plastic envelope and it was expensive.
I bought it and held onto it, without doing any research.
The postcard had a surprising subject~there is a house with a craftsman styled front door, ionic columns, stained glass upper windows and a family posed in front of it.
The family is dressed in Edwardian dress, with the mother holding a hand muffler and wearing a scarf. The father has a hat and wears a long suit with a stiff starched shirt collar. The child is in a sailor suit, the type that was very popular in the 1910 to 1920 period. At the family’s feet is a dog that looks like a brittany spaniel.

The card was a custom one, created for this family, showing off their prized asset, their house. And on the back of the card, there was a handwritten inscription:
“2825 Clark Drive E. Vancouver B.C. A glimpse of us and our new home with units. Kind love and best wishes for a very happy Xmas and New Year to you all. Edie, Arthur, Willie”

When I started to research the house I feared that it would be demolished. But it wasn’t. It is still there, near 13th Avenue on the west side of Clark Drive.
It has lost its elegant entrance way and fancy front columns, and the entrance way has been reconfigured to access from the side instead of the front. The fancy windows and stained glass are gone but the window placement and the bay on the north side of the building still exists. The shingled siding is now covered with pink stucco. From Clark Drive a shrubby tree hides the house from the street.


The view from the back of the property shows the bones of the old original house. The bay on the house is evident, and the dormer window on the house adjacent to 2825 Clark Drive can also be seen in both the old and the modern photo.

I did not expect to find the house still existing, and then decided to do a deeper dive into who lived there and to see if I could find Edie, Arthur and Willie who had produced the postcard and so proudly posed with their house. I looked through Newspapers.com and also the Vancouver Archives.
In 1913 the house’s occupants offered a Metzler piano for sale for $250.00 in the Province, noting that this was a “real deal”. Today that $250 for a British made piano is equivalent to over $6,000. That same year there is an advertisement also in the Province offering a room for one or two with an English family “three minutes from cars”


I found Mrs. Millichip who lived in the house in July 1917 and was part of the Western Star Trench and Hospital Club. There were no regular meetings of the club that summer but if people wanted to produce socks for the war effort, they could obtain yarn from Mrs. Millichip of 2825 Clark Drive.

Good works were still being done at the house in 1947 wen Mrs. B. Tolman held a homemaking meeting as part of the Women of the Moose chapter. Set up originally in 1913,the women’s division of the Royal Order of the Moose was formed. This group still does social, organizational and service work in the community.

I have still not found out who the people in the postcard, Edie, Arthur and Willie are. It would be great to find out their last name and be able to return this postcard to their descendants. If you know who this family is or can provide any more information on this remarkable house, please let me know.

The story here is that "a series of tweets by one Miami University student that were critical of a proctoring software company have been hidden by Twitter after the company filed a copyright takedown notice." Observers, such as the Electronic Frontier Foundation, argue that this is a "textbook example" of fair use, and that therefore the takedowns are inappropriate. Twitter later released his tweets after finding Proctorio’s takedown notice to be “incomplete.” Here is the restored tweet thread. The code snippets have not been restored yet to Pastebin, however. While you're reading, consider whether a company employed to enforce ethics has itself a duty to be ethical.
Web: [Direct Link] [This Post]
iOS 14.2 changes the HomePod game. If you have a HomePod, or better two HomePods, in the same room as an Apple TV, then iOS offers to create a Home Cinema setup. They all become part of only one AirPlay device for this room. If you play music, the TV stays off. If you watch TV, Apple TV sends the sound to the HomePods without changing the configuration. The TV screen gets turned on and off over the HDMI connection.
This may be replacing my Sonos TV setup.
This article is about combining language models in AI, like GPT-3, with computer vision, a process called 'vokenization'. The idea is that it will enable a system like GPT-3 to distinguish between the linguistic expression 'black sheep' and the visual recognition of black sheep and white sheep. This has been triued before; the process involves combining images with captions and presenting both to the AI. But captions are hard to get right, and so the training sets are (comparatively) tiny. Vokenization is the approach used to get around this problem. Instead of starting with images and manually adding captions, they start with language and automatically associate images using image recognition. Why would we do this? "If we want to build robotic assistants, for example, they need computer vision to navigate the world and language to communicate about it to humans.
Web: [Direct Link] [This Post]Natalie and I decided to escape San Francisco for election week, and have been holed up in Fort Bragg on the Northern California coast. I've mostly been on vacation, but I did find time to make some significant changes to sqlite-utils. Plus notes on an exciting Git scraping project.
I practice semantic versioning with sqlite-utils, which means it only gets a major version bump if I break backwards compatibility in some way.
My goal is to avoid breaking backwards compatibility as much as possible, and I was proud to have made it all the way to version 2.23 representing 23 new feature releases since the 2.0 release without breaking any documented features!
Sadly this run has come to an end: I realized that the table.search() method was poorly designed, and I also needed to grab back the -c command-line option (a shortcut for --csv output) to be used for another purpose.
The chances that either of these changes will break anyone are pretty small, but semantic versioning dictates a major version bump so here we are.
I shipped a 3.0 alpha today, which should hopefully become a stable release very shortly (milestone here).
The big new feature is sqlite-utils search - a command-line tool for executing searches against a full-text search enabled table:
$ sqlite-utils search 24ways-fts4.db articles maps -c title
[{"rowid": 163, "title": "Get To Grips with Slippy Maps", "rank": -10.028754920576421},
{"rowid": 220, "title": "Finding Your Way with Static Maps", "rank": -9.952534352591737},
{"rowid": 27, "title": "Putting Design on the Map", "rank": -5.667327088267961},
{"rowid": 168, "title": "Unobtrusively Mapping Microformats with jQuery", "rank": -4.662224207228984},
Here's full documentation for the new command.
Notably, this command works against both FTS4 and FTS5 tables in SQLite - despite FTS4 not shipping with a built-in ranking function. I'm using my sqlite-fts4 package for this, which I described back in January 2019 in Exploring search relevance algorithms with SQLite.
It's not quite over yet but the end is in sight, and one of the best tools to track the late arriving vote counts is this Election 2020 results site built by Alex Gaynor and a growing cohort of contributors.
The site is a beautiful example of Git scraping in action, and I'm thrilled that it links to my article in the README!
Take a look at the repo to see how it works. Short version: this GitHub Action workflow grabs the latest snapshot of this undocumented New York Times JSON API once every five minutes and commits it to the repository. It then runs this Python script which iterates through the Git history and generates an HTML summary showing the different batches of new votes that were reported and their impact on the overall race.
The resulting report is published to GitHub pages - resulting in a site that can handle a great deal of traffic and is updated entirely by code running in scheduled actions.
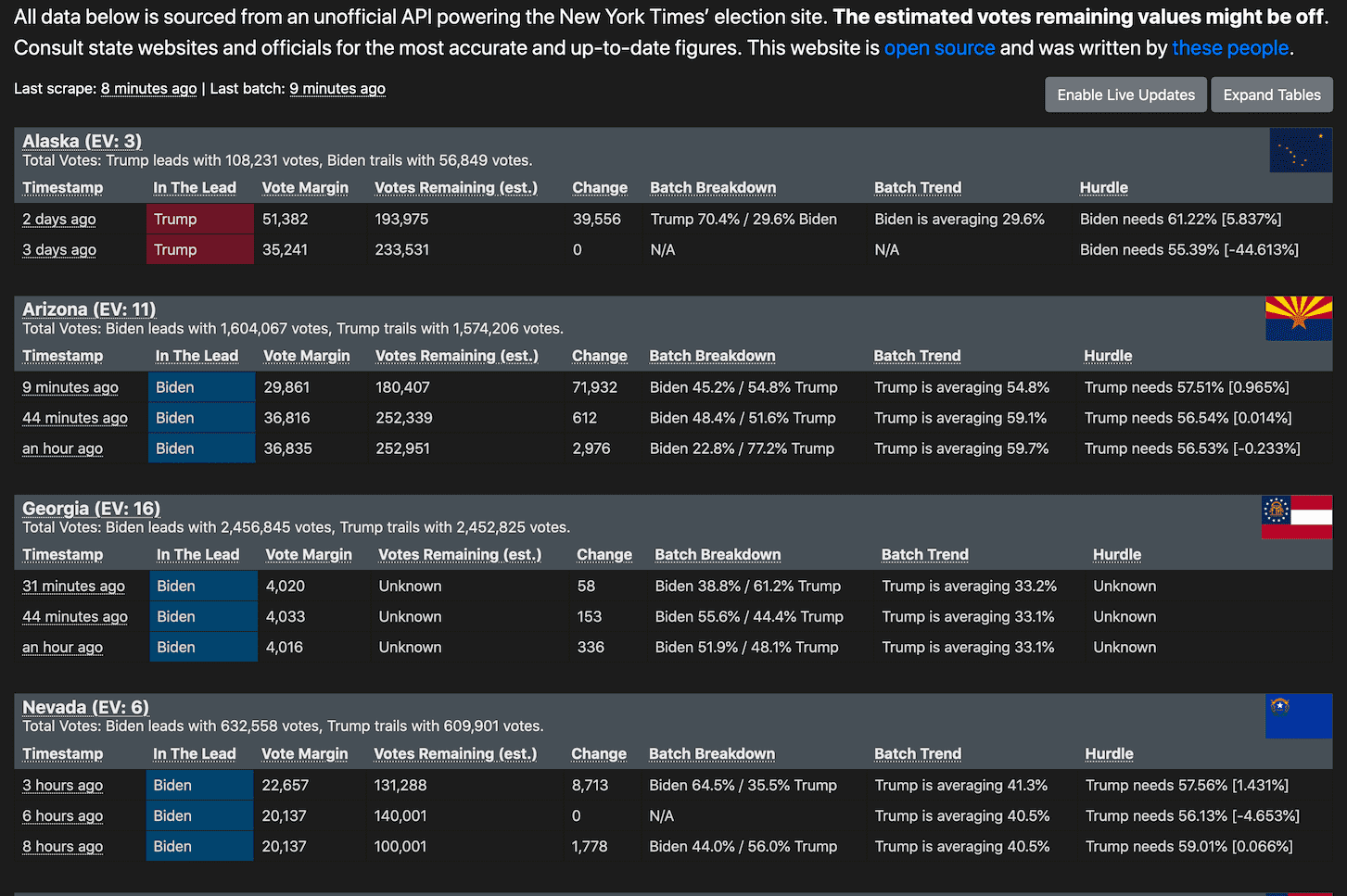
This is a perfect use-case for Git scraping: it takes a JSON endpoint that represents the current state of the world and turns it into a sequence of historic snapshots, then uses those snapshots to build a unique and useful new source of information to help people understand what's going on.
With love and respect to my friends in the US who are celebrating today, I’m not there. Yes, it’s wonderful that Donald Trump will no longer be in the White House, though I suspect the process of extricating him from the Oval Office may require more legal wrangling than many of us expect. Yes, a political world without Bill Barr and Stephen Miller in it is a much improved world.
But the 2020 election has laid bare the ugly situation the US is currently facing. I don’t just mean from the perspective of left-wing politics. Zeynep Tufekci is right that the Republicans won everything but the presidency and are setting themselves up for a more dangerous candidate in 2024. What worries me more is the ways in which American institutions are failing and leading us to an increasing state of mistrust and doubt.
Mistrust was already a key theme in Trump’s presidency – he ran against a Washington “swamp”, an allegedly corrupt system he promised his followers that he alone could fix. In taking the office, he corrupted large swaths of the executive to the point where it’s hard to have confidence in its continued functioning – reassembling the State Department, for instance, is likely to be a significant task under Biden. His packing of the federal and supreme court mean those of us on the left will be suspicious of those institutions for decades to come. In other words, Trump was elected because many on the right mistrust government, and his governance led many on the left to mistrust government.
This election drives that wedge in even deeper. Some fraction of the 69 million voters who chose Donald Trump over Joe Biden are likely to see Biden’s presidency as illegitimate and stolen. While Murdoch-controlled media may be abandoning Trump and Republican politicians may be seeking the chance to leave a sinking ship, Trump’s airing of grievances in White House press conferences combined with far-right campaigns to build the “Stop the Steal” narrative will give some percentage of Trump’s supporters the excuse to distrust any actions Biden takes on behalf of the nation.
The increased mistrust shouldn’t just be on the right. On the left, we have recently learned that political polling doesn’t work nearly as well as we thought it did, and that many of our media outlets remain surprisingly out of touch with the concerns and enthusiasms of Republican voters. The belief that America’s ongoing demographic shift to a “majority minority” nation would lead to eternal Democratic dominance has been shaken by substantial numbers of voters of color supporting Trump. Amongst any happiness we feel at retaking the White House should be a deep sense of uncertainty: what do we actually know about this nation we’re living in? What do we know about what our neighbors think, feel and believe?
And there’s a deeper worry. The US has been polarized for as long as I’ve participated in our political system. But the gaps today seem almost impossible to bridge. Beginning with Fox News, but profoundly amplified by the internet, there’s now a rightwing media ecosystem that often feels like a parallel universe in which not only interpretations, but fundamental facts are incompatible. As Roxanne Gay points out in a powerful essay, we are living in two countries, one wrestling with racism and bigotry, one unwilling to lose the privileges of a history of white supremacy and patriarchy.
How can this pair of nations be governed? How can they even come to understand one another?
The most hopeful I have been during this election week was during a discussion last night over Zoom with members of my new academic home, the School of Public Policy at the University of Massachusetts at Amherst. Our department chair, Alasdair Roberts, is a former Canadian politician as well as a public policy scholar, and a brief history lesson from him on Canadian politics gave me more hope than anything I’ve heard from a chorus of voices in American media.
Canadian politics is boring, Roberts acknowledged, but it took a lot of work to make it as boring and functional as it is right now. When he was growing up, Canada was functionally two countries, Anglophone and Francophone, divided by language into two isolated media ecosystems. Tension between the two Canadas spilled over into violence, with the paramilitary Front de libération du Québec committing bombings and kidnappings to advance their cause. What’s allowed Canada to become boring was a long process of government through tradeoff and compromise, and the hard work of constructing a national identity that went beyond either colonial roots in Britain and France, or the cheap “we’re not the USA shortcut to national self-conception.
This long, slow hope is what Roberts offered to those of us in the US terrified about this election and what it signifies. In a recent article, Roberts describes the US as being twenty years into a “descent from hubris”, the realization that the “Washington consensus” of free markets, reduced government services and deregulation hasn’t been working for most Americans on the right or the left. Realizing that the model isn’t working is part of what’s leading to our current frustration. We agree that America isn’t working, but we blame each other for the country’s apparent ungovernability.
But Canada’s past is a lesson in overcoming that ungovernability. Having a government as often functional and boring as Canada’s seems a distant dream. But that dream is better understood as a long hope, the idea that two divided camps, united by the fact that a broken system is failing them, can in the long run find a new way to coexist.
That’s a faint hope at a moment as fraught and dark as the current one. But it’s something to work with, something to learn from and I’ll take it.
The post The US, Canada and “long hope” appeared first on Ethan Zuckerman.

Ich habe die Kombination von zwei HomePods mit einem Apple TV 4K nun einmal in Ruhe ausprobiert und mit einer Sonos Playbase verglichen.
Der Setup ist super einfach. Wenn man einen zweiten HomePod in einem Raum hinzufügt, bietet die Home App an, ein Stereopaar zu konfigurieren. Diese beiden HomePods erscheinen nun als einer.
In den Apple TV-Einstellungen kann man dann auswählen, wohin die Audio-Ausgabe geschickt werden soll. Entweder zu den TV-Lautsprechern, also über das HDMI-Kabel, oder über das Netz zu den HomePods. Der Fernseher schickt bei mir Audio über ein optisches Kabel zur Sonos Playbase, so dass ich beide vergleichen kann. Die Umkonfiguration dauert dabei ein paar Sekunden.
Wichtigste Frage: Und wie klingt das? Sehr luftig. Der Ton der Playbase scheint aus dem Fernseher zu kommen, der Ton der HomePods dagegen aus der Wand. Beide können Raumklang projizieren (Beamforming), wobei man bei Sonos den Raum mit TruePlay Tuning ausmisst, während die HomePods das automatisch über ihre Mikros machen. Ich werde das jetzt mal ein paar Wochen testen und dann entscheiden, ob ich die Playbase abbaue.
Drei Einschränkungen:
Keine dieser Einschränkungen betrifft mich. Ich kann mittlerweile das gesamte Fernsehprogramm über das Apple TV abrufen und habe eine einheitliche Bedienung über das iPhone oder die Apple TV Fernbedienung. Außerdem mag die Scheffin nicht, wenn es "scheppert".
Wer an seinem Fernseher Spielekonsolen, Sat Receiver oder DVD-Player angeschlossen hat, kann mit diesem Setup nichts anfangen. Das ist nicht mein Weg. Ich finde die Software von Smart TVs so schlecht, dass ich eher Richtung Digital Signage als Bildausgabe tendiere.
Over the past couple of years, I’ve been teeter-tottering between the need to clean up some things in this site, the notion of re-writing the engine completely (again, for the third time) or just going “static” and use something like Hugo or my little sample data pipeline to push the whole thing to a storage bucket of some kind.
That goes against thr entire philosophy of the current engine, which is heavily optimized for on-the-fly rendering (a throwback to its ancient PhpWiki origins, the time I spent tuning everything for low-level HTTP responses, stacking Varnish on top, etc.).
These days I can just use CloudFlare for all of that HTTP optimization, so a lot of that code is just sitting there. But this was also designed to be an internal Wiki engine, which is why it still has its own internal indexing, automatic re-linking and search mechanisms, and those I don’t want to throw away just yet.
In fact, I use an older, internal instance of it at home for miscellaneous stuff (I’ve yet to find a simple private Wiki that I like).
But turning the current engine into yet another static site generator is something I’ve been loathe to do. And that’s largely because it’s Python, which means it’s beautifully concise, trivially easy to hack but slow to render all the 8000+ pages that I’ve published over the past 18 years.
On the other hand, none of the current crop of static site generators fit my needs. To point out just two examples (and yes, I’ve looked at many more) Hugo is extremely popular but would require me to edit every single file (which is just not going to happen), and Zola is by far the sanest thing I’ve found but would at least require massive batch renaming and some (less, but still a lot) of editing, largely because it decided to use TOML for front matter (which no Markdown editor currently handles properly).
And starting anew is not a trivial option, because I still use this site as a personal notepad for things of interest as my pages on JavaScript, Python and Clojure readily attest. And that kind of content relies on a heavily customized bit of link table generation I would always have to code in somehow.
But either way it goes (and I’m currently leaning for rolling my own as a quick hack) I need to do a few things ahead of time.
To go static, there is a lot of old content to clean up (some of it is still Textile or even raw HTML), and (most notably) the URL convention I’ve been following throughout the years has a few quirks (like pages with a space in their names), so I’m going to tackle those first and do two things:
The first bit is starting now, since the sooner the better in terms of SEO–I want people to be able to at least search for things if they come across an external reference from years back and whatever I pick for static hosting can’t do redirects or something like that.
And since CloudFlare now lets me plug directly into the Internet Archive, I can check what is and isn’t being handled properly.
The second will take longer, and will certainly happen piecemeal over the next few months. I have a lot of outdated content, but some of it I’ll keep around for entertainment value.
So please expect some link breakage for a few days (perhaps weeks) as I change page names and do some surgical site-wide searching and replacing based on a few patches I’ve been doing to the engine itself to spit out lists of broken/non-conformant internal links.
Most recent content shouldn’t be affected, but some older stuff may be hard to find the first time around.
My business partner Paul every now and then spends a few hours on the phone or eagerly refreshing a website to ensure he is allowed to buy 1 or 2 cases of beer brewed by the Westvleteren Trappist monks of the Saint Sixtus abbey. Then he drives down to Belgium with a friend to pick up a dozen or two bottles at a time.
A while ago he got the opportunity to make an extra trip: due to the pandemic lockdowns not all who had made reservations were able to do the pick-up. He gave me and my other business partners a bottle.
The bottle of Westvleteren 12 is a dark beer coming in at 10% alcohol, so not something for the warm summer days when I received the bottle.

Today however was a perfect fall day. Sunny and clear, not cold but nice enough, leaves falling, geese flying overhead to their winter destinations.
So today was the day to enjoy this beautiful dark beer, voted the best beer in the world a few times over. I’m not sure about that, wouldn’t want to make presumptions. But it was tasty, not too sweet, I like my beers on the more bitter end of the spectrum. Enjoyed it with a few nuts and some locally sourced Metworst (dried sausage).

Westvleteren don’t have labels, they differ only in the color of their caps to indicate the type.
It seems that democracy in America will live to see another cycle, and it’s such a relief to see that the system is still working. It may not be working amazingly well, granted, but at least it’s worked again this time. We all owe a debt of gratitude to state and local election officials across the country. Given the challenges, from a pandemic and foreign interference to the distrust sowed by the President himself, they’ve performed admirably.
We’re not out of the woods yet, however, not by a long stretch. Not in the short term, and definitely not in the long term. First, we’ve got to make it through the next few days of inevitable challenges and recounts. Then, assuming all goes will with that, there’s the next few months. Given President Trump’s unwillingness to deal with the reality of the election process so far, it’s hard to imagine that, even if he does concede, he will cooperate one bit in executing the transfer of power that America has managed to do so many times before.
Whether the Secret Service has to escort Trump from the White House on Inauguration Day, or less dramatically, that Trump will just disappears from the office to retreat to one of his golf courses, almost any reasonable scenario leaves the incoming administration in the very uncomfortable position of taking charge of the American government during a global pandemic without a clean handoff.
That’s going to be rough. Once we make it through that, we’ll have to consider ourselves incredibly lucky that America made it to 2021. Then, Democrats, Republicans, and independents of every stripe are going to have to come together do something to walk our country back from the brink. We have to recognize that the differences that have brought us here have so very little to do with policy and almost everything to do with absolute partisanship. If we want America to make it past 2024, there’s a lot of work to do, now. Otherwise, the next aspiring authoritarian may indeed manage to break everything.
First, however, let’s make it through this interregnum.
Over the past few weeks I have described how my usage of Obsidian has evolved since I first used in early July. This is the final post in the series. Where the previous posts described my personal knowledge management system, and how I use it for daily project work, task management, note taking, and flow using workspaces in this final post I want to mention a few more general points.
These points concern first my overall attitude towards using Obsidian as a tool, second its current functionality and third its future development of functionality.
First, what is most important to me is that Obsidian is a capable viewer on my filesystem. It lets me work in plain text files. That is my ‘natural’ environment as I was used to doing everything in text files ever since I started using computers. It’s a return of sorts. What Obsidian as a viewer views is the top folder you point it to. The data I create in that folder remains independent from Obsidian. I can interact with that data (mark down text files) through other means than just Obsidian. And I do, I use the filesystem directly to see what are the most recent notes I made. I add images by downloading or copying them directly into a folder within the Obsidian vault. I use Applescript to create new notes and write content to them, without Obsidian playing any role.
Next is that Obsidian allows me to rearrange how I see notes in different workspaces and lets me save both workspaces and searches, which means it can represent different queries on my files. In short Obsidian at this moment satisfies 3 important conditions for decentralised software: I own my own data, the app is a view, interfaces are queries. Had any one of those 3 but especially the first been missing, I would be exchanging one silo (Evernote) for the next. Obsidian after all is not open source. A similar tool Foam is. Foam is currently not far enough along their path of development to my taste, but will get there, and I will certainly explore making the switch.
When it comes to current functionality I am ensuring that I use Obsidian only in the ways that fit with those three conditions. There is some functionality I therefore refuse to use, some I likely won’t use, and some I intend to start using.
I refuse to use any functionality that creates functionality lock-in, and makes me dependent on that particular feature while compromising the 3 key conditions mentioned above. Basically this covers any functionality that determines what my data looks like, and how it is created (naming conventions, automatic lay-outs etc). Functionality that doesn’t stick to being a viewer, but actively shapes the way data looks is a no go.
There are other functions I won’t use because they do not fit my system. For instance it is possible to publish your Obsidian vault publicly online (at publish.obsidian.md, here’s a random example), and some do. To me that is unthinkable: my notes are an extension of my thinking and a personal tool. They are part of my inner space. Publishing is a very different thing, meant for a different audience (you, not me), more product than internal process. At most I can imagine having separate public versions of internal notes, but really anything I publish in a public digital garden is an output of my internal digital garden. Obviously I’d want to publish those through my own site, not through an Obsidian controlled domain.
Other functionality I am interested in exploring to use. For instance Obsidian supports using Mermaid diagrams, a mark-down style language. This is a way to use diagrams that can port to another viewer as well, and doesn’t get in the way if a viewer does not support them.


Mermaid is a way to describe a diagram, and then render it. Seen here both from within Obsidian.
Future functionality I will explore is functionality that increases the capabilities of Obsidian as a viewer. Anything to more intelligently deal with search results for instance, or showing notes on a time line or some other aspect. Being able to store graph settings in a workspace (graphs now all revert to the default when reloading a workspace). And using the API that is forthcoming, which presumably means I can have my scripts talk directly to Obsidian as well as the filesystem.
I’ve now been using Obsidian for 122 days, and it will likely stay that way for some time.

At long last, our long, shared international nightmare of having a crass, vain, unreliable person running one of the most powerful nations on Earth starts to come to an end.
I just hope it’s a peaceful transition, because the US is going to struggle to climb back from the pits of disrespect and lack of worldwide credibility it sunk down to.

Apple has launched a new mobile sales experience called the iPhone 12 Studio.
The shopping experience is only available on mobile and tablets, but the website is quite slick once you access it.
The first question that appears is what iPhone 12 model you want. You can select from all four iPhone 12 models.
After that, you can also choose to add a MagSafe Silicon/Leather case or a MagSafe wallet to your device. While useful since it gives you an overall look at the iPhone 12 combination you’re considering buying, it’s a bit odd that there’s no desktop, browser-based version of this app.
I built a Gold iPhone 12 Pro with a Cyprus Green Silicon Case and the California Poppy Leather Wallet. It looks pretty cool, but if you click the buy button, you still need to manually add all the items to your cart if you want to purchase them all.
Apple is using the #iPhone12Studio hashtag to promote the new platform, and you can check it out on mobile-only here.
If you’re interested, MobileSyrup has reviews on both the iPhone 12 and iPhone 12 Pro, with in-depth looks at the iPhone 12 mini and iPhone 12 Pro Max coming soon.
Source: Apple
The post Apple launches iPhone 12 Studio iPhone sales experience appeared first on MobileSyrup.

I just read a post from Mitch Resnick on the seeds that Seymour Papert sowed, and highlighted for myself this most important statement:
"Seymour rejected the computer-aided instruction approach in which 'the computer is being used to program the child' and argued for an alternative approach in which 'the child programs the computer.'"
As I commented in my OLDaily post, this is a lesson I have always kept in mind, and as I look at the criticisms of ed tech (and especially the work of people like Audrey Watters) I think this is the form a response should take. Or as I said in my presentation last week, "it's not about the technology all the time, it's so often about critical literacy, about perception, sense of belief, it's so often about how people see things, what their environment is, what their ways of perceiving things are, how they're going to learn."
A few minutes later I read a post in Getting Smart from Tom Vander Ark saying that
The pandemic laid bare the inequity and inadequacy of the patchwork American system of education. It made clear that learner experience (LX) is an invention opportunity. LX is not just the topics and tasks of the curriculum, it’s the supports, the culture, and how learners interact with their learning environment.
All true, and not only for the American system. But the approach Vander Ark takes is to emphasize the invention and to talk about how LX systems can do the programming. He offers a list of 12 such strategies. It's not a bad list, but we really need to change the focus.
Hence, I've adapted his list for my own needs, and repurposed is as '12 Degrees of Freedom', describing ways we can enable students to do the programming rather than have a system program them.
1. Recognize Individuality
While Vander Ark says "LX design should respect each person’s autonomy and individuality" he is silent on how systems should enable individuals to define their own identity. We can begin by rejecting the student:non-student dichotomy. Everyone learns, and an LX platform should be designed for everybody, not just those lucky enough to be 'admitted' or to be able to pay tuition.
There are many dimensions to identity, but we can begin here by enabling people to define what constitutes "healthy development, learning, academic success, and resilience" for themselves. Now to be clear: that doesn't mean just giving them a blank form with no resources. 'Freedom' doesn't mean "with no help, support, or assistance', but the difference is, it's up to the individual whether to rely on these supports, and which of them to use.
We always told people in MOOCs, "you define what counts as success". Now if you want to take a quiz, we can provide one, but passing a quiz doesn't mean 'success' unless you decide it does, and we need to be clear about that. We can give you a pathway to complete the course, but completion doesn't count as 'success' unless you decide it does. The same is true for these other four dimensions, and for the other parameters that frame individual identity.
2. Anticipate Malleability
This item makes the important point that people grow and develop over time. It should also recognize that, as we age, some of our capacities may diminish over time. These are biological facts here, and any learning system should approach learning with the biological facts in perspective.
But there are different ways that can be addressed. The popular sentiment is to somehow have the teacher or the system somehow 'recognize and adapt' to changes in in what a person knows and what a person can do. That's why Vander Ark quotes Pam Cantor as saying “None of us can know what a child can become unless we design the environments/context to reveal it,” said Dr. Cantor.
The important thing for a system to do isn't to 'reveal' what an individual can do, it is to allow them to demonstrate what they can do, and to respect the individual's decision about what to demonstrate and how to demonstrate it. Sure, recognize the growth as it happens, but respect the individual's presentation of that. This is the difference between surveillance and performance.
3. Understand Context
This item presumes a causal story of how the individual came to be, and then requires that these be appropriately identified. It also underlines a story whereby these are thought of as problems to solve. That's why Vander Ark says "Distinguish motivational issues from learning strategy problems and identify their causal factor."
We need to be clear that motivation isn't a problem with the individual, it's a problem with the way we are approaching teaching and learning. If motivation is an issue, then we're trying to force them to do something they don't want to do. If motivation is an issue we should change the tools we're offering to enable people to pursue something that matches their own interests (and everyone has something that matches their own interests).
The same is true of contextual factors. Our judgement of whether content is a 'problem' or not may well be different from the individual's. This is especially the case in cross-cultural contexts. It's not up to us to identify someone's religion or background or home as a 'problem'. Now, yes, there are extreme cases where educators are working with at-risk individuals; I've had the experience or teaching women in northern communities coming to class with a black eye. But it's not up to us to 'fix' these problems; it's up to us (as a system) to provide tools and means to help them address these problems, if they choose.
4. Build Relationships
Relationships are great; they're one of the main things we emphasize in connectivism. But there are many kinds of relationships (which I explore in my discussions of groups versus networks). There are many ways relationships are created. There can be online and offline relationships. People might form relationships with each other, with their educators, or even with the content or particular thinkers.
And there are many reasons why people form relationships. It may be true that "strong attachments and positive, long-term relationships are key to learning and development" (though I'm sure there are exceptions to that rule) but it doesn't mean that a relationship with you is that key. And that's a good thing, because it would seriously limit how many people each educator could reach.
The rule here for educational developers should be to enable relationships, but to allow people to decide for themselves how strong or weak those relationships should be, how they should work, who they should be with. Sure, we could point to studies saying people 'learn better' (whatever that means) in "safe learning communities where students feel they belong and are known", but that doesn't give us the right to impose them on people. Some of us prefer to keep our distance, to take risks, and to network rather than to belong.
5. Set Priorities
Here Vander Ark says simply, "Focus on foundational skills and belonging, self-efficacy, and a growth mindset." That takes the perspective that the person who walks into the classroom is somehow flawed and imperfect, and needs to be fixed before any real learning can occur, and in particular, that they need some 'foundational skills', to 'belong', and to have the 'right mindset'.
And, frankly, none of that is true. Or, rather, it's true only in the following sense: if they are to learn the way you teach them, then they will need some 'foundational skills', to 'belong', and to have the 'right mindset'. But what we could do, maybe, is rethink how we teach them.
I'm not saying that there are no foundational skills, no way to belong, and no good mindsets. The problem is, there are too many. Consider literacy, for example. You need if if you're going to learn by reading. But there are many kinds of literacy - social literacy, digital literacy, numeracy, etc. And there are many ways to be literate (which I describe as the 'critical literacies'). Nobody can do all of them.
So who makes the decision as to what's most important? The presumption is that it's the educator, because they 'know' what works best for learning. But in a '12 degrees of freedom' approach, it's the individual learner.
6. Build on Prior Learning
It is clear that people are not 'blank slates'. But what do we mean by "meeting students where they are?" The prototypical recognition of prior learning is via credentials or some form of pre-test. But this defines 'where they are' very narrowly. The only prior learning being recognized and acknowledged is that defined by the educator.
When we're entering environment there's really no reason to limit it this way. The worst possible outcome is that the person will be unsuccessful, which is normally not a major problem (though if people have to pay a lot of money and commit significant time in advance, this suddenly becomes a major problem).
So what we really need to do here is two-fold. First, and most clearly, in a freedom-based education, it should be up to the individual to decide for themselves whether they've already learned or mastered what they need. Having people choose what to study also addresses the question of whether content is appropriate for their situation and background. But the second part is also essential: de-risk participation in learning. We shouldn't be committing to semester-long expensive engagements, even at young ages. That lets people try something and change on a dime if it doesn't work out.
7. Engaging Tasks
Here Vander Ark is recommending "well-designed, interdisciplinary projects" that "combat the pedagogy of poverty and support rigorous academic work." Projects are great, and of course we all like things that are well-designed. But between the lines here we see the distinction between a project that is carefully crafted to lead a person to a particular outcome ('rigorous academic work', say) and a project that most closely reflects the real-world objectives of the person.
Indeed, it could be pointed out here that real-world projects are in many ways the best projects. In my work on 'personal learning' I have argued that learning should begin with what the individual is actually trying to accomplish. And here, 'well-designed' means something very different - it means providing open-ended support using tools and resources with no particular end in sight other than what the individual has in mind.
Now there are many tasks that can lead someone step-by-step through a learning process. I've done hundreds of such tasks learning to do web development, for example. They're useful if I'm working on a particular platform for the first time. But I select these tasks for myself, I do as much or as little of them as I want, and I don't feel compelled to satisfy any objectives other than my own.
8. Quality Feedback
Here we are told two things: first, "to provide the right amount of challenge, rigor, support, feedback, and formative assessment to drive and accelerate the developmental range and performance of individual students," and second, that "self-regulation and academic growth is developed with quality feedback."
Pretty much any growth is provided through feedback; without resistance it's difficult to develop muscles, and without feedback, we learn nothing from the things we do. But it's a very large leap to jump from the need for feedback to the 'right' amount and type of feedback.
And that's the real challenge here. With highly detailed and precise feedback, you might be able to direct people to specific outcomes. But this means tightly controlling all the stimulus and all the feedback. We've learned this working with artificial intelligence. But a significant effort required to create this degree of control for each individual person. And it also leaves the individual very fragile intellectually once they enter the real world where feedback is diverse and unpredictable. It's impossible to know what has been taught.
So, while feedback is always important, a freedom-based education depends on diverse and authentic feedback based either on the real world or open-ended real world models, and not carefully controlled training system feedback based on artificial metrics like challenge, rigor, support, feedback, and assessment.
9. Risk Factors
The Getting Smart article is focused mostly on children's education, and nobody believes that children should be exposed to any significant degree of risk. Moreover, it is generally recognized that the risks people face do not only include physical dangers, but also averse impacts from stress or social interaction.
The natural inclination is to want to protect people. And that's the approach that Vander Ark takes when he argues that "adult buffering of risk factors and assets from relationships and a sense of belonging foster resilience and accelerates healthy development and learning." But there's also such a thing as too little risk, and I think that's what a lot of 'buffering' creates.
A free education doesn't minimize risks so much as it limits the consequences of taking risks. In slogan form, I might say "use nets, not walls." People should expect some pushback from failure, but (as we just discussed) that's where the learning comes from. Allowing people to fail, but mitigating the worst consequences, allows people not only to feel this pushback, but to be able to determine for themselves what type of pushback matters to them, and what they can list with. After all, we all experience pain differently.
10. Explore Motivation
What Vander Ark says here is true: "a complex mix of beliefs, values, interests, goals, drives, needs, reinforcements, and identities influences choices, persistence, and effort. The perceived utility of a task and the intrinsic and extrinsic motivations are unique for each learner."
What a task, then, to design for all of these factors. It's as though we were to build a system that tests a student to find out what language they're speaking, and then to select a resource for that language. How much easier it is to just allow the person to select their own resource; we can focus on supporting different languages without worrying whether we're picking the right one.
This sometimes means listening to people expressing what they need (that will tell you what languages you need to cover) and it may sometimes mean providing access to systems that can learn from them and provide recommendations (which is what Google does). But what's key here is to enabling people to follow their own motivations without trying to interpret them or to substitute your own.
11. Metacognition
Vander Ark says, "becoming aware of one’s own thinking and learning depends on foundational self-regulation and executive function skills." I'm here to flatly say, "no it doesn't". I know that the whole literature of 'executive function' and 'self-regulation' is really popular, but I think it is wrong, and in many ways damaging.
It's wrong because 'executive function' and 'self-regulation' are not real. These are versions of the Homunculus theory of cognition. There's no little voice in our head that tells us what do do (and if you think of it, even if there were, we'd have to ask, "how does the little voice know what do say? Does it have it's own even smaller little voice?"). It's true, most of us hear an internal monologue (though some people don't even have that). But this inner voice is a chatterbox: it repeats things it hears, it lies to us, it gives us false beliefs - if there's a key to success, it's learning to ignore the 'executive function'.
And it's damaging because it assigns responsibility to the learner for failure (and especially failure to meet externally defined goals, specifically, the goals you are imposing on the learner). If only they had more willpower. If only they stayed on task. If only they had a growth mindset. Then they would be successful and doing this thing they never really wanted to do in the first place. But it's not true. Usually, success or failure depends on resources, support and environment.
And that's true of learning to learn as well. I am not saying here that people cannot learn how to learn. But learning to learn is a lot more like Kierkegaard than like Aquinas - it's a lot more about the practice, what you do, than how you think about what you do. It's incremental, it's influenced (a lot) by examples and environment, and it's something that grows as a result of having taken a leap, not of you talking yourself into leaping.
12. Unique Pathways
It's true that "there are no ideal developmental pathways." But that's mostly because, like the roads in a city, none of the pathways leads to anywhere in particular. It all depends on where you want to go.
Vander Ark says, "there are multiple pathways to healthy development, learning, academic success, and resilience." If that's what you're after, great. But most people have very different ideas of what constitutes 'healthy' and 'successful' and even 'learning' and 'resiliance'. Vander Ark's statement is like saying "All roads lead to Rome." Even those people who actually want to go to Rome will need a more precisely defined destination than that. A gladiator headed for the Colosseum feels very different from a senator on the way to the Forum.
That having been said, having pathways (or maybe more neutrally stated, 'links' or 'connections') can be useful (keeping in mind that people won't always want to follow the pathways). Building infrastructure can be useful - but we should always leave it open to allow people to build their own infrastructure - to map their own connections between concepts, create their own data flows, interact with their own network of friends and colleagues.
Postscript
Vander Ark and his colleagues are discussing education for children, and it is a common objection to all of these points to say that children need more direction and control, because they're irresponsible and reckless. They can't learn on their own. They can't direct their own learning.
This is no doubt true to an extent, but I have two major responses:
- first, to what degree is it true? My observation is that around the world children need a lot more support than they're getting, not more protection. If we paid more attention to feeding them properly, housing them and clothing them, and providing access to bandwidth and resources, we'd be doing a lot more good. Yes, children are irresponsible, but that's how they learn. Let's work with that, not against it.
- second, when does it stop being true? I've heard no small number of people making the same points about high school students, university students, even adult learners. At what point do we decide that people have mastered the basics (whatever we perceive them to be) and can both take risks and be accountable for them?
Finally...
So what are the 12 degrees of freedom? Here they are, more or less:

Microsoft and Samsung have added the ability to steam multiple apps from a smartphone to a Windows 10 PC.
We got a taste of this feature when it was shown off a few months ago, and now it’s finally rolling out to select Samsung devices.
This functionality’s premise is to allow Windows users to stream apps from their Samsung smartphone and use them on a desktop like a native Windows app.
The following phones are supported:
On the Windows side of things, you need to be running at least the Windows 10 May 2020 update, and the ‘Your phone’ app needs to be on ‘version 1.20102.132.0′ or higher.
Windows notes that not all apps will work with this software. The other issue is that some apps might not be compatible with a mouse and keyboard. In this case, only users with touchscreen laptops will be able to use those apps.
Microsoft and Samsung also state that both your phone and PC need to be connected to the same Wi-Fi network to work.
You can learn more about the feature by reading Microsoft’s support post.
Source: Microsoft
The post 2020 Samsung phones can now stream multiple apps to Windows PCs appeared first on MobileSyrup.
I’m so happy today — and full of gratitude to everyone who worked so hard for this, and to everyone who worked to make the last four years less dark than they might have been. Thank you!



There is no shortage of posts on Survivorship Bias out there, so why read yet another one? One problem I realized is that while many articles cover identifying survivorship bias, few discuss how to start thinking about solving these problems. In a time of pandemic and stressful elections it is very helpful to start to think about how we an model problems quantitatively and attempt to correct for biases like survivorship bias. It turns out that identifying this problem is far easier than dealing with it in how we model problems.
In this post we'll be taking a quick look at a real world problem of house hunting during the current pandemic. The pandemic has quickly changed the demand for houses outside of major cities and so many people maybe looking through houses for sale and despairing at their limited options. It turns out that, because of survivorship bias, good homes may be *less rare* than they initially seem.
To solve this we'll model our problem mentally, then mathematically and finally computationally using Python and the JAX library for automatic differentiation. Throughout this process we'll gain insight into what's happening the housing market as well as learning how challenging correcting for bias really is.
Survivorship bias is a common form of logical error where the data that we are presented is representative of only a subset of the population that has already survived a filtering process, meaning that our data lacking important information underestimating the true population that the data comes from.
The classic example of this is the US military looking at the bullet holes in returning bombers during WWII and trying to use this information to determine how to improve the survival rate of planes. The image below illustrates the various location of bullet holes on these planes. The initial reaction of the military was to put armored plates to protect the areas where the bullet holes were on returning planes. When the statistician Abraham Wald was shown this data, he saw this as a clear example of survivorship bias and concluded the opposite: bullet holes on returning bombers indicate where planes could be hit and still survive to fly home. What's missing from this data set are the planes that did not return.
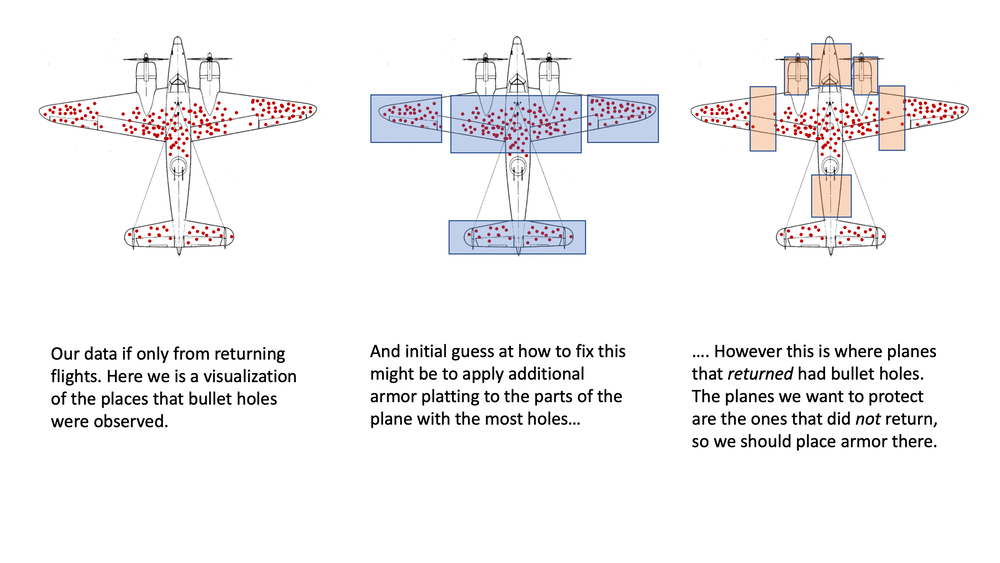
It is legally required to show this image of a plane whenever you write about survivorship bias
While the story of the surviving bombers may be a great example of survivorship bias, it doesn't give us much information about how to model and solve this problem.
In this particular example the clever solution requires a large amount of background information about how planes work. For example, seeing that the returning planes have no bullet holes around the engines leads us to immediately conclude that those bombers that did not return were shot in the engine. Since we know how important engines are to the maintenance of planes we can skip over any real mathematical modeling of this problem and use our background information to solve this easily.
But imagine if you were trying to explain this obvious solution to someone that had never heard of an airplane and had no idea how they work, someone who wanted some numerical data to support your beliefs.
The challenge of modeling survivorship bias problems is both very interesting and infrequently discussed, so in this post we'll start to poke at a problem a bit more quantitatively to get a better feel for how to start modeling the this process and how to try to come up with a solution. The main goal is not to solve a problem (because it turns out that really doing that in a satisfactory way is fairly complex) but to start thinking about modeling the problem mentally, mathematically and computationally to have some basic tools for reasoning about a survivorship bias problem quantitatively, if not in a truly statistical manner.
Like many people living in cities in the US right now, my wife and I have recently started to consider the possibility of purchasing a house in the suburbs outside of the city. Given the rapid shift from office to remote work, and the impact of the pandemic on local city restaurants and bars, it makes a lot of sense of consider moving to a more spacious home for roughly the same price.
Because many people have had this same idea, housing hunting can be an especially daunting, even depressing, experience right now. One of the first steps in the house hunting process is to look at a list of houses currently available from the Multiple Listing Service (MLS) that your realtor gives you access to.
Upon browsing the list of houses my wife and I despaired that of the hundred homes listed, only about 2 of the 100 looked promising. We both have quantiative background and were immediately concerned that going forward we might only expect to find 2% of the homes on the market to be homes we liked. This seemed to be a depressingly low number.
Before despairing too much we both realized that we were facing a survivorship bias problem!
The issue with MLS listings is that these listings might represent houses that have been on the market for up to 90 days. However, we can also assume that good houses will sell much faster than bad houses. This means that if we look at what is still on the market after 90 days the amount of good houses will be much smaller than the amount of bad houses. The question we want to answer is
"how likely are we to see another good house listed next?"
and the number we get from looking at "how many good houses are on the market in listings form the last 90 days" will wildly underestimate the true rate of how many good houses are coming on the market. We can see this visualized here:

The first step in the modeling process is to understand you mental model of how the process works.
We can see that we are dealing with a case of survivorship bias, but noticing the bias doesn't do much to help us solve our problem. What we have here is a mental model of our problem, and what we want is to have mathematical model that will help us answer more specific questions. We know that the observed 2% is much lower than we should expect, but what should we expect? Is it 5%? 10%? as high as 20%? Simply observing that we are experiencing the bias doesn't tell us anything about how we can quantitatively solve this.
To start tackling this problem we need a mathematical model so that we can at least come up with a rough ballpark figure to answer the question:
"What is probability that the next house listed on the market is good?"
For this post we aren't going to truly answer this in a statistical sense since, as we'll discuss later on, there is quite a bit of complexity in really determining our uncertainty. Nonetheless we would like some sort of mathematical model that allows us to get an estimate for the real rate of good houses appearing on the market as well as provides a foundation for building out a more sophisticated statistical model. In practice, when house hunting, you likely don't care particularly about building out full probability distributions of your believes as a much as you are just knowing roughly how much more likely it is to see a good house listed soon based on what you've observed. We'll also see in this post that answering even this "simple" question involves a surprising amount of sophistication.
We want to start by modeling our question itself as parameter and then we can answer our question using parameter estimation. We can imagine that there is some true rate that good houses appear on the market that we can't observe and we only have our listings of the last \(N\) days. We'll use the term \(\theta_\text{good}\) to represent this rate. In our model \(\theta_\text{good}\) is the part of the data generating process the produces the MLS.
Ultimately what we want is to build a model of the MLS listing themselves, of which \(\theta_\text{good}\) is only a small part. Once we have this model we can then figure out which is the best \(\theta_\text{good}\) for solving our problem. The difference between our
A vital part of our mental model is that good houses stay on the market for a shorter period of time than bad houses. What we need to do is figure out a way to model this mathematically. We can imagine good and bad houses being random variables, \(X_G\) and \(X_B\), that are drawn from two different distributions that describe how long each how will wait until it sells.
It's worth pointing out that this problem by itself could be worthy of a complex modeling process. We could imagine looking at various features of good and bad houses, looking at the day the house is listed etc. But to reduce our complexity we'll just try to find a single distribution that we can imagine each of these being sampled from differing only in the parameterization of that distribution.
At first glance we should be reminded of a Poisson distribution. If we wanted to estimate how many good houses sold in a week, we would use a Poisson distribution to estimate how many events would occur in a given period. However here we want to solve a slightly different problem: how long until an event happens the first time.
For this we can use the Exponential distribution which is used to measure the time between events in a Poisson process.
The Exponential distribution has one parameter \(\lambda\) and has the following PDF:
$$exp(x;\lambda) = e\lambda^{-\lambda x}$$
The \(\lambda\) parameter represents the rate that an event happens, and the PDF tells us the probability that \(x\) is how long we have to wait for an event. For simplicity we'll assume that we know that good houses sell on average every 7 days while bad house sell on average once every 23 days (again, estimating this from data is not as straightforward as we would hope). If we imagine our houses disappearing from the market as individual observations of an exponentially distributed random variable we can imagine something like the following image:
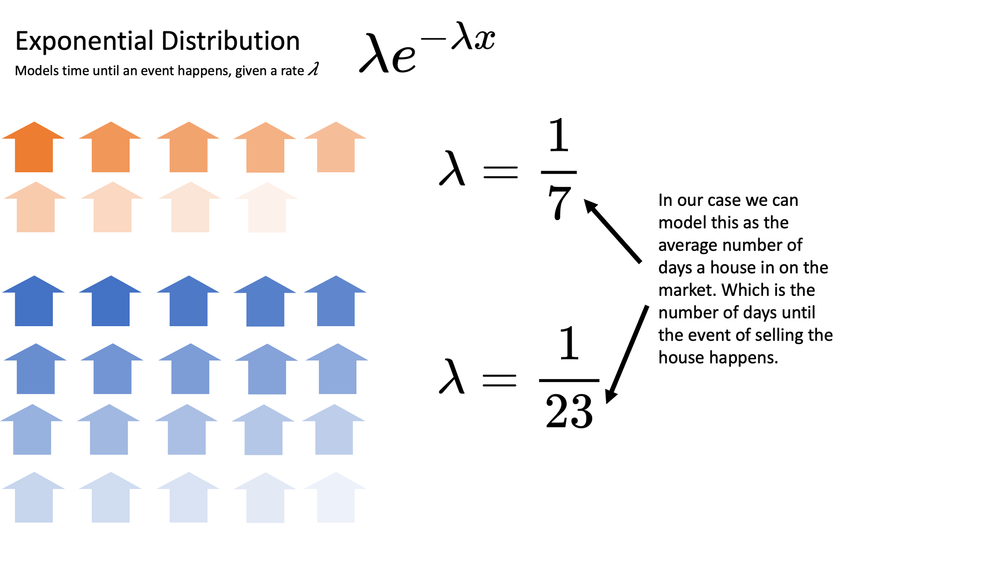
Individual listings can be modeled as observations of an exponentially distributed random variable.
This would allow us to define:
$$\lambda_\text{good} = \frac{1}{7} \text{ and }\lambda_\text{bad} = \frac{1}{23}$$
And we could define our two random variables as:
$$X_G \sim exp(\lambda_\text{good});X_B \sim exp(\lambda_\text{bad})$$
The MLS postings will have new updates every day and we know that because good houses sell faster than bad houses (at least in our mental model) the ratio of good to bad houses should change on a given day as good houses start to disappear from the listings.
To start with the basics, we can answer "what will that ratio be on the 0th day?". On the 0th day we would expect that ratio to be the probability of having a good house, \(\theta_\text{good}\) over the probability of having a bad house, which is the probability of not having a bad house:
$$\frac{\text{good}}{\text{bad}}_{n=0} = \frac{\theta_\text{good}}{(1-\theta_\text{good})}$$
You'll notice that what we have done is really just convert our probability to odds. This will be a useful form to keep this equation in because it will allow us to add together and average the ratios from each day to come up with a model of what the listings will look like with a full \(N\) days of observations.
If we next asked the question, "what will the ratio be on the 5th day" we have to edit our formula. We still have the base ratio to consider, but now we have to consider the probability that a house sold, represented by the random variables \(X_G\) and \(X_B\).
Because we want to compare how many homes are still on the market we don't want to look at the probability that the house sold but that it did not sell. In terms of our random variable, this is the probability that the value of the random variable is greater than the value \(n\) for that day. Mathematically we would view this as:
$$\frac{\text{good}}{\text{bad}}_{n=5} = \frac{\theta_\text{good}Pr(X_{G} > n=5)}{(1-\theta_\text{good})Pr(X_{B} > n=5)}$$
This basic formula will give us the ability to calculate each day in the MLS. Next we need to come up with a model for the full MLS that will give us the percent of good houses we would observe given \(\theta_\text{good}\), \(\lambda_\text{good}\) and \(\lambda_\text{bad}\).
Our listing represent 90 days of observations, which means we need to combine the results of each of these. This solution is pretty straightforward. Assume we just want to add day 0 and day 5. Clearly we can just add these ratios and, assuming we have the same number of listings each day, just average them:
$$\frac{\text{good}}{\text{bad}}_{n=0 + 5} = \frac{\frac{\text{good}}{\text{bad}}_{n=0} + \frac{\text{good}}{\text{bad}}_{n=5}}{2}$$
Note that we are making a pretty bold asymptotic assumption here. We only want to give equal weight to these ratios as the number of houses sold on each day approaches infinity. We're doing this in the name of simplicity, but this is definitely a problem we would want to correct if we were to develop a more rigorous approach to this problem.
We can now extend this logic to get the average ratio of good to bad houses after N days:
$$\frac{\text{good}}{\text{bad}} = \frac{1}{N} \Sigma_{n=1}^{n=N} \frac{\theta_\text{good}Pr(X_{G} > n)}{(1-\theta_\text{good})Pr(X_{B} > n)}$$
Finally we have to fix one small issue. We currently have this in a form that represents the ratio of good over bad, or the odds of seeing a good house in the listings. We want this to be a percentage or probability of seeing a good house. Recall that the formula for converting odds to a probability is:
$$P(H)= \frac{O(H)}{1+O(H)} = 1 - \frac{1}{O(H)}$$
With this formula in hand we can easily transform our odds of a good house into a probability of a good house:
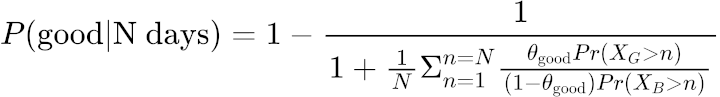
This diagram below visualizes our mental model transformed into a mathematical model:
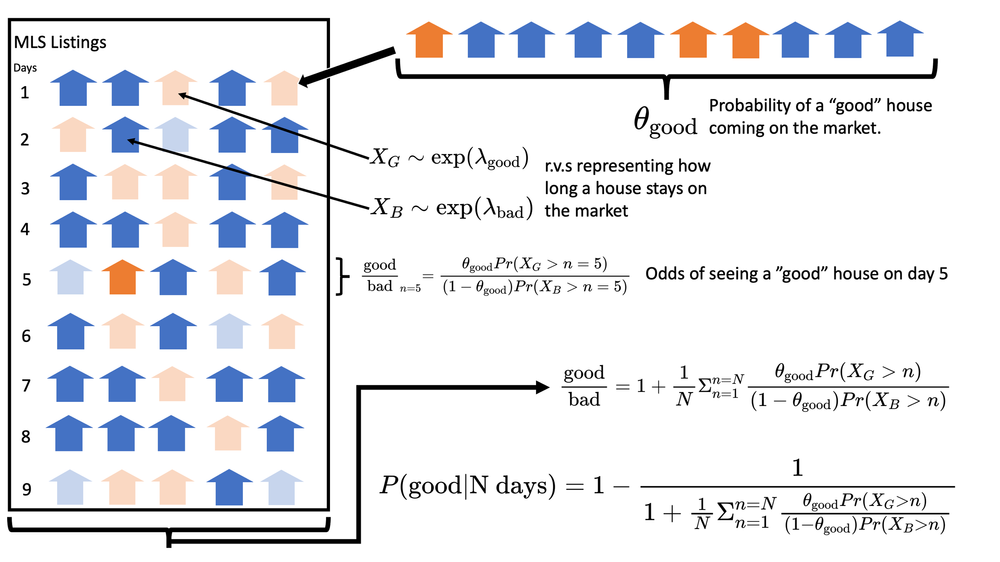
Transforming our mental model into a mathematical one allows us to quantify our beliefs.
We now have a decent first pass at a mathematical model of how the MLS works (which does make some pretty big asymptotic assumptions). Next we need a computational model to solve this problem and we're going to be using Python and the JAX library to help us out. We'll start with importing the few tools from JAX we'll need. JAX is a library that allows us to easily compute the derivatives of any Python code. To help with this JAX has it's own implementation of Numpy. We'll be importing both the JAX version of numpy as well as JAX's grad function we'll use to calculate derivatives.
import jax.numpy as np from jax import grad
Going back to our original problem let's assume the following:
The listings have 90 days of postings
We see 2% of the houses are good
The average days on the market for a good home is 7
The average days on the market for a bad home is 23
These last two are pretty big assumptions that normally we would have to estimate separately. Fortunately, because we're writing code to solve this problem, we can easily mess around with these to see how sensitive our model is to different values for these. After all our goal here is just to see roughly how likely it is that a good house appears on the market in the coming weeks.
Let's put all of our assumptions in code:
# lambda for good l_g = 1/7 # lambda for bad l_b = 1/23 # days in MLS n_days = 90 # observed probability of a good house obs_prob = 2/100
Next we want to create a model of our MLS that we have previously section. I've gone ahead and implemented some pretty straightforward helper functions including exp_cdf which is the cumulative distribution function for the Exponential distribution. This will allow us to easily calculate the probability of a Exponentially distributed random variable taking on a value greater than a given \(n\). For example the probability that a good house lasts longer than 10 days is:
1 - exp_cdf(10,l_g) > DeviceArray(0.23965102, dtype=float32)
I've also implemented to very simple functions to convert from odds to probability, and probability to odds, called odds_to_prob and prob_to_odds respectively.
With these tools we can now implement function to compute the odds that a house is good in the listings given a \(\theta_\text{good}\), \(\lambda_\text{good}\), \(\lambda_\text{bad}\) and \(N\).
def odds_good(theta_g,lmbd_g,lmbd_b,N):
#day 0 ratio is just theta_g
result = prob_to_odds(theta_g)
for n in range(1,N+1):
result += (theta_g*(1-exp_cdf(n,lmbd_g)))/((1-theta_g)*(1-exp_cdf(n,lmbd_b)))
return result * 1/N
Without much work we were able to transform our mathematical model into a computational model. The next step for us it so use this to solve our actual problem, which is determining what the value for $\theta_\text{good}$ should be given our assumptions.
To start off we need some way to assess how good a given guess for $\theta_\text{good}$ is. An obvious way is to just measure the difference between the probability of good given the model parameters and the observed probability of good houses. Here is our `target` function that does precisely this:
def target_func(target,theta_g,lmbd_g,lmbd_b,N):
return target - odds_to_prob(odds_good(theta_g,lmbd_g,lmbd_b,N))
If we know the values of target, lmbd_g, lmbd_b and N then we can think of this problem as trying to find the root of this new target function with respect to theta_g. The root of a function is the value of the argument where the result of the function is 0.
The classic way of finding the root of a function is Newton's Method. Newton's method is an iterative method that continually updates a guess \(x\) by using the derivative of the function. The traditional update rule for Newton's method is:
$$x_{t+1} = x_{t} - \frac{f(x_t)}{f'(x_t)}$$
All we have to do now is find the derivative of our target function!
In order to appreciate how nice it is to have JAX, let's take a look at what our target function, which we'll just call \(f\), looks like in full with all of our parameters in place:
$$f(x) = 0.02 - (1-\frac{1}{1+\frac{1}{90} \Sigma_{n=1}^{n=90} \frac{x(-e^{-\frac{1}{7}n})}{(1-x)( -e^{-\frac{1}{23}n})}})$$
If you want you can go ahead and work out the derivative of that by hand (or with Wolfram Alpha), but I'm going to take the JAX approach and just use grad. This following bit of JAX will automatically compute this derivative for us:
d_tf_wrt_theta_g = grad(target_func,argnums=1)
In fact this JAX code is even a bit better since it's computed the partial derivative with respect to the argument in position 1 (zero-index) which means I can still parameterize this function with what ever other values I want for the other parameters I'm assuming.
From here solving our problem is reduced to iteratively implementing Newton's method. We'll go for just 5 iterations, but could easily change that based on the stability of our answer:
guess = 0.5
iters = 5
for _ in range(iters):
f_val = target_func(obs_prob,guess,l_g,l_b,n_days)
df_val = d_tf_wrt_theta_g(obs_prob,guess,l_g,l_b,n_days)
guess -= f_val/df_val
print(guess)
> 0.14804904
In the end, based on our simple model, we should expect that about 15% of the new houses coming on the market will be good, rather than the observed 2%. This really goes quite a ways in reducing our despair!
One thing should be very clear at this point in the process: modeling for survivorship bias is wildly more difficult than correctly identifying it. The purpose of this post was to get us to start seeing how challenging that process is. At this point we have a rough sense that, given the many assumptions we are making, observing that 2% of the houses in the listings are good, accounting for survivorship bias, we should not despair as the rate good houses come on the market should be much higher.
However, other than feeling a bit better about house hunting, we have ignored a profound amount of information. Most important of all we do not have a statistical model of the MLS. We are able to derive the best guess, but right now we have absolutely no idea how to say how good that guess is. Is it possible that 20% of the houses are really good? What about 50%? In order to come up with a probabilistic model we want to solve our problem in the form of:
$$P(D|\theta_\text{good})$$
That is we want to answer the question "how likely are the MLS results we observed, given our belief in as specific \(\theta_\text{good}\)". Our work so far should provide some guide to how to get there, but we are still a long way from the correct solution.
This is also ignoring many of the other caveats that were noted throughout our modeling process. Just estimating our \(lambda\) values is going to be challenging since these too are subject survivorship bias. So even this "simple" model contains an enormous amount of complexity in modeling. This doesn't even begin to consider that maybe our basic worldview of only "good" and "bad" houses might be overly simplistic, or that the housing market behavior might change over time.
Survivorship bias is just one of many forms of bias that exist. At the time of this writing, results from the 2020 US Presidential election are still being counted and many people (myself included) are voicing their frustration with election forecasters. But I do hope that this post helps to generate some sympathy for anyone trying to tackle this problem. Election forecasters must combine vastly larger amounts of information than we see here. Additionally that data, largely from polls, is subject to a wide arrange of different biases. All of this to predict the outcome of an event that is hard to determine the result of when the data itself is present! We have a huge percentage of the votes recorded at this moment, and still don’t know officially who has one the election.
Along with sympathy for the forecasters I also recommend a hearty skepticism of the forecasts. I would argue that the most important part of the modeling isn't the prediction, but the process. Looking at forecasts for a point estimate of who will win or lose is of very limited use. Looking at the data that feeds into those forecasts, thinking about how you would quantitatively adjust for different biases, and building a model for how the world works are all tremendously insightful pieces of the processes. Being right in statistics is not nearly as important as knowing when you are surprised, what surprises you and how that should change your beliefs.
In our real estate example, suppose in the coming weeks we still saw very few good houses. Because of this model we can start asking why that is? Do "bad" houses leave the market much faster than we thought? Is the market changing as the pandemic develops? Having a model in place allows us to ask these types of questions and start thinking how we might investigate answering them quantitatively.

Support my writing on Patreon and gain access to the source code, commentary and pdfs drafts for this article as well as access to much more of my writing!
Sign up with your email address and you’ll get a link to Field Notes #1 a story about the time I almost replace a RNN with the average of 3 numbers!
Email Address Sign UpWe respect your privacy.
Thank you!
