This is the third in my series on the Library Map. Part One dealt with why I made the map. Part 2 explained how I made it. This post is about strategies I've used to automate some things to keep it up to date.
What is a GitHub Action?
A GitHub Action is an automated script that runs on a virtual machine when triggered by some kind of event. Triggers for actions are defined in a "workflow" configuration file at .github/workflows in your GitHub repository. The terminology can be a bit confusing, because "GitHub Actions" is what GitHub calls the whole system, but an "action" within that system is actually the smallest part in the series:
Workflow
- Job1
- Step1
- Action1
- Action2
- Step2
- Action3
- Job2
- Step1
- Action1
- Action2
GitHub Actions are really just GitHub's version of a Continuous Integration / Continuous Deployment (CI/CD) tool. I say "just", but it's extremely powerful. Unfortunately that does mean that even though GitHub Actions are quite extensively documented, the docs aren't necessarily all that clear if you're starting from scratch, and the process is quite confusing for the uninitiated. I spent a couple of days failing to make it work the way I wanted, so that you don't have to.
GitHub Actions ...in action
There are a zillion things you can use GitHub Actions for — auto-closing "stale" Issues, adding labels automatically, running code linters on pull requests, and so on. If you've read my previous posts, you might remember that I wrote a little Python script to merge the data from library_services_information.csv into boundaries.topo.json. But doing that manually every time the CSV file is updated is a tedious manual task. Wouldn't it be better if we could automate it? Well, we can automate it with GitHub Actions!
What we want to do here is set up a trigger that runs the script whenever the CSV file is changed. I originally tried doing this on a push event (every time code is pushed to the default branch), and it worked, but ultimately I decided it would be better to run it whenever someone (including me) makes a Pull Request. I'm in a reasonably consistent habit of always creating a new git branch rather than committing directly to the default branch, and there's less chance of something going wrong and the TopoJSON file being corrupted if the merge is done at the Pull Request stage and then manually pulled in — if there can't be a clean merge, GitHub will tell me before I break everything.
To set this up, we need to write a workflow configuration file, listing the jobs we want done, and the actions within each job. Jobs within each workflow are run concurrently unless the workflow configuration tells them to wait for the previous job, though in our case that doesn't matter, because there is only a single job. The structure is:
Workflow ('topo auto updater (PR)')
- Job1 ('auto-topo-updater')
- Step 1: git checkout code
- Step 2: add labels
- Step 3: merge files
- Step 4: git commit updated code
The first step uses an Action provided by GitHub itself. It runs a git checkout on the repository before anything else happens. This means nothing will happen in the actual repository if anything in the workflow fails, because the virtual machine that checked out your code just gets destroyed without checking the code back in.
Step 2 will use an Action created by Christian Vuerings, and automatically adds labels to an Issue or Pull Request, based on whatever criteria triggered the workflow.
Step 3 runs the python script to merge the CSV data into the TopoJSON.
Step 4 (care of Stefan Zweifel) commits and pushes the updated changes into the pull request that triggered the workflow. This is where the real magic happens, because it simply adds a second commit to the pull request as soon as it is received and before the PR is merged. I initially had set this up to create a second pull request with just the merged TopoJSON changes and then tried to work out how to auto-merge that new pull request, but someone on Mastodon helpfully asked me why I would bother creating a pull request if I wanted to auto-merge it anyway. The thought of auto-committing terrified me initially because I had no idea what I was doing, but on reflection a second PR was indeed a bit silly.
Writing the config file
To get all this to happen, we need to write a configuration file. This is written in YAML, and saved in a special directory at the top of the repository, called .github/workflows. You can name this file whatever you want, but it has to end in .yml.
First we provide some kind of trigger, and include any conditions we might want to apply. I want this workflow to happen whenever someone creates a pull request that includes changes to the website/data/library_services_information.csv file:
name: topo auto updater (PR)
on:
pull_request:
paths:
- 'website/data/library_services_information.csv'
workflow_dispatch:
The on directive lists the different 'events' that can trigger the workflow. The first one is clear enough, but what about workflow_dispatch? This event simply means "when triggered manually by pressing a button". I don't know why it has such an obscure name.
Once we've told GitHub when we want the workflow to run, we can tell it what we want it to do. First we list our jobs:
jobs:
auto-topo-updater:
runs-on: ubuntu-latest
steps:
# steps go here
The first line under 'jobs' is the name of our job (this can be anything, but without spaces). runs on tells GitHub which runner to use. A 'runner' is a special environment that runs automated continuous integration tools. In this case we're using GitHub Actions runners, but runners are also commonly used in other automated testing tools. Here we are using the "latest" Ubuntu Linux runner, which is currently using Ubuntu 18.04 even though Ubuntu 20.04 is actually the latest Ubuntu LTS release. Now we've outlined the trigger and where we want to run our steps, it's time to say what those steps are:
steps:
- uses: actions/checkout@v2
with:
ref: ${{ github.head_ref }}
- uses: christianvuerings/add-labels@v1
with:
labels: |
auto update
data
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: Merge CSV to TopoJSON
run: |
python3 ./.github/scripts/merge_csv_to_topojson.py
- uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: merge csv data to topo
Whoah, that's a lot! You can see there are two ways we describe how to perform an action: uses, or name + run. The uses directive points to an Action that someone has publicly shared on GitHub. So uses: actions/checkout@v2 means "use version 2 of the Action at the repository address https://github.com/actions/checkout". This is an official GitHub action. If we want to simply run some commands, we can just give our action a name and use the run directive:
- name: Merge CSV to TopoJSON
run: |
python3 ./.github/scripts/merge_csv_to_topojson.py
In this example, we use a pipe (|) to indicate that the next lines should be read one after another in the default shell (basically, a tiny shell script). The first step checked out out our code, so we can now use any script that is in the repository. I moved the python merging script into .github/scripts/ to make it clearer how this script is used, and now we're calling it with the python3 command.
To pass data to an action, we use with. The step below passes a list of label names to add to the pull request ('auto update' and 'data'):
- uses: christianvuerings/add-labels@v1
with:
labels: |
auto update
data
Finally, for the labels step we need to provide an environment variable. For certain activities, GitHub requires Actions to use a GITHUB_TOKEN so that you can't just run an action against any repository without permission. This is automatically stored in the "secret store", to which you can also add other secrets like API keys and so on. The env directive passes this through to the Action:
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
Putting the robots to work
Now when a pull request is sent, it gets tagged auto update and data, and a commit updating the topo.json file is automatically added to it:

You can see the full config file in the Library Map repository.
I've also worked out how to reduce the filesize of my GeoJSON file, so I was able to check it in to the repository. This allowed me to automate the transformation from GeoJSON to TopoJSON whenever the GeoJSON file is updated, with a workflow that runs some commands over the GeoJSON and creates a new pull request. One little gotcha with this is that the action I used to process the GeoJSON file into TopoJSON also cleans up the GeoJSON, which means triggering the action on any change to the GeoJSON file creates a recursive loop whereby every time the new pull request is merged, it creates a new one. To get around this, I probably should just make it auto-commit rather than create a pull request, but for now I added an if statement:
jobs:
processJson:
if: "!contains(github.event.head_commit.message, 'from hughrun/geo-to-topo')"
...
- name: Create Pull Request
uses: peter-evans/create-pull-request@v3
with:
commit-message: Update TopoJSON boundaries
title: Update TopoJSON boundaries
body: 'Clean & minify GeoJSON'
branch: geo-to-topo
labels: auto update,data
The last action creates a pull request on a new geo-to-topo branch, so if the commit message includes "from hughrun/geo-to-topo" the job won't run. Recursive pull request problem solved!
What is a Webhook?
I really like cherries, but they're not always season. Imagine me sending a text message to the local greengrocer every day in early summer, to ask whether they have any cherries yet. They text me back: usually the answer is "no", but eventually it's a "yes". Then I hit on an idea: I call them and ask them to just text me when cherries are in stock.
The first approach is how an API call works: you send a request, and the server sends a response. The second is how a webhook works — you get the response without having to even send the request, when a certain criteria is met. I've been playing around with APIs and webhooks at work, because we want to connect Eventbrite event information to a calendar on our own website. But GitHub also offers webhooks (which actually pre-dates GitHub Actions), and this is the final piece of the Library Map automation pipeline.
The big difference of course is that sending an HTTP request and receiving an HTTP request are quite different things. You can send an HTTP request in many different ways: including by just typing a URL into a browser. But to receive a request you need some kind of server. Especially if you don't know when it will be sent. Conveniently I already have a VPS that I use for a few things, including hosting this blog. So we have something to receive the webhook (a server), and something to send the webhook (GitHub). Now we need to tell those two things how to talk to each other.
What we want to do here is automatically update the data on the Library Map whenever there is an update in the repository. I could make this easier by just publishing the map with GitHub pages, but I don't want to completely rely on GitHub for everything.
Sending the webhook
First of all we need to set up the webhook. In the repository we go to settings - webhooks and then click on Add webhook. Here we enter the Payload URL (the url we will set up on our server, to receive the webhook: https://example.com/gh-library-map), the Content type (application/json), and a secret. The secret is just a password that can be any text string, but I recommend using something long and hard to guess. You could try one of my favourite URLs to create it. We want the trigger to be "Just the push event" because we don't want to trigger the webhook every time anything at all happens in the repository. Unfortunately there doesn't seem to be a way to trigger it only on a push to the primary branch, but in future we could probably put some logic in at the receiving end to filter for that. Make sure the webhook is set to "Active", and click "Add webhook".

Receiving the webhook
So setting up the webhook to be sent is reasonably straightforward. Receiving it is a bit more complicated. We need to set up a little application to hang around waiting to receive HTTP requests.
First of all, we set up nginx to serve our domain — in this post I'll refer to that as 'example.com'. Then we secure it using certbot so GitHub can send the webhook to https://example.com.
Because we might want to use other webhooks on other systems for different tasks, we're going to go with a slightly over-powered option and use Express. This gives us a bit of control over routing different requests to different functions. Express is a nodejs framework for building web apps, so first we need to make sure we have a recent version of nodejs installed. Then we create a new package metadata file, and a JavaScript file:
npm init
touch webhooks.js
In our empty webhooks.js file we set up some basic routing rules with Express:
npm install express --save
// webhook.js
const express = require('express')
const port = 4040
const app = express()
app.use(express.json())
app.post('/gh-library-map', (req, res, next) => {
// do stuff
})
// everything else should 404
app.use(function (req, res) {
res.status(404).send("There's nothing here")
})
app.listen(port, () => {
console.log(`Webhooks app listening on port ${port}`)
})
This will do something when a POST request is received at https://example.com/gh-library-map. All other requests will receive a 404 response. You can test that now.
Returning to the delicious cherries: what happens if someone else finds out about my arrangement with the greengrocer? Maybe a nefarious strawberry farmer wants to entice me to go to the greengrocer and, upon discovering there are no cherries, buy strawberries instead. They could just send a text message to me saying "Hey it's your friendly greengrocer, I totes have cherries in stock". This is the problem with our webhook endpoint as currently set up. Anyone could send a POST request to https://example.com/gh-library-map and trigger an action. Luckily GitHub has thought of that, and has a solution.
Remember the "Secret" we set when we set up the webhook? This is where we use it. But not directly. GitHub instead creates a SHA256 hash of the entire payload using your secret and includes the resulting hash in the payload itself. The hash is sent in a header called X-Hub-Signature-256. We know what our secret is, and we can therefore check the hash by running the same process over the payload at the receiving end as GitHub did at the sending end. As long as we use a strong secret and the hashes match, we can be confident the request did indeed come from GitHub, and not a nefarious strawberry farmer. The crypto library is included in nodejs automatically, so we can use that check:
// webhook.js
const crypto = require('crypto')
app.post('/gh-library-map', (req, res, next) => {
const hmac = crypto.createHmac('sha256', process.env.LIBRARY_MAP_GH_SECRET)
hmac.update(JSON.stringify(req.body))
// check has signature header and the decrypted signature matches
if (req.get('X-Hub-Signature-256')) {
if ( `sha256=${hmac.digest('hex').toString()}` === req.get('X-Hub-Signature-256') ){
// do something
} else {
console.error("signature header received but hash did not match")
res.status(403).send('Signature is missing or does not match')
}
} else {
console.error('Signature missing')
res.status(403).send('Signature is missing or does not match')
}
})
Now we just need to "do something" when the hash matches 😆.
Push and Pull
So what is the something we're going to do? The Library Map server simply contains a copy of the repository, sitting behind an nginx web proxy server. What we need to do to update it is run git pull inside that directory, and it will pull in the latest updates from the repository. Our webhook will end up calling this action more often than is strictly useful, because a "push" action happens every time someone creates a pull request, for example, but it's pretty harmless to git pull more often than necessary.
First we create a new function:
// webhook.js
const util = require('util')
const exec = util.promisify(require('child_process').exec) // run child_process.exec as a Promise/async
async function gitPull(local_repo, res) {
try {
const { stdout, stderr } = await exec(`cd ${local_repo} && git pull`);
let msg = stderr ? stderr : stdout // message is the error message if there is one, else the stdout
// do something with message
res.status(200).send('Ok')
} catch (err) {
console.error(err)
res.status(500).send('server error sorry about that')
}
}
This function is async because we need to await the git pull before we can do something with the output. To make it "awaitable" we use util.promisify() which is another built-in function in nodejs. We call this function back in our express route, where we said we would "do something":
// webhook.js
const local_repo = "/path/to/website/directory"
if (req.get('X-Hub-Signature-256')) {
if ( `sha256=${hmac.digest('hex').toString()}` === req.get('X-Hub-Signature-256') ){
gitPull(local_repo, res)
} else { ...
}
...
}
Sweet! Now every time someone does a git push we can do a git pull to add the change to the website! Maybe we want to be sure that happened though, so we can add a final piece to this, by sending ourselves an email using emailjs every time the webhook is successfully received:
npm install emailjs
// webhook.js
const { SMTPClient } = require('emailjs')
function sendEmail(msg, trigger) {
const client = new SMTPClient({
user: process.env.EMAIL_USER,
password: process.env.EMAIL_PASSWORD,
host: process.env.SMTP_DOMAIN,
ssl: true,
});
// send the message and get a callback with an error or details of the message that was sent
client.send(
{
text: `GitHub webhook for ${trigger} has triggered a "git pull" event with the following result:\n\n${msg}`,
from: `Webhook Alerts<${process.env.EMAIL_SEND_ADDRESS}>`,
to: process.env.EMAIL_RECEIVE_ADDRESS,
subject: `GitHub triggered a pull for ${trigger}`,
},
(err, message) => {
console.log(err || message);
}
);
}
async function gitPull(local_repo, res) {
try {
const { stdout, stderr } = await exec(`cd ${local_repo} && git pull`);
let msg = stderr ? stderr : stdout
sendEmail(msg, 'mysite.com')
res.status(200).send('Ok')
} catch (err) {
console.error(err)
res.status(500).send('server error sorry about that')
}
}
We can now test the webhook:
node webhooks.js
Express will start up. We can use curl to send some test payloads from a new console session on our local machine:
curl -d '{"key1":"value1", "key2":"value2"}' -H "Content-Type: application/json" -X POST https://example.com/gh-library-map
curl -H "X-Hub-Signature-256: blah" -d '{"key1":"value1", "key2":"value2"}' -H "Content-Type: application/json" -X POST https://example.com/gh-library-map
Both requests should return a 403 with Signature is missing or does not match, but in the server console the second one should log a message signature header received but hash did not match.
The last thing we need to do is set up our little express app to run automatically as a background process on the server. We can do this using systemd. I personally find the official documentation rather impenetrable, but there are lots of helpful tutorials online. Systemd helps us with two tasks:
- keeping the app running
- making the environment variables available to the app
First we create a "unit file" called webhooks.service at /etc/systemd/system:
# /etc/systemd/system/webhooks.service
Description=Keeps the webhooks express server running
After=network.target
[Service]
Type=simple
ExecStart=/usr/bin/node webhooks.js
Restart=always
RestartSec=10
User=username
WorkingDirectory=/home/username/webhooks
EnvironmentFile=/etc/systemd/system/webhooks.env
[Install]
WantedBy=multi-user.target
The User is your username, and WorkingDirectory is wherever you installed your express app. Since we're responsible server administrators, we have unattended-upgrades running, so occasionally the server will reboot itself to finish installing security updates. We can ensure the webhooks service always comes back up by setting Restart to always.
Next we create the EnvironmentFile mentioned in the unit file:
# /etc/systemd/system/webhooks.env
LIBRARY_MAP_GH_SECRET="your GitHub secret here"
EMAIL_USER="user@mail.example.com"
EMAIL_PASSWORD="top secret password"
SMTP_DOMAIN="smtp.example.com"
EMAIL_SEND_ADDRESS="webhooks@mail.example.com"
This is where all those process.env values come from in the webhooks.js file. We could hardcode them, but you might want to share your file in a blog post one day, and you definitely don't want to accidentally leave your hardcoded GitHub secret in the example!
Make sure we've stopped the app, so we don't have two conflicting installations, then run:
sudo systemctl enable webhooks.service
sudo systemctl start webhooks.service
Our webhooks service should now be running. Go back to the GitHub webhooks page in your repository settings and you should see an option to send a "ping event". This simply checks that your webhook is working by sending a test payload. Send the ping, wait a few moments, and we should see an email appear in the EMAIL_SEND_ADDRESS inbox:

What's next?
That was a pretty long and technical post, sorry not sorry. Now that I've set up all that automation, it would be great for library people to help correct and complete the data. As for me, I'll be looking for other things I can do with automation. Maybe automatically tooting release notes for ephemetoot. We'll see.















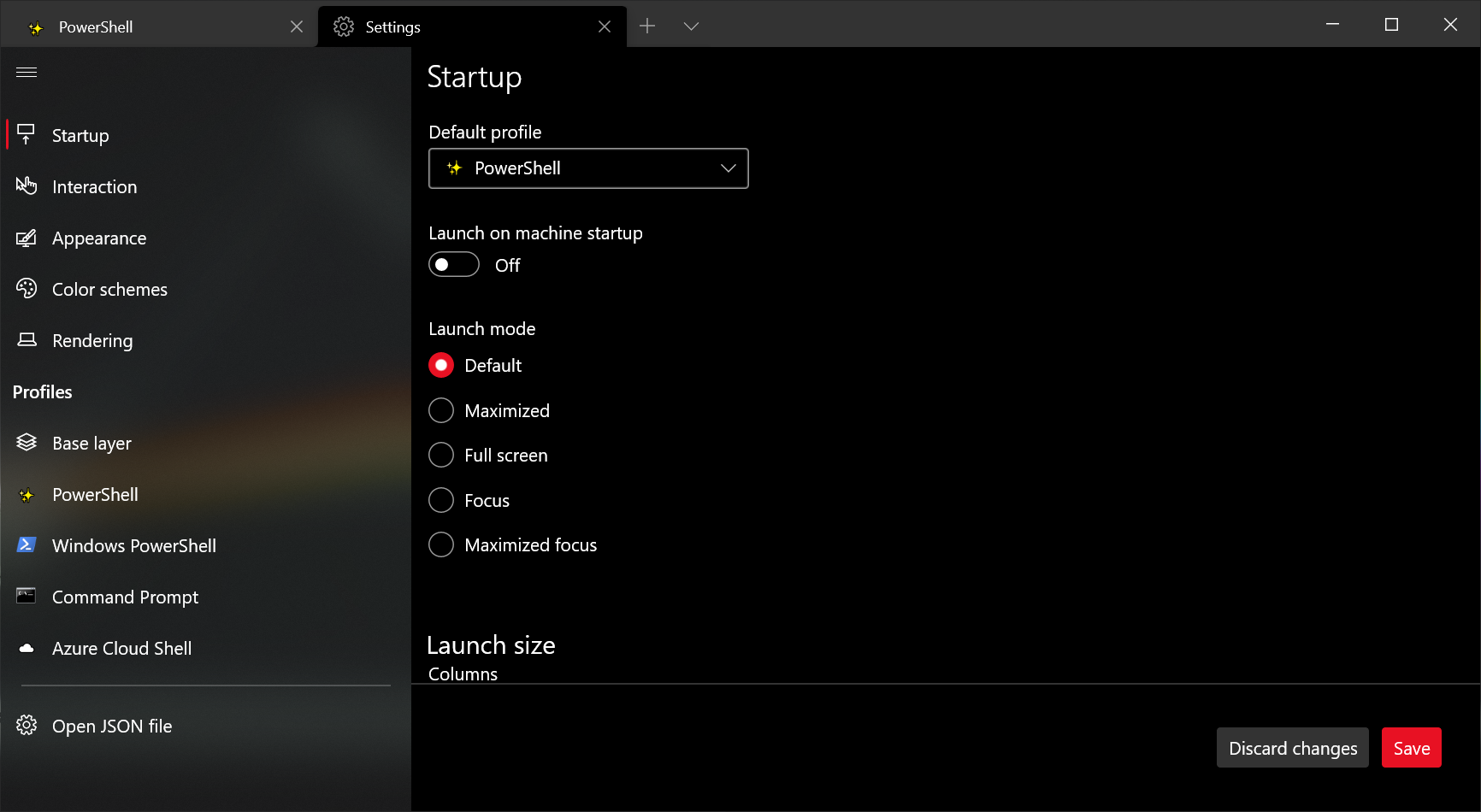
 Note: This setting is not yet available in the settings UI and is only available by editing the settings.json file.
Note: This setting is not yet available in the settings UI and is only available by editing the settings.json file.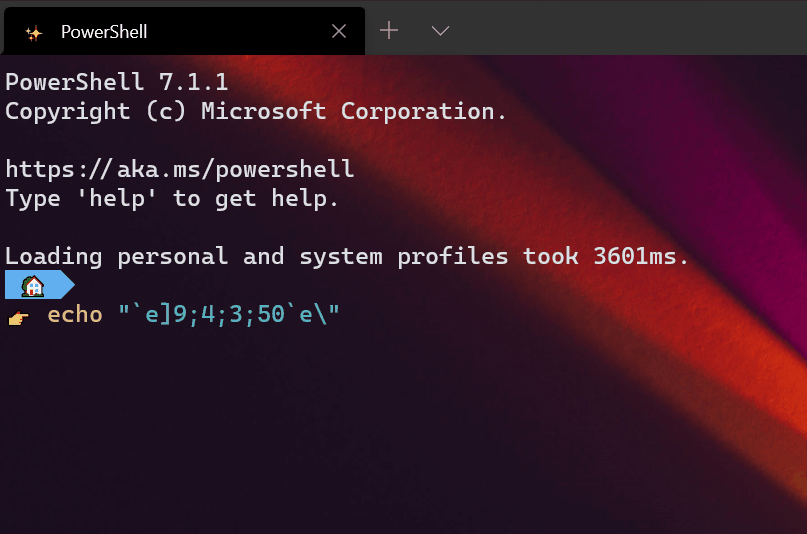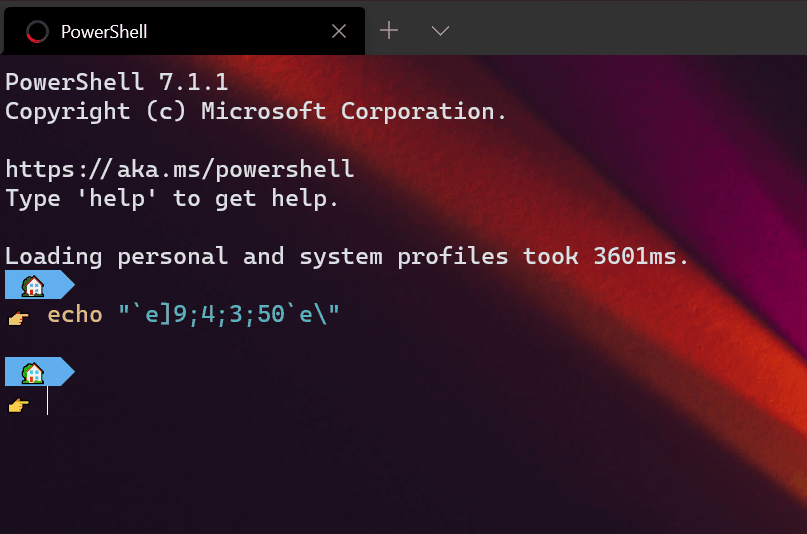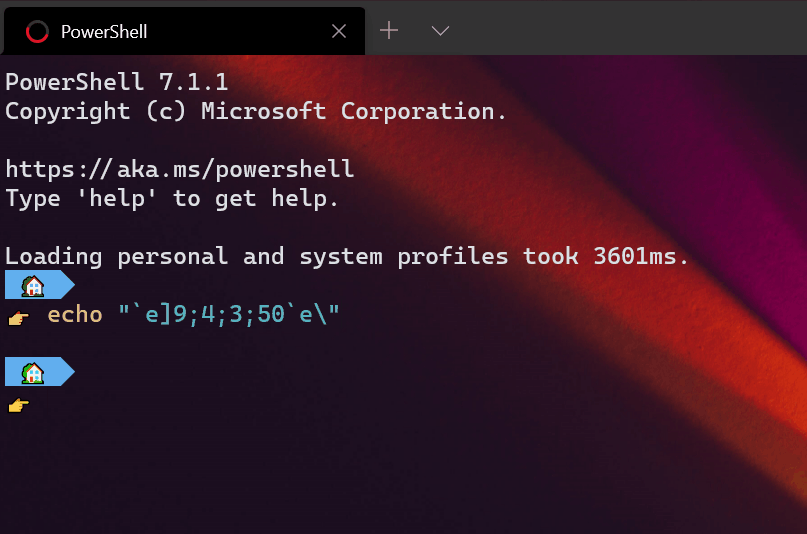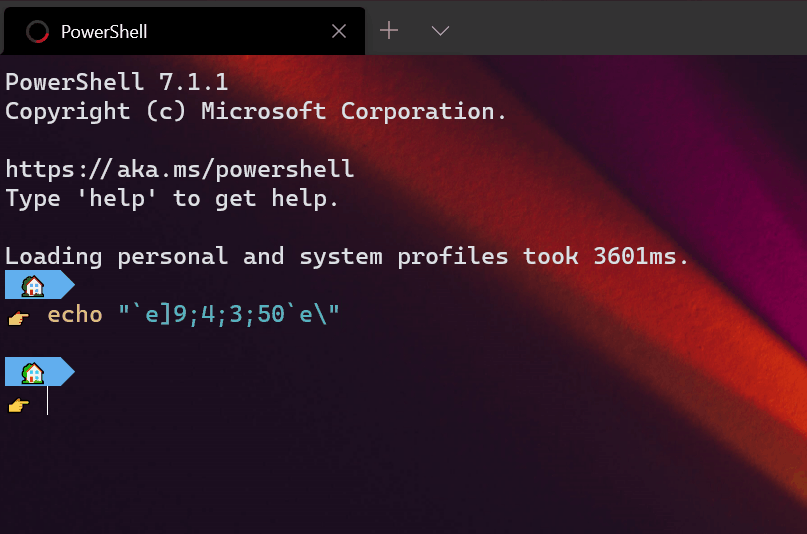
 The
The  The “Open Windows Terminal here” menu item will now show up inside directories (Thanks
The “Open Windows Terminal here” menu item will now show up inside directories (Thanks  Hyperlinks will display an underline on hover even when the window isn’t focused (Thanks
Hyperlinks will display an underline on hover even when the window isn’t focused (Thanks 



 Speeding up the process of changing the Mac’s default audio devices has always been one of SoundSource’s strong suits. With our newest in-app keyboard shortcuts, switching your devices is now faster than ever. Use SoundSource’s global hotkey to reveal SoundSource, then hit Cmd-0 to select the default output device. Arrow to your desired device, hit Return, and you’re done. Similarly, Cmd-Hyphen (-) gets you to the Mac’s default input device, while Cmd-1 through Cmd-9 will let you adjust application-specific output devices.
Speeding up the process of changing the Mac’s default audio devices has always been one of SoundSource’s strong suits. With our newest in-app keyboard shortcuts, switching your devices is now faster than ever. Use SoundSource’s global hotkey to reveal SoundSource, then hit Cmd-0 to select the default output device. Arrow to your desired device, hit Return, and you’re done. Similarly, Cmd-Hyphen (-) gets you to the Mac’s default input device, while Cmd-1 through Cmd-9 will let you adjust application-specific output devices. Many other areas of the app also feature supercharged keyboard control. When a slider is selected, typing a numerical value will now set it precisely. In addition, modifiers are now supported when using arrow keys to adjust sliders, with Shift-arrow providing a 10x modification and Option-arrow providing a 0.1x modification. Finally, tabbing between Audio Unit controls has been refined, making keyboard entry a breeze.
Many other areas of the app also feature supercharged keyboard control. When a slider is selected, typing a numerical value will now set it precisely. In addition, modifiers are now supported when using arrow keys to adjust sliders, with Shift-arrow providing a 10x modification and Option-arrow providing a 0.1x modification. Finally, tabbing between Audio Unit controls has been refined, making keyboard entry a breeze. Speaking of Audio Units, they’re now hosted in a separate process, which prevents misbehaving plugins from crashing SoundSource. On the newest M1 Macs, this enables top-notch support for Intel-based plugins running in emulation. To improve the Audio Unit experience still more, the display of MacOS’s built-in Audio Unit effects has been streamlined, with a more appealing interface that avoids redundancy.
Speaking of Audio Units, they’re now hosted in a separate process, which prevents misbehaving plugins from crashing SoundSource. On the newest M1 Macs, this enables top-notch support for Intel-based plugins running in emulation. To improve the Audio Unit experience still more, the display of MacOS’s built-in Audio Unit effects has been streamlined, with a more appealing interface that avoids redundancy. If you frequently make adjustments to effects in SoundSource, you’ll love the new “Bypass Effects” option. With it, you can quickly disable all effects processing on individual applications or the default output device, making it easy to A/B test your changes. Even better, the handy “Bypass Effects” keyboard shortcut (Option-Command-B) makes experimenting to get the perfect sound lightning fast.
If you frequently make adjustments to effects in SoundSource, you’ll love the new “Bypass Effects” option. With it, you can quickly disable all effects processing on individual applications or the default output device, making it easy to A/B test your changes. Even better, the handy “Bypass Effects” keyboard shortcut (Option-Command-B) makes experimenting to get the perfect sound lightning fast. There’s lots more when it comes to improvements for audio effects. The “Headphone EQ” effect can now load custom-created profiles, as well as files exported from Room EQ Wizard (REW). Effects can now be duplicated by copy and pasting. Using generic interfaces with Audio Units is now even easier, with an Option-click loading the generic interface once, while holding option when adding an Audio Unit will automatically toggle on the “Use Generic Audio Unit Interface” setting.
There’s lots more when it comes to improvements for audio effects. The “Headphone EQ” effect can now load custom-created profiles, as well as files exported from Room EQ Wizard (REW). Effects can now be duplicated by copy and pasting. Using generic interfaces with Audio Units is now even easier, with an Option-click loading the generic interface once, while holding option when adding an Audio Unit will automatically toggle on the “Use Generic Audio Unit Interface” setting.

 With this update to SoundSource, all of our products are now fully compatible with the new M1-based Macs, powered by Apple Silicon. Of course, they also have full compatibility with MacOS 11 (Big Sur) running on Intel.
With this update to SoundSource, all of our products are now fully compatible with the new M1-based Macs, powered by Apple Silicon. Of course, they also have full compatibility with MacOS 11 (Big Sur) running on Intel.
















 are on you.
are on you.
 only
only




















{kind=link}