It is with great pleasure that we are launching this new blog dedicated to Firefox Nightly, Nightly users and getting involved in Firefox and Mozilla contribution through Nightly.
Firefox Nightly is the earliest development stage of Firefox, rebuilt every night from the latest code produced by Mozilla. It is literally a glimpse of what the Future of Firefox will be.
Of course, this is not software meant to be used by the general public, its user base consists of developers, testers and power users that love to live on the bleeding edge of technology. They accept that some features may be unfinished, that the product has bugs or occasionally suffers from regressions that would not happen with a regular version of Firefox.
Today, tens of thousands of people use Nightly either as their main browser or as their secondary browser. That’s a lot but, ideally, we would be a lot more people using Nightly, reporting our bugs and crashes and generally speaking providing a healthy feedback loop to developers. The better the quality on Nightly, the greatest will be Firefox for the hundreds of millions of people that use Firefox to access and control their online life.
We intend this blog to be a stable point of information about what happens on Nightly, what features or core technologies landed, how Nightly users can help Mozilla fix bugs and regressions and more generally how a tech-savvy person can move from being a consumer of Firefox to a contributor of Firefox.
The initial team of writers for this blog is comprised of Marcia Knous and Pascal Chevrel from the Release Management team, and Jean-Yves Perrier from the MDN team. Three Mozilla old-timers and community builders. But this blog is also open to guest writers: Developers landing a feature and that may want to present it, Quality Assurance testers willing to explain how to report a bug or find a regression range, community members that want to relate their experience promoting Nightly in their region… You are all welcome here and can contact me (pascal AT mozilla DOT com) if you want to write content or help promote Nightly to the technical crowd.
Are you a power user and not a Firefox Nightly user yet? Then visit our download page and download it for your platform. This page only lists English (en-US) builds for desktop, we actually have the same builds available in many languages on our FTP site and yes, reporting typos or mistranslations in Nightly is also useful for our quality!
Bookmark this site, follow its RSS feed, follow us on Twitter because there is more to come soon!
During the recent Work Week in London we had the utmost pleasure of hanging out with some of you (we’re still a bit sad about not everyone making it… and that we couldn’t organize a meetup for everyone contributing to everything around Mozilla).
Among the numerous sessions, working groups, presentations, and demos we also had a SUMO Show & Tell – a story-telling session where everyone could showcase one cool thing they think everyone should know about.
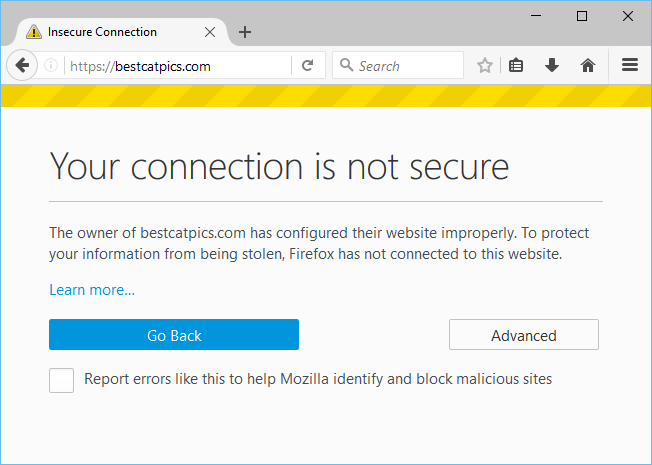
Take a look below and learn how we’re dealing with certificate errors and what the future holds in store:
One of the most common and prolonged user problems we face at SUMO and all other support channels is users being unable to visit secure HTTPS websites because they see something like this instead:
From Firefox telemetry data we know that at least 115 million users a month end up seeing such an error page – probably even more, because Firefox telemetry is depending on a working HTTPS connection as well, of course (we do care about our users’ privacy!).
Since the release of Firefox 44 there is a “Learn more…” link on those error pages, pointing to our What does “Your connection is not secure” mean? article, which quickly became the most visited troubleshooting article on SUMO after that (1.3 million monthly visitors). We try to lead users through a list of common fixes and troubleshooting steps in the article, but because there is a whole array of underlying issues that might cause such errors (for example – misconfigured web servers or networks, a skewed clock on a device, intercepted connections) and the error message we show is not very detailed, it’s not always easy for users to navigate around those problems.
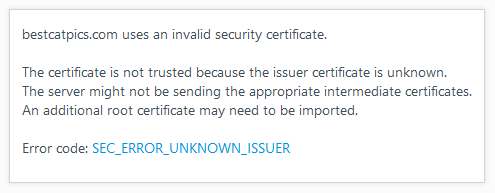
The most common cause triggering these error pages according to our experience at SUMO is a “man-in-the-middle attack”. When that happens, Firefox does not get to see the trusted certificate of the website you’re supposed to be connected to, because something is intercepting the connection and is replacing the genuine certificate. Sometimes, it can be caused by malware present within the operating system, but the software causing this doesn’t always have to be malicious by nature – security software from well-known vendors like Kaspersky, Avast, BitDefender and others will trigger the error page, as it’s trying to get into the middle of encrypted connections to perform scanning or other tasks. In this case, affected users will see the error code SEC_ERROR_UNKNOWN_ISSUER when they click on the “Advanced”-button on the error page:
In order to avoid that, those software products will place their certificate (that they use to intercept secure connections) into your browser’s trusted certificate store. However, since Firefox is implementing its own store of trusted certificates and isn’t relying on the operating system for this, things are bound to go wrong more easily for us: maybe the external software is failing to properly place its certificates in the Firefox trust store or it only does so once during its original setup but a user installs and starts to use Firefox later on, or a user might just refresh his Firefox profile and all custom certificates get lost in the process, or… You get the picture – so many ways things could go wrong!
As a result, a user might have problems accessing any sites using HTTPS (including personal or work email, favourite search engines, social networks or web banking) in Firefox, but other browsers will still continue to work as expected – so, we are in danger of disappointing and discouraging users from using Firefox!
Starting with Firefox 48, scheduled to be released in early August, users who land on a certificate error page due to a suspected “man-in-the-middle” attack, will now be lead to this custom-made SUMO article after they click on “Learn more” (Bug 1242886 – big thanks to Johann Hofmann for implementing that!). The article contains known workarounds tailored for various security suites, which can hopefully put many more affected users in the position to fix the issue and get their Firefox working securely and as expected again.
Ideally, I would imagine that we would not prohibit Firefox users from loading secure pages when a certificate from a known security software is used to intercept a secure connection in the first place… But we might find more subtle ways of helping the user realise that their connection might be monitored for safety reasons, rather than intercepted for malicious purposes.
…thank you, Philipp! What is certain is that we won’t stop there and will continue to work on reducing the biggest user pain-points from within the product wherever possible…
We also won’t stop posting more stories from the Show & Tell – at least until we run out of them ;-) I hope you enjoyed Philipp’s insight into one of the complex aspects of internet security, as provided by Firefox.
One of the power of the web ( at least for me) is linking and embedding content (like images and videos) to make new content. I have been taking digital pictures since 2006 and using flickr to host these.
About a month ago, I deleted that flickr account with 10 years of shots ( I probably have raws somewhere, but ain’t sure and some would be hard to dig out). Before deleting the account I used flickr touch to backup my pictures (had to patch it to save non ascii stuff I had). I thought I had lost most of the picture metadata, but no, most of it is still there , the one that was embedded in the jpeg by lightroom before uploading. (and yes I was a lightroom user). Deleting the account broke the web, like this web post, even flickr got broken by it, because all the pictures I use to host are now returning 404s. I’m sorry I broke the web.
Of course I couldn’t live without pictures , so I’ve reopen a new flickr account :)(more on that later. I’ve lost my grandfather right to host unlimited, I’m now limited to 1TB. I’m also rebuilding my flickr presence there and posting for now only my best pics (mostly animals, birds and landscapes). If I had a portrait of you you liked, ask me and I’ll dig it up, same for group pictures, but if not asked for it’s very probable that these pictures will be gone forever from the web. The good news is that I’ve changed my default license to a more open one.
Why did I choose to go back to flickr ?
I know how it works.
I have plenty of contacts there (even if some are not active anymore).
I like the L shortcut when looking at the picture.
Roy MacGregor@RoyMacG
"Give the game back to the players!" - PK Subban, Taylor Hall, Rogers' numbers and the curse of over-coaching. ln.is/theglobeandmai…
Graham Ballantyne@gnb
I would pay good money for a @tweetbot update that, upon encountering an Instagram URL, somehow pulled in the full caption instead of the…
This is a follow-up post to this essay on accusations of censorship on Reddit and the unpredictable consequences of algorithmic quirks.
Reddit is the self-described “front page of the internet.” Millions of users rely on Reddit to keep them informed on a wide range of topics from world news to gaming developments to the latest in pictures of cute dogs (or, often as not, reposts of pictures of cute dogs). But what happens when the front page fails us, and how do Reddit administrators respond?
In the aftermath of the Reddit debacle surrounding /r/news deletions of posts about the Orlando shooting, Reddit has rolled out new changes to the algorithm that ranks posts on /r/all. /r/all is the frontest of Reddit front pages; it is the algorithmic ranking of popular posts from all subreddits that 1) choose to be featured on the front page and 2) haven’t been quarantined based on questionable (read: bigoted) content. The exact details of Reddit’s ranking algorithm are complicated and unnecessary for this brief discussion, but it’s essentially a combination of when something was posted, how many upvotes it has received, and how recently it’s been upvoted. Time + Attention = Rank. You can read more about it in this (slightly dated) explainer.
According to Reddit CEO Steve Huffman, /u/spez, the new algorithm has been in the works for a while but was implemented earlier than intended given recent events. The quick and dirty of the incident is: /r/news mods deleted a large number of posts and comments on the Orlando shooting, leaving a huge chasm on the front page that was filled with reports from the Donald Trump subreddit /r/The_Donald. Redditors were (rightfully) outraged that the incident was only being reported on by a widely-despised, non news-related subreddit.
Huffman announced the changes shortly after the /r/The_Donald incident in a post that he called a “town hall” about /r/all. In it, he argued that “/r/all is a reflection of what is happening online in general. It is culturally important and drives many conversations around the world.” Leaving aside the grandiosity of this statement, Reddit is undoubtedly an important source for the millions of users who depend on the site to stay up to date on new, popular online content.
The changes to the algorithm are, to hear Huffman describe them, relatively simple. The goal is to “prevent any one community from dominating the listing… as a community is represented more and more often in the listing, the hotness of its posts will be increasingly lessened. This results in more variety in /r/all.” In other words, /r/The_Donald, or any other subreddit, can’t completely take over the front page.
For most users, Reddit’s algorithm is a black box. Content goes in, content comes out, and what happens in-between is neither comprehensible nor relevant. However, when the input and output of Reddit’s black box changes significantly, everyone notices.
Initial reactions in Huffman’s “town hall” thread were largely positive and hopeful. But in the following days and weeks, some redditors began noticing a major, frustrating change: not enough new content. An undoubtedly unintended consequence of the change was greater stability on /r/all, with posts hanging around longer and new content rising to the top much more slowly.
Also, porn. Lots of porn. The insurgence of porn on the first few pages of /r/all is likely due to two factors: 1) porn is really popular on Reddit and 2) there are so many porn subreddits that the possibility of any one of them overtaking /r/all and, subsequently, getting pushed down the listing is less likely.
Of course, porn is one of those things where even a small uptick is very noticeable. So just how much of /r/all is porn, relative to other things? This morning I did a rough analysis of the first five pages (top 100 posts) of /r/all. Here’s a general breakdown of the number of posts related to each of these popular topics:
Pets: 6
Sports: 6
Gifs (funny, interesting, reaction): 12
Gaming: 11
News: 3
Politics: 3
Porn: 12
It was a lot of porn. Porn’s only real competitors are gaming and gifs, and “gifs” comprises so many different topics it hardly seems fair to count it as a category. The amount of porn content on /r/all has gotten so large that some users have asked for a safe-for-work version of /r/all so they can browse during office hours.
So the algorithm change that was supposed to prevent large subreddits like /r/the_donald from dominating the front pages of /r/all has instead paved the way for a mass of porn and significantly reduced the amount of news content, while also reducing the frequency with which content changes. If most of /r/all’s news content comes from the large subreddits like /r/news, /r/worldnews, and /r/politics, then the new algorithm makes it less likely for multiple posts from these large subreddits on various topics to make it to the top pages. Meanwhile, because there are so many porn subreddits, it’s easy for that content to rise to the top.
In trying to develop some conclusions about this phenomenon, I spoke with my media studies colleague Nick Hanford. He was struck by Huffman’s description of the changes to the algorithm, and of Reddit generally, as constructing some sort of Platonic Ideal of the internet; a “true” representation of what is “really” happening at any given moment online. This is certainly one of the failings of Reddit’s /r/all algorithm, both before and after the change; it cannot hope to accomplish the lofty aims set by Huffman because the internet is a many-sided prism, and it cannot be reflected on a flat page of ranked, numbered posts. My internet may have significantly more recipes or cat gifs than yours, and “what is happening online in general” as Huffman puts it will vary greatly from region to region, not to mention various subcultural groups. /r/all can never really be /r/all, it is necessarily /r/some.
Perhaps the biggest takeaway from this story is best summed up by Mr. Hanford: “PORN RULES ALL, ESPECIALLY SO-CALLED DEMOCRACIES.”*
BlackBerry informed Verizon and AT&T that production of all BlackBerry OS 10 devices (Q10, Z10, Z30, Passport, and Classic) has been discontinued. Future carrier order fulfillment will not be guaranteed due to limited remaining stock.
This leaves a little wiggle room, because that message could be that production of branded phones for Verizon and AT& has stopped.
Despite reports of lackluster sales for its first Android smartphone, BlackBerry is tripling down on the platform in the coming year. According to a person briefed on the company’s plans, the Canadian manufacturer will be releasing one phone per quarter for the next three quarters.
There is one number frequently misreported. When The Verge et.al. report lackluster sales of the PRIV, they often say that BlackBerry only sold 600.000 in a quarter. That number is the total number of smartphones sold, not the number of PRIVs. My educated guess is that this number should be closer to 100.000.
The past few years have seen a dramatic improvement in display technology. First it was the upgrade to higher-resolution screens, starting with mobile devices and then desktops and laptops. Web developers had to understand high-DPI and know how to implement page designs that used this extra resolution. The next revolutionary improvement in displays is happening now: better color reproduction. Here I’ll explain what that means, and how you, the Web developer, can detect such displays and provide a better experience for your users.
Let’s call the typical computer monitor, the type that you’ve been using for more than a decade, an sRGB display. Apple’s recent hardware, including the late-2015 Retina iMac and early-2016 iPad Pro, are able to show more colors than an sRGB display. Such displays are called wide-gamut (I’ll explain what sRGB and gamut are below).
Why is this useful? A wide-gamut system will often provide a more accurate representation of the original color. For example, my colleague @hober has some extremely funky shoes.
Unfortunately, what you’re seeing above doesn’t really convey just how funky the shoes are! The problem is the shoe fabric uses colors that are unable to be represented by an sRGB display. The camera that took the photograph (Sony a6300) has a sensor that is able to capture more accurate color information, and that data are included in the original file, but the display can’t show it. Here’s a version of the photo where every pixel that used a color outside the range of a typical display has been replaced with a light blue:
As you can see, the colors on the shoe fabric and much of the grass are outside the range of the sRGB display. In fact, fewer than half of the pixels in the photograph are accurately represented. As a Web developer, you should be concerned by this. Suppose you’re an online store selling these shoes. Your customers are not going to know exactly what color they’ve ordered, and might be surprised when their purchase arrives.
This problem is lessened with a wide-gamut display. If you have one of the devices mentioned above, or a similar device, here is a version of the photograph that will show you more colors:
For those of you on a wide-gamut display, you’ll see the shoes are a brighter orange, and there is slightly more variation in the green grass. Unfortunately, if you don’t have a wide-gamut display, you’re probably seeing something very close to the first image above. In this case, the best I can offer is that tinted image that highlights which parts of the image you’re missing out on.
Anyway, this is great news! Wide-gamut displays are more vibrant, and provide a more accurate depiction of reality. Obviously you’re going to want to make sure you serve your users with imagery that makes use of this technology.
Here’s another example, this time with a generated image. To users on an sRGB display there is a uniform red square below. However, it’s a bit of a trick. There are actually two different shades of red in that image, one of which is only distinct on wide-gamut displays. On such a display you’ll see a faint WebKit logo inside the red square.
Sometimes the difference between a normal and wide-gamut image is subtle. Sometimes it is more dramatic.
Demo
Take a look at this page of examples that lets you swap between different versions of images to compare, as well as shows you where in the image there are pixels outside of the range of an sRGB display. There’s also a slightly more interactive version that shows you the different images side by side.
Definitions
Here’s a quick explainer for terms you often hear when discussing color.
Color Space: A color space is an environment in which you can define and compare colors. There are a few types of color spaces, each using a different set of parameters to describe the colors. For example, a greyscale color space only has one parameter which controls the level of brightness going from black to white. You’re probably familiar with RGB-type color spaces that use red, green, and blue as parameters representing the colors of the lights in a display that add together to make a final color. Print workflows often use CMYK-type color spaces, where cyan, magenta, yellow, and black are the parameters representing the colors of the inks.
Color Profile: In 1993, a group of vendors formed the ICC to define a standard that described color spaces. A color profile is data that defines what the color space of a device is, and can be used to convert between different spaces. The common ones are given names, such as sRGB (or more formally, IEC 61966-2-1). My use of sRGB above now makes a bit more sense: such a display is able to show colors corresponding to the sRGB color space. Color profile data can be written to a file, or embedded directly into an image, which allows a computer to understand what the color values in the image actually mean.
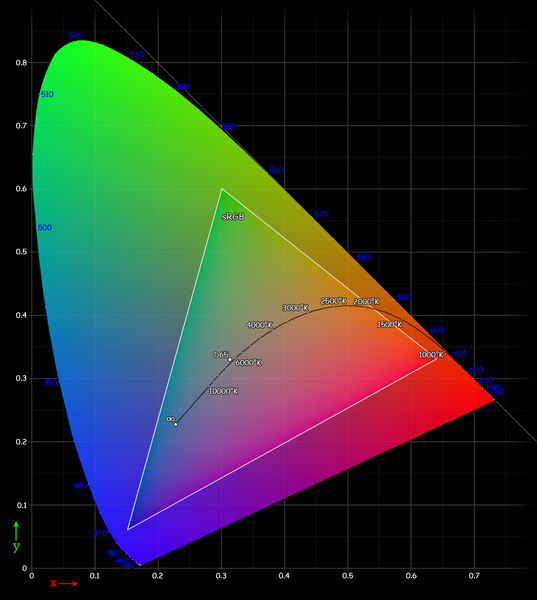
Gamut: A gamut is the range of colors a device can process, or that a color space can define. In the case of a computer display, a gamut is all the colors it can accurately show. Visualizing a gamut is a bit complicated, but it is slightly similar to the color pickers you see in design software. Imagine the range of all possible colors applied to a surface, with the primary colors at different extremes. As you move towards the red extreme, the color gets more red. Moving towards blue, more blue, etc. A gamut is the area on this imaginary surface that represents as far as the device can go in all directions. You might see a gamut represented with a diagram such as this, where the colored shape is showing what a typical human eye can see, and the white triangle shows the range of the sRGB color space (as you notice, it’s a lot smaller than what the eye could detect).
These diagrams can be a bit misleading because they are showing you colors that you can obviously see, and then telling you that a gamut doesn’t include those colors. However, they do give you a nice way to compare the size of different gamuts. Note also that here you’re seeing a two-dimensional representation of a color gamut surface, when in reality it is a three- or four-dimensional space (this is all pretty complicated – we’re just trying to give a simple introduction).
Wide-gamut: This is an informal term that the industry is using to describe devices or color spaces that have a gamut larger than sRGB, which is the gamut that nearly all computer displays have used for the last decade or so. Wider gamut displays have been around for a while, but were mostly limited to professional use. Now they are becoming available to regular consumers, which means that there are more colors available. Sometimes wide-gamut is also referred to as extended color. The modern Apple displays support the Display P3 color space, which is about 25% wider than sRGB.
Color Depth: Computers can use varying levels of precision, or depth, to represent a color. This is not the same as gamut, which describes a range of colors. Rather it is the number of distinct colors within the gamut that can be defined. Web developers are probably familiar with the CSS rgb() syntax, which takes 0-255 values for red, green and blue. That is a depth of 8 bits per channel, for a total of 16,777,216 different colors. If you add in alpha/opacity, you can store the color in 32 bits. If you use a depth of 8 bits per channel, you can only ever represent that same number of colors, no matter what color space you’re using – it would just be a different set of colors. If you chose 16 bits per channel, you would have a deeper space, and could represent more colors within the gamut. A good example of this is when you draw a gradient between similar colors: you can see banding, where the computer and display don’t have the depth to show a smooth range of colors between the end points.
Here is an example which shows how a lack of color depth produces banding, even though all the colors between the end points are within the gamut (it’s an artificial example to exaggerate the effect).
A smaller color depth might demonstrate distinct jumps between similar colors.
With a larger color depth, the jumps are much less noticeable.
With that introduction, let’s get into the details of color on the Web and recent improvements in WebKit to help you develop content that is more aware of color. We also introduce some features we’ve proposed to the W3C that will allow you to take even more advantage of this new display technology.
Colors on the Web
The Web has often struggled to handle colors correctly. I’m sure there are some readers out there who painfully remember Web-safe colors! While we’ve moved on from that, we still have limitations, such as HTML and CSS having been defined to work only in the sRGB color space. Just like the example of hober‘s shoes above, this means there are many colors that your CSS, images, and canvas are unable to represent. This is a problem if you’re trying to show your family the spring flowers blooming in your garden, or shopping for a bright red sports car to help with your mid-life crisis.
So when we showed the photograph of the shoes above, an sRGB display squished all the colors outside the sRGB gamut into colors that it could show. But a display with a wider gamut such as Display P3 didn’t need to squish into sRGB. Here’s a visual representation showing the difference between sRGB and the Display P3 color space.
The colored triangle is the sRGB space. The white triangle shows the coverage of the Display P3 space, significantly bigger than sRGB, particularly in the more saturated reds, yellows, purples and greens. The black outline shows the ability of the typical human eye.
Remember the red square with the faint WebKit logo? That was generated by creating an image in the Display P3 color space, filling it with 100% red, rgb(255, 0, 0), and then painting the logo in a slightly different red, rgb(241, 0, 0). On an sRGB display, you can’t see the logo, because all the red values above 241 in Display P3 are beyond the highest red in sRGB, so the 241 red and the 255 red end up as the same color.
Note: I saw a bit of confusion about this on Twitter, so let’s try an alternate explanation. Basically, all the fully red values between 241/255 and 255/255 in the Display P3 color space are indistinguishable when shown in sRGB. This doesn’t mean that a 241 red from Display P3 is the same as a 255 red in sRGB – unfortunately, it’s not quite that simple and I don’t want to get too detailed in this introductory article. For those who are interested, on macOS there is an app called Color Sync Utility that allows you to convert between color spaces in different ways, as well as comparing gamuts.
So now you understand why you should be aware of color, and that you should use this technology to give users a better experience. That’s the background — let’s talk about what this means for WebKit.
Color-matching Images
We mentioned above that the Web is defined to use sRGB. WebKit/Safari on Mac has operated in this color space for a number of years now, meaning you’d get consistent colors across different displays (at the time of writing, most other browser engines just operate in what’s called the device color space, which means they don’t process the color values before passing them on to the display hardware).
WebKit color-matches all images on both iOS and macOS. This means that if the image has a color profile, we will make sure the colors in the image are accurately represented on the display, whether it is normal or wide gamut. This is useful since many digital cameras don’t use sRGB in their raw format, so simply interpreting the red, green and blue values as such is unlikely to produce the correct color. Typically, you won’t have to do anything to get this color-matching. Nearly all image processing software allows you to tag an image with a color profile, and many do it by default.
With the examples linked above, you’re seeing this color-matching in action on Safari from OS X 10.11.3 and above, as well as iOS 9.3 and above (Retina devices). All I had to do was make sure that the images had been tagged with the appropriate color profile.
If an image doesn’t have a tagged profile, WebKit assumes that it is sRGB. This makes it easy for your generated artwork, such as border and background images, to match what you have defined in CSS. That is, a CSS value of rgb(255, 0, 0) would match the corresponding full sRGB red value.
Note: This was another point that provoked some comment, with some suggesting an untagged image should not be assumed to be sRGB. The reason we do this is explained above: it’s to make sure that colors in the image match the CSS colors in the page.
That’s ok for the display technology from the last decade. But now that we have displays that support a wider gamut, you’ll want more control over how your content is shown.
Detecting the Display
I’ve explained above why you should prefer to serve wide-gamut images to users on a wide-gamut display. If you serve wide-gamut images to users not on a wide-gamut display, WebKit will color-match the images and show them in the sRGB space. However, this conversion into sRGB can be done a few ways and isn’t guaranteed to happen identically on other browsers or platforms. As a discerning Web developer or designer you will want to convert your images offline to better control what the end user will see. Also, embedding the color profile adds a little to the file size, so you might not want to send that extra data if it isn’t necessary.
The best solution is to serve a wide-gamut image when the user is on a wide-gamut display, and an sRGB image when the user is not on a wide-gamut display. This is just another case of responsive images, and is exactly what the element and media queries were designed to handle.
WebKit now supports the (new to CSS Color Level 4) color-gamut media query. Here’s how you use it:
if (window.matchMedia("(color-gamut: p3)").matches) {
// Do especially colorful stuff here.
}
The color-gamut query accepts p3 and rec2020 as values, which are intentionally vague terms to specify the range of colors supported by the system, including the browser engine and the display hardware. By default, since nearly all displays support sRGB, there is no need to test for that functionality. But a typical modern wide-gamut display can support the range of colors included in the DCI P3 space, or near about, and would pass the media query. For example, the Display P3 space I mentioned above is a variant of DCI P3. The rec2020 value indicates the system has a display that supports an even wider color gamut, one approximately defined by the Rec. 2020 space (at the moment, it’s quite rare to come across hardware on the Web that actually supports Rec. 2020, so you probably don’t need to worry about that yet).
Since media queries have a graceful fallback, you can start using color-gamut right away to give wide-gamut users nicer colors while still accomodating users who don’t yet have compatible browsers or hardware.
Future Directions
Serving and rendering wide-gamut images is relatively straightforward, but what about if you want to combine it with other page elements like a background color, or paint the image into a canvas element? These are some of the challenges the standards bodies are grappling with, and I’d like to talk about where they’re going.
Wide-gamut colors in CSS
I showed above that rgb(241, 0, 0) in Display P3 is rgb(255, 0, 0) in sRGB. What can you do if you want a color defined in CSS to match something inside a wide-gamut image? We can’t yet specify those colors in CSS.
This is what members of the WebKit project have proposed for CSS. The current idea is to add a new function called color() that can take a color profile as well as the parameters defining the color.
/* NOTE: Proposed syntax. Not yet implemented. */
strong {
color: color(p3 1.0 0 0); /* 100% red in the P3 color space */
}
In practice, you’d probably use this with an @supports rule.
strong {
color: rgb(255, 0, 0); /* 100% red in the sRGB color space */
}
@supports (color: color(p3 0 0 0)) {
strong {
color: color(p3 1.0 0 0); /* 100% red in the P3 color space */
}
}
Note: I originally had a bad typo, showing the syntax as color(p3, 255, 0, 0). This is one of the annoyances of the existing rgb() function. The new color() function will take floating point numbers as parameters, not 8-bit integers.
CSS will define some known color profile names, so you can easily find the color values you want. There is still some discussion about allowing authors to link to external profiles, or maybe point at an image that has an embedded profile.
In addition, CSS might decide to allow you to specify values outside 0-255 (or 0-100%) in the existing rgb() function. For example, rgb(102.34%, -0.1%, 4%) would be a color that has more red, less green and a tiny touch of blue. The problem here is that it might be confusing to understand these values (what does it mean to be a negative green?).
Another suggestion is to be able to define a color space for the entire document, which would mean that all the regular CSS color values would be interpreted in that space. External images with embedded profiles would still be color matched.
These discussions are happening in the W3C CSS Working Group at the moment. Your opinions are valuable – the group needs more input from Web developers. If you’re interested in participating, look for emails with subjects starting “[css-color]” on the www-style email list.
WebKit hopes to implement these features as soon as we’re confident they are stable.
Wide-gamut colors in HTML
While CSS handles most of the presentation of an HTML document, there is still one important area which is outside its scope: the canvas element. Both 2D and WebGL canvases assume they operate within the sRGB color space. This means that even on wide-gamut displays, you won’t be able to create a canvas that exercises the full range of color.
The proposed solution is to add an optional flag to the getContext function, specifying the color space the canvas should be color matched to. For example:
There is something else to consider, which is how to create a canvas that has a greater color depth. For example, in WebGL you can use half-float textures that give you 16 bits of precision per color channel. However, even if you use these deeper textures inside WebGL, you’re limited to 8 bits of precision when you paint the WebGL into the document.
There needs to be a way for the developer to specify the depth of the color buffer for a canvas element.
This gets more complicated when combined with the getImageData/putImageData functions (or the readPixels equivalent in WebGL). With today’s 8 bit per channel buffers, there is no loss of precision going into and out of a canvas. Also, the transfer can be efficient, both in performance and memory, because the canvas and program side data are the same type. But when you have variable color depths, this might not be possible. For example, WebGL’s half float buffer doesn’t have an equivalent type in JavaScript, which means there will either have to be some transformation as the data is read or written, as well as use more memory to store the data, or you’ll have to work with a raw ArrayBuffer and do awkward math with bit masks.
These discussions are currently happening on the WhatWG github and soon at the W3C. Again, we’d love for you to be part of the conversation.
Summary
Wide-gamut displays have arrived and are the future of computing devices. As your audience using these beautiful displays grows, you’ll want to take advantage of the stunning range of colors on offer and provide users with a more engaging Web experience.
WebKit is very excited to provide improved color features to developers through color matching and color gamut detection, available today in the Safari Technology Preview, as well as the macOS Sierra and iOS 10 betas. We’re also keen to start implementing more advanced color features, such as specifying wide-gamut colors in CSS, tagging canvas elements with profiles and allowing greater color depth.
After the UK voted to leave the EU, I tuned in to a BBC station, where a woman (who had voted to leave) was giving comfort to those that had voted to stay. “At the very least, it’s a great day for democracy.” If I was democracy, I’d be pretty pissed off – getting trotted out once in a generation only to be patted on the back, and put back in the political cupboard. It’s been a great day for lies and liars.
I couldn’t make it to ISTE this year, so instead I joined Doug Belshaw, Noah Geisel and Ian O’Byrne remotely for some off-the-cuff thinkery on Open Badges…
I joined Mozilla in 2006 wanting to learn how to build & ship software at a large scale, to push myself to the next level, and to have an impact millions of people. Mozilla also gave me an opportunity to build teams, lead people, and focus on products. It’s been a great experience and I have definitely accomplished my original goals, but after nearly 10 years, I have decided to move on.
One of the most unexpected joys from my time at Mozilla has been working with contributors and the Mozilla Community. The mentorship and communication with contributors creates a positive environment that benefits everyone on the team. Watching someone get excited and engaged from the process of landing code in a Firefox is an awesome feeling.
People of Mozilla, past and present: Thank you for your patience, your trust and your guidance. Ten years creates a lot of memories.
Special shout-out to the Mozilla Mobile team. I’m very proud of the work we (mostly you) accomplished and continue to deliver. You’re a great group of people. Thanks for helping me become a better leader.
It’s a bit sad but unfortunately still true, in some places there is still better GSM coverage than LTE. Network operators using VoLTE thus need to be able to hand-over an ongoing VoLTE call to a GSM circuit switched channel when the user leaves the LTE coverage area. The method to do this is referred to as Single Radio Voice Call Continuity (SR-VCC) and the basic flavor of it has probably been deployed by all VoLTE operators that have a legacy radio network out there. When taking a closer look one notices that there is a surprising variety of states a voice call can be in and the basic flavor can’t handle all of them. Let’s have a closer look.
The simplest case is that the call is already established, i.e. the terminating subscriber has accepted the call and a speech path is present. That’s what the default SR-VCC implementation can handle.
Another state a voice call can be in is the alerting phase. Depending on how quickly the terminating subscriber accepts the call, this phase can take many seconds which increases the probability that the subscriber runs out of LTE coverage while the call is being alerted. The initial 3GPP specifications only defined the SR-VCC procedure for calls that have been fully established but not for the alerting phase. If the subscriber is running out of LTE coverage during the alerting phase the call would drop. As a consequence 3GPP later specified an extension referred to as Alerting-SR-VCC (aSRVCC) to close this gap. Both the network and the mobile device have to support the extension and mobile devices signal support to the IMS network with a ‘+g.3gpp.srvcc-alerting’ tag in the SIP ‘Contact’ header.
Other states a call can be in when an SR-VCC is required are for example established conference calls, call hold, or the user being active in one call while a second call is currently incoming (call waiting). To allow for these special call states to be handed over into a circuit switched connection as well, 3GPP has additionally specified SRVCC for mid-call services. Like above, both the network and the device have to support the functionality and the mobile device announces support with a ‘+g.3gpp.mid-call’ tag in the SIP ‘Contact’ header.
One of the latest SR-VCC enhancements in 3GPP TS 24.237 is to support the handover from IMS to a circuit switched channel before the alerting phase (bSRVCC), i.e. the few seconds between the initial SIP ‘Invite’ message and the SIP ‘180 Ringing’ message. And if you are really a daring operator you can try yourself at Reverse-SRVCC (rSRVCC) which hands over an ongoing GSM or UMTS circuit switched call to VoLTE when LTE coverage is regained.
In practice there are few if any network operators with legacy radio technologies who do not support at least the basic form of SR-VCC for established one to one voice calls. I strongly suspect that support of the more advanced features is less wide spread and it will depend on how fast LTE networks reach similar coverage level as legacy technologies if the more advanced features which bring significant complexity in the core network will be widely deployed in practice.
Should I tell my team I’m writing this blog post right now?
Should you share that you’re reading it?
Should your team share what they’re working on today?
Well, it depends.
Well intentioned efforts to encourage people to share what they’re doing becomes a cacophony of noise. It makes your inbox look quiet.
There might be serendipitous value within that noise. Two people might discover they’re working on similar projects. You might get advice from someone with experience. The group might also develop stronger bonds.
But you’ll need to deliberately wade through a whole lot of mundane updates to find this value.
And it’s not smart to build collaboration efforts around serendipitous encounters. The value might trump the costs, but the costs are too high.
The goal of collaboration is to achieve your goal faster, cheaper, or better than you can alone. That means dividing up tasks, specialising in what you do best, and accessing the best possible information on the topic.
Can you see the problem with sending and receiving daily updates?
It doesn’t help you achieve any of these goals very efficiently. You can achieve every serendipitous benefit better by deliberately targeting that benefit.
If you need information to help with your work, you need to know where to find that information. Who do you ask? Where do you search? What terms do you search for? What specific information do you need? Have colleagues documented this information for you?
If you need additional resources to complete a task, you need to know who has time available and what their skillsets are. This is a relatively simple project management tool and access to free time on each person’s shared calendars.
If you have a useful article to share, you need to identify who needs this information, when do they need it, and how do they need it?
If you want a stronger sense of community, you can set up proper team bonding activities, live calls, establish clear superordinate goals, have more emotive (and open) discussions.
Don’t encourage colleagues to share what they’re working on every day. Focus on the goals of collaboration and build efforts around those goals.
Imagine your employees are racing drivers. They sit atop a pile of information, technology, and processes which all need to come together at the right time. They need only the right information at the right time in the right format. Train them where to find information, whom to ask, and how to ask.
WWDC 2016 and Apple made many moves to improve accessibility across its products, but the introduction of a version of the Apple Watch Activity app for wheelchair users was a particularly big deal. You see, there’s never been an accurate fitness tracker like this before, and Apple has been working on it for at least a year.
If you want to sound like an immature, unprofessional idiot, fill your prose with exclamation points, emojis, superlatives, adverbs, and profanity. Today I’ll explain why people use these rhetorical techniques and how they undermine your meaning. There are no absolute rules about business writing. You are welcome to use any of the elements I describe here. … Continue reading Never use an exclamation point! (And other rhetorical no-nos) →
As part of a brand new global initiative to map pride festivities, Google has chosen Toronto as one of 16 major cities across the world to prominently feature the annual pride parade route on Google Maps.
The update for both Android and iOS devices will arrive on July 2, the day of the parade, and will highlight the route in festive rainbow stripes.
Additionally, for drivers trying to avoid traffic caused by the parade, road closures and detours will be visible on the map, and the app will automatically re-route vehicles to avoid congestion and roadblocks.
A spokesperson for the company told MobileSyrup that this update is part of a larger ambition by Maps to offer real-time updates and play a part in large cultural events.
“This is all about Google’s mandate bring temporal events to life and provide people with the most up-to-date, accurate, and useful information, so they can make the best decision on where to go,” stated the company’s representative.
In March we revisited GridEve, adapting it to fit more in line with the ethos of Eve; GridEve had a runtime based on data-flow, instead of the relational model we ultimately want. What we liked most about GridEve was the immediate usefulness of the grid model, so we decided to marry that with a relational engine in a new project: WikiGrid. In the last update, we looked at some interaction-level details of WikiGrid. Now, I’ll show some of our ideas about how the relational model can fit in a grid world.
Querying with Grids
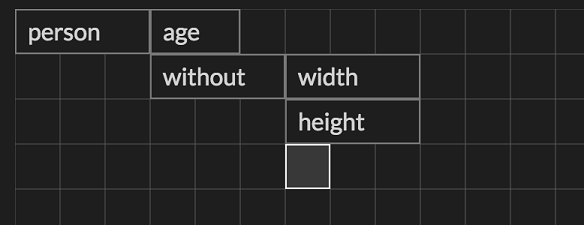
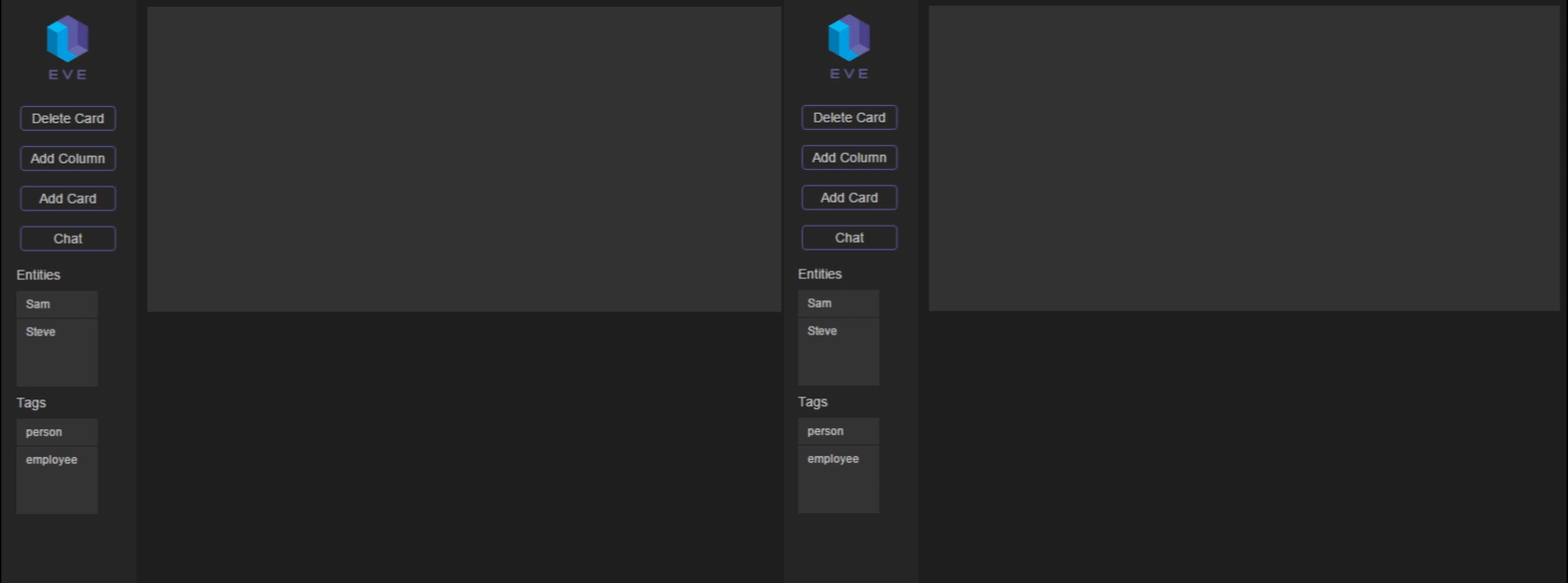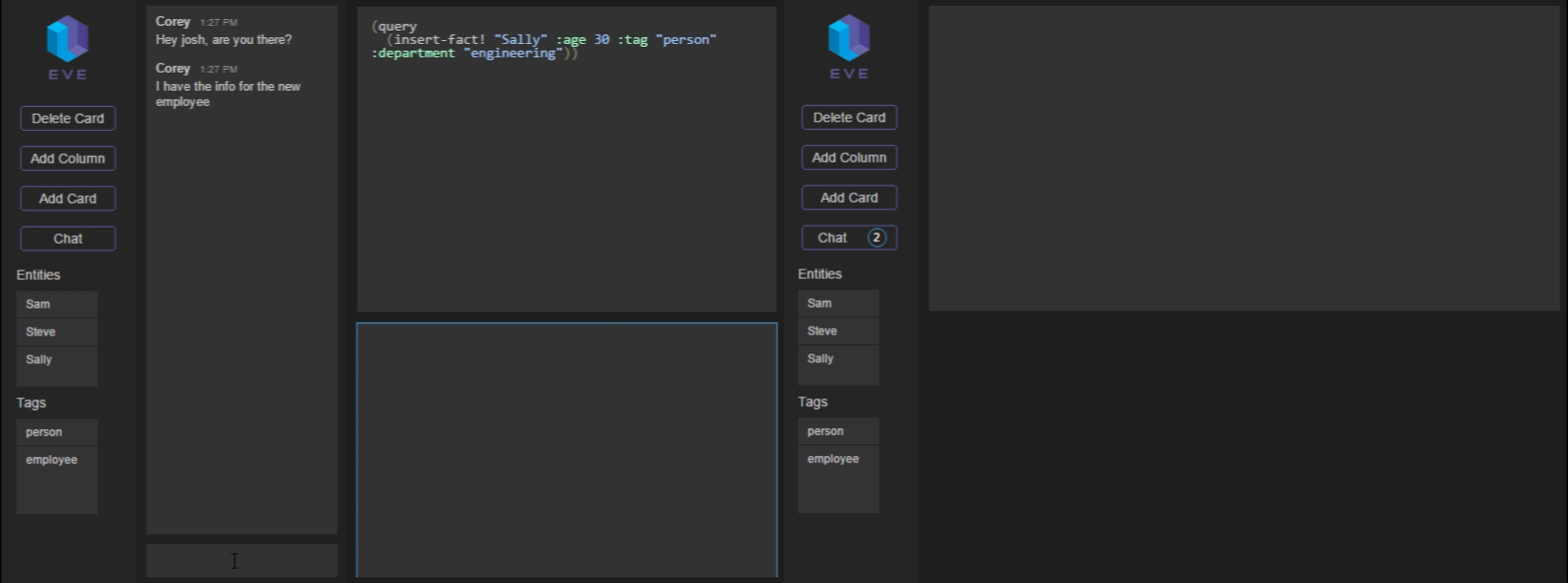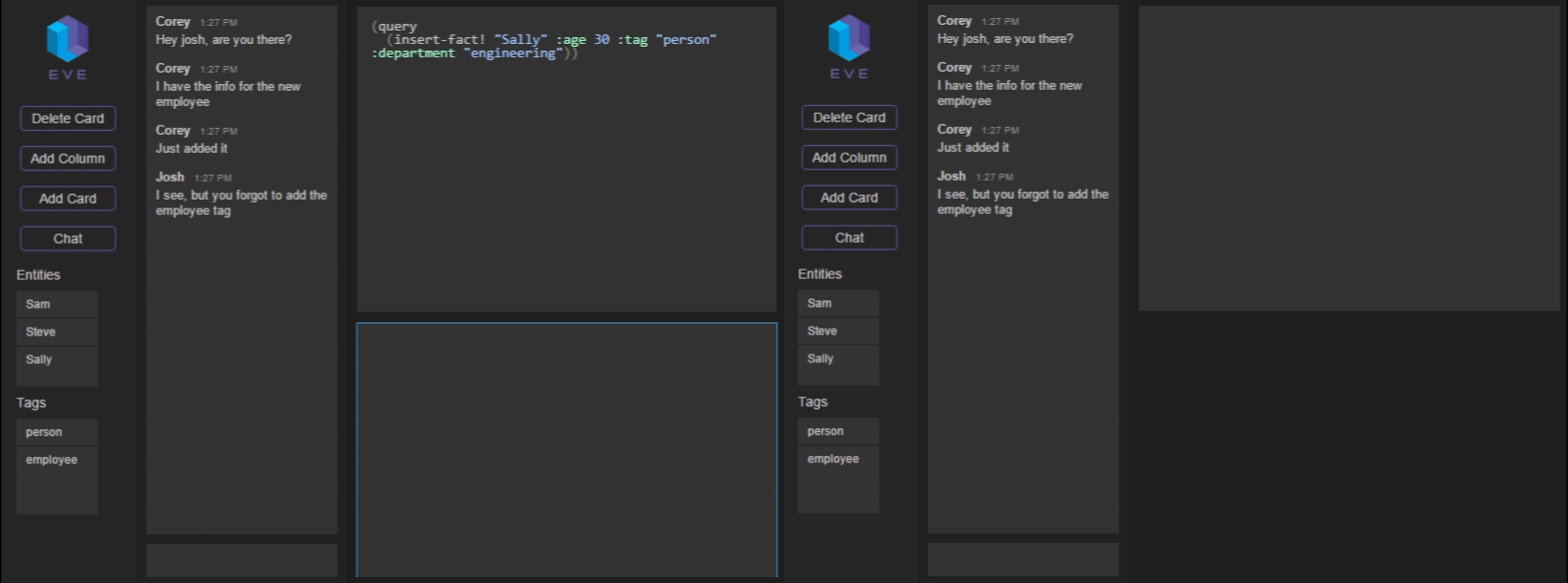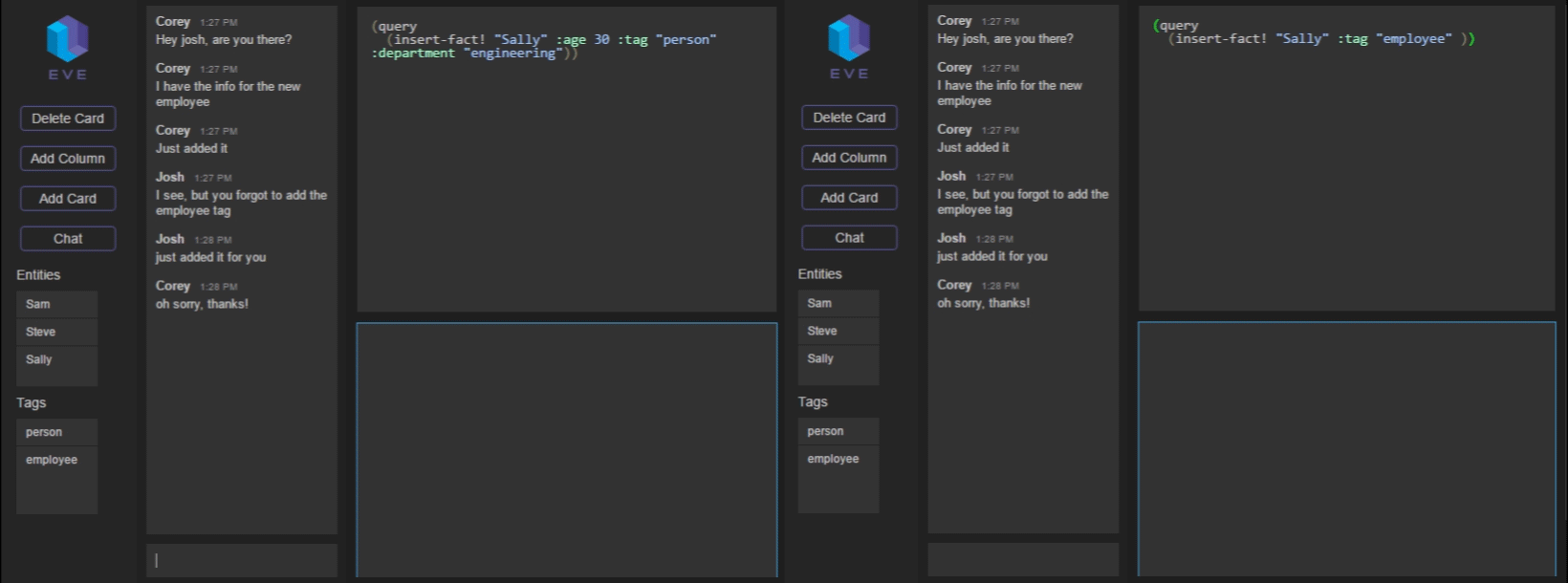
One obvious possibility is just to have relational functions and to allow the user to write them in cells. But that doesn’t really take advantage of the relational nature of the Eve platform – you could do this in any language. Eventually, we stumbled upon a really simple yet absolutely cool idea: give semantic meaning to cell adjacency. Consider this:
Here, the cell person means “select all the entities tagged person”. The adjacent cell age means “select the attribute age for the adjacent collection” i.e. person.age, which returns the set of all ages of “person”s in the system.
Building under that, we use a reserved word without, an alias for the anti-join operator. The adjacent blocks width and height mean person.width and person.height. So the overall query will select all entities with a “person” tag and an attribute age, that do not have width or height attributes.
In textual form, this would be written:
(query [age]
(fact name :tag "person" :age)
(not
(fact name :tag "person" :width :height))
This was very exciting for us, because you could basically write out a complicated query with no syntax. This was by far our fastest way to write a query yet. Here’s what writing one of these looks like in WikiGrid:
Here, we mark off a 5x4 area as a macro cell. Then we name the macro cell “test” and give it a “Formula Grid” type. If you look closely at the autocomplete that pops up, you’ll see the cell can take on many types: table, code, image, text, chart, drawing, etc. Most of these weren’t wired up yet, but it illustrated the idea that cells can contain anything.
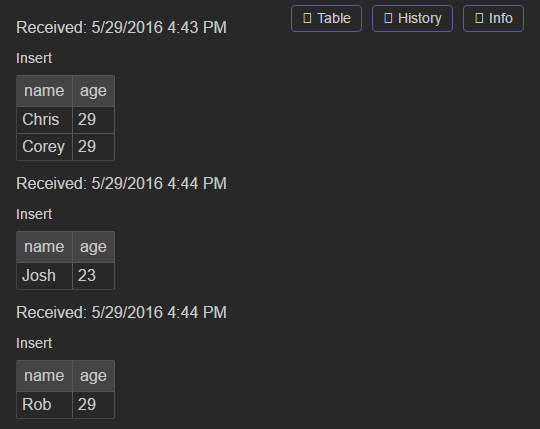
So let’s put it all together and see how it works when it’s hooked up to an evaluator. The runtime in this example was our new Clojure runtime from last month.
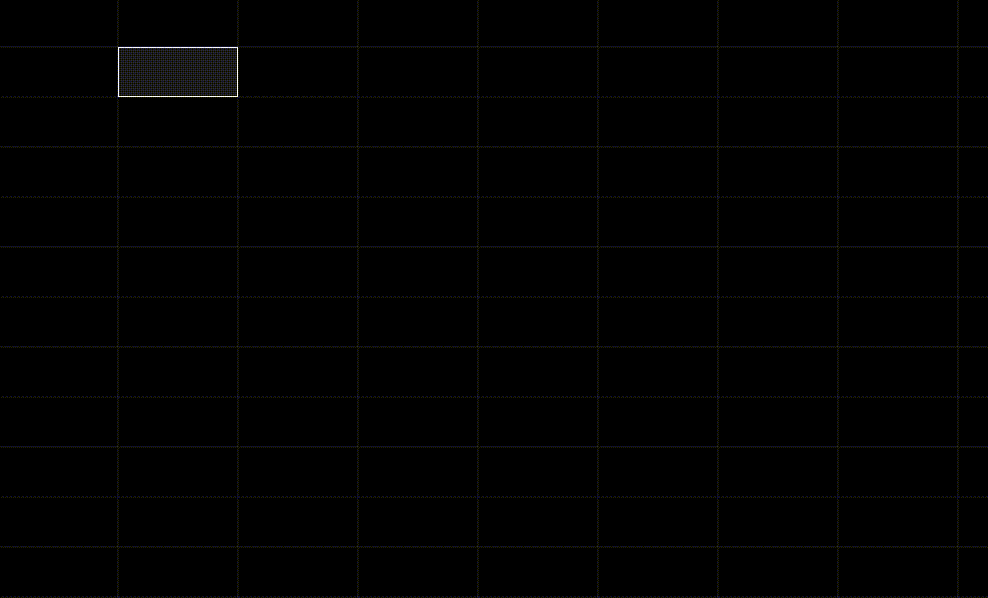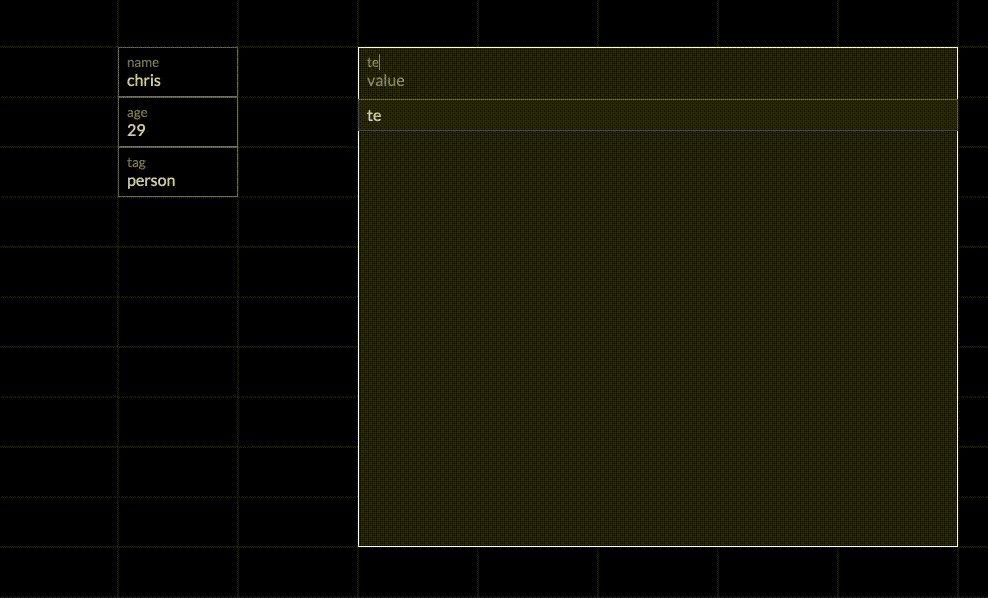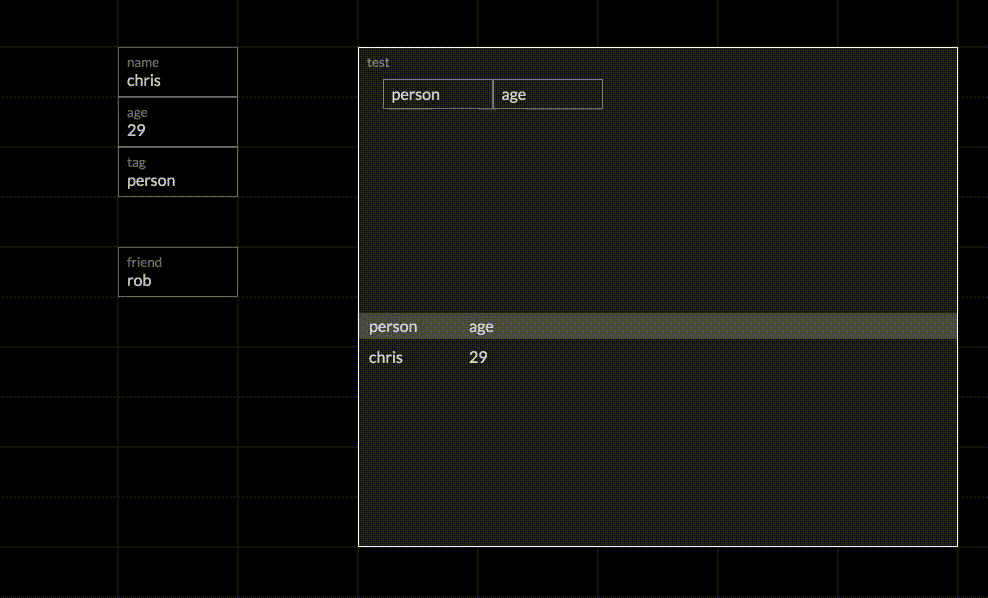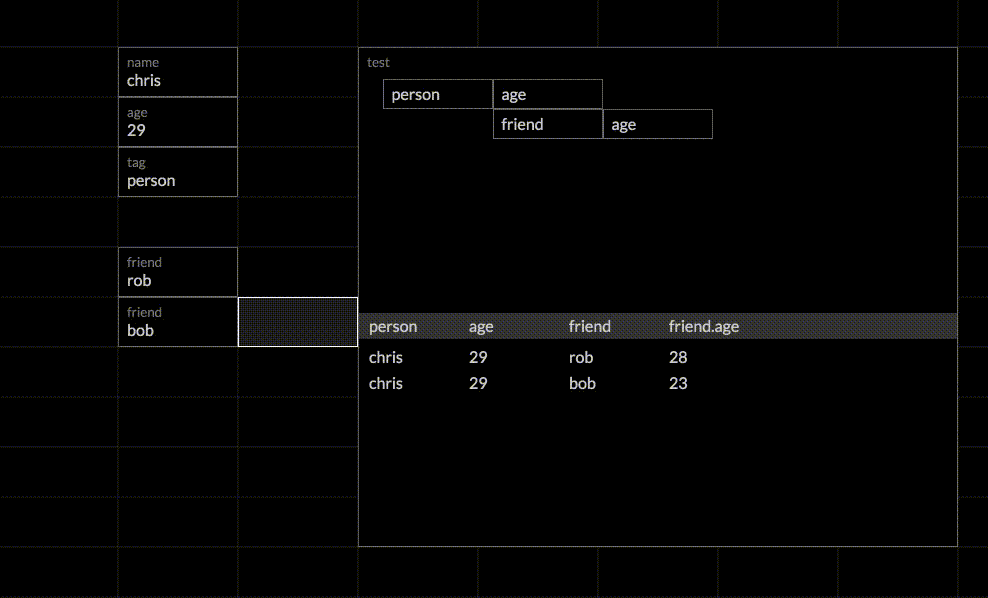
We start out in a grid and name it “Chris” by adding an attribute cell. Each grid represents a single entity, so any attributes added to the grid are attached to that entity. Grids start out nameless, so giving it a name provides a handle to the grid. We then add two more attributes: an age and tag. The tag attribute is a convention used to group similar entities. By adding the tag “person”, we are now able to talk about collections of “person”s by joining on that tag.
Next, we create a formula grid, and we query for person.age. The result of the query shows up in the bottom half of the formula grid as we type. Chris is the only result, since he’s the only entity in the system, so let’s add some more.
Chris has a friend named Rob, so we add him as a new entity under chris.friend. We then navigate to Rob’s grid, which was automatically created when we added Rob as a friend of Chris. Now we just add rob.age and rob.tag and he shows up in the formula grid. We can do the same thing for Chris’ other friend Bob, and we see he is added as well.
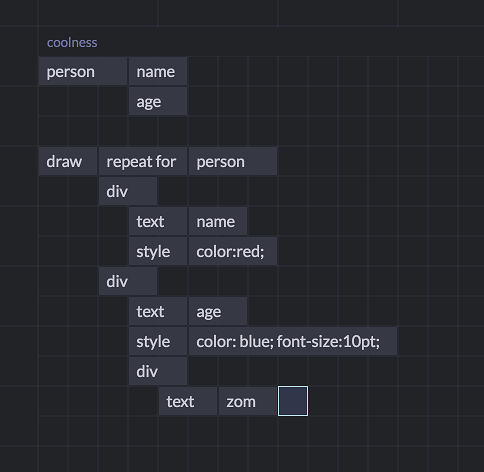
This is a relatively simple example, but we can write arbitrarily complex queries this way:
This query draws the name and age of a person in HMTL. The name is in one div, styled red, while the age is in another div, styled blue.
Platform Work
Language
We added more language features to the runtime, including choose, not, and various aggregates.
Choose
The choose statement works kind of like an if statement in other languages; it has multiple arms, one of which is evaluated based on a condition. For us, each arm is its own sub-query. The condition for evaluation is whether or not there are any results in the sub-query. The first arm of the choose with a result is the one that gets evaluated, so this is one case where order does matter in Eve. Take a look at this example:
Here, we are assigning a letter grade given a numerical score. The choose statement itself has its own projection, so you can decide which variables internal to the choose are accessible in the parent query.
Not
The not statement is an anti-join operator. Its body is a query, and any results within are excluded from the parent query. For instance:
will return all of the entities tagged “person” that are not also tagged “employee”.
Aggregates
We got some aggregates working for this version as well. Aggregates work just like regular functions, except they can change the cardinality of the output. So sum takes in a set of cardinality N and returns a set of cardinality 1. You have to keep this in mind, or your results might not be what you expect (something we didn’t really like. We later found better semantics for aggregates, which I’ll talk about in a future post). Here is an example of sum in practice:
(query [sum-result]
(fact e :score)
(= sum-result (sum score)))
This will store the sum of all the scores in sum-result.
The REPL received a visual overhaul and several additional features. First, let’s take a look at the new layout.
You can immediately see some new features here. First, we’ve changed the layout a little. We have a toolbar on the left, and the REPL “cards” on the right. We have a button to get another column of cards, which gives us a restricted grid layout.
While the REPL is still written in Typescript, we’ve bootstrapped several elements. On the side, we have a space to see all the entities and tags in the system. If we click on an entity, we can see its attributes table. If we click on a tag, we can see a list of all entities with that tag (you can see an example of this in the GIF below).
These are supported by two queries that listen for entities and tags:
// get all entities that are not system entities
(query [entities attributes values]
(fact-btu entities attributes values)
(not
(fact entities :tag "system")))
// get all tags that are not also system tags
(query [tag entity],
(fact entity :tag tag)
(not
(fact entity :tag "system")))
The client leaves these queries open, so it continuously receives updates as new entities and tags are added.
We also added various views to the output. The view defaults to the results table, which displays the current state of the results. You can also see this History, which logs the incremental changes to the table. This is just a local history according to the client, but eventually this will be a history according to the server. This will allow features like the ability to see the state of the table at an arbitrary time.
The info tab displays information from the compiler about the query for debugging purposes. So far, we display the intermediate expansion of the query, as well as Eve bytecode.
We also added a chat system. This required some notion of a user, so we added something quick and dirty. If you try to use the REPL yourself, the first thing you’ll see is a login screen. When you submit a username and password here (use eve/eve), we compare it against the users stored in the Eve DB (obviously this is not secure at all, it was just a proof of concept).
Now that you’ve logged in, you can send and receive messages:
This whole process is also supported by the Eve backend. When you send a message, we add a new fact into the database, containing the message text, as well as your user ID and the local machine timestamp:
(query [id user message time]
(fact id :tag "repl-chat"
:message message
:user user
:timestamp time))
Right now we still have more work to do to draw UI, so the messages are displayed using Typescript. But soon we’ll be able to bootstrap this whole process (actually, if you want to see what a full chat component looks like in our latest sytanx, you can check it out here. This version even has the ability to support multiple channels.).
Build instructions:
If you’d like to try out the REPL yourself, it’s pretty easy to get running. We’ve tested this under Windows 10 and OSX El Capitan, but I don’t see any reason it shouldn’t run under Linux.
First, you’ll need the following dependencies: Node.js, Clojure, Leinengen.
Then cd into where you cloned Eve. Download node dependencies and compile the REPL:
> npm install
> npm run dev
When the REPL is finished building, you can kill that process and cd into the /server directory. Then, all you need to do is:
> lein run
This will compile and run the server. When it’s finished, you’ll have a REPL hosted at http://localhost:8081/repl. The REPL was developed in Chrome, on Windows, but I’ve also verified it working on Firefox and Edge.
UI Drawing
We also added the capability to specify UI with our syntax, obviating the need for HTML or CSS. We are interested in writing useful tools for ourselves in Eve, so we decided to write a little CI report generator.
It’s pretty simple when you break it down. You can think of the code in two phases. The first phase, we collect all the information necessary to render the cards:
// Get the test runs and their results. Joins via test-run
(fact test-run :tag "testrun" :number pr-number :branch :user :title :text description :additions :deletions)
(fact test-result :tag "testresult" :run test-run :test :result)
// Sort results by tick order
(fact-btu test-result "result" :tick)
// Format some strings
(= test-order (+ 100 (sort tick)))
(= delta-text (str "(+" additions " / -" deletions ")"))
(= pr (str "#" pr-number))
(= url (str "https://github.com/witheve/eve-experiments/pull/" pr-number))
(= branch-url (str "https://github.com/witheve/eve-experiments/tree/" branch))
(= user-url (str "https://github.com/" user))
(= test-class (str "test " result))
In the second phase, we take the data and display them:
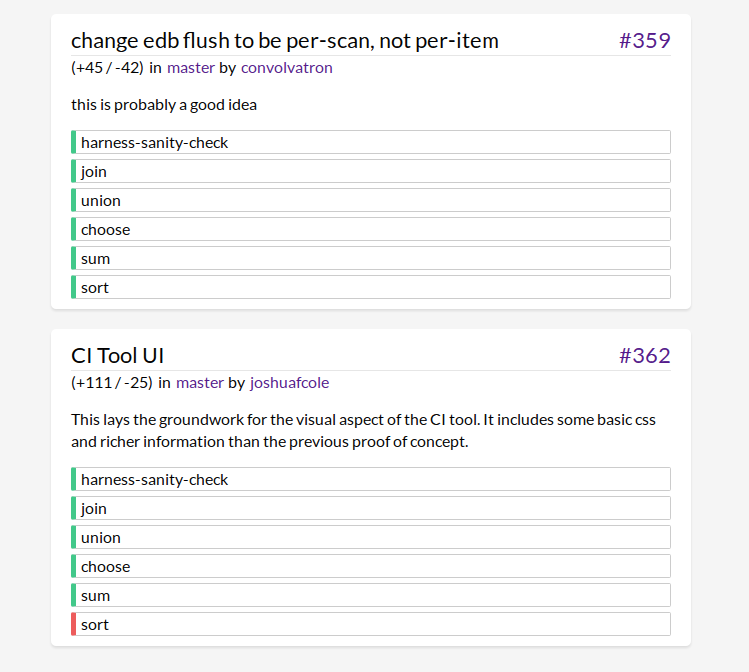
// Draws a commit card. This card is repeated once for every commit
(ui [title pr pr-number url user user-url delta-text branch branch-url description]
// Attaches the card to the DOM root
(div :id run-tile :parent "root" :ix pr-number :class "test-run")
// Draws the header
(h3 :id header :parent run-tile :ix 1)
(div :parent header :ix 0 :class "spacer" :text title)
(a :parent header :ix 1 :text pr :href url)
// Draws the line "(+{adds}/-{removes}) in {branch} by {user}"
(div :id user-tile :parent run-tile :ix 2 :class "run-info")
(div :parent user-tile :ix 0 :text delta-text)
(div :parent user-tile :ix 1 :text "in")
(a :parent user-tile :ix 2 :text branch :href branch-url)
(div :parent user-tile :ix 3 :text "by")
(a :parent user-tile :ix 4 :class "user" :text user :href user-url)
// Draws the commit message
(blockquote :parent run-tile :ix 3 :class "description" :text description))
// Draws the test results. This block is repeated once for every test
(ui [run-tile test test-class test-order]
(div :id test-tile :parent run-tile :ix test-order :class test-class)
(div :parent test-tile :ix 0 :text test)))
Here is the result:
And we did all this in Eve without having to write separate HTML! The result is completely live, so any new commits are displayed as soon as the tests complete.
The two-phase nature of this query (get some data -> do something with that data) is a general pattern we’ve found very useful for both reading and writing Eve programs. In newer versions of the Eve syntax, we make this pattern more explicit.
Moving Forward
This is the last post in our backlog of development diaries. Moving forward, we’ll keep a monthly cadence of dev diaries starting July. To cover our work in May and June, we have some special news, which we will be talking about shortly. As time goes by, and as Eve grows, I hope to keep the blog updated with more features like example Eve programs, community spotlights, tutorials, etc. So stay tuned!
Got a bullshit parking ticket? Now you can appeal it in less than a minute. The new chatbot tool, DoNotPay, uses previously successful appeal letters to draw up a customized template, allowing users to avoid courts, legal fees, stress, and having to use a lawyer.
So far, the free app has overturned 160,000 parking tickets in London and New York. With a success rate of 64%, DoNotPay has appealed $4 million in parking fines in just two cities in only nine months of operation. In 2014, New York City collected $546 million in revenue from parking tickets.
Stanford freshman Joshua Bowder created the app after spending an exorbitant amount of time crafting his own appeals for parking tickets. He read thousands of pages of documents related to parking tickets released under the Freedom of Information Act and consulted a traffic lawyer. Then, using PHP and Javascript, he created a conversation algorithm that aggregates keywords, pronouns, and word order. Like many chatbots, Browder’s app becomes more intelligent each time it is used.
DoNotPay is not commercial and Josh plans to keep it that way. In an interview with Anti-Media, Josh said he was driven by a sense of social justice and a desire to help vulnerable people who are exploited by policing-for-profit schemes. Josh also wants to use technology like artificial intelligence for humanitarian purposes.
He finds it “irritating and disappointing” that bots are usually created for vapid commercial uses. In reality, he says, algorithmic intelligence and chatbots are a “humanitarian goldmine.”
DoNotPay also assists with delayed or canceled flights, payment-protection insurance (PPI) claims, and even legally disclosing an HIV-positive health status.
Josh describes his creation as “the first robot lawyer.” People are describing him as the “Robin Hood of the Internet.”
“If it is one day possible for any citizen to get the same standard of legal representation as a billionaire,”Browder says, “how can that not be a good thing?”
Josh says government agencies have actually been supportive, even using it to test for glitches. He also received support from his friends, one of whom he says has created an app for scanning blood to test for the likelihood of malaria.
Josh wants to continue developing artificial intelligence applications for the public good. He’s spoken with entrepreneurs about how to use apps like this in conjunction with driverless cars.
What’s on the horizon? Josh’s summer project is an app to help Syrian refugees seek legal asylum. The chatbot he is planning would translate Arabic to English and then draw up legal paperwork.
Spotify is realising to its cost that competing with the owner of a platform is extremely difficult when one is perceived as a threat.
The latest disagreement relates to the fact that Apple has rejected an update to Spotify’s app preventing Spotify from upgrading the user experience it offers to its users.
Apple claims that the update violates its policy that states that apps must use the Apple billing mechanism for the purchase of subscriptions as Spotify has switched them off.
Spotify is now using the app to upgrade or subscribe through its website rather than through the app itself which Apple sees as a violation.
While Apple was not in the music streaming business this was not a problem as Spotify would simply add Apple’s cut on top of the subscription price to subscriptions purchased on iOS.
However, now that Apple is a competing service, Spotify is 30% more expensive as a result of being forced to use the Apple infrastructure which is clearly a problem when it comes to attracting new users.
If Apple allows Spotify to use another payment mechanism it will have to allow everybody to do the same which could materially dent its app store revenues.
More importantly, it will make Spotify much more competitive, potentially costing Apple Music subscribers.
The weakness of Spotify is that it is not very good at marketing, meaning that it is only existing users who know that it has a superior offering.
Put this together with a 30% price premium and one touch subscription to Apple Music and it is not difficult to see why Spotify needs to act.
The problem is that there is not much that Spotify can do because it does not own the platform and Apple has already threatened to pull the app from the store entirely.
Complaints to regulators cost a fortune and take years neither of which Spotify can afford.
This means that Spotify is likely to end up having to toe the line.
Spotify’s only, and distant, hope is to create enough negative noise with users such that Apple decides to modify its policy more than it already has when it comes to subscription based services (see here).
This is exactly the problem that Amazon has with Google when it is trying to push its ecosystem to its users on Google Android devices (see here).
Its app store and its browser have almost certainly been excluded from the Motorola and BLU devices because they compete with Google.
This is why competing with platform owners on their home turf is so perilous as they can pull the rug out from underneath one’s feet with very little notice.
Google which RFM calculates earns 50% of its mobile advertising revenues from iOS devices also has this problem, albeit to a lesser degree.
I am certain that Apple would dearly love to pull the plug on Google but the only the risk of losing large numbers of users to Android keeps it from doing so.
Unfortunately for Spotify, not having its services available on iOS would damage Spotify far more than Apple which is why I think that Spotify will end up backing down.
This is why many ecosystems prefer to control the software upon which their services are delivered because it enables them to offer their services in the best possible way with minimal interference.
This is why every successful ecosystem either directly or indirectly controls the software upon which its services run.
It also explains why the Chinese ecosystem are all busily creating their own versions of the Android software and why Facebook is hard at work removing all the dependencies its apps have with Google Play.

























{kind=link}