Deep in its heart, R is a language for making charts, and it’s genuinely fun to go into its world: statistics, natural sciences, sociology — all right there. You will never pry me away from JavaScript or Python or the whole web stack of standards and protocols. They’re how I make things happen in the world, and they are very much my home base, but using more specific tools is always an education. It’s like suddenly discovering a new wing of a big museum, and realizing that there’s still a lot to learn.
I would say it’s a language for analyzing data, and charts are a big part of the process. But the big sell of R has always been its specificity. The need to understand data drives its design and growth, which means you avoid starting a lot of analyses from scratch.
Was imho mittlerweile eigentlich Selbstverständlichkeit in Großstädten sein sollte, wird von Paris jetzt einfach mal gemacht. Dort wird noch in diesem Jahr nahezu überall eine innenstädtische Höchstgeschwindigkeit von 30 km/h eingeführt. Das könnte man dann bitte auch in anderen europäischen Städten einführen, wenn man schon Autos dort durchfahren lässt.
Aus Gründen der Verkehrssicherheit, der Lärmreduzierung und des Klimaschutzes sollen Autos ab Ende August auf fast allen Straßen der französischen Hauptstadt nur noch bis zu 30 Kilometer pro Stunde fahren. Ausgenommen seien die Ringstraße, die Ausfallstraßen und einige andere größere Verkehrsachsen, sagte der Grünen-Politiker und für Verkehrstransformation zuständige Abgeordnete im Team von Bürgermeisterin Anne Hidalgo, David Belliard.
Mozilla and the Canadian Internet Registration Authority (CIRA) have teamed up to add the organization’s ‘Canadian Shield‘ as the default DNS over HTTPS (DoH) provider for the Firefox browser in Canada.
In a blog post, Mozilla explained that starting July 20th, about one percent of Canadian Firefox users will see CIRA set as the default DoH provider. Over the next few months, the percentage will increase, with the goal of hitting 100 percent of Canadian Firefox users by late September 2021. However, those running a preview build of Firefox may already see CIRA set as the DoH provider — I use Firefox’s Nightly variant on my PC, and it had switched to CIRA DoH when I checked the setting this morning (you can learn how to check DoH settings below).
Further, a CIRA press release notes that Firefox will use Canadian Shield’s ‘Private’ feed by default. Canadians will have the option to switch to other Canadian Shield options, such as ‘Public’ for malware and phishing protection or ‘Family’ that includes blockers for pornographic content.
CIRA’s Canadian Shield is also available on mobile via a smartphone app, on Windows or Mac through system configurations or at the router level. Those interested can learn more about Canadian Shield here, or get started using the platform here.
What is DNS over HTTPS?
As a refresher, DoH is a method of protecting DNS requests by encrypting them and sending them over the secure HTTPS protocol instead of HTTP by default. DNS, or Domain Name System, is effectively the phone book of the internet — when people want to go to a website, such as ‘www.mobilesyrup.com,’ they type that domain name into their browser. The browser then uses a DNS service to look up the Internet Protocol (IP) address for that domain to connect the device to the website.
By default, most people’s internet service provider (ISP) handles DNS. However, since DNS requests are, by default, unencrypted, this can be problematic. First, unencrypted DNS requests can be intercepted by malicious actors, allowing someone to tamper with browsing activity. While DoH can help protect users from that, it doesn’t necessarily help with the other issue: data privacy.
DNS requests can include a lot of sensitive information about users, such as browsing activity. Whatever DNS resolver handles DNS requests from your computer will have access to that information. Moreover, most places don’t limit what companies can do with that data. In other words, DNS resolvers can collect the information and sell, share or license it to other groups.
DoH can protect DNS requests in transit, but when they arrive at the resolver, it can still gather the data. Instead, users must proactively protect themselves by selecting a DNS resolver they trust. That can be done at various levels — many routers have a DNS option that would apply to all traffic through a network, most computers and phones can set a system-wide DNS and browsers often have DNS or DoH options too.
As an aside, Google got into some hot water in 2019 over a plan to enable DoH settings for Chrome users. American ISPs raised concerns that Google would move Chrome users to the search giant’s DNS service, cutting ISPs out of a likely lucrative method of gathering data on customers’ browsing activities. Google later clarified that it only planned to enable DoH for users if their DNS resolver supported the feature, and that it wouldn’t change users’ DNS settings.
It appears ISPs haven’t raised similar concerns with Mozilla’s DoH approach in Firefox, likely because Firefox doesn’t have nearly as large of a user base as Chrome.
A Mozilla program helps ensure people use trustworthy DNS resolvers
Mozilla has been working to solve that second DNS problem through its Trusted Recursive Resolver (TRR) program. Through TRR, Mozilla aims to standardize data collection and retention requirements for DNS resolvers. Companies that partner with Mozilla through TRR must meet the company’s data policies, which include:
Limiting data: Mozilla requires that DNS providers only use data “for the purpose of operating the service,” can’t keep data for more than 24 hours and cannot sell, share or license the data to other parties.
Transparency: Mozilla requires DNS providers to publish public privacy notices that document what data they retain and how they use the data.
Blocking and modification: Mozilla requires DNS resolvers not to block, filter, modify or provide inaccurate responses unless strictly required by law to do so. However, Mozilla does allow DNS blocking and filtering when users specifically opt-in to it through features like parental controls.
As part of Mozilla adding CIRA’s Canadian Shield to Firefox by default for Canadians, the company also added CIRA to its TRR program. CIRA joins other DNS providers, including Cloudflare, NextDNS and Comcast (U.S. only).
What CIRA in Firefox means for Canadians
Ultimately, this change should improve privacy by default for Canadians that use Firefox. Mozilla enabled DoH by default for U.S. users in February 2020 and now Canadians will also have DoH by default as well. For the less tech-savvy users out there, the change should improve their privacy when browsing the web with Firefox through DoH.
However, some more tech-savvy users and privacy enthusiasts may prefer to use a DNS resolver of their choice over CIRA. Thankfully, Firefox still lets you customize DoH settings. To so, click the three-line menu button in the top-right corner > Settings > General > scroll to ‘Network Settings’ at the bottom and click the ‘Settings’ button > check ‘Enable DNS over HTTPS’ and use the drop-down menu to select a provider. Unfortunately, at the time of writing, Firefox’s mobile browsers didn’t have a DoH option, but those who want to use CIRA Canadian Shield can download the mobile app instead.
Currently, Firefox offers three DoH options for Canadians — Cloudflare, NextDNS or a custom option is someone wants to set up their own DoH settings. In the future, Canadians will see CIRA Canadian Shield in the menu as well. As the option rolls out, Canadians should see a pop-up message in Firefox letting them know about DoH and giving them an option to opt-out before the browser implements the change. The above image shows what the pop-up looks like.
Those interested can learn more about Mozilla’s TRR program here and Firefox’s DoH settings via this FAQ page. Those interested in learning more about CIRA Canadian Shield can do so here.
I am struck by the concept of cultural anticipations, here mentioned in High Frontiers 4 (1988) by shaman and psychonaut Terrance McKenna, as related by Thomas Rid:
The early internet was evolving fast. Yet McKenna was ahead of his time. To him, a new form of planetary connection was emerging: “Through electronic circuitry and the building of a global information system, we are essentially exteriorizing our nervous system, so that it is becoming a patina or skin around the planet,” he told High Frontiers. “And phenomena like group drug-taking and rock-and-roll concerts and this sort of thing,” he said, “these are simply cultural anticipations of this coming age of electronic-pooling-of-identity.”
Cultural anticipations! The existence of which implies the following algorithm for divining the future:
Look for new behaviours.
View those behaviours not as a phenomena in their own right, but as symptoms resultant of something else underlying and not yet in the present – either a psychological reaction against, or a pre-appropriation coping strategy toward, or some other kind of response.
Guess at what the impending something underlying is – and in this way, you discover the truth about the future.
What this method proposes is the future already exists, in some sense. Future events and future configurations of society are immanent in the world’s collective unconscious – we can’t name the future, we can’t talk about it, we can barely consciously feel it approaching, but the future is there and as real as the sluggish yet titanically unstoppable currents in the magma layer deep below the Earth’s surface.
Some people are sensitive to cultural tachyons - these particles that travel backwards through time - artists and poets and those with a certain madness - but what I like about this method is that it doesn’t rely on the individual: it’s a method of divination from dowsing the collective unconscious.
Society itself is a vast, gossamer scientific instrument to detect faint ripples from the future.
This is what has previously excited me about GPT-3. As a Large Language Model, GPT-3 was trained on a snapshot of the world’s text made in late 2019. For example, it is knowledgeless re Covid-19.
BUT:
What if there were a new GPT-3 made every 3 months? And then we looked for diffs between the models, plotting them like global weather maps? Would that reveal the telluric currents of the collective psyche? Could we use that to forecast the future?
The possibility of automating the augury algorithm!
Perhaps they are easier to recognise in retrospect.
For example: Stewart Brand’s 1966 campaign Why haven’t we seen a photograph of the whole Earth yet? (here’s Brand’s personal recollection of the campaign). Or really, the whole drive towards computing machinery and networks to think and act more powerfully and collectively, since the 1950s, and the development of the “global village”…
I read all of these as cultural anticipations of the Anthropocene, the realisation that humanity can and is acting on a planetary scale, for good and ill – but only popularly named in the year 2000, despite the fact that the whole 20th century was this slow lift of history to a rolling boil.
We’ve got the cultural tools and the perspectives we need to deal with today’s challenges (if only we use them). But somehow they were created just in time… in anticipation?
Don't expect an alternative open source version of Audacity to quickly emerge after the manager of a fork resigned after being harassed by 4chan users. Audacity was created at Carnegie Mellon University in 1999 and though it was contributed to open source in 2000, a private entity called Audacity Team retained ownership of the trademark and source code, and it was this entity that sold the rights (for an undisclosed amount of money) to Muse.
The managers of Audacity are denying claims that the music editing application contains spyware, saying it is working "to more clearly communicate" its licensing terms. But sceptics have good reason to doubt this response. As reported on podnews, "the app was 'acquired' by Muse Group, a company based in Cyprus, in May; they attempted to add analytics through Google and Yandex, but reversed that decision. They have also requested open-source developers sign a license agreement to contribute new code." And now the intent is to share is to analytics data with their company in Kaliningrad, Russia. So it is necessary to parse carefully Muse's statement that they will pass along user data "if compelled by a court of law in a jurisdiction that we serve."
Hey everyone, I thought it would be good to start sharing more about what we’re currently working on at Instagram just to give you a sense of what is coming before it comes. Right now, we are trying to build new experiences primarily in four areas. The first is creators, and I’ve talked a lot about creators and trying to help them make a living. And this has to do with the shift in power from institutions to individuals across industries. The second is video. Video is driving an immense amount of growth online for all the major platforms right now, and I think it’s something we need to lean into more — and I’m actually going to talk about that more in a minute. The third is shopping. Now the pandemic shifted, or accelerated the shift of commerce from offline to online by a number of years, and we’re trying to lean into that trend. And the fourth is messaging. How people connect with their close friends has changed a lot over the last five years or so and it has moved primarily to Messaging and away from Feed and Stories products.
But today I actually want to talk a bit more about video. And I want to start by saying we’re no longer a photo-sharing app or a square photo-sharing app. The number one reason that people say that they use Instagram in research is to be entertained. So people are looking to us for that. So actually, this past week in our internal all hands, we shared, or I shared, a lot about what we’re trying to do to lean into that trend — into entertainment and into video. Because let’s be honest: there’s some really serious competition right now. TikTok is huge, YouTube is even bigger, and there’s lots of other upstarts as well. And so people are looking to Instagram to be entertained, there’s stiff competition and there’s more to do, and we have to embrace that. And that means change.
So what you’re going to see over the next couple of months really is us start to experiment more in the space of what we call recommendations, so showing you things in Feed that you may not be following yet. We just started testing an early version of this last week. This week is a new version that’s coming out with topics where you can say which topics you want to see more of or less of. But we’re also going to be experimenting with how do we embrace video more broadly — full screen, immersive, entertaining, mobile-first video. And so you’ll see us do a number of things, or experiment with a number of things in this space over the coming months. Now we have an idea of where we want to end up in half a year or a year’s time, but I’m sure things are going to change many times between now and then. This isn’t something that we can just do overnight. So you’ll see us iterate and try and be very public about what we’re doing and why with videos like this one. Anyhow, hopefully you’ll enjoy it.
Everyone that I’ve seen, from Twitter to my teenage daughter, is quite certain they will not enjoy it. Why does the beloved photo-sharing service have to copy everyone else, and not simply do what it is best at?
The reality, though, is that this is what Instagram is best at. When Mosseri said that Instagram was no longer a photo-sharing app — particularly a “square photo-sharing app” — he was not making a forward-looking pronouncement, but simply stating what has been true for many years now. More broadly, Instagram from the very beginning — including under former CEO Kevin Systrom — has been marked first and foremost by evolution.
From Tool to Network
It may be hard to remember now, but Instagram didn’t even start as primarily a photo-sharing app: it was a photo-filter app, focused on making photos look good on ancient iPhone cameras and posting them on other social networks. It was, to use Chris Dixon’s parlance, a tool that evolved into a network:
Instagram’s initial hook was the innovative photo filters. At the time some other apps like Hipstamatic had filters but you had to pay for them. Instagram also made it easy to share your photos on other networks like Facebook and Twitter. But you could also share on Instagram’s network, which of course became the preferred way to use Instagram over time.
This was certainly an innovative approach, but even then Instagram didn’t get off the ground in isolation: the app famously booted up its initial network on top of the Twitter graph, allowing you to easily discover and follow everyone you already followed on Twitter. Instagram’s success in doing so remains one of the most powerful arguments for interoperability as a means of driving competition; it is disappointing that regulations like GDPR have redefined privacy to make it impossible to carry your contacts to other services. The important takeaway for this article, though, is that Instagram was defined by evolution from the very beginning.
Video on Instagram
To that end, the idea that Instagram isn’t simply a photo-app is hardly original to Mosseri; Instagram founder Kevin Systrom defined the service this way in 2013:
When we joined Facebook, a lot of people asked me this question: What is Instagram? What is Instagram all about? It’s a tough question, not because it’s not discoverable, not because it’s intangible, but instead because it takes on a different form depending on who asks the question and who answers it. When I think about what Instagram is I think about moments, and I think about visual imagery. What I can tell you is that at our core visual imagery is everything. It’s in our DNA, and it’s what drives us…
Photos are certainly “moments” and “visual imagery”, but only a subset; video was the obvious evolution.
If we’re about capturing and sharing the world’s moments, what’s next? What do we work on? We’ve taken photos and made them beautiful, we’ve connected people from all different countries around the world, all different cultures. What do we work on next? I’m going to tell you a story. That story is September of 2010, and Mike, my co-founder, and I were sitting in front of a whiteboard pondering what’s next. Two entrepreneurs not really knowing what to do, what’s next. We were working on a small location-sharing app called Bourbon. As part of Bourbon you could share your location, and the two parts of sharing your location were posting a photo and posting a video. We decided that we needed to do something new, so we created Instagram out of Bourbon.
The one part that we brought was photos, but we left video on the side. Why is that? Because we said the three things we want to be really good at are speed, simplicity, and beauty. And I’ll you, at the time two years ago, with the devices as they were, speed, simplicity and beauty were definitely possible with photos. But it was really hard with video. Today that all changes, and Instagram is going to be at the center of it. I’d like to introduce Video on Instagram.
One of the defining characteristics of digital services relative to analog services is that they need not be limited by medium: a magazine can only ever have photos, while a television show can only ever be videos, but when everything is 1s and 0s there is no need to be constrained by one particular manifestation of those 1s and 0s. Instagram has understood this from the beginning; the fact it started as only a photo app was due to the constraints of technology, not ideology.
Algorithmic Feed
Instagram’s third evolution was the introduction of the algorithmic feed, which was met with handwringing that sounds rather similar to the responses to Mosseri’s video. I wrote in 2016 in a Daily Update:
As is their wont, The New York Times got comments from not only analysts and Instagram executives but also a person-on-the-street, and this one delivered:
Vickie Mulkerin, a 49-year-old Instagram user…said she appreciated the immediacy of the Instagram feed. “I like how I can open the app and see what my stepsister Ashley is doing today with my niece and nephew, right in that very moment,” she said. “I want to judge what’s important, not have some algorithm tell me what it thinks is important.”
If you think that quote looks familiar, well, welcome to pretty much every story about the Facebook algorithm: users are sure they know better, but as any Facebook executive will tell you, users are much more engaged with an algorithmic feed…
One common misconception about why Facebook has an algorithmic feed is that it is to allow for advertising; that, though, doesn’t really make much sense. Facebook could include advertising in a time-based feed just as easily; indeed, that’s what the company does with Instagram today. Rather, an algorithmic feed is exactly what Facebook says it is: a way to drive engagement by showing users more of what they actually want to see, and, by virtue of driving engagement, gaining the opportunity to show users that many more ads.
Mosseri cited user research showing that Instagram users use the app for entertainment, but I strongly suspect that the service is even more convinced by the way users actually use the app: Facebook knows better than anyone that, when it comes to their services, revealed preference — what users actually do — is a far more powerful indicator than stated preference — what they say they want.
This was the biggest lesson from one of the most important episodes in Facebook’s history: the introduction of the News Feed, which was met by protests both on Facebook (naturally), and even outside of the company’s offices in Palo Alto. The irony, as David Kirkpatrick noted in The Facebook Effect, is that the reason protests sprung up so quickly is that the News Feed worked: it surfaced and organized information that users cared about in a way that was only possible with an algorithmically-driven Internet service. Facebook added some token privacy controls to mollify those initial objections, but the company didn’t compromise on the concept itself, which became the foundation of the company’s explosive growth and, it should be noted, was copied by everyone else — including Instagram.
Stories
Instagram’s biggest shift, though, and the episode from which you can draw a straight line to Mosseri’s video, was its introduction of Stories. While a feed was native to digital — endless content, customized to you — Stories, pioneered by Snapchat, were native to mobile specifically. They filled your entire screen and either advanced on their own or with a simple tap; their ephemeral nature was also a powerful lure to keep you coming back to the app day-after-day.
What was impressive about this shift was, in fact, the shamelessness; I called it The Audacity of Copying Well. What differentiated Instagram was the product of its initial evolution — the network — and adding a new format to that network was, broadly speaking, no different than adding an algorithmic feed. Now you could access “Moments”, to use Systrom’s parlance, in what was frankly a better format. That may have seemed controversial at the time, but five years on Instagram knows better than anyone the degree to which users prefer Stories to a feed; speaking for myself I find myself only scrolling the Instagram Feed once my Stories have been exhausted — which rarely happens.
This shift did cause Facebook some short-term pain; advertisers were used to feed advertising, and it took a couple of years and some painful earnings calls for them to catch up to user behavior, but catch up they did. From a Daily Update earlier this year:
The most notable takeaway from last quarter’s results was the increase in prices-per-ad for the first time since the end of 2017.
That 2018 decline was driven by the push to monetize Stories, and while many interpreted Facebook’s somewhat middling results in 2018 as a reason to be bearish, I was optimistic Stories were a big opportunity; I predicted in a Daily Update from August 2018:
The key thing to remember is that advertisers always lag users: there were millions of people using the Internet on desktops before advertisers really got on board, and then there were hundreds of million of people using mobile before advertisers came along. In every case some analysts made the mistake of assuming that advertising would never catch up, but it eventually did, and it seems far more likely than not that the story will be the same for Stories…
This is exactly what has happened. Increasing usage of Stories increased impressions, which is deflationary, but as advertisers have embraced the format that has increased competition for those impressions, ultimately increasing prices.
Facebook’s business results give credence to my anecdotal observation about user behavior: people click through Stories far more than they scroll through their feed.
Taking on TikTok
One thing that Mosseri was certainly right about is that TikTok is a serious competitive threat to Facebook. App Annie reported in its State of Mobile 2021 report that in the United States time spent on TikTok had surpassed both the Facebook app and Instagram:
While the FTC didn’t even mention TikTok in its antitrust case against Facebook — small wonder the suit was dismissed for lacking a reasonable market definition — this is clearly a big problem for an advertising-based business. The defining characteristic of digital is abundance, thanks to the zero marginal cost nature of transmitting 1s and 0s, which means that time, thanks to its inherent scarcity, is the most important plane of competition.
TikTok, though, has been particularly difficult for Facebook and Instagram to respond to for three reasons:
First, if Instagram has been defined by sharing moments, TikTok has been about manufacturing them, with easy-to-use tools that commoditize creation.
Second, TikTok has defined a new format, distinct from both a scrollable feed and tappable stories: swipeable videos that are melding of both. TikTok provides both an endless feed and a full-screen immersive experience that is easily navigable.
Third, TikTok isn’t really a social network at all, which freed the service to surface the most compelling content from anywhere in the world, not simply from your network.
The first issue was easier to address, which is how we came by Instagram Reels. Sure, it may not be as intuitive as TikTok’s video editor, but Reels is improving rapidly. The problem for Instagram, though, is that building tools is relatively easy; creating a virtuous cycle of creation and consumption is much more difficult.
This is where the shift to Stories created an opportunity: if you look at the Instagram home screen, the vast majority of time is spent in a relatively small amount of space:
While Reels did recently get its own tab at the bottom, I suspect that Instagram’s plan is to push Reels content into that main feed, and as Mosseri noted, that includes content from creators “you may not be following yet.” In other words, Instagram, having shifted the primary use case of the app from the Feed to Stories, is going to transform said feed to address its two remaining shortcomings relative to TikTok: a new consumption experience, and content from anywhere.
This is a risky shift, to be sure, but so was the shift to Stories; I wrote at the time:
It’s not certain Facebook and Instagram will succeed, and the risk is significant: the only thing harder than rewiring users’ expectations for a massively successful product is ensuring said rewiring doesn’t turn them off from the app entirely, destroying the very value you are trying to leverage.
Facebook, though, also knows the danger of standing still.
The Entertainment Goal
To this point I have framed Mosseri’s announced changes in the context of Instagram’s continual evolution as an app, from photo filters to network to video to algorithmic feed to Stories. All of those changes, though, were in the spirit of Systrom’s initial mission to capture and share moments. That is why perhaps the most momentous admission by Mosseri is that Instagram’s new mission is simply to be entertainment.
In truth, though, this has always been social media’s most important job. Back in 2015 I argued in Facebook and the Feed that the company was constraining itself by only thinking in terms of its network:
I suspect that Zuckerberg for one subscribes to the first idea: that people find what others say inherently valuable, and that it is the access to that information that makes Facebook indispensable. Conveniently, this fits with his mission for the company. For my part, though, I’m not so sure. It’s just as possible that Facebook is compelling for the content it surfaces, regardless of who surfaces it. And, if the latter is the case, then Facebook’s engagement moat is less its network effects than it is that for almost a billion users Facebook is their most essential digital habit: their door to the Internet…
This course, though, depends on Facebook giving users exactly what they want, or at least a good enough mix, in their News Feed, and as I noted, I’m not convinced personal updates is enough. Moreover, while Facebook may view “the network” as their differentiator, the fact is that a lot of “friend” sharing is indeed moving to alternative networks like Snapchat and LINE and WhatsApp. With this News Feed update I am concerned that Facebook is limiting itself and committing to a battle — the private sharing of information — it can’t necessarily win.
Consider Facebook’s smartest acquisition, Instagram. The photo-sharing service is valuable because it is a network, but it initially got traction because of filters. Sometimes what gets you started is only a lever to what makes you valuable. What, though, lies beyond the network? That was Facebook’s starting point, and I think the answer to what lies beyond is clear: the entire online experience of over a billion people. Will Facebook seek to protect its network — and Zuckerberg’s vision — or make a play to be the television of mobile?
Six years on and it seems likely that Facebook’s usage is at best holding steady — it was reportedly declining before the pandemic — and at a minimum declining relative to the competition; meanwhile, the service has been transitioning to much more of a utility, with a greater focus on Groups and offerings like Marketplace. Perhaps that was ultimately the best path for an app so deeply tied to the idea of a social network, but it also gives that much more of an impetus for Instagram to shift to an even broader vision: a one-stop shop for entertainment on your phone.
Of course the network isn’t going away: Facebook has leaned into the aforementioned shift to private messaging across its platforms, including Instagram; I probably should have added the 2013 addition of Instagram Direct to the number of ways the service has evolved over the years — it’s a long list! Indeed, that is the real answer as to what Instagram, particularly under Facebook, is ultimately about: moments, yes, but their fleeting nature. Instagram may have started with a goal of preserving them, but it has never been a service particularly concerned about getting stuck in them.
Newbie community professionals often fall into the politeness trap.
Instead of writing messages which are engaging, fun, and warm, they write messages which are polite.
Examples of polite language:
“Thank you for your contribution”
“I enjoyed reading that, thank you for sharing”
“I would welcome your contributions”
“We appreciate your attendance yesterday”
The problem is that being polite doesn’t achieve any of your message’s goals.
It doesn’t make members feel more appreciated, better understood, or excited to make their next contribution. It certainly doesn’t make members feel better connected to one another.
In fact, if someone makes a lot of effort and receives a simple polite response – it can discourage further contributions.
People don’t remember politeness, they remember kindness. Writing a kind message begins with the premise of ‘how do I make this member feel as amazing about their contributions as possible?’ Then you write that.
For examples:
“Your contribution yesterday was fab. I really liked what you said about [xyz], I don’t think anyone has quite phrased it in that way before. Judging by this post, I think your past experience in [xyz] is going to be really useful here.”
“I definitely want to know what you think. You’ve got such incredible expertise here and I know others would benefit as well”
“Yes, you folks were absolutely amazing yesterday, thank you. I thought that was one of the best sessions we’ve had yet. It’s definitely raised the bar going forward. I especially loved ….[xyz]”
If you want a deeper dive into some of the fundamentals of this work, be sure to buy my new book; Build Your Community.
Surveillance-based advertising is everywhere on the internet. It's bad for consumers, it erodes trust in businesses, and Fastmail believes it should be banned.
On June 23, 2021, a broad coalition of consumer rights organizations, civil rights groups, NGOs, academics, researchers, and privacy experts called on regulators globally to stop the invasive and privacy-hostile practices of surveillance-based advertising.
Advertising is not the problem
We have always believed in privacy for our customers and all users of the internet.
We have also always believed that advertising is an important way for businesses to connect customers to the services they need.
In the past, advertising was context-based. Businesses would distribute advertisements in a region they served or in places where a particular interest group would look (for example, advertising in industry periodicals for their target market).
This kind of advertising is appropriate. Advertisements appear in context, so customers know where to look. This method allows businesses to expose their target market to options that they didn't previously know were possible. It also helps advocacy and market building, which are essential pieces of advertising's role. Furthermore, this kind of advertising showcases its messages in the proper context—open a car magazine and see advertisements for car-related products and services.
Surveillance-based advertising is different
An important point to make about the previous example is that car advertisements don't follow you around the internet for the next three months after you open a car magazine. Similarly, after you visit an appliance store in person, you won't be prompted with offers to buy a second fridge for the rest of the year!
Today's surveillance and hyper-personalized advertising merge all contexts together. It becomes about the person rather than the role they are filling. We all have multiple roles in life—parent, child, partner, member of a club or organization, role at work, or friend. Our needs and desires differ as we inhabit our various roles, but surveillance advertising follows us around the internet regardless of what role we are inhabiting.
Surveillance advertising follows us everywhere. When you look up something for work, it follows you home. Likewise, when you search for something at home, related topics will pop up at inopportune times on your screen at work.
Data profiling is not necessary for advertising
Advertising hasn't always been this way, but it's always had a component of persuasion. With big data, this gets turned up to 11—some advertisers aren't just selling toothpaste; they're trying to change your point of view.
Contending with hyper-personalized advertising is not a fair fight for the human brain. With sufficient data, the computer knows more about how your brain works than you do yourself, and has learned how to best influence you against your will. Informed consent and free will are impossible when the computer can target you at your weakest time with a personalized sales pitch.
As data is gathered and shared through large-scale surveillance, and used to drive profiled advertising, the advertising companies (and to a lesser extent the businesses using them) know too much about us. These companies make decisions about what advertisements and services are available to us, on our behalf, without our knowledge or consent, and without any right to correct or remove the data they hold about us.
Fastmail is on your side
We are here for human-to-human communication. Fastmail helps our customers connect directly with other people, without giving up their privacy. We don't sell or share email content or any customer data, because we know that the primary use of resold data is harmful. Instead, we use a business model that's clear and transparent—"money in exchange for service."
Our customers enjoy the peace of mind that comes from being our primary stakeholder, rather than a product to be sold on the grey market of surveillance data. They also get a usable service—because that matters too—your time is valuable, and Fastmail respects that by making email as quick and painless to use as possible.
We are proud to be counted among the companies calling for regulatory restrictions on the harmful algorithmic surveillance invading everybody's digital lives.
For an ad free email experience, try Fastmail and get one month free.
One of the things I’m a bit conflicted about in the context of asset creation tools is the extent to which they should be scripted. The examples I started pulling together in my Subject Matter Notebooks demos (an effort which has stalled again…:-( are essentially scripted: the asset generating examples are generated from script. But there are other ways of creating assets within a Jupyter environment, using interactive editors such as the draw.io editor:
One of the concerns I have with tools like this in the JupyterLab context is that you can start to step away from the narrated description of how an asset was created. You can see this even more clearly in things like the plotly chart editor:
Yes, you can use this tool to create a diagram or source file from which you can generate a png or interactive chart asset, for example. And yes, you can edit that source file via the UI. But the linear, literate, narrated construction of the asset is lost.
But that’s a debate for another post… This post is about VS Code.
Just like a Jupyter user interface environment can be used as a rich (generative) interactive asset authoring and display environment (for example, OpenJALE, my Open Jupyter Authoring and Learning Environment demo), so too can VS Code. And with a much larger developer community, VS Code currently provides support for a wider range of tools than the Jupyter ecosystem, and competition between them that drives further improvement.
So here’s a quick review of just some of the tools that VS Code already integrates via extensions that support the authoring of rich media (I’ll review various extensions that support teaching computing related subjects in another post).
As we’ve mentioned draw.io already, in the context of its availability as JupyterLab extension, let’s start there: the hediet.vscode-drawio extension provides .drawio extension senstivity in the form of an embedded drawio provided in much the same way as the JupyterLab extension. I donlt know if the JupyterLab extension works in a collaborative mode, but the VS Code extension claims to, via VS Code Liveshare. Another handy feature is the ability to edit the diagram and its XML source code side by side: edit the diagram and the XML updates, edit the XML and the diagram updates (does this approach also work in JupyterLab? I guess it should if the diagram is reactive to changes in the source file?)
Support is also available (currently in the VS Code insiders preview edition) for Jupytext (donjayamanne.vscode-jupytext), which will provide VS Code notebook style editing of markdown documents.
I haven’t spotted any extensions yet to support the creation and editing of electronic circuit diagram schematics.
3D model previews are available using extensions such as slevesque.vscode-3dviewer or michead.vscode-mesh-viewer. (In terms of image viewers, I haven’t found a FITS image viewer extension yet, or extensions that provide lookup and previewing lidar or satellite imagery? Maybe the astronomers et al. don’t do VS Code?)
Here’s a pattern I’ve noticed in myself: some new thing happens, a thing outside of my lived experience. Rather than expanding to embrace this new thing, I go to ground, grit my teeth, and assume that my experience of this new thing is unique, never before experienced by anyone else ever, and that if I simply try really hard, I can self-reliantly figure out everything that needs to be figured out.
I did this in 2011 when Olivia was diagnosed with autism. I did this in 2014 when Catherine was diagnosed with incurable cancer. I did this in 2020 when Catherine died. And, most recently, this was my reaction when Olivia came out as a trans woman.
What I need to keep reminding myself, over and over and over, is that the way out of this pattern—because, let’s face it, it’s a harmful and self-defeating pattern that gets me nowhere—is to seek out peer support.
For years I rejected the idea of talking to other family members raising autistic children: I was convinced this would somehow be a denial of Olivia’s unique experience of autism, and my unique experience as her father. It was only when I got up the courage to attend a parent support group meeting organized by the Autism Society, a meeting where I looked into the tear-filled eyes of a father from Montague overwhelmed by his child’s meltdowns in exactly the same way I was, that I felt the enormous power of simply being in community with others living through the same experiences.
When Catherine died last year, I failed to apply this lesson, hunkered down, and remained dogged in my commitment to “powering through” grief. One Friday last May I received a call from Hospice PEI inviting me to a men’s grief support group. I naively told them that, no, I didn’t need help, and that everything was just fine. Fortunately, over the following weekend I came to my senses, called them back, and signed up. The eight weeks I spent in that group, plus the monthly grief support group drop-ins ever since, have played a large role in helping me keep my head above water, in helping me understand grief on a deeper level and, quite simply, in not feeling so absolutely alone.
When Olivia came out as a trans woman in May there was some evidence that I might have learned my lesson: I reached out to Peers Alliance looking for family support resources. Which they sent. And which I then let languish in my email inbox. “Everything’s fine,” I told myself, “I’ve got this.”
It wasn’t until a conversation with another parent of a trans young adult who spoke glowingly of the power of a peer support group for the parents of trans children, that I found my way to Transforming Family, a Los Angeles-based support group for “children, adolescents and their families to explore issues of gender identity.” I filled out an intake form yesterday, got a phone call a few hours later, and last night I attended my first meeting, on Zoom, of “Parents of Transgender and Non-binary Adults.” I’m so happy I did: again, the power of sharing space–safe, informed, positive space–with others in my situation, was helpful on many levels.
What I need to remember time and time again–which is why I’m writing this down–is that while peer support can help answer questions, get pointers to resources, avert possible crises, its true power lies simply in admitting to myself I don’t have to take this on myself.
Seeking support doesn’t mean I’m a bad person, it doesn’t mean I’m not autism-positive, or trans-positive, or grief-positive. It simply means I’m a human being, willing to admit my limitations, and willing to admit that I can become a better person with the help of others.
Eighteen months ago, a Mississauga, Ont., man started a Facebook group for cyclists 80 years and older who enjoy the thrill of a bike ride.
Ray Marentette, a resident of Port Credit who describes himself as "a kind of fun guy," says he gave the group a whimsical name, the Royal Academy of Octogenarian Cyclists.
Within 24 hours, he had one member. Within one week, he had 10. Now, the group now has more than 550 members from around the world.
Cycling is for everyone, Marentette says.
"You can cycle without age. Age is not a deterrent to cycling. You can cycle as long as you can get on your bike and ride," Marentette told CBC Toronto. "There's never a reason why you are too old to cycle."
The group is composed of avid riders. Some members were champion cyclists in their time. Some even competed in the Tour de France. Ten are in their 90s and the oldest member is 99.
Marentette says the group has helped cyclists of a certain age connect with one another.
"All of a sudden, here is a whole group of octogenarian cyclists who hadn't seen or heard from one another for years and years. And here they were, in an exclusive group. You had to be 80 in order to belong to our group."
When he was "a young fellow" of nine years old, Marentette developed a love of cycling. His family had moved from Windsor, Ont., to nearby Tecumseh, and he was a good mile away from school. There were no school buses in the 1940s, he says. He ended up cycling 11 months of the year.
"I've cycled right through my life. I have never stopped cycling. I'm not a competitive cyclist, like some of the champs in our group, but I enjoy cycling and I enjoy the freedom and the joy of just getting out there and feeling the breeze on my face."
Marentette says he's happy that he's found a like-minded community through the group, which he founded because he didn't know anybody in their 80s who was still cycling.
"It's such a sense of camaraderie. These individuals are just all one big family now. Because it's an exclusive group, there is a direct connection with each one."
He says the group was started before COVID-19 hit but members have provided much support to one another during the pandemic.
Marentette hopes to get some members together for a group ride and he hopes that all of its members keep on cycling.
This article reports on the results of tests of two products specializing in AI job interviews, MyInterview and Curious Thing. They are (predictably) unreliable. For example, when an intrerviewee responded by reading the Wikipedia entry for psychometrics in German, Curious Thing awarded her a 6 out of 9 for English competency. Similarly, MyInterview "pulled personality traits from her voice," despite concerns that "intonation isn’t a reliable indicator of personality." What we should take away from this article, I think, is, first, the fact that companies are using AI to assess interviews, and second, that we cannot (yet) depend on the algorithms - though, it's when they get good that the real etrhical issues will arise. Note that this article is one of '2 free stories remaining' for me; I recommend using Firefox with UBlock Origin to avoid paying for the article, but if you can't, you can see the first half of the article here or here. Meanwhile, perhaps someone can explain to me why an educational institution with an $18.4 billion endowment needs to put a paywall on scientific articles meant to inform the general public.
I listened to this podcast: an interview about Electrifying the home, and America, with Saul Griffiths and Arch Rao.
Griffiths has a great ability to speak in rules of thumb. Averages. Things that give you a sense of scale, of orders of magnitude.
I've realised that, although I've worked in energy for a while, I don't naturally think in those kinds of rules of thumb.
I'm also trying to insulate/electrify an old, leaky house in the East Midlands. Working out how best to do it. Should I get solar? Should I get heat pumps? Should I get cavity wall insulation? Do my walls have cavities?
This it turns out, is not easy. And some of that is because everyone is an expert in their own little field but very few people are good at putting it in context or explaining it to non-experts.
Here, from the podcast, is the kind of things Griffiths says / knows :
"The average US household today has two cars in the garage that burn petrol or gasoline or diesel, and it has natural gas heating and it uses about 25 kWh per day of electrical energy. If you electrify both of the vehicles in that household you'll add about another 25 kWh per day to the load of that house. And if electrify the heat you'll add about another 20 kWh again. For the majority of US homes, and this is true around the world in fact, when we electrify...you're going to double or triple the loads in that house."
"Rooftop solar is now providing 5 cent per kWh electricity in Australia"
So, I'm trying to research for myself, and document here, equivalent rules of thumb for the UK. I suspect looking it up and working it out will help me remember and understand.
Here's a start:
Ovo have a handy post that says "the average household uses 3,731 kWh per year". That's based on BEIS data. (From this page, I think). They then immediately start caveating about averages and types of home and all that, which is fair enough. But I'm going to stick at the higher level, because I just want a sense of things. And because, conveniently, 3,731 kWh per year equates to, roughly, 10 kWh per day.
(As a quick check, if you Google "how much electricity does a uk house use per day" the snippet you get says 8 - 10 kWh. There's a lot of SEOing going on in this answer. And lots of people re-using / re-writing the same content. But this seems to be an acceptable rule of thumb.)
If you want help visualising that, Arcadia have a good page, 1 kWh is enough to operate two desktop computers (or six laptops) during a standard workday. Or, if you do 65mph on a motorway, you can drive about 5 miles on 1 kWh.
According to BEIS (and everyone in SEOland) the average cost for 1 kWh of electricity was 17.2p in 2020.
This whiteboard was at an April event for Trump backers in Oklahoma. Trump is at the center of course, but it includes every imaginable association. And Jesus is King at the top, of course. Why does it matter? Because confessed and pardoned felon Gen. Michael Flynn, who was Trump’s first national security advisor, posed in … Continued
I was working with a health insurance company that was creating a new mobile application for their customers, and they needed to get a subscriber’s claims data to display in the application. An existing data endpoint gave them almost everything they needed except that it took two minutes to get a response. All the new app needed was the addition of “just a few simple things” and to improve the current response time to less than 30 seconds. When mobile asked the department who owned the service how long it would take to make the adjustments, they came back with an estimate of one month to return the new data fields and an additional five months if they wanted it under 30 seconds. When the mobile group heard the estimate of 1-6 months, they came to the team I was working with to help them get it done sooner.
0:30 | 6:00
Our first pass took us a couple of days. Initially, we reached out to the group that owned the endpoint and some of the data analysts for the system to talk about where and how the data was stored. We then threw together a very quick, simple, and dirty implementation of the endpoint that duplicated the existing logic in a very verbose and ugly way. We rewrote the same basic data call in a slightly new way, deployed a new endpoint, and had something that did everything the mobile app needed. The only problem was that the mobile call to our endpoint took six minutes to return the data.
Mobile was not happy with a 6-minute call and made it absolutely clear that such performance was unacceptable (which we already knew). Mobile also discovered that the data they’d requested was incorrect, and they needed some changes. This discovery allowed both them and us to catch and correct a missed requirement early and adjust very quickly. The existing endpoint owners sat back smugly and said, “See! We told you so!” We just smiled and said, “Just wait, that’s only version one.”, as we started on making our walking skeleton better.
0:30 | 2:00
Our second pass was delivered one day later. We’d added simple indexes to the tables that we were using, and our return time was now hovering around two minutes. Mobile was still not happy even though the data included corrected data. It was still too slow for a mobile environment. The existing endpoint owners were definitely less smug as it had only taken us three working days to implement the new fields being requested for the same two-minute call.
0:30 -> 0:02 | 0:30
Knowing two minutes was bad, we started our next refinement, querying the information database. We started looking at how the data relations, other data table sources, and data moved through the system. We found that there were other ways to aggregate the claims data and speed up the response time. This work was very detailed, and we did a lot of experimental prototyping of different ideas in the two days it took us to deliver the next endpoint version. That version returned all the data needed for the call around 30 seconds and had taken us two more days of work. Hooray, we’d hit the goal set by mobile in a total of five days! Unfortunately, as commonly happens, mobile was not satisfied with 30 seconds; they moved the goal to a two-second response time. The owners of the current REST endpoint weren’t talking to us anymore for some reason.
0:02 | 0:01
With our new goal of two seconds, we went back to work. Hitting 30 seconds for a response time had been tough and required us to do the obvious, easy, and even medium-hard data optimization. There wasn’t that much left in terms of query optimization to be done, so we started to look at the data we were retrieving. Did we need to deliver all historical claims, or could we just return a year’s worth? Mobile was trimming the claims to 12 months already. Win…less work for them and us! Armed with that new insight, we were able to go back and change some things, and after another two days’ worth of work, we beat mobile’s “new” two-second requirement by returning the data in one second.
Mobile was ecstatic and very pleased with the work that we’d done. The previous endpoint owners had taken us off their Christmas list, and we still didn’t feel we were done. We requested another couple of days to see if we could improve performance to what we felt was acceptable mobile response times, sub-100-milliseconds. Since the group had given us three months to do this work, and we’d just beaten their performance requests twice, they were happy with us taking a little extra time to “work our magic” on things.
0:02 | 0:00.024
So, we started pushing the envelope of the whole system. We added in system-level caching, something completely new to our entire system. We also implemented a data prefetching system that would put claims data into the cache when the user logged into the mobile app. We did this by creating simple subsystems that were available for the whole system to use. Now the entire system had access to caching and the ability to preload any data we wanted for a user. This work took us a little bit longer to do, but we’d played around with different prototypes of this thinking along the way, so we were able to put in a good solid system in a little over four working days. Our system now had a response time of 16-24 ms. Mobile was speechless.
This highlights the extreme power of iterating on simple things. We started by delivering something simple, quick, and dirty. We knew it was not the end state, but it minimally met the requirements and allowed for integration with everyone involved. It allowed us to play with how we were doing things by emphasizing evolutionary design, constant iterative improvement, and delivering working software. Early on in the project we were advised to take 1-2 weeks planning our approach relying on subject matter experts within the company for help. The same experts that were estimating doing this would take 5-months. No reasonable amount of planning, even with all the right people, would have resulted in the changes we made. Further I believe that this planning would have hindered us from recognizing emerging solutions due to anchoring us with false expectations and the “sunk cost” effect. In the end, the mobile group got exactly the data they needed blazingly fast - vastly outperforming their initial extremely hopeful request of 30 and later 2 seconds. Their expectation of giving us 2-3 months to deliver this was beaten too. In two days, they had something they could work against; in five working days, they had their initial request met, and in 11 working days, they had a comprehensive solution. Finally, in 12 days, they had a system that exceeded their expectations and significantly more flexibility for the whole system.
David Fisman@DFisman
Reupping, in case people didn't understand what I meant a month ago. The quiet we are experiencing in Ontario is t… twitter.com/i/web/status/1…
The Oatmeal@Oatmeal
I miss the days of RSS, where each website could plant its own little flag on the internet, rather than a massive,… twitter.com/i/web/status/1…
This week I want to share two critically important and misunderstood concepts of disruptive leadership: Power and Trust.
Why does power matter?
Leadership is about the gathering and the exercising of power, which allows you to influence people so that they take action. That is what power is all about — not control, not force, but influence. Strong, effective leaders know how to accumulate power and use it at the right times.
A key part of this definition of power is that it’s not a zero sum game. It’s not an either-or: if I have power then you don’t, and if you have power then I don’t.
In fact, power as influencing action is an abundant resource that we can build, invest in and grow. This is so exciting! We can actually increase our power in a systematic and intentional way. Here’s how:
3 Ways to Abundantly Build Power:
Referential Power: you build referential power by finding, identifying, and connecting with people in different areas. Referential power is all about connection. For example, build up the network inside of your organization, through the use of digital collaboration platforms, networking events, lunch-and-learns, so everyone can build power through a rich internal personal network.
Informational Power: you increase the informational power inside an organization by giving people access to information. I was recently working with a CEO who realized that most of the information in her organization was held by a small number of VPs and executives. Then she realized: almost all of it could be made available! So they opened up the vaults and made sure everyone knew how to access the information responsibly, so they had the power to make decisions directly.
Expertise Power: identify people who have an area of expertise, and develop that expertise and use recognition. Then let others know: Hey everybody, go to this expert because they know how to do this. Make sure the experts are tapping into informational and referential power too, so that they’re able to expand their power as well.
We’re used to thinking of power as scarce, of hoarding it for our own gain. But in today’s information-rich, data-rich and networked world, the more you share power, the more you get it. I went into more detail in my livestream Redefining “Power,” which you can watch here.
This is key to being a disruptive leader: creating a strong sense of power across your organization, where everybody has power because they have access to information, they are experts or know experts, and they have connections across the organization.
Why is trust important?
It seems like a no brainer, right? Of course trust is important. But if it’s important, why do we spend so little time talking about it and building it intentionally?
If you’re trying to create change, transformation and (my favorite word!) disruption, then you need trust… and trust scaffolding to support it. Trust is not built by luck or never making any mistakes. We can make intentional choices in our organizations and relationships to consistently build and nurture trust.
What are the elements of trust? Studies find that trust relies on four C’s: competency, communication, consistency, and compassion. So what can you do in your organization to foster these 4 C’s? How can you intentionally build trust and the scaffolding necessary to support it?
Transparency: In my research when I ask people what they really want in their leader, two things come up again and again: They want people to be honest, and they want people to be fair. You do those two things, and people will trust you. So make openness and transparency part of your culture! Be clear about what the rules are and why. Give access to information — because informational power builds trust.
Accountability: Clear rules and boundaries are meaningless unless they are reinforced fairly. When you reinforce the rules, it creates psychological safety. Imagine someone speaking over you while you’re presenting, and a colleague says, “wait,” and lets you say your piece. Consistent enforcement of rules like “we don’t interrupt each other” make all the difference in building psychological safety – and trust.
Allyship: Being an ally means I will speak up on your behalf when you don’t have power. I love this, because you can always be on the lookout for opportunities to be an ally for somebody, whether as a leader, a peer, or a friend or family member. Practicing allyship builds deep trust — it shows that you are here to support others at vulnerable points in their lives. This is always impactful, but especially so when leaders with privilege exercise their power on someone else’s behalf.
It can take decades to build trust, but seconds to destroy it (I go into more detail in my livestream on Trust Scaffolding — which you can watch here). But if you bake transparency, accountability and allyship into the fabric of your organization (and your personal life!), you will have the trust scaffolding you need to recover from mistakes and steer your team, your company, and your life from deep integrity and trust.
Your Turn
What surprised you about my definition or power? Have you ever thought about building “trust scaffolding” before? Let me know in the comments. I’ve shared a personal example when I was called out for breaking trust, and I’d love to hear a story from you!
Axel Rauschmayer explores the new proposed API for handling dates, times and timezones in JavaScript., which is under development by Ecma TC39 at the moment (and made available as a Polyfill which you are recommended not to run in production since the API is still being figured out). This is a notoriously difficult problem so it's always interesting to see the latest thinking on how to best address it.
Over the last year, I’ve been contacted by several USB-C accessory brands to test and review products. Some dodgy brands asked me to purchase via Amazon and then reimburse me after posting a review. I did not take them up on any such offers as it just seems like a dishonorable way to do business.
But a few brands seemed to actually want my feedback without any sort of Amazon shenanigans. They sent devices at no cost to mewith the understanding that my review may be positive or negative and may involve teardowns to examine the internals.
Full disclosure: While this is not a sponsored post, the product(s) reviewed were provided at no cost for evaluation purposes. Products received in this capacity are destined for teardowns and/or charitable donations.
With that out of the way, lets get to it.
The Review
I was sent the 15-in 1 USB-C docking station by Choetech (similar units are sold as 4URPC, LASUNEY, EUASOO, and several other brands). Unboxing was pleasant – just a simple thin cardboard box with two smaller boxes inside. One contained the Dock which weighed ~330g and the other had a power brick (12V @ 3A) weighing 190g. Also included was a user manual, a card inviting me to a Facebook group, and 2 generic 1m USB-C cables with no logos or markings on them. While these cables were obviously not USB-IF certified, Choetech claimed they work at 100W PD when used with the Dock. In general, I don’t like uncertified cables, but these cables seemed to be of reasonable quality weighing ~37g each with solid-formed gold-plated USB-C connectors instead of the cheap split-folded metal design. I’ll tear down one of the cables to determine the e-marker chip and wire gauges at a later date.
The Dock itself looked and felt quite nice with a smooth aluminum chassis and an unassuming size of ~115mm x ~60mm x ~73mm. All the ports were aligned to the chassis well and cables were easy to plug and unplug for the most part. The two front USB ports were a little tricky to use since they were only separated by ~3.5mm. Plugging in a larger flash drive partially blocked the other port unless I carefully angled everything in together. While the Dock did have rubber feet on the bottom, they were not enough to keep it firmly in place while plugging in cables so I had to use two hands to plug and unplug. The tension of video cables tended to slant the dock over to the side unless I had everything bundled up with zip-ties. A minor issue and comparable to other upright docks in this price class ($75-125 USD).
I plugged in the included power brick, my own 90W USB-C power adapter and a variety of devices. Dual 1080p monitors worked OK out of the HDMI ports. I did not try 4K (although the manual claims support for 2x 4K30 or 1x 4K60 and is backed up by the internal component capabilities). USB devices like mice, keyboards, fans, flash drives, and external hard drives all worked OK. I would have liked additional rear USB ports since I prefer to route all my cables to the rear. After running mouse and keyboard I didn’t have any left and was forced to use the front-facing ports cluttering up my desk. I did not measure transfer speeds as this is an uninteresting detail in this class of Dock since there are so many models using similar PCB layouts and components. Ethernet was functional as was the front-facing audio. The front USB-C port worked to charge my phone in USB-C PD mode at 10W and 15W (5V @ 3A). And the USB-C power delivery passthrough for charging the laptop worked OK. I did not test >60W charging as I didn’t have a suitable laptop on hand during this time period. But I did manage to test the cables separately with dummy loads and they worked fine for 85W+ on my USB-IF certified power supply.
I used the dock for 7-8 weeks and it performed well and didn’t get hot. The only issue I had was a few times my laptop did not come out of sleep while connected to the dock – but I suspect this is an issue with the laptop itself and not the Dock as I could not reproduce it consistently. Overall, it is a pretty typical budget Dock in a slick form factor.
There were two annoyances or quirks with this dock:
The Dock includes an extra USB-C host port and HDMI port (labeled HDMI1 and HOST1). The marketing materials show dual-PC workstations, but I can’t see how this would be helpful. There is no KVM functionality. The PC connected to HOST2 has both power delivery and dock functionality, while HOST1 has nothing except a single HDMI port. IMHO, the PCB real-estate would have been better used for more USB ports. And rather than integrate one, a discrete USB-C -> HDMI dongle would work just as well.
It needs 2 power supplies. The included 36W unit only powers the Dock electronics and downstream USB devices while a separate USB-C PD unit (not included) is needed to charge the laptop. This complicates setup and adds to cable clutter. To be fair, there are many other docks in this price class with the same 2 power supply design. I prefer the single power supply approach and is what I typically recommend to my customers on their builds.
Both of these quirks are solved in a Dock from an alternate brand in the same style and form factor. On sale for $68, the Choetech is still a fantastic deal. For the $110 list price (or ~$94 with discount codes) it is OK, but I think there are some other options you should also look into depending on what ports you need.
Teardown
So I totally goofed on this teardown and ended up destroying the dock. I’m so embarrassed. The key issue was separating the nicely machined aluminum chassis from the plastic cage holding the PCBs. There were no exposed fasteners and I could not free it with heat or spudgers. So I used a cutoff wheel and sliced the aluminum apart. That was my first mistake. Even though I wore gloves, a mask, and wetted everything down with IPA, the aluminum powder went everywhere. Yuck. Then I dug in way too deep with the cutoff wheel and cut into the PCB and plastics because I didn’t mount the Dock in my vise properly. Then I ended up crushing part of it in my vise once the aluminum gave way. I tried hammering the aluminum back into shape, but no go. She’s a goner. The components weighed as follows:
aluminum chassis: ~130g
PCBs with ribbon cable: 60g
metal weights: ~96g
plastics: ~64g
What a mess!
The power brick survived unscathed:
power brick – ~190 grams
Inside the dock were two metal weights totaling 76 grams. These along with two rubber feet on the dock didn’t do much to help it stay in place on a smooth desk surface but did give the dock a more solid feel overall.
weights – ~76g
PCB Analysis
The main PCB appeared to be 3 layers. Key components on the front:
A QFN-28 IC marked with “L170 3840 031” – probably a microcontroller
status LED surrounded by black foam shield
The Ethernet Jack was on its own tiny PCB and soldered to the main PCB with 18 ~2mm standoffs – 7 of which were connected to ground. This is one way to get the USB and Ethernet ports aligned on the same plane – a nice touch. Other docks just have the USB ports recessed by ~2mm with respect to the Ethernet port.
PCB rear
Components dedicated to the separate USB-C->HDMI converter:
A second Via Technologies VL103R-Q4 DP alt-mode & PD 3.0 controller
The larger PCB connected to a smaller one with a ribbon cable. While the ribbon cable was held in place with latching headers, a generous amount of white putty was applied to prevent it from shaking loose. The bottom housed a USB-C connector, USB-A, and a 3.5mm TRRS audio jack:
smaller PCB rear
Remember how I said I ruined the PCB? Well I managed to dislodge the audio chip. Ooops. Well here are the notable components:
Another Via Technologies VL817-Q7 4-port USB 3.1 hub is a QFN-76 package
Another Puya semiconductor P25D40H flashRAM (Why more flashRam? This second board is probably meant to be used standalone or paired with a variety of other boards)
SOP-6 power management IC (markings unclear)
3x 220uF 10V power output filtering caps for the USB ports
Monocle is a full text search engine indexed on my personal data, like my blog posts and essays, nearly a decade of journal entries, notes, contacts, Tweets, and hopefully more in the future, like emails and web browsing history. It lets me query this entire dataset to look for anything I’ve seen or written about before, and acts as a true “extended memory” for my entire life.
As soon as it went live, Monocle quickly replaced the search field on nearly every other app I use, and became the first and only place I searched for information that I knew I’d seen before. Whether I was searching up someone I had met before, a new blog idea, or a scratch piece of note about how to do something with JavaScript – Monocle had it all, and got it to me in under 5 seconds from anywhere on my computer.
This is the story of how Monocle works, how I built it in a weekend, and how I’ve been using it.
A universal search engine
I first had the idea for Monocle almost exactly a year ago, when I tweeted about potentially building a search engine that only searches my private and personal data.
Thinking about building a "personal search engine"
A search engine that only indexes my blog, my Tweets, my journal, my calendar/email and contacts, my photos, and browser history.
I want to have better memory without having to remember more stuff. What else should it index?
Since then, I’d thought about executing on this idea a few times, but got distracted or scared away by the potential complexity of the project each time. Then about a week ago, when I was writing about incremental note-taking, I realized that effective recall of information was critical to a good personal knowledge tool. This reignited my interest in this project. This past weekend, I took that idea and built a first prototype with Ink, teaching myself the basics of full text search algorithms in the process.
The headline description of Monocle is that it’s a full text search engine indexing only my personal data – I’ve explained the technical details of its architecture in the GitHub repository hosting the code. Here, I want to focus on a few specific design decisions I made in designing Monocle to make it as useful as it could be in my personal workflows.
First, I wanted Monocle’s time-to-first-result to be as quick as possible. By this, I mean that the most important metric of success for a search tool is how quickly I can go from some vague query I have in my mind, to looking through results to find what I need.
One critical constraint this imposed on Monocle’s design was that I needed to be able to search as I typed, with results arriving on every keystroke. Building many small fast tools has taught me that often, making something instantaneous doesn’t just make the tool more efficient – it changes how you use the tool. In this case, I believe searching as-you-type means the search progress becomes less of a slow question-answer cycle, and more of an interactive exploration through my knowledge base of typing a few words to see what information I have, perhaps deleting some characters, and re-typing. To make this experience possible, Monocle loads a compressed, pre-generated index of its document dataset on startup, and performs all search locally in the browser.
Like many of my other tools, the speed constraint also meant I wanted to be able to use the app entirely with the keyboard. The critical-path actions in Monocle – searching, scrolling through a list of results, and previewing them – are all a keystroke away. All of these design decisions together result in a search tool that can almost always help me find what I’m looking for in five seconds from anywhere on my computer.
Second, I wanted an indexer and search algorithm that I owned and understood. This is partly because I just wanted to learn and understand how full-text search engines worked, and the way I learn is often by building tools for myself using that knowledge. Another benefit of a fully custom, from-scratch search algorithm is that if I understand the whole system, I can be aware of its limitations and come back to improve it as I need the algorithm to improve. The “search algorithm” is really a few different parts:
the indexer, which catalogues keywords in the indexed documents
the searcher, which reads documents from the index to find matching results
the stemmer, which expands search queries to include variations of words like “tool” to “tools” or “create” to “creating”
the ranker, which is responsible for ordering search results by some measure of relevance.
In the future, if I wanted to add extra indexing or querying rules for categorizing results by their source type or date, or have other custom logic related to my data, understanding my own system would give me an edge over using something pre-made. Moreover, using something that’s only as complex as it needs to be for my needs means there are fewer opportunities for the algorithm to break, and more technical flexibility. For example, during development, I had to move the indexer from the client to the server, and my current architecture turned this challenge into little more than a copy-paste of a few lines of code.
I had a lot of fun building a full text search engine and writing custom modules for each of my data sources, but the underlying technology is not cutting-edge by any means – it’s just a full text search algorithm. The magic, as with many of my projects, is what’s possible when you apply such technologies to interesting data in a small, well-known stack that I control.
There’s one other benefit of owning the software services that drive my life. Without a doubt, the most valuable things I have these days is my data. My archive of notes, documents, photographs and music, todo lists, contacts, calendars – these collectively make up my external brain and my identity, which is the last thing I want to lose. I want to own data like this as wholly as I physically can. Storing them through online software services or apps are convenient, but I never know when a third-party notes app is going to run out of funding and shut down, or if a todo list or music app I use is going to pivot and stop caring about me as a user. These days, nearly every piece of data I own is stored and backed up on services and systems that I control from the operating system up.
As I added many of these data sources to Monocle, I realized that many parts of what makes Monocle special are only possible because I own my data and software stack to such a deep extent.
First, Monocle indexes some very personal and private data, like my journal entries. If Monocle was some third-party service from a budding startup, my journal entries would be the last thing I’d want to give up. But because I own and understand the entire search stack, I feel safe letting Monocle index such personal data. As a consequence, the search results I can get back are more personal and significant than anything extant search software could find for me.
Second, because I own my entire data stack, I can have certainty about where much of my data like contacts, notes, and archived journals are stored, and in which format they are saved. This means that writing and maintaining modules to ingest and index these data sources is pretty simple. I don’t have to worry about these data sources going away, or these sources changing their data export format. I simply talk to my file storage system and get back exactly the files I want. I feel that owning my stack for most of the data I needed to index made this problem much more tractable.
An experience report, so far
Monocle has only been live for a few days now – it went live on Saturday for me, and I’m writing this on the following Tuesday. But in that time, I think I’ve searched Monocle at least as many times as I’ve searched Google. In terms of how often I expect to use a tool I built, Monocle ranks in the top five best investments of my time across all my side projects.
In these few days, here are a few things for which I searched Monocle.
A few specific people whom I had met before, but didn’t remember very well
Topics I know I had written about before, to find links to blog posts that I could share
A few companies and projects that I knew I had heard of before, but wasn’t sure from where
Book recommendations that I had stashed in a few different places in my digital life
A few Twitter threads that I knew I had shared before about building side projects and communities
When I want to learn something new, I still search the Web. But if I’m trying to remember something from sometime in my past, I now go straight to Monocle, because it’s a more effective and powerful “extended memory” than any note-taking system I have ever used – I don’t need to enter or explicitly save anything; if I ever wrote it down somewhere, it’s here, indexed by Monocle.
In short, Monocle is the closest thing I’ve ever experienced to Vannevar Bush’s Memex. The more I use it, the more I want it to become even more powerful and even more present in my life. And because I own the whole stack, I can do so fearlessly, without any data privacy concerns. In the coming weeks and months, I hope to index other data sources like my browser history, calendar events, and perhaps even my email archive.
While I was building Monocle, I also had a more subtle insight about building my own tools. Monocle isn’t a standalone project by itself, but a cross-cutting infrastructural project that integrates with a wide range of other projects in my portfolio to provide some shared functionality: search. This is my second project like this, after Noct, which provides a shared storage and backup layer for data across many of my apps. After building Noct, backup and file sync was no longer an issue I had to address for each new project. After Monocle, it seems like search also became something that I’ll never have to address again for each individual project. These concerns are addressed universally by infrastructural projects on top of which individual apps can be integrated.
I like this idea of building pieces of dependable, shared infrastructure for cross-cutting concerns across my personal tools. It feels a little bit like building my own personal cloud platform, where I can build small apps that integrate with Monocle and Noct and other pieces of infrastructure and get those extra shared pieces of functionality “for free”. In some ways, building my own programming language and UI framework also give me the same benefit of shared infrastructure. The natural next step in this direction is to build other shared pieces of infrastructure like a universal authentication layer. A “personal cloud” sounds ambitious and grandiose, but it really feels like I’m putting together the right elementary pieces here to run towards that vision.
Writing and thinking about all of these ideas about personal information and recall, I also know that I’m in the vanishingly small minority of people on Earth who have their digital data saved and organized well enough to build a tool like Monocle. For most people, their important information lives across so many different pieces of software across a range of companies and technologies that building a personal Memex would seem impossible. In addition to building something useful for myself, I also want Monocle to serve as a kind of proof-of-concept – a statement piece, perhaps – about what’s possible when we build our own tools and manage our own information. Perhaps with the knowledge of what’s possible, we can push ourselves to draw where we are today closer to where we should be: a universe of small, personal tools that can respect our privacy and agency while leveraging it to help us see the world in new light.
That aligns with this article, which says that a study in Singapore found that Pfizer was 69% effective against all infection and “between 80 and 90 per cent” for symptomatic infection.
There has been speculation that the AZ clotting issues are a result of AZ getting into the bloodstream. (Injections into the muscle drain into the lymph system, not the bloodstream.) One theory is that very rarely, the needle aimed at the deltoid hits a blood vessel. Another theory is that the spliceosome in the nucleus makes a copying error which eliminates the membrane anchor, allowing the spike protein to get into the cell.
Today, this study was released. It looked at what happens if you inject mice with AZ intravenously instead of intramuscularly, and found antibodies which bound to platelets.
Long COVID
This study found that 77% of COVID-19 patients had zero symptoms after one year. (Ed: This seems out of line with other studies — my gut is that it’s about 30%.)
On the other hand, this study said that 50% of COVID-19 patients had symptoms after 12 weeks.
Seroprevalence
Statistics Canada did a seroprevalence study, collecting data from November 2020 to April 2021.
Note that because the study collected samples over a long period, at a time when case counts were increasing (sometimes rapidly), they are a little hard to interpret. You can’t give a specific date when these numbers held, so you can’t compare these numbers to the number of confirmed cases on any given date.
We also don’t know if the samples for each category were taken at the same time. If all the BC samples were taken in November 2020 and all the samples from Alberta were taken in April 2021, then obviously the BC numbers will be lower.
Hopefully the samples were taken at more-or-less the same time for all the categories, so hopefully it is reasonable to compare BC to Alberta (for example).
It’s also useful to get a ballpark idea. We can be pretty sure that as of April, at least, less than 10% of Canadians had gotten COVID-19.
total
from infection
from vax
Canada
3.6%
2.6%
1.0%
Atlantic provinces
1.3%
0.5%
0.8%
Territories
~21.1%
~0.0%
21.1%
Alberta
5.6%
4.0%
1.6%
BC
2.4%
1.6%
0.8%
Manitoba
3.1%
2.4%
0.7%
Ontario
3.3%
2.5%
0.8%
Quebec
4.4%
3.2%
1.2%
Saskatchewan
4.1%
2.9%
1.2%
Men
3.3%
2.8%
0.4%
Women
3.9%
2.4%
1.5%
Under 20 y/o
~3.4%
3.4%
~0.0%
20-59 y/o
4.5%
2.9%
1.6%
Over 59
2.1%
1.4%
0.7%
Visible minorities
4.8%
4.3%
0.5%
Non-minority
3.3%
2.1%
1.2%
Transmission
A preprint which I missed on 29 June 2021 said that after vaccination, IgG and antibody levels in the blood are waaay higher in blood than saliva. This newsletter wonders if that’s why vaccination does keep you from getting badly sick from Delta, but doesn’t do nearly as good a job at keeping you from getting infected at all.
This article reports on a study into perceptions of risk. It turns out that people think that activities they consider moral (e.g. going to church) are safer than activities they consider less moral (e.g. going to the beach). This helps to explain why people got bent about throngs of people at the beach (which were probably quite safe, actually).
Disease
This study looked at data collected from wearables and found that the heart rates were very different during recovery from COVID-19 than from recovery from other respiratory illnesses:
Treatments
This case study of three people with AZ-related blood clotting suggests that exchanging their blood plasma with donor plasma can help a lot.
Unintended Consequences
I have seen a number of articles which have said that the mental health impact of the pandemic has been lower than expected. For example, there hasn’t been a rush of adult suicides.
However, apparently people are drinking more. This study says that Alcohol-Associated Liver Disease went up by 62%.
Recommended Reading
This article is interviews we three people giving retrospectives on the pandemic: what did we learn, what should we do better next time? It was more interesting and provocative than I expected: Zoom bad, one-size-fits-all-mitigation bad, closing schools bad, etc.
There is a neat interactive graph showing how Treatment A compares to Treatment B. It’s not actually very informative at the moment (except to say that there aren’t very many good treatments), but they say that they will keep it updated as more results come in.
This essay talks about vaccinating kids. One thing it points out is that the age structure in low-income countries can be vastly different from in high-income countries. In wealthy countries, the average share of the population which is under 15 is 16%, but in low-income countries the average is 42%.
One of my big themes is that open source will transform every industry, with key examples being WordPress in web publishing, WooCommerce in online commerce, Wikipedia in reference, and Bitcoin/Ethereum in finance. Medicine, though, has been relatively unscathed so far. Here’s a great video introducing the Open Insulin project, which for the past 6 years has been developing their own method of manufacturing insulin and is going to open source its process to the world for anyone to recreate.
We’ve been arguing about Apple’s app store rules for a decade now, but whatever your opinion of them, it should now be clear that something is going to change. The US has proposed two bills to regulate it (one mostly sensible, one not, as I wrote here), the UK is digging in, and the EU has already decided that the current situation is unacceptable. This prompts three questions:
How much money are we talking about?
What would a new situation look like?
And, who cares?
First, the numbers. Apple says it paid $45bn to developers in 2020, and hence total consumer billings were around $60bn and Apple’s commission around $15bn*. This is around 6% of Apple’s revenue. (It was also roughly the same as the entire global music industry’s revenue from digital. Remember when Apple was the iPod company?)
Where did that come from? Apple disclosed the slides above as part of the Epic lawsuit: they show that in 2016, when billings were $28bn, 80% of that was from games, mostly in the US and north-east Asia, and mostly on iPhone. There’s no clear reason to think the proportions have changed much since then, except that China is probably bigger (Apple had only just added support for Alipay in 2016).
So, this is mostly games, and, from other disclosures, over 90% free-to-play. That’s reflected in the top ten publishers. It’s also reflected in the fact that over half of the revenue comes from just 0.5% of the users. If those proportions remain the same, then last year, Apple made $7-8bn in commission revenue from perhaps 5m people spending over $450 a quarter on in-app purchases in games. Apple has started talking a lot about helping you use your iPhone in more healthy ways, but that doesn’t seem to extend to the app store.
20% of users are spending money on the store, and 0.5% of users are 54% of spending
Second, what happens next? Apple will have to allow side-loading and third party app stores, and it will have to allow apps to ask for payment directly. What would that mean?
There are lots of privacy and security arguments about side-loading, and to some extent also third party app stores, but I would argue pretty strongly that this is mostly a waste of effort - that these are not a mainstream consumer behaviour and the dominant route-to-market for most developers will be the default, preloaded app store. That in turn means that even if regulators do force Apple to allow side-loading, they won’t stop there - they will also look at the rules inside the store.
In addition, regulators are not only looking at how an app gets onto the device - they are also looking at the sandbox itself. For example, the EU is looking at Apple’s NFC APIs, and of course there are broader questions about ‘self-preferencing’ of services and products on the device. So, side-loading doesn’t end the argument either way.
Meanwhile, while developers won’t be obliged to use Apple’s payment anymore, that doesn’t mean it will go away - after all it, it will still have lower friction and higher conversion than asking for a credit card. (That prompts the question of whether Apple is obliged to allow side-loaded apps to use it, or to allow other apps to replace Apple as the default for in-app payment.) All things being equal, it’s much easier for big publishers with well-known, trusted brands to ask for a card. So, a lot of the money might stay with Apple, and the money that leaves will mostly go to big companies, and mostly go to game developers. That prompts another question - how much of that money will then be spent on, um, search ads on the App Store?
Part of the complexity here is that US, UK and EU regulators will produce different rules on different timelines. What happens if EU regulators require side-loading but US regulators do not? Will Apple (or Google) have different rules in different places? (Microsoft had to make different versions of Windows.) And note, also, that the EU is moving fastest, but on these numbers was only about 10% of app store billings. What happens when China’s newly aggressive regulators turn their attention to app stores? How many rules will there be?
Third, a slightly more provocative question - if you’re not a shareholder in Apple, Spotify or Epic, why should you care?
Apple’s rules are a structural problem for a small number of businesses that have marginal cost for digital goods - mostly, music and books - and are effectively unable to give Apple 30% of their top line. Ending the current rule would be a big deal here. Conversely, games companies have been able to build a $50bn industry even while giving Apple 30%, though some of them would like the extra cash. Here the issue is not so much Apple’s commission as the business model rules - Stadia is not allowed on the app store at any price, though Roblox is, for reasons no-one understands. Again, this is why a narrow focus on the 30% or side-loading misses the point - regulators are looking at the whole system.
So, are there significant, valuable, mainstream consumer things that can’t happen because of Apple’s rules - not just on that 30%, but on the store and the sandbox? Are there lots of potential Stadias out there being blocked by Apple, or is this just a wealth transfer from Apple to Tencent? Is there an explosion of activity waiting to expand the model far beyond games once the rules are changed?
It’s hard to know in advance. One could argue that the reason all the money is in games is that Apple’s rules have effectively blocked anything other than games and a few other smaller industries (such as online dating) from building a big directly paid software or content model on iOS. For example, people making productivity apps have complained since the beginning about the lack of basic business tools like free trials or upgrade prices. On the other hand, there are very few mainstream consumer successes to point to where Android’s looser rules did enable something that doesn’t exist on iOS. And, of course, companies from Uber to Amazon to Snap or Instagram have built big businesses on the iPhone entirely outside Apple’s rules.
Meanwhile, there are very basic trade-offs between privacy and security, competition, and product design. Apple focuses on the first and third of these, and a lot of current regulatory ideas would deliver the first two while also delivering a system that was baffling and confusing to use. And before the iPhone, mobile apps were a tiny niche industry that delivered none of these. The iPhone app store has been quite good for software developers, after all.
That is, people in tech care deeply about the principles at stake, and some of the arguments can feel very religious. But it’s worth asking whether this is a big deal for a small number of companies, a wealth transfer for a larger number, and mostly irrelevant for most consumers and most consumer tech companies.
* Apple reported ‘over $200bn’ cumulative payments to developers in January 2021 and ‘over $155bn’ in January 2020. Disclosures in the Epic case put Apple’s average commission rate in 2019 at just over 25%, due to the various discounts available.
This is Hans, a software engineer at Datawrapper. For this week’s edition of the Weekly Chart, I tried to find a personal approach to global temperature increase.
When looking at charts about the increase in global temperature, I sometimes find myself asking: What exactly does that mean for people living now — especially younger generations? These charts often have all the data laid out, but the direct personal relevance is sometimes hard to grasp. Here is my approach:
Methodology
Using the average life expectancy for German citizens in 2017/2019, I calculated the average remaining life expectancy for each age group. Unfortunately, I couldn't find a similar data source for the whole world. The statistical projection for future warming is based on this Guardian article from 2017, which in turn is based on a paper by Raftery et al. from 2017. I chose to use the average of projections, which depicts the most likely scenario.
This chart is heavily inspired by our CTO Gregor's Weekly Chart from two years ago, and uses the same data. Head there if you want to read up on what global temperature increase is and how it affects our future.
Chart choices
The chart above looks like a bar chart — but to create it, I used a Datawrapper scatter plot. It offers the greatest flexibility of all Datawrapper chart types. I mostly used features from the Annotatetab, such as annotation, highlight ranges, and custom lines. To calculate the horizontal “bars,” I wrote a tiny script that you can run in the console of your browser. I then pasted the results in the textfield of our “custom lines and areas” feature.
const years = [2098,2088,2078,2068,2059,2049,2041,2034,2027,2024];
const age = [9,19,29,39,49,59,69,79,89,99];
let text ='';
for (let i = years.length - 1; i >= 0; i--) {text += `2021.2 + ${age[i]} + ${years[i] - 0.2} + ${age[i]} + @width:10px @color:#fff \n`;}
console.log(text);
That’s it for this week! As always, feel free to hover over the chart itself and click on the “Edit this chart” button in the upper right to play around with the chart settings or to use this chart yourself. We'll see you next week with a chart by our support engineer Eddie.
Things tend to go on as they always have — until somebody has an epiphany. A decade ago, I was the lead on hiring a new social media analyst at Forrester Research. A woman with a strong and positive social media presence interviewed with us, and got to the final stages, which included doing a … Continued
CIRA Joins Firefox’s Trusted Recursive Resolver Program
In a few weeks, Firefox will start the by-default rollout of DNS over HTTPS (or DoH for short) to its Canadian users in partnership with local DoH provider CIRA, the Canadian Internet Registration Authority. DoH will first become a default for 1% of Canadian Firefox users and will gradually reach 100% of Canadian Firefox users – thereby further increasing their security and privacy online. This follows the by-default rollout of DoH to US users in February 2020.
As part of the rollout, CIRA joins Mozilla’s Trusted Recursive Resolver (TRR) Program and becomes the first internet registration authority and the first Canadian organization to provide Canadian Firefox users with private and secure encrypted Domain Name System (DNS) services.
“Unencrypted DNS is a major privacy issue and part of the legacy of the old, insecure, Internet. We’re very excited to be able to partner with CIRA to help fix that for our Canadian users and protect more of their browsing history by default.”
Eric Rescorla, Firefox CTO.
“Protecting the privacy of Canadians is a key element of restoring trust on the internet. Our goal is to cover as many Canadians as possible with Canadian Shield, and that means finding like-minded partners who share our values. We are proud to be the first Canadian participant in the Trusted Recursive Resolver (TRR) Program and are always seeking out new ways to extend the reach of Canadian Shield to enhance the privacy of Canadians.”
Byron Holland, president and CEO, CIRA.
Once enrolled, Firefox users located in Canada will see a terminology panel pop up (see screenshot below) that will ask them to approve or opt out of DoH protection. When going to Settings in the settings menu in Firefox, then scrolling down to the Network Settings section and clicking on the Network Settings button, a dialogue box will open. Canadian Firefox users will be able to confirm that “CIRA Canadian Shield” is enabled by looking at the bottom of the dialogue box. They will also have the option to choose Cloudflare or NextDNS as an alternative Trusted Recursive Resolver.
Firefox users in Canada will see a panel letting them know that their DNS requests are encrypted and routed through a DNS over HTTPS provider who has joined Mozilla’s Trusted Recursive Resolver Program
For more than 35 years, DNS has served as a key mechanism for accessing sites and services on the internet. Functioning as the internet’s address book, DNS translates website names, like Firefox.com and cira.ca, into the internet addresses that a computer understands so that the browser can load the correct website.
Since 2018, Mozilla, CIRA, and other industry stakeholders have been working to develop, standardize, and deploy a technology called DNS over HTTPS (or DoH). DoH helps to protect browsing activity from interception, manipulation, and collection in the middle of the network by encrypting the DNS data.
Encrypting DNS data with DoH is the first step. A necessary second step is to require that the companies handling this data have appropriate rules in place – like the ones outlined in Mozilla’s TRR Program. This program aims to standardize requirements in three areas: limiting data collection and retention from the resolver, ensuring transparency for any data retention that does occur, and limiting any potential use of the resolver to block access or modify content. By combining the technology, DoH, with strict operational requirements for those implementing it, participants take an important step toward improving user privacy.
CIRA is the latest resolver, and the first internet registration authority, to join Firefox’s TRR Program, joining Cloudflare, NextDNS and Comcast. Mozilla began the rollout of encrypted DNS over HTTPS (DoH) by default for US-based Firefox users in February 2020, but began testing the protocol in 2018 and DoH has been available worldwide for Firefox users who choose to turn it on.
Should it be against the law to teach gender-neutral language? That's not an idle question, as it comes in the wake of a ban on the use of a gender-inclusive writing method announced by France’s education minister, Jean-Michel Blanquer, a ban that feels reflective of efforts in the U.S. to ban the teaching of critical race theory. This is a good article that quotes a lot from an article in Foreign Policy that draws the connection between language and wider issues: "rarely do proponents of inclusive writing argue that language is the only avenue for progress. Instead, they point to research that highlights a correlation between gender-inclusive language and attitudes toward gender equity."
shoutout to miss Marry, the kind shopwoman that let me borrow her watch for this picture
A 30 minutes lunch break? Time entry. 12 minutes of arguing with mom? Time entry. 7 minutes of stalking my ex on Instagram? You guessed it!
That was my life over the last 4 months, being my own time tracking cop while carrying out the most outrageous experiment of my life so far. The results amazed me in ways that I would never have expected, so I decided to write about them. Who knows, maybe you’re also going to find something of value in my journey.
But first…
What the hell made me do it?
To be honest, it was a combination of frustration, anxiety and fear — all generated by the fact that I kept setting goals for myself, but didn’t seem to make any progress towards them. Time was passing, and I had nothing to show for it.
All I had were vague reports at work, where “working” covered everything from writing code, to making phone calls, to watching Russian slapping contests on youtube.
I knew I had to do start tracking my time if I wanted to keep my sanity. And I also knew how something casual/half-hearted would quickly become too vague to be of any use. I had to go all-in.
Alright, so…
How exactly did I do it?
I used an app called Toggl to do all my tracking. I chose this specific app because:
it’s available on all platforms and syncs very nicely between them
it has an intuitive UI, with suggestions that become more and more accurate over time
it allows for very fine customization and reporting
At first, I devised 7 main areas where all my entries would fall, using tags and colors to mark them in the app:
Then, I created some high-level projects that I knew I was already spending time on:
After the setup was done, I would simply start a new time entry, every time I would move from one activity to the other.
One important note here was that, because I decided to go all-in, I had to be particularly careful not to have any entries “cover up” unrelated things. For example, if I would be writing code on my project and I’d receive a call, I’d have to create a separate time entry for it, even if it only took 5 minutes.
This level of strictness was a bit taxing at the beginning, but after a while, Toggl’s UI came in very handy. I rarely had to create new entries. 99% of the times when I’d switch to something else (even just short interruptions), I’d just have to press “continue” on a previous entry.
At the end of the week, here’s what my timetable would look like:
And now that the “how” is also out of the way, let’s move on to the exciting stuff. Here are the biggest changes I noticed, over these 4 months:
1. My focus and productivity improved drastically
Yep, the biggest impact of this time tracking journey didn’t come in the form of a mind-blowing insight at the end of the week, when I was looking over my timetable. The biggest impact was in how I was spending my time while I was doing the tracking.
At first, nothing big happened. But after a while, I found myself more and more often in an interesting situation. Whenever I was working and felt the need to “zone out” by jumping “just a bit” on youtube or Instagram, I’d find myself thinking “nah, I don’t want to start a new entry now. I’ll just get this thing done, and then take a bigger break for that”.
And, more often than not, I wouldn’t even feel that need for youtube or Instagram anymore, once I actually finished the task. The feeling of accomplishment was enough to give me the refreshment I needed.
This increase in focus sent my productivity through the roof. Yes, I’ve always read and heard of how context switching is a very bad idea. But, until I tracked it down, I never knew how often I was doing it — and I never knew that getting rid of it would make me get things done literally twice as fast! After seeing all this for myself, I felt like I somehow hacked my own life.
2. Saved a lot of time from unexpected places
One of the most shocking insights that I had in the beginning, after looking at my reports for a week, was that I was spending over 20 hours a week on food-related activities (buying food, cooking, eating).
Every day, 3 times a day, I would take some time off to cook. And, since eating healthy was always an important thing for me, I didn’t feel bad if it sometimes took a little longer. But I never knew I was doing the work of a part-time cook out there! At least if I’d learned to cook something more exciting than this boring salad:
sorry, mom, this is the best plating I’m capable of
Once I became aware of this, I automatically started thinking about how I could make it a bit more efficient. A simple thing that popped into mind was that, instead of cooking everything from scratch in each of the 3 breaks, I could simply prepare everything in the evening before, and have my food ready to go for the next day, with minimum adjustments.
This trick solved all my cooking for the day in under 1 hour, instead of 2–3, which amounted to over 10 hours of saved time, per week. And the best part was that I didn’t have to sacrifice anything in terms of how healthy or tasty my food was!
Such a simple solution. However, I would never have thought of it, if there wasn’t this table that was telling me straight to my face: “here’s how much time you’re actually spending on this thing”.
3. Formed habits & routines much easier
Turns out time tracking helped with my habits and routines, as well, in two not-so-obvious ways:
1. If I would have the same entries at roughly the same hours, Toggl’s mobile app would start suggesting them, in those time intervals. This made my tracking way easier, and turned the clock into a kind of trigger for the habits I was trying to form:
2. There was a deep satisfaction when I would look at my weekly timetable and see all the entries nicely aligned. Here’s one of the weeks that I’m most proud of. Just look at how satisfying those morning entries look:
It might sound trivial, but just these two simple tricks were enough to make me form and cement very helpful habits, without thinking too much about them.
4. Enjoyed my “chill time” more than ever
Here’s something interesting. This experiment, which was chiefly meant to increase my productivity, had another very unexpected — but very welcomed — effect: it increased the quality of my “chill time”, as well!
Firstly, as I was doing my work much more efficiently and saving time from all kinds of unexpected places, I found myself with more and bigger blocks of time on my hands. That meant I could fit in some leisure activities that were more time-consuming — but that I really enjoyed doing.
Secondly, all this increased amount of “chill time” came without the usual guilt I felt before, when I was “chilling” by scrolling through the Instagram feed, while I knew I had to fix that stupid programming bug at work.
This made me enjoy my free time like never before, and rekindle old passions like salsa & bachata —passions that I forgot how good they made me feel, amongst all this clutter of work and guilt and continuous distractions.
5. Made better decisions, overall
one of the toughest decisions in life
Since I was being as honest as I could with those time entries, weighing my decisions wasn’t that complicated anymore: I would look over my timetable, see exactly how much time I spent on something I decided to do, and look at how much I got out of it.
This way, “Is it a good idea to write that article for my 23rd birthday?” became “Is it a good idea to write that article for my 23rd birthday, given the fact that last week I spent 11 hours, and got nowhere with it?”. Not so hard to see the issue, from that perspective.
As a bonus, tracking my time solved another one of the biggest problems I had, in terms of decision making. I always had the tendency to overestimate my abilities and take on much more than I could actually handle. This obviously had some very bad consequences, like frustrating other people that were working with me.
Well, once I had this sheet that was telling me “this is how much it actually takes you to do it” and “this is how much free time you have on your hands right now”, deciding whether I could or could not handle something new became a factual decision, rather than a whim of my arrogant ego.
6. I finally felt in control of my time
As I said in the beginning, the irreversible passing of time was one of the biggest sources of stress and anxiety for me. And, while I’m still having my fair share of existential crises about it, doing this experiment drastically reduced that stress and anxiety. The main reason was that, again,
I finally felt in control of my time.
Yes, I was still binge-watching cat videos on youtube, probably more than I should. But at least it was a conscious decision, rather than a reaction to some algorithms designed by smart people to make me mindlessly spend hours on end on their website. And this “conscious decision” part was what made all the difference, for me.
And the coolest thing was that I didn’t have to change anything in the way I was spending my time, in order to feel better about it. Simply having it noted down was enough to give me that empowering feeling of control.
7. Felt more tense, uneasy and guilty (at first)
Surprise-surprise: this is not a silver bullet to shoot down all of life’s problems. It actually came with some not-so-nice consequences that I have to mention, if I am to paint an honest picture of my journey.
First up, I became more tensed and uneasy, especially in the beginning. I think that’s not too unexpected — just imagine having a cop on your back, 24/7, that sees every single thing your doing, and tracks it down on a sheet that’s gonna stare you in the face every Sunday. Quite a reason to feel uneasy…
shoutout to Mr. policeman, for not arresting me when I randomly asked him to pose for my blog
The other thing was guilt. Again, especially in the beginning. After the first few weeks, I was confronted with a hard truth: I was wasting time. Lots of it. And not in a vague way. I could actually count the hours I spent on things that were totally unproductive, projects that failed and times when I did something completely different than what I had to. Talk about pills that are hard to swallow…
I eventually managed to keep those bad sides under control through other habits, like meditation. That being said, this journey was definitely not all fun and rainbows.
So, that’s about it for my journey. Currently, I got so used to this system and it seems to work so well for me, that I’m gonna keep doing it — as long as I’ll be able to keep those negative sides under control.
Afterthought: it’s not as hard as it seems
I’ve been showing this article to some friends, to get some feedback before publishing it. A common response was: “Wow, that’s so impressive! You must be so disciplined! I could never do that.” And while it tickled my ego to hear this, the truth is, it’s really not that hard.
Yes, like all things, it requires effort in the beginning. But after you got it all set up and run it for a few days, it becomes pretty easy. 99% of the time, you’ll just press “continue” on a previous entry, which only takes 5 seconds. And since you’ll have to do it dozens of times a day, it will become instinctive much sooner than the usual “3–8 weeks to form a new habit”.
Even now, my timer runs “Blog — time tracking” for 9 minutes and 20 seconds. I don’t remember having made a conscious decision to start it.
Tips & tricks:
If you like the idea and consider trying it for yourself, here are some things I wish I knew when I started, and that I hope will help you in your journey:
Try to be as honest as possible. The benefits are gone if you find yourself scrolling through your Instagram feed, while your timer says “preparing yearly report”
Keep it personal. Don’t mix it up with any tracking software from work. Don’t tell anyone about it. Basically, don’t do anything that would make you feel even remotely uncomfortable about recording those 2 hours of binge-watching Japanese eating contests on youtube.
Keep it simple. As simple as possible. Don’t overkill it with tags and projects (the way I did, in the beginning). You can always add those later. The whole system should be a pleasure to use, or you’ll have trouble using it at all.
One step at a time. At first, don’t change anything in how you spend your time. Just get used to tracking down what you’re already doing. The main focus is to get used to pressing “play” every time you’re doing something new.
Be patient with yourself. Once you start doing this in full honesty, you’ll probably see that your time isn’t really spent the way you imagined. That’s an easy way for guilt to creep in. But don’t despair. Once you become aware of this, things will get better by themselves. And keep in mind that, just by trying it out, you’ve already done something very courageous that’s a huge achievement in and of itself.
Conclusion
Tracking every minute of my time is, by far, the most effective thing I’ve ever tried, in terms of becoming more focused, getting more done and improving the quality of my time.
But, at the end of the day, this is just another way in which someone on this planet is trying to deal with the fact that life is hard. And if my trick doesn’t work for you, what will definitely work is keeping this healthy mindset that makes you read these kinds of articles, in the first place. Kudos to you, for keeping an open mind in the face of life’s hardships!
We’re all trying to make the most out of our time. Thank you for spending some of yours with me, today!
PS: This is the first article I’ve ever written, so I think you can imagine how anxious I am about it 😬 Any though (positive or constructive), clap, comment, share, or feedback in any form would be very, very much appreciated!
Toggl Track@toggltrack
This Toggl Track user tracked every *minute* of their time for four months and shared seven surprising lessons. We… twitter.com/i/web/status/1…



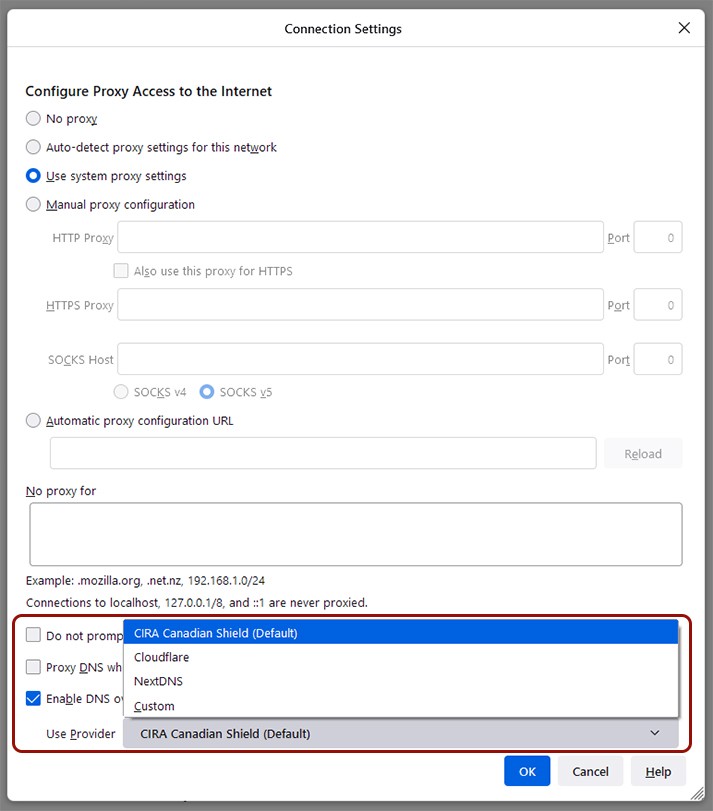
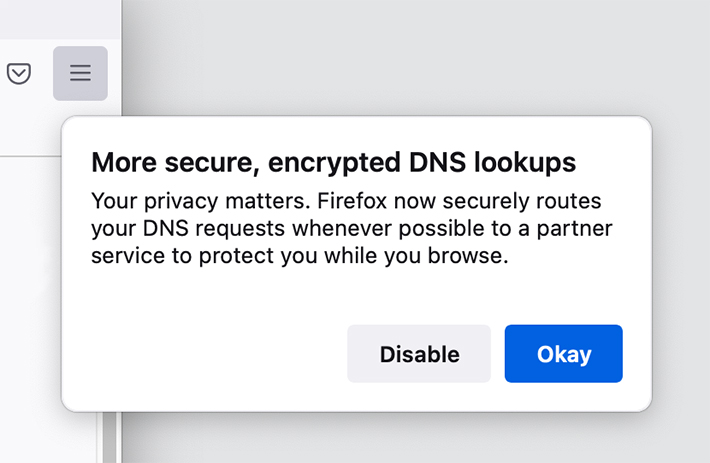





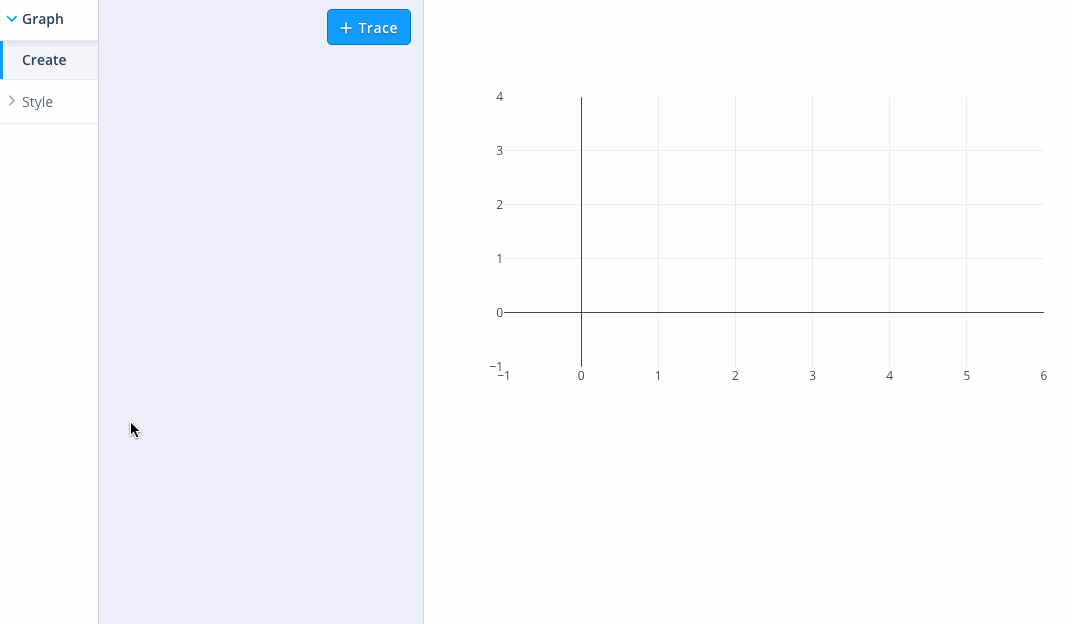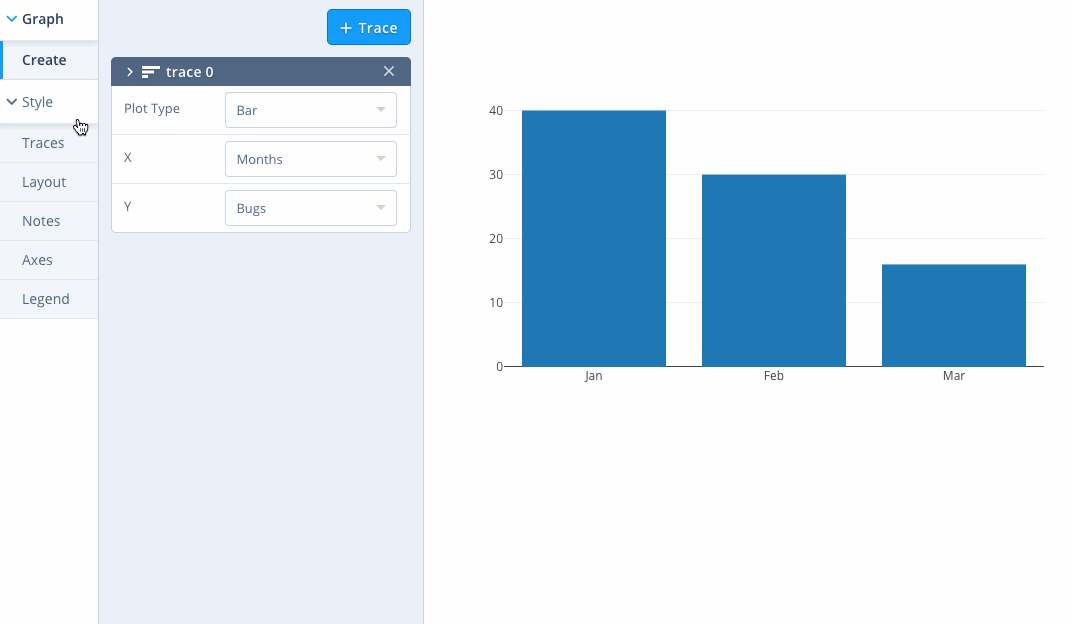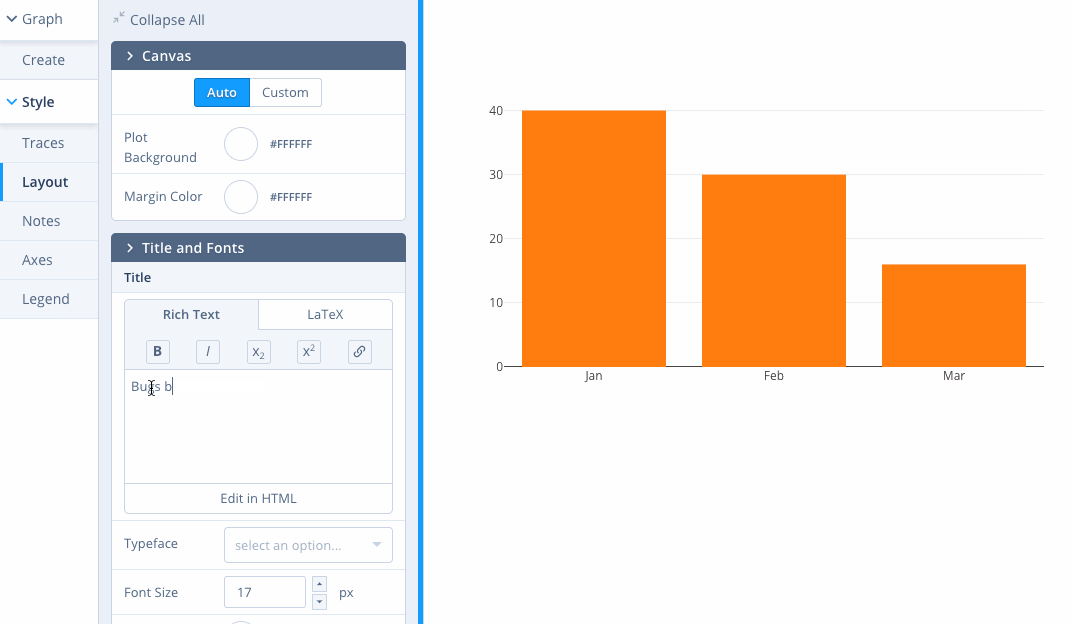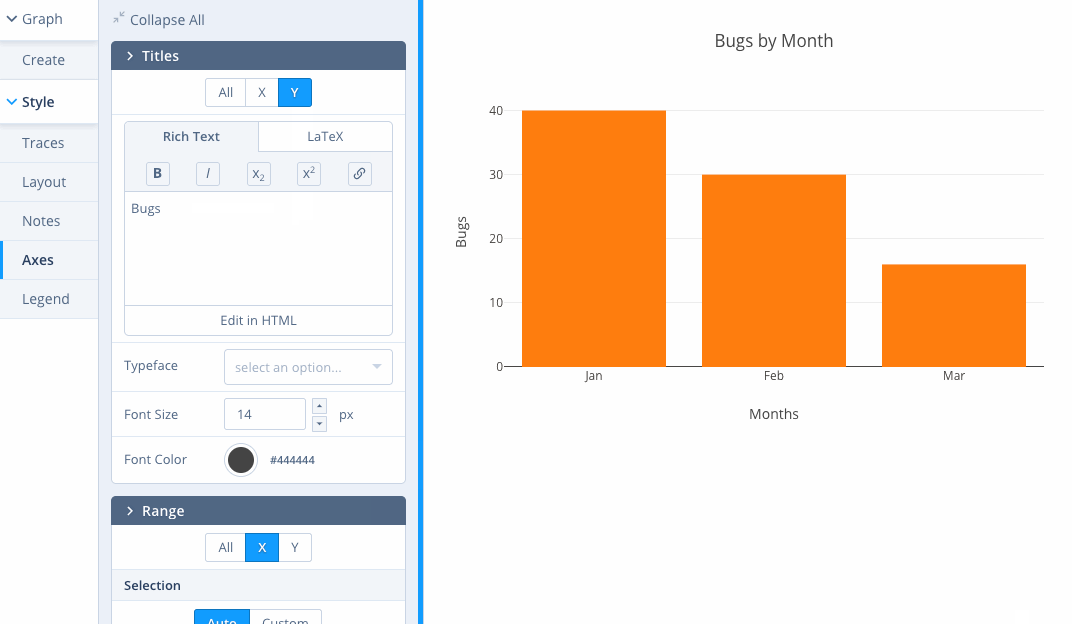
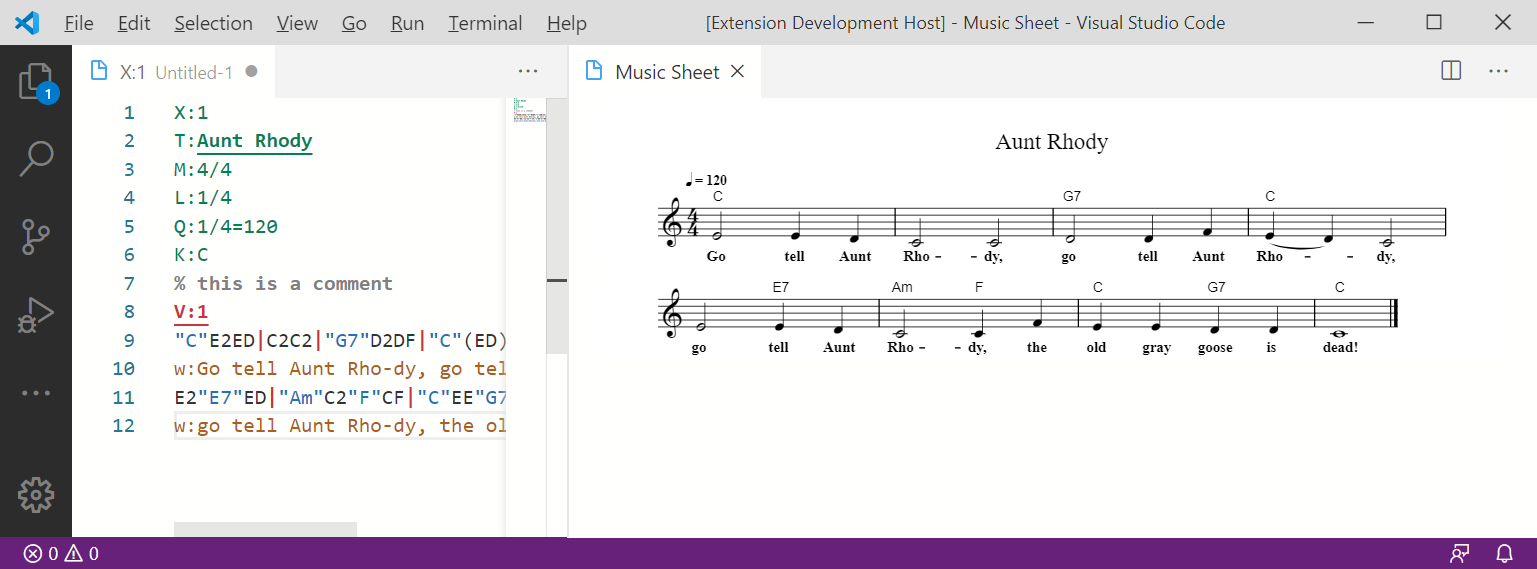
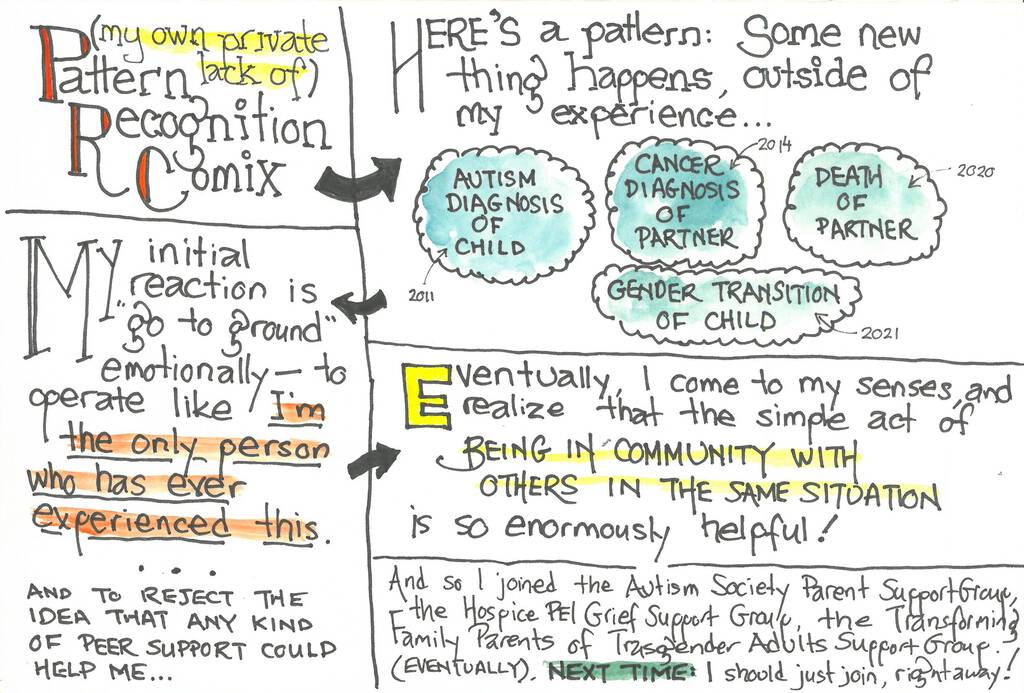
















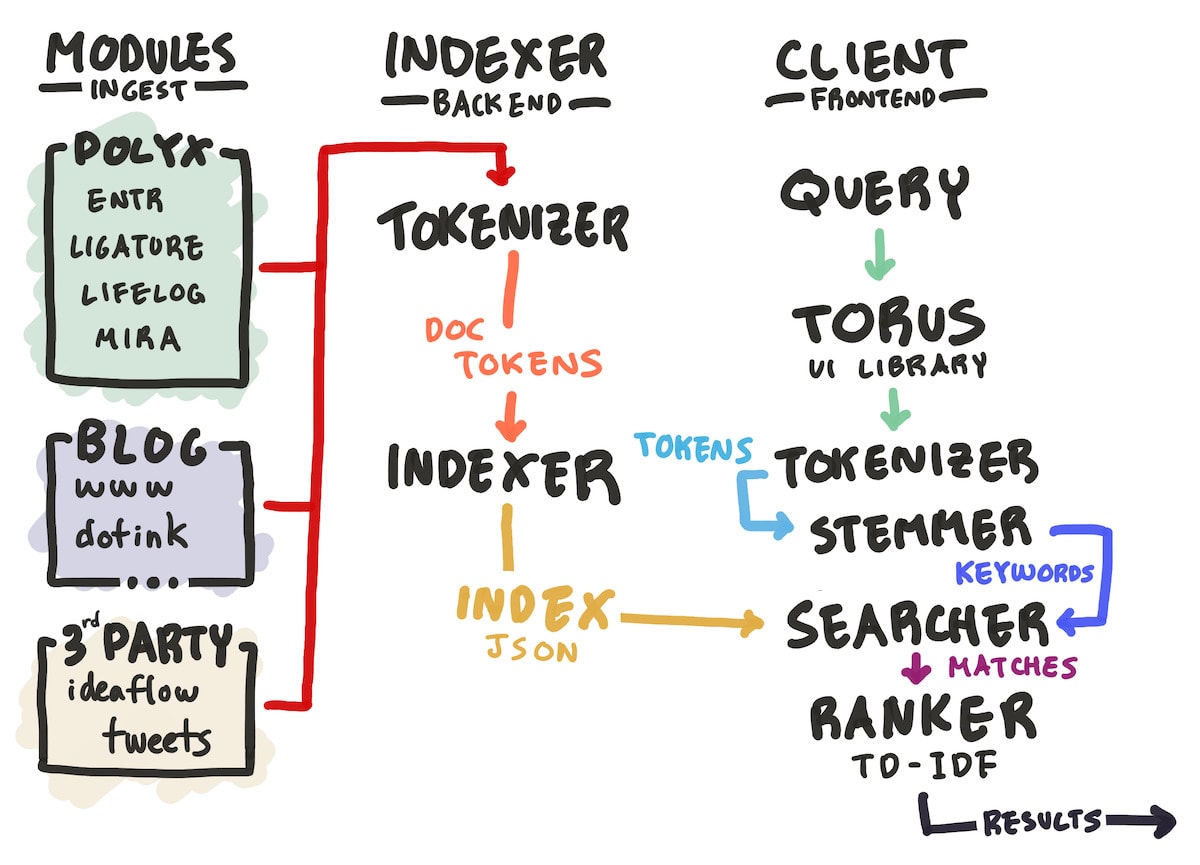







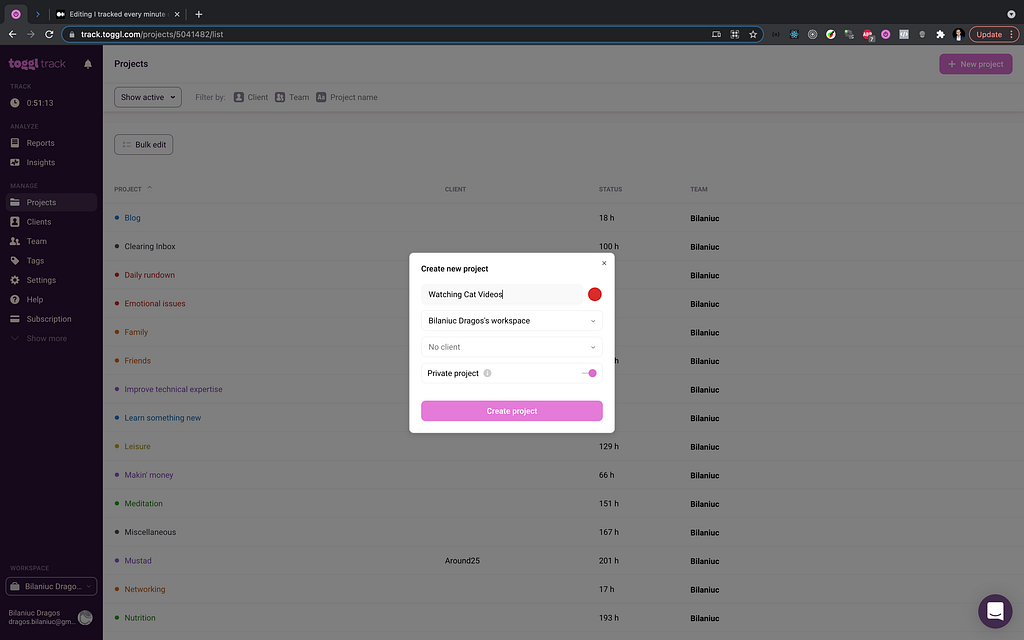







{kind=link}